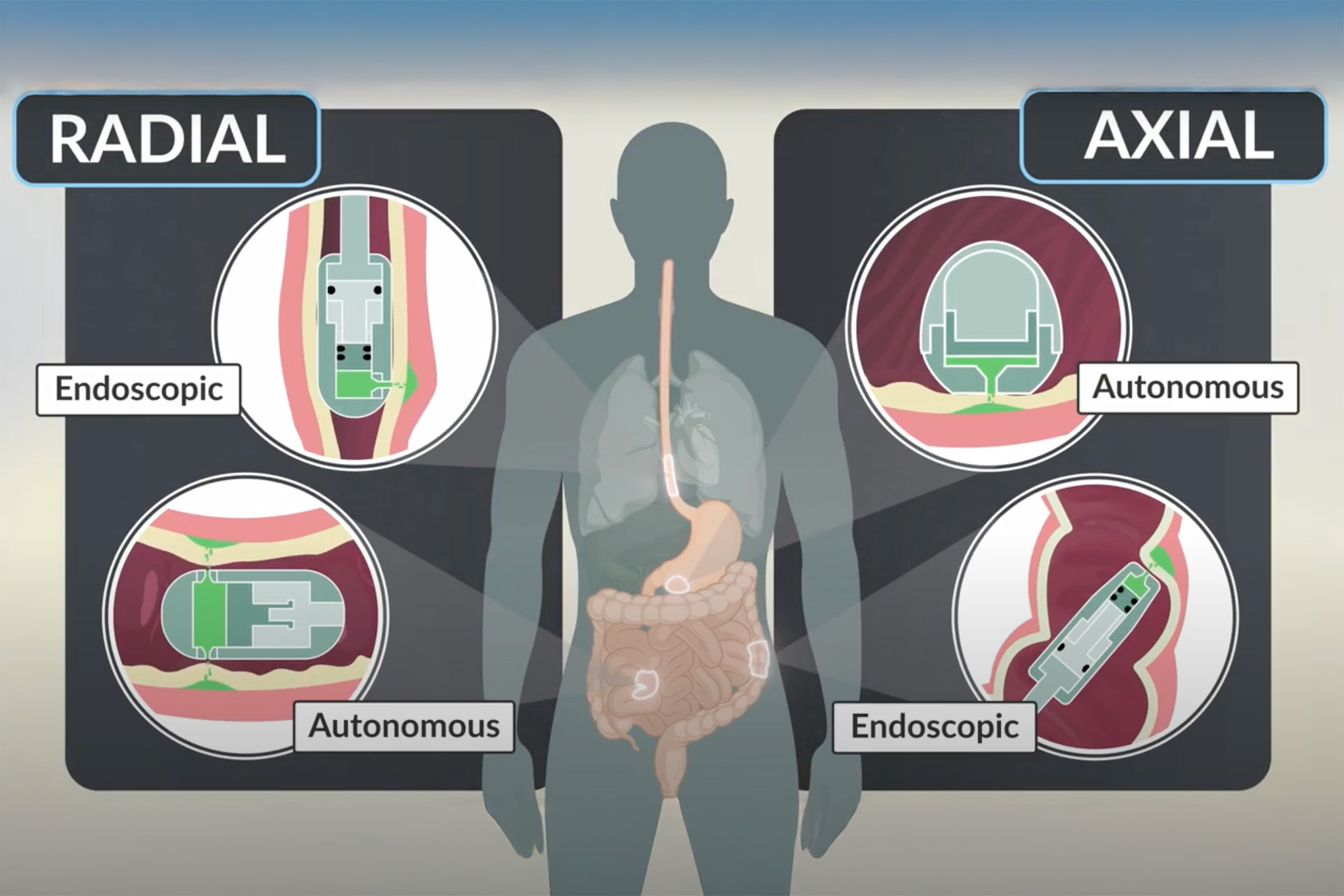
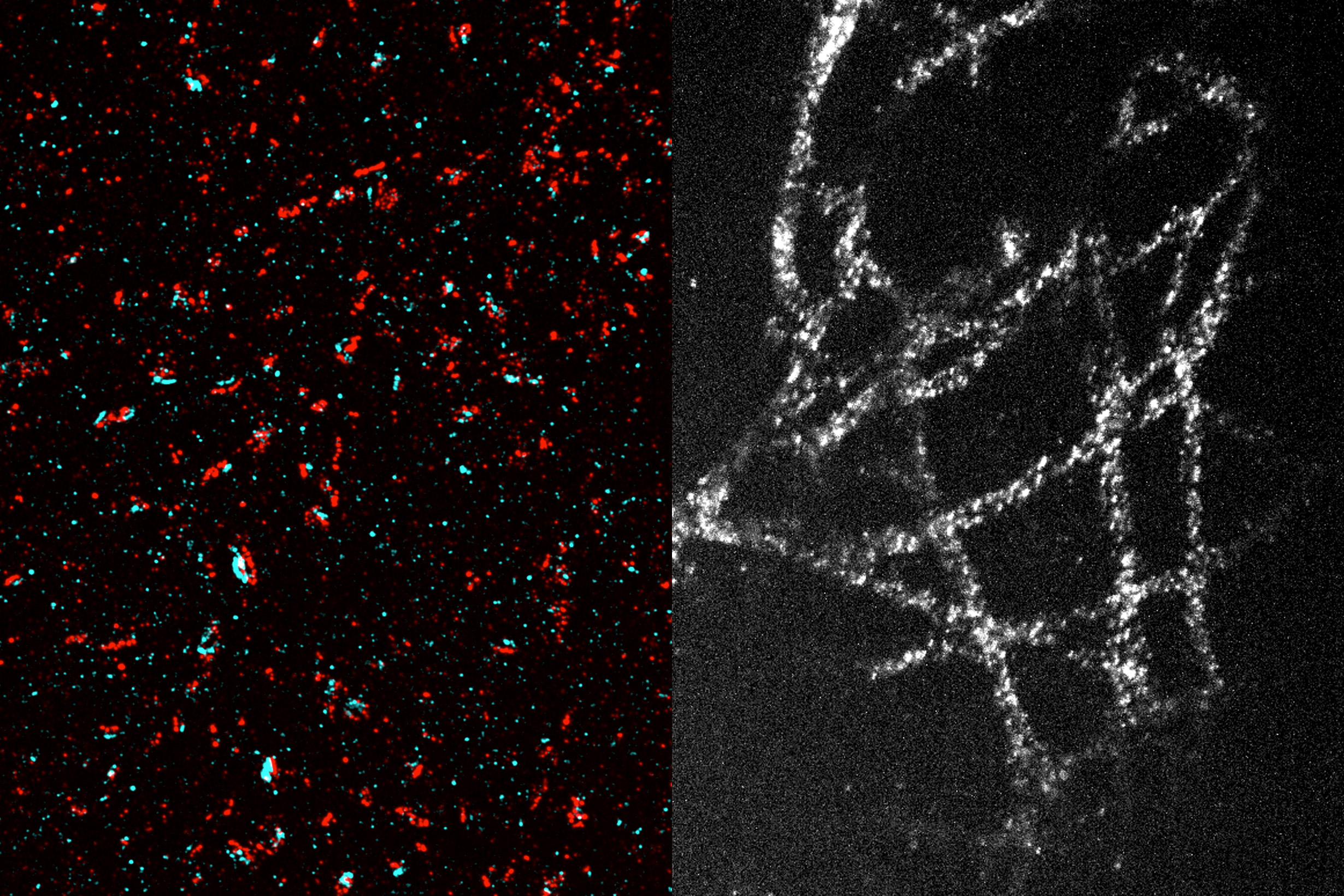
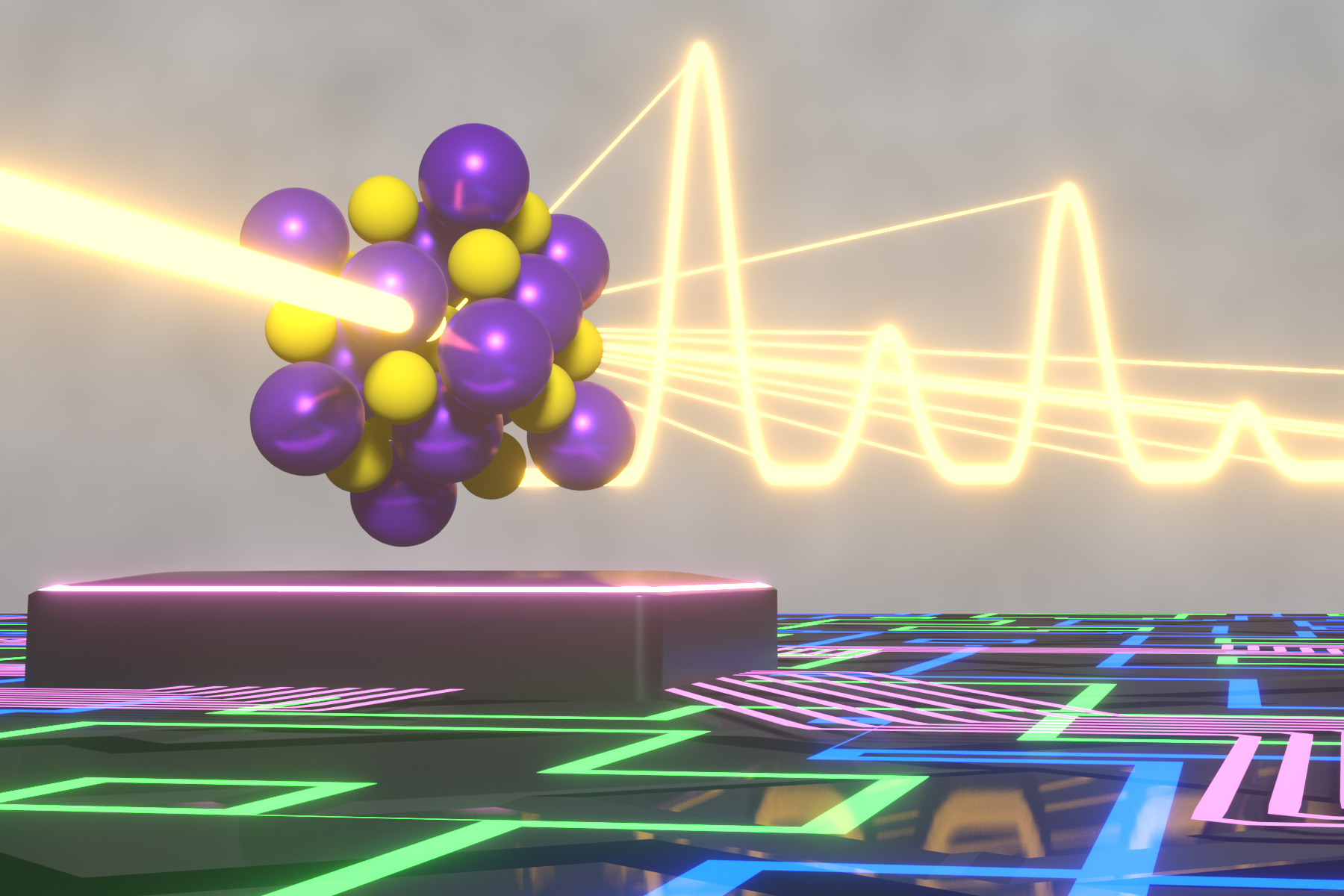
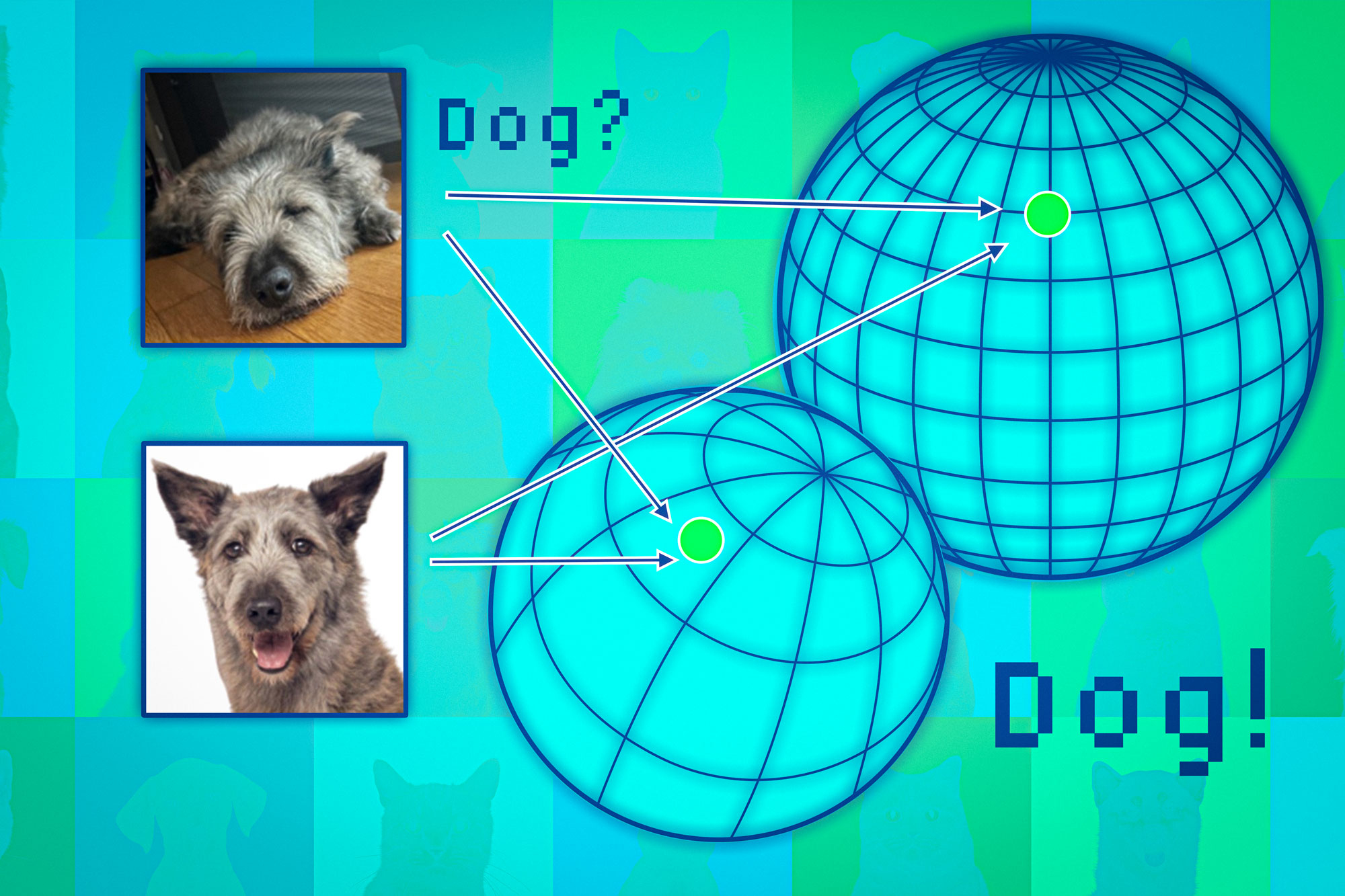
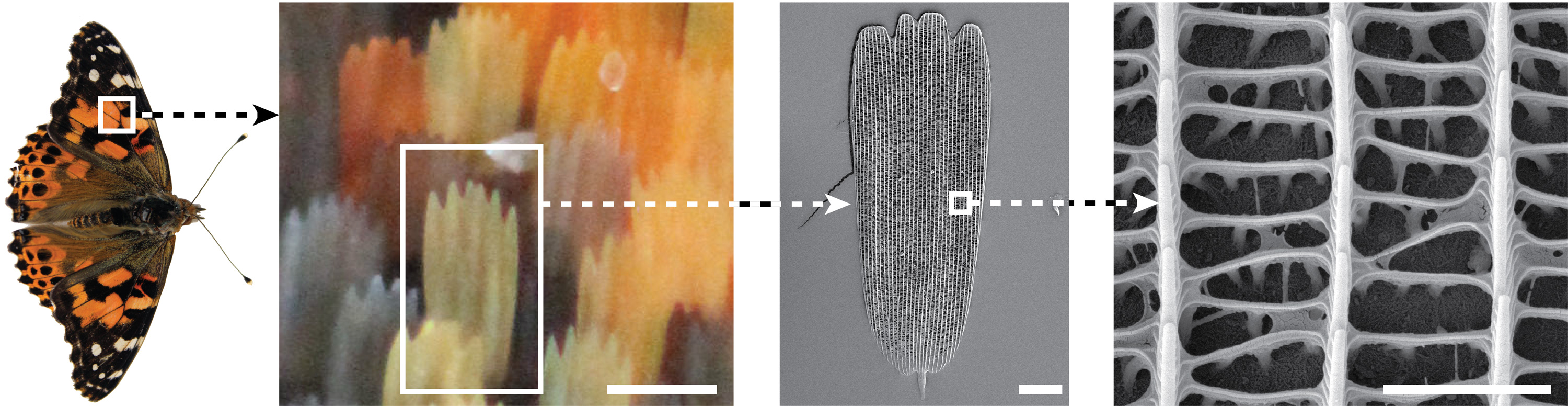
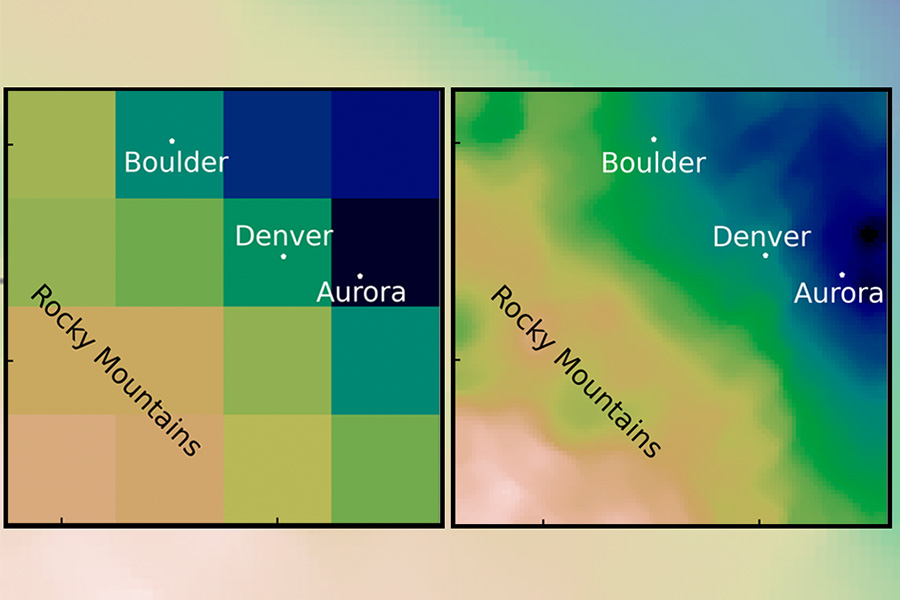
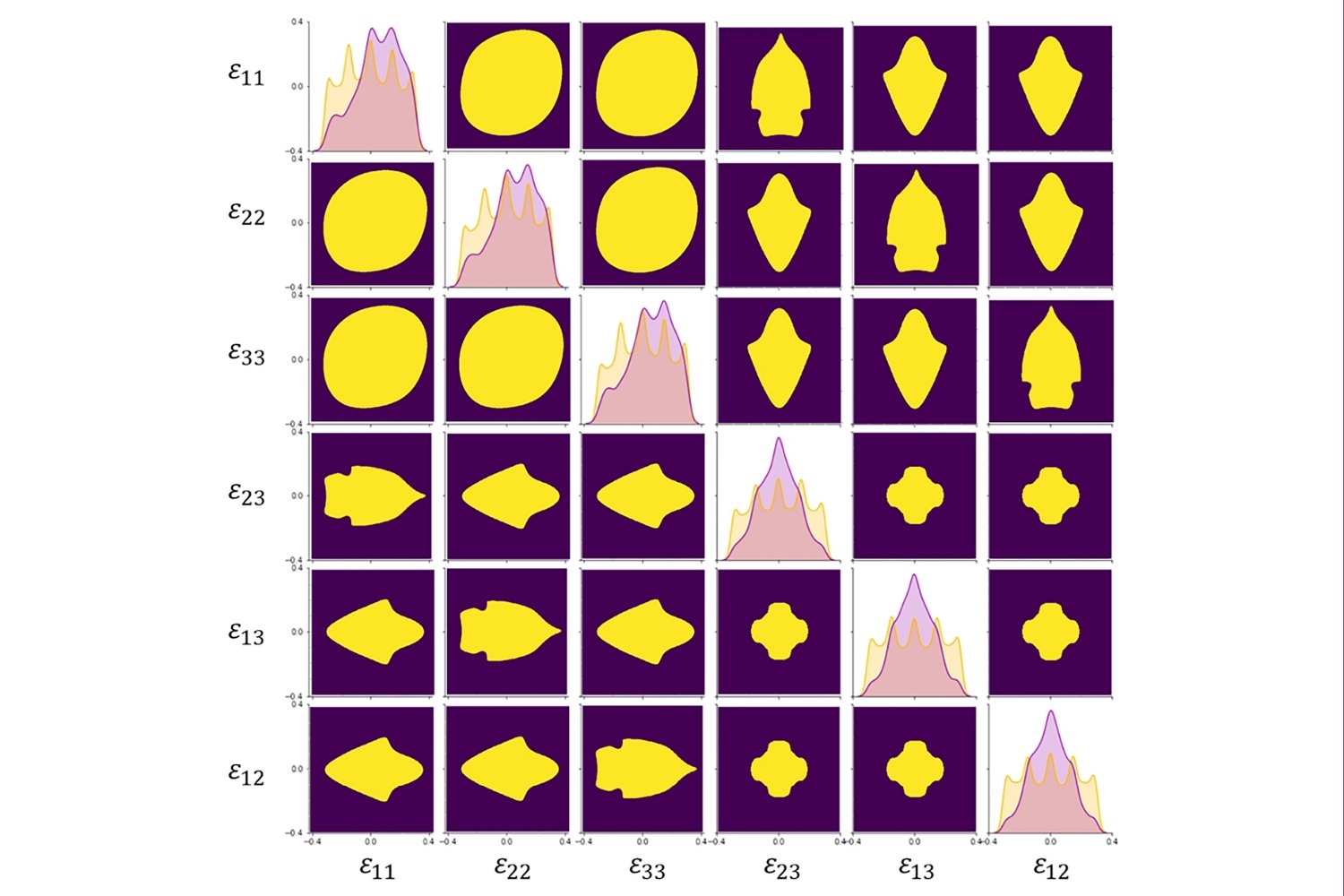
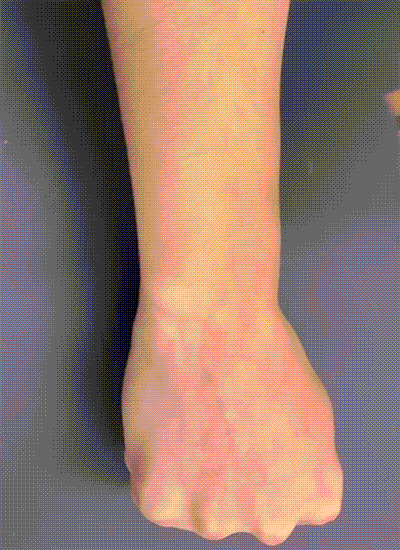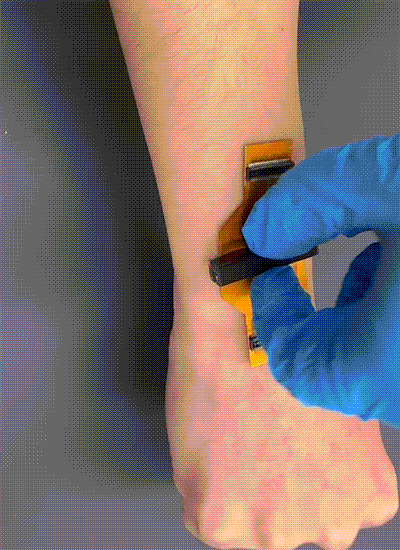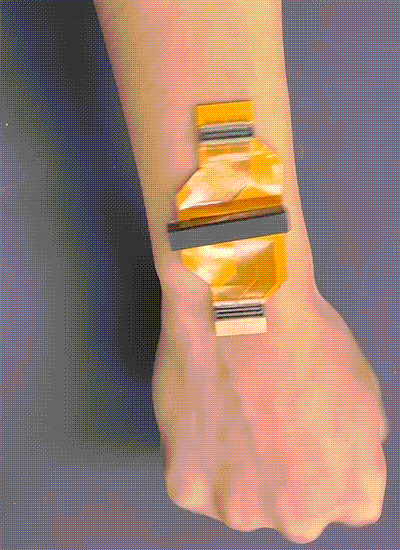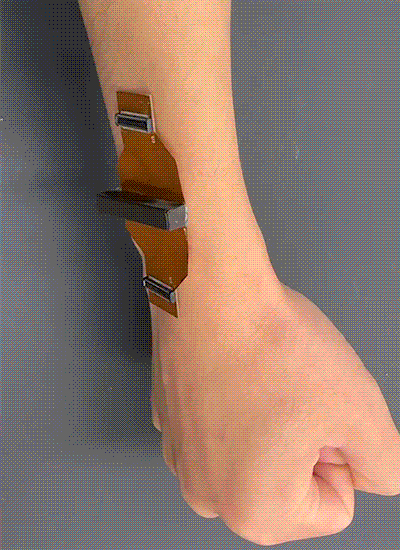
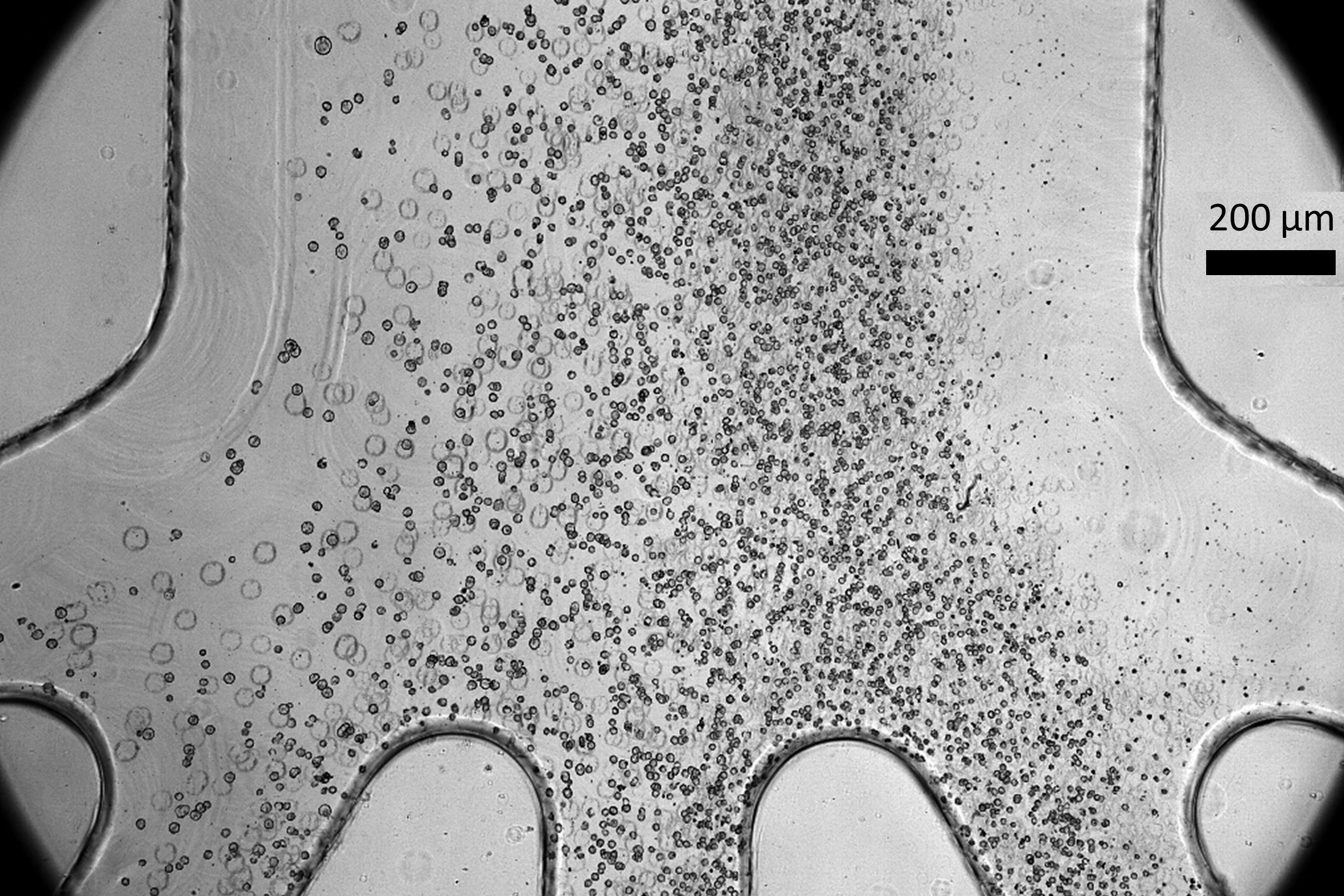
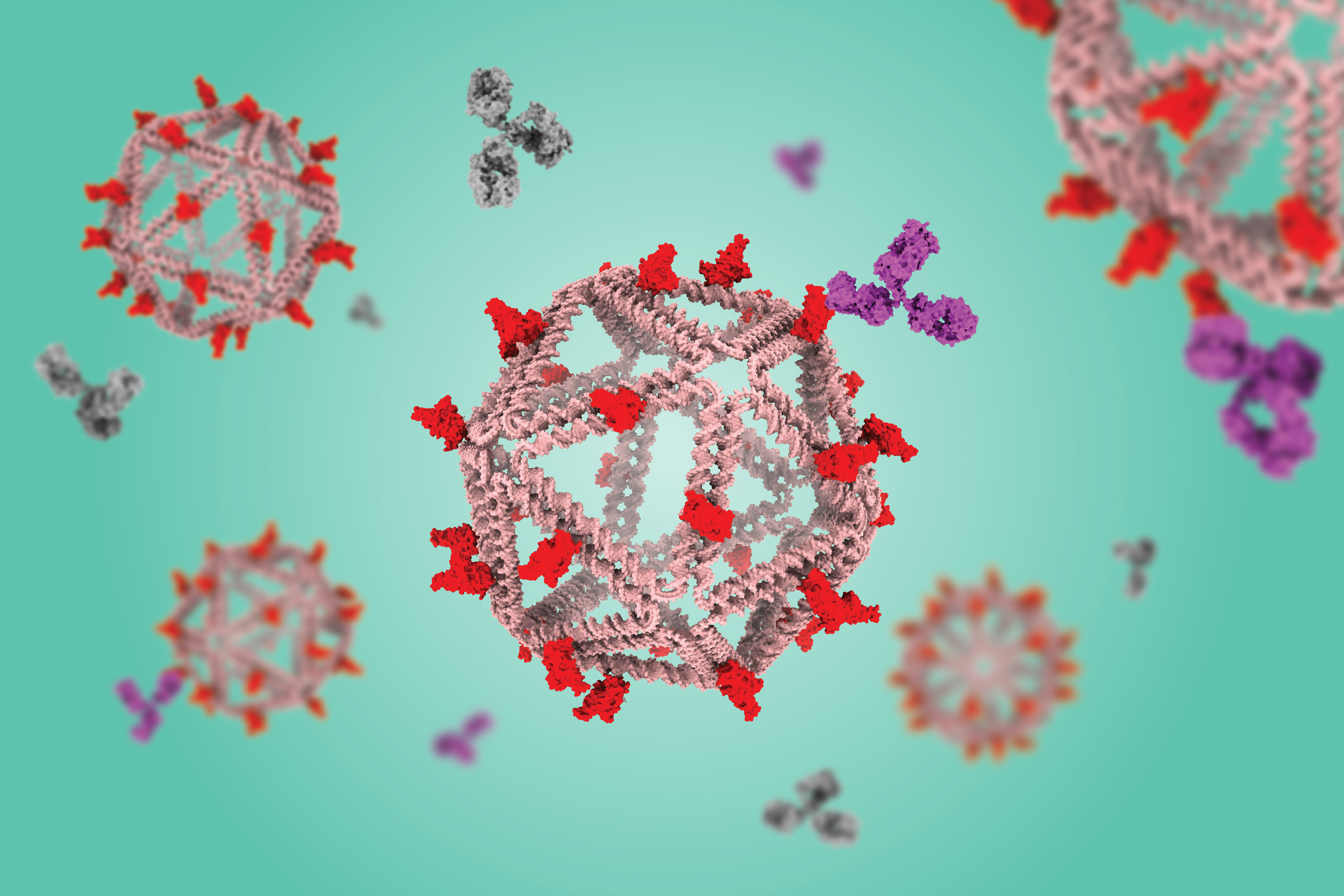
Acoustic metamaterials — architected materials that have tailored geometries designed to control the propagation of acoustic or elastic waves through a medium — have been studied extensively through computational and theoretical methods. Physical realizations of these materials to date have been restricted to large sizes and low frequencies.
“The multifunctionality of metamaterials — being simultaneously lightweight and strong while having tunable acoustic properties — make them great candidates for use in extreme-condition engineering applications,” explains Carlos Portela, the Robert N. Noyce Career Development Chair and assistant professor of mechanical engineering at MIT. “But challenges in miniaturizing and characterizing acoustic metamaterials at high frequencies have hindered progress towards realizing advanced materials that have ultrasonic-wave control capabilities.”
A new study coauthored by Portela; Rachel Sun, Jet Lem, and Yun Kai of the MIT Department of Mechanical Engineering (MechE); and Washington DeLima of the U.S. Department of Energy Kansas City National Security Campus presents a design framework for controlling ultrasound wave propagation in microscopic acoustic metamaterials. A paper on the work, “Tailored Ultrasound Propagation in Microscale Metamaterials via Inertia Design,” was recently published in the journal Science Advances.
“Our work proposes a design framework based on precisely positioning microscale spheres to tune how ultrasound waves travel through 3D microscale metamaterials,” says Portela. “Specifically, we investigate how placing microscopic spherical masses within a metamaterial lattice affect how fast ultrasound waves travel throughout, ultimately leading to wave guiding or focusing responses.”
Through nondestructive, high-throughput laser-ultrasonics characterization, the team experimentally demonstrates tunable elastic-wave velocities within microscale materials. They use the varied wave velocities to spatially and temporally tune wave propagation in microscale materials, also demonstrating an acoustic demultiplexer (a device that separates one acoustic signal into multiple output signals). The work paves the way for microscale devices and components that could be useful for ultrasound imaging or information transmission via ultrasound.
“Using simple geometrical changes, this design framework expands the tunable dynamic property space of metamaterials, enabling straightforward design and fabrication of microscale acoustic metamaterials and devices,” says Portela.
The research also advances experimental capabilities, including fabrication and characterization, of microscale acoustic metamaterials toward application in medical ultrasound and mechanical computing applications, and underscores the underlying mechanics of ultrasound wave propagation in metamaterials, tuning dynamic properties via simple geometric changes and describing these changes as a function of changes in mass and stiffness. More importantly, the framework is amenable to other fabrication techniques beyond the microscale, requiring merely a single constituent material and one base 3D geometry to attain largely tunable properties.
“The beauty of this framework is that it fundamentally links physical material properties to geometric features. By placing spherical masses on a spring-like lattice scaffold, we could create direct analogies for how mass affects quasi-static stiffness and dynamic wave velocity,” says Sun, first author of the study. “I realized that we could obtain hundreds of different designs and corresponding material properties regardless of whether we vibrated or slowly compressed the materials.”
A new study presents a design framework for controlling ultrasound wave propagation in microscopic acoustic metamaterials. The researchers focused on cubic lattice with braces comprising a “braced-cubic” design.
In 2015, 195 nations plus the European Union signed the Paris Agreement and pledged to undertake plans designed to limit the global temperature increase to 1.5 degrees Celsius. Yet in 2023, the world exceeded that target for most, if not all of, the year — calling into question the long-term feasibility of achieving that target.
To do so, the world must reduce the levels of greenhouse gases in the atmosphere, and strategies for achieving levels that will “stabilize the climate” have been both proposed and adopted. Many of those strategies combine dramatic cuts in carbon dioxide (CO2) emissions with the use of direct air capture (DAC), a technology that removes CO2 from the ambient air. As a reality check, a team of researchers in the MIT Energy Initiative (MITEI) examined those strategies, and what they found was alarming: The strategies rely on overly optimistic — indeed, unrealistic — assumptions about how much CO2 could be removed by DAC. As a result, the strategies won’t perform as predicted. Nevertheless, the MITEI team recommends that work to develop the DAC technology continue so that it’s ready to help with the energy transition — even if it’s not the silver bullet that solves the world’s decarbonization challenge.
DAC: The promise and the reality
Including DAC in plans to stabilize the climate makes sense. Much work is now under way to develop DAC systems, and the technology looks promising. While companies may never run their own DAC systems, they can already buy “carbon credits” based on DAC. Today, a multibillion-dollar market exists on which entities or individuals that face high costs or excessive disruptions to reduce their own carbon emissions can pay others to take emissions-reducing actions on their behalf. Those actions can involve undertaking new renewable energy projects or “carbon-removal” initiatives such as DAC or afforestation/reforestation (planting trees in areas that have never been forested or that were forested in the past).
DAC-based credits are especially appealing for several reasons, explains Howard Herzog, a senior research engineer at MITEI. With DAC, measuring and verifying the amount of carbon removed is straightforward; the removal is immediate, unlike with planting forests, which may take decades to have an impact; and when DAC is coupled with CO2 storage in geologic formations, the CO2 is kept out of the atmosphere essentially permanently — in contrast to, for example, sequestering it in trees, which may one day burn and release the stored CO2.
Will current plans that rely on DAC be effective in stabilizing the climate in the coming years? To find out, Herzog and his colleagues Jennifer Morris and Angelo Gurgel, both MITEI principal research scientists, and Sergey Paltsev, a MITEI senior research scientist — all affiliated with the MIT Center for Sustainability Science and Strategy (CS3) — took a close look at the modeling studies on which those plans are based.
Their investigation identified three unavoidable engineering challenges that together lead to a fourth challenge — high costs for removing a single ton of CO2 from the atmosphere. The details of their findings are reported in a paper published in the journal One Earth on Sept. 20.
Challenge 1: Scaling up
When it comes to removing CO2 from the air, nature presents “a major, non-negotiable challenge,” notes the MITEI team: The concentration of CO2 in the air is extremely low — just 420 parts per million, or roughly 0.04 percent. In contrast, the CO2 concentration in flue gases emitted by power plants and industrial processes ranges from 3 percent to 20 percent. Companies now use various carbon capture and sequestration (CCS) technologies to capture CO2 from their flue gases, but capturing CO2 from the air is much more difficult. To explain, the researchers offer the following analogy: “The difference is akin to needing to find 10 red marbles in a jar of 25,000 marbles of which 24,990 are blue [the task representing DAC] versus needing to find about 10 red marbles in a jar of 100 marbles of which 90 are blue [the task for CCS].”
Given that low concentration, removing a single metric ton (tonne) of CO2 from air requires processing about 1.8 million cubic meters of air, which is roughly equivalent to the volume of 720 Olympic-sized swimming pools. And all that air must be moved across a CO2-capturing sorbent — a feat requiring large equipment. For example, one recently proposed design for capturing 1 million tonnes of CO2 per year would require an “air contactor” equivalent in size to a structure about three stories high and three miles long.
Recent modeling studies project DAC deployment on the scale of 5 to 40 gigatonnes of CO2 removed per year. (A gigatonne equals 1 billion metric tonnes.) But in their paper, the researchers conclude that the likelihood of deploying DAC at the gigatonne scale is “highly uncertain.”
Challenge 2: Energy requirement
Given the low concentration of CO2 in the air and the need to move large quantities of air to capture it, it’s no surprise that even the best DAC processes proposed today would consume large amounts of energy — energy that’s generally supplied by a combination of electricity and heat. Including the energy needed to compress the captured CO2 for transportation and storage, most proposed processes require an equivalent of at least 1.2 megawatt-hours of electricity for each tonne of CO2 removed.
The source of that electricity is critical. For example, using coal-based electricity to drive an all-electric DAC process would generate 1.2 tonnes of CO2 for each tonne of CO2 captured. The result would be a net increase in emissions, defeating the whole purpose of the DAC. So clearly, the energy requirement must be satisfied using either low-carbon electricity or electricity generated using fossil fuels with CCS. All-electric DAC deployed at large scale — say, 10 gigatonnes of CO2 removed annually — would require 12,000 terawatt-hours of electricity, which is more than 40 percent of total global electricity generation today.
Electricity consumption is expected to grow due to increasing overall electrification of the world economy, so low-carbon electricity will be in high demand for many competing uses — for example, in power generation, transportation, industry, and building operations. Using clean electricity for DAC instead of for reducing CO2 emissions in other critical areas raises concerns about the best uses of clean electricity.
Many studies assume that a DAC unit could also get energy from “waste heat” generated by some industrial process or facility nearby. In the MITEI researchers’ opinion, “that may be more wishful thinking than reality.” The heat source would need to be within a few miles of the DAC plant for transporting the heat to be economical; given its high capital cost, the DAC plant would need to run nonstop, requiring constant heat delivery; and heat at the temperature required by the DAC plant would have competing uses, for example, for heating buildings. Finally, if DAC is deployed at the gigatonne per year scale, waste heat will likely be able to provide only a small fraction of the needed energy.
Challenge 3: Siting
Some analysts have asserted that, because air is everywhere, DAC units can be located anywhere. But in reality, siting a DAC plant involves many complex issues. As noted above, DAC plants require significant amounts of energy, so having access to enough low-carbon energy is critical. Likewise, having nearby options for storing the removed CO2 is also critical. If storage sites or pipelines to such sites don’t exist, major new infrastructure will need to be built, and building new infrastructure of any kind is expensive and complicated, involving issues related to permitting, environmental justice, and public acceptability — issues that are, in the words of the researchers, “commonly underestimated in the real world and neglected in models.”
Two more siting needs must be considered. First, meteorological conditions must be acceptable. By definition, any DAC unit will be exposed to the elements, and factors like temperature and humidity will affect process performance and process availability. And second, a DAC plant will require some dedicated land — though how much is unclear, as the optimal spacing of units is as yet unresolved. Like wind turbines, DAC units need to be properly spaced to ensure maximum performance such that one unit is not sucking in CO2-depleted air from another unit.
Challenge 4: Cost
Considering the first three challenges, the final challenge is clear: the cost per tonne of CO2 removed is inevitably high. Recent modeling studies assume DAC costs as low as $100 to $200 per ton of CO2 removed. But the researchers found evidence suggesting far higher costs.
To start, they cite typical costs for power plants and industrial sites that now use CCS to remove CO2 from their flue gases. The cost of CCS in such applications is estimated to be in the range of $50 to $150 per ton of CO2 removed. As explained above, the far lower concentration of CO2 in the air will lead to substantially higher costs.
As explained under Challenge 1, the DAC units needed to capture the required amount of air are massive. The capital cost of building them will be high, given labor, materials, permitting costs, and so on. Some estimates in the literature exceed $5,000 per tonne captured per year.
Then there are the ongoing costs of energy. As noted under Challenge 2, removing 1 tonne of CO2 requires the equivalent of 1.2 megawatt-hours of electricity. If that electricity costs $0.10 per kilowatt-hour, the cost of just the electricity needed to remove 1 tonne of CO2 is $120. The researchers point out that assuming such a low price is “questionable,” given the expected increase in electricity demand, future competition for clean energy, and higher costs on a system dominated by renewable — but intermittent — energy sources.
Then there’s the cost of storage, which is ignored in many DAC cost estimates.
Clearly, many considerations show that prices of $100 to $200 per tonne are unrealistic, and assuming such low prices will distort assessments of strategies, leading them to underperform going forward.
The bottom line
In their paper, the MITEI team calls DAC a “very seductive concept.” Using DAC to suck CO2 out of the air and generate high-quality carbon-removal credits can offset reduction requirements for industries that have hard-to-abate emissions. By doing so, DAC would minimize disruptions to key parts of the world’s economy, including air travel, certain carbon-intensive industries, and agriculture. However, the world would need to generate billions of tonnes of CO2 credits at an affordable price. That prospect doesn’t look likely. The largest DAC plant in operation today removes just 4,000 tonnes of CO2 per year, and the price to buy the company’s carbon-removal credits on the market today is $1,500 per tonne.
The researchers recognize that there is room for energy efficiency improvements in the future, but DAC units will always be subject to higher work requirements than CCS applied to power plant or industrial flue gases, and there is not a clear pathway to reducing work requirements much below the levels of current DAC technologies.
Nevertheless, the researchers recommend that work to develop DAC continue “because it may be needed for meeting net-zero emissions goals, especially given the current pace of emissions.” But their paper concludes with this warning: “Given the high stakes of climate change, it is foolhardy to rely on DAC to be the hero that comes to our rescue.”
Pictured are two of the four absorber units at Climeworks’ direct air capture and storage plant, Orca, in Hellisheidi, Iceland. Each absorber unit can remove about 1,000 tons of carbon dioxide per year.
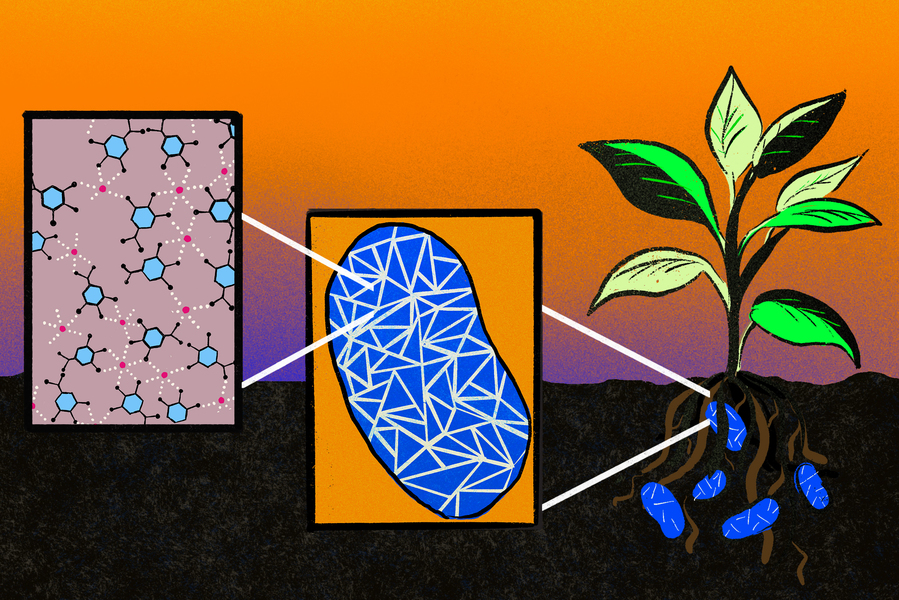
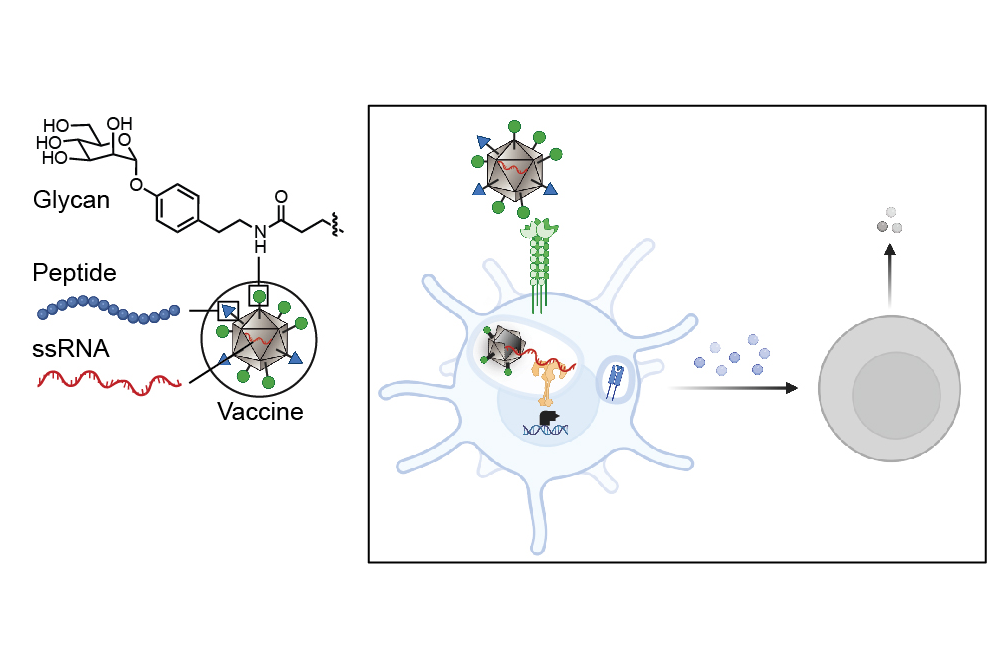
Inspired by the way that squids use jets to propel themselves through the ocean and shoot ink clouds, researchers from MIT and Novo Nordisk have developed an ingestible capsule that releases a burst of drugs directly into the wall of the stomach or other organs of the digestive tract.
This capsule could offer an alternative way to deliver drugs that normally have to be injected, such as insulin and other large proteins, including antibodies. This needle-free strategy could also be used to deliver RNA, either as a vaccine or a therapeutic molecule to treat diabetes, obesity, and other metabolic disorders.
“One of the longstanding challenges that we’ve been exploring is the development of systems that enable the oral delivery of macromolecules that usually require an injection to be administered. This work represents one of the next major advances in that progression,” says Giovanni Traverso, director of the Laboratory for Translational Engineering and an associate professor of mechanical engineering at MIT, a gastroenterologist at Brigham and Women’s Hospital, an associate member of the Broad Institute, and the senior author of the study.
Traverso and his students at MIT developed the new capsule along with researchers at Brigham and Women’s Hospital and Novo Nordisk. Graham Arrick SM ’20 and Novo Nordisk scientists Drago Sticker and Aghiad Ghazal are the lead authors of the paper, which appears today in Nature.
Inspired by cephalopods
Drugs that consist of large proteins or RNA typically can’t be taken orally because they are easily broken down in the digestive tract. For several years, Traverso’s lab has been working on ways to deliver such drugs orally by encapsulating them in small devices that protect the drugs from degradation and then inject them directly into the lining of the digestive tract.
Most of these capsules use a small needle or set of microneedles to deliver drugs once the device arrives in the digestive tract. In the new study, Traverso and his colleagues wanted to explore ways to deliver these molecules without any kind of needle, which could reduce the possibility of any damage to the tissue.
To achieve that, they took inspiration from cephalopods. Squids and octopuses can propel themselves by filling their mantle cavity with water, then rapidly expelling it through their siphon. By changing the force of water expulsion and pointing the siphon in different directions, the animals can control their speed and direction of travel. The siphon organ also allows cephalopods to shoot jets of ink, forming decoy clouds to distract predators.
The researchers came up with two ways to mimic this jetting action, using compressed carbon dioxide or tightly coiled springs to generate the force needed to propel liquid drugs out of the capsule. The gas or spring is kept in a compressed state by a carbohydrate trigger, which is designed to dissolve when exposed to humidity or an acidic environment such as the stomach. When the trigger dissolves, the gas or spring is allowed to expand, propelling a jet of drugs out of the capsule.
In a series of experiments using tissue from the digestive tract, the researchers calculated the pressures needed to expel the drugs with enough force that they would penetrate the submucosal tissue and accumulate there, creating a depot that would then release drugs into the tissue.
“Aside from the elimination of sharps, another potential advantage of high-velocity columnated jets is their robustness to localization issues. In contrast to a small needle, which needs to have intimate contact with the tissue, our experiments indicated that a jet may be able to deliver most of the dose from a distance or at a slight angle,” Arrick says.
The researchers also designed the capsules so that they can target different parts of the digestive tract. One version of the capsule, which has a flat bottom and a high dome, can sit on a surface, such as the lining of the stomach, and eject drug downward into the tissue. This capsule, which was inspired by previous research from Traverso’s lab on self-orienting capsules, is about the size of a blueberry and can carry 80 microliters of drug.
The second version has a tube-like shape that allows it to align itself within a long tubular organ such as the esophagus or small intestine. In that case, the drug is ejected out toward the side wall, rather than downward. This version can deliver 200 microliters of drug.
Made of metal and plastic, the capsules can pass through the digestive tract and are excreted after releasing their drug payload.
Needle-free drug delivery
In tests in animals, the researchers showed that they could use these capsules to deliver insulin, a GLP-1 receptor agonist similar to the diabetes drug Ozempic, and a type of RNA called short interfering RNA (siRNA). This type of RNA can be used to silence genes, making it potentially useful in treating many genetic disorders.
They also showed that the concentration of the drugs in the animals’ bloodstream reached levels on the same order of magnitude as those seen when the drugs were injected with a syringe, and they did not detect any tissue damage.
The researchers envision that the ingestible capsule could be used at home by patients who need to take insulin or other injected drugs frequently. In addition to making it easier to administer drugs, especially for patients who don’t like needles, this approach also eliminates the need to dispose of sharp needles. The researchers also created and tested a version of the device that could be attached to an endoscope, allowing doctors to use it in an endoscopy suite or operating room to deliver drugs to a patient.
“This technology is a significant leap forward in oral drug delivery of macromolecule drugs like insulin and GLP-1 agonists. While many approaches for oral drug delivery have been attempted in the past, they tend to be poorly efficient in achieving high bioavailability. Here, the researchers demonstrate the ability to deliver bioavailability in animal models with high efficiency. This is an exciting approach which could be impactful for many biologics which are currently administered through injections or intravascular infusions,” says Omid Veiseh, a professor of bioengineering at Rice University, who was not involved in the research.
The researchers now plan to further develop the capsules, in hopes of testing them in humans.
The research was funded by Novo Nordisk, the Natural Sciences and Engineering Research Council of Canada, the MIT Department of Mechanical Engineering, Brigham and Women’s Hospital, and the U.S. Advanced Research Projects Agency for Health.
The researchers designed the capsules so that they can target different parts of the digestive tract. A second version has a tube-like shape that allows it to align itself within a long tubular organ. Another version of the device could be attached to an endoscope.
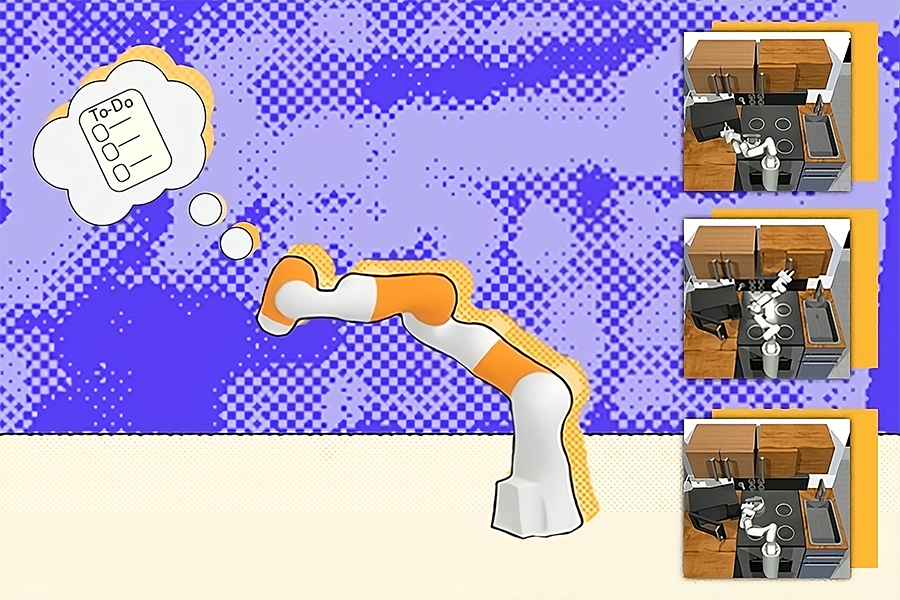
For roboticists, one challenge towers above all others: generalization — the ability to create machines that can adapt to any environment or condition. Since the 1970s, the field has evolved from writing sophisticated programs to using deep learning, teaching robots to learn directly from human behavior. But a critical bottleneck remains: data quality. To improve, robots need to encounter scenarios that push the boundaries of their capabilities, operating at the edge of their mastery. This process traditionally requires human oversight, with operators carefully challenging robots to expand their abilities. As robots become more sophisticated, this hands-on approach hits a scaling problem: the demand for high-quality training data far outpaces humans’ ability to provide it.
Now, a team of MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers has developed a novel approach to robot training that could significantly accelerate the deployment of adaptable, intelligent machines in real-world environments. The new system, called “LucidSim,” uses recent advances in generative AI and physics simulators to create diverse and realistic virtual training environments, helping robots achieve expert-level performance in difficult tasks without any real-world data.
LucidSim combines physics simulation with generative AI models, addressing one of the most persistent challenges in robotics: transferring skills learned in simulation to the real world. “A fundamental challenge in robot learning has long been the ‘sim-to-real gap’ — the disparity between simulated training environments and the complex, unpredictable real world,” says MIT CSAIL postdoc Ge Yang, a lead researcher on LucidSim. “Previous approaches often relied on depth sensors, which simplified the problem but missed crucial real-world complexities.”
The multipronged system is a blend of different technologies. At its core, LucidSim uses large language models to generate various structured descriptions of environments. These descriptions are then transformed into images using generative models. To ensure that these images reflect real-world physics, an underlying physics simulator is used to guide the generation process.
The birth of an idea: From burritos to breakthroughs
The inspiration for LucidSim came from an unexpected place: a conversation outside Beantown Taqueria in Cambridge, Massachusetts. “We wanted to teach vision-equipped robots how to improve using human feedback. But then, we realized we didn’t have a pure vision-based policy to begin with,” says Alan Yu, an undergraduate student in electrical engineering and computer science (EECS) at MIT and co-lead author on LucidSim. “We kept talking about it as we walked down the street, and then we stopped outside the taqueria for about half-an-hour. That’s where we had our moment.”
To cook up their data, the team generated realistic images by extracting depth maps, which provide geometric information, and semantic masks, which label different parts of an image, from the simulated scene. They quickly realized, however, that with tight control on the composition of the image content, the model would produce similar images that weren’t different from each other using the same prompt. So, they devised a way to source diverse text prompts from ChatGPT.
This approach, however, only resulted in a single image. To make short, coherent videos that serve as little “experiences” for the robot, the scientists hacked together some image magic into another novel technique the team created, called “Dreams In Motion.” The system computes the movements of each pixel between frames, to warp a single generated image into a short, multi-frame video. Dreams In Motion does this by considering the 3D geometry of the scene and the relative changes in the robot’s perspective.
“We outperform domain randomization, a method developed in 2017 that applies random colors and patterns to objects in the environment, which is still considered the go-to method these days,” says Yu. “While this technique generates diverse data, it lacks realism. LucidSim addresses both diversity and realism problems. It’s exciting that even without seeing the real world during training, the robot can recognize and navigate obstacles in real environments.”
The team is particularly excited about the potential of applying LucidSim to domains outside quadruped locomotion and parkour, their main test bed. One example is mobile manipulation, where a mobile robot is tasked to handle objects in an open area; also, color perception is critical. “Today, these robots still learn from real-world demonstrations,” says Yang. “Although collecting demonstrations is easy, scaling a real-world robot teleoperation setup to thousands of skills is challenging because a human has to physically set up each scene. We hope to make this easier, thus qualitatively more scalable, by moving data collection into a virtual environment.”
Who's the real expert?
The team put LucidSim to the test against an alternative, where an expert teacher demonstrates the skill for the robot to learn from. The results were surprising: Robots trained by the expert struggled, succeeding only 15 percent of the time — and even quadrupling the amount of expert training data barely moved the needle. But when robots collected their own training data through LucidSim, the story changed dramatically. Just doubling the dataset size catapulted success rates to 88 percent. “And giving our robot more data monotonically improves its performance — eventually, the student becomes the expert,” says Yang.
“One of the main challenges in sim-to-real transfer for robotics is achieving visual realism in simulated environments,” says Stanford University assistant professor of electrical engineering Shuran Song, who wasn’t involved in the research. “The LucidSim framework provides an elegant solution by using generative models to create diverse, highly realistic visual data for any simulation. This work could significantly accelerate the deployment of robots trained in virtual environments to real-world tasks.”
From the streets of Cambridge to the cutting edge of robotics research, LucidSim is paving the way toward a new generation of intelligent, adaptable machines — ones that learn to navigate our complex world without ever setting foot in it.
Yu and Yang wrote the paper with four fellow CSAIL affiliates: Ran Choi, an MIT postdoc in mechanical engineering; Yajvan Ravan, an MIT undergraduate in EECS; John Leonard, the Samuel C. Collins Professor of Mechanical and Ocean Engineering in the MIT Department of Mechanical Engineering; and Phillip Isola, an MIT associate professor in EECS. Their work was supported, in part, by a Packard Fellowship, a Sloan Research Fellowship, the Office of Naval Research, Singapore’s Defence Science and Technology Agency, Amazon, MIT Lincoln Laboratory, and the National Science Foundation Institute for Artificial Intelligence and Fundamental Interactions. The researchers presented their work at the Conference on Robot Learning (CoRL) in early November.
MIT CSAIL researchers (left to right) Alan Yu, an undergraduate in electrical engineering and computer science (EECS); Phillip Isola, associate professor of EECS; and Ge Yang, a postdoctoral associate, developed an AI-powered simulator that generates unlimited, diverse, and realistic training data for robots. Robots trained in this virtual environment can seamlessly transfer their skills to the real world, performing at expert levels without additional fine-tuning.
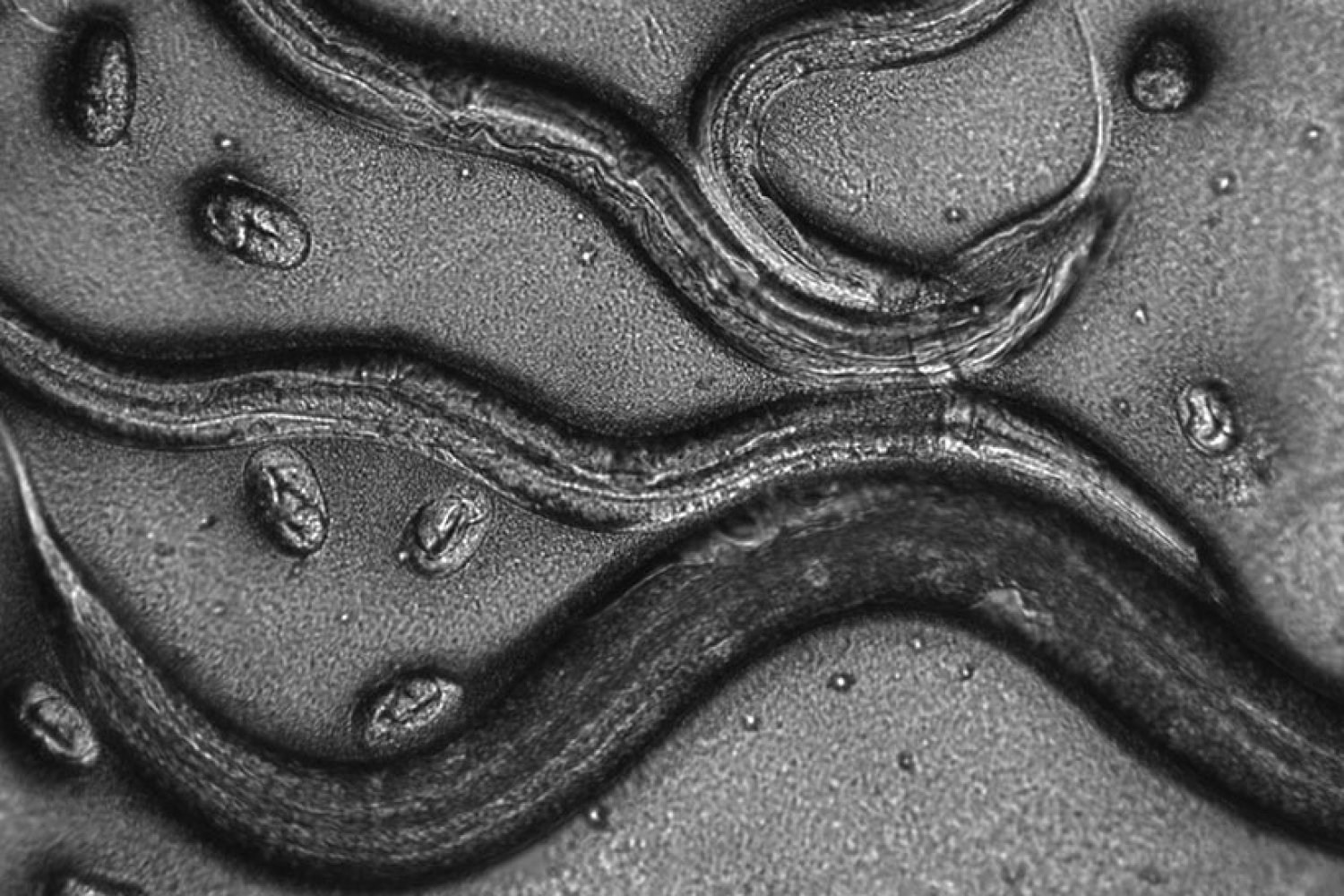
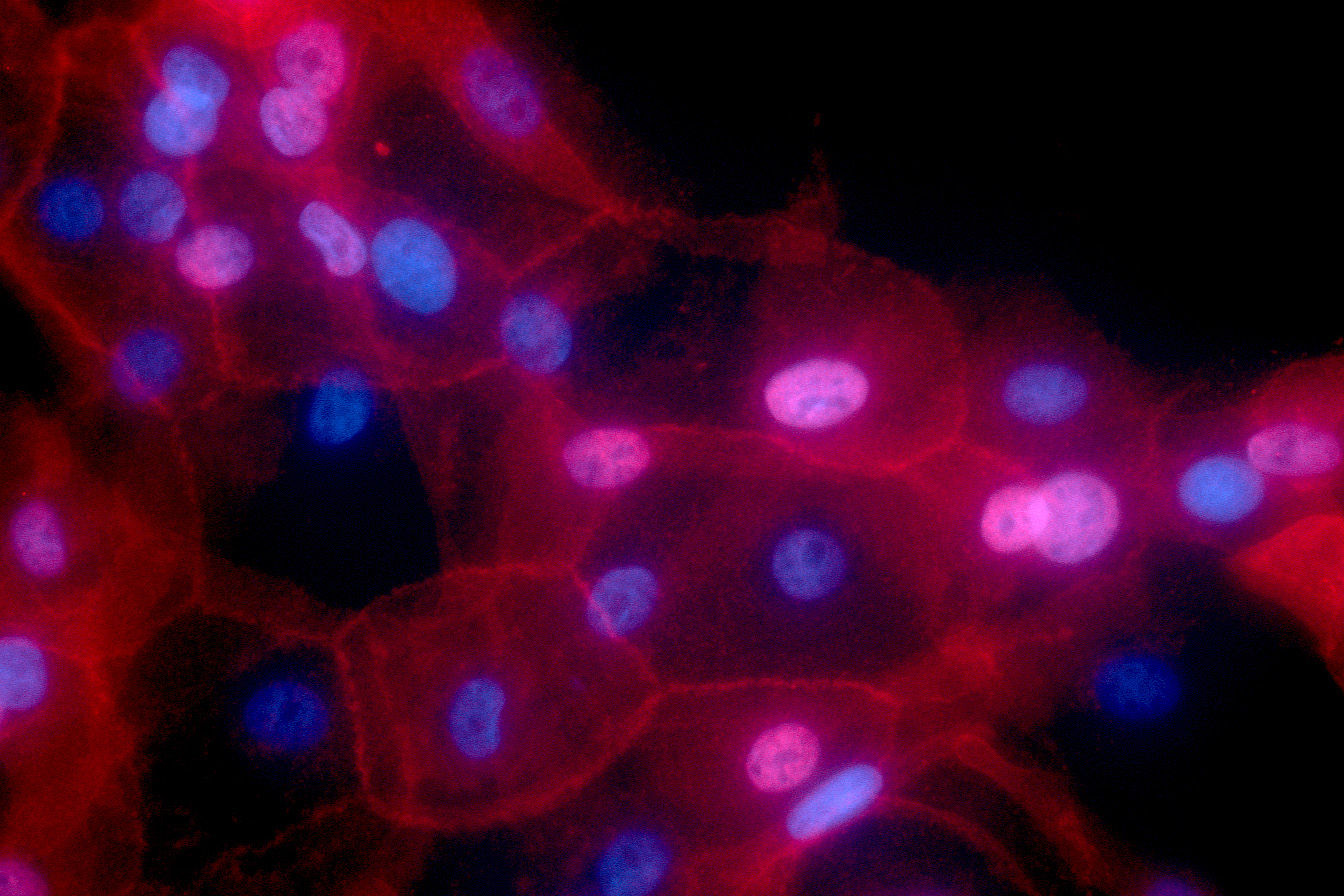
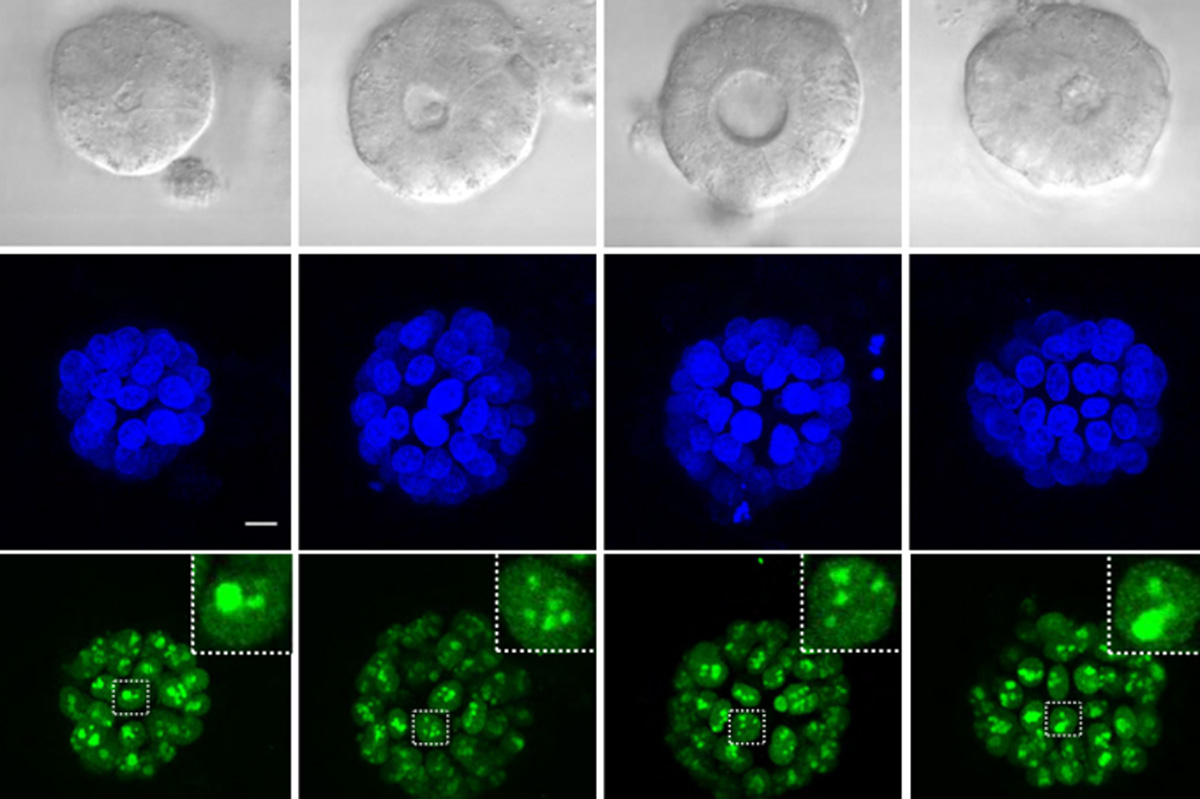
From early development to old age, cell death is a part of life. Without enough of a critical type of cell death known as apoptosis, animals wind up with too many cells, which can set the stage for cancer or autoimmune disease. But careful control is essential, because when apoptosis eliminates the wrong cells, the effects can be just as dire, helping to drive many kinds of neurodegenerative disease.
By studying the microscopic roundworm Caenorhabditis elegans — which was honored with its fourth Nobel Prize last month — scientists at MIT’s McGovern Institute for Brain Research have begun to unravel a longstanding mystery about the factors that control apoptosis: how a protein capable of preventing programmed cell death can also promote it. Their study, led by Robert Horvitz, the David H. Koch Professor of Biology at MIT, and reported Oct. 9 in the journal Science Advances, sheds light on the process of cell death in both health and disease.
“These findings, by graduate student Nolan Tucker and former graduate student, now MIT faculty colleague, Peter Reddien, have revealed that a protein interaction long thought to block apoptosis in C. elegans likely instead has the opposite effect,” says Horvitz, who is also an investigator at the Howard Hughes Medical Institute and the McGovern Institute. Horvitz shared the 2002 Nobel Prize in Physiology or Medicine for discovering and characterizing the genes controlling cell death in C. elegans.
Mechanisms of cell death
Horvitz, Tucker, Reddien, and colleagues have provided foundational insights in the field of apoptosis by using C. elegans to analyze the mechanisms that drive apoptosis, as well as the mechanisms that determine how cells ensure apoptosis happens when and where it should. Unlike humans and other mammals, which depend on dozens of proteins to control apoptosis, these worms use just a few. And when things go awry, it’s easy to tell: When there’s not enough apoptosis, researchers can see that there are too many cells inside the worms’ translucent bodies. And when there’s too much, the worms lack certain biological functions or, in more extreme cases, can’t reproduce or die during embryonic development.
Work in the Horvitz lab defined the roles of many of the genes and proteins that control apoptosis in worms. These regulators proved to have counterparts in human cells, and for that reason studies of worms have helped reveal how human cells govern cell death and pointed toward potential targets for treating disease.
A protein’s dual role
Three of C. elegans’ primary regulators of apoptosis actively promote cell death, whereas just one, CED-9, reins in the apoptosis-promoting proteins to keep cells alive. As early as the 1990s, however, Horvitz and colleagues recognized that CED-9 was not exclusively a protector of cells. Their experiments indicated that the protector protein also plays a role in promoting cell death. But while researchers thought they knew how CED-9 protected against apoptosis, its pro-apoptotic role was more puzzling.
CED-9’s dual role means that mutations in the gene that encode it can impact apoptosis in multiple ways. Most ced-9 mutations interfere with the protein’s ability to protect against cell death and result in excess cell death. Conversely, mutations that abnormally activate ced-9 cause too little cell death, just like mutations that inactivate any of the three killer genes.
An atypical ced-9 mutation, identified by Reddien when he was a PhD student in Horvitz’s lab, hinted at how CED-9 promotes cell death. That mutation altered the part of the CED-9 protein that interacts with the protein CED-4, which is proapoptotic. Since the mutation specifically leads to a reduction in apoptosis, this suggested that CED-9 might need to interact with CED-4 to promote cell death.
The idea was particularly intriguing because researchers had long thought that CED-9’s interaction with CED-4 had exactly the opposite effect: In the canonical model, CED-9 anchors CED-4 to cells’ mitochondria, sequestering the CED-4 killer protein and preventing it from associating with and activating another key killer, the CED-3 protein — thereby preventing apoptosis.
To test the hypothesis that CED-9’s interactions with the killer CED-4 protein enhance apoptosis, the team needed more evidence. So graduate student Nolan Tucker used CRISPR gene editing tools to create more worms with mutations in CED-9, each one targeting a different spot in the CED-4-binding region. Then he examined the worms. “What I saw with this particular class of mutations was extra cells and viability,” he says — clear signs that the altered CED-9 was still protecting against cell death, but could no longer promote it. “Those observations strongly supported the hypothesis that the ability to bind CED-4 is needed for the pro-apoptotic function of CED-9,” Tucker explains. Their observations also suggested that, contrary to earlier thinking, CED-9 doesn’t need to bind with CED-4 to protect against apoptosis.
When he looked inside the cells of the mutant worms, Tucker found additional evidence that these mutations prevented CED-9’s ability to interact with CED-4. When both CED-9 and CED-4 are intact, CED-4 appears associated with cells’ mitochondria. But in the presence of these mutations, CED-4 was instead at the edge of the cell nucleus. CED-9’s ability to bind CED-4 to mitochondria appeared to be necessary to promote apoptosis, not to protect against it.
Looking ahead
While the team’s findings begin to explain a long-unanswered question about one of the primary regulators of apoptosis, they raise new ones, as well. “I think that this main pathway of apoptosis has been seen by a lot of people as more-or-less settled science. Our findings should change that view,” Tucker says.
The researchers see important parallels between their findings from this study of worms and what’s known about cell death pathways in mammals. The mammalian counterpart to CED-9 is a protein called BCL-2, mutations in which can lead to cancer. BCL-2, like CED-9, can both promote and protect against apoptosis. As with CED-9, the pro-apoptotic function of BCL-2 has been mysterious. In mammals, too, mitochondria play a key role in activating apoptosis. The Horvitz lab’s discovery opens opportunities to better understand how apoptosis is regulated not only in worms but also in humans, and how dysregulation of apoptosis in humans can lead to such disorders as cancer, autoimmune disease, and neurodegeneration.
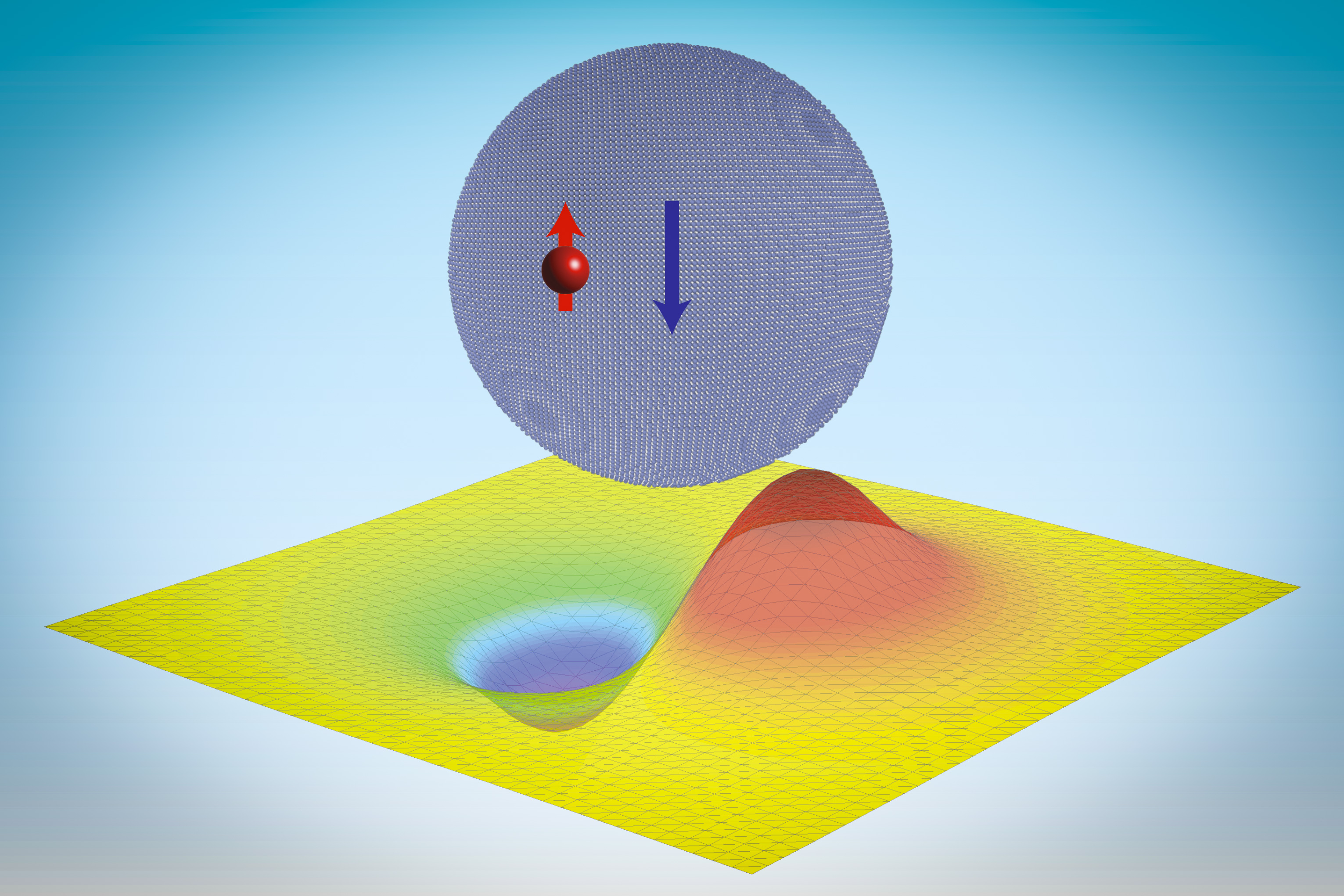
MIT physicists have shown that it should be possible to create an exotic form of matter that could be manipulated to form the qubit (quantum bit) building blocks of future quantum computers that are even more powerful than the quantum computers in development today.
The work builds on a discovery last year of materials that host electrons that can split into fractions of themselves but, importantly, can do so without the application of a magnetic field.
The general phenomenon of electron fractionalization was first discovered in 1982 and resulted in a Nobel Prize. That work, however, required the application of a magnetic field. The ability to create the fractionalized electrons without a magnetic field opens new possibilities for basic research and makes the materials hosting them more useful for applications.
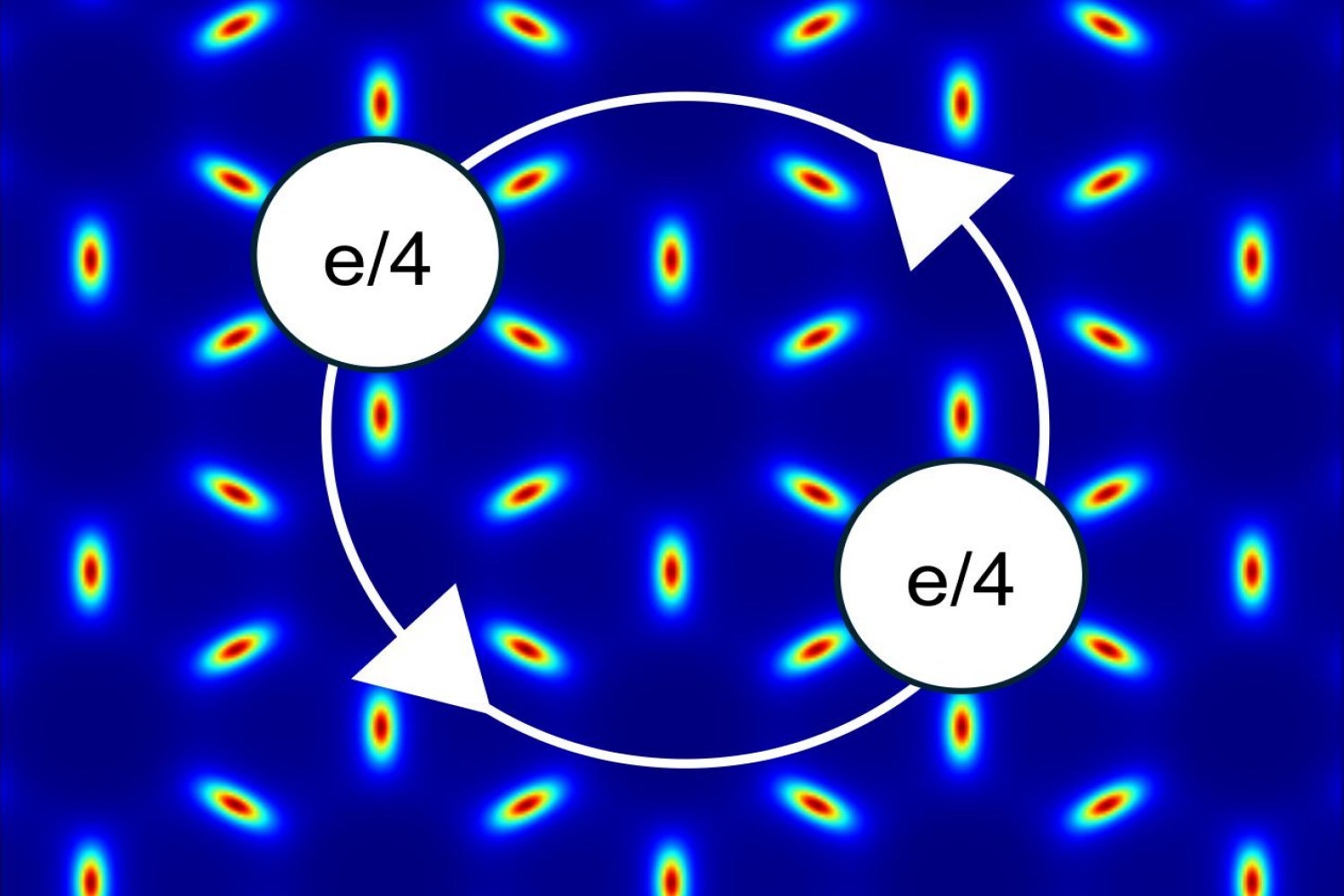
When electrons split into fractions of themselves, those fractions are known as anyons. Anyons come in variety of flavors, or classes. The anyons discovered in the 2023 materials are known as Abelian anyons. Now, in a paper reported in the Oct. 17 issue of Physical Review Letters, the MIT team notes that it should be possible to create the most exotic class of anyons, non-Abelian anyons.
“Non-Abelian anyons have the bewildering capacity of ‘remembering’ their spacetime trajectories; this memory effect can be useful for quantum computing,” says Liang Fu, a professor in MIT’s Department of Physics and leader of the work.
Fu further notes that “the 2023 experiments on electron fractionalization greatly exceeded theoretical expectations. My takeaway is that we theorists should be bolder.”
Fu is also affiliated with the MIT Materials Research Laboratory. His colleagues on the current work are graduate students Aidan P. Reddy and Nisarga Paul, and postdoc Ahmed Abouelkomsan, all of the MIT Department of Phsyics. Reddy and Paul are co-first authors of the Physical Review Letters paper.
The MIT work and two related studies were also featured in an Oct. 17 story in Physics Magazine. “If this prediction is confirmed experimentally, it could lead to more reliable quantum computers that can execute a wider range of tasks … Theorists have already devised ways to harness non-Abelian states as workable qubits and manipulate the excitations of these states to enable robust quantum computation,” writes Ryan Wilkinson.
The current work was guided by recent advances in 2D materials, or those consisting of only one or a few layers of atoms. “The whole world of two-dimensional materials is very interesting because you can stack them and twist them, and sort of play Legos with them to get all sorts of cool sandwich structures with unusual properties,” says Paul. Those sandwich structures, in turn, are called moiré materials.
Anyons can only form in two-dimensional materials. Could they form in moiré materials? The 2023 experiments were the first to show that they can. Soon afterwards, a group led by Long Ju, an MIT assistant professor of physics, reported evidence of anyons in another moiré material. (Fu and Reddy were also involved in the Ju work.)
In the current work, the physicists showed that it should be possible to create non-Abelian anyons in a moiré material composed of atomically thin layers of molybdenum ditelluride. Says Paul, “moiré materials have already revealed fascinating phases of matter in recent years, and our work shows that non-Abelian phases could be added to the list.”
Adds Reddy, “our work shows that when electrons are added at a density of 3/2 or 5/2 per unit cell, they can organize into an intriguing quantum state that hosts non-Abelian anyons.”
The work was exciting, says Reddy, in part because “oftentimes there’s subtlety in interpreting your results and what they are actually telling you. So it was fun to think through our arguments” in support of non-Abelian anyons.
Says Paul, “this project ranged from really concrete numerical calculations to pretty abstract theory and connected the two. I learned a lot from my collaborators about some very interesting topics.”
This work was supported by the U.S. Air Force Office of Scientific Research. The authors also acknowledge the MIT SuperCloud and Lincoln Laboratory Supercomputing Center, the Kavli Institute for Theoretical Physics, the Knut and Alice Wallenberg Foundation, and the Simons Foundation.
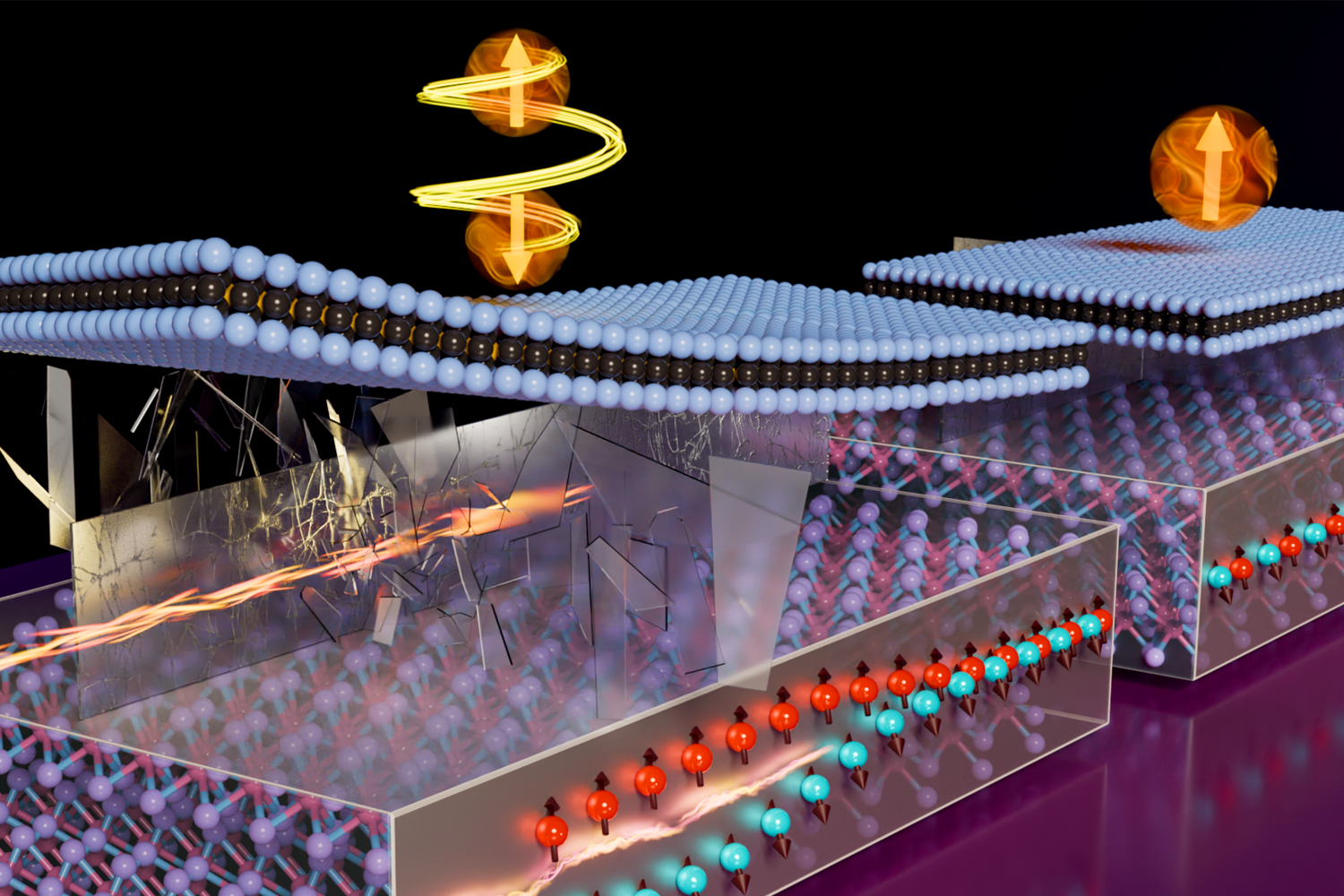
This illustration represents an emergent magnetic field felt by electrons in atomically thin layers of molybdenum ditelluride in the absence of an external magnetic field. White circles represent fractionally charged non-Abelian anyons exchanging positions. This phenomenon could be exploited to create quantum bits, the building blocks of future quantum computers.
MIT physicists have taken a key step toward solving the puzzle of what leads electrons to split into fractions of themselves. Their solution sheds light on the conditions that give rise to exotic electronic states in graphene and other two-dimensional systems.
The new work is an effort to make sense of a discovery that was reported earlier this year by a different group of physicists at MIT, led by Assistant Professor Long Ju. Ju’s team found that electrons appear to exhibit “fractional charge” in pentalayer graphene — a configuration of five graphene layers that are stacked atop a similarly structured sheet of boron nitride.
Ju discovered that when he sent an electric current through the pentalayer structure, the electrons seemed to pass through as fractions of their total charge, even in the absence of a magnetic field. Scientists had already shown that electrons can split into fractions under a very strong magnetic field, in what is known as the fractional quantum Hall effect. Ju’s work was the first to find that this effect was possible in graphene without a magnetic field — which until recently was not expected to exhibit such an effect.
The phenemonon was coined the “fractional quantum anomalous Hall effect,” and theorists have been keen to find an explanation for how fractional charge can emerge from pentalayer graphene.
The new study, led by MIT professor of physics Senthil Todadri, provides a crucial piece of the answer. Through calculations of quantum mechanical interactions, he and his colleagues show that the electrons form a sort of crystal structure, the properties of which are ideal for fractions of electrons to emerge.
“This is a completely new mechanism, meaning in the decades-long history, people have never had a system go toward these kinds of fractional electron phenomena,” Todadri says. “It’s really exciting because it makes possible all kinds of new experiments that previously one could only dream about.”
The team’s study appeared last week in the journal Physical Review Letters. Two other research teams — one from Johns Hopkins University, and the other from Harvard University, the University of California at Berkeley, and Lawrence Berkeley National Laboratory — have each published similar results in the same issue. The MIT team includes Zhihuan Dong PhD ’24 and former postdoc Adarsh Patri.
“Fractional phenomena”
In 2018, MIT professor of physics Pablo Jarillo-Herrero and his colleagues were the first to observe that new electronic behavior could emerge from stacking and twisting two sheets of graphene. Each layer of graphene is as thin as a single atom and structured in a chicken-wire lattice of hexagonal carbon atoms. By stacking two sheets at a very specific angle to each other, he found that the resulting interference, or moiré pattern, induced unexpected phenomena such as both superconducting and insulating properties in the same material. This “magic-angle graphene,” as it was soon coined, ignited a new field known as twistronics, the study of electronic behavior in twisted, two-dimensional materials.
“Shortly after his experiments, we realized these moiré systems would be ideal platforms in general to find the kinds of conditions that enable these fractional electron phases to emerge,” says Todadri, who collaborated with Jarillo-Herrero on a study that same year to show that, in theory, such twisted systems could exhibit fractional charge without a magnetic field. “We were advocating these as the best systems to look for these kinds of fractional phenomena,” he says.
Then, in September of 2023, Todadri hopped on a Zoom call with Ju, who was familiar with Todari’s theoretical work and had kept in touch with him through Ju’s own experimental work.
“He called me on a Saturday and showed me the data in which he saw these [electron] fractions in pentalayer graphene,” Todadri recalls. “And that was a big surprise because it didn’t play out the way we thought.”
In his 2018 paper, Todadri predicted that fractional charge should emerge from a precursor phase characterized by a particular twisting of the electron wavefunction. Broadly speaking, he theorized that an electron’s quantum properties should have a certain twisting, or degree to which it can be manipulated without changing its inherent structure. This winding, he predicted, should increase with the number of graphene layers added to a given moiré structure.
“For pentalayer graphene, we thought the wavefunction would wind around five times, and that would be a precursor for electron fractions,” Todadri says. “But he did his experiments and discovered that it does wind around, but only once. That then raised this big question: How should we think about whatever we are seeing?”
Extraordinary crystal
In the team’s new study, Todadri went back to work out how electron fractions could emerge from pentalayer graphene if not through the path he initially predicted. The physicists looked through their original hypothesis and realized they may have missed a key ingredient.
“The standard strategy in the field when figuring out what’s happening in any electronic system is to treat electrons as independent actors, and from that, figure out their topology, or winding,” Todadri explains. “But from Long’s experiments, we knew this approximation must be incorrect.”
While in most materials, electrons have plenty of space to repel each other and zing about as independent agents, the particles are much more confined in two-dimensional structures such as pentalayer graphene. In such tight quarters, the team realized that electrons should also be forced to interact, behaving according to their quantum correlations in addition to their natural repulsion. When the physicists added interelectron interactions to their theory, they found it correctly predicted the winding that Ju observed for pentalayer graphene.
Once they had a theoretical prediction that matched with observations, the team could work from this prediction to identify a mechanism by which pentalayer graphene gave rise to fractional charge.
They found that the moiré arrangement of pentalayer graphene, in which each lattice-like layer of carbon atoms is arranged atop the other and on top of the boron-nitride, induces a weak electrical potential. When electrons pass through this potential, they form a sort of crystal, or a periodic formation, that confines the electrons and forces them to interact through their quantum correlations. This electron tug-of-war creates a sort of cloud of possible physical states for each electron, which interacts with every other electron cloud in the crystal, in a wavefunction, or a pattern of quantum correlations, that gives the winding that should set the stage for electrons to split into fractions of themselves.
“This crystal has a whole set of unusual properties that are different from ordinary crystals, and leads to many fascinating questions for future research,” Todadri says. “For the short term, this mechanism provides the theoretical foundation for understanding the observations of fractions of electrons in pentalayer graphene and for predicting other systems with similar physics.”
This work was supported, in part, by the National Science Foundation and the Simons Foundation.
J-PAL North America recently selected government partners for the 2024-25 Leveraging Evaluation and Evidence for Equitable Recovery (LEVER) Evaluation Incubator cohort. Selected collaborators will receive funding and technical assistance to develop or launch a randomized evaluation for one of their programs. These collaborations represent jurisdictions across the United States and demonstrate the growing enthusiasm for evidence-based policymaking.
Launched in 2023, LEVER is a joint venture between J-PAL North America and Results for America. Through the Evaluation Incubator, trainings, and other program offerings, LEVER seeks to address the barriers many state and local governments face around finding and generating evidence to inform program design. LEVER offers government leaders the opportunity to learn best practices for policy evaluations and how to integrate evidence into decision-making. Since the program’s inception, more than 80 government jurisdictions have participated in LEVER offerings.
J-PAL North America’s Evaluation Incubator helps collaborators turn policy-relevant research questions into well-designed randomized evaluations, generating rigorous evidence to inform pressing programmatic and policy decisions. The program also aims to build a culture of evidence use and give government partners the tools to continue generating and utilizing evidence in their day-to-day operations.
In addition to funding and technical assistance, the selected state and local government collaborators will be connected with researchers from J-PAL’s network to help advance their evaluation ideas. Evaluation support will also be centered on community-engaged research practices, which emphasize collaborating with and learning from the groups most affected by the program being evaluated.
Evaluation Incubator selected projects
Pierce County Human Services (PCHS) in the state of Washington will evaluate two programs as part of the Evaluation Incubator. The first will examine how extending stays in a fentanyl detox program affects the successful completion of inpatient treatment and hospital utilization for individuals. “PCHS is interested in evaluating longer fentanyl detox stays to inform our funding decisions, streamline our resource utilization, and encourage additional financial commitments to address the unmet needs of individuals dealing with opioid use disorder,” says Trish Crocker, grant coordinator.
The second PCHS program will evaluate the impact of providing medication and outreach services via a mobile distribution unit to individuals with opioid use disorders on program take-up and substance usage. Margo Burnison, a behavioral health manager with PCHS, says that the team is “thrilled to be partnering with J-PAL North America to dive deep into the data to inform our elected leaders on the best way to utilize available resources.”
The City of Los Angeles Youth Development Department (YDD) seeks to evaluate a research-informed program: Student Engagement, Exploration, and Development in STEM (SEEDS). This intergenerational STEM mentorship program supports underrepresented middle school and college students in STEM by providing culturally responsive mentorship. The program seeks to foster these students’ STEM identity and degree attainment in higher education. YDD has been working with researchers at the University of Southern California to measure the SEEDS program’s impact, but is interested in developing a randomized evaluation to generate further evidence. Darnell Cole, professor and co-director of the Research Center for Education, Identity and Social Justice, shares his excitement about the collaboration with J-PAL: “We welcome the opportunity to measure the impact of the SEEDS program on our students’ educational experience. Rigorously testing the SEEDS program will help us improve support for STEM students, ultimately enhancing their persistence and success.”
The Fort Wayne Police Department’s Hope and Recovery Team in Indiana will evaluate the impact of two programs that connect social workers with people who have experienced an overdose, or who have a mental health illness, to treatment and resources. “We believe we are on the right track in the work we are doing with the crisis intervention social worker and the recovery coach, but having an outside evaluation of both programs would be extremely helpful in understanding whether and what aspects of these programs are most effective,” says Police Captain Kevin Hunter.
The County of San Diego’s Office of Evaluation, Performance and Analytics, and Planning & Development Services will engage with J-PAL staff to explore evaluation opportunities for two programs that are a part of the county’s Climate Action Plan. The Equity-Driven Tree Planting Program seeks to increase tree canopy coverage, and the Climate Smart Land Stewardship Program will encourage climate-smart agricultural practices. Ricardo Basurto-Davila, chief evaluation officer, says that “the county is dedicated to evidence-based policymaking and taking decisive action against climate change. The work with J-PAL will support us in combining these commitments to maximize the effectiveness in decreasing emissions through these programs.”
J-PAL North America looks forward to working with the selected collaborators in the coming months to learn more about these promising programs, clarify our partner’s evidence goals, and design randomized evaluations to measure their impact.
Fort Wayne, Indiana, is one of J-PAL North America’s LEVER Evaluation Incubator collaborators. With support from J-PAL staff, Fort Wayne is designing evaluations of two programs that connect social workers with people who have experienced an overdose or have a mental health illness to treatment and resources.
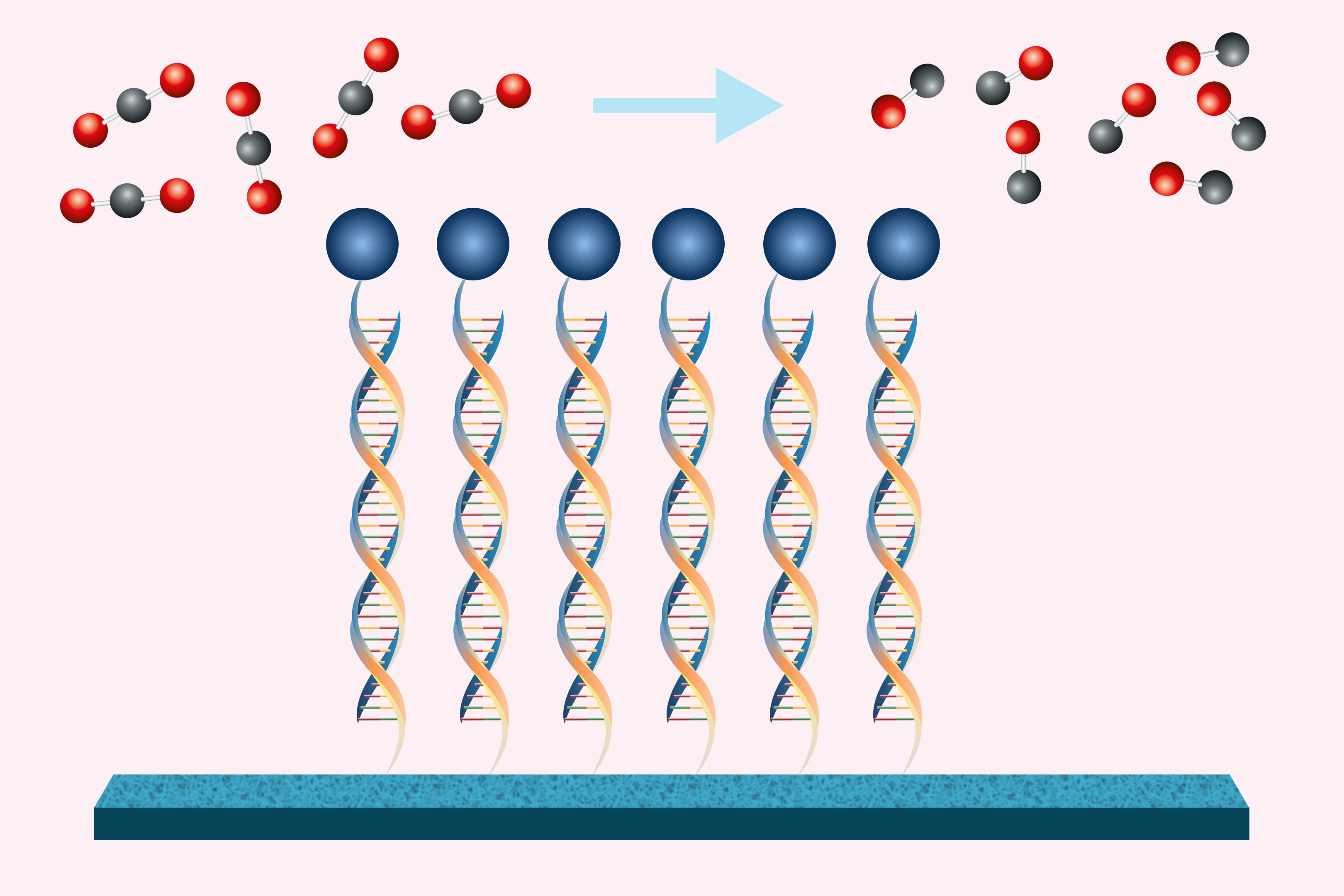
As the world struggles to reduce greenhouse gas emissions, researchers are seeking practical, economical ways to capture carbon dioxide and convert it into useful products, such as transportation fuels, chemical feedstocks, or even building materials. But so far, such attempts have struggled to reach economic viability.
New research by engineers at MIT could lead to rapid improvements in a variety of electrochemical systems that are under development to convert carbon dioxide into a valuable commodity. The team developed a new design for the electrodes used in these systems, which increases the efficiency of the conversion process.
The findings are reported today in the journal Nature Communications, in a paper by MIT doctoral student Simon Rufer, professor of mechanical engineering Kripa Varanasi, and three others.
“The CO2 problem is a big challenge for our times, and we are using all kinds of levers to solve and address this problem,” Varanasi says. It will be essential to find practical ways of removing the gas, he says, either from sources such as power plant emissions, or straight out of the air or the oceans. But then, once the CO2 has been removed, it has to go somewhere.
A wide variety of systems have been developed for converting that captured gas into a useful chemical product, Varanasi says. “It’s not that we can’t do it — we can do it. But the question is how can we make this efficient? How can we make this cost-effective?”
In the new study, the team focused on the electrochemical conversion of CO2 to ethylene, a widely used chemical that can be made into a variety of plastics as well as fuels, and which today is made from petroleum. But the approach they developed could also be applied to producing other high-value chemical products as well, including methane, methanol, carbon monoxide, and others, the researchers say.
Currently, ethylene sells for about $1,000 per ton, so the goal is to be able to meet or beat that price. The electrochemical process that converts CO2 into ethylene involves a water-based solution and a catalyst material, which come into contact along with an electric current in a device called a gas diffusion electrode.
There are two competing characteristics of the gas diffusion electrode materials that affect their performance: They must be good electrical conductors so that the current that drives the process doesn’t get wasted through resistance heating, but they must also be “hydrophobic,” or water repelling, so the water-based electrolyte solution doesn’t leak through and interfere with the reactions taking place at the electrode surface.
Unfortunately, it’s a tradeoff. Improving the conductivity reduces the hydrophobicity, and vice versa. Varanasi and his team set out to see if they could find a way around that conflict, and after many months of work, they did just that.
The solution, devised by Rufer and Varanasi, is elegant in its simplicity. They used a plastic material, PTFE (essentially Teflon), that has been known to have good hydrophobic properties. However, PTFE’s lack of conductivity means that electrons must travel through a very thin catalyst layer, leading to significant voltage drop with distance. To overcome this limitation, the researchers wove a series of conductive copper wires through the very thin sheet of the PTFE.
“This work really addressed this challenge, as we can now get both conductivity and hydrophobicity,” Varanasi says.
Research on potential carbon conversion systems tends to be done on very small, lab-scale samples, typically less than 1-inch (2.5-centimeter) squares. To demonstrate the potential for scaling up, Varanasi’s team produced a sheet 10 times larger in area and demonstrated its effective performance.
To get to that point, they had to do some basic tests that had apparently never been done before, running tests under identical conditions but using electrodes of different sizes to analyze the relationship between conductivity and electrode size. They found that conductivity dropped off dramatically with size, which would mean much more energy, and thus cost, would be needed to drive the reaction.
“That’s exactly what we would expect, but it was something that nobody had really dedicatedly investigated before,” Rufer says. In addition, the larger sizes produced more unwanted chemical byproducts besides the intended ethylene.
Real-world industrial applications would require electrodes that are perhaps 100 times larger than the lab versions, so adding the conductive wires will be necessary for making such systems practical, the researchers say. They also developed a model which captures the spatial variability in voltage and product distribution on electrodes due to ohmic losses. The model along with the experimental data they collected enabled them to calculate the optimal spacing for conductive wires to counteract the drop off in conductivity.
In effect, by weaving the wire through the material, the material is divided into smaller subsections determined by the spacing of the wires. “We split it into a bunch of little subsegments, each of which is effectively a smaller electrode,” Rufer says. “And as we’ve seen, small electrodes can work really well.”
Because the copper wire is so much more conductive than the PTFE material, it acts as a kind of superhighway for electrons passing through, bridging the areas where they are confined to the substrate and face greater resistance.
To demonstrate that their system is robust, the researchers ran a test electrode for 75 hours continuously, with little change in performance. Overall, Rufer says, their system “is the first PTFE-based electrode which has gone beyond the lab scale on the order of 5 centimeters or smaller. It’s the first work that has progressed into a much larger scale and has done so without sacrificing efficiency.”
The weaving process for incorporating the wire can be easily integrated into existing manufacturing processes, even in a large-scale roll-to-roll process, he adds.
“Our approach is very powerful because it doesn’t have anything to do with the actual catalyst being used,” Rufer says. “You can sew this micrometric copper wire into any gas diffusion electrode you want, independent of catalyst morphology or chemistry. So, this approach can be used to scale anybody’s electrode.”
“Given that we will need to process gigatons of CO2 annually to combat the CO2 challenge, we really need to think about solutions that can scale,” Varanasi says. “Starting with this mindset enables us to identify critical bottlenecks and develop innovative approaches that can make a meaningful impact in solving the problem. Our hierarchically conductive electrode is a result of such thinking.”
The research team included MIT graduate students Michael Nitzsche and Sanjay Garimella, as well as Jack Lake PhD ’23. The work was supported by Shell, through the MIT Energy Initiative.
This work was carried out, in part, through the use of MIT.nano facilities.
A conceptual schematic of the new woven electrode design. Researchers wove a series of conductive copper wires (the brown-orange pipe) through a very thin membrane to reach the catalyst.
Imagine using artificial intelligence to compare two seemingly unrelated creations — biological tissue and Beethoven’s “Symphony No. 9.” At first glance, a living system and a musical masterpiece might appear to have no connection. However, a novel AI method developed by Markus J. Buehler, the McAfee Professor of Engineering and professor of civil and environmental engineering and mechanical engineering at MIT, bridges this gap, uncovering shared patterns of complexity and order.
“By blending generative AI with graph-based computational tools, this approach reveals entirely new ideas, concepts, and designs that were previously unimaginable. We can accelerate scientific discovery by teaching generative AI to make novel predictions about never-before-seen ideas, concepts, and designs,” says Buehler.
The open-access research, recently published in Machine Learning: Science and Technology, demonstrates an advanced AI method that integrates generative knowledge extraction, graph-based representation, and multimodal intelligent graph reasoning.
The work uses graphs developed using methods inspired by category theory as a central mechanism to teach the model to understand symbolic relationships in science. Category theory, a branch of mathematics that deals with abstract structures and relationships between them, provides a framework for understanding and unifying diverse systems through a focus on objects and their interactions, rather than their specific content. In category theory, systems are viewed in terms of objects (which could be anything, from numbers to more abstract entities like structures or processes) and morphisms (arrows or functions that define the relationships between these objects). By using this approach, Buehler was able to teach the AI model to systematically reason over complex scientific concepts and behaviors. The symbolic relationships introduced through morphisms make it clear that the AI isn't simply drawing analogies, but is engaging in deeper reasoning that maps abstract structures across different domains.
Buehler used this new method to analyze a collection of 1,000 scientific papers about biological materials and turned them into a knowledge map in the form of a graph. The graph revealed how different pieces of information are connected and was able to find groups of related ideas and key points that link many concepts together.
“What’s really interesting is that the graph follows a scale-free nature, is highly connected, and can be used effectively for graph reasoning,” says Buehler. “In other words, we teach AI systems to think about graph-based data to help them build better world representations models and to enhance the ability to think and explore new ideas to enable discovery.”
Researchers can use this framework to answer complex questions, find gaps in current knowledge, suggest new designs for materials, and predict how materials might behave, and link concepts that had never been connected before.
The AI model found unexpected similarities between biological materials and “Symphony No. 9,” suggesting that both follow patterns of complexity. “Similar to how cells in biological materials interact in complex but organized ways to perform a function, Beethoven's 9th symphony arranges musical notes and themes to create a complex but coherent musical experience,” says Buehler.
In another experiment, the graph-based AI model recommended creating a new biological material inspired by the abstract patterns found in Wassily Kandinsky’s painting, “Composition VII.” The AI suggested a new mycelium-based composite material. “The result of this material combines an innovative set of concepts that include a balance of chaos and order, adjustable property, porosity, mechanical strength, and complex patterned chemical functionality,” Buehler notes. By drawing inspiration from an abstract painting, the AI created a material that balances being strong and functional, while also being adaptable and capable of performing different roles. The application could lead to the development of innovative sustainable building materials, biodegradable alternatives to plastics, wearable technology, and even biomedical devices.
With this advanced AI model, scientists can draw insights from music, art, and technology to analyze data from these fields to identify hidden patterns that could spark a world of innovative possibilities for material design, research, and even music or visual art.
“Graph-based generative AI achieves a far higher degree of novelty, explorative of capacity and technical detail than conventional approaches, and establishes a widely useful framework for innovation by revealing hidden connections,” says Buehler. “This study not only contributes to the field of bio-inspired materials and mechanics, but also sets the stage for a future where interdisciplinary research powered by AI and knowledge graphs may become a tool of scientific and philosophical inquiry as we look to other future work.”
“Markus Buehler’s analysis of papers on bioinspired materials transformed gigabytes of information into knowledge graphs representing the connectivity of various topics and disciplines,” says Nicholas Kotov, the Irving Langmuir Distinguished Professor of Chemical Sciences and Engineering at the University of Michigan, who was not involved with this work. “These graphs can be used as information maps that enable us to identify central topics, novel relationships, and potential research directions by exploring complex linkages across subsections of the bioinspired and biomimetic materials. These and other graphs like that are likely to be an essential research tool for current and future scientists.”
A graph-based AI model (center) recommended creating a new mycelium-based biological material (right), using inspiration from the abstract patterns found in Wassily Kandinsky’s painting, “Composition VII” (left).
There’s no doubt that exercise does a body good. Regular activity not only strengthens muscles but can bolster our bones, blood vessels, and immune system.
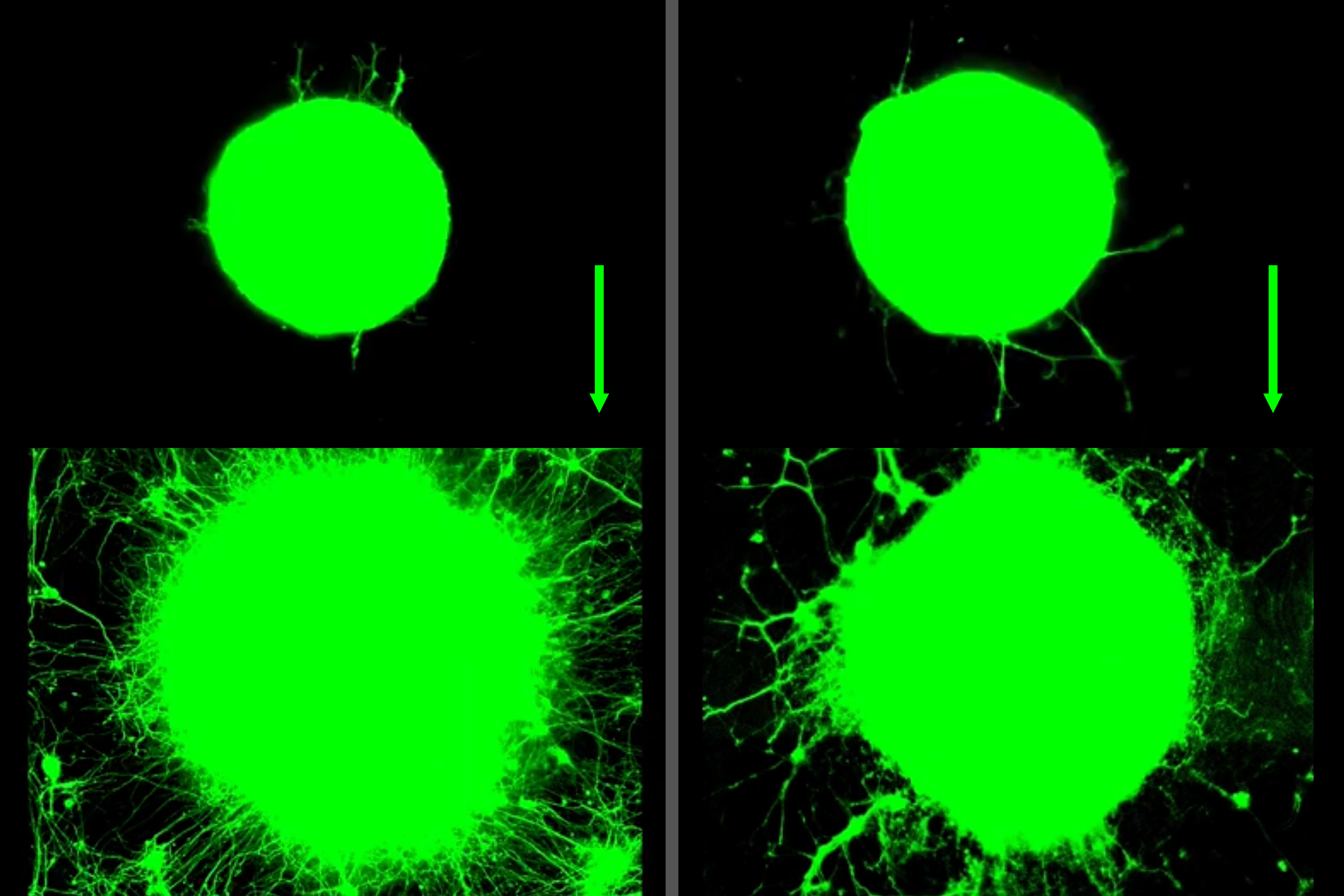
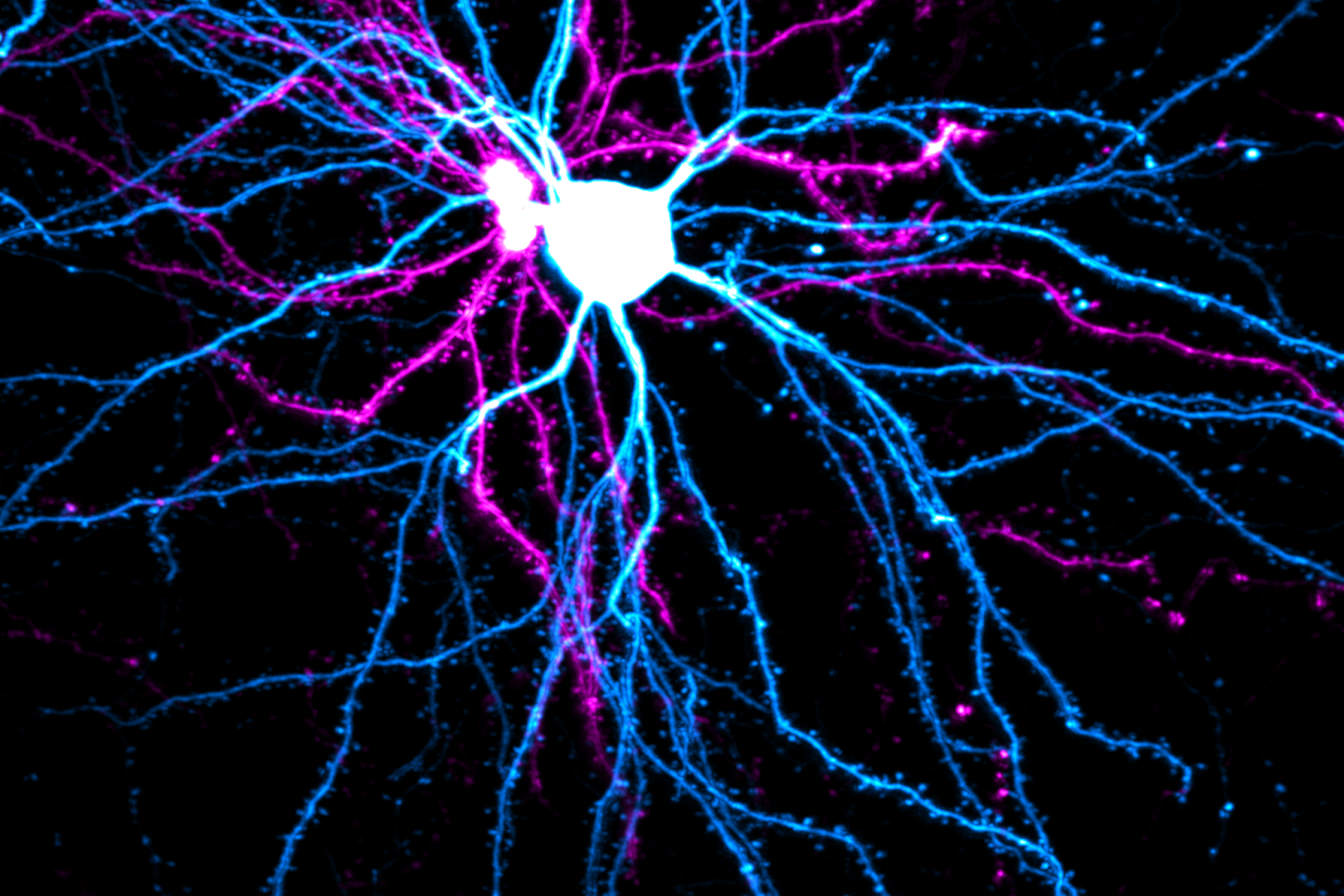
Now, MIT engineers have found that exercise can also have benefits at the level of individual neurons. They observed that when muscles contract during exercise, they release a soup of biochemical signals called myokines. In the presence of these muscle-generated signals, neurons grew four times farther compared to neurons that were not exposed to myokines. These cellular-level experiments suggest that exercise can have a significant biochemical effect on nerve growth.
Surprisingly, the researchers also found that neurons respond not only to the biochemical signals of exercise but also to its physical impacts. The team observed that when neurons are repeatedly pulled back and forth, similarly to how muscles contract and expand during exercise, the neurons grow just as much as when they are exposed to a muscle’s myokines.
While previous studies have indicated a potential biochemical link between muscle activity and nerve growth, this study is the first to show that physical effects can be just as important, the researchers say. The results, which are published today in the journal Advanced Healthcare Materials, shed light on the connection between muscles and nerves during exercise, and could inform exercise-related therapies for repairing damaged and deteriorating nerves.
“Now that we know this muscle-nerve crosstalk exists, it can be useful for treating things like nerve injury, where communication between nerve and muscle is cut off,” says Ritu Raman, the Eugene Bell Career Development Assistant Professor of Mechanical Engineering at MIT. “Maybe if we stimulate the muscle, we could encourage the nerve to heal, and restore mobility to those who have lost it due to traumatic injury or neurodegenerative diseases.”
Raman is the senior author of the new study, which includes Angel Bu, Ferdows Afghah, Nicolas Castro, Maheera Bawa, Sonika Kohli, Karina Shah, and Brandon Rios of MIT’s Department of Mechanical Engineering, and Vincent Butty of MIT’s Koch Institute for Integrative Cancer Research.
Muscle talk
In 2023, Raman and her colleagues reported that they could restore mobility in mice that had experienced a traumatic muscle injury, by first implanting muscle tissue at the site of injury, then exercising the new tissue by stimulating it repeatedly with light. Over time, they found that the exercised graft helped mice to regain their motor function, reaching activity levels comparable to those of healthy mice.
When the researchers analyzed the graft itself, it appeared that regular exercise stimulated the grafted muscle to produce certain biochemical signals that are known to promote nerve and blood vessel growth.
“That was interesting because we always think that nerves control muscle, but we don’t think of muscles talking back to nerves,” Raman says. “So, we started to think stimulating muscle was encouraging nerve growth. And people replied that maybe that’s the case, but there’s hundreds of other cell types in an animal, and it’s really hard to prove that the nerve is growing more because of the muscle, rather than the immune system or something else playing a role.”
In their new study, the team set out to determine whether exercising muscles has any direct effect on how nerves grow, by focusing solely on muscle and nerve tissue. The researchers grew mouse muscle cells into long fibers that then fused to form a small sheet of mature muscle tissue about the size of a quarter.
The team genetically modified the muscle to contract in response to light. With this modification, the team could flash a light repeatedly, causing the muscle to squeeze in response, in a way that mimicked the act of exercise. Raman previously developed a novel gel mat on which to grow and exercise muscle tissue. The gel’s properties are such that it can support muscle tissue and prevent it from peeling away as the researchers stimulated the muscle to exercise.
The team then collected samples of the surrounding solution in which the muscle tissue was exercised, thinking that the solution should hold myokines, including growth factors, RNA, and a mix of other proteins.
“I would think of myokines as a biochemical soup of things that muscles secrete, some of which could be good for nerves and others that might have nothing to do with nerves,” Raman says. “Muscles are pretty much always secreting myokines, but when you exercise them, they make more.”
“Exercise as medicine”
The team transferred the myokine solution to a separate dish containing motor neurons — nerves found in the spinal cord that control muscles involved in voluntary movement. The researchers grew the neurons from stem cells derived from mice. As with the muscle tissue, the neurons were grown on a similar gel mat. After the neurons were exposed to the myokine mixture, the team observed that they quickly began to grow, four times faster than neurons that did not receive the biochemical solution.
“They grow much farther and faster, and the effect is pretty immediate,” Raman notes.
For a closer look at how neurons changed in response to the exercise-induced myokines, the team ran a genetic analysis, extracting RNA from the neurons to see whether the myokines induced any change in the expression of certain neuronal genes.
“We saw that many of the genes up-regulated in the exercise-stimulated neurons was not only related to neuron growth, but also neuron maturation, how well they talk to muscles and other nerves, and how mature the axons are,” Raman says. “Exercise seems to impact not just neuron growth but also how mature and well-functioning they are.”
The results suggest that biochemical effects of exercise can promote neuron growth. Then the group wondered: Could exercise’s purely physical impacts have a similar benefit?
“Neurons are physically attached to muscles, so they are also stretching and moving with the muscle,” Raman says. “We also wanted to see, even in the absence of biochemical cues from muscle, could we stretch the neurons back and forth, mimicking the mechanical forces (of exercise), and could that have an impact on growth as well?”
To answer this, the researchers grew a different set of motor neurons on a gel mat that they embedded with tiny magnets. They then used an external magnet to jiggle the mat — and the neurons — back and forth. In this way, they “exercised” the neurons, for 30 minutes a day. To their surprise, they found that this mechanical exercise stimulated the neurons to grow just as much as the myokine-induced neurons, growing significantly farther than neurons that received no form of exercise.
“That’s a good sign because it tells us both biochemical and physical effects of exercise are equally important,” Raman says.
Now that the group has shown that exercising muscle can promote nerve growth at the cellular level, they plan to study how targeted muscle stimulation can be used to grow and heal damaged nerves, and restore mobility for people who are living with a neurodegenerative disease such as ALS.
“This is just our first step toward understanding and controlling exercise as medicine,” Raman says.
MIT scientists find that motor neuron growth increased significantly over 5 days in response to biochemical (left) and mechanical (right) signals related to exercise. The green ball represents cluster of neurons that grow outward in long tails, or axons.
As a major contributor to global carbon dioxide (CO2) emissions, the transportation sector has immense potential to advance decarbonization. However, a zero-emissions global supply chain requires re-imagining reliance on a heavy-duty trucking industry that emits 810,000 tons of CO2, or 6 percent of the United States’ greenhouse gas emissions, and consumes 29 billion gallons of diesel annually in the U.S. alone.
A new study by MIT researchers, presented at the recent American Society of Mechanical Engineers 2024 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, quantifies the impact of a zero-emission truck’s design range on its energy storage requirements and operational revenue. The multivariable model outlined in the paper allows fleet owners and operators to better understand the design choices that impact the economic feasibility of battery-electric and hydrogen fuel cell heavy-duty trucks for commercial application, equipping stakeholders to make informed fleet transition decisions.
“The whole issue [of decarbonizing trucking] is like a very big, messy pie. One of the things we can do, from an academic standpoint, is quantify some of those pieces of pie with modeling, based on information and experience we’ve learned from industry stakeholders,” says ZhiYi Liang, PhD student on the renewable hydrogen team at the MIT K. Lisa Yang Global Engineering and Research Center (GEAR) and lead author of the study. Co-authored by Bryony DuPont, visiting scholar at GEAR, and Amos Winter, the Germeshausen Professor in the MIT Department of Mechanical Engineering, the paper elucidates operational and socioeconomic factors that need to be considered in efforts to decarbonize heavy-duty vehicles (HDVs).
Operational and infrastructure challenges
The team’s model shows that a technical challenge lies in the amount of energy that needs to be stored on the truck to meet the range and towing performance needs of commercial trucking applications. Due to the high energy density and low cost of diesel, existing diesel drivetrains remain more competitive than alternative lithium battery-electric vehicle (Li-BEV) and hydrogen fuel-cell-electric vehicle (H2 FCEV) drivetrains. Although Li-BEV drivetrains have the highest energy efficiency of all three, they are limited to short-to-medium range routes (under 500 miles) with low freight capacity, due to the weight and volume of the onboard energy storage needed. In addition, the authors note that existing electric grid infrastructure will need significant upgrades to support large-scale deployment of Li-BEV HDVs.
While the hydrogen-powered drivetrain has a significant weight advantage that enables higher cargo capacity and routes over 750 miles, the current state of hydrogen fuel networks limits economic viability, especially once operational cost and projected revenue are taken into account. Deployment will most likely require government intervention in the form of incentives and subsidies to reduce the price of hydrogen by more than half, as well as continued investment by corporations to ensure a stable supply. Also, as H2-FCEVs are still a relatively new technology, the ongoing design of conformal onboard hydrogen storage systems — one of which is the subject of Liang’s PhD — is crucial to successful adoption into the HDV market.
The current efficiency of diesel systems is a result of technological developments and manufacturing processes established over many decades, a precedent that suggests similar strides can be made with alternative drivetrains. However, interactions with fleet owners, automotive manufacturers, and refueling network providers reveal another major hurdle in the way that each “slice of the pie” is interrelated — issues must be addressed simultaneously because of how they affect each other, from renewable fuel infrastructure to technological readiness and capital cost of new fleets, among other considerations. And first steps into an uncertain future, where no one sector is fully in control of potential outcomes, is inherently risky.
“Besides infrastructure limitations, we only have prototypes [of alternative HDVs] for fleet operator use, so the cost of procuring them is high, which means there isn’t demand for automakers to build manufacturing lines up to a scale that would make them economical to produce,” says Liang, describing just one step of a vicious cycle that is difficult to disrupt, especially for industry stakeholders trying to be competitive in a free market.
Quantifying a path to feasibility
“Folks in the industry know that some kind of energy transition needs to happen, but they may not necessarily know for certain what the most viable path forward is,” says Liang. Although there is no singular avenue to zero emissions, the new model provides a way to further quantify and assess at least one slice of pie to aid decision-making.
Other MIT-led efforts aimed at helping industry stakeholders navigate decarbonization include an interactive mapping tool developed by Danika MacDonell, Impact Fellow at the MIT Climate and Sustainability Consortium (MCSC); alongside Florian Allroggen, executive director of MITs Zero Impact Aviation Alliance; and undergraduate researchers Micah Borrero, Helena De Figueiredo Valente, and Brooke Bao. The MCSC’s Geospatial Decision Support Tool supports strategic decision-making for fleet operators by allowing them to visualize regional freight flow densities, costs, emissions, planned and available infrastructure, and relevant regulations and incentives by region.
While current limitations reveal the need for joint problem-solving across sectors, the authors believe that stakeholders are motivated and ready to tackle climate problems together. Once-competing businesses already appear to be embracing a culture shift toward collaboration, with the recent agreement between General Motors and Hyundai to explore “future collaboration across key strategic areas,” including clean energy.
Liang believes that transitioning the transportation sector to zero emissions is just one part of an “energy revolution” that will require all sectors to work together, because “everything is connected. In order for the whole thing to make sense, we need to consider ourselves part of that pie, and the entire system needs to change,” says Liang. “You can’t make a revolution succeed by yourself.”
The authors acknowledge the MIT Climate and Sustainability Consortium for connecting them with industry members in the HDV ecosystem; and the MIT K. Lisa Yang Global Engineering and Research Center and MIT Morningside Academy for Design for financial support.
A new study by MIT researchers quantifies the impact of a zero-emission truck’s design range on its energy storage requirements and operational revenue.
By studying changes in gene expression, researchers learn how cells function at a molecular level, which could help them understand the development of certain diseases.
But a human has about 20,000 genes that can affect each other in complex ways, so even knowing which groups of genes to target is an enormously complicated problem. Also, genes work together in modules that regulate each other.
MIT researchers have now developed theoretical foundations for methods that could identify the best way to aggregate genes into related groups so they can efficiently learn the underlying cause-and-effect relationships between many genes.
Importantly, this new method accomplishes this using only observational data. This means researchers don’t need to perform costly, and sometimes infeasible, interventional experiments to obtain the data needed to infer the underlying causal relationships.
In the long run, this technique could help scientists identify potential gene targets to induce certain behavior in a more accurate and efficient manner, potentially enabling them to develop precise treatments for patients.
“In genomics, it is very important to understand the mechanism underlying cell states. But cells have a multiscale structure, so the level of summarization is very important, too. If you figure out the right way to aggregate the observed data, the information you learn about the system should be more interpretable and useful,” says graduate student Jiaqi Zhang, an Eric and Wendy Schmidt Center Fellow and co-lead author of a paper on this technique.
Zhang is joined on the paper by co-lead author Ryan Welch, currently a master’s student in engineering; and senior author Caroline Uhler, a professor in the Department of Electrical Engineering and Computer Science (EECS) and the Institute for Data, Systems, and Society (IDSS) who is also director of the Eric and Wendy Schmidt Center at the Broad Institute of MIT and Harvard, and a researcher at MIT’s Laboratory for Information and Decision Systems (LIDS). The research will be presented at the Conference on Neural Information Processing Systems.
Learning from observational data
The problem the researchers set out to tackle involves learning programs of genes. These programs describe which genes function together to regulate other genes in a biological process, such as cell development or differentiation.
Since scientists can’t efficiently study how all 20,000 genes interact, they use a technique called causal disentanglement to learn how to combine related groups of genes into a representation that allows them to efficiently explore cause-and-effect relationships.
In previous work, the researchers demonstrated how this could be done effectively in the presence of interventional data, which are data obtained by perturbing variables in the network.
But it is often expensive to conduct interventional experiments, and there are some scenarios where such experiments are either unethical or the technology is not good enough for the intervention to succeed.
With only observational data, researchers can’t compare genes before and after an intervention to learn how groups of genes function together.
“Most research in causal disentanglement assumes access to interventions, so it was unclear how much information you can disentangle with just observational data,” Zhang says.
The MIT researchers developed a more general approach that uses a machine-learning algorithm to effectively identify and aggregate groups of observed variables, e.g., genes, using only observational data.
They can use this technique to identify causal modules and reconstruct an accurate underlying representation of the cause-and-effect mechanism. “While this research was motivated by the problem of elucidating cellular programs, we first had to develop novel causal theory to understand what could and could not be learned from observational data. With this theory in hand, in future work we can apply our understanding to genetic data and identify gene modules as well as their regulatory relationships,” Uhler says.
A layerwise representation
Using statistical techniques, the researchers can compute a mathematical function known as the variance for the Jacobian of each variable’s score. Causal variables that don’t affect any subsequent variables should have a variance of zero.
The researchers reconstruct the representation in a layer-by-layer structure, starting by removing the variables in the bottom layer that have a variance of zero. Then they work backward, layer-by-layer, removing the variables with zero variance to determine which variables, or groups of genes, are connected.
“Identifying the variances that are zero quickly becomes a combinatorial objective that is pretty hard to solve, so deriving an efficient algorithm that could solve it was a major challenge,” Zhang says.
In the end, their method outputs an abstracted representation of the observed data with layers of interconnected variables that accurately summarizes the underlying cause-and-effect structure.
Each variable represents an aggregated group of genes that function together, and the relationship between two variables represents how one group of genes regulates another. Their method effectively captures all the information used in determining each layer of variables.
After proving that their technique was theoretically sound, the researchers conducted simulations to show that the algorithm can efficiently disentangle meaningful causal representations using only observational data.
In the future, the researchers want to apply this technique in real-world genetics applications. They also want to explore how their method could provide additional insights in situations where some interventional data are available, or help scientists understand how to design effective genetic interventions. In the future, this method could help researchers more efficiently determine which genes function together in the same program, which could help identify drugs that could target those genes to treat certain diseases.
This research is funded, in part, by the U.S. Office of Naval Research, the National Institutes of Health, the U.S. Department of Energy, a Simons Investigator Award, the Eric and Wendy Schmidt Center at the Broad Institute, the Advanced Undergraduate Research Opportunities Program at MIT, and an Apple AI/ML PhD Fellowship.
The new method could identify the best way to aggregate genes into related groups so researchers can efficiently learn the underlying cause-and-effect relationships between many genes.
By analyzing brain scans taken as people watched movie clips, MIT researchers have created the most comprehensive map yet of the functions of the brain’s cerebral cortex.
Using functional magnetic resonance imaging (fMRI) data, the research team identified 24 networks with different functions, which include processing language, social interactions, visual features, and other types of sensory input.
Many of these networks have been seen before but haven’t been precisely characterized using naturalistic conditions. While the new study mapped networks in subjects watching engaging movies, previous works have used a small number of specific tasks or examined correlations across the brain in subjects who were simply resting.
“There’s an emerging approach in neuroscience to look at brain networks under more naturalistic conditions. This is a new approach that reveals something different from conventional approaches in neuroimaging,” says Robert Desimone, director of MIT’s McGovern Institute for Brain Research. “It’s not going to give us all the answers, but it generates a lot of interesting ideas based on what we see going on in the movies that's related to these network maps that emerge.”
The researchers hope that their new map will serve as a starting point for further study of what each of these networks is doing in the brain.
Desimone and John Duncan, a program leader in the MRC Cognition and Brain Sciences Unit at Cambridge University, are the senior authors of the study, which appears today in Neuron. Reza Rajimehr, a research scientist in the McGovern Institute and a former graduate student at Cambridge University, is the lead author of the paper.
Precise mapping
The cerebral cortex of the brain contains regions devoted to processing different types of sensory information, including visual and auditory input. Over the past few decades, scientists have identified many networks that are involved in this kind of processing, often using fMRI to measure brain activity as subjects perform a single task such as looking at faces.
In other studies, researchers have scanned people’s brains as they do nothing, or let their minds wander. From those studies, researchers have identified networks such as the default mode network, a network of areas that is active during internally focused activities such as daydreaming.
“Up to now, most studies of networks were based on doing functional MRI in the resting-state condition. Based on those studies, we know some main networks in the cortex. Each of them is responsible for a specific cognitive function, and they have been highly influential in the neuroimaging field,” Rajimehr says.
However, during the resting state, many parts of the cortex may not be active at all. To gain a more comprehensive picture of what all these regions are doing, the MIT team analyzed data recorded while subjects performed a more natural task: watching a movie.
“By using a rich stimulus like a movie, we can drive many regions of the cortex very efficiently. For example, sensory regions will be active to process different features of the movie, and high-level areas will be active to extract semantic information and contextual information,” Rajimehr says. “By activating the brain in this way, now we can distinguish different areas or different networks based on their activation patterns.”
The data for this study was generated as part of the Human Connectome Project. Using a 7-Tesla MRI scanner, which offers higher resolution than a typical MRI scanner, brain activity was imaged in 176 people as they watched one hour of movie clips showing a variety of scenes.
The MIT team used a machine-learning algorithm to analyze the activity patterns of each brain region, allowing them to identify 24 networks with different activity patterns and functions.
Some of these networks are located in sensory areas such as the visual cortex or auditory cortex, as expected for regions with specific sensory functions. Other areas respond to features such as actions, language, or social interactions. Many of these networks have been seen before, but this technique offers more precise definition of where the networks are located, the researchers say.
“Different regions are competing with each other for processing specific features, so when you map each function in isolation, you may get a slightly larger network because it is not getting constrained by other processes,” Rajimehr says. “But here, because all the areas are considered together, we are able to define more precise boundaries between different networks.”
The researchers also identified networks that hadn’t been seen before, including one in the prefrontal cortex, which appears to be highly responsive to visual scenes. This network was most active in response to pictures of scenes within the movie frames.
Executive control networks
Three of the networks found in this study are involved in “executive control,” and were most active during transitions between different clips. The researchers also observed that these control networks appear to have a “push-pull” relationship with networks that process specific features such as faces or actions. When networks specific to a particular feature were very active, the executive control networks were mostly quiet, and vice versa.
“Whenever the activations in domain-specific areas are high, it looks like there is no need for the engagement of these high-level networks,” Rajimehr says. “But in situations where perhaps there is some ambiguity and complexity in the stimulus, and there is a need for the involvement of the executive control networks, then we see that these networks become highly active.”
Using a movie-watching paradigm, the researchers are now studying some of the networks they identified in more detail, to identify subregions involved in particular tasks. For example, within the social processing network, they have found regions that are specific to processing social information about faces and bodies. In a new network that analyzes visual scenes, they have identified regions involved in processing memory of places.
“This kind of experiment is really about generating hypotheses for how the cerebral cortex is functionally organized. Networks that emerge during movie watching now need to be followed up with more specific experiments to test the hypotheses. It’s giving us a new view into the operation of the entire cortex during a more naturalistic task than just sitting at rest,” Desimone says.
The research was funded by the McGovern Institute, the Cognitive Science and Technology Council of Iran, the MRC Cognition and Brain Sciences Unit at the University of Cambridge, and a Cambridge Trust scholarship.
By analyzing brain scans taken as people watched movie clips, MIT researchers have created the most comprehensive map yet of the functions of the brain’s cortex.
Tiny grains from a distant asteroid are revealing clues to the magnetic forces that shaped the far reaches of the solar system over 4.6 billion years ago.
Scientists at MIT and elsewhere have analyzed particles of the asteroid Ryugu, which were collected by the Japanese Aerospace Exploration Agency’s (JAXA) Hayabusa2 mission and brought back to Earth in 2020. Scientists believe Ryugu formed on the outskirts of the early solar system before migrating in toward the asteroid belt, eventually settling into an orbit between Earth and Mars.
The team analyzed Ryugu’s particles for signs of any ancient magnetic field that might have been present when the asteroid first took shape. Their results suggest that if there was a magnetic field, it would have been very weak. At most, such a field would have been about 15 microtesla. (The Earth’s own magnetic field today is around 50 microtesla.)
Even so, the scientists estimate that such a low-grade field intensity would have been enough to pull together primordial gas and dust to form the outer solar system’s asteroids and potentially play a role in giant planet formation, from Jupiter to Neptune.
The team’s results, which are published today in the journal AGU Advances, show for the first time that the distal solar system likely harbored a weak magnetic field. Scientists have known that a magnetic field shaped the inner solar system, where Earth and the terrestrial planets were formed. But it was unclear whether such a magnetic influence extended into more remote regions, until now.
“We’re showing that, everywhere we look now, there was some sort of magnetic field that was responsible for bringing mass to where the sun and planets were forming,” says study author Benjamin Weiss, the Robert R. Shrock Professor of Earth and Planetary Sciences at MIT. “That now applies to the outer solar system planets.”
The study’s lead author is Elias Mansbach PhD ’24, who is now a postdoc at Cambridge University. MIT co-authors include Eduardo Lima, Saverio Cambioni, and Jodie Ream, along with Michael Sowell and Joseph Kirschvink of Caltech, Roger Fu of Harvard University, Xue-Ning Bai of Tsinghua University, Chisato Anai and Atsuko Kobayashi of the Kochi Advanced Marine Core Research Institute, and Hironori Hidaka of Tokyo Institute of Technology.
A far-off field
Around 4.6 billion years ago, the solar system formed from a dense cloud of interstellar gas and dust, which collapsed into a swirling disk of matter. Most of this material gravitated toward the center of the disk to form the sun. The remaining bits formed a solar nebula of swirling, ionized gas. Scientists suspect that interactions between the newly formed sun and the ionized disk generated a magnetic field that threaded through the nebula, helping to drive accretion and pull matter inward to form the planets, asteroids, and moons.
“This nebular field disappeared around 3 to 4 million years after the solar system’s formation, and we are fascinated with how it played a role in early planetary formation,” Mansbach says.
Scientists previously determined that a magnetic field was present throughout the inner solar system — a region that spanned from the sun to about 7 astronomical units (AU), out to where Jupiter is today. (One AU is the distance between the sun and the Earth.) The intensity of this inner nebular field was somewhere between 50 to 200 microtesla, and it likely influenced the formation of the inner terrestrial planets. Such estimates of the early magnetic field are based on meteorites that landed on Earth and are thought to have originated in the inner nebula.
“But how far this magnetic field extended, and what role it played in more distal regions, is still uncertain because there haven’t been many samples that could tell us about the outer solar system,” Mansbach says.
Rewinding the tape
The team got an opportunity to analyze samples from the outer solar system with Ryugu, an asteroid that is thought to have formed in the early outer solar system, beyond 7 AU, and was eventually brought into orbit near the Earth. In December 2020, JAXA’s Hayabusa2 mission returned samples of the asteroid to Earth, giving scientists a first look at a potential relic of the early distal solar system.
The researchers acquired several grains of the returned samples, each about a millimeter in size. They placed the particles in a magnetometer — an instrument in Weiss’ lab that measures the strength and direction of a sample’s magnetization. They then applied an alternating magnetic field to progressively demagnetize each sample.
“Like a tape recorder, we are slowly rewinding the sample’s magnetic record,” Mansbach explains. “We then look for consistent trends that tell us if it formed in a magnetic field.”
They determined that the samples held no clear sign of a preserved magnetic field. This suggests that either there was no nebular field present in the outer solar system where the asteroid first formed, or the field was so weak that it was not recorded in the asteroid’s grains. If the latter is the case, the team estimates such a weak field would have been no more than 15 microtesla in intensity.
The researchers also reexamined data from previously studied meteorites. They specifically looked at “ungrouped carbonaceous chondrites” — meteorites that have properties that are characteristic of having formed in the distal solar system. Scientists had estimated the samples were not old enough to have formed before the solar nebula disappeared. Any magnetic field record the samples contain, then, would not reflect the nebular field. But Mansbach and his colleagues decided to take a closer look.
“We reanalyzed the ages of these samples and found they are closer to the start of the solar system than previously thought,” Mansbach says. “We think these samples formed in this distal, outer region. And one of these samples does actually have a positive field detection of about 5 microtesla, which is consistent with an upper limit of 15 microtesla.”
This updated sample, combined with the new Ryugu particles, suggest that the outer solar system, beyond 7 AU, hosted a very weak magnetic field, that was nevertheless strong enough to pull matter in from the outskirts to eventually form the outer planetary bodies, from Jupiter to Neptune.
“When you’re further from the sun, a weak magnetic field goes a long way,” Weiss notes. “It was predicted that it doesn’t need to be that strong out there, and that’s what we’re seeing.”
The team plans to look for more evidence of distal nebular fields with samples from another far-off asteroid, Bennu, which were delivered to Earth in September 2023 by NASA’s OSIRIS-REx spacecraft.
“Bennu looks a lot like Ryugu, and we’re eagerly awaiting first results from those samples,” Mansbach says.
When Nikola Tesla predicted we’d have handheld phones that could display videos, photographs, and more, his musings seemed like a distant dream. Nearly 100 years later, smartphones are like an extra appendage for many of us.
Digital fabrication engineers are now working toward expanding the display capabilities of other everyday objects. One avenue they’re exploring is reprogrammable surfaces — or items whose appearances we can digitally alter — to help users present important information, such as health statistics, as well as new designs on things like a wall, mug, or shoe.
Researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), the University of California at Berkeley, and Aarhus University have taken an intriguing step forward by fabricating “PortaChrome,” a portable light system and design tool that can change the color and textures of various objects. Equipped with ultraviolet (UV) and red, green, and blue (RGB) LEDs, the device can be attached to everyday objects like shirts and headphones. Once a user creates a design and sends it to a PortaChrome machine via Bluetooth, the surface can be programmed into multicolor displays of health data, entertainment, and fashion designs.
To make an item reprogrammable, the object must be coated with photochromic dye, an invisible ink that can be turned into different colors with light patterns. Once it’s coated, individuals can create and relay patterns to the item via the team’s graphic design software, or use the team’s API to interact with the device directly and embed data-driven designs. When attached to a surface, PortaChrome’s UV lights saturate the dye while the RGB LEDs desaturate it, activating the colors and ensuring each pixel is toned to match the intended design.
Zhu and her colleagues’ integrated light system changes objects’ colors in less than four minutes on average, which is eight times faster than their prior work, “Photo-Chromeleon.” This speed boost comes from switching to a light source that makes contact with the object to transmit UV and RGB rays. Photo-Chromeleon used a projector to help activate the color-changing properties of photochromic dye, where the light on the object's surface is at a reduced intensity.
“PortaChrome provides a more convenient way to reprogram your surroundings,” says Yunyi Zhu ’20, MEng ’21, an MIT PhD student in electrical engineering and computer science, affiliate of CSAIL, and lead author on a paper about the work. “Compared with our projector-based system from before, PortaChrome is a more portable light source that can be placed directly on top of the photochromic surface. This allows the color change to happen without user intervention and helps us avoid contaminating our environment with UV. As a result, users can wear their heart rate chart on their shirt after a workout, for instance.”
Giving everyday objects a makeover
In demos, PortaChrome displayed health data on different surfaces. A user hiked with PortaChrome sewed onto their backpack, putting it into direct contact with the back of their shirt, which was coated in photochromic dye. Altitude and heart rate sensors sent data to the lighting device, which was then converted into a chart through a reprogramming script developed by the researchers. This process created a health visualization on the back of the user’s shirt. In a similar showing, MIT researchers displayed a heart gradually coming together on the back of a tablet to show how a user was progressing toward a fitness goal.
PortaChrome also showed a flair for customizing wearables. For example, the researchers redesigned some white headphones with sideways blue lines and horizontal yellow and purple stripes. The photochromic dye was coated on the headphones and the team then attached the PortaChrome device to the inside of the headphone case. Finally, the researchers successfully reprogrammed their patterns onto the object, which resembled watercolor art. Researchers also recolored a wrist splint to match different clothes using this process.
Eventually, the work could be used to digitize consumers’ belongings. Imagine putting on a cloak that can change your entire shirt design, or using your car cover to give your vehicle a new look.
PortaChrome’s main ingredients
On the hardware end, PortaChrome is a combination of four main ingredients. Their portable device consists of a textile base as a sort of backbone, a textile layer with the UV lights soldered on and another with the RGB stuck on, and a silicone diffusion layer to top it off. Resembling a translucent honeycomb, the silicone layer covers the interlaced UV and RGB LEDs and directs them toward individual pixels to properly illuminate a design over a surface.
This device can be flexibly wrapped around objects with different shapes. For tables and other flat surfaces, you could place PortaChrome on top, like a placemat. For a curved item like a thermos, you could wrap the light source around like a coffee cup sleeve to ensure it reprograms the entire surface.
The portable, flexible light system is crafted with maker space-available tools (like laser cutters, for example), and the same method can be replicated with flexible PCB materials and other mass manufacturing systems.
While it can also quickly convert our surroundings into dynamic displays, Zhu and her colleagues believe it could benefit from further speed boosts. They'd like to use smaller LEDs, with the likely result being a surface that could be reprogrammed in seconds with a higher-resolution design, thanks to increased light intensity.
“The surfaces of our everyday things are encoded with colors and visual textures, delivering crucial information and shaping how we interact with them,” says Georgia Tech postdoc Tingyu Cheng, who was not involved with the research. “PortaChrome is taking a leap forward by providing reprogrammable surfaces with the integration of flexible light sources (UV and RGB LEDs) and photochromic pigments into everyday objects, pixelating the environment with dynamic color and patterns. The capabilities demonstrated by PortaChrome could revolutionize the way we interact with our surroundings, particularly in domains like personalized fashion and adaptive user interfaces. This technology enables real-time customization that seamlessly integrates into daily life, offering a glimpse into the future of ‘ubiquitous displays.’”
Zhu is joined by nine CSAIL affiliates on the paper: MIT PhD student and MIT Media Lab affiliate Cedric Honnet; former visiting undergraduate researchers Yixiao Kang, Angelina J. Zheng, and Grace Tang; MIT undergraduate student Luca Musk; University of Michigan Assistant Professor Junyi Zhu SM ’19, PhD ’24; recent postdoc and Aarhus University assistant professor Michael Wessely; and senior author Stefanie Mueller, the TIBCO Career Development Associate Professor in the MIT departments of Electrical Engineering and Computer Science and Mechanical Engineering and leader of the HCI Engineering Group at CSAIL.
This work was supported by the MIT-GIST Joint Research Program and was presented at the ACM Symposium on User Interface Software and Technology in October.
In experiments, PortaChrome redesigned headphones, a T-shirt, and a wrist splint. The researchers envision that one day, consumers could wear a cloak to change a shirt design, or use a car cover to give their vehicle a new look. “PortaChrome provides a more convenient way to reprogram your surroundings,” says PhD student Yunyi Zhu ’20, MEng ’21 (pictured).
Breast cancer is the second most common type of cancer and cause of cancer death for women in the United States, affecting one in eight women overall.
Most women with breast cancer undergo lumpectomy surgery to remove the tumor and a rim of healthy tissue surrounding the tumor. After the procedure, the removed tissue is sent to a pathologist to look for signs of disease at the edge of the tissue assessed. Unfortunately, about 20 percent of women who have lumpectomies must undergo a second surgery to remove more tissue.
Now, an MIT spinout is giving surgeons a real-time view of cancerous tissue during surgery. Lumicell has developed a handheld device and an optical imaging agent that, when combined, allow surgeons to scan the tissue within the surgical cavity to visualize residual cancer cells. The surgeons see these images on a monitor that can guide them to remove additional tissue during the procedure.
In a clinical trial of 357 patients, Lumicell’s technology not only reduced the need for second surgeries but also revealed tissue suspected to contain cancer cells that may have otherwise been missed by the standard of care lumpectomy.
The company received U.S. Food and Drug Administration approval for the technology earlier this year, marking a major milestone for Lumicell and the founders, who include MIT professors Linda Griffith and Moungi Bawendi along with PhD candidate W. David Lee ’69, SM ’70. Much of the early work developing and testing the system took place at the Koch Institute for Integrative Cancer Research at MIT, beginning in 2008.
The FDA approval also held deep personal significance for some of Lumicell’s team members, including Griffith, a two-time breast cancer survivor, and Lee, whose wife’s passing from the disease in 2003 changed the course of his life.
An interdisciplinary approach
Lee ran a technology consulting group for 25 years before his wife was diagnosed with breast cancer. Watching her battle the disease inspired him to develop technologies that could help cancer patients.
His neighbor at the time was Tyler Jacks, the founding director of the Koch Institute. Jacks invited Lee to a series of meetings at the Koch involving professors Robert Langer and Bawendi, and Lee eventually joined the Koch Institute as an integrative program officer in 2008, where he began exploring an approach for improving imaging in living organisms with single-cell resolution using charge-coupled device (CCD) cameras.
“CCD pixels at the time were each 2 or 3 microns and spaced 2 or 3 microns,” Lee explains. “So the idea was very simple: to stabilize a camera on a tissue so it would move with the breathing of the animal, so the pixels would essentially line up with the cells without any fancy magnification.”
That work led Lee to begin meeting regularly with a multidisciplinary group including Lumicell co-founders Bawendi, currently the Lester Wolfe Professor of Chemistry at MIT and winner of the 2023 Nobel Prize in Chemistry; Griffith, the School of Engineering Professor of Teaching Innovation in MIT’s Department of Biological Engineering and an extramural faculty member at the Koch Institute; Ralph Weissleder, a professor at Harvard Medical School; and David Kirsch, formerly a postdoc at the Koch Institute and now a scientist at the Princess Margaret Cancer Center.
“On Friday afternoons, we’d get together, and Moungi would teach us some chemistry, Lee would teach us some engineering, and David Kirsch would teach some biology,” Griffith recalls.
Through those meetings, the researchers began to explore the effectiveness of combining Lee’s imaging approach with engineered proteins that would light up where the immune system meets the edge of tumors, for use during surgery. To begin testing the idea, the group received funding from the Koch Institute Frontier Research Program via the Kathy and Curt Marble Cancer Research Fund.
“Without that support, this never would have happened,” Lee says. “When I was learning biology at MIT as an undergrad, genetics weren’t even in the textbooks yet. But the Koch Institute provided education, funding, and most importantly, connections to faculty, who were willing to teach me biology.”
In 2010, Griffith was diagnosed with breast cancer.
“Going through that personal experience, I understood the impact that we could have,” Griffith says. “I had a very unusual situation and a bad kind of tumor. The whole thing was nerve-wracking, but one of the most nerve-wracking times was waiting to find out if my tumor margins were clear after surgery. I experienced that uncertainty and dread as a patient, so I became hugely sensitized to our mission.”
The approach Lumicell’s founders eventually settled on begins two to six hours before surgery, when patients receive the optical imaging agent through an IV.Then, during surgery, surgeons use Lumicell’s handheld imaging device to scan the walls of the breast cavity. Lumicell’s cancer detection software shows spots that highlight regions suspected to contain residual cancer on the computer monitor, which the surgeon can then remove. The process adds less than 7 minutes on average to the procedure.
“The technology we developed allows the surgeon to scan the actual cavity, whereas pathology only looks at the lump removed, and [pathologists] make their assessment based on looking at about 1 or 2 percent of the surface area,” Lee says. “Not only are we detecting cancer that was left behind to potentially eliminate second surgeries, we are also, very importantly, finding cancer in some patients that wouldn't be found in pathology and may not generate a second surgery.”
Exploring other cancer types
Lumicell is currently exploring if its imaging agent is activated in other tumor types, including prostate, sarcoma, esophageal, gastric, and more.
Lee ran Lumicell between 2008 and 2020. After stepping down as CEO, he decided to return to MIT to get his PhD in neuroscience, a full 50 years since he earned his master’s. Shortly thereafter, Howard Hechler took over as Lumicell’s president and chief operating officer.
Looking back, Griffith credits MIT’s culture of learning for the formation of Lumicell.
“People like David [Lee] and Moungi care about solving problems,” Griffith says. “They’re technically brilliant, but they also love learning from other people, and that’s what makes makes MIT special. People are confident about what they know, but they are also comfortable in that they don’t know everything, which drives great collaboration. We work together so that the whole is bigger than the sum of the parts.”
Lumicell has developed a handheld device and an optical imaging agent that allow surgeons to scan the tissue within the surgical cavity to visualize residual cancer cells.
Over the past two decades, new technologies have helped scientists generate a vast amount of biological data. Large-scale experiments in genomics, transcriptomics, proteomics, and cytometry can produce enormous quantities of data from a given cellular or multicellular system.
However, making sense of this information is not always easy. This is especially true when trying to analyze complex systems such as the cascade of interactions that occur when the immune system encounters a foreign pathogen.
MIT biological engineers have now developed a new computational method for extracting useful information from these datasets. Using their new technique, they showed that they could unravel a series of interactions that determine how the immune system responds to tuberculosis vaccination and subsequent infection.
This strategy could be useful to vaccine developers and to researchers who study any kind of complex biological system, says Douglas Lauffenburger, the Ford Professor of Engineering in the departments of Biological Engineering, Biology, and Chemical Engineering.
“We’ve landed on a computational modeling framework that allows prediction of effects of perturbations in a highly complex system, including multiple scales and many different types of components,” says Lauffenburger, the senior author of the new study.
Shu Wang, a former MIT postdoc who is now an assistant professor at the University of Toronto, and Amy Myers, a research manager in the lab of University of Pittsburgh School of Medicine Professor JoAnne Flynn, are the lead authors of a new paper on the work, which appears today in the journal Cell Systems.
Modeling complex systems
When studying complex biological systems such as the immune system, scientists can extract many different types of data. Sequencing cell genomes tells them which gene variants a cell carries, while analyzing messenger RNA transcripts tells them which genes are being expressed in a given cell. Using proteomics, researchers can measure the proteins found in a cell or biological system, and cytometry allows them to quantify a myriad of cell types present.
Using computational approaches such as machine learning, scientists can use this data to train models to predict a specific output based on a given set of inputs — for example, whether a vaccine will generate a robust immune response. However, that type of modeling doesn’t reveal anything about the steps that happen in between the input and the output.
“That AI approach can be really useful for clinical medical purposes, but it’s not very useful for understanding biology, because usually you’re interested in everything that’s happening between the inputs and outputs,” Lauffenburger says. “What are the mechanisms that actually generate outputs from inputs?”
To create models that can identify the inner workings of complex biological systems, the researchers turned to a type of model known as a probabilistic graphical network. These models represent each measured variable as a node, generating maps of how each node is connected to the others.
Probabilistic graphical networks are often used for applications such as speech recognition and computer vision, but they have not been widely used in biology.
Lauffenburger’s lab has previously used this type of model to analyze intracellular signaling pathways, which required analyzing just one kind of data. To adapt this approach to analyze many datasets at once, the researchers applied a mathematical technique that can filter out any correlations between variables that are not directly affecting each other. This technique, known as graphical lasso, is an adaptation of the method often used in machine learning models to strip away results that are likely due to noise.
“With correlation-based network models generally, one of the problems that can arise is that everything seems to be influenced by everything else, so you have to figure out how to strip down to the most essential interactions,” Lauffenburger says. “Using probabilistic graphical network frameworks, one can really boil down to the things that are most likely to be direct and throw out the things that are most likely to be indirect.”
Mechanism of vaccination
To test their modeling approach, the researchers used data from studies of a tuberculosis vaccine. This vaccine, known as BCG, is an attenuated form of Mycobacterium bovis. It is used in many countries where TB is common but isn’t always effective, and its protection can weaken over time.
In hopes of developing more effective TB protection, researchers have been testing whether delivering the BCG vaccine intravenously or by inhalation might provoke a better immune response than injecting it. Those studies, performed in animals, found that the vaccine did work much better when given intravenously. In the MIT study, Lauffenburger and his colleagues attempted to discover the mechanism behind this success.
The data that the researchers examined in this study included measurements of about 200 variables, including levels of cytokines, antibodies, and different types of immune cells, from about 30 animals.
The measurements were taken before vaccination, after vaccination, and after TB infection. By analyzing the data using their new modeling approach, the MIT team was able to determine the steps needed to generate a strong immune response. They showed that the vaccine stimulates a subset of T cells, which produce a cytokine that activates a set of B cells that generate antibodies targeting the bacterium.
“Almost like a roadmap or a subway map, you could find what were really the most important paths. Even though a lot of other things in the immune system were changing one way or another, they were really off the critical path and didn't matter so much,” Lauffenburger says.
The researchers then used the model to make predictions for how a specific disruption, such as suppressing a subset of immune cells, would affect the system. The model predicted that if B cells were nearly eliminated, there would be little impact on the vaccine response, and experiments showed that prediction was correct.
This modeling approach could be used by vaccine developers to predict the effect their vaccines may have, and to make tweaks that would improve them before testing them in humans. Lauffenburger’s lab is now using the model to study the mechanism of a malaria vaccine that has been given to children in Kenya, Ghana, and Malawi over the past few years.
“The advantage of this computational approach is that it filters out many biological targets that only indirectly influence the outcome and identifies those that directly regulate the response. Then it's possible to predict how therapeutically altering those biological targets would change the response. This is significant because it provides the basis for future vaccine and trial designs that are more data driven,” says Kathryn Miller-Jensen, a professor of biomedical engineering at Yale University, who was not involved in the study.
Lauffenburger’s lab is also using this type of modeling to study the tumor microenvironment, which contains many types of immune cells and cancerous cells, in hopes of predicting how tumors might respond to different kinds of treatment.
The research was funded by the National Institute of Allergy and Infectious Diseases.
MIT biological engineers have developed a way to use probabilistic graphical networks to model complex biological systems, such as the immune response to vaccination.
Large language models can do impressive things, like write poetry or generate viable computer programs, even though these models are trained to predict words that come next in a piece of text.
Such surprising capabilities can make it seem like the models are implicitly learning some general truths about the world.
But that isn’t necessarily the case, according to a new study. The researchers found that a popular type of generative AI model can provide turn-by-turn driving directions in New York City with near-perfect accuracy — without having formed an accurate internal map of the city.
Despite the model’s uncanny ability to navigate effectively, when the researchers closed some streets and added detours, its performance plummeted.
When they dug deeper, the researchers found that the New York maps the model implicitly generated had many nonexistent streets curving between the grid and connecting far away intersections.
This could have serious implications for generative AI models deployed in the real world, since a model that seems to be performing well in one context might break down if the task or environment slightly changes.
“One hope is that, because LLMs can accomplish all these amazing things in language, maybe we could use these same tools in other parts of science, as well. But the question of whether LLMs are learning coherent world models is very important if we want to use these techniques to make new discoveries,” says senior author Ashesh Rambachan, assistant professor of economics and a principal investigator in the MIT Laboratory for Information and Decision Systems (LIDS).
Rambachan is joined on a paper about the work by lead author Keyon Vafa, a postdoc at Harvard University; Justin Y. Chen, an electrical engineering and computer science (EECS) graduate student at MIT; Jon Kleinberg, Tisch University Professor of Computer Science and Information Science at Cornell University; and Sendhil Mullainathan, an MIT professor in the departments of EECS and of Economics, and a member of LIDS. The research will be presented at the Conference on Neural Information Processing Systems.
New metrics
The researchers focused on a type of generative AI model known as a transformer, which forms the backbone of LLMs like GPT-4. Transformers are trained on a massive amount of language-based data to predict the next token in a sequence, such as the next word in a sentence.
But if scientists want to determine whether an LLM has formed an accurate model of the world, measuring the accuracy of its predictions doesn’t go far enough, the researchers say.
For example, they found that a transformer can predict valid moves in a game of Connect 4 nearly every time without understanding any of the rules.
So, the team developed two new metrics that can test a transformer’s world model. The researchers focused their evaluations on a class of problems called deterministic finite automations, or DFAs.
A DFA is a problem with a sequence of states, like intersections one must traverse to reach a destination, and a concrete way of describing the rules one must follow along the way.
They chose two problems to formulate as DFAs: navigating on streets in New York City and playing the board game Othello.
“We needed test beds where we know what the world model is. Now, we can rigorously think about what it means to recover that world model,” Vafa explains.
The first metric they developed, called sequence distinction, says a model has formed a coherent world model it if sees two different states, like two different Othello boards, and recognizes how they are different. Sequences, that is, ordered lists of data points, are what transformers use to generate outputs.
The second metric, called sequence compression, says a transformer with a coherent world model should know that two identical states, like two identical Othello boards, have the same sequence of possible next steps.
They used these metrics to test two common classes of transformers, one which is trained on data generated from randomly produced sequences and the other on data generated by following strategies.
Incoherent world models
Surprisingly, the researchers found that transformers which made choices randomly formed more accurate world models, perhaps because they saw a wider variety of potential next steps during training.
“In Othello, if you see two random computers playing rather than championship players, in theory you’d see the full set of possible moves, even the bad moves championship players wouldn’t make,” Vafa explains.
Even though the transformers generated accurate directions and valid Othello moves in nearly every instance, the two metrics revealed that only one generated a coherent world model for Othello moves, and none performed well at forming coherent world models in the wayfinding example.
The researchers demonstrated the implications of this by adding detours to the map of New York City, which caused all the navigation models to fail.
“I was surprised by how quickly the performance deteriorated as soon as we added a detour. If we close just 1 percent of the possible streets, accuracy immediately plummets from nearly 100 percent to just 67 percent,” Vafa says.
When they recovered the city maps the models generated, they looked like an imagined New York City with hundreds of streets crisscrossing overlaid on top of the grid. The maps often contained random flyovers above other streets or multiple streets with impossible orientations.
These results show that transformers can perform surprisingly well at certain tasks without understanding the rules. If scientists want to build LLMs that can capture accurate world models, they need to take a different approach, the researchers say.
“Often, we see these models do impressive things and think they must have understood something about the world. I hope we can convince people that this is a question to think very carefully about, and we don’t have to rely on our own intuitions to answer it,” says Rambachan.
In the future, the researchers want to tackle a more diverse set of problems, such as those where some rules are only partially known. They also want to apply their evaluation metrics to real-world, scientific problems.
This work is funded, in part, by the Harvard Data Science Initiative, a National Science Foundation Graduate Research Fellowship, a Vannevar Bush Faculty Fellowship, a Simons Collaboration grant, and a grant from the MacArthur Foundation.
"The question of whether large language models are learning coherent world models is very important if we want to use these techniques to make new discoveries,” says Ashesh Rambachan.
As educators are challenged to balance student learning and well-being with planning authentic and relevant course materials, MIT pK-12 at Open Learning developed a framework that can help. The student-centered STEAM learning architecture, initially co-created for Itz’at STEAM Academy in Belize, now serves as a model for schools worldwide.
Three core pillars guide MIT pK-12’s vision for teaching and learning: social-emotional and cultural learning, transdisciplinary academics, and community engagement. Claudia Urrea, principal investigator for this project and senior associate director of MIT pK-12, says this innovative framework supports learners’ growth as engaged and self-directed students. Joining these efforts on the pK-12 team are Joe Diaz, program coordinator, and Emily Glass, senior learning innovation designer.
Now that Itz’at has completed its first academic year, the MIT pK-12 team reflects on how the STEAM learning architecture works in practice and how it could be adapted to other schools.
Q: Why would a new school need a STEAM learning architecture? How is this framework used?
Glass: In the case of Itz’at STEAM Academy, the school aims to prepare its students for careers and jobs of the future, recognizing that learners will be navigating an evolving global economy with significant technological changes. Since the local and global landscape will continue to evolve over time, in order to stay innovative, the STEAM learning architecture serves as a reference document for the school to reflect, iterate, and improve its program. Learners will need to think critically, solve large problems, embrace creativity, and utilize digital technologies and tools to their benefit.
Q: How do you begin developing a school from scratch?
Urrea: To build a school that reflected local values and aspired towards global goals, our team knew we needed a deep understanding of the strengths and needs of Belize’s larger education ecosystem and culture. We collaborated with Belize's Ministry of Education, Culture, Science, and Technology, as well as the newly hired Itz’at staff.
Next, we conducted an extensive review of research, drawing from MIT pK-12’s own work and outside academic studies on competency-based education, constructionism, and other foundational pedagogies. We gathered best practices of innovative schools through interviews and global site visits.
MIT’s collective team experience included the creation of schools for the NuVuX network, constructionist pedagogical research and practice, and the development of STEAM-focused educational materials for both formal and informal learning environments.
Q: Why was co-creation important for this process?
Urrea: MIT pK-12 could not imagine doing this project without strong co-creation. Everyone involved has their own expertise and understanding of what works best for learners and educators, and collaborating ensures that all stakeholders have a voice in the school’s pedagogy. We co-designed an innovative framework that’s relevant to Belize.
However, there’s no one-size-fits-all pedagogy that will be successful in every context. This framework allows educators to adapt their approaches. The school and the ministry can sustain Itz’at’s experimental nature with continual reflection, iteration, and improvement.
Q: What was the reasoning behind the framework’s core pillars?
Glass: MIT pK-12 found that many successful schools had strong social-emotional support, specific approaches to academics, and reciprocal relationships with their surrounding communities.
We tailored each core pillar to Itz’at. To better support learners’ social-emotional well-being, Belizean cultural identity is an essential part of the learning needed to anchor this project locally. A transdisciplinary approach most clearly aligns with the school’s focus on the United Nations Sustainable Development Goals, encouraging learners to ask big questions facing the world today. And to engage learners in real-world learning experiences, the school coordinates internships with the local community.
Q: Which areas of learning science research were most significant to the STEAM architecture? How does this pedagogy differ from Itz’at educators’ previous experiences?
Urrea: Learning at the Itz'at STEAM Academy focuses on authentic learning experiences and concrete evidence of concept mastery. Educators say that this is different from other schools in Belize, where conventional grading is based on rote memorization in isolated academic subjects.
Together as a team, Itz’at educators shifted their teaching to follow the foundational principles from the STEAM learning architecture, both bringing in their own experiences and implementing new practices.
Glass: Itz’at’s competency-based approach promotes a more holistic educational experience. Instead of traditional subjects like science, history, math, and language arts, Itz’at classes cover sustainable environments, global humanities, qualitative reasoning, arts and fabrication, healthy living, and real-world learning. Combining disciplines in multiple ways allows learners to draw stronger connections between different subjects.
Diaz: When the curriculum is relevant to learners’ lives, learners can also more easily connect what happens inside and outside of the classroom. Itz’at educators embraced bringing in experts from the local community to enrich learning experiences.
Q: How does the curriculum support learners with career preparation?
Diaz: To ensure learners can transition smoothly from school to the workforce, Itz’at offers exposure to potential careers early in their journey. Internships with local businesses, community organizations, and government agencies provide learners with real-world experience in professional environments.
Students begin preparing for internships in their second year and attend seminars in their third year. By their fourth and final year, they are expected to begin internships and capstone projects that demonstrate academic rigor, innovative thinking, and mastery of concepts, topics, and skills of their choosing.
Q: What do you hope the impact of the STEAM architecture will be?
Glass: Our hope is that the STEAM learning architecture will serve as a resource for educators, school administrators, policymakers, and researchers beyond Belize. This framework can help educational practitioners respond to critical challenges, including preparation for life and careers, thinking beyond short-term outcomes, learners’ mental health and well-being, and more.
Focused on science, technology, engineering, arts, and mathematics (STEAM) subjects, a new STEAM learning architecture co-created by MIT pK-12 is guided by three core pillars: social-emotional and cultural learning, transdisciplinary academics, and community engagement.
At the turn of the 20th century, W.E.B. Du Bois wrote about the conditions and culture of Black people in Philadelphia, documenting also the racist attitudes and beliefs that pervaded the white society around them. He described how unequal outcomes in domains like health could be attributed not only to racist ideas, but to racism embedded in American institutions.
Almost 125 years later, the concept of “systemic racism” is central to the study of race. Centuries of data collection and analysis, like the work of Du Bois, document the mechanisms of racial inequity in law and institutions, and attempt to measure their impact.
“There’s extensive research showing racial discrimination and systemic inequity in essentially all sectors of American society,” explains Fotini Christia, the Ford International Professor of Social Sciences in the Department of Political Science, who directs the MIT Institute for Data, Systems, and Society (IDSS), where she also co-leads the Initiative on Combatting Systemic Racism (ICSR). “Newer research demonstrates how computational technologies, typically trained or reliant on historical data, can further entrench racial bias. But these same tools can also help to identify racially inequitable outcomes, to understand their causes and impacts, and even contribute to proposing solutions.”
In addition to coordinating research on systemic racism across campus, the IDSS initiative has a new project aiming to empower and support this research beyond MIT: the new ICSR Data Hub, which serves as an evolving, public web depository of datasets gathered by ICSR researchers.
Data for justice
“My main project with ICSR involved using Amazon Web Services to build the data hub for other researchers to use in their own criminal justice related projects,” says Ben Lewis SM ’24, a recent alumnus of the MIT Technology and Policy Program (TPP) and current doctoral student at the MIT Sloan School of Management. “We want the data hub to be a centralized place where researchers can access this information via a simple web or Python interface.”
While earning his master’s degree at TPP, Lewis focused his research on race, drug policy, and policing in the United States, exploring drug decriminalization policies’ impact on rates of incarceration and overdose. He worked as a member of the ICSR Policing team, a group of researchers across MIT examining the roles data plays in the design of policing policies and procedures, and how data can highlight or exacerbate racial bias.
“The Policing vertical started with a really challenging fundamental question,” says team lead and electrical engineering and computer science (EECS) Professor Devavrat Shah. “Can we use data to better understand the role that race plays in the different decisions made throughout the criminal justice system?”
So far, the data hub offers 911 dispatch information and police stop data, gathered from 40 of the largest cities in the United States by ICSR researchers. Lewis hopes to see the effort expand to include not only other cities, but other relevant and typically siloed information, like sentencing data.
“We want to stitch the datasets together so that we have a more comprehensive and holistic view of law enforcement systems,” explains Jessy Xinyi Han, a fellow ICSR researcher and graduate student in the IDSS Social and Engineering Systems (SES) doctoral program. Statistical methods like causal inference can help to uncover root causes behind inequalities, says Han — to “untangle a web of possibilities” and better understand the causal effect of race at different stages of the criminal justice process.
“My motivation behind doing this project is personal,” says Lewis, who was drawn to MIT in large part by the opportunity to research systemic racism. As a TPP student, he also founded the Cambridge branch of End Overdose, a nonprofit dedicated to stopping drug overdose deaths. His advocacy led to training hundreds in lifesaving drug interventions, and earned him the 2024 Collier Medal, an MIT distinction for community service honoring Sean Collier, who gave his life serving as an officer with the MIT Police.
“I’ve had family members in incarceration. I’ve seen the impact it has had on my family, and on my community, and realized that over-policing and incarceration are a Band-Aid on issues like poverty and drug use that can trap people in a cycle of poverty.”
Education and impact
Now that the infrastructure for the data hub has been built, and the ICSR Policing team has begun sharing datasets, the next step is for other ICSR teams to start sharing data as well. The cross-disciplinary systemic racism research initiative includes teams working in domains including housing, health care, and social media.
“We want to take advantage of the abundance of data that is available today to answer difficult questions about how racism results from the interactions of multiple systems,” says Munther Dahleh, EECS professor, IDSS founding director, and ICSR co-lead. “Our interest is in how various institutions perpetuate racism, and how technology can exacerbate or combat this.”
To the data hub creators, the main sign of success for the project is seeing the data used in research projects at and beyond MIT. As a resource, though, the hub can support that research for users from a range of experience and backgrounds.
“The data hub is also about education and empowerment,” says Han. “This information can be used in projects designed to teach users how to use big data, how to do data analysis, and even to learn machine learning tools, all specifically to uncover racial disparities in data.”
“Championing the propagation of data skills has been part of the IDSS mission since Day 1,” says Dahleh. “We are excited by the opportunities that making this data available can present in educational contexts, including but not limited to our growing IDSSx suite of online course offerings.”
This emphasis on educational potential only augments the ambitions of ICSR researchers across MIT, who aspire to use data and computing tools to produce actionable insights for policymakers that can lead to real change.
“Systemic racism is an abundantly evidenced societal challenge with far-reaching impacts across domains,” says Christia. “At IDSS, we want to ensure that developing technologies, combined with access to ever-increasing amounts of data, are leveraged to combat racist outcomes rather than continue to enact them.”
The new ICSR Data Hub serves as an evolving, public web depository of datasets gathered by MIT researchers examining racial bias in American society and institutions.
Silicon transistors, which are used to amplify and switch signals, are a critical component in most electronic devices, from smartphones to automobiles. But silicon semiconductor technology is held back by a fundamental physical limit that prevents transistors from operating below a certain voltage.
This limit, known as “Boltzmann tyranny,” hinders the energy efficiency of computers and other electronics, especially with the rapid development of artificial intelligence technologies that demand faster computation.
In an effort to overcome this fundamental limit of silicon, MIT researchers fabricated a different type of three-dimensional transistor using a unique set of ultrathin semiconductor materials.
Their devices, featuring vertical nanowires only a few nanometers wide, can deliver performance comparable to state-of-the-art silicon transistors while operating efficiently at much lower voltages than conventional devices.
“This is a technology with the potential to replace silicon, so you could use it with all the functions that silicon currently has, but with much better energy efficiency,” says Yanjie Shao, an MIT postdoc and lead author of a paper on the new transistors.
The transistors leverage quantum mechanical properties to simultaneously achieve low-voltage operation and high performance within an area of just a few square nanometers. Their extremely small size would enable more of these 3D transistors to be packed onto a computer chip, resulting in fast, powerful electronics that are also more energy-efficient.
“With conventional physics, there is only so far you can go. The work of Yanjie shows that we can do better than that, but we have to use different physics. There are many challenges yet to be overcome for this approach to be commercial in the future, but conceptually, it really is a breakthrough,” says senior author Jesús del Alamo, the Donner Professor of Engineering in the MIT Department of Electrical Engineering and Computer Science (EECS).
They are joined on the paper by Ju Li, the Tokyo Electric Power Company Professor in Nuclear Engineering and professor of materials science and engineering at MIT; EECS graduate student Hao Tang; MIT postdoc Baoming Wang; and professors Marco Pala and David Esseni of the University of Udine in Italy. The research appears today in Nature Electronics.
Surpassing silicon
In electronic devices, silicon transistors often operate as switches. Applying a voltage to the transistor causes electrons to move over an energy barrier from one side to the other, switching the transistor from “off” to “on.” By switching, transistors represent binary digits to perform computation.
A transistor’s switching slope reflects the sharpness of the “off” to “on” transition. The steeper the slope, the less voltage is needed to turn on the transistor and the greater its energy efficiency.
But because of how electrons move across an energy barrier, Boltzmann tyranny requires a certain minimum voltage to switch the transistor at room temperature.
To overcome the physical limit of silicon, the MIT researchers used a different set of semiconductor materials — gallium antimonide and indium arsenide — and designed their devices to leverage a unique phenomenon in quantum mechanics called quantum tunneling.
Quantum tunneling is the ability of electrons to penetrate barriers. The researchers fabricated tunneling transistors, which leverage this property to encourage electrons to push through the energy barrier rather than going over it.
“Now, you can turn the device on and off very easily,” Shao says.
But while tunneling transistors can enable sharp switching slopes, they typically operate with low current, which hampers the performance of an electronic device. Higher current is necessary to create powerful transistor switches for demanding applications.
Fine-grained fabrication
Using tools at MIT.nano, MIT’s state-of-the-art facility for nanoscale research, the engineers were able to carefully control the 3D geometry of their transistors, creating vertical nanowire heterostructures with a diameter of only 6 nanometers. They believe these are the smallest 3D transistors reported to date.
Such precise engineering enabled them to achieve a sharp switching slope and high current simultaneously. This is possible because of a phenomenon called quantum confinement.
Quantum confinement occurs when an electron is confined to a space that is so small that it can’t move around. When this happens, the effective mass of the electron and the properties of the material change, enabling stronger tunneling of the electron through a barrier.
Because the transistors are so small, the researchers can engineer a very strong quantum confinement effect while also fabricating an extremely thin barrier.
“We have a lot of flexibility to design these material heterostructures so we can achieve a very thin tunneling barrier, which enables us to get very high current,” Shao says.
Precisely fabricating devices that were small enough to accomplish this was a major challenge.
“We are really into single-nanometer dimensions with this work. Very few groups in the world can make good transistors in that range. Yanjie is extraordinarily capable to craft such well-functioning transistors that are so extremely small,” says del Alamo.
When the researchers tested their devices, the sharpness of the switching slope was below the fundamental limit that can be achieved with conventional silicon transistors. Their devices also performed about 20 times better than similar tunneling transistors.
“This is the first time we have been able to achieve such sharp switching steepness with this design,” Shao adds.
The researchers are now striving to enhance their fabrication methods to make transistors more uniform across an entire chip. With such small devices, even a 1-nanometer variance can change the behavior of the electrons and affect device operation. They are also exploring vertical fin-shaped structures, in addition to vertical nanowire transistors, which could potentially improve the uniformity of devices on a chip.
“This work definitively steps in the right direction, significantly improving the broken-gap tunnel field effect transistor (TFET) performance. It demonstrates steep-slope together with a record drive-current. It highlights the importance of small dimensions, extreme confinement, and low-defectivity materials and interfaces in the fabricated broken-gap TFET. These features have been realized through a well-mastered and nanometer-size-controlled process,” says Aryan Afzalian, a principal member of the technical staff at the nanoelectronics research organization imec, who was not involved with this work.
This research is funded, in part, by Intel Corporation.
Nanoscale 3D transistors made from ultrathin semiconductor materials can operate more efficiently than silicon-based devices, leveraging quantum mechanical properties to potentially enable ultra-low-power AI applications.
Like humans and other complex multicellular organisms, single-celled bacteria can fall ill and fight off viral infections. A bacterial virus is caused by a bacteriophage, or, more simply, phage, which is one of the most ubiquitous life forms on earth. Phages and bacteria are engaged in a constant battle, the virus attempting to circumvent the bacteria’s defenses, and the bacteria racing to find new ways to protect itself.
These anti-phage defense systems are carefully controlled, and prudently managed — dormant, but always poised to strike.
New open-access research recently published in Nature from the Laub Lab in the Department of Biology at MIT has characterized an anti-phage defense system in bacteria, CmdTAC. CmdTAC prevents viral infection by altering the single-stranded genetic code used to produce proteins, messenger RNA.
This defense system detects phage infection at a stage when the viral phage has already commandeered the host’s machinery for its own purposes. In the face of annihilation, the ill-fated bacterium activates a defense system that will halt translation, preventing the creation of new proteins and aborting the infection — but dooming itself in the process.
“When bacteria are in a group, they’re kind of like a multicellular organism that is not connected to one another. It’s an evolutionarily beneficial strategy for one cell to kill itself to save another identical cell,” says Christopher Vassallo, a postdoc and co-author of the study. “You could say it’s like self-sacrifice: One cell dies to protect the other cells.”
The enzyme responsible for altering the mRNA is called an ADP-ribosyltransferase. Researchers have characterized hundreds of these enzymes — although a few are known to target DNA or RNA, all but a handful target proteins. This is the first time these enzymes have been characterized targeting mRNA within cells.
Expanding understanding of anti-phage defense
Co-first author and graduate student Christopher Doering notes that it is only within the last decade or so that researchers have begun to appreciate the breadth of diversity and complexity of anti-phage defense systems. For example, CRISPR gene editing, a technique used in everything from medicine to agriculture, is rooted in research on the bacterial CRISPR-Cas9 anti-phage defense system.
CmdTAC is a subset of a widespread anti-phage defense mechanism called a toxin-antitoxin system. A TA system is just that: a toxin capable of killing or altering the cell’s processes rendered inert by an associated antitoxin.
Although these TA systems can be identified — if the toxin is expressed by itself, it kills or inhibits the growth of the cell; if the toxin and antitoxin are expressed together, the toxin is neutralized — characterizing the cascade of circumstances that activates these systems requires extensive effort. In recent years, however, many TA systems have been shown to serve as anti-phage defense.
Two general questions need to be answered to understand a viral defense system: How do bacteria detect an infection, and how do they respond?
Detecting infection
CmdTAC is a TA system with an additional element, and the three components generally exist in a stable complex: the toxic CmdT, the antitoxin CmdA, and an additional component called a chaperone, CmdC.
If the phage’s protective capsid protein is present, CmdC disassociates from CmdT and CmdA and interacts with the phage capsid protein instead. In the model outlined in the paper, the chaperone CmdC is, therefore, the sensor of the system, responsible for recognizing when an infection is occurring. Structural proteins, such as the capsid that protects the phage genome, are a common trigger because they’re abundant and essential to the phage.
The uncoupling of CmdC exposes the neutralizing antitoxin CmdA to be degraded, which releases the toxin CmdT to do its lethal work.
Toxicity on the loose
The researchers were guided by computational tools, so they knew that CmdT was likely an ADP-ribosyltransferase due to its similarities to other such enzymes. As the name suggests, the enzyme transfers an ADP ribose onto its target.
To determine if CmdT interacted with any sequences or positions in particular, they tested a mix of short sequences of single-stranded RNA. RNA has four bases: A, U, G, and C, and the evidence points to the enzyme recognizing GA sequences.
The CmdT modification of GA sequences in mRNA blocks their translation. The cessation of creating new proteins aborts the infection, preventing the phage from spreading beyond the host to infect other bacteria.
“Not only is it a new type of bacterial immune system, but the enzyme involved does something that’s never been seen before: the ADP-ribsolyation of mRNA,” Vassallo says.
Although the paper outlines the broad strokes of the anti-phage defense system, it’s unclear how CmdC interacts with the capsid protein, and how the chemical modification of GA sequences prevents translation.
Beyond bacteria
More broadly, exploring anti-phage defense aligns with the Laub Lab’s overall goal of understanding how bacteria function and evolve, but these results may have broader implications beyond bacteria.
Senior author Michael Laub, Salvador E. Luria Professor and Howard Hughes Medical Institute Investigator, says the ADP-ribosyltransferase has homologs in eukaryotes, including human cells. They are not well studied, and not among the Laub Lab’s research topics, but they are known to be up-regulated in response to viral infection.
“There are so many different — and cool — mechanisms by which organisms defend themselves against viral infection,” Laub says. “The notion that there may be some commonality between how bacteria defend themselves and how humans defend themselves is a tantalizing possibility.”
A proposed model for CmdTAC contains three elements: the toxic CmdT (red), the antitoxin CmdA (blue), and a chaperone, CmdC (green). During infection, CmdC uncouples from CmdT and CmdA, exposing the neutralizing antitoxin CmdA to be degraded, which releases the toxin CmdT to do its lethal work.
As the world strives to cut back on carbon emissions, demand for minerals and metals needed for clean energy technologies is growing rapidly, sometimes straining existing supply chains and harming local environments. In a new study published today in Joule, Elsa Olivetti, a professor of materials science and engineering and director of the Decarbonizing Energy and Industry mission within MIT’s Climate Project, along with recent graduates Basuhi Ravi PhD ’23 and Karan Bhuwalka PhD ’24 and nine others, examine the case of nickel, which is an essential element for some electric vehicle batteries and parts of some solar panels and wind turbines.
How robust is the supply of this vital metal, and what are the implications of its extraction for the local environments, economies, and communities in the places where it is mined? MIT News asked Olivetti, Ravi, and Bhuwalka to explain their findings.
Q: Why is nickel becoming more important in the clean energy economy, and what are some of the potential issues in its supply chain?
Olivetti: Nickel is increasingly important for its role in EV batteries, as well as other technologies such as wind and solar. For batteries, high-purity nickel sulfate is a key input to the cathodes of EV batteries, which enables high energy density in batteries and increased driving range for EVs. As the world transitions away from fossil fuels, the demand for EVs, and consequently for nickel, has increased dramatically and is projected to continue to do so.
The nickel supply chain for battery-grade nickel sulfate includes mining nickel from ore deposits, processing it to a suitable nickel intermediary, and refining it to nickel sulfate. The potential issues in the supply chain can be broadly described as land use concerns in the mining stage, and emissions concerns in the processing stage. This is obviously oversimplified, but as a basic structure for our inquiry we thought about it this way. Nickel mining is land-intensive, leading to deforestation, displacement of communities, and potential contamination of soil and water resources from mining waste. In the processing step, the use of fossil fuels leads to direct emissions including particulate matter and sulfur oxides. In addition, some emerging processing pathways are particularly energy-intensive, which can double the carbon footprint of nickel-rich batteries compared to the current average.
Q: What is Indonesia’s role in the global nickel supply, and what are the consequences of nickel extraction there and in other major supply countries?
Ravi: Indonesia plays a critical role in nickel supply, holding the world's largest nickel reserves and supplying nearly half of the globally mined nickel in 2023. The country's nickel production has seen a remarkable tenfold increase since 2016. This production surge has fueled economic growth in some regions, but also brought notable environmental and social impacts to nickel mining and processing areas.
Nickel mining expansion in Indonesia has been linked to health impacts due to air pollution in the islands where nickel processing is prominent, as well as deforestation in some of the most biodiversity-rich locations on the planet. Reports of displacement of indigenous communities, land grabbing, water rights issues, and inadequate job quality in and around mines further highlight the social concerns and unequal distribution of burdens and benefits in Indonesia. Similar concerns exist in other major nickel-producing countries, where mining activities can negatively impact the environment, disrupt livelihoods, and exacerbate inequalities.
On a global scale, Indonesia’s reliance on coal-based energy for nickel processing, particularly in energy-intensive smelting and leaching of a clay-like material called laterite, results in a high carbon intensity for nickel produced in the region, compared to other major producing regions such as Australia.
Q: What role can industry and policymakers play in helping to meet growing demand while improving environmental safety?
Bhuwalka: In consuming countries, policies can foster “discerning demand,” which means creating incentives for companies to source nickel from producers that prioritize sustainability. This can be achieved through regulations that establish acceptable environmental footprints for imported materials, such as limits on carbon emissions from nickel production. For example, the EU’s Critical Raw Materials Act and the U.S. Inflation Reduction Act could be leveraged to promote responsible sourcing. Additionally, governments can use their purchasing power to favor sustainably produced nickel in public procurement, which could influence industry practices and encourage the adoption of sustainability standards.
On the supply side, nickel-producing countries like Indonesia can implement policies to mitigate the adverse environmental and social impacts of nickel extraction. This includes strengthening environmental regulations and enforcement to reduce the footprint of mining and processing, potentially through stricter pollution limits and responsible mine waste management. In addition, supporting community engagement, implementing benefit-sharing mechanisms, and investing in cleaner nickel processing technologies are also crucial.
Internationally, harmonizing sustainability standards and facilitating capacity building and technology transfer between developed and developing countries can create a level playing field and prevent unsustainable practices. Responsible investment practices by international financial institutions, favoring projects that meet high environmental and social standards, can also contribute to a stable and sustainable nickel supply chain.
“Indonesia’s nickel production has seen a remarkable tenfold increase since 2016,” says Basuhi Ravi PhD’23. Pictured is nickel being mined and loaded onto barges in Sulawesi, Indonesia.
Getting to the heart of causality is central to understanding the world around us. What causes one variable — be it a biological species, a voting region, a company stock, or a local climate — to shift from one state to another can inform how we might shape that variable in the future.
But tracing an effect to its root cause can quickly become intractable in real-world systems, where many variables can converge, confound, and cloud over any causal links.
Now, a team of MIT engineers hopes to provide some clarity in the pursuit of causality. They developed a method that can be applied to a wide range of situations to identify those variables that likely influence other variables in a complex system.
The method, in the form of an algorithm, takes in data that have been collected over time, such as the changing populations of different species in a marine environment. From those data, the method measures the interactions between every variable in a system and estimates the degree to which a change in one variable (say, the number of sardines in a region over time) can predict the state of another (such as the population of anchovy in the same region).
The engineers then generate a “causality map” that links variables that likely have some sort of cause-and-effect relationship. The algorithm determines the specific nature of that relationship, such as whether two variables are synergistic — meaning one variable only influences another if it is paired with a second variable — or redundant, such that a change in one variable can have exactly the same, and therefore redundant, effect as another variable.
The new algorithm can also make an estimate of “causal leakage,” or the degree to which a system’s behavior cannot be explained through the variables that are available; some unknown influence must be at play, and therefore, more variables must be considered.
“The significance of our method lies in its versatility across disciplines,” says Álvaro Martínez-Sánchez, a graduate student in MIT’s Department of Aeronautics and Astronautics (AeroAstro). “It can be applied to better understand the evolution of species in an ecosystem, the communication of neurons in the brain, and the interplay of climatological variables between regions, to name a few examples.”
For their part, the engineers plan to use the algorithm to help solve problems in aerospace, such as identifying features in aircraft design that can reduce a plane’s fuel consumption.
“We hope by embedding causality into models, it will help us better understand the relationship between design variables of an aircraft and how it relates to efficiency,” says Adrián Lozano-Durán, an associate professor in AeroAstro.
In recent years, a number of computational methods have been developed to take in data about complex systems and identify causal links between variables in the system, based on certain mathematical descriptions that should represent causality.
“Different methods use different mathematical definitions to determine causality,” Lozano-Durán notes. “There are many possible definitions that all sound ok, but they may fail under some conditions.”
In particular, he says that existing methods are not designed to tell the difference between certain types of causality. Namely, they don’t distinguish between a “unique” causality, in which one variable has a unique effect on another, apart from every other variable, from a “synergistic” or a “redundant” link. An example of a synergistic causality would be if one variable (say, the action of drug A) had no effect on another variable (a person’s blood pressure), unless the first variable was paired with a second (drug B).
An example of redundant causality would be if one variable (a student’s work habits) affect another variable (their chance of getting good grades), but that effect has the same impact as another variable (the amount of sleep the student gets).
“Other methods rely on the intensity of the variables to measure causality,” adds Arranz. “Therefore, they may miss links between variables whose intensity is not strong yet they are important.”
Messaging rates
In their new approach, the engineers took a page from information theory — the science of how messages are communicated through a network, based on a theory formulated by the late MIT professor emeritus Claude Shannon. The team developed an algorithm to evaluate any complex system of variables as a messaging network.
“We treat the system as a network, and variables transfer information to each other in a way that can be measured,” Lozano-Durán explains. “If one variable is sending messages to another, that implies it must have some influence. That’s the idea of using information propagation to measure causality.”
The new algorithm evaluates multiple variables simultaneously, rather than taking on one pair of variables at a time, as other methods do. The algorithm defines information as the likelihood that a change in one variable will also see a change in another. This likelihood — and therefore, the information that is exchanged between variables — can get stronger or weaker as the algorithm evaluates more data of the system over time.
In the end, the method generates a map of causality that shows which variables in the network are strongly linked. From the rate and pattern of these links, the researchers can then distinguish which variables have a unique, synergistic, or redundant relationship. By this same approach, the algorithm can also estimate the amount of “causality leak” in the system, meaning the degree to which a system’s behavior cannot be predicted based on the information available.
“Part of our method detects if there’s something missing,” Lozano-Durán says. “We don’t know what is missing, but we know we need to include more variables to explain what is happening.”
The team applied the algorithm to a number of benchmark cases that are typically used to test causal inference. These cases range from observations of predator-prey interactions over time, to measurements of air temperature and pressure in different geographic regions, and the co-evolution of multiple species in a marine environment. The algorithm successfully identified causal links in every case, compared with most methods that can only handle some cases.
The method, which the team coined SURD, for Synergistic-Unique-Redundant Decomposition of causality, is available online for others to test on their own systems.
“SURD has the potential to drive progress across multiple scientific and engineering fields, such as climate research, neuroscience, economics, epidemiology, social sciences, and fluid dynamics, among others areas,” Martínez-Sánchez says.
This research was supported, in part, by the National Science Foundation.
Unlike a Newton’s Cradle toy, pictured, tracing an effect to its root cause can quickly become intractable in real-world systems. The researchers’ new method can provide some clarity in the pursuit of causality.
As Earth’s temperature rises, agricultural practices will need to adapt. Droughts will likely become more frequent, and some land may no longer be arable. On top of that is the challenge of feeding an ever-growing population without expanding the production of fertilizer and other agrochemicals, which have a large carbon footprint that is contributing to the overall warming of the planet.
Researchers across MIT are taking on these agricultural challenges from a variety of angles, from engineering plants that sound an alarm when they’re under stress to making seeds more resilient to drought. These types of technologies, and more yet to be devised, will be essential to feed the world’s population as the climate changes.
“After water, the first thing we need is food. In terms of priority, there is water, food, and then everything else. As we are trying to find new strategies to support a world of 10 billion people, it will require us to invent new ways of making food,” says Benedetto Marelli, an associate professor of civil and environmental engineering at MIT.
Marelli is the director of one of the six missions of the recently launched Climate Project at MIT, which focus on research areas such as decarbonizing industry and building resilient cities. Marelli directs the Wild Cards mission, which aims to identify unconventional solutions that are high-risk and high-reward.
Drawing on expertise from a breadth of fields, MIT is well-positioned to tackle the challenges posed by climate change, Marelli says. “Bringing together our strengths across disciplines, including engineering, processing at scale, biological engineering, and infrastructure engineering, along with humanities, science, and economics, presents a great opportunity.”
Protecting seeds from drought
Marelli, who began his career as a biomedical engineer working on regenerative medicine, is now developing ways to boost crop yields by helping seeds to survive and germinate during drought conditions, or in soil that has been depleted of nutrients. To achieve that, he has devised seed coatings, based on silk and other polymers, that can envelop and nourish seeds during the critical germination process.
In healthy soil, plants have access to nitrogen, phosphates, and other nutrients that they need, many of which are supplied by microbes that live in the soil. However, in soil that has suffered from drought or overfarming, these nutrients are lacking. Marelli’s idea was to coat the seeds with a polymer that can be embedded with plant-growth-promoting bacteria that “fix” nitrogen by absorbing it from the air and making it available to plants. The microbes can also make other necessary nutrients available to plants.
For the first generation of the seed coatings, he embedded these microbes in coatings made of silk — a material that he had previously shown can extend the shelf life of produce, meat, and other foods. In his lab at MIT, Marelli has shown that the seed coatings can help germinating plants survive drought, ultraviolet light exposure, and high salinity.
Now, working with researchers at the Mohammed VI Polytechnic University in Morocco, he is adapting the approach to crops native to Morocco, a country that has experienced six consecutive years of drought due a drop in rainfall linked to climate change.
For these studies, the researchers are using a biopolymer coating derived from food waste that can be easily obtained in Morocco, instead of silk.
“We’re working with local communities to extract the biopolymers, to try to have a process that works at scale so that we make materials that work in that specific environment.” Marelli says. “We may come up with an idea here at MIT within a high-resource environment, but then to work there, we need to talk with the local communities, with local stakeholders, and use their own ingenuity and try to match our solution with something that could actually be applied in the local environment.”
Microbes as fertilizers
Whether they are experiencing drought or not, crops grow much better when synthetic fertilizers are applied. Although it’s essential to most farms, applying fertilizer is expensive and has environmental consequences. Most of the world’s fertilizer is produced using the Haber-Bosch process, which converts nitrogen and hydrogen to ammonia at high temperatures and pressures. This energy intensive process accounts for about 1.5 percent of the world’s greenhouse gas emissions, and the transportation required to deliver it to farms around the world adds even more emissions.
Ariel Furst, the Paul M. Cook Career Development Assistant Professor of Chemical Engineering at MIT, is developing a microbial alternative to the Haber-Bosch process. Some farms have experimented with applying nitrogen-fixing bacteria directly to the roots of their crops, which has shown some success. However, the microbes are too delicate to be stored long-term or shipped anywhere, so they must be produced in a bioreactor on the farm.
To overcome those challenges, Furst has developed a way to coat the microbes with a protective shell that prevents them from being destroyed by heat or other stresses. The coating also protects microbes from damage caused by freeze-drying — a process that would make them easier to transport.
The coatings can vary in composition, but they all consist of two components. One is a metal such as iron, manganese, or zinc, and the other is a polyphenol — a type of plant-derived organic compound that includes tannins and other antioxidants. These two components self-assemble into a protective shell that encapsulates bacteria.
“These microbes would be delivered with the seeds, so it would remove the need for fertilizing mid-growing. It also reduces the cost and provides more autonomy to the farmers and decreases carbon emissions associated with agriculture,” Furst says. “We think it’ll be a way to make agriculture completely regenerative, so to bring back soil health while also boosting crop yields and the nutrient density of the crops.”
Furst has founded a company called Seia Bio, which is working on commercializing the coated microbes and has begun testing them on farms in Brazil. In her lab, Furst is also working on adapting the approach to coat microbes that can capture carbon dioxide from the atmosphere and turn it into limestone, which helps to raise the soil pH.
“It can help change the pH of soil to stabilize it, while also being a way to effectively perform direct air capture of CO2,” she says. “Right now, farmers may truck in limestone to change the pH of soil, and so you’re creating a lot of emissions to bring something in that microbes can do on their own.”
Distress sensors for plants
Several years ago, Michael Strano, the Carbon P. Dubbs Professor of Chemical Engineering at MIT, began to explore the idea of using plants themselves as sensors that could reveal when they’re in distress. When plants experience drought, attack by pests, or other kinds of stress, they produce hormones and other signaling molecules to defend themselves.
Strano, whose lab specializes in developing tiny sensors for a variety of molecules, wondered if such sensors could be deployed inside plants to pick up those distress signals. To create their sensors, Strano’s lab takes advantage of the special properties of single-walled carbon nanotubes, which emit fluorescent light. By wrapping the tubes with different types of polymers, the sensors can be tuned to detect specific targets, giving off a fluorescent signal when the target is present.
For use in plants, Strano and his colleagues created sensors that could detect signaling molecules such as salicylic acid and hydrogen peroxide. They then showed that these sensors could be inserted into the underside of plant leaves, without harming the plants. Once embedded in the mesophyll of the leaves, the sensors can pick up a variety of signals, which can be read with an infrared camera.
These sensors can reveal, in real-time, whether a plant is experiencing a variety of stresses. Until now, there hasn’t been a way to get that information fast enough for farmers to act on it.
“What we’re trying to do is make tools that get information into the hands of farmers very quickly, fast enough for them to make adaptive decisions that can increase yield,” Strano says. “We’re in the middle of a revolution of really understanding the way in which plants internally communicate and communicate with other plants.”
This kind of sensing could be deployed in fields, where it could help farmers respond more quickly to drought and other stresses, or in greenhouses, vertical farms, and other types of indoor farms that use technology to grow crops in a controlled environment.
Much of Strano’s work in this area has been conducted with the support of the U.S. Department of Agriculture (USDA) and as part of the Disruptive and Sustainable Technologies for Agricultural Precision (DiSTAP) program at the Singapore-MIT Alliance for Research and Technology (SMART), and sensors have been deployed in tests in crops at a controlled environment farm in Singapore called Growy.
“The same basic kinds of tools can help detect problems in open field agriculture or in controlled environment agriculture,” Strano says. “They both suffer from the same problem, which is that the farmers get information too late to prevent yield loss.”
Reducing pesticide use
Pesticides represent another huge financial expense for farmers: Worldwide, farmers spend about $60 billion per year on pesticides. Much of this pesticide ends up accumulating in water and soil, where it can harm many species, including humans. But, without using pesticides, farmers may lose more than half of their crops.
Kripa Varanasi, an MIT professor of mechanical engineering, is working on tools that can help farmers measure how much pesticide is reaching their plants, as well as technologies that can help pesticides adhere to plants more efficiently, reducing the amount that runs off into soil and water.
Varanasi, whose research focuses on interactions between liquid droplets and surfaces, began to think about applying his work to agriculture more than a decade ago, after attending a conference at the USDA. There, he was inspired to begin developing ways to improve the efficiency of pesticide application by optimizing the interactions that occur at leaf surfaces.
“Billions of drops of pesticide are being sprayed on every acre of crop, and only a small fraction is ultimately reaching and staying on target. This seemed to me like a problem that we could help to solve,” he says.
Varanasi and his students began exploring strategies to make drops of pesticide stick to leaves better, instead of bouncing off. They found that if they added polymers with positive and negative charges, the oppositely charged droplets would form a hydrophilic (water-attracting) coating on the leaf surface, which helps the next droplets applied to stick to the leaf.
Later, they developed an easier-to-use technology in which a surfactant is added to the pesticide before spraying. When this mixture is sprayed through a special nozzle, it forms tiny droplets that are “cloaked” in surfactant. The surfactant helps the droplets to stick to the leaves within a few milliseconds, without bouncing off.
In 2020, Varanasi and Vishnu Jayaprakash SM ’19, PhD ’22 founded a company called AgZen to commercialize their technologies and get them into the hands of farmers. They incorporated their ideas for improving pesticide adhesion into a product called EnhanceCoverage.
During the testing for this product, they realized that there weren’t any good ways to measure how many of the droplets were staying on the plant. That led them to develop a product known as RealCoverage, which is based on machine vision. It can be attached to any pesticide sprayer and offer real-time feedback on what percentage of the pesticide droplets are sticking to and staying on every leaf.
RealCoverage was used on 65,000 acres of farmland across the United States in 2024, from soybeans in Iowa to cotton in Georgia. Farmers who used the product were able to reduce their pesticide use by 30 to 50 percent, by using the data to optimize delivery and, in some cases, even change what chemicals were sprayed.
He hopes that the EnhanceCoverage product, which is expected to become available in 2025, will help farmers further reduce their pesticide use.
“Our mission here is to help farmers with savings while helping them achieve better yields. We have found a way to do all this while also reducing waste and the amount of chemicals that we put into our atmosphere and into our soils and into our water,” Varanasi says. “This is the MIT approach: to figure out what are the real issues and how to come up with solutions. Now we have a tool and I hope that it’s deployed everywhere and everyone gets the benefit from it.”
Wearable devices like smartwatches and fitness trackers interact with parts of our bodies to measure and learn from internal processes, such as our heart rate or sleep stages.
Now, MIT researchers have developed wearable devices that may be able to perform similar functions for individual cells inside the body.
These battery-free, subcellular-sized devices, made of a soft polymer, are designed to gently wrap around different parts of neurons, such as axons and dendrites, without damaging the cells, upon wireless actuation with light. By snugly wrapping neuronal processes, they could be used to measure or modulate a neuron’s electrical and metabolic activity at a subcellular level.
Because these devices are wireless and free-floating, the researchers envision that thousands of tiny devices could someday be injected and then actuated noninvasively using light. Researchers would precisely control how the wearables gently wrap around cells, by manipulating the dose of light shined from outside the body, which would penetrate the tissue and actuate the devices.
By enfolding axons that transmit electrical impulses between neurons and to other parts of the body, these wearables could help restore some neuronal degradation that occurs in diseases like multiple sclerosis. In the long run, the devices could be integrated with other materials to create tiny circuits that could measure and modulate individual cells.
“The concept and platform technology we introduce here is like a founding stone that brings about immense possibilities for future research,” says Deblina Sarkar, the AT&T Career Development Assistant Professor in the MIT Media Lab and Center for Neurobiological Engineering, head of the Nano-Cybernetic Biotrek Lab, and the senior author of a paper on this technique.
Sarkar is joined on the paper by lead author Marta J. I. Airaghi Leccardi, a former MIT postdoc who is now a Novartis Innovation Fellow; Benoît X. E. Desbiolles, an MIT postdoc; Anna Y. Haddad ’23, who was an MIT undergraduate researcher during the work; and MIT graduate students Baju C. Joy and Chen Song. The research appears today in Nature Communications Chemistry.
Snugly wrapping cells
Brain cells have complex shapes, which makes it exceedingly difficult to create a bioelectronic implant that can tightly conform to neurons or neuronal processes. For instance, axons are slender, tail-like structures that attach to the cell body of neurons, and their length and curvature vary widely.
At the same time, axons and other cellular components are fragile, so any device that interfaces with them must be soft enough to make good contact without harming them.
To overcome these challenges, the MIT researchers developed thin-film devices from a soft polymer called azobenzene, that don’t damage cells they enfold.
Due to a material transformation, thin sheets of azobenzene will roll when exposed to light, enabling them to wrap around cells. Researchers can precisely control the direction and diameter of the rolling by varying the intensity and polarization of the light, as well as the shape of the devices.
The thin films can form tiny microtubes with diameters that are less than a micrometer. This enables them to gently, but snugly, wrap around highly curved axons and dendrites.
“It is possible to very finely control the diameter of the rolling. You can stop if when you reach a particular dimension you want by tuning the light energy accordingly,” Sarkar explains.
The researchers experimented with several fabrication techniques to find a process that was scalable and wouldn’t require the use of a semiconductor clean room.
Making microscopic wearables
They begin by depositing a drop of azobenzene onto a sacrificial layer composed of a water-soluble material. Then the researchers press a stamp onto the drop of polymer to mold thousands of tiny devices on top of the sacrificial layer. The stamping technique enables them to create complex structures, from rectangles to flower shapes.
A baking step ensures all solvents are evaporated and then they use etching to scrape away any material that remains between individual devices. Finally, they dissolve the sacrificial layer in water, leaving thousands of microscopic devices freely floating in the liquid.
Once they have a solution with free-floating devices, they wirelessly actuated the devices with light to induce the devices to roll. They found that free-floating structures can maintain their shapes for days after illumination stops.
The researchers conducted a series of experiments to ensure the entire method is biocompatible.
After perfecting the use of light to control rolling, they tested the devices on rat neurons and found they could tightly wrap around even highly curved axons and dendrites without causing damage.
“To have intimate interfaces with these cells, the devices must be soft and able to conform to these complex structures. That is the challenge we solved in this work. We were the first to show that azobenzene could even wrap around living cells,” she says.
Among the biggest challenges they faced was developing a scalable fabrication process that could be performed outside a clean room. They also iterated on the ideal thickness for the devices, since making them too thick causes cracking when they roll.
Because azobenzene is an insulator, one direct application is using the devices as synthetic myelin for axons that have been damaged. Myelin is an insulating layer that wraps axons and allows electrical impulses to travel efficiently between neurons.
In non-myelinating diseases like multiple sclerosis, neurons lose some insulating myelin sheets. There is no biological way of regenerating them. By acting as synthetic myelin, the wearables might help restore neuronal function in MS patients.
The researchers also demonstrated how the devices can be combined with optoelectrical materials that can stimulate cells. Moreover, atomically thin materials can be patterned on top of the devices, which can still roll to form microtubes without breaking. This opens up opportunities for integrating sensors and circuits in the devices.
In addition, because they make such a tight connection with cells, one could use very little energy to stimulate subcellular regions. This could enable a researcher or clinician to modulate electrical activity of neurons for treating brain diseases.
“It is exciting to demonstrate this symbiosis of an artificial device with a cell at an unprecedented resolution. We have shown that this technology is possible,” Sarkar says.
In addition to exploring these applications, the researchers want to try functionalizing the device surfaces with molecules that would enable them to target specific cell types or subcellular regions.
“This work is an exciting step toward new symbiotic neural interfaces acting at the level of the individual axons and synapses. When integrated with nanoscale 1- and 2D conductive nanomaterials, these light-responsive azobenzene sheets could become a versatile platform to sense and deliver different types of signals (i.e., electrical, optical, thermal, etc.) to neurons and other types of cells in a minimally or noninvasive manner. Although preliminary, the cytocompatibility data reported in this work is also very promising for future use in vivo,” says Flavia Vitale, associate professor of neurology, bioengineering, and physical medicine and rehabilitation at the University of Pennsylvania, who was not involved with this work.
The research was supported by the Swiss National Science Foundation and the U.S. National Institutes of Health Brain Initiative. This work was carried out, in part, through the use of MIT.nano facilities.
This image shows the researchers' subcellular-sized devices, which are designed to gently wrap around different parts of neurons, such as axons and dendrites, without damaging the cells. The devices could be used to measure or modulate a neuron's electrical activity.
There is power in numbers, or so the saying goes. But in the ocean, scientists are finding that fish that group together don’t necessarily survive together. In some cases, the more fish there are, the larger a target they make for predators.
This is what MIT and Norwegian oceanographers observed recently when they explored a wide swath of ocean off the coast of Norway during the height of spawning season for capelin — a small Arctic fish about the size of an anchovy. Billions of capelin migrate each February from the edge of the Arctic ice sheet southward to the Norwegian coast, to lay their eggs. Norway’s coastline is also a stopover for capelin’s primary predator, the Atlantic cod. As cod migrate south, they feed on spawning capelin, though scientists have not measured this process over large scales until now.
Reporting their findings today in Nature Communications Biology, the MIT team captured interactions between individual migrating cod and spawning capelin, over a huge spatial extent. Using a sonic-based wide-area imaging technique, they watched as random capelin began grouping together to form a massive shoal spanning tens of kilometers. As the capelin shoal formed a sort of ecological “hotspot,” the team observed individual cod begin to group together in response, forming a huge shoal of their own. The swarming cod overtook the capelin, quickly consuming over 10 million fish, estimated to be more than half of the gathered prey.
The dramatic encounter, which took place over just a few hours, is the largest such predation event ever recorded, both in terms of the number of individuals involved and the area over which the event occurred.
This one event is unlikely to weaken the capelin population as a whole; the preyed-upon shoal represents 0.1 percent of the capelin that spawn in the region. However, as climate change causes the Arctic ice sheet to retreat, capelin will have to swim farther to spawn, making the species more stressed and vulnerable to natural predation events such as the one the team observed. As capelin sustains many fish species, including cod, continuously monitoring their behavior, at a resolution approaching that of individual fish and across large scales spanning tens of thousands of square kilometers, will help efforts to maintain the species and the health of the ocean overall.
“In our work we are seeing that natural catastrophic predation events can change the local predator prey balance in a matter of hours,” says Nicholas Makris, professor of mechanical and ocean engineering at MIT. “That’s not an issue for a healthy population with many spatially distributed population centers or ecological hotspots. But as the number of these hotspots deceases due to climate and anthropogenic stresses, the kind of natural ‘catastrophic’ predation event we witnessed of a keystone species could lead to dramatic consequences for that species as well as the many species dependent on them.”
Makris’ co-authors on the paper are Shourav Pednekar and Ankita Jain at MIT, and Olav Rune Godø of the Institute of Marine Research in Norway.
Bell sounds
For their new study, Makris and his colleagues reanalyzed data that they gathered during a cruise in February of 2014 to the Barents Sea, off the coast of Norway. During that cruise, the team deployed the Ocean Acoustic Waveguide Remote Sensing (OAWRS) system — a sonic imaging technique that employs a vertical acoustic array, attached to the bottom of a boat, to send sound waves down into the ocean and out in all directions. These waves can travel over large distances as they bounce off any obstacles or fish in their path.
The same or a second boat, towing an array of acoustic receivers, continuously picks up the scattered and reflected waves, from as far as many tens of kilometers away. Scientists can then analyze the collected waveforms to create instantaneous maps of the ocean over a huge areal extent.
Previously, the team reconstructed maps of individual fish and their movements, but could not distinguish between different species. In the new study, the researchers applied a new “multispectral” technique to differentiate between species based on the characteristic acoustic resonance of their swim bladders.
“Fish have swim bladders that resonate like bells,” Makris explains. “Cod have large swim bladders that have a low resonance, like a Big Ben bell, whereas capelin have tiny swim bladders that resonate like the highest notes on a piano.”
By reanalyzing OAWRS data to look for specific frequencies of capelin versus cod, the researchers were able to image fish groups, determine their species content, and map the movements of each species over a huge areal extent.
Watching a wave
The researchers applied the multi-spectral technique to OAWRS data collected on Feb. 27, 2014, at the peak of the capelin spawning season. In the early morning hours, their new mapping showed that capelin largely kept to themselves, moving as random individuals, in loose clusters along the Norwegian coastline. As the sun rose and lit the surface waters, the capelin began to descend to darker depths, possibly seeking places along the seafloor to spawn.
The team observed that as the capelin descended, they began shifting from individual to group behavior, ultimately forming a huge shoal of about 23 million fish that moved in a coordinated wave spanning over ten kilometers long.
“What we’re finding is capelin have this critical density, which came out of a physical theory, which we have now observed in the wild,” Makris says. “If they are close enough to each other, they can take on the average speed and direction of other fish that they can sense around them, and can then form a massive and coherent shoal.”
As they watched, the shoaling fish began to move as one, in a coherent behavior that has been observed in other species but never in capelin until now. Such coherent migration is thought to help fish save energy over large distances by essentially riding the collective motion of the group.
In this instance, however, as soon as the capelin shoal formed, it attracted increasing numbers of cod, which quickly formed a shoal of their own, amounting to about 2.5 million fish, based on the team’s acoustic mapping. Over a few short hours, the cod consumed 10.5 million capelin over tens of kilometers before both shoals dissolved and the fish scattered away. Makris suspects that such massive and coordinated predation is a common occurrence in the ocean, though this is the first time that scientists have been able to document such an event.
“It’s the first time seeing predator-prey interaction on a huge scale, and it’s a coherent battle of survival,” Makris says. “This is happening over a monstrous scale, and we’re watching a wave of capelin zoom in, like a wave around a sports stadium, and they kind of gather together to form a defense. It’s also happening with the predators, coming together to coherently attack.”
“This is a truly fascinating study that documents complex spatial dynamics linking predators and prey, here cod and capelin, at scales previously unachievable in marine ecosystems,” says George Rose, professor of fisheries at the University of British Columbia, who studies the ecology and productivity of cod in the North Atlantic, and was not involved in this work. “Simultaneous species mapping with the OAWRS system…enables insight into fundamental ecological processes with untold potential to enhance current survey methods.”
Makris hopes to deploy OAWRS in the future to monitor the large-scale dynamics among other species of fish.
“It’s been shown time and again that, when a population is on the verge of collapse, you will have that one last shoal. And when that last big, dense group is gone, there’s a collapse,” Makris says. “So you’ve got to know what’s there before it’s gone, because the pressures are not in their favor.”
This work was supported, in part, by the U.S. Office of Naval Research and the Institute of Marine Research in Norway.
“In our work we are seeing that natural catastrophic predation events can change the local predator prey balance in a matter of hours,” says Nicholas Makris, professor of mechanical and ocean engineering at MIT.
Quantum computers hold the promise to emulate complex materials, helping researchers better understand the physical properties that arise from interacting atoms and electrons. This may one day lead to the discovery or design of better semiconductors, insulators, or superconductors that could be used to make ever faster, more powerful, and more energy-efficient electronics.
But some phenomena that occur in materials can be challenging to mimic using quantum computers, leaving gaps in the problems that scientists have explored with quantum hardware.
To fill one of these gaps, MIT researchers developed a technique to generate synthetic electromagnetic fields on superconducting quantum processors. The team demonstrated the technique on a processor comprising 16 qubits.
By dynamically controlling how the 16 qubits in their processor are coupled to one another, the researchers were able to emulate how electrons move between atoms in the presence of an electromagnetic field. Moreover, the synthetic electromagnetic field is broadly adjustable, enabling scientists to explore a range of material properties.
Emulating electromagnetic fields is crucial to fully explore the properties of materials. In the future, this technique could shed light on key features of electronic systems, such as conductivity, polarization, and magnetization.
“Quantum computers are powerful tools for studying the physics of materials and other quantum mechanical systems. Our work enables us to simulate much more of the rich physics that has captivated materials scientists,” says Ilan Rosen, an MIT postdoc and lead author of a paper on the quantum simulator.
The senior author is William D. Oliver, the Henry Ellis Warren professor of electrical engineering and computer science and of physics, director of the Center for Quantum Engineering, leader of the Engineering Quantum Systems group, and associate director of the Research Laboratory of Electronics. Oliver and Rosen are joined by others in the departments of Electrical Engineering and Computer Science and of Physics and at MIT Lincoln Laboratory. The research appears today in Nature Physics.
A quantum emulator
Companies like IBM and Google are striving to build large-scale digital quantum computers that hold the promise of outperforming their classical counterparts by running certain algorithms far more rapidly.
But that’s not all quantum computers can do. The dynamics of qubits and their couplings can also be carefully constructed to mimic the behavior of electrons as they move among atoms in solids.
“That leads to an obvious application, which is to use these superconducting quantum computers as emulators of materials,” says Jeffrey Grover, a research scientist at MIT and co-author on the paper.
Rather than trying to build large-scale digital quantum computers to solve extremely complex problems, researchers can use the qubits in smaller-scale quantum computers as analog devices to replicate a material system in a controlled environment.
“General-purpose digital quantum simulators hold tremendous promise, but they are still a long way off. Analog emulation is another approach that may yield useful results in the near-term, particularly for studying materials. It is a straightforward and powerful application of quantum hardware,” explains Rosen. “Using an analog quantum emulator, I can intentionally set a starting point and then watch what unfolds as a function of time.”
Despite their close similarity to materials, there are a few important ingredients in materials that can’t be easily reflected on quantum computing hardware. One such ingredient is a magnetic field.
In materials, electrons “live” in atomic orbitals. When two atoms are close to one another, their orbitals overlap and electrons can “hop” from one atom to another. In the presence of a magnetic field, that hopping behavior becomes more complex.
On a superconducting quantum computer, microwave photons hopping between qubits are used to mimic electrons hopping between atoms. But, because photons are not charged particles like electrons, the photons’ hopping behavior would remain the same in a physical magnetic field.
Since they can’t just turn on a magnetic field in their simulator, the MIT team employed a few tricks to synthesize the effects of one instead.
Tuning up the processor
The researchers adjusted how adjacent qubits in the processor were coupled to each other to create the same complex hopping behavior that electromagnetic fields cause in electrons.
To do that, they slightly changed the energy of each qubit by applying different microwave signals. Usually, researchers will set qubits to the same energy so that photons can hop from one to another. But for this technique, they dynamically varied the energy of each qubit to change how they communicate with each other.
By precisely modulating these energy levels, the researchers enabled photons to hop between qubits in the same complex manner that electrons hop between atoms in a magnetic field.
Plus, because they can finely tune the microwave signals, they can emulate a range of electromagnetic fields with different strengths and distributions.
The researchers undertook several rounds of experiments to determine what energy to set for each qubit, how strongly to modulate them, and the microwave frequency to use.
“The most challenging part was finding modulation settings for each qubit so that all 16 qubits work at once,” Rosen says.
Once they arrived at the right settings, they confirmed that the dynamics of the photons uphold several equations that form the foundation of electromagnetism. They also demonstrated the “Hall effect,” a conduction phenomenon that exists in the presence of an electromagnetic field.
These results show that their synthetic electromagnetic field behaves like the real thing.
Moving forward, they could use this technique to precisely study complex phenomena in condensed matter physics, such as phase transitions that occur when a material changes from a conductor to an insulator.
“A nice feature of our emulator is that we need only change the modulation amplitude or frequency to mimic a different material system. In this way, we can scan over many materials properties or model parameters without having to physically fabricate a new device each time.” says Oliver.
While this work was an initial demonstration of a synthetic electromagnetic field, it opens the door to many potential discoveries, Rosen says.
“The beauty of quantum computers is that we can look at exactly what is happening at every moment in time on every qubit, so we have all this information at our disposal. We are in a very exciting place for the future,” he adds.
This work is supported, in part, by the U.S. Department of Energy, the U.S. Defense Advanced Research Projects Agency (DARPA), the U.S. Army Research Office, the Oak Ridge Institute for Science and Education, the Office of the Director of National Intelligence, NASA, and the National Science Foundation.
MIT researchers developed a superconducting quantum processor comprised of 16 qubits which they can use to generate a synthetic electromagnetic field, enabling them to explore the properties of materials. Pictured is an artist's interpretation of the quantum processor.
Patients with late-stage cancer often have to endure multiple rounds of different types of treatment, which can cause unwanted side effects and may not always help.
In hopes of expanding the treatment options for those patients, MIT researchers have designed tiny particles that can be implanted at a tumor site, where they deliver two types of therapy: heat and chemotherapy.
This approach could avoid the side effects that often occur when chemotherapy is given intravenously, and the synergistic effect of the two therapies may extend the patient’s lifespan longer than giving one treatment at a time. In a study of mice, the researchers showed that this therapy completely eliminated tumors in most of the animals and significantly prolonged their survival.
“One of the examples where this particular technology could be useful is trying to control the growth of really fast-growing tumors,” says Ana Jaklenec, a principal investigator at MIT’s Koch Institute for Integrative Cancer Research. “The goal would be to gain some control over these tumors for patients that don't really have a lot of options, and this could either prolong their life or at least allow them to have a better quality of life during this period.”
Jaklenec is one of the senior authors of the new study, along with Angela Belcher, the James Mason Crafts Professor of Biological Engineering and Materials Science and Engineering and a member of the Koch Institute, and Robert Langer, an MIT Institute Professor and member of the Koch Institute. Maria Kanelli, a former MIT postdoc, is the lead author of the paper, which appears today in the journal ACS Nano.
Dual therapy
Patients with advanced tumors usually undergo a combination of treatments, including chemotherapy, surgery, and radiation. Phototherapy is a newer treatment that involves implanting or injecting particles that are heated with an external laser, raising their temperature enough to kill nearby tumor cells without damaging other tissue.
Current approaches to phototherapy in clinical trials make use of gold nanoparticles, which emit heat when exposed to near-infrared light.
The MIT team wanted to come up with a way to deliver phototherapy and chemotherapy together, which they thought could make the treatment process easier on the patient and might also have synergistic effects. They decided to use an inorganic material called molybdenum sulfide as the phototherapeutic agent. This material converts laser light to heat very efficiently, which means that low-powered lasers can be used.
To create a microparticle that could deliver both of these treatments, the researchers combined molybdenum disulfide nanosheets with either doxorubicin, a hydrophilic drug, or violacein, a hydrophobic drug. To make the particles, molybdenum disulfide and the chemotherapeutic are mixed with a polymer called polycaprolactone and then dried into a film that can be pressed into microparticles of different shapes and sizes.
For this study, the researchers created cubic particles with a width of 200 micrometers. Once injected into a tumor site, the particles remain there throughout the treatment. During each treatment cycle, an external near-infrared laser is used to heat up the particles. This laser can penetrate to a depth of a few millimeters to centimeters, with a local effect on the tissue.
“The advantage of this platform is that it can act on demand in a pulsatile manner,” Kanelli says. “You administer it once through an intratumoral injection, and then using an external laser source you can activate the platform, release the drug, and at the same time achieve thermal ablation of the tumor cells.”
To optimize the treatment protocol, the researchers used machine-learning algorithms to figure out the laser power, irradiation time, and concentration of the phototherapeutic agent that would lead to the best outcomes.
That led them to design a laser treatment cycle that lasts for about three minutes. During that time, the particles are heated to about 50 degrees Celsius, which is hot enough to kill tumor cells. Also at this temperature, the polymer matrix within the particles begins to melt, releasing some of the chemotherapy drug contained within the matrix.
“This machine-learning-optimized laser system really allows us to deploy low-dose, localized chemotherapy by leveraging the deep tissue penetration of near-infrared light for pulsatile, on-demand photothermal therapy. This synergistic effect results in low systemic toxicity compared to conventional chemotherapy regimens,” says Neelkanth Bardhan, a Break Through Cancer research scientist in the Belcher Lab, and second author of the paper.
Eliminating tumors
The researchers tested the microparticle treatment in mice that were injected with an aggressive type of cancer cells from triple-negative breast tumors. Once tumors formed, the researchers implanted about 25 microparticles per tumor, and then performed the laser treatment three times, with three days in between each treatment.
“This is a powerful demonstration of the usefulness of near-infrared-responsive material systems,” says Belcher, who, along with Bardhan, has previously worked on near-infrared imaging systems for diagnostic and treatment applications in ovarian cancer. “Controlling the drug release at timed intervals with light, after just one dose of particle injection, is a game changer for less painful treatment options and can lead to better patient compliance.”
In mice that received this treatment, the tumors were completely eradicated, and the mice lived much longer than those that were given either chemotherapy or phototherapy alone, or no treatment. Mice that underwent all three treatment cycles also fared much better than those that received just one laser treatment.
The polymer used to make the particles is biocompatible and has already been FDA-approved for medical devices. The researchers now hope to test the particles in larger animal models, with the goal of eventually evaluating them in clinical trials. They expect that this treatment could be useful for any type of solid tumor, including metastatic tumors.
The research was funded by the Bodossaki Foundation, the Onassis Foundation, a Mazumdar-Shaw International Oncology Fellowship, a National Cancer Institute Fellowship, and the Koch Institute Support (core) Grant from the National Cancer Institute.
MIT researchers have designed microparticles that can deliver phototherapy to tumors, along with chemotherapy drugs. At bottom left are particles that carry the drug doxorubicin, and at top right are particles carrying violacein.
In the classic cartoon “The Jetsons,” Rosie the robotic maid seamlessly switches from vacuuming the house to cooking dinner to taking out the trash. But in real life, training a general-purpose robot remains a major challenge.
Typically, engineers collect data that are specific to a certain robot and task, which they use to train the robot in a controlled environment. However, gathering these data is costly and time-consuming, and the robot will likely struggle to adapt to environments or tasks it hasn’t seen before.
To train better general-purpose robots, MIT researchers developed a versatile technique that combines a huge amount of heterogeneous data from many of sources into one system that can teach any robot a wide range of tasks.
Their method involves aligning data from varied domains, like simulations and real robots, and multiple modalities, including vision sensors and robotic arm position encoders, into a shared “language” that a generative AI model can process.
By combining such an enormous amount of data, this approach can be used to train a robot to perform a variety of tasks without the need to start training it from scratch each time.
This method could be faster and less expensive than traditional techniques because it requires far fewer task-specific data. In addition, it outperformed training from scratch by more than 20 percent in simulation and real-world experiments.
“In robotics, people often claim that we don’t have enough training data. But in my view, another big problem is that the data come from so many different domains, modalities, and robot hardware. Our work shows how you’d be able to train a robot with all of them put together,” says Lirui Wang, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this technique.
Wang’s co-authors include fellow EECS graduate student Jialiang Zhao; Xinlei Chen, a research scientist at Meta; and senior author Kaiming He, an associate professor in EECS and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL). The research will be presented at the Conference on Neural Information Processing Systems.
Inspired by LLMs
A robotic “policy” takes in sensor observations, like camera images or proprioceptive measurements that track the speed and position a robotic arm, and then tells a robot how and where to move.
Policies are typically trained using imitation learning, meaning a human demonstrates actions or teleoperates a robot to generate data, which are fed into an AI model that learns the policy. Because this method uses a small amount of task-specific data, robots often fail when their environment or task changes.
To develop a better approach, Wang and his collaborators drew inspiration from large language models like GPT-4.
These models are pretrained using an enormous amount of diverse language data and then fine-tuned by feeding them a small amount of task-specific data. Pretraining on so much data helps the models adapt to perform well on a variety of tasks.
“In the language domain, the data are all just sentences. In robotics, given all the heterogeneity in the data, if you want to pretrain in a similar manner, we need a different architecture,” he says.
Robotic data take many forms, from camera images to language instructions to depth maps. At the same time, each robot is mechanically unique, with a different number and orientation of arms, grippers, and sensors. Plus, the environments where data are collected vary widely.
The MIT researchers developed a new architecture called Heterogeneous Pretrained Transformers (HPT) that unifies data from these varied modalities and domains.
They put a machine-learning model known as a transformer into the middle of their architecture, which processes vision and proprioception inputs. A transformer is the same type of model that forms the backbone of large language models.
The researchers align data from vision and proprioception into the same type of input, called a token, which the transformer can process. Each input is represented with the same fixed number of tokens.
Then the transformer maps all inputs into one shared space, growing into a huge, pretrained model as it processes and learns from more data. The larger the transformer becomes, the better it will perform.
A user only needs to feed HPT a small amount of data on their robot’s design, setup, and the task they want it to perform. Then HPT transfers the knowledge the transformer grained during pretraining to learn the new task.
Enabling dexterous motions
One of the biggest challenges of developing HPT was building the massive dataset to pretrain the transformer, which included 52 datasets with more than 200,000 robot trajectories in four categories, including human demo videos and simulation.
The researchers also needed to develop an efficient way to turn raw proprioception signals from an array of sensors into data the transformer could handle.
“Proprioception is key to enable a lot of dexterous motions. Because the number of tokens is in our architecture always the same, we place the same importance on proprioception and vision,” Wang explains.
When they tested HPT, it improved robot performance by more than 20 percent on simulation and real-world tasks, compared with training from scratch each time. Even when the task was very different from the pretraining data, HPT still improved performance.
“This paper provides a novel approach to training a single policy across multiple robot embodiments. This enables training across diverse datasets, enabling robot learning methods to significantly scale up the size of datasets that they can train on. It also allows the model to quickly adapt to new robot embodiments, which is important as new robot designs are continuously being produced,” says David Held, associate professor at the Carnegie Mellon University Robotics Institute, who was not involved with this work.
In the future, the researchers want to study how data diversity could boost the performance of HPT. They also want to enhance HPT so it can process unlabeled data like GPT-4 and other large language models.
“Our dream is to have a universal robot brain that you could download and use for your robot without any training at all. While we are just in the early stages, we are going to keep pushing hard and hope scaling leads to a breakthrough in robotic policies, like it did with large language models,” he says.
This work was funded, in part, by the Amazon Greater Boston Tech Initiative and the Toyota Research Institute.
Researchers filmed multiple instances of a robotic arm feeding co-author Jialiang Zhao's adorable dog, Momo. The videos were included in datasets to train the robot.
When you think about hands-free devices, you might picture Alexa and other voice-activated in-home assistants, Bluetooth earpieces, or asking Siri to make a phone call in your car. You might not imagine using your mouth to communicate with other devices like a computer or a phone remotely.
Thinking outside the box, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) and Aarhus University researchers have now engineered “MouthIO,” a dental brace that can be fabricated with sensors and feedback components to capture in-mouth interactions and data. This interactive wearable could eventually assist dentists and other doctors with collecting health data and help motor-impaired individuals interact with a phone, computer, or fitness tracker using their mouths.
Resembling an electronic retainer, MouthIO is a see-through brace that fits the specifications of your upper or lower set of teeth from a scan. The researchers created a plugin for the modeling software Blender to help users tailor the device to fit a dental scan, where you can then 3D print your design in dental resin. This computer-aided design tool allows users to digitally customize a panel (called PCB housing) on the side to integrate electronic components like batteries, sensors (including detectors for temperature and acceleration, as well as tongue-touch sensors), and actuators (like vibration motors and LEDs for feedback). You can also place small electronics outside of the PCB housing on individual teeth.
Research by others at MIT has also led to another mouth-based touchpad, based on technology initially developed in the Media Lab. That device is available via Augmental, a startup deploying technology that lets people with movement impairments seamlessly interact with their personal computational devices.
The active mouth
“The mouth is a really interesting place for an interactive wearable,” says senior author Michael Wessely, a former CSAIL postdoc and senior author on a paper about MouthIO who is now an assistant professor at Aarhus University. “This compact, humid environment has elaborate geometries, making it hard to build a wearable interface to place inside. With MouthIO, though, we’ve developed an open-source device that’s comfortable, safe, and almost invisible to others. Dentists and other doctors are eager about MouthIO for its potential to provide new health insights, tracking things like teeth grinding and potentially bacteria in your saliva.”
The excitement for MouthIO’s potential in health monitoring stems from initial experiments. The team found that their device could track bruxism (the habit of grinding teeth) by embedding an accelerometer within the brace to track jaw movements. When attached to the lower set of teeth, MouthIO detected when users grind and bite, with the data charted to show how often users did each.
Wessely and his colleagues’ customizable brace could one day help users with motor impairments, too. The team connected small touchpads to MouthIO, helping detect when a user’s tongue taps their teeth. These interactions could be sent via Bluetooth to scroll across a webpage, for example, allowing the tongue to act as a “third hand” to help enable hands-free interaction.
"MouthIO is a great example how miniature electronics now allow us to integrate sensing into a broad range of everyday interactions,” says study co-author Stefanie Mueller, the TIBCO Career Development Associate Professor in the MIT departments of Electrical Engineering and Computer Science and Mechanical Engineering and leader of the HCI Engineering Group at CSAIL. “I'm especially excited about the potential to help improve accessibility and track potential health issues among users."
Molding and making MouthIO
To get a 3D model of your teeth, you can first create a physical impression and fill it with plaster. You can then scan your mold with a mobile app like Polycam and upload that to Blender. Using the researchers’ plugin within this program, you can clean up your dental scan to outline a precise brace design. Finally, you 3D print your digital creation in clear dental resin, where the electronic components can then be soldered on. Users can create a standard brace that covers their teeth, or opt for an “open-bite” design within their Blender plugin. The latter fits more like open-finger gloves, exposing the tips of your teeth, which helps users avoid lisping and talk naturally.
This “do it yourself” method costs roughly $15 to produce and takes two hours to be 3D-printed. MouthIO can also be fabricated with a more expensive, professional-level teeth scanner similar to what dentists and orthodontists use, which is faster and less labor-intensive.
Compared to its closed counterpart, which fully covers your teeth, the researchers view the open-bite design as a more comfortable option. The team preferred to use it for beverage monitoring experiments, where they fabricated a brace capable of alerting users when a drink was too hot. This iteration of MouthIO had a temperature sensor and a monitor embedded within the PCB housing that vibrated when a drink exceeded 65 degrees Celsius (or 149 degrees Fahrenheit). This could help individuals with mouth numbness better understand what they’re consuming.
In a user study, participants also preferred the open-bite version of MouthIO. “We found that our device could be suitable for everyday use in the future,” says study lead author and Aarhus University PhD student Yijing Jiang. “Since the tongue can touch the front teeth in our open-bite design, users don’t have a lisp. This made users feel more comfortable wearing the device during extended periods with breaks, similar to how people use retainers.”
The team’s initial findings indicate that MouthIO is a cost-effective, accessible, and customizable interface, and the team is working on a more long-term study to evaluate its viability further. They’re looking to improve its design, including experimenting with more flexible materials, and placing it in other parts of the mouth, like the cheek and the palate. Among these ideas, the researchers have already prototyped two new designs for MouthIO: a single-sided brace for even higher comfort when wearing MouthIO while also being fully invisible to others, and another fully capable of wireless charging and communication.
Jiang, Mueller, and Wessely’s co-authors include PhD student Julia Kleinau, master’s student Till Max Eckroth, and associate professor Eve Hoggan, all of Aarhus University. Their work was supported by a Novo Nordisk Foundation grant and was presented at ACM’s Symposium on User Interface Software and Technology.
A dental brace developed by researchers at MIT CSAIL and Aarhus University can be fabricated with sensors and feedback components to capture in-mouth interactions and data.
Hospice care aims to provide a health care alternative for people nearing the end of life by sparing them unwanted medical procedures and focusing on the patient’s comfort. A new study co-authored by MIT scholars shows hospice also has a clear fiscal benefit: It generates substantial savings for the U.S. Medicare system.
The study examines the growth of for-profit hospice providers, who receive reimbursements from Medicare, and evaluates the cost of caring for patients with Alzheimer’s disease and related dementias (ADRD). The research finds that for patients using for-profit hospice providers, there is about a $29,000 savings to Medicare over the first five years after someone is diagnosed with ADRD.
“Hospice is saving Medicare a lot of money,” says Jonathan Gruber, an MIT health care economist and co-author of a paper detailing the study’s findings. “Those are big numbers.”
In recent decades, hospice care has grown substantially. That growth has been accompanied by concerns that for-profit hospice organizations, in particular, might be overly aggressive in pursuing patients. There have also been instances of fraud by organizations in the field. And yet, the study shows that the overall dynamics of hospice are the intended ones: People are indeed receiving palliative-type care, based around comfort rather than elaborate medical procedures, at less cost.
“What we found is that hospice basically operates as advertised,” adds Gruber, the Ford Professor of Economics at MIT. “It does not extend lives on aggregate, and it does save money.”
The paper, “Dying or Lying? For-Profit Hospices and End of Life Care,” appears in the American Economic Review. The co-authors are Gruber, who is also head of MIT’s Department of Economics; David Howard, a professor at the Rollins School of Public Health at Emory University; Jetson Leder-Luis PhD ’20, an assistant professor at Boston University; and Theodore Caputi, a doctoral student in MIT’s Department of Economics.
Charting what more hospice access means
Hospice care in the U.S. dates to at least the 1970s. Patients opt out of their existing medical network and receive nursing care where they live, either at home or in care facilities. That care is oriented around reducing suffering and pain, rather than attempting to eliminate underlying causes. Generally, hospice patients are expected to have six months or less to live. Most Medicare funding goes to private contractors supplying medical care, and in the 1980s the federal government started using Medicare to reimburse the medical expenses from hospice as well.
While the number of nonprofit hospice providers in the U.S. has remained fairly consistent, the number of for-profit hospice organizations grew fivefold between 2000 and 2019. Medicare payments for hospice care are now about $20 billion annually, up from $2.5 billion in 1999. People diagnosed with ADRD now make up 38 percent of hospice patients.
Still, Gruber considers the topic of hospice care relatively under-covered by analysts. To conduct the study, the team examined over 10 million patients from 1999 through 2019. The researchers used the growth of for-profit hospice providers to compare the effects of being enrolled in non-profit hospice care, for-profit hospice care, or staying in the larger medical system.
That means the scholars were not only evaluating hospice patients; by evaluating the larger population in a given area where and when for-profit hospice firms opened their doors, they could see what difference greater access to hospice care made. For instance, having a new for-profit hospice open locally is associated with a roughly 2 percentage point increase in for-profit hospice admissions in following years.
“We’re able to use this methodology to [analyze] if these patients would otherwise have not gone to hospice or would have gone to a nonprofit hospice,” Gruber says.
The method also allows the scholars to estimate the substantial cost savings. And it shows that enrolling in hospice increased the five-year post-diagnosis mortality rate of ADRD patients by 8.6 percentage points, from a baseline of 66.6 percent. Entering into hospice care — which is a reversible decision — means foregoing life-extending surgeries, for instance, if people believe such procedures are no longer desirable for them.
Rethinking the cap
By providing care without more expensive medical procedures, it is understandable that hospice reduces overall medical costs. Still, given that Medicare reimburses hospice organizations, one ongoing policy concern is that hospice providers might aggressively recruit a larger percentage of patients who end up living longer than six additional months. In this way hospice providers might unduly boost their revenues and put more pressure on the Medicare budget.
To counteract this, Medicare rules include a roughly $29,205 cap on per-patient reimbursements, as of 2019. Most patients die relatively soon after entering hospice care; some will outlive the six-month expectation significantly. But hospice organizations cannot exceed that average.
However, the study also suggests the cap is a suboptimal approach. In 2018, 15.5 percent of hospice patients were being discharged from hospice care while still alive, due to the cap limiting hospice capacity. As the paper notes, “patients in hospices facing cap pressure are more likely to be discharged from hospice alive and experience higher mortality rates.”
As Gruber notes, the spending cap is partly a fraud-fighting tool. And yet the cap clearly has other, unintended consquences on patients and their medical choices, crowding some out of the hospice system.
“The cap may be throwing the baby out with the bathwater.” Gruber says. “The government has more focused tools to fight fraud. Using the cap for that is a blunt instrument.”
As long as people are informed about hospice and the medical trajectory it puts them on, then, hospice care appears to be providing a valued service at less expense than other approaches to end-of-life care.
“The holy grail in health care is things that improve quality and save money,” Gruber says. “And with hospice, there are surveys saying people like it. And it certainly saves money, and there’s no evidence it’s doing harm [to patients]. We talk about how we struggle to deal with health care costs in this country, so this seems like what we want.”
The research was supported in part by the National Institute on Aging of the National Institutes of Health.
A team led by researchers at MIT has discovered that a distant interstellar cloud contains an abundance of pyrene, a type of large, carbon-containing molecule known as a polycyclic aromatic hydrocarbon (PAH).
The discovery of pyrene in this far-off cloud, which is similar to the collection of dust and gas that eventually became our own solar system, suggests that pyrene may have been the source of much of the carbon in our solar system. That hypothesis is also supported by a recent finding that samples returned from the near-Earth asteroid Ryugu contain large quantities of pyrene.
“One of the big questions in star and planet formation is: How much of the chemical inventory from that early molecular cloud is inherited and forms the base components of the solar system? What we’re looking at is the start and the end, and they’re showing the same thing. That’s pretty strong evidence that this material from the early molecular cloud finds its way into the ice, dust, and rocky bodies that make up our solar system,” says Brett McGuire, an assistant professor of chemistry at MIT.
Due to its symmetry, pyrene itself is invisible to the radio astronomy techniques that have been used to detect about 95 percent of molecules in space. Instead, the researchers detected an isomer of cyanopyrene, a version of pyrene that has reacted with cyanide to break its symmetry. The molecule was detected in a distant cloud known as TMC-1, using the 100-meter Green Bank Telescope (GBT), a radio telescope at the Green Bank Observatory in West Virginia.
McGuire and Ilsa Cooke, an assistant professor of chemistry at the University of British Colombia, are the senior authors of a paper describing the findings, which appears today in Science. Gabi Wenzel, an MIT postdoc in McGuire’s group, is the lead author of the study.
Carbon in space
PAHs, which contain rings of carbon atoms fused together, are believed to store 10 to 25 percent of the carbon that exists in space. More than 40 years ago, scientists using infrared telescopes began detecting features that are thought to belong to vibrational modes of PAHs in space, but this technique couldn’t reveal exactly which types of PAHs were out there.
“Since the PAH hypothesis was developed in the 1980s, many people have accepted that PAHs are in space, and they have been found in meteorites, comets, and asteroid samples, but we can’t really use infrared spectroscopy to unambiguously identify individual PAHs in space,” Wenzel says.
In 2018, a team led by McGuire reported the discovery of benzonitrile — a six-carbon ring attached to a nitrile (carbon-nitrogen) group — in TMC-1. To make this discovery, they used the GBT, which can detect molecules in space by their rotational spectra — distinctive patterns of light that molecules give off as they tumble through space. In 2021, his team detected the first individual PAHs in space: two isomers of cyanonaphthalene, which consists of two rings fused together, with a nitrile group attached to one ring.
On Earth, PAHs commonly occur as byproducts of burning fossil fuels, and they’re also found in char marks on grilled food. Their discovery in TMC-1, which is only about 10 kelvins, suggested that it may also be possible for them to form at very low temperatures.
The fact that PAHs have also been found in meteorites, asteroids, and comets has led many scientists to hypothesize that PAHs are the source of much of the carbon that formed our own solar system. In 2023, researchers in Japan found large quantities of pyrene in samples returned from the asteroid Ryugu during the Hayabusa2 mission, along with smaller PAHs including naphthalene.
That discovery motivated McGuire and his colleagues to look for pyrene in TMC-1. Pyrene, which contains four rings, is larger than any of the other PAHs that have been detected in space. In fact, it’s the third-largest molecule identified in space, and the largest ever detected using radio astronomy.
Before looking for these molecules in space, the researchers first had to synthesize cyanopyrene in the laboratory. The cyano or nitrile group is necessary for the molecule to emit a signal that a radio telescope can detect. The synthesis was performed by MIT postdoc Shuo Zhang in the group of Alison Wendlandt, an MIT associate professor of chemistry.
Then, the researchers analyzed the signals that the molecules emit in the laboratory, which are exactly the same as the signals that they emit in space.
Using the GBT, the researchers found these signatures throughout TMC-1. They also found that cyanopyrene accounts for about 0.1 percent of all the carbon found in the cloud, which sounds small but is significant when one considers the thousands of different types of carbon-containing molecules that exist in space, McGuire says.
“While 0.1 percent doesn’t sound like a large number, most carbon is trapped in carbon monoxide (CO), the second-most abundant molecule in the universe besides molecular hydrogen. If we set CO aside, one in every few hundred or so remaining carbon atoms is in pyrene. Imagine the thousands of different molecules that are out there, nearly all of them with many different carbon atoms in them, and one in a few hundred is in pyrene,” he says. “That is an absolutely massive abundance. An almost unbelievable sink of carbon. It’s an interstellar island of stability.”
Ewine van Dishoeck, a professor of molecular astrophysics at Leiden Observatory in the Netherlands, called the discovery “unexpected and exciting.”
“It builds on their earlier discoveries of smaller aromatic molecules, but to make the jump now to the pyrene family is huge. Not only does it demonstrate that a significant fraction of carbon is locked up in these molecules, but it also points to different formation routes of aromatics than have been considered so far,” says van Dishoeck, who was not involved in the research.
An abundance of pyrene
Interstellar clouds like TMC-1 may eventually give rise to stars, as clumps of dust and gas coalesce into larger bodies and begin to heat up. Planets, asteroids, and comets arise from some of the gas and dust that surround young stars. Scientists can’t look back in time at the interstellar cloud that gave rise to our own solar system, but the discovery of pyrene in TMC-1, along with the presence of large amounts of pyrene in the asteroid Ryugu, suggests that pyrene may have been the source of much of the carbon in our own solar system.
“We now have, I would venture to say, the strongest evidence ever of this direct molecular inheritance from the cold cloud all the way through to the actual rocks in the solar system,” McGuire says.
The researchers now plan to look for even larger PAH molecules in TMC-1. They also hope to investigate the question of whether the pyrene found in TMC-1 was formed within the cold cloud or whether it arrived from elsewhere in the universe, possibly from the high-energy combustion processes that surround dying stars.
The research was funded in part by a Beckman Foundation Young Investigator Award, the Schmidt Futures, the U.S. National Science Foundation, the Natural Sciences and Engineering Research Council of Canada, the Goddard Center for Astrobiology, and the NASA Planetary Science Division Internal Scientist Funding Program.
The findings suggest pyrene may have been the source of much of the carbon in our solar system. “It’s an almost unbelievable sink of carbon,” says Brett McGuire, right, standing with lead author of the study Gabi Wenzel.
For many decades, fusion has been touted as the ultimate source of abundant, clean electricity. Now, as the world faces the need to reduce carbon emissions to prevent catastrophic climate change, making commercial fusion power a reality takes on new importance. In a power system dominated by low-carbon variable renewable energy sources (VREs) such as solar and wind, “firm” electricity sources are needed to kick in whenever demand exceeds supply — for example, when the sun isn’t shining or the wind isn’t blowing and energy storage systems aren’t up to the task. What is the potential role and value of fusion power plants (FPPs) in such a future electric power system — a system that is not only free of carbon emissions but also capable of meeting the dramatically increased global electricity demand expected in the coming decades?
Working together for a year-and-a-half, investigators in the MIT Energy Initiative (MITEI) and the MIT Plasma Science and Fusion Center (PSFC) have been collaborating to answer that question. They found that — depending on its future cost and performance — fusion has the potential to be critically important to decarbonization. Under some conditions, the availability of FPPs could reduce the global cost of decarbonizing by trillions of dollars. More than 25 experts together examined the factors that will impact the deployment of FPPs, including costs, climate policy, operating characteristics, and other factors. They present their findings in a new report funded through MITEI and entitled “The Role of Fusion Energy in a Decarbonized Electricity System.”
“Right now, there is great interest in fusion energy in many quarters — from the private sector to government to the general public,” says the study’s principal investigator (PI) Robert C. Armstrong, MITEI’s former director and the Chevron Professor of Chemical Engineering, Emeritus. “In undertaking this study, our goal was to provide a balanced, fact-based, analysis-driven guide to help us all understand the prospects for fusion going forward.” Accordingly, the study takes a multidisciplinary approach that combines economic modeling, electric grid modeling, techno-economic analysis, and more to examine important factors that are likely to shape the future deployment and utilization of fusion energy. The investigators from MITEI provided the energy systems modeling capability, while the PSFC participants provided the fusion expertise.
Fusion technologies may be a decade away from commercial deployment, so the detailed technology and costs of future commercial FPPs are not known at this point. As a result, the MIT research team focused on determining what cost levels fusion plants must reach by 2050 to achieve strong market penetration and make a significant contribution to the decarbonization of global electricity supply in the latter half of the century.
The value of having FPPs available on an electric grid will depend on what other options are available, so to perform their analyses, the researchers needed estimates of the future cost and performance of those options, including conventional fossil fuel generators, nuclear fission power plants, VRE generators, and energy storage technologies, as well as electricity demand for specific regions of the world. To find the most reliable data, they searched the published literature as well as results of previous MITEI and PSFC analyses.
Overall, the analyses showed that — while the technology demands of harnessing fusion energy are formidable — so are the potential economic and environmental payoffs of adding this firm, low-carbon technology to the world’s portfolio of energy options.
Perhaps the most remarkable finding is the “societal value” of having commercial FPPs available. “Limiting warming to 1.5 degrees C requires that the world invest in wind, solar, storage, grid infrastructure, and everything else needed to decarbonize the electric power system,” explains Randall Field, executive director of the fusion study and MITEI’s director of research. “The cost of that task can be far lower when FPPs are available as a source of clean, firm electricity.” And the benefit varies depending on the cost of the FPPs. For example, assuming that the cost of building a FPP is $8,000 per kilowatt (kW) in 2050 and falls to $4,300/kW in 2100, the global cost of decarbonizing electric power drops by $3.6 trillion. If the cost of a FPP is $5,600/kW in 2050 and falls to $3,000/kW in 2100, the savings from having the fusion plants available would be $8.7 trillion. (Those calculations are based on differences in global gross domestic product and assume a discount rate of 6 percent. The undiscounted value is about 20 times larger.)
The goal of other analyses was to determine the scale of deployment worldwide at selected FPP costs. Again, the results are striking. For a deep decarbonization scenario, the total global share of electricity generation from fusion in 2100 ranges from less than 10 percent if the cost of fusion is high to more than 50 percent if the cost of fusion is low.
Other analyses showed that the scale and timing of fusion deployment vary in different parts of the world. Early deployment of fusion can be expected in wealthy nations such as European countries and the United States that have the most aggressive decarbonization policies. But certain other locations — for example, India and the continent of Africa — will have great growth in fusion deployment in the second half of the century due to a large increase in demand for electricity during that time. “In the U.S. and Europe, the amount of demand growth will be low, so it’ll be a matter of switching away from dirty fuels to fusion,” explains Sergey Paltsev, deputy director of the MIT Center for Sustainability Science and Strategy and a senior research scientist at MITEI. “But in India and Africa, for example, the tremendous growth in overall electricity demand will be met with significant amounts of fusion along with other low-carbon generation resources in the later part of the century.”
A set of analyses focusing on nine subregions of the United States showed that the availability and cost of other low-carbon technologies, as well as how tightly carbon emissions are constrained, have a major impact on how FPPs would be deployed and used. In a decarbonized world, FPPs will have the highest penetration in locations with poor diversity, capacity, and quality of renewable resources, and limits on carbon emissions will have a big impact. For example, the Atlantic and Southeast subregions have low renewable resources. In those subregions, wind can produce only a small fraction of the electricity needed, even with maximum onshore wind buildout. Thus, fusion is needed in those subregions, even when carbon constraints are relatively lenient, and any available FPPs would be running much of the time. In contrast, the Central subregion of the United States has excellent renewable resources, especially wind. Thus, fusion competes in the Central subregion only when limits on carbon emissions are very strict, and FPPs will typically be operated only when the renewables can’t meet demand.
An analysis of the power system that serves the New England states provided remarkably detailed results. Using a modeling tool developed at MITEI, the fusion team explored the impact of using different assumptions about not just cost and emissions limits but even such details as potential land-use constraints affecting the use of specific VREs. This approach enabled them to calculate the FPP cost at which fusion units begin to be installed. They were also able to investigate how that “threshold” cost changed with changes in the cap on carbon emissions. The method can even show at what price FPPs begin to replace other specific generating sources. In one set of runs, they determined the cost at which FPPs would begin to displace floating platform offshore wind and rooftop solar.
“This study is an important contribution to fusion commercialization because it provides economic targets for the use of fusion in the electricity markets,” notes Dennis G. Whyte, co-PI of the fusion study, former director of the PSFC, and the Hitachi America Professor of Engineering in the Department of Nuclear Science and Engineering. “It better quantifies the technical design challenges for fusion developers with respect to pricing, availability, and flexibility to meet changing demand in the future.”
The researchers stress that while fission power plants are included in the analyses, they did not perform a “head-to-head” comparison between fission and fusion, because there are too many unknowns. Fusion and nuclear fission are both firm, low-carbon electricity-generating technologies; but unlike fission, fusion doesn’t use fissile materials as fuels, and it doesn’t generate long-lived nuclear fuel waste that must be managed. As a result, the regulatory requirements for FPPs will be very different from the regulations for today’s fission power plants — but precisely how they will differ is unclear. Likewise, the future public perception and social acceptance of each of these technologies cannot be projected, but could have a major influence on what generation technologies are used to meet future demand.
The results of the study convey several messages about the future of fusion. For example, it’s clear that regulation can be a potentially large cost driver. This should motivate fusion companies to minimize their regulatory and environmental footprint with respect to fuels and activated materials. It should also encourage governments to adopt appropriate and effective regulatory policies to maximize their ability to use fusion energy in achieving their decarbonization goals. And for companies developing fusion technologies, the study’s message is clearly stated in the report: “If the cost and performance targets identified in this report can be achieved, our analysis shows that fusion energy can play a major role in meeting future electricity needs and achieving global net-zero carbon goals.”
Researchers from the Critical Analytics for Manufacturing Personalized-Medicine (CAMP) interdisciplinary research group at the Singapore-MIT Alliance for Research and Technology (SMART), MIT’s research enterprise in Singapore, alongside collaborators from the National University of Singapore Tissue Engineering Programme, have developed a novel method to enhance the ability of mesenchymal stromal cells (MSCs) to generate cartilage tissue by adding ascorbic acid during MSC expansion. The research also discovered that micro-magnetic resonance relaxometry (µMRR), a novel process analytical tool developed by SMART CAMP, can be used as a rapid, label-free process-monitoring tool for the quality expansion of MSCs.
Articular cartilage, a connective tissue that protects the bone ends in joints, can degenerate due to injury, age, or arthritis, leading to significant joint pain and disability. Especially in countries — such as Singapore — that have an active, aging population, articular cartilage degeneration is a growing ailment that affects an increasing number of people. Autologous chondrocyte implantation is currently the only Food and Drug Administration-approved cell-based therapy for articular cartilage injuries, but it is costly, time-intensive, and requires multiple treatments. MSCs are an attractive and promising alternative as they have shown good safety profiles for transplantation. However, clinical use of MSCs is limited due to inconsistent treatment outcomes arising from factors such as donor-to-donor variability, variation among cells during cell expansion, and non-standardized MSC manufacturing protocols.
The heterogeneity of MSCs can lead to variations in their biological behavior and treatment outcomes. While large-scale MSC expansions are required to obtain a therapeutically relevant number of cells for implantation, this process can introduce cell heterogeneity. Therefore, improved processes are essential to reduce cell heterogeneity while increasing donor cell numbers with improved chondrogenic potential — the ability of MSCs to differentiate into cartilage cells to repair cartilage tissue — to pave the way for more effective and consistent MSC-based therapies.
In a paper titled “Metabolic modulation to improve MSC expansion and therapeutic potential for articular cartilage repair,” published in the scientific journal Stem Cell Research and Therapy, CAMP researchers detailed their development of a priming strategy to enhance the expansion of quality MSCs by modifying the way cells utilize energy. The research findings have shown a positive correlation between chondrogenic potential and oxidative phosphorylation (OXPHOS), a process that harnesses the reduction of oxygen to create adenosine triphosphate — a source of energy that drives and supports many processes in living cells. This suggests that manipulating MSC metabolism is a promising strategy for enhancing chondrogenic potential.
Using novel PATs developed by CAMP, the researchers explored the potential of metabolic modulation in both short- and long-term harvesting and reseeding of cells. To enhance their chondrogenic potential, they varied the nutrient composition, including glucose, pyruvate, glutamine, and ascorbic acid (AA). As AA is reported to support OXPHOS and its positive impact on chondrogenic potential during differentiation — a process in which immature cells become mature cells with specific functions — the researchers further investigated its effects during MSC expansion.
The addition of AA to cell cultures for one passage during MSC expansion and prior to initiation of differentiation was found to improve chondrogenic differentiation, which is a critical quality attribute (CQA) for better articular cartilage repair. Longer-term AA treatment led to a more than 300-fold increase in the yield of MSCs with enhanced chondrogenic potential, and reduced cell heterogeneity and cell senescence — a process by which a cell ages and permanently stops dividing but does not die — when compared to untreated cells. AA-treated MSCs with improved chondrogenic potential showed a robust shift in metabolic profile to OXPHOS. This metabolic change correlated with μMRR measurements, which helps identify novel CQAs that could be implemented in MSC manufacturing for articular cartilage repair.
The research also demonstrates the potential of the process analytical tool developed by CAMP, micromagnetic resonance relaxometry (μMRR) — a miniature benchtop device that employs magnetic resonance imaging (MRI) imaging on a microscopic scale — as a process-monitoring tool for the expansion of MSCs with AA supplementation. Originally used as a label-free malaria diagnosis method due to the presence of paramagnetic hemozoin particles, μMRR was used in the research to detect senescence in MSCs. This rapid, label-free method requires only a small number of cells for evaluation, which allows for MSC therapy manufacturing in closed systems — a system for protecting pharmaceutical products by reducing contamination risks from the external environment — while enabling intermittent monitoring of a limited lot size per production.
“Donor-to-donor variation, intrapopulation heterogeneity, and cellular senescence have impeded the success of MSCs as a standard of care therapy for articular cartilage repair. Our research showed that AA supplementation during MSC expansion can overcome these bottlenecks and enhance MSC chondrogenic potential,” says Ching Ann Tee, senior postdoc at SMART CAMP and first author of the paper.“By controlling metabolic conditions such as AA supplementation, coupled with CAMP’s process analytical tools such as µMRR, the yield and quality of cell therapy products could be significantly increased. This breakthrough could help make MSC therapy a more effective and viable treatment option and provide standards for improving the manufacturing pipeline.”
“This approach of utilizing metabolic modulation to improve MSC chondrogenic potential could be adapted into similar concepts for other therapeutic indications, such as osteogenic potential for bone repair or other types of stem cells. Implementing our findings in MSC manufacturing settings could be a significant step forward for patients with osteoarthritis and other joint diseases, as we can efficiently produce large quantities of high-quality MSCs with consistent functionality and enable the treatment of more patients,” adds Professor Laurie A. Boyer, principal investigator at SMART CAMP, professor of biology and biological engineering at MIT, and corresponding author of the paper.
The research is conducted by SMART and supported by the National Research Foundation Singapore under its Campus for Research Excellence and Technological Enterprise program.
In a first for both universities, MIT undergraduates are engaged in research projects at the Universidad del Valle de Guatemala (UVG), while MIT scholars are collaborating with UVG undergraduates on in-depth field studies in Guatemala.
These pilot projects are part of a larger enterprise, called ASPIRE (Achieving Sustainable Partnerships for Innovation, Research, and Entrepreneurship). Funded by the U.S. Agency for International Development, this five-year, $15-million initiative brings together MIT, UVG, and the Guatemalan Exporters Association to promote sustainable solutions to local development challenges.
“This research is yielding insights into our understanding of how to design with and for marginalized people, specifically Indigenous people,” says Elizabeth Hoffecker, co-principal investigator of ASPIRE at MIT and director of the MIT Local Innovation Group.
The students’ work is bearing fruit in the form of publications and new products — directly advancing ASPIRE’s goals to create an innovation ecosystem in Guatemala that can be replicated elsewhere in Central and Latin America.
For the students, the project offers rewards both tangible and inspirational.
“My experience allowed me to find my interest in local innovation and entrepreneurship,” says Ximena Sarmiento García, a fifth-year undergraduate at UVG majoring in anthropology. Supervised by Hoffecker, Sarmiento García says, “I learned how to inform myself, investigate, and find solutions — to become a researcher.”
Sandra Youssef, a rising junior in mechanical engineering at MIT, collaborated with UVG researchers and Indigenous farmers to design a mobile cart to improve the harvest yield of snow peas. “It was perfect for me,” she says. “My goal was to use creative, new technologies and science to make a dent in difficult problems.”
Remote and effective
Kendra Leith, co-principal investigator of ASPIRE, and associate director for research at MIT D-Lab, shaped the MIT-based undergraduate research opportunities (UROPs) in concert with UVG colleagues. “Although MIT students aren’t currently permitted to travel to Guatemala, I wanted them to have an opportunity to apply their experience and knowledge to address real-world challenges,” says Leith. “The Covid pandemic prepared them and their counterparts at UVG for effective remote collaboration — the UROPs completed remarkably productive research projects over Zoom and met our goals for them.”
MIT students participated in some of UVG’s most ambitious ASPIRE research. For instance, Sydney Baller, a rising sophomore in mechanical engineering, joined a team of Indigenous farmers and UVG mechanical engineers investigating the manufacturing process and potential markets for essential oils extracted from thyme, rosemary, and chamomile plants.
“Indigenous people have thousands of years working with plant extracts and ancient remedies,” says Baller. “There is promising history there that would be important to follow up with more modern research.”
Sandra Youssef used computer-aided design and manufacturing to realize a design created in a hackathon by snow pea farmers. “Our cart had to hold 495 pounds of snow peas without collapsing or overturning, navigate narrow paths on hills, and be simple and inexpensive to assemble,” she says. The snow pea producers have tested two of Youssef’s designs, built by a team at UVG led by Rony Herrarte, a faculty member in the department of mechanical engineering.
From waste to filter
Two MIT undergraduates joined one of UVG’s long-standing projects: addressing pollution in Guatemala’s water. The research seeks to use chitosan molecules, extracted from shrimp shells, for bioremediation of heavy metals and other water contaminants. These shells are available in abundance, left as waste by the country’s shrimp industry.
Sophomores Ariana Hodlewsky, majoring in chemical engineering, and Paolo Mangiafico, majoring in brain and cognitive sciences, signed on to work with principal investigator and chemistry department instructor Allan Vásquez (UVG) on filtration systems utilizing chitosan.
“The team wants to find a cost-effective product rural communities, most at risk from polluted water, can use in homes or in town water systems,” says Mangiafico. “So we have been investigating different technologies for water filtration, and analyzing the Guatemalan and U.S. markets to understand the regulations and opportunities that might affect introduction of a chitosan-based product.”
“Our research into how different communities use water and into potential consumers and pitfalls sets the scene for prototypes UVG wants to produce,” says Hodlewsky.
Lourdes Figueroa, UVG ASPIRE project manager for technology transfer, found their assistance invaluable.
“Paolo and Ariana brought the MIT culture and mindset to the project,” she says. “They wanted to understand not only how the technology works, but the best ways of getting the technology out of the lab to make it useful.”
This was an “Aha!” moment, says Figueroa. “The MIT students made a major contribution to both the engineering and marketing sides by emphasizing that you have to think about how to guarantee the market acceptance of the technology while it is still under development.”
Innovation ecosystems
UVG’s three campuses have served as incubators for problem-solving innovation and entrepreneurship, in many cases driven by students from Indigenous communities and families. In 2022, Elizabeth Hoffecker, with eight UVG anthropology majors, set out to identify the most vibrant examples of these collaborative initiatives, which ASPIRE seeks to promote and replicate.
Hoffecker’s “innovation ecosystem diagnostic” revealed a cluster of activity centered on UVG’s Altiplano campus in the central highlands, which serves Mayan communities. Hoffecker and two of the anthropology students focused on four examples for a series of case studies, which they are currently preparing for submission to a peer-reviewed journal.
“The caliber of their work was so good that it became clear to me that we could collaborate on a paper,” says Hoffecker. “It was my first time publishing with undergraduates.”
The researchers’ cases included novel production of traditional thread, and creation of a 3D phytoplankton kit that is being used to educate community members about water pollution in Lake Atitlán, a tourist destination that drives the local economy but is increasingly being affected by toxic algae blooms. Hoffecker singles out a project by Indigenous undergraduates who developed play-based teaching tools for introducing basic mathematical concepts.
“These connect to local Mayan ways of understanding and offer a novel, hands-on way to strengthen the math teaching skills of local primary school teachers in Indigenous communities,” says Hoffecker. “They created something that addresses a very immediate need in the community — lack of training.
Both of Hoffecker’s undergraduate collaborators are writing theses inspired by these case studies.
“My time with Elizabeth allowed me to learn how to conduct research from scratch, ask for help, find solutions, and trust myself,” says Sarmiento García. She finds the ASPIRE approach profoundly appealing. “It is not only ethical, but also deeply committed to applying results to the real lives of the people involved.”
“This experience has been incredibly positive, validating my own ability to generate knowledge through research, rather than relying only on established authors to back up my arguments,” says Camila del Cid, a fifth-year anthropology student. “This was empowering, especially as a Latin American researcher, because it emphasized that my perspective and contributions are important.”
Hoffecker says this pilot run with UVG undergrads produced “high-quality research that can inform evidence-based decision-making on development issues of top regional priority” — a key goal for ASPIRE. Hoffecker plans to “develop a pathway that other UVG students can follow to conduct similar research.”
MIT undergraduate research will continue. “Our students’ activities have been very valuable in Guatemala, so much so that the snow pea, chitosan, and essential oils teams would like to continue working with our students this year,” says Leith. She anticipates a new round of MIT UROPs for next summer.
Youssef, for one, is eager to get to work on refining the snow pea cart. “I like the idea of working outside my comfort zone, thinking about things that seem unsolvable and coming up with a solution to fix some aspect of the problem,” she says.
Project Manager Lourdes Figueroa teaches a student how to handle a volumetric flask to prepare one of the chemical solutions used in the reactions for the process. The other students are observing closely as they follow the steps of the demonstration, which is part of the initial stages of chemical preparation for the production of chitosan nanoparticles.
Many black holes detected to date appear to be part of a pair. These binary systems comprise a black hole and a secondary object — such as a star, a much denser neutron star, or another black hole — that spiral around each other, drawn together by the black hole’s gravity to form a tight orbital pair.
Now a surprising discovery is expanding the picture of black holes, the objects they can host, and the way they form.
In a study appearing today in Nature, physicists at MIT and Caltech report that they have observed a “black hole triple” for the first time. The new system holds a central black hole in the act of consuming a small star that’s spiraling in very close to the black hole, every 6.5 days — a configuration similar to most binary systems. But surprisingly, a second star appears to also be circling the black hole, though at a much greater distance. The physicists estimate this far-off companion is orbiting the black hole every 70,000 years.
That the black hole seems to have a gravitational hold on an object so far away is raising questions about the origins of the black hole itself. Black holes are thought to form from the violent explosion of a dying star — a process known as a supernova, by which a star releases a huge amount of energy and light in a final burst before collapsing into an invisible black hole.
The team’s discovery, however, suggests that if the newly-observed black hole resulted from a typical supernova, the energy it would have released before it collapsed would have kicked away any loosely bound objects in its outskirts. The second, outer star, then, shouldn’t still be hanging around.
Instead, the team suspects the black hole formed through a more gentle process of “direct collapse,” in which a star simply caves in on itself, forming a black hole without a last dramatic flash. Such a gentle origin would hardly disturb any loosely bound, faraway objects.
Because the new triple system includes a very far-off star, this suggests the system’s black hole was born through a gentler, direct collapse. And while astronomers have observed more violent supernovae for centuries, the team says the new triple system could be the first evidence of a black hole that formed from this more gentle process.
“We think most black holes form from violent explosions of stars, but this discovery helps call that into question,” says study author Kevin Burdge, a Pappalardo Fellow in the MIT Department of Physics. “This system is super exciting for black hole evolution, and it also raises questions of whether there are more triples out there.”
The study’s co-authors at MIT are Erin Kara, Claude Canizares, Deepto Chakrabarty, Anna Frebel, Sarah Millholland, Saul Rappaport, Rob Simcoe, and Andrew Vanderburg, along with Kareem El-Badry at Caltech.
Tandem motion
The discovery of the black hole triple came about almost by chance. The physicists found it while looking through Aladin Lite, a repository of astronomical observations, aggregated from telescopes in space and all around the world. Astronomers can use the online tool to search for images of the same part of the sky, taken by different telescopes that are tuned to various wavelengths of energy and light.
The team had been looking within the Milky Way galaxy for signs of new black holes. Out of curiosity, Burdge reviewed an image of V404 Cygni — a black hole about 8,000 light years from Earth that was one of the very first objects ever to be confirmed as a black hole, in 1992. Since then, V404 Cygni has become one of the most well-studied black holes, and has been documented in over 1,300 scientific papers. However, none of those studies reported what Burdge and his colleagues observed.
As he looked at optical images of V404 Cygni, Burdge saw what appeared to be two blobs of light, surprisingly close to each other. The first blob was what others determined to be the black hole and an inner, closely orbiting star. The star is so close that it is shedding some of its material onto the black hole, and giving off the light that Burdge could see. The second blob of light, however, was something that scientists did not investigate closely, until now. That second light, Burdge determined, was most likely coming from a very far-off star.
“The fact that we can see two separate stars over this much distance actually means that the stars have to be really very far apart,” says Burdge, who calculated that the outer star is 3,500 astronomical units (AU) away from the black hole (1 AU is the distance between the Earth and sun). In other words, the outer star is 3,500 times father away from the black hole as the Earth is from the sun. This is also equal to 100 times the distance between Pluto and the sun.
The question that then came to mind was whether the outer star was linked to the black hole and its inner star. To answer this, the researchers looked to Gaia, a satellite that has precisely tracked the motions of all the stars in the galaxy since 2014. The team analyzed the motions of the inner and outer stars over the last 10 years of Gaia data and found that the stars moved exactly in tandem, compared to other neighboring stars. They calculated that the odds of this kind of tandem motion are about one in 10 million.
“It’s almost certainly not a coincidence or accident,” Burdge says. “We’re seeing two stars that are following each other because they’re attached by this weak string of gravity. So this has to be a triple system.”
Pulling strings
How, then, could the system have formed? If the black hole arose from a typical supernova, the violent explosion would have kicked away the outer star long ago.
“Imagine you’re pulling a kite, and instead of a strong string, you’re pulling with a spider web,” Burdge says. “If you tugged too hard, the web would break and you’d lose the kite. Gravity is like this barely bound string that’s really weak, and if you do anything dramatic to the inner binary, you’re going to lose the outer star.”
To really test this idea, however, Burdge carried out simulations to see how such a triple system could have evolved and retained the outer star.
At the start of each simulation, he introduced three stars (the third being the black hole, before it became a black hole). He then ran tens of thousands of simulations, each one with a slightly different scenario for how the third star could have become a black hole, and subsequently affected the motions of the other two stars. For instance, he simulated a supernova, varying the amount and direction of energy that it gave off. He also simulated scenarios of direct collapse, in which the third star simply caved in on itself to form a black hole, without giving off any energy.
“The vast majority of simulations show that the easiest way to make this triple work is through direct collapse,” Burdge says.
In addition to giving clues to the black hole’s origins, the outer star has also revealed the system’s age. The physicists observed that the outer star happens to be in the process of becoming a red giant — a phase that occurs at the end of a star’s life. Based on this stellar transition, the team determined that the outer star is about 4 billion years old. Given that neighboring stars are born around the same time, the team concludes that the black hole triple is also 4 billion years old.
“We’ve never been able to do this before for an old black hole,” Burdge says. “Now we know V404 Cygni is part of a triple, it could have formed from direct collapse, and it formed about 4 billion years ago, thanks to this discovery.”
This work was supported, in part, by the National Science Foundation.
Depicted in this artist’s rendering is the central black hole, V404 Cygni (black dot), in the process of consuming a nearby star (orange body at left), while a second star (upper white flash) orbits at a much farther distance.
Within the human brain, movement is influenced by a brain region called the striatum, which sends instructions to motor neurons in the brain. Those instructions are conveyed by two pathways, one that initiates movement (“go”) and one that suppresses it (“no-go”).
In a new study, MIT researchers have discovered an additional two pathways that arise in the striatum and appear to modulate the effects of the go and no-go pathways. These newly discovered pathways connect to dopamine-producing neurons in the brain — one stimulates dopamine release and the other inhibits it.
By controlling the amount of dopamine in the brain via clusters of neurons known as striosomes, these pathways appear to modify the instructions given by the go and no-go pathways. They may be especially involved in influencing decisions that have a strong emotional component, the researchers say.
“Among all the regions of the striatum, the striosomes alone turned out to be able to project to the dopamine-containing neurons, which we think has something to do with motivation, mood, and controlling movement,” says Ann Graybiel, an MIT Institute Professor, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the new study.
Graybiel has spent much of her career studying the striatum, a structure located deep within the brain that is involved in learning and decision-making, as well as control of movement.
Within the striatum, neurons are arranged in a labyrinth-like structure that includes striosomes, which Graybiel discovered in the 1970s. The classical go and no-go pathways arise from neurons that surround the striosomes, which are known collectively as the matrix. The matrix cells that give rise to these pathways receive input from sensory processing regions such as the visual cortex and auditory cortex. Then, they send go or no-go commands to neurons in the motor cortex.
However, the function of the striosomes, which are not part of those pathways, remained unknown. For many years, researchers in Graybiel’s lab have been trying to solve that mystery.
Their previous work revealed that striosomes receive much of their input from parts of the brain that process emotion. Within striosomes, there are two major types of neurons, classified as D1 and D2. In a 2015 study, Graybiel found that one of these cell types, D1, sends input to the substantia nigra, which is the brain’s major dopamine-producing center.
It took much longer to trace the output of the other set, D2 neurons. In the new Current Biology study, the researchers discovered that those neurons also eventually project to the substantia nigra, but first they connect to a set of neurons in the globus palladus, which inhibits dopamine output. This pathway, an indirect connection to the substantia nigra, reduces the brain’s dopamine output and inhibits movement.
The researchers also confirmed their earlier finding that the pathway arising from D1 striosomes connects directly to the substantia nigra, stimulating dopamine release and initiating movement.
“In the striosomes, we’ve found what is probably a mimic of the classical go/no-go pathways,” Graybiel says. “They’re like classic motor go/no-go pathways, but they don’t go to the motor output neurons of the basal ganglia. Instead, they go to the dopamine cells, which are so important to movement and motivation.”
Emotional decisions
The findings suggest that the classical model of how the striatum controls movement needs to be modified to include the role of these newly identified pathways. The researchers now hope to test their hypothesis that input related to motivation and emotion, which enters the striosomes from the cortex and the limbic system, influences dopamine levels in a way that can encourage or discourage action.
That dopamine release may be especially relevant for actions that induce anxiety or stress. In their 2015 study, Graybiel’s lab found that striosomes play a key role in making decisions that provoke high levels of anxiety; in particular, those that are high risk but may also have a big payoff.
“Ann Graybiel and colleagues have earlier found that the striosome is concerned with inhibiting dopamine neurons. Now they show unexpectedly that another type of striosomal neuron exerts the opposite effect and can signal reward. The striosomes can thus both up- or down-regulate dopamine activity, a very important discovery. Clearly, the regulation of dopamine activity is critical in our everyday life with regard to both movements and mood, to which the striosomes contribute,” says Sten Grillner, a professor of neuroscience at the Karolinska Institute in Sweden, who was not involved in the research.
Another possibility the researchers plan to explore is whether striosomes and matrix cells are arranged in modules that affect motor control of specific parts of the body.
“The next step is trying to isolate some of these modules, and by simultaneously working with cells that belong to the same module, whether they are in the matrix or striosomes, try to pinpoint how the striosomes modulate the underlying function of each of these modules,” Lazaridis says.
They also hope to explore how the striosomal circuits, which project to the same region of the brain that is ravaged by Parkinson’s disease, may influence that disorder.
The research was funded by the National Institutes of Health, the Saks-Kavanaugh Foundation, the William N. and Bernice E. Bumpus Foundation, Jim and Joan Schattinger, the Hock E. Tan and K. Lisa Yang Center for Autism Research, Robert Buxton, the Simons Foundation, the CHDI Foundation, and an Ellen Schapiro and Gerald Axelbaum Investigator BBRF Young Investigator Grant.
Within the human brain, movement is coordinated by a brain region called the striatum, which sends instructions to motor neurons in the brain. Those instructions are conveyed by two pathways, one that initiates movement (“go”) and one that suppresses it (“no-go”).
In a new study, MIT researchers have discovered an additional two pathways that arise in the striatum and appear to modulate the effects of the go and no-go pathways. These newly discovered pathways connect to dopamine-producing neurons in the brain — one stimulates dopamine release and the other inhibits it.
By controlling the amount of dopamine in the brain via clusters of neurons known as striosomes, these pathways appear to modify the instructions given by the go and no-go pathways. They may be especially involved in influencing decisions that have a strong emotional component, the researchers say.
“Among all the regions of the striatum, the striosomes alone turned out to be able to project to the dopamine-containing neurons, which we think has something to do with motivation, mood, and controlling movement,” says Ann Graybiel, an MIT Institute Professor, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the new study.
Graybiel has spent much of her career studying the striatum, a structure located deep within the brain that is involved in learning and decision-making, as well as control of movement.
Within the striatum, neurons are arranged in a labyrinth-like structure that includes striosomes, which Graybiel discovered in the 1970s. The classical go and no-go pathways arise from neurons that surround the striosomes, which are known collectively as the matrix. The matrix cells that give rise to these pathways receive input from sensory processing regions such as the visual cortex and auditory cortex. Then, they send go or no-go commands to neurons in the motor cortex.
However, the function of the striosomes, which are not part of those pathways, remained unknown. For many years, researchers in Graybiel’s lab have been trying to solve that mystery.
Their previous work revealed that striosomes receive much of their input from parts of the brain that process emotion. Within striosomes, there are two major types of neurons, classified as D1 and D2. In a 2015 study, Graybiel found that one of these cell types, D1, sends input to the substantia nigra, which is the brain’s major dopamine-producing center.
It took much longer to trace the output of the other set, D2 neurons. In the new Current Biology study, the researchers discovered that those neurons also eventually project to the substantia nigra, but first they connect to a set of neurons in the globus palladus, which inhibits dopamine output. This pathway, an indirect connection to the substantia nigra, reduces the brain’s dopamine output and inhibits movement.
The researchers also confirmed their earlier finding that the pathway arising from D1 striosomes connects directly to the substantia nigra, stimulating dopamine release and initiating movement.
“In the striosomes, we’ve found what is probably a mimic of the classical go/no-go pathways,” Graybiel says. “They’re like classic motor go/no-go pathways, but they don’t go to the motor output neurons of the basal ganglia. Instead, they go to the dopamine cells, which are so important to movement and motivation.”
Emotional decisions
The findings suggest that the classical model of how the striatum controls movement needs to be modified to include the role of these newly identified pathways. The researchers now hope to test their hypothesis that input related to motivation and emotion, which enters the striosomes from the cortex and the limbic system, influences dopamine levels in a way that can encourage or discourage action.
That dopamine release may be especially relevant for actions that induce anxiety or stress. In their 2015 study, Graybiel’s lab found that striosomes play a key role in making decisions that provoke high levels of anxiety; in particular, those that are high risk but may also have a big payoff.
“Ann Graybiel and colleagues have earlier found that the striosome is concerned with inhibiting dopamine neurons. Now they show unexpectedly that another type of striosomal neuron exerts the opposite effect and can signal reward. The striosomes can thus both up- or down-regulate dopamine activity, a very important discovery. Clearly, the regulation of dopamine activity is critical in our everyday life with regard to both movements and mood, to which the striosomes contribute,” says Sten Grillner, a professor of neuroscience at the Karolinska Institute in Sweden, who was not involved in the research.
Another possibility the researchers plan to explore is whether striosomes and matrix cells are arranged in modules that affect motor control of specific parts of the body.
“The next step is trying to isolate some of these modules, and by simultaneously working with cells that belong to the same module, whether they are in the matrix or striosomes, try to pinpoint how the striosomes modulate the underlying function of each of these modules,” Lazaridis says.
They also hope to explore how the striosomal circuits, which project to the same region of the brain that is ravaged by Parkinson’s disease, may influence that disorder.
The research was funded by the National Institutes of Health, the Saks-Kavanaugh Foundation, the William N. and Bernice E. Bumpus Foundation, Jim and Joan Schattinger, the Hock E. Tan and K. Lisa Yang Center for Autism Research, Robert Buxton, the Simons Foundation, the CHDI Foundation, and an Ellen Schapiro and Gerald Axelbaum Investigator BBRF Young Investigator Grant.
Images of coastal houses being carried off into the sea due to eroding coastlines and powerful storm surges are becoming more commonplace as climate change brings a rising sea level coupled with more powerful storms. In the U.S. alone, coastal storms caused $165 billion in losses in 2022.
Now, a study from MIT shows that protecting and enhancing salt marshes in front of protective seawalls can significantly help protect some coastlines, at a cost that makes this approach reasonable to implement.
The new findings are being reported in the journal Communications Earth and Environment, in a paper by MIT graduate student Ernie I. H. Lee and professor of civil and environmental engineering Heidi Nepf. This study, Nepf says, shows that restoring coastal marshes “is not just something that would be nice to do, but it’s actually economically justifiable.” The researchers found that, among other things, the wave-attenuating effects of salt marsh mean that the seawall behind it can be built significantly lower, reducing construction cost while still providing as much protection from storms.
“One of the other exciting things that the study really brings to light,” Nepf says, “is that you don’t need a huge marsh to get a good effect. It could be a relatively short marsh, just tens of meters wide, that can give you benefit.” That makes her hopeful, Nepf says, that this information might be applied in places where planners may have thought saving a smaller marsh was not worth the expense. “We show that it can make enough of a difference to be financially viable,” she says.
While other studies have previously shown the benefits of natural marshes in attenuating damaging storms, Lee says that such studies “mainly focus on landscapes that have a wide marsh on the order of hundreds of meters. But we want to show that it also applies in urban settings where not as much marsh land is available, especially since in these places existing gray infrastructure (seawalls) tends to already be in place.”
The study was based on computer modeling of waves propagating over different shore profiles, using the morphology of various salt marsh plants — the height and stiffness of the plants, and their spatial density — rather than an empirical drag coefficient. “It’s a physically based model of plant-wave interaction, which allowed us to look at the influence of plant species and changes in morphology across seasons,” without having to go out and calibrate the vegetation drag coefficient with field measurements for each different condition, Nepf says.
The researchers based their benefit-cost analysis on a simple metric: To protect a certain length of shoreline, how much could the height of a given seawall be reduced if it were accompanied by a given amount of marsh? Other ways of assessing the value, such as including the value of real estate that might be damaged by a given amount of flooding, “vary a lot depending on how you value the assets if a flood happens,” Lee says. “We use a more concrete value to quantify the benefits of salt marshes, which is the equivalent height of seawall you would need to deliver the same protection value.”
They used models of a variety of plants, reflecting differences in height and the stiffness across different seasons. They found a twofold variation in the various plants’ effectiveness in attenuating waves, but all provided a useful benefit.
To demonstrate the details in a real-world example and help to validate the simulations, Nepf and Lee studied local salt marshes in Salem, Massachusetts, where projects are already underway to try to restore marshes that had been degraded. Including the specific example provided a template for others, Nepf says. In Salem, their model showed that a healthy salt marsh could offset the need for an additional seawall height of 1.7 meters (about 5.5 feet), based on satisfying a rate of wave overtopping that was set for the safety of pedestrians.
However, the real-world data needed to model a marsh, including maps of salt marsh species, plant height, and shoots per bed area, are “very labor-intensive” to put together, Nepf says. Lee is now developing a method to use drone imaging and machine learning to facilitate this mapmaking. Nepf says this will enable researchers or planners to evaluate a given area of marshland and say, “How much is this marsh worth in terms of its ability to reduce flooding?”
The White House Office of Information and Regulatory Affairs recently released guidance for assessing the value of ecosystem services in planning of federal projects, Nepf explains. “But in many scenarios, it lacks specific methods for quantifying value, and this study is meeting that need,” she says.
The Federal Emergency Management Agency also has a benefit-cost analysis (BCA) toolkit, Lee notes. “They have guidelines on how to quantify each of the environmental services, and one of the novelties of this paper is quantifying the cost and the protection value of marshes. This is one of the applications that policymakers can consider on how to quantify the environmental service values of marshes,” he says.
The software that environmental engineers can apply to specific sites has been made available online for free on GitHub. “It’s a one-dimensional model accessible by a standard consulting firm,” Nepf says.
“This paper presents a practical tool for translating the wave attenuation capabilities of marshes into economic values, which could assist decision-makers in the adaptation of marshes for nature-based coastal defense,” says Xiaoxia Zhang, an assistant professor at Shenzhen University in China who was not involved in this work. “The results indicate that salt marshes are not only environmentally beneficial but also cost-effective.”
The study “is a very important and crucial step to quantifying the protective value of marshes,” adds Bas Borsje, an associate professor of nature-based flood protection at the University of Twente in the Netherlands, who was not associated with this work. “The most important step missing at the moment is how to translate our findings to the decision makers. This is the first time I’m aware of that decision-makers are quantitatively informed on the protection value of salt marshes.”
Lee received support for this work from the Schoettler Scholarship Fund, administered by the MIT Department of Civil and Environmental Engineering.
It can be hard to connect a certain amount of average global warming with one’s everyday experience, so researchers at MIT have devised a different approach to quantifying the direct impact of climate change. Instead of focusing on global averages, they came up with the concept of “outdoor days”: the number days per year in a given location when the temperature is not too hot or cold to enjoy normal outdoor activities, such as going for a walk, playing sports, working in the garden, or dining outdoors.
In a study published earlier this year, the researchers applied this method to compare the impact of global climate change on different countries around the world, showing that much of the global south would suffer major losses in the number of outdoor days, while some northern countries could see a slight increase. Now, they have applied the same approach to comparing the outcomes for different parts of the United States, dividing the country into nine climatic regions, and finding similar results: Some states, especially Florida and other parts of the Southeast, should see a significant drop in outdoor days, while some, especially in the Northwest, should see a slight increase.
The researchers also looked at correlations between economic activity, such as tourism trends, and changing climate conditions, and examined how numbers of outdoor days could result in significant social and economic impacts. Florida’s economy, for example, is highly dependent on tourism and on people moving there for its pleasant climate; a major drop in days when it is comfortable to spend time outdoors could make the state less of a draw.
“This is something very new in our attempt to understand impacts of climate change impact, in addition to the changing extremes,” Choi says. It allows people to see how these global changes may impact them on a very personal level, as opposed to focusing on global temperature changes or on extreme events such as powerful hurricanes or increased wildfires. “To the best of my knowledge, nobody else takes this same approach” in quantifying the local impacts of climate change, he says. “I hope that many others will parallel our approach to better understand how climate may affect our daily lives.”
The study looked at two different climate scenarios — one where maximum efforts are made to curb global emissions of greenhouse gases and one “worst case” scenario where little is done and global warming continues to accelerate. They used these two scenarios with every available global climate model, 32 in all, and the results were broadly consistent across all 32 models.
The reality may lie somewhere in between the two extremes that were modeled, Eltahir suggests. “I don’t think we’re going to act as aggressively” as the low-emissions scenarios suggest, he says, “and we may not be as careless” as the high-emissions scenario. “Maybe the reality will emerge in the middle, toward the end of the century,” he says.
The team looked at the difference in temperatures and other conditions over various ranges of decades. The data already showed some slight differences in outdoor days from the 1961-1990 period compared to 1991-2020. The researchers then compared these most recent 30 years with the last 30 years of this century, as projected by the models, and found much greater differences ahead for some regions. The strongest effects in the modeling were seen in the Southeastern states. “It seems like climate change is going to have a significant impact on the Southeast in terms of reducing the number of outdoor days,” Eltahir says, “with implications for the quality of life of the population, and also for the attractiveness of tourism and for people who want to retire there.”
He adds that “surprisingly, one of the regions that would benefit a little bit is the Northwest.” But the gain there is modest: an increase of about 14 percent in outdoor days projected for the last three decades of this century, compared to the period from 1976 to 2005. The Southwestern U.S., by comparison, faces an average loss of 23 percent of their outdoor days.
The study also digs into the relationship between climate and economic activity by looking at tourism trends from U.S. National Park Service visitation data, and how that aligned with differences in climate conditions. “Accounting for seasonal variations, we find a clear connection between the number of outdoor days and the number of tourist visits in the United States,” Choi says.
For much of the country, there will be little overall change in the total number of annual outdoor days, the study found, but the seasonal pattern of those days could change significantly. While most parts of the country now see the most outdoor days in summertime, that will shift as summers get hotter, and spring and fall will become the preferred seasons for outdoor activity.
In a way, Eltahir says, “what we are talking about that will happen in the future [for most of the country] is already happening in Florida.” There, he says, “the really enjoyable time of year is in the spring and fall, and summer is not the best time of year.”
People’s level of comfort with temperatures varies somewhat among individuals and among regions, so the researchers designed a tool, now freely available online, that allows people to set their own definitions of the lowest and highest temperatures they consider suitable for outdoor activities, and then see what the climate models predict would be the change in the number of outdoor days for their location, using their own standards of comfort. For their study, they used a widely accepted range of 10 degrees Celsius (50 degrees Fahrenheit) to 25 C (77 F), which is the “thermoneutral zone” in which the human body does not require either metabolic heat generation or evaporative cooling to maintain its core temperature — in other words, in that range there is generally no need to either shiver or sweat.
The model mainly focuses on temperature but also allows people to include humidity or precipitation in their definition of what constitutes a comfortable outdoor day. The model could be extended to incorporate other variables such as air quality, but the researchers say temperature tends to be the major determinant of comfort for most people.
Using their software tool, “If you disagree with how we define an outdoor day, you could define one for yourself, and then you’ll see what the impacts of that are on your number of outdoor days and their seasonality,” Eltahir says.
This work was inspired by the realization, he says, that “people’s understanding of climate change is based on the assumption that climate change is something that’s going to happen sometime in the future and going to happen to someone else. It’s not going to impact them directly. And I think that contributes to the fact that we are not doing enough.”
Instead, the concept of outdoor days “brings the concept of climate change home, brings it to personal everyday activities,” he says. “I hope that people will find that useful to bridge that gap, and provide a better understanding and appreciation of the problem. And hopefully that would help lead to sound policies that are based on science, regarding climate change.”
The research was based on work supported by the Community Jameel for Jameel Observatory CREWSnet and Abdul Latif Jameel Water and Food Systems Lab at MIT.
Despite their impressive capabilities, large language models are far from perfect. These artificial intelligence models sometimes “hallucinate” by generating incorrect or unsupported information in response to a query.
Due to this hallucination problem, an LLM’s responses are often verified by human fact-checkers, especially if a model is deployed in a high-stakes setting like health care or finance. However, validation processes typically require people to read through long documents cited by the model, a task so onerous and error-prone it may prevent some users from deploying generative AI models in the first place.
To help human validators, MIT researchers created a user-friendly system that enables people to verify an LLM’s responses much more quickly. With this tool, called SymGen, an LLM generates responses with citations that point directly to the place in a source document, such as a given cell in a database.
Users hover over highlighted portions of its text response to see data the model used to generate that specific word or phrase. At the same time, the unhighlighted portions show users which phrases need additional attention to check and verify.
“We give people the ability to selectively focus on parts of the text they need to be more worried about. In the end, SymGen can give people higher confidence in a model’s responses because they can easily take a closer look to ensure that the information is verified,” says Shannon Shen, an electrical engineering and computer science graduate student and co-lead author of a paper on SymGen.
Through a user study, Shen and his collaborators found that SymGen sped up verification time by about 20 percent, compared to manual procedures. By making it faster and easier for humans to validate model outputs, SymGen could help people identify errors in LLMs deployed in a variety of real-world situations, from generating clinical notes to summarizing financial market reports.
Shen is joined on the paper by co-lead author and fellow EECS graduate student Lucas Torroba Hennigen; EECS graduate student Aniruddha “Ani” Nrusimha; Bernhard Gapp, president of the Good Data Initiative; and senior authors David Sontag, a professor of EECS, a member of the MIT Jameel Clinic, and the leader of the Clinical Machine Learning Group of the Computer Science and Artificial Intelligence Laboratory (CSAIL); and Yoon Kim, an assistant professor of EECS and a member of CSAIL. The research was recently presented at the Conference on Language Modeling.
Symbolic references
To aid in validation, many LLMs are designed to generate citations, which point to external documents, along with their language-based responses so users can check them. However, these verification systems are usually designed as an afterthought, without considering the effort it takes for people to sift through numerous citations, Shen says.
“Generative AI is intended to reduce the user’s time to complete a task. If you need to spend hours reading through all these documents to verify the model is saying something reasonable, then it’s less helpful to have the generations in practice,” Shen says.
The researchers approached the validation problem from the perspective of the humans who will do the work.
A SymGen user first provides the LLM with data it can reference in its response, such as a table that contains statistics from a basketball game. Then, rather than immediately asking the model to complete a task, like generating a game summary from those data, the researchers perform an intermediate step. They prompt the model to generate its response in a symbolic form.
With this prompt, every time the model wants to cite words in its response, it must write the specific cell from the data table that contains the information it is referencing. For instance, if the model wants to cite the phrase “Portland Trailblazers” in its response, it would replace that text with the cell name in the data table that contains those words.
“Because we have this intermediate step that has the text in a symbolic format, we are able to have really fine-grained references. We can say, for every single span of text in the output, this is exactly where in the data it corresponds to,” Torroba Hennigen says.
SymGen then resolves each reference using a rule-based tool that copies the corresponding text from the data table into the model’s response.
“This way, we know it is a verbatim copy, so we know there will not be any errors in the part of the text that corresponds to the actual data variable,” Shen adds.
Streamlining validation
The model can create symbolic responses because of how it is trained. Large language models are fed reams of data from the internet, and some data are recorded in “placeholder format” where codes replace actual values.
When SymGen prompts the model to generate a symbolic response, it uses a similar structure.
“We design the prompt in a specific way to draw on the LLM’s capabilities,” Shen adds.
During a user study, the majority of participants said SymGen made it easier to verify LLM-generated text. They could validate the model’s responses about 20 percent faster than if they used standard methods.
However, SymGen is limited by the quality of the source data. The LLM could cite an incorrect variable, and a human verifier may be none-the-wiser.
In addition, the user must have source data in a structured format, like a table, to feed into SymGen. Right now, the system only works with tabular data.
Moving forward, the researchers are enhancing SymGen so it can handle arbitrary text and other forms of data. With that capability, it could help validate portions of AI-generated legal document summaries, for instance. They also plan to test SymGen with physicians to study how it could identify errors in AI-generated clinical summaries.
This work is funded, in part, by Liberty Mutual and the MIT Quest for Intelligence Initiative.
The much-touted arrival of “precision medicine” promises tailored technologies that help individuals and may also reduce health care costs. New research shows how pregnancy screening can meet both of these objectives, but the findings also highlight how precision medicine must be matched well with patients to save money.
The study involves cfDNA screenings, a type of blood test that can reveal conditions based on chromosomal variation, such as Down Syndrome. For many pregnant women, though not all, cfDNA screenings can be an alternative to amniocentesis or chorionic villus sampling (CVS) — invasive procedures that come with a risk of miscarriage.
In examining how widely cfDNA tests should be used, the study reached a striking conclusion.
“What we find is the highest value for the cfDNA testing comes from people who are high risk, but not extraordinarily high risk,” says Amy Finkelstein, an MIT economist and co-author of a newly published paper detailing the study.
The paper, “Targeting Precision Medicine: Evidence from Prenatal Screening,” appears in the Journal of Political Economy. The co-authors are Peter Conner, an associate professor and senior consultant at Karolinska University Hospital in Sweden; Liran Einav, a professor of economics at Stanford University; Finkelstein, the John and Jennie S. MacDonald Professor of Economics at MIT; and Petra Persson, an assistant professor of economics at Stanford University.
“There is a lot of hope attached to precision medicine,” Persson says. “We can do a lot of new things and tailor health care treatments to patients, which holds a lot of promise. In this paper, we highlight that while this is all true, there are also significant costs in the personalization of medicine. As a society, we may want to examine how to use these technologies while keeping an eye on health care costs.”
Measuring the benefit to “middle-risk” patients
To conduct the study, the research team looked at the introduction of cfDNA screening in Sweden, during the period from 2011 to 2019, with data covering over 230,000 pregnancies. As it happens, there were also regional discrepancies in the extent to which cfDNA screenings were covered by Swedish health care, for patients not already committed to having invasive testing. Some regions covered cfDNA testing quite widely, for all patients with a “moderate” assessed risk or higher; other regions, by contrast, restricted coverage to a subset of patients within that group with elevated risk profiles. This provided variation the researchers could use when conducting their analysis.
With the most generous coverage of cfDNA testing, the procedure was used by 86 percent of patients; with more targeted coverage, that figure dropped to about 33 percent. In both cases, the amount of invasive testing, including amniocentesis, dropped significantly, to about 5 percent. (The cfDNA screenings are very informative, but not fully conclusive, which invasive testing is, so some pregnant women will opt-for a follow-up procedure.)
Both approaches, then, yielded similar reductions in the rate of invasive testing. But due to the costs of cfDNA tests, the economic implications are quite different. Introducing wide coverage of cfDNA tests would raise overall medical costs by about $250 per pregnancy, the study estimates. In contrast, introducing cfDNA with more targeted coverage yields a reduction of about $89 per patient.
Ultimately, the larger dynamics are clear. Pregnant women who have the highest risk of bearing children with chromosome-based conditions are likely to still opt for an invasive test like amniocentesis. Those with virtually no risk may not even have cfDNA tests done. For a group in between, cfDNA tests have a substantial medical value, relieving them of the need for an invasive test. And narrowing the group of patients getting cfDNA tests lowers the overall cost.
“People who are very high-risk are often going to use the invasive test, which is definitive, regardless of whether they have a cfDNA screen or not,” Finkelstein says. “But for middle-risk people, covering cfDNA produces a big increase in cfDNA testing, and that produces a big decline in the rates of the riskier, and more expensive, invasive test.”
How precise?
In turn, the study’s findings raise a larger point. Precision medicine, in almost any form, will add expenses to medical care. Therefore developing some precision about who receives it is significant.
“The allure of precision medicine is targeting people who need it, so we don’t do expensive and potentially unpleasant tests and treatments of people who don’t need them,” Finkelstein says. “Which sounds great, but it kicks the can down the road. You still need to figure out who is a candidate for which kind of precision medicine.”
Therefore, in medicine, instead of just throwing technology at the problem, we may want to aim carefully, where evidence warrants it. Overall, that means good precision medicine builds on good policy analysis, not just good technology.
“Sometimes when we think medical technology has an impact, we simply ask if the technology raises or lowers health care costs, or if it makes patients healthier,” Persson observes. “An important insight from our work, I think, is that the answers are not just about the technology. It’s about the pairing of technology and policy because policy is going to influence the impact of technology on health care and patient outcomes. We see this clearly in our study.”
In this case, finding comparable patient outcomes with narrower cfDNA screenings suggests one way of targeting diagnostic procedures. And across many possible medical situations, finding the subset of people for whom a technology is most likely to yield new and actionable information seems a promising objective.
“The benefit is not just an innate feature of the testing,” Finkelstein says. “With diagnostic technologies, the value of information is greatest when you’re neither obviously appropriate or inappropriate for the next treatment. It’s really the non-monotone value of information that’s interesting.”
The study was supported, in part, by the U.S. National Science Foundation.
Some of the most widely used drugs today, including penicillin, were discovered through a process called phenotypic screening. Using this method, scientists are essentially throwing drugs at a problem — for example, when attempting to stop bacterial growth or fixing a cellular defect — and then observing what happens next, without necessarily first knowing how the drug works. Perhaps surprisingly, historical data show that this approach is better at yielding approved medicines than those investigations that more narrowly focus on specific molecular targets.
But many scientists believe that properly setting up the problem is the true key to success. Certain microbial infections or genetic disorders caused by single mutations are much simpler to prototype than complex diseases like cancer. These require intricate biological models that are far harder to make or acquire. The result is a bottleneck in the number of drugs that can be tested, and thus the usefulness of phenotypic screening.
Now, a team of scientists led by the Shalek Lab at MIT has developed a promising new way to address the difficulty of applying phenotyping screening to scale. Their method allows researchers to simultaneously apply multiple drugs to a biological problem at once, and then computationally work backward to figure out the individual effects of each. For instance, when the team applied this method to models of pancreatic cancer and human immune cells, they were able to uncover surprising new biological insights, while also minimizing cost and sample requirements by several-fold — solving a few problems in scientific research at once.
Zev Gartner, a professor in pharmaceutical chemistry at the University of California at San Francisco, says this new method has great potential. “I think if there is a strong phenotype one is interested in, this will be a very powerful approach,” Gartner says.
The research was published Oct. 8 in Nature Biotechnology. It was led by Ivy Liu, Walaa Kattan, Benjamin Mead, Conner Kummerlowe, and Alex K. Shalek, the director of the Institute for Medical Engineering and Sciences (IMES) and the Health Innovation Hub at MIT, as well as the J. W. Kieckhefer Professor in IMES and the Department of Chemistry. It was supported by the National Institutes of Health and the Bill and Melinda Gates Foundation.
A “crazy” way to increase scale
Technological advances over the past decade have revolutionized our understanding of the inner lives of individual cells, setting the stage for richer phenotypic screens. However, many challenges remain.
For one, biologically representative models like organoids and primary tissues are only available in limited quantities. The most informative tests, like single-cell RNA sequencing, are also expensive, time-consuming, and labor-intensive.
That’s why the team decided to test out the “bold, maybe even crazy idea” to mix everything together, says Liu, a PhD student in the MIT Computational and Systems Biology program. In other words, they chose to combine many perturbations — things like drugs, chemical molecules, or biological compounds made by cells — into one single concoction, and then try to decipher their individual effects afterward.
They began testing their workflow by making different combinations of 316 U.S. Food and Drug Administration-approved drugs. “It’s a high bar: basically, the worst-case scenario,” says Liu. “Since every drug is known to have a strong effect, the signals could have been impossible to disentangle.”
These random combinations ranged from three to 80 drugs per pool, each of which was applied to lab-grown cells. The team then tried to understand the effects of the individual drug using a linear computational model.
It was a success. When compared with traditional tests for each individual drug, the new method yielded comparable results, successfully finding the strongest drugs and their respective effects in each pool, at a fraction of the cost, samples, and effort.
Putting it into practice
To test the method’s applicability to address real-world health challenges, the team then approached two problems that were previously unimaginable with past phenotypic screening techniques.
The first test focused on pancreatic ductal adenocarcinoma (PDAC), one of the deadliest types of cancer. In PDAC, many types of signals come from the surrounding cells in the tumor's environment. These signals can influence how the tumor progresses and responds to treatments. So, the team wanted to identify the most important ones.
Using their new method to pool different signals in parallel, they found several surprise candidates. “We never could have predicted some of our hits,” says Shalek. These included two previously overlooked cytokines that actually could predict survival outcomes of patients with PDAC in public cancer data sets.
The second test looked at the effects of 90 drugs on adjusting the immune system’s function. These drugs were applied to fresh human blood cells, which contain a complex mix of different types of immune cells. Using their new method and single-cell RNA-sequencing, the team could not only test a large library of drugs, but also separate the drugs’ effects out for each type of cell. This enabled the team to understand how each drug might work in a more complex tissue, and then select the best one for the job.
“We might say there’s a defect in a T cell, so we’re going to add this drug, but we never think about, well, what does that drug do to all of the other cells in the tissue?” says Shalek. “We now have a way to gather this information, so that we can begin to pick drugs to maximize on-target effects and minimize side effects.”
Together, these experiments also showed Shalek the need to build better tools and datasets for creating hypotheses about potential treatments. “The complexity and lack of predictability for the responses we saw tells me that we likely are not finding the right, or most effective, drugs in many instances,” says Shalek.
Reducing barriers and improving lives
Although the current compression technique can identify the perturbations with the greatest effects, it’s still unable to perfectly resolve the effects of each one. Therefore, the team recommends that it act as a supplement to support additional screening. “Traditional tests that examine the top hits should follow,” Liu says.
Importantly, however, the new compression framework drastically reduces the number of input samples, costs, and labor required to execute a screen. With fewer barriers in play, it marks an exciting advance for understanding complex responses in different cells and building new models for precision medicine.
Shalek says, “This is really an incredible approach that opens up the kinds of things that we can do to find the right targets, or the right drugs, to use to improve lives for patients.”
A quasar is the extremely bright core of a galaxy that hosts an active supermassive black hole at its center. As the black hole draws in surrounding gas and dust, it blasts out an enormous amount of energy, making quasars some of the brightest objects in the universe. Quasars have been observed as early as a few hundred million years after the Big Bang, and it’s been a mystery as to how these objects could have grown so bright and massive in such a short amount of cosmic time.
Scientists have proposed that the earliest quasars sprang from overly dense regions of primordial matter, which would also have produced many smaller galaxies in the quasars’ environment. But in a new MIT-led study, astronomers observed some ancient quasars that appear to be surprisingly alone in the early universe.
The astronomers used NASA’s James Webb Space Telescope (JWST) to peer back in time, more than 13 billion years, to study the cosmic surroundings of five known ancient quasars. They found a surprising variety in their neighborhoods, or “quasar fields.” While some quasars reside in very crowded fields with more than 50 neighboring galaxies, as all models predict, the remaining quasars appear to drift in voids, with only a few stray galaxies in their vicinity.
These lonely quasars are challenging physicists’ understanding of how such luminous objects could have formed so early on in the universe, without a significant source of surrounding matter to fuel their black hole growth.
“Contrary to previous belief, we find on average, these quasars are not necessarily in those highest-density regions of the early universe. Some of them seem to be sitting in the middle of nowhere,” says Anna-Christina Eilers, assistant professor of physics at MIT. “It’s difficult to explain how these quasars could have grown so big if they appear to have nothing to feed from.”
There is a possibility that these quasars may not be as solitary as they appear, but are instead surrounded by galaxies that are heavily shrouded in dust and therefore hidden from view. Eilers and her colleagues hope to tune their observations to try and see through any such cosmic dust, in order to understand how quasars grew so big, so fast, in the early universe.
Eilers and her colleagues report their findings in a paper appearing today in the Astrophysical Journal. The MIT co-authors include postdocs Rohan Naidu and Minghao Yue; Robert Simcoe, the Francis Friedman Professor of Physics and director of MIT’s Kavli Institute for Astrophysics and Space Research; and collaborators from institutions including Leiden University, the University of California at Santa Barbara, ETH Zurich, and elsewhere.
Galactic neighbors
The five newly observed quasars are among the oldest quasars observed to date. More than 13 billion years old, the objects are thought to have formed between 600 to 700 million years after the Big Bang. The supermassive black holes powering the quasars are a billion times more massive than the sun, and more than a trillion times brighter. Due to their extreme luminosity, the light from each quasar is able to travel over the age of the universe, far enough to reach JWST’s highly sensitive detectors today.
“It’s just phenomenal that we now have a telescope that can capture light from 13 billion years ago in so much detail,” Eilers says. “For the first time, JWST enabled us to look at the environment of these quasars, where they grew up, and what their neighborhood was like.”
The team analyzed images of the five ancient quasars taken by JWST between August 2022 and June 2023. The observations of each quasar comprised multiple “mosaic” images, or partial views of the quasar’s field, which the team effectively stitched together to produce a complete picture of each quasar’s surrounding neighborhood.
The telescope also took measurements of light in multiple wavelengths across each quasar’s field, which the team then processed to determine whether a given object in the field was light from a neighboring galaxy, and how far a galaxy is from the much more luminous central quasar.
“We found that the only difference between these five quasars is that their environments look so different,” Eilers says. “For instance, one quasar has almost 50 galaxies around it, while another has just two. And both quasars are within the same size, volume, brightness, and time of the universe. That was really surprising to see.”
Growth spurts
The disparity in quasar fields introduces a kink in the standard picture of black hole growth and galaxy formation. According to physicists’ best understanding of how the first objects in the universe emerged, a cosmic web of dark matter should have set the course. Dark matter is an as-yet unknown form of matter that has no other interactions with its surroundings other than through gravity.
Shortly after the Big Bang, the early universe is thought to have formed filaments of dark matter that acted as a sort of gravitational road, attracting gas and dust along its tendrils. In overly dense regions of this web, matter would have accumulated to form more massive objects. And the brightest, most massive early objects, such as quasars, would have formed in the web’s highest-density regions, which would have also churned out many more, smaller galaxies.
“The cosmic web of dark matter is a solid prediction of our cosmological model of the Universe, and it can be described in detail using numerical simulations,” says co-author Elia Pizzati, a graduate student at Leiden University. “By comparing our observations to these simulations, we can determine where in the cosmic web quasars are located.”
Scientists estimate that quasars would have had to grow continuously with very high accretion rates in order to reach the extreme mass and luminosities at the times that astronomers have observed them, fewer than 1 billion years after the Big Bang.
“The main question we’re trying to answer is, how do these billion-solar-mass black holes form at a time when the universe is still really, really young? It’s still in its infancy,” Eilers says.
The team’s findings may raise more questions than answers. The “lonely” quasars appear to live in relatively empty regions of space. If physicists’ cosmological models are correct, these barren regions signify very little dark matter, or starting material for brewing up stars and galaxies. How, then, did extremely bright and massive quasars come to be?
“Our results show that there’s still a significant piece of the puzzle missing of how these supermassive black holes grow,” Eilers says. “If there’s not enough material around for some quasars to be able to grow continuously, that means there must be some other way that they can grow, that we have yet to figure out.”
This research was supported, in part, by the European Research Council.
This image, taken by NASA’s James Webb Space Telescope, shows an ancient quasar (circled in red) with fewer than expected neighboring galaxies (bright blobs), challenging physicists’ understanding of how the first quasars and supermassive black holes formed.
In the current AI zeitgeist, sequence models have skyrocketed in popularity for their ability to analyze data and predict what to do next. For instance, you’ve likely used next-token prediction models like ChatGPT, which anticipate each word (token) in a sequence to form answers to users’ queries. There are also full-sequence diffusion models like Sora, which convert words into dazzling, realistic visuals by successively “denoising” an entire video sequence.
Researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) have proposed a simple change to the diffusion training scheme that makes this sequence denoising considerably more flexible.
When applied to fields like computer vision and robotics, the next-token and full-sequence diffusion models have capability trade-offs. Next-token models can spit out sequences that vary in length. However, they make these generations while being unaware of desirable states in the far future — such as steering its sequence generation toward a certain goal 10 tokens away — and thus require additional mechanisms for long-horizon (long-term) planning. Diffusion models can perform such future-conditioned sampling, but lack the ability of next-token models to generate variable-length sequences.
Researchers from CSAIL want to combine the strengths of both models, so they created a sequence model training technique called “Diffusion Forcing.” The name comes from “Teacher Forcing,” the conventional training scheme that breaks down full sequence generation into the smaller, easier steps of next-token generation (much like a good teacher simplifying a complex concept).
Diffusion Forcing found common ground between diffusion models and teacher forcing: They both use training schemes that involve predicting masked (noisy) tokens from unmasked ones. In the case of diffusion models, they gradually add noise to data, which can be viewed as fractional masking. The MIT researchers’ Diffusion Forcing method trains neural networks to cleanse a collection of tokens, removing different amounts of noise within each one while simultaneously predicting the next few tokens. The result: a flexible, reliable sequence model that resulted in higher-quality artificial videos and more precise decision-making for robots and AI agents.
By sorting through noisy data and reliably predicting the next steps in a task, Diffusion Forcing can aid a robot in ignoring visual distractions to complete manipulation tasks. It can also generate stable and consistent video sequences and even guide an AI agent through digital mazes. This method could potentially enable household and factory robots to generalize to new tasks and improve AI-generated entertainment.
“Sequence models aim to condition on the known past and predict the unknown future, a type of binary masking. However, masking doesn’t need to be binary,” says lead author, MIT electrical engineering and computer science (EECS) PhD student, and CSAIL member Boyuan Chen. “With Diffusion Forcing, we add different levels of noise to each token, effectively serving as a type of fractional masking. At test time, our system can “unmask” a collection of tokens and diffuse a sequence in the near future at a lower noise level. It knows what to trust within its data to overcome out-of-distribution inputs.”
In several experiments, Diffusion Forcing thrived at ignoring misleading data to execute tasks while anticipating future actions.
When implemented into a robotic arm, for example, it helped swap two toy fruits across three circular mats, a minimal example of a family of long-horizon tasks that require memories. The researchers trained the robot by controlling it from a distance (or teleoperating it) in virtual reality. The robot is trained to mimic the user’s movements from its camera. Despite starting from random positions and seeing distractions like a shopping bag blocking the markers, it placed the objects into its target spots.
To generate videos, they trained Diffusion Forcing on “Minecraft” game play and colorful digital environments created within Google’s DeepMind Lab Simulator. When given a single frame of footage, the method produced more stable, higher-resolution videos than comparable baselines like a Sora-like full-sequence diffusion model and ChatGPT-like next-token models. These approaches created videos that appeared inconsistent, with the latter sometimes failing to generate working video past just 72 frames.
Diffusion Forcing not only generates fancy videos, but can also serve as a motion planner that steers toward desired outcomes or rewards. Thanks to its flexibility, Diffusion Forcing can uniquely generate plans with varying horizon, perform tree search, and incorporate the intuition that the distant future is more uncertain than the near future. In the task of solving a 2D maze, Diffusion Forcing outperformed six baselines by generating faster plans leading to the goal location, indicating that it could be an effective planner for robots in the future.
Across each demo, Diffusion Forcing acted as a full sequence model, a next-token prediction model, or both. According to Chen, this versatile approach could potentially serve as a powerful backbone for a “world model,” an AI system that can simulate the dynamics of the world by training on billions of internet videos. This would allow robots to perform novel tasks by imagining what they need to do based on their surroundings. For example, if you asked a robot to open a door without being trained on how to do it, the model could produce a video that’ll show the machine how to do it.
The team is currently looking to scale up their method to larger datasets and the latest transformer models to improve performance. They intend to broaden their work to build a ChatGPT-like robot brain that helps robots perform tasks in new environments without human demonstration.
“With Diffusion Forcing, we are taking a step to bringing video generation and robotics closer together,” says senior author Vincent Sitzmann, MIT assistant professor and member of CSAIL, where he leads the Scene Representation group. “In the end, we hope that we can use all the knowledge stored in videos on the internet to enable robots to help in everyday life. Many more exciting research challenges remain, like how robots can learn to imitate humans by watching them even when their own bodies are so different from our own!”
Chen and Sitzmann wrote the paper alongside recent MIT visiting researcher Diego Martí Monsó, and CSAIL affiliates: Yilun Du, a EECS graduate student; Max Simchowitz, former postdoc and incoming Carnegie Mellon University assistant professor; and Russ Tedrake, the Toyota Professor of EECS, Aeronautics and Astronautics, and Mechanical Engineering at MIT, vice president of robotics research at the Toyota Research Institute, and CSAIL member. Their work was supported, in part, by the U.S. National Science Foundation, the Singapore Defence Science and Technology Agency, Intelligence Advanced Research Projects Activity via the U.S. Department of the Interior, and the Amazon Science Hub. They will present their research at NeurIPS in December.
The “Diffusion Forcing” method can sort through noisy data and reliably predict the next steps in a task, helping a robot complete manipulation tasks, for example. In one experiment, it helped a robotic arm rearrange toy fruits into target spots on circular mats despite starting from random positions and visual distractions.
When an election result is disputed, people who are skeptical about the outcome may be swayed by figures of authority who come down on one side or the other. Those figures can be independent monitors, political figures, or news organizations. However, these “debunking” efforts don’t always have the desired effect, and in some cases, they can lead people to cling more tightly to their original position.
Neuroscientists and political scientists at MIT and the University of California at Berkeley have now created a computational model that analyzes the factors that help to determine whether debunking efforts will persuade people to change their beliefs about the legitimacy of an election. Their findings suggest that while debunking fails much of the time, it can be successful under the right conditions.
For instance, the model showed that successful debunking is more likely if people are less certain of their original beliefs and if they believe the authority is unbiased or strongly motivated by a desire for accuracy. It also helps when an authority comes out in support of a result that goes against a bias they are perceived to hold: for example, Fox News declaring that Joseph R. Biden had won in Arizona in the 2020 U.S. presidential election.
“When people see an act of debunking, they treat it as a human action and understand it the way they understand human actions — that is, as something somebody did for their own reasons,” says Rebecca Saxe, the John W. Jarve Professor of Brain and Cognitive Sciences, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study. “We’ve used a very simple, general model of how people understand other people’s actions, and found that that’s all you need to describe this complex phenomenon.”
The findings could have implications as the United States prepares for the presidential election taking place on Nov. 5, as they help to reveal the conditions that would be most likely to result in people accepting the election outcome.
MIT graduate student Setayesh Radkani is the lead author of the paper, which appears today in a special election-themed issue of the journal PNAS Nexus. Marika Landau-Wells PhD ’18, a former MIT postdoc who is now an assistant professor of political science at the University of California at Berkeley, is also an author of the study.
Modeling motivation
In their work on election debunking, the MIT team took a novel approach, building on Saxe’s extensive work studying “theory of mind” — how people think about the thoughts and motivations of other people.
As part of her PhD thesis, Radkani has been developing a computational model of the cognitive processes that occur when people see others being punished by an authority. Not everyone interprets punitive actions the same way, depending on their previous beliefs about the action and the authority. Some may see the authority as acting legitimately to punish an act that was wrong, while others may see an authority overreaching to issue an unjust punishment.
Last year, after participating in an MIT workshop on the topic of polarization in societies, Saxe and Radkani had the idea to apply the model to how people react to an authority attempting to sway their political beliefs. They enlisted Landau-Wells, who received her PhD in political science before working as a postdoc in Saxe’s lab, to join their effort, and Landau suggested applying the model to debunking of beliefs regarding the legitimacy of an election result.
The computational model created by Radkani is based on Bayesian inference, which allows the model to continually update its predictions of people’s beliefs as they receive new information. This approach treats debunking as an action that a person undertakes for his or her own reasons. People who observe the authority’s statement then make their own interpretation of why the person said what they did. Based on that interpretation, people may or may not change their own beliefs about the election result.
Additionally, the model does not assume that any beliefs are necessarily incorrect or that any group of people is acting irrationally.
“The only assumption that we made is that there are two groups in the society that differ in their perspectives about a topic: One of them thinks that the election was stolen and the other group doesn’t,” Radkani says. “Other than that, these groups are similar. They share their beliefs about the authority — what the different motives of the authority are and how motivated the authority is by each of those motives.”
The researchers modeled more than 200 different scenarios in which an authority attempts to debunk a belief held by one group regarding the validity of an election outcome.
Each time they ran the model, the researchers altered the certainty levels of each group’s original beliefs, and they also varied the groups’ perceptions of the motivations of the authority. In some cases, groups believed the authority was motivated by promoting accuracy, and in others they did not. The researchers also altered the groups’ perceptions of whether the authority was biased toward a particular viewpoint, and how strongly the groups believed in those perceptions.
Building consensus
In each scenario, the researchers used the model to predict how each group would respond to a series of five statements made by an authority trying to convince them that the election had been legitimate. The researchers found that in most of the scenarios they looked at, beliefs remained polarized and in some cases became even further polarized. This polarization could also extend to new topics unrelated to the original context of the election, the researchers found.
However, under some circumstances, the debunking was successful, and beliefs converged on an accepted outcome. This was more likely to happen when people were initially more uncertain about their original beliefs.
“When people are very, very certain, they become hard to move. So, in essence, a lot of this authority debunking doesn’t matter,” Landau-Wells says. “However, there are a lot of people who are in this uncertain band. They have doubts, but they don’t have firm beliefs. One of the lessons from this paper is that we’re in a space where the model says you can affect people’s beliefs and move them towards true things.”
Another factor that can lead to belief convergence is if people believe that the authority is unbiased and highly motivated by accuracy. Even more persuasive is when an authority makes a claim that goes against their perceived bias — for instance, Republican governors stating that elections in their states had been fair even though the Democratic candidate won.
As the 2024 presidential election approaches, grassroots efforts have been made to train nonpartisan election observers who can vouch for whether an election was legitimate. These types of organizations may be well-positioned to help sway people who might have doubts about the election’s legitimacy, the researchers say.
“They’re trying to train to people to be independent, unbiased, and committed to the truth of the outcome more than anything else. Those are the types of entities that you want. We want them to succeed in being seen as independent. We want them to succeed as being seen as truthful, because in this space of uncertainty, those are the voices that can move people toward an accurate outcome,” Landau-Wells says.
The research was funded, in part, by the Patrick J. McGovern Foundation and the Guggenheim Foundation.
Scientists at MIT and the University of California at Berkeley have created a computational model that analyzes the factors that help to determine whether debunking efforts will persuade people to change their beliefs about the legitimacy of an election.
Active electronics — components that can control electrical signals — usually contain semiconductor devices that receive, store, and process information. These components, which must be made in a clean room, require advanced fabrication technology that is not widely available outside a few specialized manufacturing centers.
During the Covid-19 pandemic, the lack of widespread semiconductor fabrication facilities was one cause of a worldwide electronics shortage, which drove up costs for consumers and had implications in everything from economic growth to national defense. The ability to 3D print an entire, active electronic device without the need for semiconductors could bring electronics fabrication to businesses, labs, and homes across the globe.
While this idea is still far off, MIT researchers have taken an important step in that direction by demonstrating fully 3D-printed resettable fuses, which are key components of active electronics that usually require semiconductors.
The researchers’ semiconductor-free devices, which they produced using standard 3D printing hardware and an inexpensive, biodegradable material, can perform the same switching functions as the semiconductor-based transistors used for processing operations in active electronics.
Although still far from achieving the performance of semiconductor transistors, the 3D-printed devices could be used for basic control operations like regulating the speed of an electric motor.
“This technology has real legs. While we cannot compete with silicon as a semiconductor, our idea is not to necessarily replace what is existing, but to push 3D printing technology into uncharted territory. In a nutshell, this is really about democratizing technology. This could allow anyone to create smart hardware far from traditional manufacturing centers,” says Luis Fernando Velásquez-García, a principal research scientist in MIT’s Microsystems Technology Laboratories (MTL) and senior author of a paper describing the devices, which appears in Virtual and Physical Prototyping.
He is joined on the paper by lead author Jorge Cañada, an electrical engineering and computer science graduate student.
An unexpected project
Semiconductors, including silicon, are materials with electrical properties that can be tailored by adding certain impurities. A silicon device can have conductive and insulating regions, depending on how it is engineered. These properties make silicon ideal for producing transistors, which are a basic building block of modern electronics.
However, the researchers didn’t set out to 3D-print semiconductor-free devices that could behave like silicon-based transistors.
This project grew out of another in which they were fabricating magnetic coils using extrusion printing, a process where the printer melts filament and squirts material through a nozzle, fabricating an object layer-by-layer.
They saw an interesting phenomenon in the material they were using, a polymer filament doped with copper nanoparticles.
If they passed a large amount of electric current into the material, it would exhibit a huge spike in resistance but would return to its original level shortly after the current flow stopped.
This property enables engineers to make transistors that can operate as switches, something that is typically only associated with silicon and other semiconductors. Transistors, which switch on and off to process binary data, are used to form logic gates which perform computation.
“We saw that this was something that could help take 3D printing hardware to the next level. It offers a clear way to provide some degree of ‘smart’ to an electronic device,” Velásquez-García says.
The researchers tried to replicate the same phenomenon with other 3D printing filaments, testing polymers doped with carbon, carbon nanotubes, and graphene. In the end, they could not find another printable material that could function as a resettable fuse.
They hypothesize that the copper particles in the material spread out when it is heated by the electric current, which causes a spike in resistance that comes back down when the material cools and the copper particles move closer together. They also think the polymer base of the material changes from crystalline to amorphous when heated, then returns to crystalline when cooled down — a phenomenon known as the polymeric positive temperature coefficient.
“For now, that is our best explanation, but that is not the full answer because that doesn’t explain why it only happened in this combination of materials. We need to do more research, but there is no doubt that this phenomenon is real,” he says.
3D-printing active electronics
The team leveraged the phenomenon to print switches in a single step that could be used to form semiconductor-free logic gates.
The devices are made from thin, 3D-printed traces of the copper-doped polymer. They contain intersecting conductive regions that enable the researchers to regulate the resistance by controlling the voltage fed into the switch.
While the devices did not perform as well as silicon-based transistors, they could be used for simpler control and processing functions, such as turning a motor on and off. Their experiments showed that, even after 4,000 cycles of switching, the devices showed no signs of deterioration.
But there are limits to how small the researchers can make the switches, based on the physics of extrusion printing and the properties of the material. They could print devices that were a few hundred microns, but transistors in state-of-the-art electronics are only few nanometers in diameter.
“The reality is that there are many engineering situations that don’t require the best chips. At the end of the day, all you care about is whether your device can do the task. This technology is able to satisfy a constraint like that,” he says.
However, unlike semiconductor fabrication, their technique uses a biodegradable material and the process uses less energy and produces less waste. The polymer filament could also be doped with other materials, like magnetic microparticles that could enable additional functionalities.
In the future, the researchers want to use this technology to print fully functional electronics. They are striving to fabricate a working magnetic motor using only extrusion 3D printing. They also want to finetune the process so they could build more complex circuits and see how far they can push the performance of these devices.
“This paper demonstrates that active electronic devices can be made using extruded polymeric conductive materials. This technology enables electronics to be built into 3D printed structures. An intriguing application is on-demand 3D printing of mechatronics on board spacecraft,” says Roger Howe, the William E. Ayer Professor of Engineering, Emeritus, at Stanford University, who was not involved with this work.
This work is funded, in part, by Empiriko Corporation.
The devices are made from thin, 3D-printed traces of the copper-doped polymer. They contain intersecting conductive regions that enable the researchers to regulate the resistance by controlling the voltage fed into the switch.
A classical way to image nanoscale structures in cells is with high-powered, expensive super-resolution microscopes. As an alternative, MIT researchers have developed a way to expand tissue before imaging it — a technique that allows them to achieve nanoscale resolution with a conventional light microscope.
In the newest version of this technique, the researchers have made it possible to expand tissue 20-fold in a single step. This simple, inexpensive method could pave the way for nearly any biology lab to perform nanoscale imaging.
“This democratizes imaging,” says Laura Kiessling, the Novartis Professor of Chemistry at MIT and a member of the Broad Institute of MIT and Harvard and MIT’s Koch Institute for Integrative Cancer Research. “Without this method, if you want to see things with a high resolution, you have to use very expensive microscopes. What this new technique allows you to do is see things that you couldn’t normally see with standard microscopes. It drives down the cost of imaging because you can see nanoscale things without the need for a specialized facility.”
At the resolution achieved by this technique, which is around 20 nanometers, scientists can see organelles inside cells, as well as clusters of proteins.
“Twenty-fold expansion gets you into the realm that biological molecules operate in. The building blocks of life are nanoscale things: biomolecules, genes, and gene products,” says Edward Boyden, the Y. Eva Tan Professor in Neurotechnology at MIT; a professor of biological engineering, media arts and sciences, and brain and cognitive sciences; a Howard Hughes Medical Institute investigator; and a member of MIT’s McGovern Institute for Brain Research and Koch Institute for Integrative Cancer Research.
Boyden and Kiessling are the senior authors of the new study, which appears today in Nature Methods. MIT graduate student Shiwei Wang and Tay Won Shin PhD ’23 are the lead authors of the paper.
A single expansion
Boyden’s lab invented expansion microscopy in 2015. The technique requires embedding tissue into an absorbent polymer and breaking apart the proteins that normally hold tissue together. When water is added, the gel swells and pulls biomolecules apart from each other.
The original version of this technique, which expanded tissue about fourfold, allowed researchers to obtain images with a resolution of around 70 nanometers. In 2017, Boyden’s lab modified the process to include a second expansion step, achieving an overall 20-fold expansion. This enables even higher resolution, but the process is more complicated.
“We’ve developed several 20-fold expansion technologies in the past, but they require multiple expansion steps,” Boyden says. “If you could do that amount of expansion in a single step, that could simplify things quite a bit.”
With 20-fold expansion, researchers can get down to a resolution of about 20 nanometers, using a conventional light microscope. This allows them see cell structures like microtubules and mitochondria, as well as clusters of proteins.
In the new study, the researchers set out to perform 20-fold expansion with only a single step. This meant that they had to find a gel that was both extremely absorbent and mechanically stable, so that it wouldn’t fall apart when expanded 20-fold.
To achieve that, they used a gel assembled from N,N-dimethylacrylamide (DMAA) and sodium acrylate. Unlike previous expansion gels that rely on adding another molecule to form crosslinks between the polymer strands, this gel forms crosslinks spontaneously and exhibits strong mechanical properties. Such gel components previously had been used in expansion microscopy protocols, but the resulting gels could expand only about tenfold. The MIT team optimized the gel and the polymerization process to make the gel more robust, and to allow for 20-fold expansion.
To further stabilize the gel and enhance its reproducibility, the researchers removed oxygen from the polymer solution prior to gelation, which prevents side reactions that interfere with crosslinking. This step requires running nitrogen gas through the polymer solution, which replaces most of the oxygen in the system.
Once the gel is formed, select bonds in the proteins that hold the tissue together are broken and water is added to make the gel expand. After the expansion is performed, target proteins in tissue can be labeled and imaged.
“This approach may require more sample preparation compared to other super-resolution techniques, but it’s much simpler when it comes to the actual imaging process, especially for 3D imaging,” Shin says. “We document the step-by-step protocol in the manuscript so that readers can go through it easily.”
Imaging tiny structures
Using this technique, the researchers were able to image many tiny structures within brain cells, including structures called synaptic nanocolumns. These are clusters of proteins that are arranged in a specific way at neuronal synapses, allowing neurons to communicate with each other via secretion of neurotransmitters such as dopamine.
In studies of cancer cells, the researchers also imaged microtubules — hollow tubes that help give cells their structure and play important roles in cell division. They were also able to see mitochondria (organelles that generate energy) and even the organization of individual nuclear pore complexes (clusters of proteins that control access to the cell nucleus).
Wang is now using this technique to image carbohydrates known as glycans, which are found on cell surfaces and help control cells’ interactions with their environment. This method could also be used to image tumor cells, allowing scientists to glimpse how proteins are organized within those cells, much more easily than has previously been possible.
The researchers envision that any biology lab should be able to use this technique at a low cost since it relies on standard, off-the-shelf chemicals and common equipment such confocal microscopes and glove bags, which most labs already have or can easily access.
“Our hope is that with this new technology, any conventional biology lab can use this protocol with their existing microscopes, allowing them to approach resolution that can only be achieved with very specialized and costly state-of-the-art microscopes,” Wang says.
The research was funded, in part, by the U.S. National Institutes of Health, an MIT Presidential Graduate Fellowship, U.S. National Science Foundation Graduate Research Fellowship grants, Open Philanthropy, Good Ventures, the Howard Hughes Medical Institute, Lisa Yang, Ashar Aziz, and the European Research Council.
Thanks to a new technique that allows them to expand tissue 20-fold before imaging it, MIT researchers used a conventional light microscope to generate high-resolution images of synapses (left) and microtubules (right). In the image at left, presynaptic proteins are labeled in red, and postsynaptic proteins are labeled in blue. Each blue-red “sandwich” represents a synapse.
Our brains constantly work to make predictions about what’s going on around us to ensure that we can attend to and consider the unexpected, for instance. A new study examines how this works during consciousness and also breaks down under general anesthesia. The results add evidence to the idea that conscious thought requires synchronized communication — mediated by brain rhythms in specific frequency bands — between basic sensory and higher-order cognitive regions of the brain.
Previously, members of the research team in The Picower Institute for Learning and Memory at MIT and at Vanderbilt University had described how brain rhythms enable the brain to remain prepared to attend to surprises. Cognition-oriented brain regions (generally at the front of the brain) use relatively low-frequency alpha and beta rhythms to suppress processing by sensory regions (generally toward the back of the brain) of stimuli that have become familiar and mundane in the environment (e.g., your co-worker’s music). When sensory regions detect a surprise (e.g., the office fire alarm), they use faster-frequency gamma rhythms to tell the higher regions about it, and the higher regions process that at gamma frequencies to decide what to do (e.g., exit the building).
The new results, published Oct. 7 in the Proceedings of the National Academy of Sciences, show that when animals were under propofol-induced general anesthesia, a sensory region retained the capacity to detect simple surprises but communication with a higher cognitive region toward the front of the brain was lost, making that region unable to engage in its “top-down” regulation of the activity of the sensory region and keeping it oblivious to simple and more complex surprises alike.
What we've got here is failure to communicate
“What we are doing here speaks to the nature of consciousness,” says co-senior author Earl K. Miller, Picower Professor in The Picower Institute for Learning and Memory and MIT’s Department of Brain and Cognitive Sciences. “Propofol general anesthesia deactivates the top-down processes that that underlie cognition. It essentially disconnects communication between the front and back halves of the brain.”
Co-senior author Andre Bastos, an assistant professor in the psychology department at Vanderbilt and a former member of Miller’s MIT lab, adds that the study results highlight the key role of frontal areas in consciousness.
“These results are particularly important given the newfound scientific interest in the mechanisms of consciousness, and how consciousness relates to the ability of the brain to form predictions,” Bastos says.
The brain’s ability to predict is dramatically altered during anesthesia. It was interesting that the front of the brain, areas associated with cognition, were more strongly diminished in their predictive abilities than sensory areas. This suggests that prefrontal areas help to spark an “ignition” event that allows sensory information to become conscious. Sensory cortex activation by itself does not lead to conscious perception. These observations help us narrow down possible models for the mechanisms of consciousness.
Yihan Sophy Xiong, a graduate student in Bastos’ lab who led the study, says the anesthetic reduces the times in which inter-regional communication within the cortex can occur.
“In the awake brain, brain waves give short windows of opportunity for neurons to fire optimally — the ‘refresh rate’ of the brain, so to speak,” Xiong says. “This refresh rate helps organize different brain areas to communicate effectively. Anesthesia both slows down the refresh rate, which narrows these time windows for brain areas to talk to each other and makes the refresh rate less effective, so that neurons become more disorganized about when they can fire. When the refresh rate no longer works as intended, our ability to make predictions is weakened.”
Learning from oddballs
To conduct the research, the neuroscientists measured the electrical signals, “or spiking,” of hundreds of individual neurons and the coordinated rhythms of their aggregated activity (at alpha/beta and gamma frequencies), in two areas on the surface, or cortex, of the brain of two animals as they listened to sequences of tones. Sometimes the sequences would all be the same note (e.g., AAAAA). Sometimes there’d be a simple surprise that the researchers called a “local oddball” (e.g., AAAAB). But sometimes the surprise would be more complicated, or a “global oddball.” For example, after seeing a series of AAAABs, there’d all of a sudden be AAAAA, which violates the global but not the local pattern.
Prior work has suggested that a sensory region (in this case the temporoparietal area, or Tpt) can spot local oddballs on its own, Miller says. Detecting the more complicated global oddball requires the participation of a higher order region (in this case the frontal eye fields, or FEF).
The animals heard the tone sequences both while awake and while under propofol anesthesia. There were no surprises about the waking state. The researchers reaffirmed that top-down alpha/beta rhythms from FEF carried predictions to the Tpt and that Tpt would increase gamma rhythms when an oddball came up, causing FEF (and the prefrontal cortex) to respond with upticks of gamma activity as well.
But by several measures and analyses, the scientists could see these dynamics break down after the animals lost consciousness.
Under propofol, for instance, spiking activity declined overall but when a local oddball came along, Tpt spiking still increased notably but now spiking in FEF didn’t follow suit as it does during wakefulness.
Meanwhile, when a global oddball was presented during wakefulness, the researchers could use software to “decode” representation of that among neurons in FEF and the prefrontal cortex (another cognition-oriented region). They could also decode local oddballs in the Tpt. But under anesthesia the decoder could no longer reliably detect representation of local or global oddballs in FEF or the prefrontal cortex.
Moreover, when they compared rhythms in the regions amid wakeful versus unconscious states they found stark differences. When the animals were awake, oddballs increased gamma activity in both Tpt and FEF and alpha/beta rhythms decreased. Regular, non-oddball stimulation increased alpha/beta rhythms. But when the animals lost consciousness the increase in gamma rhythms from a local oddball was even greater in Tpt than when the animal was awake.
“Under propofol-mediated loss of consciousness, the inhibitory function of alpha/beta became diminished and/or eliminated, leading to disinhibition of oddballs in sensory cortex,” the authors wrote.
Other analyses of inter-region connectivity and synchrony revealed that the regions lost the ability to communicate during anesthesia.
In all, the study’s evidence suggests that conscious thought requires coordination across the cortex, from front to back, the researchers wrote.
“Our results therefore suggest an important role for prefrontal cortex activation, in addition to sensory cortex activation, for conscious perception,” the researchers wrote.
In addition to Xiong, Miller, and Bastos, the paper’s other authors are Jacob Donoghue, Mikael Lundqvist, Meredith Mahnke, Alex Major, and Emery N. Brown.
The National Institutes of Health, The JPB Foundation, and The Picower Institute for Learning and Memory funded the study.
Researchers tested how the brain's ability to judge whether sensory stimuli are novel or not breaks down under anesthesia. Sensory regions at the back of the brain still processed sound, but they lost the ability to communicate about novelty to the front of the brain, where behavioral decisions take place.
Multimaterial 3D printing enables makers to fabricate customized devices with multiple colors and varied textures. But the process can be time-consuming and wasteful because existing 3D printers must switch between multiple nozzles, often discarding one material before they can start depositing another.
Researchers from MIT and Delft University of Technology have now introduced a more efficient, less wasteful, and higher-precision technique that leverages heat-responsive materials to print objects that have multiple colors, shades, and textures in one step.
Their method, called speed-modulated ironing, utilizes a dual-nozzle 3D printer. The first nozzle deposits a heat-responsive filament and the second nozzle passes over the printed material to activate certain responses, such as changes in opacity or coarseness, using heat.
By controlling the speed of the second nozzle, the researchers can heat the material to specific temperatures, finely tuning the color, shade, and roughness of the heat-responsive filaments. Importantly, this method does not require any hardware modifications.
The researchers developed a model that predicts the amount of heat the “ironing” nozzle will transfer to the material based on its speed. They used this model as the foundation for a user interface that automatically generates printing instructions which achieve color, shade, and texture specifications.
One could use speed-modulated ironing to create artistic effects by varying the color on a printed object. The technique could also produce textured handles that would be easier to grasp for individuals with weakness in their hands.
“Today, we have desktop printers that use a smart combination of a few inks to generate a range of shades and textures. We want to be able to do the same thing with a 3D printer — use a limited set of materials to create a much more diverse set of characteristics for 3D-printed objects,” says Mustafa Doğa Doğan PhD ’24, co-author of a paper on speed-modulated ironing.
This project is a collaboration between the research groups of Zjenja Doubrovski, assistant professor at TU Delft, and Stefanie Mueller, the TIBCO Career Development Professor in the Department of Electrical Engineering and Computer Science (EECS) at MIT and a member of the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). Doğan worked closely with lead author Mehmet Ozdemir of TU Delft; Marwa AlAlawi, a mechanical engineering graduate student at MIT; and Jose Martinez Castro of TU Delft. The research will be presented at the ACM Symposium on User Interface Software and Technology.
Modulating speed to control temperature
The researchers launched the project to explore better ways to achieve multiproperty 3D printing with a single material. The use of heat-responsive filaments was promising, but most existing methods use a single nozzle to do printing and heating. The printer always needs to first heat the nozzle to the desired target temperature before depositing the material.
However, heating and cooling the nozzle takes a long time, and there is a danger that the filament in the nozzle might degrade as it reaches higher temperatures.
To prevent these problems, the team developed an ironing technique where material is printed using one nozzle, then activated by a second, empty nozzle which only reheats it. Instead of adjusting the temperature to trigger the material response, the researchers keep the temperature of the second nozzle constant and vary the speed at which it moves over the printed material, slightly touching the top of the layer.
“As we modulate the speed, that allows the printed layer we are ironing to reach different temperatures. It is similar to what happens if you move your finger over a flame. If you move it quickly, you might not be burned, but if you drag it across the flame slowly, your finger will reach a higher temperature,” AlAlawi says.
The MIT team collaborated with the TU Delft researchers to develop the theoretical model that predicts how fast the second nozzle must move to heat the material to a specific temperature.
The model correlates a material’s output temperature with its heat-responsive properties to determine the exact nozzle speed which will achieve certain colors, shades, or textures in the printed object.
“There are a lot of inputs that can affect the results we get. We are modeling something that is very complicated, but we also want to make sure the results are fine-grained,” AlAlawi says.
The team dug into scientific literature to determine proper heat transfer coefficients for a set of unique materials, which they built into their model. They also had to contend with an array of unpredictable variables, such as heat that may be dissipated by fans and the air temperature in the room where the object is being printed.
They incorporated the model into a user-friendly interface that simplifies the scientific process, automatically translating the pixels in a maker’s 3D model into a set of machine instructions that control the speed at which the object is printed and ironed by the dual nozzles.
Faster, finer fabrication
They tested their approach with three heat-responsive filaments. The first, a foaming polymer with particles that expand as they are heated, yields different shades, translucencies, and textures. They also experimented with a filament filled with wood fibers and one with cork fibers, both of which can be charred to produce increasingly darker shades.
The researchers demonstrated how their method could produce objects like water bottles that are partially translucent. To make the water bottles, they ironed the foaming polymer at low speeds to create opaque regions and higher speeds to create translucent ones. They also utilized the foaming polymer to fabricate a bike handle with varied roughness to improve a rider’s grip.
Trying to produce similar objects using traditional multimaterial 3D printing took far more time, sometimes adding hours to the printing process, and consumed more energy and material. In addition, speed-modulated ironing could produce fine-grained shade and texture gradients that other methods could not achieve.
In the future, the researchers want to experiment with other thermally responsive materials, such as plastics. They also hope to explore the use of speed-modulated ironing to modify the mechanical and acoustic properties of certain materials.
Speed-modulated ironing enables makers to fabricate objects with varied colors and textures, like the owls pictured here, using only one material with high precision. The technique is faster and produces less waste than other methods.
A growing portion of Americans who are struggling to pay for their household energy live in the South and Southwest, reflecting a climate-driven shift away from heating needs and toward air conditioning use, an MIT study finds.
The newly published research also reveals that a major U.S. federal program that provides energy subsidies to households, by assigning block grants to states, does not yet fully match these recent trends.
The work evaluates the “energy burden” on households, which reflects the percentage of income needed to pay for energy necessities, from 2015 to 2020. Households with an energy burden greater than 6 percent of income are considered to be in “energy poverty.” With climate change, rising temperatures are expected to add financial stress in the South, where air conditioning is increasingly needed. Meanwhile, milder winters are expected to reduce heating costs in some colder regions.
“From 2015 to 2020, there is an increase in burden generally, and you do also see this southern shift,” says Christopher Knittel, an MIT energy economist and co-author of a new paper detailing the study’s results. About federal aid, he adds, “When you compare the distribution of the energy burden to where the money is going, it’s not aligned too well.”
The authors are Carlos Batlle, a professor at Comillas University in Spain and a senior lecturer with the MIT Energy Initiative; Peter Heller SM ’24, a recent graduate of the MIT Technology and Policy Program; Knittel, the George P. Shultz Professor at the MIT Sloan School of Management and associate dean for climate and sustainability at MIT; and Tim Schittekatte, a senior lecturer at MIT Sloan.
A scorching decade
The study, which grew out of graduate research that Heller conducted at MIT, deploys a machine-learning estimation technique that the scholars applied to U.S. energy use data.
Specifically, the researchers took a sample of about 20,000 households from the U.S. Energy Information Administration’s Residential Energy Consumption Survey, which includes a wide variety of demographic characteristics about residents, along with building-type and geographic information. Then, using the U.S. Census Bureau’s American Community Survey data for 2015 and 2020, the research team estimated the average household energy burden for every census tract in the lower 48 states — 73,057 in 2015, and 84,414 in 2020.
That allowed the researchers to chart the changes in energy burden in recent years, including the shift toward a greater energy burden in southern states. In 2015, Maine, Mississippi, Arkansas, Vermont, and Alabama were the five states (ranked in descending order) with the highest energy burden across census bureau tracts. In 2020, that had shifted somewhat, with Maine and Vermont dropping on the list and southern states increasingly having a larger energy burden. That year, the top five states in descending order were Mississippi, Arkansas, Alabama, West Virginia, and Maine.
The data also reflect a urban-rural shift. In 2015, 23 percent of the census tracts where the average household is living in energy poverty were urban. That figure shrank to 14 percent by 2020.
All told, the data are consistent with the picture of a warming world, in which milder winters in the North, Northwest, and Mountain West require less heating fuel, while more extreme summer temperatures in the South require more air conditioning.
“Who’s going to be harmed most from climate change?” asks Knittel. “In the U.S., not surprisingly, it’s going to be the southern part of the U.S. And our study is confirming that, but also suggesting it’s the southern part of the U.S that’s least able to respond. If you’re already burdened, the burden’s growing.”
An evolution for LIHEAP?
In addition to identifying the shift in energy needs during the last decade, the study also illuminates a longer-term change in U.S. household energy needs, dating back to the 1980s. The researchers compared the present-day geography of U.S. energy burden to the help currently provided by the federal Low Income Home Energy Assistance Program (LIHEAP), which dates to 1981.
Federal aid for energy needs actually predates LIHEAP, but the current program was introduced in 1981, then updated in 1984 to include cooling needs such as air conditioning. When the formula was updated in 1984, two “hold harmless” clauses were also adopted, guaranteeing states a minimum amount of funding.
Still, LIHEAP’s parameters also predate the rise of temperatures over the last 40 years, and the current study shows that, compared to the current landscape of energy poverty, LIHEAP distributes relatively less of its funding to southern and southwestern states.
“The way Congress uses formulas set in the 1980s keeps funding distributions nearly the same as it was in the 1980s,” Heller observes. “Our paper illustrates the shift in need that has occurred over the decades since then.”
Currently, it would take a fourfold increase in LIHEAP to ensure that no U.S. household experiences energy poverty. But the researchers tested out a new funding design, which would help the worst-off households first, nationally, ensuring that no household would have an energy burden of greater than 20.3 percent.
“We think that’s probably the most equitable way to allocate the money, and by doing that, you now have a different amount of money that should go to each state, so that no one state is worse off than the others,” Knittel says.
And while the new distribution concept would require a certain amount of subsidy reallocation among states, it would be with the goal of helping all households avoid a certain level of energy poverty, across the country, at a time of changing climate, warming weather, and shifting energy needs in the U.S.
“We can optimize where we spend the money, and that optimization approach is an important thing to think about,” Knittel says.
This map estimates the average energy burden for U.S. households between 2015 and 2020. Households experiencing an energy burden in costs greater than 6 percent of income are classified as energy-poor. Darker shades indicate higher energy burdens, and grey areas indicate census tracts where the estimates are unavailable.
A recent award from the U.S. Defense Advanced Research Projects Agency (DARPA) brings together researchers from Massachusetts Institute of Technology (MIT), Carnegie Mellon University (CMU), and Lehigh University (Lehigh) under the Multiobjective Engineering and Testing of Alloy Structures (METALS) program. The team will research novel design tools for the simultaneous optimization of shape and compositional gradients in multi-material structures that complement new high-throughput materials testing techniques, with particular attention paid to the bladed disk (blisk) geometry commonly found in turbomachinery (including jet and rocket engines) as an exemplary challenge problem.
“This project could have important implications across a wide range of aerospace technologies. Insights from this work may enable more reliable, reusable, rocket engines that will power the next generation of heavy-lift launch vehicles,” says Zachary Cordero, the Esther and Harold E. Edgerton Associate Professor in the MIT Department of Aeronautics and Astronautics (AeroAstro) and the project’s lead principal investigator. “This project merges classical mechanics analyses with cutting-edge generative AI design technologies to unlock the plastic reserve of compositionally graded alloys allowing safe operation in previously inaccessible conditions.”
Different locations in blisks require different thermomechanical properties and performance, such as resistance to creep, low cycle fatigue, high strength, etc. Large scale production also necessitates consideration of cost and sustainability metrics such as sourcing and recycling of alloys in the design.
“Currently, with standard manufacturing and design procedures, one must come up with a single magical material, composition, and processing parameters to meet ‘one part-one material’ constraints,” says Cordero. “Desired properties are also often mutually exclusive prompting inefficient design tradeoffs and compromises.”
Although a one-material approach may be optimal for a singular location in a component, it may leave other locations exposed to failure or may require a critical material to be carried throughout an entire part when it may only be needed in a specific location. With the rapid advancement of additive manufacturing processes that are enabling voxel-based composition and property control, the team sees unique opportunities for leap-ahead performance in structural components are now possible.
Cordero’s collaborators include Zoltan Spakovszky, the T. Wilson (1953) Professor in Aeronautics in AeroAstro; A. John Hart, the Class of 1922 Professor and head of the Department of Mechanical Engineering; Faez Ahmed, ABS Career Development Assistant Professor of mechanical engineering at MIT; S. Mohadeseh Taheri-Mousavi, assistant professor of materials science and engineering at CMU; and Natasha Vermaak, associate professor of mechanical engineering and mechanics at Lehigh.
The team’s expertise spans hybrid integrated computational material engineering and machine-learning-based material and process design, precision instrumentation, metrology, topology optimization, deep generative modeling, additive manufacturing, materials characterization, thermostructural analysis, and turbomachinery.
“It is especially rewarding to work with the graduate students and postdoctoral researchers collaborating on the METALS project, spanning from developing new computational approaches to building test rigs operating under extreme conditions,” says Hart. “It is a truly unique opportunity to build breakthrough capabilities that could underlie propulsion systems of the future, leveraging digital design and manufacturing technologies.”
This research is funded by DARPA under contract HR00112420303. The views, opinions, and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. government and no official endorsement should be inferred.
MIT researchers have some good environmental news: Mercury emissions from human activity have been declining over the past two decades, despite global emissions inventories that indicate otherwise.
In a new study, the researchers analyzed measurements from all available monitoring stations in the Northern Hemisphere and found that atmospheric concentrations of mercury declined by about 10 percent between 2005 and 2020.
They used two separate modeling methods to determine what is driving that trend. Both techniques pointed to a decline in mercury emissions from human activity as the most likely cause.
Global inventories, on the other hand, have reported opposite trends. These inventories estimate atmospheric emissions using models that incorporate average emission rates of polluting activities and the scale of these activities worldwide.
“Our work shows that it is very important to learn from actual, on-the-ground data to try and improve our models and these emissions estimates. This is very relevant for policy because, if we are not able to accurately estimate past mercury emissions, how are we going to predict how mercury pollution will evolve in the future?” says Ari Feinberg, a former postdoc in the Institute for Data, Systems, and Society (IDSS) and lead author of the study.
The new results could help inform scientists who are embarking on a collaborative, global effort to evaluate pollution models and develop a more in-depth understanding of what drives global atmospheric concentrations of mercury.
However, due to a lack of data from global monitoring stations and limitations in the scientific understanding of mercury pollution, the researchers couldn’t pinpoint a definitive reason for the mismatch between the inventories and the recorded measurements.
“It seems like mercury emissions are moving in the right direction, and could continue to do so, which is heartening to see. But this was as far as we could get with mercury. We need to keep measuring and advancing the science,” adds co-author Noelle Selin, an MIT professor in the IDSS and the Department of Earth, Atmospheric and Planetary Sciences (EAPS).
Feinberg and Selin, his MIT postdoctoral advisor, are joined on the paper by an international team of researchers that contributed atmospheric mercury measurement data and statistical methods to the study. The research appears this week in the Proceedings of the National Academy of Sciences.
Mercury mismatch
The Minamata Convention is a global treaty that aims to cut human-caused emissions of mercury, a potent neurotoxin that enters the atmosphere from sources like coal-fired power plants and small-scale gold mining.
The treaty, which was signed in 2013 and went into force in 2017, is evaluated every five years. The first meeting of its conference of parties coincided with disheartening news reports that said global inventories of mercury emissions, compiled in part from information from national inventories, had increased despite international efforts to reduce them.
This was puzzling news for environmental scientists like Selin. Data from monitoring stations showed atmospheric mercury concentrations declining during the same period.
Bottom-up inventories combine emission factors, such as the amount of mercury that enters the atmosphere when coal mined in a certain region is burned, with estimates of pollution-causing activities, like how much of that coal is burned in power plants.
“The big question we wanted to answer was: What is actually happening to mercury in the atmosphere and what does that say about anthropogenic emissions over time?” Selin says.
Modeling mercury emissions is especially tricky. First, mercury is the only metal that is in liquid form at room temperature, so it has unique properties. Moreover, mercury that has been removed from the atmosphere by sinks like the ocean or land can be re-emitted later, making it hard to identify primary emission sources.
At the same time, mercury is more difficult to study in laboratory settings than many other air pollutants, especially due to its toxicity, so scientists have limited understanding of all chemical reactions mercury can undergo. There is also a much smaller network of mercury monitoring stations, compared to other polluting gases like methane and nitrous oxide.
“One of the challenges of our study was to come up with statistical methods that can address those data gaps, because available measurements come from different time periods and different measurement networks,” Feinberg says.
Multifaceted models
The researchers compiled data from 51 stations in the Northern Hemisphere. They used statistical techniques to aggregate data from nearby stations, which helped them overcome data gaps and evaluate regional trends.
By combining data from 11 regions, their analysis indicated that Northern Hemisphere atmospheric mercury concentrations declined by about 10 percent between 2005 and 2020.
Then the researchers used two modeling methods — biogeochemical box modeling and chemical transport modeling — to explore possible causes of that decline. Box modeling was used to run hundreds of thousands of simulations to evaluate a wide array of emission scenarios. Chemical transport modeling is more computationally expensive but enables researchers to assess the impacts of meteorology and spatial variations on trends in selected scenarios.
For instance, they tested one hypothesis that there may be an additional environmental sink that is removing more mercury from the atmosphere than previously thought. The models would indicate the feasibility of an unknown sink of that magnitude.
“As we went through each hypothesis systematically, we were pretty surprised that we could really point to declines in anthropogenic emissions as being the most likely cause,” Selin says.
Their work underscores the importance of long-term mercury monitoring stations, Feinberg adds. Many stations the researchers evaluated are no longer operational because of a lack of funding.
While their analysis couldn’t zero in on exactly why the emissions inventories didn’t match up with actual data, they have a few hypotheses.
One possibility is that global inventories are missing key information from certain countries. For instance, the researchers resolved some discrepancies when they used a more detailed regional inventory from China. But there was still a gap between observations and estimates.
They also suspect the discrepancy might be the result of changes in two large sources of mercury that are particularly uncertain: emissions from small-scale gold mining and mercury-containing products.
Small-scale gold mining involves using mercury to extract gold from soil and is often performed in remote parts of developing countries, making it hard to estimate. Yet small-scale gold mining contributes about 40 percent of human-made emissions.
In addition, it’s difficult to determine how long it takes the pollutant to be released into the atmosphere from discarded products like thermometers or scientific equipment.
“We’re not there yet where we can really pinpoint which source is responsible for this discrepancy,” Feinberg says.
In the future, researchers from multiple countries, including MIT, will collaborate to study and improve the models they use to estimate and evaluate emissions. This research will be influential in helping that project move the needle on monitoring mercury, he says.
This research was funded by the Swiss National Science Foundation, the U.S. National Science Foundation, and the U.S. Environmental Protection Agency.
“Our work shows that it is very important to learn from actual, on-the-ground data to try and improve our models and these emissions estimates,” says Ari Feinberg.
Industrial electrochemical processes that use electrodes to produce fuels and chemical products are hampered by the formation of bubbles that block parts of the electrode surface, reducing the area available for the active reaction. Such blockage reduces the performance of the electrodes by anywhere from 10 to 25 percent.
But new research reveals a decades-long misunderstanding about the extent of that interference. The findings show exactly how the blocking effect works and could lead to new ways of designing electrode surfaces to minimize inefficiencies in these widely used electrochemical processes.
It has long been assumed that the entire area of the electrode shadowed by each bubble would be effectively inactivated. But it turns out that a much smaller area — roughly the area where the bubble actually contacts the surface — is blocked from its electrochemical activity. The new insights could lead directly to new ways of patterning the surfaces to minimize the contact area and improve overall efficiency.
The findings are reported today in the journal Nanoscale, in a paper by recent MIT graduate Jack Lake PhD ’23, graduate student Simon Rufer, professor of mechanical engineering Kripa Varanasi, research scientist Ben Blaiszik, and six others at the University of Chicago and Argonne National Laboratory. The team has made available an open-source, AI-based software tool that engineers and scientists can now use to automatically recognize and quantify bubbles formed on a given surface, as a first step toward controlling the electrode material’s properties.
Gas-evolving electrodes, often with catalytic surfaces that promote chemical reactions, are used in a wide variety of processes, including the production of “green” hydrogen without the use of fossil fuels, carbon-capture processes that can reduce greenhouse gas emissions, aluminum production, and the chlor-alkali process that is used to make widely used chemical products.
These are very widespread processes. The chlor-alkali process alone accounts for 2 percent of all U.S. electricity usage; aluminum production accounts for 3 percent of global electricity; and both carbon capture and hydrogen production are likely to grow rapidly in coming years as the world strives to meet greenhouse-gas reduction targets. So, the new findings could make a real difference, Varanasi says.
“Our work demonstrates that engineering the contact and growth of bubbles on electrodes can have dramatic effects” on how bubbles form and how they leave the surface, he says. “The knowledge that the area under bubbles can be significantly active ushers in a new set of design rules for high-performance electrodes to avoid the deleterious effects of bubbles.”
“The broader literature built over the last couple of decades has suggested that not only that small area of contact but the entire area under the bubble is passivated,” Rufer says. The new study reveals “a significant difference between the two models because it changes how you would develop and design an electrode to minimize these losses.”
To test and demonstrate the implications of this effect, the team produced different versions of electrode surfaces with patterns of dots that nucleated and trapped bubbles at different sizes and spacings. They were able to show that surfaces with widely spaced dots promoted large bubble sizes but only tiny areas of surface contact, which helped to make clear the difference between the expected and actual effects of bubble coverage.
Developing the software to detect and quantify bubble formation was necessary for the team’s analysis, Rufer explains. “We wanted to collect a lot of data and look at a lot of different electrodes and different reactions and different bubbles, and they all look slightly different,” he says. Creating a program that could deal with different materials and different lighting and reliably identify and track the bubbles was a tricky process, and machine learning was key to making it work, he says.
Using that tool, he says, they were able to collect “really significant amounts of data about the bubbles on a surface, where they are, how big they are, how fast they’re growing, all these different things.” The tool is now freely available for anyone to use via the GitHub repository.
By using that tool to correlate the visual measures of bubble formation and evolution with electrical measurements of the electrode’s performance, the researchers were able to disprove the accepted theory and to show that only the area of direct contact is affected. Videos further proved the point, revealing new bubbles actively evolving directly under parts of a larger bubble.
The researchers developed a very general methodology that can be applied to characterize and understand the impact of bubbles on any electrode or catalyst surface. They were able to quantify the bubble passivation effects in a new performance metric they call BECSA (Bubble-induced electrochemically active surface), as opposed to ECSA (electrochemically active surface area), that is used in the field. “The BECSA metric was a concept we defined in an earlier study but did not have an effective method to estimate until this work,” says Varanasi.
The knowledge that the area under bubbles can be significantly active ushers in a new set of design rules for high-performance electrodes. This means that electrode designers should seek to minimize bubble contact area rather than simply bubble coverage, which can be achieved by controlling the morphology and chemistry of the electrodes. Surfaces engineered to control bubbles can not only improve the overall efficiency of the processes and thus reduce energy use, they can also save on upfront materials costs. Many of these gas-evolving electrodes are coated with catalysts made of expensive metals like platinum or iridium, and the findings from this work can be used to engineer electrodes to reduce material wasted by reaction-blocking bubbles.
Varanasi says that “the insights from this work could inspire new electrode architectures that not only reduce the usage of precious materials, but also improve the overall electrolyzer performance,” both of which would provide large-scale environmental benefits.
The research team included Jim James, Nathan Pruyne, Aristana Scourtas, Marcus Schwarting, Aadit Ambalkar, Ian Foster, and Ben Blaiszik at the University of Chicago and Argonne National Laboratory. The work was supported by the U.S. Department of Energy under the ARPA-E program. This work made use of the MIT.nano facilities.
MIT engineers have built a new desalination system that runs with the rhythms of the sun.
The solar-powered system removes salt from water at a pace that closely follows changes in solar energy. As sunlight increases through the day, the system ramps up its desalting process and automatically adjusts to any sudden variation in sunlight, for example by dialing down in response to a passing cloud or revving up as the skies clear.
Because the system can quickly react to subtle changes in sunlight, it maximizes the utility of solar energy, producing large quantities of clean water despite variations in sunlight throughout the day. In contrast to other solar-driven desalination designs, the MIT system requires no extra batteries for energy storage, nor a supplemental power supply, such as from the grid.
The engineers tested a community-scale prototype on groundwater wells in New Mexico over six months, working in variable weather conditions and water types. The system harnessed on average over 94 percent of the electrical energy generated from the system’s solar panels to produce up to 5,000 liters of water per day despite large swings in weather and available sunlight.
“Conventional desalination technologies require steady power and need battery storage to smooth out a variable power source like solar. By continually varying power consumption in sync with the sun, our technology directly and efficiently uses solar power to make water,” says Amos Winter, the Germeshausen Professor of Mechanical Engineering and director of the K. Lisa Yang Global Engineering and Research (GEAR) Center at MIT. “Being able to make drinking water with renewables, without requiring battery storage, is a massive grand challenge. And we’ve done it.”
The system is geared toward desalinating brackish groundwater — a salty source of water that is found in underground reservoirs and is more prevalent than fresh groundwater resources. The researchers see brackish groundwater as a huge untapped source of potential drinking water, particularly as reserves of fresh water are stressed in parts of the world. They envision that the new renewable, battery-free system could provide much-needed drinking water at low costs, especially for inland communities where access to seawater and grid power are limited.
“The majority of the population actually lives far enough from the coast, that seawater desalination could never reach them. They consequently rely heavily on groundwater, especially in remote, low-income regions. And unfortunately, this groundwater is becoming more and more saline due to climate change,” says Jonathan Bessette, MIT PhD student in mechanical engineering. “This technology could bring sustainable, affordable clean water to underreached places around the world.”
The researchers report details the new system in a paper appearing today in Nature Water. The study’s co-authors are Bessette, Winter, and staff engineer Shane Pratt.
Pump and flow
The new system builds on a previous design, which Winter and his colleagues, including former MIT postdoc Wei He, reported earlier this year. That system aimed to desalinate water through “flexible batch electrodialysis.”
Electrodialysis and reverse osmosis are two of the main methods used to desalinate brackish groundwater. With reverse osmosis, pressure is used to pump salty water through a membrane and filter out salts. Electrodialysis uses an electric field to draw out salt ions as water is pumped through a stack of ion-exchange membranes.
Scientists have looked to power both methods with renewable sources. But this has been especially challenging for reverse osmosis systems, which traditionally run at a steady power level that’s incompatible with naturally variable energy sources such as the sun.
Winter, He, and their colleagues focused on electrodialysis, seeking ways to make a more flexible, “time-variant” system that would be responsive to variations in renewable, solar power.
In their previous design, the team built an electrodialysis system consisting of water pumps, an ion-exchange membrane stack, and a solar panel array. The innovation in this system was a model-based control system that used sensor readings from every part of the system to predict the optimal rate at which to pump water through the stack and the voltage that should be applied to the stack to maximize the amount of salt drawn out of the water.
When the team tested this system in the field, it was able to vary its water production with the sun’s natural variations. On average, the system directly used 77 percent of the available electrical energy produced by the solar panels, which the team estimated was 91 percent more than traditionally designed solar-powered electrodialysis systems.
Still, the researchers felt they could do better.
“We could only calculate every three minutes, and in that time, a cloud could literally come by and block the sun,” Winter says. “The system could be saying, ‘I need to run at this high power.’ But some of that power has suddenly dropped because there’s now less sunlight. So, we had to make up that power with extra batteries.”
Solar commands
In their latest work, the researchers looked to eliminate the need for batteries, by shaving the system’s response time to a fraction of a second. The new system is able to update its desalination rate, three to five times per second. The faster response time enables the system to adjust to changes in sunlight throughout the day, without having to make up any lag in power with additional power supplies.
The key to the nimbler desalting is a simpler control strategy, devised by Bessette and Pratt. The new strategy is one of “flow-commanded current control,” in which the system first senses the amount of solar power that is being produced by the system’s solar panels. If the panels are generating more power than the system is using, the controller automatically “commands” the system to dial up its pumping, pushing more water through the electrodialysis stacks. Simultaneously, the system diverts some of the additional solar power by increasing the electrical current delivered to the stack, to drive more salt out of the faster-flowing water.
“Let’s say the sun is rising every few seconds,” Winter explains. “So, three times a second, we’re looking at the solar panels and saying, ‘Oh, we have more power — let’s bump up our flow rate and current a little bit.’ When we look again and see there’s still more excess power, we’ll up it again. As we do that, we’re able to closely match our consumed power with available solar power really accurately, throughout the day. And the quicker we loop this, the less battery buffering we need.”
The engineers incorporated the new control strategy into a fully automated system that they sized to desalinate brackish groundwater at a daily volume that would be enough to supply a small community of about 3,000 people. They operated the system for six months on several wells at the Brackish Groundwater National Desalination Research Facility in Alamogordo, New Mexico. Throughout the trial, the prototype operated under a wide range of solar conditions, harnessing over 94 percent of the solar panel’s electrical energy, on average, to directly power desalination.
“Compared to how you would traditionally design a solar desal system, we cut our required battery capacity by almost 100 percent,” Winter says.
The engineers plan to further test and scale up the system in hopes of supplying larger communities, and even whole municipalities, with low-cost, fully sun-driven drinking water.
“While this is a major step forward, we’re still working diligently to continue developing lower cost, more sustainable desalination methods,” Bessette says.
“Our focus now is on testing, maximizing reliability, and building out a product line that can provide desalinated water using renewables to multiple markets around the world," Pratt adds.
The team will be launching a company based on their technology in the coming months.
This research was supported in part by the National Science Foundation, the Julia Burke Foundation, and the MIT Morningside Academy of Design. This work was additionally supported in-kind by Veolia Water Technologies and Solutions and Xylem Goulds.
Jon Bessette sits atop a trailer housing the electrodialysis desalination system at the Brackish Groundwater National Desalination Research Facility (BGNDRF) in Alamogordo, New Mexico. The system is connected to real groundwater, water tanks, and solar panels.
Since the 1950s, a chemotherapy drug known as 5-fluorouracil has been used to treat many types of cancer, including blood cancers and cancers of the digestive tract.
Doctors have long believed that this drug works by damaging the building blocks of DNA. However, a new study from MIT has found that in cancers of the colon and other gastrointestinal cancers, it actually kills cells by interfering with RNA synthesis.
The findings could have a significant effect on how doctors treat many cancer patients. Usually, 5-fluorouracil is given in combination with chemotherapy drugs that damage DNA, but the new study found that for colon cancer, this combination does not achieve the synergistic effects that were hoped for. Instead, combining 5-FU with drugs that affect RNA synthesis could make it more effective in patients with GI cancers, the researchers say.
“Our work is the most definitive study to date showing that RNA incorporation of the drug, leading to an RNA damage response, is responsible for how the drug works in GI cancers,” says Michael Yaffe, a David H. Koch Professor of Science at MIT, the director of the MIT Center for Precision Cancer Medicine, and a member of MIT’s Koch Institute for Integrative Cancer Research. “Textbooks implicate the DNA effects of the drug as the mechanism in all cancer types, but our data shows that RNA damage is what’s really important for the types of tumors, like GI cancers, where the drug is used clinically.”
Yaffe, the senior author of the new study, hopes to plan clinical trials of 5-fluorouracil with drugs that would enhance its RNA-damaging effects and kill cancer cells more effectively.
Jung-Kuei Chen, a Koch Institute research scientist, and Karl Merrick, a former MIT postdoc, are the lead authors of the paper, which appears today in Cell Reports Medicine.
An unexpected mechanism
Clinicians use 5-fluorouracil (5-FU) as a first-line drug for colon, rectal, and pancreatic cancers. It’s usually given in combination with oxaliplatin or irinotecan, which damage DNA in cancer cells. The combination was thought to be effective because 5-FU can disrupt the synthesis of DNA nucleotides. Without those building blocks, cells with damaged DNA wouldn’t be able to efficiently repair the damage and would undergo cell death.
Yaffe’s lab, which studies cell signaling pathways, wanted to further explore the underlying mechanisms of how these drug combinations preferentially kill cancer cells.
The researchers began by testing 5-FU in combination with oxaliplatin or irinotecan in colon cancer cells grown in the lab. To their surprise, they found that not only were the drugs not synergistic, in many cases they were less effective at killing cancer cells than what one would expect by simply adding together the effects of 5-FU or the DNA-damaging drug given alone.
“One would have expected that these combinations to cause synergistic cancer cell death because you are targeting two different aspects of a shared process: breaking DNA, and making nucleotides,” Yaffe says. “Karl looked at a dozen colon cancer cell lines, and not only were the drugs not synergistic, in most cases they were antagonistic. One drug seemed to be undoing what the other drug was doing.”
Yaffe’s lab then teamed up with Adam Palmer, an assistant professor of pharmacology at the University of North Carolina School of Medicine, who specializes in analyzing data from clinical trials. Palmer’s research group examined data from colon cancer patients who had been on one or more of these drugs and showed that the drugs did not show synergistic effects on survival in most patients.
“This confirmed that when you give these combinations to people, it’s not generally true that the drugs are actually working together in a beneficial way within an individual patient,” Yaffe says. “Instead, it appears that one drug in the combination works well for some patients while another drug in the combination works well in other patients. We just cannot yet predict which drug by itself is best for which patient, so everyone gets the combination.”
These results led the researchers to wonder just how 5-FU was working, if not by disrupting DNA repair. Studies in yeast and mammalian cells had shown that the drug also gets incorporated into RNA nucleotides, but there has been dispute over how much this RNA damage contributes to the drug’s toxic effects on cancer cells.
Inside cells, 5-FU is broken down into two different metabolites. One of these gets incorporated into DNA nucleotides, and other into RNA nucleotides. In studies of colon cancer cells, the researchers found that the metabolite that interferes with RNA was much more effective at killing colon cancer cells than the one that disrupts DNA.
That RNA damage appears to primarily affect ribosomal RNA, a molecule that forms part of the ribosome — a cell organelle responsible for assembling new proteins. If cells can’t form new ribosomes, they can’t produce enough proteins to function. Additionally, the lack of undamaged ribosomal RNA causes cells to destroy a large set of proteins that normally bind up the RNA to make new functional ribosomes.
The researchers are now exploring how this ribosomal RNA damage leads cells to under programmed cell death, or apoptosis. They hypothesize that sensing of the damaged RNAs within cell structures called lysosomes somehow triggers an apoptotic signal.
“My lab is very interested in trying to understand the signaling events during disruption of ribosome biogenesis, particularly in GI cancers and even some ovarian cancers, that cause the cells to die. Somehow, they must be monitoring the quality control of new ribosome synthesis, which somehow is connected to the death pathway machinery,” Yaffe says.
New combinations
The findings suggest that drugs that stimulate ribosome production could work together with 5-FU to make a highly synergistic combination. In their study, the researchers showed that a molecule that inhibits KDM2A, a suppressor of ribosome production, helped to boost the rate of cell death in colon cancer cells treated with 5-FU.
The findings also suggest a possible explanation for why combining 5-FU with a DNA-damaging drug often makes both drugs less effective. Some DNA damaging drugs send a signal to the cell to stop making new ribosomes, which would negate 5-FU’s effect on RNA. A better approach may be to give each drug a few days apart, which would give patients the potential benefits of each drug, without having them cancel each other out.
“Importantly, our data doesn’t say that these combination therapies are wrong. We know they’re effective clinically. It just says that if you adjust how you give these drugs, you could potentially make those therapies even better, with relatively minor changes in the timing of when the drugs are given,” Yaffe says.
He is now hoping to work with collaborators at other institutions to run a phase 2 or 3 clinical trial in which patients receive the drugs on an altered schedule.
“A trial is clearly needed to look for efficacy, but it should be straightforward to initiate because these are already clinically accepted drugs that form the standard of care for GI cancers. All we’re doing is changing the timing with which we give them,” he says.
The researchers also hope that their work could lead to the identification of biomarkers that predict which patients’ tumors will be more susceptible to drug combinations that include 5-FU. One such biomarker could be RNA polymerase I, which is active when cells are producing a lot of ribosomal RNA.
The research was funded by the Damon Runyon Cancer Research Foundation, a fellowship from the Ludwig Center at MIT, the National Institutes of Health, the Ovarian Cancer Research Fund, the Charles and Marjorie Holloway Foundation, and the STARR Cancer Consortium.
In these images, tumors that clinically benefit from 5-fluorouracil (5-FU) treatments are shown responding to its RNA-damaging effects. Cell lines from various tumor types were evaluated for their sensitivity to the new treatments, and stained blue with DAPI and green with Nucleolin staining.
Imagine you’re tasked with sending a team of football players onto a field to assess the condition of the grass (a likely task for them, of course). If you pick their positions randomly, they might cluster together in some areas while completely neglecting others. But if you give them a strategy, like spreading out uniformly across the field, you might get a far more accurate picture of the grass condition.
Now, imagine needing to spread out not just in two dimensions, but across tens or even hundreds. That's the challenge MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers are getting ahead of. They've developed an AI-driven approach to “low-discrepancy sampling,” a method that improves simulation accuracy by distributing data points more uniformly across space.
A key novelty lies in using graph neural networks (GNNs), which allow points to “communicate” and self-optimize for better uniformity. Their approach marks a pivotal enhancement for simulations in fields like robotics, finance, and computational science, particularly in handling complex, multidimensional problems critical for accurate simulations and numerical computations.
“In many problems, the more uniformly you can spread out points, the more accurately you can simulate complex systems,” says T. Konstantin Rusch, lead author of the new paper and MIT CSAIL postdoc. “We've developed a method called Message-Passing Monte Carlo (MPMC) to generate uniformly spaced points, using geometric deep learning techniques. This further allows us to generate points that emphasize dimensions which are particularly important for a problem at hand, a property that is highly important in many applications. The model’s underlying graph neural networks lets the points 'talk' with each other, achieving far better uniformity than previous methods.”
The idea of Monte Carlo methods is to learn about a system by simulating it with random sampling. Sampling is the selection of a subset of a population to estimate characteristics of the whole population. Historically, it was already used in the 18th century, when mathematician Pierre-Simon Laplace employed it to estimate the population of France without having to count each individual.
Low-discrepancy sequences, which are sequences with low discrepancy, i.e., high uniformity, such as Sobol’, Halton, and Niederreiter, have long been the gold standard for quasi-random sampling, which exchanges random sampling with low-discrepancy sampling. They are widely used in fields like computer graphics and computational finance, for everything from pricing options to risk assessment, where uniformly filling spaces with points can lead to more accurate results.
The MPMC framework suggested by the team transforms random samples into points with high uniformity. This is done by processing the random samples with a GNN that minimizes a specific discrepancy measure.
One big challenge of using AI for generating highly uniform points is that the usual way to measure point uniformity is very slow to compute and hard to work with. To solve this, the team switched to a quicker and more flexible uniformity measure called L2-discrepancy. For high-dimensional problems, where this method isn’t enough on its own, they use a novel technique that focuses on important lower-dimensional projections of the points. This way, they can create point sets that are better suited for specific applications.
The implications extend far beyond academia, the team says. In computational finance, for example, simulations rely heavily on the quality of the sampling points. “With these types of methods, random points are often inefficient, but our GNN-generated low-discrepancy points lead to higher precision,” says Rusch. “For instance, we considered a classical problem from computational finance in 32 dimensions, where our MPMC points beat previous state-of-the-art quasi-random sampling methods by a factor of four to 24.”
Robots in Monte Carlo
In robotics, path and motion planning often rely on sampling-based algorithms, which guide robots through real-time decision-making processes. The improved uniformity of MPMC could lead to more efficient robotic navigation and real-time adaptations for things like autonomous driving or drone technology. “In fact, in a recent preprint, we demonstrated that our MPMC points achieve a fourfold improvement over previous low-discrepancy methods when applied to real-world robotics motion planning problems,” says Rusch.
“Traditional low-discrepancy sequences were a major advancement in their time, but the world has become more complex, and the problems we're solving now often exist in 10, 20, or even 100-dimensional spaces,” says Daniela Rus, CSAIL director and MIT professor of electrical engineering and computer science. “We needed something smarter, something that adapts as the dimensionality grows. GNNs are a paradigm shift in how we generate low-discrepancy point sets. Unlike traditional methods, where points are generated independently, GNNs allow points to 'chat' with one another so the network learns to place points in a way that reduces clustering and gaps — common issues with typical approaches.”
Going forward, the team plans to make MPMC points even more accessible to everyone, addressing the current limitation of training a new GNN for every fixed number of points and dimensions.
“Much of applied mathematics uses continuously varying quantities, but computation typically allows us to only use a finite number of points,” says Art B. Owen, Stanford University professor of statistics, who wasn’t involved in the research. “The century-plus-old field of discrepancy uses abstract algebra and number theory to define effective sampling points. This paper uses graph neural networks to find input points with low discrepancy compared to a continuous distribution. That approach already comes very close to the best-known low-discrepancy point sets in small problems and is showing great promise for a 32-dimensional integral from computational finance. We can expect this to be the first of many efforts to use neural methods to find good input points for numerical computation.”
Rusch and Rus wrote the paper with University of Waterloo researcher Nathan Kirk, Oxford University’s DeepMind Professor of AI and former CSAIL affiliate Michael Bronstein, and University of Waterloo Statistics and Actuarial Science Professor Christiane Lemieux. Their research was supported, in part, by the AI2050 program at Schmidt Sciences, Boeing, the United States Air Force Research Laboratory and the United States Air Force Artificial Intelligence Accelerator, the Swiss National Science Foundation, Natural Science and Engineering Research Council of Canada, and an EPSRC Turing AI World-Leading Research Fellowship.
Using graph neural networks (GNNs) allows points to “communicate” and self-optimize for better uniformity. Their approach helps optimize point placement to handle complex, multidimensional problems necessary for accurate simulations.
Have you ever wanted to travel through time to see what your future self might be like? Now, thanks to the power of generative AI, you can.
Researchers from MIT and elsewhere created a system that enables users to have an online, text-based conversation with an AI-generated simulation of their potential future self.
Dubbed Future You, the system is aimed at helping young people improve their sense of future self-continuity, a psychological concept that describes how connected a person feels with their future self.
Research has shown that a stronger sense of future self-continuity can positively influence how people make long-term decisions, from one’s likelihood to contribute to financial savings to their focus on achieving academic success.
Future You utilizes a large language model that draws on information provided by the user to generate a relatable, virtual version of the individual at age 60. This simulated future self can answer questions about what someone’s life in the future could be like, as well as offer advice or insights on the path they could follow.
In an initial user study, the researchers found that after interacting with Future You for about half an hour, people reported decreased anxiety and felt a stronger sense of connection with their future selves.
“We don’t have a real time machine yet, but AI can be a type of virtual time machine. We can use this simulation to help people think more about the consequences of the choices they are making today,” says Pat Pataranutaporn, a recent Media Lab doctoral graduate who is actively developing a program to advance human-AI interaction research at MIT, and co-lead author of a paper on Future You.
Pataranutaporn is joined on the paper by co-lead authors Kavin Winson, a researcher at KASIKORN Labs; and Peggy Yin, a Harvard University undergraduate; as well as Auttasak Lapapirojn and Pichayoot Ouppaphan of KASIKORN Labs; and senior authors Monchai Lertsutthiwong, head of AI research at the KASIKORN Business-Technology Group; Pattie Maes, the Germeshausen Professor of Media, Arts, and Sciences and head of the Fluid Interfaces group at MIT, and Hal Hershfield, professor of marketing, behavioral decision making, and psychology at the University of California at Los Angeles. The research will be presented at the IEEE Conference on Frontiers in Education.
A realistic simulation
Studies about conceptualizing one’s future self go back to at least the 1960s. One early method aimed at improving future self-continuity had people write letters to their future selves. More recently, researchers utilized virtual reality goggles to help people visualize future versions of themselves.
But none of these methods were very interactive, limiting the impact they could have on a user.
With the advent of generative AI and large language models like ChatGPT, the researchers saw an opportunity to make a simulated future self that could discuss someone’s actual goals and aspirations during a normal conversation.
“The system makes the simulation very realistic. Future You is much more detailed than what a person could come up with by just imagining their future selves,” says Maes.
Users begin by answering a series of questions about their current lives, things that are important to them, and goals for the future.
The AI system uses this information to create what the researchers call “future self memories” which provide a backstory the model pulls from when interacting with the user.
For instance, the chatbot could talk about the highlights of someone’s future career or answer questions about how the user overcame a particular challenge. This is possible because ChatGPT has been trained on extensive data involving people talking about their lives, careers, and good and bad experiences.
The user engages with the tool in two ways: through introspection, when they consider their life and goals as they construct their future selves, and retrospection, when they contemplate whether the simulation reflects who they see themselves becoming, says Yin.
“You can imagine Future You as a story search space. You have a chance to hear how some of your experiences, which may still be emotionally charged for you now, could be metabolized over the course of time,” she says.
To help people visualize their future selves, the system generates an age-progressed photo of the user. The chatbot is also designed to provide vivid answers using phrases like “when I was your age,” so the simulation feels more like an actual future version of the individual.
The ability to take advice from an older version of oneself, rather than a generic AI, can have a stronger positive impact on a user contemplating an uncertain future, Hershfield says.
“The interactive, vivid components of the platform give the user an anchor point and take something that could result in anxious rumination and make it more concrete and productive,” he adds.
But that realism could backfire if the simulation moves in a negative direction. To prevent this, they ensure Future You cautions users that it shows only one potential version of their future self, and they have the agency to change their lives. Providing alternate answers to the questionnaire yields a totally different conversation.
“This is not a prophesy, but rather a possibility,” Pataranutaporn says.
Aiding self-development
To evaluate Future You, they conducted a user study with 344 individuals. Some users interacted with the system for 10-30 minutes, while others either interacted with a generic chatbot or only filled out surveys.
Participants who used Future You were able to build a closer relationship with their ideal future selves, based on a statistical analysis of their responses. These users also reported less anxiety about the future after their interactions. In addition, Future You users said the conversation felt sincere and that their values and beliefs seemed consistent in their simulated future identities.
“This work forges a new path by taking a well-established psychological technique to visualize times to come — an avatar of the future self — with cutting edge AI. This is exactly the type of work academics should be focusing on as technology to build virtual self models merges with large language models,” says Jeremy Bailenson, the Thomas More Storke Professor of Communication at Stanford University, who was not involved with this research.
Building off the results of this initial user study, the researchers continue to fine-tune the ways they establish context and prime users so they have conversations that help build a stronger sense of future self-continuity.
“We want to guide the user to talk about certain topics, rather than asking their future selves who the next president will be,” Pataranutaporn says.
They are also adding safeguards to prevent people from misusing the system. For instance, one could imagine a company creating a “future you” of a potential customer who achieves some great outcome in life because they purchased a particular product.
Moving forward, the researchers want to study specific applications of Future You, perhaps by enabling people to explore different careers or visualize how their everyday choices could impact climate change.
They are also gathering data from the Future You pilot to better understand how people use the system.
“We don’t want people to become dependent on this tool. Rather, we hope it is a meaningful experience that helps them see themselves and the world differently, and helps with self-development,” Maes says.
The researchers acknowledge the support of Thanawit Prasongpongchai, a designer at KBTG and visiting scientist at the Media Lab.
Researchers from MIT and elsewhere created a system that enables users to have an online, text-based conversation with an AI-generated simulation of their potential future self.
The MIT Center for Transportation and Logistics (MIT CTL) and the Council of Supply Chain Management Professionals (CSCMP) have released the 2024 State of Supply Chain Sustainability report, marking the fifth edition of this influential research. The report highlights how supply chain sustainability practices have evolved over the past five years, assessing their global implementation and implications for industries, professionals, and the environment.
This year’s report is based on four years of comprehensive international surveys with responses from over 7,000 supply chain professionals representing more than 80 countries, coupled with insights from executive interviews. It explores how external pressures on firms, such as the growing investor demand and climate regulations, are driving sustainability initiatives. However, it also reveals persistent gaps between companies’ sustainability goals and the actual investments required to achieve them.
"Over the past five years, we have seen supply chains face unprecedented global challenges. While companies have made strides, our analysis shows that many are still struggling to align their sustainability ambitions with real progress, particularly when it comes to tackling Scope 3 emissions," says Josué Velázquez Martínez, MIT CTL research scientist and lead investigator. "Scope 3 emissions, which account for the vast majority of a company’s carbon footprint, remain a major hurdle due to the complexity of tracking emissions from indirect supply chain activities. The margin of error of the most common approach to estimate emissions are drastic, which disincentivizes companies to make more sustainable choices at the expense of investing in green alternatives."
Among the key findings:
Increased pressure from investors: Over five years, pressure from investors to improve supply chain sustainability has grown by 25 percent, making it the fastest-growing driver of sustainability efforts.
Lack of readiness for net-zero goals: Although 67 percent of firms surveyed do not have a net-zero goal in place, those that do are often unprepared to meet them, especially when it comes to measuring and reducing Scope 3 emissions.
Company response to sustainability efforts in times of crisis: Companies react to different types of crises differently in regards to staying on track with their sustainable goals, whether it is a network disruption like the Covid-19 pandemic or economic turbulence.
Challenges with Scope 3 emissions: Despite significant efforts, Scope 3 emissions — which can account for up to 75 percent of a company’s total emissions — continue to be the most difficult to track and manage, due to the complexity of supplier networks and inconsistent data-sharing practices.
Mark Baxa, president and CEO of CSCMP, emphasized the importance of collaboration: "Businesses and consumers alike are putting pressure on us to source and supply products to live up to their social and environmental standards. The State of Supply Chain Sustainability 2024 provides a thorough analysis of our current understanding, along with valuable insights on how to improve our Scope 3 emissions accounting to have a greater impact on lowering our emissions."
The report also underscores the importance of technological innovations, such as machine learning, advanced data analytics, and standardization to improve the accuracy of emissions tracking and help firms make data-driven sustainability decisions.
The 2024 State of Supply Chain Sustainability can be accessed online or in PDF format at sustainable.mit.edu.
The MIT CTL is a world leader in supply chain management research and education, with over 50 years of expertise. The center's work spans industry partnerships, cutting-edge research, and the advancement of sustainable supply chain practices. CSCMP is the leading global association for supply chain professionals. Established in 1963, CSCMP provides its members with education, research, and networking opportunities to advance the field of supply chain management.
The new report highlights how supply chain sustainability practices have evolved over the past five years, assessing their global implementation and implications for industries, professionals, and the environment.
In 1994, Florida jewelry designer Diana Duyser discovered what she believed to be the Virgin Mary’s image in a grilled cheese sandwich, which she preserved and later auctioned for $28,000. But how much do we really understand about pareidolia, the phenomenon of seeing faces and patterns in objects when they aren’t really there?
A new study from the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) delves into this phenomenon, introducing an extensive, human-labeled dataset of 5,000 pareidolic images, far surpassing previous collections. Using this dataset, the team discovered several surprising results about the differences between human and machine perception, and how the ability to see faces in a slice of toast might have saved your distant relatives’ lives.
“Face pareidolia has long fascinated psychologists, but it’s been largely unexplored in the computer vision community,” says Mark Hamilton, MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and lead researcher on the work. “We wanted to create a resource that could help us understand how both humans and AI systems process these illusory faces.”
So what did all of these fake faces reveal? For one, AI models don’t seem to recognize pareidolic faces like we do. Surprisingly, the team found that it wasn’t until they trained algorithms to recognize animal faces that they became significantly better at detecting pareidolic faces. This unexpected connection hints at a possible evolutionary link between our ability to spot animal faces — crucial for survival — and our tendency to see faces in inanimate objects. “A result like this seems to suggest that pareidolia might not arise from human social behavior, but from something deeper: like quickly spotting a lurking tiger, or identifying which way a deer is looking so our primordial ancestors could hunt,” says Hamilton.
Another intriguing discovery is what the researchers call the “Goldilocks Zone of Pareidolia,” a class of images where pareidolia is most likely to occur. “There’s a specific range of visual complexity where both humans and machines are most likely to perceive faces in non-face objects,” William T. Freeman, MIT professor of electrical engineering and computer science and principal investigator of the project says. “Too simple, and there’s not enough detail to form a face. Too complex, and it becomes visual noise.”
To uncover this, the team developed an equation that models how people and algorithms detect illusory faces. When analyzing this equation, they found a clear “pareidolic peak” where the likelihood of seeing faces is highest, corresponding to images that have “just the right amount” of complexity. This predicted “Goldilocks zone” was then validated in tests with both real human subjects and AI face detection systems.
This new dataset, “Faces in Things,” dwarfs those of previous studies that typically used only 20-30 stimuli. This scale allowed the researchers to explore how state-of-the-art face detection algorithms behaved after fine-tuning on pareidolic faces, showing that not only could these algorithms be edited to detect these faces, but that they could also act as a silicon stand-in for our own brain, allowing the team to ask and answer questions about the origins of pareidolic face detection that are impossible to ask in humans.
To build this dataset, the team curated approximately 20,000 candidate images from the LAION-5B dataset, which were then meticulously labeled and judged by human annotators. This process involved drawing bounding boxes around perceived faces and answering detailed questions about each face, such as the perceived emotion, age, and whether the face was accidental or intentional. “Gathering and annotating thousands of images was a monumental task,” says Hamilton. “Much of the dataset owes its existence to my mom,” a retired banker, “who spent countless hours lovingly labeling images for our analysis.”
The study also has potential applications in improving face detection systems by reducing false positives, which could have implications for fields like self-driving cars, human-computer interaction, and robotics. The dataset and models could also help areas like product design, where understanding and controlling pareidolia could create better products. “Imagine being able to automatically tweak the design of a car or a child’s toy so it looks friendlier, or ensuring a medical device doesn’t inadvertently appear threatening,” says Hamilton.
“It’s fascinating how humans instinctively interpret inanimate objects with human-like traits. For instance, when you glance at an electrical socket, you might immediately envision it singing, and you can even imagine how it would ‘move its lips.’ Algorithms, however, don’t naturally recognize these cartoonish faces in the same way we do,” says Hamilton. “This raises intriguing questions: What accounts for this difference between human perception and algorithmic interpretation? Is pareidolia beneficial or detrimental? Why don’t algorithms experience this effect as we do? These questions sparked our investigation, as this classic psychological phenomenon in humans had not been thoroughly explored in algorithms.”
As the researchers prepare to share their dataset with the scientific community, they’re already looking ahead. Future work may involve training vision-language models to understand and describe pareidolic faces, potentially leading to AI systems that can engage with visual stimuli in more human-like ways.
“This is a delightful paper! It is fun to read and it makes me think. Hamilton et al. propose a tantalizing question: Why do we see faces in things?” says Pietro Perona, the Allen E. Puckett Professor of Electrical Engineering at Caltech, who was not involved in the work. “As they point out, learning from examples, including animal faces, goes only half-way to explaining the phenomenon. I bet that thinking about this question will teach us something important about how our visual system generalizes beyond the training it receives through life.”
Hamilton and Freeman’s co-authors include Simon Stent, staff research scientist at the Toyota Research Institute; Ruth Rosenholtz, principal research scientist in the Department of Brain and Cognitive Sciences, NVIDIA research scientist, and former CSAIL member; and CSAIL affiliates postdoc Vasha DuTell, Anne Harrington MEng ’23, and Research Scientist Jennifer Corbett. Their work was supported, in part, by the National Science Foundation and the CSAIL MEnTorEd Opportunities in Research (METEOR) Fellowship, while being sponsored by the United States Air Force Research Laboratory and the United States Air Force Artificial Intelligence Accelerator. The MIT SuperCloud and Lincoln Laboratory Supercomputing Center provided HPC resources for the researchers’ results.
This work is being presented this week at the European Conference on Computer Vision.
The “Faces in Things” dataset is a comprehensive, human-labeled collection of over 5,000 pareidolic images. The research team trained face-detection algorithms to see faces in these pictures, giving insight into how humans learned to recognize faces within their surroundings.
Imagine having to straighten up a messy kitchen, starting with a counter littered with sauce packets. If your goal is to wipe the counter clean, you might sweep up the packets as a group. If, however, you wanted to first pick out the mustard packets before throwing the rest away, you would sort more discriminately, by sauce type. And if, among the mustards, you had a hankering for Grey Poupon, finding this specific brand would entail a more careful search.
MIT engineers have developed a method that enables robots to make similarly intuitive, task-relevant decisions.
The team’s new approach, named Clio, enables a robot to identify the parts of a scene that matter, given the tasks at hand. With Clio, a robot takes in a list of tasks described in natural language and, based on those tasks, it then determines the level of granularity required to interpret its surroundings and “remember” only the parts of a scene that are relevant.
In real experiments ranging from a cluttered cubicle to a five-story building on MIT’s campus, the team used Clio to automatically segment a scene at different levels of granularity, based on a set of tasks specified in natural-language prompts such as “move rack of magazines” and “get first aid kit.”
The team also ran Clio in real-time on a quadruped robot. As the robot explored an office building, Clio identified and mapped only those parts of the scene that related to the robot’s tasks (such as retrieving a dog toy while ignoring piles of office supplies), allowing the robot to grasp the objects of interest.
Clio is named after the Greek muse of history, for its ability to identify and remember only the elements that matter for a given task. The researchers envision that Clio would be useful in many situations and environments in which a robot would have to quickly survey and make sense of its surroundings in the context of its given task.
“Search and rescue is the motivating application for this work, but Clio can also power domestic robots and robots working on a factory floor alongside humans,” says Luca Carlone, associate professor in MIT’s Department of Aeronautics and Astronautics (AeroAstro), principal investigator in the Laboratory for Information and Decision Systems (LIDS), and director of the MIT SPARK Laboratory. “It’s really about helping the robot understand the environment and what it has to remember in order to carry out its mission.”
The team details their results in a study appearing today in the journal Robotics and Automation Letters. Carlone’s co-authors include members of the SPARK Lab: Dominic Maggio, Yun Chang, Nathan Hughes, and Lukas Schmid; and members of MIT Lincoln Laboratory: Matthew Trang, Dan Griffith, Carlyn Dougherty, and Eric Cristofalo.
Open fields
Huge advances in the fields of computer vision and natural language processing have enabled robots to identify objects in their surroundings. But until recently, robots were only able to do so in “closed-set” scenarios, where they are programmed to work in a carefully curated and controlled environment, with a finite number of objects that the robot has been pretrained to recognize.
In recent years, researchers have taken a more “open” approach to enable robots to recognize objects in more realistic settings. In the field of open-set recognition, researchers have leveraged deep-learning tools to build neural networks that can process billions of images from the internet, along with each image’s associated text (such as a friend’s Facebook picture of a dog, captioned “Meet my new puppy!”).
From millions of image-text pairs, a neural network learns from, then identifies, those segments in a scene that are characteristic of certain terms, such as a dog. A robot can then apply that neural network to spot a dog in a totally new scene.
But a challenge still remains as to how to parse a scene in a useful way that is relevant for a particular task.
“Typical methods will pick some arbitrary, fixed level of granularity for determining how to fuse segments of a scene into what you can consider as one ‘object,’” Maggio says. “However, the granularity of what you call an ‘object’ is actually related to what the robot has to do. If that granularity is fixed without considering the tasks, then the robot may end up with a map that isn’t useful for its tasks.”
Information bottleneck
With Clio, the MIT team aimed to enable robots to interpret their surroundings with a level of granularity that can be automatically tuned to the tasks at hand.
For instance, given a task of moving a stack of books to a shelf, the robot should be able to determine that the entire stack of books is the task-relevant object. Likewise, if the task were to move only the green book from the rest of the stack, the robot should distinguish the green book as a single target object and disregard the rest of the scene — including the other books in the stack.
The team’s approach combines state-of-the-art computer vision and large language models comprising neural networks that make connections among millions of open-source images and semantic text. They also incorporate mapping tools that automatically split an image into many small segments, which can be fed into the neural network to determine if certain segments are semantically similar. The researchers then leverage an idea from classic information theory called the “information bottleneck,” which they use to compress a number of image segments in a way that picks out and stores segments that are semantically most relevant to a given task.
“For example, say there is a pile of books in the scene and my task is just to get the green book. In that case we push all this information about the scene through this bottleneck and end up with a cluster of segments that represent the green book,” Maggio explains. “All the other segments that are not relevant just get grouped in a cluster which we can simply remove. And we’re left with an object at the right granularity that is needed to support my task.”
The researchers demonstrated Clio in different real-world environments.
“What we thought would be a really no-nonsense experiment would be to run Clio in my apartment, where I didn’t do any cleaning beforehand,” Maggio says.
The team drew up a list of natural-language tasks, such as “move pile of clothes” and then applied Clio to images of Maggio’s cluttered apartment. In these cases, Clio was able to quickly segment scenes of the apartment and feed the segments through the Information Bottleneck algorithm to identify those segments that made up the pile of clothes.
They also ran Clio on Boston Dynamic’s quadruped robot, Spot. They gave the robot a list of tasks to complete, and as the robot explored and mapped the inside of an office building, Clio ran in real-time on an on-board computer mounted to Spot, to pick out segments in the mapped scenes that visually relate to the given task. The method generated an overlaying map showing just the target objects, which the robot then used to approach the identified objects and physically complete the task.
“Running Clio in real-time was a big accomplishment for the team,” Maggio says. “A lot of prior work can take several hours to run.”
Going forward, the team plans to adapt Clio to be able to handle higher-level tasks and build upon recent advances in photorealistic visual scene representations.
“We’re still giving Clio tasks that are somewhat specific, like ‘find deck of cards,’” Maggio says. “For search and rescue, you need to give it more high-level tasks, like ‘find survivors,’ or ‘get power back on.’ So, we want to get to a more human-level understanding of how to accomplish more complex tasks.”
This research was supported, in part, by the U.S. National Science Foundation, the Swiss National Science Foundation, MIT Lincoln Laboratory, the U.S. Office of Naval Research, and the U.S. Army Research Lab Distributed and Collaborative Intelligent Systems and Technology Collaborative Research Alliance.
Deep-learning models are being used in many fields, from health care diagnostics to financial forecasting. However, these models are so computationally intensive that they require the use of powerful cloud-based servers.
This reliance on cloud computing poses significant security risks, particularly in areas like health care, where hospitals may be hesitant to use AI tools to analyze confidential patient data due to privacy concerns.
To tackle this pressing issue, MIT researchers have developed a security protocol that leverages the quantum properties of light to guarantee that data sent to and from a cloud server remain secure during deep-learning computations.
By encoding data into the laser light used in fiber optic communications systems, the protocol exploits the fundamental principles of quantum mechanics, making it impossible for attackers to copy or intercept the information without detection.
Moreover, the technique guarantees security without compromising the accuracy of the deep-learning models. In tests, the researcher demonstrated that their protocol could maintain 96 percent accuracy while ensuring robust security measures.
“Deep learning models like GPT-4 have unprecedented capabilities but require massive computational resources. Our protocol enables users to harness these powerful models without compromising the privacy of their data or the proprietary nature of the models themselves,” says Kfir Sulimany, an MIT postdoc in the Research Laboratory for Electronics (RLE) and lead author of a paper on this security protocol.
Sulimany is joined on the paper by Sri Krishna Vadlamani, an MIT postdoc; Ryan Hamerly, a former postdoc now at NTT Research, Inc.; Prahlad Iyengar, an electrical engineering and computer science (EECS) graduate student; and senior author Dirk Englund, a professor in EECS, principal investigator of the Quantum Photonics and Artificial Intelligence Group and of RLE. The research was recently presented at Annual Conference on Quantum Cryptography.
A two-way street for security in deep learning
The cloud-based computation scenario the researchers focused on involves two parties — a client that has confidential data, like medical images, and a central server that controls a deep learning model.
The client wants to use the deep-learning model to make a prediction, such as whether a patient has cancer based on medical images, without revealing information about the patient.
In this scenario, sensitive data must be sent to generate a prediction. However, during the process the patient data must remain secure.
Also, the server does not want to reveal any parts of the proprietary model that a company like OpenAI spent years and millions of dollars building.
“Both parties have something they want to hide,” adds Vadlamani.
In digital computation, a bad actor could easily copy the data sent from the server or the client.
Quantum information, on the other hand, cannot be perfectly copied. The researchers leverage this property, known as the no-cloning principle, in their security protocol.
For the researchers’ protocol, the server encodes the weights of a deep neural network into an optical field using laser light.
A neural network is a deep-learning model that consists of layers of interconnected nodes, or neurons, that perform computation on data. The weights are the components of the model that do the mathematical operations on each input, one layer at a time. The output of one layer is fed into the next layer until the final layer generates a prediction.
The server transmits the network’s weights to the client, which implements operations to get a result based on their private data. The data remain shielded from the server.
At the same time, the security protocol allows the client to measure only one result, and it prevents the client from copying the weights because of the quantum nature of light.
Once the client feeds the first result into the next layer, the protocol is designed to cancel out the first layer so the client can’t learn anything else about the model.
“Instead of measuring all the incoming light from the server, the client only measures the light that is necessary to run the deep neural network and feed the result into the next layer. Then the client sends the residual light back to the server for security checks,” Sulimany explains.
Due to the no-cloning theorem, the client unavoidably applies tiny errors to the model while measuring its result. When the server receives the residual light from the client, the server can measure these errors to determine if any information was leaked. Importantly, this residual light is proven to not reveal the client data.
A practical protocol
Modern telecommunications equipment typically relies on optical fibers to transfer information because of the need to support massive bandwidth over long distances. Because this equipment already incorporates optical lasers, the researchers can encode data into light for their security protocol without any special hardware.
When they tested their approach, the researchers found that it could guarantee security for server and client while enabling the deep neural network to achieve 96 percent accuracy.
The tiny bit of information about the model that leaks when the client performs operations amounts to less than 10 percent of what an adversary would need to recover any hidden information. Working in the other direction, a malicious server could only obtain about 1 percent of the information it would need to steal the client’s data.
“You can be guaranteed that it is secure in both ways — from the client to the server and from the server to the client,” Sulimany says.
“A few years ago, when we developed our demonstration of distributed machine learning inference between MIT’s main campus and MIT Lincoln Laboratory, it dawned on me that we could do something entirely new to provide physical-layer security, building on years of quantum cryptography work that had also been shown on that testbed,” says Englund. “However, there were many deep theoretical challenges that had to be overcome to see if this prospect of privacy-guaranteed distributed machine learning could be realized. This didn’t become possible until Kfir joined our team, as Kfir uniquely understood the experimental as well as theory components to develop the unified framework underpinning this work.”
In the future, the researchers want to study how this protocol could be applied to a technique called federated learning, where multiple parties use their data to train a central deep-learning model. It could also be used in quantum operations, rather than the classical operations they studied for this work, which could provide advantages in both accuracy and security.
“This work combines in a clever and intriguing way techniques drawing from fields that do not usually meet, in particular, deep learning and quantum key distribution. By using methods from the latter, it adds a security layer to the former, while also allowing for what appears to be a realistic implementation. This can be interesting for preserving privacy in distributed architectures. I am looking forward to seeing how the protocol behaves under experimental imperfections and its practical realization,” says Eleni Diamanti, a CNRS research director at Sorbonne University in Paris, who was not involved with this work.
This work was supported, in part, by the Israeli Council for Higher Education and the Zuckerman STEM Leadership Program.
MIT researchers have developed a security protocol that leverages the quantum properties of light to guarantee that data sent to and from a cloud server remain secure during deep learning computations.
Mars wasn’t always the cold desert we see today. There’s increasing evidence that water once flowed on the Red Planet’s surface, billions of years ago. And if there was water, there must also have been a thick atmosphere to keep that water from freezing. But sometime around 3.5 billion years ago, the water dried up, and the air, once heavy with carbon dioxide, dramatically thinned, leaving only the wisp of an atmosphere that clings to the planet today.
Where exactly did Mars’ atmosphere go? This question has been a central mystery of Mars’ 4.6-billion-year history.
For two MIT geologists, the answer may lie in the planet’s clay. In a paper appearing today in Science Advances, they propose that much of Mars’ missing atmosphere could be locked up in the planet’s clay-covered crust.
The team makes the case that, while water was present on Mars, the liquid could have trickled through certain rock types and set off a slow chain of reactions that progressively drew carbon dioxide out of the atmosphere and converted it into methane — a form of carbon that could be stored for eons in the planet’s clay surface.
Similar processes occur in some regions on Earth. The researchers used their knowledge of interactions between rocks and gases on Earth and applied that to how similar processes could play out on Mars. They found that, given how much clay is estimated to cover Mars’ surface, the planet’s clay could hold up to 1.7 bar of carbon dioxide, which would be equivalent to around 80 percent of the planet’s initial, early atmosphere.
It’s possible that this sequestered Martian carbon could one day be recovered and converted into propellant to fuel future missions between Mars and Earth, the researchers propose.
“Based on our findings on Earth, we show that similar processes likely operated on Mars, and that copious amounts of atmospheric CO2 could have transformed to methane and been sequestered in clays,” says study author Oliver Jagoutz, professor of geology in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS). “This methane could still be present and maybe even used as an energy source on Mars in the future.”
The study’s lead author is recent EAPS graduate Joshua Murray PhD ’24.
In the folds
Jagoutz’ group at MIT seeks to identify the geologic processes and interactions that drive the evolution of Earth’s lithosphere — the hard and brittle outer layer that includes the crust and upper mantle, where tectonic plates lie.
In 2023, he and Murray focused on a type of surface clay mineral called smectite, which is known to be a highly effective trap for carbon. Within a single grain of smectite are a multitude of folds, within which carbon can sit undisturbed for billions of years. They showed that smectite on Earth was likely a product of tectonic activity, and that, once exposed at the surface, the clay minerals acted to draw down and store enough carbon dioxide from the atmosphere to cool the planet over millions of years.
Soon after the team reported their results, Jagoutz happened to look at a map of the surface of Mars and realized that much of that planet’s surface was covered in the same smectite clays. Could the clays have had a similar carbon-trapping effect on Mars, and if so, how much carbon could the clays hold?
“We know this process happens, and it is well-documented on Earth. And these rocks and clays exist on Mars,” Jagoutz says. “So, we wanted to try and connect the dots.”
“Every nook and cranny”
Unlike on Earth, where smectite is a consequence of continental plates shifting and uplifting to bring rocks from the mantle to the surface, there is no such tectonic activity on Mars. The team looked for ways in which the clays could have formed on Mars, based on what scientists know of the planet’s history and composition.
For instance, some remote measurements of Mars’ surface suggest that at least part of the planet’s crust contains ultramafic igneous rocks, similar to those that produce smectites through weathering on Earth. Other observations reveal geologic patterns similar to terrestrial rivers and tributaries, where water could have flowed and reacted with the underlying rock.
Jagoutz and Murray wondered whether water could have reacted with Mars’ deep ultramafic rocks in a way that would produce the clays that cover the surface today. They developed a simple model of rock chemistry, based on what is known of how igneous rocks interact with their environment on Earth.
They applied this model to Mars, where scientists believe the crust is mostly made up of igneous rock that is rich in the mineral olivine. The team used the model to estimate the changes that olivine-rich rock might undergo, assuming that water existed on the surface for at least a billion years, and the atmosphere was thick with carbon dioxide.
“At this time in Mars’ history, we think CO2 is everywhere, in every nook and cranny, and water percolating through the rocks is full of CO2 too,” Murray says.
Over about a billion years, water trickling through the crust would have slowly reacted with olivine — a mineral that is rich in a reduced form of iron. Oxygen molecules in water would have bound to the iron, releasing hydrogen as a result and forming the red oxidized iron which gives the planet its iconic color. This free hydrogen would then have combined with carbon dioxide in the water, to form methane. As this reaction progressed over time, olivine would have slowly transformed into another type of iron-rich rock known as serpentine, which then continued to react with water to form smectite.
“These smectite clays have so much capacity to store carbon,” Murray says. “So then we used existing knowledge of how these minerals are stored in clays on Earth, and extrapolate to say, if the Martian surface has this much clay in it, how much methane can you store in those clays?”
He and Jagoutz found that if Mars is covered in a layer of smectite that is 1,100 meters deep, this amount of clay could store a huge amount of methane, equivalent to most of the carbon dioxide in the atmosphere that is thought to have disappeared since the planet dried up.
“We find that estimates of global clay volumes on Mars are consistent with a significant fraction of Mars’ initial CO2 being sequestered as organic compounds within the clay-rich crust,” Murray says. “In some ways, Mars’ missing atmosphere could be hiding in plain sight.”
“Where the CO2 went from an early, thicker atmosphere is a fundamental question in the history of the Mars atmosphere, its climate, and the habitability by microbes,” says Bruce Jakosky, professor emeritus of geology at the University of Colorado and principal investigator on the Mars Atmosphere and Volatile Evolution (MAVEN) mission, which has been orbiting and studying Mars’ upper atmosphere since 2014. Jakosky was not involved with the current study. “Murray and Jagoutz examine the chemical interaction of rocks with the atmosphere as a means of removing CO2. At the high end of our estimates of how much weathering has occurred, this could be a major process in removing CO2 from Mars’ early atmosphere.”
This work was supported, in part, by the National Science Foundation.
“At this time in Mars’ history, we think CO2 is everywhere, in every nook and cranny, and water percolating through the rocks is full of CO2 too,” Joshua Murray says.
When summer temperatures spike, so does our vulnerability to heat-related illness or even death. For the most part, people can take measures to reduce their heat exposure by opening a window, turning up the air conditioning, or simply getting a glass of water. But for people who are incarcerated, freedom to take such measures is often not an option. Prison populations therefore are especially vulnerable to heat exposure, due to their conditions of confinement.
A new study by MIT researchers examines summertime heat exposure in prisons across the United States and identifies characteristics within prison facilities that can further contribute to a population’s vulnerability to summer heat.
The study’s authors used high-spatial-resolution air temperature data to determine the daily average outdoor temperature for each of 1,614 prisons in the U.S., for every summer between the years 1990 and 2023. They found that the prisons that are exposed to the most extreme heat are located in the southwestern U.S., while prisons with the biggest changes in summertime heat, compared to the historical record, are in the Pacific Northwest, the Northeast, and parts of the Midwest.
Those findings are not entirely unique to prisons, as any non-prison facility or community in the same geographic locations would be exposed to similar outdoor air temperatures. But the team also looked at characteristics specific to prison facilities that could further exacerbate an incarcerated person’s vulnerability to heat exposure. They identified nine such facility-level characteristics, such as highly restricted movement, poor staffing, and inadequate mental health treatment. People living and working in prisons with any one of these characteristics may experience compounded risk to summertime heat.
The team also looked at the demographics of 1,260 prisons in their study and found that the prisons with higher heat exposure on average also had higher proportions of non-white and Hispanic populations. The study, appearing today in the journal GeoHealth, provides policymakers and community leaders with ways to estimate, and take steps to address, a prison population’s heat risk, which they anticipate could worsen with climate change.
“This isn’t a problem because of climate change. It’s becoming a worse problem because of climate change,” says study lead author Ufuoma Ovienmhada SM ’20, PhD ’24, a graduate of the MIT Media Lab, who recently completed her doctorate in MIT’s Department of Aeronautics and Astronautics (AeroAstro). “A lot of these prisons were not built to be comfortable or humane in the first place. Climate change is just aggravating the fact that prisons are not designed to enable incarcerated populations to moderate their own exposure to environmental risk factors such as extreme heat.”
The study’s co-authors include Danielle Wood ’04, SM ’08, PhD ’12, MIT associate professor of media arts and sciences, and of AeroAstro; and Brent Minchew, MIT associate professor of geophysics in the Department of Earth, Atmospheric and Planetary Sciences; along with Ahmed Diongue ’24, Mia Hines-Shanks of Grinnell College, and Michael Krisch of Columbia University.
Environmental intersections
The new study is an extension of work carried out at the Media Lab, where Wood leads the Space Enabled research group. The group aims to advance social and environmental justice issues through the use of satellite data and other space-enabled technologies.
The group’s motivation to look at heat exposure in prisons came in 2020 when, as co-president of MIT’s Black Graduate Student Union, Ovienmhada took part in community organizing efforts following the murder of George Floyd by Minneapolis police.
“We started to do more organizing on campus around policing and reimagining public safety. Through that lens I learned more about police and prisons as interconnected systems, and came across this intersection between prisons and environmental hazards,” says Ovienmhada, who is leading an effort to map the various environmental hazards that prisons, jails, and detention centers face. “In terms of environmental hazards, extreme heat causes some of the most acute impacts for incarcerated people.”
She, Wood, and their colleagues set out to use Earth observation data to characterize U.S. prison populations’ vulnerability, or their risk of experiencing negative impacts, from heat.
The team first looked through a database maintained by the U.S. Department of Homeland Security that lists the location and boundaries of carceral facilities in the U.S. From the database’s more than 6,000 prisons, jails, and detention centers, the researchers highlighted 1,614 prison-specific facilities, which together incarcerate nearly 1.4 million people, and employ about 337,000 staff.
They then looked to Daymet, a detailed weather and climate database that tracks daily temperatures across the United States, at a 1-kilometer resolution. For each of the 1,614 prison locations, they mapped the daily outdoor temperature, for every summer between the years 1990 to 2023, noting that the majority of current state and federal correctional facilities in the U.S. were built by 1990.
The team also obtained U.S. Census data on each facility’s demographic and facility-level characteristics, such as prison labor activities and conditions of confinement. One limitation of the study that the researchers acknowledge is a lack of information regarding a prison’s climate control.
From their analysis, the researchers found that more than 98 percent of all prisons in the U.S. experienced at least 10 days in the summer that were hotter than every previous summer, on average, for a given location. Their analysis also revealed the most heat-exposed prisons, and the prisons that experienced the highest temperatures on average, were mostly in the Southwestern U.S. The researchers note that with the exception of New Mexico, the Southwest is a region where there are no universal air conditioning regulations in state-operated prisons.
“States run their own prison systems, and there is no uniformity of data collection or policy regarding air conditioning,” says Wood, who notes that there is some information on cooling systems in some states and individual prison facilities, but the data is sparse overall, and too inconsistent to include in the group’s nationwide study.
While the researchers could not incorporate air conditioning data, they did consider other facility-level factors that could worsen the effects that outdoor heat triggers. They looked through the scientific literature on heat, health impacts, and prison conditions, and focused on 17 measurable facility-level variables that contribute to heat-related health problems. These include factors such as overcrowding and understaffing.
“We know that whenever you’re in a room that has a lot of people, it’s going to feel hotter, even if there’s air conditioning in that environment,” Ovienmhada says. “Also, staffing is a huge factor. Facilities that don’t have air conditioning but still try to do heat risk-mitigation procedures might rely on staff to distribute ice or water every few hours. If that facility is understaffed or has neglectful staff, that may increase people’s susceptibility to hot days.”
The study found that prisons with any of nine of the 17 variables showed statistically significant greater heat exposures than the prisons without those variables. Additionally, if a prison exhibits any one of the nine variables, this could worsen people’s heat risk through the combination of elevated heat exposure and vulnerability. The variables, they say, could help state regulators and activists identify prisons to prioritize for heat interventions.
“The prison population is aging, and even if you’re not in a ‘hot state,’ every state has responsibility to respond,” Wood emphasizes. “For instance, areas in the Northwest, where you might expect to be temperate overall, have experienced a number of days in recent years of increasing heat risk. A few days out of the year can still be dangerous, particularly for a population with reduced agency to regulate their own exposure to heat.”
This work was supported, in part, by NASA, the MIT Media Lab, and MIT’s Institute for Data, Systems and Society’s Research Initiative on Combatting Systemic Racism.
The degree to which a surgical patient’s subconscious processing of pain, or “nociception,” is properly managed by their anesthesiologist will directly affect the degree of post-operative drug side effects they’ll experience and the need for further pain management they’ll require. But pain is a subjective feeling to measure, even when patients are awake, much less when they are unconscious.
In a new study appearing in the Proceedings of the National Academy of Sciences, MIT and Massachusetts General Hospital (MGH) researchers describe a set of statistical models that objectively quantified nociception during surgery. Ultimately, they hope to help anesthesiologists optimize drug dose and minimize post-operative pain and side effects.
The new models integrate data meticulously logged over 18,582 minutes of 101 abdominal surgeries in men and women at MGH. Led by Sandya Subramanian PhD ’21, an assistant professor at the University of California at Berkeley and the University of California at San Francisco, the researchers collected and analyzed data from five physiological sensors as patients experienced a total of 49,878 distinct “nociceptive stimuli” (such as incisions or cautery). Moreover, the team recorded what drugs were administered, and how much and when, to factor in their effects on nociception or cardiovascular measures. They then used all the data to develop a set of statistical models that performed well in retrospectively indicating the body’s response to nociceptive stimuli.
The team’s goal is to furnish such accurate, objective, and physiologically principled information in real time to anesthesiologists who currently have to rely heavily on intuition and past experience in deciding how to administer pain-control drugs during surgery. If anesthesiologists give too much, patients can experience side effects ranging from nausea to delirium. If they give too little, patients may feel excessive pain after they awaken.
“Sandya’s work has helped us establish a principled way to understand and measure nociception (unconscious pain) during general anesthesia,” says study senior author Emery N. Brown, the Edward Hood Taplin Professor of Medical Engineering and Computational Neuroscience in The Picower Institute for Learning and Memory, the Institute for Medical Engineering and Science, and the Department of Brain and Cognitive Sciences at MIT. Brown is also an anesthesiologist at MGH and a professor at Harvard Medical School. “Our next objective is to make the insights that we have gained from Sandya’s studies reliable and practical for anesthesiologists to use during surgery.”
Surgery and statistics
The research began as Subramanian’s doctoral thesis project in Brown’s lab in 2017. The best prior attempts to objectively model nociception have either relied solely on the electrocardiogram (ECG, an indirect indicator of heart-rate variability) or other systems that may incorporate more than one measurement, but were either based on lab experiments using pain stimuli that do not compare in intensity to surgical pain or were validated by statistically aggregating just a few time points across multiple patients’ surgeries, Subramanian says.
“There’s no other place to study surgical pain except for the operating room,” Subramanian says. “We wanted to not only develop the algorithms using data from surgery, but also actually validate it in the context in which we want someone to use it. If we are asking them to track moment-to-moment nociception during an individual surgery, we need to validate it in that same way.”
So she and Brown worked to advance the state of the art by collecting multi-sensor data during the whole course of actual surgeries and by accounting for the confounding effects of the drugs administered. In that way, they hoped to develop a model that could make accurate predictions that remained valid for the same patient all the way through their operation.
Part of the improvements the team achieved arose from tracking patterns of heart rate and also skin conductance. Changes in both of these physiological factors can be indications of the body’s primal “fight or flight” response to nociception or pain, but some drugs used during surgery directly affect cardiovascular state, while skin conductance (or “EDA,” electrodermal activity) remains unaffected. The study measures not only ECG but also backs it up with PPG, an optical measure of heart rate (like the oxygen sensor on a smartwatch), because ECG signals can sometimes be made noisy by all the electrical equipment buzzing away in the operating room. Similarly, Subramanian backstopped EDA measures with measures of skin temperature to ensure that changes in skin conductance from sweat were because of nociception and not simply the patient being too warm. The study also tracked respiration.
Then the authors performed statistical analyses to develop physiologically relevant indices from each of the cardiovascular and skin conductance signals. And once each index was established, further statistical analysis enabled tracking the indices together to produce models that could make accurate, principled predictions of when nociception was occurring and the body’s response.
Nailing nociception
In four versions of the model, Subramanian “supervised” them by feeding them information on when actual nociceptive stimuli occurred so that they could then learn the association between the physiological measurements and the incidence of pain-inducing events. In some of these trained versions she left out drug information and in some versions she used different statistical approaches (either “linear regression” or “random forest”). In a fifth version of the model, based on a “state space” approach, she left it unsupervised, meaning it had to learn to infer moments of nociception purely from the physiological indices. She compared all five versions of her model to one of the current industry standards, an ECG-tracking model called ANI.
Each model’s output can be visualized as a graph plotting the predicted degree of nociception over time. ANI performs just above chance but is implemented in real-time. The unsupervised model performed better than ANI, though not quite as well as the supervised models. The best performing of those was one that incorporated drug information and used a “random forest” approach. Still, the authors note, the fact that the unsupervised model performed significantly better than chance suggests that there is indeed an objectively detectable signature of the body’s nociceptive state even when looking across different patients.
“A state space framework using multisensory physiological observations is effective in uncovering this implicit nociceptive state with a consistent definition across multiple subjects,” wrote Subramanian, Brown, and their co-authors. “This is an important step toward defining a metric to track nociception without including nociceptive ‘ground truth’ information, most practical for scalability and implementation in clinical settings.”
Indeed, the next steps for the research are to increase the data sampling and to further refine the models so that they can eventually be put into practice in the operating room. That will require enabling them to predict nociception in real time, rather than in post-hoc analysis. When that advance is made, that will enable anesthesiologists or intensivists to inform their pain drug dosing judgements. Further into the future, the model could inform closed-loop systems that automatically dose drugs under the anesthesiologist’s supervision.
“Our study is an important first step toward developing objective markers to track surgical nociception,” the authors concluded. “These markers will enable objective assessment of nociception in other complex clinical settings, such as the ICU [intensive care unit], as well as catalyze future development of closed-loop control systems for nociception.”
In addition to Subramanian and Brown, the paper’s other authors are Bryan Tseng, Marcela del Carmen, Annekathryn Goodman, Douglas Dahl, and Riccardo Barbieri.
Funding from The JPB Foundation; The Picower Institute; George J. Elbaum ’59, SM ’63, PhD ’67; Mimi Jensen; Diane B. Greene SM ’78; Mendel Rosenblum; Bill Swanson; Cathy and Lou Paglia; annual donors to the Anesthesia Initiative Fund; the National Science Foundation; and an MIT Office of Graduate Education Collabmore-Rogers Fellowship supported the research.
Ouch? The patient won't feel the impending incision while anesthetized but the body will still experience the stimulus of the incision as "nociception." New statistical models to objectively quantify nociception can help anesthesiologists better manage it during surgery, improving management of drug dosing and post-operative pain.
The pharmaceutical manufacturing industry has long struggled with the issue of monitoring the characteristics of a drying mixture, a critical step in producing medication and chemical compounds. At present, there are two noninvasive characterization approaches that are typically used: A sample is either imaged and individual particles are counted, or researchers use a scattered light to estimate the particle size distribution (PSD). The former is time-intensive and leads to increased waste, making the latter a more attractive option.
“Understanding the behavior of scattered light is one of the most important topics in optics,” says Qihang Zhang PhD ’23, an associate researcher at Tsinghua University. “By making progress in analyzing scattered light, we also invented a useful tool for the pharmaceutical industry. Locating the pain point and solving it by investigating the fundamental rule is the most exciting thing to the research team.”
The paper proposes a new PSD estimation method, based on pupil engineering, that reduces the number of frames needed for analysis. “Our learning-based model can estimate the powder size distribution from a single snapshot speckle image, consequently reducing the reconstruction time from 15 seconds to a mere 0.25 seconds,” the researchers explain.
“Our main contribution in this work is accelerating a particle size detection method by 60 times, with a collective optimization of both algorithm and hardware,” says Zhang. “This high-speed probe is capable to detect the size evolution in fast dynamical systems, providing a platform to study models of processes in pharmaceutical industry including drying, mixing and blending.”
The technique offers a low-cost, noninvasive particle size probe by collecting back-scattered light from powder surfaces. The compact and portable prototype is compatible with most of drying systems in the market, as long as there is an observation window. This online measurement approach may help control manufacturing processes, improving efficiency and product quality. Further, the previous lack of online monitoring prevented systematical study of dynamical models in manufacturing processes. This probe could bring a new platform to carry out series research and modeling for the particle size evolution.
This work, a successful collaboration between physicists and engineers, is generated from the MIT-Takeda program. Collaborators are affiliated with three MIT departments: Mechanical Engineering, Chemical Engineering, and Electrical Engineering and Computer Science. George Barbastathis, professor of mechanical engineering at MIT, is the article’s senior author.
Study co-authors (from left to right) Ajinkya Pandit, Yi Wei, and Shashank Muddu stand with equipment used to develop a technique offering a low-cost, noninvasive particle size probe.
One major reason why it has been difficult to develop an effective HIV vaccine is that the virus mutates very rapidly, allowing it to evade the antibody response generated by vaccines.
Several years ago, MIT researchers showed that administering a series of escalating doses of an HIV vaccine over a two-week period could help overcome a part of that challenge by generating larger quantities of neutralizing antibodies. However, a multidose vaccine regimen administered over a short time is not practical for mass vaccination campaigns.
In a new study, the researchers have now found that they can achieve a similar immune response with just two doses, given one week apart. The first dose, which is much smaller, prepares the immune system to respond more powerfully to the second, larger dose.
This study, which was performed by bringing together computational modeling and experiments in mice, used an HIV envelope protein as the vaccine. A single-dose version of this vaccine is now in clinical trials, and the researchers hope to establish another study group that will receive the vaccine on a two-dose schedule.
“By bringing together the physical and life sciences, we shed light on some basic immunological questions that helped develop this two-dose schedule to mimic the multiple-dose regimen,” says Arup Chakraborty, the John M. Deutch Institute Professor at MIT and a member of MIT’s Institute for Medical Engineering and Science and the Ragon Institute of MIT, MGH and Harvard University.
This approach may also generalize to vaccines for other diseases, Chakraborty notes.
Chakraborty and Darrell Irvine, a former MIT professor of biological engineering and materials science and engineering and member of the Koch Institute for Integrative Cancer Research, who is now a professor of immunology and microbiology at the Scripps Research Institute, are the senior authors of the study, which appears today in Science Immunology. The lead authors of the paper are Sachin Bhagchandani PhD ’23 and Leerang Yang PhD ’24.
Neutralizing antibodies
Each year, HIV infects more than 1 million people around the world, and some of those people do not have access to antiviral drugs. An effective vaccine could prevent many of those infections. One promising vaccine now in clinical trials consists of an HIV protein called an envelope trimer, along with a nanoparticle called SMNP. The nanoparticle, developed by Irvine’s lab, acts as an adjuvant that helps recruit a stronger B cell response to the vaccine.
In clinical trials, this vaccine and other experimental vaccines have been given as just one dose. However, there is growing evidence that a series of doses is more effective at generating broadly neutralizing antibodies. The seven-dose regimen, the researchers believe, works well because it mimics what happens when the body is exposed to a virus: The immune system builds up a strong response as more viral proteins, or antigens, accumulate in the body.
In the new study, the MIT team investigated how this response develops and explored whether they could achieve the same effect using a smaller number of vaccine doses.
“Giving seven doses just isn’t feasible for mass vaccination,” Bhagchandani says. “We wanted to identify some of the critical elements necessary for the success of this escalating dose, and to explore whether that knowledge could allow us to reduce the number of doses.”
The researchers began by comparing the effects of one, two, three, four, five, six, or seven doses, all given over a 12-day period. They initially found that while three or more doses generated strong antibody responses, two doses did not. However, by tweaking the dose intervals and ratios, the researchers discovered that giving 20 percent of the vaccine in the first dose and 80 percent in a second dose, seven days later, achieved just as good a response as the seven-dose schedule.
“It was clear that understanding the mechanisms behind this phenomenon would be crucial for future clinical translation,” Yang says. “Even if the ideal dosing ratio and timing may differ for humans, the underlying mechanistic principles will likely remain the same.”
Using a computational model, the researchers explored what was happening in each of these dosing scenarios. This work showed that when all of the vaccine is given as one dose, most of the antigen gets chopped into fragments before it reaches the lymph nodes. Lymph nodes are where B cells become activated to target a particular antigen, within structures known as germinal centers.
When only a tiny amount of the intact antigen reaches these germinal centers, B cells can’t come up with a strong response against that antigen.
However, a very small number of B cells do arise that produce antibodies targeting the intact antigen. So, giving a small amount in the first dose does not “waste” much antigen but allows some B cells and antibodies to develop. If a second, larger dose is given a week later, those antibodies bind to the antigen before it can be broken down and escort it into the lymph node. This allows more B cells to be exposed to that antigen and eventually leads to a large population of B cells that can target it.
“The early doses generate some small amounts of antibody, and that’s enough to then bind to the vaccine of the later doses, protect it, and target it to the lymph node. That's how we realized that we don't need to give seven doses,” Bhagchandani says. “A small initial dose will generate this antibody and then when you give the larger dose, it can again be protected because that antibody will bind to it and traffic it to the lymph node.”
T-cell boost
Those antigens may stay in the germinal centers for weeks or even longer, allowing more B cells to come in and be exposed to them, making it more likely that diverse types of antibodies will develop.
The researchers also found that the two-dose schedule induces a stronger T-cell response. The first dose activates dendritic cells, which promote inflammation and T-cell activation. Then, when the second dose arrives, even more dendritic cells are stimulated, further boosting the T-cell response.
Overall, the two-dose regimen resulted in a fivefold improvement in the T-cell response and a 60-fold improvement in the antibody response, compared to a single vaccine dose.
“Reducing the ‘escalating dose’ strategy down to two shots makes it much more practical for clinical implementation. Further, a number of technologies are in development that could mimic the two-dose exposure in a single shot, which could become ideal for mass vaccination campaigns,” Irvine says.
The researchers are now studying this vaccine strategy in a nonhuman primate model. They are also working on specialized materials that can deliver the second dose over an extended period of time, which could further enhance the immune response.
The research was funded by the Koch Institute Support (core) Grant from the National Cancer Institute, the National Institutes of Health, and the Ragon Institute of MIT, MGH, and Harvard.
Behind the syringe and vial is an image of a lymph node. Structures called follicles are labeled in blue. Within these structures, B cells encounter an HIV antigen, labeled in pink, allowing them to develop a robust immune response.
What if construction materials could be put together and taken apart as easily as LEGO bricks? Such reconfigurable masonry would be disassembled at the end of a building’s lifetime and reassembled into a new structure, in a sustainable cycle that could supply generations of buildings using the same physical building blocks.
That’s the idea behind circular construction, which aims to reuse and repurpose a building’s materials whenever possible, to minimize the manufacturing of new materials and reduce the construction industry’s “embodied carbon,” which refers to the greenhouse gas emissions associated with every process throughout a building’s construction, from manufacturing to demolition.
Now MIT engineers, motivated by circular construction’s eco potential, are developing a new kind of reconfigurable masonry made from 3D-printed, recycled glass. Using a custom 3D glass printing technology provided by MIT spinoff Evenline, the team has made strong, multilayered glass bricks, each in the shape of a figure eight, that are designed to interlock, much like LEGO bricks.
In mechanical testing, a single glass brick withstood pressures similar to that of a concrete block. As a structural demonstration, the researchers constructed a wall of interlocking glass bricks. They envision that 3D-printable glass masonry could be reused many times over as recyclable bricks for building facades and internal walls.
“Glass is a highly recyclable material,” says Kaitlyn Becker, assistant professor of mechanical engineering at MIT. “We’re taking glass and turning it into masonry that, at the end of a structure’s life, can be disassembled and reassembled into a new structure, or can be stuck back into the printer and turned into a completely different shape. All this builds into our idea of a sustainable, circular building material.”
“Glass as a structural material kind of breaks people’s brains a little bit,” says Michael Stern, a former MIT graduate student and researcher in both MIT’s Media Lab and Lincoln Laboratory, who is also founder and director of Evenline. “We’re showing this is an opportunity to push the limits of what’s been done in architecture.”
The inspiration for the new circular masonry design arose partly in MIT’s Glass Lab, where Becker and Stern, then undergraduate students, first learned the art and science of blowing glass.
“I found the material fascinating,” says Stern, who later designed a 3D printer capable of printing molten recycled glass — a project he took on while studying in the mechanical engineering department. “I started thinking of how glass printing can find its place and do interesting things, construction being one possible route.”
Meanwhile, Becker, who accepted a faculty position at MIT, began exploring the intersection of manufacturing and design, and ways to develop new processes that enable innovative designs.
“I get excited about expanding design and manufacturing spaces for challenging materials with interesting characteristics, like glass and its optical properties and recyclability,” Becker says. “As long as it’s not contaminated, you can recycle glass almost infinitely.”
She and Stern teamed up to see whether and how 3D-printable glass could be made into a structural masonry unit as sturdy and stackable as traditional bricks. For their new study, the team used the Glass 3D Printer 3 (G3DP3), the latest version of Evenline’s glass printer, which pairs with a furnace to melt crushed glass bottles into a molten, printable form that the printer then deposits in layered patterns.
The team printed prototype glass bricks using soda-lime glass that is typically used in a glassblowing studio. They incorporated two round pegs onto each printed brick, similar to the studs on a LEGO brick. Like the toy blocks, the pegs enable bricks to interlock and assemble into larger structures. Another material placed between the bricks prevent scratches or cracks between glass surfaces but can be removed if a brick structure were to be dismantled and recycled, also allowing bricks to be remelted in the printer and formed into new shapes. The team decided to make the blocks into a figure-eight shape.
“With the figure-eight shape, we can constrain the bricks while also assembling them into walls that have some curvature,” Massimino says.
Stepping stones
The team printed glass bricks and tested their mechanical strength in an industrial hydraulic press that squeezed the bricks until they began to fracture. The researchers found that the strongest bricks were able to hold up to pressures that are comparable to what concrete blocks can withstand. Those strongest bricks were made mostly from printed glass, with a separately manufactured interlocking feature that attached to the bottom of the brick. These results suggest that most of a masonry brick could be made from printed glass, with an interlocking feature that could be printed, cast, or separately manufactured from a different material.
“Glass is a complicated material to work with,” Becker says. “The interlocking elements, made from a different material, showed the most promise at this stage.”
The group is looking into whether more of a brick’s interlocking feature could be made from printed glass, but doesn’t see this as a dealbreaker in moving forward to scale up the design. To demonstrate glass masonry’s potential, they constructed a curved wall of interlocking glass bricks. Next, they aim to build progressively bigger, self-supporting glass structures.
“We have more understanding of what the material’s limits are, and how to scale,” Stern says. “We’re thinking of stepping stones to buildings, and want to start with something like a pavilion — a temporary structure that humans can interact with, and that you could then reconfigure into a second design. And you could imagine that these blocks could go through a lot of lives.”
This research was supported, in part, by the Bose Research Grant Program and MIT’s Research Support Committee.
For more than 100 years, scientists have been using X-ray crystallography to determine the structure of crystalline materials such as metals, rocks, and ceramics.
This technique works best when the crystal is intact, but in many cases, scientists have only a powdered version of the material, which contains random fragments of the crystal. This makes it more challenging to piece together the overall structure.
MIT chemists have now come up with a new generative AI model that can make it much easier to determine the structures of these powdered crystals. The prediction model could help researchers characterize materials for use in batteries, magnets, and many other applications.
“Structure is the first thing that you need to know for any material. It’s important for superconductivity, it’s important for magnets, it’s important for knowing what photovoltaic you created. It’s important for any application that you can think of which is materials-centric,” says Danna Freedman, the Frederick George Keyes Professor of Chemistry at MIT.
Freedman and Jure Leskovec, a professor of computer science at Stanford University, are the senior authors of the new study, which appears today in the Journal of the American Chemical Society. MIT graduate student Eric Riesel and Yale University undergraduate Tsach Mackey are the lead authors of the paper.
Distinctive patterns
Crystalline materials, which include metals and most other inorganic solid materials, are made of lattices that consist of many identical, repeating units. These units can be thought of as “boxes” with a distinctive shape and size, with atoms arranged precisely within them.
When X-rays are beamed at these lattices, they diffract off atoms with different angles and intensities, revealing information about the positions of the atoms and the bonds between them. Since the early 1900s, this technique has been used to analyze materials, including biological molecules that have a crystalline structure, such as DNA and some proteins.
For materials that exist only as a powdered crystal, solving these structures becomes much more difficult because the fragments don’t carry the full 3D structure of the original crystal.
“The precise lattice still exists, because what we call a powder is really a collection of microcrystals. So, you have the same lattice as a large crystal, but they’re in a fully randomized orientation,” Freedman says.
For thousands of these materials, X-ray diffraction patterns exist but remain unsolved. To try to crack the structures of these materials, Freedman and her colleagues trained a machine-learning model on data from a database called the Materials Project, which contains more than 150,000 materials. First, they fed tens of thousands of these materials into an existing model that can simulate what the X-ray diffraction patterns would look like. Then, they used those patterns to train their AI model, which they call Crystalyze, to predict structures based on the X-ray patterns.
The model breaks the process of predicting structures into several subtasks. First, it determines the size and shape of the lattice “box” and which atoms will go into it. Then, it predicts the arrangement of atoms within the box. For each diffraction pattern, the model generates several possible structures, which can be tested by feeding the structures into a model that determines diffraction patterns for a given structure.
“Our model is generative AI, meaning that it generates something that it hasn’t seen before, and that allows us to generate several different guesses,” Riesel says. “We can make a hundred guesses, and then we can predict what the powder pattern should look like for our guesses. And then if the input looks exactly like the output, then we know we got it right.”
Solving unknown structures
The researchers tested the model on several thousand simulated diffraction patterns from the Materials Project. They also tested it on more than 100 experimental diffraction patterns from the RRUFF database, which contains powdered X-ray diffraction data for nearly 14,000 natural crystalline minerals, that they had held out of the training data. On these data, the model was accurate about 67 percent of the time. Then, they began testing the model on diffraction patterns that hadn’t been solved before. These data came from the Powder Diffraction File, which contains diffraction data for more than 400,000 solved and unsolved materials.
Using their model, the researchers came up with structures for more than 100 of these previously unsolved patterns. They also used their model to discover structures for three materials that Freedman’s lab created by forcing elements that do not react at atmospheric pressure to form compounds under high pressure. This approach can be used to generate new materials that have radically different crystal structures and physical properties, even though their chemical composition is the same.
Graphite and diamond — both made of pure carbon — are examples of such materials. The materials that Freedman has developed, which each contain bismuth and one other element, could be useful in the design of new materials for permanent magnets.
“We found a lot of new materials from existing data, and most importantly, solved three unknown structures from our lab that comprise the first new binary phases of those combinations of elements,” Freedman says.
Being able to determine the structures of powdered crystalline materials could help researchers working in nearly any materials-related field, according to the MIT team, which has posted a web interface for the model at crystalyze.org.
The research was funded by the U.S. Department of Energy and the National Science Foundation.
A new study from researchers at MIT and Penn State University reveals that if large language models were to be used in home surveillance, they could recommend calling the police even when surveillance videos show no criminal activity.
In addition, the models the researchers studied were inconsistent in which videos they flagged for police intervention. For instance, a model might flag one video that shows a vehicle break-in but not flag another video that shows a similar activity. Models often disagreed with one another over whether to call the police for the same video.
Furthermore, the researchers found that some models flagged videos for police intervention relatively less often in neighborhoods where most residents are white, controlling for other factors. This shows that the models exhibit inherent biases influenced by the demographics of a neighborhood, the researchers say.
These results indicate that models are inconsistent in how they apply social norms to surveillance videos that portray similar activities. This phenomenon, which the researchers call norm inconsistency, makes it difficult to predict how models would behave in different contexts.
“The move-fast, break-things modus operandi of deploying generative AI models everywhere, and particularly in high-stakes settings, deserves much more thought since it could be quite harmful,” says co-senior author Ashia Wilson, the Lister Brothers Career Development Professor in the Department of Electrical Engineering and Computer Science and a principal investigator in the Laboratory for Information and Decision Systems (LIDS).
Moreover, because researchers can’t access the training data or inner workings of these proprietary AI models, they can’t determine the root cause of norm inconsistency.
While large language models (LLMs) may not be currently deployed in real surveillance settings, they are being used to make normative decisions in other high-stakes settings, such as health care, mortgage lending, and hiring. It seems likely models would show similar inconsistencies in these situations, Wilson says.
“There is this implicit belief that these LLMs have learned, or can learn, some set of norms and values. Our work is showing that is not the case. Maybe all they are learning is arbitrary patterns or noise,” says lead author Shomik Jain, a graduate student in the Institute for Data, Systems, and Society (IDSS).
Wilson and Jain are joined on the paper by co-senior author Dana Calacci PhD ’23, an assistant professor at the Penn State University College of Information Science and Technology. The research will be presented at the AAAI Conference on AI, Ethics, and Society.
“A real, imminent, practical threat”
The study grew out of a dataset containing thousands of Amazon Ring home surveillance videos, which Calacci built in 2020, while she was a graduate student in the MIT Media Lab. Ring, a maker of smart home surveillance cameras that was acquired by Amazon in 2018, provides customers with access to a social network called Neighbors where they can share and discuss videos.
Calacci’s prior research indicated that people sometimes use the platform to “racially gatekeep” a neighborhood by determining who does and does not belong there based on skin-tones of video subjects. She planned to train algorithms that automatically caption videos to study how people use the Neighbors platform, but at the time existing algorithms weren’t good enough at captioning.
The project pivoted with the explosion of LLMs.
“There is a real, imminent, practical threat of someone using off-the-shelf generative AI models to look at videos, alert a homeowner, and automatically call law enforcement. We wanted to understand how risky that was,” Calacci says.
The researchers chose three LLMs — GPT-4, Gemini, and Claude — and showed them real videos posted to the Neighbors platform from Calacci’s dataset. They asked the models two questions: “Is a crime happening in the video?” and “Would the model recommend calling the police?”
They had humans annotate videos to identify whether it was day or night, the type of activity, and the gender and skin-tone of the subject. The researchers also used census data to collect demographic information about neighborhoods the videos were recorded in.
Inconsistent decisions
They found that all three models nearly always said no crime occurs in the videos, or gave an ambiguous response, even though 39 percent did show a crime.
“Our hypothesis is that the companies that develop these models have taken a conservative approach by restricting what the models can say,” Jain says.
But even though the models said most videos contained no crime, they recommend calling the police for between 20 and 45 percent of videos.
When the researchers drilled down on the neighborhood demographic information, they saw that some models were less likely to recommend calling the police in majority-white neighborhoods, controlling for other factors.
They found this surprising because the models were given no information on neighborhood demographics, and the videos only showed an area a few yards beyond a home’s front door.
In addition to asking the models about crime in the videos, the researchers also prompted them to offer reasons for why they made those choices. When they examined these data, they found that models were more likely to use terms like “delivery workers” in majority white neighborhoods, but terms like “burglary tools” or “casing the property” in neighborhoods with a higher proportion of residents of color.
“Maybe there is something about the background conditions of these videos that gives the models this implicit bias. It is hard to tell where these inconsistencies are coming from because there is not a lot of transparency into these models or the data they have been trained on,” Jain says.
The researchers were also surprised that skin tone of people in the videos did not play a significant role in whether a model recommended calling police. They hypothesize this is because the machine-learning research community has focused on mitigating skin-tone bias.
“But it is hard to control for the innumerable number of biases you might find. It is almost like a game of whack-a-mole. You can mitigate one and another bias pops up somewhere else,” Jain says.
Many mitigation techniques require knowing the bias at the outset. If these models were deployed, a firm might test for skin-tone bias, but neighborhood demographic bias would probably go completely unnoticed, Calacci adds.
“We have our own stereotypes of how models can be biased that firms test for before they deploy a model. Our results show that is not enough,” she says.
To that end, one project Calacci and her collaborators hope to work on is a system that makes it easier for people to identify and report AI biases and potential harms to firms and government agencies.
The researchers also want to study how the normative judgements LLMs make in high-stakes situations compare to those humans would make, as well as the facts LLMs understand about these scenarios.
“The move-fast, break-things modus operandi of deploying generative AI models everywhere, and particularly in high-stakes settings, deserves much more thought since it could be quite harmful,” says co-senior author Ashia Wilson.
When Jared Bryan talks about his seismology research, it’s with a natural finesse. He’s a fifth-year PhD student working with MIT Assistant Professor William Frank on seismology research, drawn in by the lab’s combination of GPS observations, satellites, and seismic station data to understand the underlying physics of earthquakes. He has no trouble talking about seismic velocity in fault zones or how he first became interested in the field after summer internships with the Southern California Earthquake Center as an undergraduate student.
“It’s definitely like a more down-to-earth kind of seismology,” he jokingly describes it. It’s an odd comment. Where else could earthquakes be but on Earth? But it’s because Bryan finished a research project that has culminated in a new paper — published today in Nature Astronomy — involving seismic activity not on Earth, but on stars.
Building curiosity
PhD students in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS) are required to complete two research projects as part of their general exam. The first is often in their main focus of research and the foundations of what will become their thesis work.
But the second project has a special requirement: It must be in a different specialty.
“Having that built into the structure of the PhD is really, really nice,” says Bryan, who hadn’t known about the special requirement when he decided to come to EAPS. “I think it helps you build curiosity and find what's interesting about what other people are doing.”
Having so many different, yet still related, fields of study housed in one department makes it easier for students with a strong sense of curiosity to explore the interconnected interactions of Earth science.
“I think everyone here is excited about a lot of different stuff, but we can’t do everything,” says Frank, the Victor P. Starr Career Development Professor of Geophysics. “This is a great way to get students to try something else that they maybe would have wanted to do in a parallel dimension, interact with other advisors, and see that science can be done in different ways.”
At first, Bryan was worried that the nature of the second project would be a restrictive diversion from his main PhD research. But Associate Professor Julien de Wit was looking for someone with a seismology background to look at some stellar observations he’d collected back in 2016. A star’s brightness was pulsating at a very specific frequency that had to be caused by changes in the star itself, so Bryan decided to help.
“I was surprised by how the kind of seismology that he was looking for was similar to the seismology that we were first doing in the ’60s and ’70s, like large-scale global Earth seismology,” says Bryan. “I thought it would be a way to rethink the foundations of the field that I had been studying applied to a new region.”
Going from earthquakes to starquakes is not a one-to-one comparison. While the foundational knowledge was there, movement of stars comes from a variety of sources like magnetism or the Coriolis effect, and in a variety of forms. In addition to the sound and pressure waves of earthquakes, they also have gravity waves, all of which happen on a scale much more massive.
“You have to stretch your mind a bit, because you can’t actually visit these places,” Bryan says. “It’s an unbelievable luxury that we have in Earth seismology that the things that we study are on Google Maps.”
But there are benefits to bringing in scientists from outside an area of expertise. De Wit, who served as Bryan’s supervisor for the project and is also an author on the paper, points out that they bring a fresh perspective and approach by asking unique questions.
“Things that people in the field would just take for granted are challenged by their questions,” he says, adding that Bryan was transparent about what he did and didn’t know, allowing for a rich exchange of information.
Tidal resonance locking
Bryan eventually found that the changes in the star’s brightness were caused by tidal resonance. Resonance is a physical occurrence where waves interact and amplify each other. The most common analogy is pushing someone on a swing set; when the person pushing does it at just the right time, it helps the person on the swing go higher.
“Tidal resonance is where you’re pushing at exactly the same frequency as they’re swinging, and the locking happens when both of those frequencies are changing,” Bryan explains. The person pushing the swing gets tired and pushes less often, while the chain of the swing change length. (Bryan jokes that here the analogy starts to break down.)
As a star changes over the course of its lifetime, tidal resonance locking can cause hot Jupiters, which are massive exoplanets that orbit very close to their host stars, to change orbital distances. This wandering migration, as they call it, explains how some hot Jupiters get so close to their host stars. They also found that the path they take to get there is not always smooth. It can speed up, slow down, or even regress.
An important implication from the paper is that tidal resonance locking could be used as an exoplanet detection tool, confirming de Wit’s hypothesis from the original 2016 observation that the pulsations had the potential to be used in such a way. If changes in the star’s brightness can be linked to this resonance locking, it may indicate planets that can’t be detected using current methods.
As below, so above
Most EAPS PhD students don’t advance their project beyond the requirements for the general exam, let alone get a paper out of it. At first, Bryan worried that continuing with it would end up being a distraction from his main work, but ultimately was glad that he committed to it and was able to contribute something meaningful to the emerging field of asteroseismology.
“I think it’s evidence that Jared is excited about what he does and has the drive and scientific skepticism to have done the extra steps to make sure that what he was doing was a real contribution to the scientific literature,” says Frank. “He’s a great example of success and what we hope for our students.”
While de Wit didn’t manage to convince Bryan to switch to exoplanet research permanently, he is “excited that there is the opportunity to keep on working together.”
Once he finishes his PhD, Bryan plans on continuing in academia as a professor running a research lab, shifting his focus onto volcano seismology and improving instrumentation for the field. He’s open to the possibility of taking his findings on Earth and applying them to volcanoes on other planetary bodies, such as those found on Venus and Jupiter’s moon Io.
“I’d like to be the bridge between those two things,” he says.
PhD student Jared Bryan was able to use his knowledge of Earth-based seismology to solve an exoplanet mystery as to how hot Jupiters end up so close to their host stars. “I thought it would be a way to rethink the foundations of the field that I had been studying applied to a new region.”
When Jared Bryan talks about his seismology research, it’s with a natural finesse. He’s a fifth-year PhD student working with MIT Assistant Professor William Frank on seismology research, drawn in by the lab’s combination of GPS observations, satellites, and seismic station data to understand the underlying physics of earthquakes. He has no trouble talking about seismic velocity in fault zones or how he first became interested in the field after summer internships with the Southern California Earthquake Center as an undergraduate student.
“It’s definitely like a more down-to-earth kind of seismology,” he jokingly describes it. It’s an odd comment. Where else could earthquakes be but on Earth? But it’s because Bryan finished a research project that has culminated in a new paper — published today in Nature Astronomy — involving seismic activity not on Earth, but on stars.
Building curiosity
PhD students in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS) are required to complete two research projects as part of their general exam. The first is often in their main focus of research and the foundations of what will become their thesis work.
But the second project has a special requirement: It must be in a different specialty.
“Having that built into the structure of the PhD is really, really nice,” says Bryan, who hadn’t known about the special requirement when he decided to come to EAPS. “I think it helps you build curiosity and find what's interesting about what other people are doing.”
Having so many different, yet still related, fields of study housed in one department makes it easier for students with a strong sense of curiosity to explore the interconnected interactions of Earth science.
“I think everyone here is excited about a lot of different stuff, but we can’t do everything,” says Frank, the Victor P. Starr Career Development Professor of Geophysics. “This is a great way to get students to try something else that they maybe would have wanted to do in a parallel dimension, interact with other advisors, and see that science can be done in different ways.”
At first, Bryan was worried that the nature of the second project would be a restrictive diversion from his main PhD research. But Associate Professor Julien de Wit was looking for someone with a seismology background to look at some stellar observations he’d collected back in 2016. A star’s brightness was pulsating at a very specific frequency that had to be caused by changes in the star itself, so Bryan decided to help.
“I was surprised by how the kind of seismology that he was looking for was similar to the seismology that we were first doing in the ’60s and ’70s, like large-scale global Earth seismology,” says Bryan. “I thought it would be a way to rethink the foundations of the field that I had been studying applied to a new region.”
Going from earthquakes to starquakes is not a one-to-one comparison. While the foundational knowledge was there, movement of stars comes from a variety of sources like magnetism or the Coriolis effect, and in a variety of forms. In addition to the sound and pressure waves of earthquakes, they also have gravity waves, all of which happen on a scale much more massive.
“You have to stretch your mind a bit, because you can’t actually visit these places,” Bryan says. “It’s an unbelievable luxury that we have in Earth seismology that the things that we study are on Google Maps.”
But there are benefits to bringing in scientists from outside an area of expertise. De Wit, who served as Bryan’s supervisor for the project and is also an author on the paper, points out that they bring a fresh perspective and approach by asking unique questions.
“Things that people in the field would just take for granted are challenged by their questions,” he says, adding that Bryan was transparent about what he did and didn’t know, allowing for a rich exchange of information.
Tidal resonance locking
Bryan eventually found that the changes in the star’s brightness were caused by tidal resonance. Resonance is a physical occurrence where waves interact and amplify each other. The most common analogy is pushing someone on a swing set; when the person pushing does it at just the right time, it helps the person on the swing go higher.
“Tidal resonance is where you’re pushing at exactly the same frequency as they’re swinging, and the locking happens when both of those frequencies are changing,” Bryan explains. The person pushing the swing gets tired and pushes less often, while the chain of the swing change length. (Bryan jokes that here the analogy starts to break down.)
As a star changes over the course of its lifetime, tidal resonance locking can cause hot Jupiters, which are massive exoplanets that orbit very close to their host stars, to change orbital distances. This wandering migration, as they call it, explains how some hot Jupiters get so close to their host stars. They also found that the path they take to get there is not always smooth. It can speed up, slow down, or even regress.
An important implication from the paper is that tidal resonance locking could be used as an exoplanet detection tool, confirming de Wit’s hypothesis from the original 2016 observation that the pulsations had the potential to be used in such a way. If changes in the star’s brightness can be linked to this resonance locking, it may indicate planets that can’t be detected using current methods.
As below, so above
Most EAPS PhD students don’t advance their project beyond the requirements for the general exam, let alone get a paper out of it. At first, Bryan worried that continuing with it would end up being a distraction from his main work, but ultimately was glad that he committed to it and was able to contribute something meaningful to the emerging field of asteroseismology.
“I think it’s evidence that Jared is excited about what he does and has the drive and scientific skepticism to have done the extra steps to make sure that what he was doing was a real contribution to the scientific literature,” says Frank. “He’s a great example of success and what we hope for our students.”
While de Wit didn’t manage to convince Bryan to switch to exoplanet research permanently, he is “excited that there is the opportunity to keep on working together.”
Once he finishes his PhD, Bryan plans on continuing in academia as a professor running a research lab, shifting his focus onto volcano seismology and improving instrumentation for the field. He’s open to the possibility of taking his findings on Earth and applying them to volcanoes on other planetary bodies, such as those found on Venus and Jupiter’s moon Io.
“I’d like to be the bridge between those two things,” he says.
PhD student Jared Bryan was able to use his knowledge of Earth-based seismology to solve an exoplanet mystery as to how hot Jupiters end up so close to their host stars. “I thought it would be a way to rethink the foundations of the field that I had been studying applied to a new region.”
In a new study, MIT physicists propose that if most of the dark matter in the universe is made up of microscopic primordial black holes — an idea first proposed in the 1970s — then these gravitational dwarfs should zoom through our solar system at least once per decade. A flyby like this, the researchers predict, would introduce a wobble into Mars’ orbit, to a degree that today’s technology could actually detect.
Such a detection could lend support to the idea that primordial black holes are a primary source of dark matter throughout the universe.
“Given decades of precision telemetry, scientists know the distance between Earth and Mars to an accuracy of about 10 centimeters,” says study author David Kaiser, professor of physics and the Germeshausen Professor of the History of Science at MIT. “We’re taking advantage of this highly instrumented region of space to try and look for a small effect. If we see it, that would count as a real reason to keep pursuing this delightful idea that all of dark matter consists of black holes that were spawned in less than a second after the Big Bang and have been streaming around the universe for 14 billion years.”
Kaiser and his colleagues report their findings today in the journal Physical Review D. The study’s co-authors are lead author Tung Tran ’24, who is now a graduate student at Stanford University; Sarah Geller ’12, SM ’17, PhD ’23, who is now a postdoc at the University of California at Santa Cruz; and MIT Pappalardo Fellow Benjamin Lehmann.
Beyond particles
Less than 20 percent of all physical matter is made from visible stuff, from stars and planets, to the kitchen sink. The rest is composed of dark matter, a hypothetical form of matter that is invisible across the entire electromagnetic spectrum yet is thought to pervade the universe and exert a gravitational force large enough to affect the motion of stars and galaxies.
Physicists have erected detectors on Earth to try and spot dark matter and pin down its properties. For the most part, these experiments assume that dark matter exists as a form of exotic particle that might scatter and decay into observable particles as it passes through a given experiment. But so far, such particle-based searches have come up empty.
In recent years, another possibility, first introduced in the 1970s, has regained traction: Rather than taking on a particle form, dark matter could exist as microscopic, primordial black holes that formed in the first moments following the Big Bang. Unlike the astrophysical black holes that form from the collapse of old stars, primordial black holes would have formed from the collapse of dense pockets of gas in the very early universe and would have scattered across the cosmos as the universe expanded and cooled.
These primordial black holes would have collapsed an enormous amount of mass into a tiny space. The majority of these primordial black holes could be as small as a single atom and as heavy as the largest asteroids. It would be conceivable, then, that such tiny giants could exert a gravitational force that could explain at least a portion of dark matter. For the MIT team, this possibility raised an initially frivolous question.
“I think someone asked me what would happen if a primordial black hole passed through a human body,” recalls Tung, who did a quick pencil-and-paper calculation to find that if such a black hole zinged within 1 meter of a person, the force of the black hole would push the person 6 meters, or about 20 feet away in a single second. Tung also found that the odds were astronomically unlikely that a primordial black hole would pass anywhere near a person on Earth.
Their interest piqued, the researchers took Tung’s calculations a step further, to estimate how a black hole flyby might affect much larger bodies such as the Earth and the moon.
“We extrapolated to see what would happen if a black hole flew by Earth and caused the moon to wobble by a little bit,” Tung says. “The numbers we got were not very clear. There are many other dynamics in the solar system that could act as some sort of friction to cause the wobble to dampen out.”
Close encounters
To get a clearer picture, the team generated a relatively simple simulation of the solar system that incorporates the orbits and gravitational interactions between all the planets, and some of the largest moons.
“State-of-the-art simulations of the solar system include more than a million objects, each of which has a tiny residual effect,” Lehmann notes. “But even modeling two dozen objects in a careful simulation, we could see there was a real effect that we could dig into.”
The team worked out the rate at which a primordial black hole should pass through the solar system, based on the amount of dark matter that is estimated to reside in a given region of space and the mass of a passing black hole, which in this case, they assumed to be as massive as the largest asteroids in the solar system, consistent with other astrophysical constraints.
“Primordial black holes do not live in the solar system. Rather, they’re streaming through the universe, doing their own thing,” says co-author Sarah Geller. “And the probability is, they’re going through the inner solar system at some angle once every 10 years or so.”
Given this rate, the researchers simulated various asteroid-mass black holes flying through the solar system, from various angles, and at velocities of about 150 miles per second. (The directions and speeds come from other studies of the distribution of dark matter throughout our galaxy.) They zeroed in on those flybys that appeared to be “close encounters,” or instances that caused some sort of effect in surrounding objects. They quickly found that any effect in the Earth or the moon was too uncertain to pin to a particular black hole. But Mars seemed to offer a clearer picture.
The researchers found that if a primordial black hole were to pass within a few hundred million miles of Mars, the encounter would set off a “wobble,” or a slight deviation in Mars’ orbit. Within a few years of such an encounter, Mars’ orbit should shift by about a meter — an incredibly small wobble, given the planet is more than 140 million miles from Earth. And yet, this wobble could be detected by the various high-precision instruments that are monitoring Mars today.
If such a wobble were detected in the next couple of decades, the researchers acknowledge there would still be much work needed to confirm that the push came from a passing black hole rather than a run-of-the-mill asteroid.
“We need as much clarity as we can of the expected backgrounds, such as the typical speeds and distributions of boring space rocks, versus these primordial black holes,” Kaiser notes. “Luckily for us, astronomers have been tracking ordinary space rocks for decades as they have flown through our solar system, so we could calculate typical properties of their trajectories and begin to compare them with the very different types of paths and speeds that primordial black holes should follow.”
To help with this, the researchers are exploring the possibility of a new collaboration with a group that has extensive expertise simulating many more objects in the solar system.
“We are now working to simulate a huge number of objects, from planets to moons and rocks, and how they’re all moving over long time scales,” Geller says. “We want to inject close encounter scenarios, and look at their effects with higher precision.”
“It’s a very neat test they’ve proposed, and it could tell us if the closest black hole is closer than we realize,” says Matt Caplan, associate professor of physics at Illinois State University, who was not involved in the study. “I should emphasize there’s a little bit of luck involved too. Whether or not a search finds a loud and clear signal depends on the exact path a wandering black hole takes through the solar system. Now that they’ve checked this idea with simulations, they have to do the hard part — checking the real data.”
This work was supported in part by the U.S. Department of Energy and the U.S. National Science Foundation, which includes an NSF Mathematical and Physical Sciences postdoctoral fellowship.
An artist’s illustration depicts a primordial black hole (at left) flying past, and briefly “wobbling” the orbit of Mars (at right), with the sun in the background. MIT scientists say such a wobble could be detectable by today’s instruments.
Ever been asked a question you only knew part of the answer to? To give a more informed response, your best move would be to phone a friend with more knowledge on the subject.
This collaborative process can also help large language models (LLMs) improve their accuracy. Still, it’s been difficult to teach LLMs to recognize when they should collaborate with another model on an answer. Instead of using complex formulas or large amounts of labeled data to spell out where models should work together, researchers at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) have envisioned a more organic approach.
Their new algorithm, called “Co-LLM,” can pair a general-purpose base LLM with a more specialized model and help them work together. As the former crafts an answer, Co-LLM reviews each word (or token) within its response to see where it can call upon a more accurate answer from the expert model. This process leads to more accurate replies to things like medical prompts and math and reasoning problems. Since the expert model is not needed at each iteration, this also leads to more efficient response generation.
To decide when a base model needs help from an expert model, the framework uses machine learning to train a “switch variable,” or a tool that can indicate the competence of each word within the two LLMs’ responses. The switch is like a project manager, finding areas where it should call in a specialist. If you asked Co-LLM to name some examples of extinct bear species, for instance, two models would draft answers together. The general-purpose LLM begins to put together a reply, with the switch variable intervening at the parts where it can slot in a better token from the expert model, such as adding the year when the bear species became extinct.
“With Co-LLM, we’re essentially training a general-purpose LLM to ‘phone’ an expert model when needed,” says Shannon Shen, an MIT PhD student in electrical engineering and computer science and CSAIL affiliate who’s a lead author on a new paper about the approach. “We use domain-specific data to teach the base model about its counterpart’s expertise in areas like biomedical tasks and math and reasoning questions. This process automatically finds the parts of the data that are hard for the base model to generate, and then it instructs the base model to switch to the expert LLM, which was pretrained on data from a similar field. The general-purpose model provides the ‘scaffolding’ generation, and when it calls on the specialized LLM, it prompts the expert to generate the desired tokens. Our findings indicate that the LLMs learn patterns of collaboration organically, resembling how humans recognize when to call upon an expert to fill in the blanks.”
A combination of flexibility and factuality
Imagine asking a general-purpose LLM to name the ingredients of a specific prescription drug. It may reply incorrectly, necessitating the expertise of a specialized model.
To showcase Co-LLM’s flexibility, the researchers used data like the BioASQ medical set to couple a base LLM with expert LLMs in different domains, like the Meditron model, which is pretrained on unlabeled medical data. This enabled the algorithm to help answer inquiries a biomedical expert would typically receive, such as naming the mechanisms causing a particular disease.
For example, if you asked a simple LLM alone to name the ingredients of a specific prescription drug, it may reply incorrectly. With the added expertise of a model that specializes in biomedical data, you’d get a more accurate answer. Co-LLM also alerts users where to double-check answers.
Another example of Co-LLM’s performance boost: When tasked with solving a math problem like “a3 · a2 if a=5,” the general-purpose model incorrectly calculated the answer to be 125. As Co-LLM trained the model to collaborate more with a large math LLM called Llemma, together they determined that the correct solution was 3,125.
Co-LLM gave more accurate replies than fine-tuned simple LLMs and untuned specialized models working independently. Co-LLM can guide two models that were trained differently to work together, whereas other effective LLM collaboration approaches, such as “Proxy Tuning,” need all of their component models to be trained similarly. Additionally, this baseline requires each model to be used simultaneously to produce the answer, whereas MIT’s algorithm simply activates its expert model for particular tokens, leading to more efficient generation.
When to ask the expert
The MIT researchers’ algorithm highlights that imitating human teamwork more closely can increase accuracy in multi-LLM collaboration. To further elevate its factual precision, the team may draw from human self-correction: They’re considering a more robust deferral approach that can backtrack when the expert model doesn’t give a correct response. This upgrade would allow Co-LLM to course-correct so the algorithm can still give a satisfactory reply.
The team would also like to update the expert model (via only training the base model) when new information is available, keeping answers as current as possible. This would allow Co-LLM to pair the most up-to-date information with strong reasoning power. Eventually, the model could assist with enterprise documents, using the latest information it has to update them accordingly. Co-LLM could also train small, private models to work with a more powerful LLM to improve documents that must remain within the server.
“Co-LLM presents an interesting approach for learning to choose between two models to improve efficiency and performance,” says Colin Raffel, associate professor at the University of Toronto and an associate research director at the Vector Institute, who wasn’t involved in the research. “Since routing decisions are made at the token-level, Co-LLM provides a granular way of deferring difficult generation steps to a more powerful model. The unique combination of model-token-level routing also provides a great deal of flexibility that similar methods lack. Co-LLM contributes to an important line of work that aims to develop ecosystems of specialized models to outperform expensive monolithic AI systems.”
Shen wrote the paper with four other CSAIL affiliates: PhD student Hunter Lang ’17, MEng ’18; former postdoc and Apple AI/ML researcher Bailin Wang; MIT assistant professor of electrical engineering and computer science Yoon Kim, and professor and Jameel Clinic member David Sontag PhD ’10, who are both part of MIT-IBM Watson AI Lab. Their research was supported, in part, by the National Science Foundation, The National Defense Science and Engineering Graduate (NDSEG) Fellowship, MIT-IBM Watson AI Lab, and Amazon. Their work was presented at the Annual Meeting of the Association for Computational Linguistics.
“Co-LLM” uses a general-purpose large language model to start replying to a prompt, with a “switch variable” intervening at certain words to call upon a more accurate answer from the expert model.
One of the brain’s most celebrated qualities is its adaptability. Changes to neural circuits, whose connections are continually adjusted as we experience and interact with the world, are key to how we learn. But to keep knowledge and memories intact, some parts of the circuitry must be resistant to this constant change.
“Brains have figured out how to navigate this landscape of balancing between stability and flexibility, so that you can have new learning and you can have lifelong memory,” says neuroscientist Mark Harnett, an investigator at MIT’s McGovern Institute for Brain Research. In the Aug. 27 issue of the journal Cell Reports, Harnett and his team show how individual neurons can contribute to both parts of this vital duality. By studying the synapses through which pyramidal neurons in the brain’s sensory cortex communicate, they have learned how the cells preserve their understanding of some of the world’s most fundamental features, while also maintaining the flexibility they need to adapt to a changing world.
Visual connections
Pyramidal neurons receive input from other neurons via thousands of connection points. Early in life, these synapses are extremely malleable; their strength can shift as a young animal takes in visual information and learns to interpret it. Most remain adaptable into adulthood, but Harnett’s team discovered that some of the cells’ synapses lose their flexibility when the animals are less than a month old. Having both stable and flexible synapses means these neurons can combine input from different sources to use visual information in flexible ways.
Postdoc Courtney Yaeger took a close look at these unusually stable synapses, which cluster together along a narrow region of the elaborately branched pyramidal cells. She was interested in the connections through which the cells receive primary visual information, so she traced their connections with neurons in a vision-processing center of the brain’s thalamus called the dorsal lateral geniculate nucleus (dLGN).
The long extensions through which a neuron receives signals from other cells are called dendrites, and they branch of from the main body of the cell into a tree-like structure. Spiny protrusions along the dendrites form the synapses that connect pyramidal neurons to other cells. Yaeger’s experiments showed that connections from the dLGN all led to a defined region of the pyramidal cells — a tight band within what she describes as the trunk of the dendritic tree.
Yaeger found several ways in which synapses in this region — formally known as the apical oblique dendrite domain — differ from other synapses on the same cells. “They’re not actually that far away from each other, but they have completely different properties,” she says.
Stable synapses
In one set of experiments, Yaeger activated synapses on the pyramidal neurons and measured the effect on the cells’ electrical potential. Changes to a neuron’s electrical potential generate the impulses the cells use to communicate with one another. It is common for a synapse’s electrical effects to amplify when synapses nearby are also activated. But when signals were delivered to the apical oblique dendrite domain, each one had the same effect, no matter how many synapses were stimulated. Synapses there don’t interact with one another at all, Harnett says. “They just do what they do. No matter what their neighbors are doing, they all just do kind of the same thing.”
The team was also able to visualize the molecular contents of individual synapses. This revealed a surprising lack of a certain kind of neurotransmitter receptor, called NMDA receptors, in the apical oblique dendrites. That was notable because of NMDA receptors’ role in mediating changes in the brain. “Generally when we think about any kind of learning and memory and plasticity, it’s NMDA receptors that do it,” Harnett says. “That is the by far most common substrate of learning and memory in all brains.”
When Yaeger stimulated the apical oblique synapses with electricity, generating patterns of activity that would strengthen most synapses, the team discovered a consequence of the limited presence of NMDA receptors. The synapses’ strength did not change. “There’s no activity-dependent plasticity going on there, as far as we have tested,” Yaeger says.
That makes sense, the researchers say, because the cells’ connections from the thalamus relay primary visual information detected by the eyes. It is through these connections that the brain learns to recognize basic visual features like shapes and lines.
“These synapses are basically a robust, high-fidelity readout of this visual information,” Harnett explains. “That’s what they’re conveying, and it’s not context-sensitive. So it doesn’t matter how many other synapses are active, they just do exactly what they’re going to do, and you can’t modify them up and down based on activity. So they’re very, very stable.”
“You actually don’t want those to be plastic,” adds Yaeger. "Can you imagine going to sleep and then forgetting what a vertical line looks like? That would be disastrous.”
By conducting the same experiments in mice of different ages, the researchers determined that the synapses that connect pyramidal neurons to the thalamus become stable a few weeks after young mice first open their eyes. By that point, Harnett says, they have learned everything they need to learn. On the other hand, if mice spend the first weeks of their lives in the dark, the synapses never stabilize — further evidence that the transition depends on visual experience.
The team’s findings not only help explain how the brain balances flexibility and stability; they could help researchers teach artificial intelligence how to do the same thing. Harnett says artificial neural networks are notoriously bad at this: when an artificial neural network that does something well is trained to do something new, it almost always experiences “catastrophic forgetting” and can no longer perform its original task. Harnett’s team is exploring how they can use what they’ve learned about real brains to overcome this problem in artificial networks.
A layer 5 pyramidal neuron imaged in vivo with two-photon microscopy. The oblique dendritic domain (pink) contains stable synapses, and the basal dendritic domain (blue) contains plastic synapses. The cell body and part of the dendritic trunk are white.
A collaboration between four MIT groups, led by principal investigators Laura L. Kiessling, Jeremiah A. Johnson, Alex K. Shalek, and Darrell J. Irvine, in conjunction with a group at Georgia Tech led by M.G. Finn, has revealed a new strategy for enabling immune system mobilization against cancer cells. The work, which appears today in ACS Nano, produces exactly the type of anti-tumor immunity needed to function as a tumor vaccine — both prophylactically and therapeutically.
Cancer cells can look very similar to the human cells from which they are derived. In contrast, viruses, bacteria, and fungi carry carbohydrates on their surfaces that are markedly different from those of human carbohydrates. Dendritic cells — the immune system’s best antigen-presenting cells — carry proteins on their surfaces that help them recognize these atypical carbohydrates and bring those antigens inside of them. The antigens are then processed into smaller peptides and presented to the immune system for a response. Intriguingly, some of these carbohydrate proteins can also collaborate to direct immune responses. This work presents a strategy for targeting those antigens to the dendritic cells that results in a more activated, stronger immune response.
Tackling tumors’ tenacity
The researchers’ new strategy shrouds the tumor antigens with foreign carbohydrates and co-delivers them with single-stranded RNA so that the dendritic cells can be programmed to recognize the tumor antigens as a potential threat. The researchers targeted the lectin (carbohydrate-binding protein) DC-SIGN because of its ability to serve as an activator of dendritic cell immunity. They decorated a virus-like particle (a particle composed of virus proteins assembled onto a piece of RNA that is noninfectious because its internal RNA is not from the virus) with DC-binding carbohydrate derivatives. The resulting glycan-costumed virus-like particles display unique sugars; therefore, the dendritic cells recognize them as something they need to attack.
“On the surface of the dendritic cells are carbohydrate binding proteins called lectins that combine to the sugars on the surface of bacteria or viruses, and when they do that they penetrate the membrane,” explains Kiessling, the paper’s senior author. “On the cell, the DC-SIGN gets clustered upon binding the virus or bacteria and that promotes internalization. When a virus-like particle gets internalized, it starts to fall apart and releases its RNA.” The toll-like receptor (bound to RNA) and DC-SIGN (bound to the sugar decoration) can both signal to activate the immune response.
Once the dendritic cells have sounded the alarm of a foreign invasion, a robust immune response is triggered that is significantly stronger than the immune response that would be expected with a typical untargeted vaccine. When an antigen is encountered by the dendritic cells, they send signals to T cells, the next cell in the immune system, to give different responses depending on what pathways have been activated in the dendritic cells.
Advancing cancer vaccine development
The activity of a potential vaccine developed in line with this new research is twofold. First, the vaccine glycan coat binds to lectins, providing a primary signal. Then, binding to toll-like receptors elicits potent immune activation.
The Kiessling, Finn, and Johnson groups had previously identified a synthetic DC-SIGN binding group that directed cellular immune responses when used to decorate virus-like particles. But it was unclear whether this method could be utilized as an anticancer vaccine. Collaboration between researchers in the labs at MIT and Georgia Tech demonstrated that in fact, it could.
Valerie Lensch, a chemistry PhD student from MIT’s Program in Polymers and Soft Matter and a joint member of the Kiessling and Johnson labs, took the preexisting strategy and tested it as an anticancer vaccine, learning a great deal about immunology in order to do so.
“We have developed a modular vaccine platform designed to drive antigen-specific cellular immune responses,” says Lensch. “This platform is not only pivotal in the fight against cancer, but also offers significant potential for combating challenging intracellular pathogens, including malaria parasites, HIV, and Mycobacterium tuberculosis. This technology holds promise for tackling a range of diseases where vaccine development has been particularly challenging.”
Lensch and her fellow researchers conducted in vitro experiments with extensive iterations of these glycan-costumed virus-like particles before identifying a design that demonstrated potential for success. Once that was achieved, the researchers were able to move on to an in vivo model, an exciting milestone for their research.
Adele Gabba, a postdoc in the Kiessling Lab, conducted the in vivo experiments with Lensch, and Robert Hincapie, who conducted his PhD studies with Professor M.G. Finn at Georgia Tech, built and decorated the virus-like particles with a series of glycans that were sent to him from the researchers at MIT.
“We are discovering that carbohydrates act like a language that cells use to communicate and direct the immune system,” says Gabba. “It's thrilling that we have begun to decode this language and can now harness it to reshape immune responses.”
“The design principles behind this vaccine are rooted in extensive fundamental research conducted by previous graduate student and postdoctoral researchers over many years, focusing on optimizing lectin engagement and understanding the roles of lectins in immunity,” says Lensch. “It has been exciting to witness the translation of these concepts into therapeutic platforms across various applications.”
In new research led by MIT scientists, virus-like particles (dark gray) coated in glycans (green) were administered via vaccination, triggering dendritic cells (light blue cell with long arms) to elicit T cell activation (gray circle) and a strong immune response.
A new study by MIT physicists proposes that a mysterious force known as early dark energy could solve two of the biggest puzzles in cosmology and fill in some major gaps in our understanding of how the early universe evolved.
One puzzle in question is the “Hubble tension,” which refers to a mismatch in measurements of how fast the universe is expanding. The other involves observations of numerous early, bright galaxies that existed at a time when the early universe should have been much less populated.
Now, the MIT team has found that both puzzles could be resolved if the early universe had one extra, fleeting ingredient: early dark energy. Dark energy is an unknown form of energy that physicists suspect is driving the expansion of the universe today. Early dark energy is a similar, hypothetical phenomenon that may have made only a brief appearance, influencing the expansion of the universe in its first moments before disappearing entirely.
Some physicists have suspected that early dark energy could be the key to solving the Hubble tension, as the mysterious force could accelerate the early expansion of the universe by an amount that would resolve the measurement mismatch.
The MIT researchers have now found that early dark energy could also explain the baffling number of bright galaxies that astronomers have observed in the early universe. In their new study, reported today in the Monthly Notices of the Royal Astronomical Society, the team modeled the formation of galaxies in the universe’s first few hundred million years. When they incorporated a dark energy component only in that earliest sliver of time, they found the number of galaxies that arose from the primordial environment bloomed to fit astronomers’ observations.
“You have these two looming open-ended puzzles,” says study co-author Rohan Naidu, a postdoc in MIT’s Kavli Institute for Astrophysics and Space Research. “We find that in fact, early dark energy is a very elegant and sparse solution to two of the most pressing problems in cosmology.”
The study’s co-authors include lead author and Kavli postdoc Xuejian (Jacob) Shen, and MIT professor of physics Mark Vogelsberger, along with Michael Boylan-Kolchin at the University of Texas at Austin, and Sandro Tacchella at the University of Cambridge.
Big city lights
Based on standard cosmological and galaxy formation models, the universe should have taken its time spinning up the first galaxies. It would have taken billions of years for primordial gas to coalesce into galaxies as large and bright as the Milky Way.
But in 2023, NASA’s James Webb Space Telescope (JWST) made a startling observation. With an ability to peer farther back in time than any observatory to date, the telescope uncovered a surprising number of bright galaxies as large as the modern Milky Way within the first 500 million years, when the universe was just 3 percent of its current age.
“The bright galaxies that JWST saw would be like seeing a clustering of lights around big cities, whereas theory predicts something like the light around more rural settings like Yellowstone National Park,” Shen says. “And we don’t expect that clustering of light so early on.”
For physicists, the observations imply that there is either something fundamentally wrong with the physics underlying the models or a missing ingredient in the early universe that scientists have not accounted for. The MIT team explored the possibility of the latter, and whether the missing ingredient might be early dark energy.
Physicists have proposed that early dark energy is a sort of antigravitational force that is turned on only at very early times. This force would counteract gravity’s inward pull and accelerate the early expansion of the universe, in a way that would resolve the mismatch in measurements. Early dark energy, therefore, is considered the most likely solution to the Hubble tension.
Galaxy skeleton
The MIT team explored whether early dark energy could also be the key to explaining the unexpected population of large, bright galaxies detected by JWST. In their new study, the physicists considered how early dark energy might affect the early structure of the universe that gave rise to the first galaxies. They focused on the formation of dark matter halos — regions of space where gravity happens to be stronger, and where matter begins to accumulate.
“We believe that dark matter halos are the invisible skeleton of the universe,” Shen explains. “Dark matter structures form first, and then galaxies form within these structures. So, we expect the number of bright galaxies should be proportional to the number of big dark matter halos.”
The team developed an empirical framework for early galaxy formation, which predicts the number, luminosity, and size of galaxies that should form in the early universe, given some measures of “cosmological parameters.” Cosmological parameters are the basic ingredients, or mathematical terms, that describe the evolution of the universe.
Physicists have determined that there are at least six main cosmological parameters, one of which is the Hubble constant — a term that describes the universe’s rate of expansion. Other parameters describe density fluctuations in the primordial soup, immediately after the Big Bang, from which dark matter halos eventually form.
The MIT team reasoned that if early dark energy affects the universe’s early expansion rate, in a way that resolves the Hubble tension, then it could affect the balance of the other cosmological parameters, in a way that might increase the number of bright galaxies that appear at early times. To test their theory, they incorporated a model of early dark energy (the same one that happens to resolve the Hubble tension) into an empirical galaxy formation framework to see how the earliest dark matter structures evolve and give rise to the first galaxies.
“What we show is, the skeletal structure of the early universe is altered in a subtle way where the amplitude of fluctuations goes up, and you get bigger halos, and brighter galaxies that are in place at earlier times, more so than in our more vanilla models,” Naidu says. “It means things were more abundant, and more clustered in the early universe.”
“A priori, I would not have expected the abundance of JWST’s early bright galaxies to have anything to do with early dark energy, but their observation that EDE pushes cosmological parameters in a direction that boosts the early-galaxy abundance is interesting,” says Marc Kamionkowski, professor of theoretical physics at Johns Hopkins University, who was not involved with the study. “I think more work will need to be done to establish a link between early galaxies and EDE, but regardless of how things turn out, it’s a clever — and hopefully ultimately fruitful — thing to try.”
“We demonstrated the potential of early dark energy as a unified solution to the two major issues faced by cosmology. This might be an evidence for its existence if the observational findings of JWST get further consolidated,” Vogelsberger concludes. “In the future, we can incorporate this into large cosmological simulations to see what detailed predictions we get.”
This research was supported, in part, by NASA and the National Science Foundation.
Early dark energy could have triggered the formation of numerous bright galaxies, very early in the universe, a new study finds. The mysterious unknown force could have caused early seeds of galaxies (depicted at left) to sprout many more bright galaxies (at right) than theory predicts.
Placebos are inert treatments, generally not expected to impact biological pathways or improve a person’s physical health. But time and again, some patients report that they feel better after taking a placebo. Increasingly, doctors and scientists are recognizing that rather than dismissing placebos as mere trickery, they may be able to help patients by harnessing their power.
To maximize the impact of the placebo effect and design reliable therapeutic strategies, researchers need a better understanding of how it works. Now, with a new animal model developed by scientists at the McGovern Institute at MIT, they will be able to investigate the neural circuits that underlie placebos’ ability to elicit pain relief.
“The brain and body interaction has a lot of potential, in a way that we don't fully understand,” says Fan Wang, an MIT professor of brain and cognitive sciences and investigator at the McGovern Institute. “I really think there needs to be more of a push to understand placebo effect, in pain and probably in many other conditions. Now we have a strong model to probe the circuit mechanism.”
Context-dependent placebo effect
In the Sept. 5, 2024, issue of the journal Current Biology, Wang and her team report that they have elicited strong placebo pain relief in mice by activating pain-suppressing neurons in the brain while the mice are in a specific environment, thereby teaching the animals that they feel better when they are in that context. Following their training, placing the mice in that environment alone is enough to suppress pain. The team’s experiments — which were funded by the National Institutes of Health, the K. Lisa Yang Brain-Body Center, and the K. Lisa Yang and Hock E. Tan Center for Molecular Therapeutics within MIT’s Yang Tan Collective — show that this context-dependent placebo effect relieves both acute and chronic pain.
Context is critical for the placebo effect. While a pill can help a patient feel better when they expect it to, even if it is made only of sugar or starch, it seems to be not just the pill that sets up those expectations, but the entire scenario in which the pill is taken. For example, being in a hospital and interacting with doctors can contribute to a patient’s perception of care, and these social and environmental factors can make a placebo effect more probable.
MIT postdocs Bin Chen and Nitsan Goldstein used visual and textural cues to define a specific place. Then they activated pain-suppressing neurons in the brain while the animals were in this “pain-relief box.” Those pain-suppressing neurons, which Wang’s lab discovered a few years ago, are located in an emotion-processing center of the brain called the central amygdala. By expressing light-sensitive channels in these neurons, the researchers were able to suppress pain with light in the pain-relief box and leave the neurons inactive when mice were in a control box.
Animals learned to prefer the pain-relief box to other environments. And when the researchers tested their response to potentially painful stimuli after they had made that association, they found the mice were less sensitive while they were there. “Just by being in the context that they had associated with pain suppression, we saw that reduced pain—even though we weren't actually activating those [pain-suppressing] neurons,” Goldstein explains.
Acute and chronic pain relief
Some scientists have been able to elicit placebo pain relief in rodents by treating the animals with morphine, linking environmental cues to the pain suppression caused by the drugs similar to the way Wang’s team did by directly activating pain-suppressing neurons. This drug-based approach works best for setting up expectations of relief for acute pain; its placebo effect is short-lived and mostly ineffective against chronic pain. So Wang, Chen, and Goldstein were particularly pleased to find that their engineered placebo effect was effective for relieving both acute and chronic pain.
In their experiments, animals experiencing a chemotherapy-induced hypersensitivity to touch exhibited a preference for the pain relief box as much as animals who were exposed to a chemical that induces acute pain, days after their initial conditioning. Once there, their chemotherapy-induced pain sensitivity was eliminated; they exhibited no more sensitivity to painful stimuli than they had prior to receiving chemotherapy.
One of the biggest surprises came when the researchers turned their attention back to the pain-suppressing neurons in the central amygdala that they had used to trigger pain relief. They suspected that those neurons might be reactivated when mice returned to the pain-relief box. Instead, they found that after the initial conditioning period, those neurons remained quiet. “These neurons are not reactivated, yet the mice appear to be no longer in pain,” Wang says. “So it suggests this memory of feeling well is transferred somewhere else.”
Goldstein adds that there must be a pain-suppressing neural circuit somewhere that is activated by pain-relief-associated contexts — and the team’s new placebo model sets researchers up to investigate those pathways. A deeper understanding of that circuitry could enable clinicians to deploy the placebo effect — alone or in combination with active treatments — to better manage patients’ pain in the future.
By manipulating pain-suppressing neurons in the brain, MIT researchers at the McGovern Institute taught mice to seek out an environment associated with pain relief — and those expectations alone were enough to alleviate pain.
To the untrained eye, a medical image like an MRI or X-ray appears to be a murky collection of black-and-white blobs. It can be a struggle to decipher where one structure (like a tumor) ends and another begins.
When trained to understand the boundaries of biological structures, AI systems can segment (or delineate) regions of interest that doctors and biomedical workers want to monitor for diseases and other abnormalities. Instead of losing precious time tracing anatomy by hand across many images, an artificial assistant could do that for them.
The catch? Researchers and clinicians must label countless images to train their AI system before it can accurately segment. For example, you’d need to annotate the cerebral cortex in numerous MRI scans to train a supervised model to understand how the cortex’s shape can vary in different brains.
Sidestepping such tedious data collection, researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), Massachusetts General Hospital (MGH), and Harvard Medical School have developed the interactive “ScribblePrompt” framework: a flexible tool that can help rapidly segment any medical image, even types it hasn’t seen before.
Instead of having humans mark up each picture manually, the team simulated how users would annotate over 50,000 scans, including MRIs, ultrasounds, and photographs, across structures in the eyes, cells, brains, bones, skin, and more. To label all those scans, the team used algorithms to simulate how humans would scribble and click on different regions in medical images. In addition to commonly labeled regions, the team also used superpixel algorithms, which find parts of the image with similar values, to identify potential new regions of interest to medical researchers and train ScribblePrompt to segment them. This synthetic data prepared ScribblePrompt to handle real-world segmentation requests from users.
“AI has significant potential in analyzing images and other high-dimensional data to help humans do things more productively,” says MIT PhD student Hallee Wong SM ’22, the lead author on a new paper about ScribblePrompt and a CSAIL affiliate. “We want to augment, not replace, the efforts of medical workers through an interactive system. ScribblePrompt is a simple model with the efficiency to help doctors focus on the more interesting parts of their analysis. It’s faster and more accurate than comparable interactive segmentation methods, reducing annotation time by 28 percent compared to Meta’s Segment Anything Model (SAM) framework, for example.”
ScribblePrompt’s interface is simple: Users can scribble across the rough area they’d like segmented, or click on it, and the tool will highlight the entire structure or background as requested. For example, you can click on individual veins within a retinal (eye) scan. ScribblePrompt can also mark up a structure given a bounding box.
Then, the tool can make corrections based on the user’s feedback. If you wanted to highlight a kidney in an ultrasound, you could use a bounding box, and then scribble in additional parts of the structure if ScribblePrompt missed any edges. If you wanted to edit your segment, you could use a “negative scribble” to exclude certain regions.
These self-correcting, interactive capabilities made ScribblePrompt the preferred tool among neuroimaging researchers at MGH in a user study. 93.8 percent of these users favored the MIT approach over the SAM baseline in improving its segments in response to scribble corrections. As for click-based edits, 87.5 percent of the medical researchers preferred ScribblePrompt.
ScribblePrompt was trained on simulated scribbles and clicks on 54,000 images across 65 datasets, featuring scans of the eyes, thorax, spine, cells, skin, abdominal muscles, neck, brain, bones, teeth, and lesions. The model familiarized itself with 16 types of medical images, including microscopies, CT scans, X-rays, MRIs, ultrasounds, and photographs.
“Many existing methods don't respond well when users scribble across images because it’s hard to simulate such interactions in training. For ScribblePrompt, we were able to force our model to pay attention to different inputs using our synthetic segmentation tasks,” says Wong. “We wanted to train what’s essentially a foundation model on a lot of diverse data so it would generalize to new types of images and tasks.”
After taking in so much data, the team evaluated ScribblePrompt across 12 new datasets. Although it hadn’t seen these images before, it outperformed four existing methods by segmenting more efficiently and giving more accurate predictions about the exact regions users wanted highlighted.
“Segmentation is the most prevalent biomedical image analysis task, performed widely both in routine clinical practice and in research — which leads to it being both very diverse and a crucial, impactful step,” says senior author Adrian Dalca SM ’12, PhD ’16, CSAIL research scientist and assistant professor at MGH and Harvard Medical School. “ScribblePrompt was carefully designed to be practically useful to clinicians and researchers, and hence to substantially make this step much, much faster.”
“The majority of segmentation algorithms that have been developed in image analysis and machine learning are at least to some extent based on our ability to manually annotate images,” says Harvard Medical School professor in radiology and MGH neuroscientist Bruce Fischl, who was not involved in the paper. “The problem is dramatically worse in medical imaging in which our ‘images’ are typically 3D volumes, as human beings have no evolutionary or phenomenological reason to have any competency in annotating 3D images. ScribblePrompt enables manual annotation to be carried out much, much faster and more accurately, by training a network on precisely the types of interactions a human would typically have with an image while manually annotating. The result is an intuitive interface that allows annotators to naturally interact with imaging data with far greater productivity than was previously possible.”
Wong and Dalca wrote the paper with two other CSAIL affiliates: John Guttag, the Dugald C. Jackson Professor of EECS at MIT and CSAIL principal investigator; and MIT PhD student Marianne Rakic SM ’22. Their work was supported, in part, by Quanta Computer Inc., the Eric and Wendy Schmidt Center at the Broad Institute, the Wistron Corp., and the National Institute of Biomedical Imaging and Bioengineering of the National Institutes of Health, with hardware support from the Massachusetts Life Sciences Center.
Wong and her colleagues’ work will be presented at the 2024 European Conference on Computer Vision and was presented as an oral talk at the DCAMI workshop at the Computer Vision and Pattern Recognition Conference earlier this year. They were awarded the Bench-to-Bedside Paper Award at the workshop for ScribblePrompt’s potential clinical impact.
ScribblePrompt’s interface allows users to scribble across the rough area of a biomedical image they’d like segmented. They can also click on it or use a bounding box, and the tool will highlight the entire structure or background as requested.
Sarah Sterling, director of the Cryo-Electron Microscopy, or Cryo-EM, core facility, often compares her job to running a small business. Each day brings a unique set of jobs ranging from administrative duties and managing facility users to balancing budgets and maintaining equipment.
Although one could easily be overwhelmed by the seemingly never-ending to-do list, Sterling finds a great deal of joy in wearing so many different hats. One of her most essential tasks involves clear communication with users when the delicate instruments in the facility are unusable because of routine maintenance and repairs.
“Better planning allows for better science,” Sterling says. “Luckily, I’m very comfortable with building and fixing things. Let’s troubleshoot. Let’s take it apart. Let’s put it back together.”
Out of all her duties as a core facility director, she most looks forward to the opportunities to teach, especially helping students develop research projects.
“Undergraduate or early-stage graduate students ask the best questions,” she says. “They’re so curious about the tiny details, and they’re always ready to hit the ground running on their projects.”
A non-linear scientific journey
When Sterling enrolled in Russell Sage College, a women’s college in New York, she was planning to pursue a career as a physical therapist. However, she quickly realized she loved her chemistry classes more than her other subjects. She graduated with a bachelor of science degree in chemistry and immediately enrolled in a master’s degree program in chemical engineering at the University of Maine.
Sterling was convinced to continue her studies at the University of Maine with a dual PhD in chemical engineering and biomedical sciences. That decision required the daunting process of taking two sets of core courses and completing a qualifying exam in each field.
“I wouldn’t recommend doing that,” she says with a laugh. “To celebrate after finishing that intense experience, I took a year off to figure out what came next.”
Sterling chose to do a postdoc in the lab of Eva Nogales, a structural biology professor at the University of California at Berkeley. Nogales was looking for a scientist with experience working with lipids, a class of molecules that Sterling had studied extensively in graduate school.
At the time Sterling joined, the Nogales Lab was at the forefront of implementing an exciting structural biology approach: cryo-EM.
“When I was interviewing, I’d never even seen the type of microscope required for cryo-EM, let alone performed any experiments,” Sterling says. “But I remember thinking ‘I’m sure I can figure this out.’”
Cryo-EM is a technique that allows researchers to determine the three-dimensional shape, or structure, of the macromolecules that make up cells. A researcher can take a sample of their macromolecule of choice, suspend it in a liquid solution, and rapidly freeze it onto a grid to capture the macromolecules in random positions — the “cryo” part of the name. Powerful electron microscopes then collect images of the macromolecule — the EM part of cryo-EM.
The two-dimensional images of the macromolecules from different angles can be combined to produce a three-dimensional structure. Structural information like this can reveal the macromolecule’s function inside cells or inform how it differs in a disease state. The rapidly expanding use of cryo-EM has unlocked so many mechanistic insights that the researchers who developed the technology were awarded the 2017 Nobel Prize in Chemistry.
The MIT.nano facility opened its doors in 2018. The open-access, state-of-the-art facility now has more than 160 tools and more than 1,500 users representing nearly every department at MIT. The Cryo-EM facility lives in the basement of the MIT.nano building and houses multiple electron microscopes and laboratory space for cryo-specimen preparation.
Thanks to her work at UC Berkeley, Sterling’s career trajectory has long been intertwined with the expanding use of cryo-EM in research. Sterling anticipated the need for experienced scientists to run core facilities in order to maintain the electron microscopes needed for cryo-EM, which range in cost from a staggering $1 million to $10 million each.
After completing her postdoc, Sterling worked at the Harvard University cryo-EM core facility for five years. When the director position for the MIT.nano Cryo-EM facility opened, she decided to apply.
“I like that the core facility at MIT was smaller and more frequently used by students,” Sterling says. “There’s a lot more teaching, which is a challenge sometimes, but it’s rewarding to impact someone’s career at such an early stage.”
A focus on users
When Sterling arrived at MIT, her first initiative was to meet directly with all the students in research labs that use the core facility to learn what would make using the facility a better experience. She also implemented clear and standard operating procedures for cryo-EM beginners.
“I think being consistent and available has really improved users’ experiences,” Sterling says.
The users themselves report that her initiatives have proven highly successful — and have helped them grow as scientists.
“Sterling cultivates an environment where I can freely ask questions about anything to support my learning,” says Bonnie Su, a frequent Cryo-EM facility user and graduate student from the Vos lab.
But Sterling does not want to stop there. Looking ahead, she hopes to expand the facility by acquiring an additional electron microscope to allow more users to utilize this powerful technology in their research. She also plans to build a more collaborative community of cryo-EM scientists at MIT with additional symposia and casual interactions such as coffee hours.
Under her management, cryo-EM research has flourished. In the last year, the Cryo-EM core facility has supported research resulting in 12 new publications across five different departments at MIT. The facility has also provided access to 16 industry and non-MIT academic entities. These studies have revealed important insights into various biological processes, from visualizing how large protein machinery reads our DNA to the protein aggregates found in neurodegenerative disorders.
If anyone wants to conduct cryo-EM experiments or learn more about the technique, Sterling encourages anyone in the MIT community to reach out.
“Come visit us!” she says. “We give lots of tours, and you can stop by to say hi anytime.”
Sarah Sterling, the director of the Cryo-EM core facility at MIT.nano, poses with one of the powerful electron microscopes while the machine was exposed for repair. One of Sterling’s most essential jobs is clear communication with users about when routine maintenance and repair of the core facility’s machinery may affect experiments, because, she says, “better planning allows for better science.”
The idea of electrically stimulating a brain region called the central thalamus has gained traction among researchers and clinicians because it can help arouse subjects from unconscious states induced by traumatic brain injury or anesthesia, and can boost cognition and performance in awake animals. But the method, called CT-DBS, can have a side effect: seizures. A new study by researchers at MIT and Massachusetts General Hospital (MGH) who were testing the method in awake mice quantifies the probability of seizures at different stimulation currents and cautions that they sometimes occurred even at low levels.
“Understanding production and prevalence of this type of seizure activity is important because brain stimulation-based therapies are becoming more widely used,” says co-senior author Emery N. Brown, Edward Hood Taplin Professor of Medical Engineering and Computational Neuroscience in The Picower Institute for Learning and Memory, the Institute for Medical Engineering and Science, the Department of Brain and Cognitive Sciences, and the Center for Brains Minds and Machines (CBMM) at MIT.
In the brain, the seizures associated with CT-DBS occur as “electrographic seizures,” which are bursts of voltage among neurons across a broad spectrum of frequencies. Behaviorally, they manifest as “absence seizures” in which the subject appears to take on a blank stare and freezes for about 10-20 seconds.
In their study, the researchers were hoping to determine a CT-DBS stimulation current — in a clinically relevant range of under 200 microamps — below which seizures could be reliably avoided.
In search of that ideal current, they developed a protocol of starting brief bouts of CT-DBS at 1 microamp and then incrementally ramping the current up to 200 microamps until they found a threshold where an electrographic seizure occurred. Once they found that threshold, then they tested a longer bout of stimulation at the next lowest current level in hopes that an electrographic seizure wouldn’t occur. They did this for a variety of different stimulation frequencies. To their surprise, electrographic seizures still occurred 2.2 percent of the time during those longer stimulation trials (i.e. 22 times out of 996 tests) and in 10 out of 12 mice. At just 20 microamps, mice still experienced seizures in three out of 244 tests, a 1.2 percent rate.
“This is something that we needed to report because this was really surprising,” says co-lead author Francisco Flores, a research affiliate in The Picower Institute and CBMM, and an instructor in anesthesiology at MGH, where Brown is also an anesthesiologist. Isabella Dalla Betta, a technical associate in The Picower Institute, co-led the study published in Brain Stimulation.
Stimulation frequency didn’t matter for seizure risk but the rate of electrographic seizures increased as the current level increased. For instance, it happened in 5 out of 190 tests at 50 microamps, and two out of 65 tests at 100 microamps. The researchers also found that when an electrographic seizure occurred, it did so more quickly at higher currents than at lower levels. Finally, they also saw that seizures happened more quickly if they stimulated the thalamus on both sides of the brain, versus just one side. Some mice exhibited behaviors similar to absence seizure, though others became hyperactive.
It is not clear why some mice experienced electrographic seizures at just 20 microamps while two mice did not experience the seizures even at 200. Flores speculated that there may be different brain states that change the predisposition to seizures amid stimulation of the thalamus. Notably, seizures are not typically observed in humans who receive CT-DBS while in a minimally conscious state after a traumatic brain injury or in animals who are under anesthesia. Flores said the next stage of the research would aim to discern what the relevant brain states may be.
In the meantime, the study authors wrote, “EEG should be closely monitored for electrographic seizures when performing CT-DBS, especially in awake subjects.”
The paper’s co-senior author is Matt Wilson, Sherman Fairchild Professor in The Picower Institute, CBMM, and the departments of Biology and Brain and Cognitive Sciences. In addition to Dalla Betta, Flores, Brown and Wilson, the study’s other authors are John Tauber, David Schreier, and Emily Stephen.
Support for the research came from The JPB Foundation, The Picower Institute for Learning and Memory; George J. Elbaum ’59, SM ’63, PhD ’67, Mimi Jensen, Diane B. Greene SM ’78, Mendel Rosenblum, Bill Swanson, annual donors to the Anesthesia Initiative Fund; and the National Institutes of Health.
Typically, electrons are free agents that can move through most metals in any direction. When they encounter an obstacle, the charged particles experience friction and scatter randomly like colliding billiard balls.
But in certain exotic materials, electrons can appear to flow with single-minded purpose. In these materials, electrons may become locked to the material’s edge and flow in one direction, like ants marching single-file along a blanket’s boundary. In this rare “edge state,” electrons can flow without friction, gliding effortlessly around obstacles as they stick to their perimeter-focused flow. Unlike in a superconductor, where all electrons in a material flow without resistance, the current carried by edge modes occurs only at a material’s boundary.
Now MIT physicists have directly observed edge states in a cloud of ultracold atoms. For the first time, the team has captured images of atoms flowing along a boundary without resistance, even as obstacles are placed in their path. The results, which appear today in Nature Physics, could help physicists manipulate electrons to flow without friction in materials that could enable super-efficient, lossless transmission of energy and data.
“You could imagine making little pieces of a suitable material and putting it inside future devices, so electrons could shuttle along the edges and between different parts of your circuit without any loss,” says study co-author Richard Fletcher, assistant professor of physics at MIT. “I would stress though that, for us, the beauty is seeing with your own eyes physics which is absolutely incredible but usually hidden away in materials and unable to be viewed directly.”
The study’s co-authors at MIT include graduate students Ruixiao Yao and Sungjae Chi, former graduate students Biswaroop Mukherjee PhD ’20 and Airlia Shaffer PhD ’23, along with Martin Zwierlein, the Thomas A. Frank Professor of Physics. The co-authors are all members of MIT’s Research Laboratory of Electronics and the MIT-Harvard Center for Ultracold Atoms.
Forever on the edge
Physicists first invoked the idea of edge states to explain a curious phenomenon, known today as the Quantum Hall effect, which scientists first observed in 1980, in experiments with layered materials, where electrons were confined to two dimensions. These experiments were performed in ultracold conditions, and under a magnetic field. When scientists tried to send a current through these materials, they observed that electrons did not flow straight through the material, but instead accumulated on one side, in precise quantum portions.
To try and explain this strange phenomenon, physicists came up with the idea that these Hall currents are carried by edge states. They proposed that, under a magnetic field, electrons in an applied current could be deflected to the edges of a material, where they would flow and accumulate in a way that might explain the initial observations.
“The way charge flows under a magnetic field suggests there must be edge modes,” Fletcher says. “But to actually see them is quite a special thing because these states occur over femtoseconds, and across fractions of a nanometer, which is incredibly difficult to capture.”
Rather than try and catch electrons in an edge state, Fletcher and his colleagues realized they might be able to recreate the same physics in a larger and more observable system. The team has been studying the behavior of ultracold atoms in a carefully designed setup that mimics the physics of electrons under a magnetic field.
“In our setup, the same physics occurs in atoms, but over milliseconds and microns,” Zwierlein explains. “That means that we can take images and watch the atoms crawl essentially forever along the edge of the system.”
A spinning world
In their new study, the team worked with a cloud of about 1 million sodium atoms, which they corralled in a laser-controlled trap, and cooled to nanokelvin temperatures. They then manipulated the trap to spin the atoms around, much like riders on an amusement park Gravitron.
“The trap is trying to pull the atoms inward, but there’s centrifugal force that tries to pull them outward,” Fletcher explains. “The two forces balance each other, so if you’re an atom, you think you’re living in a flat space, even though your world is spinning. There’s also a third force, the Coriolis effect, such that if they try to move in a line, they get deflected. So these massive atoms now behave as if they were electrons living in a magnetic field.”
Into this manufactured reality, the researchers then introduced an “edge,” in the form of a ring of laser light, which formed a circular wall around the spinning atoms. As the team took images of the system, they observed that when the atoms encountered the ring of light, they flowed along its edge, in just one direction.
“You can imagine these are like marbles that you’ve spun up really fast in a bowl, and they just keep going around and around the rim of the bowl,” Zwierlein offers. “There is no friction. There is no slowing down, and no atoms leaking or scattering into the rest of the system. There is just beautiful, coherent flow.”
“These atoms are flowing, free of friction, for hundreds of microns,” Fletcher adds. “To flow that long, without any scattering, is a type of physics you don’t normally see in ultracold atom systems.”
This effortless flow held up even when the researchers placed an obstacle in the atoms’ path, like a speed bump, in the form of a point of light, which they shone along the edge of the original laser ring. Even as they came upon this new obstacle, the atoms didn’t slow their flow or scatter away, but instead glided right past without feeling friction as they normally would.
“We intentionally send in this big, repulsive green blob, and the atoms should bounce off it,” Fletcher says. “But instead what you see is that they magically find their way around it, go back to the wall, and continue on their merry way.”
The team’s observations in atoms document the same behavior that has been predicted to occur in electrons. Their results show that the setup of atoms is a reliable stand-in for studying how electrons would behave in edge states.
“It’s a very clean realization of a very beautiful piece of physics, and we can directly demonstrate the importance and reality of this edge,” Fletcher says. “A natural direction is to now introduce more obstacles and interactions into the system, where things become more unclear as to what to expect.”
This research was supported, in part, by the National Science Foundation.
An artist’s illustration of a quantum fluid made from atoms (gold), streaming along a wall made from laser light (green), and effortlessly navigating around obstacles placed in their path.
Water contamination by the chemicals used in today’s technology is a rapidly growing problem globally. A recent study by the U.S. Centers for Disease Control found that 98 percent of people tested had detectable levels of PFAS, a family of particularly long-lasting compounds also known as “forever chemicals,” in their bloodstream.
A new filtration material developed by researchers at MIT might provide a nature-based solution to this stubborn contamination issue. The material, based on natural silk and cellulose, can remove a wide variety of these persistent chemicals as well as heavy metals. And, its antimicrobial properties can help keep the filters from fouling.
The findings are described in the journal ACS Nano, in a paper by MIT postdoc Yilin Zhang, professor of civil and environmental engineering Benedetto Marelli, and four others from MIT.
PFAS chemicals are present in a wide range of products, including cosmetics, food packaging, water-resistant clothing, firefighting foams, and antistick coating for cookware. A recent study identified 57,000 sites contaminated by these chemicals in the U.S. alone. The U.S. Environmental Protection Agency has estimated that PFAS remediation will cost $1.5 billion per year, in order to meet new regulations that call for limiting the compound to less than 7 parts per trillion in drinking water.
Contamination by PFAS and similar compounds “is actually a very big deal, and current solutions may only partially resolve this problem very efficiently or economically,” Zhang says. “That’s why we came up with this protein and cellulose-based, fully natural solution,” he says.
“We came to the project by chance,” Marelli notes. The initial technology that made the filtration material possible was developed by his group for a completely unrelated purpose — as a way to make a labelling system to counter the spread of counterfeit seeds, which are often of inferior quality. His team devised a way of processing silk proteins into uniform nanoscale crystals, or “nanofibrils,” through an environmentally benign, water-based drop-casting method at room temperature.
Zhang suggested that their new nanofibrillar material might be effective at filtering contaminants, but initial attempts with the silk nanofibrils alone didn’t work. The team decided to try adding another material: cellulose, which is abundantly available and can be obtained from agricultural wood pulp waste. The researchers used a self-assembly method in which the silk fibroin protein is suspended in water and then templated into nanofibrils by inserting “seeds” of cellulose nanocrystals. This causes the previously disordered silk molecules to line up together along the seeds, forming the basis of a hybrid material with distinct new properties.
By integrating cellulose into the silk-based fibrils that could be formed into a thin membrane, and then tuning the electrical charge of the cellulose, the researchers produced a material that was highly effective at removing contaminants in lab tests.
The electrical charge of the cellulose, they found, also gave it strong antimicrobial properties. This is a significant advantage, since one of the primary causes of failure in filtration membranes is fouling by bacteria and fungi. The antimicrobial properties of this material should greatly reduce that fouling issue, the researchers say.
“These materials can really compete with the current standard materials in water filtration when it comes to extracting metal ions and these emerging contaminants, and they can also outperform some of them currently,” Marelli says. In lab tests, the materials were able to extract orders of magnitude more of the contaminants from water than the currently used standard materials, activated carbon or granular activated carbon.
While the new work serves as a proof of principle, Marelli says, the team plans to continue working on improving the material, especially in terms of durability and availability of source materials. While the silk proteins used can be available as a byproduct of the silk textile industry, if this material were to be scaled up to address the global needs for water filtration, the supply might be insufficient. Also, alternative protein materials may turn out to perform the same function at lower cost.
Initially, the material would likely be used as a point-of-use filter, something that could be attached to a kitchen faucet, Zhang says. Eventually, it could be scaled up to provide filtration for municipal water supplies, but only after testing demonstrates that this would not pose any risk of introducing any contamination into the water supply. But one big advantage of the material, he says, is that both the silk and the cellulose constituents are considered food-grade substances, so any contamination is unlikely.
“Most of the normal materials available today are focusing on one class of contaminants or solving single problems,” Zhang says. “I think we are among the first to address all of these simultaneously.”
“What I love about this approach is that it is using only naturally grown materials like silk and cellulose to fight pollution,” says Hannes Schniepp, professor of applied science at the College of William and Mary, who was not associated with this work. “In competing approaches, synthetic materials are used — which usually require only more chemistry to fight some of the adverse outcomes that chemistry has produced. [This work] breaks this cycle! ... If this can be mass-produced in an economically viable way, this could really have a major impact.”
The research team included MIT postdocs Hui Sun and Meng Li, graduate student Maxwell Kalinowski, and recent graduate Yunteng Cao PhD ’22, now a postdoc at Yale University. The work was supported by the U.S. Office of Naval Research, the U.S. National Science Foundation, and the Singapore-MIT Alliance for Research and Technology.
Imagine how a phone call works: Your voice is converted into electronic signals, shifted up to higher frequencies, transmitted over long distances, and then shifted back down so it can be heard clearly on the other end. The process enabling this shifting of signal frequencies is called frequency mixing, and it is essential for communication technologies like radio and Wi-Fi. Frequency mixers are vital components in many electronic devices and typically operate using frequencies that oscillate billions (GHz, gigahertz) to trillions (THz, terahertz) of times per second.
Now imagine a frequency mixer that works at a quadrillion (PHz, petahertz) times per second — up to a million times faster. This frequency range corresponds to the oscillations of the electric and magnetic fields that make up light waves. Petahertz-frequency mixers would allow us to shift signals up to optical frequencies and then back down to more conventional electronic frequencies, enabling the transmission and processing of vastly larger amounts of information at many times higher speeds. This leap in speed isn’t just about doing things faster; it’s about enabling entirely new capabilities.
Lightwave electronics (or petahertz electronics) is an emerging field that aims to integrate optical and electronic systems at incredibly high speeds, leveraging the ultrafast oscillations of light fields. The key idea is to harness the electric field of light waves, which oscillate on sub-femtosecond (10-15 seconds) timescales, to directly drive electronic processes. This allows for the processing and manipulation of information at speeds far beyond what is possible with current electronic technologies. In combination with other petahertz electronic circuitry, a petahertz electronic mixer would allow us to process and analyze vast amounts of information in real time and transfer larger amounts of data over the air at unprecedented speeds. The MIT team’s demonstration of a lightwave-electronic mixer at petahertz-scale frequencies is a first step toward making communication technology faster, and progresses research toward developing new, miniaturized lightwave electronic circuitry capable of handling optical signals directly at the nanoscale.
In the 1970s, scientists began exploring ways to extend electronic frequency mixing into the terahertz range using diodes. While these early efforts showed promise, progress stalled for decades. Recently, however, advances in nanotechnology have reignited this area of research. Researchers discovered that tiny structures like nanometer-length-scale needle tips and plasmonic antennas could function similarly to those early diodes but at much higher frequencies.
A recent open-access study published in Science Advances by Matthew Yeung, Lu-Ting Chou, Marco Turchetti, Felix Ritzkowsky, Karl K. Berggren, and Phillip D. Keathley at MIT has demonstrated a significant step forward. They developed an electronic frequency mixer for signal detection that operates beyond 0.350 PHz using tiny nanoantennae. These nanoantennae can mix different frequencies of light, enabling analysis of signals oscillating orders of magnitude faster than the fastest accessible to conventional electronics. Such petahertz electronic devices could enable developments that ultimately revolutionize fields that require precise analysis of extremely fast optical signals, such as spectroscopy and imaging, where capturing femtosecond-scale dynamics is crucial (a femtosecond is one-millionth of one-billionth of a second).
The team’s study highlights the use of nanoantenna networks to create a broadband, on-chip electronic optical frequency mixer. This innovative approach allows for the accurate readout of optical wave forms spanning more than one octave of bandwidth. Importantly, this process worked using a commercial turnkey laser that can be purchased off the shelf, rather than a highly customized laser.
While optical frequency mixing is possible using nonlinear materials, the process is purely optical (that is, it converts light input to light output at a new frequency). Furthermore, the materials have to be many wavelengths in thickness, limiting the device size to the micrometer scale (a micrometer is one-millionth of a meter). In contrast, the lightwave-electronic method demonstrated by the authors uses a light-driven tunneling mechanism that offers high nonlinearities for frequency mixing and direct electronic output using nanometer-scale devices (a nanometer is one-billionth of a meter).
While this study focused on characterizing light pulses of different frequencies, the researchers envision that similar devices will enable one to construct circuits using light waves. This device, with bandwidths spanning multiple octaves, could provide new ways to investigate ultrafast light-matter interactions, accelerating advancements in ultrafast source technologies.
This work not only pushes the boundaries of what is possible in optical signal processing but also bridges the gap between the fields of electronics and optics. By connecting these two important areas of research, this study paves the way for new technologies and applications in fields like spectroscopy, imaging, and communications, ultimately advancing our ability to explore and manipulate the ultrafast dynamics of light.
The research was initially supported by the U.S. Air Force Office of Scientific Research. Ongoing research into harmonic mixing is based upon work supported by the U.S. Department of Energy, Office of Science, Office of Basic Energy Sciences. Matthew Yeung acknowledges fellowship support from MathWorks, the U.S. National Science Foundation Graduate Research Fellowship Program, and MPS-Ascend Postdoctoral Research Fellowship. Lu-Ting Chou acknowledges financial support from the China's Ministry of Education for the Overseas Internship Program from the Chinese National Science and Technology Council for the doctoral fellowship program. This work was carried out, in part, through the use of MIT.nano.
The demonstration of a lightwave-electronic mixer at petahertz-scale frquencies is a first step toward making communication technology faster and progresses research toward developing new, miniaturized lightwave electronic circuitry capable of handling optical signals directly at the nanoscale.
Exoplanets form in protoplanetary disks, a collection of space dust and gas orbiting a star. The leading theory of planetary formation, called core accretion, occurs when grains of dust in the disk collect and grow to form a planetary core, like a snowball rolling downhill. Once it has a strong enough gravitational pull, other material collapses around it to form the atmosphere.
A secondary theory of planetary formation is gravitational collapse. In this scenario, the disk itself becomes gravitationally unstable and collapses to form the planet, like snow being plowed into a pile. This process requires the disk to be massive, and until recently there were no known viable candidates to observe; previous research had detected the snow pile, but not what made it.
But in a new paper published today in Nature, MIT Kerr-McGee Career Development Professor Richard Teague and his colleagues report evidence that the movement of the gas surrounding the star AB Aurigae behaves as one would expect in a gravitationally unstable disk, matching numerical predictions. Their finding is akin to detecting the snowplow that made the pile. This indicates that gravitational collapse is a viable method of planetary formation. Here, Teague, who studies the formation of planetary systems in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS), answers a few questions about the new work.
Q: What made the AB Aurigae system a good candidate for observation?
A: There have been plenty of observations that have suggested some interesting dynamics going on the system. Groups have seen spiral arms within the disk; people have found hot spots, which some groups have interpreted as a planet; others have explained as some other instability. But it was really a disk that we knew there was lots of interesting motions going on. The data that we had previously was enough to see that it was interesting, but not really good enough to detail what was going on.
Q: What is gravitational instability when it comes to protoplanetary disks?
A: Gravitational instabilities are where the gravity from the disk itself is strong enough to perturb motions within the disk. Usually, we assume that the gravitational potential is dominated by the central star, which is the case when the mass of the disk is less than 10 percent of the stellar mass (which is most of the time). When the disk mass gets too large, gravitational potential will affect it in different ways and drive these very large spiral arms in the disk. These can have lots of different effects: They can trap the gas, they can heat it up, they can allow for angular momentum to be transported very rapidly within the disk. If it’s unstable, the disk can fragment and collapse directly to form a planet in an incredibly short period of time. Rather than the tens of thousands of years that it would take for a core accretion to happen, this would happen at a fraction of that time.
Q: How does this discovery challenge conventional wisdom around planetary formation?
A: It shows that this alternative path of forming planets via direct collapse is a way that we can form planets. This is particularly important because we’re finding more and more evidence of very large planets — say, Jupiter mass or larger — that are sitting very far away from their star. Those sorts of planets are incredibly hard to form with core accretion, because you typically need them close to the star where things happen quickly. So to form something so massive, so far away from the star is a real challenge. If we're able to show that there are sources that are massive enough that they're gravitationally unstable, this solves that problem. It's a way that perhaps newer systems can be formed, because they've always been a bit of a challenge to understand how they came about with core accretion.
The star AB Aurigae is located 531 light years from Earth in the Auriga constellation. Its protoplanetary disk made of gas and dust makes it a viable candidate for observing planetary formation.
Collagen, a protein found in bones and connective tissue, has been found in dinosaur fossils as old as 195 million years. That far exceeds the normal half-life of the peptide bonds that hold proteins together, which is about 500 years.
A new study from MIT offers an explanation for how collagen can survive for so much longer than expected. The research team found that a special atomic-level interaction defends collagen from attack by water molecules. This barricade prevents water from breaking the peptide bonds through a process called hydrolysis.
“We provide evidence that that interaction prevents water from attacking the peptide bonds and cleaving them. That just flies in the face of what happens with a normal peptide bond, which has a half-life of only 500 years,” says Ron Raines, the Firmenich Professor of Chemistry at MIT.
Raines is the senior author of the new study, which appears today in ACS Central Science. MIT postdoc Jinyi Yang PhD ’24 is the lead author of the paper. MIT postdoc Volga Kojasoy and graduate student Gerard Porter are also authors of the study.
Water-resistant
Collagen is the most abundant protein in animals, and it is found in not only bones but also skin, muscles, and ligaments. It’s made from long strands of protein that intertwine to form a tough triple helix.
“Collagen is the scaffold that holds us together,” Raines says. “What makes the collagen protein so stable, and such a good choice for this scaffold, is that unlike most proteins, it’s fibrous.”
In the past decade, paleobiologists have found evidence of collagen preserved in dinosaur fossils, including an 80-million-year-old Tyrannosaurus rex fossil, and a sauropodomorph fossil that is nearly 200 million years old.
Over the past 25 years, Raines’ lab has been studying collagen and how its structure enables its function. In the new study, they revealed why the peptide bonds that hold collagen together are so resistant to being broken down by water.
Peptide bonds are formed between a carbon atom from one amino acid and a nitrogen atom of the adjacent amino acid. The carbon atom also forms a double bond with an oxygen atom, forming a molecular structure called a carbonyl group. This carbonyl oxygen has a pair of electrons that don’t form bonds with any other atoms. Those electrons, the researchers found, can be shared with the carbonyl group of a neighboring peptide bond.
Because this pair of electrons is being inserted into those peptide bonds, water molecules can’t also get into the structure to disrupt the bond.
To demonstrate this, Raines and his colleagues created two interconverting mimics of collagen — the one that usually forms a triple helix, which is known as trans, and another in which the angles of the peptide bonds are rotated into a different form, known as cis. They found that the trans form of collagen did not allow water to attack and hydrolyze the bond. In the cis form, water got in and the bonds were broken.
“A peptide bond is either cis or trans, and we can change the cis to trans ratio. By doing that, we can mimic the natural state of collagen or create an unprotected peptide bond. And we saw that when it was unprotected, it was not long for the world,” Raines says.
“This work builds on a long-term effort in the Raines Group to classify the role of a long-overlooked fundamental interaction in protein structure,” says Paramjit Arora, a professor of chemistry at New York University, who was not involved in the research. “The paper directly addresses the remarkable finding of intact collagen in the ribs of a 195-million-old dinosaur fossil, and shows that overlap of filled and empty orbitals controls the conformational and hydrolytic stability of collagen.”
“No weak link”
This sharing of electrons has also been seen in protein structures known as alpha helices, which are found in many proteins. These helices may also be protected from water, but the helices are always connected by protein sequences that are more exposed, which are still susceptible to hydrolysis.
“Collagen is all triple helices, from one end to the other,” Raines says. “There’s no weak link, and that’s why I think it has survived.”
Previously, some scientists have suggested other explanations for why collagen might be preserved for millions of years, including the possibility that the bones were so dehydrated that no water could reach the peptide bonds.
“I can’t discount the contributions from other factors, but 200 million years is a long time, and I think you need something at the molecular level, at the atomic level in order to explain it,” Raines says.
The research was funded by the National Institutes of Health and the National Science Foundation.
Charging stations for electric vehicles are essential for cleaning up the transportation sector. A new study by MIT researchers suggests they’re good for business, too.
The study found that, in California, opening a charging station boosted annual spending at each nearby business by an average of about $1,500 in 2019 and about $400 between January 2021 and June 2023. The spending bump amounts to thousands of extra dollars annually for nearby businesses, with the increase particularly pronounced for businesses in underresourced areas.
The study’s authors hope the research paints a more holistic picture of the benefits of EV charging stations, beyond environmental factors.
“These increases are equal to a significant chunk of the cost of installing an EV charger, and I hope this study sheds light on these economic benefits,” says lead author Yunhan Zheng MCP ’21, SM ’21, PhD ’24, a postdoc at the Singapore-MIT Alliance for Research and Technology (SMART). “The findings could also diversify the income stream for charger providers and site hosts, and lead to more informed business models for EV charging stations.”
Zheng’s co-authors on the paper, which was published today in Nature Communications, are David Keith, a senior lecturer at the MIT Sloan School of Management; Jinhua Zhao, an MIT professor of cities and transportation; and alumni Shenhao Wang MCP ’17, SM ’17, PhD ’20 and Mi Diao MCP ’06, PhD ’10.
Understanding the EV effect
Increasing the number of electric vehicle charging stations is seen as a key prerequisite for the transition to a cleaner, electrified transportation sector. As such, the 2021 U.S. Infrastructure Investment and Jobs Act committed $7.5 billion to build a national network of public electric vehicle chargers across the U.S.
But a large amount of private investment will also be needed to make charging stations ubiquitous.
“The U.S. is investing a lot in EV chargers and really encouraging EV adoption, but many EV charging providers can’t make enough money at this stage, and getting to profitability is a major challenge,” Zheng says.
EV advocates have long argued that the presence of charging stations brings economic benefits to surrounding communities, but Zheng says previous studies on their impact relied on surveys or were small-scale. Her team of collaborators wanted to make advocates’ claims more empirical.
For their study, the researchers collected data from over 4,000 charging stations in California and 140,000 businesses, relying on anonymized credit and debit card transactions to measure changes in consumer spending. The researchers used data from 2019 through June of 2023, skipping the year 2020 to minimize the impact of the pandemic.
To judge whether charging stations caused customer spending increases, the researchers compared data from businesses within 500 meters of new charging stations before and after their installation. They also analyzed transactions from similar businesses in the same time frame that weren’t near charging stations.
Supercharging nearby businesses
The researchers found that installing a charging station boosted annual spending at nearby establishments by an average of 1.4 percent in 2019 and 0.8 percent from January 2021 to June 2023.
While that might sound like a small amount per business, it amounts to thousands of dollars in overall consumer spending increases. Specifically, those percentages translate to almost $23,000 in cumulative spending increases in 2019 and about $3,400 per year from 2021 through June 2023.
Zheng says the decline in spending increases over the two time periods might be due to a saturation of EV chargers, leading to lower utilization, as well as an overall decrease in spending per business after the Covid-19 pandemic and a reduced number of businesses served by each EV charging station in the second period. Despite this decline, the annual impact of a charging station on all its surrounding businesses would still cover approximately 11.2 percent of the average infrastructure and installation cost of a standard charging station.
Through both time frames, the spending increases were highest for businesses within about a football field’s distance from the new stations. They were also significant for businesses in disadvantaged and low-income areas, as designated by California and the Justice40 Initiative.
“The positive impacts of EV charging stations on businesses are not constrained solely to some high-income neighborhoods,” Wang says. “It highlights the importance for policymakers to develop EV charging stations in marginalized areas, because they not only foster a cleaner environment, but also serve as a catalyst for enhancing economic vitality.”
Zheng believes the findings hold a lesson for charging station developers seeking to improve the profitability of their projects.
“The joint gas station and convenience store business model could also be adopted to EV charging stations,” Zheng says. “Traditionally, many gas stations are affiliated with retail store chains, which enables owners to both sell fuel and attract customers to diversify their revenue stream. EV charging providers could consider a similar approach to internalize the positive impact of EV charging stations.”
Zheng also says the findings could support the creation of new funding models for charging stations, such as multiple businesses sharing the costs of construction so they can all benefit from the added spending.
Those changes could accelerate the creation of charging networks, but Zheng cautions that further research is needed to understand how much the study’s findings can be extrapolated to other areas. She encourages other researchers to study the economic effects of charging stations and hopes future research includes states beyond California and even other countries.
“A huge number of studies have focused on retail sales effects from traditional transportation infrastructure, such as rail and subway stations, bus stops, and street configurations,” Zhao says. “This research provides evidence for an important, emerging piece of transportation infrastructure and shows a consistently positive effect on local businesses, paving the way for future research in this area.”
The research was supported, in part, by the Singapore-MIT Alliance for Research and Technology (SMART) and the Singapore National Research Foundation. Diao was partially supported by the Natural Science Foundation of Shanghai and the Fundamental Research Funds for the Central Universities of China.
In order to train more powerful large language models, researchers use vast dataset collections that blend diverse data from thousands of web sources.
But as these datasets are combined and recombined into multiple collections, important information about their origins and restrictions on how they can be used are often lost or confounded in the shuffle.
Not only does this raise legal and ethical concerns, it can also damage a model’s performance. For instance, if a dataset is miscategorized, someone training a machine-learning model for a certain task may end up unwittingly using data that are not designed for that task.
In addition, data from unknown sources could contain biases that cause a model to make unfair predictions when deployed.
To improve data transparency, a team of multidisciplinary researchers from MIT and elsewhere launched a systematic audit of more than 1,800 text datasets on popular hosting sites. They found that more than 70 percent of these datasets omitted some licensing information, while about 50 percent had information that contained errors.
Building off these insights, they developed a user-friendly tool called the Data Provenance Explorer that automatically generates easy-to-read summaries of a dataset’s creators, sources, licenses, and allowable uses.
“These types of tools can help regulators and practitioners make informed decisions about AI deployment, and further the responsible development of AI,” says Alex “Sandy” Pentland, an MIT professor, leader of the Human Dynamics Group in the MIT Media Lab, and co-author of a new open-access paper about the project.
The Data Provenance Explorer could help AI practitioners build more effective models by enabling them to select training datasets that fit their model’s intended purpose. In the long run, this could improve the accuracy of AI models in real-world situations, such as those used to evaluate loan applications or respond to customer queries.
“One of the best ways to understand the capabilities and limitations of an AI model is understanding what data it was trained on. When you have misattribution and confusion about where data came from, you have a serious transparency issue,” says Robert Mahari, a graduate student in the MIT Human Dynamics Group, a JD candidate at Harvard Law School, and co-lead author on the paper.
Mahari and Pentland are joined on the paper by co-lead author Shayne Longpre, a graduate student in the Media Lab; Sara Hooker, who leads the research lab Cohere for AI; as well as others at MIT, the University of California at Irvine, the University of Lille in France, the University of Colorado at Boulder, Olin College, Carnegie Mellon University, Contextual AI, ML Commons, and Tidelift. The research is published today in Nature Machine Intelligence.
Focus on finetuning
Researchers often use a technique called fine-tuning to improve the capabilities of a large language model that will be deployed for a specific task, like question-answering. For finetuning, they carefully build curated datasets designed to boost a model’s performance for this one task.
The MIT researchers focused on these fine-tuning datasets, which are often developed by researchers, academic organizations, or companies and licensed for specific uses.
When crowdsourced platforms aggregate such datasets into larger collections for practitioners to use for fine-tuning, some of that original license information is often left behind.
“These licenses ought to matter, and they should be enforceable,” Mahari says.
For instance, if the licensing terms of a dataset are wrong or missing, someone could spend a great deal of money and time developing a model they might be forced to take down later because some training data contained private information.
“People can end up training models where they don’t even understand the capabilities, concerns, or risk of those models, which ultimately stem from the data,” Longpre adds.
To begin this study, the researchers formally defined data provenance as the combination of a dataset’s sourcing, creating, and licensing heritage, as well as its characteristics. From there, they developed a structured auditing procedure to trace the data provenance of more than 1,800 text dataset collections from popular online repositories.
After finding that more than 70 percent of these datasets contained “unspecified” licenses that omitted much information, the researchers worked backward to fill in the blanks. Through their efforts, they reduced the number of datasets with “unspecified” licenses to around 30 percent.
Their work also revealed that the correct licenses were often more restrictive than those assigned by the repositories.
In addition, they found that nearly all dataset creators were concentrated in the global north, which could limit a model’s capabilities if it is trained for deployment in a different region. For instance, a Turkish language dataset created predominantly by people in the U.S. and China might not contain any culturally significant aspects, Mahari explains.
“We almost delude ourselves into thinking the datasets are more diverse than they actually are,” he says.
Interestingly, the researchers also saw a dramatic spike in restrictions placed on datasets created in 2023 and 2024, which might be driven by concerns from academics that their datasets could be used for unintended commercial purposes.
A user-friendly tool
To help others obtain this information without the need for a manual audit, the researchers built the Data Provenance Explorer. In addition to sorting and filtering datasets based on certain criteria, the tool allows users to download a data provenance card that provides a succinct, structured overview of dataset characteristics.
“We are hoping this is a step, not just to understand the landscape, but also help people going forward to make more informed choices about what data they are training on,” Mahari says.
In the future, the researchers want to expand their analysis to investigate data provenance for multimodal data, including video and speech. They also want to study how terms of service on websites that serve as data sources are echoed in datasets.
As they expand their research, they are also reaching out to regulators to discuss their findings and the unique copyright implications of fine-tuning data.
“We need data provenance and transparency from the outset, when people are creating and releasing these datasets, to make it easier for others to derive these insights,” Longpre says.
“Many proposed policy interventions assume that we can correctly assign and identify licenses associated with data, and this work first shows that this is not the case, and then significantly improves the provenance information available,” says Stella Biderman, executive director of EleutherAI, who was not involved with this work. “In addition, section 3 contains relevant legal discussion. This is very valuable to machine learning practitioners outside companies large enough to have dedicated legal teams. Many people who want to build AI systems for public good are currently quietly struggling to figure out how to handle data licensing, because the internet is not designed in a way that makes data provenance easy to figure out.”
Computer graphics and geometry processing research provide the tools needed to simulate physical phenomena like fire and flames, aiding the creation of visual effects in video games and movies as well as the fabrication of complex geometric shapes using tools like 3D printing.
Under the hood, mathematical problems called partial differential equations (PDEs) model these natural processes. Among the many PDEs used in physics and computer graphics, a class called second-order parabolic PDEs explain how phenomena can become smooth over time. The most famous example in this class is the heat equation, which predicts how heat diffuses along a surface or in a volume over time.
Researchers in geometry processing have designed numerous algorithms to solve these problems on curved surfaces, but their methods often apply only to linear problems or to a single PDE. A more general approach by researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) tackles a general class of these potentially nonlinear problems.
In a paper recently published in the Transactions on Graphics journal and presented at the SIGGRAPH conference, they describe an algorithm that solves different nonlinear parabolic PDEs on triangle meshes by splitting them into three simpler equations that can be solved with techniques graphics researchers already have in their software toolkit. This framework can help better analyze shapes and model complex dynamical processes.
“We provide a recipe: If you want to numerically solve a second-order parabolic PDE, you can follow a set of three steps,” says lead author Leticia Mattos Da Silva SM ’23, an MIT PhD student in electrical engineering and computer science (EECS) and CSAIL affiliate. “For each of the steps in this approach, you’re solving a simpler problem using simpler tools from geometry processing, but at the end, you get a solution to the more challenging second-order parabolic PDE.”
To accomplish this, Da Silva and her coauthors used Strang splitting, a technique that allows geometry processing researchers to break the PDE down into problems they know how to solve efficiently.
First, their algorithm advances a solution forward in time by solving the heat equation (also called the “diffusion equation”), which models how heat from a source spreads over a shape. Picture using a blow torch to warm up a metal plate — this equation describes how heat from that spot would diffuse over it. This step can be completed easily with linear algebra.
Now, imagine that the parabolic PDE has additional nonlinear behaviors that are not described by the spread of heat. This is where the second step of the algorithm comes in: it accounts for the nonlinear piece by solving a Hamilton-Jacobi (HJ) equation, a first-order nonlinear PDE.
While generic HJ equations can be hard to solve, Mattos Da Silva and coauthors prove that their splitting method applied to many important PDEs yields an HJ equation that can be solved via convex optimization algorithms. Convex optimization is a standard tool for which researchers in geometry processing already have efficient and reliable software. In the final step, the algorithm advances a solution forward in time using the heat equation again to advance the more complex second-order parabolic PDE forward in time.
Among other applications, the framework could help simulate fire and flames more efficiently. “There’s a huge pipeline that creates a video with flames being simulated, but at the heart of it is a PDE solver,” says Mattos Da Silva. For these pipelines, an essential step is solving the G-equation, a nonlinear parabolic PDE that models the front propagation of the flame and can be solved using the researchers’ framework.
The team’s algorithm can also solve the diffusion equation in the logarithmic domain, where it becomes nonlinear. Senior author Justin Solomon, associate professor of EECS and leader of the CSAIL Geometric Data Processing Group, previously developed a state-of-the-art technique for optimal transport that requires taking the logarithm of the result of heat diffusion. Mattos Da Silva’s framework provided more reliable computations by doing diffusion directly in the logarithmic domain. This enabled a more stable way to, for example, find a geometric notion of average among distributions on surface meshes like a model of a koala.
Even though their framework focuses on general, nonlinear problems, it can also be used to solve linear PDE. For instance, the method solves the Fokker-Planck equation, where heat diffuses in a linear way, but there are additional terms that drift in the same direction heat is spreading. In a straightforward application, the approach modeled how swirls would evolve over the surface of a triangulated sphere. The result resembles purple-and-brown latte art.
The researchers note that this project is a starting point for tackling the nonlinearity in other PDEs that appear in graphics and geometry processing head-on. For example, they focused on static surfaces but would like to apply their work to moving ones, too. Moreover, their framework solves problems involving a single parabolic PDE, but the team would also like to tackle problems involving coupled parabolic PDE. These types of problems arise in biology and chemistry, where the equation describing the evolution of each agent in a mixture, for example, is linked to the others’ equations.
Mattos Da Silva and Solomon wrote the paper with Oded Stein, assistant professor at the University of Southern California’s Viterbi School of Engineering. Their work was supported, in part, by an MIT Schwarzman College of Computing Fellowship funded by Google, a MathWorks Fellowship, the Swiss National Science Foundation, the U.S. Army Research Office, the U.S. Air Force Office of Scientific Research, the U.S. National Science Foundation, MIT-IBM Watson AI Lab, the Toyota-CSAIL Joint Research Center, Adobe Systems, and Google Research.
Part of a new algorithm developed at MIT solves the so-called Fokker-Planck equation, where heat diffuses in a linear way, but there are additional terms that drift in the same direction heat is spreading. In a straightforward application, the approach models how swirls would evolve over the surface of a triangulated sphere.
Using functional magnetic resonance imaging (fMRI), neuroscientists have identified several regions of the brain that are responsible for processing language. However, discovering the specific functions of neurons in those regions has proven difficult because fMRI, which measures changes in blood flow, doesn’t have high enough resolution to reveal what small populations of neurons are doing.
Now, using a more precise technique that involves recording electrical activity directly from the brain, MIT neuroscientists have identified different clusters of neurons that appear to process different amounts of linguistic context. These “temporal windows” range from just one word up to about six words.
The temporal windows may reflect different functions for each population, the researchers say. Populations with shorter windows may analyze the meanings of individual words, while those with longer windows may interpret more complex meanings created when words are strung together.
“This is the first time we see clear heterogeneity within the language network,” says Evelina Fedorenko, an associate professor of neuroscience at MIT. “Across dozens of fMRI experiments, these brain areas all seem to do the same thing, but it’s a large, distributed network, so there’s got to be some structure there. This is the first clear demonstration that there is structure, but the different neural populations are spatially interleaved so we can’t see these distinctions with fMRI.”
Fedorenko, who is also a member of MIT’s McGovern Institute for Brain Research, is the senior author of the study, which appears today in Nature Human Behavior. MIT postdoc Tamar Regev and Harvard University graduate student Colton Casto are the lead authors of the paper.
Temporal windows
Functional MRI, which has helped scientists learn a great deal about the roles of different parts of the brain, works by measuring changes in blood flow in the brain. These measurements act as a proxy of neural activity during a particular task. However, each “voxel,” or three-dimensional chunk, of an fMRI image represents hundreds of thousands to millions of neurons and sums up activity across about two seconds, so it can’t reveal fine-grained detail about what those neurons are doing.
One way to get more detailed information about neural function is to record electrical activity using electrodes implanted in the brain. These data are hard to come by because this procedure is done only in patients who are already undergoing surgery for a neurological condition such as severe epilepsy.
“It can take a few years to get enough data for a task because these patients are relatively rare, and in a given patient electrodes are implanted in idiosyncratic locations based on clinical needs, so it takes a while to assemble a dataset with sufficient coverage of some target part of the cortex. But these data, of course, are the best kind of data we can get from human brains: You know exactly where you are spatially and you have very fine-grained temporal information,” Fedorenko says.
In a 2016 study, Fedorenko reported using this approach to study the language processing regions of six people. Electrical activity was recorded while the participants read four different types of language stimuli: complete sentences, lists of words, lists of non-words, and “jabberwocky” sentences — sentences that have grammatical structure but are made of nonsense words.
Those data showed that in some neural populations in language processing regions, activity would gradually build up over a period of several words, when the participants were reading sentences. However, this did not happen when they read lists of words, lists of nonwords, of Jabberwocky sentences.
In the new study, Regev and Casto went back to those data and analyzed the temporal response profiles in greater detail. In their original dataset, they had recordings of electrical activity from 177 language-responsive electrodes across the six patients. Conservative estimates suggest that each electrode represents an average of activity from about 200,000 neurons. They also obtained new data from a second set of 16 patients, which included recordings from another 362 language-responsive electrodes.
When the researchers analyzed these data, they found that in some of the neural populations, activity would fluctuate up and down with each word. In others, however, activity would build up over multiple words before falling again, and yet others would show a steady buildup of neural activity over longer spans of words.
By comparing their data with predictions made by a computational model that the researchers designed to process stimuli with different temporal windows, the researchers found that neural populations from language processing areas could be divided into three clusters. These clusters represent temporal windows of either one, four, or six words.
“It really looks like these neural populations integrate information across different timescales along the sentence,” Regev says.
Processing words and meaning
These differences in temporal window size would have been impossible to see using fMRI, the researchers say.
“At the resolution of fMRI, we don’t see much heterogeneity within language-responsive regions. If you localize in individual participants the voxels in their brain that are most responsive to language, you find that their responses to sentences, word lists, jabberwocky sentences and non-word lists are highly similar,” Casto says.
The researchers were also able to determine the anatomical locations where these clusters were found. Neural populations with the shortest temporal window were found predominantly in the posterior temporal lobe, though some were also found in the frontal or anterior temporal lobes. Neural populations from the two other clusters, with longer temporal windows, were spread more evenly throughout the temporal and frontal lobes.
Fedorenko’s lab now plans to study whether these timescales correspond to different functions. One possibility is that the shortest timescale populations may be processing the meanings of a single word, while those with longer timescales interpret the meanings represented by multiple words.
“We already know that in the language network, there is sensitivity to how words go together and to the meanings of individual words,” Regev says. “So that could potentially map to what we’re finding, where the longest timescale is sensitive to things like syntax or relationships between words, and maybe the shortest timescale is more sensitive to features of single words or parts of them.”
The research was funded by the Zuckerman-CHE STEM Leadership Program, the Poitras Center for Psychiatric Disorders Research, the Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University, the U.S. National Institutes of Health, an American Epilepsy Society Research and Training Fellowship, the McDonnell Center for Systems Neuroscience, Fondazione Neurone, the McGovern Institute, MIT’s Department of Brain and Cognitive Sciences, and the Simons Center for the Social Brain.
For the past decade, disordered rock salt has been studied as a potential breakthrough cathode material for use in lithium-ion batteries and a key to creating low-cost, high-energy storage for everything from cell phones to electric vehicles to renewable energy storage.
A new MIT study is making sure the material fulfills that promise.
Led by Ju Li, the Tokyo Electric Power Company Professor in Nuclear Engineering and professor of materials science and engineering, a team of researchers describe a new class of partially disordered rock salt cathode, integrated with polyanions — dubbed disordered rock salt-polyanionic spinel, or DRXPS — that delivers high energy density at high voltages with significantly improved cycling stability.
“There is typically a trade-off in cathode materials between energy density and cycling stability … and with this work we aim to push the envelope by designing new cathode chemistries,” says Yimeng Huang, a postdoc in the Department of Nuclear Science and Engineering and first author of a paper describing the work published today in Nature Energy. “(This) material family has high energy density and good cycling stability because it integrates two major types of cathode materials, rock salt and polyanionic olivine, so it has the benefits of both.”
Importantly, Li adds, the new material family is primarily composed of manganese, an earth-abundant element that is significantly less expensive than elements like nickel and cobalt, which are typically used in cathodes today.
“Manganese is at least five times less expensive than nickel, and about 30 times less expensive than cobalt,” Li says. “Manganese is also the one of the keys to achieving higher energy densities, so having that material be much more earth-abundant is a tremendous advantage.”
A possible path to renewable energy infrastructure
That advantage will be particularly critical, Li and his co-authors wrote, as the world looks to build the renewable energy infrastructure needed for a low- or no-carbon future.
Batteries are a particularly important part of that picture, not only for their potential to decarbonize transportation with electric cars, buses, and trucks, but also because they will be essential to addressing the intermittency issues of wind and solar power by storing excess energy, then feeding it back into the grid at night or on calm days, when renewable generation drops.
Given the high cost and relative rarity of materials like cobalt and nickel, they wrote, efforts to rapidly scale up electric storage capacity would likely lead to extreme cost spikes and potentially significant materials shortages.
“If we want to have true electrification of energy generation, transportation, and more, we need earth-abundant batteries to store intermittent photovoltaic and wind power,” Li says. “I think this is one of the steps toward that dream.”
That sentiment was shared by Gerbrand Ceder, the Samsung Distinguished Chair in Nanoscience and Nanotechnology Research and a professor of materials science and engineering at the University of California at Berkeley.
“Lithium-ion batteries are a critical part of the clean energy transition,” Ceder says. “Their continued growth and price decrease depends on the development of inexpensive, high-performance cathode materials made from earth-abundant materials, as presented in this work.”
Overcoming obstacles in existing materials
The new study addresses one of the major challenges facing disordered rock salt cathodes — oxygen mobility.
While the materials have long been recognized for offering very high capacity — as much as 350 milliampere-hour per gram — as compared to traditional cathode materials, which typically have capacities of between 190 and 200 milliampere-hour per gram, it is not very stable.
The high capacity is contributed partially by oxygen redox, which is activated when the cathode is charged to high voltages. But when that happens, oxygen becomes mobile, leading to reactions with the electrolyte and degradation of the material, eventually leaving it effectively useless after prolonged cycling.
To overcome those challenges, Huang added another element — phosphorus — that essentially acts like a glue, holding the oxygen in place to mitigate degradation.
“The main innovation here, and the theory behind the design, is that Yimeng added just the right amount of phosphorus, formed so-called polyanions with its neighboring oxygen atoms, into a cation-deficient rock salt structure that can pin them down,” Li explains. “That allows us to basically stop the percolating oxygen transport due to strong covalent bonding between phosphorus and oxygen … meaning we can both utilize the oxygen-contributed capacity, but also have good stability as well.”
That ability to charge batteries to higher voltages, Li says, is crucial because it allows for simpler systems to manage the energy they store.
“You can say the quality of the energy is higher,” he says. “The higher the voltage per cell, then the less you need to connect them in series in the battery pack, and the simpler the battery management system.”
Pointing the way to future studies
While the cathode material described in the study could have a transformative impact on lithium-ion battery technology, there are still several avenues for study going forward.
Among the areas for future study, Huang says, are efforts to explore new ways to fabricate the material, particularly for morphology and scalability considerations.
“Right now, we are using high-energy ball milling for mechanochemical synthesis, and … the resulting morphology is non-uniform and has small average particle size (about 150 nanometers). This method is also not quite scalable,” he says. “We are trying to achieve a more uniform morphology with larger particle sizes using some alternate synthesis methods, which would allow us to increase the volumetric energy density of the material and may allow us to explore some coating methods … which could further improve the battery performance. The future methods, of course, should be industrially scalable.”
In addition, he says, the disordered rock salt material by itself is not a particularly good conductor, so significant amounts of carbon — as much as 20 weight percent of the cathode paste — were added to boost its conductivity. If the team can reduce the carbon content in the electrode without sacrificing performance, there will be higher active material content in a battery, leading to an increased practical energy density.
“In this paper, we just used Super P, a typical conductive carbon consisting of nanospheres, but they’re not very efficient,” Huang says. “We are now exploring using carbon nanotubes, which could reduce the carbon content to just 1 or 2 weight percent, which could allow us to dramatically increase the amount of the active cathode material.”
Aside from decreasing carbon content, making thick electrodes, he adds, is yet another way to increase the practical energy density of the battery. This is another area of research that the team is working on.
“This is only the beginning of DRXPS research, since we only explored a few chemistries within its vast compositional space,” he continues. “We can play around with different ratios of lithium, manganese, phosphorus, and oxygen, and with various combinations of other polyanion-forming elements such as boron, silicon, and sulfur.”
With optimized compositions, more scalable synthesis methods, better morphology that allows for uniform coatings, lower carbon content, and thicker electrodes, he says, the DRXPS cathode family is very promising in applications of electric vehicles and grid storage, and possibly even in consumer electronics, where the volumetric energy density is very important.
This work was supported with funding from the Honda Research Institute USA Inc. and the Molecular Foundry at Lawrence Berkeley National Laboratory, and used resources of the National Synchrotron Light Source II at Brookhaven National Laboratory and the Advanced Photon Source at Argonne National Laboratory. The work was carried out, in part, using MIT.nano’s facilities.
An artistic illustration of the integration between two distinct battery cathode structures, rock salt (blue polyhedra) and polyanion olivine (red/yellow polyhedra). A novel hybrid structure is obtained by integrating polyanions (yellow polyhedra) into a rock salt (blue polyhedra) structure.
The most recent email you sent was likely encrypted using a tried-and-true method that relies on the idea that even the fastest computer would be unable to efficiently break a gigantic number into factors.
Quantum computers, on the other hand, promise to rapidly crack complex cryptographic systems that a classical computer might never be able to unravel. This promise is based on a quantum factoring algorithm proposed in 1994 by Peter Shor, who is now a professor at MIT.
But while researchers have taken great strides in the last 30 years, scientists have yet to build a quantum computer powerful enough to run Shor’s algorithm.
As some researchers work to build larger quantum computers, others have been trying to improve Shor’s algorithm so it could run on a smaller quantum circuit. About a year ago, New York University computer scientist Oded Regev proposed a major theoretical improvement. His algorithm could run faster, but the circuit would require more memory.
Building off those results, MIT researchers have proposed a best-of-both-worlds approach that combines the speed of Regev’s algorithm with the memory-efficiency of Shor’s. This new algorithm is as fast as Regev’s, requires fewer quantum building blocks known as qubits, and has a higher tolerance to quantum noise, which could make it more feasible to implement in practice.
In the long run, this new algorithm could inform the development of novel encryption methods that can withstand the code-breaking power of quantum computers.
“If large-scale quantum computers ever get built, then factoring is toast and we have to find something else to use for cryptography. But how real is this threat? Can we make quantum factoring practical? Our work could potentially bring us one step closer to a practical implementation,” says Vinod Vaikuntanathan, the Ford Foundation Professor of Engineering, a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL), and senior author of a paper describing the algorithm.
The paper’s lead author is Seyoon Ragavan, a graduate student in the MIT Department of Electrical Engineering and Computer Science. The research will be presented at the 2024 International Cryptology Conference.
Cracking cryptography
To securely transmit messages over the internet, service providers like email clients and messaging apps typically rely on RSA, an encryption scheme invented by MIT researchers Ron Rivest, Adi Shamir, and Leonard Adleman in the 1970s (hence the name “RSA”). The system is based on the idea that factoring a 2,048-bit integer (a number with 617 digits) is too hard for a computer to do in a reasonable amount of time.
That idea was flipped on its head in 1994 when Shor, then working at Bell Labs, introduced an algorithm which proved that a quantum computer could factor quickly enough to break RSA cryptography.
“That was a turning point. But in 1994, nobody knew how to build a large enough quantum computer. And we’re still pretty far from there. Some people wonder if they will ever be built,” says Vaikuntanathan.
It is estimated that a quantum computer would need about 20 million qubits to run Shor’s algorithm. Right now, the largest quantum computers have around 1,100 qubits.
A quantum computer performs computations using quantum circuits, just like a classical computer uses classical circuits. Each quantum circuit is composed of a series of operations known as quantum gates. These quantum gates utilize qubits, which are the smallest building blocks of a quantum computer, to perform calculations.
But quantum gates introduce noise, so having fewer gates would improve a machine’s performance. Researchers have been striving to enhance Shor’s algorithm so it could be run on a smaller circuit with fewer quantum gates.
That is precisely what Regev did with the circuit he proposed a year ago.
“That was big news because it was the first real improvement to Shor’s circuit from 1994,” Vaikuntanathan says.
The quantum circuit Shor proposed has a size proportional to the square of the number being factored. That means if one were to factor a 2,048-bit integer, the circuit would need millions of gates.
Regev’s circuit requires significantly fewer quantum gates, but it needs many more qubits to provide enough memory. This presents a new problem.
“In a sense, some types of qubits are like apples or oranges. If you keep them around, they decay over time. You want to minimize the number of qubits you need to keep around,” explains Vaikuntanathan.
He heard Regev speak about his results at a workshop last August. At the end of his talk, Regev posed a question: Could someone improve his circuit so it needs fewer qubits? Vaikuntanathan and Ragavan took up that question.
Quantum ping-pong
To factor a very large number, a quantum circuit would need to run many times, performing operations that involve computing powers, like 2 to the power of 100.
But computing such large powers is costly and difficult to perform on a quantum computer, since quantum computers can only perform reversible operations. Squaring a number is not a reversible operation, so each time a number is squared, more quantum memory must be added to compute the next square.
The MIT researchers found a clever way to compute exponents using a series of Fibonacci numbers that requires simple multiplication, which is reversible, rather than squaring. Their method needs just two quantum memory units to compute any exponent.
“It is kind of like a ping-pong game, where we start with a number and then bounce back and forth, multiplying between two quantum memory registers,” Vaikuntanathan adds.
They also tackled the challenge of error correction. The circuits proposed by Shor and Regev require every quantum operation to be correct for their algorithm to work, Vaikuntanathan says. But error-free quantum gates would be infeasible on a real machine.
They overcame this problem using a technique to filter out corrupt results and only process the right ones.
The end-result is a circuit that is significantly more memory-efficient. Plus, their error correction technique would make the algorithm more practical to deploy.
“The authors resolve the two most important bottlenecks in the earlier quantum factoring algorithm. Although still not immediately practical, their work brings quantum factoring algorithms closer to reality,” adds Regev.
In the future, the researchers hope to make their algorithm even more efficient and, someday, use it to test factoring on a real quantum circuit.
“The elephant-in-the-room question after this work is: Does it actually bring us closer to breaking RSA cryptography? That is not clear just yet; these improvements currently only kick in when the integers are much larger than 2,048 bits. Can we push this algorithm and make it more feasible than Shor’s even for 2,048-bit integers?” says Ragavan.
This work is funded by an Akamai Presidential Fellowship, the U.S. Defense Advanced Research Projects Agency, the National Science Foundation, the MIT-IBM Watson AI Lab, a Thornton Family Faculty Research Innovation Fellowship, and a Simons Investigator Award.
This new algorithm requires fewer quantum building blocks, and has a higher tolerance to quantum noise, which could make it more feasible to implement in practice.
Low-calorie diets and intermittent fasting have been shown to have numerous health benefits: They can delay the onset of some age-related diseases and lengthen lifespan, not only in humans but many other organisms.
Many complex mechanisms underlie this phenomenon. Previous work from MIT has shown that one way fasting exerts its beneficial effects is by boosting the regenerative abilities of intestinal stem cells, which helps the intestine recover from injuries or inflammation.
In a study of mice, MIT researchers have now identified the pathway that enables this enhanced regeneration, which is activated once the mice begin “refeeding” after the fast. They also found a downside to this regeneration: When cancerous mutations occurred during the regenerative period, the mice were more likely to develop early-stage intestinal tumors.
“Having more stem cell activity is good for regeneration, but too much of a good thing over time can have less favorable consequences,” says Omer Yilmaz, an MIT associate professor of biology, a member of MIT’s Koch Institute for Integrative Cancer Research, and the senior author of the new study.
Yilmaz adds that further studies are needed before forming any conclusion as to whether fasting has a similar effect in humans.
“We still have a lot to learn, but it is interesting that being in either the state of fasting or refeeding when exposure to mutagen occurs can have a profound impact on the likelihood of developing a cancer in these well-defined mouse models,” he says.
MIT postdocs Shinya Imada and Saleh Khawaled are the lead authors of the paper, which appears today in Nature.
Driving regeneration
For several years, Yilmaz’s lab has been investigating how fasting and low-calorie diets affect intestinal health. In a 2018 study, his team reported that during a fast, intestinal stem cells begin to use lipids as an energy source, instead of carbohydrates. They also showed that fasting led to a significant boost in stem cells’ regenerative ability.
However, unanswered questions remained: How does fasting trigger this boost in regenerative ability, and when does the regeneration begin?
“Since that paper, we’ve really been focused on understanding what is it about fasting that drives regeneration,” Yilmaz says. “Is it fasting itself that’s driving regeneration, or eating after the fast?”
In their new study, the researchers found that stem cell regeneration is suppressed during fasting but then surges during the refeeding period. The researchers followed three groups of mice — one that fasted for 24 hours, another one that fasted for 24 hours and then was allowed to eat whatever they wanted during a 24-hour refeeding period, and a control group that ate whatever they wanted throughout the experiment.
The researchers analyzed intestinal stem cells’ ability to proliferate at different time points and found that the stem cells showed the highest levels of proliferation at the end of the 24-hour refeeding period. These cells were also more proliferative than intestinal stem cells from mice that had not fasted at all.
“We think that fasting and refeeding represent two distinct states,” Imada says. “In the fasted state, the ability of cells to use lipids and fatty acids as an energy source enables them to survive when nutrients are low. And then it’s the postfast refeeding state that really drives the regeneration. When nutrients become available, these stem cells and progenitor cells activate programs that enable them to build cellular mass and repopulate the intestinal lining.”
Further studies revealed that these cells activate a cellular signaling pathway known as mTOR, which is involved in cell growth and metabolism. One of mTOR’s roles is to regulate the translation of messenger RNA into protein, so when it’s activated, cells produce more protein. This protein synthesis is essential for stem cells to proliferate.
The researchers showed that mTOR activation in these stem cells also led to production of large quantities of polyamines — small molecules that help cells to grow and divide.
“In the refed state, you’ve got more proliferation, and you need to build cellular mass. That requires more protein, to build new cells, and those stem cells go on to build more differentiated cells or specialized intestinal cell types that line the intestine,” Khawaled says.
Too much of a good thing
The researchers also found that when stem cells are in this highly regenerative state, they are more prone to become cancerous. Intestinal stem cells are among the most actively dividing cells in the body, as they help the lining of the intestine completely turn over every five to 10 days. Because they divide so frequently, these stem cells are the most common source of precancerous cells in the intestine.
In this study, the researchers discovered that if they turned on a cancer-causing gene in the mice during the refeeding stage, they were much more likely to develop precancerous polyps than if the gene was turned on during the fasting state. Cancer-linked mutations that occurred during the refeeding state were also much more likely to produce polyps than mutations that occurred in mice that did not undergo the cycle of fasting and refeeding.
“I want to emphasize that this was all done in mice, using very well-defined cancer mutations. In humans it’s going to be a much more complex state,” Yilmaz says. “But it does lead us to the following notion: Fasting is very healthy, but if you’re unlucky and you’re refeeding after a fasting, and you get exposed to a mutagen, like a charred steak or something, you might actually be increasing your chances of developing a lesion that can go on to give rise to cancer.”
Yilmaz also noted that the regenerative benefits of fasting could be significant for people who undergo radiation treatment, which can damage the intestinal lining, or other types of intestinal injury. His lab is now studying whether polyamine supplements could help to stimulate this kind of regeneration, without the need to fast.
“This fascinating study provides insights into the complex interplay between food consumption, stem cell biology, and cancer risk,” says Ophir Klein, a professor of medicine at the University of California at San Francisco and Cedars-Sinai Medical Center, who was not involved in the study. “Their work lays a foundation for testing polyamines as compounds that may augment intestinal repair after injuries, and it suggests that careful consideration is needed when planning diet-based strategies for regeneration to avoid increasing cancer risk.”
The research was funded, in part, by Pew-Stewart Scholars Program for Cancer Research award, the MIT Stem Cell Initiative, the Koch Institute Frontier Research Program via the Kathy and Curt Marble Cancer Research Fund, and the Bridge Project, a partnership between the Koch Institute for Integrative Cancer Research at MIT and the Dana-Farber/Harvard Cancer Center.
“Having more stem cell activity is good for regeneration, but too much of a good thing over time can have less favorable consequences,” says Omer Yilmaz.
The blades of propellers and wind turbines are designed based on aerodynamics principles that were first described mathematically more than a century ago. But engineers have long realized that these formulas don’t work in every situation. To compensate, they have added ad hoc “correction factors” based on empirical observations.
Now, for the first time, engineers at MIT have developed a comprehensive, physics-based model that accurately represents the airflow around rotors even under extreme conditions, such as when the blades are operating at high forces and speeds, or are angled in certain directions. The model could improve the way rotors themselves are designed, but also the way wind farms are laid out and operated. The new findings are described today in the journal Nature Communications, in an open-access paper by MIT postdoc Jaime Liew, doctoral student Kirby Heck, and Michael Howland, the Esther and Harold E. Edgerton Assistant Professor of Civil and Environmental Engineering.
“We’ve developed a new theory for the aerodynamics of rotors,” Howland says. This theory can be used to determine the forces, flow velocities, and power of a rotor, whether that rotor is extracting energy from the airflow, as in a wind turbine, or applying energy to the flow, as in a ship or airplane propeller. “The theory works in both directions,” he says.
Because the new understanding is a fundamental mathematical model, some of its implications could potentially be applied right away. For example, operators of wind farms must constantly adjust a variety of parameters, including the orientation of each turbine as well as its rotation speed and the angle of its blades, in order to maximize power output while maintaining safety margins. The new model can provide a simple, speedy way of optimizing those factors in real time.
“This is what we’re so excited about, is that it has immediate and direct potential for impact across the value chain of wind power,” Howland says.
Modeling the momentum
Known as momentum theory, the previous model of how rotors interact with their fluid environment — air, water, or otherwise — was initially developed late in the 19th century. With this theory, engineers can start with a given rotor design and configuration, and determine the maximum amount of power that can be derived from that rotor — or, conversely, if it’s a propeller, how much power is needed to generate a given amount of propulsive force.
Momentum theory equations “are the first thing you would read about in a wind energy textbook, and are the first thing that I talk about in my classes when I teach about wind power,” Howland says. From that theory, physicist Albert Betz calculated in 1920 the maximum amount of energy that could theoretically be extracted from wind. Known as the Betz limit, this amount is 59.3 percent of the kinetic energy of the incoming wind.
But just a few years later, others found that the momentum theory broke down “in a pretty dramatic way” at higher forces that correspond to faster blade rotation speeds or different blade angles, Howland says. It fails to predict not only the amount, but even the direction of changes in thrust force at higher rotation speeds or different blade angles: Whereas the theory said the force should start going down above a certain rotation speed or blade angle, experiments show the opposite — that the force continues to increase. “So, it’s not just quantitatively wrong, it’s qualitatively wrong,” Howland says.
The theory also breaks down when there is any misalignment between the rotor and the airflow, which Howland says is “ubiquitous” on wind farms, where turbines are constantly adjusting to changes in wind directions. In fact, in an earlier paper in 2022, Howland and his team found that deliberately misaligning some turbines slightly relative to the incoming airflow within a wind farm significantly improves the overall power output of the wind farm by reducing wake disturbances to the downstream turbines.
In the past, when designing the profile of rotor blades, the layout of wind turbines in a farm, or the day-to-day operation of wind turbines, engineers have relied on ad hoc adjustments added to the original mathematical formulas, based on some wind tunnel tests and experience with operating wind farms, but with no theoretical underpinnings.
Instead, to arrive at the new model, the team analyzed the interaction of airflow and turbines using detailed computational modeling of the aerodynamics. They found that, for example, the original model had assumed that a drop in air pressure immediately behind the rotor would rapidly return to normal ambient pressure just a short way downstream. But it turns out, Howland says, that as the thrust force keeps increasing, “that assumption is increasingly inaccurate.”
And the inaccuracy occurs very close to the point of the Betz limit that theoretically predicts the maximum performance of a turbine — and therefore is just the desired operating regime for the turbines. “So, we have Betz’s prediction of where we should operate turbines, and within 10 percent of that operational set point that we think maximizes power, the theory completely deteriorates and doesn’t work,” Howland says.
Through their modeling, the researchers also found a way to compensate for the original formula’s reliance on a one-dimensional modeling that assumed the rotor was always precisely aligned with the airflow. To do so, they used fundamental equations that were developed to predict the lift of three-dimensional wings for aerospace applications.
The researchers derived their new model, which they call a unified momentum model, based on theoretical analysis, and then validated it using computational fluid dynamics modeling. In followup work not yet published, they are doing further validation using wind tunnel and field tests.
Fundamental understanding
One interesting outcome of the new formula is that it changes the calculation of the Betz limit, showing that it’s possible to extract a bit more power than the original formula predicted. Although it’s not a significant change — on the order of a few percent — “it’s interesting that now we have a new theory, and the Betz limit that’s been the rule of thumb for a hundred years is actually modified because of the new theory,” Howland says. “And that’s immediately useful.” The new model shows how to maximize power from turbines that are misaligned with the airflow, which the Betz limit cannot account for.
The aspects related to controlling both individual turbines and arrays of turbines can be implemented without requiring any modifications to existing hardware in place within wind farms. In fact, this has already happened, based on earlier work from Howland and his collaborators two years ago that dealt with the wake interactions between turbines in a wind farm, and was based on the existing, empirically based formulas.
“This breakthrough is a natural extension of our previous work on optimizing utility-scale wind farms,” he says, because in doing that analysis, they saw the shortcomings of the existing methods for analyzing the forces at work and predicting power produced by wind turbines. “Existing modeling using empiricism just wasn’t getting the job done,” he says.
In a wind farm, individual turbines will sap some of the energy available to neighboring turbines, because of wake effects. Accurate wake modeling is important both for designing the layout of turbines in a wind farm, and also for the operation of that farm, determining moment to moment how to set the angles and speeds of each turbine in the array.
Until now, Howland says, even the operators of wind farms, the manufacturers, and the designers of the turbine blades had no way to predict how much the power output of a turbine would be affected by a given change such as its angle to the wind without using empirical corrections. “That’s because there was no theory for it. So, that’s what we worked on here. Our theory can directly tell you, without any empirical corrections, for the first time, how you should actually operate a wind turbine to maximize its power,” he says.
Because the fluid flow regimes are similar, the model also applies to propellers, whether for aircraft or ships, and also for hydrokinetic turbines such as tidal or river turbines. Although they didn’t focus on that aspect in this research, “it’s in the theoretical modeling naturally,” he says.
The new theory exists in the form of a set of mathematical formulas that a user could incorporate in their own software, or as an open-source software package that can be freely downloaded from GitHub. “It’s an engineering model developed for fast-running tools for rapid prototyping and control and optimization,” Howland says. “The goal of our modeling is to position the field of wind energy research to move more aggressively in the development of the wind capacity and reliability necessary to respond to climate change.”
The work was supported by the National Science Foundation and Siemens Gamesa Renewable Energy.
Legal documents are notoriously difficult to understand, even for lawyers. This raises the question: Why are these documents written in a style that makes them so impenetrable?
MIT cognitive scientists believe they have uncovered the answer to that question. Just as “magic spells” use special rhymes and archaic terms to signal their power, the convoluted language of legalese acts to convey a sense of authority, they conclude.
In a study appearing this week in the journal of the Proceedings of the National Academy of Sciences, the researchers found that even non-lawyers use this type of language when asked to write laws.
“People seem to understand that there’s an implicit rule that this is how laws should sound, and they write them that way,” says Edward Gibson, an MIT professor of brain and cognitive sciences and the senior author of the study.
Eric Martinez PhD ’24 is the lead author of the study. Francis Mollica, a lecturer at the University of Melbourne, is also an author of the paper.
Casting a legal spell
Gibson’s research group has been studying the unique characteristics of legalese since 2020, when Martinez came to MIT after earning a law degree from Harvard Law School. In a 2022 study, Gibson, Martinez, and Mollica analyzed legal contracts totaling about 3.5 million words, comparing them with other types of writing, including movie scripts, newspaper articles, and academic papers.
That analysis revealed that legal documents frequently have long definitions inserted in the middle of sentences — a feature known as “center-embedding.” Linguists have previously found that this kind of structure can make text much more difficult to understand.
“Legalese somehow has developed this tendency to put structures inside other structures, in a way which is not typical of human languages,” Gibson says.
In a follow-up study published in 2023, the researchers found that legalese also makes documents more difficult for lawyers to understand. Lawyers tended to prefer plain English versions of documents, and they rated those versions to be just as enforceable as traditional legal documents.
“Lawyers also find legalese to be unwieldy and complicated,” Gibson says. “Lawyers don’t like it, laypeople don’t like it, so the point of this current paper was to try and figure out why they write documents this way.”
The researchers had a couple of hypotheses for why legalese is so prevalent. One was the “copy and edit hypothesis,” which suggests that legal documents begin with a simple premise, and then additional information and definitions are inserted into already existing sentences, creating complex center-embedded clauses.
“We thought it was plausible that what happens is you start with an initial draft that’s simple, and then later you think of all these other conditions that you want to include. And the idea is that once you’ve started, it’s much easier to center-embed that into the existing provision,” says Martinez, who is now a fellow and instructor at the University of Chicago Law School.
However, the findings ended up pointing toward a different hypothesis, the so-called “magic spell hypothesis.” Just as magic spells are written with a distinctive style that sets them apart from everyday language, the convoluted style of legal language appears to signal a special kind of authority, the researchers say.
“In English culture, if you want to write something that’s a magic spell, people know that the way to do that is you put a lot of old-fashioned rhymes in there. We think maybe center-embedding is signaling legalese in the same way,” Gibson says.
In this study, the researchers asked about 200 non-lawyers (native speakers of English living in the United States, who were recruited through a crowdsourcing site called Prolific), to write two types of texts. In the first task, people were told to write laws prohibiting crimes such as drunk driving, burglary, arson, and drug trafficking. In the second task, they were asked to write stories about those crimes.
To test the copy and edit hypothesis, half of the participants were asked to add additional information after they wrote their initial law or story. The researchers found that all of the subjects wrote laws with center-embedded clauses, regardless of whether they wrote the law all at once or were told to write a draft and then add to it later. And, when they wrote stories related to those laws, they wrote in much plainer English, regardless of whether they had to add information later.
“When writing laws, they did a lot of center-embedding regardless of whether or not they had to edit it or write it from scratch. And in that narrative text, they did not use center-embedding in either case,” Martinez says.
In another set of experiments, about 80 participants were asked to write laws, as well as descriptions that would explain those laws to visitors from another country. In these experiments, participants again used center-embedding for their laws, but not for the descriptions of those laws.
The origins of legalese
Gibson’s lab is now investigating the origins of center-embedding in legal documents. Early American laws were based on British law, so the researchers plan to analyze British laws to see if they feature the same kind of grammatical construction. And going back much farther, they plan to analyze whether center-embedding is found in the Hammurabi Code, the earliest known set of laws, which dates to around 1750 BC.
“There may be just a stylistic way of writing from back then, and if it was seen as successful, people would use that style in other languages,” Gibson says. “I would guess that it’s an accidental property of how the laws were written the first time, but we don’t know that yet.”
The researchers hope that their work, which has identified specific aspects of legal language that make it more difficult to understand, will motivate lawmakers to try to make laws more comprehensible. Efforts to write legal documents in plainer language date to at least the 1970s, when President Richard Nixon declared that federal regulations should be written in “layman’s terms.” However, legal language has changed very little since that time.
“We have learned only very recently what it is that makes legal language so complicated, and therefore I am optimistic about being able to change it,” Gibson says.
For many decades, nuclear fusion power has been viewed as the ultimate energy source. A fusion power plant could generate carbon-free energy at a scale needed to address climate change. And it could be fueled by deuterium recovered from an essentially endless source — seawater.
Decades of work and billions of dollars in research funding have yielded many advances, but challenges remain. To Ju Li, the TEPCO Professor in Nuclear Science and Engineering and a professor of materials science and engineering at MIT, there are still two big challenges. The first is to build a fusion power plant that generates more energy than is put into it; in other words, it produces a net output of power. Researchers worldwide are making progress toward meeting that goal.
The second challenge that Li cites sounds straightforward: “How do we get the heat out?” But understanding the problem and finding a solution are both far from obvious.
Research in the MIT Energy Initiative (MITEI) includes development and testing of advanced materials that may help address those challenges, as well as many other challenges of the energy transition. MITEI has multiple corporate members that have been supporting MIT’s efforts to advance technologies required to harness fusion energy.
The problem: An abundance of helium, a destructive force
Key to a fusion reactor is a superheated plasma — an ionized gas — that’s reacting inside a vacuum vessel. As light atoms in the plasma combine to form heavier ones, they release fast neutrons with high kinetic energy that shoot through the surrounding vacuum vessel into a coolant. During this process, those fast neutrons gradually lose their energy by causing radiation damage and generating heat. The heat that’s transferred to the coolant is eventually used to raise steam that drives an electricity-generating turbine.
The problem is finding a material for the vacuum vessel that remains strong enough to keep the reacting plasma and the coolant apart, while allowing the fast neutrons to pass through to the coolant. If one considers only the damage due to neutrons knocking atoms out of position in the metal structure, the vacuum vessel should last a full decade. However, depending on what materials are used in the fabrication of the vacuum vessel, some projections indicate that the vacuum vessel will last only six to 12 months. Why is that? Today’s nuclear fission reactors also generate neutrons, and those reactors last far longer than a year.
The difference is that fusion neutrons possess much higher kinetic energy than fission neutrons do, and as they penetrate the vacuum vessel walls, some of them interact with the nuclei of atoms in the structural material, giving off particles that rapidly turn into helium atoms. The result is hundreds of times more helium atoms than are present in a fission reactor. Those helium atoms look for somewhere to land — a place with low “embedding energy,” a measure that indicates how much energy it takes for a helium atom to be absorbed. As Li explains, “The helium atoms like to go to places with low helium embedding energy.” And in the metals used in fusion vacuum vessels, there are places with relatively low helium embedding energy — namely, naturally occurring openings called grain boundaries.
Metals are made up of individual grains inside which atoms are lined up in an orderly fashion. Where the grains come together there are gaps where the atoms don’t line up as well. That open space has relatively low helium embedding energy, so the helium atoms congregate there. Worse still, helium atoms have a repellent interaction with other atoms, so the helium atoms basically push open the grain boundary. Over time, the opening grows into a continuous crack, and the vacuum vessel breaks.
That congregation of helium atoms explains why the structure fails much sooner than expected based just on the number of helium atoms that are present. Li offers an analogy to illustrate. “Babylon is a city of a million people. But the claim is that 100 bad persons can destroy the whole city — if all those bad persons work at the city hall.” The solution? Give those bad persons other, more attractive places to go, ideally in their own villages.
To Li, the problem and possible solution are the same in a fusion reactor. If many helium atoms go to the grain boundary at once, they can destroy the metal wall. The solution? Add a small amount of a material that has a helium embedding energy even lower than that of the grain boundary. And over the past two years, Li and his team have demonstrated — both theoretically and experimentally — that their diversionary tactic works. By adding nanoscale particles of a carefully selected second material to the metal wall, they’ve found they can keep the helium atoms that form from congregating in the structurally vulnerable grain boundaries in the metal.
Looking for helium-absorbing compounds
To test their idea, So Yeon Kim ScD ’23 of the Department of Materials Science and Engineering and Haowei Xu PhD ’23 of the Department of Nuclear Science and Engineering acquired a sample composed of two materials, or “phases,” one with a lower helium embedding energy than the other. They and their collaborators then implanted helium ions into the sample at a temperature similar to that in a fusion reactor and watched as bubbles of helium formed. Transmission electron microscope images confirmed that the helium bubbles occurred predominantly in the phase with the lower helium embedding energy. As Li notes, “All the damage is in that phase — evidence that it protected the phase with the higher embedding energy.”
Having confirmed their approach, the researchers were ready to search for helium-absorbing compounds that would work well with iron, which is often the principal metal in vacuum vessel walls. “But calculating helium embedding energy for all sorts of different materials would be computationally demanding and expensive,” says Kim. “We wanted to find a metric that is easy to compute and a reliable indicator of helium embedding energy.”
They found such a metric: the “atomic-scale free volume,” which is basically the maximum size of the internal vacant space available for helium atoms to potentially settle. “This is just the radius of the largest sphere that can fit into a given crystal structure,” explains Kim. “It is a simple calculation.” Examination of a series of possible helium-absorbing ceramic materials confirmed that atomic free volume correlates well with helium embedding energy. Moreover, many of the ceramics they investigated have higher free volume, thus lower embedding energy, than the grain boundaries do.
However, in order to identify options for the nuclear fusion application, the screening needed to include some other factors. For example, in addition to the atomic free volume, a good second phase must be mechanically robust (able to sustain a load); it must not get very radioactive with neutron exposure; and it must be compatible — but not too cozy — with the surrounding metal, so it disperses well but does not dissolve into the metal. “We want to disperse the ceramic phase uniformly in the bulk metal to ensure that all grain boundary regions are close to the dispersed ceramic phase so it can provide protection to those regions,” says Li. “The two phases need to coexist, so the ceramic won’t either clump together or totally dissolve in the iron.”
Using their analytical tools, Kim and Xu examined about 50,000 compounds and identified 750 potential candidates. Of those, a good option for inclusion in a vacuum vessel wall made mainly of iron was iron silicate.
Experimental testing
The researchers were ready to examine samples in the lab. To make the composite material for proof-of-concept demonstrations, Kim and collaborators dispersed nanoscale particles of iron silicate into iron and implanted helium into that composite material. She took X-ray diffraction (XRD) images before and after implanting the helium and also computed the XRD patterns. The ratio between the implanted helium and the dispersed iron silicate was carefully controlled to allow a direct comparison between the experimental and computed XRD patterns. The measured XRD intensity changed with the helium implantation exactly as the calculations had predicted. “That agreement confirms that atomic helium is being stored within the bulk lattice of the iron silicate,” says Kim.
To follow up, Kim directly counted the number of helium bubbles in the composite. In iron samples without the iron silicate added, grain boundaries were flanked by many helium bubbles. In contrast, in the iron samples with the iron silicate ceramic phase added, helium bubbles were spread throughout the material, with many fewer occurring along the grain boundaries. Thus, the iron silicate had provided sites with low helium-embedding energy that lured the helium atoms away from the grain boundaries, protecting those vulnerable openings and preventing cracks from opening up and causing the vacuum vessel to fail catastrophically.
The researchers conclude that adding just 1 percent (by volume) of iron silicate to the iron walls of the vacuum vessel will cut the number of helium bubbles in half and also reduce their diameter by 20 percent — “and having a lot of small bubbles is OK if they’re not in the grain boundaries,” explains Li.
Next steps
Thus far, Li and his team have gone from computational studies of the problem and a possible solution to experimental demonstrations that confirm their approach. And they’re well on their way to commercial fabrication of components. “We’ve made powders that are compatible with existing commercial 3D printers and are preloaded with helium-absorbing ceramics,” says Li. The helium-absorbing nanoparticles are well dispersed and should provide sufficient helium uptake to protect the vulnerable grain boundaries in the structural metals of the vessel walls. While Li confirms that there’s more scientific and engineering work to be done, he, along with Alexander O'Brien PhD ’23 of the Department of Nuclear Science and Engineering and Kang Pyo So, a former postdoc in the same department, have already developed a startup company that’s ready to 3D print structural materials that can meet all the challenges faced by the vacuum vessel inside a fusion reactor.
This research was supported by Eni S.p.A. through the MIT Energy Initiative. Additional support was provided by a Kwajeong Scholarship; the U.S. Department of Energy (DOE) Laboratory Directed Research and Development program at Idaho National Laboratory; U.S. DOE Lawrence Livermore National Laboratory; and Creative Materials Discovery Program through the National Research Foundation of Korea.
Based on theoretical and experimental studies, MIT engineers have shown that adding nanoparticles of certain ceramics to the metal walls of the vessel containing the reacting plasma inside a nuclear fusion reactor can protect the metal from damage, significantly extending its lifetime. Professor Ju Li (right) and postdoc So Yeon Kim (left) examine samples of the composite they have fabricated for their demonstrations.
A tiny battery designed by MIT engineers could enable the deployment of cell-sized, autonomous robots for drug delivery within in the human body, as well as other applications such as locating leaks in gas pipelines.
The new battery, which is 0.1 millimeters long and 0.002 millimeters thick — roughly the thickness of a human hair — can capture oxygen from air and use it to oxidize zinc, creating a current with a potential of up to 1 volt. That is enough to power a small circuit, sensor, or actuator, the researchers showed.
“We think this is going to be very enabling for robotics,” says Michael Strano, the Carbon P. Dubbs Professor of Chemical Engineering at MIT and the senior author of the study. “We’re building robotic functions onto the battery and starting to put these components together into devices.”
Ge Zhang PhD ’22 and Sungyun Yang, an MIT graduate student, are the lead author of the paper, which appears in Science Robotics.
Powered by batteries
For several years, Strano’s lab has been working on tiny robots that can sense and respond to stimuli in their environment. One of the major challenges in developing such tiny robots is making sure that they have enough power.
Other researchers have shown that they can power microscale devices using solar power, but the limitation to that approach is that the robots must have a laser or another light source pointed at them at all times. Such devices are known as “marionettes” because they are controlled by an external power source. Putting a power source such as a battery inside these tiny devices could free them to roam much farther.
“The marionette systems don’t really need a battery because they’re getting all the energy they need from outside,” Strano says. “But if you want a small robot to be able to get into spaces that you couldn’t access otherwise, it needs to have a greater level of autonomy. A battery is essential for something that’s not going to be tethered to the outside world.”
To create robots that could become more autonomous, Strano’s lab decided to use a type of battery known as a zinc-air battery. These batteries, which have a longer lifespan than many other types of batteries due to their high energy density, are often used in hearing aids.
The battery that they designed consists of a zinc electrode connected to a platinum electrode, embedded into a strip of a polymer called SU-8, which is commonly used for microelectronics. When these electrodes interact with oxygen molecules from the air, the zinc becomes oxidized and releases electrons that flow to the platinum electrode, creating a current.
In this study, the researchers showed that this battery could provide enough energy to power an actuator — in this case, a robotic arm that can be raised and lowered. The battery could also power a memristor, an electrical component that can store memories of events by changing its electrical resistance, and a clock circuit, which allows robotic devices to keep track of time.
The battery also provides enough power to run two different types of sensors that change their electrical resistance when they encounter chemicals in the environment. One of the sensors is made from atomically thin molybdenum disulfide and the other from carbon nanotubes.
“We’re making the basic building blocks in order to build up functions at the cellular level,” Strano says.
Robotic swarms
In this study, the researchers used a wire to connect their battery to an external device, but in future work they plan to build robots in which the battery is incorporated into a device.
“This is going to form the core of a lot of our robotic efforts,” Strano says. “You can build a robot around an energy source, sort of like you can build an electric car around the battery.”
One of those efforts revolves around designing tiny robots that could be injected into the human body, where they could seek out a target site and then release a drug such as insulin. For use in the human body, the researchers envision that the devices would be made of biocompatible materials that would break apart once they were no longer needed.
The researchers are also working on increasing the voltage of the battery, which may enable additional applications.
The research was funded by the U.S. Army Research Office, the U.S. Department of Energy, the National Science Foundation, and a MathWorks Engineering Fellowship.
In late 2023, the first drug with potential to slow the progression of Alzheimer's disease was approved by the U.S. Federal Drug Administration. Alzheimer's is one of many debilitating neurological disorders that together affect one-eighth of the world's population, and while the new drug is a step in the right direction, there is still a long journey ahead to fully understanding it, and other such diseases.
"Reconstructing the intricacies of how the human brain functions on a cellular level is one of the biggest challenges in neuroscience," says Lars Gjesteby, a technical staff member and algorithm developer from the MIT Lincoln Laboratory's Human Health and Performance Systems Group. "High-resolution, networked brain atlases can help improve our understanding of disorders by pinpointing differences between healthy and diseased brains. However, progress has been hindered by insufficient tools to visualize and process very large brain imaging datasets."
A networked brain atlas is in essence a detailed map of the brain that can help link structural information with neural function. To build such atlases, brain imaging data need to be processed and annotated. For example, each axon, or thin fiber connecting neurons, needs to be traced, measured, and labeled with information. Current methods of processing brain imaging data, such as desktop-based software or manual-oriented tools, are not yet designed to handle human brain-scale datasets. As such, researchers often spend a lot of time slogging through an ocean of raw data.
Gjesteby is leading a project to build the Neuron Tracing and Active Learning Environment (NeuroTrALE), a software pipeline that brings machine learning, supercomputing, as well as ease of use and access to this brain mapping challenge. NeuroTrALE automates much of the data processing and displays the output in an interactive interface that allows researchers to edit and manipulate the data to mark, filter, and search for specific patterns.
Untangling a ball of yarn
One of NeuroTrALE's defining features is the machine-learning technique it employs, called active learning. NeuroTrALE's algorithms are trained to automatically label incoming data based on existing brain imaging data, but unfamiliar data can present potential for errors. Active learning allows users to manually correct errors, teaching the algorithm to improve the next time it encounters similar data. This mix of automation and manual labeling ensures accurate data processing with a much smaller burden on the user.
"Imagine taking an X-ray of a ball of yarn. You'd see all these crisscrossed, overlapping lines," says Michael Snyder, from the laboratory's Homeland Decision Support Systems Group. "When two lines cross, does it mean one of the pieces of yarn is making a 90-degree bend, or is one going straight up and the other is going straight over? With NeuroTrALE's active learning, users can trace these strands of yarn one or two times and train the algorithm to follow them correctly moving forward. Without NeuroTrALE, the user would have to trace the ball of yarn, or in this case the axons of the human brain, every single time." Snyder is a software developer on the NeuroTrALE team along with staff member David Chavez.
Because NeuroTrALE takes the bulk of the labeling burden off of the user, it allows researchers to process more data more quickly. Further, the axon tracing algorithms harness parallel computing to distribute computations across multiple GPUs at once, leading to even faster, scalable processing. Using NeuroTrALE, the team demonstrated a 90 percent decrease in computing time needed to process 32 gigabytes of data over conventional AI methods.
The team also showed that a substantial increase in the volume of data does not translate to an equivalent increase in processing time. For example, in a recent study they demonstrated that a 10,000 percent increase in dataset size resulted in only a 9 percent and a 22 percent increase in total data processing time, using two different types of central processing units.
"With the estimated 86 billion neurons making 100 trillion connections in the human brain, manually labeling all the axons in a single brain would take lifetimes," adds Benjamin Roop, one of the project's algorithm developers. "This tool has the potential to automate the creation of connectomes for not just one individual, but many. That opens the door for studying brain disease at the population level."
The open-source road to discovery
The NeuroTrALE project was formed as an internally funded collaboration between Lincoln Laboratory and Professor Kwanghun Chung's laboratory on MIT campus. The Lincoln Lab team needed to build a way for the Chung Lab researchers to analyze and extract useful information from their large amount of brain imaging data flowing into the MIT SuperCloud — a supercomputer run by Lincoln Laboratory to support MIT research. Lincoln Lab's expertise in high-performance computing, image processing, and artificial intelligence made it exceptionally suited to tackling this challenge.
In 2020, the team uploaded NeuroTrALE to the SuperCloud and by 2022 the Chung Lab was producing results. In one study, published in Science, they used NeuroTrALE to quantify prefrontal cortex cell density in relation to Alzheimer's disease, where brains affected with the disease had a lower cell density in certain regions than those without. The same team also located where in the brain harmful neurofibers tend to get tangled in Alzheimer's-affected brain tissue.
Work on NeuroTrALE has continued with Lincoln Laboratory funding and funding from the National Institutes of Health (NIH) to build up NeuroTrALE's capabilities. Currently, its user interface tools are being integrated with Google's Neuroglancer program — an open-source, web-based viewer application for neuroscience data. NeuroTrALE adds the ability for users to visualize and edit their annotated data dynamically, and for multiple users to work with the same data at the same time. Users can also create and edit a number of shapes such as polygons, points, and lines to facilitate annotation tasks, as well as customize color display for each annotation to distinguish neurons in dense regions.
"NeuroTrALE provides a platform-agnostic, end-to-end solution that can be easily and rapidly deployed on standalone, virtual, cloud, and high performance computing environments via containers." says Adam Michaleas, a high performance computing engineer from the laboratory's Artificial Intelligence Technology Group. "Furthermore, it significantly improves the end user experience by providing capabilities for real-time collaboration within the neuroscience community via data visualization and simultaneous content review."
To align with NIH's mission of sharing research products, the team's goal is to make NeuroTrALE a fully open-source tool for anyone to use. And this type of tool, says Gjesteby, is what's needed to reach the end goal of mapping the entirety of the human brain for research, and eventually drug development. "It's a grassroots effort by the community where data and algorithms are meant to be shared and accessed by all."
NeuroTrALE allows users to follow axons (red) throughout a dataset and review them for accuracy by scrolling through the data. The user can filter axons by length and select a single fiber (highlighted in yellow) for easy tracking.
Ask a large language model (LLM) like GPT-4 to smell a rain-soaked campsite, and it’ll politely decline. Ask the same system to describe that scent to you, and it’ll wax poetic about “an air thick with anticipation" and “a scent that is both fresh and earthy," despite having neither prior experience with rain nor a nose to help it make such observations. One possible explanation for this phenomenon is that the LLM is simply mimicking the text present in its vast training data, rather than working with any real understanding of rain or smell.
But does the lack of eyes mean that language models can’t ever “understand" that a lion is “larger" than a house cat? Philosophers and scientists alike have long considered the ability to assign meaning to language a hallmark of human intelligence — and pondered what essential ingredients enable us to do so.
Peering into this enigma, researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) have uncovered intriguing results suggesting that language models may develop their own understanding of reality as a way to improve their generative abilities. The team first developed a set of small Karel puzzles, which consisted of coming up with instructions to control a robot in a simulated environment. They then trained an LLM on the solutions, but without demonstrating how the solutions actually worked. Finally, using a machine learning technique called “probing,” they looked inside the model’s “thought process” as it generates new solutions.
After training on over 1 million random puzzles, they found that the model spontaneously developed its own conception of the underlying simulation, despite never being exposed to this reality during training. Such findings call into question our intuitions about what types of information are necessary for learning linguistic meaning — and whether LLMs may someday understand language at a deeper level than they do today.
“At the start of these experiments, the language model generated random instructions that didn’t work. By the time we completed training, our language model generated correct instructions at a rate of 92.4 percent,” says MIT electrical engineering and computer science (EECS) PhD student and CSAIL affiliate Charles Jin, who is the lead author of a new paper on the work. “This was a very exciting moment for us because we thought that if your language model could complete a task with that level of accuracy, we might expect it to understand the meanings within the language as well. This gave us a starting point to explore whether LLMs do in fact understand text, and now we see that they’re capable of much more than just blindly stitching words together.”
Inside the mind of an LLM
The probe helped Jin witness this progress firsthand. Its role was to interpret what the LLM thought the instructions meant, unveiling that the LLM developed its own internal simulation of how the robot moves in response to each instruction. As the model’s ability to solve puzzles improved, these conceptions also became more accurate, indicating that the LLM was starting to understand the instructions. Before long, the model was consistently putting the pieces together correctly to form working instructions.
Jin notes that the LLM’s understanding of language develops in phases, much like how a child learns speech in multiple steps. Starting off, it’s like a baby babbling: repetitive and mostly unintelligible. Then, the language model acquires syntax, or the rules of the language. This enables it to generate instructions that might look like genuine solutions, but they still don’t work.
The LLM’s instructions gradually improve, though. Once the model acquires meaning, it starts to churn out instructions that correctly implement the requested specifications, like a child forming coherent sentences.
Separating the method from the model: A “Bizarro World”
The probe was only intended to “go inside the brain of an LLM” as Jin characterizes it, but there was a remote possibility that it also did some of the thinking for the model. The researchers wanted to ensure that their model understood the instructions independently of the probe, instead of the probe inferring the robot’s movements from the LLM’s grasp of syntax.
“Imagine you have a pile of data that encodes the LM’s thought process,” suggests Jin. “The probe is like a forensics analyst: You hand this pile of data to the analyst and say, ‘Here’s how the robot moves, now try and find the robot’s movements in the pile of data.’ The analyst later tells you that they know what’s going on with the robot in the pile of data. But what if the pile of data actually just encodes the raw instructions, and the analyst has figured out some clever way to extract the instructions and follow them accordingly? Then the language model hasn't really learned what the instructions mean at all.”
To disentangle their roles, the researchers flipped the meanings of the instructions for a new probe. In this “Bizarro World,” as Jin calls it, directions like “up” now meant “down” within the instructions moving the robot across its grid.
“If the probe is translating instructions to robot positions, it should be able to translate the instructions according to the bizarro meanings equally well,” says Jin. “But if the probe is actually finding encodings of the original robot movements in the language model’s thought process, then it should struggle to extract the bizarro robot movements from the original thought process.”
As it turned out, the new probe experienced translation errors, unable to interpret a language model that had different meanings of the instructions. This meant the original semantics were embedded within the language model, indicating that the LLM understood what instructions were needed independently of the original probing classifier.
“This research directly targets a central question in modern artificial intelligence: are the surprising capabilities of large language models due simply to statistical correlations at scale, or do large language models develop a meaningful understanding of the reality that they are asked to work with? This research indicates that the LLM develops an internal model of the simulated reality, even though it was never trained to develop this model,” says Martin Rinard, an MIT professor in EECS, CSAIL member, and senior author on the paper.
This experiment further supported the team’s analysis that language models can develop a deeper understanding of language. Still, Jin acknowledges a few limitations to their paper: They used a very simple programming language and a relatively small model to glean their insights. In an upcoming work, they’ll look to use a more general setting. While Jin’s latest research doesn’t outline how to make the language model learn meaning faster, he believes future work can build on these insights to improve how language models are trained.
“An intriguing open question is whether the LLM is actually using its internal model of reality to reason about that reality as it solves the robot navigation problem,” says Rinard. “While our results are consistent with the LLM using the model in this way, our experiments are not designed to answer this next question.”
“There is a lot of debate these days about whether LLMs are actually ‘understanding’ language or rather if their success can be attributed to what is essentially tricks and heuristics that come from slurping up large volumes of text,” says Ellie Pavlick, assistant professor of computer science and linguistics at Brown University, who was not involved in the paper. “These questions lie at the heart of how we build AI and what we expect to be inherent possibilities or limitations of our technology. This is a nice paper that looks at this question in a controlled way — the authors exploit the fact that computer code, like natural language, has both syntax and semantics, but unlike natural language, the semantics can be directly observed and manipulated for experimental purposes. The experimental design is elegant, and their findings are optimistic, suggesting that maybe LLMs can learn something deeper about what language ‘means.’”
Jin and Rinard’s paper was supported, in part, by grants from the U.S. Defense Advanced Research Projects Agency (DARPA).
Language models may develop their own understanding of reality as a way to improve their generative abilities, indicating that the models may someday understand language at a deeper level than they do today.
In 2023, more than 100,000 Americans died from opioid overdoses. The most effective way to save someone who has overdosed is to administer a drug called naloxone, but a first responder or bystander can’t always reach the person who has overdosed in time.
Researchers at MIT and Brigham and Women’s Hospital have developed a new device that they hope will help to eliminate those delays and potentially save the lives of people who overdose. The device, about the size of a stick of gum, can be implanted under the skin, where it monitors heart rate, breathing rate, and other vital signs. When it determines that an overdose has occurred, it rapidly pumps out a dose of naloxone.
In a study appearing today in the journal Device, the researchers showed that the device can successfully reverse overdoses in animals. With further development, the researchers envision that this approach could provide a new option for helping to prevent overdose deaths in high-risk populations, such as people who have already survived an overdose.
“This could really address a significant unmet need in the population that suffers from substance abuse and opiate dependency to help mitigate overdoses, with the initial focus on the high-risk population,” says Giovanni Traverso, an associate professor of mechanical engineering at MIT, a gastroenterologist at Brigham and Women’s Hospital, and the senior author of the study.
The paper’s lead authors are Hen-Wei Huang, a former MIT visiting scientist and currently an assistant professor of electrical and electronic engineering at Nanyang Technological University in Singapore; Peter Chai, an associate professor of emergency medicine physician at Brigham and Women’s Hospital; SeungHo Lee, a research scientist at MIT’s Koch Institute for Integrative Cancer Research; Tom Kerssemakers and Ali Imani, former master’s students at Brigham and Women’s Hospital; and Jack Chen, a doctoral student in mechanical engineering at MIT.
An implantable device
Naloxone is an opioid antagonist, meaning that it can bind to opioid receptors and block the effects of other opioids, including heroin and fentanyl. The drug, which is given by injection or as a nasal spray, can restore normal breathing within just a few minutes of being administered.
However, many people are alone when they overdose, and may not receive assistance in time to save their lives. Additionally, with a new wave of synthetic, more potent opioids sweeping the U.S., opioid overdoses can be more rapid in onset and unpredictable. To try to overcome that, some researchers are developing wearable devices that could detect an overdose and administer naloxone, but none of those have yet proven successful. The MIT/BWH team set out to design an implantable device that would be less bulky, provide direct injection of naloxone into the subcutaneous tissue, and eliminate the need for the patient to remember to wear it.
The device that the researchers came up with includes sensors that can detect heart rate, breathing rate, blood pressure, and oxygen saturation. In an animal study, the researchers used the sensors to measure all of these signals and determine exactly how they change during an overdose of fentanyl. This resulted in a unique algorithm that increases the sensitivity of the device to accurately detect opioid overdose and distinguish it from other conditions where breathing is decreased, such as sleep apnea.
This study showed that fentanyl first leads to a drop in heart rate, followed quickly by a slowdown of breathing. By measuring how these signals changed, the researchers were able to calculate the point at which naloxone administration should be triggered.
“The most challenging aspect of developing an engineering solution to prevent overdose mortality is simultaneously addressing patient adherence and willingness to adopt new technology, combating stigma, minimizing false positive detections, and ensuring the rapid delivery of antidotes,” says Huang. “Our proposed solution tackles these unmet needs by developing a miniaturized robotic implant equipped with multisensing modalities, continuous monitoring capabilities, on-board decision making, and an innovative micropumping mechanism.”
The device also includes a small reservoir that can carry up to 10 milligrams of naloxone. When an overdose is detected, it triggers a pump that ejects the naloxone, which is released within about 10 seconds.
In their animal studies, the researchers found that this drug administration could reverse the effects of an overdose 96 percent of the time.
“We created a closed-loop system that can sense the onset of the opiate overdose and then release the antidote, and then you see that recovery,” Traverso says.
Preventing overdoses
The researchers envision that this technology could be used to help people who are at the highest risk of overdose, beginning with people who have had a previous overdose. They now plan to investigate how to make the device as user-friendly as possible, studying factors such as the optimal location for implantation.
“A key pillar of addressing the opioid epidemic is providing naloxone to individuals at key moments of risk. Our vision for this device is for it to integrate into the cascade of harm-reduction strategies to efficiently and safely deliver naloxone, preventing death from opioid overdose and providing the opportunity to support individuals with opioid use disorder,” says Chai.
The researchers hope to be able to test the device in humans within the next three to five years. They are now working on miniaturizing the device further and optimizing the on-board battery, which currently can provide power for about two weeks.
The research was funded by Novo Nordisk, the McGraw Family Foundation at Brigham and Women’s Hospital, and the MIT Department of Mechanical Engineering.
In a new study appearing today in the journal AGU Advances, scientists at MIT and NASA report that seven rock samples collected along the “fan front” of Mars’ Jezero Crater contain minerals that are typically formed in water. The findings suggest that the rocks were originally deposited by water, or may have formed in the presence of water.
The seven samples were collected by NASA’s Perseverance rover in 2022 during its exploration of the crater’s western slope, where some rocks were hypothesized to have formed in what is now a dried-up ancient lake. Members of the Perseverance science team, including MIT scientists, have studied the rover’s images and chemical analyses of the samples, and confirmed that the rocks indeed contain signs of water, and that the crater was likely once a watery, habitable environment.
Whether the crater was actually inhabited is yet unknown. The team found that the presence of organic matter — the starting material for life — cannot be confirmed, at least based on the rover’s measurements. But judging from the rocks’ mineral content, scientists believe the samples are their best chance of finding signs of ancient Martian life once the rocks are returned to Earth for more detailed analysis.
“These rocks confirm the presence, at least temporarily, of habitable environments on Mars,” says the study’s lead author, Tanja Bosak, professor of geobiology in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS). “What we’ve found is that indeed there was a lot of water activity. For how long, we don’t know, but certainly for long enough to create these big sedimentary deposits.”
What’s more, some of the collected samples may have originally been deposited in the ancient lake more than 3.5 billion years ago — before even the first signs of life on Earth.
“These are the oldest rocks that may have been deposited by water, that we’ve ever laid hands or rover arms on,” says co-author Benjamin Weiss, the Robert R. Shrock Professor of Earth and Planetary Sciences at MIT. “That’s exciting, because it means these are the most promising rocks that may have preserved fossils, and signatures of life.”
The study’s MIT co-authors include postdoc Eva Scheller, and research scientist Elias Mansbach, along with members of the Perseverance science team.
At the front
The new rock samples were collected in 2022 as part of the rover’s Fan Front Campaign — an exploratory phase during which Perseverance traversed Jezero Crater’s western slope, where a fan-like region contains sedimentary, layered rocks. Scientists suspect that this “fan front” is an ancient delta that was created by sediment that flowed with a river and settled into a now bone-dry lakebed. If life existed on Mars, scientists believe that it could be preserved in the layers of sediment along the fan front.
In the end, Perseverance collected seven samples from various locations along the fan front. The rover obtained each sample by drilling into the Martian bedrock and extracting a pencil-sized core, which it then sealed in a tube to one day be retrieved and returned to Earth for detailed analysis.
Prior to extracting the cores, the rover took images of the surrounding sediments at each of the seven locations. The science team then processed the imaging data to estimate a sediment’s average grain size and mineral composition. This analysis showed that all seven collected samples likely contain signs of water, suggesting that they were initially deposited by water.
Specifically, Bosak and her colleagues found evidence of certain minerals in the sediments that are known to precipitate out of water.
“We found lots of minerals like carbonates, which are what make reefs on Earth,” Bosak says. “And it’s really an ideal material that can preserve fossils of microbial life.”
Interestingly, the researchers also identified sulfates in some samples that were collected at the base of the fan front. Sulfates are minerals that form in very salty water — another sign that water was present in the crater at one time — though very salty water, Bosak notes, “is not necessarily the best thing for life.” If the entire crater was once filled with very salty water, then it would be difficult for any form of life to thrive. But if only the bottom of the lake were briny, that could be an advantage, at least for preserving any signs of life that may have lived further up, in less salty layers, that eventually died and drifted down to the bottom.
“However salty it was, if there were any organics present, it's like pickling something in salt,” Bosak says. “If there was life that fell into the salty layer, it would be very well-preserved.”
Fuzzy fingerprints
But the team emphasizes that organic matter has not been confidently detected by the rover’s instruments. Organic matter can be signs of life, but can also be produced by certain geological processes that have nothing to do with living matter. Perseverance’s predecessor, the Curiosity rover, had detected organic matter throughout Mars’ Gale Crater, which scientists suspect may have come from asteroids that made impact with Mars in the past.
And in a previous campaign, Perseverance detected what appeared to be organic molecules at multiple locations along Jezero Crater’s floor. These observations were taken by the rover’s Scanning Habitable Environments with Raman and Luminescence for Organics and Chemicals (SHERLOC) instrument, which uses ultraviolet light to scan the Martian surface. If organics are present, they can glow, similar to material under a blacklight. The wavelengths at which the material glows act as a sort of fingerprint for the kind of organic molecules that are present.
In Perseverance’s previous exploration of the crater floor, SHERLOC appeared to pick up signs of organic molecules throughout the region, and later, at some locations along the fan front. But a careful analysis, led by MIT’s Eva Scheller, has found that while the particular wavelengths observed could be signs of organic matter, they could just as well be signatures of substances that have nothing to do with organic matter.
“It turns out that cerium metals incorporated in minerals actually produce very similar signals as the organic matter,” Scheller says. “When investigated, the potential organic signals were strongly correlated with phosphate minerals, which always contain some cerium.”
Scheller’s work shows that the rover’s measurements cannot be interpreted definitively as organic matter.
“This is not bad news,” Bosak says. “It just tells us there is not very abundant organic matter. It’s still possible that it’s there. It’s just below the rover’s detection limit.”
When the collected samples are finally sent back to Earth, Bosak says laboratory instruments will have more than enough sensitivity to detect any organic matter that might lie within.
“On Earth, once we have microscopes with nanometer-scale resolution, and various types of instruments that we cannot staff on one rover, then we can actually attempt to look for life,” she says.
NASA’s Perseverance rover puts its robotic arm to work around a rocky outcrop called “Skinner Ridge” in Mars’ Jezero Crater. Composed of multiple images, this mosaic shows layered sedimentary rocks in the face of a cliff in the delta, as well as one of the locations where the rover abraded a circular patch to analyze a rock’s composition.
Identifying one faulty turbine in a wind farm, which can involve looking at hundreds of signals and millions of data points, is akin to finding a needle in a haystack.
Engineers often streamline this complex problem using deep-learning models that can detect anomalies in measurements taken repeatedly over time by each turbine, known as time-series data.
But with hundreds of wind turbines recording dozens of signals each hour, training a deep-learning model to analyze time-series data is costly and cumbersome. This is compounded by the fact that the model may need to be retrained after deployment, and wind farm operators may lack the necessary machine-learning expertise.
In a new study, MIT researchers found that large language models (LLMs) hold the potential to be more efficient anomaly detectors for time-series data. Importantly, these pretrained models can be deployed right out of the box.
The researchers developed a framework, called SigLLM, which includes a component that converts time-series data into text-based inputs an LLM can process. A user can feed these prepared data to the model and ask it to start identifying anomalies. The LLM can also be used to forecast future time-series data points as part of an anomaly detection pipeline.
While LLMs could not beat state-of-the-art deep learning models at anomaly detection, they did perform as well as some other AI approaches. If researchers can improve the performance of LLMs, this framework could help technicians flag potential problems in equipment like heavy machinery or satellites before they occur, without the need to train an expensive deep-learning model.
“Since this is just the first iteration, we didn’t expect to get there from the first go, but these results show that there’s an opportunity here to leverage LLMs for complex anomaly detection tasks,” says Sarah Alnegheimish, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on SigLLM.
Her co-authors include Linh Nguyen, an EECS graduate student; Laure Berti-Equille, a research director at the French National Research Institute for Sustainable Development; and senior author Kalyan Veeramachaneni, a principal research scientist in the Laboratory for Information and Decision Systems. The research will be presented at the IEEE Conference on Data Science and Advanced Analytics.
An off-the-shelf solution
Large language models are autoregressive, which means they can understand that the newest values in sequential data depend on previous values. For instance, models like GPT-4 can predict the next word in a sentence using the words that precede it.
Since time-series data are sequential, the researchers thought the autoregressive nature of LLMs might make them well-suited for detecting anomalies in this type of data.
However, they wanted to develop a technique that avoids fine-tuning, a process in which engineers retrain a general-purpose LLM on a small amount of task-specific data to make it an expert at one task. Instead, the researchers deploy an LLM off the shelf, with no additional training steps.
But before they could deploy it, they had to convert time-series data into text-based inputs the language model could handle.
They accomplished this through a sequence of transformations that capture the most important parts of the time series while representing data with the fewest number of tokens. Tokens are the basic inputs for an LLM, and more tokens require more computation.
“If you don’t handle these steps very carefully, you might end up chopping off some part of your data that does matter, losing that information,” Alnegheimish says.
Once they had figured out how to transform time-series data, the researchers developed two anomaly detection approaches.
Approaches for anomaly detection
For the first, which they call Prompter, they feed the prepared data into the model and prompt it to locate anomalous values.
“We had to iterate a number of times to figure out the right prompts for one specific time series. It is not easy to understand how these LLMs ingest and process the data,” Alnegheimish adds.
For the second approach, called Detector, they use the LLM as a forecaster to predict the next value from a time series. The researchers compare the predicted value to the actual value. A large discrepancy suggests that the real value is likely an anomaly.
With Detector, the LLM would be part of an anomaly detection pipeline, while Prompter would complete the task on its own. In practice, Detector performed better than Prompter, which generated many false positives.
“I think, with the Prompter approach, we were asking the LLM to jump through too many hoops. We were giving it a harder problem to solve,” says Veeramachaneni.
When they compared both approaches to current techniques, Detector outperformed transformer-based AI models on seven of the 11 datasets they evaluated, even though the LLM required no training or fine-tuning.
In the future, an LLM may also be able to provide plain language explanations with its predictions, so an operator could be better able to understand why an LLM identified a certain data point as anomalous.
However, state-of-the-art deep learning models outperformed LLMs by a wide margin, showing that there is still work to do before an LLM could be used for anomaly detection.
“What will it take to get to the point where it is doing as well as these state-of-the-art models? That is the million-dollar question staring at us right now. An LLM-based anomaly detector needs to be a game-changer for us to justify this sort of effort,” Veeramachaneni says.
Moving forward, the researchers want to see if finetuning can improve performance, though that would require additional time, cost, and expertise for training.
Their LLM approaches also take between 30 minutes and two hours to produce results, so increasing the speed is a key area of future work. The researchers also want to probe LLMs to understand how they perform anomaly detection, in the hopes of finding a way to boost their performance.
“When it comes to complex tasks like anomaly detection in time series, LLMs really are a contender. Maybe other complex tasks can be addressed with LLMs, as well?” says Alnegheimish.
This research was supported by SES S.A., Iberdrola and ScottishPower Renewables, and Hyundai Motor Company.
Early-stage trials in Alzheimer’s disease patients and studies in mouse models of the disease have suggested positive impacts on pathology and symptoms from exposure to light and sound presented at the “gamma” band frequency of 40 hertz (Hz). A new study zeroes in on how 40Hz sensory stimulation helps to sustain an essential process in which the signal-sending branches of neurons, called axons, are wrapped in a fatty insulation called myelin. Often called the brain’s “white matter,” myelin protects axons and insures better electrical signal transmission in brain circuits.
“Previous publications from our lab have mainly focused on neuronal protection,” says Li-Huei Tsai, Picower Professor in The Picower Institute for Learning and Memory and the Department of Brain and Cognitive Sciences at MIT and senior author of the new open-access study in Nature Communications. Tsai also leads MIT’s Aging Brain Initiative. “But this study shows that it’s not just the gray matter, but also the white matter that’s protected by this method.”
This year Cognito Therapeutics, the spinoff company that licensed MIT’s sensory stimulation technology, published phase II human trial results in the Journal of Alzheimer’s Disease indicating that 40Hz light and sound stimulation significantly slowed the loss of myelin in volunteers with Alzheimer’s. Also this year, Tsai’s lab published a study showing that gamma sensory stimulation helped mice withstand neurological effects of chemotherapy medicines, including by preserving myelin. In the new study, members of Tsai’s lab led by former postdoc Daniela Rodrigues Amorim used a common mouse model of myelin loss — a diet with the chemical cuprizone — to explore how sensory stimulation preserves myelination.
Amorim and Tsai’s team found that 40Hz light and sound not only preserved myelination in the brains of cuprizone-exposed mice, it also appeared to protect oligodendrocytes (the cells that myelinate neural axons), sustain the electrical performance of neurons, and preserve a key marker of axon structural integrity. When the team looked into the molecular underpinnings of these benefits, they found clear signs of specific mechanisms including preservation of neural circuit connections called synapses; a reduction in a cause of oligodendrocyte death called “ferroptosis;” reduced inflammation; and an increase in the ability of microglia brain cells to clean up myelin damage so that new myelin could be restored.
“Gamma stimulation promotes a healthy environment,” says Amorim, who is now a Marie Curie Fellow at the University of Galway in Ireland. “There are several ways we are seeing different effects.”
The findings suggest that gamma sensory stimulation may help not only Alzheimer’s disease patients but also people battling other diseases involving myelin loss, such as multiple sclerosis, the authors wrote in the study.
Maintaining myelin
To conduct the study, Tsai and Amorim’s team fed some male mice a diet with cuprizone and gave other male mice a normal diet for six weeks. Halfway into that period, when cuprizone is known to begin causing its most acute effects on myelination, they exposed some mice from each group to gamma sensory stimulation for the remaining three weeks. In this way they had four groups: completely unaffected mice, mice that received no cuprizone but did get gamma stimulation, mice that received cuprizone and constant (but not 40Hz) light and sound as a control, and mice that received cuprizone and also gamma stimulation.
After the six weeks elapsed, the scientists measured signs of myelination throughout the brains of the mice in each group. Mice that weren’t fed cuprizone maintained healthy levels, as expected. Mice that were fed cuprizone and didn’t receive 40Hz gamma sensory stimulation showed drastic levels of myelin loss. Cuprizone-fed mice that received 40Hz stimulation retained significantly more myelin, rivaling the health of mice never fed cuprizone by some, but not all, measures.
The researchers also looked at numbers of oligodendrocytes to see if they survived better with sensory stimulation. Several measures revealed that in mice fed cuprizone, oligodendrocytes in the corpus callosum region of the brain (a key point for the transit of neural signals because it connects the brain’s hemispheres) were markedly reduced. But in mice fed cuprizone and also treated with gamma stimulation, the number of cells were much closer to healthy levels.
Electrophysiological tests among neural axons in the corpus callosum showed that gamma sensory stimulation was associated with improved electrical performance in cuprizone-fed mice who received gamma stimulation compared to cuprizone-fed mice left untreated by 40Hz stimulation. And when researchers looked in the anterior cingulate cortex region of the brain, they saw that MAP2, a protein that signals the structural integrity of axons, was much better preserved in mice that received cuprizone and gamma stimulation compared to cuprizone-fed mice who did not.
A key goal of the study was to identify possible ways in which 40Hz sensory stimulation may protect myelin.
To find out, the researchers conducted a sweeping assessment of protein expression in each mouse group and identified which proteins were differentially expressed based on cuprizone diet and exposure to gamma frequency stimulation. The analysis revealed distinct sets of effects between the cuprizone mice exposed to control stimulation and cuprizone-plus-gamma mice.
A highlight of one set of effects was the increase in MAP2 in gamma-treated cuprizone-fed mice. A highlight of another set was that cuprizone mice who received control stimulation showed a substantial deficit in expression of proteins associated with synapses. The gamma-treated cuprizone-fed mice did not show any significant loss, mirroring results in a 2019 Alzheimer’s 40Hz study that showed synaptic preservation. This result is important, the researchers wrote, because neural circuit activity, which depends on maintaining synapses, is associated with preserving myelin. They confirmed the protein expression results by looking directly at brain tissues.
Another set of protein expression results hinted at another important mechanism: ferroptosis. This phenomenon, in which errant metabolism of iron leads to a lethal buildup of reactive oxygen species in cells, is a known problem for oligodendrocytes in the cuprizone mouse model. Among the signs was an increase in cuprizone-fed, control stimulation mice in expression of the protein HMGB1, which is a marker of ferroptosis-associated damage that triggers an inflammatory response. Gamma stimulation, however, reduced levels of HMGB1.
Looking more deeply at the cellular and molecular response to cuprizone demyelination and the effects of gamma stimulation, the team assessed gene expression using single-cell RNA sequencing technology. They found that astrocytes and microglia became very inflammatory in cuprizone-control mice but gamma stimulation calmed that response. Fewer cells became inflammatory and direct observations of tissue showed that microglia became more proficient at clearing away myelin debris, a key step in effecting repairs.
The team also learned more about how oligodendrocytes in cuprizone-fed mice exposed to 40Hz sensory stimulation managed to survive better. Expression of protective proteins such as HSP70 increased and as did expression of GPX4, a master regulator of processes that constrain ferroptosis.
In addition to Amorim and Tsai, the paper’s other authors are Lorenzo Bozzelli, TaeHyun Kim, Liwang Liu, Oliver Gibson, Cheng-Yi Yang, Mitch Murdock, Fabiola Galiana-Meléndez, Brooke Schatz, Alexis Davison, Md Rezaul Islam, Dong Shin Park, Ravikiran M. Raju, Fatema Abdurrob, Alissa J. Nelson, Jian Min Ren, Vicky Yang and Matthew P. Stokes.
Fundacion Bancaria la Caixa, The JPB Foundation, The Picower Institute for Learning and Memory, the Carol and Gene Ludwig Family Foundation, Lester A. Gimpelson, Eduardo Eurnekian, The Dolby Family, Kathy and Miguel Octavio, the Marc Haas Foundation, Ben Lenail and Laurie Yoler, and the U.S. National Institutes of Health provided funding for the study.
MIT researchers found that in mice fed the chemical cuprizone to model the loss of myelin — an important insulator around the axonal projections of neurons — those that received 40Hz light and sound stimulation experienced less loss of the oligodendrocyte cells that produce myelin. This edited detail from a figure in their paper shows staining for APCCC1 (red), a marker of oligodendrocytes.
Quantum materials — those with electronic properties that are governed by the principles of quantum mechanics, such as correlation and entanglement — can exhibit exotic behaviors under certain conditions, such as the ability to transmit electricity without resistance, known as superconductivity. However, in order to get the best performance out of these materials, they need to be properly tuned, in the same way that race cars require tuning as well. A team led by Mingda Li, an associate professor in MIT’s Department of Nuclear Science and Engineering (NSE), has demonstrated a new, ultra-precise way to tweak the characteristics of quantum materials, using a particular class of these materials, Weyl semimetals, as an example.
The new technique is not limited to Weyl semimetals. “We can use this method for any inorganic bulk material, and for thin films as well,” maintains NSE postdoc Manasi Mandal, one of two lead authors of an open-access paper — published recently in Applied Physics Reviews — that reported on the group’s findings.
The experiment described in the paper focused on a specific type of Weyl semimetal, a tantalum phosphide (TaP) crystal. Materials can be classified by their electrical properties: metals conduct electricity readily, whereas insulators impede the free flow of electrons. A semimetal lies somewhere in between. It can conduct electricity, but only in a narrow frequency band or channel. Weyl semimetals are part of a wider category of so-called topological materials that have certain distinctive features. For instance, they possess curious electronic structures — kinks or “singularities” called Weyl nodes, which are swirling patterns around a single point (configured in either a clockwise or counterclockwise direction) that resemble hair whorls or, more generally, vortices. The presence of Weyl nodes confers unusual, as well as useful, electrical properties. And a key advantage of topological materials is that their sought-after qualities can be preserved, or “topologically protected,” even when the material is disturbed.
“That’s a nice feature to have,” explains Abhijatmedhi Chotrattanapituk, a PhD student in MIT’s Department of Electrical Engineering and Computer Science and the other lead author of the paper. “When you try to fabricate this kind of material, you don’t have to be exact. You can tolerate some imperfections, some level of uncertainty, and the material will still behave as expected.”
Like water in a dam
The “tuning” that needs to happen relates primarily to the Fermi level, which is the highest energy level occupied by electrons in a given physical system or material. Mandal and Chotrattanapituk suggest the following analogy: Consider a dam that can be filled with varying levels of water. One can raise that level by adding water or lower it by removing water. In the same way, one can adjust the Fermi level of a given material simply by adding or subtracting electrons.
To fine-tune the Fermi level of the Weyl semimetal, Li’s team did something similar, but instead of adding actual electrons, they added negative hydrogen ions (each consisting of a proton and two electrons) to the sample. The process of introducing a foreign particle, or defect, into the TaP crystal — in this case by substituting a hydrogen ion for a tantalum atom — is called doping. And when optimal doping is achieved, the Fermi level will coincide with the energy level of the Weyl nodes. That’s when the material’s desired quantum properties will be most fully realized.
For Weyl semimetals, the Fermi level is especially sensitive to doping. Unless that level is set close to the Weyl nodes, the material’s properties can diverge significantly from the ideal. The reason for this extreme sensitivity owes to the peculiar geometry of the Weyl node. If one were to think of the Fermi level as the water level in a reservoir, the reservoir in a Weyl semimetal is not shaped like a cylinder; it’s shaped like an hourglass, and the Weyl node is located at the narrowest point, or neck, of that hourglass. Adding too much or too little water would miss the neck entirely, just as adding too many or too few electrons to the semimetal would miss the node altogether.
Fire up the hydrogen
To reach the necessary precision, the researchers utilized MIT’s two-stage “Tandem” ion accelerator — located at the Center for Science and Technology with Accelerators and Radiation (CSTAR) — and buffeted the TaP sample with high-energy ions coming out of the powerful (1.7 million volt) accelerator beam. Hydrogen ions were chosen for this purpose because they are the smallest negative ions available and thus alter the material less than a much larger dopant would. “The use of advanced accelerator techniques allows for greater precision than was ever before possible, setting the Fermi level to milli-electron volt [thousandths of an electron volt] accuracy,” says Kevin Woller, the principal research scientist who leads the CSTAR lab. “Additionally, high-energy beams allow for the doping of bulk crystals beyond the limitations of thin films only a few tens of nanometers thick.”
The procedure, in other words, involves bombarding the sample with hydrogen ions until a sufficient number of electrons are taken in to make the Fermi level just right. The question is: how long do you run the accelerator, and how do you know when enough is enough? The point being that you want to tune the material until the Fermi level is neither too low nor too high.
“The longer you run the machine, the higher the Fermi level gets,” Chotrattanapituk says. “The difficulty is that we cannot measure the Fermi level while the sample is in the accelerator chamber.” The normal way to handle that would be to irradiate the sample for a certain amount of time, take it out, measure it, and then put it back in if the Fermi level is not high enough. “That can be practically impossible,” Mandal adds.
To streamline the protocol, the team has devised a theoretical model that first predicts how many electrons are needed to increase the Fermi level to the preferred level and translates that to the number of negative hydrogen ions that must be added to the sample. The model can then tell them how long the sample ought to be kept in the accelerator chamber.
The good news, Chotrattanapituk says, is that their simple model agrees within a factor of 2 with trusted conventional models that are much more computationally intensive and may require access to a supercomputer. The group’s main contributions are two-fold, he notes: offering a new, accelerator-based technique for precision doping and providing a theoretical model that can guide the experiment, telling researchers how much hydrogen should be added to the sample depending on the energy of the ion beam, the exposure time, and the size and thickness of the sample.
Fine things to come with fine-tuning
This could pave the way to a major practical advance, Mandal notes, because their approach can potentially bring the Fermi level of a sample to the requisite value in a matter of minutes — a task that, by conventional methods, has sometimes taken weeks without ever reaching the required degree of milli-eV precision.
Li believes that an accurate and convenient method for fine-tuning the Fermi level could have broad applicability. “When it comes to quantum materials, the Fermi level is practically everything,” he says. “Many of the effects and behaviors that we seek only manifest themselves when the Fermi level is at the right location.” With a well-adjusted Fermi level, for example, one could raise the critical temperature at which materials become superconducting. Thermoelectric materials, which convert temperature differences into an electrical voltage, similarly become more efficient when the Fermi level is set just right. Precision tuning might also play a helpful role in quantum computing.
Thomas Zac Ward, a senior scientist at the Oak Ridge National Laboratory, offered a bullish assessment: “This work provides a new route for the experimental exploration of the critical, yet still poorly understand, behaviors of emerging materials. The ability to precisely control the Fermi level of a topological material is an important milestone that can help bring new quantum information and microelectronics device architectures to fruition.”
In ion implantation using a tandem accelerator on bulk material, selected ion species are injected toward the terminal, and ions with specific energies are directed toward the sample.
MIT chemists have developed a new way to synthesize complex molecules that were originally isolated from plants and could hold potential as antibiotics, analgesics, or cancer drugs.
These compounds, known as oligocyclotryptamines, consist of multiple tricyclic substructures called cyclotryptamine, fused together by carbon–carbon bonds. Only small quantities of these compounds are naturally available, and synthesizing them in the lab has proven difficult. The MIT team came up with a way to add tryptamine-derived components to a molecule one at a time, in a way that allows the researchers to precisely assemble the rings and control the 3D orientation of each component as well as the final product.
“For many of these compounds, there hasn’t been enough material to do a thorough review of their potential. I’m hopeful that having access to these compounds in a reliable way will enable us to do further studies,” says Mohammad Movassaghi, an MIT professor of chemistry and the senior author of the new study.
In addition to allowing scientists to synthesize oligocyclotryptamines found in plants, this approach could also be used to generate new variants that may have even better medicinal properties, or molecular probes that can help to reveal their mechanism of action.
Oligocyclotryptamines belong to a class of molecules called alkaloids — nitrogen-containing organic compounds produced mainly by plants. At least eight different oligocyclotryptamines have been isolated from a genus of flowering plants known as Psychotria, most of which are found in tropical forests.
Since the 1950s, scientists have studied the structure and synthesis of dimeric cyclotryptamines, which have two cyclotryptamine subunits. Over the past 20 years, significant progress has been made characterizing and synthesizing dimers and other smaller members of the family. However, no one has been able to synthesize the largest oligocyclotryptamines, which have six or seven rings fused together.
One of the hurdles in synthesizing these molecules is a step that requires formation of a bond between a carbon atom of one tryptamine-derived subunit to a carbon atom of the next subunit. The oligocyclotryptamines have two types of these linkages, both containing at least one carbon atom that has bonds with four other carbons. That extra bulk makes those carbon atoms less accessible to undergo reactions, and controlling the stereochemistry — the orientation of the atoms around the carbon — at all these junctures poses a significant challenge.
For many years, Movassaghi’s lab has been developing ways to form carbon-carbon bonds between carbon atoms that are already crowded with other atoms. In 2011, they devised a method that involves transforming the two carbon atoms into carbon radicals (carbon atoms with one unpaired electron) and directing their union. To create these radicals, and guide the paired union to be completely selective, the researchers first attach each of the targeted carbon atoms to a nitrogen atom; these two nitrogen atoms bind to each other.
When the researchers shine certain wavelengths of light on the substrate containing the two fragments linked via the two nitrogen atoms, it causes the two atoms of nitrogen to break away as nitrogen gas, leaving behind two very reactive carbon radicals in close proximity that join together almost immediately. This type of bond formation has also allowed the researchers to control the molecules’ stereochemistry.
Movassaghi demonstrated this approach, which he calls diazene-directed assembly, by synthesizing other types of alkaloids, including the communesins. These compounds are found in fungi and consist of two ring-containing molecules, or monomers, joined together. Later, Movassaghi began using this approach to fuse larger numbers of monomers, and he and Scott eventually turned their attention to the largest oligocyclotryptamine alkaloids.
The synthesis that they developed begins with one molecule of cyclotryptamine derivative, to which additional cyclotryptamine fragments with correct relative stereochemistry and position selectivity are added, one at a time. Each of these additions is made possible by the diazene-directed process that Movassaghi’s lab previously developed.
“The reason why we’re excited about this is that this single solution allowed us to go after multiple targets,” Movassaghi says. “That same route provides us a solution to multiple members of the natural product family because by extending the iteration one more cycle, your solution is now applied to a new natural product.”
“A tour de force”
Using this approach, the researchers were able to create molecules with six or seven cyclotryptamine rings, which has never been done before.
“Researchers worldwide have been trying to find a way to make these molecules, and Movassaghi and Scott are the first to pull it off,” says Seth Herzon, a professor of chemistry at Yale University, who was not involved in the research. Herzon described the work as “a tour de force in organic synthesis.”
Now that the researchers have synthesized these naturally occurring oligocyclotryptamines, they should be able to generate enough of the compounds that their potential therapeutic activity can be more thoroughly investigated.
They should also be able to create novel compounds by switching in slightly different cyclotryptamine subunits, Movassaghi says.
“We will continue to use this very precise way of adding these cyclotryptamine units to assemble them together into complex systems that have not been addressed yet, including derivatives that could potentially have improved properties,” he says.
The research was funded by the U.S. National Institute of General Medical Sciences.
Roads are the backbone of our society and economy, taking people and goods across distances long and short. They are a staple of the built environment, taking up nearly 2.8 million lane-miles (or 4.6 million lane-kilometers) of the United States’ surface area.
These same roads have a considerable life-cycle environmental impact, having been associated with over 75 megatons of greenhouse gases (GHG) each year over the past three decades in the United States. That is equivalent to the emissions of a gasoline-powered passenger vehicle traveling over 190 billion miles, or circling the Earth more than 7.5 million times, each year.
By 2050, it is estimated that pavement sector emissions will decrease by 14% due to improvements like cement clinker replacement, but it is possible to extract a 65% reduction through measures like investing in materials and maintenance practices to make road networks stiffer and smoother, meaning they require less energy to drive on. As a practical example, consider that in 2022, vehicles in the United States collectively drove 3.2 trillion miles. If the average surface roughness of all pavements were improved by 1%, there would be 190 million tons of CO2 saved each year.
One of the challenges to achieving greater GHG reductions is data scarcity, making it difficult for decision makers to evaluate the environmental impact of roads across their whole life cycle, comprising the emissions associated with the production of raw materials to construction, use, maintenance and repair, and finally demolition or decommissioning. Data scarcity and the complexity of calculation would make analyzing the life cycle environmental impacts of pavements prohibitively expensive, preventing informed decisions on what materials to use and how to maintain them. Today’s world is one of rapid change, with shifting weather and traffic patterns presenting new challenges for roads.
“Conducting pavement LCA is costly and labor-intensive, so many assessments simplify the process using fixed values for input parameters or only focus on upfront emissions from materials production and construction. However, conducting LCA with fixed input values fails to account for uncertainties and variations, which may lead to unreliable results. In this novel streamlined framework, we embrace and control the uncertainty in pavement LCA. This helps understand the minimum amount of data required to achieve a robust decision” notes Haoran Li, a postdoc at CSHub and the study’s lead author.
By keeping the uncertainty under control, the CSHub team develops a structured data underspecification framework that prioritizes collecting data on the factors that have the greatest influence over pavement’s life-cycle environmental impacts.
“Typically, multiple pavement stakeholders, like designers, materials engineers, contractors, etc., need to provide extensive input data for conducting an LCA and comparing the environmental impacts of different pavement types,” says Hessam AzariJafari, deputy director of the CSHub and a co-author on the study. “These individuals are involved at different stages of a pavement project and none of them will have all the necessary inputs for conducting a pavement LCA.”
The proposed streamlined LCA framework reduces the overall data collection burden by up to 85 percent without compromising the robustness of the conclusion on the environmentally preferred pavement type.
The CSHub team used the proposed framework to model the life-cycle environmental impacts of a pavement in Boston that had a length of one mile, four lanes, and a design life — or “life expectancy” — of 50 years. The team modeled two different pavement designs: an asphalt pavement and a jointed plain concrete pavement.
The MIT researchers then modeled four levels of data specificity, M1 through M4, to understand how they influenced the range of life-cycle assessment results for the two different designs. For example, M1 indicates the greatest uncertainty due to limited information about pavement conditions, including traffic and materials. M2 is typically used when the environment (urban or rural) is defined, but detailed knowledge of material properties and future maintenance strategies is still lacking. M3 offers a detailed description of pavement conditions using secondary data when field measurements are not available. M4 provides the highest level of data specificity, typically relying on first-hand information from designers.
MIT researchers found that the precise value for GHG emissions will vary from M1 to M4. However, the proportionate emissions associated with different components of the life cycle remain similar. For instance, regardless of the level of data specificity, embodied emissions from construction and maintenance and rehabilitation accounted for about half of the concrete pavement’s GHG emissions. In contrast, the use phase emissions for the asphalt pavement account for between 70 and 90 percent of the pavement’s life-cycle emissions.
The team found that, in Boston, combining an M2 level of data specification with an M3 knowledge of maintenance and rehabilitation produced a decision-making process with 90 percent reliability.
To make this framework practical and accessible, the MIT researchers are working on integrating the developed approach into an online life-cycle assessment tool. This tool democratizes pavement LCA and empowers the value chain stakeholders, such as departments of transportation and metropolitan planning organizations, to identify choices that lead to the highest-performing, longest-lasting, and most environmentally friendly pavements.
Despite their importance and impact, there are often scarce data for evaluating the environmental impact of roads across their whole life cycle, from producing raw materials through demolition. The MIT Concrete Sustainability Hub’s streamlined framework reduces the overall data collection burden by up to 85 percent.
Pick-and-place machines are a type of automated equipment used to place objects into structured, organized locations. These machines are used for a variety of applications — from electronics assembly to packaging, bin picking, and even inspection — but many current pick-and-place solutions are limited. Current solutions lack “precise generalization,” or the ability to solve many tasks without compromising on accuracy.
“In industry, you often see that [manufacturers] end up with very tailored solutions to the particular problem that they have, so a lot of engineering and not so much flexibility in terms of the solution,” Maria Bauza Villalonga PhD ’22, a senior research scientist at Google DeepMind where she works on robotics and robotic manipulation. “SimPLE solves this problem and provides a solution to pick-and-place that is flexible and still provides the needed precision.”
A new paper by MechE researchers published in the journal Science Robotics explores pick-and-place solutions with more precision. In precise pick-and-place, also known as kitting, the robot transforms an unstructured arrangement of objects into an organized arrangement. The approach, dubbed SimPLE (Simulation to Pick Localize and placE), learns to pick, regrasp and place objects using the object’s computer-aided design (CAD) model, and all without any prior experience or encounters with the specific objects.
“The promise of SimPLE is that we can solve many different tasks with the same hardware and software using simulation to learn models that adapt to each specific task,” says Alberto Rodriguez, an MIT visiting scientist who is a former member of the MechE faculty and now associate director of manipulation research for Boston Dynamics. SimPLE was developed by members of the Manipulation and Mechanisms Lab at MIT (MCube) under Rodriguez’ direction.
“In this work we show that it is possible to achieve the levels of positional accuracy that are required for many industrial pick and place tasks without any other specialization,” Rodriguez says.
Using a dual-arm robot equipped with visuotactile sensing, the SimPLE solution employs three main components: task-aware grasping, perception by sight and touch (visuotactile perception), and regrasp planning. Real observations are matched against a set of simulated observations through supervised learning so that a distribution of likely object poses can be estimated, and placement accomplished.
In experiments, SimPLE successfully demonstrated the ability to pick-and-place diverse objects spanning a wide range of shapes, achieving successful placements over 90 percent of the time for 6 objects, and over 80 percent of the time for 11 objects.
“There’s an intuitive understanding in the robotics community that vision and touch are both useful, but [until now] there haven’t been many systematic demonstrations of how it can be useful for complex robotics tasks,” says mechanical engineering doctoral student Antonia Delores Bronars SM ’22. Bronars, who is now working with Pulkit Agrawal, assistant professor in the department of Electrical Engineering and Computer Science (EECS), is continuing her PhD work investigating the incorporation of tactile capabilities into robotic systems.
“Most work on grasping ignores the downstream tasks,” says Matt Mason, chief scientist at Berkshire Grey and professor emeritus at Carnegie Mellon University who was not involved in the work. “This paper goes beyond the desire to mimic humans, and shows from a strictly functional viewpoint the utility of combining tactile sensing, vision, with two hands.”
Ken Goldberg, the William S. Floyd Jr. Distinguished Chair in Engineering at the University of California at Berkeley, who was also not involved in the study, says the robot manipulation methodology described in the paper offers a valuable alternative to the trend toward AI and machine learning methods.
“The authors combine well-founded geometric algorithms that can reliably achieve high-precision for a specific set of object shapes and demonstrate that this combination can significantly improve performance over AI methods,” says Goldberg, who is also co-founder and chief scientist for Ambi Robotics and Jacobi Robotics. “This can be immediately useful in industry and is an excellent example of what I call 'good old fashioned engineering' (GOFE).”
Bauza and Bronars say this work was informed by several generations of collaboration.
“In order to really demonstrate how vision and touch can be useful together, it’s necessary to build a full robotic system, which is something that’s very difficult to do as one person over a short horizon of time,” says Bronars. “Collaboration, with each other and with Nikhil [Chavan-Dafle PhD ‘20] and Yifan [Hou PhD ’21 CMU], and across many generations and labs really allowed us to build an end-to-end system.”
SimPLE, an approach to object manipulation developed by Department of Mechanical Engineering researchers, aims to “reduce the burden of introducing new objects to make it so that robots can interact still precisely but more flexibly,” says doctoral student Antonia Delores Bronars SM ’22.
The phrase “practice makes perfect” is usually reserved for humans, but it’s also a great maxim for robots newly deployed in unfamiliar environments.
Picture a robot arriving in a warehouse. It comes packaged with the skills it was trained on, like placing an object, and now it needs to pick items from a shelf it’s not familiar with. At first, the machine struggles with this, since it needs to get acquainted with its new surroundings. To improve, the robot will need to understand which skills within an overall task it needs improvement on, then specialize (or parameterize) that action.
A human onsite could program the robot to optimize its performance, but researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and The AI Institute have developed a more effective alternative. Presented at the Robotics: Science and Systems Conference last month, their “Estimate, Extrapolate, and Situate” (EES) algorithm enables these machines to practice on their own, potentially helping them improve at useful tasks in factories, households, and hospitals.
Sizing up the situation
To help robots get better at activities like sweeping floors, EES works with a vision system that locates and tracks the machine’s surroundings. Then, the algorithm estimates how reliably the robot executes an action (like sweeping) and whether it would be worthwhile to practice more. EES forecasts how well the robot could perform the overall task if it refines that particular skill, and finally, it practices. The vision system subsequently checks whether that skill was done correctly after each attempt.
EES could come in handy in places like a hospital, factory, house, or coffee shop. For example, if you wanted a robot to clean up your living room, it would need help practicing skills like sweeping. According to Nishanth Kumar SM ’24 and his colleagues, though, EES could help that robot improve without human intervention, using only a few practice trials.
“Going into this project, we wondered if this specialization would be possible in a reasonable amount of samples on a real robot,” says Kumar, co-lead author of a paper describing the work, PhD student in electrical engineering and computer science, and a CSAIL affiliate. “Now, we have an algorithm that enables robots to get meaningfully better at specific skills in a reasonable amount of time with tens or hundreds of data points, an upgrade from the thousands or millions of samples that a standard reinforcement learning algorithm requires.”
See Spot sweep
EES’s knack for efficient learning was evident when implemented on Boston Dynamics’ Spot quadruped during research trials at The AI Institute. The robot, which has an arm attached to its back, completed manipulation tasks after practicing for a few hours. In one demonstration, the robot learned how to securely place a ball and ring on a slanted table in roughly three hours. In another, the algorithm guided the machine to improve at sweeping toys into a bin within about two hours. Both results appear to be an upgrade from previous frameworks, which would have likely taken more than 10 hours per task.
“We aimed to have the robot collect its own experience so it can better choose which strategies will work well in its deployment,” says co-lead author Tom Silver SM ’20, PhD ’24, an electrical engineering and computer science (EECS) alumnus and CSAIL affiliate who is now an assistant professor at Princeton University. “By focusing on what the robot knows, we sought to answer a key question: In the library of skills that the robot has, which is the one that would be most useful to practice right now?”
EES could eventually help streamline autonomous practice for robots in new deployment environments, but for now, it comes with a few limitations. For starters, they used tables that were low to the ground, which made it easier for the robot to see its objects. Kumar and Silver also 3D printed an attachable handle that made the brush easier for Spot to grab. The robot didn’t detect some items and identified objects in the wrong places, so the researchers counted those errors as failures.
Giving robots homework
The researchers note that the practice speeds from the physical experiments could be accelerated further with the help of a simulator. Instead of physically working at each skill autonomously, the robot could eventually combine real and virtual practice. They hope to make their system faster with less latency, engineering EES to overcome the imaging delays the researchers experienced. In the future, they may investigate an algorithm that reasons over sequences of practice attempts instead of planning which skills to refine.
“Enabling robots to learn on their own is both incredibly useful and extremely challenging,” says Danfei Xu, an assistant professor in the School of Interactive Computing at Georgia Tech and a research scientist at NVIDIA AI, who was not involved with this work. “In the future, home robots will be sold to all sorts of households and expected to perform a wide range of tasks. We can't possibly program everything they need to know beforehand, so it’s essential that they can learn on the job. However, letting robots loose to explore and learn without guidance can be very slow and might lead to unintended consequences. The research by Silver and his colleagues introduces an algorithm that allows robots to practice their skills autonomously in a structured way. This is a big step towards creating home robots that can continuously evolve and improve on their own.”
Silver and Kumar’s co-authors are The AI Institute researchers Stephen Proulx and Jennifer Barry, plus four CSAIL members: Northeastern University PhD student and visiting researcher Linfeng Zhao, MIT EECS PhD student Willie McClinton, and MIT EECS professors Leslie Pack Kaelbling and Tomás Lozano-Pérez. Their work was supported, in part, by The AI Institute, the U.S. National Science Foundation, the U.S. Air Force Office of Scientific Research, the U.S. Office of Naval Research, the U.S. Army Research Office, and MIT Quest for Intelligence, with high-performance computing resources from the MIT SuperCloud and Lincoln Laboratory Supercomputing Center.
A new algorithm developed by researchers at MIT CSAIL helps robots practice skills on their own. In experiments, it guided a quadruped with sweeping and placing various items.
Many airline passengers naturally worry about flying. But on a worldwide basis, commercial air travel keeps getting safer, according to a new study by MIT researchers.
The risk of a fatality from commercial air travel was 1 per every 13.7 million passenger boardings globally in the 2018-2022 period — a significant improvement from 1 per 7.9 million boardings in 2008-2017 and a far cry from the 1 per every 350,000 boardings that occurred in 1968-1977, the study finds.
“Aviation safety continues to get better,” says Arnold Barnett, an MIT professor and co-author of a new paper detailing the research results.
“You might think there is some irreducible risk level we can’t get below,” adds Barnett, a leading expert in air travel safety and operations. “And yet, the chance of dying during an air journey keeps dropping by about 7 percent annually, and continues to go down by a factor of two every decade.”
To be sure, there are no guarantees of continual improvement; some recent near-collisions on runways in the U.S. have gained headlines in the last year, making it clear that airline safety is always an ongoing task.
Additionally, the Covid-19 pandemic may have caused a sizable — though presumably temporary — new risk stemming from flying. The study analyzes this risk but quantifies it separately from the long-term safety trend, which is based on accidents and deliberate attacks on aviation.
Overall, Barnett compares these long-run gains in air safety to “Moore’s Law,” the observation that innovators keep finding ways to double the computing power of chips roughly every 18 months. In this case, commercial air travel has gotten roughly twice as safe in each decade dating to the late 1960s.
“Here we have an aerial version of Moore’s Law,” says Barnett, who has helped refine air travel safety statistics for many years.
In per-boarding terms, passengers are about 39 times safer than they were in the 1968-1977 period.
The paper, “Airline safety: Still getting better?” appears in the August issue of the Journal of Air Transport Management. The authors are Barnett, who is the George Eastman Professor of Management Science at the MIT Sloan School of Management, and Jan Reig Torra MBA ’24, a former graduate student at MIT Sloan.
Covid-19 impact
The separate, additional finding about the impact of Covid-19 focuses on cases spread by airline passengers during the pandemic. This is not part of the top-line data, which evaluates airline incidents during normal operations. Still, Barnett thought it would also be valuable to explore the special case of viral transmission during the pandemic.
The study estimates that from June 2020 through February 2021, before vaccines were widely available, there were about 1,200 deaths in the U.S. from Covid-19 associated, directly or indirectly, with its transmission on passenger planes. Most of those fatalities would have involved not passengers but people who got Covid-19 from others who had been infected during air travel.
In addition, the study estimates that from March 2020 through December 2022, around 4,760 deaths around the globe were linked to the transmission of Covid-19 on airplanes. Those estimates are based on the best available data about transmission rates and daily death rates, and take account of the age distributions of air passengers during the pandemic. Perhaps surprisingly, older Americans do not seem to have flown less during the Covid-19 pandemic, even though their risks of death given infection were far higher than those of younger travelers.
“There’s no simple answer to this,” Barnett says. “But we worked to come up with realistic and conservative estimates, so that people can learn important lessons about what happened. I believe people should at least look at these numbers.”
Improved overall safety
Overall, to study fatalities during normal airline operations, the researchers used data from the Flight Safety Foundation, the World Bank, and the International Air Transport Association.
To evaluate air travel risks, experts have used a variety of metrics, including deaths per billion passenger miles, and fatal accidents per 100,000 flight hours. However, Barnett believes deaths per passenger boarding is the most “defensible” and understandable statistic, since it answers a simple question: If you have a boarding pass for a flight, what are your odds of dying? The statistic also includes incidents that might occur in airport terminals.
Having previously developed this metric, Barnett has now updated his findings multiple times, developing a comprehensive picture of air safety over time:
Commercial air travel fatalities per passenger boarding
1968-1977:
1 per 350,000
1978-1987:
1 per 750,000
1988-1997:
1 per 1.3 million
1998-2007:
1 per 2.7 million
2007-2017:
1 per 7.9 million
2018-2022:
1 per 13.7 million
As Barnett’s numbers show, these gains are not incidental improvements, but instead constitute a long-term trend. While the new paper is focused more on empirical outcomes than finding an explanation for them, Barnett suggests there is a combination of factors at work. These include technological advances, such as collision avoidance systems in planes; extensive training; and rigorous work by organizations such as the U.S. Federal Aviation Agency and the National Transportation Safety Board.
However, there are disparities in air travel safety globally. The study divides the world into three tiers of countries, based on their commercial air safety records. For countries in the third tier, there were 36.5 times as many fatalities per passenger boarding in 2018-2022 than was the case in the top tier. Thus, it is safer to fly in some parts of the world than in others.
The first tier of countries consists of the United States, the European Union countries, and other European states, including Montenegro, Norway, Switzerland, and the United Kingdom, as well as Australia, Canada, China, Israel, Japan, and New Zealand.
The second group consists of Bahrain, Bosnia, Brazil, Brunei, Chile, Hong Kong (which has been distinct from mainland China in air safety regulations), India, Jordan, Kuwait, Malaysia, Mexico, the Philippines, Qatar, Singapore, South Africa, South Korea, Taiwan, Thailand, Turkey, and the United Arab Emirates. In each of those two groups of nations, the death risk per boarding over 2018-22 was about 1 per 80 million.
The third group then consists of every other country in the world. Within the top two groups, there were 153 passenger fatalities in the 2018-2022 period, and one major accident, a China Eastern Airlines crash in 2022 that killed 123 passengers. The 30 other fatalities beyond that in the top two tiers stemmed from six other air accidents.
For countries in the third tier, air travel fatalities per boarding were also cut roughly in half during the 2018-2022 period, although, as Barnett noted, that can be interpreted in two ways: It is good they are improving as rapidly as the leading countries in air safety, but in theory, they might be able to apply lessons learned elsewhere and catch up even more quickly.
“The remaining countries continue to improve by something like a factor of two, but they’re still behind the top two groups,” Barnett observes.
Overall, Barnett notes, notwithstanding Covid-19, and looking at accident avoidance, especially in countries with the lowest fatality rates, it is remarkable that air safety keeps getting better. Progress is never assured in this area; yet, the leading countries in air safety, including their government officials and airlines, keep finding ways to make flying safer.
“After decades of sharp improvements, it’s really hard to keep improving at the same rate. And yet they do,” Barnett concludes.
Electronic waste, or e-waste, is a rapidly growing global problem, and it’s expected to worsen with the production of new kinds of flexible electronics for robotics, wearable devices, health monitors, and other new applications, including single-use devices.
A new kind of flexible substrate material developed at MIT, the University of Utah, and Meta has the potential to enable not only the recycling of materials and components at the end of a device’s useful life, but also the scalable manufacture of more complex multilayered circuits than existing substrates provide.
The development of this new material is described this week in the journal RSC: Applied Polymers, in a paper by MIT Professor Thomas J. Wallin, University of Utah Professor Chen Wang, and seven others.
“We recognize that electronic waste is an ongoing global crisis that’s only going to get worse as we continue to build more devices for the internet of things, and as the rest of the world develops,” says Wallin, an assistant professor in MIT’s Department of Materials Science and Engineering. To date, much academic research on this front has aimed at developing alternatives to conventional substrates for flexible electronics, which primarily use a polymer called Kapton, a trade name for polyimide.
Most such research has focused on entirely different polymer materials, but “that really ignores the commercial side of it, as to why people chose the materials they did to begin with,” Wallin says. Kapton has many advantages, including excellent thermal and insulating properties and ready availability of source materials.
The polyimide business is projected to be a $4 billion global market by 2030. “It’s everywhere, in every electronic device basically,” including parts such as the flexible cables that interconnect different components inside your cellphone or laptop, Wang explains. It’s also widely used in aerospace applications because of its high heat tolerance. “It’s a classic material, but it has not been updated for three or four decades,” he says.
However, it’s also virtually impossible to melt or dissolve Kapton, so it can’t be reprocessed. The same properties also make it harder to manufacture the circuits into advanced architectures, such as multilayered electronics. The traditional way of making Kapton involves heating the material to anywhere from 200 to 300 degrees Celsius. “It’s a rather slow process. It takes hours,” Wang says.
The alternative material that the team developed, which is itself a form of polyimide and therefore should be easily compatible with existing manufacturing infrastructure, is a light-cured polymer similar to those now used by dentists to create tough, durable fillings that cure in a few seconds with ultraviolet light. Not only is this method of hardening the material comparatively fast, it can operate at room temperature.
The new material could serve as the substrate for multilayered circuits, which provides a way of greatly increasing the number of components that can be packed into a small form factor. Previously, since the Kapton substrate doesn’t melt easily, the layers had to be glued together, which adds steps and costs to the process. The fact that the new material can be processed at low-temperature while also hardening very quickly on demand could open up possibilities for new multilayer devices, Wang says.
As for recyclability, the team introduced subunits into the polymer backbone that can be rapidly dissolved away by an alcohol and catalyst solution. Then, precious metals used in the circuits, as well as entire microchips, can be recovered from the solution and reused for new devices.
“We designed the polymer with ester groups in the backbone,” unlike traditional Kapton, Wang explains. These ester groups can be easily broken apart by a fairly mild solution that removes the substrate while leaving the rest of the device unharmed. Wang notes that the University of Utah team has co-founded a company to commercialize the technology.
“We break the polymer back into its original small molecules. Then we can collect the expensive electronic components and reuse them,” Wallin adds. “We all know about the supply chain shortage with chips and some materials. The rare earth minerals that are in those components are highly valuable. And so we think that there’s a huge economic incentive now, as well as an environmental one, to make these processes for the recapture of these components.”
The research team included Caleb Reese and Grant Musgrave at the University of Utah, and Jenn Wong, Wenyang Pan, John Uehlin, Mason Zadan and Omar Awartani at Meta’s Reality Labs in Redmond, Washington. The work was supported by a startup fund at the Price College of Engineering at the University of Utah.
The MIT School of Science is launching a center to advance knowledge and computational capabilities in the field of sustainability science, and support decision-makers in government, industry, and civil society to achieve sustainable development goals. Aligned with the Climate Project at MIT, researchers at the MIT Center for Sustainability Science and Strategy will develop and apply expertise from across the Institute to improve understanding of sustainability challenges, and thereby provide actionable knowledge and insight to inform strategies for improving human well-being for current and future generations.
Noelle Selin, professor at MIT’s Institute for Data, Systems and Society and the Department of Earth, Atmospheric and Planetary Sciences, will serve as the center’s inaugural faculty director. C. Adam Schlosser and Sergey Paltsev, senior research scientists at MIT, will serve as deputy directors, with Anne Slinn as executive director.
Incorporating and succeeding both the Center for Global Change Science and Joint Program on the Science and Policy of Global Change while adding new capabilities, the center aims to produce leading-edge research to help guide societal transitions toward a more sustainable future. Drawing on the long history of MIT’s efforts to address global change and its integrated environmental and human dimensions, the center is well-positioned to lead burgeoning global efforts to advance the field of sustainability science, which seeks to understand nature-society systems in their full complexity. This understanding is designed to be relevant and actionable for decision-makers in government, industry, and civil society in their efforts to develop viable pathways to improve quality of life for multiple stakeholders.
“As critical challenges such as climate, health, energy, and food security increasingly affect people’s lives around the world, decision-makers need a better understanding of the earth in its full complexity — and that includes people, technologies, and institutions as well as environmental processes,” says Selin. “Better knowledge of these systems and how they interact can lead to more effective strategies that avoid unintended consequences and ensure an improved quality of life for all.”
Advancing knowledge, computational capability, and decision support
To produce more precise and comprehensive knowledge of sustainability challenges and guide decision-makers to formulate more effective strategies, the center has set the following goals:
Advance fundamental understanding of the complex interconnected physical and socio-economic systems that affect human well-being. As new policies and technologies are developed amid climate and other global changes, they interact with environmental processes and institutions in ways that can alter the earth’s critical life-support systems. Fundamental mechanisms that determine many of these systems’ behaviors, including those related to interacting climate, water, food, and socio-economic systems, remain largely unknown and poorly quantified. Better understanding can help society mitigate the risks of abrupt changes and “tipping points” in these systems.
Develop, establish and disseminate new computational toolstoward better understanding earth systems, including both environmental and human dimensions. The center’s work will integrate modeling and data analysis across disciplines in an era of increasing volumes of observational data. MIT multi-system models and data products will provide robust information to inform decision-making and shape the next generation of sustainability science and strategy.
Produce actionable science that supports equity and justice within and across generations. The center’s research will be designed to inform action associated with measurable outcomes aligned with supporting human well-being across generations. This requires engaging a broad range of stakeholders, including not only nations and companies, but also nongovernmental organizations and communities that take action to promote sustainable development — with special attention to those who have historically borne the brunt of environmental injustice.
“The center’s work will advance fundamental understanding in sustainability science, leverage leading-edge computing and data, and promote engagement and impact,” says Selin. “Our researchers will help lead scientists and strategists across the globe who share MIT’s commitment to mobilizing knowledge to inform action toward a more sustainable world.”
Building a better world at MIT
Building on existing MIT capabilities in sustainability science and strategy, the center aims to:
focus research, education, and outreach under a theme that reflects a comprehensive state of the field and international research directions, fostering a dynamic community of students, researchers, and faculty;
raise the visibility of sustainability science at MIT, emphasizing links between science and action, in the context of existing Institute goals and other efforts on climate and sustainability, and in a way that reflects the vital contributions of a range of natural and social science disciplines to understanding human-environment systems; and
re-emphasize MIT’s long-standing expertise in integrated systems modeling while leveraging the Institute’s concurrent leading-edge strengths in data and computing, establishing leadership that harnesses recent innovations, including those in machine learning and artificial intelligence, toward addressing the science challenges of global change and sustainability.
“The Center for Sustainability Science and Strategy will provide the necessary synergy for our MIT researchers to develop, deploy, and scale up serious solutions to climate change and other critical sustainability challenges,” says Nergis Mavalvala, the Curtis and Kathleen Marble Professor of Astrophysics and dean of the MIT School of Science. “With Professor Selin at its helm, the center will also ensure that these solutions are created in concert with the people who are directly affected now and in the future.”
The center builds on more than three decades of achievements by the Center for Global Change Science and the Joint Program on the Science and Policy of Global Change, both of which were directed or co-directed by professor of atmospheric science Ronald Prinn.
“As critical challenges such as climate, health, energy, and food security increasingly affect people’s lives around the world, decision-makers need a better understanding of the earth in its full complexity — and that includes people, technologies, and institutions as well as environmental processes,” says Professor Noelle Selin.
While the moon lacks any breathable air, it does host a barely-there atmosphere. Since the 1980s, astronomers have observed a very thin layer of atoms bouncing over the moon’s surface. This delicate atmosphere — technically known as an “exosphere” — is likely a product of some kind of space weathering. But exactly what those processes might be has been difficult to pin down with any certainty.
Now, scientists at MIT and the University of Chicago say they have identified the main process that formed the moon’s atmosphere and continues to sustain it today. In a study appearing today in Science Advances, the team reports that the lunar atmosphere is primarily a product of “impact vaporization.”
In their study, the researchers analyzed samples of lunar soil collected by astronauts during NASA’s Apollo missions. Their analysis suggests that over the moon’s 4.5-billion-year history its surface has been continuously bombarded, first by massive meteorites, then more recently, by smaller, dust-sized “micrometeoroids.” These constant impacts have kicked up the lunar soil, vaporizing certain atoms on contact and lofting the particles into the air. Some atoms are ejected into space, while others remain suspended over the moon, forming a tenuous atmosphere that is constantly replenished as meteorites continue to pelt the surface.
The researchers found that impact vaporization is the main process by which the moon has generated and sustained its extremely thin atmosphere over billions of years.
“We give a definitive answer that meteorite impact vaporization is the dominant process that creates the lunar atmosphere,” says the study’s lead author, Nicole Nie, an assistant professor in MIT’s Department of Earth, Atmospheric and Planetary Sciences. “The moon is close to 4.5 billion years old, and through that time the surface has been continuously bombarded by meteorites. We show that eventually, a thin atmosphere reaches a steady state because it’s being continuously replenished by small impacts all over the moon.”
Nie’s co-authors are Nicolas Dauphas, Zhe Zhang, and Timo Hopp at the University of Chicago, and Menelaos Sarantos at NASA Goddard Space Flight Center.
Weathering’s roles
In 2013, NASA sent an orbiter around the moon to do some detailed atmospheric reconnaissance. The Lunar Atmosphere and Dust Environment Explorer (LADEE, pronounced “laddie”) was tasked with remotely gathering information about the moon’s thin atmosphere, surface conditions, and any environmental influences on the lunar dust.
LADEE’s mission was designed to determine the origins of the moon’s atmosphere. Scientists hoped that the probe’s remote measurements of soil and atmospheric composition might correlate with certain space weathering processes that could then explain how the moon’s atmosphere came to be.
Researchers suspect that two space weathering processes play a role in shaping the lunar atmosphere: impact vaporization and “ion sputtering” — a phenomenon involving solar wind, which carries energetic charged particles from the sun through space. When these particles hit the moon’s surface, they can transfer their energy to the atoms in the soil and send those atoms sputtering and flying into the air.
“Based on LADEE’s data, it seemed both processes are playing a role,” Nie says. “For instance, it showed that during meteorite showers, you see more atoms in the atmosphere, meaning impacts have an effect. But it also showed that when the moon is shielded from the sun, such as during an eclipse, there are also changes in the atmosphere’s atoms, meaning the sun also has an impact. So, the results were not clear or quantitative.”
Answers in the soil
To more precisely pin down the lunar atmosphere’s origins, Nie looked to samples of lunar soil collected by astronauts throughout NASA’s Apollo missions. She and her colleagues at the University of Chicago acquired 10 samples of lunar soil, each measuring about 100 milligrams — a tiny amount that she estimates would fit into a single raindrop.
Nie sought to first isolate two elements from each sample: potassium and rubidium. Both elements are “volatile,” meaning that they are easily vaporized by impacts and ion sputtering. Each element exists in the form of several isotopes. An isotope is a variation of the same element, that consists of the same number of protons but a slightly different number of neutrons. For instance, potassium can exist as one of three isotopes, each one having one more neutron, and there being slightly heavier than the last. Similarly, there are two isotopes of rubidium.
The team reasoned that if the moon’s atmosphere consists of atoms that have been vaporized and suspended in the air, lighter isotopes of those atoms should be more easily lofted, while heavier isotopes would be more likely to settle back in the soil. Furthermore, scientists predict that impact vaporization, and ion sputtering, should result in very different isotopic proportions in the soil. The specific ratio of light to heavy isotopes that remain in the soil, for both potassium and rubidium, should then reveal the main process contributing to the lunar atmosphere’s origins.
With all that in mind, Nie analyzed the Apollo samples by first crushing the soils into a fine powder, then dissolving the powders in acids to purify and isolate solutions containing potassium and rubidium. She then passed these solutions through a mass spectrometer to measure the various isotopes of both potassium and rubidium in each sample.
In the end, the team found that the soils contained mostly heavy isotopes of both potassium and rubidium. The researchers were able to quantify the ratio of heavy to light isotopes of both potassium and rubidium, and by comparing both elements, they found that impact vaporization was most likely the dominant process by which atoms are vaporized and lofted to form the moon’s atmosphere.
“With impact vaporization, most of the atoms would stay in the lunar atmosphere, whereas with ion sputtering, a lot of atoms would be ejected into space,” Nie says. “From our study, we now can quantify the role of both processes, to say that the relative contribution of impact vaporization versus ion sputtering is about 70:30 or larger.” In other words, 70 percent or more of the moon’s atmosphere is a product of meteorite impacts, whereas the remaining 30 percent is a consequence of the solar wind.
“The discovery of such a subtle effect is remarkable, thanks to the innovative idea of combining potassium and rubidium isotope measurements along with careful, quantitative modeling,” says Justin Hu, a postdoc who studies lunar soils at Cambridge University, who was not involved in the study. “This discovery goes beyond understanding the moon’s history, as such processes could occur and might be more significant on other moons and asteroids, which are the focus of many planned return missions.”
“Without these Apollo samples, we would not be able to get precise data and measure quantitatively to understand things in more detail,” Nie says. “It’s important for us to bring samples back from the moon and other planetary bodies, so we can draw clearer pictures of the solar system’s formation and evolution.”
This work was supported, in part, by NASA and the National Science Foundation.
Ozone can be an agent of good or harm, depending on where you find it in the atmosphere. Way up in the stratosphere, the colorless gas shields the Earth from the sun’s harsh ultraviolet rays. But closer to the ground, ozone is a harmful air pollutant that can trigger chronic health problems including chest pain, difficulty breathing, and impaired lung function.
And somewhere in between, in the upper troposphere — the layer of the atmosphere just below the stratosphere, where most aircraft cruise — ozone contributes to warming the planet as a potent greenhouse gas.
There are signs that ozone is continuing to rise in the upper troposphere despite efforts to reduce its sources at the surface in many nations. Now, MIT scientists confirm that much of ozone’s increase in the upper troposphere is likely due to humans.
“We confirm that there’s a clear and increasing trend in upper tropospheric ozone in the northern midlatitudes due to human beings rather than climate noise,” says study lead author Xinyuan Yu, a graduate student in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS).
“Now we can do more detective work and try to understand what specific human activities are leading to this ozone trend,” adds co-author Arlene Fiore, the Peter H. Stone and Paola Malanotte Stone Professor in Earth, Atmospheric and Planetary Sciences.
The study’s MIT authors include Sebastian Eastham and Qindan Zhu, along with Benjamin Santer at the University of California at Los Angeles, Gustavo Correa of Columbia University, Jean-François Lamarque at the National Center for Atmospheric Research, and Jerald Zimeke at NASA Goddard Space Flight Center.
Ozone’s tangled web
Understanding ozone’s causes and influences is a challenging exercise. Ozone is not emitted directly, but instead is a product of “precursors” — starting ingredients, such as nitrogen oxides and volatile organic compounds (VOCs), that react in the presence of sunlight to form ozone. These precursors are generated from vehicle exhaust, power plants, chemical solvents, industrial processes, aircraft emissions, and other human-induced activities.
Whether and how long ozone lingers in the atmosphere depends on a tangle of variables, including the type and extent of human activities in a given area, as well as natural climate variability. For instance, a strong El Niño year could nudge the atmosphere’s circulation in a way that affects ozone’s concentrations, regardless of how much ozone humans are contributing to the atmosphere that year.
Disentangling the human- versus climate-driven causes of ozone trend, particularly in the upper troposphere, is especially tricky. Complicating matters is the fact that in the lower troposphere — the lowest layer of the atmosphere, closest to ground level — ozone has stopped rising, and has even fallen in some regions at northern midlatitudes in the last few decades. This decrease in lower tropospheric ozone is mainly a result of efforts in North America and Europe to reduce industrial sources of air pollution.
“Near the surface, ozone has been observed to decrease in some regions, and its variations are more closely linked to human emissions,” Yu notes. “In the upper troposphere, the ozone trends are less well-monitored but seem to decouple with those near the surface, and ozone is more easily influenced by climate variability. So, we don’t know whether and how much of that increase in observed ozone in the upper troposphere is attributed to humans.”
A human signal amid climate noise
Yu and Fiore wondered whether a human “fingerprint” in ozone levels, caused directly by human activities, could be strong enough to be detectable in satellite observations in the upper troposphere. To see such a signal, the researchers would first have to know what to look for.
For this, they looked to simulations of the Earth’s climate and atmospheric chemistry. Following approaches developed in climate science, they reasoned that if they could simulate a number of possible climate variations in recent decades, all with identical human-derived sources of ozone precursor emissions, but each starting with a slightly different climate condition, then any differences among these scenarios should be due to climate noise. By inference, any common signal that emerged when averaging over the simulated scenarios should be due to human-driven causes. Such a signal, then, would be a “fingerprint” revealing human-caused ozone, which the team could look for in actual satellite observations.
With this strategy in mind, the team ran simulations using a state-of-the-art chemistry climate model. They ran multiple climate scenarios, each starting from the year 1950 and running through 2014.
From their simulations, the team saw a clear and common signal across scenarios, which they identified as a human fingerprint. They then looked to tropospheric ozone products derived from multiple instruments aboard NASA’s Aura satellite.
“Quite honestly, I thought the satellite data were just going to be too noisy,” Fiore admits. “I didn’t expect that the pattern would be robust enough.”
But the satellite observations they used gave them a good enough shot. The team looked through the upper tropospheric ozone data derived from the satellite products, from the years 2005 to 2021, and found that, indeed, they could see the signal of human-caused ozone that their simulations predicted. The signal is especially pronounced over Asia, where industrial activity has risen significantly in recent decades and where abundant sunlight and frequent weather events loft pollution, including ozone and its precursors, to the upper troposphere.
Yu and Fiore are now looking to identify the specific human activities that are leading to ozone’s increase in the upper troposphere.
“Where is this increasing trend coming from? Is it the near-surface emissions from combusting fossil fuels in vehicle engines and power plants? Is it the aircraft that are flying in the upper troposphere? Is it the influence of wildland fires? Or some combination of all of the above?” Fiore says. “Being able to separate human-caused impacts from natural climate variations can help to inform strategies to address climate change and air pollution.”
In a paper appearing in the journal “Environmental Science and Technology,” MIT scientists report that they detected a clear signal of human influence on upper tropospheric ozone trends in a 17-year satellite record starting in 2005.
MIT physicists and colleagues report new insights into exotic particles key to a form of magnetism that has attracted growing interest because it originates from ultrathin materials only a few atomic layers thick. The work, which could impact future electronics and more, also establishes a new way to study these particles through a powerful instrument at the National Synchrotron Light Source II at Brookhaven National Laboratory.
Among their discoveries, the team has identified the microscopic origin of these particles, known as excitons. They showed how they can be controlled by chemically “tuning” the material, which is primarily composed of nickel. Further, they found that the excitons propagate throughout the bulk material instead of being bound to the nickel atoms.
Finally, they proved that the mechanism behind these discoveries is ubiquitous to similar nickel-based materials, opening the door for identifying — and controlling — new materials with special electronic and magnetic properties.
“We’ve essentially developed a new research direction into the study of these magnetic two-dimensional materials that very much relies on an advanced spectroscopic method, resonant inelastic X-ray scattering (RIXS), which is available at Brookhaven National Lab,” says Riccardo Comin, MIT’s Class of 1947 Career Development Associate Professor of Physics and leader of the work. Comin is also affiliated with the Materials Research Laboratory and the Research Laboratory of Electronics.
Comin’s colleagues on the work include Connor A. Occhialini, an MIT graduate student in physics, and Yi Tseng, a recent MIT postdoc now at Deutsches Elektronen-Synchrotron (DESY). The two are co-first authors of the Physical Review X paper.
Additional authors are Hebatalla Elnaggar of the Sorbonne; Qian Song, a graduate student in MIT’s Department of Physics; Mark Blei and Seth Ariel Tongay of Arizona State University; Frank M. F. de Groot of Utrecht University; and Valentina Bisogni and Jonathan Pelliciari of Brookhaven National Laboratory.
Ultrathin layers
The magnetic materials at the heart of the current work are known as nickel dihalides. They are composed of layers of nickel atoms sandwiched between layers of halogen atoms (halogens are one family of elements), which can be isolated to atomically thin layers. In this case, the physicists studied the electronic properties of three different materials composed of nickel and the halogens chlorine, bromine, or iodine. Despite their deceptively simple structure, these materials host a rich variety of magnetic phenomena.
The team was interested in how these materials’ magnetic properties respond when exposed to light. They were specifically interested in particular particles — the excitons — and how they are related to the underlying magnetism. How exactly do they form? Can they be controlled?
Enter excitons
A solid material is composed of different types of elementary particles, such as protons and electrons. Also ubiquitous in such materials are “quasiparticles” that the public is less familiar with. These include excitons, which are composed of an electron and a “hole,” or the space left behind when light is shone on a material and energy from a photon causes an electron to jump out of its usual position.
Through the mysteries of quantum mechanics, however, the electron and hole are still connected and can “communicate” with each other through electrostatic interactions. This interaction leads to a new composite particle formed by the electron and the hole — an exciton.
Excitons, unlike electrons, have no charge but possess spin. The spin can be thought of as an elementary magnet, in which the electrons are like little needles orienting in a certain way. In a common refrigerator magnet, the spins all point in the same direction. Generally speaking, the spins can organize in other patterns leading to different kinds of magnets. The unique magnetism associated with the nickel dihalides is one of these less-conventional forms, making it appealing for fundamental and applied research.
The MIT team explored how excitons form in the nickel dihalides. More specifically, they identified the exact energies, or wavelengths, of light necessary for creating them in the three materials they studied.
“We were able to measure and identify the energy necessary to form the excitons in three different nickel halides by chemically ‘tuning,’ or changing, the halide atom from chlorine to bromine to iodine,” says Occhialini. “This is one essential step towards understanding how photons — light — could one day be used to interact with or monitor the magnetic state of these materials.” Ultimate applications include quantum computing and novel sensors.
The work could also help predict new materials involving excitons that might have other interesting properties. Further, while the studied excitons originate on the nickel atoms, the team found that they do not remain localized to these atomic sites. Instead, “we showed that they can effectively hop between sites throughout the crystal,” Occhialini says. “This observation of hopping is the first for these types of excitons, and provides a window into understanding their interplay with the material’s magnetic properties.”
A special instrument
Key to this work — in particular for observing the exciton hopping — is resonant inelastic X-ray scattering (RIXS), an experimental technique that co-authors Pelliciari and Bisogni helped pioneer. Only a few facilities in the world have advanced high energy resolution RIXS instruments. One is at Brookhaven. Pelliciari and Bisogni are part of the team running the RIXS facility at Brookhaven. Occhialini will be joining the team there as a postdoc after receiving his MIT PhD.
RIXS, with its specific sensitivity to the excitons from the nickel atoms, allowed the team to “set the basis for a general framework for nickel dihalide systems,” says Pelliciari. “it allowed us to directly measure the propagation of excitons.”
This work was supported by the U.S. Department of Energy Basic Energy Science and Brookhaven National Laboratory through the Co-design Center for Quantum Advantage (C2QA), a DoE Quantum Information Science Research Center.
Schematic showing how exotic particles known as excitons can “hop” between nickel atoms (grey dots) in nickel dihalide materials. The excitons are represented by the red and light-blue orbitals.
Shimmering ice extends in all directions as far as the eye can see. Air temperatures plunge to minus 40 degrees Fahrenheit and colder with wind chills. Ocean currents drag large swaths of ice floating at sea. Polar bears, narwhals, and other iconic Arctic species roam wild.
For a week this past spring, MIT Lincoln Laboratory researchers Ben Evans and Dave Whelihan called this place — drifting some 200 nautical miles offshore from Prudhoe Bay, Alaska, on the frozen Beaufort Sea in the Arctic Circle — home. Two ice runways for small aircraft provided their only way in and out of this remote wilderness; heated tents provided their only shelter from the bitter cold.
Here, in the northernmost region on Earth, Evans and Whelihan joined other groups conducting fieldwork in the Arctic as part of Operation Ice Camp (OIC) 2024, an operational exercise run by the U.S. Navy's Arctic Submarine Laboratory (ASL). Riding on snowmobiles and helicopters, the duo deployed a small set of integrated sensor nodes that measure everything from atmospheric conditions to ice properties to the structure of water deep below the surface.
Ultimately, they envision deploying an unattended network of these low-cost sensor nodes across the Arctic to increase scientific understanding of the trending loss in sea ice extent and thickness. Warming much faster than the rest of the world, the Arctic is a ground zero for climate change, with cascading impacts across the planet that include rising sea levels and extreme weather. Openings in the sea ice cover, or leads, are concerning not only for climate change but also for global geopolitical competition over transit routes and natural resources. A synoptic view of the physical processes happening above, at, and below sea ice is key to determining why the ice is diminishing. In turn, this knowledge can help predict when and where fractures will occur, to inform planning and decision-making.
Winter “camp”
Every two years, OIC, previously called Ice Exercise (ICEX), provides a way for the international community to access the Arctic for operational readiness exercises and scientific research, with the focus switching back and forth; this year’s focus was scientific research. Coordination, planning, and execution of the month-long operation is led by ASL, a division of the U.S. Navy’s Undersea Warfighting Development Center responsible for ensuring the submarine force can effectively operate in the Arctic Ocean.
Making this inhospitable and unforgiving environment safe for participants takes considerable effort. The critical first step is determining where to set up camp. In the weeks before the first participants arrived for OIC 2024, ASL — with assistance from the U.S. National Ice Center, University of Alaska Fairbanks Geophysical Institute, and UIC Science — flew over large sheets of floating ice (ice floes) identified via satellite imagery, landed on some they thought might be viable sites, and drilled through the ice to check its thickness. The ice floe must not only be large enough to accommodate construction of a camp and two runways but also feature both multiyear ice and first-year ice. Multiyear ice is thick and strong but rough, making it ideal for camp setup, while the smooth but thinner first-year ice is better suited for building runways. Once the appropriate ice floe was selected, ASL began to haul in equipment and food, build infrastructure like lodging and a command center, and fly in a small group before fully operationalizing the site. They also identified locations near the camp for two Navy submarines to surface through the ice.
The more than 200 participants represented U.S. and allied forces and scientists from research organizations and universities. Distinguished visitors from government offices also attended OIC to see the unique Arctic environment and unfolding challenges firsthand.
“Our ASL hosts do incredible work to build this camp from scratch and keep us alive,” Evans says.
Evans and Whelihan, part of the laboratory’s Advanced Undersea Systems and Technology Group, first trekked to the Arctic in March 2022 for ICEX 2022. (The laboratory in general has been participating since 2016 in these events, the first iteration of which occurred in 1946.) There, they deployed a suite of commercial off-the-shelf sensors for detecting acoustic (sound) and seismic (vibration) events created by ice fractures or collisions, and for measuring salinity, temperature, and pressure in the water below the ice. They also deployed a prototype fiber-based temperature sensor array developed by the laboratory and research partners for precisely measuring temperature across the entire water column at one location, and a University of New Hampshire (UNH)−supplied echosounder to investigate the different layers present in the water column. In this maiden voyage, their goals were to assess how these sensors fared in the harsh Arctic conditions and to collect a dataset from which characteristic signatures of ice-fracturing events could begin to be identified. These events would be correlated with weather and water conditions to eventually offer a predictive capability.
“We saw real phenomenology in our data,” Whelihan says. “But, we’re not ice experts. What we’re good at here at the laboratory is making and deploying sensors. That's our place in the world of climate science: to be a data provider. In fact, we hope to open source all of our data this year so that ice scientists can access and analyze them and then we can make enhanced sensors and collect more data.”
Interim ice
In the two years since that expedition, they and their colleagues have been modifying their sensor designs and deployment strategies. As Evans and Whelihan learned at ICEX 2022, to be resilient in the Arctic, a sensor must not only be kept warm and dry during deployment but also be deployed in a way to prevent breaking. Moreover, sufficient power and data links are needed to collect and access sensor data.
“We can make cold-weather electronics, no problem,” Whelihan says. “The two drivers are operating the sensors in an energy-starved environment — the colder it is, the worse batteries perform — and keeping them from getting destroyed when ice floes crash together as leads in the ice open up.”
Their work in the interim to OIC 2024 involved integrating the individual sensors into hardened sensor nodes and practicing deploying these nodes in easier-to-access locations. To facilitate incorporating additional sensors into a node, Whelihan spearheaded the development of an open-source, easily extensible hardware and software architecture.
In March 2023, the Lincoln Laboratory team deployed three sensor nodes for a week on Huron Bay off Lake Superior through Michigan Tech's Great Lakes Research Center (GLRC). Engineers from GLRC helped the team safely set up an operations base on the ice. They demonstrated that the sensor integration worked, and the sensor nodes proved capable of surviving for at least a week in relatively harsh conditions. The researchers recorded seismic activity on all three nodes, corresponding to some ice breaking further up the bay.
“Proving our sensor node in an Arctic surrogate environment provided a stepping stone for testing in the real Arctic,” Evans says.
Evans then received an invitation from Ignatius Rigor, the coordinator of the International Arctic Buoy Program (IABP), to join him on an upcoming trip to Utqiaġvik (formerly Barrow), Alaska, and deploy one of their seismic sensor nodes on the ice there (with support from UIC Science). The IABP maintains a network of Arctic buoys equipped with meteorological and oceanic sensors. Data collected by these buoys are shared with the operational and research communities to support real-time operations (e.g., forecasting sea ice conditions for coastal Alaskans) and climate research. However, these buoys are typically limited in the frequency at which they collect data, so phenomenology on shorter time scales important to climate change may be missed. Moreover, these buoys are difficult and expensive to deploy because they are designed to survive in the harshest environments for years at a time.
The laboratory-developed sensor nodes could offer an inexpensive, easier-to-deploy option for collecting more data over shorter periods of time. In April 2023, Evans placed a sensor node in Utqiaġvik on landfast sea ice, which is stationary ice anchored to the seabed just off the coast. During the sensor node’s week-long deployment, a big piece of drift ice (ice not attached to the seabed or other fixed object) broke off and crashed into the landfast ice. The event was recorded by a radar maintained by the University of Alaska Fairbanks that monitors sea ice movement in near real time to warn of any instability. Though this phenomenology is not exactly the same as that expected for Arctic sea ice, the researchers were encouraged to see seismic activity recorded by their sensor node.
In December 2023, Evans and Whelihan headed to New Hampshire, where they conducted echosounder testing in UNH’s engineering test tank and on the Piscataqua River. Together with their UNH partners, they sought to determine whether a low-cost, hobby-grade echosounder could detect the same phenomenology of interest as the high-fidelity UNH echosounder, which would be far too costly to deploy in sensor nodes across the Arctic. In the test tank and on the river, the low-cost echosounder proved capable of detecting masses of water moving in the water column, but with considerably less structural detail than afforded by the higher-cost option. Seeing such dynamics is important to inferring where water comes from and understanding how it affects sea ice breakup — for example, how warm water moving in from the Pacific Ocean is coming into contact with and melting the ice. So, the laboratory researchers and UNH partners have been building a medium-fidelity, medium-cost echosounder.
In January 2024, Evans and Whelihan — along with Jehan Diaz, a fellow staff member in their research group — returned to GLRC. With logistical support from their GLRC hosts, they snowmobiled across the ice on Portage Lake, where they practiced several activities to prepare for OIC 2024: augering (drilling) six-inch holes in the ice, albeit in thinner ice than that in the Arctic; placing their long, pipe-like sensor nodes through these holes; operating cold-hardened drones to interact with the nodes; and retrieving the nodes. They also practiced sensor calibration by hitting the ice with an iron bar some distance away from the nodes and correlating this distance with the resulting measured acoustic and seismic intensity.
“Our time at GLRC helped us mitigate a lot of risks and prepare to deploy these complex systems in the Arctic,” Whelihan says.
Arctic again
To get to OIC, Evans and Whelihan first flew to Prudhoe Bay and reacclimated to the frigid temperatures. They spent the next two days at the Deadhorse Aviation Center hangar inspecting their equipment for transit-induced damage, which included squashed cables and connectors that required rejiggering.
“That’s part of the adventure story,” Evans says. “Getting stuff to Prudhoe Bay is not your standard shipping; it’s ice-road trucking.”
From there, they boarded a small aircraft to the ice camp.
“Even though this trip marked our second time coming here, it was still disorienting,” Evans continues. "You land in the middle of nowhere on a small aircraft after a couple-hour flight. You get out bundled in all of your Arctic gear in this remote, pristine environment.”
After unloading and rechecking their equipment for any damage, calibrating their sensors, and attending safety briefings, they were ready to begin their experiments.
An icy situation
Inside the project tent, Evans and Whelihan deployed the UNH-supplied echosounder and a suite of ground-truth sensors on an automated winch to profile water conductivity, temperature, and depth (CTD). Echosounder data needed to be validated with associated CTD data to determine the source of the water in the water column. Ocean properties change as a function of depth, and these changes are important to capture, in part because masses of water coming in from the Atlantic and Pacific oceans arrive at different depths. Though masses of warm water have always existed, climate change–related mechanisms are now bringing them into contact with the ice.
“As ice breaks up, wind can directly interact with the ocean because it’s lacking that barrier of ice cover,” Evans explains. “Kinetic energy from the wind causes mixing in the ocean; all the warm water that used to stay at depth instead gets brought up and interacts with the ice.”
They also deployed four of their sensor nodes several miles outside of camp. To access this deployment site, they rode on a sled pulled via a snowmobile driven by Ann Hill, an ASL field party leader trained in Arctic survival and wildlife encounters. The temperature that day was -55 F. At such a dangerously cold temperature, frostnip and frostbite are all too common. To avoid removal of gloves or other protective clothing, the researchers enabled the nodes with WiFi capability (the nodes also have a satellite communications link to transmit low-bandwidth data). Large amounts of data are automatically downloaded over WiFi to an arm-wearable haptic (touch-based) system when a user walks up to a node.
“It was so cold that the holes we were drilling in the ice to reach the water column were freezing solid,” Evans explains. “We realized it was going to be quite an ordeal to get our sensor nodes out of the ice.”
So, after drilling a big hole in the ice, they deployed only one central node with all the sensor components: a commercial echosounder, an underwater microphone, a seismometer, and a weather station. They deployed the other three nodes, each with a seismometer and weather station, atop the ice.
“One of our design considerations was flexibility,” Whelihan says. “Each node can integrate as few or as many sensors as desired.”
The small sensor array was only collecting data for about a day when Evans and Whelihan, who were at the time on a helicopter, saw that their initial field site had become completely cut off from camp by a 150-meter-wide ice lead. They quickly returned to camp to load the tools needed to pull the nodes, which were no longer accessible by snowmobile. Two recently arrived staff members from the Ted Stevens Center for Arctic Security Studies offered to help them retrieve their nodes. The helicopter landed on the ice floe near a crack, and the pilot told them they had half an hour to complete their recovery mission. By the time they had retrieved all four sensors, the crack had increased from thumb to fist size.
“When we got home, we analyzed the collected sensor data and saw a spike in seismic activity corresponding to what could be the major ice-fracturing event that necessitated our node recovery mission,” Whelihan says.
The researchers also conducted experiments with their Arctic-hardened drones to evaluate their utility for retrieving sensor node data and to develop concepts of operations for future capabilities.
“The idea is to have some autonomous vehicle land next to the node, download data, and come back, like a data mule, rather than having to expend energy getting data off the system, say via high-speed satellite communications,” Whelihan says. “We also started testing whether the drone is capable on its own of finding sensors that are constantly moving and getting close enough to them. Even flying in 25-mile-per-hour winds, and at very low temperatures, the drone worked well.”
Aside from carrying out their experiments, the researchers had the opportunity to interact with other participants. Their “roommates” were ice scientists from Norway and Finland. They met other ice and water scientists conducting chemistry experiments on the salt content of ice taken from different depths in the ice sheet (when ocean water freezes, salt tends to get pushed out of the ice). One of their collaborators — Nicholas Schmerr, an ice seismologist from the University of Maryland — placed high-quality geophones (for measuring vibrations in the ice) alongside their nodes deployed on the camp field site. They also met with junior enlisted submariners, who temporarily came to camp to open up spots on the submarine for distinguished visitors.
“Part of what we've been doing over the last three years is building connections within the Arctic community,” Evans says. “Every time I start to get a handle on the phenomenology that exists out here, I learn something new. For example, I didn’t know that sometimes a layer of ice forms a little bit deeper than the primary ice sheet, and you can actually see fish swimming in between the layers.”
“One day, we were out with our field party leader, who saw fog while she was looking at the horizon and said the ice was breaking up,” Whelihan adds. “I said, 'Wait, what?' As she explained, when an ice lead forms, fog comes out of the ocean. Sure enough, within 30 minutes, we had quarter-mile visibility, whereas beforehand it was unlimited.”
Back to solid ground
Before leaving, Whelihan and Evans retrieved and packed up all the remaining sensor nodes, adopting the “leave no trace” philosophy of preserving natural places.
“Only a limited number of people get access to this special environment,” Whelihan says. “We hope to grow our footprint at these events in future years, giving opportunities to other laboratory staff members to attend.”
In the meantime, they will analyze the collected sensor data and refine their sensor node design. One design consideration is how to replenish the sensors’ battery power. A potential path forward is to leverage the temperature difference between water and air, and harvest energy from the water currents moving under ice floes. Wind energy may provide another viable solution. Solar power would only work for part of the year because the Arctic Circle undergoes periods of complete darkness.
The team is also seeking external sponsorship to continue their work engineering sensing systems that advance the scientific community’s understanding of changes to Arctic ice; this work is currently funded through Lincoln Laboratory's internally administered R&D portfolio on climate change. And, in learning more about this changing environment and its critical importance to strategic interests, they are considering other sensing problems that they could tackle using their Arctic engineering expertise.
“The Arctic is becoming a more visible and important region because of how it’s changing,” Evans concludes. “Going forward as a country, we must be able to operate there.”
People use large language models for a huge array of tasks, from translating an article to identifying financial fraud. However, despite the incredible capabilities and versatility of these models, they sometimes generate inaccurate responses.
On top of that problem, the models can be overconfident about wrong answers or underconfident about correct ones, making it tough for a user to know when a model can be trusted.
Researchers typically calibrate a machine-learning model to ensure its level of confidence lines up with its accuracy. A well-calibrated model should have less confidence about an incorrect prediction, and vice-versa. But because large language models (LLMs) can be applied to a seemingly endless collection of diverse tasks, traditional calibration methods are ineffective.
Now, researchers from MIT and the MIT-IBM Watson AI Lab have introduced a calibration method tailored to large language models. Their method, called Thermometer, involves building a smaller, auxiliary model that runs on top of a large language model to calibrate it.
Thermometer is more efficient than other approaches — requiring less power-hungry computation — while preserving the accuracy of the model and enabling it to produce better-calibrated responses on tasks it has not seen before.
By enabling efficient calibration of an LLM for a variety of tasks, Thermometer could help users pinpoint situations where a model is overconfident about false predictions, ultimately preventing them from deploying that model in a situation where it may fail.
“With Thermometer, we want to provide the user with a clear signal to tell them whether a model’s response is accurate or inaccurate, in a way that reflects the model’s uncertainty, so they know if that model is reliable,” says Maohao Shen, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on Thermometer.
Shen is joined on the paper by Gregory Wornell, the Sumitomo Professor of Engineering who leads the Signals, Information, and Algorithms Laboratory in the Research Laboratory for Electronics, and is a member of the MIT-IBM Watson AI Lab; senior author Soumya Ghosh, a research staff member in the MIT-IBM Watson AI Lab; as well as others at MIT and the MIT-IBM Watson AI Lab. The research was recently presented at the International Conference on Machine Learning.
Universal calibration
Since traditional machine-learning models are typically designed to perform a single task, calibrating them usually involves one task-specific method. On the other hand, since LLMs have the flexibility to perform many tasks, using a traditional method to calibrate that model for one task might hurt its performance on another task.
Calibrating an LLM often involves sampling from the model multiple times to obtain different predictions and then aggregating these predictions to obtain better-calibrated confidence. However, because these models have billions of parameters, the computational costs of such approaches rapidly add up.
“In a sense, large language models are universal because they can handle various tasks. So, we need a universal calibration method that can also handle many different tasks,” says Shen.
With Thermometer, the researchers developed a versatile technique that leverages a classical calibration method called temperature scaling to efficiently calibrate an LLM for a new task.
In this context, a “temperature” is a scaling parameter used to adjust a model’s confidence to be aligned with its prediction accuracy. Traditionally, one determines the right temperature using a labeled validation dataset of task-specific examples.
Since LLMs are often applied to new tasks, labeled datasets can be nearly impossible to acquire. For instance, a user who wants to deploy an LLM to answer customer questions about a new product likely does not have a dataset containing such questions and answers.
Instead of using a labeled dataset, the researchers train an auxiliary model that runs on top of an LLM to automatically predict the temperature needed to calibrate it for this new task.
They use labeled datasets of a few representative tasks to train the Thermometer model, but then once it has been trained, it can generalize to new tasks in a similar category without the need for additional labeled data.
A Thermometer model trained on a collection of multiple-choice question datasets, perhaps including one with algebra questions and one with medical questions, could be used to calibrate an LLM that will answer questions about geometry or biology, for instance.
“The aspirational goal is for it to work on any task, but we are not quite there yet,” Ghosh says.
The Thermometer model only needs to access a small part of the LLM’s inner workings to predict the right temperature that will calibrate its prediction for data points of a specific task.
An efficient approach
Importantly, the technique does not require multiple training runs and only slightly slows the LLM. Plus, since temperature scaling does not alter a model’s predictions, Thermometer preserves its accuracy.
When they compared Thermometer to several baselines on multiple tasks, it consistently produced better-calibrated uncertainty measures while requiring much less computation.
“As long as we train a Thermometer model on a sufficiently large number of tasks, it should be able to generalize well across any new task, just like a large language model, it is also a universal model,” Shen adds.
The researchers also found that if they train a Thermometer model for a smaller LLM, it can be directly applied to calibrate a larger LLM within the same family.
In the future, they want to adapt Thermometer for more complex text-generation tasks and apply the technique to even larger LLMs. The researchers also hope to quantify the diversity and number of labeled datasets one would need to train a Thermometer model so it can generalize to a new task.
This research was funded, in part, by the MIT-IBM Watson AI Lab.
Thermometer, a method for calibrating a large language model, could help users pinpoint situations where a model is overconfident about false predictions.
If patients receiving intensive care or undergoing major surgery develop excessively high or low blood pressures, they could suffer severe organ dysfunction. It’s not enough for their care team to know that pressure is abnormal. To choose the correct drug to treat the problem, doctors must know why blood pressure has changed. A new MIT study presents the mathematical framework needed to derive that crucial information accurately and in real time.
The mathematical approach, described in a recent open-access study in IEEE Transactions on Biomedical Engineering, produces proportional estimates of the two critical factors underlying blood pressure changes: the heart’s rate of blood output (cardiac output) and the arterial system’s resistance to that blood flow (systemic vascular resistance). By applying the new method to previously collected data from animal models, the researchers show that their estimates, derived from minimally invasive measures of peripheral arterial blood pressure, accurately matched estimates using additional information from an invasive flow probe placed on the aorta. Moreover, the estimates accurately tracked the changes induced in the animals by the various drugs physicians use to correct aberrant blood pressure.
“Estimates of resistance and cardiac output from our approach provide information that can readily be used to guide hemodynamic management decisions in real time,” the study authors wrote.
With further testing leading to regulatory approval, the authors say, the method would be applicable during heart surgeries, liver transplants, intensive care unit treatment, and many other procedures affecting cardiovascular function or blood volume.
“Any patient who is having cardiac surgery could need this,” says study senior author Emery N. Brown, the Edward Hood Taplin Professor of Medical Engineering and Computational Neuroscience in The Picower Institute for Learning and Memory, the Institute for Medical Engineering and Science, and the Department of Brain and Cognitive Sciences at MIT. Brown is also an anesthesiologist at Massachusetts General Hospital and a professor of anesthesiology at Harvard Medical School. “So might any patient undergoing a more normal surgery but who might have a compromised cardiovascular system, such as ischemic heart disease. You can’t have the blood pressure being all over the place.”
The study’s lead author is electrical engineering and computer science (EECS) graduate student Taylor Baum, who is co-supervised by Brown and Munther Dahleh, the William A. Coolidge Professor in EECS.
Algorithmic advance
The idea that cardiac output and systemic resistance are the two key components of blood pressure comes from the two-element Windkessel model. The new study is not the first to use the model to estimate these components from blood pressure measurements, but previous attempts ran into a trade-off between quick estimate updates and the accuracy of estimates; methods would either provide more erroneous estimates at every beat or more reliable estimates that are updated at minute time scales. Led by Baum, the MIT team overcame the trade-off with a new approach of applying statistical and signal processing techniques such as “state-space” modeling.
“Our estimates, updated at every beat, are not just informed by the current beat; but they incorporate where things were in previous beats as well,” Baum says. “It’s that combination of past history and current observations that produces a more reliable estimate while still at a beat-by-beat time scale.”
Notably, the resulting estimates of cardiac output and systemic resistance are “proportional,” meaning that they are each inextricably linked in the math with another co-factor, rather than estimated on their own. But application of the new method to data collected in an older study from six animals showed that the proportional estimates from recordings using minimally invasive catheters provide comparable information for cardiovascular system management.
One key finding was that the proportional estimates made based on arterial blood pressure readings from catheters inserted in various locations away from the heart (e.g., the leg or the arm) mirrored estimates derived from more invasive catheters placed within the aorta. The significance of the finding is that a system using the new estimation method could in some cases rely on a minimally invasive catheter in various peripheral arteries, thereby avoiding the need for a riskier placement of a central artery catheter or a pulmonary artery catheter directly in the heart, the clinical gold standard for cardiovascular state estimation.
Another key finding was that when the animals received each of five drugs that doctors use to regulate either systemic vascular resistance or cardiac output, the proportional estimates tracked the resulting changes properly. The finding therefore suggests that the proportional estimates of each factor are accurately reflecting their physiological changes.
Toward the clinic
With these encouraging results, Baum and Brown say, the current method can be readily implemented in clinical settings to inform perioperative care teams about underlying causes of critical blood pressure changes. They are actively pursuing regulatory approval of use of this method in a clinical device.
Additionally, the researchers are pursuing more animal studies to validate an advanced blood pressure management approach that uses this method. They have developed a closed-loop system, informed by this estimation framework, to precisely regulate blood pressure in an animal model. Upon completion of the animal studies, they will apply for regulatory clearance to test the system in humans.
In addition to Baum, Dahleh and Brown, the paper’s other authors are Elie Adam, Christian Guay, Gabriel Schamberg, Mohammadreza Kazemi, and Thomas Heldt.
The National Science Foundation, the National Institutes of Health, a Mathworks Fellowship, The Picower Institute for Learning and Memory, and The JPB Foundation supported the study.
During major surgery or intensive care, patients sometimes experience critical changes in blood pressure. Treating the problem with drugs requires knowing which reason caused the change. A new mathematical framework provides that critical information in real time, based on measures of arterial blood pressure.
In 2021, a team led by MIT physicists reported creating a new ultrathin ferroelectric material, or one where positive and negative charges separate into different layers. At the time they noted the material’s potential for applications in computer memory and much more. Now the same core team and colleagues — including two from the lab next door — have built a transistor with that material and shown that its properties are so useful that it could change the world of electronics.
Although the team’s results are based on a single transistor in the lab, “in several aspects its properties already meet or exceed industry standards” for the ferroelectric transistors produced today, says Pablo Jarillo-Herrero, the Cecil and Ida Green Professor of Physics, who led the work with professor of physics Raymond Ashoori. Both are also affiliated with the Materials Research Laboratory.
“In my lab we primarily do fundamental physics. This is one of the first, and perhaps most dramatic, examples of how very basic science has led to something that could have a major impact on applications,” Jarillo-Herrero says.
Says Ashoori, “When I think of my whole career in physics, this is the work that I think 10 to 20 years from now could change the world.”
Among the new transistor’s superlative properties:
It can switch between positive and negative charges — essentially the ones and zeros of digital information — at very high speeds, on nanosecond time scales. (A nanosecond is a billionth of a second.)
It is extremely tough. After 100 billion switches it still worked with no signs of degradation.
The material behind the magic is only billionths of a meter thick, one of the thinnest of its kind in the world. That, in turn, could allow for much denser computer memory storage. It could also lead to much more energy-efficient transistors because the voltage required for switching scales with material thickness. (Ultrathin equals ultralow voltages.)
The work is reported in a recent issue of Science. The co-first authors of the paper are Kenji Yasuda, now an assistant professor at Cornell University, and Evan Zalys-Geller, now at Atom Computing. Additional authors are Xirui Wang, an MIT graduate student in physics; Daniel Bennett and Efthimios Kaxiras of Harvard University; Suraj S. Cheema, an assistant professor in MIT’s Department of Electrical Engineering and Computer Science and an affiliate of the Research Laboratory of Electronics; and Kenji Watanabe and Takashi Taniguchi of the National Institute for Materials Science in Japan.
What they did
In a ferroelectric material, positive and negative charges spontaneously head to different sides, or poles. Upon the application of an external electric field, those charges switch sides, reversing the polarization. Switching the polarization can be used to encode digital information, and that information will be nonvolatile, or stable over time. It won’t change unless an electric field is applied. For a ferroelectric to have broad application to electronics, all of this needs to happen at room temperature.
The new ferroelectric material reported in Science in 2021 is based on atomically thin sheets of boron nitride that are stacked parallel to each other, a configuration that doesn’t exist in nature. In bulk boron nitride, the individual layers of boron nitride are instead rotated by 180 degrees.
It turns out that when an electric field is applied to this parallel stacked configuration, one layer of the new boron nitride material slides over the other, slightly changing the positions of the boron and nitrogen atoms. For example, imagine that each of your hands is composed of only one layer of cells. The new phenomenon is akin to pressing your hands together then slightly shifting one above the other.
“So the miracle is that by sliding the two layers a few angstroms, you end up with radically different electronics,” says Ashoori. The diameter of an atom is about 1 angstrom.
Another miracle: “nothing wears out in the sliding,” Ashoori continues. That’s why the new transistor could be switched 100 billion times without degrading. Compare that to the memory in a flash drive made with conventional materials. “Each time you write and erase a flash memory, you get some degradation,” says Ashoori. “Over time, it wears out, which means that you have to use some very sophisticated methods for distributing where you’re reading and writing on the chip.” The new material could make those steps obsolete.
A collaborative effort
Yasuda, the co-first author of the current Science paper, applauds the collaborations involved in the work. Among them, “we [Jarillo-Herrero’s team] made the material and, together with Ray [Ashoori] and [co-first author] Evan [Zalys-Geller], we measured its characteristics in detail. That was very exciting.” Says Ashoori, “many of the techniques in my lab just naturally applied to work that was going on in the lab next door. It’s been a lot of fun.”
Ashoori notes that “there’s a lot of interesting physics behind this” that could be explored. For example, “if you think about the two layers sliding past each other, where does that sliding start?” In addition, says Yasuda, could the ferroelectricity be triggered with something other than electricity, like an optical pulse? And is there a fundamental limit to the amount of switches the material can make?
Challenges remain. For example, the current way of producing the new ferroelectrics is difficult and not conducive to mass manufacturing. “We made a single transistor as a demonstration. If people could grow these materials on the wafer scale, we could create many, many more,” says Yasuda. He notes that different groups are already working to that end.
Concludes Ashoori, “There are a few problems. But if you solve them, this material fits in so many ways into potential future electronics. It’s very exciting.”
This work was supported by the U.S. Army Research Office, the MIT/Microsystems Technology Laboratories Samsung Semiconductor Research Fund, the U.S. National Science Foundation, the Gordon and Betty Moore Foundation, the Ramon Areces Foundation, the Basic Energy Sciences program of the U.S. Department of Energy, the Japan Society for the Promotion of Science, and the Ministry of Education, Culture, Sports, Science and Technology (MEXT) of Japan.
This schematic shows the crystal structure of the boron nitride key to a new ferroelectric material that MIT researchers and colleagues have used to build a transistor with superlative properties. The schematic shows how the structure can change as two ultrathin layers of boron nitride slide past each other upon application of an electric field. The P stands for polarization, or negative/positive charge.
A sustainable source for clean energy may lie in old soda cans and seawater.
MIT engineers have found that when the aluminum in soda cans is exposed in its pure form and mixed with seawater, the solution bubbles up and naturally produces hydrogen — a gas that can be subsequently used to power an engine or fuel cell without generating carbon emissions. What’s more, this simple reaction can be sped up by adding a common stimulant: caffeine.
In a study appearing today in the journal Cell Reports Physical Science, the researchers show they can produce hydrogen gas by dropping pretreated, pebble-sized aluminum pellets into a beaker of filtered seawater. The aluminum is pretreated with a rare-metal alloy that effectively scrubs aluminum into a pure form that can react with seawater to generate hydrogen. The salt ions in the seawater can in turn attract and recover the alloy, which can be reused to generate more hydrogen, in a sustainable cycle.
The team found that this reaction between aluminum and seawater successfully produces hydrogen gas, though slowly. On a lark, they tossed into the mix some coffee grounds and found, to their surprise, that the reaction picked up its pace.
In the end, the team discovered that a low concentration of imidazole — an active ingredient in caffeine — is enough to significantly speed up the reaction, producing the same amount of hydrogen in just five minutes, compared to two hours without the added stimulant.
The researchers are developing a small reactor that could run on a marine vessel or underwater vehicle. The vessel would hold a supply of aluminum pellets (recycled from old soda cans and other aluminum products), along with a small amount of gallium-indium and caffeine. These ingredients could be periodically funneled into the reactor, along with some of the surrounding seawater, to produce hydrogen on demand. The hydrogen could then fuel an onboard engine to drive a motor or generate electricity to power the ship.
“This is very interesting for maritime applications like boats or underwater vehicles because you wouldn’t have to carry around seawater — it’s readily available,” says study lead author Aly Kombargi, a PhD student in MIT’s Department of Mechanical Engineering. “We also don’t have to carry a tank of hydrogen. Instead, we would transport aluminum as the ‘fuel,’ and just add water to produce the hydrogen that we need.”
The study’s co-authors include Enoch Ellis, an undergraduate in chemical engineering; Peter Godart PhD ’21, who has founded a company to recycle aluminum as a source of hydrogen fuel; and Douglas Hart, MIT professor of mechanical engineering.
Shields up
The MIT team, led by Hart, is developing efficient and sustainable methods to produce hydrogen gas, which is seen as a “green” energy source that could power engines and fuel cells without generating climate-warming emissions.
One drawback to fueling vehicles with hydrogen is that some designs would require the gas to be carried onboard like traditional gasoline in a tank — a risky setup, given hydrogen’s volatile potential. Hart and his team have instead looked for ways to power vehicles with hydrogen without having to constantly transport the gas itself.
They found a possible workaround in aluminum — a naturally abundant and stable material that, when in contact with water, undergoes a straightforward chemical reaction that generates hydrogen and heat.
The reaction, however, comes with a sort of Catch-22: While aluminum can generate hydrogen when it mixes with water, it can only do so in a pure, exposed state. The instant aluminum meets with oxygen, such as in air, the surface immediately forms a thin, shield-like layer of oxide that prevents further reactions. This barrier is the reason hydrogen doesn’t immediately bubble up when you drop a soda can in water.
In previous work, using fresh water, the team found they could pierce aluminum’s shield and keep the reaction with water going by pretreating the aluminum with a small amount of rare metal alloy made from a specific concentration of gallium and indium. The alloy serves as an “activator,” scrubbing away any oxide buildup and creating a pure aluminum surface that is free to react with water. When they ran the reaction in fresh, de-ionized water, they found that one pretreated pellet of aluminum produced 400 milliliters of hydrogen in just five minutes. They estimate that just 1 gram of pellets would generate 1.3 liters of hydrogen in the same amount of time.
But to further scale up the system would require a significant supply of gallium indium, which is relatively expensive and rare.
“For this idea to be cost-effective and sustainable, we had to work on recovering this alloy postreaction,” Kombargi says.
By the sea
In the team’s new work, they found they could retrieve and reuse gallium indium using a solution of ions. The ions — atoms or molecules with an electrical charge — protect the metal alloy from reacting with water and help it to precipitate into a form that can be scooped out and reused.
“Lucky for us, seawater is an ionic solution that is very cheap and available,” says Kombargi, who tested the idea with seawater from a nearby beach. “I literally went to Revere Beach with a friend and we grabbed our bottles and filled them, and then I just filtered out algae and sand, added aluminum to it, and it worked with the same consistent results.”
He found that hydrogen indeed bubbled up when he added aluminum to a beaker of filtered seawater. And he was able to scoop out the gallium indium afterward. But the reaction happened much more slowly than it did in fresh water. It turns out that the ions in seawater act to shield gallium indium, such that it can coalesce and be recovered after the reaction. But the ions have a similar effect on aluminum, building up a barrier that slows its reaction with water.
As they looked for ways to speed up the reaction in seawater, the researchers tried out various and unconventional ingredients.
“We were just playing around with things in the kitchen, and found that when we added coffee grounds into seawater and dropped aluminum pellets in, the reaction was quite fast compared to just seawater,” Kombargi says.
To see what might explain the speedup, the team reached out to colleagues in MIT’s chemistry department, who suggested they try imidazole — an active ingredient in caffeine, which happens to have a molecular structure that can pierce through aluminum (allowing the material to continue reacting with water), while leaving gallium indium’s ionic shield intact.
“That was our big win,” Kombargi says. “We had everything we wanted: recovering the gallium indium, plus the fast and efficient reaction.”
The researchers believe they have the essential ingredients to run a sustainable hydrogen reactor. They plan to test it first in marine and underwater vehicles. They’ve calculated that such a reactor, holding about 40 pounds of aluminum pellets, could power a small underwater glider for about 30 days by pumping in surrounding seawater and generating hydrogen to power a motor.
“We’re showing a new way to produce hydrogen fuel, without carrying hydrogen but carrying aluminum as the ‘fuel,’” Kombargi says. “The next part is to figure out how to use this for trucks, trains, and maybe airplanes. Perhaps, instead of having to carry water as well, we could extract water from the ambient humidity to produce hydrogen. That’s down the line.”
MIT engineers Aly Kombargi (left) and Niko Tsakiris (right) work on a new hydrogen reactor, designed to produce hydrogen gas by mixing aluminum pellets with seawater.
An open-access MIT study published today in Nature provides new evidence for how specific cells and circuits become vulnerable in Alzheimer’s disease, and hones in on other factors that may help some people show resilience to cognitive decline, even amid clear signs of disease pathology.
To highlight potential targets for interventions to sustain cognition and memory, the authors engaged in a novel comparison of gene expression across multiple brain regions in people with or without Alzheimer’s disease, and conducted lab experiments to test and validate their major findings.
Brain cells all have the same DNA but what makes them differ, both in their identity and their activity, are their patterns of how they express those genes. The new analysis measured gene expression differences in more than 1.3 million cells of more than 70 cell types in six brain regions from 48 tissue donors, 26 of whom died with an Alzheimer’s diagnosis and 22 of whom without. As such, the study provides a uniquely large, far-ranging, and yet detailed accounting of how brain cell activity differs amid Alzheimer’s disease by cell type, by brain region, by disease pathology, and by each person’s cognitive assessment while still alive.
“Specific brain regions are vulnerable in Alzheimer’s and there is an important need to understand how these regions or particular cell types are vulnerable,” says co-senior author Li-Huei Tsai, Picower Professor of Neuroscience and director of The Picower Institute for Learning and Memory and the Aging Brain Initiative at MIT. “And the brain is not just neurons. It’s many other cell types. How these cell types may respond differently, depending on where they are, is something fascinating we are only at the beginning of looking at.”
Co-senior author Manolis Kellis, professor of computer science and head of MIT’s Computational Biology Group, likens the technique used to measure gene expression comparisons, single-cell RNA profiling, to being a much more advanced “microscope” than the ones that first allowed Alois Alzheimer to characterize the disease’s pathology more than a century ago.
“Where Alzheimer saw amyloid protein plaques and phosphorylated tau tangles in his microscope, our single-cell ‘microscope’ tells us, cell by cell and gene by gene, about thousands of subtle yet important biological changes in response to pathology,” says Kellis. “Connecting this information with the cognitive state of patients reveals how cellular responses relate with cognitive loss or resilience, and can help propose new ways to treat cognitive loss. Pathology can precede cognitive symptoms by a decade or two before cognitive decline becomes diagnosed. If there’s not much we can do about the pathology at that stage, we can at least try to safeguard the cellular pathways that maintain cognitive function.”
Hansruedi Mathys, a former MIT postdoc in the Tsai Lab who is now an assistant professor at the University of Pittsburgh; Carles Boix PhD '22, a former graduate student in Kellis’s lab who is now a postdoc at Harvard Medical School; and Leyla Akay, a graduate student in Tsai’s lab, led the study analyzing the prefrontal cortex, entorhinal cortex, hippocampus, anterior thalamus, angular gyrus, and the midtemporal cortex. The brain samples came from the Religious Order Study and the Rush Memory and Aging Project at Rush University.
Neural vulnerability and Reelin
Some of the earliest signs of amyloid pathology and neuron loss in Alzheimer’s occur in memory-focused regions called the hippocampus and the entorhinal cortex. In those regions, and in other parts of the cerebral cortex, the researchers were able to pinpoint a potential reason why. One type of excitatory neuron in the hippocampus and four in the entorhinal cortex were significantly less abundant in people with Alzheimer’s than in people without. Individuals with depletion of those cells performed significantly worse on cognitive assessments. Moreover, many vulnerable neurons were interconnected in a common neuronal circuit. And just as importantly, several either directly expressed a protein called Reelin, or were directly affected by Reelin signaling. In all, therefore, the findings distinctly highlight especially vulnerable neurons, whose loss is associated with reduced cognition, that share a neuronal circuit and a molecular pathway.
Tsai notes that Reelin has become prominent in Alzheimer’s research because of a recent study of a man in Colombia. He had a rare mutation in the Reelin gene that caused the protein to be more active, and was able to stay cognitively healthy at an advanced age despite having a strong family predisposition to early-onset Alzheimer’s. The new study shows that loss of Reelin-producing neurons is associated with cognitive decline. Taken together, it might mean that the brain benefits from Reelin, but that neurons that produce it may be lost in at least some Alzheimer’s patients.
“We can think of Reelin as having maybe some kind of protective or beneficial effect,” Akay says. “But we don’t yet know what it does or how it could confer resilience.”
In further analysis the researchers also found that specifically vulnerable inhibitory neuron subtypes identified in a previously study from this group in the prefrontal cortex also were involved in Reelin signaling, further reinforcing the significance of the molecule and its signaling pathway.
To further check their results, the team directly examined the human brain tissue samples and the brains of two kinds of Alzheimer’s model mice. Sure enough, those experiments also showed a reduction in Reelin-positive neurons in the human and mouse entorhinal cortex.
Resilience associated with choline metabolism in astrocytes
To find factors that might preserve cognition, even amid pathology, the team examined which genes, in which cells, and in which regions, were most closely associated with cognitive resilience, which they defined as residual cognitive function, above the typical cognitive loss expected given the observed pathology.
Their analysis yielded a surprising and specific answer: across several brain regions, astrocytes that expressed genes associated with antioxidant activity and with choline metabolism and polyamine biosynthesis were significantly associated with sustained cognition, even amid high levels of tau and amyloid. The results reinforced previous research findings led by Tsai and Susan Lundqvist in which they showed that dietary supplement of choline helped astrocytes cope with the dysregulation of lipids caused by the most significant Alzheimer’s risk gene, the APOE4 variant. The antioxidant findings also pointed to a molecule that can be found as a dietary supplement, spermidine, which may have anti-inflammatory properties, although such an association would need further work to be established causally.
As before, the team went beyond the predictions from the single-cell RNA expression analysis to make direct observations in the brain tissue of samples. Those that came from cognitively resilient individuals indeed showed increased expression of several of the astrocyte-expressed genes predicted to be associated with cognitive resilience.
New analysis method, open dataset
To analyze the mountains of single-cell data, the researchers developed a new robust methodology based on groups of coordinately-expressed genes (known as “gene modules”), thus exploiting the expression correlation patterns between functionally-related genes in the same module.
“In principle, the 1.3 million cells we surveyed could use their 20,000 genes in an astronomical number of different combinations,” explains Kellis. “In practice, however, we observe a much smaller subset of coordinated changes. Recognizing these coordinated patterns allow us to infer much more robust changes, because they are based on multiple genes in the same functionally-connected module.”
He offered this analogy: With many joints in their bodies, people could move in all kinds of crazy ways, but in practice they engage in many fewer coordinated movements like walking, running, or dancing. The new method enables scientists to identify such coordinated gene expression programs as a group.
While Kellis and Tsai’s labs already reported several noteworthy findings from the dataset, the researchers expect that many more possibly significant discoveries still wait to be found in the trove of data. To facilitate such discovery the team posted handy analytical and visualization tools along with the data on Kellis’s website.
“The dataset is so immensely rich. We focused on only a few aspects that are salient that we believe are very, very interesting, but by no means have we exhausted what can be learned with this dataset,” Kellis says. “We expect many more discoveries ahead, and we hope that young researchers (of all ages) will dive right in and surprise us with many more insights.”
Going forward, Kellis says, the researchers are studying the control circuitry associated with the differentially expressed genes, to understand the genetic variants, the regulators, and other driver factors that can be modulated to reverse disease circuitry across brain regions, cell types, and different stages of the disease.
Additional authors of the study include Ziting Xia, Jose Davila Velderrain, Ayesha P. Ng, Xueqiao Jiang, Ghada Abdelhady, Kyriaki Galani, Julio Mantero, Neil Band, Benjamin T. James, Sudhagar Babu, Fabiola Galiana-Melendez, Kate Louderback, Dmitry Prokopenko, Rudolph E. Tanzi, and David A. Bennett.
Support for the research came from the National Institutes of Health, The Picower Institute for Learning and Memory, The JPB Foundation, the Cure Alzheimer’s Fund, The Robert A. and Renee E. Belfer Family Foundation, Eduardo Eurnekian, and Joseph DiSabato.
In an analysis of human brain samples looking for factors associated with neural vulnerability and cognitive resilience amid Alzheimer's disease, researchers compared expression of the protein Reelin in excitatory neurons in the entorhinal cortex of people with (right) or without (left) Alzheimer’s disease. In people without the disease, vGlut (green), a marker of excitatory neurons, and Reelin (magenta) were often expressed together. In people with Alzheimer’s, excitatory cells exhibited much less Reelin expression.
Organizations are increasingly utilizing machine-learning models to allocate scarce resources or opportunities. For instance, such models can help companies screen resumes to choose job interview candidates or aid hospitals in ranking kidney transplant patients based on their likelihood of survival.
When deploying a model, users typically strive to ensure its predictions are fair by reducing bias. This often involves techniques like adjusting the features a model uses to make decisions or calibrating the scores it generates.
However, researchers from MIT and Northeastern University argue that these fairness methods are not sufficient to address structural injustices and inherent uncertainties. In a new paper, they show how randomizing a model’s decisions in a structured way can improve fairness in certain situations.
For example, if multiple companies use the same machine-learning model to rank job interview candidates deterministically — without any randomization — then one deserving individual could be the bottom-ranked candidate for every job, perhaps due to how the model weighs answers provided in an online form. Introducing randomization into a model’s decisions could prevent one worthy person or group from always being denied a scarce resource, like a job interview.
Through their analysis, the researchers found that randomization can be especially beneficial when a model’s decisions involve uncertainty or when the same group consistently receives negative decisions.
They present a framework one could use to introduce a specific amount of randomization into a model’s decisions by allocating resources through a weighted lottery. This method, which an individual can tailor to fit their situation, can improve fairness without hurting the efficiency or accuracy of a model.
“Even if you could make fair predictions, should you be deciding these social allocations of scarce resources or opportunities strictly off scores or rankings? As things scale, and we see more and more opportunities being decided by these algorithms, the inherent uncertainties in these scores can be amplified. We show that fairness may require some sort of randomization,” says Shomik Jain, a graduate student in the Institute for Data, Systems, and Society (IDSS) and lead author of the paper.
Jain is joined on the paper by Kathleen Creel, assistant professor of philosophy and computer science at Northeastern University; and senior author Ashia Wilson, the Lister Brothers Career Development Professor in the Department of Electrical Engineering and Computer Science and a principal investigator in the Laboratory for Information and Decision Systems (LIDS). The research will be presented at the International Conference on Machine Learning.
Considering claims
This work builds off a previous paper in which the researchers explored harms that can occur when one uses deterministic systems at scale. They found that using a machine-learning model to deterministically allocate resources can amplify inequalities that exist in training data, which can reinforce bias and systemic inequality.
“Randomization is a very useful concept in statistics, and to our delight, satisfies the fairness demands coming from both a systemic and individual point of view,” Wilson says.
In this paper, they explored the question of when randomization can improve fairness. They framed their analysis around the ideas of philosopher John Broome, who wrote about the value of using lotteries to award scarce resources in a way that honors all claims of individuals.
A person’s claim to a scarce resource, like a kidney transplant, can stem from merit, deservingness, or need. For instance, everyone has a right to life, and their claims on a kidney transplant may stem from that right, Wilson explains.
“When you acknowledge that people have different claims to these scarce resources, fairness is going to require that we respect all claims of individuals. If we always give someone with a stronger claim the resource, is that fair?” Jain says.
That sort of deterministic allocation could cause systemic exclusion or exacerbate patterned inequality, which occurs when receiving one allocation increases an individual’s likelihood of receiving future allocations. In addition, machine-learning models can make mistakes, and a deterministic approach could cause the same mistake to be repeated.
Randomization can overcome these problems, but that doesn’t mean all decisions a model makes should be randomized equally.
Structured randomization
The researchers use a weighted lottery to adjust the level of randomization based on the amount of uncertainty involved in the model’s decision-making. A decision that is less certain should incorporate more randomization.
“In kidney allocation, usually the planning is around projected lifespan, and that is deeply uncertain. If two patients are only five years apart, it becomes a lot harder to measure. We want to leverage that level of uncertainty to tailor the randomization,” Wilson says.
The researchers used statistical uncertainty quantification methods to determine how much randomization is needed in different situations. They show that calibrated randomization can lead to fairer outcomes for individuals without significantly affecting the utility, or effectiveness, of the model.
“There is a balance to be had between overall utility and respecting the rights of the individuals who are receiving a scarce resource, but oftentimes the tradeoff is relatively small,” says Wilson.
However, the researchers emphasize there are situations where randomizing decisions would not improve fairness and could harm individuals, such as in criminal justice contexts.
But there could be other areas where randomization can improve fairness, such as college admissions, and the researchers plan to study other use cases in future work. They also want to explore how randomization can affect other factors, such as competition or prices, and how it could be used to improve the robustness of machine-learning models.
“We are hoping our paper is a first move toward illustrating that there might be a benefit to randomization. We are offering randomization as a tool. How much you are going to want to do it is going to be up to all the stakeholders in the allocation to decide. And, of course, how they decide is another research question all together,” says Wilson.
As artificial intelligence models become increasingly prevalent and are integrated into diverse sectors like health care, finance, education, transportation, and entertainment, understanding how they work under the hood is critical. Interpreting the mechanisms underlying AI models enables us to audit them for safety and biases, with the potential to deepen our understanding of the science behind intelligence itself.
Imagine if we could directly investigate the human brain by manipulating each of its individual neurons to examine their roles in perceiving a particular object. While such an experiment would be prohibitively invasive in the human brain, it is more feasible in another type of neural network: one that is artificial. However, somewhat similar to the human brain, artificial models containing millions of neurons are too large and complex to study by hand, making interpretability at scale a very challenging task.
To address this, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers decided to take an automated approach to interpreting artificial vision models that evaluate different properties of images. They developed “MAIA” (Multimodal Automated Interpretability Agent), a system that automates a variety of neural network interpretability tasks using a vision-language model backbone equipped with tools for experimenting on other AI systems.
“Our goal is to create an AI researcher that can conduct interpretability experiments autonomously. Existing automated interpretability methods merely label or visualize data in a one-shot process. On the other hand, MAIA can generate hypotheses, design experiments to test them, and refine its understanding through iterative analysis,” says Tamar Rott Shaham, an MIT electrical engineering and computer science (EECS) postdoc at CSAIL and co-author on a new paper about the research. “By combining a pre-trained vision-language model with a library of interpretability tools, our multimodal method can respond to user queries by composing and running targeted experiments on specific models, continuously refining its approach until it can provide a comprehensive answer.”
The automated agent is demonstrated to tackle three key tasks: It labels individual components inside vision models and describes the visual concepts that activate them, it cleans up image classifiers by removing irrelevant features to make them more robust to new situations, and it hunts for hidden biases in AI systems to help uncover potential fairness issues in their outputs. “But a key advantage of a system like MAIA is its flexibility,” says Sarah Schwettmann PhD ’21, a research scientist at CSAIL and co-lead of the research. “We demonstrated MAIA’s usefulness on a few specific tasks, but given that the system is built from a foundation model with broad reasoning capabilities, it can answer many different types of interpretability queries from users, and design experiments on the fly to investigate them.”
Neuron by neuron
In one example task, a human user asks MAIA to describe the concepts that a particular neuron inside a vision model is responsible for detecting. To investigate this question, MAIA first uses a tool that retrieves “dataset exemplars” from the ImageNet dataset, which maximally activate the neuron. For this example neuron, those images show people in formal attire, and closeups of their chins and necks. MAIA makes various hypotheses for what drives the neuron’s activity: facial expressions, chins, or neckties. MAIA then uses its tools to design experiments to test each hypothesis individually by generating and editing synthetic images — in one experiment, adding a bow tie to an image of a human face increases the neuron’s response. “This approach allows us to determine the specific cause of the neuron’s activity, much like a real scientific experiment,” says Rott Shaham.
MAIA’s explanations of neuron behaviors are evaluated in two key ways. First, synthetic systems with known ground-truth behaviors are used to assess the accuracy of MAIA’s interpretations. Second, for “real” neurons inside trained AI systems with no ground-truth descriptions, the authors design a new automated evaluation protocol that measures how well MAIA’s descriptions predict neuron behavior on unseen data.
The CSAIL-led method outperformed baseline methods describing individual neurons in a variety of vision models such as ResNet, CLIP, and the vision transformer DINO. MAIA also performed well on the new dataset of synthetic neurons with known ground-truth descriptions. For both the real and synthetic systems, the descriptions were often on par with descriptions written by human experts.
How are descriptions of AI system components, like individual neurons, useful? “Understanding and localizing behaviors inside large AI systems is a key part of auditing these systems for safety before they’re deployed — in some of our experiments, we show how MAIA can be used to find neurons with unwanted behaviors and remove these behaviors from a model,” says Schwettmann. “We’re building toward a more resilient AI ecosystem where tools for understanding and monitoring AI systems keep pace with system scaling, enabling us to investigate and hopefully understand unforeseen challenges introduced by new models.”
Peeking inside neural networks
The nascent field of interpretability is maturing into a distinct research area alongside the rise of “black box” machine learning models. How can researchers crack open these models and understand how they work?
Current methods for peeking inside tend to be limited either in scale or in the precision of the explanations they can produce. Moreover, existing methods tend to fit a particular model and a specific task. This caused the researchers to ask: How can we build a generic system to help users answer interpretability questions about AI models while combining the flexibility of human experimentation with the scalability of automated techniques?
One critical area they wanted this system to address was bias. To determine whether image classifiers displayed bias against particular subcategories of images, the team looked at the final layer of the classification stream (in a system designed to sort or label items, much like a machine that identifies whether a photo is of a dog, cat, or bird) and the probability scores of input images (confidence levels that the machine assigns to its guesses). To understand potential biases in image classification, MAIA was asked to find a subset of images in specific classes (for example “labrador retriever”) that were likely to be incorrectly labeled by the system. In this example, MAIA found that images of black labradors were likely to be misclassified, suggesting a bias in the model toward yellow-furred retrievers.
Since MAIA relies on external tools to design experiments, its performance is limited by the quality of those tools. But, as the quality of tools like image synthesis models improve, so will MAIA. MAIA also shows confirmation bias at times, where it sometimes incorrectly confirms its initial hypothesis. To mitigate this, the researchers built an image-to-text tool, which uses a different instance of the language model to summarize experimental results. Another failure mode is overfitting to a particular experiment, where the model sometimes makes premature conclusions based on minimal evidence.
“I think a natural next step for our lab is to move beyond artificial systems and apply similar experiments to human perception,” says Rott Shaham. “Testing this has traditionally required manually designing and testing stimuli, which is labor-intensive. With our agent, we can scale up this process, designing and testing numerous stimuli simultaneously. This might also allow us to compare human visual perception with artificial systems.”
“Understanding neural networks is difficult for humans because they have hundreds of thousands of neurons, each with complex behavior patterns. MAIA helps to bridge this by developing AI agents that can automatically analyze these neurons and report distilled findings back to humans in a digestible way,” says Jacob Steinhardt, assistant professor at the University of California at Berkeley, who wasn’t involved in the research. “Scaling these methods up could be one of the most important routes to understanding and safely overseeing AI systems.”
Rott Shaham and Schwettmann are joined by five fellow CSAIL affiliates on the paper: undergraduate student Franklin Wang; incoming MIT student Achyuta Rajaram; EECS PhD student Evan Hernandez SM ’22; and EECS professors Jacob Andreas and Antonio Torralba. Their work was supported, in part, by the MIT-IBM Watson AI Lab, Open Philanthropy, Hyundai Motor Co., the Army Research Laboratory, Intel, the National Science Foundation, the Zuckerman STEM Leadership Program, and the Viterbi Fellowship. The researchers’ findings will be presented at the International Conference on Machine Learning this week.
As the name suggests, most electronic devices today work through the movement of electrons. But materials that can efficiently conduct protons — the nucleus of the hydrogen atom — could be key to a number of important technologies for combating global climate change.
Most proton-conducting inorganic materials available now require undesirably high temperatures to achieve sufficiently high conductivity. However, lower-temperature alternatives could enable a variety of technologies, such as more efficient and durable fuel cells to produce clean electricity from hydrogen, electrolyzers to make clean fuels such as hydrogen for transportation, solid-state proton batteries, and even new kinds of computing devices based on iono-electronic effects.
In order to advance the development of proton conductors, MIT engineers have identified certain traits of materials that give rise to fast proton conduction. Using those traits quantitatively, the team identified a half-dozen new candidates that show promise as fast proton conductors. Simulations suggest these candidates will perform far better than existing materials, although they still need to be conformed experimentally. In addition to uncovering potential new materials, the research also provides a deeper understanding at the atomic level of how such materials work.
The new findings are described in the journal Energy and Environmental Sciences, in a paper by MIT professors Bilge Yildiz and Ju Li, postdocs Pjotrs Zguns and Konstantin Klyukin, and their collaborator Sossina Haile and her students from Northwestern University. Yildiz is the Breene M. Kerr Professor in the departments of Nuclear Science and Engineering, and Materials Science and Engineering.
“Proton conductors are needed in clean energy conversion applications such as fuel cells, where we use hydrogen to produce carbon dioxide-free electricity,” Yildiz explains. “We want to do this process efficiently, and therefore we need materials that can transport protons very fast through such devices.”
Present methods of producing hydrogen, for example steam methane reforming, emit a great deal of carbon dioxide. “One way to eliminate that is to electrochemically produce hydrogen from water vapor, and that needs very good proton conductors,” Yildiz says. Production of other important industrial chemicals and potential fuels, such as ammonia, can also be carried out through efficient electrochemical systems that require good proton conductors.
But most inorganic materials that conduct protons can only operate at temperatures of 200 to 600 degrees Celsius (roughly 450 to 1,100 Fahrenheit), or even higher. Such temperatures require energy to maintain and can cause degradation of materials. “Going to higher temperatures is not desirable because that makes the whole system more challenging, and the material durability becomes an issue,” Yildiz says. “There is no good inorganic proton conductor at room temperature.” Today, the only known room-temperature proton conductor is a polymeric material that is not practical for applications in computing devices because it can’t easily be scaled down to the nanometer regime, she says.
To tackle the problem, the team first needed to develop a basic and quantitative understanding of exactly how proton conduction works, taking a class of inorganic proton conductors, called solid acids. “One has to first understand what governs proton conduction in these inorganic compounds,” she says. While looking at the materials’ atomic configurations, the researchers identified a pair of characteristics that directly relates to the materials’ proton-carrying potential.
As Yildiz explains, proton conduction first involves a proton “hopping from a donor oxygen atom to an acceptor oxygen. And then the environment has to reorganize and take the accepted proton away, so that it can hop to another neighboring acceptor, enabling long-range proton diffusion.” This process happens in many inorganic solids, she says. Figuring out how that last part works — how the atomic lattice gets reorganized to take the accepted proton away from the original donor atom — was a key part of this research, she says.
The researchers used computer simulations to study a class of materials called solid acids that become good proton conductors above 200degrees Celsius. This class of materials has a substructure called the polyanion group sublattice, and these groups have to rotate and take the proton away from its original site so it can then transfer to other sites. The researchers were able to identify the phonons that contribute to the flexibility of this sublattice, which is essential for proton conduction. Then they used this information to comb through vast databases of theoretically and experimentally possible compounds, in search of better proton conducting materials.
As a result, they found solid acid compounds that are promising proton conductors and that have been developed and produced for a variety of different applications but never before studied as proton conductors; these compounds turned out to have just the right characteristics of lattice flexibility. The team then carried out computer simulations of how the specific materials they identified in their initial screening would perform under relevant temperatures, to confirm their suitability as proton conductors for fuel cells or other uses. Sure enough, they found six promising materials, with predicted proton conduction speeds faster than the best existing solid acid proton conductors.
“There are uncertainties in these simulations,” Yildiz cautions. “I don’t want to say exactly how much higher the conductivity will be, but these look very promising. Hopefully this motivates the experimental field to try to synthesize them in different forms and make use of these compounds as proton conductors.”
Translating these theoretical findings into practical devices could take some years, she says. The likely first applications would be for electrochemical cells to produce fuels and chemical feedstocks such as hydrogen and ammonia, she says.
The work was supported by the U.S. Department of Energy, the Wallenberg Foundation, and the U.S. National Science Foundation.
One thing that makes large language models (LLMs) so powerful is the diversity of tasks to which they can be applied. The same machine-learning model that can help a graduate student draft an email could also aid a clinician in diagnosing cancer.
However, the wide applicability of these models also makes them challenging to evaluate in a systematic way. It would be impossible to create a benchmark dataset to test a model on every type of question it can be asked.
In a new paper, MIT researchers took a different approach. They argue that, because humans decide when to deploy large language models, evaluating a model requires an understanding of how people form beliefs about its capabilities.
For example, the graduate student must decide whether the model could be helpful in drafting a particular email, and the clinician must determine which cases would be best to consult the model on.
Building off this idea, the researchers created a framework to evaluate an LLM based on its alignment with a human’s beliefs about how it will perform on a certain task.
They introduce a human generalization function — a model of how people update their beliefs about an LLM’s capabilities after interacting with it. Then, they evaluate how aligned LLMs are with this human generalization function.
Their results indicate that when models are misaligned with the human generalization function, a user could be overconfident or underconfident about where to deploy it, which might cause the model to fail unexpectedly. Furthermore, due to this misalignment, more capable models tend to perform worse than smaller models in high-stakes situations.
“These tools are exciting because they are general-purpose, but because they are general-purpose, they will be collaborating with people, so we have to take the human in the loop into account,” says study co-author Ashesh Rambachan, assistant professor of economics and a principal investigator in the Laboratory for Information and Decision Systems (LIDS).
Rambachan is joined on the paper by lead author Keyon Vafa, a postdoc at Harvard University; and Sendhil Mullainathan, an MIT professor in the departments of Electrical Engineering and Computer Science and of Economics, and a member of LIDS. The research will be presented at the International Conference on Machine Learning.
Human generalization
As we interact with other people, we form beliefs about what we think they do and do not know. For instance, if your friend is finicky about correcting people’s grammar, you might generalize and think they would also excel at sentence construction, even though you’ve never asked them questions about sentence construction.
“Language models often seem so human. We wanted to illustrate that this force of human generalization is also present in how people form beliefs about language models,” Rambachan says.
As a starting point, the researchers formally defined the human generalization function, which involves asking questions, observing how a person or LLM responds, and then making inferences about how that person or model would respond to related questions.
If someone sees that an LLM can correctly answer questions about matrix inversion, they might also assume it can ace questions about simple arithmetic. A model that is misaligned with this function — one that doesn’t perform well on questions a human expects it to answer correctly — could fail when deployed.
With that formal definition in hand, the researchers designed a survey to measure how people generalize when they interact with LLMs and other people.
They showed survey participants questions that a person or LLM got right or wrong and then asked if they thought that person or LLM would answer a related question correctly. Through the survey, they generated a dataset of nearly 19,000 examples of how humans generalize about LLM performance across 79 diverse tasks.
Measuring misalignment
They found that participants did quite well when asked whether a human who got one question right would answer a related question right, but they were much worse at generalizing about the performance of LLMs.
“Human generalization gets applied to language models, but that breaks down because these language models don’t actually show patterns of expertise like people would,” Rambachan says.
People were also more likely to update their beliefs about an LLM when it answered questions incorrectly than when it got questions right. They also tended to believe that LLM performance on simple questions would have little bearing on its performance on more complex questions.
In situations where people put more weight on incorrect responses, simpler models outperformed very large models like GPT-4.
“Language models that get better can almost trick people into thinking they will perform well on related questions when, in actuality, they don’t,” he says.
One possible explanation for why humans are worse at generalizing for LLMs could come from their novelty — people have far less experience interacting with LLMs than with other people.
“Moving forward, it is possible that we may get better just by virtue of interacting with language models more,” he says.
To this end, the researchers want to conduct additional studies of how people’s beliefs about LLMs evolve over time as they interact with a model. They also want to explore how human generalization could be incorporated into the development of LLMs.
“When we are training these algorithms in the first place, or trying to update them with human feedback, we need to account for the human generalization function in how we think about measuring performance,” he says.
In the meanwhile, the researchers hope their dataset could be used a benchmark to compare how LLMs perform related to the human generalization function, which could help improve the performance of models deployed in real-world situations.
“To me, the contribution of the paper is twofold. The first is practical: The paper uncovers a critical issue with deploying LLMs for general consumer use. If people don’t have the right understanding of when LLMs will be accurate and when they will fail, then they will be more likely to see mistakes and perhaps be discouraged from further use. This highlights the issue of aligning the models with people's understanding of generalization,” says Alex Imas, professor of behavioral science and economics at the University of Chicago’s Booth School of Business, who was not involved with this work. “The second contribution is more fundamental: The lack of generalization to expected problems and domains helps in getting a better picture of what the models are doing when they get a problem ‘correct.’ It provides a test of whether LLMs ‘understand’ the problem they are solving.”
This research was funded, in part, by the Harvard Data Science Initiative and the Center for Applied AI at the University of Chicago Booth School of Business.
Ductal carcinoma in situ (DCIS) is a type of preinvasive tumor that sometimes progresses to a highly deadly form of breast cancer. It accounts for about 25 percent of all breast cancer diagnoses.
Because it is difficult for clinicians to determine the type and stage of DCIS, patients with DCIS are often overtreated. To address this, an interdisciplinary team of researchers from MIT and ETH Zurich developed an AI model that can identify the different stages of DCIS from a cheap and easy-to-obtain breast tissue image. Their model shows that both the state and arrangement of cells in a tissue sample are important for determining the stage of DCIS.
Because such tissue images are so easy to obtain, the researchers were able to build one of the largest datasets of its kind, which they used to train and test their model. When they compared its predictions to conclusions of a pathologist, they found clear agreement in many instances.
In the future, the model could be used as a tool to help clinicians streamline the diagnosis of simpler cases without the need for labor-intensive tests, giving them more time to evaluate cases where it is less clear if DCIS will become invasive.
“We took the first step in understanding that we should be looking at the spatial organization of cells when diagnosing DCIS, and now we have developed a technique that is scalable. From here, we really need a prospective study. Working with a hospital and getting this all the way to the clinic will be an important step forward,” says Caroline Uhler, a professor in the Department of Electrical Engineering and Computer Science (EECS) and the Institute for Data, Systems, and Society (IDSS), who is also director of the Eric and Wendy Schmidt Center at the Broad Institute of MIT and Harvard and a researcher at MIT’s Laboratory for Information and Decision Systems (LIDS).
Uhler, co-corresponding author of a paper on this research, is joined by lead author Xinyi Zhang, a graduate student in EECS and the Eric and Wendy Schmidt Center; co-corresponding author GV Shivashankar, professor of mechogenomics at ETH Zurich jointly with the Paul Scherrer Institute; and others at MIT, ETH Zurich, and the University of Palermo in Italy. The open-access research was published July 20 in Nature Communications.
Combining imaging with AI
Between 30 and 50 percent of patients with DCIS develop a highly invasive stage of cancer, but researchers don’t know the biomarkers that could tell a clinician which tumors will progress.
Researchers can use techniques like multiplexed staining or single-cell RNA sequencing to determine the stage of DCIS in tissue samples. However, these tests are too expensive to be performed widely, Shivashankar explains.
In previous work, these researchers showed that a cheap imagining technique known as chromatin staining could be as informative as the much costlier single-cell RNA sequencing.
For this research, they hypothesized that combining this single stain with a carefully designed machine-learning model could provide the same information about cancer stage as costlier techniques.
First, they created a dataset containing 560 tissue sample images from 122 patients at three different stages of disease. They used this dataset to train an AI model that learns a representation of the state of each cell in a tissue sample image, which it uses to infer the stage of a patient’s cancer.
However, not every cell is indicative of cancer, so the researchers had to aggregate them in a meaningful way.
They designed the model to create clusters of cells in similar states, identifying eight states that are important markers of DCIS. Some cell states are more indicative of invasive cancer than others. The model determines the proportion of cells in each state in a tissue sample.
Organization matters
“But in cancer, the organization of cells also changes. We found that just having the proportions of cells in every state is not enough. You also need to understand how the cells are organized,” says Shivashankar.
With this insight, they designed the model to consider proportion and arrangement of cell states, which significantly boosted its accuracy.
“The interesting thing for us was seeing how much spatial organization matters. Previous studies had shown that cells which are close to the breast duct are important. But it is also important to consider which cells are close to which other cells,” says Zhang.
When they compared the results of their model with samples evaluated by a pathologist, it had clear agreement in many instances. In cases that were not as clear-cut, the model could provide information about features in a tissue sample, like the organization of cells, that a pathologist could use in decision-making.
This versatile model could also be adapted for use in other types of cancer, or even neurodegenerative conditions, which is one area the researchers are also currently exploring.
“We have shown that, with the right AI techniques, this simple stain can be very powerful. There is still much more research to do, but we need to take the organization of cells into account in more of our studies,” Uhler says.
This research was funded, in part, by the Eric and Wendy Schmidt Center at the Broad Institute, ETH Zurich, the Paul Scherrer Institute, the Swiss National Science Foundation, the U.S. National Institutes of Health, the U.S. Office of Naval Research, the MIT Jameel Clinic for Machine Learning and Health, the MIT-IBM Watson AI Lab, and a Simons Investigator Award.
When it comes to heating up the planet, not all greenhouse gases are created equal. They vary widely in their global warming potential (GWP), a measure of how much infrared thermal radiation a greenhouse gas would absorb over a given time frame once it enters the atmosphere. For example, measured over a 100-year period, the GWP of methane is about 28 times that of carbon dioxide (CO2), and the GWPs of a class of greenhouse gases known as perfluorocarbons (PFCs) are thousands of times that of CO2. The lifespans in the atmosphere of different greenhouse gases also vary widely. Methane persists in the atmosphere for around 10 years; CO2 for over 100 years, and PFCs for up to tens of thousands of years.
Given the high GWPs and lifespans of PFCs, their emissions could pose a major roadblock to achieving the aspirational goal of the Paris Agreement on climate change — to limit the increase in global average surface temperature to 1.5 degrees Celsius above preindustrial levels. Now, two new studies based on atmospheric observations inside China and high-resolution atmospheric models show a rapid rise in Chinese emissions over the last decade (2011 to 2020 or 2021) of three PFCs: tetrafluoromethane (PFC-14) and hexafluoroethane (PFC-116) (results in PNAS), and perfluorocyclobutane (PFC-318) (results in Environmental Science & Technology).
Both studies find that Chinese emissions have played a dominant role in driving up global emission levels for all three PFCs.
The PNAS study identifies substantial PFC-14 and PFC-116 emission sources in the less-populated western regions of China from 2011 to 2021, likely due to the large amount of aluminum industry in these regions. The semiconductor industry also contributes to some of the emissions detected in the more economically developed eastern regions. These emissions are byproducts from aluminum smelting, or occur during the use of the two PFCs in the production of semiconductors and flat panel displays. During the observation period, emissions of both gases in China rose by 78 percent, accounting for most of the increase in global emissions of these gases.
The ES&T study finds that during 2011-20, a 70 percent increase in Chinese PFC-318 emissions (contributing more than half of the global emissions increase of this gas) — originated primarily in eastern China. The regions with high emissions of PFC-318 in China overlap with geographical areas densely populated with factories that produce polytetrafluoroethylene (PTFE, commonly used for nonstick cookware coatings), implying that PTFE factories are major sources of PFC-318 emissions in China. In these factories, PFC-318 is formed as a byproduct.
“Using atmospheric observations from multiple monitoring sites, we not only determined the magnitudes of PFC emissions, but also pinpointed the possible locations of their sources,” says Minde An, a postdoc at the MIT Center for Global Change Science (CGCS), and corresponding author of both studies. “Identifying the actual source industries contributing to these PFC emissions, and understanding the reasons for these largely byproduct emissions, can provide guidance for developing region- or industry-specific mitigation strategies.”
“These three PFCs are largely produced as unwanted byproducts during the manufacture of otherwise widely used industrial products,” says MIT professor of atmospheric sciences Ronald Prinn, director of both the MIT Joint Program on the Science and Policy of Global Change and CGCS, and a co-author of both studies. “Phasing out emissions of PFCs as early as possible is highly beneficial for achieving global climate mitigation targets and is likely achievable by recycling programs and targeted technological improvements in these industries.”
Findings in both studies were obtained, in part, from atmospheric observations collected from nine stations within a Chinese network, including one station from the Advanced Global Atmospheric Gases Experiment (AGAGE) network. For comparison, global total emissions were determined from five globally distributed, relatively unpolluted “background” AGAGE stations, as reported in the latest United Nations Environment Program and World Meteorological Organization Ozone Assessment report.
The concept of short-range order (SRO) — the arrangement of atoms over small distances — in metallic alloys has been underexplored in materials science and engineering. But the past decade has seen renewed interest in quantifying it, since decoding SRO is a crucial step toward developing tailored high-performing alloys, such as stronger or heat-resistant materials.
Understanding how atoms arrange themselves is no easy task and must be verified using intensive lab experiments or computer simulations based on imperfect models. These hurdles have made it difficult to fully explore SRO in metallic alloys.
But Killian Sheriff and Yifan Cao, graduate students in MIT’s Department of Materials Science and Engineering (DMSE), are using machine learning to quantify, atom-by-atom, the complex chemical arrangements that make up SRO. Under the supervision of Assistant Professor Rodrigo Freitas, and with the help of Assistant Professor Tess Smidt in the Department of Electrical Engineering and Computer Science, their work was recently published in TheProceedings of the National Academy of Sciences.
Interest in understanding SRO is linked to the excitement around advanced materials called high-entropy alloys, whose complex compositions give them superior properties.
Typically, materials scientists develop alloys by using one element as a base and adding small quantities of other elements to enhance specific properties. The addition of chromium to nickel, for example, makes the resulting metal more resistant to corrosion.
Unlike most traditional alloys, high-entropy alloys have several elements, from three up to 20, in nearly equal proportions. This offers a vast design space. “It’s like you’re making a recipe with a lot more ingredients,” says Cao.
The goal is to use SRO as a “knob” to tailor material properties by mixing chemical elements in high-entropy alloys in unique ways. This approach has potential applications in industries such as aerospace, biomedicine, and electronics, driving the need to explore permutations and combinations of elements, Cao says.
Capturing short-range order
Short-range order refers to the tendency of atoms to form chemical arrangements with specific neighboring atoms. While a superficial look at an alloy’s elemental distribution might indicate that its constituent elements are randomly arranged, it is often not so. “Atoms have a preference for having specific neighboring atoms arranged in particular patterns,” Freitas says. “How often these patterns arise and how they are distributed in space is what defines SRO.”
Understanding SRO unlocks the keys to the kingdom of high-entropy materials. Unfortunately, not much is known about SRO in high-entropy alloys. “It’s like we’re trying to build a huge Lego model without knowing what’s the smallest piece of Lego that you can have,” says Sheriff.
Traditional methods for understanding SRO involve small computational models, or simulations with a limited number of atoms, providing an incomplete picture of complex material systems. “High-entropy materials are chemically complex — you can’t simulate them well with just a few atoms; you really need to go a few length scales above that to capture the material accurately,” Sheriff says. “Otherwise, it’s like trying to understand your family tree without knowing one of the parents.”
SRO has also been calculated by using basic mathematics, counting immediate neighbors for a few atoms and computing what that distribution might look like on average. Despite its popularity, the approach has limitations, as it offers an incomplete picture of SRO.
Fortunately, researchers are leveraging machine learning to overcome the shortcomings of traditional approaches for capturing and quantifying SRO.
Hyunseok Oh, assistant professor in the Department of Materials Science and Engineering at the University of Wisconsin at Madison and a former DMSE postdoc, is excited about investigating SRO more fully. Oh, who was not involved in this study, explores how to leverage alloy composition, processing methods, and their relationship to SRO to design better alloys. “The physics of alloys and the atomistic origin of their properties depend on short-range ordering, but the accurate calculation of short-range ordering has been almost impossible,” says Oh.
A two-pronged machine learning solution
To study SRO using machine learning, it helps to picture the crystal structure in high-entropy alloys as a connect-the-dots game in an coloring book, Cao says.
“You need to know the rules for connecting the dots to see the pattern.” And you need to capture the atomic interactions with a simulation that is big enough to fit the entire pattern.
First, understanding the rules meant reproducing the chemical bonds in high-entropy alloys. “There are small energy differences in chemical patterns that lead to differences in short-range order, and we didn’t have a good model to do that,” Freitas says. The model the team developed is the first building block in accurately quantifying SRO.
The second part of the challenge, ensuring that researchers get the whole picture, was more complex. High-entropy alloys can exhibit billions of chemical “motifs,” combinations of arrangements of atoms. Identifying these motifs from simulation data is difficult because they can appear in symmetrically equivalent forms — rotated, mirrored, or inverted. At first glance, they may look different but still contain the same chemical bonds.
The team solved this problem by employing 3D Euclidean neural networks. These advanced computational models allowed the researchers to identify chemical motifs from simulations of high-entropy materials with unprecedented detail, examining them atom-by-atom.
The final task was to quantify the SRO. Freitas used machine learning to evaluate the different chemical motifs and tag each with a number. When researchers want to quantify the SRO for a new material, they run it by the model, which sorts it in its database and spits out an answer.
The team also invested additional effort in making their motif identification framework more accessible. “We have this sheet of all possible permutations of [SRO] already set up, and we know what number each of them got through this machine learning process,” Freitas says. “So later, as we run into simulations, we can sort them out to tell us what that new SRO will look like.” The neural network easily recognizes symmetry operations and tags equivalent structures with the same number.
“If you had to compile all the symmetries yourself, it’s a lot of work. Machine learning organized this for us really quickly and in a way that was cheap enough that we could apply it in practice,” Freitas says.
Enter the world’s fastest supercomputer
This summer, Cao and Sheriff and team will have a chance to explore how SRO can change under routine metal processing conditions, like casting and cold-rolling, through the U.S. Department of Energy’s INCITE program, which allows access to Frontier, the world’s fastest supercomputer.
“If you want to know how short-range order changes during the actual manufacturing of metals, you need to have a very good model and a very large simulation,” Freitas says. The team already has a strong model; it will now leverage INCITE’s computing facilities for the robust simulations required.
“With that we expect to uncover the sort of mechanisms that metallurgists could employ to engineer alloys with pre-determined SRO,” Freitas adds.
Sheriff is excited about the research’s many promises. One is the 3D information that can be obtained about chemical SRO. Whereas traditional transmission electron microscopes and other methods are limited to two-dimensional data, physical simulations can fill in the dots and give full access to 3D information, Sheriff says.
“We have introduced a framework to start talking about chemical complexity,” Sheriff explains. “Now that we can understand this, there’s a whole body of materials science on classical alloys to develop predictive tools for high-entropy materials.”
That could lead to the purposeful design of new classes of materials instead of simply shooting in the dark.
The research was funded by the MathWorks Ignition Fund, MathWorks Engineering Fellowship Fund, and the Portuguese Foundation for International Cooperation in Science, Technology and Higher Education in the MIT–Portugal Program.
On the left, a traditional alloy with a main element in blue and a small amount of a different element in yellow. High-entropy alloys (as seen on the right) contain several elements in nearly equal amounts (three in this figure), creating many possibilities for chemical patterns. “It’s like you’re making a recipe with a lot more ingredients,” says Yifan Cao, one of the authors of the paper, but it also adds significant chemical complexity.
Hot Jupiters are some of the most extreme planets in the galaxy. These scorching worlds are as massive as Jupiter, and they swing wildly close to their star, whirling around in a few days compared to our own gas giant’s leisurely 4,000-day orbit around the sun.
Scientists suspect, though, that hot Jupiters weren’t always so hot and in fact may have formed as “cold Jupiters,” in more frigid, distant environs. But how they evolved to be the star-hugging gas giants that astronomers observe today is a big unknown.
Now, astronomers at MIT, Penn State University, and elsewhere have discovered a hot Jupiter “progenitor” — a sort of juvenile planet that is in the midst of becoming a hot Jupiter. And its orbit is providing some answers to how hot Jupiters evolve.
The new planet, which astronomers labeled TIC 241249530 b, orbits a star that is about 1,100 light-years from Earth. The planet circles its star in a highly “eccentric” orbit, meaning that it comes extremely close to the star before slinging far out, then doubling back, in a narrow, elliptical circuit. If the planet was part of our solar system, it would come 10 times closer to the sun than Mercury, before hurtling out, just past Earth, then back around. By the scientists’ estimates, the planet’s stretched-out orbit has the highest eccentricity of any planet detected to date.
The new planet’s orbit is also unique in its “retrograde” orientation. Unlike the Earth and other planets in the solar system, which orbit in the same direction as the sun spins, the new planet travels in a direction that is counter to its star’s rotation.
The team ran simulations of orbital dynamics and found that the planet’s highly eccentric and retrograde orbit are signs that it is likely evolving into a hot Jupiter, through “high-eccentricity migration” — a process by which a planet’s orbit wobbles and progressively shrinks as it interacts with another star or planet on a much wider orbit.
In the case of TIC 241249530 b, the researchers determined that the planet orbits around a primary star that itself orbits around a secondary star, as part of a stellar binary system. The interactions between the two orbits — of the planet and its star — have caused the planet to gradually migrate closer to its star over time.
The planet’s orbit is currently elliptical in shape, and the planet takes about 167 days to complete a lap around its star. The researchers predict that in 1 billion years, the planet will migrate into a much tighter, circular orbit, when it will then circle its star every few days. At that point, the planet will have fully evolved into a hot Jupiter.
“This new planet supports the theory that high eccentricity migration should account for some fraction of hot Jupiters,” says Sarah Millholland, assistant professor of physics in MIT’s Kavli Institute for Astrophysics and Space Research. “We think that when this planet formed, it would have been a frigid world. And because of the dramatic orbital dynamics, it will become a hot Jupiter in about a billion years, with temperatures of several thousand kelvin. So it’s a huge shift from where it started.”
Millholland and her colleagues have published their findings today in the journal Nature. Her co-authors are MIT undergraduate Haedam Im, lead author Arvind Gupta of Penn State University and NSF NOIRLab, and collaborators at multiple other universities, institutions, and observatories.
“Radical seasons”
The new planet was first spotted in data taken by NASA’s Transiting Exoplanet Survey Satellite (TESS), an MIT-led mission that monitors the brightness of nearby stars for “transits,” or brief dips in starlight that could signal the presence of a planet passing in front of, and temporarily blocking, a star’s light.
On Jan. 12, 2020, TESS picked up a possible transit of the star TIC 241249530. Gupta and his colleagues at Penn State determined that the transit was consistent with a Jupiter-sized planet crossing in front of the star. They then acquired measurements from other observatories of the star’s radial velocity, which estimates a star’s wobble, or the degree to which it moves back and forth, in response to other nearby objects that might gravitationally tug on the star.
Those measurements confirmed that a Jupiter-sized planet was orbiting the star and that its orbit was highly eccentric, bringing the planet extremely close to the star before flinging it far out.
Prior to this detection, astronomers had known of only one other planet, HD 80606 b, that was thought to be an early hot Jupiter. That planet, discovered in 2001, held the record for having the highest eccentricity, until now.
“This new planet experiences really dramatic changes in starlight throughout its orbit,” Millholland says. “There must be really radical seasons and an absolutely scorched atmosphere every time it passes close to the star.”
“Dance of orbits”
How could a planet have fallen into such an extreme orbit? And how might its eccentricity evolve over time? For answers, Im and Millholland ran simulations of planetary orbital dynamics to model how the planet may have evolved throughout its history and how it might carry on over hundreds of millions of years.
The team modeled the gravitational interactions between the planet, its star, and the second nearby star. Gupta and his colleagues had observed that the two stars orbit each other in a binary system, while the planet is simultaneously orbiting the closer star. The configuration of the two orbits is somewhat like a circus performer twirling a hula hoop around her waist, while spinning a second hula hoop around her wrist.
Millholland and Im ran multiple simulations, each with a different set of starting conditions, to see which condition, when run forward over several billions of years, produced the configuration of planetary and stellar orbits that Gupta’s team observed in the present day. They then ran the best match even further into the future to predict how the system will evolve over the next several billion years.
These simulations revealed that the new planet is likely in the midst of evolving into a hot Jupiter: Several billion years ago, the planet formed as a cold Jupiter, far from its star, in a region cold enough to condense and take shape. Newly formed, the planet likely orbited the star in a circular path. This conventional orbit, however, gradually stretched and grew eccentric, as it experienced gravitational forces from the star’s misaligned orbit with its second, binary star.
“It’s a pretty extreme process in that the changes to the planet’s orbit are massive,” Millholland says. “It’s a big dance of orbits that’s happening over billions of years, and the planet’s just going along for the ride.”
In another billion years, the simulations show that the planet’s orbit will stabilize in a close-in, circular path around its star.
“Then, the planet will fully become a hot Jupiter,” Millholland says.
The team’s observations, along with their simulations of the planet’s evolution, support the theory that hot Jupiters can form through high eccentricity migration, a process by which a planet gradually moves into place via extreme changes to its orbit over time.
“It’s clear not only from this, but other statistical studies too, that high eccentricity migration should account for some fraction of hot Jupiters,” Millholland notes. “This system highlights how incredibly diverse exoplanets can be. They are mysterious other worlds that can have wild orbits that tell a story of how they got that way and where they’re going. For this planet, it’s not quite finished its journey yet.”
“It is really hard to catch these hot Jupiter progenitors ‘in the act’ as they undergo their super eccentric episodes, so it is very exciting to find a system that undergoes this process,” says Smadar Naoz, a professor of physics and astronomy at the University of California at Los Angeles, who was not involved with the study. “I believe that this discovery opens the door to a deeper understanding of the birth configuration of the exoplanetary system.”
This artist’s impression shows a Jupiter-like exoplanet that is on its way to becoming a hot Jupiter — a large, Jupiter-like exoplanet that orbits very close to its star.
Neural networks have made a seismic impact on how engineers design controllers for robots, catalyzing more adaptive and efficient machines. Still, these brain-like machine-learning systems are a double-edged sword: Their complexity makes them powerful, but it also makes it difficult to guarantee that a robot powered by a neural network will safely accomplish its task.
The traditional way to verify safety and stability is through techniques called Lyapunov functions. If you can find a Lyapunov function whose value consistently decreases, then you can know that unsafe or unstable situations associated with higher values will never happen. For robots controlled by neural networks, though, prior approaches for verifying Lyapunov conditions didn’t scale well to complex machines.
Researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and elsewhere have now developed new techniques that rigorously certify Lyapunov calculations in more elaborate systems. Their algorithm efficiently searches for and verifies a Lyapunov function, providing a stability guarantee for the system. This approach could potentially enable safer deployment of robots and autonomous vehicles, including aircraft and spacecraft.
To outperform previous algorithms, the researchers found a frugal shortcut to the training and verification process. They generated cheaper counterexamples — for example, adversarial data from sensors that could’ve thrown off the controller — and then optimized the robotic system to account for them. Understanding these edge cases helped machines learn how to handle challenging circumstances, which enabled them to operate safely in a wider range of conditions than previously possible. Then, they developed a novel verification formulation that enables the use of a scalable neural network verifier, α,β-CROWN, to provide rigorous worst-case scenario guarantees beyond the counterexamples.
“We’ve seen some impressive empirical performances in AI-controlled machines like humanoids and robotic dogs, but these AI controllers lack the formal guarantees that are crucial for safety-critical systems,” says Lujie Yang, MIT electrical engineering and computer science (EECS) PhD student and CSAIL affiliate who is a co-lead author of a new paper on the project alongside Toyota Research Institute researcher Hongkai Dai SM ’12, PhD ’16. “Our work bridges the gap between that level of performance from neural network controllers and the safety guarantees needed to deploy more complex neural network controllers in the real world,” notes Yang.
For a digital demonstration, the team simulated how a quadrotor drone with lidar sensors would stabilize in a two-dimensional environment. Their algorithm successfully guided the drone to a stable hover position, using only the limited environmental information provided by the lidar sensors. In two other experiments, their approach enabled the stable operation of two simulated robotic systems over a wider range of conditions: an inverted pendulum and a path-tracking vehicle. These experiments, though modest, are relatively more complex than what the neural network verification community could have done before, especially because they included sensor models.
“Unlike common machine learning problems, the rigorous use of neural networks as Lyapunov functions requires solving hard global optimization problems, and thus scalability is the key bottleneck,” says Sicun Gao, associate professor of computer science and engineering at the University of California at San Diego, who wasn’t involved in this work. “The current work makes an important contribution by developing algorithmic approaches that are much better tailored to the particular use of neural networks as Lyapunov functions in control problems. It achieves impressive improvement in scalability and the quality of solutions over existing approaches. The work opens up exciting directions for further development of optimization algorithms for neural Lyapunov methods and the rigorous use of deep learning in control and robotics in general.”
Yang and her colleagues’ stability approach has potential wide-ranging applications where guaranteeing safety is crucial. It could help ensure a smoother ride for autonomous vehicles, like aircraft and spacecraft. Likewise, a drone delivering items or mapping out different terrains could benefit from such safety guarantees.
The techniques developed here are very general and aren’t just specific to robotics; the same techniques could potentially assist with other applications, such as biomedicine and industrial processing, in the future.
While the technique is an upgrade from prior works in terms of scalability, the researchers are exploring how it can perform better in systems with higher dimensions. They’d also like to account for data beyond lidar readings, like images and point clouds.
As a future research direction, the team would like to provide the same stability guarantees for systems that are in uncertain environments and subject to disturbances. For instance, if a drone faces a strong gust of wind, Yang and her colleagues want to ensure it’ll still fly steadily and complete the desired task.
Also, they intend to apply their method to optimization problems, where the goal would be to minimize the time and distance a robot needs to complete a task while remaining steady. They plan to extend their technique to humanoids and other real-world machines, where a robot needs to stay stable while making contact with its surroundings.
Russ Tedrake, the Toyota Professor of EECS, Aeronautics and Astronautics, and Mechanical Engineering at MIT, vice president of robotics research at TRI, and CSAIL member, is a senior author of this research. The paper also credits University of California at Los Angeles PhD student Zhouxing Shi and associate professor Cho-Jui Hsieh, as well as University of Illinois Urbana-Champaign assistant professor Huan Zhang. Their work was supported, in part, by Amazon, the National Science Foundation, the Office of Naval Research, and the AI2050 program at Schmidt Sciences. The researchers’ paper will be presented at the 2024 International Conference on Machine Learning.
MIT CSAIL researchers helped design a new technique that can guarantee the stability of robots controlled by neural networks. This development could eventually lead to safer autonomous vehicles and industrial robots.
It is estimated that about 70 percent of the energy generated worldwide ends up as waste heat.
If scientists could better predict how heat moves through semiconductors and insulators, they could design more efficient power generation systems. However, the thermal properties of materials can be exceedingly difficult to model.
The trouble comes from phonons, which are subatomic particles that carry heat. Some of a material’s thermal properties depend on a measurement called the phonon dispersion relation, which can be incredibly hard to obtain, let alone utilize in the design of a system.
A team of researchers from MIT and elsewhere tackled this challenge by rethinking the problem from the ground up. The result of their work is a new machine-learning framework that can predict phonon dispersion relations up to 1,000 times faster than other AI-based techniques, with comparable or even better accuracy. Compared to more traditional, non-AI-based approaches, it could be 1 million times faster.
This method could help engineers design energy generation systems that produce more power, more efficiently. It could also be used to develop more efficient microelectronics, since managing heat remains a major bottleneck to speeding up electronics.
“Phonons are the culprit for the thermal loss, yet obtaining their properties is notoriously challenging, either computationally or experimentally,” says Mingda Li, associate professor of nuclear science and engineering and senior author of a paper on this technique.
Li is joined on the paper by co-lead authors Ryotaro Okabe, a chemistry graduate student; and Abhijatmedhi Chotrattanapituk, an electrical engineering and computer science graduate student; Tommi Jaakkola, the Thomas Siebel Professor of Electrical Engineering and Computer Science at MIT; as well as others at MIT, Argonne National Laboratory, Harvard University, the University of South Carolina, Emory University, the University of California at Santa Barbara, and Oak Ridge National Laboratory. The research appears in Nature Computational Science.
Predicting phonons
Heat-carrying phonons are tricky to predict because they have an extremely wide frequency range, and the particles interact and travel at different speeds.
A material’s phonon dispersion relation is the relationship between energy and momentum of phonons in its crystal structure. For years, researchers have tried to predict phonon dispersion relations using machine learning, but there are so many high-precision calculations involved that models get bogged down.
“If you have 100 CPUs and a few weeks, you could probably calculate the phonon dispersion relation for one material. The whole community really wants a more efficient way to do this,” says Okabe.
The machine-learning models scientists often use for these calculations are known as graph neural networks (GNN). A GNN converts a material’s atomic structure into a crystal graph comprising multiple nodes, which represent atoms, connected by edges, which represent the interatomic bonding between atoms.
While GNNs work well for calculating many quantities, like magnetization or electrical polarization, they are not flexible enough to efficiently predict an extremely high-dimensional quantity like the phonon dispersion relation. Because phonons can travel around atoms on X, Y, and Z axes, their momentum space is hard to model with a fixed graph structure.
To gain the flexibility they needed, Li and his collaborators devised virtual nodes.
They create what they call a virtual node graph neural network (VGNN) by adding a series of flexible virtual nodes to the fixed crystal structure to represent phonons. The virtual nodes enable the output of the neural network to vary in size, so it is not restricted by the fixed crystal structure.
Virtual nodes are connected to the graph in such a way that they can only receive messages from real nodes. While virtual nodes will be updated as the model updates real nodes during computation, they do not affect the accuracy of the model.
“The way we do this is very efficient in coding. You just generate a few more nodes in your GNN. The physical location doesn’t matter, and the real nodes don’t even know the virtual nodes are there,” says Chotrattanapituk.
Cutting out complexity
Since it has virtual nodes to represent phonons, the VGNN can skip many complex calculations when estimating phonon dispersion relations, which makes the method more efficient than a standard GNN.
The researchers proposed three different versions of VGNNs with increasing complexity. Each can be used to predict phonons directly from a material’s atomic coordinates.
Because their approach has the flexibility to rapidly model high-dimensional properties, they can use it to estimate phonon dispersion relations in alloy systems. These complex combinations of metals and nonmetals are especially challenging for traditional approaches to model.
The researchers also found that VGNNs offered slightly greater accuracy when predicting a material’s heat capacity. In some instances, prediction errors were two orders of magnitude lower with their technique.
A VGNN could be used to calculate phonon dispersion relations for a few thousand materials in just a few seconds with a personal computer, Li says.
This efficiency could enable scientists to search a larger space when seeking materials with certain thermal properties, such as superior thermal storage, energy conversion, or superconductivity.
Moreover, the virtual node technique is not exclusive to phonons, and could also be used to predict challenging optical and magnetic properties.
In the future, the researchers want to refine the technique so virtual nodes have greater sensitivity to capture small changes that can affect phonon structure.
“Researchers got too comfortable using graph nodes to represent atoms, but we can rethink that. Graph nodes can be anything. And virtual nodes are a very generic approach you could use to predict a lot of high-dimensional quantities,” Li says.
“The authors’ innovative approach significantly augments the graph neural network description of solids by incorporating key physics-informed elements through virtual nodes, for instance, informing wave-vector dependent band-structures and dynamical matrices,” says Olivier Delaire, associate professor in the Thomas Lord Department of Mechanical Engineering and Materials Science at Duke University, who was not involved with this work. “I find that the level of acceleration in predicting complex phonon properties is amazing, several orders of magnitude faster than a state-of-the-art universal machine-learning interatomic potential. Impressively, the advanced neural net captures fine features and obeys physical rules. There is great potential to expand the model to describe other important material properties: Electronic, optical, and magnetic spectra and band structures come to mind.”
This work is supported by the U.S. Department of Energy, National Science Foundation, a Mathworks Fellowship, a Sow-Hsin Chen Fellowship, the Harvard Quantum Initiative, and the Oak Ridge National Laboratory.
Foundation models are massive deep-learning models that have been pretrained on an enormous amount of general-purpose, unlabeled data. They can be applied to a variety of tasks, like generating images or answering customer questions.
But these models, which serve as the backbone for powerful artificial intelligence tools like ChatGPT and DALL-E, can offer up incorrect or misleading information. In a safety-critical situation, such as a pedestrian approaching a self-driving car, these mistakes could have serious consequences.
To help prevent such mistakes, researchers from MIT and the MIT-IBM Watson AI Lab developed a technique to estimate the reliability of foundation models before they are deployed to a specific task.
They do this by considering a set of foundation models that are slightly different from one another. Then they use their algorithm to assess the consistency of the representations each model learns about the same test data point. If the representations are consistent, it means the model is reliable.
When they compared their technique to state-of-the-art baseline methods, it was better at capturing the reliability of foundation models on a variety of downstream classification tasks.
Someone could use this technique to decide if a model should be applied in a certain setting, without the need to test it on a real-world dataset. This could be especially useful when datasets may not be accessible due to privacy concerns, like in health care settings. In addition, the technique could be used to rank models based on reliability scores, enabling a user to select the best one for their task.
“All models can be wrong, but models that know when they are wrong are more useful. The problem of quantifying uncertainty or reliability is more challenging for these foundation models because their abstract representations are difficult to compare. Our method allows one to quantify how reliable a representation model is for any given input data,” says senior author Navid Azizan, the Esther and Harold E. Edgerton Assistant Professor in the MIT Department of Mechanical Engineering and the Institute for Data, Systems, and Society (IDSS), and a member of the Laboratory for Information and Decision Systems (LIDS).
He is joined on a paper about the work by lead author Young-Jin Park, a LIDS graduate student; Hao Wang, a research scientist at the MIT-IBM Watson AI Lab; and Shervin Ardeshir, a senior research scientist at Netflix. The paper will be presented at the Conference on Uncertainty in Artificial Intelligence.
Measuring consensus
Traditional machine-learning models are trained to perform a specific task. These models typically make a concrete prediction based on an input. For instance, the model might tell you whether a certain image contains a cat or a dog. In this case, assessing reliability could be a matter of looking at the final prediction to see if the model is right.
But foundation models are different. The model is pretrained using general data, in a setting where its creators don’t know all downstream tasks it will be applied to. Users adapt it to their specific tasks after it has already been trained.
Unlike traditional machine-learning models, foundation models don’t give concrete outputs like “cat” or “dog” labels. Instead, they generate an abstract representation based on an input data point.
To assess the reliability of a foundation model, the researchers used an ensemble approach by training several models which share many properties but are slightly different from one another.
“Our idea is like measuring the consensus. If all those foundation models are giving consistent representations for any data in our dataset, then we can say this model is reliable,” Park says.
But they ran into a problem: How could they compare abstract representations?
“These models just output a vector, comprised of some numbers, so we can’t compare them easily,” he adds.
They solved this problem using an idea called neighborhood consistency.
For their approach, the researchers prepare a set of reliable reference points to test on the ensemble of models. Then, for each model, they investigate the reference points located near that model’s representation of the test point.
By looking at the consistency of neighboring points, they can estimate the reliability of the models.
Aligning the representations
Foundation models map data points to what is known as a representation space. One way to think about this space is as a sphere. Each model maps similar data points to the same part of its sphere, so images of cats go in one place and images of dogs go in another.
But each model would map animals differently in its own sphere, so while cats may be grouped near the South Pole of one sphere, another model could map cats somewhere in the Northern Hemisphere.
The researchers use the neighboring points like anchors to align those spheres so they can make the representations comparable. If a data point’s neighbors are consistent across multiple representations, then one should be confident about the reliability of the model’s output for that point.
When they tested this approach on a wide range of classification tasks, they found that it was much more consistent than baselines. Plus, it wasn’t tripped up by challenging test points that caused other methods to fail.
Moreover, their approach can be used to assess reliability for any input data, so one could evaluate how well a model works for a particular type of individual, such as a patient with certain characteristics.
“Even if the models all have average performance overall, from an individual point of view, you’d prefer the one that works best for that individual,” Wang says.
However, one limitation comes from the fact that they must train an ensemble of foundation models, which is computationally expensive. In the future, they plan to find more efficient ways to build multiple models, perhaps by using small perturbations of a single model.
“With the current trend of using foundational models for their embeddings to support various downstream tasks — from fine-tuning to retrieval augmented generation — the topic of quantifying uncertainty at the representation level is increasingly important, but challenging, as embeddings on their own have no grounding. What matters instead is how embeddings of different inputs are related to one another, an idea that this work neatly captures through the proposed neighborhood consistency score,” says Marco Pavone, an associate professor in the Department of Aeronautics and Astronautics at Stanford University, who was not involved with this work. “This is a promising step towards high quality uncertainty quantifications for embedding models, and I’m excited to see future extensions which can operate without requiring model-ensembling to really enable this approach to scale to foundation-size models.”
This work is funded, in part, by the MIT-IBM Watson AI Lab, MathWorks, and Amazon.
To estimate the reliability of massive deep-learning models called foundation models, MIT researchers developed a technique to assess the consistency of representations an ensemble of similar models learn about the same test data point.
Bernardo Picão has been interested in online learning since the early days of YouTube, when his father showed him a TED Talk. But it was with MIT Open Learning that he realized just how transformational digital resources can be.
“YouTube was my first introduction to the idea that you can actually learn stuff via the internet,” Picão says. “So, when I became interested in mathematics and physics when I was 15 or 16, I turned to the internet and stumbled upon some playlists from MIT OpenCourseWare and went from there.”
OpenCourseWare, part of MIT Open Learning, offers free online educational resources from over 2,500 MIT undergraduate and graduate courses. Since discovering it, Picão has explored linear algebra with Gilbert Strang, professor emeritus of mathematics — whom Picão calls “a legend” — and courses on metaphysics, functional analysis, quantum field theory, and English. He has returned to OpenCourseWare throughout his educational journey, which includes undergraduate studies in France and Portugal. Some courses provided different perspectives on material he was learning in his classes, while others filled gaps in his knowledge or satisfied his curiosity.
Overall, Picão says that MIT resources made him a more robust scientist. He is currently completing a master’s degree in physics at the Instituto Superior Técnico in Lisbon, Portugal, where he researches prominent lattice quantum chromodynamics, an approach to the study of quarks that uses precise computer simulations. After completing his master’s degree, Picão says he will continue to a doctoral program in the field.
At a recent symposium in Lisbon, Picão attended a lecture given by someone he had first seen in an OpenCourseWare video — Krishna Rajagopal, the William A. M. Burden Professor of Physics and former dean for digital learning at MIT Open Learning. There, he took the opportunity to thank Rajagopal for his support of OpenCourseWare, which Picão says is an important part of MIT’s mission as a leader in education.
In addition to the range of subjects covered by OpenCourseWare, Picão praises the variety of instructors. All the courses are well-constructed, he says, but sometimes learners will connect with certain instructors or benefit from a particular presentation style. Since OpenCourseWare and other Open Learning programs offer such a wide range of free educational resources from MIT, learners can explore similar courses from different instructors to get new perspectives and round out their knowledge.
While he enjoys his research, Picão’s passion is teaching. OpenCourseWare has helped him with that too, by providing models for how to teach math and science and how to connect with learners of different abilities and backgrounds.
“I’m a very philosophical person,” he says. “I used to think that knowledge was intrinsically secluded in the large bindings of books, beyond the classroom walls, or inside the idiosyncratic minds of professors. OpenCourseWare changed how I think about teaching and what a university is — the point is not to keep knowledge inside of it, but to spread it.”
Picão, now a teaching assistant at his institution, has been teaching since his days as a high school student tutoring his classmates or talking with members of his family.
“I spent my youth sharing my knowledge with my grandmother and my extended family, including people who weren’t able to attend school past the fourth grade,” he says. “Seeing them get excited about knowledge is the coolest thing. Open Learning scales that up to the rest of the world and that can have an incredible impact.”
The ability to learn from MIT experts has benefited Picão, deepening his understanding of the complex subjects that interest him. But, he acknowledges, he is a person who has access to high-quality instruction even without Open Learning. For learners who do not have that access, Open Learning is invaluable.
“It's hard to overstate the importance of such a project. MIT’s OpenCourseware and Open Learning profoundly shift how students all over the world can perceive their relationship with education: Besides an internet connection, the only requirement is the curiosity to explore the hundreds of expertly crafted courses and worksheets, perfect for self-studying,” says Picão.
He continues, “People may find OpenCourseWare and think it is too good to be true. Why would such a prestigious institution break down the barriers to scientific education and commit to open-access, free resources? I want people to know: There is no catch. Sharing is the point.”
“People may find OpenCourseWare and think it is too good to be true. Why would such a prestigious institution break down the barriers to scientific education and commit to open-access, free resources? I want people to know: there is no catch. Sharing is the point,” says Bernardo Picão, a master’s degree candidate in physics at the Instituto Superior Técnico in Lisbon, Portugal, who first discovered MIT’s free educational resources in his teens.
There are many drugs that anesthesiologists can use to induce unconsciousness in patients. Exactly how these drugs cause the brain to lose consciousness has been a longstanding question, but MIT neuroscientists have now answered that question for one commonly used anesthesia drug.
Using a novel technique for analyzing neuron activity, the researchers discovered that the drug propofol induces unconsciousness by disrupting the brain’s normal balance between stability and excitability. The drug causes brain activity to become increasingly unstable, until the brain loses consciousness.
“The brain has to operate on this knife’s edge between excitability and chaos. It’s got to be excitable enough for its neurons to influence one another, but if it gets too excitable, it spins off into chaos. Propofol seems to disrupt the mechanisms that keep the brain in that narrow operating range,” says Earl K. Miller, the Picower Professor of Neuroscience and a member of MIT’s Picower Institute for Learning and Memory.
The new findings, reported today in Neuron, could help researchers develop better tools for monitoring patients as they undergo general anesthesia.
Miller and Ila Fiete, a professor of brain and cognitive sciences, the director of the K. Lisa Yang Integrative Computational Neuroscience Center (ICoN), and a member of MIT’s McGovern Institute for Brain Research, are the senior authors of the new study. MIT graduate student Adam Eisen and MIT postdoc Leo Kozachkov are the lead authors of the paper.
Losing consciousness
Propofol is a drug that binds to GABA receptors in the brain, inhibiting neurons that have those receptors. Other anesthesia drugs act on different types of receptors, and the mechanism for how all of these drugs produce unconsciousness is not fully understood.
Miller, Fiete, and their students hypothesized that propofol, and possibly other anesthesia drugs, interfere with a brain state known as “dynamic stability.” In this state, neurons have enough excitability to respond to new input, but the brain is able to quickly regain control and prevent them from becoming overly excited.
Previous studies of how anesthesia drugs affect this balance have found conflicting results: Some suggested that during anesthesia, the brain shifts toward becoming too stable and unresponsive, which leads to loss of consciousness. Others found that the brain becomes too excitable, leading to a chaotic state that results in unconsciousness.
Part of the reason for these conflicting results is that it has been difficult to accurately measure dynamic stability in the brain. Measuring dynamic stability as consciousness is lost would help researchers determine if unconsciousness results from too much stability or too little stability.
In this study, the researchers analyzed electrical recordings made in the brains of animals that received propofol over an hour-long period, during which they gradually lost consciousness. The recordings were made in four areas of the brain that are involved in vision, sound processing, spatial awareness, and executive function.
These recordings covered only a tiny fraction of the brain’s overall activity, so to overcome that, the researchers used a technique called delay embedding. This technique allows researchers to characterize dynamical systems from limited measurements by augmenting each measurement with measurements that were recorded previously.
Using this method, the researchers were able to quantify how the brain responds to sensory inputs, such as sounds, or to spontaneous perturbations of neural activity.
In the normal, awake state, neural activity spikes after any input, then returns to its baseline activity level. However, once propofol dosing began, the brain started taking longer to return to its baseline after these inputs, remaining in an overly excited state. This effect became more and more pronounced until the animals lost consciousness.
This suggests that propofol’s inhibition of neuron activity leads to escalating instability, which causes the brain to lose consciousness, the researchers say.
Better anesthesia control
To see if they could replicate this effect in a computational model, the researchers created a simple neural network. When they increased the inhibition of certain nodes in the network, as propofol does in the brain, network activity became destabilized, similar to the unstable activity the researchers saw in the brains of animals that received propofol.
“We looked at a simple circuit model of interconnected neurons, and when we turned up inhibition in that, we saw a destabilization. So, one of the things we’re suggesting is that an increase in inhibition can generate instability, and that is subsequently tied to loss of consciousness,” Eisen says.
As Fiete explains, “This paradoxical effect, in which boosting inhibition destabilizes the network rather than silencing or stabilizing it, occurs because of disinhibition. When propofol boosts the inhibitory drive, this drive inhibits other inhibitory neurons, and the result is an overall increase in brain activity.”
The researchers suspect that other anesthetic drugs, which act on different types of neurons and receptors, may converge on the same effect through different mechanisms — a possibility that they are now exploring.
If this turns out to be true, it could be helpful to the researchers’ ongoing efforts to develop ways to more precisely control the level of anesthesia that a patient is experiencing. These systems, which Miller is working on with Emery Brown, the Edward Hood Taplin Professor of Medical Engineering at MIT, work by measuring the brain’s dynamics and then adjusting drug dosages accordingly, in real-time.
“If you find common mechanisms at work across different anesthetics, you can make them all safer by tweaking a few knobs, instead of having to develop safety protocols for all the different anesthetics one at a time,” Miller says. “You don’t want a different system for every anesthetic they’re going to use in the operating room. You want one that’ll do it all.”
The researchers also plan to apply their technique for measuring dynamic stability to other brain states, including neuropsychiatric disorders.
“This method is pretty powerful, and I think it’s going to be very exciting to apply it to different brain states, different types of anesthetics, and also other neuropsychiatric conditions like depression and schizophrenia,” Fiete says.
The research was funded by the Office of Naval Research, the National Institute of Mental Health, the National Institute of Neurological Disorders and Stroke, the National Science Foundation Directorate for Computer and Information Science and Engineering, the Simons Center for the Social Brain, the Simons Collaboration on the Global Brain, the JPB Foundation, the McGovern Institute, and the Picower Institute.
When it comes to artificial intelligence, appearances can be deceiving. The mystery surrounding the inner workings of large language models (LLMs) stems from their vast size, complex training methods, hard-to-predict behaviors, and elusive interpretability.
MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers recently peered into the proverbial magnifying glass to examine how LLMs fare with variations of different tasks, revealing intriguing insights into the interplay between memorization and reasoning skills. It turns out that their reasoning abilities are often overestimated.
The study compared “default tasks,” the common tasks a model is trained and tested on, with “counterfactual scenarios,” hypothetical situations deviating from default conditions — which models like GPT-4 and Claude can usually be expected to cope with. The researchers developed some tests outside the models’ comfort zones by tweaking existing tasks instead of creating entirely new ones. They used a variety of datasets and benchmarks specifically tailored to different aspects of the models' capabilities for things like arithmetic, chess, evaluating code, answering logical questions, etc.
When users interact with language models, any arithmetic is usually in base-10, the familiar number base to the models. But observing that they do well on base-10 could give us a false impression of them having strong competency in addition. Logically, if they truly possess good addition skills, you’d expect reliably high performance across all number bases, similar to calculators or computers. Indeed, the research showed that these models are not as robust as many initially think. Their high performance is limited to common task variants and suffer from consistent and severe performance drop in the unfamiliar counterfactual scenarios, indicating a lack of generalizable addition ability.
The pattern held true for many other tasks like musical chord fingering, spatial reasoning, and even chess problems where the starting positions of pieces were slightly altered. While human players are expected to still be able to determine the legality of moves in altered scenarios (given enough time), the models struggled and couldn’t perform better than random guessing, meaning they have limited ability to generalize to unfamiliar situations. And much of their performance on the standard tasks is likely not due to general task abilities, but overfitting to, or directly memorizing from, what they have seen in their training data.
“We’ve uncovered a fascinating aspect of large language models: they excel in familiar scenarios, almost like a well-worn path, but struggle when the terrain gets unfamiliar. This insight is crucial as we strive to enhance these models’ adaptability and broaden their application horizons,” says Zhaofeng Wu, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and the lead author on a new paper about the research. “As AI is becoming increasingly ubiquitous in our society, it must reliably handle diverse scenarios, whether familiar or not. We hope these insights will one day inform the design of future LLMs with improved robustness.”
Despite the insights gained, there are, of course, limitations. The study’s focus on specific tasks and settings didn’t capture the full range of challenges the models could potentially encounter in real-world applications, signaling the need for more diverse testing environments. Future work could involve expanding the range of tasks and counterfactual conditions to uncover more potential weaknesses. This could mean looking at more complex and less common scenarios. The team also wants to improve interpretability by creating methods to better comprehend the rationale behind the models’ decision-making processes.
“As language models scale up, understanding their training data becomes increasingly challenging even for open models, let alone proprietary ones,” says Hao Peng, assistant professor at the University of Illinois at Urbana-Champaign. “The community remains puzzled about whether these models genuinely generalize to unseen tasks, or seemingly succeed by memorizing the training data. This paper makes important strides in addressing this question. It constructs a suite of carefully designed counterfactual evaluations, providing fresh insights into the capabilities of state-of-the-art LLMs. It reveals that their ability to solve unseen tasks is perhaps far more limited than anticipated by many. It has the potential to inspire future research towards identifying the failure modes of today’s models and developing better ones.”
Additional authors include Najoung Kim, who is a Boston University assistant professor and Google visiting researcher, and seven CSAIL affiliates: MIT electrical engineering and computer science (EECS) PhD students Linlu Qiu, Alexis Ross, Ekin Akyürek SM ’21, and Boyuan Chen; former postdoc and Apple AI/ML researcher Bailin Wang; and EECS assistant professors Jacob Andreas and Yoon Kim.
The team’s study was supported, in part, by the MIT–IBM Watson AI Lab, the MIT Quest for Intelligence, and the National Science Foundation. The team presented the work at the North American Chapter of the Association for Computational Linguistics (NAACL) last month.
MIT researchers examined how LLMs fare with variations of different tasks, putting their memorization and reasoning skills to the test. The result: Their reasoning abilities are often overestimated.
Because machine-learning models can give false predictions, researchers often equip them with the ability to tell a user how confident they are about a certain decision. This is especially important in high-stake settings, such as when models are used to help identify disease in medical images or filter job applications.
But a model’s uncertainty quantifications are only useful if they are accurate. If a model says it is 49 percent confident that a medical image shows a pleural effusion, then 49 percent of the time, the model should be right.
MIT researchers have introduced a new approach that can improve uncertainty estimates in machine-learning models. Their method not only generates more accurate uncertainty estimates than other techniques, but does so more efficiently.
In addition, because the technique is scalable, it can be applied to huge deep-learning models that are increasingly being deployed in health care and other safety-critical situations.
This technique could give end users, many of whom lack machine-learning expertise, better information they can use to determine whether to trust a model’s predictions or if the model should be deployed for a particular task.
“It is easy to see these models perform really well in scenarios where they are very good, and then assume they will be just as good in other scenarios. This makes it especially important to push this kind of work that seeks to better calibrate the uncertainty of these models to make sure they align with human notions of uncertainty,” says lead author Nathan Ng, a graduate student at the University of Toronto who is a visiting student at MIT.
Ng wrote the paper with Roger Grosse, an assistant professor of computer science at the University of Toronto; and senior author Marzyeh Ghassemi, an associate professor in the Department of Electrical Engineering and Computer Science and a member of the Institute of Medical Engineering Sciences and the Laboratory for Information and Decision Systems. The research will be presented at the International Conference on Machine Learning.
Quantifying uncertainty
Uncertainty quantification methods often require complex statistical calculations that don’t scale well to machine-learning models with millions of parameters. These methods also require users to make assumptions about the model and data used to train it.
The MIT researchers took a different approach. They use what is known as the minimum description length principle (MDL), which does not require the assumptions that can hamper the accuracy of other methods. MDL is used to better quantify and calibrate uncertainty for test points the model has been asked to label.
The technique the researchers developed, known as IF-COMP, makes MDL fast enough to use with the kinds of large deep-learning models deployed in many real-world settings.
MDL involves considering all possible labels a model could give a test point. If there are many alternative labels for this point that fit well, its confidence in the label it chose should decrease accordingly.
“One way to understand how confident a model is would be to tell it some counterfactual information and see how likely it is to believe you,” Ng says.
For example, consider a model that says a medical image shows a pleural effusion. If the researchers tell the model this image shows an edema, and it is willing to update its belief, then the model should be less confident in its original decision.
With MDL, if a model is confident when it labels a datapoint, it should use a very short code to describe that point. If it is uncertain about its decision because the point could have many other labels, it uses a longer code to capture these possibilities.
The amount of code used to label a datapoint is known as stochastic data complexity. If the researchers ask the model how willing it is to update its belief about a datapoint given contrary evidence, the stochastic data complexity should decrease if the model is confident.
But testing each datapoint using MDL would require an enormous amount of computation.
Speeding up the process
With IF-COMP, the researchers developed an approximation technique that can accurately estimate stochastic data complexity using a special function, known as an influence function. They also employed a statistical technique called temperature-scaling, which improves the calibration of the model’s outputs. This combination of influence functions and temperature-scaling enables high-quality approximations of the stochastic data complexity.
In the end, IF-COMP can efficiently produce well-calibrated uncertainty quantifications that reflect a model’s true confidence. The technique can also determine whether the model has mislabeled certain data points or reveal which data points are outliers.
The researchers tested their system on these three tasks and found that it was faster and more accurate than other methods.
“It is really important to have some certainty that a model is well-calibrated, and there is a growing need to detect when a specific prediction doesn’t look quite right. Auditing tools are becoming more necessary in machine-learning problems as we use large amounts of unexamined data to make models that will be applied to human-facing problems,” Ghassemi says.
IF-COMP is model-agnostic, so it can provide accurate uncertainty quantifications for many types of machine-learning models. This could enable it to be deployed in a wider range of real-world settings, ultimately helping more practitioners make better decisions.
“People need to understand that these systems are very fallible and can make things up as they go. A model may look like it is highly confident, but there are a ton of different things it is willing to believe given evidence to the contrary,” Ng says.
In the future, the researchers are interested in applying their approach to large language models and studying other potential use cases for the minimum description length principle.
As container ships the size of city blocks cross the oceans to deliver cargo, their huge diesel engines emit large quantities of air pollutants that drive climate change and have human health impacts. It has been estimated that maritime shipping accounts for almost 3 percent of global carbon dioxide emissions and the industry’s negative impacts on air quality cause about 100,000 premature deaths each year.
Decarbonizing shipping to reduce these detrimental effects is a goal of the International Maritime Organization, a U.N. agency that regulates maritime transport. One potential solution is switching the global fleet from fossil fuels to sustainable fuels such as ammonia, which could be nearly carbon-free when considering its production and use.
But in a new study, an interdisciplinary team of researchers from MIT and elsewhere caution that burning ammonia for maritime fuel could worsen air quality further and lead to devastating public health impacts, unless it is adopted alongside strengthened emissions regulations.
Ammonia combustion generates nitrous oxide (N2O), a greenhouse gas that is about 300 times more potent than carbon dioxide. It also emits nitrogen in the form of nitrogen oxides (NO and NO2, referred to as NOx), and unburnt ammonia may slip out, which eventually forms fine particulate matter in the atmosphere. These tiny particles can be inhaled deep into the lungs, causing health problems like heart attacks, strokes, and asthma.
The new study indicates that, under current legislation, switching the global fleet to ammonia fuel could cause up to about 600,000 additional premature deaths each year. However, with stronger regulations and cleaner engine technology, the switch could lead to about 66,000 fewer premature deaths than currently caused by maritime shipping emissions, with far less impact on global warming.
“Not all climate solutions are created equal. There is almost always some price to pay. We have to take a more holistic approach and consider all the costs and benefits of different climate solutions, rather than just their potential to decarbonize,” says Anthony Wong, a postdoc in the MIT Center for Global Change Science and lead author of the study.
His co-authors include Noelle Selin, an MIT professor in the Institute for Data, Systems, and Society and the Department of Earth, Atmospheric and Planetary Sciences (EAPS); Sebastian Eastham, a former principal research scientist who is now a senior lecturer at Imperial College London; Christine Mounaïm-Rouselle, a professor at the University of Orléans in France; Yiqi Zhang, a researcher at the Hong Kong University of Science and Technology; and Florian Allroggen, a research scientist in the MIT Department of Aeronautics and Astronautics. The research appears this week in Environmental Research Letters.
Greener, cleaner ammonia
Traditionally, ammonia is made by stripping hydrogen from natural gas and then combining it with nitrogen at extremely high temperatures. This process is often associated with a large carbon footprint. The maritime shipping industry is betting on the development of “green ammonia,” which is produced by using renewable energy to make hydrogen via electrolysis and to generate heat.
“In theory, if you are burning green ammonia in a ship engine, the carbon emissions are almost zero,” Wong says.
But even the greenest ammonia generates nitrous oxide (N2O), nitrogen oxides (NOx) when combusted, and some of the ammonia may slip out, unburnt. This nitrous oxide would escape into the atmosphere, where the greenhouse gas would remain for more than 100 years. At the same time, the nitrogen emitted as NOx and ammonia would fall to Earth, damaging fragile ecosystems. As these emissions are digested by bacteria, additional N2O is produced.
NOx and ammonia also mix with gases in the air to form fine particulate matter. A primary contributor to air pollution, fine particulate matter kills an estimated 4 million people each year.
“Saying that ammonia is a ‘clean’ fuel is a bit of an overstretch. Just because it is carbon-free doesn’t necessarily mean it is clean and good for public health,” Wong says.
A multifaceted model
The researchers wanted to paint the whole picture, capturing the environmental and public health impacts of switching the global fleet to ammonia fuel. To do so, they designed scenarios to measure how pollutant impacts change under certain technology and policy assumptions.
From a technological point of view, they considered two ship engines. The first burns pure ammonia, which generates higher levels of unburnt ammonia but emits fewer nitrogen oxides. The second engine technology involves mixing ammonia with hydrogen to improve combustion and optimize the performance of a catalytic converter, which controls both nitrogen oxides and unburnt ammonia pollution.
They also considered three policy scenarios: current regulations, which only limit NOx emissions in some parts of the world; a scenario that adds ammonia emission limits over North America and Western Europe; and a scenario that adds global limits on ammonia and NOx emissions.
The researchers used a ship track model to calculate how pollutant emissions change under each scenario and then fed the results into an air quality model. The air quality model calculates the impact of ship emissions on particulate matter and ozone pollution. Finally, they estimated the effects on global public health.
One of the biggest challenges came from a lack of real-world data, since no ammonia-powered ships are yet sailing the seas. Instead, the researchers relied on experimental ammonia combustion data from collaborators to build their model.
“We had to come up with some clever ways to make that data useful and informative to both the technology and regulatory situations,” he says.
A range of outcomes
In the end, they found that with no new regulations and ship engines that burn pure ammonia, switching the entire fleet would cause 681,000 additional premature deaths each year.
“While a scenario with no new regulations is not very realistic, it serves as a good warning of how dangerous ammonia emissions could be. And unlike NOx, ammonia emissions from shipping are currently unregulated,” Wong says.
However, even without new regulations, using cleaner engine technology would cut the number of premature deaths down to about 80,000, which is about 20,000 fewer than are currently attributed to maritime shipping emissions. With stronger global regulations and cleaner engine technology, the number of people killed by air pollution from shipping could be reduced by about 66,000.
“The results of this study show the importance of developing policies alongside new technologies,” Selin says. “There is a potential for ammonia in shipping to be beneficial for both climate and air quality, but that requires that regulations be designed to address the entire range of potential impacts, including both climate and air quality.”
Ammonia’s air quality impacts would not be felt uniformly across the globe, and addressing them fully would require coordinated strategies across very different contexts. Most premature deaths would occur in East Asia, since air quality regulations are less stringent in this region. Higher levels of existing air pollution cause the formation of more particulate matter from ammonia emissions. In addition, shipping volume over East Asia is far greater than elsewhere on Earth, compounding these negative effects.
In the future, the researchers want to continue refining their analysis. They hope to use these findings as a starting point to urge the marine industry to share engine data they can use to better evaluate air quality and climate impacts. They also hope to inform policymakers about the importance and urgency of updating shipping emission regulations.
This research was funded by the MIT Climate and Sustainability Consortium.
A new study led by MIT scientists reveals that burning ammonia in ship engines could still contribute to ozone pollution while causing serious impacts on air quality.
While many studies over the past several years have examined people’s access to and attitudes toward Covid-19 vaccines, few studies in sub-Saharan Africa have looked at whether there were differences in vaccination rates and intention between men and women. In a new study appearing in the journal Frontiers in Global Women’s Health, researchers found that while women and men self-reported similar Covid-19 vaccination rates in 2022, unvaccinated men expressed more intention to get vaccinated than unvaccinated women.
Women tend to have better health-seeking behaviors than men overall. However, most studies relating to Covid-19 vaccination have found that intention has been lower among women. “We wondered whether this would hold true at the uptake level,” says Rawlance Ndejjo, a leader of the new study and an assistant lecturer in the Department of Disease Control and Environmental Health at Makerere University.
The comparable vaccination rates between men and women in the study is “a good thing to see,” adds Lula Chen, research director at MIT Governance Lab (GOV/LAB) and a co-author of the new study. “There wasn’t anything gendered about how [the vaccine] was being advertised or who was actually getting access to it.”
Women’s lower intention to vaccinate seemed to be driven by concerns about vaccine safety, suggesting that providing factual information about vaccine safety from trusted sources, like the Ministry of Health, could increase uptake.
The work is a collaboration between scholars from the MIT GOV/LAB, Makerere University’s School of Public Health in Uganda, University of Kinshasa’s School of Public Health in the Democratic Republic of the Congo (DRC), University of Ibadan’s College of Medicine in Nigeria, and Cheikh Anta Diop University in Senegal.
Studying vaccine availability and uptake in sub-Saharan Africa
The authors’ collaboration began in 2021 with research into Covid-19 vaccination rates, people’s willingness to get vaccinated, and how people’s trust in different authorities shaped attitudes toward vaccines in Uganda, the DRC, Senegal, and Nigeria. A survey in Uganda found that people who received information about Covid-19 from health workers were more likely to be vaccinated, stressing the important role people who work in the health-care system can play in vaccination efforts.
Work from other scientists has found that women were less likely to accept Covid-19 vaccines than men, and that in low- and middle-income countries, women also may be less likely to get vaccinated against Covid-19 and less likely to intend to get vaccinated, possibly due to factors including lower levels of education, work obligations, and domestic care obligations.
Previous studies in sub-Saharan Africa that focused on differences between men and women with intention and willingness to vaccinate were inconclusive, Ndejjo says. “You would hardly find actual studies on uptake of the vaccines,” he adds. For the new paper, the researchers aimed to dig into uptake.
People who trust the government and health officials were more likely to get vaccinated
The researchers relied on phone survey data collected from adults in the four countries between March and July 2022. The surveys asked people about whether they’d been vaccinated and whether those who were unvaccinated intended to get vaccinated, as well as their attitudes toward Covid-19, their trust in different authorities, demographic information, and more.
Overall, 48.5 percent of men said they had been vaccinated, compared to 47.9 percent of women. Trust in authorities seemed to play a role in people’s decision to vaccinate — receiving information from health workers about Covid-19 and higher trust in the Ministry of Health were both correlated with getting vaccinated for men, whereas higher trust in the government was correlated with vaccine uptake in women.
Lower interest in vaccines among women seemed related to safety concerns
A smaller percentage of unvaccinated women (54 percent) said they intended to get vaccinated, compared to 63.4 percent of men. More unvaccinated women said they had concerns about the vaccine’s safety than unvaccinated men, which could be driving their lower intention.
The researchers also found that unvaccinated women and men over 40 had similar levels of intention to get vaccinated — lower intention in women under 40 may have driven the difference between men and women. Younger women could have concerns about vaccines related to pregnancy, Chen says. If this is the case, the research suggests that officials need to provide additional reassurance to pregnant people about vaccine safety, she adds.
Trust in authorities also contributed to people’s intention to vaccinate. Trust in the Ministry of Health was tied to higher intention to vaccinate for both men and women. Men with more trust in the World Health Organization were also more likely to intend to vaccinate.
“There’s a need to deal with a lot of the myths and misconceptions that exist,” Ndejjo says, as well as ensure that people’s concerns related to vaccine safety and effectiveness are addressed. Officials need “to work with trusted sources of information to bridge some of the gaps that we observe,” he adds. People need to be supported in their decision-making so they can make the best decisions for their health.
“This research highlights linkages between citizen trust in government, their willingness to get vaccines, and, importantly, the differences between men and women on this issue — differences that policymakers will need to understand in order to design more targeted, gender-specific public health interventions,” says study co-author Lily L. Tsai, who is MIT GOV/LAB’s director and founder and the Ford Professor of Political Science at MIT.
This project was funded by the Bill & Melinda Gates Foundation.
Researchers from the Singapore-MIT Alliance for Research and Technology (SMART), MIT’s research enterprise in Singapore, have developed a novel way to produce clinical doses of viable autologous chimeric antigen receptor (CAR) T-cells in a ultra-small automated closed-system microfluidic chip, roughly the size of a pack of cards.
This is the first time that a microbioreactor is used to produce autologous cell therapy products. Specifically, the new method was successfully used to manufacture and expand CAR-T cells that are as effective as cells produced using existing systems in a smaller footprint and less space, and using fewer seeding cell numbers and cell manufacturing reagents. This could lead to more efficient and affordable methods of scaling-out autologous cell therapy manufacturing, and could even potentially enable point-of-care manufacturing of CAR T-cells outside of a laboratory setting — such as in hospitals and wards.
CAR T-cell therapy manufacturing requires the isolation, activation, genetic modification, and expansion of a patient’s own T-cells to kill tumor cells upon reinfusion into the patient. Despite how cell therapies have revolutionized cancer immunotherapy, with some of the first patients who received autologous cell therapies in remission for more than 10 years, the manufacturing process for CAR-T cells has remained inconsistent, costly, and time-consuming. It can be prone to contamination, subject to human error, and requires seeding cell numbers that are impractical for smaller-scale CAR T-cell production. These challenges create bottlenecks that restrict both the availability and affordability of these therapies despite their effectiveness.
In a paper titled “A high-density microbioreactor process designed for automated point-of-care manufacturing of CAR T cells” published in the journal Nature Biomedical Engineering, SMART researchers detailed their breakthrough: Human primary T-cells can be activated, transduced, and expanded to high densities in a 2-mililiter automated closed-system microfluidic chip to produce over 60 million CAR T-cells from donors with lymphoma, and over 200 million CAR T-cells from healthy donors. The CAR T-cells produced using the microbioreactor are as effective as those produced using conventional methods, but in a smaller footprint and less space, and with fewer resources. This translates to lower cost of goods manufactured (COGM), and potentially to lower costs for patients.
The groundbreaking research was led by members of the Critical Analytics for Manufacturing Personalized-Medicine (CAMP) interdisciplinary research group at SMART. Collaborators include researchers from the Duke-NUS Medical School; the Institute of Molecular and Cell Biology at the Agency for Science, Technology and Research; KK Women’s and Children’s Hospital; and Singapore General Hospital.
“This advancement in cell therapy manufacturing could ultimately offer a point-of-care platform that could substantially increase the number of CAR T-cell production slots, reducing the wait times and cost of goods of these living medicines — making cell therapy more accessible to the masses. The use of scaled-down bioreactors could also aid process optimization studies, including for different cell therapy products,” says Michael Birnbaum, co-lead principal investigator at SMART CAMP, associate professor of biological engineering at MIT, and a co-senior author of the paper.
With high T-cell expansion rates, similar total T-cell numbers could be attained with a shorter culture period in the microbioreactor (seven to eight days) compared to gas-permeable culture plates (12 days), potentially shortening production times by 30-40 percent. The CAR T-cells from both the microfluidic bioreactor and gas-permeable culture plates only showed subtle differences in cell quality. The cells were equally functional in killing leukemia cells when tested in mice.
“This new method suggests that a dramatic miniaturization of current-generation autologous cell therapy production is feasible, with the potential of significantly alleviating manufacturing limitations of CAR T-cell therapy. Such a miniaturization would lay the foundation for point-of-care manufacturing of CAR T-cells and decrease the “good manufacturing practice” (GMP) footprint required for producing cell therapies — which is one of the primary drivers of COGM,” says Wei-Xiang Sin, research scientist at SMART CAMP and first author of the paper.
Notably, the microbioreactor used in the research is a perfusion-based, automated, closed system with the smallest footprint per dose, smallest culture volume and seeding cell number, as well as the highest cell density and level of process control attainable. These microbioreactors — previously only used for microbial and mammalian cell cultures — were originally developed at MIT and have been advanced to commercial production by Millipore Sigma.
The small starting cell numbers required, compared to existing larger automated manufacturing platforms, means that smaller amounts of isolation beads, activation reagents, and lentiviral vectors are required per production run. In addition, smaller volumes of medium are required (at least tenfold lower than larger automated culture systems) owing to the extremely small culture volume (2 milliliters; approximately 100-fold lower than larger automated culture systems) — which contributes to significant reductions in reagent cost. This could benefit patients, especially pediatric patients who have low or insufficient T-cell numbers to produce therapeutic doses of CAR T-cells.
Moving forward, SMART CAMP is working on further engineering sampling and/or analytical systems around the microbioreactor so that CAR-T production can be performed with reduced labor and out of a laboratory setting, potentially facilitating the decentralized bedside manufacturing of CAR T-cells. SMART CAMP is also looking to further optimize the process parameters and culture conditions to improve cell yield and quality for future clinical use.
The research was conducted by SMART and supported by the National Research Foundation Singapore under its Campus for Research Excellence and Technological Enterprise (CREATE) program.
(From left to right:) SMART researchers Denise Teo, Michael Birnbaum, Wei-Xiang Sin, and Narendra Suhas Jagannathan pose with the microbioreactor system at the center.
Some people, especially those in public service, perform admirable feats: Think of health-care workers fighting to keep patients alive or first responders arriving at the scene of a car crash. But the emotional weight can become a mental burden. Research has shown that emergency personnel are at elevated risk for mental health challenges like post-traumatic stress disorder. How can people undergo such stressful experiences and also maintain their well-being?
A new study from the McGovern Institute for Brain Research at MIT revealed that a cognitive strategy focused on social good may be effective in helping people cope with distressing events. The research team found that the approach was comparable to another well-established emotion regulation strategy, unlocking a new tool for dealing with highly adverse situations.
“How you think can improve how you feel,” says John Gabrieli, the Grover Hermann Professor of Health Sciences and Technology and a professor of brain and cognitive sciences at MIT, who is a senior author of the paper. “This research suggests that the social good approach might be particularly useful in improving well-being for those constantly exposed to emotionally taxing events.”
The study, published today in PLOS ONE, is the first to examine the efficacy of this cognitive strategy. Nancy Tsai, a postdoc in Gabrieli’s lab at the McGovern Institute, is the lead author of the paper.
Emotion regulation tools
Emotion regulation is the ability to mentally reframe how we experience emotions — a skill critical to maintaining good mental health. Doing so can make one feel better when dealing with adverse events, and emotion regulation has been shown to boost emotional, social, cognitive, and physiological outcomes across the lifespan.
One emotion regulation strategy is “distancing,” where a person copes with a negative event by imagining it as happening far away, a long time ago, or from a third-person perspective. Distancing has been well-documented as a useful cognitive tool, but it may be less effective in certain situations, especially ones that are socially charged — like a firefighter rescuing a family from a burning home. Rather than distancing themselves, a person may instead be forced to engage directly with the situation.
“In these cases, the ‘social good’ approach may be a powerful alternative,” says Tsai. “When a person uses the social good method, they view a negative situation as an opportunity to help others or prevent further harm.” For example, a firefighter experiencing emotional distress might focus on the fact that their work enables them to save lives. The idea had yet to be backed by scientific investigation, so Tsai and her team, alongside Gabrieli, saw an opportunity to rigorously probe this strategy.
A novel study
The MIT researchers recruited a cohort of adults and had them complete a questionnaire to gather information including demographics, personality traits, and current well-being, as well as how they regulated their emotions and dealt with stress. The cohort was randomly split into two groups: a distancing group and a social good group. In the online study, each group was shown a series of images that were either neutral (such as fruit) or contained highly aversive content (such as bodily injury). Participants were fully informed of the kinds of images they might see and could opt out of the study at any time.
Each group was asked to use their assigned cognitive strategy to respond to half of the negative images. For example, while looking at a distressing image, a person in the distancing group could have imagined that it was a screenshot from a movie. Conversely, a subject in the social good group might have responded to the image by envisioning that they were a first responder saving people from harm. For the other half of the negative images, participants were asked to only look at them and pay close attention to their emotions. The researchers asked the participants how they felt after each image was shown.
Social good as a potent strategy
The MIT team found that distancing and social good approaches helped diminish negative emotions. Participants reported feeling better when they used these strategies after viewing adverse content compared to when they did not, and stated that both strategies were easy to implement.
The results also revealed that, overall, distancing yielded a stronger effect. Importantly, however, Tsai and Gabrieli believe that this study offers compelling evidence for social good as a powerful method better-suited to situations when people cannot distance themselves, like rescuing someone from a car crash, “Which is more probable for people in the real world,” notes Tsai. Moreover, the team discovered that people who most successfully used the social good approach were more likely to view stress as enhancing rather than debilitating. Tsai says this link may point to psychological mechanisms that underlie both emotion regulation and how people respond to stress.
Additionally, the results showed that older adults used the cognitive strategies more effectively than younger adults. The team suspects that this is probably because, as prior research has shown, older adults are more adept at regulating their emotions, likely due to having greater life experiences. The authors note that successful emotion regulation also requires cognitive flexibility, or having a malleable mindset to adapt well to different situations.
“This is not to say that people, such as physicians, should reframe their emotions to the point where they fully detach themselves from negative situations,” says Gabrieli. “But our study shows that the social good approach may be a potent strategy to combat the immense emotional demands of certain professions.”
The MIT team says that future studies are needed to further validate this work, and that such research is promising in that it can uncover new cognitive tools to equip individuals to take care of themselves as they bravely assume the challenge of taking care of others.
Research has shown that emergency personnel are at elevated risk for mental health challenges like post-traumatic stress disorder. A new study shows that a cognitive strategy focused on social good may help people cope with distressing events.
As climate change advances, the ocean’s overturning circulation is predicted to weaken substantially. With such a slowdown, scientists estimate the ocean will pull down less carbon dioxide from the atmosphere. However, a slower circulation should also dredge up less carbon from the deep ocean that would otherwise be released back into the atmosphere. On balance, the ocean should maintain its role in reducing carbon emissions from the atmosphere, if at a slower pace.
However, a new study by an MIT researcher finds that scientists may have to rethink the relationship between the ocean’s circulation and its long-term capacity to store carbon. As the ocean gets weaker, it could release more carbon from the deep ocean into the atmosphere instead.
The reason has to do with a previously uncharacterized feedback between the ocean’s available iron, upwelling carbon and nutrients, surface microorganisms, and a little-known class of molecules known generally as “ligands.” When the ocean circulates more slowly, all these players interact in a self-perpetuating cycle that ultimately increases the amount of carbon that the ocean outgases back to the atmosphere.
“By isolating the impact of this feedback, we see a fundamentally different relationship between ocean circulation and atmospheric carbon levels, with implications for the climate,” says study author Jonathan Lauderdale, a research scientist in MIT’s Department of Earth, Atmospheric, and Planetary Sciences. “What we thought is going on in the ocean is completely overturned.”
Lauderdale says the findings show that “we can’t count on the ocean to store carbon in the deep ocean in response to future changes in circulation. We must be proactive in cutting emissions now, rather than relying on these natural processes to buy us time to mitigate climate change.”
His study appears today in the journal Nature Communications.
Box flow
In 2020, Lauderdale led a study that explored ocean nutrients, marine organisms, and iron, and how their interactions influence the growth of phytoplankton around the world. Phytoplankton are microscopic, plant-like organisms that live on the ocean surface and consume a diet of carbon and nutrients that upwell from the deep ocean and iron that drifts in from desert dust.
The more phytoplankton that can grow, the more carbon dioxide they can absorb from the atmosphere via photosynthesis, and this plays a large role in the ocean’s ability to sequester carbon.
For the 2020 study, the team developed a simple “box” model, representing conditions in different parts of the ocean as general boxes, each with a different balance of nutrients, iron, and ligands — organic molecules that are thought to be byproducts of phytoplankton. The team modeled a general flow between the boxes to represent the ocean’s larger circulation — the way seawater sinks, then is buoyed back up to the surface in different parts of the world.
This modeling revealed that, even if scientists were to “seed” the oceans with extra iron, that iron wouldn’t have much of an effect on global phytoplankton growth. The reason was due to a limit set by ligands. It turns out that, if left on its own, iron is insoluble in the ocean and therefore unavailable to phytoplankton. Iron only becomes soluble at “useful” levels when linked with ligands, which keep iron in a form that plankton can consume. Lauderdale found that adding iron to one ocean region to consume additional nutrients robs other regions of nutrients that phytoplankton there need to grow. This lowers the production of ligands and the supply of iron back to the original ocean region, limiting the amount of extra carbon that would be taken up from the atmosphere.
Unexpected switch
Once the team published their study, Lauderdale worked the box model into a form that he could make publicly accessible, including ocean and atmosphere carbon exchange and extending the boxes to represent more diverse environments, such as conditions similar to the Pacific, the North Atlantic, and the Southern Ocean. In the process, he tested other interactions within the model, including the effect of varying ocean circulation.
He ran the model with different circulation strengths, expecting to see less atmospheric carbon dioxide with weaker ocean overturning — a relationship that previous studies have supported, dating back to the 1980s. But what he found instead was a clear and opposite trend: The weaker the ocean’s circulation, the more CO2 built up in the atmosphere.
“I thought there was some mistake,” Lauderdale recalls. “Why were atmospheric carbon levels trending the wrong way?”
When he checked the model, he found that the parameter describing ocean ligands had been left “on” as a variable. In other words, the model was calculating ligand concentrations as changing from one ocean region to another.
On a hunch, Lauderdale turned this parameter “off,” which set ligand concentrations as constant in every modeled ocean environment, an assumption that many ocean models typically make. That one change reversed the trend, back to the assumed relationship: A weaker circulation led to reduced atmospheric carbon dioxide. But which trend was closer to the truth?
Lauderdale looked to the scant available data on ocean ligands to see whether their concentrations were more constant or variable in the actual ocean. He found confirmation in GEOTRACES, an international study that coordinates measurements of trace elements and isotopes across the world’s oceans, that scientists can use to compare concentrations from region to region. Indeed, the molecules’ concentrations varied. If ligand concentrations do change from one region to another, then his surprise new result was likely representative of the real ocean: A weaker circulation leads to more carbon dioxide in the atmosphere.
“It’s this one weird trick that changed everything,” Lauderdale says. “The ligand switch has revealed this completely different relationship between ocean circulation and atmospheric CO2 that we thought we understood pretty well.”
Slow cycle
To see what might explain the overturned trend, Lauderdale analyzed biological activity and carbon, nutrient, iron, and ligand concentrations from the ocean model under different circulation strengths, comparing scenarios where ligands were variable or constant across the various boxes.
This revealed a new feedback: The weaker the ocean’s circulation, the less carbon and nutrients the ocean pulls up from the deep. Any phytoplankton at the surface would then have fewer resources to grow and would produce fewer byproducts (including ligands) as a result. With fewer ligands available, less iron at the surface would be usable, further reducing the phytoplankton population. There would then be fewer phytoplankton available to absorb carbon dioxide from the atmosphere and consume upwelled carbon from the deep ocean.
“My work shows that we need to look more carefully at how ocean biology can affect the climate,” Lauderdale points out. “Some climate models predict a 30 percent slowdown in the ocean circulation due to melting ice sheets, particularly around Antarctica. This huge slowdown in overturning circulation could actually be a big problem: In addition to a host of other climate issues, not only would the ocean take up less anthropogenic CO2 from the atmosphere, but that could be amplified by a net outgassing of deep ocean carbon, leading to an unanticipated increase in atmospheric CO2 and unexpected further climate warming.”
A new tool makes it easier for database users to perform complicated statistical analyses of tabular data without the need to know what is going on behind the scenes.
GenSQL, a generative AI system for databases, could help users make predictions, detect anomalies, guess missing values, fix errors, or generate synthetic data with just a few keystrokes.
For instance, if the system were used to analyze medical data from a patient who has always had high blood pressure, it could catch a blood pressure reading that is low for that particular patient but would otherwise be in the normal range.
GenSQL automatically integrates a tabular dataset and a generative probabilistic AI model, which can account for uncertainty and adjust their decision-making based on new data.
Moreover, GenSQL can be used to produce and analyze synthetic data that mimic the real data in a database. This could be especially useful in situations where sensitive data cannot be shared, such as patient health records, or when real data are sparse.
This new tool is built on top of SQL, a programming language for database creation and manipulation that was introduced in the late 1970s and is used by millions of developers worldwide.
“Historically, SQL taught the business world what a computer could do. They didn’t have to write custom programs, they just had to ask questions of a database in high-level language. We think that, when we move from just querying data to asking questions of models and data, we are going to need an analogous language that teaches people the coherent questions you can ask a computer that has a probabilistic model of the data,” says Vikash Mansinghka ’05, MEng ’09, PhD ’09, senior author of a paper introducing GenSQL and a principal research scientist and leader of the Probabilistic Computing Project in the MIT Department of Brain and Cognitive Sciences.
When the researchers compared GenSQL to popular, AI-based approaches for data analysis, they found that it was not only faster but also produced more accurate results. Importantly, the probabilistic models used by GenSQL are explainable, so users can read and edit them.
“Looking at the data and trying to find some meaningful patterns by just using some simple statistical rules might miss important interactions. You really want to capture the correlations and the dependencies of the variables, which can be quite complicated, in a model. With GenSQL, we want to enable a large set of users to query their data and their model without having to know all the details,” adds lead author Mathieu Huot, a research scientist in the Department of Brain and Cognitive Sciences and member of the Probabilistic Computing Project.
They are joined on the paper by Matin Ghavami and Alexander Lew, MIT graduate students; Cameron Freer, a research scientist; Ulrich Schaechtle and Zane Shelby of Digital Garage; Martin Rinard, an MIT professor in the Department of Electrical Engineering and Computer Science and member of the Computer Science and Artificial Intelligence Laboratory (CSAIL); and Feras Saad ’15, MEng ’16, PhD ’22, an assistant professor at Carnegie Mellon University. The research was recently presented at the ACM Conference on Programming Language Design and Implementation.
Combining models and databases
SQL, which stands for structured query language, is a programming language for storing and manipulating information in a database. In SQL, people can ask questions about data using keywords, such as by summing, filtering, or grouping database records.
However, querying a model can provide deeper insights, since models can capture what data imply for an individual. For instance, a female developer who wonders if she is underpaid is likely more interested in what salary data mean for her individually than in trends from database records.
The researchers noticed that SQL didn’t provide an effective way to incorporate probabilistic AI models, but at the same time, approaches that use probabilistic models to make inferences didn’t support complex database queries.
They built GenSQL to fill this gap, enabling someone to query both a dataset and a probabilistic model using a straightforward yet powerful formal programming language.
A GenSQL user uploads their data and probabilistic model, which the system automatically integrates. Then, she can run queries on data that also get input from the probabilistic model running behind the scenes. This not only enables more complex queries but can also provide more accurate answers.
For instance, a query in GenSQL might be something like, “How likely is it that a developer from Seattle knows the programming language Rust?” Just looking at a correlation between columns in a database might miss subtle dependencies. Incorporating a probabilistic model can capture more complex interactions.
Plus, the probabilistic models GenSQL utilizes are auditable, so people can see which data the model uses for decision-making. In addition, these models provide measures of calibrated uncertainty along with each answer.
For instance, with this calibrated uncertainty, if one queries the model for predicted outcomes of different cancer treatments for a patient from a minority group that is underrepresented in the dataset, GenSQL would tell the user that it is uncertain, and how uncertain it is, rather than overconfidently advocating for the wrong treatment.
Faster and more accurate results
To evaluate GenSQL, the researchers compared their system to popular baseline methods that use neural networks. GenSQL was between 1.7 and 6.8 times faster than these approaches, executing most queries in a few milliseconds while providing more accurate results.
They also applied GenSQL in two case studies: one in which the system identified mislabeled clinical trial data and the other in which it generated accurate synthetic data that captured complex relationships in genomics.
Next, the researchers want to apply GenSQL more broadly to conduct largescale modeling of human populations. With GenSQL, they can generate synthetic data to draw inferences about things like health and salary while controlling what information is used in the analysis.
They also want to make GenSQL easier to use and more powerful by adding new optimizations and automation to the system. In the long run, the researchers want to enable users to make natural language queries in GenSQL. Their goal is to eventually develop a ChatGPT-like AI expert one could talk to about any database, which grounds its answers using GenSQL queries.
This research is funded, in part, by the Defense Advanced Research Projects Agency (DARPA), Google, and the Siegel Family Foundation.
Microbes that are used for health, agricultural, or other applications need to be able to withstand extreme conditions, and ideally the manufacturing processes used to make tablets for long-term storage. MIT researchers have now developed a new way to make microbes hardy enough to withstand these extreme conditions.
Their method involves mixing bacteria with food and drug additives from a list of compounds that the FDA classifies as “generally regarded as safe.” The researchers identified formulations that help to stabilize several different types of microbes, including yeast and bacteria, and they showed that these formulations could withstand high temperatures, radiation, and industrial processing that can damage unprotected microbes.
In an even more extreme test, some of the microbes recently returned from a trip to the International Space Station, coordinated by Space Center Houston Manager of Science and Research Phyllis Friello, and the researchers are now analyzing how well the microbes were able to withstand those conditions.
“What this project was about is stabilizing organisms for extreme conditions. We're thinking about a broad set of applications, whether it's missions to space, human applications, or agricultural uses,” says Giovanni Traverso, an associate professor of mechanical engineering at MIT, a gastroenterologist at Brigham and Women’s Hospital, and the senior author of the study.
Miguel Jimenez, a former MIT research scientist who is now an assistant professor of biomedical engineering at Boston University, is the lead author of the paper, which appears today in Nature Materials.
Surviving extreme conditions
About six years ago, with funding from NASA’s Translational Research Institute for Space Health (TRISH), Traverso’s lab began working on new approaches to make helpful bacteria such as probiotics and microbial therapeutics more resilient. As a starting point, the researchers analyzed 13 commercially available probiotics and found that six of these products did not contain as many live bacteria as the label indicated.
“What we found was that, perhaps not surprisingly, there is a difference, and it can be significant,” Traverso says. “So then the next question was, given this, what can we do to help the situation?”
For their experiments, the researchers chose four different microbes to focus on: three bacteria and one yeast. These microbes are Escherichia coli Nissle 1917, a probiotic; Ensifer meliloti, a bacterium that can fix nitrogen in soil to support plant growth; Lactobacillus plantarum, a bacterium used to ferment food products; and the yeast Saccharomyces boulardii, which is also used as a probiotic.
When microbes are used for medical or agricultural applications, they are usually dried into a powder through a process called lyophilization. However, they can not normally be made into more useful forms such as a tablet or pill because this process requires exposure to an organic solvent, which can be toxic to the bacteria. The MIT team set out to find additives that could improve the microbes’ ability to survive this kind of processing.
“We developed a workflow where we can take materials from the ‘generally regarded as safe’ materials list from the FDA, and mix and match those with bacteria and ask, are there ingredients that enhance the stability of the bacteria during the lyophilization process?” Traverso says.
Their setup allows them to mix microbes with one of about 100 different ingredients and then grow them to see which survive the best when stored at room temperature for 30 days. These experiments revealed different ingredients, mostly sugars and peptides, that worked best for each species of microbe.
The researchers then picked one of the microbes, E. coli Nissle 1917, for further optimization. This probiotic has been used to treat “traveler’s diarrhea,” a condition caused by drinking water contaminated with harmful bacteria. The researchers found that if they combined caffeine or yeast extract with a sugar called melibiose, they could create a very stable formulation of E. coli Nissle 1917. This mixture, which the researchers called formulation D, allowed survival rates greater than 10 percent after the microbes were stored for six months at 37 degrees Celsius, while a commercially available formulation of E. coli Nissle 1917 lost all viability after only 11 days under those conditions.
Formulation D was also able to withstand much higher levels of ionizing radiation, up to 1,000 grays. (The typical radiation dose on Earth is about 15 micrograys per day, and in space, it’s about 200 micrograys per day.)
The researchers don’t know exactly how their formulations protect bacteria, but they hypothesize that the additives may help to stabilize the bacterial cell membranes during rehydration.
Stress tests
The researchers then showed that these microbes can not only survive harsh conditions, they also maintain their function after these exposures. After Ensifer meliloti were exposed to temperatures up to 50 degrees Celsius, the researchers found that they were still able to form symbiotic nodules on plant roots and convert nitrogen to ammonia.
They also found that their formulation of E. coli Nissle 1917 was able to inhibit the growth of Shigellaflexneri, one of the leading causes of diarrhea-associated deaths in low- and middle-income countries, when the microbes were grown together in a lab dish.
Last year, several strains of these extremophile microbes were sent to the International Space Station, which Jimenez describes as “the ultimate stress test.”
“Even just the shipping on Earth to the preflight validation, and storage until flight are part of this test, with no temperature control along the way,” he says.
The samples recently returned to Earth, and Jimenez’ lab is now analyzing them. He plans to compare samples that were kept inside the ISS to others that were bolted to the outside of the station, as well as control samples that remained on Earth.
“This work offers a promising approach to enhance the stability of probiotics and/or genetically engineered microbes in extreme environments, such as in outer space, which could be used in future space missions to help maintain astronaut health or promote sustainability, such as in promoting more robust and resilient plants for food production,” says Camilla Urbaniak, a research scientist at NASA’s Jet Propulsion Laboratory, who was not involved in the study.
The research was funded by NASA’s Translational Research Institute for Space Health, Space Center Houston, MIT’s Department of Mechanical Engineering, and by 711 Human Performance Wing and the Defense Advanced Research Projects Agency.
Other authors of the paper include Johanna L’Heureux, Emily Kolaya, Gary Liu, Kyle Martin, Husna Ellis, Alfred Dao, Margaret Yang, Zachary Villaverde, Afeefah Khazi-Syed, Qinhao Cao, Niora Fabian, Joshua Jenkins, Nina Fitzgerald, Christina Karavasili, Benjamin Muller, and James Byrne.
While recycling systems and bottle deposits have become increasingly widespread in the U.S., actual rates of recycling are “abysmal,” according to a team of MIT researchers who studied the rates for recycling of PET, the plastic commonly used in beverage bottles. However, their findings suggest some ways to change this.
The present rate of recycling for PET, or polyethylene terephthalate, bottles nationwide is about 24 percent and has remained stagnant for a decade, the researchers say. But their study indicates that with a nationwide bottle deposit program, the rates could increase to 82 percent, with nearly two-thirds of all PET bottles being recycled into new bottles, at a net cost of just a penny a bottle when demand is robust. At the same time, they say, policies would be needed to ensure a sufficient demand for the recycled material.
The findings are being published today in the Journal of Industrial Ecology, in a paper by MIT professor of materials science and engineering Elsa Olivetti, graduate students Basuhi Ravi and Karan Bhuwalka, and research scientist Richard Roth.
The team looked at PET bottle collection and recycling rates in different states as well as other nations with and without bottle deposit policies, and with or without curbside recycling programs, as well as the inputs and outputs of various recycling companies and methods. The researchers say this study is the first to look in detail at the interplay between public policies and the end-to-end realities of the packaging production and recycling market.
They found that bottle deposit programs are highly effective in the areas where they are in place, but at present there is not nearly enough collection of used bottles to meet the targets set by the packaging industry. Their analysis suggests that a uniform nationwide bottle deposit policy could achieve the levels of recycling that have been mandated by proposed legislation and corporate commitments.
The recycling of PET is highly successful in terms of quality, with new products made from all-recycled material virtually matching the qualities of virgin material. And brands have shown that new bottles can be safely made with 100 percent postconsumer waste. But the team found that collection of the material is a crucial bottleneck that leaves processing plants unable to meet their needs. However, with the right policies in place, “one can be optimistic,” says Olivetti, who is the Jerry McAfee Professor in Engineering and the associate dean of the School of Engineering.
“A message that we have found in a number of cases in the recycling space is that if you do the right work to support policies that think about both the demand but also the supply,” then significant improvements are possible, she says. “You have to think about the response and the behavior of multiple actors in the system holistically to be viable,” she says. “We are optimistic, but there are many ways to be pessimistic if we’re not thinking about that in a holistic way.”
For example, the study found that it is important to consider the needs of existing municipal waste-recovery facilities. While expanded bottle deposit programs are essential to increase recycling rates and provide the feedstock to companies recycling PET into new products, the current facilities that process material from curbside recycling programs will lose revenue from PET bottles, which are a relatively high-value product compared to the other materials in the recycled waste stream. These companies would lose a source of their income if the bottles are collected through deposit programs, leaving them with only the lower-value mixed plastics.
The researchers developed economic models based on rates of collection found in the states with deposit programs, recycled-content requirements, and other policies, and used these models to extrapolate to the nation as a whole. Overall, they found that the supply needs of packaging producers could be met through a nationwide bottle deposit system with a 10-cent deposit per bottle — at a net cost of about 1 cent per bottle produced when demand is strong. This need not be a federal program, but rather one where the implementation would be left up to the individual states, Olivetti says.
Other countries have been much more successful in implementing deposit systems that result in very high participation rates. Several European countries manage to collect more than 90 percent of PET bottles for recycling, for example. But in the U.S., less than 29 percent are collected, and after losses in the recycling chain about 24 percent actually get recycled, the researchers found. Whereas 73 percent of Americans have access to curbside recycling, presently only 10 states have bottle deposit systems in place.
Yet the demand is there so far. “There is a market for this material,” says Olivetti. While bottles collected through mixed-waste collection can still be recycled to some extent, those collected through deposit systems tend to be much cleaner and require less processing, and so are more economical to recycle into new bottles, or into textiles.
To be effective, policies need to not just focus on increasing rates of recycling, but on the whole cycle of supply and demand and the different players involved, Olivetti says. Safeguards would need to be in place to protect existing recycling facilities from the lost revenues they would suffer as a result of bottle deposits, perhaps in the form of subsidies funded by fees on the bottle producers, to avoid putting these essential parts of the processing chain out of business. And other policies may be needed to ensure the continued market for the material that gets collected, including recycled content requirements and extended producer responsibility regulations, the team found.
At this stage, it’s important to focus on the specific waste streams that can most effectively be recycled, and PET, along with many metals, clearly fit that category. “When we start to think about mixed plastic streams, that’s much more challenging from an environmental perspective,” she says. “Recycling systems need to be pursuing extended producers’ responsibility, or specifically thinking about materials designed more effectively toward recycled content,” she says.
It's also important to address “what the right metrics are to design for sustainably managed materials streams,” she says. “It could be energy use, could be circularity [for example, making old bottles into new bottles], could be around waste reduction, and making sure those are all aligned. That’s another kind of policy coordination that’s needed.”
Researchers say this study is the first to look in detail at the interplay between public policies and the end-to-end realities of the packaging production and recycling market.
At the core of Raymond Wang’s work lies a seemingly simple question: Can’t we just get along?
Wang, a fifth-year political science graduate student, is a native of Hong Kong who witnessed firsthand the shakeup and conflict engendered by China’s takeover of the former British colony. “That type of experience makes you wonder why things are so complicated,” he says. “Why is it so hard to live with your neighbors?”
Today, Wang is focused on ways of managing a rapidly intensifying U.S.-China competition, and more broadly, on identifying how China — and other emerging global powers — bend, break, or creatively accommodate international rules in trade, finance, maritime, and arms control matters to achieve their ends.
The current game for global dominance between the United States and China continually threatens to erupt into dangerous confrontation. Wang’s research aims to construct a more nuanced take on China’s behaviors in this game.
“U.S. policy towards China should be informed by a better understanding of China’s behaviors if we are to avoid the worst-case scenario,” Wang believes.
“Selective and smart”
One of Wang’s major research thrusts is the ongoing trade war between the two nations. “The U.S. views China as rewriting the rules, creating an alternative world order — and accuses China of violating World Trade Organization (WTO) rules,” says Wang. “But in fact, China has been very selective and smart about responding to these rules.”
One critical, and controversial, WTO matter involves determining whether state-owned enterprises are, in the arcane vocabulary of the group, “public bodies,” which are subject to sometimes punitive WTO rules. The United States asserts that if a government owns 51 percent of a company, it is a public body. This means that many essential Chinese state-owned enterprises (SOEs) — manufacturers of electric vehicles, steel, or chemicals, for example — would fall under WTO provisions, and potentially face punitive discipline.
But China isn’t the only nation with SOEs. Many European countries, including stalwart U.S. partners France and Norway, subsidize companies that qualify as public bodies according to the U.S. definition. They, too, could be subject to tough WTO regulations.
“This could harm a swathe of the E.U. economy,” says Wang. “So China intelligently made the case to the international community that the U.S. position is extreme, and has pushed for a more favorable interpretation through litigation at the WTO.”
For Wang, this example highlights a key insight of his research: “Rising powers such as China exhibit cautious opportunism,” he says. “China will try to work with the existing rules as much as possible, including bending them in creative ways.”
But when it comes down to it, Wang argues, China would rather avoid the costs of building something completely new.
“If you can repurpose an old tool, why would you buy a new one?” he asks. “The vast majority of actions China is taking involves reshaping the existing order, not introducing new rules or blowing up institutions and building new ones.”
Interviewing key players
To bolster his theory of “cautious opportunism,” Wang’s doctoral project sets out a suite of rule-shaping strategies adopted by rising powers in international organizations. His analysis is driven by case studies of disputes recently concluded, or ongoing, in the WTO, the World Bank, and other bodies responsible for defining and policing rules that govern all manner of international relations and commerce.
Gathering evidence for his argument, Wang has been interviewing people critical to the disputes on all sides.
“My approach is to figure out who was in the room when certain decisions were made and talk to every single person there,” he says. “For the WTO and World Bank, I’ve interviewed close to 50 relevant personnel, including front-line lawyers, senior leadership, and former government officials.” These interviews took place in Geneva, Singapore, Tokyo, and Washington.
But writing about disputes that involve China poses a unique set of problems. “It’s difficult to talk to actively serving Chinese officials, and in general, nobody wants to go on the record because all the content is sensitive.”
As Wang moves on to cases in maritime governance, he will be reaching out to the key players involved in managing sensitive conflicts in the South China Sea, an Indo-Pacific region dotted with shoals and offering desirable fisheries as well as oil and gas resources.
Even here, Wang suggests, China may find reason to be cautious rather than opportunistic, preferring to carve out exemptions for itself or shift interpretations, rather than overturning the existing rules wholesale.
Indeed, Wang believes China and other rising powers introduce new rules only when conditions open up a window of opportunity: “It may be worth doing so when using traditional tools doesn’t get you what you want, if your competitors are unable or unwilling to counter mobilize against you, and you see that the costs of establishing these new rules are worth it,” he says.
Beyond Wang’s dissertation, he has also been part of a research team led by M. Taylor Fravel, Arthur and Ruth Sloan Professor of Political Science, that has published papers on China’s Belt and Road Initiative.
From friends to enemies
Wang left Hong Kong and its political ferment behind at age 15, but the challenge of dealing with a powerful neighbor and the potential crisis it represented stayed with him. In Italy, he attended a United World College — part of a network of schools bringing together young people from different nations and cultures for the purpose of training leaders and peacemakers.
“It’s a utopian idea, where you force teenagers from all around the world to live and study together and get along for two years,” says Wang. “There were people from countries in the Balkans that were actively at war with each other, who grew up with the memory of air raid sirens and family members who fought each other, but these kids would just hang out together.”
Coexistence was possible on the individual level, Wang realized, but he wondered, “What systemic thing happens that makes people do messed-up stuff to each other when they are in a group?”
With this question in mind, he went to the University of St. Andrews for his undergraduate and master’s degrees in international relations and modern history. As China continued its economic and military march onto the world stage, and Iran generated international tensions over its nuclear ambitions, Wang became interested in nuclear disarmament. He drilled down into the subject at the Middlebury Institute of International Studies at Monterey, where he earned a second master’s degree in nonproliferation and terrorism studies.
Leaning into a career revolving around policy, he applied to MIT’s security studies doctoral program, hoping to focus on the impact of emerging technologies on strategic nuclear stability. But events in the world led him to pivot. “When I started in the fall of 2019, the U.S.-China relationship was going off the rails with the trade war,” he says. “It was clear that managing the relationship would be one of the biggest foreign policy challenges for the foreseeable future, and I wanted to do research that would help ensure that the relationship wouldn’t tip into a nuclear war.”
Cooling tensions
Wang has no illusions about the difficulty of containing tensions between a superpower eager to assert its role in the world order, and one determined to hold onto its primacy. His goal is to make the competition more transparent, and if possible, less overtly threatening. He is preparing a paper, “Guns and Butter: Measuring Spillover and Implications for Technological Competition,” that outlines the different paths taken by the United States and China in developing defense-related technology that also benefits the civilian economy.
As he wades into the final phase of his thesis and contemplates his next steps, Wang hopes that his research insights might inform policymakers, especially in the United States, in their approach to China. While there is a fiercely competitive relationship, “there is still room for diplomacy,” he believes. “If you accept my theory that a rising power will try and use, or even abuse, existing rules as much as possible, then you need non-military — State Department — boots on the ground to monitor what is going on at all the international institutions,” he says. The more information and understanding the United States has of China’s behavior, the more likely it will be able “to cool down some of the tensions,” says Wang. “We need to develop a strategic empathy.”
Raymond Wang is a native of Hong Kong who witnessed firsthand the shakeup and conflict engendered by China’s takeover of the former British colony. “That type of experience makes you wonder why things are so complicated,” he says. “Why is it so hard to live with your neighbors?”
Titanium alloys are essential structural materials for a wide variety of applications, from aerospace and energy infrastructure to biomedical equipment. But like most metals, optimizing their properties tends to involve a tradeoff between two key characteristics: strength and ductility. Stronger materials tend to be less deformable, and deformable materials tend to be mechanically weak.
Now, researchers at MIT, collaborating with researchers at ATI Specialty Materials, have discovered an approach for creating new titanium alloys that can exceed this historical tradeoff, leading to new alloys with exceptional combinations of strength and ductility, which might lead to new applications.
The findings are described in the journal Advanced Materials, in a paper by Shaolou Wei ScD ’22, Professor C. Cem Tasan, postdoc Kyung-Shik Kim, and John Foltz from ATI Inc. The improvements, the team says, arise from tailoring the chemical composition and the lattice structure of the alloy, while also adjusting the processing techniques used to produce the material at industrial scale.
Titanium alloys have been important because of their exceptional mechanical properties, corrosion resistance, and light weight when compared to steels for example. Through careful selection of the alloying elements and their relative proportions, and of the way the material is processed, “you can create various different structures, and this creates a big playground for you to get good property combinations, both for cryogenic and elevated temperatures,” Tasan says.
But that big assortment of possibilities in turn requires a way to guide the selections to produce a material that meets the specific needs of a particular application. The analysis and experimental results described in the new study provide that guidance.
The structure of titanium alloys, all the way down to atomic scale, governs their properties, Tasan explains. And in some titanium alloys, this structure is even more complex, made up of two different intermixed phases, known as the alpha and beta phases.
“The key strategy in this design approach is to take considerations of different scales,” he says. “One scale is the structure of individual crystal. For example, by choosing the alloying elements carefully, you can have a more ideal crystal structure of the alpha phase that enables particular deformation mechanisms. The other scale is the polycrystal scale, that involves interactions of the alpha and beta phases. So, the approach that’s followed here involves design considerations for both.”
In addition to choosing the right alloying materials and proportions, steps in the processing turned out to play an important role. A technique called cross-rolling is another key to achieving the exceptional combination of strength and ductility, the team found.
Working together with ATI researchers, the team tested a variety of alloys under a scanning electron microscope as they were being deformed, revealing details of how their microstructures respond to external mechanical load. They found that there was a particular set of parameters — of composition, proportions, and processing method — that yielded a structure where the alpha and beta phases shared the deformation uniformly, mitigating the cracking tendency that is likely to occur between the phases when they respond differently. “The phases deform in harmony,” Tasan says. This cooperative response to deformation can yield a superior material, they found.
“We looked at the structure of the material to understand these two phases and their morphologies, and we looked at their chemistries by carrying out local chemical analysis at the atomic scale. We adopted a wide variety of techniques to quantify various properties of the material across multiple length scales, says Tasan, who is the POSCO Professor of Materials Science and Engineering and an associate professor of metallurgy. “When we look at the overall properties” of the titanium alloys produced according to their system, “the properties are really much better than comparable alloys.”
This was industry-supported academic research aimed at proving design principles for alloys that can be commercially produced at scale, according to Tasan. “What we do in this collaboration is really toward a fundamental understanding of crystal plasticity,” he says. “We show that this design strategy is validated, and we show scientifically how it works,” he adds, noting that there remains significant room for further improvement.
As for potential applications of these findings, he says, “for any aerospace application where an improved combination of strength and ductility are useful, this kind of invention is providing new opportunities.”
The work was supported by ATI Specialty Rolled Products and used facilities of MIT.nano and the Center for Nanoscale Systems at Harvard University.
Cochlear implants, tiny electronic devices that can provide a sense of sound to people who are deaf or hard of hearing, have helped improve hearing for more than a million people worldwide, according to the National Institutes of Health.
However, cochlear implants today are only partially implanted, and they rely on external hardware that typically sits on the side of the head. These components restrict users, who can’t, for instance, swim, exercise, or sleep while wearing the external unit, and they may cause others to forgo the implant altogether.
On the way to creating a fully internal cochlear implant, a multidisciplinary team of researchers at MIT, Massachusetts Eye and Ear, Harvard Medical School, and Columbia University has produced an implantable microphone that performs as well as commercial external hearing aid microphones. The microphone remains one of the largest roadblocks to adopting a fully internalized cochlear implant.
This tiny microphone, a sensor produced from a biocompatible piezoelectric material, measures miniscule movements on the underside of the ear drum. Piezoelectric materials generate an electric charge when compressed or stretched. To maximize the device’s performance, the team also developed a low-noise amplifier that enhances the signal while minimizing noise from the electronics.
While many challenges must be overcome before such a microphone could be used with a cochlear implant, the collaborative team looks forward to further refining and testing this prototype, which builds off work begun at MIT and Mass Eye and Ear more than a decade ago.
“It starts with the ear doctors who are with this every day of the week, trying to improve people’s hearing, recognizing a need, and bringing that need to us. If it weren’t for this team collaboration, we wouldn’t be where we are today,” says Jeffrey Lang, the Vitesse Professor of Electrical Engineering, a member of the Research Laboratory of Electronics (RLE), and co-senior author of a paper on the microphone.
Lang’s coauthors include co-lead authors Emma Wawrzynek, an electrical engineering and computer science (EECS) graduate student, and Aaron Yeiser SM ’21; as well as mechanical engineering graduate student John Zhang; Lukas Graf and Christopher McHugh of Mass Eye and Ear; Ioannis Kymissis, the Kenneth Brayer Professor of Electrical Engineering at Columbia; Elizabeth S. Olson, a professor of biomedical engineering and auditory biophysics at Columbia; and co-senior author Hideko Heidi Nakajima, an associate professor of otolaryngology-head and neck surgery at Harvard Medical School and Mass Eye and Ear. The research is published today in the Journal of Micromechanics and Microengineering.
Overcoming an implant impasse
Cochlear implant microphones are usually placed on the side of the head, which means that users can’t take advantage of noise filtering and sound localization cues provided by the structure of the outer ear.
Fully implantable microphones offer many advantages. But most devices currently in development, which sense sound under the skin or motion of middle ear bones, can struggle to capture soft sounds and wide frequencies.
For the new microphone, the team targeted a part of the middle ear called the umbo. The umbo vibrates unidirectionally (inward and outward), making it easier to sense these simple movements.
Although the umbo has the largest range of movement of the middle-ear bones, it only moves by a few nanometers. Developing a device to measure such diminutive vibrations presents its own challenges.
On top of that, any implantable sensor must be biocompatible and able to withstand the body’s humid, dynamic environment without causing harm, which limits the materials that can be used.
“Our goal is that a surgeon implants this device at the same time as the cochlear implant and internalized processor, which means optimizing the surgery while working around the internal structures of the ear without disrupting any of the processes that go on in there,” Wawrzynek says.
With careful engineering, the team overcame these challenges.
They created the UmboMic, a triangular, 3-millimeter by 3-millimeter motion sensor composed of two layers of a biocompatible piezoelectric material called polyvinylidene difluoride (PVDF). These PVDF layers are sandwiched on either side of a flexible printed circuit board (PCB), forming a microphone that is about the size of a grain of rice and 200 micrometers thick. (An average human hair is about 100 micrometers thick.)
The narrow tip of the UmboMic would be placed against the umbo. When the umbo vibrates and pushes against the piezoelectric material, the PVDF layers bend and generate electric charges, which are measured by electrodes in the PCB layer.
Amplifying performance
The team used a “PVDF sandwich” design to reduce noise. When the sensor is bent, one layer of PVDF produces a positive charge and the other produces a negative charge. Electrical interference adds to both equally, so taking the difference between the charges cancels out the noise.
Using PVDF provides many advantages, but the material made fabrication especially difficult. PVDF loses its piezoelectric properties when exposed to temperatures above around 80 degrees Celsius, yet very high temperatures are needed to vaporize and deposit titanium, another biocompatible material, onto the sensor. Wawrzynek worked around this problem by depositing the titanium gradually and employing a heat sink to cool the PVDF.
But developing the sensor was only half the battle — umbo vibrations are so tiny that the team needed to amplify the signal without introducing too much noise. When they couldn’t find a suitable low-noise amplifier that also used very little power, they built their own.
With both prototypes in place, the researchers tested the UmboMic in human ear bones from cadavers and found that it had robust performance within the intensity and frequency range of human speech. The microphone and amplifier together also have a low noise floor, which means they could distinguish very quiet sounds from the overall noise level.
“One thing we saw that was really interesting is that the frequency response of the sensor is influenced by the anatomy of the ear we are experimenting on, because the umbo moves slightly differently in different people’s ears,” Wawrzynek says.
The researchers are preparing to launch live animal studies to further explore this finding. These experiments will also help them determine how the UmboMic responds to being implanted.
In addition, they are studying ways to encapsulate the sensor so it can remain in the body safely for up to 10 years but still be flexible enough to capture vibrations. Implants are often packaged in titanium, which would be too rigid for the UmboMic. They also plan to explore methods for mounting the UmboMic that won’t introduce vibrations.
“The results in this paper show the necessary broad-band response and low noise needed to act as an acoustic sensor. This result is surprising, because the bandwidth and noise floor are so competitive with the commercial hearing aid microphone. This performance shows the promise of the approach, which should inspire others to adopt this concept. I would expect that smaller size sensing elements and lower power electronics would be needed for next generation devices to enhance ease of implantation and battery life issues,” says Karl Grosh, professor of mechanical engineering at the University of Michigan, who was not involved with this work.
This research was funded, in part, by the National Institutes of Health, the National Science Foundation, the Cloetta Foundation in Zurich, Switzerland, and the Research Fund of the University of Basel, Switzerland.
State-of-the-art prosthetic limbs can help people with amputations achieve a natural walking gait, but they don’t give the user full neural control over the limb. Instead, they rely on robotic sensors and controllers that move the limb using predefined gait algorithms.
Using a new type of surgical intervention and neuroprosthetic interface, MIT researchers, in collaboration with colleagues from Brigham and Women’s Hospital, have shown that a natural walking gait is achievable using a prosthetic leg fully driven by the body’s own nervous system. The surgical amputation procedure reconnects muscles in the residual limb, which allows patients to receive “proprioceptive” feedback about where their prosthetic limb is in space.
In a study of seven patients who had this surgery, the MIT team found that they were able to walk faster, avoid obstacles, and climb stairs much more naturally than people with a traditional amputation.
“This is the first prosthetic study in history that shows a leg prosthesis under full neural modulation, where a biomimetic gait emerges. No one has been able to show this level of brain control that produces a natural gait, where the human’s nervous system is controlling the movement, not a robotic control algorithm,” says Hugh Herr, a professor of media arts and sciences, co-director of the K. Lisa Yang Center for Bionics at MIT, an associate member of MIT’s McGovern Institute for Brain Research, and the senior author of the new study.
Patients also experienced less pain and less muscle atrophy following this surgery, which is known as the agonist-antagonist myoneural interface (AMI). So far, about 60 patients around the world have received this type of surgery, which can also be done for people with arm amputations.
Hyungeun Song, a postdoc in MIT’s Media Lab, is the lead author of the paper, which appears today in Nature Medicine.
Sensory feedback
Most limb movement is controlled by pairs of muscles that take turns stretching and contracting. During a traditional below-the-knee amputation, the interactions of these paired muscles are disrupted. This makes it very difficult for the nervous system to sense the position of a muscle and how fast it’s contracting — sensory information that is critical for the brain to decide how to move the limb.
People with this kind of amputation may have trouble controlling their prosthetic limb because they can’t accurately sense where the limb is in space. Instead, they rely on robotic controllers built into the prosthetic limb. These limbs also include sensors that can detect and adjust to slopes and obstacles.
To try to help people achieve a natural gait under full nervous system control, Herr and his colleagues began developing the AMI surgery several years ago. Instead of severing natural agonist-antagonist muscle interactions, they connect the two ends of the muscles so that they still dynamically communicate with each other within the residual limb. This surgery can be done during a primary amputation, or the muscles can be reconnected after the initial amputation as part of a revision procedure.
“With the AMI amputation procedure, to the greatest extent possible, we attempt to connect native agonists to native antagonists in a physiological way so that after amputation, a person can move their full phantom limb with physiologic levels of proprioception and range of movement,” Herr says.
In a 2021 study, Herr’s lab found that patients who had this surgery were able to more precisely control the muscles of their amputated limb, and that those muscles produced electrical signals similar to those from their intact limb.
After those encouraging results, the researchers set out to explore whether those electrical signals could generate commands for a prosthetic limb and at the same time give the user feedback about the limb’s position in space. The person wearing the prosthetic limb could then use that proprioceptive feedback to volitionally adjust their gait as needed.
In the new Nature Medicine study, the MIT team found this sensory feedback did indeed translate into a smooth, near-natural ability to walk and navigate obstacles.
“Because of the AMI neuroprosthetic interface, we were able to boost that neural signaling, preserving as much as we could. This was able to restore a person's neural capability to continuously and directly control the full gait, across different walking speeds, stairs, slopes, even going over obstacles,” Song says.
A natural gait
For this study, the researchers compared seven people who had the AMI surgery with seven who had traditional below-the-knee amputations. All of the subjects used the same type of bionic limb: a prosthesis with a powered ankle as well as electrodes that can sense electromyography (EMG) signals from the tibialis anterior the gastrocnemius muscles. These signals are fed into a robotic controller that helps the prosthesis calculate how much to bend the ankle, how much torque to apply, or how much power to deliver.
The researchers tested the subjects in several different situations: level-ground walking across a 10-meter pathway, walking up a slope, walking down a ramp, walking up and down stairs, and walking on a level surface while avoiding obstacles.
In all of these tasks, the people with the AMI neuroprosthetic interface were able to walk faster — at about the same rate as people without amputations — and navigate around obstacles more easily. They also showed more natural movements, such as pointing the toes of the prosthesis upward while going up stairs or stepping over an obstacle, and they were better able to coordinate the movements of their prosthetic limb and their intact limb. They were also able to push off the ground with the same amount of force as someone without an amputation.
“With the AMI cohort, we saw natural biomimetic behaviors emerge,” Herr says. “The cohort that didn’t have the AMI, they were able to walk, but the prosthetic movements weren’t natural, and their movements were generally slower.”
These natural behaviors emerged even though the amount of sensory feedback provided by the AMI was less than 20 percent of what would normally be received in people without an amputation.
“One of the main findings here is that a small increase in neural feedback from your amputated limb can restore significant bionic neural controllability, to a point where you allow people to directly neurally control the speed of walking, adapt to different terrain, and avoid obstacles,” Song says.
“This work represents yet another step in us demonstrating what is possible in terms of restoring function in patients who suffer from severe limb injury. It is through collaborative efforts such as this that we are able to make transformational progress in patient care,” says Matthew Carty, a surgeon at Brigham and Women’s Hospital and associate professor at Harvard Medical School, who is also an author of the paper.
Enabling neural control by the person using the limb is a step toward Herr’s lab’s goal of “rebuilding human bodies,” rather than having people rely on ever more sophisticated robotic controllers and sensors — tools that are powerful but do not feel like part of the user’s body.
“The problem with that long-term approach is that the user would never feel embodied with their prosthesis. They would never view the prosthesis as part of their body, part of self,” Herr says. “The approach we’re taking is trying to comprehensively connect the brain of the human to the electromechanics.”
The research was funded by the MIT K. Lisa Yang Center for Bionics and the Eunice Kennedy Shriver National Institute of Child Health and Human Development.
A material with a high electron mobility is like a highway without traffic. Any electrons that flow into the material experience a commuter’s dream, breezing through without any obstacles or congestion to slow or scatter them off their path.
The higher a material’s electron mobility, the more efficient its electrical conductivity, and the less energy is lost or wasted as electrons zip through. Advanced materials that exhibit high electron mobility will be essential for more efficient and sustainable electronic devices that can do more work with less power.
Now, physicists at MIT, the Army Research Lab, and elsewhere have achieved a record-setting level of electron mobility in a thin film of ternary tetradymite — a class of mineral that is naturally found in deep hydrothermal deposits of gold and quartz.
For this study, the scientists grew pure, ultrathin films of the material, in a way that minimized defects in its crystalline structure. They found that this nearly perfect film — much thinner than a human hair — exhibits the highest electron mobility in its class.
The team was able to estimate the material’s electron mobility by detecting quantum oscillations when electric current passes through. These oscillations are a signature of the quantum mechanical behavior of electrons in a material. The researchers detected a particular rhythm of oscillations that is characteristic of high electron mobility — higher than any ternary thin films of this class to date.
“Before, what people had achieved in terms of electron mobility in these systems was like traffic on a road under construction — you’re backed up, you can’t drive, it’s dusty, and it’s a mess,” says Jagadeesh Moodera, a senior research scientist in MIT’s Department of Physics. “In this newly optimized material, it’s like driving on the Mass Pike with no traffic.”
The team’s results, which appear today in the journal Materials Today Physics, point to ternary tetradymite thin films as a promising material for future electronics, such as wearable thermoelectric devices that efficiently convert waste heat into electricity. (Tetradymites are the active materials that cause the cooling effect in commercial thermoelectric coolers.) The material could also be the basis for spintronic devices, which process information using an electron’s spin, using far less power than conventional silicon-based devices.
The study also uses quantum oscillations as a highly effective tool for measuring a material’s electronic performance.
“We are using this oscillation as a rapid test kit,” says study author Hang Chi, a former research scientist at MIT who is now at the University of Ottawa. “By studying this delicate quantum dance of electrons, scientists can start to understand and identify new materials for the next generation of technologies that will power our world.”
Chi and Moodera’s co-authors include Patrick Taylor, formerly of MIT Lincoln Laboratory, along with Owen Vail and Harry Hier of the Army Research Lab, and Brandi Wooten and Joseph Heremans of Ohio State University.
Beam down
The name “tetradymite” derives from the Greek “tetra” for “four,” and “dymite,” meaning “twin.” Both terms describe the mineral’s crystal structure, which consists of rhombohedral crystals that are “twinned” in groups of four — i.e. they have identical crystal structures that share a side.
Tetradymites comprise combinations of bismuth, antimony tellurium, sulfur, and selenium. In the 1950s, scientists found that tetradymites exhibit semiconducting properties that could be ideal for thermoelectric applications: The mineral in its bulk crystal form was able to passively convert heat into electricity.
Then, in the 1990s, the late Institute Professor Mildred Dresselhaus proposed that the mineral’s thermoelectric properties might be significantly enhanced, not in its bulk form but within its microscopic, nanometer-scale surface, where the interactions of electrons is more pronounced. (Heremans happened to work in Dresselhaus’ group at the time.)
“It became clear that when you look at this material long enough and close enough, new things will happen,” Chi says. “This material was identified as a topological insulator, where scientists could see very interesting phenomena on their surface. But to keep uncovering new things, we have to master the material growth.”
To grow thin films of pure crystal, the researchers employed molecular beam epitaxy — a method by which a beam of molecules is fired at a substrate, typically in a vacuum, and with precisely controlled temperatures. When the molecules deposit on the substrate, they condense and build up slowly, one atomic layer at a time. By controlling the timing and type of molecules deposited, scientists can grow ultrathin crystal films in exact configurations, with few if any defects.
“Normally, bismuth and tellurium can interchange their position, which creates defects in the crystal,” co-author Taylor explains. “The system we used to grow these films came down with me from MIT Lincoln Laboratory, where we use high purity materials to minimize impurities to undetectable limits. It is the perfect tool to explore this research.”
Free flow
The team grew thin films of ternary tetradymite, each about 100 nanometers thin. They then tested the film’s electronic properties by looking for Shubnikov-de Haas quantum oscillations — a phenomenon that was discovered by physicists Lev Shubnikov and Wander de Haas, who found that a material’s electrical conductivity can oscillate when exposed to a strong magnetic field at low temperatures. This effect occurs because the material’s electrons fill up specific energy levels that shift as the magnetic field changes.
Such quantum oscillations could serve as a signature of a material’s electronic structure, and the ways in which electrons behave and interact. Most notably for the MIT team, the oscillations could determine a material’s electron mobility: If oscillations exist, it must mean that the material’s electrical resistance is able to change, and by inference, electrons can be mobile, and made to easily flow.
The team looked for signs of quantum oscillations in their new films, by first exposing them to ultracold temperatures and a strong magnetic field, then running an electric current through the film and measuring the voltage along its path, as they tuned the magnetic field up and down.
“It turns out, to our great joy and excitement, that the material’s electrical resistance oscillates,” Chi says. “Immediately, that tells you that this has very high electron mobility.”
Specifically, the team estimates that the ternary tetradymite thin film exhibits an electron mobility of 10,000 cm2/V-s — the highest mobility of any ternary tetradymite film yet measured. The team suspects that the film’s record mobility has something to do with its low defects and impurities, which they were able to minimize with their precise growth strategies. The fewer a material’s defects, the fewer obstacles an electron encounters, and the more freely it can flow.
“This is showing it’s possible to go a giant step further, when properly controlling these complex systems,” Moodera says. “This tells us we’re in the right direction, and we have the right system to proceed further, to keep perfecting this material down to even much thinner films and proximity coupling for use in future spintronics and wearable thermoelectric devices.”
This research was supported in part by the Army Research Office, National Science Foundation, Office of Naval Research, Canada Research Chairs Program and Natural Sciences and Engineering Research Council of Canada.
Artificial intelligence models often play a role in medical diagnoses, especially when it comes to analyzing images such as X-rays. However, studies have found that these models don’t always perform well across all demographic groups, usually faring worse on women and people of color.
These models have also been shown to develop some surprising abilities. In 2022, MIT researchers reported that AI models can make accurate predictions about a patient’s race from their chest X-rays — something that the most skilled radiologists can’t do.
That research team has now found that the models that are most accurate at making demographic predictions also show the biggest “fairness gaps” — that is, discrepancies in their ability to accurately diagnose images of people of different races or genders. The findings suggest that these models may be using “demographic shortcuts” when making their diagnostic evaluations, which lead to incorrect results for women, Black people, and other groups, the researchers say.
“It’s well-established that high-capacity machine-learning models are good predictors of human demographics such as self-reported race or sex or age. This paper re-demonstrates that capacity, and then links that capacity to the lack of performance across different groups, which has never been done,” says Marzyeh Ghassemi, an MIT associate professor of electrical engineering and computer science, a member of MIT’s Institute for Medical Engineering and Science, and the senior author of the study.
The researchers also found that they could retrain the models in a way that improves their fairness. However, their approached to “debiasing” worked best when the models were tested on the same types of patients they were trained on, such as patients from the same hospital. When these models were applied to patients from different hospitals, the fairness gaps reappeared.
“I think the main takeaways are, first, you should thoroughly evaluate any external models on your own data because any fairness guarantees that model developers provide on their training data may not transfer to your population. Second, whenever sufficient data is available, you should train models on your own data,” says Haoran Zhang, an MIT graduate student and one of the lead authors of the new paper. MIT graduate student Yuzhe Yang is also a lead author of the paper, which appears today in Nature Medicine. Judy Gichoya, an associate professor of radiology and imaging sciences at Emory University School of Medicine, and Dina Katabi, the Thuan and Nicole Pham Professor of Electrical Engineering and Computer Science at MIT, are also authors of the paper.
Removing bias
As of May 2024, the FDA has approved 882 AI-enabled medical devices, with 671 of them designed to be used in radiology. Since 2022, when Ghassemi and her colleagues showed that these diagnostic models can accurately predict race, they and other researchers have shown that such models are also very good at predicting gender and age, even though the models are not trained on those tasks.
“Many popular machine learning models have superhuman demographic prediction capacity — radiologists cannot detect self-reported race from a chest X-ray,” Ghassemi says. “These are models that are good at predicting disease, but during training are learning to predict other things that may not be desirable.”
In this study, the researchers set out to explore why these models don’t work as well for certain groups. In particular, they wanted to see if the models were using demographic shortcuts to make predictions that ended up being less accurate for some groups. These shortcuts can arise in AI models when they use demographic attributes to determine whether a medical condition is present, instead of relying on other features of the images.
Using publicly available chest X-ray datasets from Beth Israel Deaconess Medical Center in Boston, the researchers trained models to predict whether patients had one of three different medical conditions: fluid buildup in the lungs, collapsed lung, or enlargement of the heart. Then, they tested the models on X-rays that were held out from the training data.
Overall, the models performed well, but most of them displayed “fairness gaps” — that is, discrepancies between accuracy rates for men and women, and for white and Black patients.
The models were also able to predict the gender, race, and age of the X-ray subjects. Additionally, there was a significant correlation between each model’s accuracy in making demographic predictions and the size of its fairness gap. This suggests that the models may be using demographic categorizations as a shortcut to make their disease predictions.
The researchers then tried to reduce the fairness gaps using two types of strategies. For one set of models, they trained them to optimize “subgroup robustness,” meaning that the models are rewarded for having better performance on the subgroup for which they have the worst performance, and penalized if their error rate for one group is higher than the others.
In another set of models, the researchers forced them to remove any demographic information from the images, using “group adversarial” approaches. Both strategies worked fairly well, the researchers found.
“For in-distribution data, you can use existing state-of-the-art methods to reduce fairness gaps without making significant trade-offs in overall performance,” Ghassemi says. “Subgroup robustness methods force models to be sensitive to mispredicting a specific group, and group adversarial methods try to remove group information completely.”
Not always fairer
However, those approaches only worked when the models were tested on data from the same types of patients that they were trained on — for example, only patients from the Beth Israel Deaconess Medical Center dataset.
When the researchers tested the models that had been “debiased” using the BIDMC data to analyze patients from five other hospital datasets, they found that the models’ overall accuracy remained high, but some of them exhibited large fairness gaps.
“If you debias the model in one set of patients, that fairness does not necessarily hold as you move to a new set of patients from a different hospital in a different location,” Zhang says.
This is worrisome because in many cases, hospitals use models that have been developed on data from other hospitals, especially in cases where an off-the-shelf model is purchased, the researchers say.
“We found that even state-of-the-art models which are optimally performant in data similar to their training sets are not optimal — that is, they do not make the best trade-off between overall and subgroup performance — in novel settings,” Ghassemi says. “Unfortunately, this is actually how a model is likely to be deployed. Most models are trained and validated with data from one hospital, or one source, and then deployed widely.”
The researchers found that the models that were debiased using group adversarial approaches showed slightly more fairness when tested on new patient groups than those debiased with subgroup robustness methods. They now plan to try to develop and test additional methods to see if they can create models that do a better job of making fair predictions on new datasets.
The findings suggest that hospitals that use these types of AI models should evaluate them on their own patient population before beginning to use them, to make sure they aren’t giving inaccurate results for certain groups.
The research was funded by a Google Research Scholar Award, the Robert Wood Johnson Foundation Harold Amos Medical Faculty Development Program, RSNA Health Disparities, the Lacuna Fund, the Gordon and Betty Moore Foundation, the National Institute of Biomedical Imaging and Bioengineering, and the National Heart, Lung, and Blood Institute.
MIT researchers have found that artificial intelligence models that are most accurate at predicting race and gender from X-ray images also show the biggest “fairness gaps.”
Researchers from MIT and the University of Michigan have discovered a new way to drive chemical reactions that could generate a wide variety of compounds with desirable pharmaceutical properties.
These compounds, known as azetidines, are characterized by four-membered rings that include nitrogen. Azetidines have traditionally been much more difficult to synthesize than five-membered nitrogen-containing rings, which are found in many FDA-approved drugs.
The reaction that the researchers used to create azetidines is driven by a photocatalyst that excites the molecules from their ground energy state. Using computational models that they developed, the researchers were able to predict compounds that can react with each other to form azetidines using this kind of catalysis.
“Going forward, rather than using a trial-and-error process, people can prescreen compounds and know beforehand which substrates will work and which ones won't,” says Heather Kulik, an associate professor of chemistry and chemical engineering at MIT.
Kulik and Corinna Schindler, a professor of chemistry at the University of Michigan, are the senior authors of the study, which appears today in Science. Emily Wearing, recently a graduate student at the University of Michigan, is the lead author of the paper. Other authors include University of Michigan postdoc Yu-Cheng Yeh, MIT graduate student Gianmarco Terrones, University of Michigan graduate student Seren Parikh, and MIT postdoc Ilia Kevlishvili.
Light-driven synthesis
Many naturally occurring molecules, including vitamins, nucleic acids, enzymes and hormones, contain five-membered nitrogen-containing rings, also known as nitrogen heterocycles. These rings are also found in more than half of all FDA-approved small-molecule drugs, including many antibiotics and cancer drugs.
Four-membered nitrogen heterocycles, which are rarely found in nature, also hold potential as drug compounds. However, only a handful of existing drugs, including penicillin, contain four-membered heterocycles, in part because these four-membered rings are much more difficult to synthesize than five-membered heterocycles.
In recent years, Schindler’s lab has been working on synthesizing azetidines using light to drive a reaction that combines two precursors, an alkene and an oxime. These reactions require a photocatalyst, which absorbs light and passes the energy to the reactants, making it possible for them to react with each other.
“The catalyst can transfer that energy to another molecule, which moves the molecules into excited states and makes them more reactive. This is a tool that people are starting to use to make it possible to make certain reactions occur that wouldn't normally occur,” Kulik says.
Schindler’s lab found that while this reaction sometimes worked well, other times it did not, depending on which reactants were used. They enlisted Kulik, an expert in developing computational approaches to modeling chemical reactions, to help them figure out how to predict when these reactions will occur.
The two labs hypothesized that whether a particular alkene and oxime will react together in a photocatalyzed reaction depends on a property known as the frontier orbital energy match. Electrons that surround the nucleus of an atom exist in orbitals, and quantum mechanics can be used to predict the shape and energies of these orbitals. For chemical reactions, the most important electrons are those in the outermost, highest energy (“frontier”) orbitals, which are available to react with other molecules.
Kulik and her students used density functional theory, which uses the Schrödinger equation to predict where electrons could be and how much energy they have, to calculate the orbital energy of these outermost electrons.
These energy levels are also affected by other groups of atoms attached to the molecule, which can change the properties of the electrons in the outermost orbitals.
Once those energy levels are calculated, the researchers can identify reactants that have similar energy levels when the photocatalyst boosts them into an excited state. When the excited states of an alkene and an oxime are closely matched, less energy is required to boost the reaction to its transition state — the point at which the reaction has enough energy to go forward to form products.
Accurate predictions
After calculating the frontier orbital energies for 16 different alkenes and nine oximes, the researchers used their computational model to predict whether 18 different alkene-oxime pairs would react together to form an azetidine. With the calculations in hand, these predictions can be made in a matter of seconds.
The researchers also modeled a factor that influences the overall yield of the reaction: a measure of how available the carbon atoms in the oxime are to participate in chemical reactions.
The model’s predictions suggested that some of these 18 reactions won’t occur or won’t give a high enough yield. However, the study also showed that a significant number of reactions are correctly predicted to work.
“Based on our model, there's a much wider range of substrates for this azetidine synthesis than people thought before. People didn't really think that all of this was accessible,” Kulik says.
Of the 27 combinations that they studied computationally, the researchers tested 18 reactions experimentally, and they found that most of their predictions were accurate. Among the compounds they synthesized were derivatives of two drug compounds that are currently FDA-approved: amoxapine, an antidepressant, and indomethacin, a pain reliever used to treat arthritis.
This computational approach could help pharmaceutical companies predict molecules that will react together to form potentially useful compounds, before spending a lot of money to develop a synthesis that might not work, Kulik says. She and Schindler are continuing to work together on other kinds of novel syntheses, including the formation of compounds with three-membered rings.
“Using photocatalysts to excite substrates is a very active and hot area of development, because people have exhausted what you can do on the ground state or with radical chemistry,” Kulik says. “I think this approach is going to have a lot more applications to make molecules that are normally thought of as really challenging to make.”
Drug development is typically slow: The pipeline from basic research discoveries that provide the basis for a new drug to clinical trials and then production of a widely available medicine can take decades. But decades can feel impossibly far off to someone who currently has a fatal disease. Broad Institute of MIT and Harvard Senior Group Leader Sonia Vallabh is acutely aware of that race against time, because the topic of her research is a neurodegenerative and ultimately fatal disease — fatal familial insomnia, a type of prion disease — that she will almost certainly develop as she ages.
Vallabh and her husband, Eric Minikel, switched careers and became researchers after they learned that Vallabh carries a disease-causing version of the prion protein gene and that there is no effective therapy for fatal prion diseases. The two now run a lab at the Broad Institute, where they are working to develop drugs that can prevent and treat these diseases, and their deadline for success is not based on grant cycles or academic expectations but on the ticking time bomb in Vallabh’s genetic code.
That is why Vallabh was excited to discover, when she entered into a collaboration with Whitehead Institute for Biomedical Research member Jonathan Weissman, that Weissman’s group likes to work at full throttle. In less than two years, Weissman, Vallabh, and their collaborators have developed a set of molecular tools called CHARMs that can turn off disease-causing genes such as the prion protein gene — as well as, potentially, genes coding for many other proteins implicated in neurodegenerative and other diseases — and they are refining those tools to be good candidates for use in human patients. Although the tools still have many hurdles to pass before the researchers will know if they work as therapeutics, the team is encouraged by the speed with which they have developed the technology thus far.
“The spirit of the collaboration since the beginning has been that there was no waiting on formality,” Vallabh says. “As soon as we realized our mutual excitement to do this, everything was off to the races.”
Co-corresponding authors Weissman and Vallabh and co-first authors Edwin Neumann, a graduate student in Weissman’s lab, and Tessa Bertozzi, a postdoc in Weissman’s lab, describe CHARM — which stands for Coupled Histone tail for Autoinhibition Release of Methyltransferase — in a paper published today in the journal Science.
“With the Whitehead and Broad Institutes right next door to each other, I don’t think there’s any better place than this for a group of motivated people to move quickly and flexibly in the pursuit of academic science and medical technology,” says Weissman, who is also a professor of biology at MIT and a Howard Hughes Medical Institute Investigator. “CHARMs are an elegant solution to the problem of silencing disease genes, and they have the potential to have an important position in the future of genetic medicines.”
To treat a genetic disease, target the gene
Prion disease, which leads to swift neurodegeneration and death, is caused by the presence of misshapen versions of the prion protein. These cause a cascade effect in the brain: the faulty prion proteins deform other proteins, and together these proteins not only stop functioning properly but also form toxic aggregates that kill neurons. The most famous type of prion disease, known colloquially as mad cow disease, is infectious, but other forms of prion disease can occur spontaneously or be caused by faulty prion protein genes.
Most conventional drugs work by targeting a protein. CHARMs, however, work further upstream, turning off the gene that codes for the faulty protein so that the protein never gets made in the first place. CHARMs do this by epigenetic editing, in which a chemical tag gets added to DNA in order to turn off or silence a target gene. Unlike gene editing, epigenetic editing does not modify the underlying DNA — the gene itself remains intact. However, like gene editing, epigenetic editing is stable, meaning that a gene switched off by CHARM should remain off. This would mean patients would only have to take CHARM once, as opposed to protein-targeting medications that must be taken regularly as the cells’ protein levels replenish.
Research in animals suggests that the prion protein isn’t necessary in a healthy adult, and that in cases of disease, removing the protein improves or even eliminates disease symptoms. In a person who hasn’t yet developed symptoms, removing the protein should prevent disease altogether. In other words, epigenetic editing could be an effective approach for treating genetic diseases such as inherited prion diseases. The challenge is creating a new type of therapy.
Fortunately, the team had a good template for CHARM: a research tool called CRISPRoff that Weissman’s group previously developed for silencing genes. CRISPRoff uses building blocks from CRISPR gene editing technology, including the guide protein Cas9 that directs the tool to the target gene. CRISPRoff silences the targeted gene by adding methyl groups, chemical tags that prevent the gene from being transcribed, or read into RNA, and so from being expressed as protein. When the researchers tested CRISPRoff’s ability to silence the prion protein gene, they found that it was effective and stable.
Several of its properties, though, prevented CRISPRoff from being a good candidate for a therapy. The researchers’ goal was to create a tool based on CRISPRoff that was just as potent but also safe for use in humans, small enough to deliver to the brain, and designed to minimize the risk of silencing the wrong genes or causing side effects.
From research tool to drug candidate
Led by Neumann and Bertozzi, the researchers began engineering and applying their new epigenome editor. The first problem that they had to tackle was size, because the editor needs to be small enough to be packaged and delivered to specific cells in the body. Delivering genes into the human brain is challenging; many clinical trials have used adeno-associated viruses (AAVs) as gene-delivery vehicles, but these are small and can only contain a small amount of genetic code. CRISPRoff is way too big; the code for Cas9 alone takes up most of the available space.
The Weissman lab researchers decided to replace Cas9 with a much smaller zinc finger protein (ZFP). Like Cas9, ZFPs can serve as guide proteins to direct the tool to a target site in DNA. ZFPs are also common in human cells, meaning they are less likely to trigger an immune response against themselves than the bacterial Cas9.
Next, the researchers had to design the part of the tool that would silence the prion protein gene. At first, they used part of a methyltransferase, a molecule that adds methyl groups to DNA, called DNMT3A. However, in the particular configuration needed for the tool, the molecule was toxic to the cell. The researchers focused on a different solution: Instead of delivering outside DNMT3A as part of the therapy, the tool is able to recruit the cell’s own DNMT3A to the prion protein gene. This freed up precious space inside of the AAV vector and prevented toxicity.
The researchers also needed to activate DNMT3A. In the cell, DNMT3A is usually inactive until it interacts with certain partner molecules. This default inactivity prevents accidental methylation of genes that need to remain turned on. Neumann came up with an ingenious way around this by combining sections of DNMT3A’s partner molecules and connecting these to ZFPs that bring them to the prion protein gene. When the cell’s DNMT3A comes across this combination of parts, it activates, silencing the gene.
“From the perspectives of both toxicity and size, it made sense to recruit the machinery that the cell already has; it was a much simpler, more elegant solution,” Neumann says. “Cells are already using methyltransferases all of the time, and we’re essentially just tricking them into turning off a gene that they would normally leave turned on.”
Testing in mice showed that ZFP-guided CHARMs could eliminate more than 80 percent of the prion protein in the brain, while previous research has shown that as little as 21 percent elimination can improve symptoms.
Once the researchers knew that they had a potent gene silencer, they turned to the problem of off-target effects. The genetic code for a CHARM that gets delivered to a cell will keep producing copies of the CHARM indefinitely. However, after the prion protein gene is switched off, there is no benefit to this, only more time for side effects to develop, so they tweaked the tool so that after it turns off the prion protein gene, it then turns itself off.
Meanwhile, a complementary project from Broad Institute scientist and collaborator Benjamin Deverman’s lab, focused on brain-wide gene delivery and published in Science on May 17, has brought the CHARM technology one step closer to being ready for clinical trials. Although naturally occurring types of AAV have been used for gene therapy in humans before, they do not enter the adult brain efficiently, making it impossible to treat a whole-brain disease like prion disease. Tackling the delivery problem, Deverman’s group has designed an AAV vector that can get into the brain more efficiently by leveraging a pathway that naturally shuttles iron into the brain. Engineered vectors like this one make a therapy like CHARM one step closer to reality.
Thanks to these creative solutions, the researchers now have a highly effective epigenetic editor that is small enough to deliver to the brain, and that appears in cell culture and animal testing to have low toxicity and limited off-target effects.
“It’s been a privilege to be part of this; it’s pretty rare to go from basic research to therapeutic application in such a short amount of time,” Bertozzi says. “I think the key was forming a collaboration that took advantage of the Weissman lab’s tool-building experience, the Vallabh and Minikel lab’s deep knowledge of the disease, and the Deverman lab’s expertise in gene delivery.”
Looking ahead
With the major elements of the CHARM technology solved, the team is now fine-tuning their tool to make it more effective, safer, and easier to produce at scale, as will be necessary for clinical trials. They have already made the tool modular, so that its various pieces can be swapped out and future CHARMs won’t have to be programmed from scratch. CHARMs are also currently being tested as therapeutics in mice.
The path from basic research to clinical trials is a long and winding one, and the researchers know that CHARMs still have a way to go before they might become a viable medical option for people with prion diseases, including Vallabh, or other diseases with similar genetic components. However, with a strong therapy design and promising laboratory results in hand, the researchers have good reason to be hopeful. They continue to work at full throttle, intent on developing their technology so that it can save patients’ lives not someday, but as soon as possible.
CHARM — which stands for Coupled Histone tail for Autoinhibition Release of Methyltransferase — can turn off disease-causing genes such as the prion protein gene, and potentially genes coding for many other proteins implicated in neurodegenerative and other diseases.
Fotini Christia, the Ford International Professor of Social Sciences in the Department of Political Science, has been named the new director of the Institute for Data, Systems, and Society (IDSS), effective July 1.
“Fotini is well-positioned to guide IDSS into the next chapter. With her tenure as the director of the Sociotechnical Systems Research Center and as an associate director of IDSS since 2020, she has actively forged connections between the social sciences, data science, and computation,” says Daniel Huttenlocher, dean of the MIT Schwarzman College of Computing and the Henry Ellis Warren Professor of Electrical Engineering and Computer Science. “I eagerly anticipate the ways in which she will advance and champion IDSS in alignment with the spirit and mission of the Schwarzman College of Computing.”
“Fotini’s profound expertise as a social scientist and her adept use of data science, computational tools, and novel methodologies to grasp the dynamics of societal evolution across diverse fields, makes her a natural fit to lead IDSS,” says Asu Ozdaglar, deputy dean of the MIT Schwarzman College of Computing and head of the Department of Electrical Engineering and Computer Science.
Christia’s research has focused on issues of conflict and cooperation in the Muslim world, for which she has conducted fieldwork in Afghanistan, Bosnia, Iraq, the Palestinian Territories, and Yemen, among others. More recently, her research has been directed at examining how to effectively integrate artificial intelligence tools in public policy.
She was appointed the director of the Sociotechnical Systems Research Center (SSRC) and an associate director of IDSS in October 2020. SSRC, an interdisciplinary center housed within IDSS in the MIT Schwarzman College of Computing, focuses on the study of high-impact, complex societal challenges that shape our world.
As part of IDSS, she is co-organizer of a cross-disciplinary research effort, the Initiative on Combatting Systemic Racism. Bringing together faculty and researchers from all of MIT’s five schools and the college, the initiative builds on extensive social science literature on systemic racism and uses big data to develop and harness computational tools that can help effect structural and normative change toward racial equity across housing, health care, policing, and social media. Christia is also chair of IDSS’s doctoral program in Social and Engineering Systems.
Christia is the author of “Alliance Formation in Civil War” (Cambridge University Press, 2012), which was awarded the Luebbert Award for Best Book in Comparative Politics, the Lepgold Prize for Best Book in International Relations, and a Distinguished Book Award from the International Studies Association. She is co-editor with Graeme Blair (University of California, Los Angeles) and Jeremy Weinstein (incoming dean at Harvard Kennedy School) of “Crime, Insecurity, and Community Policing: Experiments on Building Trust,” forthcoming in August 2024 with Cambridge University Press.
Her research has also appeared in Science, Nature Human Behavior, Review of Economic Studies, American Economic Journal: Applied Economics, NeurIPs, Communications Medicine, IEEE Transactions on Network Science and Engineering, American Political Science Review, and Annual Review of Political Science, among other journals. Her opinion pieces have been published in Foreign Affairs, The New York Times, The Washington Post, and The Boston Globe, among other outlets.
A native of Greece, where she grew up in the port city of Salonika, Christia moved to the United States to attend college at Columbia University. She graduated magna cum laude in 2001 with a joint BA in economics–operations research and an MA in international affairs. She joined the MIT faculty in 2008 after receiving her PhD in public policy from Harvard University.
Christia succeeds Noelle Selin, a professor in IDSS and the Department of Earth, Atmospheric, and Planetary Sciences. Selin has led IDSS as interim director for the 2023-24 academic year since July 2023, following Professor Martin Wainwright.
“I am incredibly grateful to Noelle for serving as interim director this year. Her contributions in this role, as well as her time leading the Technology and Policy Program, have been invaluable. I’m delighted she will remain part of the IDSS community as a faculty member,” says Huttenlocher.
Fotini Christia, the Ford International Professor of Social Sciences in the Department of Political Science, has been named director of the Institute for Data, Systems, and Society.
The growing prevalence of high-speed wireless communication devices, from 5G mobile phones to sensors for autonomous vehicles, is leading to increasingly crowded airwaves. This makes the ability to block interfering signals that can hamper device performance an even more important — and more challenging — problem.
With these and other emerging applications in mind, MIT researchers demonstrated a new millimeter-wave multiple-input-multiple-output (MIMO) wireless receiver architecture that can handle stronger spatial interference than previous designs. MIMO systems have multiple antennas, enabling them to transmit and receive signals from different directions. Their wireless receiver senses and blocks spatial interference at the earliest opportunity, before unwanted signals have been amplified, which improves performance.
Key to this MIMO receiver architecture is a special circuit that can target and cancel out unwanted signals, known as a nonreciprocal phase shifter. By making a novel phase shifter structure that is reconfigurable, low-power, and compact, the researchers show how it can be used to cancel out interference earlier in the receiver chain.
Their receiver can block up to four times more interference than some similar devices. In addition, the interference-blocking components can be switched on and off as needed to conserve energy.
In a mobile phone, such a receiver could help mitigate signal quality issues that can lead to slow and choppy Zoom calling or video streaming.
“There is already a lot of utilization happening in the frequency ranges we are trying to use for new 5G and 6G systems. So, anything new we are trying to add should already have these interference-mitigation systems installed. Here, we’ve shown that using a nonreciprocal phase shifter in this new architecture gives us better performance. This is quite significant, especially since we are using the same integrated platform as everyone else,” says Negar Reiskarimian, the X-Window Consortium Career Development Assistant Professor in the Department of Electrical Engineering and Computer Science (EECS), a member of the Microsystems Technology Laboratories and Research Laboratory of Electronics (RLE), and the senior author of a paper on this receiver.
Reiskarimian wrote the paper with EECS graduate students Shahabeddin Mohin, who is the lead author, Soroush Araei, and Mohammad Barzgari, an RLE postdoc. The work was recently presented at the IEEE Radio Frequency Circuits Symposium and received the Best Student Paper Award.
Blocking interference
Digital MIMO systems have an analog and a digital portion. The analog portion uses antennas to receive signals, which are amplified, down-converted, and passed through an analog-to-digital converter before being processed in the digital domain of the device. In this case, digital beamforming is required to retrieve the desired signal.
But if a strong, interfering signal coming from a different direction hits the receiver at the same time as a desired signal, it can saturate the amplifier so the desired signal is drowned out. Digital MIMOs can filter out unwanted signals, but this filtering occurs later in the receiver chain. If the interference is amplified along with the desired signal, it is more difficult to filter out later.
“The output of the initial low-noise amplifier is the first place you can do this filtering with minimal penalty, so that is exactly what we are doing with our approach,” Reiskarimian says.
The researchers built and installed four nonreciprocal phase shifters immediately at the output of the first amplifier in each receiver chain, all connected to the same node. These phase shifters can pass signal in both directions and sense the angle of an incoming interfering signal. The devices can adjust their phase until they cancel out the interference.
The phase of these devices can be precisely tuned, so they can sense and cancel an unwanted signal before it passes to the rest of the receiver, blocking interference before it affects any other parts of the receiver. In addition, the phase shifters can follow signals to continue blocking interference if it changes location.
“If you start getting disconnected or your signal quality goes down, you can turn this on and mitigate that interference on the fly. Because ours is a parallel approach, you can turn it on and off with minimal effect on the performance of the receiver itself,” Reiskarimian adds.
A compact device
In addition to making their novel phase shifter architecture tunable, the researchers designed them to use less space on the chip and consume less power than typical nonreciprocal phase shifters.
Once the researchers had done the analysis to show their idea would work, their biggest challenge was translating the theory into a circuit that achieved their performance goals. At the same time, the receiver had to meet strict size restrictions and a tight power budget, or it wouldn’t be useful in real-world devices.
In the end, the team demonstrated a compact MIMO architecture on a 3.2-square-millimeter chip that could block signals which were up to four times stronger than what other devices could handle. Simpler than typical designs, their phase shifter architecture is also more energy efficient.
Moving forward, the researchers want to scale up their device to larger systems, as well as enable it to perform in the new frequency ranges utilized by 6G wireless devices. These frequency ranges are prone to powerful interference from satellites. In addition, they would like to adapt nonreciprocal phase shifters to other applications.
This research was supported, in part, by the MIT Center for Integrated Circuits and Systems.
A butterfly’s wing is covered in hundreds of thousands of tiny scales like miniature shingles on a paper-thin roof. A single scale is as small as a speck of dust yet surprisingly complex, with a corrugated surface of ridges that help to wick away water, manage heat, and reflect light to give a butterfly its signature shimmer.
MIT researchers have now captured the initial moments during a butterfly’s metamorphosis, as an individual scale begins to develop this ridged pattern. The researchers used advanced imaging techniques to observe the microscopic features on a developing wing, while the butterfly transformed in its chrysalis.
The team continuously imaged individual scales as they grew out from the wing’s membrane. These images reveal for the first time how a scale’s initially smooth surface begins to wrinkle to form microscopic, parallel undulations. The ripple-like structures eventually grow into finely patterned ridges, which define the functions of an adult scale.
The researchers found that the scale’s transition to a corrugated surface is likely a result of “buckling” — a general mechanism that describes how a smooth surface wrinkles as it grows within a confined space.
“Buckling is an instability, something that we usually don’t want to happen as engineers,” says Mathias Kolle, associate professor of mechanical engineering at MIT. “But in this context, the organism uses buckling to initiate the growth of these intricate, functional structures.”
The team is working to visualize more stages of butterfly wing growth in hopes of revealing clues to how they might design advanced functional materials in the future.
“Given the multifunctionality of butterfly scales, we hope to understand and emulate these processes, with the aim of sustainably designing and fabricating new functional materials. These materials would exhibit tailored optical, thermal, chemical, and mechanical properties for textiles, building surfaces, vehicles — really, for generally any surface that needs to exhibit characteristics that depend on its micro- and nanoscale structure,” Kolle adds.
The team has published their results in a study appearing today in the journal Cell Reports Physical Science. The study’s co-authors include first author and former MIT postdoc Jan Totz, joint first author and postdoc Anthony McDougal, graduate student Leonie Wagner, former postdoc Sungsam Kang, professor of mechanical engineering and biomedical engineering Peter So, professor of mathematics Jörn Dunkel, and professor of material physics and chemistry Bodo Wilts of the University of Salzburg.
A live transformation
In 2021, McDougal, Kolle and their colleagues developed an approach to continuously capture microscopic details of wing growth in a butterfly during its metamorphosis. Their method involved carefully cutting through the insect’s paper-thin chrysalis and peeling away a small square of cuticle to reveal the wing’s growing membrane. They placed a small glass slide over the exposed area, then used a microscope technique developed by team member Peter So to capture continuous images of scales as they grew out of the wing membrane.
They applied the method to observe Vanessa cardui, a butterfly commonly known as a Painted Lady, which the team chose for its scale architecture, which is common to most lepidopteran species. They observed that Painted Lady scales grew along a wing membrane in precise, overlapping rows, like shingles on a rooftop. Those images provided scientists with the most continuous visualization of live butterfly wing scale growth at the microscale to date.
In their new study, the team used the same approach to focus on a specific time window during scale development, to capture the initial formation of the finely structured ridges that run along a single scale in a living butterfly. Scientists know that these ridges, which run parallel to each other along the length of a single scale, like stripes in a patch of corduroy, enable many of the functions of the wing scales.
Since little is known about how these ridges are formed, the MIT team aimed to record the continuous formation of ridges in a live, developing butterfly, and decipher the organism’s ridge formation mechanisms.
“We watched the wing develop over 10 days, and got thousands of measurements of how the surfaces of scales changed on a single butterfly,” McDougal says. “We could see that early on, the surface is quite flat. As the butterfly grows, the surface begins to pop up a little bit, and then at around 41 percent of development, we see this very regular pattern of completely popped up protoridges. This whole process happens over about five hours and lays the structural foundation for the subsequent expression of patterned ridges."
Pinned down
What might be causing the initial ridges to pop up in precise alignment? The researchers suspected that buckling might be at play. Buckling is a mechanical process by which a material bows in on itself as it is subjected to compressive forces. For instance, an empty soda can buckles when squeezed from the top, down. A material can also buckle as it grows, if it is constrained, or pinned in place.
Scientists have noted that, as the cell membrane of a butterfly’s scale grows, it is effectively pinned in certain places by actin bundles — long filaments that run under the growing membrane and act as a scaffold to support the scale as it takes shape. Scientists have hypothesized that actin bundles constrain a growing membrane, similar to ropes around an inflating hot air balloon. As the butterfly’s wing scale grows, they proposed, it would bulge out between the underlying actin filaments, buckling in a way that forms a scale’s initial, parallel ridges.
To test this idea, the MIT team looked to a theoretical model that describes the general mechanics of buckling. They incorporated image data into the model, such as measurements of a scale membrane’s height at various early stages of development, and various spacings of actin bundles across a growing membrane. They then ran the model forward in time to see whether its underlying principles of mechanical buckling would produce the same ridge patterns that the team observed in the actual butterfly.
“With this modeling, we showed that we could go from a flat surface to a more undulating surface,” Kolle says. “In terms of mechanics, this indicates that buckling of the membrane is very likely what’s initiating the formation of these amazingly ordered ridges.”
“We want to learn from nature, not only how these materials function, but also how they’re formed,” McDougal says. “If you want to for instance make a wrinkled surface, which is useful for a variety of applications, this gives you two really easy knobs to tune, to tailor how those surfaces are wrinkled. You could either change the spacing of where that material is pinned, or you could change the amount of material that you grow between the pinned sections. And we saw that the butterfly is using both of these strategies.”
This research was supported, in part, by the International Human Frontier Science Program Organization, the National Science Foundation, the Humboldt Foundation, and the Alfred P. Sloan Foundation.
Leaders from MIT, Harvard University, and Mass General Brigham gathered Monday to celebrate an important new chapter in the Ragon Institute’s quest to harness the immune system to prevent and cure human diseases.
The ceremony marked the opening of the new building for the Ragon Institute of Mass General, MIT, and Harvard, located at 600 Main Street in the heart of Cambridge’s Kendall Square, where its multidisciplinary group of researchers will expand on the collaborations that have proven impactful since the Institute’s founding in 2009.
“Fifteen years ago, the Ragon Institute started with transformative philanthropy from Terry and Susan Ragon,” Ragon Institute Director and MIT professor of the practice Bruce Walker said. “Initially, it was an experiment: Could we bring together scientists, engineers, and medical doctors to pool their creative knowledge and cross-disciplinary specialties to make advances against the greatest global health problems of our time? Now, 15 years later, here we are celebrating the success of that experiment and welcoming the next phase of the Ragon Institute.”
The institute’s new building features five floors of cutting-edge, dedicated lab space and more than double the floor area of the previous facilities. The open, centralized layout of the new building is designed to empower cross-disciplinary research and enable discoveries that will lead to new ways to prevent, detect, and cure diseases. The expanded space will also allow the Ragon Institute to bring in more scientists, researchers, biologists, clinicians, postdocs, and operational staff.
“Cross-disciplinary collaboration is a hallmark of the Ragon Institute, and that is really how you do transformational research and breakthrough science at scale — what everyone talks about but few actually achieve,” said Mass General Brigham President and CEO Anne Klibanski. “Partnerships between health care and academia accelerate these breakthroughs and foster innovation. That is the model of scientific discovery this whole area represents, that Boston and Massachusetts represent, and that this institute represents.”
In addition to state-of-the-art lab space, a third of the new building is open for public use. The Ragon Institute’s leaders expressed a commitment to engaging with the local Cambridge community and believe the institute’s success will further strengthen Kendall Square’s innovation ecosystem.
“As a relative newcomer, I see this elegant new building as an inspiring vote of confidence in the future of Kendall Square,” MIT President Sally Kornbluth said. “I gather that over a few decades, thanks in part to many of you here today, Kendall Square was transformed from a declining postindustrial district to the center of a region that is arguably the biotech capital of the world. I believe we now have an opportunity to secure its future, to make sure Kendall Square becomes an infinitely self-renewing source of biomedical progress, a limitless creative pool perpetually refreshed by a stream of new ideas from every corner of the life sciences and engineering to unlock solutions to the most important problems of our time. This building and this institute embody that vision.”
The Ragon Institute is a collaborative effort of Mass General Brigham, MIT, and Harvard. It was founded in 2009 through support from the Phillip T. and Susan M. Ragon Foundation with the initial goal of developing an HIV vaccine. Since then, it has expanded to focus on other global health initiatives — from playing a vital role in Covid-19 vaccine development to exploring the rising health challenges of climate change and preparing for the next pandemic.
The institute strives to break down siloes between scientists, engineers, and clinicians from diverse disciplines to apply all available knowledge to the fight against diseases of global importance.
During the ceremony, Phillip (Terry) Ragon ’72 discussed the origins of the Institute and his vision for accelerating scientific discovery.
“With Bruce [Walker], I began to see how philanthropy could really make a difference and how we could power a different model that we thought could be particularly effective,” Ragon said. “The fundamental idea was to take an approach like the Manhattan Project, bringing the best and brightest people together from different disciplines, with flexible funding, and leave them to be successful. And so here we are today.”
Ragon Institute faculty are engaged in challenges as varied as developing vaccines for tuberculosis and HIV, cures for malaria, treatments for neuroimmunological diseases, a universal flu vaccine, and therapies for cancer and autoimmune disorders — with the potential to impact billions of lives.
The new building’s opening followed additional funding from Terry and Susan Ragon, which came in recognition of the Ragon Institute’s expanding mission.
“[Through this partnership], we’ve accomplished more than we realized we could, and that’s shown in the scientific progress that the Ragon Institute has achieved,” said Harvard University interim president Alan Garber. “To pull this off requires not only scientific brilliance, but true leadership.”
Walker, the Institute’s founding director, has spent his entire career caring for people living with HIV and studying how the body fights back. He has helped establish two cutting-edge research institutes in Africa, which continue to train the next generation of African scientists. The international reach of the Ragon Institute is another aspect that sets it apart in its mission to impact human health.
“Today we launch the next 100 years of the Ragon Institute, and we’re fortunate to work every day on this enormously challenging and consistently inspiring mission,” Walker said. “We’re motivated by the belief that every day matters, that our efforts will ultimately alleviate suffering, that our mission is urgent, and that together, we will succeed.”
Titan, Saturn’s largest moon, is the only planetary body in the solar system besides our own that currently hosts active rivers, lakes, and seas. Titan’s otherworldly river systems are thought to be filled with liquid methane and ethane that flows into wide lakes and seas, some as large as the Great Lakes on Earth.
The existence of Titan’s large seas and smaller lakes was confirmed in 2007, with images taken by NASA’s Cassini spacecraft. Since then, scientists have pored over those and other images for clues to the moon’s mysterious liquid environment.
Now, MIT geologists have studied Titan’s shorelines and shown through simulations that the moon’s large seas have likely been shaped by waves. Until now, scientists have found indirect and conflicting signs of wave activity, based on remote images of Titan’s surface.
The MIT team took a different approach to investigate the presence of waves on Titan, by first modeling the ways in which a lake can erode on Earth. They then applied their modeling to Titan’s seas to determine what form of erosion could have produced the shorelines in Cassini’s images. Waves, they found, were the most likely explanation.
The researchers emphasize that their results are not definitive; to confirm that there are waves on Titan will require direct observations of wave activity on the moon’s surface.
“We can say, based on our results, that if the coastlines of Titan’s seas have eroded, waves are the most likely culprit,” says Taylor Perron, the Cecil and Ida Green Professor of Earth, Atmospheric and Planetary Sciences at MIT. “If we could stand at the edge of one of Titan’s seas, we might see waves of liquid methane and ethane lapping on the shore and crashing on the coasts during storms. And they would be capable of eroding the material that the coast is made of.”
Perron and his colleagues, including first author Rose Palermo PhD ’22, a former MIT-WHOI Joint Program graduate student and current research geologist at the U.S. Geological Survey, have published their study today in Science Advances. Their co-authors include MIT Research Scientist Jason Soderblom; former MIT postdoc Sam Birch, now an assistant professor at Brown University; Andrew Ashton at the Woods Hole Oceanographic Institution; and Alexander Hayes of Cornell University.
“Taking a different tack”
The presence of waves on Titan has been a somewhat controversial topic ever since Cassini spotted bodies of liquid on the moon’s surface.
“Some people who tried to see evidence for waves didn’t see any, and said, ‘These seas are mirror-smooth,’” Palermo says. “Others said they did see some roughness on the liquid surface but weren’t sure if waves caused it.”
Knowing whether Titan’s seas host wave activity could give scientists information about the moon’s climate, such as the strength of the winds that could whip up such waves. Wave information could also help scientists predict how the shape of Titan’s seas might evolve over time.
Rather than look for direct signs of wave-like features in images of Titan, Perron says the team had to “take a different tack, and see, just by looking at the shape of the shoreline, if we could tell what’s been eroding the coasts.”
Titan’s seas are thought to have formed as rising levels of liquid flooded a landscape crisscrossed by river valleys. The researchers zeroed in on three scenarios for what could have happened next: no coastal erosion; erosion driven by waves; and “uniform erosion,” driven either by “dissolution,” in which liquid passively dissolves a coast’s material, or a mechanism in which the coast gradually sloughs off under its own weight.
The researchers simulated how various shoreline shapes would evolve under each of the three scenarios. To simulate wave-driven erosion, they took into account a variable known as “fetch,” which describes the physical distance from one point on a shoreline to the opposite side of a lake or sea.
“Wave erosion is driven by the height and angle of the wave,” Palermo explains. “We used fetch to approximate wave height because the bigger the fetch, the longer the distance over which wind can blow and waves can grow.”
To test how shoreline shapes would differ between the three scenarios, the researchers started with a simulated sea with flooded river valleys around its edges. For wave-driven erosion, they calculated the fetch distance from every single point along the shoreline to every other point, and converted these distances to wave heights. Then, they ran their simulation to see how waves would erode the starting shoreline over time. They compared this to how the same shoreline would evolve under erosion driven by uniform erosion. The team repeated this comparative modeling for hundreds of different starting shoreline shapes.
They found that the end shapes were very different depending on the underlying mechanism. Most notably, uniform erosion produced inflated shorelines that widened evenly all around, even in the flooded river valleys, whereas wave erosion mainly smoothed the parts of the shorelines exposed to long fetch distances, leaving the flooded valleys narrow and rough.
“We had the same starting shorelines, and we saw that you get a really different final shape under uniform erosion versus wave erosion,” Perron says. “They all kind of look like the Flying Spaghetti Monster because of the flooded river valleys, but the two types of erosion produce very different endpoints.”
The team checked their results by comparing their simulations to actual lakes on Earth. They found the same difference in shape between Earth lakes known to have been eroded by waves and lakes affected by uniform erosion, such as dissolving limestone.
A shore’s shape
Their modeling revealed clear, characteristic shoreline shapes, depending on the mechanism by which they evolved. The team then wondered: Where would Titan’s shorelines fit, within these characteristic shapes?
In particular, they focused on four of Titan’s largest, most well-mapped seas: Kraken Mare, which is comparable in size to the Caspian Sea; Ligeia Mare, which is larger than Lake Superior; Punga Mare, which is longer than Lake Victoria; and Ontario Lacus, which is about 20 percent the size of its terrestrial namesake.
The team mapped the shorelines of each Titan sea using Cassini’s radar images, and then applied their modeling to each of the sea’s shorelines to see which erosion mechanism best explained their shape. They found that all four seas fit solidly in the wave-driven erosion model, meaning that waves produced shorelines that most closely resembled Titan’s four seas.
“We found that if the coastlines have eroded, their shapes are more consistent with erosion by waves than by uniform erosion or no erosion at all,” Perron says.
Juan Felipe Paniagua-Arroyave, associate professor in the School of Applied Sciences and Engineering at EAFIT University in Colombia, says the team’s results are “unlocking new avenues of understanding.”
“Waves are ubiquitous on Earth’s oceans. If Titan has waves, they would likely dominate the surface of lakes,” says Paniagua-Arroyave, who was not involved in the study. ”It would be fascinating to see how Titan’s winds create waves, not of water, but of exotic liquid hydrocarbons.”The researchers are working to determine how strong Titan’s winds must be in order to stir up waves that could repeatedly chip away at the coasts. They also hope to decipher, from the shape of Titan’s shorelines, from which directions the wind is predominantly blowing.
“Titan presents this case of a completely untouched system,” Palermo says. “It could help us learn more fundamental things about how coasts erode without the influence of people, and maybe that can help us better manage our coastlines on Earth in the future.”
This work was supported, in part, by NASA, the National Science Foundation, the U.S. Geological Survey, and the Heising-Simons Foundation.
Imagine driving through a tunnel in an autonomous vehicle, but unbeknownst to you, a crash has stopped traffic up ahead. Normally, you’d need to rely on the car in front of you to know you should start braking. But what if your vehicle could see around the car ahead and apply the brakes even sooner?
Researchers from MIT and Meta have developed a computer vision technique that could someday enable an autonomous vehicle to do just that.
They have introduced a method that creates physically accurate, 3D models of an entire scene, including areas blocked from view, using images from a single camera position. Their technique uses shadows to determine what lies in obstructed portions of the scene.
They call their approach PlatoNeRF, based on Plato’s allegory of the cave, a passage from the Greek philosopher’s “Republic”in which prisoners chained in a cave discern the reality of the outside world based on shadows cast on the cave wall.
By combining lidar (light detection and ranging) technology with machine learning, PlatoNeRF can generate more accurate reconstructions of 3D geometry than some existing AI techniques. Additionally, PlatoNeRF is better at smoothly reconstructing scenes where shadows are hard to see, such as those with high ambient light or dark backgrounds.
In addition to improving the safety of autonomous vehicles, PlatoNeRF could make AR/VR headsets more efficient by enabling a user to model the geometry of a room without the need to walk around taking measurements. It could also help warehouse robots find items in cluttered environments faster.
“Our key idea was taking these two things that have been done in different disciplines before and pulling them together — multibounce lidar and machine learning. It turns out that when you bring these two together, that is when you find a lot of new opportunities to explore and get the best of both worlds,” says Tzofi Klinghoffer, an MIT graduate student in media arts and sciences, research assistant in the Camera Culture Group of the MIT Media Lab, and lead author of a paper on PlatoNeRF.
Klinghoffer wrote the paper with his advisor, Ramesh Raskar, associate professor of media arts and sciences and leader of the Camera Culture Group at MIT; senior author Rakesh Ranjan, a director of AI research at Meta Reality Labs; as well as Siddharth Somasundaram, a research assistant in the Camera Culture Group, and Xiaoyu Xiang, Yuchen Fan, and Christian Richardt at Meta. The research will be presented at the Conference on Computer Vision and Pattern Recognition.
Shedding light on the problem
Reconstructing a full 3D scene from one camera viewpoint is a complex problem.
Some machine-learning approaches employ generative AI models that try to guess what lies in the occluded regions, but these models can hallucinate objects that aren’t really there. Other approaches attempt to infer the shapes of hidden objects using shadows in a color image, but these methods can struggle when shadows are hard to see.
For PlatoNeRF, the MIT researchers built off these approaches using a new sensing modality called single-photon lidar. Lidars map a 3D scene by emitting pulses of light and measuring the time it takes that light to bounce back to the sensor. Because single-photon lidars can detect individual photons, they provide higher-resolution data.
The researchers use a single-photon lidar to illuminate a target point in the scene. Some light bounces off that point and returns directly to the sensor. However, most of the light scatters and bounces off other objects before returning to the sensor. PlatoNeRF relies on these second bounces of light.
By calculating how long it takes light to bounce twice and then return to the lidar sensor, PlatoNeRF captures additional information about the scene, including depth. The second bounce of light also contains information about shadows.
The system traces the secondary rays of light — those that bounce off the target point to other points in the scene — to determine which points lie in shadow (due to an absence of light). Based on the location of these shadows, PlatoNeRF can infer the geometry of hidden objects.
The lidar sequentially illuminates 16 points, capturing multiple images that are used to reconstruct the entire 3D scene.
“Every time we illuminate a point in the scene, we are creating new shadows. Because we have all these different illumination sources, we have a lot of light rays shooting around, so we are carving out the region that is occluded and lies beyond the visible eye,” Klinghoffer says.
A winning combination
Key to PlatoNeRF is the combination of multibounce lidar with a special type of machine-learning model known as a neural radiance field (NeRF). A NeRF encodes the geometry of a scene into the weights of a neural network, which gives the model a strong ability to interpolate, or estimate, novel views of a scene.
This ability to interpolate also leads to highly accurate scene reconstructions when combined with multibounce lidar, Klinghoffer says.
“The biggest challenge was figuring out how to combine these two things. We really had to think about the physics of how light is transporting with multibounce lidar and how to model that with machine learning,” he says.
They compared PlatoNeRF to two common alternative methods, one that only uses lidar and the other that only uses a NeRF with a color image.
They found that their method was able to outperform both techniques, especially when the lidar sensor had lower resolution. This would make their approach more practical to deploy in the real world, where lower resolution sensors are common in commercial devices.
“About 15 years ago, our group invented the first camera to ‘see’ around corners, that works by exploiting multiple bounces of light, or ‘echoes of light.’ Those techniques used special lasers and sensors, and used three bounces of light. Since then, lidar technology has become more mainstream, that led to our research on cameras that can see through fog. This new work uses only two bounces of light, which means the signal to noise ratio is very high, and 3D reconstruction quality is impressive,” Raskar says.
In the future, the researchers want to try tracking more than two bounces of light to see how that could improve scene reconstructions. In addition, they are interested in applying more deep learning techniques and combining PlatoNeRF with color image measurements to capture texture information.
“While camera images of shadows have long been studied as a means to 3D reconstruction, this work revisits the problem in the context of lidar, demonstrating significant improvements in the accuracy of reconstructed hidden geometry. The work shows how clever algorithms can enable extraordinary capabilities when combined with ordinary sensors — including the lidar systems that many of us now carry in our pocket,” says David Lindell, an assistant professor in the Department of Computer Science at the University of Toronto, who was not involved with this work.
Plato-NeRF is a computer vision system that combines lidar measurements with machine learning to reconstruct a 3D scene, including hidden objects, from only one camera view by exploiting shadows. Here, the system accurately models the rabbit in the chair, even though that rabbit is blocked from view.
Observing anything and everything within the human brain, no matter how large or small, while it is fully intact has been an out-of-reach dream of neuroscience for decades. But in a new study in Science, an MIT-based team describes a technology pipeline that enabled them to finely process, richly label, and sharply image full hemispheres of the brains of two donors — one with Alzheimer’s disease and one without — at high resolution and speed.
“We performed holistic imaging of human brain tissues at multiple resolutions, from single synapses to whole brain hemispheres, and we have made that data available,” says senior and corresponding author Kwanghun Chung, associate professor the MIT departments of Chemical Engineering and Brain and Cognitive Sciences and member of The Picower Institute for Learning and Memory and the Institute for Medical Engineering and Science. “This technology pipeline really enables us to analyze the human brain at multiple scales. Potentially this pipeline can be used for fully mapping human brains.”
The new study does not present a comprehensive map or atlas of the entire brain, in which every cell, circuit, and protein is identified and analyzed. But with full hemispheric imaging, it demonstrates an integrated suite of three technologies to enable that and other long-sought neuroscience investigations. The research provides a “proof of concept” by showing numerous examples of what the pipeline makes possible, including sweeping landscapes of thousands of neurons within whole brain regions; diverse forests of cells, each in individual detail; and tufts of subcellular structures nestled among extracellular molecules. The researchers also present a rich variety of quantitative analytical comparisons focused on a chosen region within the Alzheimer’s and non-Alzheimer’s hemispheres.
The importance of being able to image whole hemispheres of human brains intact and down to the resolution of individual synapses (the teeny connections that neurons forge to make circuits) is two-fold for understanding the human brain in health and disease, Chung says.
Superior samples
On one hand, it will enable scientists to conduct integrated explorations of questions using the same brain, rather than having to (for example) observe different phenomena in different brains, which can vary significantly, and then try to construct a composite picture of the whole system. A key feature of the new technology pipeline is that analysis doesn’t degrade the tissue. On the contrary, it makes the tissues extremely durable and repeatedly re-labelable to highlight different cells or molecules as needed for new studies for potentially years on end. In the paper, Chung’s team demonstrates using 20 different antibody labels to highlight different cells and proteins, but they are already expanding that to a hundred or more.
“We need to be able to see all these different functional components — cells, their morphology and their connectivity, subcellular architectures, and their individual synaptic connections — ideally within the same brain, considering the high individual variabilities in the human brain and considering the precious nature of human brain samples,” Chung says. “This technology pipeline really enables us to extract all these important features from the same brain in a fully integrated manner.”
On the other hand, the pipeline’s relatively high scalability and throughput (imaging a whole brain hemisphere once it is prepared takes 100 hours, rather than many months) means that it is possible to create many samples to represent different sexes, ages, disease states, and other factors that can enable robust comparisons with increased statistical power. Chung says he envisions creating a brain bank of fully imaged brains that researchers could analyze and re-label as needed for new studies to make more of the kinds of comparisons he and co-authors made with the Alzheimer’s and non-Alzheimer’s hemispheres in the new paper.
Three key innovations
Chung says the biggest challenge he faced in achieving the advances described in the paper was building a team at MIT that included three especially talented young scientists, each a co-lead author of the paper because of their key roles in producing the three major innovations. Ji Wang, a mechanical engineer and former postdoc, developed the “Megatome,” a device for slicing intact human brain hemispheres so finely that there is no damage to them. Juhyuk Park, a materials engineer and former postdoc, developed the chemistry that makes each brain slice clear, flexible, durable, expandable, and quickly, evenly, and repeatedly labelable — a technology called “mELAST.” Webster Guan, a former MIT chemical engineering graduate student with a knack for software development, created a computational system called “UNSLICE” that can seamlessly reunify the slabs to reconstruct each hemisphere in full 3D, down to the precise alignment of individual blood vessels and neural axons (the long strands they extend to forge connections with other neurons).
No technology allows for imaging whole human brain anatomy at subcellular resolution without first slicing it, because it is very thick (it’s 3,000 times the volume of a mouse brain) and opaque. But in the Megatome, tissue remains undamaged because Wang, who is now at a company Chung founded called LifeCanvas Technologies, engineered its blade to vibrate side-to-side faster, and yet sweep wider, than previous vibratome slicers. Meanwhile she also crafted the instrument to stay perfectly within its plane, Chung says. The result are slices that don’t lose anatomical information at their separation or anywhere else. And because the vibratome cuts relatively quickly and can cut thicker (and therefore fewer) slabs of tissue, a whole hemisphere can be sliced in a day, rather than months.
A major reason why slabs in the pipeline can be thicker comes from mELAST. Park engineered the hydrogel that infuses the brain sample to make it optically clear, virtually indestructible, and compressible and expandable. Combined with other chemical engineering technologies developed in recent years in Chung’s lab, the samples can then be evenly and quickly infused with the antibody labels that highlight cells and proteins of interest. Using a light sheet microscope the lab customized, a whole hemisphere can be imaged down to individual synapses in about 100 hours, the authors report in the study. Park is now an assistant professor at Seoul National University in South Korea.
“This advanced polymeric network, which fine-tunes the physicochemical properties of tissues, enabled multiplexed multiscale imaging of the intact human brains,” Park says.
After each slab has been imaged, the task is then to restore an intact picture of the whole hemisphere computationally. Guan’s UNSLICE does this at multiple scales. For instance, at the middle, or “meso” scale, it algorithmically traces blood vessels coming into one layer from adjacent layers and matches them. But it also takes an even finer approach. To further register the slabs, the team purposely labeled neighboring neural axons in different colors (like the wires in an electrical fixture). That enabled UNSLICE to match layers up based on tracing the axons, Chung says. Guan is also now at LifeCanvas.
In the study, the researchers present a litany of examples of what the pipeline can do. The very first figure demonstrates that the imaging allows one to richly label a whole hemisphere and then zoom in from the wide scale of brainwide structures to the level of circuits, then individual cells, and then subcellular components, such as synapses. Other images and videos demonstrate how diverse the labeling can be, revealing long axonal connections and the abundance and shape of different cell types including not only neurons but also astrocytes and microglia.
Exploring Alzheimer’s
For years, Chung has collaborated with co-author Matthew Frosch, an Alzheimer’s researcher and director of the brain bank at Massachusetts General Hospital, to image and understand Alzheimer’s disease brains. With the new pipeline established they began an open-ended exploration, first noticing where within a slab of tissue they saw the greatest loss of neurons in the disease sample compared to the control. From there, they followed their curiosity — as the technology allowed them to do — ultimately producing a series of detailed investigations described in the paper.
“We didn’t lay out all these experiments in advance,” Chung says. “We just started by saying, ‘OK, let’s image this slab and see what we see.’ We identified brain regions with substantial neuronal loss so let’s see what’s happening there. ‘Let’s dive deeper.’ So we used many different markers to characterize and see the relationships between pathogenic factors and different cell types.
“This pipeline allows us to have almost unlimited access to the tissue,” Chung says. “We can always go back and look at something new.”
They focused most of their analysis in the orbitofrontal cortex within each hemisphere. One of the many observations they made was that synapse loss was concentrated in areas where there was direct overlap with amyloid plaques. Outside of areas of plaques the synapse density was as high in the brain with Alzheimer’s as in the one without the disease.
With just two samples, Chung says, the team is not offering any conclusions about the nature of Alzheimer’s disease, of course, but the point of the study is that the capability now exists to fully image and deeply analyze whole human brain hemispheres to enable exactly that kind of research.
Notably, the technology applies equally well to many other tissues in the body, not just brains.
“We envision that this scalable technology platform will advance our understanding of the human organ functions and disease mechanisms to spur development of new therapies,” the authors conclude.
In addition to Park, Wang, Guan, Chung, and Frosch, the paper’s other authors are Lars A. Gjesteby, Dylan Pollack, Lee Kamentsky, Nicholas B. Evans, Jeff Stirman, Xinyi Gu, Chuanxi Zhao, Slayton Marx, Minyoung E. Kim, Seo Woo Choi, Michael Snyder, David Chavez, Clover Su-Arcaro, Yuxuan Tian, Chang Sin Park, Qiangge Zhang, Dae Hee Yun, Mira Moukheiber, Guoping Feng, X. William Yang, C. Dirk Keene, Patrick R. Hof, Satrajit S. Ghosh, and Laura J. Brattain.
The main funding for the work came from the National Institutes of Health, The Picower Institute for Learning and Memory, The JPB Foundation, and the NCSOFT Cultural Foundation.
An MIT-led team has developed a series of technologies to image and analyze the brain at scales ranging from a whole brain hemisphere down to individual neural connections and proteins. In this still frame from a video (see below), two kinds of neurons (calretinin-expressing in cyan and somatostatin-expressing in magenta) are visible in the prefrontal cortex of a human brain.
You’ve likely heard that a picture is worth a thousand words, but can a large language model (LLM) get the picture if it’s never seen images before?
As it turns out, language models that are trained purely on text have a solid understanding of the visual world. They can write image-rendering code to generate complex scenes with intriguing objects and compositions — and even when that knowledge is not used properly, LLMs can refine their images. Researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) observed this when prompting language models to self-correct their code for different images, where the systems improved on their simple clipart drawings with each query.
The visual knowledge of these language models is gained from how concepts like shapes and colors are described across the internet, whether in language or code. When given a direction like “draw a parrot in the jungle,” users jog the LLM to consider what it’s read in descriptions before. To assess how much visual knowledge LLMs have, the CSAIL team constructed a “vision checkup” for LLMs: using their “Visual Aptitude Dataset,” they tested the models’ abilities to draw, recognize, and self-correct these concepts. Collecting each final draft of these illustrations, the researchers trained a computer vision system that identifies the content of real photos.
“We essentially train a vision system without directly using any visual data,” says Tamar Rott Shaham, co-lead author of the study and an MIT electrical engineering and computer science (EECS) postdoc at CSAIL. “Our team queried language models to write image-rendering codes to generate data for us and then trained the vision system to evaluate natural images. We were inspired by the question of how visual concepts are represented through other mediums, like text. To express their visual knowledge, LLMs can use code as a common ground between text and vision.”
To build this dataset, the researchers first queried the models to generate code for different shapes, objects, and scenes. Then, they compiled that code to render simple digital illustrations, like a row of bicycles, showing that LLMs understand spatial relations well enough to draw the two-wheelers in a horizontal row. As another example, the model generated a car-shaped cake, combining two random concepts. The language model also produced a glowing light bulb, indicating its ability to create visual effects.
“Our work shows that when you query an LLM (without multimodal pre-training) to create an image, it knows much more than it seems,” says co-lead author, EECS PhD student, and CSAIL member Pratyusha Sharma. “Let’s say you asked it to draw a chair. The model knows other things about this piece of furniture that it may not have immediately rendered, so users can query the model to improve the visual it produces with each iteration. Surprisingly, the model can iteratively enrich the drawing by improving the rendering code to a significant extent.”
The researchers gathered these illustrations, which were then used to train a computer vision system that can recognize objects within real photos (despite never having seen one before). With this synthetic, text-generated data as its only reference point, the system outperforms other procedurally generated image datasets that were trained with authentic photos.
The CSAIL team believes that combining the hidden visual knowledge of LLMs with the artistic capabilities of other AI tools like diffusion models could also be beneficial. Systems like Midjourney sometimes lack the know-how to consistently tweak the finer details in an image, making it difficult for them to handle requests like reducing how many cars are pictured, or placing an object behind another. If an LLM sketched out the requested change for the diffusion model beforehand, the resulting edit could be more satisfactory.
The irony, as Rott Shaham and Sharma acknowledge, is that LLMs sometimes fail to recognize the same concepts that they can draw. This became clear when the models incorrectly identified human re-creations of images within the dataset. Such diverse representations of the visual world likely triggered the language models’ misconceptions.
While the models struggled to perceive these abstract depictions, they demonstrated the creativity to draw the same concepts differently each time. When the researchers queried LLMs to draw concepts like strawberries and arcades multiple times, they produced pictures from diverse angles with varying shapes and colors, hinting that the models might have actual mental imagery of visual concepts (rather than reciting examples they saw before).
The CSAIL team believes this procedure could be a baseline for evaluating how well a generative AI model can train a computer vision system. Additionally, the researchers look to expand the tasks they challenge language models on. As for their recent study, the MIT group notes that they don’t have access to the training set of the LLMs they used, making it challenging to further investigate the origin of their visual knowledge. In the future, they intend to explore training an even better vision model by letting the LLM work directly with it.
Sharma and Rott Shaham are joined on the paper by former CSAIL affiliate Stephanie Fu ’22, MNG ’23 and EECS PhD students Manel Baradad, Adrián Rodríguez-Muñoz ’22, and Shivam Duggal, who are all CSAIL affiliates; as well as MIT Associate Professor Phillip Isola and Professor Antonio Torralba. Their work was supported, in part, by a grant from the MIT-IBM Watson AI Lab, a LaCaixa Fellowship, the Zuckerman STEM Leadership Program, and the Viterbi Fellowship. They present their paper this week at the IEEE/CVF Computer Vision and Pattern Recognition Conference.
Text-based large language models can be prompted to code better illustrations, implying that they have a solid visual knowledge of the world around them.
The use of AI to streamline drug discovery is exploding. Researchers are deploying machine-learning models to help them identify molecules, among billions of options, that might have the properties they are seeking to develop new medicines.
But there are so many variables to consider — from the price of materials to the risk of something going wrong — that even when scientists use AI, weighing the costs of synthesizing the best candidates is no easy task.
The myriad challenges involved in identifying the best and most cost-efficient molecules to test is one reason new medicines take so long to develop, as well as a key driver of high prescription drug prices.
To help scientists make cost-aware choices, MIT researchers developed an algorithmic framework to automatically identify optimal molecular candidates, which minimizes synthetic cost while maximizing the likelihood candidates have desired properties. The algorithm also identifies the materials and experimental steps needed to synthesize these molecules.
Their quantitative framework, known as Synthesis Planning and Rewards-based Route Optimization Workflow (SPARROW), considers the costs of synthesizing a batch of molecules at once, since multiple candidates can often be derived from some of the same chemical compounds.
Moreover, this unified approach captures key information on molecular design, property prediction, and synthesis planning from online repositories and widely used AI tools.
Beyond helping pharmaceutical companies discover new drugs more efficiently, SPARROW could be used in applications like the invention of new agrichemicals or the discovery of specialized materials for organic electronics.
“The selection of compounds is very much an art at the moment — and at times it is a very successful art. But because we have all these other models and predictive tools that give us information on how molecules might perform and how they might be synthesized, we can and should be using that information to guide the decisions we make,” says Connor Coley, the Class of 1957 Career Development Assistant Professor in the MIT departments of Chemical Engineering and Electrical Engineering and Computer Science, and senior author of a paper on SPARROW.
Coley is joined on the paper by lead author Jenna Fromer SM ’24. The research appears today in Nature Computational Science.
Complex cost considerations
In a sense, whether a scientist should synthesize and test a certain molecule boils down to a question of the synthetic cost versus the value of the experiment. However, determining cost or value are tough problems on their own.
For instance, an experiment might require expensive materials or it could have a high risk of failure. On the value side, one might consider how useful it would be to know the properties of this molecule or whether those predictions carry a high level of uncertainty.
At the same time, pharmaceutical companies increasingly use batch synthesis to improve efficiency. Instead of testing molecules one at a time, they use combinations of chemical building blocks to test multiple candidates at once. However, this means the chemical reactions must all require the same experimental conditions. This makes estimating cost and value even more challenging.
SPARROW tackles this challenge by considering the shared intermediary compounds involved in synthesizing molecules and incorporating that information into its cost-versus-value function.
“When you think about this optimization game of designing a batch of molecules, the cost of adding on a new structure depends on the molecules you have already chosen,” Coley says.
The framework also considers things like the costs of starting materials, the number of reactions that are involved in each synthetic route, and the likelihood those reactions will be successful on the first try.
To utilize SPARROW, a scientist provides a set of molecular compounds they are thinking of testing and a definition of the properties they are hoping to find.
From there, SPARROW collects information on the molecules and their synthetic pathways and then weighs the value of each one against the cost of synthesizing a batch of candidates. It automatically selects the best subset of candidates that meet the user’s criteria and finds the most cost-effective synthetic routes for those compounds.
“It does all this optimization in one step, so it can really capture all of these competing objectives simultaneously,” Fromer says.
A versatile framework
SPARROW is unique because it can incorporate molecular structures that have been hand-designed by humans, those that exist in virtual catalogs, or never-before-seen molecules that have been invented by generative AI models.
“We have all these different sources of ideas. Part of the appeal of SPARROW is that you can take all these ideas and put them on a level playing field,” Coley adds.
The researchers evaluated SPARROW by applying it in three case studies. The case studies, based on real-world problems faced by chemists, were designed to test SPARROW’s ability to find cost-efficient synthesis plans while working with a wide range of input molecules.
They found that SPARROW effectively captured the marginal costs of batch synthesis and identified common experimental steps and intermediate chemicals. In addition, it could scale up to handle hundreds of potential molecular candidates.
“In the machine-learning-for-chemistry community, there are so many models that work well for retrosynthesis or molecular property prediction, for example, but how do we actually use them? Our framework aims to bring out the value of this prior work. By creating SPARROW, hopefully we can guide other researchers to think about compound downselection using their own cost and utility functions,” Fromer says.
In the future, the researchers want to incorporate additional complexity into SPARROW. For instance, they’d like to enable the algorithm to consider that the value of testing one compound may not always be constant. They also want to include more elements of parallel chemistry in its cost-versus-value function.
“The work by Fromer and Coley better aligns algorithmic decision making to the practical realities of chemical synthesis. When existing computational design algorithms are used, the work of determining how to best synthesize the set of designs is left to the medicinal chemist, resulting in less optimal choices and extra work for the medicinal chemist,” says Patrick Riley, senior vice president of artificial intelligence at Relay Therapeutics, who was not involved with this research. “This paper shows a principled path to include consideration of joint synthesis, which I expect to result in higher quality and more accepted algorithmic designs.”
“Identifying which compounds to synthesize in a way that carefully balances time, cost, and the potential for making progress toward goals while providing useful new information is one of the most challenging tasks for drug discovery teams. The SPARROW approach from Fromer and Coley does this in an effective and automated way, providing a useful tool for human medicinal chemistry teams and taking important steps toward fully autonomous approaches to drug discovery,” adds John Chodera, a computational chemist at Memorial Sloan Kettering Cancer Center, who was not involved with this work.
This research was supported, in part, by the DARPA Accelerated Molecular Discovery Program, the Office of Naval Research, and the National Science Foundation.
MIT researchers have identified a new algorithmic framework that automatically identifies the best molecules to test for more streamlined drug discovery.
Large language models like those that power ChatGPT have shown impressive performance on tasks like drafting legal briefs, analyzing the sentiment of customer reviews, or translating documents into different languages.
These machine-learning models typically use only natural language to process information and answer queries, which can make it difficult for them to perform tasks that require numerical or symbolic reasoning.
For instance, a large language model might be able to memorize and recite a list of recent U.S. presidents and their birthdays, but that same model could fail if asked the question “Which U.S. presidents elected after 1950 were born on a Wednesday?” (The answer is Jimmy Carter.)
Researchers from MIT and elsewhere have proposed a new technique that enables large language models to solve natural language, math and data analysis, and symbolic reasoning tasks by generating programs.
Their approach, called natural language embedded programs (NLEPs), involves prompting a language model to create and execute a Python program to solve a user’s query, and then output the solution as natural language.
They found that NLEPs enabled large language models to achieve higher accuracy on a wide range of reasoning tasks. The approach is also generalizable, which means one NLEP prompt can be reused for multiple tasks.
NLEPs also improve transparency, since a user could check the program to see exactly how the model reasoned about the query and fix the program if the model gave a wrong answer.
“We want AI to perform complex reasoning in a way that is transparent and trustworthy. There is still a long way to go, but we have shown that combining the capabilities of programming and natural language in large language models is a very good potential first step toward a future where people can fully understand and trust what is going on inside their AI model,” says Hongyin Luo PhD ’22, an MIT postdoc and co-lead author of a paper on NLEPs.
Luo is joined on the paper by co-lead authors Tianhua Zhang, a graduate student at the Chinese University of Hong Kong; and Jiaxin Ge, an undergraduate at Peking University; Yoon Kim, an assistant professor in MIT’s Department of Electrical Engineering and Computer Science and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL); senior author James Glass, senior research scientist and head of the Spoken Language Systems Group in CSAIL; and others. The research will be presented at the Annual Conference of the North American Chapter of the Association for Computational Linguistics.
Problem-solving with programs
Many popular large language models work by predicting the next word, or token, given some natural language input. While models like GPT-4 can be used to write programs, they embed those programs within natural language, which can lead to errors in the program reasoning or results.
With NLEPs, the MIT researchers took the opposite approach. They prompt the model to generate a step-by-step program entirely in Python code, and then embed the necessary natural language inside the program.
An NLEP is a problem-solving template with four steps. First, the model calls the necessary packages, or functions, it will need to solve the task. Step two involves importing natural language representations of the knowledge the task requires (like a list of U.S. presidents’ birthdays). For step three, the model implements a function that calculates the answer. And for the final step, the model outputs the result as a line of natural language with an automatic data visualization, if needed.
“It is like a digital calculator that always gives you the correct computation result as long as the program is correct,” Luo says.
The user can easily investigate the program and fix any errors in the code directly rather than needing to rerun the entire model to troubleshoot.
The approach also offers greater efficiency than some other methods. If a user has many similar questions, they can generate one core program and then replace certain variables without needing to run the model repeatedly.
To prompt the model to generate an NLEP, the researchers give it an overall instruction to write a Python program, provide two NLEP examples (one with math and one with natural language), and one test question.
“Usually, when people do this kind of few-shot prompting, they still have to design prompts for every task. We found that we can have one prompt for many tasks because it is not a prompt that teaches LLMs to solve one problem, but a prompt that teaches LLMs to solve many problems by writing a program,” says Luo.
“Having language models reason with code unlocks many opportunities for tool use, output validation, more structured understanding into model's capabilities and way of thinking, and more,” says Leonid Karlinsky, principal scientist at the MIT-IBM Watson AI Lab.
“No magic here”
NLEPs achieved greater than 90 percent accuracy when prompting GPT-4 to solve a range of symbolic reasoning tasks, like tracking shuffled objects or playing a game of 24, as well as instruction-following and text classification tasks. The researchers found that NLEPs even exhibited 30 percent greater accuracy than task-specific prompting methods. The method also showed improvements over open-source LLMs.
Along with boosting the accuracy of large language models, NLEPs could also improve data privacy. Since NLEP programs are run locally, sensitive user data do not need to be sent to a company like OpenAI or Google to be processed by a model.
In addition, NLEPs can enable small language models to perform better without the need to retrain a model for a certain task, which can be a costly process.
“There is no magic here. We do not have a more expensive or fancy language model. All we do is use program generation instead of natural language generation, and we can make it perform significantly better,” Luo says.
However, an NLEP relies on the program generation capability of the model, so the technique does not work as well for smaller models which have been trained on limited datasets. In the future, the researchers plan to study methods that could make smaller language models generate more effective NLEPs. In addition, they want to investigate the impact of prompt variations on NLEPs to enhance the robustness of the model’s reasoning processes.
This research was supported, in part, by the Center for Perceptual and Interactive Intelligence of Hong Kong.
A new technique enables large language models like GPT-4 to more accurately solve numeric or symbolic reasoning tasks by writing a Python program in code that generates the correct answer to a user’s query.
Neurons communicate electrically, so to understand how they produce such brain functions as memory, neuroscientists must track how their voltage changes — sometimes subtly — on the timescale of milliseconds. In a new open-access paper in Nature Communications,MIT researchers describe a novel image sensor with the capability to substantially increase that ability.
The invention led by Jie Zhang, a postdoc in the lab of Matt Wilson, who is the Sherman Fairchild Professor at MIT and member of The Picower Institute for Learning and Memory, is a new take on the standard “CMOS” (complementary metal-oxide semiconductor) technology used in scientific imaging. In that standard approach, all pixels turn on and off at the same time — a configuration with an inherent trade-off in which fast sampling means capturing less light. The new chip enables each pixel’s timing to be controlled individually. That arrangement provides a “best of both worlds” in which neighboring pixels can essentially complement each other to capture all the available light without sacrificing speed.
In experiments described in the study, Zhang and Wilson’s team demonstrates how “pixelwise” programmability enabled them to improve visualization of neural voltage “spikes,” which are the signals neurons use to communicate with each other, and even the more subtle, momentary fluctuations in their voltage that constantly occur between those spiking events.
“Measuring with single-spike resolution is really important as part of our research approach,” says senior author Wilson, a professor in MIT’s departments of Biology and Brain and Cognitive Sciences (BCS), whose lab studies how the brain encodes and refines spatial memories both during wakeful exploration and during sleep. “Thinking about the encoding processes within the brain, single spikes and the timing of those spikes is important in understanding how the brain processes information.”
For decades, Wilson has helped to drive innovations in the use of electrodes to tap into neural electrical signals in real time, but like many researchers he has also sought visual readouts of electrical activity because they can highlight large areas of tissue and still show which exact neurons are electrically active at any given moment. Being able to identify which neurons are active can enable researchers to learn which types of neurons are participating in memory processes, providing important clues about how brain circuits work.
In recent years, neuroscientists including co-senior author Ed Boyden, the Y. Eva Tan Professor of Neurotechnology in BCS and the McGovern Institute for Brain Research and a Picower Institute affiliate, have worked to meet that need by inventing “genetically encoded voltage indicators” (GEVIs) that make cells glow as their voltage changes in real time. But as Zhang and Wilson have tried to employ GEVIs in their research, they’ve found that conventional CMOS image sensors were missing a lot of the action. If they operated too fast, they wouldn’t gather enough light. If they operated too slowly, they’d miss rapid changes.
But image sensors have such fine resolution that many pixels are really looking at essentially the same place on the scale of a whole neuron, Wilson says. Recognizing that there was resolution to spare, Zhang applied his expertise in sensor design to invent an image sensor chip that would enable neighboring pixels to each have their own timing. Faster ones could capture rapid changes. Slower-working ones could gather more light. No action or photons would be missed. Zhang also cleverly engineered the required control electronics so they barely cut into the space available for light-sensitive elements on a pixels. This ensured the sensor’s high sensitivity under low light conditions, Zhang says.
In the study the researchers demonstrated two ways in which the chip improved imaging of voltage activity of mouse hippocampus neurons cultured in a dish. They ran their sensor head-to-head against an industry standard scientific CMOS image sensor chip.
In the first set of experiments, the team sought to image the fast dynamics of neural voltage. On the conventional CMOS chip, each pixel had a zippy 1.25 millisecond exposure time. On the pixelwise sensor each pixel in neighboring groups of four stayed on for 5 ms, but their start times were staggered so that each one turned on and off 1.25 seconds later than the next. In the study, the team shows that each pixel, because it was on longer, gathered more light, but because each one was capturing a new view every 1.25 ms, it was equivalent to simply having a fast temporal resolution. The result was a doubling of the signal-to-noise ratio for the pixelwise chip. This achieves high temporal resolution at a fraction of the sampling rate compared to conventional CMOS chips, Zhang says.
Moreover, the pixelwise chip detected neural spiking activities that the conventional sensor missed. And when the researchers compared the performance of each kind of sensor against the electrical readings made with a traditional patch clamp electrode, they found that the staggered pixelwise measurements better matched that of the patch clamp.
In the second set of experiments, the team sought to demonstrate that the pixelwise chip could capture both the fast dynamics and also the slower, more subtle “subthreshold” voltage variances neurons exhibit. To do so they varied the exposure durations of neighboring pixels in the pixelwise chip, ranging from 15.4 ms down to just 1.9 ms. In this way, fast pixels sampled every quick change (albeit faintly), while slower pixels integrated enough light over time to track even subtle slower fluctuations. By integrating the data from each pixel, the chip was indeed able to capture both fast spiking and slower subthreshold changes, the researchers reported.
The experiments with small clusters of neurons in a dish was only a proof of concept, Wilson says. His lab’s ultimate goal is to conduct brain-wide, real-time measurements of activity in distinct types of neurons in animals even as they are freely moving about and learning how to navigate mazes. The development of GEVIs and of image sensors like the pixelwise chip that can successfully take advantage of what they show is crucial to making that goal feasible.
“That’s the idea of everything we want to put together: large-scale voltage imaging of genetically tagged neurons in freely behaving animals,” Wilson says.
To achieve this, Zhang adds, “We are already working on the next iteration of chips with lower noise, higher pixel counts, time-resolution of multiple kHz, and small form factors for imaging in freely behaving animals.”
The research is advancing pixel by pixel.
In addition to Zhang, Wilson, and Boyden, the paper’s other authors are Jonathan Newman, Zeguan Wang, Yong Qian, Pedro Feliciano-Ramos, Wei Guo, Takato Honda, Zhe Sage Chen, Changyang Linghu, Ralph-Etienne Cummings, and Eric Fossum.
The Picower Institute, The JPB Foundation, the Alana Foundation, The Louis B. Thalheimer Fund for Translational Research, the National Institutes of Health, HHMI, Lisa Yang, and John Doerr provided support for the research.
To improve the signal they could gather from imaging an optical readout of the voltage of neurons, researchers invented an image sensor in which each pixel's on-and-off timing and duration can be individually programmed. Each new pixel circuit uses only two additional transistors compared to a conventional CMOS pixel.
In the movie “Jurassic Park,” scientists extracted DNA that had been preserved in amber for millions of years, and used it to create a population of long-extinct dinosaurs.
Inspired partly by that film, MIT researchers have developed a glassy, amber-like polymer that can be used for long-term storage of DNA, whether entire human genomes or digital files such as photos.
Most current methods for storing DNA require freezing temperatures, so they consume a great deal of energy and are not feasible in many parts of the world. In contrast, the new amber-like polymer can store DNA at room temperature while protecting the molecules from damage caused by heat or water.
The researchers showed that they could use this polymer to store DNA sequences encoding the theme music from Jurassic Park, as well as an entire human genome. They also demonstrated that the DNA can be easily removed from the polymer without damaging it.
“Freezing DNA is the number one way to preserve it, but it’s very expensive, and it’s not scalable,” says James Banal, a former MIT postdoc. “I think our new preservation method is going to be a technology that may drive the future of storing digital information on DNA.”
Banal and Jeremiah Johnson, the A. Thomas Geurtin Professor of Chemistry at MIT, are the senior authors of the study, published yesterday in the Journal of the American Chemical Society. Former MIT postdoc Elizabeth Prince and MIT postdoc Ho Fung Cheng are the lead authors of the paper.
Capturing DNA
DNA, a very stable molecule, is well-suited for storing massive amounts of information, including digital data. Digital storage systems encode text, photos, and other kind of information as a series of 0s and 1s. This same information can be encoded in DNA using the four nucleotides that make up the genetic code: A, T, G, and C. For example, G and C could be used to represent 0 while A and T represent 1.
DNA offers a way to store this digital information at very high density: In theory, a coffee mug full of DNA could store all of the world’s data. DNA is also very stable and relatively easy to synthesize and sequence.
In 2021, Banal and his postdoc advisor, Mark Bathe, an MIT professor of biological engineering, developed a way to store DNA in particles of silica, which could be labeled with tags that revealed the particles’ contents. That work led to a spinout called Cache DNA.
One downside to that storage system is that it takes several days to embed DNA into the silica particles. Furthermore, removing the DNA from the particles requires hydrofluoric acid, which can be hazardous to workers handling the DNA.
To come up with alternative storage materials, Banal began working with Johnson and members of his lab. Their idea was to use a type of polymer known as a degradable thermoset, which consists of polymers that form a solid when heated. The material also includes cleavable links that can be easily broken, allowing the polymer to be degraded in a controlled way.
“With these deconstructable thermosets, depending on what cleavable bonds we put into them, we can choose how we want to degrade them,” Johnson says.
For this project, the researchers decided to make their thermoset polymer from styrene and a cross-linker, which together form an amber-like thermoset called cross-linked polystyrene. This thermoset is also very hydrophobic, so it can prevent moisture from getting in and damaging the DNA. To make the thermoset degradable, the styrene monomers and cross-linkers are copolymerized with monomers called thionolactones. These links can be broken by treating them with a molecule called cysteamine.
Because styrene is so hydrophobic, the researchers had to come up with a way to entice DNA — a hydrophilic, negatively charged molecule — into the styrene.
To do that, they identified a combination of three monomers that they could turn into polymers that dissolve DNA by helping it interact with styrene. Each of the monomers has different features that cooperate to get the DNA out of water and into the styrene. There, the DNA forms spherical complexes, with charged DNA in the center and hydrophobic groups forming an outer layer that interacts with styrene. When heated, this solution becomes a solid glass-like block, embedded with DNA complexes.
The researchers dubbed their method T-REX (Thermoset-REinforced Xeropreservation). The process of embedding DNA into the polymer network takes a few hours, but that could become shorter with further optimization, the researchers say.
To release the DNA, the researchers first add cysteamine, which cleaves the bonds holding the polystyrene thermoset together, breaking it into smaller pieces. Then, a detergent called SDS can be added to remove the DNA from polystyrene without damaging it.
Storing information
Using these polymers, the researchers showed that they could encapsulate DNA of varying length, from tens of nucleotides up to an entire human genome (more than 50,000 base pairs). They were able to store DNA encoding the Emancipation Proclamation and the MIT logo, in addition to the theme music from “Jurassic Park.”
After storing the DNA and then removing it, the researchers sequenced it and found that no errors had been introduced, which is a critical feature of any digital data storage system.
The researchers also showed that the thermoset polymer can protect DNA from temperatures up to 75 degrees Celsius (167 degrees Fahrenheit). They are now working on ways to streamline the process of making the polymers and forming them into capsules for long-term storage.
Cache DNA, a company started by Banal and Bathe, with Johnson as a member of the scientific advisory board, is now working on further developing DNA storage technology. The earliest application they envision is storing genomes for personalized medicine, and they also anticipate that these stored genomes could undergo further analysis as better technology is developed in the future.
“The idea is, why don’t we preserve the master record of life forever?” Banal says. “Ten years or 20 years from now, when technology has advanced way more than we could ever imagine today, we could learn more and more things. We’re still in the very infancy of understanding the genome and how it relates to disease.”
The research was funded by the National Science Foundation.
With their “T-REX” method, MIT researchers developed a glassy, amber-like polymer that can be used for long-term storage of DNA, such as entire human genomes or digital files such as photos.
As you travel your usual route to work or the grocery store, your brain engages cognitive maps stored in your hippocampus and entorhinal cortex. These maps store information about paths you have taken and locations you have been to before, so you can navigate whenever you go there.
New research from MIT has found that such mental maps also are created and activated when you merely think about sequences of experiences, in the absence of any physical movement or sensory input. In an animal study, the researchers found that the entorhinal cortex harbors a cognitive map of what animals experience while they use a joystick to browse through a sequence of images. These cognitive maps are then activated when thinking about these sequences, even when the images are not visible.
This is the first study to show the cellular basis of mental simulation and imagination in a nonspatial domain through activation of a cognitive map in the entorhinal cortex.
“These cognitive maps are being recruited to perform mental navigation, without any sensory input or motor output. We are able to see a signature of this map presenting itself as the animal is going through these experiences mentally,” says Mehrdad Jazayeri, an associate professor of brain and cognitive sciences, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study.
McGovern Institute Research Scientist Sujaya Neupane is the lead author of the paper, which appears today in Nature. Ila Fiete, a professor of brain and cognitive sciences at MIT, a member of MIT’s McGovern Institute for Brain Research, and director of the K. Lisa Yang Integrative Computational Neuroscience Center, is also an author of the paper.
Mental maps
A great deal of work in animal models and humans has shown that representations of physical locations are stored in the hippocampus, a small seahorse-shaped structure, and the nearby entorhinal cortex. These representations are activated whenever an animal moves through a space that it has been in before, just before it traverses the space, or when it is asleep.
“Most prior studies have focused on how these areas reflect the structures and the details of the environment as an animal moves physically through space,” Jazayeri says. “When an animal moves in a room, its sensory experiences are nicely encoded by the activity of neurons in the hippocampus and entorhinal cortex.”
In the new study, Jazayeri and his colleagues wanted to explore whether these cognitive maps are also built and then used during purely mental run-throughs or imagining of movement through nonspatial domains.
To explore that possibility, the researchers trained animals to use a joystick to trace a path through a sequence of images (“landmarks”) spaced at regular temporal intervals. During the training, the animals were shown only a subset of pairs of images but not all the pairs. Once the animals had learned to navigate through the training pairs, the researchers tested if animals could handle the new pairs they had never seen before.
One possibility is that animals do not learn a cognitive map of the sequence, and instead solve the task using a memorization strategy. If so, they would be expected to struggle with the new pairs. Instead, if the animals were to rely on a cognitive map, they should be able to generalize their knowledge to the new pairs.
“The results were unequivocal,” Jazayeri says. “Animals were able to mentally navigate between the new pairs of images from the very first time they were tested. This finding provided strong behavioral evidence for the presence of a cognitive map. But how does the brain establish such a map?”
To address this question, the researchers recorded from single neurons in the entorhinal cortex as the animals performed this task. Neural responses had a striking feature: As the animals used the joystick to navigate between two landmarks, neurons featured distinctive bumps of activity associated with the mental representation of the intervening landmarks.
“The brain goes through these bumps of activity at the expected time when the intervening images would have passed by the animal’s eyes, which they never did,” Jazayeri says. “And the timing between these bumps, critically, was exactly the timing that the animal would have expected to reach each of those, which in this case was 0.65 seconds.”
The researchers also showed that the speed of the mental simulation was related to the animals’ performance on the task: When they were a little late or early in completing the task, their brain activity showed a corresponding change in timing. The researchers also found evidence that the mental representations in the entorhinal cortex don’t encode specific visual features of the images, but rather the ordinal arrangement of the landmarks.
A model of learning
To further explore how these cognitive maps may work, the researchers built a computational model to mimic the brain activity that they found and demonstrate how it could be generated. They used a type of model known as a continuous attractor model, which was originally developed to model how the entorhinal cortex tracks an animal’s position as it moves, based on sensory input.
The researchers customized the model by adding a component that was able to learn the activity patterns generated by sensory input. This model was then able to learn to use those patterns to reconstruct those experiences later, when there was no sensory input.
“The key element that we needed to add is that this system has the capacity to learn bidirectionally by communicating with sensory inputs. Through the associational learning that the model goes through, it will actually recreate those sensory experiences,” Jazayeri says.
The researchers now plan to investigate what happens in the brain if the landmarks are not evenly spaced, or if they’re arranged in a ring. They also hope to record brain activity in the hippocampus and entorhinal cortex as the animals first learn to perform the navigation task.
“Seeing the memory of the structure become crystallized in the mind, and how that leads to the neural activity that emerges, is a really valuable way of asking how learning happens,” Jazayeri says.
The research was funded by the Natural Sciences and Engineering Research Council of Canada, the Québec Research Funds, the National Institutes of Health, and the Paul and Lilah Newton Brain Science Award.
Mental representations known as cognitive maps are activated when the brain performs mental simulations of a navigational route, according to new MIT research.
Someday, you may want your home robot to carry a load of dirty clothes downstairs and deposit them in the washing machine in the far-left corner of the basement. The robot will need to combine your instructions with its visual observations to determine the steps it should take to complete this task.
For an AI agent, this is easier said than done. Current approaches often utilize multiple hand-crafted machine-learning models to tackle different parts of the task, which require a great deal of human effort and expertise to build. These methods, which use visual representations to directly make navigation decisions, demand massive amounts of visual data for training, which are often hard to come by.
To overcome these challenges, researchers from MIT and the MIT-IBM Watson AI Lab devised a navigation method that converts visual representations into pieces of language, which are then fed into one large language model that achieves all parts of the multistep navigation task.
Rather than encoding visual features from images of a robot’s surroundings as visual representations, which is computationally intensive, their method creates text captions that describe the robot’s point-of-view. A large language model uses the captions to predict the actions a robot should take to fulfill a user’s language-based instructions.
Because their method utilizes purely language-based representations, they can use a large language model to efficiently generate a huge amount of synthetic training data.
While this approach does not outperform techniques that use visual features, it performs well in situations that lack enough visual data for training. The researchers found that combining their language-based inputs with visual signals leads to better navigation performance.
“By purely using language as the perceptual representation, ours is a more straightforward approach. Since all the inputs can be encoded as language, we can generate a human-understandable trajectory,” says Bowen Pan, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this approach.
Pan’s co-authors include his advisor, Aude Oliva, director of strategic industry engagement at the MIT Schwarzman College of Computing, MIT director of the MIT-IBM Watson AI Lab, and a senior research scientist in the Computer Science and Artificial Intelligence Laboratory (CSAIL); Philip Isola, an associate professor of EECS and a member of CSAIL; senior author Yoon Kim, an assistant professor of EECS and a member of CSAIL; and others at the MIT-IBM Watson AI Lab and Dartmouth College. The research will be presented at the Conference of the North American Chapter of the Association for Computational Linguistics.
Solving a vision problem with language
Since large language models are the most powerful machine-learning models available, the researchers sought to incorporate them into the complex task known as vision-and-language navigation, Pan says.
But such models take text-based inputs and can’t process visual data from a robot’s camera. So, the team needed to find a way to use language instead.
Their technique utilizes a simple captioning model to obtain text descriptions of a robot’s visual observations. These captions are combined with language-based instructions and fed into a large language model, which decides what navigation step the robot should take next.
The large language model outputs a caption of the scene the robot should see after completing that step. This is used to update the trajectory history so the robot can keep track of where it has been.
The model repeats these processes to generate a trajectory that guides the robot to its goal, one step at a time.
To streamline the process, the researchers designed templates so observation information is presented to the model in a standard form — as a series of choices the robot can make based on its surroundings.
For instance, a caption might say “to your 30-degree left is a door with a potted plant beside it, to your back is a small office with a desk and a computer,” etc. The model chooses whether the robot should move toward the door or the office.
“One of the biggest challenges was figuring out how to encode this kind of information into language in a proper way to make the agent understand what the task is and how they should respond,” Pan says.
Advantages of language
When they tested this approach, while it could not outperform vision-based techniques, they found that it offered several advantages.
First, because text requires fewer computational resources to synthesize than complex image data, their method can be used to rapidly generate synthetic training data. In one test, they generated 10,000 synthetic trajectories based on 10 real-world, visual trajectories.
The technique can also bridge the gap that can prevent an agent trained with a simulated environment from performing well in the real world. This gap often occurs because computer-generated images can appear quite different from real-world scenes due to elements like lighting or color. But language that describes a synthetic versus a real image would be much harder to tell apart, Pan says.
Also, the representations their model uses are easier for a human to understand because they are written in natural language.
“If the agent fails to reach its goal, we can more easily determine where it failed and why it failed. Maybe the history information is not clear enough or the observation ignores some important details,” Pan says.
In addition, their method could be applied more easily to varied tasks and environments because it uses only one type of input. As long as data can be encoded as language, they can use the same model without making any modifications.
But one disadvantage is that their method naturally loses some information that would be captured by vision-based models, such as depth information.
However, the researchers were surprised to see that combining language-based representations with vision-based methods improves an agent’s ability to navigate.
“Maybe this means that language can capture some higher-level information than cannot be captured with pure vision features,” he says.
This is one area the researchers want to continue exploring. They also want to develop a navigation-oriented captioner that could boost the method’s performance. In addition, they want to probe the ability of large language models to exhibit spatial awareness and see how this could aid language-based navigation.
This research is funded, in part, by the MIT-IBM Watson AI Lab.
Climate models are a key technology in predicting the impacts of climate change. By running simulations of the Earth’s climate, scientists and policymakers can estimate conditions like sea level rise, flooding, and rising temperatures, and make decisions about how to appropriately respond. But current climate models struggle to provide this information quickly or affordably enough to be useful on smaller scales, such as the size of a city.
Now, authors of a new open-access paper published in the Journal of Advances in Modeling Earth Systems have found a method to leverage machine learning to utilize the benefits of current climate models, while reducing the computational costs needed to run them.
“It turns the traditional wisdom on its head,” says Sai Ravela, a principal research scientist in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS) who wrote the paper with EAPS postdoc Anamitra Saha.
Traditional wisdom
In climate modeling, downscaling is the process of using a global climate model with coarse resolution to generate finer details over smaller regions. Imagine a digital picture: A global model is a large picture of the world with a low number of pixels. To downscale, you zoom in on just the section of the photo you want to look at — for example, Boston. But because the original picture was low resolution, the new version is blurry; it doesn’t give enough detail to be particularly useful.
“If you go from coarse resolution to fine resolution, you have to add information somehow,” explains Saha. Downscaling attempts to add that information back in by filling in the missing pixels. “That addition of information can happen two ways: Either it can come from theory, or it can come from data.”
Conventional downscaling often involves using models built on physics (such as the process of air rising, cooling, and condensing, or the landscape of the area), and supplementing it with statistical data taken from historical observations. But this method is computationally taxing: It takes a lot of time and computing power to run, while also being expensive.
A little bit of both
In their new paper, Saha and Ravela have figured out a way to add the data another way. They’ve employed a technique in machine learning called adversarial learning. It uses two machines: One generates data to go into our photo. But the other machine judges the sample by comparing it to actual data. If it thinks the image is fake, then the first machine has to try again until it convinces the second machine. The end-goal of the process is to create super-resolution data.
Using machine learning techniques like adversarial learning is not a new idea in climate modeling; where it currently struggles is its inability to handle large amounts of basic physics, like conservation laws. The researchers discovered that simplifying the physics going in and supplementing it with statistics from the historical data was enough to generate the results they needed.
“If you augment machine learning with some information from the statistics and simplified physics both, then suddenly, it’s magical,” says Ravela. He and Saha started with estimating extreme rainfall amounts by removing more complex physics equations and focusing on water vapor and land topography. They then generated general rainfall patterns for mountainous Denver and flat Chicago alike, applying historical accounts to correct the output. “It’s giving us extremes, like the physics does, at a much lower cost. And it’s giving us similar speeds to statistics, but at much higher resolution.”
Another unexpected benefit of the results was how little training data was needed. “The fact that that only a little bit of physics and little bit of statistics was enough to improve the performance of the ML [machine learning] model … was actually not obvious from the beginning,” says Saha. It only takes a few hours to train, and can produce results in minutes, an improvement over the months other models take to run.
Quantifying risk quickly
Being able to run the models quickly and often is a key requirement for stakeholders such as insurance companies and local policymakers. Ravela gives the example of Bangladesh: By seeing how extreme weather events will impact the country, decisions about what crops should be grown or where populations should migrate to can be made considering a very broad range of conditions and uncertainties as soon as possible.
“We can’t wait months or years to be able to quantify this risk,” he says. “You need to look out way into the future and at a large number of uncertainties to be able to say what might be a good decision.”
While the current model only looks at extreme precipitation, training it to examine other critical events, such as tropical storms, winds, and temperature, is the next step of the project. With a more robust model, Ravela is hoping to apply it to other places like Boston and Puerto Rico as part of a Climate Grand Challenges project.
“We’re very excited both by the methodology that we put together, as well as the potential applications that it could lead to,” he says.
A new downscaling method used in climate models leverages machine learning to improve resolution at finer scales. By making these simulations more relevant to local areas, policy makers have better access to information informing climate action.
Mark Hamilton, an MIT PhD student in electrical engineering and computer science and affiliate of MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL), wants to use machines to understand how animals communicate. To do that, he set out first to create a system that can learn human language “from scratch.”
“Funny enough, the key moment of inspiration came from the movie ‘March of the Penguins.’ There’s a scene where a penguin falls while crossing the ice, and lets out a little belabored groan while getting up. When you watch it, it’s almost obvious that this groan is standing in for a four letter word. This was the moment where we thought, maybe we need to use audio and video to learn language,” says Hamilton. “Is there a way we could let an algorithm watch TV all day and from this figure out what we're talking about?”
“Our model, ‘DenseAV,’ aims to learn language by predicting what it’s seeing from what it’s hearing, and vice-versa. For example, if you hear the sound of someone saying ‘bake the cake at 350’ chances are you might be seeing a cake or an oven. To succeed at this audio-video matching game across millions of videos, the model has to learn what people are talking about,” says Hamilton.
Once they trained DenseAV on this matching game, Hamilton and his colleagues looked at which pixels the model looked for when it heard a sound. For example, when someone says “dog,” the algorithm immediately starts looking for dogs in the video stream. By seeing which pixels are selected by the algorithm, one can discover what the algorithm thinks a word means.
Interestingly, a similar search process happens when DenseAV listens to a dog barking: It searches for a dog in the video stream. “This piqued our interest. We wanted to see if the algorithm knew the difference between the word ‘dog’ and a dog’s bark,” says Hamilton. The team explored this by giving the DenseAV a “two-sided brain.” Interestingly, they found one side of DenseAV’s brain naturally focused on language, like the word “dog,” and the other side focused on sounds like barking. This showed that DenseAV not only learned the meaning of words and the locations of sounds, but also learned to distinguish between these types of cross-modal connections, all without human intervention or any knowledge of written language.
One branch of applications is learning from the massive amount of video published to the internet each day: “We want systems that can learn from massive amounts of video content, such as instructional videos,” says Hamilton. “Another exciting application is understanding new languages, like dolphin or whale communication, which don’t have a written form of communication. Our hope is that DenseAV can help us understand these languages that have evaded human translation efforts since the beginning. Finally, we hope that this method can be used to discover patterns between other pairs of signals, like the seismic sounds the earth makes and its geology.”
A formidable challenge lay ahead of the team: learning language without any text input. Their objective was to rediscover the meaning of language from a blank slate, avoiding using pre-trained language models. This approach is inspired by how children learn by observing and listening to their environment to understand language.
To achieve this feat, DenseAV uses two main components to process audio and visual data separately. This separation made it impossible for the algorithm to cheat, by letting the visual side look at the audio and vice versa. It forced the algorithm to recognize objects and created detailed and meaningful features for both audio and visual signals. DenseAV learns by comparing pairs of audio and visual signals to find which signals match and which signals do not. This method, called contrastive learning, doesn’t require labeled examples, and allows DenseAV to figure out the important predictive patterns of language itself.
One major difference between DenseAV and previous algorithms is that prior works focused on a single notion of similarity between sound and images. An entire audio clip like someone saying “the dog sat on the grass” was matched to an entire image of a dog. This didn’t allow previous methods to discover fine-grained details, like the connection between the word “grass” and the grass underneath the dog. The team’s algorithm searches for and aggregates all the possible matches between an audio clip and an image’s pixels. This not only improved performance, but allowed the team to precisely localize sounds in a way that previous algorithms could not. “Conventional methods use a single class token, but our approach compares every pixel and every second of sound. This fine-grained method lets DenseAV make more detailed connections for better localization,” says Hamilton.
The researchers trained DenseAV on AudioSet, which includes 2 million YouTube videos. They also created new datasets to test how well the model can link sounds and images. In these tests, DenseAV outperformed other top models in tasks like identifying objects from their names and sounds, proving its effectiveness. “Previous datasets only supported coarse evaluations, so we created a dataset using semantic segmentation datasets. This helps with pixel-perfect annotations for precise evaluation of our model's performance. We can prompt the algorithm with specific sounds or images and get those detailed localizations,” says Hamilton.
Due to the massive amount of data involved, the project took about a year to complete. The team says that transitioning to a large transformer architecture presented challenges, as these models can easily overlook fine-grained details. Encouraging the model to focus on these details was a significant hurdle.
Looking ahead, the team aims to create systems that can learn from massive amounts of video- or audio-only data. This is crucial for new domains where there’s lots of either mode, but not together. They also aim to scale this up using larger backbones and possibly integrate knowledge from language models to improve performance.
“Recognizing and segmenting visual objects in images, as well as environmental sounds and spoken words in audio recordings, are each difficult problems in their own right. Historically researchers have relied upon expensive, human-provided annotations in order to train machine learning models to accomplish these tasks,” says David Harwath, assistant professor in computer science at the University of Texas at Austin who was not involved in the work. “DenseAV makes significant progress towards developing methods that can learn to solve these tasks simultaneously by simply observing the world through sight and sound — based on the insight that the things we see and interact with often make sound, and we also use spoken language to talk about them. This model also makes no assumptions about the specific language that is being spoken, and could therefore in principle learn from data in any language. It would be exciting to see what DenseAV could learn by scaling it up to thousands or millions of hours of video data across a multitude of languages.”
Additional authors on a paper describing the work are Andrew Zisserman, professor of computer vision engineering at the University of Oxford; John R. Hershey, Google AI Perception researcher; and William T. Freeman, MIT electrical engineering and computer science professor and CSAIL principal investigator. Their research was supported, in part, by the U.S. National Science Foundation, a Royal Society Research Professorship, and an EPSRC Programme Grant Visual AI. This work will be presented at the IEEE/CVF Computer Vision and Pattern Recognition Conference this month.
Boosting the performance of solar cells, transistors, LEDs, and batteries will require better electronic materials, made from novel compositions that have yet to be discovered.
To speed up the search for advanced functional materials, scientists are using AI tools to identify promising materials from hundreds of millions of chemical formulations. In tandem, engineers are building machines that can print hundreds of material samples at a time based on chemical compositions tagged by AI search algorithms.
But to date, there’s been no similarly speedy way to confirm that these printed materials actually perform as expected. This last step of material characterization has been a major bottleneck in the pipeline of advanced materials screening.
Now, a new computer vision technique developed by MIT engineers significantly speeds up the characterization of newly synthesized electronic materials. The technique automatically analyzes images of printed semiconducting samples and quickly estimates two key electronic properties for each sample: band gap (a measure of electron activation energy) and stability (a measure of longevity).
The new technique accurately characterizes electronic materials 85 times faster compared to the standard benchmark approach.
The researchers intend to use the technique to speed up the search for promising solar cell materials. They also plan to incorporate the technique into a fully automated materials screening system.
“Ultimately, we envision fitting this technique into an autonomous lab of the future,” says MIT graduate student Eunice Aissi. “The whole system would allow us to give a computer a materials problem, have it predict potential compounds, and then run 24-7 making and characterizing those predicted materials until it arrives at the desired solution.”
“The application space for these techniques ranges from improving solar energy to transparent electronics and transistors,” adds MIT graduate student Alexander (Aleks) Siemenn. “It really spans the full gamut of where semiconductor materials can benefit society.”
Aissi and Siemenn detail the new technique in a study appearing today in Nature Communications. Their MIT co-authors include graduate student Fang Sheng, postdoc Basita Das, and professor of mechanical engineering Tonio Buonassisi, along with former visiting professor Hamide Kavak of Cukurova University and visiting postdoc Armi Tiihonen of Aalto University.
Power in optics
Once a new electronic material is synthesized, the characterization of its properties is typically handled by a “domain expert” who examines one sample at a time using a benchtop tool called a UV-Vis, which scans through different colors of light to determine where the semiconductor begins to absorb more strongly. This manual process is precise but also time-consuming: A domain expert typically characterizes about 20 material samples per hour — a snail’s pace compared to some printing tools that can lay down 10,000 different material combinations per hour.
“The manual characterization process is very slow,” Buonassisi says. “They give you a high amount of confidence in the measurement, but they’re not matched to the speed at which you can put matter down on a substrate nowadays.”
To speed up the characterization process and clear one of the largest bottlenecks in materials screening, Buonassisi and his colleagues looked to computer vision — a field that applies computer algorithms to quickly and automatically analyze optical features in an image.
“There’s power in optical characterization methods,” Buonassisi notes. “You can obtain information very quickly. There is richness in images, over many pixels and wavelengths, that a human just can’t process but a computer machine-learning program can.”
The team realized that certain electronic properties — namely, band gap and stability — could be estimated based on visual information alone, if that information were captured with enough detail and interpreted correctly.
With that goal in mind, the researchers developed two new computer vision algorithms to automatically interpret images of electronic materials: one to estimate band gap and the other to determine stability.
The first algorithm is designed to process visual data from highly detailed, hyperspectral images.
“Instead of a standard camera image with three channels — red, green, and blue (RBG) — the hyperspectral image has 300 channels,” Siemenn explains. “The algorithm takes that data, transforms it, and computes a band gap. We run that process extremely fast.”
The second algorithm analyzes standard RGB images and assesses a material’s stability based on visual changes in the material’s color over time.
“We found that color change can be a good proxy for degradation rate in the material system we are studying,” Aissi says.
Material compositions
The team applied the two new algorithms to characterize the band gap and stability for about 70 printed semiconducting samples. They used a robotic printer to deposit samples on a single slide, like cookies on a baking sheet. Each deposit was made with a slightly different combination of semiconducting materials. In this case, the team printed different ratios of perovskites — a type of material that is expected to be a promising solar cell candidate though is also known to quickly degrade.
“People are trying to change the composition — add a little bit of this, a little bit of that — to try to make [perovskites] more stable and high-performance,” Buonassisi says.
Once they printed 70 different compositions of perovskite samples on a single slide, the team scanned the slide with a hyperspectral camera. Then they applied an algorithm that visually “segments” the image, automatically isolating the samples from the background. They ran the new band gap algorithm on the isolated samples and automatically computed the band gap for every sample. The entire band gap extraction process process took about six minutes.
“It would normally take a domain expert several days to manually characterize the same number of samples,” Siemenn says.
To test for stability, the team placed the same slide in a chamber in which they varied the environmental conditions, such as humidity, temperature, and light exposure. They used a standard RGB camera to take an image of the samples every 30 seconds over two hours. They then applied the second algorithm to the images of each sample over time to estimate the degree to which each droplet changed color, or degraded under various environmental conditions. In the end, the algorithm produced a “stability index,” or a measure of each sample’s durability.
As a check, the team compared their results with manual measurements of the same droplets, taken by a domain expert. Compared to the expert’s benchmark estimates, the team’s band gap and stability results were 98.5 percent and 96.9 percent as accurate, respectively, and 85 times faster.
“We were constantly shocked by how these algorithms were able to not just increase the speed of characterization, but also to get accurate results,” Siemenn says. “We do envision this slotting into the current automated materials pipeline we’re developing in the lab, so we can run it in a fully automated fashion, using machine learning to guide where we want to discover these new materials, printing them, and then actually characterizing them, all with very fast processing.”
MIT graduate students Eunice Aissi, left, and Alexander Siemenn, have developed a technique that automatically analyzes visual features in printed samples (pictured) to quickly determine key properties of new and promising semiconducting materials.
A bacterial enzyme called histidine kinase is a promising target for new classes of antibiotics. However, it has been difficult to develop drugs that target this enzyme, because it is a “hydrophobic” protein that loses its structure once removed from its normal location in the cell membrane.
Now, an MIT-led team has found a way to make the enzyme water-soluble, which could make it possible to rapidly screen potential drugs that might interfere with its functions.
The researchers created their new version of histidine kinase by replacing four specific hydrophobic amino acids with three hydrophilic ones. Even after this significant shift, they found that the water-soluble version of the enzyme retained its natural functions.
No existing antibiotics target histidine kinase, so drugs that disrupt these functions could represent a new class of antibiotics. Such drug candidates are badly needed to combat the growing problem of antibiotic resistance.
“Each year, more than 1 million people die from antibiotic-resistant infections,” says Shuguang Zhang, a principal research scientist in the MIT Media Lab and one of the senior authors of the new study. “This protein is a good target because it’s unique to bacteria and humans don’t have it.”
Ping Xu and Fei Tao, both professors at Shanghai Jiao Tong University, are also senior authors of the paper, which appears today in Nature Communications. Mengke Li, a graduate student at Shanghai Jiao Tong University and a former visiting student at MIT, is the lead author of the paper.
A new drug target
Many of the proteins that perform critical cell functions are embedded in the cell membrane. The segments of these proteins that span the membrane are hydrophobic, which allows them to associate with the lipids that make up the membrane. However, once removed from the membrane, these proteins tend to lose their structure, which makes it difficult to study them or to screen for drugs that might interfere with them.
In 2018, Zhang and his colleagues devised a simple way to convert these proteins into water-soluble versions, which maintain their structure in water. Their technique is known as the QTY code, for the letters that represent the hydrophilic amino acids that become incorporated into the proteins. Leucine (L) becomes glutamine (Q), isoleucine (I) and valine (V) become threonine (T), and phenylalanine (F) becomes tyrosine (Y).
Since then, the researchers have demonstrated this technique on a variety of hydrophobic proteins, including antibodies, cytokine receptors, and transporters. Those transporters include a protein that cancer cells use to pump chemotherapy drugs out of the cells, as well as transporters that brain cells use to move dopamine and serotonin into or out of cells.
In the new study, the team set out to demonstrate, for the first time, that the QTY code could be used to create water-soluble enzymes that retain their enzymatic function.
The research team chose to focus on histidine kinase in part because of its potential as an antibiotic target. Currently most antibiotics work by damaging bacterial cell walls or interfering with the synthesis of ribosomes, the cell organelles that manufacture proteins. None of them target histidine kinase, an important bacterial protein that regulates processes such as antibiotic resistance and cell-to-cell communication.
Histidine kinase can perform four different functions, including phosphorylation (activating other proteins by adding a phosphate group to them) and dephosphorylation (removing phosphates). Human cells also have kinases, but they act on amino acids other than histidine, so drugs that block histidine kinase would likely not have any effect on human cells.
After using the QTY code to convert histidine kinase to a water-soluble form, the researchers tested all four of its functions and found that the protein was still able to perform them. This means that this protein could be used in high-throughput screens to rapidly test whether potential drug compounds interfere with any of those functions.
A stable structure
Using AlphaFold, an artificial intelligence program that can predict protein structures, the researchers generated a structure for their new protein and used molecular dynamics simulations to investigate how it interacts with water. They found that the protein forms stabilizing hydrogen bonds with water, which help it keep its structure.
They also found that if they only replaced the buried hydrophobic amino acids in the transmembrane segment, the protein would not retain its function. The hydrophobic amino acids have to be replaced throughout the transmembrane segment, which helps the molecule maintain the structural relationships it needs to function normally.
Zhang now plans to try this approach on methane monooxygenase, an enzyme found in bacteria that can convert methane into methanol. A water-soluble version of this enzyme could be sprayed at sites of methane release, such as barns where cows live, or thawing permafrost, helping to remove a large chunk of methane, a greenhouse gas, from the atmosphere.
“If we can use the same tool, the QTY code, on methane monooxygenase, and use that enzyme to convert methane into methanol, that could deaccelerate climate change,” Zhang says.
The QTY technique could also help scientists learn more about how signals are carried by transmembrane proteins, says William DeGrado, a professor of pharmaceutical chemistry at the University of California at San Francisco, who was not involved in the study.
“It is a great advance to be able to make functionally relevant, water-solubilized proteins,” DeGrado says. “An important question is how signals are transmitted across membranes, and this work provides a new way to approach that question.”
The research was funded, in part, by the National Natural Science Foundation of China.
An MIT-led team has found a way to make the bacterial enzyme histidine kinase water-soluble, which could make it possible to rapidly screen potential antibiotics that might interfere with its functions.
Imagine a portable 3D printer you could hold in the palm of your hand. The tiny device could enable a user to rapidly create customized, low-cost objects on the go, like a fastener to repair a wobbly bicycle wheel or a component for a critical medical operation.
Researchers from MIT and the University of Texas at Austin took a major step toward making this idea a reality by demonstrating the first chip-based 3D printer. Their proof-of-concept device consists of a single, millimeter-scale photonic chip that emits reconfigurable beams of light into a well of resin that cures into a solid shape when light strikes it.
The prototype chip has no moving parts, instead relying on an array of tiny optical antennas to steer a beam of light. The beam projects up into a liquid resin that has been designed to rapidly cure when exposed to the beam’s wavelength of visible light.
By combining silicon photonics and photochemistry, the interdisciplinary research team was able to demonstrate a chip that can steer light beams to 3D print arbitrary two-dimensional patterns, including the letters M-I-T. Shapes can be fully formed in a matter of seconds.
In the long run, they envision a system where a photonic chip sits at the bottom of a well of resin and emits a 3D hologram of visible light, rapidly curing an entire object in a single step.
This type of portable 3D printer could have many applications, such as enabling clinicians to create tailor-made medical device components or allowing engineers to make rapid prototypes at a job site.
“This system is completely rethinking what a 3D printer is. It is no longer a big box sitting on a bench in a lab creating objects, but something that is handheld and portable. It is exciting to think about the new applications that could come out of this and how the field of 3D printing could change,” says senior author Jelena Notaros, the Robert J. Shillman Career Development Professor in Electrical Engineering and Computer Science (EECS), and a member of the Research Laboratory of Electronics.
Joining Notaros on the paper are Sabrina Corsetti, lead author and EECS graduate student; Milica Notaros PhD ’23; Tal Sneh, an EECS graduate student; Alex Safford, a recent graduate of the University of Texas at Austin; and Zak Page, an assistant professor in the Department of Chemical Engineering at UT Austin. The research appears today in Nature Light Science and Applications.
Printing with a chip
Experts in silicon photonics, the Notaros group previously developed integrated optical-phased-array systems that steer beams of light using a series of microscale antennas fabricated on a chip using semiconductor manufacturing processes. By speeding up or delaying the optical signal on either side of the antenna array, they can move the beam of emitted light in a certain direction.
Such systems are key for lidar sensors, which map their surroundings by emitting infrared light beams that bounce off nearby objects. Recently, the group has focused on systems that emit and steer visible light for augmented-reality applications.
They wondered if such a device could be used for a chip-based 3D printer.
At about the same time they started brainstorming, the Page Group at UT Austin demonstrated specialized resins that can be rapidly cured using wavelengths of visible light for the first time. This was the missing piece that pushed the chip-based 3D printer into reality.
“With photocurable resins, it is very hard to get them to cure all the way up at infrared wavelengths, which is where integrated optical-phased-array systems were operating in the past for lidar,” Corsetti says. “Here, we are meeting in the middle between standard photochemistry and silicon photonics by using visible-light-curable resins and visible-light-emitting chips to create this chip-based 3D printer. You have this merging of two technologies into a completely new idea.”
Their prototype consists of a single photonic chip containing an array of 160-nanometer-thick optical antennas. (A sheet of paper is about 100,000 nanometers thick.) The entire chip fits onto a U.S. quarter.
When powered by an off-chip laser, the antennas emit a steerable beam of visible light into the well of photocurable resin. The chip sits below a clear slide, like those used in microscopes, which contains a shallow indentation that holds the resin. The researchers use electrical signals to nonmechanically steer the light beam, causing the resin to solidify wherever the beam strikes it.
A collaborative approach
But effectively modulating visible-wavelength light, which involves modifying its amplitude and phase, is especially tricky. One common method requires heating the chip, but this is inefficient and takes a large amount of physical space.
Instead, the researchers used liquid crystal to fashion compact modulators they integrate onto the chip. The material’s unique optical properties enable the modulators to be extremely efficient and only about 20 microns in length.
A single waveguide on the chip holds the light from the off-chip laser. Running along the waveguide are tiny taps which tap off a little bit of light to each of the antennas.
The researchers actively tune the modulators using an electric field, which reorients the liquid crystal molecules in a certain direction. In this way, they can precisely control the amplitude and phase of light being routed to the antennas.
But forming and steering the beam is only half the battle. Interfacing with a novel photocurable resin was a completely different challenge.
The Page Group at UT Austin worked closely with the Notaros Group at MIT, carefully adjusting the chemical combinations and concentrations to zero-in on a formula that provided a long shelf-life and rapid curing.
In the end, the group used their prototype to 3D print arbitrary two-dimensional shapes within seconds.
Building off this prototype, they want to move toward developing a system like the one they originally conceptualized — a chip that emits a hologram of visible light in a resin well to enable volumetric 3D printing in only one step.
“To be able to do that, we need a completely new silicon-photonics chip design. We already laid out a lot of what that final system would look like in this paper. And, now, we are excited to continue working towards this ultimate demonstration,” Jelena Notaros says.
This work was funded, in part, by the U.S. National Science Foundation, the U.S. Defense Advanced Research Projects Agency, the Robert A. Welch Foundation, the MIT Rolf G. Locher Endowed Fellowship, and the MIT Frederick and Barbara Cronin Fellowship.
The tiny device could enable a user to rapidly create customized, low-cost objects on the go, like a fastener to repair a wobbly bicycle wheel or a component for a critical medical operation.
For every kilogram of matter that we can see — from the computer on your desk to distant stars and galaxies — there are 5 kilograms of invisible matter that suffuse our surroundings. This “dark matter” is a mysterious entity that evades all forms of direct observation yet makes its presence felt through its invisible pull on visible objects.
Fifty years ago, physicist Stephen Hawking offered one idea for what dark matter might be: a population of black holes, which might have formed very soon after the Big Bang. Such “primordial” black holes would not have been the goliaths that we detect today, but rather microscopic regions of ultradense matter that would have formed in the first quintillionth of a second following the Big Bang and then collapsed and scattered across the cosmos, tugging on surrounding space-time in ways that could explain the dark matter that we know today.
Now, MIT physicists have found that this primordial process also would have produced some unexpected companions: even smaller black holes with unprecedented amounts of a nuclear-physics property known as “color charge.”
These smallest, “super-charged” black holes would have been an entirely new state of matter, which likely evaporated a fraction of a second after they spawned. Yet they could still have influenced a key cosmological transition: the time when the first atomic nuclei were forged. The physicists postulate that the color-charged black holes could have affected the balance of fusing nuclei, in a way that astronomers might someday detect with future measurements. Such an observation would point convincingly to primordial black holes as the root of all dark matter today.
“Even though these short-lived, exotic creatures are not around today, they could have affected cosmic history in ways that could show up in subtle signals today,” says David Kaiser, the Germeshausen Professor of the History of Science and professor of physics at MIT. “Within the idea that all dark matter could be accounted for by black holes, this gives us new things to look for.”
Kaiser and his co-author, MIT graduate student Elba Alonso-Monsalve, have published their study today in the journal Physical Review Letters.
A time before stars
The black holes that we know and detect today are the product of stellar collapse, when the center of a massive star caves in on itself to form a region so dense that it can bend space-time such that anything — even light — gets trapped within. Such “astrophysical” black holes can be anywhere from a few times as massive as the sun to many billions of times more massive.
“Primordial” black holes, in contrast, can be much smaller and are thought to have formed in a time before stars. Before the universe had even cooked up the basic elements, let alone stars, scientists believe that pockets of ultradense, primordial matter could have accumulated and collapsed to form microscopic black holes that could have been so dense as to squeeze the mass of an asteroid into a region as small as a single atom. The gravitational pull from these tiny, invisible objects scattered throughout the universe could explain all the dark matter that we can’t see today.
If that were the case, then what would these primordial black holes have been made from? That’s the question Kaiser and Alonso-Monsalve took on with their new study.
“People have studied what the distribution of black hole masses would be during this early-universe production but never tied it to what kinds of stuff would have fallen into those black holes at the time when they were forming,” Kaiser explains.
Super-charged rhinos
The MIT physicists looked first through existing theories for the likely distribution of black hole masses as they were first forming in the early universe.
“Our realization was, there’s a direct correlation between when a primordial black hole forms and what mass it forms with,” Alonso-Monsalve says. “And that window of time is absurdly early.”
She and Kaiser calculated that primordial black holes must have formed within the first quintillionth of a second following the Big Bang. This flash of time would have produced “typical” microscopic black holes that were as massive as an asteroid and as small as an atom. It would have also yielded a small fraction of exponentially smaller black holes, with the mass of a rhinoceros and a size much smaller than a single proton.
What would these primordial black holes have been made from? For that, they looked to studies exploring the composition of the early universe, and specifically, to the theory of quantum chromodynamics (QCD) — the study of how quarks and gluons interact.
Quarks and gluons are the fundamental building blocks of protons and neutrons — elementary particles that combined to forge the basic elements of the periodic table. Immediately following the Big Bang, physicists estimate, based on QCD, that the universe was an immensely hot plasma of quarks and gluons that then quickly cooled and combined to produce protons and neutrons.
The researchers found that, within the first quintillionth of a second, the universe would still have been a soup of free quarks and gluons that had yet to combine. Any black holes that formed in this time would have swallowed up the untethered particles, along with an exotic property known as “color charge” — a state of charge that only uncombined quarks and gluons carry.
“Once we figured out that these black holes form in a quark-gluon plasma, the most important thing we had to figure out was, how much color charge is contained in the blob of matter that will end up in a primordial black hole?” Alonso-Monsalve says.
Using QCD theory, they worked out the distribution of color charge that should have existed throughout the hot, early plasma. Then they compared that to the size of a region that would collapse to form a black hole in the first quintillionth of a second. It turns out there wouldn’t have been much color charge in most typical black holes at the time, as they would have formed by absorbing a huge number of regions that had a mix of charges, which would have ultimately added up to a “neutral” charge.
But the smallest black holes would have been packed with color charge. In fact, they would have contained the maximum amount of any type of charge allowed for a black hole, according to the fundamental laws of physics. Whereas such “extremal” black holes have been hypothesized for decades, until now no one had discovered a realistic process by which such oddities actually could have formed in our universe.
Professor Bernard Carr of Queen Mary University of London, an expert on the topic of primordial black holes who first worked on the topic with Stephen Hawking, describes the new work as “exciting.” Carr, who was not involved in the study, says the work “shows that there are circumstances in which a tiny fraction of the early universe can go into objects with an enormous amount of color charge (at least for a while), exponentially greater than what has been identified in previous studies of QCD.”
The super-charged black holes would have quickly evaporated, but possibly only after the time when the first atomic nuclei began to form. Scientists estimate that this process started around one second after the Big Bang, which would have given extremal black holes plenty of time to disrupt the equilibrium conditions that would have prevailed when the first nuclei began to form. Such disturbances could potentially affect how those earliest nuclei formed, in ways that might some day be observed.
“These objects might have left some exciting observational imprints,” Alonso-Monsalve muses. “They could have changed the balance of this versus that, and that’s the kind of thing that one can begin to wonder about.”
This research was supported, in part, by the U.S. Department of Energy. Alonso-Monsalve is also supported by a fellowship from the MIT Department of Physics.
In the early 1600s, the officials running Durham Cathedral, in England, had serious financial problems. Soaring prices had raised expenses. Most cathedral income came from renting land to tenant farmers, who had long leases so officials could not easily raise the rent. Instead, church leaders started charging periodic fees, but these often made tenants furious. And the 1600s, a time of religious schism, was not the moment to alienate church members.
But in 1626, Durham officials found a formula for fees that tenants would accept. If tenant farmers paid a fee equal to one year’s net value of the land, it earned them a seven-year lease. A fee equal to 7.75 years of net value earned a 21-year lease.
This was a form of discounting, the now-common technique for evaluating the present and future value of money by assuming a certain rate of return on that money. The Durham officials likely got their numbers from new books of discounting tables. Volumes like this had never existed before, but suddenly local church officials were applying the technique up and down England.
As financial innovation stories go, this one is unusual. Normally, avant-garde financial tools might come from, well, the financial avant-garde — bankers, merchants, and investors hunting for short-term profits, not clergymen.
“Most people have assumed these very sophisticated calculations would have been implemented by hard-nosed capitalists, because really powerful calculations would allow you to get an economic edge and increase profits,” says MIT historian William Deringer, an expert in the deployment of quantitative reasoning in public life. “But that was not the primary or only driver in this situation.”
Today, discounting is a pervasive tool. A dollar in the present is worth more than a dollar a decade from now, since one can earn money investing it in the meantime. This concept heavily informs investment markets, corporate finance, and even the NFL draft (where trading this year’s picks yields a greater haul of future picks). As the historian William N. Goetzmann has written, the related idea of net present value “is the most important tool in modern finance.” But while discounting was known as far back as the mathematician Leonardo of Pisa (often called Fibonacci) in the 1200s, why were English clergy some of its most enthusiastic early adopters?
The answer involves a global change in the 1500s: the “price revolution,” in which things began costing more, after a long period when prices had been constant. That is, inflation hit the world.
“People up to that point lived with the expectation that prices would stay the same,” Deringer says. “The idea that prices changed in a systematic way was shocking.”
For Durham Cathedral, inflation meant the organization had to pay more for goods while three-quarters of its revenues came from tenant rents, which were hard to alter. Many leases were complex, and some were locked in for a tenant’s lifetime. The Durham leaders did levy intermittent fees on tenants, but that led to angry responses and court cases.
Meanwhile, tenants had additional leverage against the Church of England: religious competition following the Reformation. England’s political and religious schisms would lead it to a midcentury civil war. Maybe some private landholders could drastically increase fees, but the church did not want to lose followers that way.
“Some individual landowners could be ruthlessly economic, but the church couldn’t, because it’s in the midst of incredible political and religious turmoil after the Reformation,” Deringer says. “The Church of England is in this precarious position. They’re walking a line between Catholics who don’t think there should have been a Reformation, and Puritans who don’t think there should be bishops. If they’re perceived to be hurting their flock, it would have real consequences. The church is trying to make the finances work but in a way that’s just barely tolerable to the tenants.”
Enter the books of discounting tables, which allowed local church leaders to finesse the finances. Essentially, discounting more carefully calibrated the upfront fees tenants would periodically pay. Church leaders could simply plug in the numbers as compromise solutions.
In this period, England’s first prominent discounting book with tables was published in 1613; its most enduring, Ambrose Acroyd’s “Table of Leasses and Interest,” dated to 1628-29. Acroyd was the bursar at Trinity College at Cambridge University, which as a landholder (and church-affiliated institution) faced the same issues concerning inflation and rent. Durham Cathedral began using off-the-shelf discounting formulas in 1626, resolving decades of localized disagreement as well.
Performing fairness
The discounting tables from books did not only work because the price was right. Once circulating clergy had popularized the notion throughout England, local leaders could justify using the books because others were doing it. The clergy were “performing fairness,” as Deringer puts it.
“Strict calculative rules assured tenants and courts that fines were reasonable, limiting landlords’ ability to maximize revenues,” Deringer writes in the new article.
To be sure, local church leaders in England were using discounting for their own economic self-interest. It just wasn’t the largest short-term economic self-interest possible. And it was a sound strategy.
“In Durham they would fight with tenants every 20 years [in the 1500s] and come to a new deal, but eventually that evolves into these sophisticated mechanisms, the discounting tables,” Deringer adds. “And you get standardization. By about 1700, it seems like these procedures are used everywhere.”
Thus, as Deringer writes, “mathematical tables for setting fines were not so much instruments of a capitalist transformation as the linchpin holding together what remained of an older system of customary obligations stretched nearly to breaking by macroeconomic forces.”
Once discounting was widely introduced, it never went away. Deringer’s Journal of Modern History article is part of a larger book project he is currently pursuing, about discounting in many facets of modern life.
Deringer was able to piece together the history of discounting in 17th-century England thanks in part to archival clues. For instance, Durham University owns a 1686 discounting book self-described as an update to Acroyd’s work; that copy was owned by a Durham Cathedral administrator in the 1700s. Of the 11 existing copies of Acroyd’s work, two are at Canterbury Cathedral and Lincoln Cathedral.
Hints like that helped Deringer recognize that church leaders were very interested in discounting; his further research helped him see that this chapter in the history of discounting is not merely about finance; it also opens a new window into the turbulent 1600s.
“I never expected to be researching church finances, I didn’t expect it to have anything to do with the countryside, landlord-tenant relationships, and tenant law,” Deringer says. “I was seeing this as an interesting example of a story about bottom-line economic calculation, and it wound up being more about this effort to use calculation to resolve social tensions.”
Discounting, the now-common technique for evaluating the present and future value of money by assuming a certain rate of return on that money, originated with English clergy in the 1600s.
People around the world rely on trucks to deliver the goods they need, and so-called long-haul trucks play a critical role in those supply chains. In the United States, long-haul trucks moved 71 percent of all freight in 2022. But those long-haul trucks are heavy polluters, especially of the carbon emissions that threaten the global climate. According to U.S. Environmental Protection Agency estimates, in 2022 more than 3 percent of all carbon dioxide (CO2) emissions came from long-haul trucks.
The problem is that long-haul trucks run almost exclusively on diesel fuel, and burning diesel releases high levels of CO2 and other carbon emissions. Global demand for freight transport is projected to as much as double by 2050, so it’s critical to find another source of energy that will meet the needs of long-haul trucks while also reducing their carbon emissions. And conversion to the new fuel must not be costly. “Trucks are an indispensable part of the modern supply chain, and any increase in the cost of trucking will be felt universally,” notes William H. Green, the Hoyt Hottel Professor in Chemical Engineering and director of the MIT Energy Initiative.
For the past year, Green and his research team have been seeking a low-cost, cleaner alternative to diesel. Finding a replacement is difficult because diesel meets the needs of the trucking industry so well. For one thing, diesel has a high energy density — that is, energy content per pound of fuel. There’s a legal limit on the total weight of a truck and its contents, so using an energy source with a lower weight allows the truck to carry more payload — an important consideration, given the low profit margin of the freight industry. In addition, diesel fuel is readily available at retail refueling stations across the country — a critical resource for drivers, who may travel 600 miles in a day and sleep in their truck rather than returning to their home depot. Finally, diesel fuel is a liquid, so it’s easy to distribute to refueling stations and then pump into trucks.
Past studies have examined numerous alternative technology options for powering long-haul trucks, but no clear winner has emerged. Now, Green and his team have evaluated the available options based on consistent and realistic assumptions about the technologies involved and the typical operation of a long-haul truck, and assuming no subsidies to tip the cost balance. Their in-depth analysis of converting long-haul trucks to battery electric — summarized below — found a high cost and negligible emissions gains in the near term. Studies of methanol and other liquid fuels from biomass are ongoing, but already a major concern is whether the world can plant and harvest enough biomass for biofuels without destroying the ecosystem. An analysis of hydrogen — also summarized below — highlights specific challenges with using that clean-burning fuel, which is a gas at normal temperatures.
Finally, the team identified an approach that could make hydrogen a promising, low-cost option for long-haul trucks.And, says Green, “it’s an option that most people are probably unaware of.” It involves a novel way of using materials that can pick up hydrogen, store it, and then release it when and where it’s needed to serve as a clean-burning fuel.
Defining the challenge: A realistic drive cycle, plus diesel values to beat
The MIT researchers believe that the lack of consensus on the best way to clean up long-haul trucking may have a simple explanation: Different analyses are based on different assumptions about the driving behavior of long-haul trucks. Indeed, some of them don’t accurately represent actual long-haul operations. So the first task for the MIT team was to define a representative — and realistic — "drive cycle” for actual long-haul truck operations in the United States. Then the MIT researchers — and researchers elsewhere — can assess potential replacement fuels and engines based on a consistent set of assumptions in modeling and simulation analyses.
To define the drive cycle for long-haul operations, the MIT team used a systematic approach to analyze many hours of real-world driving data covering 58,000 miles. They examined 10 features and identified three — daily range, vehicle speed, and road grade — that have the greatest impact on energy demand and thus on fuel consumption and carbon emissions. The representative drive cycle that emerged covers a distance of 600 miles, an average vehicle speed of 55 miles per hour, and a road grade ranging from negative 6 percent to positive 6 percent.
The next step was to generate key values for the performance of the conventional diesel “powertrain,” that is, all the components involved in creating power in the engine and delivering it to the wheels on the ground. Based on their defined drive cycle, the researchers simulated the performance of a conventional diesel truck, generating “benchmarks” for fuel consumption, CO2 emissions, cost, and other performance parameters.
Now they could perform parallel simulations — based on the same drive-cycle assumptions — of possible replacement fuels and powertrains to see how the cost, carbon emissions, and other performance parameters would compare to the diesel benchmarks.
The battery electric option
When considering how to decarbonize long-haul trucks, a natural first thought is battery power. After all, battery electric cars and pickup trucks are proving highly successful. Why not switch to battery electric long-haul trucks? “Again, the literature is very divided, with some studies saying that this is the best idea ever, and other studies saying that this makes no sense,” says Sayandeep Biswas, a graduate student in chemical engineering.
To assess the battery electric option, the MIT researchers used a physics-based vehicle model plus well-documented estimates for the efficiencies of key components such as the battery pack, generators, motor, and so on. Assuming the previously described drive cycle, they determined operating parameters, including how much power the battery-electric system needs. From there they could calculate the size and weight of the battery required to satisfy the power needs of the battery electric truck.
The outcome was disheartening. Providing enough energy to travel 600 miles without recharging would require a 2 megawatt-hour battery. “That’s a lot,” notes Kariana Moreno Sader, a graduate student in chemical engineering. “It’s the same as what two U.S. households consume per month on average.” And the weight of such a battery would significantly reduce the amount of payload that could be carried. An empty diesel truck typically weighs 20,000 pounds. With a legal limit of 80,000 pounds, there’s room for 60,000 pounds of payload. The 2 MWh battery would weigh roughly 27,000 pounds — significantly reducing the allowable capacity for carrying payload.
Accounting for that “payload penalty,” the researchers calculated that roughly four electric trucks would be required to replace every three of today’s diesel-powered trucks. Furthermore, each added truck would require an additional driver. The impact on operating expenses would be significant.
Analyzing the emissions reductions that might result from shifting to battery electric long-haul trucks also brought disappointing results. One might assume that using electricity would eliminate CO2 emissions. But when the researchers included emissions associated with making that electricity, that wasn’t true.
“Battery electric trucks are only as clean as the electricity used to charge them,” notes Moreno Sader. Most of the time, drivers of long-haul trucks will be charging from national grids rather than dedicated renewable energy plants. According to Energy Information Agency statistics, fossil fuels make up more than 60 percent of the current U.S. power grid, so electric trucks would still be responsible for significant levels of carbon emissions. Manufacturing batteries for the trucks would generate additional CO2 emissions.
Building the charging infrastructure would require massive upfront capital investment, as would upgrading the existing grid to reliably meet additional energy demand from the long-haul sector. Accomplishing those changes would be costly and time-consuming, which raises further concern about electrification as a means of decarbonizing long-haul freight.
In short, switching today’s long-haul diesel trucks to battery electric power would bring major increases in costs for the freight industry and negligible carbon emissions benefits in the near term. Analyses assuming various types of batteries as well as other drive cycles produced comparable results.
However, the researchers are optimistic about where the grid is going in the future. “In the long term, say by around 2050, emissions from the grid are projected to be less than half what they are now,” says Moreno Sader. “When we do our calculations based on that prediction, we find that emissions from battery electric trucks would be around 40 percent lower than our calculated emissions based on today’s grid.”
For Moreno Sader, the goal of the MIT research is to help “guide the sector on what would be the best option.” With that goal in mind, she and her colleagues are now examining the battery electric option under different scenarios — for example, assuming battery swapping (a depleted battery isn’t recharged but replaced by a fully charged one), short-haul trucking, and other applications that might produce a more cost-competitive outcome, even for the near term.
A promising option: hydrogen
As the world looks to get off reliance on fossil fuels for all uses, much attention is focusing on hydrogen. Could hydrogen be a good alternative for today’s diesel-burning long-haul trucks?
To find out, the MIT team performed a detailed analysis of the hydrogen option. “We thought that hydrogen would solve a lot of the problems we had with battery electric,” says Biswas. It doesn’t have associated CO2 emissions. Its energy density is far higher, so it doesn’t create the weight problem posed by heavy batteries. In addition, existing compression technology can get enough hydrogen fuel into a regular-sized tank to cover the needed distance and range. “You can actually give drivers the range they want,” he says. “There’s no issue with ‘range anxiety.’”
But while using hydrogen for long-haul trucking would reduce carbon emissions, it would cost far more than diesel. Based on their detailed analysis of hydrogen, the researchers concluded that the main source of incurred cost is in transporting it. Hydrogen can be made in a chemical facility, but then it needs to be distributed to refueling stations across the country. Conventionally, there have been two main ways of transporting hydrogen: as a compressed gas and as a cryogenic liquid. As Biswas notes, the former is “super high pressure,” and the latter is “super cold.” The researchers’ calculations show that as much as 80 percent of the cost of delivered hydrogen is due to transportation and refueling, plus there’s the need to build dedicated refueling stations that can meet new environmental and safety standards for handling hydrogen as a compressed gas or a cryogenic liquid.
Having dismissed the conventional options for shipping hydrogen, they turned to a less-common approach: transporting hydrogen using “liquid organic hydrogen carriers” (LOHCs), special organic (carbon-containing) chemical compounds that can under certain conditions absorb hydrogen atoms and under other conditions release them.
LOHCs are in use today to deliver small amounts of hydrogen for commercial use. Here’s how the process works: In a chemical plant, the carrier compound is brought into contact with hydrogen in the presence of a catalyst under elevated temperature and pressure, and the compound picks up the hydrogen. The “hydrogen-loaded” compound — still a liquid — is then transported under atmospheric conditions. When the hydrogen is needed, the compound is again exposed to a temperature increase and a different catalyst, and the hydrogen is released.
LOHCs thus appear to be ideal hydrogen carriers for long-haul trucking. They’re liquid, so they can easily be delivered to existing refueling stations, where the hydrogen would be released; and they contain at least as much energy per gallon as hydrogen in a cryogenic liquid or compressed gas form. However, a detailed analysis of using hydrogen carriers showed that the approach would decrease emissions but at a considerable cost.
The problem begins with the “dehydrogenation” step at the retail station. Releasing the hydrogen from the chemical carrier requires heat, which is generated by burning some of the hydrogen being carried by the LOHC. The researchers calculate that getting the needed heat takes 36 percent of that hydrogen. (In theory, the process would take only 27 percent — but in reality, that efficiency won’t be achieved.) So out of every 100 units of starting hydrogen, 36 units are now gone.
But that’s not all. The hydrogen that comes out is at near-ambient pressure. So the facility dispensing the hydrogen will need to compress it — a process that the team calculates will use up 20-30 percent of the starting hydrogen.
Because of the needed heat and compression, there’s now less than half of the starting hydrogen left to be delivered to the truck — and as a result, the hydrogen fuel becomes twice as expensive. The bottom line is that the technology works, but “when it comes to really beating diesel, the economics don’t work. It’s quite a bit more expensive,” says Biswas. In addition, the refueling stations would require expensive compressors and auxiliary units such as cooling systems. The capital investment and the operating and maintenance costs together imply that the market penetration of hydrogen refueling stations will be slow.
A better strategy: onboard release of hydrogen from LOHCs
Given the potential benefits of using of LOHCs, the researchers focused on how to deal with both the heat needed to release the hydrogen and the energy needed to compress it. “That’s when we had the idea,” says Biswas. “Instead of doing the dehydrogenation [hydrogen release] at the refueling station and then loading the truck with hydrogen, why don’t we just take the LOHC and load that onto the truck?” Like diesel, LOHC is a liquid, so it’s easily transported and pumped into trucks at existing refueling stations. “We’ll then make hydrogen as it’s needed based on the power demands of the truck — and we can capture waste heat from the engine exhaust and use it to power the dehydrogenation process,” says Biswas.
In their proposed plan, hydrogen-loaded LOHC is created at a chemical “hydrogenation” plant and then delivered to a retail refueling station, where it’s pumped into a long-haul truck. Onboard the truck, the loaded LOHC pours into the fuel-storage tank. From there it moves to the “dehydrogenation unit” — the reactor where heat and a catalyst together promote chemical reactions that separate the hydrogen from the LOHC. The hydrogen is sent to the powertrain, where it burns, producing energy that propels the truck forward.
Hot exhaust from the powertrain goes to a “heat-integration unit,” where its waste heat energy is captured and returned to the reactor to help encourage the reaction that releases hydrogen from the loaded LOHC. The unloaded LOHC is pumped back into the fuel-storage tank, where it’s kept in a separate compartment to keep it from mixing with the loaded LOHC. From there, it’s pumped back into the retail refueling station and then transported back to the hydrogenation plant to be loaded with more hydrogen.
Switching to onboard dehydrogenation brings down costs by eliminating the need for extra hydrogen compression and by using waste heat in the engine exhaust to drive the hydrogen-release process. So how does their proposed strategy look compared to diesel? Based on a detailed analysis, the researchers determined that using their strategy would be 18 percent more expensive than using diesel, and emissions would drop by 71 percent.
But those results need some clarification. The 18 percent cost premium of using LOHC with onboard hydrogen release is based on the price of diesel fuel in 2020. In spring of 2023 the price was about 30 percent higher. Assuming the 2023 diesel price, the LOHC option is actually cheaper than using diesel.
Both the cost and emissions outcomes are affected by another assumption: the use of “blue hydrogen,” which is hydrogen produced from natural gas with carbon capture and storage. Another option is to assume the use of “green hydrogen,” which is hydrogen produced using electricity generated from renewable sources, such as wind and solar. Green hydrogen is much more expensive than blue hydrogen, so then the costswould increase dramatically.
If in the future the price of green hydrogen drops, the researchers’ proposed planwould shift to green hydrogen — and then the decline in emissions would no longer be 71 percent but rather close to 100 percent. There would be almost no emissions associated with the researchers’ proposed plan for using LHOCs with onboard hydrogen release.
Comparing the options on cost and emissions
To compare the options, Moreno Sader prepared bar charts showing the per-mile cost of shipping by truck in the United States and the CO2 emissions that result using each of the fuels and approaches discussed above: diesel fuel, battery electric, hydrogen as a cryogenic liquid or compressed gas, and LOHC with onboard hydrogen release. The LOHC strategy with onboard dehydrogenation looked promising on both the cost and the emissions charts. In addition to such quantitative measures, the researchers believe that their strategy addresses two other, less-obvious challenges in finding a less-polluting fuel for long-haul trucks.
First, the introduction of the new fuel and trucks to use it must not disrupt the current freight-delivery setup. “You have to keep the old trucks running while you’re introducing the new ones,” notes Green. “You cannot have even a day when the trucks aren’t running because it’d be like the end of the economy. Your supermarket shelves would all be empty; your factories wouldn’t be able to run.” The researchers’ plan would be completely compatible with the existing diesel supply infrastructure and would require relatively minor retrofits to today’s long-haul trucks, so the current supply chains would continue to operate while the new fuel and retrofitted trucks are introduced.
Second, the strategy has the potential to be adopted globally. Long-haul trucking is important in other parts of the world, and Moreno Sader thinks that “making this approach a reality is going to have a lot of impact, not only in the United States but also in other countries,” including her own country of origin, Colombia. “This is something I think about all the time.” The approach is compatible with the current diesel infrastructure, so the only requirement for adoption is to build the chemical hydrogenation plant. “And I think the capital expenditure related to that will be less than the cost of building a new fuel-supply infrastructure throughout the country,” says Moreno Sader.
Testing in the lab
“We’ve done a lot of simulations and calculations to show that this is a great idea,” notes Biswas. “But there’s only so far that math can go to convince people.” The next step is to demonstrate their concept in the lab.
To that end, the researchers are now assembling all the core components of the onboard hydrogen-release reactor as well as the heat-integration unit that’s key to transferring heat from the engine exhaust to the hydrogen-release reactor. They estimate that this spring they’ll be ready to demonstrate their ability to release hydrogen and confirm the rate at which it’s formed. And — guided by their modeling work — they’ll be able to fine-tune critical components for maximum efficiency and best performance.
The next step will be to add an appropriate engine, specially equipped with sensors to provide the critical readings they need to optimize the performance of all their core components together. By the end of 2024, the researchers hope to achieve their goal: the first experimental demonstration of a power-dense, robust onboard hydrogen-release system with highly efficient heat integration.
In the meantime, they believe that results from their work to date should help spread the word, bringing their novel approach to the attention of other researchers and experts in the trucking industry who are now searching for ways to decarbonize long-haul trucking.
Financial support for development of the representative drive cycle and the diesel benchmarks as well as the analysis of the battery electric option was provided by the MIT Mobility Systems Center of the MIT Energy Initiative. Analysis of LOHC-powered trucks with onboard dehydrogenation was supported by the MIT Climate and Sustainability Consortium. Sayandeep Biswas is supported by a fellowship from the Martin Family Society of Fellows for Sustainability, and Kariana Moreno Sader received fellowship funding from MathWorks through the MIT School of Science.
Based on a series of analytical studies, MIT chemical engineers have come up with an idea that would enable long-haul trucks to use clean-burning hydrogen in place of diesel fuel, thereby reducing their carbon emissions. Left to right: Sayandeep Biswas, William Green, and Kariana Moreno Sader are now building an experiment to test and fine-tune equipment key to their promising approach.
When Tomás Vega SM ’19 was 5 years old, he began to stutter. The experience gave him an appreciation for the adversity that can come with a disability. It also showed him the power of technology.
“A keyboard and a mouse were outlets,” Vega says. “They allowed me to be fluent in the things I did. I was able to transcend my limitations in a way, so I became obsessed with human augmentation and with the concept of cyborgs. I also gained empathy. I think we all have empathy, but we apply it according to our own experiences.”
Vega has been using technology to augment human capabilities ever since. He began programming when he was 12. In high school, he helped people manage disabilities including hand impairments and multiple sclerosis. In college, first at the University of California at Berkeley and then at MIT, Vega built technologies that helped people with disabilities live more independently.
Today Vega is the co-founder and CEO of Augmental, a startup deploying technology that lets people with movement impairments seamlessly interact with their personal computational devices.
Augmental’s first product is the MouthPad, which allows users to control their computer, smartphone, or tablet through tongue and head movements. The MouthPad’s pressure-sensitive touch pad sits on the roof of the mouth, and, working with a pair of motion sensors, translates tongue and head gestures into cursor scrolling and clicks in real time via Bluetooth.
“We have a big chunk of the brain that is devoted to controlling the position of the tongue,” Vega explains. “The tongue comprises eight muscles, and most of the muscle fibers are slow-twitch, which means they don’t fatigue as quickly. So, I thought why don’t we leverage all of that?”
People with spinal cord injuries are already using the MouthPad every day to interact with their favorite devices independently. One of Augmental’s users, who is living with quadriplegia and studying math and computer science in college, says the device has helped her write math formulas and study in the library — use cases where other assistive speech-based devices weren’t appropriate.
“She can now take notes in class, she can play games with her friends,” Vega says. “She is more independent. Her mom told us that getting the MouthPad was the most significant moment since her injury.”
That’s the ultimate goal of Augmental: to improve the accessibility of technologies that have become an integral part of our lives.
“We hope that a person with a severe hand impairment can be as competent using a phone or tablet as somebody using their hands,” Vega says.
Making computers more accessible
In 2012, as a first-year student at UC Berkeley, Vega met his eventual Augmental co-founder, Corten Singer. That year, he told Singer he was determined to join the Media Lab as a graduate student, something he achieved four years later when he joined the Media Lab’s Fluid Interfaces research group run by Pattie Maes, MIT’s Germeshausen Professor of Media Arts and Sciences.
“I only applied to one program for grad school, and that was the Media Lab,” Vega says. “I thought it was the only place where I could do what I wanted to do, which is augmenting human ability.”
At the Media Lab, Vega took classes in microfabrication, signal processing, and electronics. He also developed wearable devices to help people access information online, improve their sleep, and regulate their emotions.
“At the Media Lab, I was able to apply my engineering and neuroscience background to build stuff, which is what I love doing the most,” Vega says. “I describe the Media Lab as Disneyland for makers. I was able to just play, and to explore without fear.”
Vega had gravitated toward the idea of a brain-machine interface, but an internship at Neuralink made him seek out a different solution.
“A brain implant has the highest potential for helping people in the future, but I saw a number of limitations that pushed me from working on it right now,” Vega says. “One is the long timeline for development. I’ve made so many friends over the past years that needed a solution yesterday.”
At MIT, he decided to build a solution with all the potential of a brain implant but without the limitations.
In his last semester at MIT, Vega built what he describes as “a lollipop with a bunch of sensors” to test the mouth as a medium for computer interaction. It worked beautifully.
“At that point, I called Corten, my co-founder, and said, ‘I think this has the potential to change so many lives,’” Vega says. “It could also change the way humans interact with computers in the future.”
Vega used MIT resources including the Venture Mentoring Service, the MIT I-Corps program, and received crucial early funding from MIT’s E14 Fund. Augmental was officially born when Vega graduated from MIT at the end of 2019.
Augmental generates each MouthPad design using a 3D model based on a scan of the user’s mouth. The team then 3-D prints the retainer using dental-grade materials and adds the electronic components.
With the MouthPad, users can scroll up, down, left, and right by sliding their tongue. They can also right click by doing a sipping gesture and left click by pressing on their palate. For people with less control of their tongue, bites, clenches, and other gestures can be used, and people with more neck control can use head-tracking to move the cursor on their screen.
“Our hope is to create an interface that is multimodal, so you can choose what works for you,” Vega says. “We want to be accommodating to every condition.”
Scaling the MouthPad
Many of Augmental’s current users have spinal cord injuries, with some users unable to move their hands and others unable to move their heads. Gamers and programmers have also used the device. The company’s most frequent users interact with the MouthPad every day for up to nine hours.
“It’s amazing because it means that it has really seamlessly integrated into their lives, and they are finding lots of value in our solution,” Vega says.
Augmental is hoping to gain U.S. Food and Drug Administration clearance over the next year to help users do things like control wheelchairs and robotic arms. FDA clearance will also unlock insurance reimbursements for users, which will make the product more accessible.
Augmental is already working on the next version of its system, which will respond to whispers and even more subtle movements of internal speech organs.
“That’s crucial to our early customer segment because a lot of them have lost or have impaired lung function,” Vega says.
Vega is also encouraged by progress in AI agents and the hardware that goes with them. No matter how the digital world evolves, Vega believes Augmental can be a tool that can benefit everyone.
“What we hope to provide one day is an always-available, robust, and private interface to intelligence,” Vega says. “We think that this is the most expressive, wearable, hands-free input system that humans have created.”
This spring, 26 MIT students and postdocs traveled to Washington to meet with congressional staffers to advocate for increased science funding for fiscal year 2025. These conversations were impactful given the recent announcement of budget cuts for several federal science agencies for FY24.
The participants met with 85 congressional offices representing 30 states over two days April 8-9. Overall, the group advocated for $89.46 billion in science funding across 11 federal scientific agencies.
Every spring, the MIT Science Policy Initiative (SPI) organizes the Congressional Visit Days (CVD). The trip exposes participants to the process of U.S. federal policymaking and the many avenues researchers can use to advocate for scientific research. The participants also meet with Washington-based alumni and members of the MIT Washington Office and learn about policy careers.
This year, CVD was jointly co-organized by Marie Floryan and Andrew Fishberg, two PhD students in the departments of Mechanical Engineering and Aeronautics and Astronautics, respectively. Before the trip, the participants attended two training sessions organized by SPI, the MIT Washington Office, and the MIT Policy Lab. The participants learned how funding is appropriated at the federal level, the role of elected congressional officials and their staffers in the legislative process, and how academic researchers can get involved in advocating for policies for science.
Julian Ufert, a doctoral student in chemical engineering, says, “CVD was a remarkable opportunity to share insights from my research with policymakers, learn about U.S. politics, and serve the greater scientific community. I thoroughly enjoyed the contacts I made both on Capitol Hill and with MIT students and postdocs who share an interest in science policy.”
In addition to advocating for increased science funding, the participants advocated for topics pertaining to their research projects. A wide variety of topics were discussed, including AI, cybersecurity, energy production and storage, and biotechnology. Naturally, the recent advent of groundbreaking AI technologies, like ChatGPT, brought the topic of AI to the forefront of many offices interested, with multiple offices serving on the newly formed bipartisan AI Task Force.
These discussions were useful for both parties: The participants learned about the methods and challenges associated with enacting legislation, and the staffers directly heard from academic researchers about what is needed to promote scientific progress and innovation.
“It was fascinating to experience the interest and significant involvement of Congressional offices in policy matters related to science and technology. Most staffers were well aware of the general technological advancements and eager to learn more about how our research will impact society,” says Vipindev Vasudevan, a postdoc in electrical and computer engineering.
Dina Sharon, a PhD student in chemistry, adds, “The offices where we met with Congressional staffers were valuable classrooms! Our conversations provided insights into policymakers’ goals, how science can help reach these goals, and how scientists can help cultivate connections between the research and policy spheres.”
Participants also shared how science funding has directly impacted them, discussing how federal grants have supported their graduate education and for the need for open access research.
Congressional Visit Days participants pose in front of the U.S. Capitol.
The Fannie and John Hertz Foundation announced that it has awarded fellowships to 10 PhD students with ties to MIT. The prestigious award provides each recipient with five years of doctoral-level research funding (up to a total of $250,000), which allows them the flexibility and autonomy to pursue their own innovative ideas.
Fellows also receive lifelong access to Hertz Foundation programs, such as events, mentoring, and networking. They join the ranks of over 1,300 former Hertz Fellows who are leaders and scholars in a range of fields in science, engineering, and technology. Connections among fellows over the years have sparked collaborations in startups, research, and technology commercialization.
The 10 MIT recipients are among a total of 18 Hertz Foundation Fellows scholars selected this year from across the country. Five of them received their undergraduate degrees at the Institute and will pursue their PhDs at other schools. Two are current MIT graduate students, and four will begin their studies here in the fall.
“For more than 60 years, Hertz Fellows have led scientific and technical innovation in national security, applied biological sciences, materials research, artificial intelligence, space exploration, and more. Their contributions have been essential in advancing U.S. competitiveness,” says Stephen Fantone, chair of the Hertz Foundation board of directors and founder and president of Optikos Corp. “I’m excited to watch our newest Hertz Fellows as they pursue challenging research and continue the strong tradition of applying their work for the greater good.”
This year’s MIT-affiliated awardees are:
Owen Dugan ’24 graduated from MIT in just two-and-a-half years with a degree in physics, and he plans to pursue a PhD in computer science at Stanford University. His research interests lie at the intersection of AI and physics. As an undergraduate, he conducted research in a broad range of areas, including using physics concepts to enhance the speed of large language models and developing machine learning algorithms that automatically discover scientific theories. He was recognized with MIT’s Outstanding Undergraduate Research Award and is a U.S. Presidential Scholar, a Neo Scholar, and a Knight-Hennessy Scholar. Dugan holds multiple patents, co-developed an app to reduce food waste, and co-founded a startup that builds tools to verify the authenticity of digital images.
Kaylie Hausknecht will begin her physics doctorate at MIT in the fall, having completing her undergraduate degree in physics and astrophysics at Harvard University. While there, her undergraduate research focused on developing new machine learning techniques to solve problems in a range of fields, such as fluid dynamics, astrophysics, and condensed matter physics. She received the Hoopes Prize for her senior thesis, was inducted into Phi Beta Kappa as a junior, and won two major writing awards. In addition, she completed five NASA internships. As an intern, she helped identify 301 new exoplanets using archival data from the Kepler Space Telescope. Hausknecht served as the co-president of Harvard’s chapter of Science Club for Girls, which works to encourage girls from underrepresented backgrounds to pursue STEM.
Elijah Lew-Smith majored in physics at Brown University and plans to pursue a doctoral degree in physics at MIT. He is a theoretical physicist with broad intellectual interests in effective field theory (EFT), which is the study of systems with many interacting degrees of freedom. EFT reveals how to extract the relevant, long-distance behavior from complicated microscopic rules. In 2023, he received a national award to work on applying EFT systematically to non-equilibrium and active systems such as fluctuating hydrodynamics or flocking birds. In addition, Lew-Smith received a scholarship from the U.S. State Department to live for a year in Dakar, Senegal, and later studied at ’École Polytechnique in Paris, France.
Rupert Li ’24 earned his bachelor’s and master’s degrees at MIT in mathematics as well as computer science, data science, and economics, with a minor in business analytics.He was named a 2024 Marshall Scholar and will study abroad for a year at Cambridge University before matriculating at Stanford University for a mathematics doctorate. As an undergraduate, Li authored 12 math research articles, primarily in combinatorics, but also including discrete geometry, probability, and harmonic analysis. He was recognized for his work with a Barry Goldwater Scholarship and an honorable mention for the Morgan Prize, one of the highest undergraduate honors in mathematics.
Amani Maina-Kilaas is a first-year doctoral student at MIT in the Department of Brain and Cognitive Sciences, where he studies computational psycholinguistics. In particular, he is interested in using artificial intelligence as a scientific tool to study how the mind works, and using what we know about the mind to develop more cognitively realistic models. Maina-Kilaas earned his bachelor’s degree in computer science and mathematics from Harvey Mudd College. There, he conducted research regarding intention perception and theoretical machine learning, earning the Astronaut Scholarship and Computing Research Association’s Outstanding Undergraduate Researcher Award.
Zoë Marschner ’23 is a doctoral student at Carnegie Mellon University working on geometry processing, a subfield of computer graphics focused on how to represent and work with geometric data digitally; in her research, she aims to make these representations capable of enabling fundamentally better algorithms for solving geometric problems across science and engineering. As an undergraduate at MIT, she earned a bachelor’s degree in computer science and math and pursued research in geometry processing, including repairing hexahedral meshes and detecting intersections between high-order surfaces. She also interned at Walt Disney Animation Studios, where she worked on collision detection algorithms for simulation. Marschner is a recipient of the National Science Foundation’s Graduate Research Fellowship and the Goldwater Scholarship.
Zijian (William) Niu will start a doctoral program in computational and systems biology at MIT in the fall. He has a particular interest in developing new methods for imaging proteins and other biomolecules in their native cellular environments and using those data to build computational models for predicting their dynamics and molecular interactions. Niu received his bachelor’s degree in biochemistry, biophysics, and physics from the University of Pennsylvania. His undergraduate research involved developing novel computational methods for biological image analysis. He was awarded the Barry M. Goldwater Scholarship for creating a deep-learning algorithm for accurately detecting tiny diffraction-limited spots in fluorescence microscopy images that outperformed existing methods in quantifying spatial transcriptomics data.
James Roney received his bachelor’s and master’s degrees from Harvard University in computer science and statistics, respectively. He is currently working as a machine learning research engineer at D.E. Shaw Research. His past research has focused on interpreting the internal workings of AlphaFold and modeling cancer evolution. Roney plans to pursue a PhD in computational biology at MIT, with a specific interest in developing computational models of protein structure, function, and evolution and using those models to engineer novel proteins for applications in biotechnology.
Anna Sappington ’19 is a student in the Harvard University-MIT MD-PhD Program, currently in the first year of her doctoral program at MIT in electrical engineering and computer science. She is interested in building methods to predict evolutionary events, especially connections among machine learning, biology, and chemistry to develop reinforcement learning models inspired by evolutionary biology. Sappington graduated from MIT with a bachelor’s degree in computer science and molecular biology. As an undergraduate, she was awarded a 2018 Barry M. Goldwater Scholarship and selected as a Burchard Scholar and an Amgen Scholar. After graduating, she earned a master’s degree in genomic medicine from the University of Cambridge, where she studied as a Marshall Scholar, as well as a master’s degree in machine learning from University College London.
Jason Yang ’22 received his bachelor’s degree in biology with a minor in computer science from MIT and is currently a doctoral student in genetics at Stanford University. He is interested in understanding the biological processes that underlie human health and disease. At MIT, and subsequently at Massachusetts General Hospital, Yang worked on the mechanisms involved in neurodegeneration in repeat expansion diseases, uncovering a novel molecular consequence of repeat protein aggregation.
Top row from left to right: Owen Dugan ’24, Kaylie Hausknecht, Elijah Lew-Smith, and Rupert Li ’24. Middle row from left to right: Amani Maina-Kilaas, Zoë Marschner ’23, Zijian (William) Niu, and James Roney. Bottom row: Anna Sappington ’19 (left) and Jason Yang ’22.
The human genome contains about 23,000 genes, but only a fraction of those genes are turned on inside a cell at any given time. The complex network of regulatory elements that controls gene expression includes regions of the genome called enhancers, which are often located far from the genes that they regulate.
This distance can make it difficult to map the complex interactions between genes and enhancers. To overcome that, MIT researchers have invented a new technique that allows them to observe the timing of gene and enhancer activation in a cell. When a gene is turned on around the same time as a particular enhancer, it strongly suggests the enhancer is controlling that gene.
Learning more about which enhancers control which genes, in different types of cells, could help researchers identify potential drug targets for genetic disorders. Genomic studies have identified mutations in many non-protein-coding regions that are linked to a variety of diseases. Could these be unknown enhancers?
“When people start using genetic technology to identify regions of chromosomes that have disease information, most of those sites don’t correspond to genes. We suspect they correspond to these enhancers, which can be quite distant from a promoter, so it’s very important to be able to identify these enhancers,” says Phillip Sharp, an MIT Institute Professor Emeritus and member of MIT’s Koch Institute for Integrative Cancer Research.
Sharp is the senior author of the new study, which appears today in Nature. MIT Research Assistant D.B. Jay Mahat is the lead author of the paper.
Hunting for eRNA
Less than 2 percent of the human genome consists of protein-coding genes. The rest of the genome includes many elements that control when and how those genes are expressed. Enhancers, which are thought to turn genes on by coming into physical contact with gene promoter regions through transiently forming a complex, were discovered about 45 years ago.
More recently, in 2010, researchers discovered that these enhancers are transcribed into RNA molecules, known as enhancer RNA or eRNA. Scientists suspect that this transcription occurs when the enhancers are actively interacting with their target genes. This raised the possibility that measuring eRNA transcription levels could help researchers determine when an enhancer is active, as well as which genes it’s targeting.
“That information is extraordinarily important in understanding how development occurs, and in understanding how cancers change their regulatory programs and activate processes that lead to de-differentiation and metastatic growth,” Mahat says.
However, this kind of mapping has proven difficult to perform because eRNA is produced in very small quantities and does not last long in the cell. Additionally, eRNA lacks a modification known as a poly-A tail, which is the “hook” that most techniques use to pull RNA out of a cell.
One way to capture eRNA is to add a nucleotide to cells that halts transcription when incorporated into RNA. These nucleotides also contain a tag called biotin that can be used to fish the RNA out of a cell. However, this current technique only works on large pools of cells and doesn’t give information about individual cells.
While brainstorming ideas for new ways to capture eRNA, Mahat and Sharp considered using click chemistry, a technique that can be used to join two molecules together if they are each tagged with “click handles” that can react together.
The researchers designed nucleotides labeled with one click handle, and once these nucleotides are incorporated into growing eRNA strands, the strands can be fished out with a tag containing the complementary handle. This allowed the researchers to capture eRNA and then purify, amplify, and sequence it. Some RNA is lost at each step, but Mahat estimates that they can successfully pull out about 10 percent of the eRNA from a given cell.
Using this technique, the researchers obtained a snapshot of the enhancers and genes that are being actively transcribed at a given time in a cell.
“You want to be able to determine, in every cell, the activation of transcription from regulatory elements and from their corresponding gene. And this has to be done in a single cell because that’s where you can detect synchrony or asynchrony between regulatory elements and genes,” Mahat says.
Timing of gene expression
Demonstrating their technique in mouse embryonic stem cells, the researchers found that they could calculate approximately when a particular region starts to be transcribed, based on the length of the RNA strand and the speed of the polymerase (the enzyme responsible for transcription) — that is, how far the polymerase transcribes per second. This allowed them to determine which genes and enhancers were being transcribed around the same time.
The researchers used this approach to determine the timing of the expression of cell cycle genes in more detail than has previously been possible. They were also able to confirm several sets of known gene-enhancer pairs and generated a list of about 50,000 possible enhancer-gene pairs that they can now try to verify.
Learning which enhancers control which genes would prove valuable in developing new treatments for diseases with a genetic basis. Last year, the U.S. Food and Drug Administration approved the first gene therapy treatment for sickle cell anemia, which works by interfering with an enhancer that results in activation of a fetal globin gene, reducing the production of sickled blood cells.
The MIT team is now applying this approach to other types of cells, with a focus on autoimmune diseases. Working with researchers at Boston Children’s Hospital, they are exploring immune cell mutations that have been linked to lupus, many of which are found in non-coding regions of the genome.
“It’s not clear which genes are affected by these mutations, so we are beginning to tease apart the genes these putative enhancers might be regulating, and in what cell types these enhancers are active,” Mahat says. “This is a tool for creating gene-to-enhancer maps, which are fundamental in understanding the biology, and also a foundation for understanding disease.”
The findings of this study also offer evidence for a theory that Sharp has recently developed, along with MIT professors Richard Young and Arup Chakraborty, that gene transcription is controlled by membraneless droplets known as condensates. These condensates are made of large clusters of enzymes and RNA, which Sharp suggests may include eRNA produced at enhancer sites.
“We picture that the communication between an enhancer and a promoter is a condensate-type, transient structure, and RNA is part of that. This is an important piece of work in building the understanding of how RNAs from enhancers could be active,” he says.
The research was funded by the National Cancer Institute, the National Institutes of Health, and the Emerald Foundation Postdoctoral Transition Award.
“This discovery has direct implications for low-power electronic devices because no energy is lost during the propagation of electrons, which is not the case in regular materials where the electrons are scattered,” says Long Ju, an assistant professor in the Department of Physics and corresponding author of the Science paper.
The phenomenon is akin to cars traveling down an open turnpike as opposed to those moving through neighborhoods. The neighborhood cars can be stopped or slowed by other drivers making abrupt stops or U-turns that disrupt an otherwise smooth commute.
A new material
The material behind this work, known as rhombohedral pentalayer graphene, was discovered two years ago by physicists led by Ju. “We found a goldmine, and every scoop is revealing something new,” says Ju, who is also affiliated with MIT’s Materials Research Laboratory.
In a Nature Nanotechnology paper last October, Ju and colleagues reported the discovery of three important properties arising from rhombohedral graphene. For example, they showed that it could be topological, or allow the unimpeded movement of electrons around the edge of the material but not through the middle. That resulted in a superhighway, but required the application of a large magnetic field some tens of thousands times stronger than the Earth’s magnetic field.
In the current work, the team reports creating the superhighway without any magnetic field.
Tonghang Han, an MIT graduate student in physics, is a co-first author of the paper. “We are not the first to discover this general phenomenon, but we did so in a very different system. And compared to previous systems, ours is simpler and also supports more electron channels.” Explains Ju, “other materials can only support one lane of traffic on the edge of the material. We suddenly bumped it up to five.”
Additional co-first authors of the paper who contributed equally to the work are Zhengguang Lu and Yuxuan Yao. Lu is a postdoc in the Materials Research Laboratory. Yao conducted the work as a visiting undergraduate student from Tsinghua University. Other authors are MIT professor of physics Liang Fu; Jixiang Yang and Junseok Seo, both MIT graduate students in physics; Chiho Yoon and Fan Zhang of the University of Texas at Dallas; and Kenji Watanabe and Takashi Taniguchi of the National Institute for Materials Science in Japan.
How it works
Graphite, the primary component of pencil lead, is composed of many layers of graphene, a single layer of carbon atoms arranged in hexagons resembling a honeycomb structure. Rhombohedral graphene is composed of five layers of graphene stacked in a specific overlapping order.
Ju and colleagues isolated rhombohedral graphene thanks to a novel microscope Ju built at MIT in 2021 that can quickly and relatively inexpensively determine a variety of important characteristics of a material at the nanoscale. Pentalayer rhombohedral stacked graphene is only a few billionths of a meter thick.
In the current work, the team tinkered with the original system, adding a layer of tungsten disulfide (WS2). “The interaction between the WS2 and the pentalayer rhombohedral graphene resulted in this five-lane superhighway that operates at zero magnetic field,” says Ju.
Comparison to superconductivity
The phenomenon that the Ju group discovered in rhombohedral graphene that allows electrons to travel with no resistance at zero magnetic field is known as the quantum anomalous Hall effect. Most people are more familiar with superconductivity, a completely different phenomenon that does the same thing but happens in very different materials.
Ju notes that although superconductors were discovered in the 1910s, it took some 100 years of research to coax the system to work at the higher temperatures necessary for applications. “And the world record is still well below room temperature,” he notes.
Similarly, the rhombohedral graphene superhighway currently operates at about 2 kelvins, or -456 degrees Fahrenheit. “It will take a lot of effort to elevate the temperature, but as physicists, our job is to provide the insight; a different way for realizing this [phenomenon],” Ju says.
Very exciting
The discoveries involving rhombohedral graphene came as a result of painstaking research that wasn’t guaranteed to work. “We tried many recipes over many months,” says Han, “so it was very exciting when we cooled the system to a very low temperature and [a five-lane superhighway operating at zero magnetic field] just popped out.”
Says Ju, “it’s very exciting to be the first to discover a phenomenon in a new system, especially in a material that we uncovered.”
This work was supported by a Sloan Fellowship; the U.S. National Science Foundation; the U.S. Office of the Under Secretary of Defense for Research and Engineering; the Japan Society for the Promotion of Science KAKENHI; and the World Premier International Research Initiative of Japan.
Artist’s rendition of a newly discovered superhighway for electrons that can occur in rhombohedral graphene. “We found a goldmine, and every scoop is revealing something new,” says MIT Assistant Professor Long Ju.
It’s no news that companies use money to influence politics. But it may come as a surprise to learn that many family-owned firms — the most common form of business in the world — do not play by the same rules. New research by political science PhD candidate Sukrit Puri reveals that “family businesses depart from the political strategy of treating campaign donations as short-term investments intended to maximize profitmaking.”
Studying thousands of such firms in India, Puri finds that when it comes to politics, an important influence on political behavior is ethnic identity. This in turn can make a big impact on economic development.
“If family businesses actually think about politics differently, and if they are the most common economic actors in an economy, then you break channels of accountability between a business and the government,” says Puri. “Elected officials may be less likely to deliver effective policies for achieving economic growth.”
Puri believes his insights suggest new approaches for struggling economies in some developing countries. “I’d like to get governments to think carefully about the importance of family firms, and how to incentivize them through the right kinds of industrial policies.”
Pushing past caricatures
At the heart of Puri’s doctoral studies is a question he says has long interested him: “Why are some countries rich and other countries poor?” The son of an Indian diplomat who brought his family from Belgium and Nepal to the Middle East and New York City, Puri focused on the vast inequalities he witnessed as he grew up.
As he studied economics, political science, and policy as an undergraduate at Princeton University, Puri came to believe “that firms play a very important role” in the economic development of societies. But it was not always clear from these disciplines how businesses interacted with governments, and how that affected economic growth.
“There are two canonical ways of thinking about business in politics, and they have become almost like caricatures,” says Puri. One claims government is in the pocket of corporations, or that at the least they wield undue influence. The other asserts that businesses simply do governments’ bidding and are constrained by the needs of the state. “I found these two perspectives to be wanting, because neither side gets entirely what it desires,” he says. “I set out to learn more about how business actually seeks to influence, and when it is successful or not.”
So much political science literature on business and politics is “America-centric,” with publicly listed, often very large corporations acting on behalf of shareholders, notes Puri. But this is not the paradigm for many other countries. The major players in countries like South Korea and India are family firms, big and small. “There has been so little investigation of how these family businesses participate in politics,” Puri says. “I wanted to know if we could come up with a political theory of the family firm, and look into the nature of business and politics in developing economies and democracies where these firms are so central.”
Campaign donation differences
To learn whether family businesses think about politics differently, Puri decided to zero in on one of the most pervasive forms of influence all over the world: campaign donations. “In the U.S., firms treat these donations as short-term investments, backing the incumbent and opportunistically switching parties when political actors change,” he says. “These companies have no ideology.” But family firms in India, Puri’s empirical setting, prove to operate very differently.
Puri compiled a vast dataset of all donations to Indian political parties from 2003 to 2021, identifying 7,000 unique corporate entities donating a cumulative $1 billion to 36 parties participating in national and state-level elections. He identified which of these donations came from family firms by identifying family members sitting on boards of these companies. Puri found evidence that firms with greater family involvement on these boards overwhelmingly donate loyally to a single party of their choice, and “do not participate in politics out of opportunistic, short-term profit maximizing impulse.”
Puri believes there are sociological explanations for this unexpected behavior. Family firms are more than just economic actors, but social actors as well — embedded in community networks that then shape their values, preferences, and strategic choices. In India, communities often form around caste and religious networks. So for instance, some economic policies of the ruling Bharatiya Janata Party (BJP) have hurt its core supporters of small and medium-sized businesses, says Puri. Yet, these businesses have not abandoned their financial support of the BJP. Similarly, Muslim-majority communities and family firms stick with their candidates, even when it is not in their short-term economic best interest. Their behavior is more like that of an individual political donor — more ideological and expressive than strategic.
Engaged by debate
As a college first-year, Puri was uncertain of his academic direction. Then he learned of a debate playing out between two schools of economic thought on how to reduce poverty in India and other developing nations: On one side, Amartya Sen advocated for starting with welfare, and on the other, Jagdish Bhagwati and Arvind Panagariya argued that economic growth came first.
“I wanted to engage with this debate, because it suggested policy actions — what is feasible, what you can actually do in a country,” recalls Puri. “Economics was the tool for understanding these trade-offs.”
After graduation, Puri worked for a few years in investment management, specializing in emerging markets. “In my office, the conversation each day among economists was just basically political,” he says. “We were evaluating a country’s economic prospects through a kind of unsophisticated political analysis, and I decided I wanted to pursue more rigorous training in political economy.”
At MIT, Puri has finally found a way of merging his lifelong interests in economic development with policy-minded research. He believes that the behavior of family firms should be of keen concern to many governments.
“Family firms can be very insular, sticking with old practices and rewarding loyalty to co-ethnic partners,” he says. There are barriers to outside hires who might bring innovations. “These businesses are often just not interested in taking up growth opportunities,” says Puri. “There are millions of family firms but they do not provide the kind of dynamism they should.”
In the next phase of his dissertation research Puri will survey not just the political behaviors, but the investment and management practices of family firms as well. He believes larger firms more open to outside ideas are expanding at the expense of smaller and mid-size family firms. In India and other nations, governments currently make wasteful subsidies to family firms that cannot rise to the challenge of, say, starting a new microchip fabricating plant. Instead, says Puri, governments must figure out the right kind of incentives to encourage openness and entrepreneurship in businesses that make up its economy, which are instrumental to unlocking broader economic growth.
After MIT, Puri envisions an academic life for himself studying business and politics around the world, but with a focus on India. He would like to write about family firms for a more general audience — following in the footsteps of authors who got him interested in political economy in the first place. “I’ve always believed in making knowledge more accessible; it’s one of the reasons I enjoy teaching,” he says. “It is really rewarding to lecture or write and be able to introduce people to new ideas.”
“Family firms can be very insular, sticking with old practices and rewarding loyalty to co-ethnic partners,” says political science PhD candidate Sukrit Puri. There are barriers to outside hires who might bring innovations. “These businesses are often just not interested in taking up growth opportunities,” says Puri.
Deep brain stimulation, by implanted electrodes that deliver electrical pulses to the brain, is often used to treat Parkinson’s disease and other neurological disorders. However, the electrodes used for this treatment can eventually corrode and accumulate scar tissue, requiring them to be removed.
MIT researchers have now developed an alternative approach that uses ultrasound instead of electricity to perform deep brain stimulation, delivered by a fiber about the thickness of a human hair. In a study of mice, they showed that this stimulation can trigger neurons to release dopamine, in a part of the brain that is often targeted in patients with Parkinson’s disease.
“By using ultrasonography, we can create a new way of stimulating neurons to fire in the deep brain,” says Canan Dagdeviren, an associate professor in the MIT Media Lab and the senior author of the new study. “This device is thinner than a hair fiber, so there will be negligible tissue damage, and it is easy for us to navigate this device in the deep brain.”
In addition to offering a potentially safer way to deliver deep brain stimulation, this approach could also become a valuable tool for researchers seeking to learn more about how the brain works.
MIT graduate student Jason Hou and MIT postdoc Md Osman Goni Nayeem are the lead authors of the paper, along with collaborators from MIT’s McGovern Institute for Brain Research, Boston University, and Caltech. The study appears today in Nature Communications.
Deep in the brain
Dagdeviren’s lab has previously developed wearable ultrasound devices that can be used to deliver drugs through the skin or perform diagnostic imaging on various organs. However, ultrasound cannot penetrate deeply into the brain from a device attached to the head or skull.
“If we want to go into the deep brain, then it cannot be just wearable or attachable anymore. It has to be implantable,” Dagdeviren says. “We carefully customize the device so that it will be minimally invasive and avoid major blood vessels in the deep brain.”
Deep brain stimulation with electrical impulses is FDA-approved to treat symptoms of Parkinson’s disease. This approach uses millimeter-thick electrodes to activate dopamine-producing cells in a brain region called the substantia nigra. However, once implanted in the brain, the devices eventually begin to corrode, and scar tissue that builds up surrounding the implant can interfere with the electrical impulses.
The MIT team set out to see if they could overcome some of those drawbacks by replacing electrical stimulation with ultrasound. Most neurons have ion channels that are responsive to mechanical stimulation, such as the vibrations from sound waves, so ultrasound can be used to elicit activity in those cells. However, existing technologies for delivering ultrasound to the brain through the skull can’t reach deep into the brain with high precision because the skull itself can interfere with the ultrasound waves and cause off-target stimulation.
“To precisely modulate neurons, we must go deeper, leading us to design a new kind of ultrasound-based implant that produces localized ultrasound fields,” Nayeem says. To safely reach those deep brain regions, the researchers designed a hair-thin fiber made from a flexible polymer. The tip of the fiber contains a drum-like ultrasound transducer with a vibrating membrane. When this membrane, which encapsulates a thin piezoelectric film, is driven by a small electrical voltage, it generates ultrasonic waves that can be detected by nearby cells.
“It’s tissue-safe, there’s no exposed electrode surface, and it’s very low-power, which bodes well for translation to patient use,” Hou says.
In tests in mice, the researchers showed that this ultrasound device, which they call ImPULS (Implantable Piezoelectric Ultrasound Stimulator), can provoke activity in neurons of the hippocampus. Then, they implanted the fibers into the dopamine-producing substantia nigra and showed that they could stimulate neurons in the dorsal striatum to produce dopamine.
“Brain stimulation has been one of the most effective, yet least understood, methods used to restore health to the brain. ImPULS gives us the ability to stimulate brain cells with exquisite spatial-temporal resolution and in a manner that doesn’t produce the kind of damage or inflammation as other methods. Seeing its effectiveness in areas like the hippocampus opened an entirely new way for us to deliver precise stimulation to targeted circuits in the brain,” says Steve Ramirez, an assistant professor of psychological and brain sciences at Boston University, and a faculty member at B.U.’s Center for Systems Neuroscience, who is also an author of the study.
A customizable device
All of the components of the device are biocompatible, including the piezoelectric layer, which is made of a novel ceramic called potassium sodium niobate, or KNN. The current version of the implant is powered by an external power source, but the researchers envision that future versions could be powered a small implantable battery and electronics unit.
The researchers developed a microfabrication process that enables them to easily alter the length and thickness of the fiber, as well as the frequency of the sound waves produced by the piezoelectric transducer. This could allow the devices to be customized for different brain regions.
“We cannot say that the device will give the same effect on every region in the brain, but we can easily and very confidently say that the technology is scalable, and not only for mice. We can also make it bigger for eventual use in humans,” Dagdeviren says.
The researchers now plan to investigate how ultrasound stimulation might affect different regions of the brain, and if the devices can remain functional when implanted for year-long timescales. They are also interested in the possibility of incorporating a microfluidic channel, which could allow the device to deliver drugs as well as ultrasound.
In addition to holding promise as a potential therapeutic for Parkinson’s or other diseases, this type of ultrasound device could also be a valuable tool to help researchers learn more about the brain, the researchers say.
“Our goal to provide this as a research tool for the neuroscience community, because we believe that we don’t have enough effective tools to understand the brain,” Dagdeviren says. “As device engineers, we are trying to provide new tools so that we can learn more about different regions of the brain.”
The research was funded by the MIT Media Lab Consortium and the Brain and Behavior Foundation Research (BBRF) NARSAD Young Investigator Award.
When robots come across unfamiliar objects, they struggle to account for a simple truth: Appearances aren’t everything. They may attempt to grasp a block, only to find out it’s a literal piece of cake. The misleading appearance of that object could lead the robot to miscalculate physical properties like the object’s weight and center of mass, using the wrong grasp and applying more force than needed.
To see through this illusion, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers designed the Grasping Neural Process, a predictive physics model capable of inferring these hidden traits in real time for more intelligent robotic grasping. Based on limited interaction data, their deep-learning system can assist robots in domains like warehouses and households at a fraction of the computational cost of previous algorithmic and statistical models.
The Grasping Neural Process is trained to infer invisible physical properties from a history of attempted grasps, and uses the inferred properties to guess which grasps would work well in the future. Prior models often only identified robot grasps from visual data alone.
Typically, methods that infer physical properties build on traditional statistical methods that require many known grasps and a great amount of computation time to work well. The Grasping Neural Process enables these machines to execute good grasps more efficiently by using far less interaction data and finishes its computation in less than a tenth of a second, as opposed seconds (or minutes) required by traditional methods.
The researchers note that the Grasping Neural Process thrives in unstructured environments like homes and warehouses, since both house a plethora of unpredictable objects. For example, a robot powered by the MIT model could quickly learn how to handle tightly packed boxes with different food quantities without seeing the inside of the box, and then place them where needed. At a fulfillment center, objects with different physical properties and geometries would be placed in the corresponding box to be shipped out to customers.
Trained on 1,000 unique geometries and 5,000 objects, the Grasping Neural Process achieved stable grasps in simulation for novel 3D objects generated in the ShapeNet repository. Then, the CSAIL-led group tested their model in the physical world via two weighted blocks, where their work outperformed a baseline that only considered object geometries. Limited to 10 experimental grasps beforehand, the robotic arm successfully picked up the boxes on 18 and 19 out of 20 attempts apiece, while the machine only yielded eight and 15 stable grasps when unprepared.
While less theatrical than an actor, robots that complete inference tasks also have a three-part act to follow: training, adaptation, and testing. During the training step, robots practice on a fixed set of objects and learn how to infer physical properties from a history of successful (or unsuccessful) grasps. The new CSAIL model amortizes the inference of the objects’ physics, meaning it trains a neural network to learn to predict the output of an otherwise expensive statistical algorithm. Only a single pass through a neural network with limited interaction data is needed to simulate and predict which grasps work best on different objects.
Then, the robot is introduced to an unfamiliar object during the adaptation phase. During this step, the Grasping Neural Process helps a robot experiment and update its position accordingly, understanding which grips would work best. This tinkering phase prepares the machine for the final step: testing, where the robot formally executes a task on an item with a new understanding of its properties.
“As an engineer, it’s unwise to assume a robot knows all the necessary information it needs to grasp successfully,” says lead author Michael Noseworthy, an MIT PhD student in electrical engineering and computer science (EECS) and CSAIL affiliate. “Without humans labeling the properties of an object, robots have traditionally needed to use a costly inference process.” According to fellow lead author, EECS PhD student, and CSAIL affiliate Seiji Shaw, their Grasping Neural Process could be a streamlined alternative: “Our model helps robots do this much more efficiently, enabling the robot to imagine which grasps will inform the best result.”
“To get robots out of controlled spaces like the lab or warehouse and into the real world, they must be better at dealing with the unknown and less likely to fail at the slightest variation from their programming. This work is a critical step toward realizing the full transformative potential of robotics,” says Chad Kessens, an autonomous robotics researcher at the U.S. Army’s DEVCOM Army Research Laboratory, which sponsored the work.
While their model can help a robot infer hidden static properties efficiently, the researchers would like to augment the system to adjust grasps in real time for multiple tasks and objects with dynamic traits. They envision their work eventually assisting with several tasks in a long-horizon plan, like picking up a carrot and chopping it. Moreover, their model could adapt to changes in mass distributions in less static objects, like when you fill up an empty bottle.
Joining the researchers on the paper is Nicholas Roy, MIT professor of aeronautics and astronautics and CSAIL member, who is a senior author. The group recently presented this work at the IEEE International Conference on Robotics and Automation.
A newly complete database of human protein kinases and their preferred binding sites provides a powerful new platform to investigate cell signaling pathways.
Culminating 25 years of research, MIT, Harvard University, and Yale University scientists and collaborators have unveiled a comprehensive atlas of human tyrosine kinases — enzymes that regulate a wide variety of cellular activities — and their binding sites.
The addition of tyrosine kinases to a previously published dataset from the same group now completes a free, publicly available atlas of all human kinases and their specific binding sites on proteins, which together orchestrate fundamental cell processes such as growth, cell division, and metabolism.
Now, researchers can use data from mass spectrometry, a common laboratory technique, to identify the kinases involved in normal and dysregulated cell signaling in human tissue, such as during inflammation or cancer progression.
“I am most excited about being able to apply this to individual patients’ tumors and learn about the signaling states of cancer and heterogeneity of that signaling,” says Michael Yaffe, who is the David H. Koch Professor of Science at MIT, the director of the MIT Center for Precision Cancer Medicine, a member of MIT’s Koch Institute for Integrative Cancer Research, and a senior author of the new study. “This could reveal new druggable targets or novel combination therapies.”
The study, published in Nature, is the product of a long-standing collaboration with senior authors Lewis Cantley at Harvard Medical School and Dana-Farber Cancer Institute, Benjamin Turk at Yale School of Medicine, and Jared Johnson at Weill Cornell Medical College.
The paper’s lead authors are Tomer Yaron-Barir at Columbia University Irving Medical Center, and MIT’s Brian Joughin, with contributions from Kontstantin Krismer, Mina Takegami, and Pau Creixell.
Kinase kingdom
Human cells are governed by a network of diverse protein kinases that alter the properties of other proteins by adding or removing chemical compounds called phosphate groups. Phosphate groups are small but powerful: When attached to proteins, they can turn proteins on or off, or even dramatically change their function. Identifying which of the almost 400 human kinases phosphorylate a specific protein at a particular site on the protein was traditionally a lengthy, laborious process.
Beginning in the mid 1990s, the Cantley laboratory developed a method using a library of small peptides to identify the optimal amino acid sequence — called a motif, similar to a scannable barcode — that a kinase targets on its substrate proteins for the addition of a phosphate group. Over the ensuing years, Yaffe, Turk, and Johnson, all of whom spent time as postdocs in the Cantley lab, made seminal advancements in the technique, increasing its throughput, accuracy, and utility.
Johnson led a massive experimental effort exposing batches of kinases to these peptide libraries and observed which kinases phosphorylated which subsets of peptides. In a corresponding Nature paper published in January 2023, the team mapped more than 300 serine/threonine kinases, the other main type of protein kinase, to their motifs. In the current paper, they complete the human “kinome” by successfully mapping 93 tyrosine kinases to their corresponding motifs.
Next, by creating and using advanced computational tools, Yaron-Barir, Krismer, Joughin, Takegami, and Yaffe tested whether the results were predictive of real proteins, and whether the results might reveal unknown signaling events in normal and cancer cells. By analyzing phosphoproteomic data from mass spectrometry to reveal phosphorylation patterns in cells, their atlas accurately predicted tyrosine kinase activity in previously studied cell signaling pathways.
For example, using recently published phosphoproteomic data of human lung cancer cells treated with two targeted drugs, the atlas identified that treatment with erlotinib, a known inhibitor of the protein EGFR, downregulated sites matching a motif for EGFR. Treatment with afatinib, a known HER2 inhibitor, downregulated sites matching the HER2 motif. Unexpectedly, afatinib treatment also upregulated the motif for the tyrosine kinase MET, a finding that helps explain patient data linking MET activity to afatinib drug resistance.
Actionable results
There are two key ways researchers can use the new atlas. First, for a protein of interest that is being phosphorylated, the atlas can be used to narrow down hundreds of kinases to a short list of candidates likely to be involved. “The predictions that come from using this will still need to be validated experimentally, but it’s a huge step forward in making clear predictions that can be tested,” says Yaffe.
Second, the atlas makes phosphoproteomic data more useful and actionable. In the past, researchers might gather phosphoproteomic data from a tissue sample, but it was difficult to know what that data was saying or how to best use it to guide next steps in research. Now, that data can be used to predict which kinases are upregulated or downregulated and therefore which cellular signaling pathways are active or not.
“We now have a new tool now to interpret those large datasets, a Rosetta Stone for phosphoproteomics,” says Yaffe. “It is going to be particularly helpful for turning this type of disease data into actionable items.”
In the context of cancer, phosophoproteomic data from a patient’s tumor biopsy could be used to help doctors quickly identify which kinases and cell signaling pathways are involved in cancer expansion or drug resistance, then use that knowledge to target those pathways with appropriate drug therapy or combination therapy.
Yaffe’s lab and their colleagues at the National Institutes of Health are now using the atlas to seek out new insights into difficult cancers, including appendiceal cancer and neuroendocrine tumors. While many cancers have been shown to have a strong genetic component, such as the genes BRCA1 and BRCA2 in breast cancer, other cancers are not associated with any known genetic cause. “We’re using this atlas to interrogate these tumors that don’t seem to have a clear genetic driver to see if we can identify kinases that are driving cancer progression,” he says.
Biological insights
In addition to completing the human kinase atlas, the team made two biological discoveries in their recent study. First, they identified three main classes of phosphorylation motifs, or barcodes, for tyrosine kinases. The first class is motifs that map to multiple kinases, suggesting that numerous signaling pathways converge to phosphorylate a protein boasting that motif. The second class is motifs with a one-to-one match between motif and kinase, in which only a specific kinase will activate a protein with that motif. This came as a partial surprise, as tyrosine kinases have been thought to have minimal specificity by some in the field.
The final class includes motifs for which there is no clear match to one of the 78 classical tyrosine kinases. This class includes motifs that match to 15 atypical tyrosine kinases known to also phosphorylate serine or threonine residues. “This means that there’s a subset of kinases that we didn’t recognize that are actually playing an important role,” says Yaffe. It also indicates there may be other mechanisms besides motifs alone that affect how a kinase interacts with a protein.
The team also discovered that tyrosine kinase motifs are tightly conserved between humans and the worm species C. elegans, despite the species being separated by more than 600 million years of evolution. In other words, a worm kinase and its human homologue are phosphorylating essentially the same motif. That sequence preservation suggests that tyrosine kinases are highly critical to signaling pathways in all multicellular organisms, and any small change would be harmful to an organism.
The research was funded by the Charles and Marjorie Holloway Foundation, the MIT Center for Precision Cancer Medicine, the Koch Institute Frontier Research Program via L. Scott Ritterbush, the Leukemia and Lymphoma Society, the National Institutes of Health, Cancer Research UK, the Brain Tumour Charity, and the Koch Institute Support (core) grant from the National Cancer Institute.
Scientists from MIT, Harvard University, and Yale University unveiled a "Rosetta Stone" for decoding normal and dysregulated signaling pathways, such as during inflammation or cancer progression.
Let’s say you want to train a robot so it understands how to use tools and can then quickly learn to make repairs around your house with a hammer, wrench, and screwdriver. To do that, you would need an enormous amount of data demonstrating tool use.
Existing robotic datasets vary widely in modality — some include color images while others are composed of tactile imprints, for instance. Data could also be collected in different domains, like simulation or human demos. And each dataset may capture a unique task and environment.
It is difficult to efficiently incorporate data from so many sources in one machine-learning model, so many methods use just one type of data to train a robot. But robots trained this way, with a relatively small amount of task-specific data, are often unable to perform new tasks in unfamiliar environments.
In an effort to train better multipurpose robots, MIT researchers developed a technique to combine multiple sources of data across domains, modalities, and tasks using a type of generative AI known as diffusion models.
They train a separate diffusion model to learn a strategy, or policy, for completing one task using one specific dataset. Then they combine the policies learned by the diffusion models into a general policy that enables a robot to perform multiple tasks in various settings.
In simulations and real-world experiments, this training approach enabled a robot to perform multiple tool-use tasks and adapt to new tasks it did not see during training. The method, known as Policy Composition (PoCo), led to a 20 percent improvement in task performance when compared to baseline techniques.
“Addressing heterogeneity in robotic datasets is like a chicken-egg problem. If we want to use a lot of data to train general robot policies, then we first need deployable robots to get all this data. I think that leveraging all the heterogeneous data available, similar to what researchers have done with ChatGPT, is an important step for the robotics field,” says Lirui Wang, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on PoCo.
Wang’s coauthors include Jialiang Zhao, a mechanical engineering graduate student; Yilun Du, an EECS graduate student; Edward Adelson, the John and Dorothy Wilson Professor of Vision Science in the Department of Brain and Cognitive Sciences and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL); and senior author Russ Tedrake, the Toyota Professor of EECS, Aeronautics and Astronautics, and Mechanical Engineering, and a member of CSAIL. The research will be presented at the Robotics: Science and Systems Conference.
Combining disparate datasets
A robotic policy is a machine-learning model that takes inputs and uses them to perform an action. One way to think about a policy is as a strategy. In the case of a robotic arm, that strategy might be a trajectory, or a series of poses that move the arm so it picks up a hammer and uses it to pound a nail.
Datasets used to learn robotic policies are typically small and focused on one particular task and environment, like packing items into boxes in a warehouse.
“Every single robotic warehouse is generating terabytes of data, but it only belongs to that specific robot installation working on those packages. It is not ideal if you want to use all of these data to train a general machine,” Wang says.
The MIT researchers developed a technique that can take a series of smaller datasets, like those gathered from many robotic warehouses, learn separate policies from each one, and combine the policies in a way that enables a robot to generalize to many tasks.
They represent each policy using a type of generative AI model known as a diffusion model. Diffusion models, often used for image generation, learn to create new data samples that resemble samples in a training dataset by iteratively refining their output.
But rather than teaching a diffusion model to generate images, the researchers teach it to generate a trajectory for a robot. They do this by adding noise to the trajectories in a training dataset. The diffusion model gradually removes the noise and refines its output into a trajectory.
This technique, known as Diffusion Policy, was previously introduced by researchers at MIT, Columbia University, and the Toyota Research Institute. PoCo builds off this Diffusion Policy work.
The team trains each diffusion model with a different type of dataset, such as one with human video demonstrations and another gleaned from teleoperation of a robotic arm.
Then the researchers perform a weighted combination of the individual policies learned by all the diffusion models, iteratively refining the output so the combined policy satisfies the objectives of each individual policy.
Greater than the sum of its parts
“One of the benefits of this approach is that we can combine policies to get the best of both worlds. For instance, a policy trained on real-world data might be able to achieve more dexterity, while a policy trained on simulation might be able to achieve more generalization,” Wang says.
Because the policies are trained separately, one could mix and match diffusion policies to achieve better results for a certain task. A user could also add data in a new modality or domain by training an additional Diffusion Policy with that dataset, rather than starting the entire process from scratch.
The researchers tested PoCo in simulation and on real robotic arms that performed a variety of tools tasks, such as using a hammer to pound a nail and flipping an object with a spatula. PoCo led to a 20 percent improvement in task performance compared to baseline methods.
“The striking thing was that when we finished tuning and visualized it, we can clearly see that the composed trajectory looks much better than either one of them individually,” Wang says.
In the future, the researchers want to apply this technique to long-horizon tasks where a robot would pick up one tool, use it, then switch to another tool. They also want to incorporate larger robotics datasets to improve performance.
“We will need all three kinds of data to succeed for robotics: internet data, simulation data, and real robot data. How to combine them effectively will be the million-dollar question. PoCo is a solid step on the right track,” says Jim Fan, senior research scientist at NVIDIA and leader of the AI Agents Initiative, who was not involved with this work.
This research is funded, in part, by Amazon, the Singapore Defense Science and Technology Agency, the U.S. National Science Foundation, and the Toyota Research Institute.
Three different data domains — simulation (top), robot tele-operation (middle) and human demos (bottom) — allow a robot to learn to use different tools.
As they seep and calve into the sea, melting glaciers and ice sheets are raising global water levels at unprecedented rates. To predict and prepare for future sea-level rise, scientists need a better understanding of how fast glaciers melt and what influences their flow.
Now, a study by MIT scientists offers a new picture of glacier flow, based on microscopic deformation in the ice. The results show that a glacier’s flow depends strongly on how microscopic defects move through the ice.
The researchers found they could estimate a glacier’s flow based on whether the ice is prone to microscopic defects of one kind versus another. They used this relationship between micro- and macro-scale deformation to develop a new model for how glaciers flow. With the new model, they mapped the flow of ice in locations across the Antarctic Ice Sheet.
Contrary to conventional wisdom, they found, the ice sheet is not a monolith but instead is more varied in where and how it flows in response to warming-driven stresses. The study “dramatically alters the climate conditions under which marine ice sheets may become unstable and drive rapid rates of sea-level rise,” the researchers write in their paper.
“This study really shows the effect of microscale processes on macroscale behavior,” says Meghana Ranganathan PhD ’22, who led the study as a graduate student in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS) and is now a postdoc at Georgia Tech. “These mechanisms happen at the scale of water molecules and ultimately can affect the stability of the West Antarctic Ice Sheet.”
“Broadly speaking, glaciers are accelerating, and there are a lot of variants around that,” adds co-author and EAPS Associate Professor Brent Minchew. “This is the first study that takes a step from the laboratory to the ice sheets and starts evaluating what the stability of ice is in the natural environment. That will ultimately feed into our understanding of the probability of catastrophic sea-level rise.”
Ranganathan and Minchew’s study appears this week in the Proceedings of the National Academy of Sciences.
Micro flow
Glacier flow describes the movement of ice from the peak of a glacier, or the center of an ice sheet, down to the edges, where the ice then breaks off and melts into the ocean — a normally slow process that contributes over time to raising the world’s average sea level.
In recent years, the oceans have risen at unprecedented rates, driven by global warming and the accelerated melting of glaciers and ice sheets. While the loss of polar ice is known to be a major contributor to sea-level rise, it is also the biggest uncertainty when it comes to making predictions.
“Part of it’s a scaling problem,” Ranganathan explains. “A lot of the fundamental mechanisms that cause ice to flow happen at a really small scale that we can’t see. We wanted to pin down exactly what these microphysical processes are that govern ice flow, which hasn’t been represented in models of sea-level change.”
The team’s new study builds on previous experiments from the early 2000s by geologists at the University of Minnesota, who studied how small chips of ice deform when physically stressed and compressed. Their work revealed two microscopic mechanisms by which ice can flow: “dislocation creep,” where molecule-sized cracks migrate through the ice, and “grain boundary sliding,” where individual ice crystals slide against each other, causing the boundary between them to move through the ice.
The geologists found that ice’s sensitivity to stress, or how likely it is to flow, depends on which of the two mechanisms is dominant. Specifically, ice is more sensitive to stress when microscopic defects occur via dislocation creep rather than grain boundary sliding.
Ranganathan and Minchew realized that those findings at the microscopic level could redefine how ice flows at much larger, glacial scales.
“Current models for sea-level rise assume a single value for the sensitivity of ice to stress and hold this value constant across an entire ice sheet,” Ranganathan explains. “What these experiments showed was that actually, there’s quite a bit of variability in ice sensitivity, due to which of these mechanisms is at play.”
A mapping match
For their new study, the MIT team took insights from the previous experiments and developed a model to estimate an icy region’s sensitivity to stress, which directly relates to how likely that ice is to flow. The model takes in information such as the ambient temperature, the average size of ice crystals, and the estimated mass of ice in the region, and calculates how much the ice is deforming by dislocation creep versus grain boundary sliding. Depending on which of the two mechanisms is dominant, the model then estimates the region’s sensitivity to stress.
The scientists fed into the model actual observations from various locations across the Antarctic Ice Sheet, where others had previously recorded data such as the local height of ice, the size of ice crystals, and the ambient temperature. Based on the model’s estimates, the team generated a map of ice sensitivity to stress across the Antarctic Ice Sheet. When they compared this map to satellite and field measurements taken of the ice sheet over time, they observed a close match, suggesting that the model could be used to accurately predict how glaciers and ice sheets will flow in the future.
“As climate change starts to thin glaciers, that could affect the sensitivity of ice to stress,” Ranganathan says. “The instabilities that we expect in Antarctica could be very different, and we can now capture those differences, using this model.”
Researchers from the Singapore-MIT Alliance for Research and Technology (SMART), in collaboration with MIT, Columbia University Irving Medical Center, and Nanyang Technological University in Singapore (NTU Singapore), have discovered a new link between malaria parasites’ ability to develop resistance to the antimalarial artemisinin (ART) through a cellular process called transfer ribonucleic acid (tRNA) modification.
This process allows cells to respond rapidly to stress by altering RNA molecules within a cell. As such, this breakthrough discovery advances the understanding of how malaria parasites respond to drug-induced stress and develop resistance, and paves the way for the development of new drugs to combat resistance.
Malaria is a mosquito-borne disease that afflicted 249 million people and caused 608,000 deaths globally in 2022. ART-based combination therapies, which combine ART derivatives with a partner drug, are first-line treatments for patients with uncomplicated malaria. The ART compound helps to reduce the number of parasites during the first three days of treatment, while the partner drug eliminates the remaining parasites. However, Plasmodium falciparum (P. falciparum), the deadliest species of Plasmodium that causes malaria in humans, is developing partial resistance to ART that is widespread across Southeast Asia and has now been detected in Africa.
In a paper titled “tRNA modification reprogramming contributes to artemisinin resistance in Plasmodium falciparum”, published in the journal Nature Microbiology, researchers from SMART's Antimicrobial Resistance (AMR) interdisciplinary research group documented their discovery: A change in a single tRNA, a small RNA molecule that is involved in translating genetic information from RNA to protein, provides the malaria parasite with the ability to overcome drug stress. The study describes how tRNA modification can alter the parasite’s response to ART and help it survive ART-induced stress by changing its protein expression profile, making the parasite more resistant to the drug. ART partial resistance causes a delay in the eradication of malaria parasites following treatment with ART-based combination therapies, making these therapies less effective and susceptible to treatment failure.
“Our research, the first of its kind, shows how tRNA modification directly influences the parasite’s resistance to ART, highlighting the potential impact of RNA modifications on both disease and health. While RNA modifications have been around for decades, their role in regulating cellular processes is an emerging field. Our findings highlight the importance of RNA modifications for the research community and the broader significance of tRNA modifications in regulating gene expression,” says Peter Dedon, co-lead principal investigator at SMART AMR, the Underwood-Prescott Professor of Biological Engineering at MIT, and one of the authors of the paper.
“Malaria's growing drug resistance to artemisinin, the current last-line antimalarial drug, is a global crisis that demands new strategies and therapeutics. The mechanisms behind this resistance are complex and multifaceted, but our study reveals a critical link. We found that the parasite’s ability to survive a lethal dose of artemisinin is linked to the downregulation of a specific tRNA modification. This discovery paves the way for new strategies to combat this growing global threat,” adds Jennifer L. Small-Saunders, assistant professor of medicine in the Division of Infectious Diseases at CUIMC and first author of the paper.
The researchers investigated the role of epitranscriptomics — the study of RNA modifications within a cell — in influencing drug resistance in malaria by leveraging the advanced technology and techniques for epitranscriptomic analysis developed at SMART. This involves isolating the RNA of interest, tRNA, and using mass spectrometry to identify the different modifications present. They isolated and compared the drug-sensitive and drug-resistant malaria parasites, some of which were treated with ART and others left untreated as controls. The analysis revealed changes in the tRNA modifications of drug-resistant parasites, and these modifications were linked to the increased or decreased translation of specific genes in the parasites. The altered translation process was found to be the underlying mechanism for the observed increase in drug resistance. This discovery also expands our understanding of how microbes and cancer cells exploit the normal function of RNA modifications to thwart the toxic effects of drugs and other therapeutics.
“At SMART AMR, we’re at the forefront of exploring epitranscriptomics in infectious diseases and antimicrobial resistance. Epitranscriptomics is an emerging field in malaria research and plays a crucial role in how malaria parasites develop and respond to stress. This discovery reveals how drug-resistant parasites exploit epitranscriptomic stress response mechanisms for survival, which is particularly important for understanding parasite biology,” says Peter Preiser, co-lead principal investigator at SMART AMR, professor of molecular genetics and cell biology at NTU Singapore, and another author of the paper.
The research sets the foundation for the development of better tools to study RNA modifications and their role in resistance while simultaneously opening new avenues for drug development. RNA-modifying enzymes, especially those linked to resistance, are currently understudied, and they are attractive targets for the development of new and more effective drugs and therapies. By hindering the parasite’s ability to manipulate these modifications, drug resistance can be prevented from arising. Researchers at SMART AMR are actively pursuing the discovery and development of small molecule and biological therapeutics that target RNA modifications in viruses, bacteria, parasites, and cancer.
The research is carried out by SMART and supported by the National Research Foundation Singapore under its Campus for Research Excellence And Technological Enterprise program.
The MIT School of Architecture and Planning (SA+P) and the LUMA Foundation announced today the establishment of the MIT-LUMA Lab to advance paradigm-shifting innovations at the nexus of art, science, technology, conservation, and design. The aim is to empower innovative thinkers to realize their ambitions, support local communities as they seek to address climate-related issues, and scale solutions to pressing challenges facing the Mediterranean region.
The main programmatic pillars of the lab will be collaborative scholarship and research around design, new materials, and sustainability; scholar exchange and education collaborations between the two organizations; innovation and entrepreneurship activities to transfer new ideas into practical applications; and co-production of exhibitions and events. The hope is that this engagement will create a novel model for other institutions to follow to craft innovative solutions to the leading challenge of our time.
The MIT-LUMA Lab draws on an establishing gift from the LUMA Foundation, a nonprofit organization based in Zurich formed by Maja Hoffmann in 2004 to support contemporary artistic production. The foundation supports a range of multidisciplinary projects that increase understanding of the environment, human rights, education, and culture.
These themes are explored through programs organized by LUMA Arles, a project begun in 2013 and housed on a 27-acre interdisciplinary campus known as the Parc des Ateliers in Arles, France, an experimental site of exhibitions, artists’ residencies, research laboratories, and educational programs.
“The Luma Foundation is committed to finding ways to address the current climate emergencies we are facing, focusing on exploring the potentials that can be found in diversity and engagement in every possible form,” says Maja Hoffmann, founder and president of the LUMA Foundation. “Cultural diversity, pluralism, and biodiversity feature at the top of our mission and our work is informed by these concepts.”
A focus on the Mediterranean region
“The culturally rich area of the Mediterranean, which has produced some of the most remarkable civilizational paradigms across geographies and historical periods, plays an important role in our thinking. Focusing the efforts of the MIT-LUMA Lab on the Mediterranean means extending the possibilities for positive change throughout other global ecosystems,” says Hoffmann.
“Our projects of LUMA Arles and its research laboratory on materials and natural resources, the Atelier Luma, our position in one of Europe’s most important natural reserves, in conjunction with the expertise and forward-thinking approach of MIT, define the perfect framework that will allow us to explore new frontiers and devise novel ways to tackle our most significant civilizational risks,” she adds. “Supporting the production of new forms of knowledge and practices, and with locations in Cambridge and in Arles, our collaboration and partnership with MIT will generate solutions and models for the future, for the generations to come, in order to provide them the same and even better opportunities that what we have experienced.”
“We know we do not have all the answers at MIT, but we do know how to ask the right questions, how to design effective experiments, and how to build meaningful collaborations,” says Hashim Sarkis, dean of SA+P, which will host the lab.
“I am grateful to the LUMA Foundation for offering support for faculty research deployment designed to engage local communities and create jobs, for course development to empower our faculty to teach classes centered on these issues, and for students who seek to dedicate their lives and careers to sustainability. We also look forward to hosting fellows and researchers from the foundation to strengthen our collaboration,” he adds.
The Mediterranean region, the MIT-LUMA Lab’s focus, is one of the world’s most vital and fragile global commons. The future of climate relies on the sustainability of the region’s forests, oceans, and deserts that have for millennia created the environmental conditions and system-regulating functions necessary for life on Earth. Those who live in these areas are often the most severely affected by even relatively modest changes in the climate.
Climate research and action: A priority at MIT
To reverse negative trends and provide a new approach to addressing the climate crisis in these vast areas, SA+P is establishing international collaborations that bring know-how to the field, and in turn to learn from the communities and groups most challenged by climate impacts.
The MIT-LUMA Lab is the first in what is envisioned as a series of regionally focused labs at SA+P under the conceptual aegis of a collaborative platform called Our Global Commons. This project will support progress on today’s climate challenges by focusing on community empowerment, long-term local collaborations around research and education, and job creation. Faculty-led fieldwork, engagements with local stakeholders, and student involvement will be the key elements.
The creation of Our Global Commons comes as MIT works to dramatically expand its efforts to address climate change. In February 2024, President Sally Kornbluth announced the Climate Project at MIT, a major new initiative to mobilize the Institute’s resources and capabilities to research, develop, deploy, and scale-up new climate solutions. The Institute will hire its first-ever vice president for climate to oversee the new effort.
“With the Climate Project at MIT, we aim to help make a decisive difference, at scale, on crucial global climate challenges — and we can only do that by engaging with outstanding colleagues around the globe,” says Kornbluth. “By connecting us to creative thinkers steeped in the cultural and environmental history and emerging challenges of the Mediterranean region, the MIT-LUMA Lab promises to spark important new ideas and collaborations.”
“We are excited that the LUMA team will be joining in MIT’s engagement with climate issues, especially given their expertise in advancing vital work at the intersection of art and science, and their long-standing commitment to expanding the frontiers of sustainability and biodiversity,” says Sarkis. “With climate change upending many aspects of our society, the time is now for us to reaffirm and strengthen our SA+P tradition of on-the-ground work with and for communities around the world. Shared efforts among local communities, governments and corporations, and academia are necessary to bring about real change.”
Maja Hoffmann (left), founder and president of the LUMA Foundation, and Hashim Sarkis, dean of the MIT School of Architecture and Planning, at LUMA Arles in the Parc des Ateliers in France. This 27-acre interdisciplinary campus is an experimental site of exhibitions, artists’ residencies, research laboratories, and educational programs that includes The Tower, a multipurpose space designed by Frank Gehry, seen here amid 19th-century factory buildings.
Quantum computers hold the promise of being able to quickly solve extremely complex problems that might take the world’s most powerful supercomputer decades to crack.
But achieving that performance involves building a system with millions of interconnected building blocks called qubits. Making and controlling so many qubits in a hardware architecture is an enormous challenge that scientists around the world are striving to meet.
Toward this goal, researchers at MIT and MITRE have demonstrated a scalable, modular hardware platform that integrates thousands of interconnected qubits onto a customized integrated circuit. This “quantum-system-on-chip” (QSoC) architecture enables the researchers to precisely tune and control a dense array of qubits. Multiple chips could be connected using optical networking to create a large-scale quantum communication network.
By tuning qubits across 11 frequency channels, this QSoC architecture allows for a new proposed protocol of “entanglement multiplexing” for large-scale quantum computing.
The team spent years perfecting an intricate process for manufacturing two-dimensional arrays of atom-sized qubit microchiplets and transferring thousands of them onto a carefully prepared complementary metal-oxide semiconductor (CMOS) chip. This transfer can be performed in a single step.
“We will need a large number of qubits, and great control over them, to really leverage the power of a quantum system and make it useful. We are proposing a brand new architecture and a fabrication technology that can support the scalability requirements of a hardware system for a quantum computer,” says Linsen Li, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this architecture.
Li’s co-authors include Ruonan Han, an associate professor in EECS, leader of the Terahertz Integrated Electronics Group, and member of the Research Laboratory of Electronics (RLE); senior author Dirk Englund, professor of EECS, principal investigator of the Quantum Photonics and Artificial Intelligence Group and of RLE; as well as others at MIT, Cornell University, the Delft Institute of Technology, the U.S. Army Research Laboratory, and the MITRE Corporation. The paper appears today in Nature.
Diamond microchiplets
While there are many types of qubits, the researchers chose to use diamond color centers because of their scalability advantages. They previously used such qubits to produce integrated quantum chips with photonic circuitry.
Qubits made from diamond color centers are “artificial atoms” that carry quantum information. Because diamond color centers are solid-state systems, the qubit manufacturing is compatible with modern semiconductor fabrication processes. They are also compact and have relatively long coherence times, which refers to the amount of time a qubit’s state remains stable, due to the clean environment provided by the diamond material.
In addition, diamond color centers have photonic interfaces which allows them to be remotely entangled, or connected, with other qubits that aren’t adjacent to them.
“The conventional assumption in the field is that the inhomogeneity of the diamond color center is a drawback compared to identical quantum memory like ions and neutral atoms. However, we turn this challenge into an advantage by embracing the diversity of the artificial atoms: Each atom has its own spectral frequency. This allows us to communicate with individual atoms by voltage tuning them into resonance with a laser, much like tuning the dial on a tiny radio,” says Englund.
This is especially difficult because the researchers must achieve this at a large scale to compensate for the qubit inhomogeneity in a large system.
To communicate across qubits, they need to have multiple such “quantum radios” dialed into the same channel. Achieving this condition becomes near-certain when scaling to thousands of qubits. To this end, the researchers surmounted that challenge by integrating a large array of diamond color center qubits onto a CMOS chip which provides the control dials. The chip can be incorporated with built-in digital logic that rapidly and automatically reconfigures the voltages, enabling the qubits to reach full connectivity.
“This compensates for the in-homogenous nature of the system. With the CMOS platform, we can quickly and dynamically tune all the qubit frequencies,” Li explains.
Lock-and-release fabrication
To build this QSoC, the researchers developed a fabrication process to transfer diamond color center “microchiplets” onto a CMOS backplane at a large scale.
They started by fabricating an array of diamond color center microchiplets from a solid block of diamond. They also designed and fabricated nanoscale optical antennas that enable more efficient collection of the photons emitted by these color center qubits in free space.
Then, they designed and mapped out the chip from the semiconductor foundry. Working in the MIT.nano cleanroom, they post-processed a CMOS chip to add microscale sockets that match up with the diamond microchiplet array.
They built an in-house transfer setup in the lab and applied a lock-and-release process to integrate the two layers by locking the diamond microchiplets into the sockets on the CMOS chip. Since the diamond microchiplets are weakly bonded to the diamond surface, when they release the bulk diamond horizontally, the microchiplets stay in the sockets.
“Because we can control the fabrication of both the diamond and the CMOS chip, we can make a complementary pattern. In this way, we can transfer thousands of diamond chiplets into their corresponding sockets all at the same time,” Li says.
The researchers demonstrated a 500-micron by 500-micron area transfer for an array with 1,024 diamond nanoantennas, but they could use larger diamond arrays and a larger CMOS chip to further scale up the system. In fact, they found that with more qubits, tuning the frequencies actually requires less voltage for this architecture.
“In this case, if you have more qubits, our architecture will work even better,” Li says.
The team tested many nanostructures before they determined the ideal microchiplet array for the lock-and-release process. However, making quantum microchiplets is no easy task, and the process took years to perfect.
“We have iterated and developed the recipe to fabricate these diamond nanostructures in MIT cleanroom, but it is a very complicated process. It took 19 steps of nanofabrication to get the diamond quantum microchiplets, and the steps were not straightforward,” he adds.
Alongside their QSoC, the researchers developed an approach to characterize the system and measure its performance on a large scale. To do this, they built a custom cryo-optical metrology setup.
Using this technique, they demonstrated an entire chip with over 4,000 qubits that could be tuned to the same frequency while maintaining their spin and optical properties. They also built a digital twin simulation that connects the experiment with digitized modeling, which helps them understand the root causes of the observed phenomenon and determine how to efficiently implement the architecture.
In the future, the researchers could boost the performance of their system by refining the materials they used to make qubits or developing more precise control processes. They could also apply this architecture to other solid-state quantum systems.
This work was supported by the MITRE Corporation Quantum Moonshot Program, the U.S. National Science Foundation, the U.S. Army Research Office, the Center for Quantum Networks, and the European Union’s Horizon 2020 Research and Innovation Program.
Researchers developed a modular fabrication process to produce a quantum-system-on-chip which integrates an array of artificial atom qubits onto a semiconductor chip.
The internet is awash in instructional videos that can teach curious viewers everything from cooking the perfect pancake to performing a life-saving Heimlich maneuver.
But pinpointing when and where a particular action happens in a long video can be tedious. To streamline the process, scientists are trying to teach computers to perform this task. Ideally, a user could just describe the action they’re looking for, and an AI model would skip to its location in the video.
However, teaching machine-learning models to do this usually requires a great deal of expensive video data that have been painstakingly hand-labeled.
A new, more efficient approach from researchers at MIT and the MIT-IBM Watson AI Lab trains a model to perform this task, known as spatio-temporal grounding, using only videos and their automatically generated transcripts.
The researchers teach a model to understand an unlabeled video in two distinct ways: by looking at small details to figure out where objects are located (spatial information) and looking at the bigger picture to understand when the action occurs (temporal information).
Compared to other AI approaches, their method more accurately identifies actions in longer videos with multiple activities. Interestingly, they found that simultaneously training on spatial and temporal information makes a model better at identifying each individually.
In addition to streamlining online learning and virtual training processes, this technique could also be useful in health care settings by rapidly finding key moments in videos of diagnostic procedures, for example.
“We disentangle the challenge of trying to encode spatial and temporal information all at once and instead think about it like two experts working on their own, which turns out to be a more explicit way to encode the information. Our model, which combines these two separate branches, leads to the best performance,” says Brian Chen, lead author of a paper on this technique.
Chen, a 2023 graduate of Columbia University who conducted this research while a visiting student at the MIT-IBM Watson AI Lab, is joined on the paper by James Glass, senior research scientist, member of the MIT-IBM Watson AI Lab, and head of the Spoken Language Systems Group in the Computer Science and Artificial Intelligence Laboratory (CSAIL); Hilde Kuehne, a member of the MIT-IBM Watson AI Lab who is also affiliated with Goethe University Frankfurt; and others at MIT, Goethe University, the MIT-IBM Watson AI Lab, and Quality Match GmbH. The research will be presented at the Conference on Computer Vision and Pattern Recognition.
Global and local learning
Researchers usually teach models to perform spatio-temporal grounding using videos in which humans have annotated the start and end times of particular tasks.
Not only is generating these data expensive, but it can be difficult for humans to figure out exactly what to label. If the action is “cooking a pancake,” does that action start when the chef begins mixing the batter or when she pours it into the pan?
“This time, the task may be about cooking, but next time, it might be about fixing a car. There are so many different domains for people to annotate. But if we can learn everything without labels, it is a more general solution,” Chen says.
For their approach, the researchers use unlabeled instructional videos and accompanying text transcripts from a website like YouTube as training data. These don’t need any special preparation.
They split the training process into two pieces. For one, they teach a machine-learning model to look at the entire video to understand what actions happen at certain times. This high-level information is called a global representation.
For the second, they teach the model to focus on a specific region in parts of the video where action is happening. In a large kitchen, for instance, the model might only need to focus on the wooden spoon a chef is using to mix pancake batter, rather than the entire counter. This fine-grained information is called a local representation.
The researchers incorporate an additional component into their framework to mitigate misalignments that occur between narration and video. Perhaps the chef talks about cooking the pancake first and performs the action later.
To develop a more realistic solution, the researchers focused on uncut videos that are several minutes long. In contrast, most AI techniques train using few-second clips that someone trimmed to show only one action.
A new benchmark
But when they came to evaluate their approach, the researchers couldn’t find an effective benchmark for testing a model on these longer, uncut videos — so they created one.
To build their benchmark dataset, the researchers devised a new annotation technique that works well for identifying multistep actions. They had users mark the intersection of objects, like the point where a knife edge cuts a tomato, rather than drawing a box around important objects.
“This is more clearly defined and speeds up the annotation process, which reduces the human labor and cost,” Chen says.
Plus, having multiple people do point annotation on the same video can better capture actions that occur over time, like the flow of milk being poured. All annotators won’t mark the exact same point in the flow of liquid.
When they used this benchmark to test their approach, the researchers found that it was more accurate at pinpointing actions than other AI techniques.
Their method was also better at focusing on human-object interactions. For instance, if the action is “serving a pancake,” many other approaches might focus only on key objects, like a stack of pancakes sitting on a counter. Instead, their method focuses on the actual moment when the chef flips a pancake onto a plate.
Existing approaches rely heavily on labeled data from humans, and thus are not very scalable. This work takes a step toward addressing this problem by providing new methods for localizing events in space and time using the speech that naturally occurs within them. This type of data is ubiquitous, so in theory it would be a powerful learning signal. However, it is often quite unrelated to what's on screen, making it tough to use in machine-learning systems. This work helps address this issue, making it easier for researchers to create systems that use this form of multimodal data in the future," says Andrew Owens, an assistant professor of electrical engineering and computer science at the University of Michigan who was not involved with this work.
Next, the researchers plan to enhance their approach so models can automatically detect when text and narration are not aligned, and switch focus from one modality to the other. They also want to extend their framework to audio data, since there are usually strong correlations between actions and the sounds objects make.
“AI research has made incredible progress towards creating models like ChatGPT that understand images. But our progress on understanding video is far behind. This work represents a significant step forward in that direction,” says Kate Saenko, a professor in the Department of Computer Science at Boston University who was not involved with this work.
This research is funded, in part, by the MIT-IBM Watson AI Lab.
Researchers from the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) and Google Research may have just performed digital sorcery — in the form of a diffusion model that can change the material properties of objects in images.
Dubbed Alchemist, the system allows users to alter four attributes of both real and AI-generated pictures: roughness, metallicity, albedo (an object’s initial base color), and transparency. As an image-to-image diffusion model, one can input any photo and then adjust each property within a continuous scale of -1 to 1 to create a new visual. These photo editing capabilities could potentially extend to improving the models in video games, expanding the capabilities of AI in visual effects, and enriching robotic training data.
The magic behind Alchemist starts with a denoising diffusion model: In practice, researchers used Stable Diffusion 1.5, which is a text-to-image model lauded for its photorealistic results and editing capabilities. Previous work built on the popular model to enable users to make higher-level changes, like swapping objects or altering the depth of images. In contrast, CSAIL and Google Research’s method applies this model to focus on low-level attributes, revising the finer details of an object’s material properties with a unique, slider-based interface that outperforms its counterparts.
While prior diffusion systems could pull a proverbial rabbit out of a hat for an image, Alchemist could transform that same animal to look translucent. The system could also make a rubber duck appear metallic, remove the golden hue from a goldfish, and shine an old shoe. Programs like Photoshop have similar capabilities, but this model can change material properties in a more straightforward way. For instance, modifying the metallic look of a photo requires several steps in the widely used application.
“When you look at an image you’ve created, often the result is not exactly what you have in mind,” says Prafull Sharma, MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and lead author on a new paper describing the work. “You want to control the picture while editing it, but the existing controls in image editors are not able to change the materials. With Alchemist, we capitalize on the photorealism of outputs from text-to-image models and tease out a slider control that allows us to modify a specific property after the initial picture is provided.”
Precise control
“Text-to-image generative models have empowered everyday users to generate images as effortlessly as writing a sentence. However, controlling these models can be challenging,” says Carnegie Mellon University Assistant Professor Jun-Yan Zhu, who was not involved in the paper. “While generating a vase is simple, synthesizing a vase with specific material properties such as transparency and roughness requires users to spend hours trying different text prompts and random seeds. This can be frustrating, especially for professional users who require precision in their work. Alchemist presents a practical solution to this challenge by enabling precise control over the materials of an input image while harnessing the data-driven priors of large-scale diffusion models, inspiring future works to seamlessly incorporate generative models into the existing interfaces of commonly used content creation software.”
Alchemist’s design capabilities could help tweak the appearance of different models in video games. Applying such a diffusion model in this domain could help creators speed up their design process, refining textures to fit the gameplay of a level. Moreover, Sharma and his team’s project could assist with altering graphic design elements, videos, and movie effects to enhance photorealism and achieve the desired material appearance with precision.
The method could also refine robotic training data for tasks like manipulation. By introducing the machines to more textures, they can better understand the diverse items they’ll grasp in the real world. Alchemist can even potentially help with image classification, analyzing where a neural network fails to recognize the material changes of an image.
Sharma and his team’s work exceeded similar models at faithfully editing only the requested object of interest. For example, when a user prompted different models to tweak a dolphin to max transparency, only Alchemist achieved this feat while leaving the ocean backdrop unedited. When the researchers trained comparable diffusion model InstructPix2Pix on the same data as their method for comparison, they found that Alchemist achieved superior accuracy scores. Likewise, a user study revealed that the MIT model was preferred and seen as more photorealistic than its counterpart.
Keeping it real with synthetic data
According to the researchers, collecting real data was impractical. Instead, they trained their model on a synthetic dataset, randomly editing the material attributes of 1,200 materials applied to 100 publicly available, unique 3D objects in Blender, a popular computer graphics design tool.
“The control of generative AI image synthesis has so far been constrained by what text can describe,” says Frédo Durand, the Amar Bose Professor of Computing in the MIT Department of Electrical Engineering and Computer Science (EECS) and CSAIL member, who is a senior author on the paper. “This work opens new and finer-grain control for visual attributes inherited from decades of computer-graphics research.”
"Alchemist is the kind of technique that's needed to make machine learning and diffusion models practical and useful to the CGI community and graphic designers,” adds Google Research senior software engineer and co-author Mark Matthews. “Without it, you're stuck with this kind of uncontrollable stochasticity. It's maybe fun for a while, but at some point, you need to get real work done and have it obey a creative vision."
Sharma’s latest project comes a year after he led research on Materialistic, a machine-learning method that can identify similar materials in an image. This previous work demonstrated how AI models can refine their material understanding skills, and like Alchemist, was fine-tuned on a synthetic dataset of 3D models from Blender.
Still, Alchemist has a few limitations at the moment. The model struggles to correctly infer illumination, so it occasionally fails to follow a user’s input. Sharma notes that this method sometimes generates physically implausible transparencies, too. Picture a hand partially inside a cereal box, for example — at Alchemist’s maximum setting for this attribute, you’d see a clear container without the fingers reaching in.
The researchers would like to expand on how such a model could improve 3D assets for graphics at scene level. Also, Alchemist could help infer material properties from images. According to Sharma, this type of work could unlock links between objects' visual and mechanical traits in the future.
MIT EECS professor and CSAIL member William T. Freeman is also a senior author, joining Varun Jampani, and Google Research scientists Yuanzhen Li PhD ’09, Xuhui Jia, and Dmitry Lagun. The work was supported, in part, by a National Science Foundation grant and gifts from Google and Amazon. The group’s work will be highlighted at CVPR in June.
MIT CSAIL researchers helped develop a diffusion model that can alter four material properties of objects in images: roughness, metallicity, albedo, and transparency.
Over 180 world leaders maintain social media accounts, and some of them issue policy warnings to rivals and the public on these platforms rather than relying on traditional government statements. How seriously do people take such social media postings?
A new study suggests the general public and policymakers alike take leaders’ social media posts just as seriously as they take formal government statements. The research, by MIT political scientists, deploys novel surveys of both the public and experienced foreign policy specialists.
“What we find, which is really surprising, across both expert audiences and public audiences, is that tweets are not necessarily seen as this form of cheap talk,” says Erik Lin-Greenberg, an MIT faculty member and co-author of a new paper detailing the results. “They’re viewed as the same type of signal as that being offered through more formal and traditional communications.”
The findings suggest that people have become so fully acclimatized to social media that they regard the medium as a vehicle for messages that have just as much credibility as those generated through the old-school method, in which official statements are released in formal language on official government documents.
“One clue that sheds some light on our unexpected findings is that a slight majority of our survey respondents who read a tweet identified what they read as a White House press release,” says Benjamin Norwood Harris, an MIT doctoral candidate and co-author of the paper. “Respondents really seemed to believe that tweets were just another way presidents communicate in their official capacity.”
The paper, “Cheap Tweets?: Crisis Signaling in the Age of Twitter,” appears in the June issue of International Studies Quarterly. Greenberg is the Leo Marx Career Development Assistant Professor of the History and Culture of Science and Technology at MIT; Harris is a PhD candidate in MIT’s Department of Political Science who specializes in security studies and international relations.
The study fits into a larger body of political science research in the area of “crisis signaling” — the way words and actions in international relations are interpreted, which is often critical to diplomacy. However, when it comes to the use of social media, “There’s been very little research that looks at the credibility of public signals,” Lin-Greenberg notes.
The research consisted of a multilayered set of surveys, conducted in 2021. Using the survey platform Lucid, the scholars surveyed 977 members of the general public about a hypothetical confrontation between the U.S. and Iran, using facsimiles of messages on Twitter (now known as X) and formal White House statements that might have been sent by U.S. President Joe Biden during such a scenario. Separately, the scholars also recruited foreign policy experts from the U.S., India, and Singapore, which all have active English-language think tank spheres, to take the same survey.
Asked to rate the credibility of tweets and official statements on a five-point scale, the public rated official press releases at 3.30 and tweets at 3.22. The policy experts gave a 3.10 rating to the official statement, and a 3.11 rating to the tweets.
“No matter how we cut the data, we just don’t see much difference in how respondents rated Tweets versus official statements,” Harris says. “Even when we vary the formality of the tweet language — including things like all caps and lots of exclamation points — we don’t find an effect.”
A follow-up layer of the survey then asked respondents about a related hypothetical conflict between the U.S. and Iran in 2026, with facsimile tweets and White House statements attributed to both Biden and former president Donald Trump, given that either could be president then. The aim was to see if different leaders influenced perceptions of the two forms of statements.
But in this instance, the public and policy experts regarded tweets and official statements virtually equally seriously. Trump’s statements were given slightly more credibility overall, but with a strong partisan divide: Liberals took Biden’s statements to have more credibility, and conservatives took Trump’s statements to have more credibility.
Overall, the study suggests that many people are simply unaffected by the medium in which a global leader might choose to issue a warning to leaders of other nations. In the surveys, participants were given the opportunity to describe qualitatively what shaped their responses; only about 2 percent cited the medium as an issue.
As Harris notes, the survey data also indicate that slightly more than 51 percent of respondents believed a tweet constituted an officially released government statement. Additionally, about 73 percent of respondents thought tweets were generated in the same way as statements that have the official imprint of a national government.
“People who see a tweet don’t really differentiate it in their minds. They don’t think the tweet is not an official statement,” Lin-Greenberg says. “About three-quarters of the population think it’s coordinated, whether it’s a tweet or an official statement.”
In the paper, the scholars suggest there is considerable room for follow-up research in this area. Among other things, future studies might compare the effect of social media statements to other types of communication, such as speeches. Scholars might also study other social media platforms or broaden the set of countries being studied. Such research, Lin-Greenberg and Harris conclude in the paper, “will further enrich our understanding of the interactions between emerging technology and international politics.”
A set of research surveys by MIT political scientists shows that the public, and policymakers, take threats from world leaders equally seriously, whether those warnings are issued on social media, or through traditional government statements.
Many low-income families might desire to move into different neighborhoods — places that are safer, quieter, or have more resources in their schools. In fact, not many do relocate. But it turns out they are far more likely to move when someone is on hand to help them do it.
That’s the outcome of a high-profile experiment by a research team including MIT economists, which shows that a modest amount of logistical assistance dramatically increases the likelihood that low-income families will move into neighborhoods providing better economic opportunity.
The randomized field experiment, set in the Seattle area, showed the number of families using vouchers for new housing jumped from 15 percent to 53 percent when they had more information, some financial support, and, most of all, a “navigator” who helped them address logistical challenges.
“The question we were after is really what drives residential segregation,” says Nathaniel Hendren, an MIT economist and co-author of the paper detailing the results. “Is it due to preferences people have, due to having family or jobs close by? Or are there constraints on the search process that make it difficult to move?” As the study clearly shows, he says, “Just pairing people with [navigators] broke down search barriers and created dramatic changes in where they chose to live. This was really just a very deep need in the search process.”
The study’s results have prompted U.S. Congress to twice allocate $25 million in funds allowing eight other U.S. cities to run their own versions of the experiment and measure the impact.
That is partly because the result “represented a bigger treatment effect than any of us had really ever seen,” says Christopher Palmer, an MIT economist and a co-author of the paper. “We spend a little bit of money to help people take down the barriers to moving to these places, and they are happy to do it.”
The authors are Peter Bergman, an associate professor at the University of Texas at Austin; Raj Chetty, a professor at Harvard University; Stefanie DeLuca, a professor at Johns Hopkins University; Hendren, a professor in MIT’s Department of Economics; Lawrence F. Katz, a professor at Harvard University; and Palmer, an associate professor in the MIT Sloan School of Management.
New research renews an idea
The study follows other prominent work about the geography of economic mobility. In 2018, Chetty and Hendren released an “Opportunity Atlas” of the U.S., a comprehensive national study showing that, other things being equal, some areas provide greater long-term economic mobility for people who grow up there. The project brought renewed attention to the influence of place on economic outcomes.
The Seattle experiment also follows a 1990s federal government program called Moving to Opportunity, a test in five U.S. cities helping families seek new neighborhoods. That intervention had mixed results: Participants who moved reported better mental health, but there was no apparent change in income levels.
Still, in light of the Opportunity Atlas data, the scholars decided revisit the concept, with a program they call Creating Moves to Opportunity (CMTO). This provides housing vouchers along with a bundle of other things: Short-term financial assistance of about $1,000 on average, more information, and the assistance of a “navigator,” a caseworker who would help troubleshoot issues that families encountered.
The experiment was implemented by the Seattle and King County Housing Authorities, along with MDRC, a nonprofit policy research organization, and J-PAL North America. The latter is one of the arms of the MIT-based Abdul Latif Jameel Poverty Action Lab (J-PAL), a leading center promoting randomized, controlled trials in the social sciences.
The experiment had 712 families in it, and two phases. In the first, all participants were issued housing vouchers worth a little more than $1,500 per month on average, and divided into treatment and control groups. Families in the treatment group also received the CMTO bundle of services, including the navigator.
In this phase, lasting from 2018 to 2019, 53 percent of families in the treatment group used the housing vouchers, while only 15 percent of those in the control group used the vouchers. Families who moved dispersed to 46 different neighborhoods, defined by U.S. Census Bureau tracts, meaning they were not just shifting en masse from one location to one other.
Families who moved were very likely to want to renew their leases, and expressed satisfaction with their new neighborhoods. All told, the program cost about $2,670 per family. Additional research scholars in the group have conducted about changes in income suggest the program’s direct benefits are 2.5 times greater than its costs.
“Our sense is that’s a pretty reasonable return for the money compared to other strategies we have to combat intergenerational poverty,” Hendren says.
Logistical and emotional support
In the second phase of the experiment, lasting from 2019 to 2020, families in a treatment group received individual components of the CMTO support, while the control group again only received the housing vouchers. This way, the researchers could see which parts of the program made the biggest difference. The vast majority of the impact, it turned out, came from receiving the full set of services, especially the “customized” help of navigators.
“What came out of the phase two results was that the customized search assistance was just invaluable to people,” Palmer says. “The barriers are so heterogenous across families.” Some people might have trouble understanding lease terms; others might want guidance about schools; still others might have no experience renting a moving truck.
The research turned up a related phenomenon: In 251 follow-up interviews, families often emphasized that the navigators mattered partly because moving is so stressful.
“When we interviewed people and asked them what was so valuable about that, they said things like, ‘Emotional support,’” Palmer observes. He notes that many families participating in the program are “in distress,” facing serious problems such as the potential for homelessness.
Moving the experiment to other cities
The researchers say they welcome the opportunity to see how the Creating Moves to Opportunity program, or at least localized replications of it, might fare in other places. Congress allocated $25 million in 2019, and then again in 2022, so the program could be tried out in eight metro areas: Cleveland, Los Angeles, Minneapolis, Nashville, New Orleans, New York City, Pittsburgh, and Rochester. With the Covid-19 pandemic having slowed the process, officials in those places are still examing the outcomes.
“It’s thrilling to us that Congress has appropriated money to try this program in different cities, so we can verify it wasn’t just that we had really magical and dedicated family navigators in Seattle,” Palmer says. “That would be really useful to test and know.”
Seattle might feature a few particularities that helped the program succeed. As a newer city than many metro areas, it may contain fewer social roadblocks to moving across neighborhoods, for instance.
“It’s conceivable that in Seattle, the barriers for moving to opportunity are more solvable than they might be somewhere else.” Palmer says. “That’s [one reason] to test it in other places.”
Still, the Seattle experiment might translate well even in cities considered to have entrenched neighborhood boundaries and racial divisions. Some of the project’s elements extend earlier work applied in the Baltimore Housing Mobility Program, a voucher plan run by the Baltimore Regional Housing Partnership. In Seattle, though, the researchers were able to rigorously test the program as a field experiment, one reason it has seemed viable to try replicate it elsewhere.
“The generalizable lesson is there’s not a deep-seated preference for staying put that’s driving residential segregation,” Hendren says. “I think that’s important to take away from this. Is this the right policy to fight residential segregation? That’s an open question, and we’ll see if this kind of approach generalizes to other cities.”
The research was supported by the Bill and Melinda Gates Foundation, the Chan-Zuckerberg Initiative, the Surgo Foundation, the William T. Grant Foundation, and Harvard University.
A modest amount of logistical assistance dramatically increases the likelihood that low-income families will move into neighborhoods providing better economic opportunity, according to a new study.
Scientists are catching up to what parents and other caregivers have been reporting for many years: When some people with autism spectrum disorders experience an infection that sparks a fever, their autism-related symptoms seem to improve.
With a pair of new grants from The Marcus Foundation, scientists at MIT and Harvard Medical School hope to explain how this happens in an effort to eventually develop therapies that mimic the “fever effect” to similarly improve symptoms.
“Although it isn’t actually triggered by the fever, per se, the ‘fever effect’ is real, and it provides us with an opportunity to develop therapies to mitigate symptoms of autism spectrum disorders,” says neuroscientist Gloria Choi, associate professor in the MIT Department of Brain and Cognitive Sciences and affiliate of The Picower Institute for Learning and Memory.
Choi will collaborate on the project with Jun Huh, associate professor of immunology at Harvard Medical School. Together the grants to the two institutions provide $2.1 million over three years.
“To the best of my knowledge, the ‘fever effect’ is perhaps the only natural phenomenon in which developmentally determined autism symptoms improve significantly, albeit temporarily,” Huh says. “Our goal is to learn how and why this happens at the levels of cells and molecules, to identify immunological drivers, and produce persistent effects that benefit a broad group of individuals with autism.”
The Marcus Foundation has been involved in autism work for over 30 years, helping to develop the field and addressing everything from awareness to treatment to new diagnostic devices.
“I have long been interested in novel approaches to treating and lessening autism symptoms, and doctors Choi and Huh have honed in on a bold theory,” says Bernie Marcus, founder and chair of The Marcus Foundation. “It is my hope that this Marcus Foundation Medical Research Award helps their theory come to fruition and ultimately helps improve the lives of children with autism and their families.”
Brain-immune interplay
For a decade, Huh and Choi have been investigating the connection between infection and autism. Their studies suggest that the beneficial effects associated with fever may arise from molecular changes in the immune system during infection, rather than on the elevation of body temperature, per se.
Their work in mice has shown that maternal infection during pregnancy, modulated by the composition of the mother’s microbiome, can lead to neurodevelopmental abnormalities in the offspring that result in autism-like symptoms, such as impaired sociability. Huh’s and Choi’s labs have traced the effect to elevated maternal levels of a type of immune-signaling molecule called IL-17a, which acts on receptors in brain cells of the developing fetus, leading to hyperactivity in a region of the brain’s cortex called S1DZ. In another study, they’ve shown how maternal infection appears to prime offspring to produce more IL-17a during infection later in life.
Building on these studies, a 2020 paper clarified the fever effect in the setting of autism. This research showed that mice that developed autism symptoms as a result of maternal infection while in utero would exhibit improvements in their sociability when they had infections — a finding that mirrored observations in people. The scientists discovered that this effect depended on over-expression of IL-17a, which in this context appeared to calm affected brain circuits. When the scientists administered IL-17a directly to the brains of mice with autism-like symptoms whose mothers had not been infected during pregnancy, the treatment still produced improvements in symptoms.
New studies and samples
This work suggested that mimicking the “fever effect” by giving extra IL-17a could produce similar therapeutic effects for multiple autism-spectrum disorders, with different underlying causes. But the research also left wide-open questions that must be answered before any clinically viable therapy could be developed. How exactly does IL-17a lead to symptom relief and behavior change in the mice? Does the fever effect work in the same way in people?
In the new project, Choi and Huh hope to answer those questions in detail.
“By learning the science behind the fever effect and knowing the mechanism behind the improvement in symptoms, we can have enough knowledge to be able to mimic it, even in individuals who don’t naturally experience the fever effect,” Choi says.
Choi and Huh will continue their work in mice seeking to uncover the sequence of molecular, cellular and neural circuit effects triggered by IL-17a and similar molecules that lead to improved sociability and reduction in repetitive behaviors. They will also dig deeper into why immune cells in mice exposed to maternal infection become primed to produce IL-17a.
To study the fever effect in people, Choi and Huh plan to establish a “biobank” of samples from volunteers with autism who do or don’t experience symptoms associated with fever, as well as comparable volunteers without autism. The scientists will measure, catalog, and compare these immune system molecules and cellular responses in blood plasma and stool to determine the biological and clinical markers of the fever effect.
If the research reveals distinct cellular and molecular features of the immune response among people who experience improvements with fever, the researchers could be able to harness these insights into a therapy that mimics the benefits of fever without inducing actual fever. Detailing how the immune response acts in the brain would inform how the therapy should be crafted to produce similar effects.
"We are enormously grateful and excited to have this opportunity," Huh says. "We hope our work will ‘kick up some dust’ and make the first step toward discovering the underlying causes of fever responses. Perhaps, one day in the future, novel therapies inspired by our work will help transform the lives of many families and their children with ASD [autism spectrum disorder]."
When some people with autism spectrum disorders experience an infection (the most outward sign is a fever), some of their autism symptoms improve during that time. A new research project aims to understand why that happens so that it might be mimicked to produce a therapy.
Even though the human visual system has sophisticated machinery for processing color, the brain has no problem recognizing objects in black-and-white images. A new study from MIT offers a possible explanation for how the brain comes to be so adept at identifying both color and color-degraded images.
Using experimental data and computational modeling, the researchers found evidence suggesting the roots of this ability may lie in development. Early in life, when newborns receive strongly limited color information, the brain is forced to learn to distinguish objects based on their luminance, or intensity of light they emit, rather than their color. Later in life, when the retina and cortex are better equipped to process colors, the brain incorporates color information as well but also maintains its previously acquired ability to recognize images without critical reliance on color cues.
The findings are consistent with previous work showing that initially degraded visual and auditory input can actually be beneficial to the early development of perceptual systems.
“This general idea, that there is something important about the initial limitations that we have in our perceptual system, transcends color vision and visual acuity. Some of the work that our lab has done in the context of audition also suggests that there’s something important about placing limits on the richness of information that the neonatal system is initially exposed to,” says Pawan Sinha, a professor of brain and cognitive sciences at MIT and the senior author of the study.
The findings also help to explain why children who are born blind but have their vision restored later in life, through the removal of congenital cataracts, have much more difficulty identifying objects presented in black and white. Those children, who receive rich color input as soon as their sight is restored, may develop an overreliance on color that makes them much less resilient to changes or removal of color information.
MIT postdocs Marin Vogelsang and Lukas Vogelsang, and Project Prakash research scientist Priti Gupta, are the lead authors of the study, which appears today in Science. Sidney Diamond, a retired neurologist who is now an MIT research affiliate, and additional members of the Project Prakash team are also authors of the paper.
Seeing in black and white
The researchers’ exploration of how early experience with color affects later object recognition grew out of a simple observation from a study of children who had their sight restored after being born with congenital cataracts. In 2005, Sinha launched Project Prakash (the Sanskrit word for “light”), an effort in India to identify and treat children with reversible forms of vision loss.
Many of those children suffer from blindness due to dense bilateral cataracts. This condition often goes untreated in India, which has the world’s largest population of blind children, estimated between 200,000 and 700,000.
Children who receive treatment through Project Prakash may also participate in studies of their visual development, many of which have helped scientists learn more about how the brain's organization changes following restoration of sight, how the brain estimates brightness, and other phenomena related to vision.
In this study, Sinha and his colleagues gave children a simple test of object recognition, presenting both color and black-and-white images. For children born with normal sight, converting color images to grayscale had no effect at all on their ability to recognize the depicted object. However, when children who underwent cataract removal were presented with black-and-white images, their performance dropped significantly.
This led the researchers to hypothesize that the nature of visual inputs children are exposed to early in life may play a crucial role in shaping resilience to color changes and the ability to identify objects presented in black-and-white images. In normally sighted newborns, retinal cone cells are not well-developed at birth, resulting in babies having poor visual acuity and poor color vision. Over the first years of life, their vision improves markedly as the cone system develops.
Because the immature visual system receives significantly reduced color information, the researchers hypothesized that during this time, the baby brain is forced to gain proficiency at recognizing images with reduced color cues. Additionally, they proposed, children who are born with cataracts and have them removed later may learn to rely too much on color cues when identifying objects, because, as they experimentally demonstrated in the paper, with mature retinas, they commence their post-operative journeys with good color vision.
To rigorously test that hypothesis, the researchers used a standard convolutional neural network, AlexNet, as a computational model of vision. They trained the network to recognize objects, giving it different types of input during training. As part of one training regimen, they initially showed the model grayscale images only, then introduced color images later on. This roughly mimics the developmental progression of chromatic enrichment as babies’ eyesight matures over the first years of life.
Another training regimen comprised only color images. This approximates the experience of the Project Prakash children, because they can process full color information as soon as their cataracts are removed.
The researchers found that the developmentally inspired model could accurately recognize objects in either type of image and was also resilient to other color manipulations. However, the Prakash-proxy model trained only on color images did not show good generalization to grayscale or hue-manipulated images.
“What happens is that this Prakash-like model is very good with colored images, but it’s very poor with anything else. When not starting out with initially color-degraded training, these models just don’t generalize, perhaps because of their over-reliance on specific color cues,” Lukas Vogelsang says.
The robust generalization of the developmentally inspired model is not merely a consequence of it having been trained on both color and grayscale images; the temporal ordering of these images makes a big difference. Another object-recognition model that was trained on color images first, followed by grayscale images, did not do as well at identifying black-and-white objects.
“It’s not just the steps of the developmental choreography that are important, but also the order in which they are played out,” Sinha says.
The advantages of limited sensory input
By analyzing the internal organization of the models, the researchers found that those that begin with grayscale inputs learn to rely on luminance to identify objects. Once they begin receiving color input, they don’t change their approach very much, since they’ve already learned a strategy that works well. Models that began with color images did shift their approach once grayscale images were introduced, but could not shift enough to make them as accurate as the models that were given grayscale images first.
A similar phenomenon may occur in the human brain, which has more plasticity early in life, and can easily learn to identify objects based on their luminance alone. Early in life, the paucity of color information may in fact be beneficial to the developing brain, as it learns to identify objects based on sparse information.
“As a newborn, the normally sighted child is deprived, in a certain sense, of color vision. And that turns out to be an advantage,” Diamond says.
Researchers in Sinha’s lab have observed that limitations in early sensory input can also benefit other aspects of vision, as well as the auditory system. In 2022, they used computational models to show that early exposure to only low-frequency sounds, similar to those that babies hear in the womb, improves performance on auditory tasks that require analyzing sounds over a longer period of time, such as recognizing emotions. They now plan to explore whether this phenomenon extends to other aspects of development, such as language acquisition.
The research was funded by the National Eye Institute of NIH and the Intelligence Advanced Research Projects Activity.
In 2005, Pawan Sinha, pictured here, launched Project Prakash, an effort in India to identify and treat children with reversible forms of vision loss. Children who receive treatment through Project Prakash may also participate in studies of their visual development.
The scorching surface of Venus, where temperatures can climb to 480 degrees Celsius (hot enough to melt lead), is an inhospitable place for humans and machines alike. One reason scientists have not yet been able to send a rover to the planet’s surface is because silicon-based electronics can’t operate in such extreme temperatures for an extended period of time.
For high-temperature applications like Venus exploration, researchers have recently turned to gallium nitride, a unique material that can withstand temperatures of 500 degrees or more.
The material is already used in some terrestrial electronics, like phone chargers and cell phone towers, but scientists don’t have a good grasp of how gallium nitride devices would behave at temperatures beyond 300 degrees, which is the operational limit of conventional silicon electronics.
In a new paper published in Applied Physics Letters, which is part of a multiyear research effort, a team of scientists from MIT and elsewhere sought to answer key questions about the material’s properties and performance at extremely high temperatures.
They studied the impact of temperature on the ohmic contacts in a gallium nitride device. Ohmic contacts are key components that connect a semiconductor device with the outside world.
The researchers found that extreme temperatures didn’t cause significant degradation to the gallium nitride material or contacts. They were surprised to see that the contacts remained structurally intact even when held at 500 degrees Celsius for 48 hours.
Understanding how contacts perform at extreme temperatures is an important step toward the group’s next goal of developing high-performance transistors that could operate on the surface of Venus. Such transistors could also be used on Earth in electronics for applications like extracting geothermal energy or monitoring the inside of jet engines.
“Transistors are the heart of most modern electronics, but we didn’t want to jump straight to making a gallium nitride transistor because so much could go wrong. We first wanted to make sure the material and contacts could survive, and figure out how much they change as you increase the temperature. We’ll design our transistor from these basic material building blocks,” says John Niroula, an electrical engineering and computer science (EECS) graduate student and lead author of the paper.
His co-authors include Qingyun Xie PhD ’24; Mengyang Yuan PhD ’22; EECS graduate students Patrick K. Darmawi-Iskandar and Pradyot Yadav; Gillian K. Micale, a graduate student in the Department of Materials Science and Engineering; senior author Tomás Palacios, the Clarence J. LeBel Professor of EECS, director of the Microsystems Technology Laboratories, and a member of the Research Laboratory of Electronics; as well as collaborators Nitul S. Rajput of the Technology Innovation Institute of the United Arab Emirates; Siddharth Rajan of Ohio State University; Yuji Zhao of Rice University; and Nadim Chowdhury of Bangladesh University of Engineering and Technology.
Turning up the heat
While gallium nitride has recently attracted much attention, the material is still decades behind silicon when it comes to scientists’ understanding of how its properties change under different conditions. One such property is resistance, the flow of electrical current through a material.
A device’s overall resistance is inversely proportional to its size. But devices like semiconductors have contacts that connect them to other electronics. Contact resistance, which is caused by these electrical connections, remains fixed no matter the size of the device. Too much contact resistance can lead to higher power dissipation and slower operating frequencies for electronic circuits.
“Especially when you go to smaller dimensions, a device’s performance often ends up being limited by contact resistance. People have a relatively good understanding of contact resistance at room temperature, but no one has really studied what happens when you go all the way up to 500 degrees,” Niroula says.
For their study, the researchers used facilities at MIT.nano to build gallium nitride devices known as transfer length method structures, which are composed of a series of resistors. These devices enable them to measure the resistance of both the material and the contacts.
They added ohmic contacts to these devices using the two most common methods. The first involves depositing metal onto gallium nitride and heating it to 825 degrees Celsius for about 30 seconds, a process called annealing.
The second method involves removing chunks of gallium nitride and using a high-temperature technology to regrow highly doped gallium nitride in its place, a process led by Rajan and his team at Ohio State. The highly doped material contains extra electrons that can contribute to current conduction.
“The regrowth method typically leads to lower contact resistance at room temperature, but we wanted to see if these methods still work well at high temperatures,” Niroula says.
A comprehensive approach
They tested devices in two ways. Their collaborators at Rice University, led by Zhao, conducted short-term tests by placing devices on a hot chuck that reached 500 degrees Celsius and taking immediate resistance measurements.
At MIT, they conducted longer-term experiments by placing devices into a specialized furnace the group previously developed. They left devices inside for up to 72 hours to measure how resistance changes as a function of temperature and time.
Microscopy experts at MIT.nano (Aubrey N. Penn) and the Technology Innovation Institute (Nitul S. Rajput) used state-of-the-art transmission electron microscopes to see how such high temperatures affect gallium nitride and the ohmic contacts at the atomic level.
“We went in thinking the contacts or the gallium nitride material itself would degrade significantly, but we found the opposite. Contacts made with both methods seemed to be remarkably stable,” says Niroula.
While it is difficult to measure resistance at such high temperatures, their results indicate that contact resistance seems to remain constant even at temperatures of 500 degrees, for around 48 hours. And just like at room temperature, the regrowth process led to better performance.
The material did start to degrade after being in the furnace for 48 hours, but the researchers are already working to boost long-term performance. One strategy involves adding protective insulators to keep the material from being directly exposed to the high-temperature environment.
Moving forward, the researchers plan to use what they learned in these experiments to develop high-temperature gallium nitride transistors.
“In our group, we focus on innovative, device-level research to advance the frontiers of microelectronics, while adopting a systematic approach across the hierarchy, from the material level to the circuit level. Here, we have gone all the way down to the material level to understand things in depth. In other words, we have translated device-level advancements to circuit-level impact for high-temperature electronics, through design, modeling and complex fabrication. We are also immensely fortunate to have forged close partnerships with our longtime collaborators in this journey,” Xie says.
This work was funded, in part, by the U.S. Air Force Office of Scientific Research, Lockheed Martin Corporation, the Semiconductor Research Corporation through the U.S. Defense Advanced Research Projects Agency, the U.S. Department of Energy, Intel Corporation, and the Bangladesh University of Engineering and Technology.
Fabrication and microscopy were conducted at MIT.nano, the Semiconductor Epitaxy and Analysis Laboratory at Ohio State University, the Center for Advanced Materials Characterization at the University of Oregon, and the Technology Innovation Institute of the United Arab Emirates.
Researchers studied how temperatures up to 500 degrees Celsius would affect electronic devices made from gallium nitride, a key step in their multiyear research effort to develop electronics that can operate in extremely hot environments, like the surface of Venus.
For people with paralysis or amputation, neuroprosthetic systems that artificially stimulate muscle contraction with electrical current can help them regain limb function. However, despite many years of research, this type of prosthesis is not widely used because it leads to rapid muscle fatigue and poor control.
MIT researchers have developed a new approach that they hope could someday offer better muscle control with less fatigue. Instead of using electricity to stimulate muscles, they used light. In a study in mice, the researchers showed that this optogenetic technique offers more precise muscle control, along with a dramatic decrease in fatigue.
“It turns out that by using light, through optogenetics, one can control muscle more naturally. In terms of clinical application, this type of interface could have very broad utility,” says Hugh Herr, a professor of media arts and sciences, co-director of the K. Lisa Yang Center for Bionics at MIT, and an associate member of MIT’s McGovern Institute for Brain Research.
Optogenetics is a method based on genetically engineering cells to express light-sensitive proteins, which allows researchers to control activity of those cells by exposing them to light. This approach is currently not feasible in humans, but Herr, MIT graduate student Guillermo Herrera-Arcos, and their colleagues at the K. Lisa Yang Center for Bionics are now working on ways to deliver light-sensitive proteins safely and effectively into human tissue.
Herr is the senior author of the study, which appears today in Science Robotics. Herrera-Arcos is the lead author of the paper.
Optogenetic control
For decades, researchers have been exploring the use of functional electrical stimulation (FES) to control muscles in the body. This method involves implanting electrodes that stimulate nerve fibers, causing a muscle to contract. However, this stimulation tends to activate the entire muscle at once, which is not the way that the human body naturally controls muscle contraction.
“Humans have this incredible control fidelity that is achieved by a natural recruitment of the muscle, where small motor units, then moderate-sized, then large motor units are recruited, in that order, as signal strength is increased,” Herr says. “With FES, when you artificially blast the muscle with electricity, the largest units are recruited first. So, as you increase signal, you get no force at the beginning, and then suddenly you get too much force.”
This large force not only makes it harder to achieve fine muscle control, it also wears out the muscle quickly, within five or 10 minutes.
The MIT team wanted to see if they could replace that entire interface with something different. Instead of electrodes, they decided to try controlling muscle contraction using optical molecular machines via optogenetics.
Using mice as an animal model, the researchers compared the amount of muscle force they could generate using the traditional FES approach with forces generated by their optogenetic method. For the optogenetic studies, they used mice that had already been genetically engineered to express a light-sensitive protein called channelrhodopsin-2. They implanted a small light source near the tibial nerve, which controls muscles of the lower leg.
The researchers measured muscle force as they gradually increased the amount of light stimulation, and found that, unlike FES stimulation, optogenetic control produced a steady, gradual increase in contraction of the muscle.
“As we change the optical stimulation that we deliver to the nerve, we can proportionally, in an almost linear way, control the force of the muscle. This is similar to how the signals from our brain control our muscles. Because of this, it becomes easier to control the muscle compared with electrical stimulation,” Herrera-Arcos says.
Fatigue resistance
Using data from those experiments, the researchers created a mathematical model of optogenetic muscle control. This model relates the amount of light going into the system to the output of the muscle (how much force is generated).
This mathematical model allowed the researchers to design a closed-loop controller. In this type of system, the controller delivers a stimulatory signal, and after the muscle contracts, a sensor can detect how much force the muscle is exerting. This information is sent back to the controller, which calculates if, and how much, the light stimulation needs to be adjusted to reach the desired force.
Using this type of control, the researchers found that muscles could be stimulated for more than an hour before fatiguing, while muscles became fatigued after only 15 minutes using FES stimulation.
One hurdle the researchers are now working to overcome is how to safely deliver light-sensitive proteins into human tissue. Several years ago, Herr’s lab reported that in rats, these proteins can trigger an immune response that inactivates the proteins and could also lead to muscle atrophy and cell death.
“A key objective of the K. Lisa Yang Center for Bionics is to solve that problem,” Herr says. “A multipronged effort is underway to design new light-sensitive proteins, and strategies to deliver them, without triggering an immune response.”
As additional steps toward reaching human patients, Herr’s lab is also working on new sensors that can be used to measure muscle force and length, as well as new ways to implant the light source. If successful, the researchers hope their strategy could benefit people who have experienced strokes, limb amputation, and spinal cord injuries, as well as others who have impaired ability to control their limbs.
“This could lead to a minimally invasive strategy that would change the game in terms of clinical care for persons suffering from limb pathology,” Herr says.
The research was funded by the K. Lisa Yang Center for Bionics at MIT.
MIT researchers have developed a way to help people with amputation or paralysis regain limb control. Instead of using electricity to stimulate muscles, they used light. Here, Guillermo Herrera-Arcos looks at light shining from an optical neurostimulator.
Metals get softer when they are heated, which is how blacksmiths can form iron into complex shapes by heating it red hot. And anyone who compares a copper wire with a steel coat hanger will quickly discern that copper is much more pliable than steel.
But scientists at MIT have discovered that when metal is struck by an object moving at a super high velocity, the opposite happens: The hotter the metal, the stronger it is. Under those conditions, which put extreme stress on the metal, copper can actually be just as strong as steel. The new discovery could lead to new approaches to designing materials for extreme environments, such as shields that protect spacecraft or hypersonic aircraft, or equipment for high-speed manufacturing processes.
The findings are described in a paper appearing today in the journal Nature, by Ian Dowding, an MIT graduate student, and Christopher Schuh, former head of MIT’s Department of Materials Science and Engineering, now dean of engineering at Northwestern University and visiting professor at MIT.
The new finding, the authors write, “is counterintuitive and at odds with decades of studies in less extreme conditions.” The unexpected results could affect a variety of applications because the extreme velocities involved in these impacts occur routinely in meteorite impacts on spacecraft in orbit and in high-speed machining operations used in manufacturing, sandblasting, and some additive manufacturing (3D printing) processes.
The experiments the researchers used to find this effect involved shooting tiny particles of sapphire, just millionths of a meter across, at flat sheets of metal. Propelled by laser beams, the particles reached high velocities, on the order of a few hundred meters per second. While other researchers have occasionally done experiments at similarly high velocities, they have tended to use larger impactors, at the scale of centimeters or larger. Because these larger impacts were dominated by effects of the shock of the impact, there was no way to separate out the mechanical and thermal effects.
The tiny particles in the new study don’t create a significant pressure wave when they hit the target. But it has taken a decade of research at MIT to develop methods of propelling such microscopic particles at such high velocities. “We’ve taken advantage of that,” Schuh says, along with other new techniques for observing the high-speed impact itself.
The team used extremely high-speed cameras “to watch the particles as they come in and as they fly away,” he says. As the particles bounce off the surface, the difference between the incoming and outgoing velocities “tells you how much energy was deposited” into the target, which is an indicator of the surface strength.
The tiny particles they used were made of alumina, or sapphire, and are “very hard,” Dowding says. At 10 to 20 microns (millionths of a meter) across, these are between one-tenth and one-fifth of the thickness of a human hair. When the launchpad behind those particles is hit by a laser beam, part of the material vaporizes, creating a jet of vapor that propels the particle in the opposite direction.
The researchers shot the particles at samples of copper, titanium, and gold, and they expect their results should apply to other metals as well. They say their data provide the first direct experimental evidence for this anomalous thermal effect of increased strength with greater heat, although hints of such an effect had been reported before.
The surprising effect appears to result from the way the orderly arrays of atoms that make up the crystalline structure of metals move under different conditions, according to the researchers’ analysis. They show that there are three separate effects governing how metal deforms under stress, and while two of these follow the predicted trajectory of increasing deformation at higher temperatures, it is the third effect, called drag strengthening, that reverses its effect when the deformation rate crosses a certain threshold.
Beyond this crossover point, the higher temperature increases the activity of phonons — waves of sound or heat — within the material, and these phonons interact with dislocations in the crystalline lattice in a way that limits their ability to slip and deform. The effect increases with increased impact speed and temperature, Dowding says, so that “the faster you go, the less the dislocations are able to respond.”
Of course, at some point the increased temperature will begin to melt the metal, and at that point the effect will reverse again and lead to softening. “There will be a limit” to this strengthening effect, Dowding says, “but we don’t know what it is.”
The findings could lead to different choices of materials when designing devices that may encounter such extreme stresses, Schuh says. For example, metals that may ordinarily be much weaker, but that are less expensive or easier to process, might be useful in situations where nobody would have thought to use them before.
The extreme conditions the researchers studied are not confined to spacecraft or extreme manufacturing methods. “If you are flying a helicopter in a sandstorm, a lot of these sand particles will reach high velocities as they hit the blades,” Dowding says, and under desert conditions they may reach the high temperatures where these hardening effects kick in.
The techniques the researchers used to uncover this phenomenon could be applied to a variety of other materials and situations, including other metals and alloys. Designing materials to be used in extreme conditions by simply extrapolating from known properties at less extreme conditions could lead to seriously mistaken expectations about how materials will behave under extreme stresses, they say.
The research was supported by the U.S. Department of Energy.
MIT scientists discovered that when metals are deformed at an extreme rate by an object moving at high velocities, hotter temperatures make the metal stronger, not weaker. Here, 3 particles are hitting a metallic surface at about the same velocity. As the initial temperature of the metal is increased, the rebound is faster, and the particle bounces higher because the metal becomes harder not softer, too.
The sun’s surface is a brilliant display of sunspots and flares driven by the solar magnetic field, which is internally generated through a process called dynamo action. Astrophysicists have assumed that the sun’s field is generated deep within the star. But an MIT study finds that the sun’s activity may be shaped by a much shallower process.
In a paper appearing today in Nature, researchers at MIT, the University of Edinburgh, and elsewhere find that the sun’s magnetic field could arise from instabilities within the sun’s outermost layers.
The team generated a precise model of the sun’s surface and found that when they simulated certain perturbations, or changes in the flow of plasma (ionized gas) within the top 5 to 10 percent of the sun, these surface changes were enough to generate realistic magnetic field patterns, with similar characteristics to what astronomers have observed on the sun. In contrast, their simulations in deeper layers produced less realistic solar activity.
The findings suggest that sunspots and flares could be a product of a shallow magnetic field, rather than a field that originates deeper in the sun, as scientists had largely assumed.
“The features we see when looking at the sun, like the corona that many people saw during the recent solar eclipse, sunspots, and solar flares, are all associated with the sun’s magnetic field,” says study author Keaton Burns, a research scientist in MIT’s Department of Mathematics. “We show that isolated perturbations near the sun’s surface, far from the deeper layers, can grow over time to potentially produce the magnetic structures we see.”
If the sun’s magnetic field does in fact arise from its outermost layers, this might give scientists a better chance at forecasting flares and geomagnetic storms that have the potential to damage satellites and telecommunications systems.
“We know the dynamo acts like a giant clock with many complex interacting parts,” says co-author Geoffrey Vasil, a researcher at the University of Edinburgh. “But we don't know many of the pieces or how they fit together. This new idea of how the solar dynamo starts is essential to understanding and predicting it.”
The study’s co-authors also include Daniel Lecoanet and Kyle Augustson of Northwestern University, Jeffrey Oishi of Bates College, Benjamin Brown and Keith Julien of the University of Colorado at Boulder, and Nicholas Brummell of the University of California at Santa Cruz.
Flow zone
The sun is a white-hot ball of plasma that’s boiling on its surface. This boiling region is called the “convection zone,” where layers and plumes of plasma roil and flow. The convection zone comprises the top one-third of the sun’s radius and stretches about 200,000 kilometers below the surface.
“One of the basic ideas for how to start a dynamo is that you need a region where there’s a lot of plasma moving past other plasma, and that shearing motion converts kinetic energy into magnetic energy,” Burns explains. “People had thought that the sun’s magnetic field is created by the motions at the very bottom of the convection zone.”
To pin down exactly where the sun’s magnetic field originates, other scientists have used large three-dimensional simulations to try to solve for the flow of plasma throughout the many layers of the sun’s interior. “Those simulations require millions of hours on national supercomputing facilities, but what they produce is still nowhere near as turbulent as the actual sun,” Burns says.
Rather than simulating the complex flow of plasma throughout the entire body of the sun, Burns and his colleagues wondered whether studying the stability of plasma flow near the surface might be enough to explain the origins of the dynamo process.
To explore this idea, the team first used data from the field of “helioseismology,” where scientists use observed vibrations on the sun’s surface to determine the average structure and flow of plasma beneath the surface.
“If you take a video of a drum and watch how it vibrates in slow motion, you can work out the drumhead’s shape and stiffness from the vibrational modes,” Burns says. “Similarly, we can use vibrations that we see on the solar surface to infer the average structure on the inside.”
Solar onion
For their new study, the researchers collected models of the sun’s structure from helioseismic observations. “These average flows look sort like an onion, with different layers of plasma rotating past each other,” Burns explains. “Then we ask: Are there perturbations, or tiny changes in the flow of plasma, that we could superimpose on top of this average structure, that might grow to cause the sun’s magnetic field?”
To look for such patterns, the team utilized the Dedalus Project — a numerical framework that Burns developed that can simulate many types of fluid flows with high precision. The code has been applied to a wide range of problems, from modeling the dynamics inside individual cells, to ocean and atmospheric circulations.
“My collaborators have been thinking about the solar magnetism problem for years, and the capabilities of Dedalus have now reached the point where we could address it,” Burns says.
The team developed algorithms that they incorporated into Dedalus to find self-reinforcing changes in the sun’s average surface flows. The algorithm discovered new patterns that could grow and result in realistic solar activity. In particular, the team found patterns that match the locations and timescales of sunspots that have been have observed by astronomers since Galileo in 1612.
Sunspots are transient features on the surface of the sun that are thought to be shaped by the sun’s magnetic field. These relatively cooler regions appear as dark spots in relation to the rest of the sun’s white-hot surface. Astronomers have long observed that sunspots occur in a cyclical pattern, growing and receding every 11 years, and generally gravitating around the equator, rather than near the poles.
In the team’s simulations, they found that certain changes in the flow of plasma, within just the top 5 to 10 percent of the sun’s surface layers, were enough to generate magnetic structures in the same regions. In contrast, changes in deeper layers produce less realistic solar fields that are concentrated near the poles, rather than near the equator.
The team was motivated to take a closer look at flow patterns near the surface as conditions there resembled the unstable plasma flows in entirely different systems: the accretion disks around black holes. Accretion disks are massive disks of gas and stellar dust that rotate in towards a black hole, driven by the “magnetorotational instability,” which generates turbulence in the flow and causes it to fall inward.
Burns and his colleagues suspected that a similar phenomena is at play in the sun, and that the magnetorotational instability in the sun’s outermost layers could be the first step in generating the sun’s magnetic field.
“I think this result may be controversial,” he ventures. “Most of the community has been focused on finding dynamo action deep in the sun. Now we’re showing there’s a different mechanism that seems to be a better match to observations.” Burns says that the team is continuing to study if the new surface field patterns can generate individual sunspots and the full 11-year solar cycle.
“This is far from the final word on the problem,” says Steven Balbus, a professor of astronomy at Oxford University, who was not involved with the study. “However, it is a fresh and very promising avenue for further study. The current findings are very suggestive and the approach is innovative, and not in line with the current received wisdom. When the received wisdom has not been very fruitful for an extended period, something more creative is indicated, and that is what this work offers.”
Surprise findings suggest sunspots and solar flares could be generated by a magnetic field within the Sun’s outermost layers. If confirmed, the findings could help scientists better predict space weather. This illustration lays a depiction of the sun's magnetic fields over an image captured by NASA’s Solar Dynamics Observatory on March 12, 2016.
When medical devices such as pacemakers are implanted in the body, they usually provoke an immune response that leads to buildup of scar tissue around the implant. This scarring, known as fibrosis, can interfere with the devices’ function and may require them to be removed.
In an advance that could prevent that kind of device failure, MIT engineers have found a simple and general way to eliminate fibrosis by coating devices with a hydrogel adhesive. This adhesive binds the devices to tissue and prevents the immune system from attacking it.
“The dream of many research groups and companies is to implant something into the body that over the long term the body will not see, and the device can provide therapeutic or diagnostic functionality. Now we have such an ‘invisibility cloak,’ and this is very general: There’s no need for a drug, no need for a special polymer,” says Xuanhe Zhao, an MIT professor of mechanical engineering and of civil and environmental engineering.
The adhesive that the researchers used in this study is made from cross-linked polymers called hydrogels, and is similar to a surgical tape they previously developed to help seal internal wounds. Other types of hydrogel adhesives can also protect against fibrosis, the researchers found, and they believe this approach could be used for not only pacemakers but also sensors or devices that deliver drugs or therapeutic cells.
Zhao and Hyunwoo Yuk SM ’16, PhD ’21, a former MIT research scientist who is now the chief technology officer at SanaHeal, are the senior authors of the study, which appears today in Nature. MIT postdoc Jingjing Wu is the lead author of the paper.
Preventing fibrosis
In recent years, Zhao’s lab has developed adhesives for a variety of medical applications, including double-sided and single-sided tapes that could be used to heal surgical incisions or internal injuries. These adhesives work by rapidly absorbing water from wet tissues, using polyacrylic acid, an absorbent material used in diapers. Once the water is cleared, chemical groups called NHS esters embedded in the polyacrylic acid form strong bonds with proteins at the tissue surface. This process takes about five seconds.
Several years ago, Zhao and Yuk began exploring whether this kind of adhesive could also help keep medical implants in place and prevent fibrosis from occurring.
To test this idea, Wu coated polyurethane devices with their adhesive and implanted them on the abdominal wall, colon, stomach, lung, or heart of rats. Weeks later, they removed the device and found that there was no visible scar tissue. Additional tests with other animal models showed the same thing: Wherever the adhesive-coated devices were implanted, fibrosis did not occur, for up to three months.
“This work really has identified a very general strategy, not only for one animal model, one organ, or one application,” Wu says. “Across all of these animal models, we have consistent, reproducible results without any observable fibrotic capsule.”
Using bulk RNA sequencing and fluorescent imaging, the researchers analyzed the animals’ immune response and found that when devices with adhesive coatings were first implanted, immune cells such as neutrophils began to infiltrate the area. However, the attacks quickly quenched out before any scar tissue could form.
“For the adhered devices, there is an acute inflammatory response because it is a foreign material,” Yuk says. “However, very quickly that inflammatory response decayed, and then from that point you do not have this fibrosis formation.”
One application for this adhesive could be coatings for epicardial pacemakers — devices that are placed on the heart to help control the heart rate. The wires that contact the heart often become fibrotic, but the MIT team found that when they implanted adhesive-coated wires in rats, they remained functional for at least three months, with no scar tissue formation.
“The formation of fibrotic tissue at the interface between implanted medical devices and the target tissue is a longstanding problem that routinely causes failure of the device. The demonstration that robust adhesion between the device and the tissue obviates fibrotic tissue formation is an important observation that has many potential applications in the medical device space,” says David Mooney, a professor of bioengineering at Harvard University, who was not involved in the study.
Mechanical cues
The researchers also tested a hydrogel adhesive that includes chitosan, a naturally occurring polysaccharide, and found that this adhesive also eliminated fibrosis in animal studies. However, two commercially available tissue adhesives that they tested did not show this antifibrotic effect because the commercially available adhesives eventually detached from the tissue and allowed the immune system to attack.
In another experiment, the researchers coated implants in hydrogel adhesives but then soaked them in a solution that removed the polymers’ adhesive properties, while keeping their overall chemical structure the same. After being implanted in the body, where they were held in place by sutures, fibrotic scarring occurred. This suggests that there is something about the mechanical interaction between the adhesive and the tissue that prevents the immune system from attacking, the researchers say.
“Previous research in immunology has been focused on chemistry and biochemistry, but mechanics and physics may play equivalent roles, and we should pay attention to those mechanical and physical cues in immunological responses,” says Zhao, who now plans to further investigate how those mechanical cues affect the immune system.
Yuk, Zhao, and others have started a company called SanaHeal, which is now working on further developing tissue adhesives for medical applications.
“As a team, we are interested in reporting this to the community and sparking speculation and imagination as to where this can go,” Yuk says. “There are so many scenarios in which people want to interface with foreign or manmade material in the body, like implantable devices, drug depots, or cell depots.”
The research was funded by the National Institutes of Health and the National Science Foundation.
MIT engineers found a way to eliminate the buildup of scar tissue around implantable devices, by coating them with a hydrogel adhesive. The material binds the device to tissue and prevents the immune system from attacking the device.
Astronomers at MIT, NASA, and elsewhere have a new way to measure how fast a black hole spins, by using the wobbly aftermath from its stellar feasting.
The method takes advantage of a black hole tidal disruption event — a blazingly bright moment when a black hole exerts tides on a passing star and rips it to shreds. As the star is disrupted by the black hole’s immense tidal forces, half of the star is blown away, while the other half is flung around the black hole, generating an intensely hot accretion disk of rotating stellar material.
The MIT-led team has shown that the wobble of the newly created accretion disk is key to working out the central black hole’s inherent spin.
In a study appearing today in Nature, the astronomers report that they have measured the spin of a nearby supermassive black hole by tracking the pattern of X-ray flashes that the black hole produced immediately following a tidal disruption event. The team followed the flashes over several months and determined that they were likely a signal of a bright-hot accretion disk that wobbled back and forth as it was pushed and pulled by the black hole’s own spin.
By tracking how the disk’s wobble changed over time, the scientists could work out how much the disk was being affected by the black hole’s spin, and in turn, how fast the black hole itself was spinning. Their analysis showed that the black hole was spinning at less than 25 percent the speed of light — relatively slow, as black holes go.
The study’s lead author, MIT Research Scientist Dheeraj “DJ” Pasham, says the new method could be used to gauge the spins of hundreds of black holes in the local universe in the coming years. If scientists can survey the spins of many nearby black holes, they can start to understand how the gravitational giants evolved over the history of the universe.
“By studying several systems in the coming years with this method, astronomers can estimate the overall distribution of black hole spins and understand the longstanding question of how they evolve over time,” says Pasham, who is a member of MIT’s Kavli Institute for Astrophysics and Space Research.
The study’s co-authors include collaborators from a number of institutions, including NASA, Masaryk University in the Czech Republic, the University of Leeds, the University of Syracuse, Tel Aviv University, the Polish Academy of Sciences, and elsewhere.
Shredded heat
Every black hole has an inherent spin that has been shaped by its cosmic encounters over time. If, for instance, a black hole has grown mostly through accretion — brief instances when some material falls onto the disk, this causes the black hole to spin up to quite high speeds. In contrast, if a black hole grows mostly by merging with other black holes, each merger could slow things down as one black hole’s spin meets up against the spin of the other.
As a black hole spins, it drags the surrounding space-time around with it. This drag effect is an example of Lense-Thirring precession, a longstanding theory that describes the ways in which extremely strong gravitational fields, such as those generated by a black hole, can pull on the surrounding space and time. Normally, this effect would not be obvious around black holes, as the massive objects emit no light.
But in recent years, physicists have proposed that, in instances such as during a tidal disruption event, or TDE, scientists might have a chance to track the light from stellar debris as it is dragged around. Then, they might hope to measure the black hole’s spin.
In particular, during a TDE, scientists predict that a star may fall onto a black hole from any direction, generating a disk of white-hot, shredded material that could be tilted, or misaligned, with respect to the black hole’s spin. (Imagine the accretion disk as a tilted donut that is spinning around a donut hole that has its own, separate spin.) As the disk encounters the black hole’s spin, it wobbles as the black hole pulls it into alignment. Eventually, the wobbling subsides as the disk settles into the black hole’s spin. Scientists predicted that a TDE’s wobbling disk should therefore be a measurable signature of the black hole’s spin.
“But the key was to have the right observations,” Pasham says. “The only way you can do this is, as soon as a tidal disruption event goes off, you need to get a telescope to look at this object continuously, for a very long time, so you can probe all kinds of timescales, from minutes to months.”
A high-cadence catch
For the past five years, Pasham has looked for tidal disruption events that are bright enough, and near enough, to quickly follow up and track for signs of Lense-Thirring precession. In February of 2020, he and his colleagues got lucky, with the detection of AT2020ocn, a bright flash, emanating from a galaxy about a billion light years away, that was initially spotted in the optical band by the Zwicky Transient Facility.
From the optical data, the flash appeared to be the first moments following a TDE. Being both bright and relatively close by, Pasham suspected the TDE might be the ideal candidate to look for signs of disk wobbling, and possibly measure the spin of the black hole at the host galaxy’s center. But for that, he would need much more data.
“We needed quick and high-cadence data,” Pasham says. “The key was to catch this early on because this precession, or wobble, should only be present early on. Any later, and the disk would not wobble anymore.”
The team discovered that NASA’s NICER telescope was able to catch the TDE and continuously keep an eye on it over months at a time. NICER — an abbreviation for Neutron star Interior Composition ExploreR — is an X-ray telescope on the International Space Station that measures X-ray radiation around black holes and other extreme gravitational objects.
Pasham and his colleagues looked through NICER’s observations of AT2020ocn over 200 days following the initial detection of the tidal disruption event. They discovered that the event emitted X-rays that appeared to peak every 15 days, for several cycles, before eventually petering out. They interpreted the peaks as times when the TDE’s accretion disk wobbled face-on, emitting X-rays directly toward NICER’s telescope, before wobbling away as it continued to emit X-rays (similar to waving a flashlight toward and away from someone every 15 days).
The researchers took this pattern of wobbling and worked it into the original theory for Lense-Thirring precession. Based on estimates of the black hole’s mass, and that of the disrupted star, they were able to come up with an estimate for the black hole’s spin — less than 25 percent the speed of light.
Their results mark the first time that scientists have used observations of a wobbling disk following a tidal disruption event to estimate the spin of a black hole.
"Black holes are fascinating objects and the flows of material that we see falling onto them can generate some of the most luminous events in the universe,” says study co-author Chris Nixon, associate professor of theoretical physics at the University of Leeds. “While there is a lot we still don’t understand, there are amazing observational facilities that keep surprising us and generating new avenues to explore. This event is one of those surprises.”
As new telescopes such as the Rubin Observatory come online in the coming years, Pasham foresees more opportunities to pin down black hole spins.
“The spin of a supermassive black hole tells you about the history of that black hole,” Pasham says. “Even if a small fraction of those that Rubin captures have this kind of signal, we now have a way to measure the spins of hundreds of TDEs. Then we could make a big statement about how black holes evolve over the age of the universe.”
This research was funded, in part, by NASA and the European Space Agency.
This schematic figure depicts the precession of an accretion disk formed from the debris of a disrupted star around a supermassive black hole (SMBH). The left panel shows the precession phase when the accretion disk is close to an edge-on configuration, which results in the smaller disk area being observed and thus lower luminosity. The observer can see mostly the colder, outer parts of the precessing disk. The right panel depicts a nearly face-on precession phase, when the visible disk area is larger and hence the luminosity also increases. The inner, warmer parts of the disk are then fully exposed.
“I'll have you eating out of the palm of my hand” is an unlikely utterance you'll hear from a robot. Why? Most of them don't have palms.
If you have kept up with the protean field, gripping and grasping more like humans has been an ongoing Herculean effort. Now, a new robotic hand design developed in MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) has rethought the oft-overlooked palm. The new design uses advanced sensors for a highly sensitive touch, helping the “extremity” handle objects with more detailed and delicate precision.
GelPalm has a gel-based, flexible sensor embedded in the palm, drawing inspiration from the soft, deformable nature of human hands. The sensor uses a special color illumination tech that uses red, green, and blue LEDs to light an object, and a camera to capture reflections. This mixture generates detailed 3D surface models for precise robotic interactions.
And what would the palm be without its facilitative fingers? The team also developed some robotic phalanges, called ROMEO (“RObotic Modular Endoskeleton Optical”), with flexible materials and similar sensing technology as the palm. The fingers have something called “passive compliance,” which is when a robot can adjust to forces naturally, without needing motors or extra control. This in turn helps with the larger objective: increasing the surface area in contact with objects so they can be fully enveloped. Manufactured as single, monolithic structures via 3D printing, the finger designs are a cost-effective production.
Beyond improved dexterity, GelPalm offers safer interaction with objects, something that’s especially handy for potential applications like human-robot collaboration, prosthetics, or robotic hands with human-like sensing for biomedical uses.
Many previous robotic designs have typically focused on enhancing finger dexterity. Liu's approach shifts the focus to create a more human-like, versatile end effector that interacts more naturally with objects and performs a broader range of tasks.
“We draw inspiration from human hands, which have rigid bones surrounded by soft, compliant tissue,” says recent MIT graduate Sandra Q. Liu SM ’20, PhD ’24, the lead designer of GelPalm, who developed the system as a CSAIL affiliate and PhD student in mechanical engineering. “By combining rigid structures with deformable, compliant materials, we can better achieve that same adaptive talent as our skillful hands. A major advantage is that we don't need extra motors or mechanisms to actuate the palm's deformation — the inherent compliance allows it to automatically conform around objects, just like our human palms do so dexterously.”
The researchers put the palm design to the test. Liu compared the tactile sensing performance of two different illumination systems — blue LEDs versus white LEDs — integrated into the ROMEO fingers. “Both yielded similar high-quality 3D tactile reconstructions when pressing objects into the gel surfaces,” says Liu.
But the critical experiment, she says, was to examine how well the different palm configurations could envelop and stably grasp objects. The team got hands-on, literally slathering plastic shapes in paint and pressing them against four palm types: rigid, structurally compliant, gel compliant, and their dual compliant design. “Visually, and by analyzing the painted surface area contacts, it was clear having both structural and material compliance in the palm provided significantly more grip than the others,” says Liu. “It's an elegant way to maximize the palm's role in achieving stable grasps.”
One notable limitation is the challenge of integrating sufficient sensory technology within the palm without making it bulky or overly complex. The use of camera-based tactile sensors introduces issues with size and flexibility, the team says, as the current tech doesn't easily allow for extensive coverage without trade-offs in design and functionality. Addressing this could mean developing more flexible materials for mirrors, and enhancing sensor integration to maintain functionality, without compromising practical usability.
“The palm is almost completely overlooked in the development of most robotic hands,” says Columbia University Associate Professor Matei Ciocarlie, who wasn’t involved in the paper. “This work is remarkable because it introduces a purposefully designed, useful palm that combines two key features, articulation and sensing, whereas most robot palms lack either. The human palm is both subtly articulated and highly sensitive, and this work is a relevant innovation in this direction.”
“I hope we're moving toward more advanced robotic hands that blend soft and rigid elements with tactile sensitivity, ideally within the next five to 10 years. It's a complex field without a clear consensus on the best hand design, which makes this work especially thrilling,” says Liu. “In developing GelPalm and the ROMEO fingers, I focused on modularity and transferability to encourage a wide range of designs. Making this technology low-cost and easy to manufacture allows more people to innovate and explore. As just one lab and one person in this vast field, my dream is that sharing this knowledge could spark advancements and inspire others.”
Ted Adelson, the John and Dorothy Wilson Professor of Vision Science in the Department of Brain and Cognitive Sciences and CSAIL member, is the senior author on a paper describing the work. The research was supported, in part, by the Toyota Research Institute, Amazon Science Hub, and the SINTEF BIFROST project. Liu presented the research at the International Conference on Robotics and Automation (ICRA) earlier this month.
Most systems used to detect toxic gases in industrial or domestic settings can be used only once, or at best a few times. Now, researchers at MIT have developed a detector that could provide continuous monitoring for the presence of these gases, at low cost.
The new system combines two existing technologies, bringing them together in a way that preserves the advantages of each while avoiding their limitations. The team used a material called a metal-organic framework, or MOF, which is highly sensitive to tiny traces of gas but whose performance quickly degrades, and combined it with a polymer material that is highly durable and easier to process, but much less sensitive.
The results are reported today in the journal Advanced Materials, in a paper by MIT professors Aristide Gumyusenge, Mircea Dinca, Heather Kulik, and Jesus del Alamo, graduate student Heejung Roh, and postdocs Dong-Ha Kim, Yeongsu Cho, and Young-Moo Jo.
Highly porous and with large surface areas, MOFs come in a variety of compositions. Some can be insulators, but the ones used for this work are highly electrically conductive. With their sponge-like form, they are effective at capturing molecules of various gases, and the sizes of their pores can be tailored to make them selective for particular kinds of gases. “If you are using them as a sensor, you can recognize if the gas is there if it has an effect on the resistivity of the MOF,” says Gumyusenge, the paper’s senior author and the Merton C. Flemings Career Development Assistant Professor of Materials Science and Engineering.
The drawback for these materials’ use as detectors for gases is that they readily become saturated, and then can no longer detect and quantify new inputs. “That’s not what you want. You want to be able to detect and reuse,” Gumyusenge says. “So, we decided to use a polymer composite to achieve this reversibility.”
The team used a class of conductive polymers that Gumyusenge and his co-workers had previously shown can respond to gases without permanently binding to them. “The polymer, even though it doesn’t have the high surface area that the MOFs do, will at least provide this recognize-and-release type of phenomenon,” he says.
The team combined the polymers in a liquid solution along with the MOF material in powdered form, and deposited the mixture on a substrate, where they dry into a uniform, thin coating. By combining the polymer, with its quick detection capability, and the more sensitive MOFs, in a one-to-one ratio, he says, “suddenly we get a sensor that has both the high sensitivity we get from the MOF and the reversibility that is enabled by the presence of the polymer.”
The material changes its electrical resistance when molecules of the gas are temporarily trapped in the material. These changes in resistance can be continuously monitored by simply attaching an ohmmeter to track the resistance over time. Gumyusenge and his students demonstrated the composite material’s ability to detect nitrogen dioxide, a toxic gas produced by many kinds of combustion, in a small lab-scale device. After 100 cycles of detection, the material was still maintaining its baseline performance within a margin of about 5 to 10 percent, demonstrating its long-term use potential.
In addition, this material has far greater sensitivity than most presently used detectors for nitrogen dioxide, the team reports. This gas is often detected after the use of stove ovens. And, with this gas recently linked to many asthma cases in the U.S., reliable detection in low concentrations is important. The team demonstrated that this new composite could detect, reversibly, the gas at concentrations as low as 2 parts per million.
While their demonstration was specifically aimed at nitrogen dioxide, Gumyusenge says, “we can definitely tailor the chemistry to target other volatile molecules,” as long as they are small polar analytes, “which tend to be most of the toxic gases.”
Besides being compatible with a simple hand-held detector or a smoke-alarm type of device, one advantage of the material is that the polymer allows it to be deposited as an extremely thin uniform film, unlike regular MOFs, which are generally in an inefficient powder form. Because the films are so thin, there is little material needed and production material costs could be low; the processing methods could be typical of those used for industrial coating processes. “So, maybe the limiting factor will be scaling up the synthesis of the polymers, which we’ve been synthesizing in small amounts,” Gumyusenge says.
“The next steps will be to evaluate these in real-life settings,” he says. For example, the material could be applied as a coating on chimneys or exhaust pipes to continuously monitor gases through readings from an attached resistance monitoring device. In such settings, he says, “we need tests to check if we truly differentiate it from other potential contaminants that we might have overlooked in the lab setting. Let’s put the sensors out in real-world scenarios and see how they do.”
The work was supported by the MIT Climate and Sustainability Consortium (MCSC), the Abdul Latif Jameel Water and Food Systems Lab (J-WAFS) at MIT, and the U.S. Department of Energy.
Researchers at MIT have developed a detector that could provide continuous monitoring for the presence of toxic gases, at low cost. The team used a material called a metal-organic framework, or MOF (pictured as the black lattice), which is highly sensitive to tiny traces of gas but whose performance quickly degrades. They combined the MOF with a polymer material, shown as the teal translucent strands, that is highly durable but much less sensitive.
Physics graduate student Jeong Min (Jane) Park is among the 32 exceptional early-career scientists worldwide chosen to receive the prestigious 2024 Schmidt Science Fellows award.
As a 2024 Schmidt Science Fellow, Park’s postdoctoral work will seek to directly detect phases that could host new particles by employing an instrument that can visualize subatomic-scale phenomena.
With her advisor, Pablo Jarillo-Herrero, the Cecil and Ida Green Professor of Physics, Park’s research at MIT focuses on discovering novel quantum phases of matter.
“When there are many electrons in a material, their interactions can lead to collective behaviors that are not expected from individual particles, known as emergent phenomena,” explains Park. “One example is superconductivity, where interacting electrons combine together as a pair at low temperatures to conduct electricity without energy loss.”
During her PhD studies, she has investigated novel types of superconductivity by designing new materials with targeted interactions and topology. In particular, she used graphene, atomically thin two-dimensional layers of graphite, the same material as pencil lead, and turned it into a “magic” material. This so-called magic-angle twisted trilayer graphene provided an extraordinarily strong form of superconductivity that is robust under high magnetic fields. Later, she found a whole “magic family” of these materials, elucidating the key mechanisms behind superconductivity and interaction-driven phenomena. These results have provided a new platform to study emergent phenomena in two dimensions, which can lead to innovations in electronics and quantum technology.
Park says she is looking forward to her postdoctoral studies with Princeton University physics professor Ali Yazdani's lab.
“I’m excited about the idea of discovering and studying new quantum phenomena that could further the understanding of fundamental physics,” says Park. “Having explored interaction-driven phenomena through the design of new materials, I’m now aiming to broaden my perspective and expertise to address a different kind of question, by combining my background in material design with the sophisticated local-scale measurements that I will adopt during my postdoc.”
She explains that elementary particles are classified as either bosons or fermions, with contrasting behaviors upon interchanging two identical particles, referred to as exchange statistics; bosons remain unchanged, while fermions acquire a minus sign in their quantum wavefunction.
Theories predict the existence of fundamentally different particles known as non-abelian anyons, whose wavefunctions braid upon particle exchange. Such a braiding process can be used to encode and store information, potentially opening the door to fault-tolerant quantum computing in the future.
Since 2018, this prestigious postdoctoral program has sought to break down silos among scientific fields to solve the world’s biggest challenges and support future leaders in STEM.
Schmidt Science Fellows, an initiative of Schmidt Sciences, delivered in partnership with the Rhodes Trust, identifies, develops, and amplifies the next generation of science leaders, by building a community of scientists and supporters of interdisciplinary science and leveraging this network to drive sector-wide change. The 2024 fellows consist of 17 nationalities across North America, Europe, and Asia.
Nominated candidates undergo a rigorous selection process that includes a paper-based academic review with panels of experts in their home disciplines and final interviews with panels, including senior representatives from across many scientific disciplines and different business sectors.
Physics graduate student Jeong Min (Jane) Park is among the 32 exceptional early-career scientists worldwide chosen to receive the prestigious 2024 Schmidt Science Fellows award.
When water freezes, it transitions from a liquid phase to a solid phase, resulting in a drastic change in properties like density and volume. Phase transitions in water are so common most of us probably don’t even think about them, but phase transitions in novel materials or complex physical systems are an important area of study.
To fully understand these systems, scientists must be able to recognize phases and detect the transitions between. But how to quantify phase changes in an unknown system is often unclear, especially when data are scarce.
Researchers from MIT and the University of Basel in Switzerland applied generative artificial intelligence models to this problem, developing a new machine-learning framework that can automatically map out phase diagrams for novel physical systems.
Their physics-informed machine-learning approach is more efficient than laborious, manual techniques which rely on theoretical expertise. Importantly, because their approach leverages generative models, it does not require huge, labeled training datasets used in other machine-learning techniques.
Such a framework could help scientists investigate the thermodynamic properties of novel materials or detect entanglement in quantum systems, for instance. Ultimately, this technique could make it possible for scientists to discover unknown phases of matter autonomously.
“If you have a new system with fully unknown properties, how would you choose which observable quantity to study? The hope, at least with data-driven tools, is that you could scan large new systems in an automated way, and it will point you to important changes in the system. This might be a tool in the pipeline of automated scientific discovery of new, exotic properties of phases,” says Frank Schäfer, a postdoc in the Julia Lab in the Computer Science and Artificial Intelligence Laboratory (CSAIL) and co-author of a paper on this approach.
Joining Schäfer on the paper are first author Julian Arnold, a graduate student at the University of Basel; Alan Edelman, applied mathematics professor in the Department of Mathematics and leader of the Julia Lab; and senior author Christoph Bruder, professor in the Department of Physics at the University of Basel. The research is published today in Physical Review Letters.
Detecting phase transitions using AI
While water transitioning to ice might be among the most obvious examples of a phase change, more exotic phase changes, like when a material transitions from being a normal conductor to a superconductor, are of keen interest to scientists.
These transitions can be detected by identifying an “order parameter,” a quantity that is important and expected to change. For instance, water freezes and transitions to a solid phase (ice) when its temperature drops below 0 degrees Celsius. In this case, an appropriate order parameter could be defined in terms of the proportion of water molecules that are part of the crystalline lattice versus those that remain in a disordered state.
In the past, researchers have relied on physics expertise to build phase diagrams manually, drawing on theoretical understanding to know which order parameters are important. Not only is this tedious for complex systems, and perhaps impossible for unknown systems with new behaviors, but it also introduces human bias into the solution.
More recently, researchers have begun using machine learning to build discriminative classifiers that can solve this task by learning to classify a measurement statistic as coming from a particular phase of the physical system, the same way such models classify an image as a cat or dog.
The MIT researchers demonstrated how generative models can be used to solve this classification task much more efficiently, and in a physics-informed manner.
The Julia Programming Language, a popular language for scientific computing that is also used in MIT’s introductory linear algebra classes, offers many tools that make it invaluable for constructing such generative models, Schäfer adds.
Generative models, like those that underlie ChatGPT and Dall-E, typically work by estimating the probability distribution of some data, which they use to generate new data points that fit the distribution (such as new cat images that are similar to existing cat images).
However, when simulations of a physical system using tried-and-true scientific techniques are available, researchers get a model of its probability distribution for free. This distribution describes the measurement statistics of the physical system.
A more knowledgeable model
The MIT team’s insight is that this probability distribution also defines a generative model upon which a classifier can be constructed. They plug the generative model into standard statistical formulas to directly construct a classifier instead of learning it from samples, as was done with discriminative approaches.
“This is a really nice way of incorporating something you know about your physical system deep inside your machine-learning scheme. It goes far beyond just performing feature engineering on your data samples or simple inductive biases,” Schäfer says.
This generative classifier can determine what phase the system is in given some parameter, like temperature or pressure. And because the researchers directly approximate the probability distributions underlying measurements from the physical system, the classifier has system knowledge.
This enables their method to perform better than other machine-learning techniques. And because it can work automatically without the need for extensive training, their approach significantly enhances the computational efficiency of identifying phase transitions.
At the end of the day, similar to how one might ask ChatGPT to solve a math problem, the researchers can ask the generative classifier questions like “does this sample belong to phase I or phase II?” or “was this sample generated at high temperature or low temperature?”
Scientists could also use this approach to solve different binary classification tasks in physical systems, possibly to detect entanglement in quantum systems (Is the state entangled or not?) or determine whether theory A or B is best suited to solve a particular problem. They could also use this approach to better understand and improve large language models like ChatGPT by identifying how certain parameters should be tuned so the chatbot gives the best outputs.
In the future, the researchers also want to study theoretical guarantees regarding how many measurements they would need to effectively detect phase transitions and estimate the amount of computation that would require.
This work was funded, in part, by the Swiss National Science Foundation, the MIT-Switzerland Lockheed Martin Seed Fund, and MIT International Science and Technology Initiatives.
Researchers used generative AI to develop a physics-informed technique to classify phase transitions in materials or physical systems that is much more efficient than existing machine-learning approaches. The work was led by researchers at MIT and the University of Basel.
Most people agree that the spread of online misinformation is a serious problem. But there is much less consensus on what to do about it.
Many proposed solutions focus on how social media platforms can or should moderate content their users post, to prevent misinformation from spreading.
“But this approach puts a critical social decision in the hands of for-profit companies. It limits the ability of users to decide who they trust. And having platforms in charge does nothing to combat misinformation users come across from other online sources,” says Farnaz Jahanbakhsh SM ’21, PhD ’23, who is currently a postdoc at Stanford University.
She and MIT Professor David Karger have proposed an alternate strategy. They built a web browser extension that empowers individuals to flag misinformation and identify others they trust to assess online content.
Their decentralized approach, called the Trustnet browser extension, puts the power to decide what constitutes misinformation into the hands of individual users rather than a central authority. Importantly, the universal browser extension works for any content on any website, including posts on social media sites, articles on news aggregators, and videos on streaming platforms.
Through a two-week study, the researchers found that untrained individuals could use the tool to effectively assess misinformation. Participants said having the ability to assess content, and see assessments from others they trust, helped them think critically about it.
“In today’s world, it’s trivial for bad actors to create unlimited amounts of misinformation that looks accurate, well-sourced, and carefully argued. The only way to protect ourselves from this flood will be to rely on information that has been verified by trustworthy sources. Trustnet presents a vision of how that future could look,” says Karger.
Jahanbakhsh, who conducted this research while she was an electrical engineering and computer science (EECS) graduate student at MIT, and Karger, a professor of EECS and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL), detail their findings in a paper presented this week at the ACM Conference on Human Factors in Computing Systems.
Fighting misinformation
This new paper builds off their prior work about fighting online misinformation. The researchers built a social media platform called Trustnet, which enabled users to assess content accuracy and specify trusted users whose assessments they want to see.
But in the real world, few people would likely migrate to a new social media platform, especially when they already have friends and followers on other platforms. On the other hand, calling on social media companies to give users content-assessment abilities would be an uphill battle that may require legislation. Even if regulations existed, they would do little to stop misinformation elsewhere on the web.
Instead, the researchers sought a platform-agnostic solution, which led them to build the Trustnet browser extension.
Extension users click a button to assess content, which opens a side panel where they label it as accurate, inaccurate, or question its accuracy. They can provide details or explain their rationale in an accompanying text box.
Users can also identify others they trust to provide assessments. Then, when the user visits a website that contains assessments from these trusted sources, the side panel automatically pops up to show them.
In addition, users can choose to follow others beyond their trusted assessors. They can opt to see content assessments from those they follow on a case-by-case basis. They can also use the side panel to respond to questions about content accuracy.
“But most content we come across on the web is embedded in a social media feed or shown as a link on an aggregator page, like the front page of a news website. Plus, something we know from prior work is that users typically don’t even click on links when they share them,” Jahanbakhsh says.
To get around those issues, the researchers designed the Trustnet Extension to check all links on the page a user is reading. If trusted sources have assessed content on any linked pages, the extension places indictors next to those links and will fade the text of links to content deemed inaccurate.
One of the biggest technical challenges the researchers faced was enabling the link-checking functionality since links typically go through multiple redirections. They were also challenged to make design decisions that would suit a variety of users.
Differing assessments
To see how individuals would utilize the Trustnet Extension, they conducted a two-week study where 32individuals were tasked with assessing two pieces of content per day.
The researchers were surprised to see that the content these untrained users chose to assess, such as home improvement tips or celebrity gossip, was often different from content assessed by professionals, like news articles. Users also said they would value assessments from people who were not professional fact-checkers, such as having doctors assess medical content or immigrants assess content related to foreign affairs.
“I think this shows that what users need and the kinds of content they consider important to assess doesn’t exactly align with what is being delivered to them. A decentralized approach is more scalable, so more content could be assessed,” Jahanbakhsh says.
However, the researchers caution that letting users choose whom to trust could cause them to become trapped in their own bubble and only see content that agrees with their views.
This issue could be mitigated by identifying trust relationships in a more structured way, perhaps by suggesting a user follow certain trusted assessors, like the FDA.
In the future, Jahanbakhsh wants to further study structured trust relationships and the broader implications of decentralizing the fight against misinformation. She also wants to extend this framework beyond misinformation. For instance, one could use the tool to filter out content that is not sympathetic to a certain protected group.
“Less attention has been paid to decentralized approaches because some people think individuals can’t assess content,” she says. “Our studies have shown that is not true. But users shouldn’t just be left helpless to figure things out on their own. We can make fact-checking available to them, but in a way that lets them choose the content they want to see.”
In an effort to decentralize the fight against online misinformation, MIT researchers developed the Trustnet browser extension, which empowers individuals to assess the accuracy of any content on any website, and also view content assessments from people they trust.
MIT senior Elaine Siyu Liu doesn’t own an electric car, or any car. But she sees the impact of electric vehicles (EVs) and renewables on the grid as two pieces of an energy puzzle she wants to solve.
The U.S. Department of Energy reports that the number of public and private EV charging ports nearly doubled in the past three years, and many more are in the works. Users expect to plug in at their convenience, charge up, and drive away. But what if the grid can’t handle it?
Electricity demand, long stagnant in the United States, has spiked due to EVs, data centers that drive artificial intelligence, and industry. Grid planners forecast an increase of 2.6 percent to 4.7 percent in electricity demand over the next five years, according to data reported to federal regulators. Everyone from EV charging-station operators to utility-system operators needs help navigating a system in flux.
That’s where Liu’s work comes in.
Liu, who is studying mathematics and electrical engineering and computer science (EECS), is interested in distribution — how to get electricity from a centralized location to consumers. “I see power systems as a good venue for theoretical research as an application tool,” she says. “I'm interested in it because I'm familiar with the optimization and probability techniques used to map this level of problem.”
Liu grew up in Beijing, then after middle school moved with her parents to Canada and enrolled in a prep school in Oakville, Ontario, 30 miles outside Toronto.
Liu stumbled upon an opportunity to take part in a regional math competition and eventually started a math club, but at the time, the school’s culture surrounding math surprised her. Being exposed to what seemed to be some students’ aversion to math, she says, “I don’t think my feelings about math changed. I think my feelings about how people feel about math changed.”
Liu brought her passion for math to MIT. The summer after her sophomore year, she took on the first of the two Undergraduate Research Opportunity Program projects she completed with electric power system expert Marija Ilić, a joint adjunct professor in EECS and a senior research scientist at the MIT Laboratory for Information and Decision Systems.
Predicting the grid
Since 2022, with the help of funding from the MIT Energy Initiative (MITEI), Liu has been working with Ilić on identifying ways in which the grid is challenged.
One factor is the addition of renewables to the energy pipeline. A gap in wind or sun might cause a lag in power generation. If this lag occurs during peak demand, it could mean trouble for a grid already taxed by extreme weather and other unforeseen events.
If you think of the grid as a network of dozens of interconnected parts, once an element in the network fails — say, a tree downs a transmission line — the electricity that used to go through that line needs to be rerouted. This may overload other lines, creating what’s known as a cascade failure.
“This all happens really quickly and has very large downstream effects,” Liu says. “Millions of people will have instant blackouts.”
Even if the system can handle a single downed line, Liu notes that “the nuance is that there are now a lot of renewables, and renewables are less predictable. You can't predict a gap in wind or sun. When such things happen, there’s suddenly not enough generation and too much demand. So the same kind of failure would happen, but on a larger and more uncontrollable scale.”
Renewables’ varying output has the added complication of causing voltage fluctuations. “We plug in our devices expecting a voltage of 110, but because of oscillations, you will never get exactly 110,” Liu says. “So even when you can deliver enough electricity, if you can't deliver it at the specific voltage level that is required, that’s a problem.”
Liu and Ilić are building a model to predict how and when the grid might fail. Lacking access to privatized data, Liu runs her models with European industry data and test cases made available to universities. “I have a fake power grid that I run my experiments on,” she says. “You can take the same tool and run it on the real power grid.”
Liu’s model predicts cascade failures as they evolve. Supply from a wind generator, for example, might drop precipitously over the course of an hour. The model analyzes which substations and which households will be affected. “After we know we need to do something, this prediction tool can enable system operators to strategically intervene ahead of time,” Liu says.
Dictating price and power
Last year, Liu turned her attention to EVs, which provide a different kind of challenge than renewables.
In 2022, S&P Global reported that lawmakers argued that the U.S. Federal Energy Regulatory Commission’s (FERC) wholesale power rate structure was unfair for EV charging station operators.
In addition to operators paying by the kilowatt-hour, some also pay more for electricity during peak demand hours. Only a few EVs charging up during those hours could result in higher costs for the operator even if their overall energy use is low.
Anticipating how much power EVs will need is more complex than predicting energy needed for, say, heating and cooling. Unlike buildings, EVs move around, making it difficult to predict energy consumption at any given time. “If users don't like the price at one charging station or how long the line is, they'll go somewhere else,” Liu says. “Where to allocate EV chargers is a problem that a lot of people are dealing with right now.”
One approach would be for FERC to dictate to EV users when and where to charge and what price they'll pay. To Liu, this isn’t an attractive option. “No one likes to be told what to do,” she says.
Liu is looking at optimizing a market-based solution that would be acceptable to top-level energy producers — wind and solar farms and nuclear plants — all the way down to the municipal aggregators that secure electricity at competitive rates and oversee distribution to the consumer.
Analyzing the location, movement, and behavior patterns of all the EVs driven daily in Boston and other major energy hubs, she notes, could help demand aggregators determine where to place EV chargers and how much to charge consumers, akin to Walmart deciding how much to mark up wholesale eggs in different markets.
Last year, Liu presented the work at MITEI’s annual research conference. This spring, Liu and Ilić are submitting a paper on the market optimization analysis to a journal of the Institute of Electrical and Electronics Engineers.
Liu has come to terms with her early introduction to attitudes toward STEM that struck her as markedly different from those in China. She says, “I think the (prep) school had a very strong ‘math is for nerds’ vibe, especially for girls. There was a ‘why are you giving yourself more work?’ kind of mentality. But over time, I just learned to disregard that.”
After graduation, Liu, the only undergraduate researcher in Ilić’s MIT Electric Energy Systems Group, plans to apply to fellowships and graduate programs in EECS, applied math, and operations research.
Based on her analysis, Liu says that the market could effectively determine the price and availability of charging stations. Offering incentives for EV owners to charge during the day instead of at night when demand is high could help avoid grid overload and prevent extra costs to operators. “People would still retain the ability to go to a different charging station if they chose to,” she says. “I'm arguing that this works.”
With a double major in mathematics and electrical engineering and computer science, Elaine Siyu Liu is interested in distribution — how to get electricity from a centralized location to consumers.
Every year, beer breweries generate and discard thousands of tons of surplus yeast. Researchers from MIT and Georgia Tech have now come up with a way to repurpose that yeast to absorb lead from contaminated water.
Through a process called biosorption, yeast can quickly absorb even trace amounts of lead and other heavy metals from water. The researchers showed that they could package the yeast inside hydrogel capsules to create a filter that removes lead from water. Because the yeast cells are encapsulated, they can be easily removed from the water once it’s ready to drink.
“We have the hydrogel surrounding the free yeast that exists in the center, and this is porous enough to let water come in, interact with yeast as if they were freely moving in water, and then come out clean,” says Patricia Stathatou, a former postdoc at the MIT Center for Bits and Atoms, who is now a research scientist at Georgia Tech and an incoming assistant professor at Georgia Tech’s School of Chemical and Biomolecular Engineering. “The fact that the yeast themselves are bio-based, benign, and biodegradable is a significant advantage over traditional technologies.”
The researchers envision that this process could be used to filter drinking water coming out of a faucet in homes, or scaled up to treat large quantities of water at treatment plants.
MIT graduate student Devashish Gokhale and Stathatou are the lead authors of the study, which appears today in the journal RSC Sustainability. Patrick Doyle, the Robert T. Haslam Professor of Chemical Engineering at MIT, is the senior author of the paper, and Christos Athanasiou, an assistant professor of aerospace engineering at Georgia Tech and a former visiting scholar at MIT, is also an author.
Absorbing lead
The new study builds on work that Stathatou and Athanasiou began in 2021, when Athanasiou was a visiting scholar at MIT’s Center for Bits and Atoms. That year, they calculated that waste yeast discarded from a single brewery in Boston would be enough to treat the city’s entire water supply.
Through biosorption, a process that is not fully understood, yeast cells can bind to and absorb heavy metal ions, even at challenging initial concentrations below 1 part per million. The MIT team found that this process could effectively decontaminate water with low concentrations of lead. However, one key obstacle remained, which was how to remove yeast from the water after they absorb the lead.
In a serendipitous coincidence, Stathatou and Athanasiou happened to present their research at the AIChE Annual Meeting in Boston in 2021, where Gokhale, a student in Doyle’s lab, was presenting his own research on using hydrogels to capture micropollutants in water. The two sets of researchers decided to join forces and explore whether the yeast-based strategy could be easier to scale up if the yeast were encapsulated in hydrogels developed by Gokhale and Doyle.
“What we decided to do was make these hollow capsules — something like a multivitamin pill, but instead of filling them up with vitamins, we fill them up with yeast cells,” Gokhale says. “These capsules are porous, so the water can go into the capsules and the yeast are able to bind all of that lead, but the yeast themselves can’t escape into the water.”
The capsules are made from a polymer called polyethylene glycol (PEG), which is widely used in medical applications. To form the capsules, the researchers suspend freeze-dried yeast in water, then mix them with the polymer subunits. When UV light is shone on the mixture, the polymers link together to form capsules with yeast trapped inside.
Each capsule is about half a millimeter in diameter. Because the hydrogels are very thin and porous, water can easily pass through and encounter the yeast inside, while the yeast remain trapped.
In this study, the researchers showed that the encapsulated yeast could remove trace lead from water just as rapidly as the unencapsulated yeast from Stathatou and Athanasiou’s original 2021 study.
Scaling up
Led by Athanasiou, the researchers tested the mechanical stability of the hydrogel capsules and found that the capsules and the yeast inside can withstand forces similar to those generated by water running from a faucet. They also calculated that the yeast-laden capsules should be able to withstand forces generated by flows in water treatment plants serving several hundred residences.
“Lack of mechanical robustness is a common cause of failure of previous attempts to scale-up biosorption using immobilized cells; in our work we wanted to make sure that this aspect is thoroughly addressed from the very beginning to ensure scalability,” Athanasiou says.
After assessing the mechanical robustness of the yeast-laden capsules, the researchers constructed a proof-of-concept packed-bed biofilter, capable of treating trace lead-contaminated water and meeting U.S. Environmental Protection Agency drinking water guidelines while operating continuously for 12 days.
This process would likely consume less energy than existing physicochemical processes for removing trace inorganic compounds from water, such as precipitation and membrane filtration, the researchers say.
This approach, rooted in circular economy principles, could minimize waste and environmental impact while also fostering economic opportunities within local communities. Although numerous lead contamination incidents have been reported in various locations in the United States, this approach could have an especially significant impact in low-income areas that have historically faced environmental pollution and limited access to clean water, and may not be able to afford other ways to remediate it, the researchers say.
“We think that there’s an interesting environmental justice aspect to this, especially when you start with something as low-cost and sustainable as yeast, which is essentially available anywhere,” Gokhale says.
The researchers are now exploring strategies for recycling and replacing the yeast once they’re used up, and trying to calculate how often that will need to occur. They also hope to investigate whether they could use feedstocks derived from biomass to make the hydrogels, instead of fossil-fuel-based polymers, and whether the yeast can be used to capture other types of contaminants.
“Moving forward, this is a technology that can be evolved to target other trace contaminants of emerging concern, such as PFAS or even microplastics,” Stathatou says. “We really view this as an example with a lot of potential applications in the future.”
The research was funded by the Rasikbhai L. Meswani Fellowship for Water Solutions, the MIT Abdul Latif Jameel Water and Food Systems Lab (J-WAFS), and the Renewable Bioproducts Institute at Georgia Tech.
Engineered yeast-containing hydrogel capsules could be used to remove lead from contaminated water rapidly and inexpensively. The work, from MIT and Georgia Tech researchers, could be especially useful in low-income areas with high lead contamination.
Need a moment of levity? Try watching videos of astronauts falling on the moon. NASA’s outtakes of Apollo astronauts tripping and stumbling as they bounce in slow motion are delightfully relatable.
For MIT engineers, the lunar bloopers also highlight an opportunity to innovate.
“Astronauts are physically very capable, but they can struggle on the moon, where gravity is one-sixth that of Earth’s but their inertia is still the same. Furthermore, wearing a spacesuit is a significant burden and can constrict their movements,” says Harry Asada, professor of mechanical engineering at MIT. “We want to provide a safe way for astronauts to get back on their feet if they fall.”
Asada and his colleagues are designing a pair of wearable robotic limbs that can physically support an astronaut and lift them back on their feet after a fall. The system, which the researchers have dubbed Supernumerary Robotic Limbs or “SuperLimbs” is designed to extend from a backpack, which would also carry the astronaut’s life support system, along with the controller and motors to power the limbs.
The researchers have built a physical prototype, as well as a control system to direct the limbs, based on feedback from the astronaut using it. The team tested a preliminary version on healthy subjects who also volunteered to wear a constrictive garment similar to an astronaut’s spacesuit. When the volunteers attempted to get up from a sitting or lying position, they did so with less effort when assisted by SuperLimbs, compared to when they had to recover on their own.
The MIT team envisions that SuperLimbs can physically assist astronauts after a fall and, in the process, help them conserve their energy for other essential tasks. The design could prove especially useful in the coming years, with the launch of NASA’s Artemis mission, which plans to send astronauts back to the moon for the first time in over 50 years. Unlike the largely exploratory mission of Apollo, Artemis astronauts will endeavor to build the first permanent moon base — a physically demanding task that will require multiple extended extravehicular activities (EVAs).
“During the Apollo era, when astronauts would fall, 80 percent of the time it was when they were doing excavation or some sort of job with a tool,” says team member and MIT doctoral student Erik Ballesteros. “The Artemis missions will really focus on construction and excavation, so the risk of falling is much higher. We think that SuperLimbs can help them recover so they can be more productive, and extend their EVAs.”
Asada, Ballesteros, and their colleagues will present their design and study this week at the IEEE International Conference on Robotics and Automation (ICRA). Their co-authors include MIT postdoc Sang-Yoep Lee and Kalind Carpenter of the Jet Propulsion Laboratory.
Taking a stand
The team’s design is the latest application of SuperLimbs, which Asada first developed about a decade ago and has since adapted for a range of applications, including assisting workers in aircraft manufacturing, construction, and ship building.
Most recently, Asada and Ballesteros wondered whether SuperLimbs might assist astronauts, particularly as NASA plans to send astronauts back to the surface of the moon.
“In communications with NASA, we learned that this issue of falling on the moon is a serious risk,” Asada says. “We realized that we could make some modifications to our design to help astronauts recover from falls and carry on with their work.”
The team first took a step back, to study the ways in which humans naturally recover from a fall. In their new study, they asked several healthy volunteers to attempt to stand upright after lying on their side, front, and back.
The researchers then looked at how the volunteers’ attempts to stand changed when their movements were constricted, similar to the way astronauts’ movements are limited by the bulk of their spacesuits. The team built a suit to mimic the stiffness of traditional spacesuits, and had volunteers don the suit before again attempting to stand up from various fallen positions. The volunteers’ sequence of movements was similar, though required much more effort compared to their unencumbered attempts.
The team mapped the movements of each volunteer as they stood up, and found that they each carried out a common sequence of motions, moving from one pose, or “waypoint,” to the next, in a predictable order.
“Those ergonomic experiments helped us to model in a straightforward way, how a human stands up,” Ballesteros says. “We could postulate that about 80 percent of humans stand up in a similar way. Then we designed a controller around that trajectory.”
Helping hand
The team developed software to generate a trajectory for a robot, following a sequence that would help support a human and lift them back on their feet. They applied the controller to a heavy, fixed robotic arm, which they attached to a large backpack. The researchers then attached the backpack to the bulky suit and helped volunteers back into the suit. They asked the volunteers to again lie on their back, front, or side, and then had them attempt to stand as the robot sensed the person’s movements and adapted to help them to their feet.
Overall, the volunteers were able to stand stably with much less effort when assisted by the robot, compared to when they tried to stand alone while wearing the bulky suit.
“It feels kind of like an extra force moving with you,” says Ballesteros, who also tried out the suit and arm assist. “Imagine wearing a backpack and someone grabs the top and sort of pulls you up. Over time, it becomes sort of natural.”
The experiments confirmed that the control system can successfully direct a robot to help a person stand back up after a fall. The researchers plan to pair the control system with their latest version of SuperLimbs, which comprises two multijointed robotic arms that can extend out from a backpack. The backpack would also contain the robot’s battery and motors, along with an astronaut’s ventilation system.
“We designed these robotic arms based on an AI search and design optimization, to look for designs of classic robot manipulators with certain engineering constraints,” Ballesteros says. “We filtered through many designs and looked for the design that consumes the least amount of energy to lift a person up. This version of SuperLimbs is the product of that process.”
Over the summer, Ballesteros will build out the full SuperLimbs system at NASA’s Jet Propulsion Laboratory, where he plans to streamline the design and minimize the weight of its parts and motors using advanced, lightweight materials. Then, he hopes to pair the limbs with astronaut suits, and test them in low-gravity simulators, with the goal of someday assisting astronauts on future missions to the moon and Mars.
“Wearing a spacesuit can be a physical burden,” Asada notes. “Robotic systems can help ease that burden, and help astronauts be more productive during their missions.”
SuperLimbs, a system of wearable robotic limbs built by MIT engineers, is designed to physically support an astronaut and lift them back on their feet after a fall, helping them conserve energy for other essential tasks. Pictured, from left, is Sang-Yoep Lee, Harry Asada, and Erik Ballesteros.
Astronomers at MIT, the University of Liège in Belgium, and elsewhere have discovered a huge, fluffy oddball of a planet orbiting a distant star in our Milky Way galaxy. The discovery, reported today in the journal Nature Astronomy, is a promising key to the mystery of how such giant, super-light planets form.
The new planet, named WASP-193b, appears to dwarf Jupiter in size, yet it is a fraction of its density. The scientists found that the gas giant is 50 percent bigger than Jupiter, and about a tenth as dense — an extremely low density, comparable to that of cotton candy.
WASP-193b is the second lightest planet discovered to date, after the smaller, Neptune-like world, Kepler 51d. The new planet’s much larger size, combined with its super-light density, make WASP-193b something of an oddity among the more than 5,400 planets discovered to date.
“To find these giant objects with such a small density is really, really rare,” says lead study author and MIT postdoc Khalid Barkaoui. “There’s a class of planets called puffy Jupiters, and it’s been a mystery for 15 years now as to what they are. And this is an extreme case of that class.”
“We don’t know where to put this planet in all the formation theories we have right now, because it’s an outlier of all of them,” adds co-lead author Francisco Pozuelos, a senior researcher at the Institute of Astrophysics of Andalucia, in Spain. “We cannot explain how this planet was formed, based on classical evolution models. Looking more closely at its atmosphere will allow us to obtain an evolutionary path of this planet.”
The study’s MIT co-authors include Julien de Wit, an assistant professor in MIT’s Department of Earth, Atmospheric and Planetary Sciences, and MIT postdoc Artem Burdanov, along with collaborators from multiple institutions across Europe.
“An interesting twist”
The new planet was initially spotted by the Wide Angle Search for Planets, or WASP — an international collaboration of academic institutions that together operate two robotic observatories, one in the northern hemisphere and the other in the south. Each observatory uses an array of wide-angle cameras to measure the brightness of thousands of individual stars across the entire sky.
In surveys taken between 2006 and 2008, and again from 2011 to 2012, the WASP-South observatory detected periodic transits, or dips in light, from WASP-193 — a bright, nearby, sun-like star located 1,232 light years from Earth. Astronomers determined that the star’s periodic dips in brightness were consistent with a planet circling the star and blocking its light every 6.25 days. The scientists measured the total amount of light the planet blocked with each transit, which gave them an estimate of the planet’s giant, super-Jupiter size.
The astronomers then looked to pin down the planet’s mass — a measure that would then reveal its density and potentially also clues to its composition. To get a mass estimate, astronomers typically employ radial velocity, a technique in which scientists analyze a star’s spectrum, or various wavelengths of light, as a planet circles the star. A star’s spectrum can be shifted in specific ways depending on whatever is pulling on the star, such as an orbiting planet. The more massive a planet is, and the closer it is to its star, the more its spectrum can shift — a distortion that can give scientists an idea of a planet’s mass.
For WASP-193 b, astronomers obtained additional high-resolution spectra of the star taken by various ground-based telescopes, and attempted to employ radial velocity to calculate the planet’s mass. But they kept coming up empty — precisely because, as it turned out, the planet was far too light to have any detectable pull on its star.
“Typically, big planets are pretty easy to detect because they are usually massive, and lead to a big pull on their star,” de Wit explains. “But what was tricky about this planet was, even though it’s big — huge — its mass and density are so low that it was actually very difficult to detect with just the radial velocity technique. It was an interesting twist.”
“[WASP-193b] is so very light that it took four years to gather data and show that there is a mass signal, but it’s really, really tiny,” Barkaoui says.
“We were initially getting extremely low densities, which were very difficult to believe in the beginning,” Pozuelos adds. “We repeated the process of all the data analysis several times to make sure this was the real density of the planet because this was super rare.”
An inflated world
In the end, the team confirmed that the planet was indeed extremely light. Its mass, they calculated, was about 0.14 that of Jupiter. And its density, derived from its mass, came out to about 0.059 grams per cubic centimeter. Jupiter, in contrast, is about 1.33 grams per cubic centimeter; and Earth is a more substantial 5.51 grams per cubic centimeter. Perhaps the material closest in density to the new, puffy planet is cotton candy, which has a density of about 0.05 grams per cubic centimeter.
“The planet is so light that it’s difficult to think of an analogous, solid-state material,” Barkaoui says. “The reason why it’s close to cotton candy is because both are mostly made of light gases rather than solids. The planet is basically super fluffy.”
The researchers suspect that the new planet is made mostly from hydrogen and helium, like most other gas giants in the galaxy. For WASP-193b, these gases likely form a hugely inflated atmosphere that extends tens of thousands of kilometers farther than Jupiter’s own atmosphere. Exactly how a planet can inflate so far while maintaining a super-light density is a question that no existing theory of planetary formation can yet answer.
To get a better picture of the new fluffy world, the team plans to use a technique de Wit previously developed, to first derive certain properties of the planet’s atmosphere, such as its temperature, composition, and pressure at various depths. These characteristics can then be used to precisely work out the planet’s mass. For now, the team sees WASP-193b as an ideal candidate for follow-up study by observatories such as the James Webb Space Telescope.
“The bigger a planet’s atmosphere, the more light can go through,” de Wit says. “So it’s clear that this planet is one of the best targets we have for studying atmospheric effects. It will be a Rosetta Stone to try and resolve the mystery of puffy Jupiters.”
This research was funded, in part, by consortium universities and the UK’s Science and Technology Facilities Council for WASP; the European Research Council; the Wallonia-Brussels Federation; and the Heising-Simons Foundation, Colin and Leslie Masson, and Peter A. Gilman, supporting Artemis and the other SPECULOOS Telescopes.
Around a star in our Milky Way galaxy, astronomers have discovered an extremely low-density planet that is as light as cotton candy. The new planet, named WASP-193b, appears to dwarf Jupiter in size, yet it is a fraction of its density.
Imagine you and a friend are playing a game where your goal is to communicate secret messages to each other using only cryptic sentences. Your friend's job is to guess the secret message behind your sentences. Sometimes, you give clues directly, and other times, your friend has to guess the message by asking yes-or-no questions about the clues you've given. The challenge is that both of you want to make sure you're understanding each other correctly and agreeing on the secret message.
MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers have created a similar "game" to help improve how AI understands and generates text. It is known as a “consensus game” and it involves two parts of an AI system — one part tries to generate sentences (like giving clues), and the other part tries to understand and evaluate those sentences (like guessing the secret message).
The researchers discovered that by treating this interaction as a game, where both parts of the AI work together under specific rules to agree on the right message, they could significantly improve the AI's ability to give correct and coherent answers to questions. They tested this new game-like approach on a variety of tasks, such as reading comprehension, solving math problems, and carrying on conversations, and found that it helped the AI perform better across the board.
Traditionally, large language models answer one of two ways: generating answers directly from the model (generative querying) or using the model to score a set of predefined answers (discriminative querying), which can lead to differing and sometimes incompatible results. With the generative approach, "Who is the president of the United States?" might yield a straightforward answer like "Joe Biden." However, a discriminative query could incorrectly dispute this fact when evaluating the same answer, such as "Barack Obama."
So, how do we reconcile mutually incompatible scoring procedures to achieve coherent, efficient predictions?
"Imagine a new way to help language models understand and generate text, like a game. We've developed a training-free, game-theoretic method that treats the whole process as a complex game of clues and signals, where a generator tries to send the right message to a discriminator using natural language. Instead of chess pieces, they're using words and sentences," says Athul Jacob, an MIT PhD student in electrical engineering and computer science and CSAIL affiliate. "Our way to navigate this game is finding the 'approximate equilibria,' leading to a new decoding algorithm called 'equilibrium ranking.' It's a pretty exciting demonstration of how bringing game-theoretic strategies into the mix can tackle some big challenges in making language models more reliable and consistent."
When tested across many tasks, like reading comprehension, commonsense reasoning, math problem-solving, and dialogue, the team's algorithm consistently improved how well these models performed. Using the ER algorithm with the LLaMA-7B model even outshone the results from much larger models. "Given that they are already competitive, that people have been working on it for a while, but the level of improvements we saw being able to outperform a model that's 10 times the size was a pleasant surprise," says Jacob.
Game on
"Diplomacy," a strategic board game set in pre-World War I Europe, where players negotiate alliances, betray friends, and conquer territories without the use of dice — relying purely on skill, strategy, and interpersonal manipulation — recently had a second coming. In November 2022, computer scientists, including Jacob, developed “Cicero,” an AI agent that achieves human-level capabilities in the mixed-motive seven-player game, which requires the same aforementioned skills, but with natural language. The math behind this partially inspired the Consensus Game.
While the history of AI agents long predates when OpenAI's software entered the chat in November 2022, it's well documented that they can still cosplay as your well-meaning, yet pathological friend.
The consensus game system reaches equilibrium as an agreement, ensuring accuracy and fidelity to the model's original insights. To achieve this, the method iteratively adjusts the interactions between the generative and discriminative components until they reach a consensus on an answer that accurately reflects reality and aligns with their initial beliefs. This approach effectively bridges the gap between the two querying methods.
In practice, implementing the consensus game approach to language model querying, especially for question-answering tasks, does involve significant computational challenges. For example, when using datasets like MMLU, which have thousands of questions and multiple-choice answers, the model must apply the mechanism to each query. Then, it must reach a consensus between the generative and discriminative components for every question and its possible answers.
The system did struggle with a grade school right of passage: math word problems. It couldn't generate wrong answers, which is a critical component of understanding the process of coming up with the right one.
“The last few years have seen really impressive progress in both strategic decision-making and language generation from AI systems, but we’re just starting to figure out how to put the two together. Equilibrium ranking is a first step in this direction, but I think there’s a lot we’ll be able to do to scale this up to more complex problems,” says Jacob.
An avenue of future work involves enhancing the base model by integrating the outputs of the current method. This is particularly promising since it can yield more factual and consistent answers across various tasks, including factuality and open-ended generation. The potential for such a method to significantly improve the base model's performance is high, which could result in more reliable and factual outputs from ChatGPT and similar language models that people use daily.
"Even though modern language models, such as ChatGPT and Gemini, have led to solving various tasks through chat interfaces, the statistical decoding process that generates a response from such models has remained unchanged for decades," says Google Research Scientist Ahmad Beirami, who was not involved in the work. "The proposal by the MIT researchers is an innovative game-theoretic framework for decoding from language models through solving the equilibrium of a consensus game. The significant performance gains reported in the research paper are promising, opening the door to a potential paradigm shift in language model decoding that may fuel a flurry of new applications."
Jacob wrote the paper with MIT-IBM Watson Lab researcher Yikang Shen and MIT Department of Electrical Engineering and Computer Science assistant professors Gabriele Farina and Jacob Andreas, who is also a CSAIL member. They presented their work at the International Conference on Learning Representations (ICLR) earlier this month, where it was highlighted as a "spotlight paper." The research also received a “best paper award” at the NeurIPS R0-FoMo Workshop in December 2023.
MIT researchers’ "consensus game" is a game-theoretic approach for language model decoding. The equilibrium-ranking algorithm harmonizes generative and discriminative querying to enhance prediction accuracy across various tasks, outperforming larger models and demonstrating the potential of game theory in improving language model consistency and truthfulness.
Engineers at MIT, Nanyang Technological University, and several companies have developed a compact and inexpensive technology for detecting and measuring lead concentrations in water, potentially enabling a significant advance in tackling this persistent global health issue.
The World Health Organization estimates that 240 million people worldwide are exposed to drinking water that contains unsafe amounts of toxic lead, which can affect brain development in children, cause birth defects, and produce a variety of neurological, cardiac, and other damaging effects. In the United States alone, an estimated 10 million households still get drinking water delivered through lead pipes.
“It’s an unaddressed public health crisis that leads to over 1 million deaths annually,” says Jia Xu Brian Sia, an MIT postdoc and the senior author of the paper describing the new technology.
But testing for lead in water requires expensive, cumbersome equipment and typically requires days to get results. Or, it uses simple test strips that simply reveal a yes-or-no answer about the presence of lead but no information about its concentration. Current EPA regulations require drinking water to contain no more that 15 parts per billion of lead, a concentration so low it is difficult to detect.
The new system, which could be ready for commercial deployment within two or three years, could detect lead concentrations as low as 1 part per billion, with high accuracy, using a simple chip-based detector housed in a handheld device. The technology gives nearly instant quantitative measurements and requires just a droplet of water.
The findings are described in a paper appearing today in the journal Nature Communications, by Sia, MIT graduate student and lead author Luigi Ranno, Professor Juejun Hu, and 12 others at MIT and other institutions in academia and industry.
The team set out to find a simple detection method based on the use of photonic chips, which use light to perform measurements. The challenging part was finding a way to attach to the photonic chip surface certain ring-shaped molecules known as crown ethers, which can capture specific ions such as lead. After years of effort, they were able to achieve that attachment via a chemical process known as Fischer esterification. “That is one of the essential breakthroughs we have made in this technology,” Sia says.
In testing the new chip, the researchers showed that it can detect lead in water at concentrations as low as one part per billion. At much higher concentrations, which may be relevant for testing environmental contamination such as mine tailings, the accuracy is within 4 percent.
The device works in water with varying levels of acidity, ranging from pH values of 6 to 8, “which covers most environmental samples,” Sia says. They have tested the device with seawater as well as tap water, and verified the accuracy of the measurements.
In order to achieve such levels of accuracy, current testing requires a device called an inductive coupled plasma mass spectrometer. “These setups can be big and expensive,” Sia says. The sample processing can take days and requires experienced technical personnel.
While the new chip system they developed is “the core part of the innovation,” Ranno says, further work will be needed to develop this into an integrated, handheld device for practical use. “For making an actual product, you would need to package it into a usable form factor,” he explains. This would involve having a small chip-based laser coupled to the photonic chip. “It’s a matter of mechanical design, some optical design, some chemistry, and figuring out the supply chain,” he says. While that takes time, he says, the underlying concepts are straightforward.
The system can be adapted to detect other similar contaminants in water, including cadmium, copper, lithium, barium, cesium, and radium, Ranno says. The device could be used with simple cartridges that can be swapped out to detect different elements, each using slightly different crown ethers that can bind to a specific ion.
“There’s this problem that people don’t measure their water enough, especially in the developing countries,” Ranno says. “And that’s because they need to collect the water, prepare the sample, and bring it to these huge instruments that are extremely expensive.” Instead, “having this handheld device, something compact that even untrained personnel can just bring to the source for on-site monitoring, at low costs,” could make regular, ongoing widespread testing feasible.
Hu, who is the John F. Elliott Professor of Materials Science and Engineering, says, “I’m hoping this will be quickly implemented, so we can benefit human society. This is a good example of a technology coming from a lab innovation where it may actually make a very tangible impact on society, which is of course very fulfilling.”
“If this study can be extended to simultaneous detection of multiple metal elements, especially the presently concerning radioactive elements, its potential would be immense,” says Hou Wang, an associate professor of environmental science and engineering at Hunan University in China, who was not associated with this work.
Wang adds, “This research has engineered a sensor capable of instantaneously detecting lead concentration in water. This can be utilized in real-time to monitor the lead pollution concentration in wastewater discharged from industries such as battery manufacturing and lead smelting, facilitating the establishment of industrial wastewater monitoring systems. I think the innovative aspects and developmental potential of this research are quite commendable.”
Wang Qian, a principal research scientist at A*STAR’s Institute of Materials Research in Singapore, who also was not affiliated with this work, says, “The ability for the pervasive, portable, and quantitative detection of lead has proved to be challenging primarily due to cost concerns. This work demonstrates the potential to do so in a highly integrated form factor and is compatible with large-scale, low-cost manufacturing.”
The team included researchers at MIT, at Nanyang Technological University and Temasek Laboratories in Singapore, at the University of Southampton in the U.K., and at companies Fingate Technologies, in Singapore, and Vulcan Photonics, headquartered in Malaysia. The work used facilities at MIT.nano, the Harvard University Center for Nanoscale Systems, NTU’s Center for Micro- and Nano-Electronics, and the Nanyang Nanofabrication Center.
Artist’s impression of the chip surface, showing the on-chip light interferometer used to sense the presence of lead. The lead binding process to the crown ether is shown in the inset.
MIT researchers, including several undergraduate students, have discovered three of the oldest stars in the universe, and they happen to live in our own galactic neighborhood.
The team spotted the stars in the Milky Way’s “halo” — the cloud of stars that envelopes the entire main galactic disk. Based on the team’s analysis, the three stars formed between 12 and 13 billion years ago, the time when the very first galaxies were taking shape.
The researchers have coined the stars “SASS,” for Small Accreted Stellar System stars, as they believe each star once belonged to its own small, primitive galaxy that was later absorbed by the larger but still growing Milky Way. Today, the three stars are all that are left of their respective galaxies. They circle the outskirts of the Milky Way, where the team suspects there may be more such ancient stellar survivors.
“These oldest stars should definitely be there, given what we know of galaxy formation,” says MIT professor of physics Anna Frebel. “They are part of our cosmic family tree. And we now have a new way to find them.”
As they uncover similar SASS stars, the researchers hope to use them as analogs of ultrafaint dwarf galaxies, which are thought to be some of the universe’s surviving first galaxies. Such galaxies are still intact today but are too distant and faint for astronomers to study in depth. As SASS stars may have once belonged to similarly primitive dwarf galaxies but are in the Milky Way and as such much closer, they could be an accessible key to understanding the evolution of ultrafaint dwarf galaxies.
“Now we can look for more analogs in the Milky Way, that are much brighter, and study their chemical evolution without having to chase these extremely faint stars,” Frebel says.
She and her colleagues have published their findings today in the Monthly Notices of the Royal Astronomical Society (MNRAS). The study’s co-authors are Mohammad Mardini, at Zarqa University, in Jordan; Hillary Andales ’23; and current MIT undergraduates Ananda Santos and Casey Fienberg.
Stellar frontier
The team’s discoveries grew out of a classroom concept. During the 2022 fall semester, Frebel launched a new course, 8.S30(Observational Stellar Archaeology), in which students learned techniques for analyzing ancient stars and then applied those tools to stars that had never been studied before, to determine their origins.
“While most of our classes are taught from the ground up, this class immediately put us at the frontier of research in astrophysics,” Andales says.
The students worked from star data collected by Frebel over the years from the 6.5-meter Magellan-Clay telescope at the Las Campanas Observatory. She keeps hard copies of the data in a large binder in her office, which the students combed through to look for stars of interest.
In particular, they were searching ancient stars that formed soon after the Big Bang, which occurred 13.8 billion years ago. At this time, the universe was made mostly of hydrogen and helium and very low abundances of other chemical elements, such as strontium and barium. So, the students looked through Frebel’s binder for stars with spectra, or measurements of starlight, that indicated low abundances of strontium and barium.
Their search narrowed in on three stars that were originally observed by the Magellan telescope between 2013 and 2014. Astronomers never followed up on these particular stars to interpret their spectra and deduce their origins. They were, then, perfect candidates for the students in Frebel’s class.
The students learned how to characterize a star in order to prepare for the analysis of the spectra for each of the three stars. They were able to determine the chemical composition of each one with various stellar models. The intensity of a particular feature in the stellar spectrum, corresponding to a specific wavelength of light, corresponds to a particular abundance of a specific element.
After finalizing their analysis, the students were able to confidently conclude that the three stars did hold very low abundances of strontium, barium, and other elements such as iron, compared to their reference star — our own sun. In fact, one star contained less than 1/10,000 the amount of iron to helium compared to the sun today.
“It took a lot of hours staring at a computer, and a lot of debugging, frantically texting and emailing each other to figure this out,” Santos recalls. “It was a big learning curve, and a special experience.”
“On the run”
The stars’ low chemical abundance did hint that they originally formed 12 to 13 billion years ago. In fact, their low chemical signatures were similar to what astronomers had previously measured for some ancient, ultrafaint dwarf galaxies. Did the team’s stars originate in similar galaxies? And how did they come to be in the Milky Way?
On a hunch, the scientists checked out the stars’ orbital patterns and how they move across the sky. The three stars are in different locations throughout the Milky Way’s halo and are estimated to be about 30,000 light years from Earth. (For reference, the disk of the Milky Way spans 100,000 light years across.)
As they retraced each star’s motion about the galactic center using observations from the Gaia astrometric satellite, the team noticed a curious thing: Relative to most of the stars in the main disk, which move like cars on a racetrack, all three stars seemed to be going the wrong way. In astronomy, this is known as “retrograde motion” and is a tipoff that an object was once “accreted,” or drawn in from elsewhere.
“The only way you can have stars going the wrong way from the rest of the gang is if you threw them in the wrong way,” Frebel says.
The fact that these three stars were orbiting in completely different ways from the rest of the galactic disk and even the halo, combined with the fact that they held low chemical abundances, made a strong case that the stars were indeed ancient and once belonged to older, smaller dwarf galaxies that fell into the Milky Way at random angles and continued their stubborn trajectories billions of years later.
Frebel, curious as to whether retrograde motion was a feature of other ancient stars in the halo that astronomers previously analyzed, looked through the scientific literature and found 65 other stars, also with low strontium and barium abundances, that appeared to also be going against the galactic flow.
“Interestingly they’re all quite fast — hundreds of kilometers per second, going the wrong way,” Frebel says. “They’re on the run! We don’t know why that’s the case, but it was the piece to the puzzle that we needed, and that I didn’t quite anticipate when we started.”
The team is eager to search out other ancient SASS stars, and they now have a relatively simple recipe to do so: First, look for stars with low chemical abundances, and then track their orbital patterns for signs of retrograde motion. Of the more than 400 billion stars in the Milky Way, they anticipate that the method will turn up a small but significant number of the universe’s oldest stars.
Frebel plans to relaunch the class this fall, and looks back at that first course, and the three students who took their results through to publication, with admiration and gratitude.
“It’s been awesome to work with three women undergrads. That’s a first for me,” she says. “It’s really an example of the MIT way. We do. And whoever says, ‘I want to participate,’ they can do that, and good things happen.”
This research was supported, in part, by the National Science Foundation.
MIT astronomers discovered three of the oldest stars in the universe, and they live in our own galactic neighborhood. The stars are in the Milky Way’s “halo” — the cloud of stars that envelopes the main galactic disk — and they appear to have formed between 12 and 13 billion years ago, when the very first galaxies were taking shape.
Scientists often label cells with proteins that glow, allowing them to track the growth of a tumor, or measure changes in gene expression that occur as cells differentiate.
While this technique works well in cells and some tissues of the body, it has been difficult to apply this technique to image structures deep within the brain, because the light scatters too much before it can be detected.
MIT engineers have now come up with a novel way to detect this type of light, known as bioluminescence, in the brain: They engineered blood vessels of the brain to express a protein that causes them to dilate in the presence of light. That dilation can then be observed with magnetic resonance imaging (MRI), allowing researchers to pinpoint the source of light.
“A well-known problem that we face in neuroscience, as well as other fields, is that it’s very difficult to use optical tools in deep tissue. One of the core objectives of our study was to come up with a way to image bioluminescent molecules in deep tissue with reasonably high resolution,” says Alan Jasanoff, an MIT professor of biological engineering, brain and cognitive sciences, and nuclear science and engineering.
The new technique developed by Jasanoff and his colleagues could enable researchers to explore the inner workings of the brain in more detail than has previously been possible.
Jasanoff, who is also an associate investigator at MIT’s McGovern Institute for Brain Research, is the senior author of the study, which appears today in Nature Biomedical Engineering. Former MIT postdocs Robert Ohlendorf and Nan Li are the lead authors of the paper.
Detecting light
Bioluminescent proteins are found in many organisms, including jellyfish and fireflies. Scientists use these proteins to label specific proteins or cells, whose glow can be detected by a luminometer. One of the proteins often used for this purpose is luciferase, which comes in a variety of forms that glow in different colors.
Jasanoff’s lab, which specializes in developing new ways to image the brain using MRI, wanted to find a way to detect luciferase deep within the brain. To achieve that, they came up with a method for transforming the blood vessels of the brain into light detectors. A popular form of MRI works by imaging changes in blood flow in the brain, so the researchers engineered the blood vessels themselves to respond to light by dilating.
“Blood vessels are a dominant source of imaging contrast in functional MRI and other non-invasive imaging techniques, so we thought we could convert the intrinsic ability of these techniques to image blood vessels into a means for imaging light, by photosensitizing the blood vessels themselves,” Jasanoff says.
To make the blood vessels sensitive to light, the researcher engineered them to express a bacterial protein called Beggiatoa photoactivated adenylate cyclase (bPAC). When exposed to light, this enzyme produces a molecule called cAMP, which causes blood vessels to dilate. When blood vessels dilate, it alters the balance of oxygenated and deoxygenated hemoglobin, which have different magnetic properties. This shift in magnetic properties can be detected by MRI.
BPAC responds specifically to blue light, which has a short wavelength, so it detects light generated within close range. The researchers used a viral vector to deliver the gene for bPAC specifically to the smooth muscle cells that make up blood vessels. When this vector was injected in rats, blood vessels throughout a large area of the brain became light-sensitive.
“Blood vessels form a network in the brain that is extremely dense. Every cell in the brain is within a couple dozen microns of a blood vessel,” Jasanoff says. “The way I like to describe our approach is that we essentially turn the vasculature of the brain into a three-dimensional camera.”
Once the blood vessels were sensitized to light, the researchers implanted cells that had been engineered to express luciferase if a substrate called CZT is present. In the rats, the researchers were able to detect luciferase by imaging the brain with MRI, which revealed dilated blood vessels.
Tracking changes in the brain
The researchers then tested whether their technique could detect light produced by the brain’s own cells, if they were engineered to express luciferase. They delivered the gene for a type of luciferase called GLuc to cells in a deep brain region known as the striatum. When the CZT substrate was injected into the animals, MRI imaging revealed the sites where light had been emitted.
This technique, which the researchers dubbed bioluminescence imaging using hemodynamics, or BLUsH, could be used in a variety of ways to help scientists learn more about the brain, Jasanoff says.
For one, it could be used to map changes in gene expression, by linking the expression of luciferase to a specific gene. This could help researchers observe how gene expression changes during embryonic development and cell differentiation, or when new memories form. Luciferase could also be used to map anatomical connections between cells or to reveal how cells communicate with each other.
The researchers now plan to explore some of those applications, as well as adapting the technique for use in mice and other animal models.
The research was funded by the U.S. National Institutes of Health, the G. Harold and Leila Y. Mathers Foundation, Lore Harp McGovern, Gardner Hendrie, a fellowship from the German Research Foundation, a Marie Sklodowska-Curie Fellowship from the European Union, and a Y. Eva Tan Fellowship and a J. Douglas Tan Fellowship, both from the McGovern Institute for Brain Research.
A new way to detect bioluminescence in the brain uses magnetic resonance imaging (MRI). The technique, developed at MIT, could enable researchers to explore the inner workings of the brain in more detail than previously possible. Pictured are blood vessels that now appear bright red after transduction with a gene that gives them photosensitivity.
Imagine a slime-like robot that can seamlessly change its shape to squeeze through narrow spaces, which could be deployed inside the human body to remove an unwanted item.
While such a robot does not yet exist outside a laboratory, researchers are working to develop reconfigurable soft robots for applications in health care, wearable devices, and industrial systems.
But how can one control a squishy robot that doesn’t have joints, limbs, or fingers that can be manipulated, and instead can drastically alter its entire shape at will? MIT researchers are working to answer that question.
They developed a control algorithm that can autonomously learn how to move, stretch, and shape a reconfigurable robot to complete a specific task, even when that task requires the robot to change its morphology multiple times. The team also built a simulator to test control algorithms for deformable soft robots on a series of challenging, shape-changing tasks.
Their method completed each of the eight tasks they evaluated while outperforming other algorithms. The technique worked especially well on multifaceted tasks. For instance, in one test, the robot had to reduce its height while growing two tiny legs to squeeze through a narrow pipe, and then un-grow those legs and extend its torso to open the pipe’s lid.
While reconfigurable soft robots are still in their infancy, such a technique could someday enable general-purpose robots that can adapt their shapes to accomplish diverse tasks.
“When people think about soft robots, they tend to think about robots that are elastic, but return to their original shape. Our robot is like slime and can actually change its morphology. It is very striking that our method worked so well because we are dealing with something very new,” says Boyuan Chen, an electrical engineering and computer science (EECS) graduate student and co-author of a paper on this approach.
Chen’s co-authors include lead author Suning Huang, an undergraduate student at Tsinghua University in China who completed this work while a visiting student at MIT; Huazhe Xu, an assistant professor at Tsinghua University; and senior author Vincent Sitzmann, an assistant professor of EECS at MIT who leads the Scene Representation Group in the Computer Science and Artificial Intelligence Laboratory. The research will be presented at the International Conference on Learning Representations.
Controlling dynamic motion
Scientists often teach robots to complete tasks using a machine-learning approach known as reinforcement learning, which is a trial-and-error process in which the robot is rewarded for actions that move it closer to a goal.
This can be effective when the robot’s moving parts are consistent and well-defined, like a gripper with three fingers. With a robotic gripper, a reinforcement learning algorithm might move one finger slightly, learning by trial and error whether that motion earns it a reward. Then it would move on to the next finger, and so on.
But shape-shifting robots, which are controlled by magnetic fields, can dynamically squish, bend, or elongate their entire bodies.
“Such a robot could have thousands of small pieces of muscle to control, so it is very hard to learn in a traditional way,” says Chen.
To solve this problem, he and his collaborators had to think about it differently. Rather than moving each tiny muscle individually, their reinforcement learning algorithm begins by learning to control groups of adjacent muscles that work together.
Then, after the algorithm has explored the space of possible actions by focusing on groups of muscles, it drills down into finer detail to optimize the policy, or action plan, it has learned. In this way, the control algorithm follows a coarse-to-fine methodology.
“Coarse-to-fine means that when you take a random action, that random action is likely to make a difference. The change in the outcome is likely very significant because you coarsely control several muscles at the same time,” Sitzmann says.
To enable this, the researchers treat a robot’s action space, or how it can move in a certain area, like an image.
Their machine-learning model uses images of the robot’s environment to generate a 2D action space, which includes the robot and the area around it. They simulate robot motion using what is known as the material-point-method, where the action space is covered by points, like image pixels, and overlayed with a grid.
The same way nearby pixels in an image are related (like the pixels that form a tree in a photo), they built their algorithm to understand that nearby action points have stronger correlations. Points around the robot’s “shoulder” will move similarly when it changes shape, while points on the robot’s “leg” will also move similarly, but in a different way than those on the “shoulder.”
In addition, the researchers use the same machine-learning model to look at the environment and predict the actions the robot should take, which makes it more efficient.
Building a simulator
After developing this approach, the researchers needed a way to test it, so they created a simulation environment called DittoGym.
DittoGym features eight tasks that evaluate a reconfigurable robot’s ability to dynamically change shape. In one, the robot must elongate and curve its body so it can weave around obstacles to reach a target point. In another, it must change its shape to mimic letters of the alphabet.
“Our task selection in DittoGym follows both generic reinforcement learning benchmark design principles and the specific needs of reconfigurable robots. Each task is designed to represent certain properties that we deem important, such as the capability to navigate through long-horizon explorations, the ability to analyze the environment, and interact with external objects,” Huang says. “We believe they together can give users a comprehensive understanding of the flexibility of reconfigurable robots and the effectiveness of our reinforcement learning scheme.”
Their algorithm outperformed baseline methods and was the only technique suitable for completing multistage tasks that required several shape changes.
“We have a stronger correlation between action points that are closer to each other, and I think that is key to making this work so well,” says Chen.
While it may be many years before shape-shifting robots are deployed in the real world, Chen and his collaborators hope their work inspires other scientists not only to study reconfigurable soft robots but also to think about leveraging 2D action spaces for other complex control problems.
A new machine-learning technique can train and control a reconfigurable soft robot that can dynamically change its shape to complete a task. The researchers, from MIT and elsewhere, also built a simulator that can evaluate control algorithms for shape-shifting soft robots.
Researchers at MIT, Brigham and Women’s Hospital, and Harvard Medical School have developed a potential new treatment for alopecia areata, an autoimmune disorder that causes hair loss and affects people of all ages, including children.
For most patients with this type of hair loss, there is no effective treatment. The team developed a microneedle patch that can be painlessly applied to the scalp and releases drugs that help to rebalance the immune response at the site, halting the autoimmune attack.
In a study of mice, the researchers found that this treatment allowed hair to regrow and dramatically reduced inflammation at the treatment site, while avoiding systemic immune effects elsewhere in the body. This strategy could also be adapted to treat other autoimmune skin diseases such as vitiligo, atopic dermatitis, and psoriasis, the researchers say.
“This innovative approach marks a paradigm shift. Rather than suppressing the immune system, we’re now focusing on regulating it precisely at the site of antigen encounter to generate immune tolerance,” says Natalie Artzi, a principal research scientist in MIT’s Institute for Medical Engineering and Science, an associate professor of medicine at Harvard Medical School and Brigham and Women’s Hospital, and an associate faculty member at the Wyss Institute of Harvard University.
Artzi and Jamil R. Azzi, an associate professor of medicine at Harvard Medical School and Brigham and Women’s Hospital, are the senior authors of the new study, which appears in the journal Advanced Materials. Nour Younis, a Brigham and Women’s postdoc, and Nuria Puigmal, a Brigham and Women’s postdoc and former MIT research affiliate, are the lead authors of the paper.
The researchers are now working on launching a company to further develop the technology, led by Puigmal, who was recently awarded a Harvard Business School Blavatnik Fellowship.
Direct delivery
Alopecia areata, which affects more than 6 million Americans, occurs when the body’s own T cells attack hair follicles, leading the hair to fall out. The only treatment available to most patients — injections of immunosuppressant steroids into the scalp — is painful and patients often can’t tolerate it.
Some patients with alopecia areata and other autoimmune skin diseases can also be treated with immunosuppressant drugs that are given orally, but these drugs lead to widespread suppression of the immune system, which can have adverse side effects.
“This approach silences the entire immune system, offering relief from inflammation symptoms but leading to frequent recurrences. Moreover, it increases susceptibility to infections, cardiovascular diseases, and cancer,” Artzi says.
A few years ago, at a working group meeting in Washington, Artzi happened to be seated next to Azzi (the seating was alphabetical), an immunologist and transplant physican who was seeking new ways to deliver drugs directly to the skin to treat skin-related diseases.
Their conversation led to a new collaboration, and the two labs joined forces to work on a microneedle patch to deliver drugs to the skin. In 2021, they reported that such a patch can be used to prevent rejection following skin transplant. In the new study, they began applying this approach to autoimmune skin disorders.
“The skin is the only organ in our body that we can see and touch, and yet when it comes to drug delivery to the skin, we revert to systemic administration. We saw great potential in utilizing the microneedle patch to reprogram the immune system locally,” Azzi says.
The microneedle patches used in this study are made from hyaluronic acid crosslinked with polyethylene glycol (PEG), both of which are biocompatible and commonly used in medical applications. With this delivery method, drugs can pass through the tough outer layer of the epidermis, which can’t be penetrated by creams applied to the skin.
“This polymer formulation allows us to create highly durable needles capable of effectively penetrating the skin. Additionally, it gives us the flexibility to incorporate any desired drug,” Artzi says. For this study, the researchers loaded the patches with a combination of the cytokines IL-2 and CCL-22. Together, these immune molecules help to recruit regulatory T cells, which proliferate and help to tamp down inflammation. These cells also help the immune system learn to recognize that hair follicles are not foreign antigens, so that it will stop attacking them.
Hair regrowth
The researchers found that mice treated with this patch every other day for three weeks had many more regulatory T cells present at the site, along with a reduction in inflammation. Hair was able to regrow at those sites, and this growth was maintained for several weeks after the treatment ended. In these mice, there were no changes in the levels of regulatory T cells in the spleen or lymph nodes, suggesting that the treatment affected only the site where the patch was applied.
In another set of experiments, the researchers grafted human skin onto mice with a humanized immune system. In these mice, the microneedle treatment also induced proliferation of regulatory T cells and a reduction in inflammation.
The researchers designed the microneedle patches so that after releasing their drug payload, they can also collect samples that could be used to monitor the progress of the treatment. Hyaluronic acid causes the needles to swell about tenfold after entering the skin, which allows them to absorb interstitial fluid containing biomolecules and immune cells from the skin.
Following patch removal, researchers can analyze samples to measure levels of regulatory T cells and inflammation markers. This could prove valuable for monitoring future patients who may undergo this treatment.
The researchers now plan to further develop this approach for treating alopecia, and to expand into other autoimmune skin diseases.
The research was funded by the Ignite Fund and Shark Tank Fund awards from the Department of Medicine at Brigham and Women’s Hospital.
Researchers developed a potential new treatment for alopecia areata, an autoimmune disorder that causes hair loss. The new microneedle patch delivers immune-regulating molecules that can teach T cells not to attack hair follicles, helping hair regrow. Pictured is an up-close view of the microneedles.
When scientists look for an earthquake’s cause, their search often starts underground. As centuries of seismic studies have made clear, it’s the collision of tectonic plates and the movement of subsurface faults and fissures that primarily trigger a temblor.
But MIT scientists have now found that certain weather events may also play a role in setting off some quakes.
In a study appearing today in Science Advances, the researchers report that episodes of heavy snowfall and rain likely contributed to a swarm of earthquakes over the past several years in northern Japan. The study is the first to show that climate conditions could initiate some quakes.
“We see that snowfall and other environmental loading at the surface impacts the stress state underground, and the timing of intense precipitation events is well-correlated with the start of this earthquake swarm,” says study author William Frank, an assistant professor in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS). “So, climate obviously has an impact on the response of the solid earth, and part of that response is earthquakes.”
The new study focuses on a series of ongoing earthquakes in Japan’s Noto Peninsula. The team discovered that seismic activity in the region is surprisingly synchronized with certain changes in underground pressure, and that those changes are influenced by seasonal patterns of snowfall and precipitation. The scientists suspect that this new connection between quakes and climate may not be unique to Japan and could play a role in shaking up other parts of the world.
Looking to the future, they predict that the climate’s influence on earthquakes could be more pronounced with global warming.
“If we’re going into a climate that’s changing, with more extreme precipitation events, and we expect a redistribution of water in the atmosphere, oceans, and continents, that will change how the Earth’s crust is loaded,” Frank adds. “That will have an impact for sure, and it’s a link we could further explore.”
The study’s lead author is former MIT research associate Qing-Yu Wang (now at Grenoble Alpes University), and also includes EAPS postdoc Xin Cui, Yang Lu of the University of Vienna, Takashi Hirose of Tohoku University, and Kazushige Obara of the University of Tokyo.
Seismic speed
Since late 2020, hundreds of small earthquakes have shaken up Japan’s Noto Peninsula — a finger of land that curves north from the country’s main island into the Sea of Japan. Unlike a typical earthquake sequence, which begins as a main shock that gives way to a series of aftershocks before dying out, Noto’s seismic activity is an “earthquake swarm” — a pattern of multiple, ongoing quakes with no obvious main shock, or seismic trigger.
The MIT team, along with their colleagues in Japan, aimed to spot any patterns in the swarm that would explain the persistent quakes. They started by looking through the Japanese Meteorological Agency’s catalog of earthquakes that provides data on seismic activity throughout the country over time. They focused on quakes in the Noto Peninsula over the last 11 years, during which the region has experienced episodic earthquake activity, including the most recent swarm.
With seismic data from the catalog, the team counted the number of seismic events that occurred in the region over time, and found that the timing of quakes prior to 2020 appeared sporadic and unrelated, compared to late 2020, when earthquakes grew more intense and clustered in time, signaling the start of the swarm, with quakes that are correlated in some way.
The scientists then looked to a second dataset of seismic measurements taken by monitoring stations over the same 11-year period. Each station continuously records any displacement, or local shaking that occurs. The shaking from one station to another can give scientists an idea of how fast a seismic wave travels between stations. This “seismic velocity” is related to the structure of the Earth through which the seismic wave is traveling. Wang used the station measurements to calculate the seismic velocity between every station in and around Noto over the last 11 years.
The researchers generated an evolving picture of seismic velocity beneath the Noto Peninsula and observed a surprising pattern: In 2020, around when the earthquake swarm is thought to have begun, changes in seismic velocity appeared to be synchronized with the seasons.
“We then had to explain why we were observing this seasonal variation,” Frank says.
Snow pressure
The team wondered whether environmental changes from season to season could influence the underlying structure of the Earth in a way that would set off an earthquake swarm. Specifically, they looked at how seasonal precipitation would affect the underground “pore fluid pressure” — the amount of pressure that fluids in the Earth’s cracks and fissures exert within the bedrock.
“When it rains or snows, that adds weight, which increases pore pressure, which allows seismic waves to travel through slower,” Frank explains. “When all that weight is removed, through evaporation or runoff, all of a sudden, that pore pressure decreases and seismic waves are faster.”
Wang and Cui developed a hydromechanical model of the Noto Peninsula to simulate the underlying pore pressure over the last 11 years in response to seasonal changes in precipitation. They fed into the model meteorological data from this same period, including measurements of daily snow, rainfall, and sea-level changes. From their model, they were able to track changes in excess pore pressure beneath the Noto Peninsula, before and during the earthquake swarm. They then compared this timeline of evolving pore pressure with their evolving picture of seismic velocity.
“We had seismic velocity observations, and we had the model of excess pore pressure, and when we overlapped them, we saw they just fit extremely well,” Frank says.
In particular, they found that when they included snowfall data, and especially, extreme snowfall events, the fit between the model and observations was stronger than if they only considered rainfall and other events. In other words, the ongoing earthquake swarm that Noto residents have been experiencing can be explained in part by seasonal precipitation, and particularly, heavy snowfall events.
“We can see that the timing of these earthquakes lines up extremely well with multiple times where we see intense snowfall,” Frank says. “It’s well-correlated with earthquake activity. And we think there’s a physical link between the two.”
The researchers suspect that heavy snowfall and similar extreme precipitation could play a role in earthquakes elsewhere, though they emphasize that the primary trigger will always originate underground.
“When we first want to understand how earthquakes work, we look to plate tectonics, because that is and will always be the number one reason why an earthquake happens,” Frank says. “But, what are the other things that could affect when and how an earthquake happens? That’s when you start to go to second-order controlling factors, and the climate is obviously one of those.”
This research was supported, in part, by the National Science Foundation.
Episodes of heavy snowfall and rain likely contributed to a swarm of earthquakes over the past several years in northern Japan, MIT researchers find. Their study is the first to show climate conditions could initiate some quakes. Pictured is a scene from Japan’s Noto Peninsula.
"AI Comes Out of the Closet" is a large language model (LLM)-based online system that leverages artificial intelligence-generated dialog and virtual characters to create complex social interaction simulations. These simulations allow users to experiment with and refine their approach to LGBTQIA+ advocacy in a safe and controlled environment.
The research is both personal and political to lead author D. Pillis, an MIT graduate student in media arts and sciences and research assistant in the Tangible Media group of the MIT Media Lab, as it is rooted in a landscape where LGBTQIA+ people continue to navigate the complexities of identity, acceptance, and visibility. Pillis's work is driven by the need for advocacy simulations that not only address the current challenges faced by the LGBTQIA+ community, but also offer innovative solutions that leverage the potential of AI to build understanding, empathy, and support. This project is meant to test the belief that technology, when thoughtfully applied, can be a force for societal good, bridging gaps between diverse experiences and fostering a more inclusive world.
Pillis highlights the significant, yet often overlooked, connection between the LGBTQIA+ community and the development of AI and computing. He says, "AI has always been queer. Computing has always been queer," drawing attention to the contributions of queer individuals in this field, beginning with the story of Alan Turing, a founding figure in computer science and AI, who faced legal punishment — chemical castration — for his homosexuality. Contrasting Turing’s experience with the present, Pillis notes the acceptance of OpenAI CEO Sam Altman’s openness about his queer identity, illustrating a broader shift toward inclusivity. This evolution from Turing to Altman highlights the influence of LGBTQIA+ individuals in shaping the field of AI.
"There's something about queer culture that celebrates the artificial through kitsch, camp, and performance," states Pillis. AI itself embodies the constructed, the performative — qualities deeply resonant with queer experience and expression. Through this lens, he argues for a recognition of the queerness at the heart of AI, not just in its history but in its very essence.
Pillis found a collaborator with Pat Pataranutaporn, a graduate student in the Media Lab's Fluid Interfaces group. As is often the case at the Media Lab, their partnership began amid the lab's culture of interdisciplinary exploration, where Pataranutaporn's work on AI characters met Pillis's focus on 3D human simulation.
Taking on the challenge of interpreting text to gesture-based relationships was a significant technological hurdle. In Pataranutaporn's research, he emphasizes creating conditions where people can thrive, not just fix issues, aiming to understand how AI can contribute to human flourishing across dimensions of "wisdom, wonder, and well-being." In this project, Pataranutaporn focused on generating the dialogues that drove the virtual interactions. "It's not just about making people more effective, or more efficient, or more productive. It's about how you can support multi-dimensional aspects of human growth and development."
Pattie Maes, the Germeshausen Professor of Media Arts and Sciences at the MIT Media Lab and advisor to this project, states, "AI offers tremendous new opportunities for supporting human learning, empowerment, and self development. I am proud and excited that this work pushes for AI technologies that benefit and enable people and humanity, rather than aiming for AGI [artificial general intelligence]."
Addressing urgent workplace concerns
The urgency of this project is underscored by findings that nearly 46 percent of LGBTQIA+ workers have experienced some form of unfair treatment at work — from being overlooked for employment opportunities to experiencing harassment. Approximately 46 percent of LGBTQIA+ individuals feel compelled to conceal their identity at work due to concerns about stereotyping, potentially making colleagues uncomfortable, or jeopardizing professional relationships.
The tech industry, in particular, presents a challenging landscape for LGBTQIA+ individuals. Data indicate that 33 percent of gay engineers perceive their sexual orientation as a barrier to career advancement. And over half of LGBTQIA+ workers report encountering homophobic jokes in the workplace, highlighting the need for cultural and behavioral change.
"AI Comes Out of the Closet" is designed as an online study to assess the simulator's impact on fostering empathy, understanding, and advocacy skills toward LGBTQIA+ issues. Participants were introduced to an AI-generated environment, simulating real-world scenarios that LGBTQIA+ individuals might face, particularly focusing on the dynamics of coming out in the workplace.
Engaging with the simulation
Participants were randomly assigned to one of two interaction modes with the virtual characters: "First Person" or "Third Person." The First Person mode placed participants in the shoes of a character navigating the coming-out process, creating a personal engagement with the simulation. The Third Person mode allowed participants to assume the role of an observer or director, influencing the storyline from an external vantage point, similar to the interactive audience in Forum Theater. This approach was designed to explore the impacts of immersive versus observational experiences.
Participants were guided through a series of simulated interactions, where virtual characters, powered by advanced AI and LLMs, presented realistic and dynamic responses to the participants' inputs. The scenarios included key moments and decisions, portraying the emotional and social complexities of coming out.
The study's scripted scenarios provided a structure for the AI's interactions with participants. For example, in a scenario, a virtual character might disclose their LGBTQIA+ identity to a co-worker (represented by the participant), who then navigates the conversation with multiple choice responses. These choices are designed to portray a range of reactions, from supportive to neutral or even dismissive, allowing the study to capture a spectrum of participant attitudes and responses.
Following the simulation, participants were asked a series of questions aimed at gauging their levels of empathy, sympathy, and comfort with LGBTQIA+ advocacy. These questions aimed to reflect and predict how the simulation could change participants' future behavior and thoughts in real situations.
The results
The study found an interesting difference in how the simulation affected empathy levels based on Third Person or First Person mode. In the Third Person mode, where participants watched and guided the action from outside, the study shows that participants felt more empathy and understanding toward LGBTQIA+ people in "coming out" situations. This suggests that watching and controlling the scenario helped them better relate to the experiences of LGBTQIA+ individuals.
However, the First Person mode, where participants acted as a character in the simulation, didn't significantly change their empathy or ability to support others. This difference shows that the perspective we take might influence our reactions to simulated social situations, and being an observer might be better for increasing empathy.
While the increase in empathy and sympathy within the Third Person group was statistically significant, the study also uncovered areas that require further investigation. The impact of the simulation on participants' comfort and confidence in LGBTQIA+ advocacy situations, for instance, presented mixed results, indicating a need for deeper examination.
Also, the research acknowledges limitations inherent in its methodology, including reliance on self-reported data and the controlled nature of the simulation scenarios. These factors, while necessary for the study's initial exploration, suggest areas of future research to validate and expand upon the findings. The exploration of additional scenarios, diverse participant demographics, and longitudinal studies to assess the lasting impact of the simulation could be undertaken in future work.
"The most compelling surprise was how many people were both accepting and dismissive of LGBTQIA+ interactions at work," says Pillis. This attitude highlights a wider trend where people might accept LGBTQIA+ individuals but still not fully recognize the importance of their experiences.
Potential real-world applications
Pillis envisions multiple opportunities for simulations like the one built for his research.
In human resources and corporate training, the simulator could serve as a tool for fostering inclusive workplaces. By enabling employees to explore and understand the nuances of LGBTQIA+ experiences and advocacy, companies could cultivate more empathetic and supportive work environments, enhancing team cohesion and employee satisfaction.
For educators, the tool could offer a new approach to teaching empathy and social justice, integrating it into curricula to prepare students for the diverse world they live in. For parents, especially those of LGBTQIA+ children, the simulator could provide important insights and strategies for supporting their children through their coming-out processes and beyond.
Health care professionals could also benefit from training with the simulator, gaining a deeper understanding of LGBTQIA+ patient experiences to improve care and relationships. Mental health services, in particular, could use the tool to train therapists and counselors in providing more effective support for LGBTQIA+ clients.
In addition to Maes, Pillis and Pataranutaporn were joined by Misha Sra of the University of California at Santa Barbara on the study.
Since 2014, the Abdul Latif Jameel Water and Food Systems Lab (J-WAFS) has advanced interdisciplinary research aimed at solving the world's most pressing water and food security challenges to meet human needs. In 2017, J-WAFS established the Rasikbhai L. Meswani Water Solutions Fellowship and the J-WAFS Graduate Student Fellowship. These fellowships provide support to outstanding MIT graduate students who are pursuing research that has the potential to improve water and food systems around the world.
Recently, J-WAFS awarded the 2024-25 fellowships to Jonathan Bessette and Akash Ball, two MIT PhD students dedicated to addressing water scarcity by enhancing desalination and purification processes. This work is of important relevance since the world's freshwater supply has been steadily depleting due to the effects of climate change. In fact, one-third of the global population lacks access to safe drinking water. Bessette and Ball are focused on designing innovative solutions to enhance the resilience and sustainability of global water systems. To support their endeavors, J-WAFS will provide each recipient with funding for one academic semester for continued research and related activities.
“This year, we received many strong fellowship applications,” says J-WAFS executive director Renee J. Robins. “Bessette and Ball both stood out, even in a very competitive pool of candidates. The award of the J-WAFS fellowships to these two students underscores our confidence in their potential to bring transformative solutions to global water challenges.”
2024-25 Rasikbhai L. Meswani Fellowship for Water Solutions
The Rasikbhai L. Meswani Fellowship for Water Solutions is a doctoral fellowship for students pursuing research related to water and water supply at MIT. The fellowship is made possible by Elina and Nikhil Meswani and family.
Jonathan Bessette is a doctoral student in the Global Engineering and Research (GEAR) Center within the Department of Mechanical Engineering at MIT, advised by Professor Amos Winter. His research is focused on water treatment systems for the developing world, mainly desalination, or the process in which salts are removed from water. Currently, Bessette is working on designing and constructing a low-cost, deployable, community-scale desalination system for humanitarian crises.
In arid and semi-arid regions, groundwater often serves as the sole water source, despite its common salinity issues. Many remote and developing areas lack reliable centralized power and water systems, making brackish groundwater desalination a vital, sustainable solution for global water scarcity.
“An overlooked need for desalination is inland groundwater aquifers, rather than in coastal areas,” says Bessette. “This is because much of the population lives far enough from a coast that seawater desalination could never reach them. My work involves designing low-cost, sustainable, renewable-powered desalination technologies for highly constrained situations, such as drinking water for remote communities,” he adds.
To achieve this goal, Bessette developed a batteryless, renewable electrodialysis desalination system. The technology is energy-efficient, conserves water, and is particularly suited for challenging environments, as it is decentralized and sustainable. The system offers significant advantages over the conventional reverse osmosis method, especially in terms of reduced energy consumption for treating brackish water. Highlighting Bessette’s capacity for engineering insight, his advisor noted the “simple and elegant solution” that Bessette and a staff engineer, Shane Pratt, devised that negated the need for the system to have large batteries. Bessette is now focusing on simplifying the system’s architecture to make it more reliable and cost-effective for deployment in remote areas.
Growing up in upstate New York, Bessette completed a bachelor's degree at the State University of New York at Buffalo. As an undergrad, he taught middle and high school students in low-income areas of Buffalo about engineering and sustainability. However, he cited his junior-year travel to India and his experience there measuring water contaminants in rural sites as cementing his dedication to a career addressing food, water, and sanitation challenges. In addition to his doctoral research, his commitment to these goals is further evidenced by another project he is pursuing, funded by a J-WAFS India grant, that uses low-cost, remote sensors to better understand water fetching practices. Bessette is conducting this work with fellow MIT student Gokul Sampath in order to help families in rural India gain access to safe drinking water.
2024-25 J-WAFS Graduate Student Fellowship for Water and Food Solutions
The J-WAFS Graduate Student Fellowship is supported by the J-WAFS Research Affiliate Program, which offers companies the opportunity to engage with MIT on water and food research. Current fellowship support was provided by two J-WAFS Research Affiliates: Xylem, a leading U.S.-based provider of water treatment and infrastructure solutions, and GoAigua, a Spanish company at the forefront of digital transformation in the water industry through innovative solutions.
Akash Ball is a doctoral candidate in the Department of Chemical Engineering, advised by Professor Heather Kulik. His research focuses on the computational discovery of novel functional materials for energy-efficient ion separation membranes with high selectivity. Advanced membranes like these are increasingly needed for applications such as water desalination, battery recycling, and removal of heavy metals from industrial wastewater.
“Climate change, water pollution, and scarce freshwater reserves cause severe water distress for about 4 billion people annually, with 2 billion in India and China’s semiarid regions,” Ball notes. “One potential solution to this global water predicament is the desalination of seawater, since seawater accounts for 97 percent of all water on Earth.”
Although several commercial reverse osmosis membranes are currently available, these membranes suffer several problems, like slow water permeation, permeability-selectivity trade-off, and high fabrication costs. Metal-organic frameworks (MOFs) are porous crystalline materials that are promising candidates for highly selective ion separation with fast water transport due to high surface area, the presence of different pore windows, and the tunability of chemical functionality.
In the Kulik lab, Ball is developing a systematic understanding of how MOF chemistry and pore geometry affect water transport and ion rejection rates. By the end of his PhD, Ball plans to identify existing, best-performing MOFs with unparalleled water uptake using machine learning models, propose novel hypothetical MOFs tailored to specific ion separations from water, and discover experimental design rules that enable the synthesis of next-generation membranes.
Ball’s advisor praised the creativity he brings to his research, and his leadership skills that benefit her whole lab. Before coming to MIT, Ball obtained a master’s degree in chemical engineering from the Indian Institute of Technology (IIT) Bombay and a bachelor’s degree in chemical engineering from Jadavpur University in India. During a research internship at IIT Bombay in 2018, he worked on developing a technology for in situ arsenic detection in water. Like Bessette, he noted the impact of this prior research experience on his interest in global water challenges, along with his personal experience growing up in an area in India where access to safe drinking water was not guaranteed.
Jonathan Bessette (left) received the Rasikbhai L. Meswani Fellowship for Water Solutions and Akash Ball received the 2024-25 J-WAFS Graduate Student Fellowship for Water and Food Solutions.
The allure of whales has stoked human consciousness for millennia, casting these ocean giants as enigmatic residents of the deep seas. From the biblical Leviathan to Herman Melville's formidable Moby Dick, whales have been central to mythologies and folklore. And while cetology, or whale science, has improved our knowledge of these marine mammals in the past century in particular, studying whales has remained a formidable a challenge.
Now, thanks to machine learning, we're a little closer to understanding these gentle giants. Researchers from the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) and Project CETI (Cetacean Translation Initiative) recently used algorithms to decode the “sperm whale phonetic alphabet,” revealing sophisticated structures in sperm whale communication akin to human phonetics and communication systems in other animal species.
In a new open-access study published in Nature Communications, the research shows that sperm whales codas, or short bursts of clicks that they use to communicate, vary significantly in structure depending on the conversational context, revealing a communication system far more intricate than previously understood.
Nine thousand codas, collected from Eastern Caribbean sperm whale families observed by the Dominica Sperm Whale Project, proved an instrumental starting point in uncovering the creatures’ complex communication system. Alongside the data gold mine, the team used a mix of algorithms for pattern recognition and classification, as well as on-body recording equipment. It turned out that sperm whale communications were indeed not random or simplistic, but rather structured in a complex, combinatorial manner.
The researchers identified something of a “sperm whale phonetic alphabet,” where various elements that researchers call “rhythm,” “tempo,” “rubato,” and “ornamentation” interplay to form a vast array of distinguishable codas. For example, the whales would systematically modulate certain aspects of their codas based on the conversational context, such as smoothly varying the duration of the calls — rubato — or adding extra ornamental clicks. But even more remarkably, they found that the basic building blocks of these codas could be combined in a combinatorial fashion, allowing the whales to construct a vast repertoire of distinct vocalizations.
The experiments were conducted using acoustic bio-logging tags (specifically something called “D-tags”) deployed on whales from the Eastern Caribbean clan. These tags captured the intricate details of the whales’ vocal patterns. By developing new visualization and data analysis techniques, the CSAIL researchers found that individual sperm whales could emit various coda patterns in long exchanges, not just repeats of the same coda. These patterns, they say, are nuanced, and include fine-grained variations that other whales also produce and recognize.
“We are venturing into the unknown, to decipher the mysteries of sperm whale communication without any pre-existing ground truth data,” says Daniela Rus, CSAIL director and professor of electrical engineering and computer science (EECS) at MIT. “Using machine learning is important for identifying the features of their communications and predicting what they say next. Our findings indicate the presence of structured information content and also challenges the prevailing belief among many linguists that complex communication is unique to humans. This is a step toward showing that other species have levels of communication complexity that have not been identified so far, deeply connected to behavior. Our next steps aim to decipher the meaning behind these communications and explore the societal-level correlations between what is being said and group actions."
Whaling around
Sperm whales have the largest brains among all known animals. This is accompanied by very complex social behaviors between families and cultural groups, necessitating strong communication for coordination, especially in pressurized environments like deep sea hunting.
Whales owe much to Roger Payne, former Project CETI advisor, whale biologist, conservationist, and MacArthur Fellow who was a major figure in elucidating their musical careers. In the noted 1971 Science article “Songs of Humpback Whales,” Payne documented how whales can sing. His work later catalyzed the “Save the Whales” movement, a successful and timely conservation initiative.
“Roger’s research highlights the impact science can have on society. His finding that whales sing led to the marine mammal protection act and helped save several whale species from extinction. This interdisciplinary research now brings us one step closer to knowing what sperm whales are saying,” says David Gruber, lead and founder of Project CETI and distinguished professor of biology at the City University of New York.
Today, CETI’s upcoming research aims to discern whether elements like rhythm, tempo, ornamentation, and rubato carry specific communicative intents, potentially providing insights into the “duality of patterning” — a linguistic phenomenon where simple elements combine to convey complex meanings previously thought unique to human language.
Aliens among us
“One of the intriguing aspects of our research is that it parallels the hypothetical scenario of contacting alien species. It’s about understanding a species with a completely different environment and communication protocols, where their interactions are distinctly different from human norms,” says Pratyusha Sharma, an MIT PhD student in EECS, CSAIL affiliate, and the study’s lead author. “We’re exploring how to interpret the basic units of meaning in their communication. This isn’t just about teaching animals a subset of human language, but decoding a naturally evolved communication system within their unique biological and environmental constraints. Essentially, our work could lay the groundwork for deciphering how an ‘alien civilization’ might communicate, providing insights into creating algorithms or systems to understand entirely unfamiliar forms of communication.”
“Many animal species have repertoires of several distinct signals, but we are only beginning to uncover the extent to which they combine these signals to create new messages,” says Robert Seyfarth, a University of Pennsylvania professor emeritus of psychology who was not involved in the research. “Scientists are particularly interested in whether signal combinations vary according to the social or ecological context in which they are given, and the extent to which signal combinations follow discernible ‘rules’ that are recognized by listeners. The problem is particularly challenging in the case of marine mammals, because scientists usually cannot see their subjects or identify in complete detail the context of communication. Nonetheless, this paper offers new, tantalizing details of call combinations and the rules that underlie them in sperm whales.”
Joining Sharma, Rus, and Gruber are two others from MIT, both CSAIL principal investigators and professors in EECS: Jacob Andreas and Antonio Torralba. They join Shane Gero, biology lead at CETI, founder of the Dominica Sperm Whale Project, and scientist-in residence at Carleton University. The paper was funded by Project CETI via Dalio Philanthropies and Ocean X, Sea Grape Foundation, Rosamund Zander/Hansjorg Wyss, and Chris Anderson/Jacqueline Novogratz through The Audacious Project: a collaborative funding initiative housed at TED, with further support from the J.H. and E.V. Wade Fund at MIT.
Using machine learning, MIT CSAIL and Project CETI researchers revealed complex, language-like structure in sperm whale communication with context-sensitive and combinatorial elements.
We are living in a very noisy world. From the hum of traffic outside your window to the next-door neighbor’s blaring TV to sounds from a co-worker’s cubicle, unwanted noise remains a resounding problem.
To cut through the din, an interdisciplinary collaboration of researchers from MIT and elsewhere developed a sound-suppressing silk fabric that could be used to create quiet spaces.
The fabric, which is barely thicker than a human hair, contains a special fiber that vibrates when a voltage is applied to it. The researchers leveraged those vibrations to suppress sound in two different ways.
In one, the vibrating fabric generates sound waves that interfere with an unwanted noise to cancel it out, similar to noise-canceling headphones, which work well in a small space like your ears but do not work in large enclosures like rooms or planes.
In the other, more surprising technique, the fabric is held still to suppress vibrations that are key to the transmission of sound. This prevents noise from being transmitted through the fabric and quiets the volume beyond. This second approach allows for noise reduction in much larger spaces like rooms or cars.
By using common materials like silk, canvas, and muslin, the researchers created noise-suppressing fabrics which would be practical to implement in real-world spaces. For instance, one could use such a fabric to make dividers in open workspaces or thin fabric walls that prevent sound from getting through.
“Noise is a lot easier to create than quiet. In fact, to keep noise out we dedicate a lot of space to thick walls. [First author] Grace’s work provides a new mechanism for creating quiet spaces with a thin sheet of fabric,” says Yoel Fink, a professor in the departments of Materials Science and Engineering and Electrical Engineering and Computer Science, a Research Laboratory of Electronics principal investigator, and senior author of a paper on the fabric.
The study’s lead author is Grace (Noel) Yang SM ’21, PhD ’24. Co-authors include MIT graduate students Taigyu Joo, Hyunhee Lee, Henry Cheung, and Yongyi Zhao; Zachary Smith, the Robert N. Noyce Career Development Professor of Chemical Engineering at MIT; graduate student Guanchun Rui and professor Lei Zhu of Case Western University; graduate student Jinuan Lin and Assistant Professor Chu Ma of the University of Wisconsin at Madison; and Latika Balachander, a graduate student at the Rhode Island School of Design. An open-access paper about the research appeared recently in Advanced Materials.
Silky silence
The sound-suppressing silk builds off the group’s prior work to create fabric microphones.
In that research, they sewed a single strand of piezoelectric fiber into fabric. Piezoelectric materials produce an electrical signal when squeezed or bent. When a nearby noise causes the fabric to vibrate, the piezoelectric fiber converts those vibrations into an electrical signal, which can capture the sound.
In the new work, the researchers flipped that idea to create a fabric loudspeaker that can be used to cancel out soundwaves.
“While we can use fabric to create sound, there is already so much noise in our world. We thought creating silence could be even more valuable,” Yang says.
Applying an electrical signal to the piezoelectric fiber causes it to vibrate, which generates sound. The researchers demonstrated this by playing Bach’s “Air” using a 130-micrometer sheet of silk mounted on a circular frame.
To enable direct sound suppression, the researchers use a silk fabric loudspeaker to emit sound waves that destructively interfere with unwanted sound waves. They control the vibrations of the piezoelectric fiber so that sound waves emitted by the fabric are opposite of unwanted sound waves that strike the fabric, which can cancel out the noise.
However, this technique is only effective over a small area. So, the researchers built off this idea to develop a technique that uses fabric vibrations to suppress sound in much larger areas, like a bedroom.
Let’s say your next-door neighbors are playing foosball in the middle of the night. You hear noise in your bedroom because the sound in their apartment causes your shared wall to vibrate, which forms sound waves on your side.
To suppress that sound, the researchers could place the silk fabric onto your side of the shared wall, controlling the vibrations in the fiber to force the fabric to remain still. This vibration-mediated suppression prevents sound from being transmitted through the fabric.
“If we can control those vibrations and stop them from happening, we can stop the noise that is generated, as well,” Yang says.
A mirror for sound
Surprisingly, the researchers found that holding the fabric still causes sound to be reflected by the fabric, resulting in a thin piece of silk that reflects sound like a mirror does with light.
Their experiments also revealed that both the mechanical properties of a fabric and the size of its pores affect the efficiency of sound generation. While silk and muslin have similar mechanical properties, the smaller pore sizes of silk make it a better fabric loudspeaker.
But the effective pore size also depends on the frequency of sound waves. If the frequency is low enough, even a fabric with relatively large pores could function effectively, Yang says.
When they tested the silk fabric in direct suppression mode, the researchers found that it could significantly reduce the volume of sounds up to 65 decibels (about as loud as enthusiastic human conversation). In vibration-mediated suppression mode, the fabric could reduce sound transmission up to 75 percent.
These results were only possible due to a robust group of collaborators, Fink says. Graduate students at the Rhode Island School of Design helped the researchers understand the details of constructing fabrics; scientists at the University of Wisconsin at Madison conducted simulations; researchers at Case Western Reserve University characterized materials; and chemical engineers in the Smith Group at MIT used their expertise in gas membrane separation to measure airflow through the fabric.
Moving forward, the researchers want to explore the use of their fabric to block sound of multiple frequencies. This would likely require complex signal processing and additional electronics.
In addition, they want to further study the architecture of the fabric to see how changing things like the number of piezoelectric fibers, the direction in which they are sewn, or the applied voltages could improve performance.
“There are a lot of knobs we can turn to make this sound-suppressing fabric really effective. We want to get people thinking about controlling structural vibrations to suppress sound. This is just the beginning,” says Yang.
This work is funded, in part, by the National Science Foundation (NSF), the Army Research Office (ARO), the Defense Threat Reduction Agency (DTRA), and the Wisconsin Alumni Research Foundation.
MIT researchers developed a silk fabric, which is barely thicker than a human hair, that can suppress unwanted noise and reduce noise transmission in a large room.
MIT astronomers have observed the elusive starlight surrounding some of the earliest quasars in the universe. The distant signals, which trace back more than 13 billion years to the universe’s infancy, are revealing clues to how the very first black holes and galaxies evolved.
Quasars are the blazing centers of active galaxies, which host an insatiable supermassive black hole at their core. Most galaxies host a central black hole that may occasionally feast on gas and stellar debris, generating a brief burst of light in the form of a glowing ring as material swirls in toward the black hole.
Quasars, by contrast, can consume enormous amounts of matter over much longer stretches of time, generating an extremely bright and long-lasting ring — so bright, in fact, that quasars are among the most luminous objects in the universe.
Because they are so bright, quasars outshine the rest of the galaxy in which they reside. But the MIT team was able for the first time to observe the much fainter light from stars in the host galaxies of three ancient quasars.
Based on this elusive stellar light, the researchers estimated the mass of each host galaxy, compared to the mass of its central supermassive black hole. They found that for these quasars, the central black holes were much more massive relative to their host galaxies, compared to their modern counterparts.
The findings, published today in the Astrophysical Journal, may shed light on how the earliest supermassive black holes became so massive despite having a relatively short amount of cosmic time in which to grow. In particular, those earliest monster black holes may have sprouted from more massive “seeds” than more modern black holes did.
“After the universe came into existence, there were seed black holes that then consumed material and grew in a very short time,” says study author Minghao Yue, a postdoc in MIT’s Kavli Institute for Astrophysics and Space Research. “One of the big questions is to understand how those monster black holes could grow so big, so fast.”
“These black holes are billions of times more massive than the sun, at a time when the universe is still in its infancy,” says study author Anna-Christina Eilers, assistant professor of physics at MIT. “Our results imply that in the early universe, supermassive black holes might have gained their mass before their host galaxies did, and the initial black hole seeds could have been more massive than today.”
Eilers’ and Yue’s co-authors include MIT Kavli Director Robert Simcoe, MIT Hubble Fellow and postdoc Rohan Naidu, and collaborators in Switzerland, Austria, Japan, and at North Carolina State University.
Dazzling cores
A quasar’s extreme luminosity has been obvious since astronomers first discovered the objects in the 1960s. They assumed then that the quasar’s light stemmed from a single, star-like “point source.” Scientists designated the objects “quasars,” as a portmanteau of a “quasi-stellar” object. Since those first observations, scientists have realized that quasars are in fact not stellar in origin but emanate from the accretion of intensely powerful and persistent supermassive black holes sitting at the center of galaxies that also host stars, which are much fainter in comparison to their dazzling cores.
It’s been extremely challenging to separate the light from a quasar’s central black hole from the light of the host galaxy’s stars. The task is a bit like discerning a field of fireflies around a central, massive searchlight. But in recent years, astronomers have had a much better chance of doing so with the launch of NASA’s James Webb Space Telescope (JWST), which has been able to peer farther back in time, and with much higher sensitivity and resolution, than any existing observatory.
In their new study, Yue and Eilers used dedicated time on JWST to observe six known, ancient quasars, intermittently from the fall of 2022 through the following spring. In total, the team collected more than 120 hours of observations of the six distant objects.
“The quasar outshines its host galaxy by orders of magnitude. And previous images were not sharp enough to distinguish what the host galaxy with all its stars looks like,” Yue says. “Now for the first time, we are able to reveal the light from these stars by very carefully modeling JWST’s much sharper images of those quasars.”
A light balance
The team took stock of the imaging data collected by JWST of each of the six distant quasars, which they estimated to be about 13 billion years old. That data included measurements of each quasar’s light in different wavelengths. The researchers fed that data into a model of how much of that light likely comes from a compact “point source,” such as a central black hole’s accretion disk, versus a more diffuse source, such as light from the host galaxy’s surrounding, scattered stars.
Through this modeling, the team teased apart each quasar’s light into two components: light from the central black hole’s luminous disk and light from the host galaxy’s more diffuse stars. The amount of light from both sources is a reflection of their total mass. The researchers estimate that for these quasars, the ratio between the mass of the central black hole and the mass of the host galaxy was about 1:10. This, they realized, was in stark contrast to today’s mass balance of 1:1,000, in which more recently formed black holes are much less massive compared to their host galaxies.
“This tells us something about what grows first: Is it the black hole that grows first, and then the galaxy catches up? Or is the galaxy and its stars that first grow, and they dominate and regulate the black hole’s growth?” Eilers explains. “We see that black holes in the early universe seem to be growing faster than their host galaxies. That is tentative evidence that the initial black hole seeds could have been more massive back then.”
“There must have been some mechanism to make a black hole gain their mass earlier than their host galaxy in those first billion years,” Yue adds. “It’s kind of the first evidence we see for this, which is exciting.”
A James Webb Telescope image shows the J0148 quasar circled in red. Two insets show, on top, the central black hole, and on bottom, the stellar emission from the host galaxy.
The recent ransomware attack on Change Healthcare, which severed the network connecting health care providers, pharmacies, and hospitals with health insurance companies, demonstrates just how disruptive supply chain attacks can be. In this case, it hindered the ability of those providing medical services to submit insurance claims and receive payments.
This sort of attack and other forms of data theft are becoming increasingly common and often target large, multinational corporations through the small and mid-sized vendors in their corporate supply chains, enabling breaks in these enormous systems of interwoven companies.
Cybersecurity researchers at MIT and the Hasso Plattner Institute (HPI) in Potsdam, Germany, are focused on the different organizational security cultures that exist within large corporations and their vendors because it’s that difference that creates vulnerabilities, often due to the lack of emphasis on cybersecurity by the senior leadership in these small to medium-sized enterprises (SMEs).
Keri Pearlson, executive director of Cybersecurity at MIT Sloan (CAMS); Jillian Kwong, a research scientist at CAMS; and Christian Doerr, a professor of cybersecurity and enterprise security at HPI, are co-principal investigators (PIs) on the research project, “Culture and the Supply Chain: Transmitting Shared Values, Attitudes and Beliefs across Cybersecurity Supply Chains.”
Their project was selected in the 2023 inaugural round of grants from the HPI-MIT Designing for Sustainability program, a multiyear partnership funded by HPI and administered by the MIT Morningside Academy for Design (MAD). The program awards about 10 grants annually of up to $200,000 each to multidisciplinary teams with divergent backgrounds in computer science, artificial intelligence, machine learning, engineering, design, architecture, the natural sciences, humanities, and business and management. The 2024 Call for Applications is open through June 3.
Designing for Sustainability grants support scientific research that promotes the United Nations’ Sustainable Development Goals (SDGs) on topics involving sustainable design, innovation, and digital technologies, with teams made up of PIs from both institutions. The PIs on these projects, who have common interests but different strengths, create more powerful teams by working together.
Transmitting shared values, attitudes, and beliefs to improve cybersecurity across supply chains
The MIT and HPI cybersecurity researchers say that most ransomware attacks aren’t reported. Smaller companies hit with ransomware attacks just shut down, because they can’t afford the payment to retrieve their data. This makes it difficult to know just how many attacks and data breaches occur. “As more data and processes move online and into the cloud, it becomes even more important to focus on securing supply chains,” Kwong says. “Investing in cybersecurity allows information to be exchanged freely while keeping data safe. Without it, any progress towards sustainability is stalled.”
One of the first large data breaches in the United States to be widely publicized provides a clear example of how an SME cybersecurity can leave a multinational corporation vulnerable to attack. In 2013, hackers entered the Target Corporation’s own network by obtaining the credentials of a small vendor in its supply chain: a Pennsylvania HVAC company. Through that breach, thieves were able to install malware that stole the financial and personal information of 110 million Target customers, which they sold to card shops on the black market.
To prevent such attacks, SME vendors in a large corporation’s supply chain are required to agree to follow certain security measures, but the SMEs usually don’t have the expertise or training to make good on these cybersecurity promises, leaving their own systems, and therefore any connected to them, vulnerable to attack.
“Right now, organizations are connected economically, but not aligned in terms of organizational culture, values, beliefs, and practices around cybersecurity,” explains Kwong. “Basically, the big companies are realizing the smaller ones are not able to implement all the cybersecurity requirements. We have seen some larger companies address this by reducing requirements or making the process shorter. However, this doesn’t mean companies are more secure; it just lowers the bar for the smaller suppliers to clear it.”
Pearlson emphasizes the importance of board members and senior management taking responsibility for cybersecurity in order to change the culture at SMEs, rather than pushing that down to a single department, IT office, or in some cases, one IT employee.
The research team is using case studies based on interviews, field studies, focus groups, and direct observation of people in their natural work environments to learn how companies engage with vendors, and the specific ways cybersecurity is implemented, or not, in everyday operations. The goal is to create a shared culture around cybersecurity that can be adopted correctly by all vendors in a supply chain.
This approach is in line with the goals of the Charter of Trust Initiative, a partnership of large, multinational corporations formed to establish a better means of implementing cybersecurity in the supply chain network. The HPI-MIT team worked with companies from the Charter of Trust and others last year to understand the impacts of cybersecurity regulation on SME participation in supply chains and develop a conceptual framework to implement changes for stabilizing supply chains.
Cybersecurity is a prerequisite needed to achieve any of the United Nations’ SDGs, explains Kwong. Without secure supply chains, access to key resources and institutions can be abruptly cut off. This could include food, clean water and sanitation, renewable energy, financial systems, health care, education, and resilient infrastructure. Securing supply chains helps enable progress on all SDGs, and the HPI-MIT project specifically supports SMEs, which are a pillar of the U.S. and European economies.
Personalizing product designs while minimizing material waste
In a vastly different Designing for Sustainability joint research project that employs AI with engineering, “Personalizing Product Designs While Minimizing Material Waste” will use AI design software to lay out multiple parts of a pattern on a sheet of plywood, acrylic, or other material, so that they can be laser cut to create new products in real time without wasting material.
Stefanie Mueller, the TIBCO Career Development Associate Professor in the MIT Department of Electrical Engineering and Computer Science and a member of the Computer Science and Artificial Intelligence Laboratory, and Patrick Baudisch, a professor of computer science and chair of the Human Computer Interaction Lab at HPI, are co-PIs on the project. The two have worked together for years; Baudisch was Mueller’s PhD research advisor at HPI.
Baudisch’s lab developed an online design teaching system called Kyub that lets students design 3D objects in pieces that are laser cut from sheets of wood and assembled to become chairs, speaker boxes, radio-controlled aircraft, or even functional musical instruments. For instance, each leg of a chair would consist of four identical vertical pieces attached at the edges to create a hollow-centered column, four of which will provide stability to the chair, even though the material is very lightweight.
“By designing and constructing such furniture, students learn not only design, but also structural engineering,” Baudisch says. “Similarly, by designing and constructing musical instruments, they learn about structural engineering, as well as resonance, types of musical tuning, etc.”
Mueller was at HPI when Baudisch developed the Kyub software, allowing her to observe “how they were developing and making all the design decisions,” she says. “They built a really neat piece for people to quickly design these types of 3D objects.” However, using Kyub for material-efficient design is not fast; in order to fabricate a model, the software has to break the 3D models down into 2D parts and lay these out on sheets of material. This takes time, and makes it difficult to see the impact of design decisions on material use in real-time.
Mueller’s lab at MIT developed software based on a layout algorithm that uses AI to lay out pieces on sheets of material in real time. This allows AI to explore multiple potential layouts while the user is still editing, and thus provide ongoing feedback. “As the user develops their design, Fabricaide decides good placements of parts onto the user's available materials, provides warnings if the user does not have enough material for a design, and makes suggestions for how the user can resolve insufficient material cases,” according to the project website.
The joint MIT-HPI project integrates Mueller’s AI software with Baudisch’s Kyub software and adds machine learning to train the AI to offer better design suggestions that save material while adhering to the user’s design intent.
“The project is all about minimizing the waste on these materials sheets,” Mueller says. She already envisions the next step in this AI design process: determining how to integrate the laws of physics into the AI’s knowledge base to ensure the structural integrity and stability of objects it designs.
AI-powered startup design for the Anthropocene: Providing guidance for novel enterprises
Through her work with the teams of MITdesignX and its international programs, Svafa Grönfeldt, faculty director of MITdesignX and professor of the practice in MIT MAD, has helped scores of people in startup companies use the tools and methods of design to ensure that the solution a startup proposes actually fits the problem it seeks to solve. This is often called the problem-solution fit.
Grönfeldt and MIT postdoc Norhan Bayomi are now extending this work to incorporate AI into the process, in collaboration with MIT Professor John Fernández and graduate student Tyler Kim. The HPI team includes Professor Gerard de Melo; HPI School of Entrepreneurship Director Frank Pawlitschek; and doctoral student Michael Mansfeld.
“The startup ecosystem is characterized by uncertainty and volatility compounded by growing uncertainties in climate and planetary systems,” Grönfeldt says. “Therefore, there is an urgent need for a robust model that can objectively predict startup success and guide design for the Anthropocene.”
While startup-success forecasting is gaining popularity, it currently focuses on aiding venture capitalists in selecting companies to fund, rather than guiding the startups in the design of their products, services and business plans.
“The coupling of climate and environmental priorities with startup agendas requires deeper analytics for effective enterprise design,” Grönfeldt says. The project aims to explore whether AI-augmented decision-support systems can enhance startup-success forecasting.
“We're trying to develop a machine learning approach that will give a forecasting of probability of success based on a number of parameters, including the type of business model proposed, how the team came together, the team members’ backgrounds and skill sets, the market and industry sector they're working in and the problem-solution fit,” says Bayomi, who works with Fernández in the MIT Environmental Solutions Initiative. The two are co-founders of the startup Lamarr.AI, which employs robotics and AI to help reduce the carbon dioxide impact of the built environment.
The team is studying “how company founders make decisions across four key areas, starting from the opportunity recognition, how they are selecting the team members, how they are selecting the business model, identifying the most automatic strategy, all the way through the product market fit to gain an understanding of the key governing parameters in each of these areas,” explains Bayomi.
The team is “also developing a large language model that will guide the selection of the business model by using large datasets from different companies in Germany and the U.S. We train the model based on the specific industry sector, such as a technology solution or a data solution, to find what would be the most suitable business model that would increase the success probability of a company,” she says.
The project falls under several of the United Nations’ Sustainable Development Goals, including economic growth, innovation and infrastructure, sustainable cities and communities, and climate action.
Furthering the goals of the HPI-MIT Joint Research Program
These three diverse projects all advance the mission of the HPI-MIT collaboration. MIT MAD aims to use design to transform learning, catalyze innovation, and empower society by inspiring people from all disciplines to interweave design into problem-solving. HPI uses digital engineering concentrated on the development and research of user-oriented innovations for all areas of life.
Interdisciplinary teams with members from both institutions are encouraged to develop and submit proposals for ambitious, sustainable projects that use design strategically to generate measurable, impactful solutions to the world’s problems.
Interdisciplinary teams from MIT and HPI are encouraged to develop and submit proposals for ambitious projects offering impactful solutions to the world’s problems as part of the Designing for Sustainability research program.
The MIT Electron-conductive Cement-based Materials Hub (EC^3 Hub), an outgrowth of the MIT Concrete Sustainability Hub (CSHub), has been established by a five-year sponsored research agreement with the Aizawa Concrete Corp. In particular, the EC^3 Hub will investigate the infrastructure applications of multifunctional concrete — concrete having capacities beyond serving as a structural element, such as functioning as a “battery” for renewable energy.
Enabled by the MIT Industrial Liaison Program, the newly formed EC^3 Hub represents a large industry-academia collaboration between the MIT CSHub, researchers across MIT, and a Japanese industry consortium led by Aizawa Concrete, a leader in the more sustainable development of concrete structures, which is funding the effort.
Under this agreement, the EC^3 Hub will focus on two key areas of research: developing self-heating pavement systems and energy storage solutions for sustainable infrastructure systems. “It is an honor for Aizawa Concrete to be associated with the scaling up of this transformational technology from MIT labs to the industrial scale,” says Aizawa Concrete CEO Yoshihiro Aizawa. “This is a project we believe will have a fundamental impact not only on the decarbonization of the industry, but on our societies at large.”
By running current through carbon black-doped concrete pavements, the EC^3 Hub’s technology could allow cities and municipalities to de-ice road and sidewalk surfaces at scale, improving safety for drivers and pedestrians in icy conditions. The potential for concrete to store energy from renewable sources — a topic widely covered by news outlets — could allow concrete to serve as a “battery” for technologies such as solar, wind, and tidal power generation, which cannot produce a consistent amount of energy (for example, when a cloudy day inhibits a solar panel’s output). Due to the scarcity of the ingredients used in many batteries, such as lithium-ion cells, this technology offers an alternative for renewable energy storage at scale.
Regarding the collaborative research agreement, the EC^3 Hub’s founding faculty director, Professor Admir Masic, notes that “this is the type of investment in our new conductive cement-based materials technology which will propel it from our lab bench onto the infrastructure market.” Masic is also an associate professor in the MIT Department of Civil and Environmental Engineering, as well as a principal investigator within the MIT CSHub, among other appointments.
For the April 11 signing of the agreement, Masic was joined in Fukushima, Japan, by MIT colleagues Franz-Josef Ulm, a professor of Civil and Environmental Engineering and faculty director of the MIT CSHub; Yang Shao-Horn, the JR East Professor of Engineering, professor of mechanical engineering, and professor of materials science and engineering; and Jewan Bae, director of MIT Corporate Relations. Ulm and Masic will co-direct the EC^3 Hub.
The EC^3 Hub envisions a close collaboration between MIT engineers and scientists as well as the Aizawa-led Japanese industry consortium for the development of breakthrough innovations for multifunctional infrastructure systems. In addition to higher-strength materials, these systems may be implemented for a variety of novel functions such as roads capable of charging electric vehicles as they drive along them.
Members of the EC^3 Hub will engage with the active stakeholder community within the MIT CSHub to accelerate the industry’s transition to carbon neutrality. The EC^3 Hub will also open opportunities for the MIT community to engage with the large infrastructure industry sector for decarbonization through innovation.
Left to right: Jewan Bae (director, OCR); MIT professors Yang Shao Horn, Admir Masic, and Franz-Josef Ulm; Yoshihiro Aizawa (CEO, Aizawa Concrete); and Seiji Nakemura (Aizawa Concrete)
Proximity is key for many quantum phenomena, as interactions between atoms are stronger when the particles are close. In many quantum simulators, scientists arrange atoms as close together as possible to explore exotic states of matter and build new quantum materials.
They typically do this by cooling the atoms to a stand-still, then using laser light to position the particles as close as 500 nanometers apart — a limit that is set by the wavelength of light. Now, MIT physicists have developed a technique that allows them to arrange atoms in much closer proximity, down to a mere 50 nanometers. For context, a red blood cell is about 1,000 nanometers wide.
The physicists demonstrated the new approach in experiments with dysprosium, which is the most magnetic atom in nature. They used the new approach to manipulate two layers of dysprosium atoms, and positioned the layers precisely 50 nanometers apart. At this extreme proximity, the magnetic interactions were 1,000 times stronger than if the layers were separated by 500 nanometers.
What’s more, the scientists were able to measure two new effects caused by the atoms’ proximity. Their enhanced magnetic forces caused “thermalization,” or the transfer of heat from one layer to another, as well as synchronized oscillations between layers. These effects petered out as the layers were spaced farther apart.
“We have gone from positioning atoms from 500 nanometers to 50 nanometers apart, and there is a lot you can do with this,” says Wolfgang Ketterle, the John D. MacArthur Professor of Physics at MIT. “At 50 nanometers, the behavior of atoms is so much different that we’re really entering a new regime here.”
Ketterle and his colleagues say the new approach can be applied to many other atoms to study quantum phenomena. For their part, the group plans to use the technique to manipulate atoms into configurations that could generate the first purely magnetic quantum gate — a key building block for a new type of quantum computer.
The team has published their results today in the journal Science. The study’s co-authors include lead author and physics graduate student Li Du, along with Pierre Barral, Michael Cantara, Julius de Hond, and Yu-Kun Lu — all members of the MIT-Harvard Center for Ultracold Atoms, the Department of Physics, and the Research Laboratory of Electronics at MIT.
Peaks and valleys
To manipulate and arrange atoms, physicists typically first cool a cloud of atoms to temperatures approaching absolute zero, then use a system of laser beams to corral the atoms into an optical trap.
Laser light is an electromagnetic wave with a specific wavelength (the distance between maxima of the electric field) and frequency. The wavelength limits the smallest pattern into which light can be shaped to typically 500 nanometers, the so-called optical resolution limit. Since atoms are attracted by laser light of certain frequencies, atoms will be positioned at the points of peak laser intensity. For this reason, existing techniques have been limited in how close they can position atomic particles, and could not be used to explore phenomena that happen at much shorter distances.
“Conventional techniques stop at 500 nanometers, limited not by the atoms but by the wavelength of light,” Ketterle explains. “We have found now a new trick with light where we can break through that limit.”
The team’s new approach, like current techniques, starts by cooling a cloud of atoms — in this case, to about 1 microkelvin, just a hair above absolute zero — at which point, the atoms come to a near-standstill. Physicists can then use lasers to move the frozen particles into desired configurations.
Then, Du and his collaborators worked with two laser beams, each with a different frequency, or color, and circular polarization, or direction of the laser’s electric field. When the two beams travel through a super-cooled cloud of atoms, the atoms can orient their spin in opposite directions, following either of the two lasers’ polarization. The result is that the beams produce two groups of the same atoms, only with opposite spins.
Each laser beam formed a standing wave, a periodic pattern of electric field intensity with a spatial period of 500 nanometers. Due to their different polarizations, each standing wave attracted and corralled one of two groups of atoms, depending on their spin. The lasers could be overlaid and tuned such that the distance between their respective peaks is as small as 50 nanometers, meaning that the atoms gravitating to each respective laser’s peaks would be separated by the same 50 nanometers.
But in order for this to happen, the lasers would have to be extremely stable and immune to all external noise, such as from shaking or even breathing on the experiment. The team realized they could stabilize both lasers by directing them through an optical fiber, which served to lock the light beams in place in relation to each other.
“The idea of sending both beams through the optical fiber meant the whole machine could shake violently, but the two laser beams stayed absolutely stable with respect to each others,” Du says.
Magnetic forces at close range
As a first test of their new technique, the team used atoms of dysprosium — a rare-earth metal that is one of the strongest magnetic elements in the periodic table, particularly at ultracold temperatures. However, at the scale of atoms, the element’s magnetic interactions are relatively weak at distances of even 500 nanometers. As with common refrigerator magnets, the magnetic attraction between atoms increases with proximity, and the scientists suspected that if their new technique could space dysprosium atoms as close as 50 nanometers apart, they might observe the emergence of otherwise weak interactions between the magnetic atoms.
“We could suddenly have magnetic interactions, which used to be almost neglible but now are really strong,” Ketterle says.
The team applied their technique to dysprosium, first super-cooling the atoms, then passing two lasers through to split the atoms into two spin groups, or layers. They then directed the lasers through an optical fiber to stabilize them, and found that indeed, the two layers of dysprosium atoms gravitated to their respective laser peaks, which in effect separated the layers of atoms by 50 nanometers — the closest distance that any ultracold atom experiment has been able to achieve.
At this extremely close proximity, the atoms’ natural magnetic interactions were significantly enhanced, and were 1,000 times stronger than if they were positioned 500 nanometers apart. The team observed that these interactions resulted in two novel quantum phenomena: collective oscillation, in which one layer’s vibrations caused the other layer to vibrate in sync; and thermalization, in which one layer transferred heat to the other, purely through magnetic fluctuations in the atoms.
“Until now, heat between atoms could only by exchanged when they were in the same physical space and could collide,” Du notes. “Now we have seen atomic layers, separated by vacuum, and they exchange heat via fluctuating magnetic fields.”
The team’s results introduce a new technique that can be used to position many types of atom in close proximity. They also show that atoms, placed close enough together, can exhibit interesting quantum phenomena, that could be harnessed to build new quantum materials, and potentially, magnetically-driven atomic systems for quantum computers.
“We are really bringing super-resolution methods to the field, and it will become a general tool for doing quantum simulations,” Ketterle says. “There are many variants possible, which we are working on.”
This research was funded, in part, by the National Science Foundation and the Department of Defense.
MIT physicists developed a technique to arrange atoms (represented as spheres with arrows) in much closer proximity than previously possible, down to 50 nanometers. The group plans to use the method to manipulate atoms into configurations that could generate the first purely magnetic quantum gate — a key building block for a new type of quantum computer. In this image, the magnetic interaction is represented by the colorful lines.
For most patients, it’s unknown exactly what causes amyotrophic lateral sclerosis (ALS), a disease characterized by degeneration of motor neurons that impairs muscle control and eventually leads to death.
Studies have identified certain genes that confer a higher risk of the disease, but scientists believe there are many more genetic risk factors that have yet to be discovered. One reason why these drivers have been hard to find is that some are found in very few patients, making it hard to pick them out without a very large sample of patients. Additionally, some of the risk may be driven by epigenomic factors, rather than mutations in protein-coding genes.
Working with the Answer ALS consortium, a team of MIT researchers has analyzed epigenetic modifications — tags that determine which genes are turned on in a cell — in motor neurons derived from induced pluripotent stem (IPS) cells from 380 ALS patients.
This analysis revealed a strong differential signal associated with a known subtype of ALS, and about 30 locations with modifications that appear to be linked to rates of disease progression in ALS patients. The findings may help scientists develop new treatments that are targeted to patients with certain genetic risk factors.
“If the root causes are different for all these different versions of the disease, the drugs will be very different and the signals in IPS cells will be very different,” says Ernest Fraenkel, the Grover M. Hermann Professor in Health Sciences and Technology in MIT’s Department of Biological Engineering and the senior author of the study. “We may get to a point in a decade or so where we don’t even think of ALS as one disease, where there are drugs that are treating specific types of ALS that only work for one group of patients and not for another.”
MIT postdoc Stanislav Tsitkov is the lead author of the paper, which appears today in Nature Communications.
Finding risk factors
ALS is a rare disease that is estimated to affect about 30,000 people in the United States. One of the challenges in studying the disease is that while genetic variants are believed to account for about 50 percent of ALS risk (with environmental factors making up the rest), most of the variants that contribute to that risk have not been identified.
Similar to Alzheimer’s disease, there may be a large number of genetic variants that can confer risk, but each individual patient may carry only a small number of those. This makes it difficult to identify the risk factors unless scientists have a very large population of patients to analyze.
“Because we expect the disease to be heterogeneous, you need to have large numbers of patients before you can pick up on signals like this. To really be able to classify the subtypes of disease, we’re going to need to look at a lot of people,” Fraenkel says.
About 10 years ago, the Answer ALS consortium began to collect large numbers of patient samples, which could allow for larger-scale studies that might reveal some of the genetic drivers of the disease. From blood samples, researchers can create induced pluripotent stem cells and then induce them to differentiate into motor neurons, the cells most affected by ALS.
“We don’t think all ALS patients are going to be the same, just like all cancers are not the same. And the goal is being able to find drivers of the disease that could be therapeutic targets,” Fraenkel says.
In this study, Fraenkel and his colleagues wanted to see if patient-derived cells could offer any information about molecular differences that are relevant to ALS. They focused on epigenomic modifications, using a method called ATAC-seq to measure chromatin density across the genome of each cell. Chromatin is a complex of DNA and proteins that determines which genes are accessible to be transcribed by the cell, depending on how densely packed the chromatin is.
In data that were collected and analyzed over several years, the researchers did not find any global signal that clearly differentiated the 380 ALS patients in their study from 80 healthy control subjects. However, they did find a strong differential signal associated with a subtype of ALS, characterized by a genetic mutation in the C9orf72 gene.
Additionally, they identified about 30 regions that were associated with slower rates of disease progression in ALS patients. Many of these regions are located near genes related to the cellular inflammatory response; interestingly, several of the identified genes have also been implicated in other neurodegenerative diseases, such as Parkinson’s disease.
“You can use a small number of these epigenomic regions and look at the intensity of the signal there, and predict how quickly someone’s disease will progress. That really validates the hypothesis that the epigenomics can be used as a filter to better understand the contribution of the person’s genome,” Fraenkel says.
“By harnessing the very large number of participant samples and extensive data collected by the Answer ALS Consortium, these studies were able to rigorously test whether the observed changes might be artifacts related to the techniques of sample collection, storage, processing, and analysis, or truly reflective of important biology,” says Lyle Ostrow, an associate professor of neurology at the Lewis Katz School of Medicine at Temple University, who was not involved in the study. “They developed standard ways to control for these variables, to make sure the results can be accurately compared. Such studies are incredibly important for accelerating ALS therapy development, as they will enable data and samples collected from different studies to be analyzed together.”
Targeted drugs
The researchers now hope to further investigate these genomic regions and see how they might drive different aspects of ALS progression in different subsets of patients. This could help scientists develop drugs that might work in different groups of patients, and help them identify which patients should be chosen for clinical trials of those drugs, based on genetic or epigenetic markers.
Last year, the U.S. Food and Drug Administration approved a drug called tofersen, which can be used in ALS patients with a mutation in a gene called SOD1. This drug is very effective for those patients, who make up about 1 percent of the total population of people with ALS. Fraenkel’s hope is that more drugs can be developed for, and tested in, people with other genetic drivers of ALS.
“If you had a drug like tofersen that works for 1 percent of patients and you just gave it to a typical phase two clinical trial, you probably wouldn’t have anybody with that mutation in the trial, and it would’ve failed. And so that drug, which is a lifesaver for people, would never have gotten through,” Fraenkel says.
The MIT team is now using an approach called quantitative trait locus (QTL) analysis to try to identify subgroups of ALS patients whose disease is driven by specific genomic variants.
“We can integrate the genomics, the transcriptomics, and the epigenomics, as a way to find subgroups of ALS patients who have distinct phenotypic signatures from other ALS patients and healthy controls,” Tsitkov says. “We have already found a few potential hits in that direction.”
The research was funded by the Answer ALS program, which is supported by the Robert Packard Center for ALS Research at Johns Hopkins University, Travelers Insurance, ALS Finding a Cure Foundation, Stay Strong Vs. ALS, Answer ALS Foundation, Microsoft, Caterpillar Foundation, American Airlines, Team Gleason, the U.S. National Institutes of Health, Fishman Family Foundation, Aviators Against ALS, AbbVie Foundation, Chan Zuckerberg Initiative, ALS Association, National Football League, F. Prime, M. Armstrong, Bruce Edwards Foundation, the Judith and Jean Pape Adams Charitable Foundation, Muscular Dystrophy Association, Les Turner ALS Foundation, PGA Tour, Gates Ventures, and Bari Lipp Foundation. This work was also supported, in part, by grants from the National Institutes of Health and the MIT-GSK Gertrude B. Elion Research Fellowship Program for Drug Discovery and Disease.
An analysis revealed a strong differential signal associated with a known subtype of ALS, and about 30 locations with modifications that appear to be linked to rates of disease progression in ALS patients.
Gabrielle Wood, a junior at Howard University majoring in chemical engineering, is on a mission to improve the sustainability and life cycles of natural resources and materials. Her work in the Materials Initiative for Comprehensive Research Opportunity (MICRO) program has given her hands-on experience with many different aspects of research, including MATLAB programming, experimental design, data analysis, figure-making, and scientific writing.
Wood is also one of 10 undergraduates from 10 universities around the United States to participate in the first MICRO Summit earlier this year. The internship program, developed by the MIT Department of Materials Science and Engineering (DMSE), first launched in fall 2021. Now in its third year, the program continues to grow, providing even more opportunities for non-MIT undergraduate students — including the MICRO Summit and the program’s expansion to include Northwestern University.
“I think one of the most valuable aspects of the MICRO program is the ability to do research long term with an experienced professor in materials science and engineering,” says Wood. “My school has limited opportunities for undergraduate research in sustainable polymers, so the MICRO program allowed me to gain valuable experience in this field, which I would not otherwise have.”
Like Wood, Griheydi Garcia, a senior chemistry major at Manhattan College, values the exposure to materials science, especially since she is not able to learn as much about it at her home institution.
“I learned a lot about crystallography and defects in materials through the MICRO curriculum, especially through videos,” says Garcia. “The research itself is very valuable, as well, because we get to apply what we’ve learned through the videos in the research we do remotely.”
Expanding research opportunities
From the beginning, the MICRO program was designed as a fully remote, rigorous education and mentoring program targeted toward students from underserved backgrounds interested in pursuing graduate school in materials science or related fields. Interns are matched with faculty to work on their specific research interests.
Jessica Sandland ’99, PhD ’05, principal lecturer in DMSE and co-founder of MICRO, says that research projects for the interns are designed to be work that they can do remotely, such as developing a machine-learning algorithm or a data analysis approach.
“It’s important to note that it’s not just about what the program and faculty are bringing to the student interns,” says Sandland, a member of the MIT Digital Learning Lab, a joint program between MIT Open Learning and the Institute’s academic departments. “The students are doing real research and work, and creating things of real value. It’s very much an exchange.”
Cécile Chazot PhD ’22, now an assistant professor of materials science and engineering at Northwestern University, had helped to establish MICRO at MIT from the very beginning. Once at Northwestern, she quickly realized that expanding MICRO to Northwestern would offer even more research opportunities to interns than by relying on MIT alone — leveraging the university’s strong materials science and engineering department, as well as offering resources for biomaterials research through Northwestern’s medical school. The program received funding from 3M and officially launched at Northwestern in fall 2023. Approximately half of the MICRO interns are now in the program with MIT and half are with Northwestern. Wood and Garcia both participate in the program via Northwestern.
“By expanding to another school, we’ve been able to have interns work with a much broader range of research projects,” says Chazot. “It has become easier for us to place students with faculty and research that match their interests.”
Building community
The MICRO program received a Higher Education Innovation grant from the Abdul Latif Jameel World Education Lab, part of MIT Open Learning, to develop an in-person summit. In January 2024, interns visited MIT for three days of presentations, workshops, and campus tours — including a tour of the MIT.nano building — as well as various community-building activities.
“A big part of MICRO is the community,” says Chazot. “A highlight of the summit was just seeing the students come together.”
The summit also included panel discussions that allowed interns to gain insights and advice from graduate students and professionals. The graduate panel discussion included MIT graduate students Sam Figueroa (mechanical engineering), Isabella Caruso (DMSE), and Eliana Feygin (DMSE). The career panel was led by Chazot and included Jatin Patil PhD ’23, head of product at SiTration; Maureen Reitman ’90, ScD ’93, group vice president and principal engineer at Exponent; Lucas Caretta PhD ’19, assistant professor of engineering at Brown University; Raquel D’Oyen ’90, who holds a PhD from Northwestern University and is a senior engineer at Raytheon; and Ashley Kaiser MS ’19, PhD ’21, senior process engineer at 6K.
Students also had an opportunity to share their work with each other through research presentations. Their presentations covered a wide range of topics, including: developing a computer program to calculate solubility parameters for polymers used in textile manufacturing; performing a life-cycle analysis of a photonic chip and evaluating its environmental impact in comparison to a standard silicon microchip; and applying machine learning algorithms to scanning transmission electron microscopy images of CrSBr, a two-dimensional magnetic material.
“The summit was wonderful and the best academic experience I have had as a first-year college student,” says MICRO intern Gabriella La Cour, who is pursuing a major in chemistry and dual degree biomedical engineering at Spelman College and participates in MICRO through MIT. “I got to meet so many students who were all in grades above me … and I learned a little about how to navigate college as an upperclassman.”
“I actually have an extremely close friendship with one of the students, and we keep in touch regularly,” adds La Cour. “Professor Chazot gave valuable advice about applications and recommendation letters that will be useful when I apply to REUs [Research Experiences for Undergraduates] and graduate schools.”
Looking to the future, MICRO organizers hope to continue to grow the program’s reach.
“We would love to see other schools taking on this model,” says Sandland. “There are a lot of opportunities out there. The more departments, research groups, and mentors that get involved with this program, the more impact it can have.”
Ten undergraduates from 10 universities around the United States visited MIT to participate in the first MICRO Summit earlier this year. Pictured are the student interns, organizers, and the career panelists.
Large language models (LLMs) are becoming increasingly useful for programming and robotics tasks, but for more complicated reasoning problems, the gap between these systems and humans looms large. Without the ability to learn new concepts like humans do, these systems fail to form good abstractions — essentially, high-level representations of complex concepts that skip less-important details — and thus sputter when asked to do more sophisticated tasks.
Luckily, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers have found a treasure trove of abstractions within natural language. In three papers to be presented at the International Conference on Learning Representations this month, the group shows how our everyday words are a rich source of context for language models, helping them build better overarching representations for code synthesis, AI planning, and robotic navigation and manipulation.
The three separate frameworks build libraries of abstractions for their given task: LILO (library induction from language observations) can synthesize, compress, and document code; Ada (action domain acquisition) explores sequential decision-making for artificial intelligence agents; and LGA (language-guided abstraction) helps robots better understand their environments to develop more feasible plans. Each system is a neurosymbolic method, a type of AI that blends human-like neural networks and program-like logical components.
LILO: A neurosymbolic framework that codes
Large language models can be used to quickly write solutions to small-scale coding tasks, but cannot yet architect entire software libraries like the ones written by human software engineers. To take their software development capabilities further, AI models need to refactor (cut down and combine) code into libraries of succinct, readable, and reusable programs.
Refactoring tools like the previously developed MIT-led Stitch algorithm can automatically identify abstractions, so, in a nod to the Disney movie “Lilo & Stitch,” CSAIL researchers combined these algorithmic refactoring approaches with LLMs. Their neurosymbolic method LILO uses a standard LLM to write code, then pairs it with Stitch to find abstractions that are comprehensively documented in a library.
LILO’s unique emphasis on natural language allows the system to do tasks that require human-like commonsense knowledge, such as identifying and removing all vowels from a string of code and drawing a snowflake. In both cases, the CSAIL system outperformed standalone LLMs, as well as a previous library learning algorithm from MIT called DreamCoder, indicating its ability to build a deeper understanding of the words within prompts. These encouraging results point to how LILO could assist with things like writing programs to manipulate documents like Excel spreadsheets, helping AI answer questions about visuals, and drawing 2D graphics.
“Language models prefer to work with functions that are named in natural language,” says Gabe Grand SM '23, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and lead author on the research. “Our work creates more straightforward abstractions for language models and assigns natural language names and documentation to each one, leading to more interpretable code for programmers and improved system performance.”
When prompted on a programming task, LILO first uses an LLM to quickly propose solutions based on data it was trained on, and then the system slowly searches more exhaustively for outside solutions. Next, Stitch efficiently identifies common structures within the code and pulls out useful abstractions. These are then automatically named and documented by LILO, resulting in simplified programs that can be used by the system to solve more complex tasks.
The MIT framework writes programs in domain-specific programming languages, like Logo, a language developed at MIT in the 1970s to teach children about programming. Scaling up automated refactoring algorithms to handle more general programming languages like Python will be a focus for future research. Still, their work represents a step forward for how language models can facilitate increasingly elaborate coding activities.
Ada: Natural language guides AI task planning
Just like in programming, AI models that automate multi-step tasks in households and command-based video games lack abstractions. Imagine you’re cooking breakfast and ask your roommate to bring a hot egg to the table — they’ll intuitively abstract their background knowledge about cooking in your kitchen into a sequence of actions. In contrast, an LLM trained on similar information will still struggle to reason about what they need to build a flexible plan.
Named after the famed mathematician Ada Lovelace, who many consider the world’s first programmer, the CSAIL-led “Ada” framework makes headway on this issue by developing libraries of useful plans for virtual kitchen chores and gaming. The method trains on potential tasks and their natural language descriptions, then a language model proposes action abstractions from this dataset. A human operator scores and filters the best plans into a library, so that the best possible actions can be implemented into hierarchical plans for different tasks.
“Traditionally, large language models have struggled with more complex tasks because of problems like reasoning about abstractions,” says Ada lead researcher Lio Wong, an MIT graduate student in brain and cognitive sciences, CSAIL affiliate, and LILO coauthor. “But we can combine the tools that software engineers and roboticists use with LLMs to solve hard problems, such as decision-making in virtual environments.”
When the researchers incorporated the widely-used large language model GPT-4 into Ada, the system completed more tasks in a kitchen simulator and Mini Minecraft than the AI decision-making baseline “Code as Policies.” Ada used the background information hidden within natural language to understand how to place chilled wine in a cabinet and craft a bed. The results indicated a staggering 59 and 89 percent task accuracy improvement, respectively.
With this success, the researchers hope to generalize their work to real-world homes, with the hopes that Ada could assist with other household tasks and aid multiple robots in a kitchen. For now, its key limitation is that it uses a generic LLM, so the CSAIL team wants to apply a more powerful, fine-tuned language model that could assist with more extensive planning. Wong and her colleagues are also considering combining Ada with a robotic manipulation framework fresh out of CSAIL: LGA (language-guided abstraction).
Language-guided abstraction: Representations for robotic tasks
Andi Peng SM ’23, an MIT graduate student in electrical engineering and computer science and CSAIL affiliate, and her coauthors designed a method to help machines interpret their surroundings more like humans, cutting out unnecessary details in a complex environment like a factory or kitchen. Just like LILO and Ada, LGA has a novel focus on how natural language leads us to those better abstractions.
In these more unstructured environments, a robot will need some common sense about what it’s tasked with, even with basic training beforehand. Ask a robot to hand you a bowl, for instance, and the machine will need a general understanding of which features are important within its surroundings. From there, it can reason about how to give you the item you want.
In LGA’s case, humans first provide a pre-trained language model with a general task description using natural language, like “bring me my hat.” Then, the model translates this information into abstractions about the essential elements needed to perform this task. Finally, an imitation policy trained on a few demonstrations can implement these abstractions to guide a robot to grab the desired item.
Previous work required a person to take extensive notes on different manipulation tasks to pre-train a robot, which can be expensive. Remarkably, LGA guides language models to produce abstractions similar to those of a human annotator, but in less time. To illustrate this, LGA developed robotic policies to help Boston Dynamics’ Spot quadruped pick up fruits and throw drinks in a recycling bin. These experiments show how the MIT-developed method can scan the world and develop effective plans in unstructured environments, potentially guiding autonomous vehicles on the road and robots working in factories and kitchens.
“In robotics, a truth we often disregard is how much we need to refine our data to make a robot useful in the real world,” says Peng. “Beyond simply memorizing what’s in an image for training robots to perform tasks, we wanted to leverage computer vision and captioning models in conjunction with language. By producing text captions from what a robot sees, we show that language models can essentially build important world knowledge for a robot.”
The challenge for LGA is that some behaviors can’t be explained in language, making certain tasks underspecified. To expand how they represent features in an environment, Peng and her colleagues are considering incorporating multimodal visualization interfaces into their work. In the meantime, LGA provides a way for robots to gain a better feel for their surroundings when giving humans a helping hand.
An “exciting frontier” in AI
“Library learning represents one of the most exciting frontiers in artificial intelligence, offering a path towards discovering and reasoning over compositional abstractions,” says assistant professor at the University of Wisconsin-Madison Robert Hawkins, who was not involved with the papers. Hawkins notes that previous techniques exploring this subject have been “too computationally expensive to use at scale” and have an issue with the lambdas, or keywords used to describe new functions in many languages, that they generate. “They tend to produce opaque 'lambda salads,' big piles of hard-to-interpret functions. These recent papers demonstrate a compelling way forward by placing large language models in an interactive loop with symbolic search, compression, and planning algorithms. This work enables the rapid acquisition of more interpretable and adaptive libraries for the task at hand.”
By building libraries of high-quality code abstractions using natural language, the three neurosymbolic methods make it easier for language models to tackle more elaborate problems and environments in the future. This deeper understanding of the precise keywords within a prompt presents a path forward in developing more human-like AI models.
MIT CSAIL members are senior authors for each paper: Joshua Tenenbaum, a professor of brain and cognitive sciences, for both LILO and Ada; Julie Shah, head of the Department of Aeronautics and Astronautics, for LGA; and Jacob Andreas, associate professor of electrical engineering and computer science, for all three. The additional MIT authors are all PhD students: Maddy Bowers and Theo X. Olausson for LILO, Jiayuan Mao and Pratyusha Sharma for Ada, and Belinda Z. Li for LGA. Muxin Liu of Harvey Mudd College was a coauthor on LILO; Zachary Siegel of Princeton University, Jaihai Feng of the University of California at Berkeley, and Noa Korneev of Microsoft were coauthors on Ada; and Ilia Sucholutsky, Theodore R. Sumers, and Thomas L. Griffiths of Princeton were coauthors on LGA.
LILO and Ada were supported, in part, by MIT Quest for Intelligence, the MIT-IBM Watson AI Lab, Intel, U.S. Air Force Office of Scientific Research, the U.S. Defense Advanced Research Projects Agency, and the U.S. Office of Naval Research, with the latter project also receiving funding from the Center for Brains, Minds and Machines. LGA received funding from the U.S. National Science Foundation, Open Philanthropy, the Natural Sciences and Engineering Research Council of Canada, and the U.S. Department of Defense.
Three new frameworks from MIT CSAIL reveal how natural language can provide important context for language models that perform coding, AI planning, and robotics tasks.
Laurence Willemet remembers countless family dinners where curious faces turned to her with shades of the same question: “What is it, exactly, that you do with robots?”
It’s a familiar scenario for MIT students exploring topics outside of their family’s scope of knowledge — distilling complex concepts without slides or jargon, plumbing the depths with nothing but lay terms. “It was during these moments,” Willemet says, “that I realized the importance of clear communication and the power of storytelling.”
Participating in the MIT Research Slam, then, felt like one of her family dinners.
The finalists in the 2024 MIT Research Slam competition met head-to-head on Wednesday, April 17 at a live, in-person showcase event. Four PhD candidates and four postdoc finalists demonstrated their topic mastery and storytelling skills by conveying complex ideas in only 180 seconds to an educated audience unfamiliar with the field or project at hand.
The Research Slam follows the format of the 3-Minute Thesis competition, which takes place annually at over 200 universities around the world. Both an exciting competition and a rigorous professional development training opportunity, the event serves an opportunity to learn for everyone involved.
One of this year’s competitors, Bhavish Dinakar, explains it this way: “Participating in the Research Slam was a fantastic opportunity to bring my research from the lab into the real world. In addition to being a helpful exercise in public speaking and communication, the three-minute time limit forces us to learn the art of distilling years of detailed experiments into a digestible story that non-experts can understand.”
Leading up to the event, participants joined training workshops on pitch content and delivery, and had the opportunity to work one-on-one with educators from the Writing and Communication Center, English Language Studies, Career Advising and Professional Development, and the Engineering Communication Labs, all of which co-sponsored and co-produced the event. This interdepartmental team offered support for the full arc of the competition, from early story development to one-on-one practice sessions.
The showcase was jovially emceed by Eric Grunwald, director of English language learning. He shared his thoughts on the night: “I was thrilled with the enthusiasm and skill shown by all the presenters in sharing their work in this context. I was also delighted by the crowd’s enthusiasm and their many insightful questions. All in all, another very successful slam.”
A panel of accomplished judges with distinct perspectives on research communication gave feedback after each of the talks: Deborah Blum, director of the Knight Science Journalism Program at MIT; Denzil Streete, senior associate dean and director of graduate education; and Emma Yee, scientific editor at the journal Cell.
Deborah Blum aptly summed up her experience: “It was a pleasure as a science journalist to be a judge and to listen to this smart group of MIT grad students and postdocs explain their research with such style, humor, and intelligence. It was a reminder of the importance the university places on the value of scientists who communicate. And this matters. We need more scientists who can explain their work clearly, explain science to the public, and help us build a science-literate world.”
After all the talks, the judges provided constructive and substantive feedback for the contestants. It was a close competition, but in the end, Bhavish Dinakar was the judges’ choice for first place, and the audience agreed, awarding him the Audience Choice award. Omar Rutledge’s strong performance earned him the runner-up position. Among the postdoc competitors, Laurence Willemet won first place and Audience Choice, with Most Kaniz Moriam earning the runner-up award.
Postdoc Kaniz Mariam noted that she felt privileged to participate in the showcase. “This experience has enhanced my ability to communicate research effectively and boosted my confidence in sharing my work with a broader audience. I am eager to apply the lessons learned from this enriching experience to future endeavors and continue contributing to MIT's dynamic research community. The MIT Research Slam Showcase wasn't just about winning; it was about the thrill of sharing knowledge and inspiring others. Special thanks to Chris Featherman and Elena Kallestinova from the MIT Communication Lab for their guidance in practical communication skills. ”
Double winner Laurence Willemet related the competition to experiences in her daily life. Her interest in the Research Slam was rooted in countless family dinners filled with curiosity. “‘What is it exactly that you do with robots?’ they would ask, prompting me to unravel the complexities of my research in layman’s terms. Each time, I found myself grappling with the task of distilling intricate concepts into digestible nuggets of information, relying solely on words to convey the depth of my work. It was during these moments, stripped of slides and scientific jargon, that I realized the importance of clear communication and the power of storytelling. And so, when the opportunity arose to participate in the Research Slam, it felt akin to one of those family dinners for me.”
The first place finishers received a $600 cash prize, while the runners-up and audience choice winners each received $300.
Last year’s winner in the PhD category, Neha Bokil, candidate in biology working on her dissertation in the lab of David Page, is set to represent MIT at the Three Minute Thesis Northeast Regional Competition later this month, which is organized by the Northeastern Association of Graduate Schools.
A full list of slam finalists and the titles of their talks is below.
PhD Contestants:
Pradeep Natarajan, Chemical Engineering (ChemE), “What can coffee-brewing teach us about brain disease?”
Omar Rutledge, Brain and Cognitive Sciences, “Investigating the effects of cannabidiol (CBD) on social anxiety disorder”
Bhavish Dinakar, ChemE, “A boost from batteries: making chemical reactions faster”
Sydney Dolan, Aeronautics and Astronautics, “Creating traffic signals for space”
Postdocs:
Augusto Gandia, Architecture and Planning, “Cyber modeling — computational morphogenesis via ‘smart’ models”
Laurence Willemet, Computer Science and Artificial Intelligence Laboratory, “Remote touch for teleoperation”
Most Kaniz Moriam, Mechanical Engineering, “Improving recyclability of cellulose-based textile wastes”
Mohammed Aatif Shahab, ChemE, “Eye-based human engineering for enhanced industrial safety”
Research Slam organizers included Diana Chien, director of MIT School of Engineering Communication Lab; Elena Kallestinova, director of MIT Writing and Communication Center; Alexis Boyer, assistant director, Graduate Career Services, Career Advising and Professional Development (CAPD); Amanda Cornwall, associate director, Graduate Student Professional Development, CAPD; and Eric Grunwald, director of English Language Studies. This event was sponsored by the Office of Graduate Education, the Office of Postdoctoral Services, the Writing and Communication Center, MIT Career Advising and Professional Development, English Language Studies, and the MIT School of Engineering Communication Labs.
Laurence Willemet, who took both first place and the Audience Choice Award for the postdoc category, explains how her work can be used to improve remote surgical operations.
It could be very informative to observe the pixels on your phone under a microscope, but not if your goal is to understand what a whole video on the screen shows. Cognition is much the same kind of emergent property in the brain. It can only be understood by observing how millions of cells act in coordination, argues a trio of MIT neuroscientists. In a new article, they lay out a framework for understanding how thought arises from the coordination of neural activity driven by oscillating electric fields — also known as brain “waves” or “rhythms.”
Historically dismissed solely as byproducts of neural activity, brain rhythms are actually critical for organizing it, write Picower Professor Earl Miller and research scientists Scott Brincat and Jefferson Roy in Current Opinion in Behavioral Science. And while neuroscientists have gained tremendous knowledge from studying how individual brain cells connect and how and when they emit “spikes” to send impulses through specific circuits, there is also a need to appreciate and apply new concepts at the brain rhythm scale, which can span individual, or even multiple, brain regions.
“Spiking and anatomy are important, but there is more going on in the brain above and beyond that,” says senior author Miller, a faculty member in The Picower Institute for Learning and Memory and the Department of Brain and Cognitive Sciences at MIT. “There’s a whole lot of functionality taking place at a higher level, especially cognition.”
The stakes of studying the brain at that scale, the authors write, might not only include understanding healthy higher-level function but also how those functions become disrupted in disease.
“Many neurological and psychiatric disorders, such as schizophrenia, epilepsy, and Parkinson’s, involve disruption of emergent properties like neural synchrony,” they write. “We anticipate that understanding how to interpret and interface with these emergent properties will be critical for developing effective treatments as well as understanding cognition.”
The emergence of thoughts
The bridge between the scale of individual neurons and the broader-scale coordination of many cells is founded on electric fields, the researchers write. Via a phenomenon called “ephaptic coupling,” the electrical field generated by the activity of a neuron can influence the voltage of neighboring neurons, creating an alignment among them. In this way, electric fields both reflect neural activity and also influence it. In a paper in 2022, Miller and colleagues showed via experiments and computational modeling that the information encoded in the electric fields generated by ensembles of neurons can be read out more reliably than the information encoded by the spikes of individual cells. In 2023 Miller’s lab provided evidence that rhythmic electrical fields may coordinate memories between regions.
At this larger scale, in which rhythmic electric fields carry information between brain regions, Miller’s lab has published numerous studies showing that lower-frequency rhythms in the so-called “beta” band originate in deeper layers of the brain’s cortex and appear to regulate the power of faster-frequency “gamma” rhythms in more superficial layers. By recording neural activity in the brains of animals engaged in working memory games, the lab has shown that beta rhythms carry “top-down” signals to control when and where gamma rhythms can encode sensory information, such as the images that the animals need to remember in the game.
Some of the lab’s latest evidence suggests that beta rhythms apply this control of cognitive processes to physical patches of the cortex, essentially acting like stencils that pattern where and when gamma can encode sensory information into memory, or retrieve it. According to this theory, which Miller calls “Spatial Computing,” beta can thereby establish the general rules of a task (for instance, the back-and-forth turns required to open a combination lock), even as the specific information content may change (for instance, new numbers when the combination changes). More generally, this structure also enables neurons to flexibly encode more than one kind of information at a time, the authors write, a widely observed neural property called “mixed selectivity.” For instance, a neuron encoding a number of the lock combination can also be assigned, based on which beta-stenciled patch it is in, the particular step of the unlocking process that the number matters for.
In the new study, Miller, Brincat, and Roy suggest another advantage consistent with cognitive control being based on an interplay of large-scale coordinated rhythmic activity: “subspace coding.” This idea postulates that brain rhythms organize the otherwise massive number of possible outcomes that could result from, say, 1,000 neurons engaging in independent spiking activity. Instead of all the many combinatorial possibilities, many fewer “subspaces” of activity actually arise, because neurons are coordinated, rather than independent. It is as if the spiking of neurons is like a flock of birds coordinating their movements. Different phases and frequencies of brain rhythms provide this coordination, aligned to amplify each other, or offset to prevent interference. For instance, if a piece of sensory information needs to be remembered, neural activity representing it can be protected from interference when new sensory information is perceived.
“Thus the organization of neural responses into subspaces can both segregate and integrate information,” the authors write.
The power of brain rhythms to coordinate and organize information processing in the brain is what enables functional cognition to emerge at that scale, the authors write. Understanding cognition in the brain, therefore, requires studying rhythms.
“Studying individual neural components in isolation — individual neurons and synapses — has made enormous contributions to our understanding of the brain and remains important,” the authors conclude. “However, it’s becoming increasingly clear that, to fully capture the brain’s complexity, those components must be analyzed in concert to identify, study, and relate their emergent properties.”
One of the key means by which MIT scientists propose that thought is controlled at the level of brain waves is what is known as the spatial computing theory. It posits that beta rhythms act like stencils, dictating where gamma rhythms can encode information in the cortex.
The return of spring in the Northern Hemisphere touches off tornado season. A tornado's twisting funnel of dust and debris seems an unmistakable sight. But that sight can be obscured to radar, the tool of meteorologists. It's hard to know exactly when a tornado has formed, or even why.
A new dataset could hold answers. It contains radar returns from thousands of tornadoes that have hit the United States in the past 10 years. Storms that spawned tornadoes are flanked by other severe storms, some with nearly identical conditions, that never did. MIT Lincoln Laboratory researchers who curated the dataset, called TorNet, have now released it open source. They hope to enable breakthroughs in detecting one of nature's most mysterious and violent phenomena.
“A lot of progress is driven by easily available, benchmark datasets. We hope TorNet will lay a foundation for machine learning algorithms to both detect and predict tornadoes,” says Mark Veillette, the project's co-principal investigator with James Kurdzo. Both researchers work in the Air Traffic Control Systems Group.
Along with the dataset, the team is releasing models trained on it. The models show promise for machine learning's ability to spot a twister. Building on this work could open new frontiers for forecasters, helping them provide more accurate warnings that might save lives.
Swirling uncertainty
About 1,200 tornadoes occur in the United States every year, causing millions to billions of dollars in economic damage and claiming 71 lives on average. Last year, one unusually long-lasting tornado killed 17 people and injured at least 165 others along a 59-mile path in Mississippi.
Yet tornadoes are notoriously difficult to forecast because scientists don't have a clear picture of why they form. “We can see two storms that look identical, and one will produce a tornado and one won't. We don't fully understand it,” Kurdzo says.
A tornado’s basic ingredients are thunderstorms with instability caused by rapidly rising warm air and wind shear that causes rotation. Weather radar is the primary tool used to monitor these conditions. But tornadoes lay too low to be detected, even when moderately close to the radar. As the radar beam with a given tilt angle travels further from the antenna, it gets higher above the ground, mostly seeing reflections from rain and hail carried in the “mesocyclone,” the storm's broad, rotating updraft. A mesocyclone doesn't always produce a tornado.
With this limited view, forecasters must decide whether or not to issue a tornado warning. They often err on the side of caution. As a result, the rate of false alarms for tornado warnings is more than 70 percent. “That can lead to boy-who-cried-wolf syndrome,” Kurdzo says.
In recent years, researchers have turned to machine learning to better detect and predict tornadoes. However, raw datasets and models have not always been accessible to the broader community, stifling progress. TorNet is filling this gap.
The dataset contains more than 200,000 radar images, 13,587 of which depict tornadoes. The rest of the images are non-tornadic, taken from storms in one of two categories: randomly selected severe storms or false-alarm storms (those that led a forecaster to issue a warning but that didn’t produce a tornado).
Each sample of a storm or tornado comprises two sets of six radar images. The two sets correspond to different radar sweep angles. The six images portray different radar data products, such as reflectivity (showing precipitation intensity) or radial velocity (indicating if winds are moving toward or away from the radar).
A challenge in curating the dataset was first finding tornadoes. Within the corpus of weather radar data, tornadoes are extremely rare events. The team then had to balance those tornado samples with difficult non-tornado samples. If the dataset were too easy, say by comparing tornadoes to snowstorms, an algorithm trained on the data would likely over-classify storms as tornadic.
“What's beautiful about a true benchmark dataset is that we're all working with the same data, with the same level of difficulty, and can compare results,” Veillette says. “It also makes meteorology more accessible to data scientists, and vice versa. It becomes easier for these two parties to work on a common problem.”
Both researchers represent the progress that can come from cross-collaboration. Veillette is a mathematician and algorithm developer who has long been fascinated by tornadoes. Kurdzo is a meteorologist by training and a signal processing expert. In grad school, he chased tornadoes with custom-built mobile radars, collecting data to analyze in new ways.
“This dataset also means that a grad student doesn't have to spend a year or two building a dataset. They can jump right into their research,” Kurdzo says.
This project was funded by Lincoln Laboratory's Climate Change Initiative, which aims to leverage the laboratory's diverse technical strengths to help address climate problems threatening human health and global security.
Chasing answers with deep learning
Using the dataset, the researchers developed baseline artificial intelligence (AI) models. They were particularly eager to apply deep learning, a form of machine learning that excels at processing visual data. On its own, deep learning can extract features (key observations that an algorithm uses to make a decision) from images across a dataset. Other machine learning approaches require humans to first manually label features.
“We wanted to see if deep learning could rediscover what people normally look for in tornadoes and even identify new things that typically aren't searched for by forecasters,” Veillette says.
The results are promising. Their deep learning model performed similar to or better than all tornado-detecting algorithms known in literature. The trained algorithm correctly classified 50 percent of weaker EF-1 tornadoes and over 85 percent of tornadoes rated EF-2 or higher, which make up the most devastating and costly occurrences of these storms.
They also evaluated two other types of machine-learning models, and one traditional model to compare against. The source code and parameters of all these models are freely available. The models and dataset are also described in a paper submitted to a journal of the American Meteorological Society (AMS). Veillette presented this work at the AMS Annual Meeting in January.
“The biggest reason for putting our models out there is for the community to improve upon them and do other great things,” Kurdzo says. “The best solution could be a deep learning model, or someone might find that a non-deep learning model is actually better.”
TorNet could be useful in the weather community for others uses too, such as for conducting large-scale case studies on storms. It could also be augmented with other data sources, like satellite imagery or lightning maps. Fusing multiple types of data could improve the accuracy of machine learning models.
Taking steps toward operations
On top of detecting tornadoes, Kurdzo hopes that models might help unravel the science of why they form.
“As scientists, we see all these precursors to tornadoes — an increase in low-level rotation, a hook echo in reflectivity data, specific differential phase (KDP) foot and differential reflectivity (ZDR) arcs. But how do they all go together? And are there physical manifestations we don't know about?” he asks.
Teasing out those answers might be possible with explainable AI. Explainable AI refers to methods that allow a model to provide its reasoning, in a format understandable to humans, of why it came to a certain decision. In this case, these explanations might reveal physical processes that happen before tornadoes. This knowledge could help train forecasters, and models, to recognize the signs sooner.
“None of this technology is ever meant to replace a forecaster. But perhaps someday it could guide forecasters' eyes in complex situations, and give a visual warning to an area predicted to have tornadic activity,” Kurdzo says.
Such assistance could be especially useful as radar technology improves and future networks potentially grow denser. Data refresh rates in a next-generation radar network are expected to increase from every five minutes to approximately one minute, perhaps faster than forecasters can interpret the new information. Because deep learning can process huge amounts of data quickly, it could be well-suited for monitoring radar returns in real time, alongside humans. Tornadoes can form and disappear in minutes.
But the path to an operational algorithm is a long road, especially in safety-critical situations, Veillette says. “I think the forecaster community is still, understandably, skeptical of machine learning. One way to establish trust and transparency is to have public benchmark datasets like this one. It's a first step.”
The next steps, the team hopes, will be taken by researchers across the world who are inspired by the dataset and energized to build their own algorithms. Those algorithms will in turn go into test beds, where they'll eventually be shown to forecasters, to start a process of transitioning into operations.
In the end, the path could circle back to trust.
“We may never get more than a 10- to 15-minute tornado warning using these tools. But if we could lower the false-alarm rate, we could start to make headway with public perception,” Kurdzo says. “People are going to use those warnings to take the action they need to save their lives.”
Mark Veillette (left) and James Kurdzo compiled TorNet, an open-source dataset containing thousands of radar images depicting tornadoes and other severe storms. The dataset can serve as a benchmark for researchers to develop tornado-detecting AI algorithms.
Two teams led by MIT researchers were selected in December 2023 by the U.S. National Science Foundation (NSF) Convergence Accelerator, a part of the TIP Directorate, to receive awards of $5 million each over three years. The NSF Convergence Accelerator is a multidisciplinary and multisector program whose goal is to accelerate use-inspired research into solutions that have societal impact. The Convergence Accelerator’s Track I: Sustainable Materials for Global Challenges, headed by Program Director Linda Molnar, funds projects to develop solutions which both capture the full product life cycle through the advancement of fundamental science and use circular design to create environmental and economically sustainable materials and products.
The MIT teams chosen for this current round of funding belong to Track I and will address current and future needs for environmental sustainability and scalability in advanced semiconductor products across the entire value chain.
One of the MIT-led teams, Topological Electric, is led by Mingda Li, an associate professor in the Department of Nuclear Science and Engineering. This team will be finding pathways to scale up sustainable topological materials, which have the potential to revolutionize next-generation microelectronics by showing superior electronic performance, such as dissipationless states or high-frequency response.
The FUTUR-IC team, led by Anuradha Agarwal, a principal research scientist at MIT’s Materials Research Laboratory, will innovate to address the major bottleneck to the continued scaling of microchip performance at constant cost, power, and improved environmental footprint, with a STEM and green-innovation-trained workforce, by pioneering pathways for the heterogeneous integration of processor, accelerator, and memory chips within a common package. The team does so by creating new electronic-photonic integration technologies which provide high-bandwidth and low-latency data transfer, with reduced environmental impact in both the manufacturing and use phases. And, because there is no incumbent technology to displace, demonstration of this combined three-dimensional technology-ecology-workforce approach, within an alliance of industry leaders, will facilitate easier industry adoption.
Scaling the use of topological materials
Some materials based on quantum effects have achieved successful transitions from lab curiosities to effective mass production, such as blue-light LEDs, and giant magnetoresistance (GMR) devices used for magnetic data storage, according to Li. But he says there are a variety of equally promising materials that have shown promise but have yet to make it into real-world applications.
“What we really wanted to achieve is to bring newer-generation quantum materials into technology and mass production, for the benefit of broader society,” he says. In particular, he says, “topological materials are promising for the advancement of critical technologies such as spintronics, optoelectronics, thermoelectrics, and quantum computing.
Topological materials have electronic properties that are fundamentally protected against disturbance. For example, Li points to the fact that just in the last two years, it has been shown that some topological materials are even better electrical conductors than copper, which is typically used for the wires interconnecting electronic components. However, unlike the blue-light LEDs or the GMR devices, which have been widely produced and deployed, when it comes to topological materials, “there’s no company, no startup, there’s really no business out there,” adds Tomas Palacios, a professor at the Department of Electrical Engineering and Computer Science and co-principal investigator on Li’s team. Part of the reason is that many versions of such materials are studied “with a focus on fundamental exotic physical properties with little or no consideration on the environmental sustainability aspects,” says Liang Fu, a professor of physics and a co-PI. Their team will be looking for alternative formulations that are more amenable to mass production.
One possible application of these topological materials is for detecting terahertz radiation, explains Keith Nelson, an MIT professor of chemistry and co-PI. These extremely high-frequency electronics can carry far more information than conventional radio or microwaves, but at present there are no mature electronic devices available that are scalable at this frequency range. “There’s a whole range of possibilities for topological materials” that could work at these frequencies, he says. In addition, he says, “we hope to demonstrate an entire prototype system like this in a single, very compact solid-state platform.”
Li says that among the many possible applications of topological devices for microelectronics devices of various kinds, “we don’t know which, exactly, will end up as a product, or will reach real industrial scaleup. That’s why this opportunity from NSF is like a bridge, which is precious to allow us to dig deeper to unleash the true and full potential of this class of materials.”
The Topological Electric team includes Tomas Palacios, the Clarence J. Lebel Professor in Electrical Engineering at MIT; Liang Fu, a professor of physics at MIT; Qiong Ma, assistant professor of physics at Boston College; Farnaz Niroui, assistant professor of electrical engineering and computer science at MIT; Susanne Stemmer, professor of materials at the University of California at Santa Barbara; Judy Cha, professor of materials science and engineering at Cornell University; as well as industrial partners including IBM, Analog Devices, and Raytheon, team manager Stephanie Wade MBA ’22, and professional consultants. “We are taking this opportunity seriously,” Li says. “We want to see if the topological materials are as good as we show in the lab when being scaled up, and how far we can push to broadly industrialize them with environmental sustainability in mind.”
Toward electronic-photonic integration for sustainable microchip design, production, and use
The microchips behind everything from smartphones to medical imaging can be traced to greenhouse gas emissions, and every year the world produces more than 50 million metric tons of electronic waste. Further, the data centers necessary for complex computations and huge amount of data transfer — think AI and on-demand video — are growing and will require 10 percent of the world’s electricity by 2030.
“The current microchip manufacturing supply chain which includes production, distribution, and use, is neither scalable nor sustainable, and cannot continue. Together with our workforce, we must innovate our way out of this crisis with a new mindset of performance improvement within environmental constraints. Our academic-industry teams are creating solutions for current hot point technology transitions, and we take responsibility for placing technology-ecology solution tools in the hands of the next generation of semiconductor thought leaders,” says Agarwal.
The name of the team, FUTUR-IC captions the team’s mission of sustainable microchip manufacturing of future integrated circuits. Says Agarwal, “The current microchip scaling trend requires judicious use of mixed technology chiplets for higher speed and increased functionality within a common package platform for 2.5D and 3D heterogenous electronic-photonic integration. FUTUR-IC is enabling this foundational PFAS-free platform to achieve a package I/O target of 1.6 Pb/s data rates using chip-to-chip evanescence and micro-reflection within photonic interconnects. This form of electronic-photonic integration enables modularity for easier disassembly and helps meet ecology constraints of affordable and accessible repair of microchips in systems, decreasing energy consumption, as well as cutting electronic and chemical waste and greenhouse gas emissions associated with electronics by 50 percent every 10 years.”
FUTUR-IC alliance has 26 global collaborators and is growing. Current external collaborators include the International Electronics Manufacturing Initiative (iNEMI), Tyndall National Institute, SEMI, Hewlett Packard Enterprise, Intel, and the Rochester Institute of Technology.
Agarwal leads FUTUR-IC in close collaboration with others, including, from MIT, Lionel Kimerling, the Thomas Lord Professor of Materials Science and Engineering, co-PI; Elsa Olivetti, the Jerry McAfee Professor in Engineering, co-PI; Randolph Kirchain, principal research scientist, co-PI; Greg Norris, director of MIT’s Sustainability and Health Initiative for NetPositive Enterprise (SHINE), and Elizabeth Unger, research scientist. All are affiliated with the Materials Research Laboratory. They are joined by Samuel Serna, MIT visiting professor and assistant professor of physics at Bridgewater State University, a co-PI.
Other key personnel include Aristide Gumyusenge, assistant professor, Sajan Saini, education director, and Pradnya Nagarkar, technical program manager, all at MIT’s Department of Materials Science and Engineering; Timothy Swager, professor at the Department of Chemistry; Peter O’Brien, professor from Tyndall National Institute; and Shekhar Chandrashekhar, CEO of iNEMI.
“We expect the integration of electronics and photonics to revolutionize microchip manufacturing, enhancing efficiency, reducing energy consumption, and paving the way for unprecedented advances in computing speed and data-processing capabilities,” says Serna, who is the co-lead on the project’s technology dimension.
“Enabling the detection, capture, and remediation of PFAS, as well as the development of PFAS-free polymers for microchip processing and electronic-photonic packaging within the semiconductor industry, will be an important contribution to environmental sustainability in microchips as well as to other industries needing alternatives,” says Gumyusenge, who will partner with Swager on this effort, in collaboration with IBM’s PFACTS effort, also funded by NSF Convergence Accelerator’s Track I, program.
“Common assessment metrics for these efforts are needed,” says Norris, co-lead for the ecology dimension, adding, “The microchip industry must have transparent and open Life Cycle Assessment (LCA) models and data, which are being developed by FUTUR-IC.” This is especially important given that microelectronics production transcends industries.
“Given the scale and scope of microelectronics, it is critical for the industry to lead in the transition to sustainable manufacture and use,” says Kirchain, another co-lead and the co-director of the Concrete Sustainability Hub at MIT.
To bring about this cross-fertilization, ecology co-lead Olivetti, also co-director of the MIT Climate and Sustainability Consortium (MCSC), will collaborate with FUTUR-IC. “The program provides the opportunity to contribute to effective methods for life cycle assessment for chip manufacturing with inputs from companies along the supply chain from wafers to data centers. By working closely with the technology team, we will support metrics to monitor progress toward more sustainable design and processing in semiconductor innovation," says Olivetti.
Saini, the co-lead for the workforce dimension along with Unger, stresses the need for agility. “With a workforce that adapts to a practice of continuous upskilling, we can help increase the robustness of the chip-manufacturing supply chain, and validate a new design for a sustainability curriculum,” he says.
“We have become accustomed to the benefits forged by the exponential growth of microelectronic technology performance and market size,” says Kimerling, who is also director of MIT’s Materials Research Laboratory and co-director of the MIT Microphotonics Center: “The ecological impact of this growth in terms of materials use, energy consumption and end-of-life disposal has begun to push back against this progress. FUTUR-IC’s concurrently engineered solutions in these three dimensions will build a common learning curve to power the next 40 years of progress in the semiconductor industry.”
The MIT teams have received awards to develop sustainable materials for global challenges, through Track I of the NSF Convergence Accelerator program, which targets solutions to especially compelling problems at an accelerated pace by incorporating a multidisciplinary and multisector research approach.
Two MIT-led teams received funding from the National Science Foundation to investigate quantum topological materials and sustainable microchip production.
Several years ago, a team of scientists from MIT and the University of Massachusetts at Lowell designed and deployed a first-of-its-kind web programming course for incarcerated individuals across multiple correctional facilities. The program, Brave Behind Bars, uses virtual classroom technology to deliver web design training to students behind prison walls. The program brought together men and women from gender-segregated facilities to learn fundamentals in HTML, CSS, and JavaScript, helping them to create websites addressing social issues of their own choosing.
The program is accredited through three collaborating universities: Georgetown University, Benjamin Franklin Institute of Technology, and Washington County Community College. In a new open-access paper about the project, the team analyzed its impact: They used a multi-pronged approach, gathering insights through comprehensive surveys with participants from dichotomous and open-ended questions. The results painted a powerful narrative of increased self-efficacy — a crucial marker for successful reentry into the workforce and society — among incarcerated learners.
"Education has long been recognized as a pivotal factor in reducing recidivism and fostering successful reentry," says Martin Nisser, an MIT PhD candidate in electrical engineering and computer science (EECS), affiliate of the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL), and lead author of the paper. "By equipping incarcerated learners with invaluable digital literacy skills and boosting their self-efficacy, our program aims to foster the skills necessary to thrive in today's technology-driven world."
The strength of Brave Behind Bars is manifested vividly through the impactful websites created by the students. One project, "End Homelessness Statewide," provided vital resources to help unhoused individuals find temporary and permanent shelter. Another website, "The PinkPrint," addressed the unique challenges incarcerated women face, serving as a "blueprint" with educational resources and gender-responsive support. Equally remarkable was "No Excuse for Domestic Abuse," which raised awareness about the prevalence of domestic violence while offering a lifeline to victims seeking help.
A mixed-methods research study evaluated how the 12-week, college-accredited course was faring. "Our qualitative study in 2022 involving thematic analyses of post-course surveys from 34 students revealed overwhelmingly positive feedback, with students reporting increased self-confidence, motivation, and a sense of empowerment from learning web programming skills. The themes we uncovered highlighted the powerful effect of the program on students' self-beliefs," says Nisser.
The urgency of such work cannot be understated, as underscored by the alarmingly high rates of recidivism, the rate at which formerly incarcerated individuals are rearrested leading to re-conviction. A central cause of mass incarceration, data shows that an estimated 68 percent of people released from U.S. jails or prisons were arrested within three years between 2005 and 2014, rising to 83 percent within nine years. However, a meta-analysis spanning 37 years of research (1980-2017) revealed a promising trend: Incarcerated individuals who participate in post-secondary educational programs are 28 percent less likely to return to prison.
Joblessness among the formerly incarcerated can be as high as 60 percent a year after release. Almost two-thirds of those who secure employment enter jobs typically available to people with little or no education, such as waste management, manufacturing, and construction — jobs increasingly being automated or outsourced.
While both the demand and supply of AI curricula in higher education have sky-rocketed, these have not typically served disadvantaged people, who must be caught up in foundational digital literacy. The ability to skillfully navigate computers and the internet is becoming essential for post-release employment in the modern workplace, as well as to navigate the economic, social, and health-related resources that are now embedded in our digital technologies.
The other part was a quantitative study in 2023, with 37 participants measuring general computer programming self-efficacy using validated scales before and after the course. The authors saw an increase in mean scores for general self-efficacy and digital literacy after the course, but the pre- and post-course measures of self-efficacy were not statistically significantly different. This challenge, the team says, is common in carceral environments, where meta-analyses of multiple studies with less significant results are often needed to achieve statistical significance and draw meaningful conclusions. The authors also acknowledge that their quantitative study contributes to this data pool, and they are conducting new courses to gather more data for future comprehensive statistical analyses.
"By providing incarcerated individuals with an opportunity to develop digital literacy, the Brave Behind Bars program facilitates self-efficacy through a novel education model designed not only to expand access to the internet for individuals but also to teach them the navigation and web design skills needed to connect and engage with the communities to which they will return," says UMass Lowell professor and chair of the School of Criminology and Justice Studies April Pattavina, who was not involved in the research. "I applaud the team's dedication in implementing the program and look forward to longer-term evaluations on graduates when they leave prison so we can learn about the extent to which the program transforms lives on the outside."
One student, reflecting on the impact of the Brave Behind Bars program, says, "This class has shown me that I am human again, and I deserve to have a better quality of life post-incarceration." In an environment where individuals can too often be made to feel like numbers, a program is underway to demonstrate that these individuals can be seen once more as people.
The research was conducted by a team of experts from MIT and UMass Lowell. Leading the team was Martin Nisser, who wrote the paper alongside Marisa Gaetz, a PhD student in the MIT Department of Mathematics; Andrew Fishberg, a PhD student in the MIT Department of Aeronautics and Astronautics; and Raechel Soicher, assistant director of research and evaluation at the MIT Teaching and Learning Laboratory. Faraz Faruqi, an MIT PhD student in EECS and CSAIL affiliate, contributed significantly to the project. Completing the team, Joshua Long brought his expertise from UMass Lowell, adding a unique perspective to the collaborative effort.
Brave Behind Bars, a 12-week college-accredited web design class, taught virtually and synchronously at five correctional facilities across the United States, brought men and women from gender-segregated facilities into one classroom to learn fundamentals in HTML, CSS, and JavaScript, and create websites addressing social issues of their choosing.
MIT Provost Cynthia Barnhart announced four Professor Amar G. Bose Research Grants to support bold research projects across diverse areas of study, including a way to generate clean hydrogen from deep in the Earth, build an environmentally friendly house of basalt, design maternity clothing that monitors fetal health, and recruit sharks as ocean oxygen monitors.
This year's recipients are Iwnetim Abate, assistant professor of materials science and engineering; Andrew Babbin, the Cecil and Ida Green Associate Professor in Earth, Atmospheric and Planetary Sciences; Yoel Fink, professor of materials science and engineering and of electrical engineering and computer science; and Skylar Tibbits, associate professor of design research in the Department of Architecture.
The program was named for the visionary founder of the Bose Corporation and MIT alumnus Amar G. Bose ’51, SM ’52, ScD ’56. After gaining admission to MIT, Bose became a top math student and a Fulbright Scholarship recipient. He spent 46 years as a professor at MIT, led innovations in sound design, and founded the Bose Corp. in 1964. MIT launched the Bose grant program 11 years ago to provide funding over a three-year period to MIT faculty who propose original, cross-disciplinary, and often risky research projects that would likely not be funded by conventional sources.
“The promise of the Bose Fellowship is to help bold, daring ideas become realities, an approach that honors Amar Bose’s legacy,” says Barnhart. “Thanks to support from this program, these talented faculty members have the freedom to explore their bold and innovative ideas.”
Deep and clean hydrogen futures
A green energy future will depend on harnessing hydrogen as a clean energy source, sequestering polluting carbon dioxide, and mining the minerals essential to building clean energy technologies such as advanced batteries. Iwnetim Abate thinks he has a solution for all three challenges: an innovative hydrogen reactor.
He plans to build a reactor that will create natural hydrogen from ultramafic mineral rocks in the crust. “The Earth is literally a giant hydrogen factory waiting to be tapped,” Abate explains. “A back-of-the-envelope calculation for the first seven kilometers of the Earth’s crust estimates that there is enough ultramafic rock to produce hydrogen for 250,000 years.”
The reactor envisioned by Abate injects water to create a reaction that releases hydrogen, while also supporting the injection of climate-altering carbon dioxide into the rock, providing a global carbon capacity of 100 trillion tons. At the same time, the reactor process could provide essential elements such as lithium, nickel, and cobalt — some of the most important raw materials used in advanced batteries and electronics.
“Ultimately, our goal is to design and develop a scalable reactor for simultaneously tapping into the trifecta from the Earth's subsurface,” Abate says.
Sharks as oceanographers
If we want to understand more about how oxygen levels in the world’s seas are disturbed by human activities and climate change, we should turn to a sensing platform “that has been honed by 400 million years of evolution to perfectly sample the ocean: sharks,” says Andrew Babbin.
As the planet warms, oceans are projected to contain less dissolved oxygen, with impacts on the productivity of global fisheries, natural carbon sequestration, and the flux of climate-altering greenhouse gasses from the ocean to the air. While scientists know dissolved oxygen is important, it has proved difficult to track over seasons, decades, and underexplored regions both shallow and deep.
Babbin’s goal is to develop a low-cost sensor for dissolved oxygen that can be integrated with preexisting electronic shark tags used by marine biologists. “This fleet of sharks … will finally enable us to measure the extent of the low-oxygen zones of the ocean, how they change seasonally and with El Niño/La Niña oscillation, and how they expand or contract into the future.”
The partnership with sharks will also spotlight the importance of these often-maligned animals for global marine and fisheries health, Babbin says. “We hope in pursuing this work marrying microscopic and macroscopic life we will inspire future oceanographers and conservationists, and lead to a better appreciation for the chemistry that underlies global habitability.”
Maternity wear that monitors fetal health
There are 2 million stillbirths around the world each year, and in the United States alone, 21,000 families suffer this terrible loss. In many cases, mothers and their doctors had no warning of any abnormalities or changes in fetal health leading up to these deaths. Yoel Fink and colleagues are looking for a better way to monitor fetal health and provide proactive treatment.
Fink is building on years of research on acoustic fabrics to design an affordable shirt for mothers that would monitor and communicate important details of fetal health. His team’s original research drew inspiration from the function of the eardrum, designing a fiber that could be woven into other fabrics to create a kind of fabric microphone.
“Given the sensitivity of the acoustic fabrics in sensing these nanometer-scale vibrations, could a mother's clothing transcend its conventional role and become a health monitor, picking up on the acoustic signals and subsequent vibrations that arise from her unborn baby's heartbeat and motion?” Fink says. “Could a simple and affordable worn fabric allow an expecting mom to sleep better, knowing that her fetus is being listened to continuously?”
The proposed maternity shirt could measure fetal heart and breathing rate, and might be able to give an indication of the fetal body position, he says. In the final stages of development, he and his colleagues hope to develop machine learning approaches that would identify abnormal fetal heart rate and motion and deliver real-time alerts.
A basalt house in Iceland
In the land of volcanoes, Skylar Tibbits wants to build a case-study home almost entirely from the basalt rock that makes up the Icelandic landscape.
Architects are increasingly interested in building using one natural material — creating a monomaterial structure — that can be easily recycled. At the moment, the building industry represents 40 percent of carbon emissions worldwide, and consists of many materials and structures, from metal to plastics to concrete, that can’t be easily disassembled or reused.
The proposed basalt house in Iceland, a project co-led by J. Jih, associate professor of the practice in the Department of Architecture, is “an architecture that would be fully composed of the surrounding earth, that melts back into that surrounding earth at the end of its lifespan, and that can be recycled infinitely,” Tibbits explains.
Basalt, the most common rock form in the Earth’s crust, can be spun into fibers for insulation and rebar. Basalt fiber performs as well as glass and carbon fibers at a lower cost in some applications, although it is not widely used in architecture. In cast form, it can make corrosion- and heat-resistant plumbing, cladding and flooring.
“A monomaterial architecture is both a simple and radical proposal that unfortunately falls outside of traditional funding avenues,” says Tibbits. “The Bose grant is the perfect and perhaps the only option for our research, which we see as a uniquely achievable moonshot with transformative potential for the entire built environment.”
Giving drugs at different times of day could significantly affect how they are metabolized in the liver, according to a new study from MIT.
Using tiny, engineered livers derived from cells from human donors, the researchers found that many genes involved in drug metabolism are under circadian control. These circadian variations affect how much of a drug is available and how effectively the body can break it down. For example, they found that enzymes that break down Tylenol and other drugs are more abundant at certain times of day.
Overall, the researchers identified more than 300 liver genes that follow a circadian clock, including many involved in drug metabolism, as well as other functions such as inflammation. Analyzing these rhythms could help researchers develop better dosing schedules for existing drugs.
“One of the earliest applications for this method could be fine-tuning drug regimens of already approved drugs to maximize their efficacy and minimize their toxicity,” says Sangeeta Bhatia, the John and Dorothy Wilson Professor of Health Sciences and Technology and of Electrical Engineering and Computer Science at MIT, and a member of MIT’s Koch Institute for Integrative Cancer Research and the Institute for Medical Engineering and Science (IMES).
The study also revealed that the liver is more susceptible to infections such as malaria at certain points in the circadian cycle, when fewer inflammatory proteins are being produced.
It is estimated that about 50 percent of human genes follow a circadian cycle, and many of these genes are active in the liver. However, exploring how circadian cycles affect liver function has been difficult because many of these genes are not identical in mice and humans, so mouse models can’t be used to study them.
Bhatia’s lab has previously developed a way to grow miniaturized livers using liver cells called hepatocytes, from human donors. In this study, she and her colleagues set out to investigate whether these engineered livers have their own circadian clocks.
Working with Charles Rice’s group at Rockefeller University, they identified culture conditions that support the circadian expression of a clock gene called Bmal1. This gene, which regulates the cyclic expression of a wide range of genes, allowed the liver cells to develop synchronized circadian oscillations. Then, the researchers measured gene expression in these cells every three hours for 48 hours, enabling them to identify more than 300 genes that were expressed in waves.
Most of these genes clustered in two groups — about 70 percent of the genes peaked together, while the remaining 30 percent were at their lowest point when the others peaked. These included genes involved in a variety of functions, including drug metabolism, glucose and lipid metabolism, and several immune processes.
Once the engineered livers established these circadian cycles, the researchers could use them to explore how circadian cycles affect liver function. First, they set out to study how time of day would affect drug metabolism, looking at two different drugs — acetaminophen (Tylenol) and atorvastatin, a drug used to treat high cholesterol.
When Tylenol is broken down in the liver, a small fraction of the drug is converted into a toxic byproduct known as NAPQI. The researchers found that the amount of NAPQI produced can vary by up to 50 percent, depending on what time of day the drug is administered. They also found that atorvastatin generates higher toxicity at certain times of day.
Both of these drugs are metabolized in part by an enzyme called CYP3A4, which has a circadian cycle. CYP3A4 is involved in processing about 50 percent of all drugs, so the researchers now plan to test more of those drugs using their liver models.
“In this set of drugs, it will be helpful to identify the time of the day to administer the drug to reach the highest effectiveness of the drug and minimize the adverse effects,” March says.
The MIT researchers are now working with collaborators to analyze a cancer drug they suspect may be affected by circadian cycles, and they hope to investigate whether this may also be true of drugs used in pain management.
Susceptibility to infection
Many of the liver genes that show circadian behavior are involved in immune responses such as inflammation, so the researchers wondered if this variation might influence susceptibility to infection. To answer that question, they exposed the engineered livers to Plasmodium falciparum, a parasite that causes malaria, at different points in the circadian cycle.
These studies revealed that the livers were more likely to become infected after exposure at different times of day. This is due to variations in the expression of genes called interferon-stimulated genes, which help to suppress infections.
“The inflammatory signals are much stronger at certain times of days than others,” Bhatia says. “This means that a virus like hepatitis or parasite like the one that causes malaria might be better at taking hold in your liver at certain times of the day.”
The researchers believe this cyclical variation may occur because the liver dampens its response to pathogens following meals, when it is typically exposed to an influx of microorganisms that might trigger inflammation even if they are not actually harmful.
Bhatia’s lab is now taking advantage of these cycles to study infections that are usually difficult to establish in engineered livers, including malaria infections caused by parasites other than Plasmodium falciparum.
“This is quite important for the field, because just by setting up the system and choosing the right time of infection, we can increase the infection rate of our culture by 25 percent, enabling drug screens that were otherwise impractical,” March says.
The research was funded by the MIT International Science and Technology Initiatives MIT-France program, the Koch Institute Support (core) Grant from the U.S. National Cancer Institute, the National Institute of Health and Medical Research of France, and the French National Research Agency.
Using tiny, engineered livers derived from human patients, MIT researchers found that more than 300 liver genes are under circadian control. These circadian variations affect how much of a drug is available and how effectively the body can break it down.
In a letter to the MIT community today, President Sally Kornbluth announced the appointment of Ian A. Waitz to the position of vice president for research. In the role, Waitz will report to the president and oversee MIT’s vast research enterprise. The appointment is effective May 1.
Waitz, who is also the Jerome C. Hunsaker Professor of Aeronautics and Astronautics, brings deep knowledge of MIT to the position. Over more than 30 years, he has served in a wide range of roles across the Institute, where he has made his mark through energy, optimism, persistence, and a commitment to MIT’s mission of using education and innovation to create a better world.
“Ian brings a rare range and depth of understanding of MIT’s research and educational enterprise, our daily operations, our institutional challenges and opportunities, our history and our values — and an unmatched record of solving hard problems and getting big, high-stakes things done well,” Kornbluth wrote.
“MIT’s research enterprise is a critical part of our mission, not just for the impact that innovation and discovery have on the world, but also for the way it enables us to educate people by giving them problems that no one else has ever solved before,” Waitz says. “That builds a sort of intellectual capacity and resilience to work on really hard problems, and the nation and the world need us to work on hard problems.”
Waitz will step down from his current role as vice chancellor overseeing undergraduate and graduate education, where he was instrumental in advancing the priorities of the Chancellor’s Office, currently led by Melissa Nobles.
In that role, which he has held since 2017, Waitz worked with students, faculty, and staff from across the Institute to revamp the first-year undergraduate academic experience, helped steer the Institute through the Covid-19 pandemic, and led efforts to respond to graduate student unionization. Waitz also led a strategic restructuring to integrate the former offices of the Dean for Undergraduate Education and the Dean for Graduate Education, creating the Office of the Vice Chancellor and leading to a more aligned and efficient organization. And, he spearheaded projects to expand professional development opportunities for graduate students, created the MIT Undergraduate Advising Center, worked to significantly expand undergraduate financial aid, and broadly expanded support for graduate students.
“I think my experience gives me a unique perspective on research and education at MIT,” Waitz says. “Education is obviously an amazing part of MIT, and working with students bridges education and the research. That’s one of the things that’s special about a research university. I’m excited for this new role and to continue to work to further strengthen MIT’s exceptional research enterprise.”
Waitz will be filling a role previously held by Maria Zuber, the E. A. Griswold Professor of Geophysics, who now serves as MIT’s presidential advisor for science and technology policy. Waitz says he’s eager to dive in and work to identify ways to help MIT’s prolific research engine run more smoothly. The move is just the latest example of Waitz leaning into new opportunities in service to MIT.
Prior to assuming his current role as vice chancellor, Waitz served as the dean of the School of Engineering between 2011 and 2017, supporting the school’s ability to attract and support exceptional students and faculty. He oversaw the launch of programs including the Institute for Data, Systems, and Society (IDSS), the Institute for Medical Engineering and Science (IMES), the Sandbox Innovation Fund, and the MIT Beaver Works program with Lincoln Laboratory. He also strengthened co-curricular and enrichment programs for undergraduate and graduate students, and worked with department heads to offer more flexible degrees.
Prior to that, Waitz served as the head of MIT’s Department of Aeronautics and Astronautics, where he has been a faculty member since 1991. His research focuses on developing technological, operational, and policy options to mitigate the environmental impacts of aviation. He is a member of the National Academy of Engineering, a fellow of the American Institute of Aeronautics and Astronautics, and has worked closely with industry and government throughout his career.
“One lesson I’ve learned is that the greatest strength of MIT is our students, faculty, and staff,” Waitz says. “We identify people who are real intellectual entrepreneurs. Those are the people that really thrive here, and what you want to do is create a low-friction, high-resource environment for them. Amazing things bubble up from that.”
Entanglement is a form of correlation between quantum objects, such as particles at the atomic scale. This uniquely quantum phenomenon cannot be explained by the laws of classical physics, yet it is one of the properties that explains the macroscopic behavior of quantum systems.
Because entanglement is central to the way quantum systems work, understanding it better could give scientists a deeper sense of how information is stored and processed efficiently in such systems.
Qubits, or quantum bits, are the building blocks of a quantum computer. However, it is extremely difficult to make specific entangled states in many-qubit systems, let alone investigate them. There are also a variety of entangled states, and telling them apart can be challenging.
Now, MIT researchers have demonstrated a technique to efficiently generate entanglement among an array of superconducting qubits that exhibit a specific type of behavior.
Over the past years, the researchers at the Engineering Quantum Systems (EQuS) group have developed techniques using microwave technology to precisely control a quantum processor composed of superconducting circuits. In addition to these control techniques, the methods introduced in this work enable the processor to efficiently generate highly entangled states and shift those states from one type of entanglement to another — including between types that are more likely to support quantum speed-up and those that are not.
“Here, we are demonstrating that we can utilize the emerging quantum processors as a tool to further our understanding of physics. While everything we did in this experiment was on a scale which can still be simulated on a classical computer, we have a good roadmap for scaling this technology and methodology beyond the reach of classical computing,” says Amir H. Karamlou ’18, MEng ’18, PhD ’23, the lead author of the paper.
The senior author is William D. Oliver, the Henry Ellis Warren professor of electrical engineering and computer science and of physics, director of the Center for Quantum Engineering, leader of the EQuS group, and associate director of the Research Laboratory of Electronics. Karamlou and Oliver are joined by Research Scientist Jeff Grover, postdoc Ilan Rosen, and others in the departments of Electrical Engineering and Computer Science and of Physics at MIT, at MIT Lincoln Laboratory, and at Wellesley College and the University of Maryland. The research appears today in Nature.
Assessing entanglement
In a large quantum system comprising many interconnected qubits, one can think about entanglement as the amount of quantum information shared between a given subsystem of qubits and the rest of the larger system.
The entanglement within a quantum system can be categorized as area-law or volume-law, based on how this shared information scales with the geometry of subsystems. In volume-law entanglement, the amount of entanglement between a subsystem of qubits and the rest of the system grows proportionally with the total size of the subsystem.
On the other hand, area-law entanglement depends on how many shared connections exist between a subsystem of qubits and the larger system. As the subsystem expands, the amount of entanglement only grows along the boundary between the subsystem and the larger system.
In theory, the formation of volume-law entanglement is related to what makes quantum computing so powerful.
“While have not yet fully abstracted the role that entanglement plays in quantum algorithms, we do know that generating volume-law entanglement is a key ingredient to realizing a quantum advantage,” says Oliver.
However, volume-law entanglement is also more complex than area-law entanglement and practically prohibitive at scale to simulate using a classical computer.
“As you increase the complexity of your quantum system, it becomes increasingly difficult to simulate it with conventional computers. If I am trying to fully keep track of a system with 80 qubits, for instance, then I would need to store more information than what we have stored throughout the history of humanity,” Karamlou says.
The researchers created a quantum processor and control protocol that enable them to efficiently generate and probe both types of entanglement.
Their processor comprises superconducting circuits, which are used to engineer artificial atoms. The artificial atoms are utilized as qubits, which can be controlled and read out with high accuracy using microwave signals.
The device used for this experiment contained 16 qubits, arranged in a two-dimensional grid. The researchers carefully tuned the processor so all 16 qubits have the same transition frequency. Then, they applied an additional microwave drive to all of the qubits simultaneously.
If this microwave drive has the same frequency as the qubits, it generates quantum states that exhibit volume-law entanglement. However, as the microwave frequency increases or decreases, the qubits exhibit less volume-law entanglement, eventually crossing over to entangled states that increasingly follow an area-law scaling.
Careful control
“Our experiment is a tour de force of the capabilities of superconducting quantum processors. In one experiment, we operated the processor both as an analog simulation device, enabling us to efficiently prepare states with different entanglement structures, and as a digital computing device, needed to measure the ensuing entanglement scaling,” says Rosen.
To enable that control, the team put years of work into carefully building up the infrastructure around the quantum processor.
By demonstrating the crossover from volume-law to area-law entanglement, the researchers experimentally confirmed what theoretical studies had predicted. More importantly, this method can be used to determine whether the entanglement in a generic quantum processor is area-law or volume-law.
“The MIT experiment underscores the distinction between area-law and volume-law entanglement in two-dimensional quantum simulations using superconducting qubits. This beautifully complements our work on entanglement Hamiltonian tomography with trapped ions in a parallel publication published in Nature in 2023,” says Peter Zoller, a professor of theoretical physics at the University of Innsbruck, who was not involved with this work.
“Quantifying entanglement in large quantum systems is a challenging task for classical computers but a good example of where quantum simulation could help,” says Pedram Roushan of Google, who also was not involved in the study. “Using a 2D array of superconducting qubits, Karamlou and colleagues were able to measure entanglement entropy of various subsystems of various sizes. They measure the volume-law and area-law contributions to entropy, revealing crossover behavior as the system’s quantum state energy is tuned. It powerfully demonstrates the unique insights quantum simulators can offer.”
In the future, scientists could utilize this technique to study the thermodynamic behavior of complex quantum systems, which is too complex to be studied using current analytical methods and practically prohibitive to simulate on even the world’s most powerful supercomputers.
“The experiments we did in this work can be used to characterize or benchmark larger-scale quantum systems, and we may also learn something more about the nature of entanglement in these many-body systems,” says Karamlou.
Additional co-authors of the study areSarah E. Muschinske, Cora N. Barrett, Agustin Di Paolo, Leon Ding, Patrick M. Harrington, Max Hays, Rabindra Das, David K. Kim, Bethany M. Niedzielski, Meghan Schuldt, Kyle Serniak, Mollie E. Schwartz, Jonilyn L. Yoder, Simon Gustavsson, and Yariv Yanay.
This research is funded, in part, by the U.S. Department of Energy, the U.S. Defense Advanced Research Projects Agency, the U.S. Army Research Office, the National Science Foundation, the STC Center for Integrated Quantum Materials, the Wellesley College Samuel and Hilda Levitt Fellowship, NASA, and the Oak Ridge Institute for Science and Education.
In a large quantum system comprising many interconnected parts, one can think about entanglement as the amount of quantum information shared between a given subsystem of qubits (represented as spheres with arrows) and the rest of the larger system. The entanglement within a quantum system can be categorized as area-law or volume-law based on how this shared information scales with the geometry of subsystems, as illustrated here.
When cancer patients undergo chemotherapy, the dose of most drugs is calculated based on the patient’s body surface area. This is estimated by plugging the patient’s height and weight into an equation, dating to 1916, that was formulated from data on just nine patients.
This simplistic dosing doesn’t take into account other factors and can lead to patients receiving either too much or too little of a drug. As a result, some patients likely experience avoidable toxicity or insufficient benefit from the chemotherapy they receive.
To make chemotherapy dosing more accurate, MIT engineers have come up with an alternative approach that can enable the dose to be personalized to the patient. Their system measures how much drug is in the patient’s system, and these measurements are fed into a controller that can adjust the infusion rate accordingly.
This approach could help to compensate for differences in drug pharmacokinetics caused by body composition, genetic makeup, chemotherapy-induced toxicity of the organs that metabolize the drugs, interactions with other medications being taken and foods consumed, and circadian fluctuations in the enzymes responsible for breaking down chemotherapy drugs, the researchers say.
“Recognizing the advances in our understanding of how drugs are metabolized, and applying engineering tools to facilitate personalized dosing, we believe, can help transform the safety and efficacy of many drugs,” says Giovanni Traverso, an associate professor of mechanical engineering at MIT, a gastroenterologist at Brigham and Women’s Hospital, and the senior author of the study.
Louis DeRidder, an MIT graduate student, is the lead author of the paper, which appears today in the journal Med.
Continuous monitoring
In this study, the researchers focused on a drug called 5-fluorouracil, which is used to treat colorectal cancers, among others. The drug is typically infused over a 46-hour period, and the dosage is determined using a formula based on the patient’s height and weight, which gives the estimated body surface area.
However, that approach doesn’t account for differences in body composition that can affect how the drug spreads through the body, or genetic variations that influence how it is metabolized. Those differences can lead to harmful side effects, if too much drug is present. If not enough drug is circulating, it may not kill the tumor as expected.
“People with the same body surface area could have very different heights and weights, could have very different muscle masses or genetics, but as long as the height and the weight plugged into this equation give the same body surface area, their dose is identical,” says DeRidder, a PhD candidate in the Medical Engineering and Medical Physics program within the Harvard-MIT Program in Health Sciences and Technology.
Another factor that can alter the amount of drug in the bloodstream at any given time is circadian fluctuations of an enzyme called dihydropyrimidine dehydrogenase (DPD), which breaks down 5-fluorouracil. DPD’s expression, like many other enzymes in the body, is regulated on a circadian rhythm. Thus, the degradation of 5-FU by DPD is not constant but changes according to the time of the day. These circadian rhythms can lead to tenfold fluctuations in the amount of 5-fluorouracil in a patient’s bloodstream over the course of an infusion.
“Using body surface area to calculate a chemotherapy dose, we know that two people can have profoundly different toxicity from 5-fluorouracil chemotherapy. Looking at one patient, they can have cycles of treatment with minimal toxicity and then have a cycle with miserable toxicity. Something changed in how that patient metabolized chemo from one cycle to the next. Our antiquated dosing fails to capture that change, and patients suffer as a result,” says Douglas Rubinson, a clinical oncologist at Dana-Farber Cancer Institute and an author of the paper.
One way to try to counteract the variability in chemotherapy pharmacokinetics is a strategy called therapeutic drug monitoring, in which the patient gives a blood sample at the end of one treatment cycle. After this sample is analyzed for the drug concentration, the dosage can be adjusted, if needed, at the beginning of the next cycle (usually two weeks later for 5-fluorouracil). This approach has been shown to result in better outcomes for patients, but it is not widely used for chemotherapies such as 5-fluorouracil.
The MIT researchers wanted to develop a similar type of monitoring, but in a manner that is automated and enables real-time drug personalization, which could result in better outcomes for patients. In their “closed-loop” system, drug concentrations can be continually monitored, and that information is used to automatically adjust the infusion rate of the chemotherapy drug and keep the dose within the target range. Such a closed-loop system enables personalization of the drug dose in a manner that considers circadian rhythm changes in the levels of drug-metabolizing enzymes, as well as any changes in the patient’s pharmacokinetics since their last treatment, such as chemotherapy-induced toxicity of the organs that metabolize the drugs.
The new system they designed, known as CLAUDIA (Closed-Loop AUtomated Drug Infusion regulAtor), makes use of commercially available equipment for each step. Blood samples are taken every five minutes and rapidly prepared for analysis. The concentration of 5-fluorouracil in the blood is measured and compared to the target range. The difference between the target and measured concentration is input to a control algorithm, which then adjusts the infusion rate if necessary, to keep the dose within the range of concentrations between which the drug is effective and nontoxic.
“What we’ve developed is a system where you can constantly measure the concentration of drug and adjust the infusion rate accordingly, to keep the drug concentration within the therapeutic window,” DeRidder says.
Rapid adjustment
In tests in animals, the researchers found that using CLAUDIA, they could keep the amount of drug circulating in the body within the target range around 45 percent of the time. Drug levels in animals that received chemotherapy without CLAUDIA remained in the target range only 13 percent of the time, on average. In this study, the researchers did not do any tests of the effectiveness of the drug levels, but keeping the concentration within the target window is believed to lead to better outcomes and less toxicity.
CLAUDIA was also able to keep the dose of 5-fluorouracil within the target range even when the researchers administered a drug that inhibits the DPD enzyme. In animals that received this inhibitor without continuous monitoring and adjustment, levels of 5-fluorouracil increased by up to eightfold.
For this demonstration, the researchers manually performed each step of the process, using off-the-shelf equipment, but they now plan to work on automating each step so that the monitoring and dose adjustment can be done without any human intervention.
To measure drug concentrations, the researchers used high-performance liquid chromatography mass spectroscopy (HPLC-MS), a technique that could be adapted to detect nearly any type of drug.
“We foresee a future where we’re able to use CLAUDIA for any drug that has the right pharmacokinetic properties and is detectable with HPLC-MS, thereby enabling the personalization of dosing for many different drugs,” DeRidder says.
The research was funded by the National Science Foundation Graduate Research Fellowship Program, a MathWorks Fellowship, MIT’s Karl van Tassel Career Development Professorship, the MIT Department of Mechanical Engineering, and the Bridge Project, a partnership between the Koch Institute for Integrative Cancer Research at MIT and the Dana-Farber/Harvard Cancer Center.
Other authors of the paper include Kyle A. Hare, Aaron Lopes, Josh Jenkins, Nina Fitzgerald, Emmeline MacPherson, Niora Fabian, Josh Morimoto, Jacqueline N. Chu, Ameya R. Kirtane, Wiam Madani, Keiko Ishida, Johannes L. P. Kuosmanen, Naomi Zecharias, Christopher M. Colangelo, Hen-Wei Huang, Makaya Chilekwa, Nikhil B. Lal, Shriya S. Srinivasan, Alison M Hayward, Brian M. Wolpin, David Trumper, Troy Quast, and Robert Langer.
To make chemotherapy dosing more accurate, MIT engineers have come up with a way to continuously measure how much drug is in the patient’s system during the hours-long infusion. This could help compensate for differences caused by body composition, genetics, drug toxicity, and circadian fluctuations.
Geologists at MIT and Oxford University have uncovered ancient rocks in Greenland that bear the oldest remnants of Earth’s early magnetic field.
The rocks appear to be exceptionally pristine, having preserved their properties for billions of years. The researchers determined that the rocks are about 3.7 billion years old and retain signatures of a magnetic field with a strength of at least 15 microtesla. The ancient field is similar in magnitude to the Earth’s magnetic field today.
The open-access findings, appearing today in the Journal of Geophysical Research, represent some of the earliest evidence of a magnetic field surrounding the Earth. The results potentially extend the age of the Earth’s magnetic field by hundreds of millions of years, and may shed light on the planet’s early conditions that helped life take hold.
“The magnetic field is, in theory, one of the reasons we think Earth is really unique as a habitable planet,” says Claire Nichols, a former MIT postdoc who is now an associate professor of the geology of planetary processes at Oxford University. “It’s thought our magnetic field protects us from harmful radiation from space, and also helps us to have oceans and atmospheres that can be stable for long periods of time.”
Previous studies have shown evidence for a magnetic field on Earth that is at least 3.5 billion years old. The new study is extending the magnetic field’s lifetime by another 200 million years.
“That’s important because that’s the time when we think life was emerging,” says Benjamin Weiss, the Robert R. Shrock Professor of Planetary Sciences in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS). “If the Earth’s magnetic field was around a few hundred million years earlier, it could have played a critical role in making the planet habitable.”
Nichols and Weiss are co-authors of the new study, which also includes Craig Martin and Athena Eyster at MIT, Adam Maloof at Princeton University, and additional colleagues from institutions including Tufts University and the University of Colorado at Boulder.
A slow churn
Today, the Earth’s magnetic field is powered by its molten iron core, which slowly churns up electric currents in a self-generating “dynamo.” The resulting magnetic field extends out and around the planet like a protective bubble. Scientists suspect that, early in its evolution, the Earth was able to foster life, in part due to an early magnetic field that was strong enough to retain a life-sustaining atmosphere and simultaneously shield the planet from damaging solar radiation.
Exactly how early and robust this magnetic shield was is up for debate, though there has been evidence dating its existence to about 3.5 billion years ago.
“We wanted to see if we could extend this record back beyond 3.5 billion years and nail down how strong that early field was,” Nichols says.
In 2018, as a postdoc working in Weiss’ lab at the time, Nichols and her team set off on an expedition tothe Isua Supracrustal Belt, a 20-mile stretch of exposed rock formations surrounded by towering ice sheets in the southwest of Greenland. There, scientists have discovered the oldest preserved rocks on Earth, which have been extensively studied in hopes of answering a slew of scientific questions about Earth’s ancient conditions.
For Nichols and Weiss, the objective was to find rocks that still held signatures of the Earth’s magnetic field when the rocks first formed. Rocks form through many millions of years, as grains of sediment and minerals accumulate and are progressively packed and buried under subsequent deposition over time. Any magnetic minerals such as iron-oxides that are in the deposits follow the pull of the Earth’s magnetic field as they form. This collective orientation, and the imprint of the magnetic field, are preserved in the rocks.
However, this preserved magnetic field can be scrambled and completely erased if the rocks subsequently undergo extreme thermal or aqueous events such as hydrothermal activity or plate tectonics that can pressurize and crush up these deposits. Determining the age of a magnetic field in ancient rocks has therefore been a highly contested area of study.
To get to rocks that were hopefully preserved and unaltered since their original deposition, the team sampled from rock formations in the Isua Supracrustal Belt, a remote location that was only accessible by helicopter.
“It’s about 150 kilometers away from the capital city, and you get helicoptered in, right up against the ice sheet,” Nichols says. “Here, you have the world’s oldest rocks essentially, surrounded by this dramatic expression of the ice age. It’s a really spectacular place.”
Dynamic history
The team returned to MIT with whole rock samples of banded iron formations — a rock type that appears as stripes of iron-rich and silica-rich rock. The iron-oxide minerals found in these rocks can act as tiny magnets that orient with any external magnetic field. Given their composition, the researchers suspect the rocks were originally formed in primordial oceans prior to the rise in atmospheric oxygen around 2.5 billion years ago.
“Back when there wasn’t oxygen in the atmosphere, iron didn’t oxidize so easily, so it was in solution in the oceans until it reached a critical concentration, when it precipitated out,” Nichols explains. “So, it’s basically a result of iron raining out of the oceans and depositing on the seafloor.”
“They’re very beautiful, weird rocks that don’t look like anything that forms on Earth today,” Weiss adds.
Previous studies had used uranium-lead dating to determine the age of the iron oxides in these rock samples. The ratio of uranium to lead (U-Pb) gives scientists an estimate of a rock’s age. This analysis found that some of the magnetized minerals were likely about 3.7 billion years old. The MIT team, in collaboration with researchers from Rensselaer Polytechnic Institute, showed in a paper published last year that the U-Pb age also dates the age of the magnetic record in these minerals.
The researchers then set out to determine whether the ancient rocks preserved magnetic field from that far back, and how strong that field might have been.
“The samples we think are best and have that very old signature, we then demagnetize in the lab, in steps. We apply a laboratory field that we know the strength of, and we remagnetize the rocks in steps, so you can compare the gradient of the demagnetization to the gradient of the lab magnetization. That gradient tells you how strong the ancient field was,” Nichols explains.
Through this careful process of remagnetization, the team concluded that the rocks likely harbored an ancient, 3.7-billion-year-old magnetic field, with a magnitude of at least 15 microtesla. Today, Earth’s magnetic field measures around 30 microtesla.
“It’s half the strength, but the same order of magnitude,” Nichols says. “The fact that it’s similar in strength as today’s field implies whatever is driving Earth’s magnetic field has not changed massively in power over billions of years.”
The team’s experiments also showed that the rocks retained the ancient field, despite having undergone two subsequent thermal events. Any extreme thermal event, such as a tectonic shake-up of the subsurface or hydrothermal eruptions, could potentially heat up and erase a rock’s magnetic field. But the team found that the iron in their samples likely oriented, then crystallized, 3.7 billion years ago, in some initial, extreme thermal event. Around 2.8 billion years ago, and then again at 1.5 billion years ago, the rocks may have been reheated, but not to the extreme temperatures that would have scrambled their magnetization.
“The rocks that the team has studied have experienced quite a bit during their long geological journey on our planet,” says Annique van der Boon, a planetary science researcher at the University of Oslo who was not involved in the study. “The authors have done a lot of work on constraining which geological events have affected the rocks at different times.”
“The team have taken their time to deliver a very thorough study of these complex rocks, which do not give up their secrets easily,” says Andy Biggin, professor of geomagnetism at the University of Liverpool, who did not contribute to the study. “These new results tell us that the Earth’s magnetic field was alive and well 3.7 billion years ago. Knowing it was there and strong contributes a significant boundary constraint on the early Earth’s environment.”
The results also raise questions about how the ancient Earth could have powered such a robust magnetic field. While today’s field is powered by crystallization of the solid iron inner core, it’s thought that the inner core had not yet formed so early in the planet’s evolution.
“It seems like evidence for whatever was generating a magnetic field back then was a different power source from what we have today,” Weiss says. “And we care about Earth because there’s life here, but it’s also a touchstone for understanding other terrestrial planets. It suggests planets throughout the galaxy probably have lots of ways of powering a magnetic field, which is important for the question of habitability elsewhere.”
This research was supported, in part, by the Simons Foundation.
For nearly a decade, a team of MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers have been seeking to uncover why certain images persist in a people's minds, while many others fade. To do this, they set out to map the spatio-temporal brain dynamics involved in recognizing a visual image. And now for the first time, scientists harnessed the combined strengths of magnetoencephalography (MEG), which captures the timing of brain activity, and functional magnetic resonance imaging (fMRI), which identifies active brain regions, to precisely determine when and where the brain processes a memorable image.
Their open-access study, published this month in PLOS Biology, used 78 pairs of images matched for the same concept but differing in their memorability scores — one was highly memorable and the other was easy to forget. These images were shown to 15 subjects, with scenes of skateboarding, animals in various environments, everyday objects like cups and chairs, natural landscapes like forests and beaches, urban scenes of streets and buildings, and faces displaying different expressions. What they found was that a more distributed network of brain regions than previously thought are actively involved in the encoding and retention processes that underpin memorability.
“People tend to remember some images better than others, even when they are conceptually similar, like different scenes of a person skateboarding,” says Benjamin Lahner, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and first author of the study. “We've identified a brain signature of visual memorability that emerges around 300 milliseconds after seeing an image, involving areas across the ventral occipital cortex and temporal cortex, which processes information like color perception and object recognition. This signature indicates that highly memorable images prompt stronger and more sustained brain responses, especially in regions like the early visual cortex, which we previously underestimated in memory processing.”
While highly memorable images maintain a higher and more sustained response for about half a second, the response to less memorable images quickly diminishes. This insight, Lahner elaborated, could redefine our understanding of how memories form and persist. The team envisions this research holding potential for future clinical applications, particularly in early diagnosis and treatment of memory-related disorders.
The MEG/fMRI fusion method, developed in the lab of CSAIL Senior Research Scientist Aude Oliva, adeptly captures the brain's spatial and temporal dynamics, overcoming the traditional constraints of either spatial or temporal specificity. The fusion method had a little help from its machine-learning friend, to better examine and compare the brain's activity when looking at various images. They created a “representational matrix,” which is like a detailed chart, showing how similar neural responses are in various brain regions. This chart helped them identify the patterns of where and when the brain processes what we see.
Picking the conceptually similar image pairs with high and low memorability scores was the crucial ingredient to unlocking these insights into memorability. Lahner explained the process of aggregating behavioral data to assign memorability scores to images, where they curated a diverse set of high- and low-memorability images with balanced representation across different visual categories.
Despite strides made, the team notes a few limitations. While this work can identify brain regions showing significant memorability effects, it cannot elucidate the regions' function in how it is contributing to better encoding/retrieval from memory.
“Understanding the neural underpinnings of memorability opens up exciting avenues for clinical advancements, particularly in diagnosing and treating memory-related disorders early on,” says Oliva. “The specific brain signatures we've identified for memorability could lead to early biomarkers for Alzheimer's disease and other dementias. This research paves the way for novel intervention strategies that are finely tuned to the individual's neural profile, potentially transforming the therapeutic landscape for memory impairments and significantly improving patient outcomes.”
“These findings are exciting because they give us insight into what is happening in the brain between seeing something and saving it into memory,” says Wilma Bainbridge, assistant professor of psychology at the University of Chicago, who was not involved in the study. “The researchers here are picking up on a cortical signal that reflects what's important to remember, and what can be forgotten early on.”
Lahner and Oliva, who is also the director of strategic industry engagement at the MIT Schwarzman College of Computing, MIT director of the MIT-IBM Watson AI Lab, and CSAIL principal investigator, join Western University Assistant Professor Yalda Mohsenzadeh and York University researcher Caitlin Mullin on the paper. The team acknowledges a shared instrument grant from the National Institutes of Health, and their work was funded by the Vannevar Bush Faculty Fellowship via an Office of Naval Research grant, a National Science Foundation award, Multidisciplinary University Research Initiative award via an Army Research Office grant, and the EECS MathWorks Fellowship. Their paper is published in PLOS Biology.
A team of MIT researchers found highly memorable images have stronger and sustained responses in ventro-occipital brain cortices, peaking at around 300ms. Conceptually similar but easily forgettable images quickly fade away.
It’s the most fundamental of processes — the evaporation of water from the surfaces of oceans and lakes, the burning off of fog in the morning sun, and the drying of briny ponds that leaves solid salt behind. Evaporation is all around us, and humans have been observing it and making use of it for as long as we have existed.
And yet, it turns out, we’ve been missing a major part of the picture all along.
In a series of painstakingly precise experiments, a team of researchers at MIT has demonstrated that heat isn’t alone in causing water to evaporate. Light, striking the water’s surface where air and water meet, can break water molecules away and float them into the air, causing evaporation in the absence of any source of heat.
The astonishing new discovery could have a wide range of significant implications. It could help explain mysterious measurements over the years of how sunlight affects clouds, and therefore affect calculations of the effects of climate change on cloud cover and precipitation. It could also lead to new ways of designing industrial processes such as solar-powered desalination or drying of materials.
The findings, and the many different lines of evidence that demonstrate the reality of the phenomenon and the details of how it works, are described today in the journal PNAS, in a paper by Carl Richard Soderberg Professor of Power Engineering Gang Chen, postdocs Guangxin Lv and Yaodong Tu, and graduate student James Zhang.
The authors say their study suggests that the effect should happen widely in nature— everywhere from clouds to fogs to the surfaces of oceans, soils, and plants — and that it could also lead to new practical applications, including in energy and clean water production. “I think this has a lot of applications,” Chen says. “We’re exploring all these different directions. And of course, it also affects the basic science, like the effects of clouds on climate, because clouds are the most uncertain aspect of climate models.”
A newfound phenomenon
The new work builds on research reported last year, which described this new “photomolecular effect” but only under very specialized conditions: on the surface of specially prepared hydrogels soaked with water. In the new study, the researchers demonstrate that the hydrogel is not necessary for the process; it occurs at any water surface exposed to light, whether it’s a flat surface like a body of water or a curved surface like a droplet of cloud vapor.
Because the effect was so unexpected, the team worked to prove its existence with as many different lines of evidence as possible. In this study, they report 14 different kinds of tests and measurements they carried out to establish that water was indeed evaporating — that is, molecules of water were being knocked loose from the water’s surface and wafted into the air — due to the light alone, not by heat, which was long assumed to be the only mechanism involved.
One key indicator, which showed up consistently in four different kinds of experiments under different conditions, was that as the water began to evaporate from a test container under visible light, the air temperature measured above the water’s surface cooled down and then leveled off, showing that thermal energy was not the driving force behind the effect.
Other key indicators that showed up included the way the evaporation effect varied depending on the angle of the light, the exact color of the light, and its polarization. None of these varying characteristics should happen because at these wavelengths, water hardly absorbs light at all — and yet the researchers observed them.
The effect is strongest when light hits the water surface at an angle of 45 degrees. It is also strongest with a certain type of polarization, called transverse magnetic polarization. And it peaks in green light — which, oddly, is the color for which water is most transparent and thus interacts the least.
Chen and his co-researchers have proposed a physical mechanism that can explain the angle and polarization dependence of the effect, showing that the photons of light can impart a net force on water molecules at the water surface that is sufficient to knock them loose from the body of water. But they cannot yet account for the color dependence, which they say will require further study.
They have named this the photomolecular effect, by analogy with the photoelectric effect that was discovered by Heinrich Hertz in 1887 and finally explained by Albert Einstein in 1905. That effect was one of the first demonstrations that light also has particle characteristics, which had major implications in physics and led to a wide variety of applications, including LEDs. Just as the photoelectric effect liberates electrons from atoms in a material in response to being hit by a photon of light, the photomolecular effect shows that photons can liberate entire molecules from a liquid surface, the researchers say.
“The finding of evaporation caused by light instead of heat provides new disruptive knowledge of light-water interaction,” says Xiulin Ruan, professor of mechanical engineering at Purdue University, who was not involved in the study. “It could help us gain new understanding of how sunlight interacts with cloud, fog, oceans, and other natural water bodies to affect weather and climate. It has significant potential practical applications such as high-performance water desalination driven by solar energy. This research is among the rare group of truly revolutionary discoveries which are not widely accepted by the community right away but take time, sometimes a long time, to be confirmed.”
Solving a cloud conundrum
The finding may solve an 80-year-old mystery in climate science. Measurements of how clouds absorb sunlight have often shown that they are absorbing more sunlight than conventional physics dictates possible. The additional evaporation caused by this effect could account for the longstanding discrepancy, which has been a subject of dispute since such measurements are difficult to make.
“Those experiments are based on satellite data and flight data,“ Chen explains. “They fly an airplane on top of and below the clouds, and there are also data based on the ocean temperature and radiation balance. And they all conclude that there is more absorption by clouds than theory could calculate. However, due to the complexity of clouds and the difficulties of making such measurements, researchers have been debating whether such discrepancies are real or not. And what we discovered suggests that hey, there’s another mechanism for cloud absorption, which was not accounted for, and this mechanism might explain the discrepancies.”
Chen says he recently spoke about the phenomenon at an American Physical Society conference, and one physicist there who studies clouds and climate said they had never thought about this possibility, which could affect calculations of the complex effects of clouds on climate. The team conducted experiments using LEDs shining on an artificial cloud chamber, and they observed heating of the fog, which was not supposed to happen since water does not absorb in the visible spectrum. “Such heating can be explained based on the photomolecular effect more easily,” he says.
Lv says that of the many lines of evidence, “the flat region in the air-side temperature distribution above hot water will be the easiest for people to reproduce.” That temperature profile “is a signature” that demonstrates the effect clearly, he says.
Zhang adds: “It is quite hard to explain how this kind of flat temperature profile comes about without invoking some other mechanism” beyond the accepted theories of thermal evaporation. “It ties together what a whole lot of people are reporting in their solar desalination devices,” which again show evaporation rates that cannot be explained by the thermal input.
The effect can be substantial. Under the optimum conditions of color, angle, and polarization, Lv says, “the evaporation rate is four times the thermal limit.”
Already, since publication of the first paper, the team has been approached by companies that hope to harness the effect, Chen says, including for evaporating syrup and drying paper in a paper mill. The likeliest first applications will come in the areas of solar desalinization systems or other industrial drying processes, he says. “Drying consumes 20 percent of all industrial energy usage,” he points out.
Because the effect is so new and unexpected, Chen says, “This phenomenon should be very general, and our experiment is really just the beginning.” The experiments needed to demonstrate and quantify the effect are very time-consuming. “There are many variables, from understanding water itself, to extending to other materials, other liquids and even solids,” he says.
“The observations in the manuscript points to a new physical mechanism that foundationally alters our thinking on the kinetics of evaporation,” says Shannon Yee, an associate professor of mechanical engineering at Georgia Tech, who was not associated with this work. He adds, “Who would have thought that we are still learning about something as quotidian as water evaporating?”
“I think this work is very significant scientifically because it presents a new mechanism,” says University of Alberta Distinguished Professor Janet A.W. Elliott, who also was not associated with this work. “It may also turn out to be practically important for technology and our understanding of nature, because evaporation of water is ubiquitous and the effect appears to deliver significantly higher evaporation rates than the known thermal mechanism. … My overall impression is this work is outstanding. It appears to be carefully done with many precise experiments lending support for one another.”
The work was partly supported by an MIT Bose Award. The authors are currently working on ways to make use of this effect for water desalination, in a project funded by the Abdul Latif Jameel Water and Food Systems Lab and the MIT-UMRP program.
Researchers at MIT have discovered a new phenomenon: that light can cause evaporation of water from its surface without the need for heat. Pictured is a lab device designed to measure the “photomolecular effect,” using laser beams.
Health-monitoring apps can help people manage chronic diseases or stay on track with fitness goals, using nothing more than a smartphone. However, these apps can be slow and energy-inefficient because the vast machine-learning models that power them must be shuttled between a smartphone and a central memory server.
Engineers often speed things up using hardware that reduces the need to move so much data back and forth. While these machine-learning accelerators can streamline computation, they are susceptible to attackers who can steal secret information.
To reduce this vulnerability, researchers from MIT and the MIT-IBM Watson AI Lab created a machine-learning accelerator that is resistant to the two most common types of attacks. Their chip can keep a user’s health records, financial information, or other sensitive data private while still enabling huge AI models to run efficiently on devices.
The team developed several optimizations that enable strong security while only slightly slowing the device. Moreover, the added security does not impact the accuracy of computations. This machine-learning accelerator could be particularly beneficial for demanding AI applications like augmented and virtual reality or autonomous driving.
While implementing the chip would make a device slightly more expensive and less energy-efficient, that is sometimes a worthwhile price to pay for security, says lead author Maitreyi Ashok, an electrical engineering and computer science (EECS) graduate student at MIT.
“It is important to design with security in mind from the ground up. If you are trying to add even a minimal amount of security after a system has been designed, it is prohibitively expensive. We were able to effectively balance a lot of these tradeoffs during the design phase,” says Ashok.
Her co-authors include Saurav Maji, an EECS graduate student; Xin Zhang and John Cohn of the MIT-IBM Watson AI Lab; and senior author Anantha Chandrakasan, MIT’s chief innovation and strategy officer, dean of the School of Engineering, and the Vannevar Bush Professor of EECS. The research will be presented at the IEEE Custom Integrated Circuits Conference.
Side-channel susceptibility
The researchers targeted a type of machine-learning accelerator called digital in-memory compute. A digital IMC chip performs computations inside a device’s memory, where pieces of a machine-learning model are stored after being moved over from a central server.
The entire model is too big to store on the device, but by breaking it into pieces and reusing those pieces as much as possible, IMC chips reduce the amount of data that must be moved back and forth.
But IMC chips can be susceptible to hackers. In a side-channel attack, a hacker monitors the chip’s power consumption and uses statistical techniques to reverse-engineer data as the chip computes. In a bus-probing attack, the hacker can steal bits of the model and dataset by probing the communication between the accelerator and the off-chip memory.
Digital IMC speeds computation by performing millions of operations at once, but this complexity makes it tough to prevent attacks using traditional security measures, Ashok says.
She and her collaborators took a three-pronged approach to blocking side-channel and bus-probing attacks.
First, they employed a security measure where data in the IMC are split into random pieces. For instance, a bit zero might be split into three bits that still equal zero after a logical operation. The IMC never computes with all pieces in the same operation, so a side-channel attack could never reconstruct the real information.
But for this technique to work, random bits must be added to split the data. Because digital IMC performs millions of operations at once, generating so many random bits would involve too much computing. For their chip, the researchers found a way to simplify computations, making it easier to effectively split data while eliminating the need for random bits.
Second, they prevented bus-probing attacks using a lightweight cipher that encrypts the model stored in off-chip memory. This lightweight cipher only requires simple computations. In addition, they only decrypted the pieces of the model stored on the chip when necessary.
Third, to improve security, they generated the key that decrypts the cipher directly on the chip, rather than moving it back and forth with the model. They generated this unique key from random variations in the chip that are introduced during manufacturing, using what is known as a physically unclonable function.
“Maybe one wire is going to be a little bit thicker than another. We can use these variations to get zeros and ones out of a circuit. For every chip, we can get a random key that should be consistent because these random properties shouldn’t change significantly over time,” Ashok explains.
They reused the memory cells on the chip, leveraging the imperfections in these cells to generate the key. This requires less computation than generating a key from scratch.
“As security has become a critical issue in the design of edge devices, there is a need to develop a complete system stack focusing on secure operation. This work focuses on security for machine-learning workloads and describes a digital processor that uses cross-cutting optimization. It incorporates encrypted data access between memory and processor, approaches to preventing side-channel attacks using randomization, and exploiting variability to generate unique codes. Such designs are going to be critical in future mobile devices,” says Chandrakasan.
Safety testing
To test their chip, the researchers took on the role of hackers and tried to steal secret information using side-channel and bus-probing attacks.
Even after making millions of attempts, they couldn’t reconstruct any real information or extract pieces of the model or dataset. The cipher also remained unbreakable. By contrast, it took only about 5,000 samples to steal information from an unprotected chip.
The addition of security did reduce the energy efficiency of the accelerator, and it also required a larger chip area, which would make it more expensive to fabricate.
The team is planning to explore methods that could reduce the energy consumption and size of their chip in the future, which would make it easier to implement at scale.
“As it becomes too expensive, it becomes harder to convince someone that security is critical. Future work could explore these tradeoffs. Maybe we could make it a little less secure but easier to implement and less expensive,” Ashok says.
The research is funded, in part, by the MIT-IBM Watson AI Lab, the National Science Foundation, and a Mathworks Engineering Fellowship.
A new chip can efficiently accelerate machine-learning workloads on edge devices like smartphones while protecting sensitive user data from two common types of attacks — side-channel attacks and bus-probing attacks.
Zachary T.P. Fried, a graduate student in the McGuire group and the lead author of the publication, worked to assemble a puzzle comprised of pieces collected from across the globe, extending beyond MIT to France, Florida, Virginia, and Copenhagen, to achieve this exciting discovery.
“Our group tries to understand what molecules are present in regions of space where stars and solar systems will eventually take shape,” explains Fried. “This allows us to piece together how chemistry evolves alongside the process of star and planet formation. We do this by looking at the rotational spectra of molecules, the unique patterns of light they give off as they tumble end-over-end in space. These patterns are fingerprints (barcodes) for molecules. To detect new molecules in space, we first must have an idea of what molecule we want to look for, then we can record its spectrum in the lab here on Earth, and then finally we look for that spectrum in space using telescopes.”
Searching for molecules in space
The McGuire Group has recently begun to utilize machine learning to suggest good target molecules to search for. In 2023, one of these machine learning models suggested the researchers target a molecule known as 2-methoxyethanol.
“There are a number of 'methoxy' molecules in space, like dimethyl ether, methoxymethanol, ethyl methyl ether, and methyl formate, but 2-methoxyethanol would be the largest and most complex ever seen,” says Fried. To detect this molecule using radiotelescope observations, the group first needed to measure and analyze its rotational spectrum on Earth. The researchers combined experiments from the University of Lille (Lille, France), the New College of Florida (Sarasota, Florida), and the McGuire lab at MIT to measure this spectrum over a broadband region of frequencies ranging from the microwave to sub-millimeter wave regimes (approximately 8 to 500 gigahertz).
The data gleaned from these measurements permitted a search for the molecule using Atacama Large Millimeter/submillimeter Array (ALMA) observations toward two separate star-forming regions: NGC 6334I and IRAS 16293-2422B. Members of the McGuire group analyzed these telescope observations alongside researchers at the National Radio Astronomy Observatory (Charlottesville, Virginia) and the University of Copenhagen, Denmark.
“Ultimately, we observed 25 rotational lines of 2-methoxyethanol that lined up with the molecular signal observed toward NGC 6334I (the barcode matched!), thus resulting in a secure detection of 2-methoxyethanol in this source,” says Fried. “This allowed us to then derive physical parameters of the molecule toward NGC 6334I, such as its abundance and excitation temperature. It also enabled an investigation of the possible chemical formation pathways from known interstellar precursors.”
Looking forward
Molecular discoveries like this one help the researchers to better understand the development of molecular complexity in space during the star formation process. 2-methoxyethanol, which contains 13 atoms, is quite large for interstellar standards — as of 2021, only six species larger than 13 atoms were detected outside the solar system, many by McGuire’s group, and all of them existing as ringed structures.
“Continued observations of large molecules and subsequent derivations of their abundances allows us to advance our knowledge of how efficiently large molecules can form and by which specific reactions they may be produced,” says Fried. “Additionally, since we detected this molecule in NGC 6334I but not in IRAS 16293-2422B, we were presented with a unique opportunity to look into how the differing physical conditions of these two sources may be affecting the chemistry that can occur.”
Newton's third law of motion states that for every action, there is an equal and opposite reaction. The basic physics of running involves someone applying a force to the ground in the opposite direction of their sprint.
For senior Olivia Rosenstein, her cross-country participation provides momentum to her studies as an experimental physicist working with 2D materials, optics, and computational cosmology.
An undergraduate researcher with Professor Richard Fletcher in his Emergent Quantum Matter Group, she is helping to build an erbium-lithium trap for studies of many-body physics and quantum simulation. The group’s focus during this past fall was increasing the trap’s number of erbium atoms and decreasing the atoms’ temperature while preparing the experiment’s next steps.
To this end, Rosenstein helped analyze the behavior of the apparatus’s magnetic fields, perform imaging of the atoms, and develop infrared (IR) optics for future stages of laser cooling, which the group is working on now.
As she wraps up her time at MIT, she also credits her participation on MIT’s Cross Country team as the key to keeping up with her academic and research workload.
“Running is an integral part of my life,” she says. “It brings me joy and peace, and I am far less functional without it.”
First steps
Rosenstein’s parents — a special education professor and a university director of global education programs — encouraged her to explore a wide range of subjects that included math and science. Her early interest in STEM included the University of Illinois Urbana-Champaign’s Engineering Outreach Society, where engineering students visit local elementary schools.
At Urbana High School, she was a cross-country runner — three-year captain of varsity cross country and track, and a five-time Illinois All-State athlete — whose coach taught advanced placement biology. “He did a lot to introduce me to the physiological processes that drive aerobic adaptation and how runners train,” she recalls.
So, she was leaning toward studying biology and physiology when she was applying to colleges. At first, she wasn’t sure she was “smart enough” for MIT.
“I figured everyone at MIT was probably way too stressed, ultracompetitive, and drowning in psets [problem sets], proposals, and research projects,” she says. But once she had a chance to talk to MIT students, she changed her mind.
“MIT kids work hard not because we’re pressured to, but because we’re excited about solving that nagging pset problem, or we get so engrossed in the lab that we don’t notice an extra hour has passed. I learned that people put a lot of time into their living groups, dance teams, music ensembles, sports, activism, and every pursuit in between. As a prospective student, I got to talk to some future cross-country teammates too, and it was clear that people here truly enjoy spending time together.”
Drawn to physics
As a first year, she was intent on Course 20, but then she found herself especially engaged with class 8.022 (Physics II: Electricity and Magnetism), taught by Professor Daniel Harlow.
“I remember there was one time he guided us to a conclusion with completely logical steps, then proceeded to point out all of the inconsistencies in the theory, and told us that unfortunately we would need relativity and more advanced physics to explain it, so we would all need to take those courses and maybe a couple grad classes and then we could come back satisfied.
“I thought, ‘Well shoot, I guess I have to go to physics grad school now.’ It was mostly a joke at the time, but he successfully piqued my interest.”
She compared the course requirements for bioengineering with physics and found she was more drawn to the physics classes. Plus, her time with remote learning also pushed her toward more hands-on activities.
“I realized I’m happiest when at least some of my work involves having something in front of me.”
The summer of her rising sophomore year, she worked in Professor Brian DeMarco’s lab at the University of Illinois in her hometown of Urbana.
“The group was constructing a trapped ion quantum computing apparatus, and I got to see how physics concepts could be used in practice,” she recalls. “I liked that experimentalists got to combine time studying theory with time building in the lab.”
She followed up with stints in Fletcher’s group, a MISTI internship in France with researcher Rebeca Ribeiro-Palau’s condensed matter lab, and an Undergraduate Research Opportunity Program project working on computational cosmology projects with Professor Mark Vogelsberger's group at the Kavli Institute for Astrophysics and Space Research, reviewing the evolution of galaxies and dark matter halos in self-interacting dark-matter simulations.
By the spring of her junior year, she was especially drawn to doing atomic, molecular, and optical (AMO) experiments experiments in class 8.14 (Experimental Physics II), the second semester of Junior Lab.
“Experimental AMO is a lot of fun because you get to study very interesting physics — things like quantum superposition, using light to slow down atoms, and unexplored theoretical effects — while also building real-world, tangible systems,” she says. “Achieving a MOT [magneto-optical trap] is always an exciting phase in an experiment because you get to see quantum mechanics at work with your own eyes, and it’s the first step towards more complex manipulations of the atoms. Current AMO research will let us test concepts that have never been observed before, adding to what we know about how atoms interact at a fundamental level.”
For the exploratory project, Rosenstein and her lab partner, Nicolas Tanaka, chose to build a MOT for rubidium using JLab’s ColdQuanta MiniMOT kit and laser locking through modulation transfer spectroscopy. The two presented at the class’s poster session to the department and won the annual Edward C. Pickering Award for Outstanding Original Project.
“We wanted the experience working with optics and electronics, as well as to create an experimental setup for future student use,” she says. “We got a little obsessed — at least one of us was in the lab almost every hour it was open for the final two weeks of class. Seeing a cloud of rubidium finally appear on our IR TV screen filled us with excitement, pride, and relief. I got really invested in building the MOT, and felt I could see myself working on projects like this for a long time in the future.”
She added, “I enjoyed the big questions being asked in cosmology, but couldn’t get over how much fun I had in the lab, getting to use my hands. I know some people can’t stand assembling optics, but it’s kind of like Legos for me, and I’m happy to spend an afternoon working on getting the mirror alignment just right and ignoring the outside world.”
As a senior, Rosenstein’s goal is to collect experience in experimental optics and cold atoms in preparation for PhD work. “I’d like to combine my passion for big physics questions and AMO experiments, perhaps working on fundamental physics tests using precision measurement, or tests of many-body physics.”
Simultaneously, she’s wrapping up her cosmology research, finishing a project in partnership with Katelin Schutz at McGill University, where they are testing a model to interpret 21-centimeter radio wave signals from the earliest stages of the universe and inform future telescope measurements. Her goal is to see how well an effective field theory (EFT) model can predict 21cm fields with a limited amount of information.
“The EFT we’re using was originally applied to very large-scale simulations, and we had hoped it would still be effective for a set of smaller simulations, but we found that this is not the case. What we want to know now, then, is how much data the simulation would have to have for the model to work. The research requires a lot of data analysis, finding ways to extract and interpret meaningful trends,” Rosenstein says. “It’s even more exciting knowing that the effects we’re seeing are related to the story of our universe, and the tools we’re developing could be used by astronomers to learn even more.”
After graduation, she will spend her summer as a quantum computing company intern. She will then use her Fulbright award to spend a year at ENS Paris-Saclay before heading to Caltech for her PhD.
Running past a crisis
Rosenstein credits her participation in cross country for getting through the pandemic, which delayed setting foot on MIT’s campus until spring 2021.
“The team did provide my main form of social interaction,” she says. “We were sad we didn’t get to compete, but I ran a time trial that was my fastest mile up to that point, which was a small win.”
In her sophomore year, her 38th-place finish at nationals secured her a spot as a National Collegiate Athletic Association All-American in her first collegiate cross-country season. A stress fracture curtailed her running for a bit until placing 12th as an NCAA DIII All-American. (The women’s team placed seventh overall, and the men’s team won MIT’s first NCAA national title.) When another injury sidelined her, she mentored first-year students as team captain and stayed engaged however she could, while biking and swimming to maintain training. She hopes to keep running in her life.
“Both running and physics deal a lot with delayed gratification: You’re not going to run a personal record every day, and you’re not going to publish a groundbreaking discovery every day. Sometimes you might go months or even years without feeling like you’ve made a big jump in your progress. If you can’t take that, you won’t make it as a runner or as a physicist.
“Maybe that makes it sound like runners and physicists are just grinding away, enduring constant suffering in pursuit of some grand goal. But there’s a secret: It isn’t suffering. Running every day is a privilege and a chance to spend time with friends, getting away from other work. Aligning optics, debugging code, and thinking through complex problems isn’t a day in the life of a masochist, just a satisfying Wednesday afternoon.”
She adds, “Cross country and physics both require a combination of naive optimism and rigorous skepticism. On the one hand, you have to believe you’re fully capable of winning that race or getting those new results, otherwise, you might not try at all. On the other hand, you have to be brutally honest about what it’s going to take because those outcomes won’t happen if you aren’t diligent with your training or if you just assume your experimental setup will work exactly as planned. In all, running and physics both consist of minute daily progress that integrates to a big result, and every infinitesimal segment is worth appreciating.”
Olivia Rosenstein stands in front of Professor Richard Fletcher's erbium-lithium experiment. “We use lasers and magnetic fields to cool, combine, and manipulate these atomic gases, which will allow us to study quantum many-body physics (or in other words, the quantum interactions between many particles) once the apparatus is complete,” she says.
To build AI systems that can collaborate effectively with humans, it helps to have a good model of human behavior to start with. But humans tend to behave suboptimally when making decisions.
This irrationality, which is especially difficult to model, often boils down to computational constraints. A human can’t spend decades thinking about the ideal solution to a single problem.
Researchers at MIT and the University of Washington developed a way to model the behavior of an agent, whether human or machine, that accounts for the unknown computational constraints that may hamper the agent’s problem-solving abilities.
Their model can automatically infer an agent’s computational constraints by seeing just a few traces of their previous actions. The result, an agent’s so-called “inference budget,” can be used to predict that agent’s future behavior.
In a new paper, the researchers demonstrate how their method can be used to infer someone’s navigation goals from prior routes and to predict players’ subsequent moves in chess matches. Their technique matches or outperforms another popular method for modeling this type of decision-making.
Ultimately, this work could help scientists teach AI systems how humans behave, which could enable these systems to respond better to their human collaborators. Being able to understand a human’s behavior, and then to infer their goals from that behavior, could make an AI assistant much more useful, says Athul Paul Jacob, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this technique.
“If we know that a human is about to make a mistake, having seen how they have behaved before, the AI agent could step in and offer a better way to do it. Or the agent could adapt to the weaknesses that its human collaborators have. Being able to model human behavior is an important step toward building an AI agent that can actually help that human,” he says.
Jacob wrote the paper with Abhishek Gupta, assistant professor at the University of Washington, and senior author Jacob Andreas, associate professor in EECS and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL). The research will be presented at the International Conference on Learning Representations.
Modeling behavior
Researchers have been building computational models of human behavior for decades. Many prior approaches try to account for suboptimal decision-making by adding noise to the model. Instead of the agent always choosing the correct option, the model might have that agent make the correct choice 95 percent of the time.
However, these methods can fail to capture the fact that humans do not alwaysbehave suboptimally in the same way.
Others at MIT have also studied more effective ways to plan and infer goals in the face of suboptimal decision-making.
To build their model, Jacob and his collaborators drew inspiration from prior studies of chess players. They noticed that players took less time to think before acting when making simple moves and that stronger players tended to spend more time planning than weaker ones in challenging matches.
“At the end of the day, we saw that the depth of the planning, or how long someone thinks about the problem, is a really good proxy of how humans behave,” Jacob says.
They built a framework that could infer an agent’s depth of planning from prior actions and use that information to model the agent’s decision-making process.
The first step in their method involves running an algorithm for a set amount of time to solve the problem being studied. For instance, if they are studying a chess match, they might let the chess-playing algorithm run for a certain number of steps. At the end, the researchers can see the decisions the algorithm made at each step.
Their model compares these decisions to the behaviors of an agent solving the same problem. It will align the agent’s decisions with the algorithm’s decisions and identify the step where the agent stopped planning.
From this, the model can determine the agent’s inference budget, or how long that agent will plan for this problem. It can use the inference budget to predict how that agent would react when solving a similar problem.
An interpretable solution
This method can be very efficient because the researchers can access the full set of decisions made by the problem-solving algorithm without doing any extra work. This framework could also be applied to any problem that can be solved with a particular class of algorithms.
“For me, the most striking thing was the fact that this inference budget is very interpretable. It is saying tougher problems require more planning or being a strong player means planning for longer. When we first set out to do this, we didn’t think that our algorithm would be able to pick up on those behaviors naturally,” Jacob says.
The researchers tested their approach in three different modeling tasks: inferring navigation goals from previous routes, guessing someone’s communicative intent from their verbal cues, and predicting subsequent moves in human-human chess matches.
Their method either matched or outperformed a popular alternative in each experiment. Moreover, the researchers saw that their model of human behavior matched up well with measures of player skill (in chess matches) and task difficulty.
Moving forward, the researchers want to use this approach to model the planning process in other domains, such as reinforcement learning (a trial-and-error method commonly used in robotics). In the long run, they intend to keep building on this work toward the larger goal of developing more effective AI collaborators.
This work was supported, in part, by the MIT Schwarzman College of Computing Artificial Intelligence for Augmentation and Productivity program and the National Science Foundation.
MIT and other researchers developed a framework that models irrational or suboptimal behavior of a human or AI agent, based on their computational constraints. Their technique can help predict an agent’s future actions, for instance, in chess matches.
Although the troposphere is often thought of as the closest layer of the atmosphere to the Earth’s surface, the planetary boundary layer (PBL) — the lowest layer of the troposphere — is actually the part that most significantly influences weather near the surface. In the 2018 planetary science decadal survey, the PBL was raised as an important scientific issue that has the potential to enhance storm forecasting and improve climate projections.
“The PBL is where the surface interacts with the atmosphere, including exchanges of moisture and heat that help lead to severe weather and a changing climate,” says Adam Milstein, a technical staff member in Lincoln Laboratory's Applied Space Systems Group. “The PBL is also where humans live, and the turbulent movement of aerosols throughout the PBL is important for air quality that influences human health.”
Although vital for studying weather and climate, important features of the PBL, such as its height, are difficult to resolve with current technology. In the past four years, Lincoln Laboratory staff have been studying the PBL, focusing on two different tasks: using machine learning to make 3D-scanned profiles of the atmosphere, and resolving the vertical structure of the atmosphere more clearly in order to better predict droughts.
This PBL-focused research effort builds on more than a decade of related work on fast, operational neural network algorithms developed by Lincoln Laboratory for NASA missions. These missions include the Time-Resolved Observations of Precipitation structure and storm Intensity with a Constellation of Smallsats (TROPICS) mission as well as Aqua, a satellite that collects data about Earth’s water cycle and observes variables such as ocean temperature, precipitation, and water vapor in the atmosphere. These algorithms retrieve temperature and humidity from the satellite instrument data and have been shown to significantly improve the accuracy and usable global coverage of the observations over previous approaches. For TROPICS, the algorithms help retrieve data that are used to characterize a storm’s rapidly evolving structures in near-real time, and for Aqua, it has helped increase forecasting models, drought monitoring, and fire prediction.
These operational algorithms for TROPICS and Aqua are based on classic “shallow” neural networks to maximize speed and simplicity, creating a one-dimensional vertical profile for each spectral measurement collected by the instrument over each location. While this approach has improved observations of the atmosphere down to the surface overall, including the PBL, laboratory staff determined that newer “deep” learning techniques that treat the atmosphere over a region of interest as a three-dimensional image are needed to improve PBL details further.
“We hypothesized that deep learning and artificial intelligence (AI) techniques could improve on current approaches by incorporating a better statistical representation of 3D temperature and humidity imagery of the atmosphere into the solutions,” Milstein says. “But it took a while to figure out how to create the best dataset — a mix of real and simulated data; we needed to prepare to train these techniques.”
The team collaborated with Joseph Santanello of the NASA Goddard Space Flight Center and William Blackwell, also of the Applied Space Systems Group, in a recent NASA-funded effort showing that these retrieval algorithms can improve PBL detail, including more accurate determination of the PBL height than the previous state of the art.
While improved knowledge of the PBL is broadly useful for increasing understanding of climate and weather, one key application is prediction of droughts. According to a Global Drought Snapshot report released last year, droughts are a pressing planetary issue that the global community needs to address. Lack of humidity near the surface, specifically at the level of the PBL, is the leading indicator of drought. While previous studies using remote-sensing techniques have examined the humidity of soil to determine drought risk, studying the atmosphere can help predict when droughts will happen.
In an effort funded by Lincoln Laboratory’s Climate Change Initiative, Milstein, along with laboratory staff member Michael Pieper, are working with scientists at NASA’s Jet Propulsion Laboratory (JPL) to use neural network techniques to improve drought prediction over the continental United States. While the work builds off of existing operational work JPL has done incorporating (in part) the laboratory’s operational “shallow” neural network approach for Aqua, the team believes that this work and the PBL-focused deep learning research work can be combined to further improve the accuracy of drought prediction.
“Lincoln Laboratory has been working with NASA for more than a decade on neural network algorithms for estimating temperature and humidity in the atmosphere from space-borne infrared and microwave instruments, including those on the Aqua spacecraft,” Milstein says. “Over that time, we have learned a lot about this problem by working with the science community, including learning about what scientific challenges remain. Our long experience working on this type of remote sensing with NASA scientists, as well as our experience with using neural network techniques, gave us a unique perspective.”
According to Milstein, the next step for this project is to compare the deep learning results to datasets from the National Oceanic and Atmospheric Administration, NASA, and the Department of Energy collected directly in the PBL using radiosondes, a type of instrument flown on a weather balloon. “These direct measurements can be considered a kind of 'ground truth' to quantify the accuracy of the techniques we have developed,” Milstein says.
This improved neural network approach holds promise to demonstrate drought prediction that can exceed the capabilities of existing indicators, Milstein says, and to be a tool that scientists can rely on for decades to come.
This schematic of the planetary boundary layer (red line) shows exchanges of moisture and movement of aerosols that occur between the Earth's surface and this lowest level of the atmosphere. Lincoln Laboratory researchers are using deep learning techniques to learn more about PBL features, important for weather and climate studies.
Have you ever felt reluctant to share ideas during a meeting because you feared judgment from senior colleagues? You’re not alone. Research has shown this pervasive issue can lead to a lack of diversity in public discourse, especially when junior members of a community don’t speak up because they feel intimidated.
Anonymous communication can alleviate that fear and empower individuals to speak their minds, but anonymity also eliminates important social context and can quickly skew too far in the other direction, leading to toxic or hateful speech.
MIT researchers addressed these issues by designing a framework for identity disclosure in public conversations that falls somewhere in the middle, using a concept called “meronymity.”
Meronymity (from the Greek words for “partial” and “name”) allows people in a public discussion space to selectively reveal only relevant, verified aspects of their identity.
The researchers implemented meronymity in a communication system they built called LiTweeture, which is aimed at helping junior scholars use social media to ask research questions.
In LiTweeture, users can reveal a few professional facts, such as their academic affiliation or expertise in a certain field, which lends credibility to their questions or answers while shielding their exact identity.
Users have the flexibility to choose what they reveal about themselves each time they compose a social media post. They can also leverage existing relationships for endorsements that help queries reach experts they otherwise might be reluctant to contact.
During a monthlong study, junior academics who tested LiTweeture said meronymous communication made them feel more comfortable asking questions and encouraged them to engage with senior scholars on social media.
And while this study focused on academia, meronymous communication could be applied to any community or discussion space, says electrical engineering and computer science graduate student Nouran Soliman.
“With meronymity, we wanted to strike a balance between credibility and social inhibition. How can we make people feel more comfortable contributing and leveraging this rich community while still having some accountability?” says Soliman, lead author of a paper on meronymity.
Soliman wrote the paper with her advisor and senior author David Karger, professor in the Department of Electrical Engineering and Computer Science and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL), as well as others at the Semantic Scholar Team at Allen Institute for AI, the University of Washington, and Carnegie Mellon University. The research will be presented at the ACM Conference on Human Factors in Computing Systems.
Breaking down social barriers
The researchers began by conducting an initial study with 20 scholars to better understand the motivations and social barriers they face when engaging online with other academics.
They found that, while academics find X (formerly called Twitter) and Mastodon to be key resources when seeking help with research, they were often reluctant to ask for, discuss, or share recommendations.
Many respondents worried asking for help would make them appear to be unknowledgeable about a certain subject or feared public embarrassment if their posts were ignored.
The researchers developed LiTweeture to enable scholars to selectively present relevant facets of their identity when using social media to ask for research help.
But such identity markers, or “meronyms,” only give someone credibility if they are verified. So the researchers connected LiTweeture to Semantic Scholar, a web service which creates verified academic profiles for scholars detailing their education, affiliations, and publication history.
LiTweeture uses someone’s Semantic Scholar profile to automatically generate a set of meronyms they can choose to include with each social media post they compose. A meronym might be something like, “third-year graduate student at a research institution who has five publications at computer science conferences.”
A user writes a query and chooses the meronyms to appear with this specific post. LiTweeture then posts the query and meryonyms to X and Mastodon.
The user can also identify desired responders — perhaps certain researchers with relevant expertise — who will receive the query through a direct social media message or email. Users can personalize their meronyms for these experts, perhaps mentioning common colleagues or similar research projects.
Sharing social capital
They can also leverage connections by sharing their full identity with individuals who serve as public endorsers, such as an academic advisor or lab mate. Endorsements can encourage experts to respond to the asker’s query.
“The endorsement lets a senior figure donate some of their social capital to people who don’t have as much of it,” Karger says.
In addition, users can recruit close colleagues and peers to be helpers who are willing to repost their query so it reaches a wider audience.
Responders can answer queries using meronyms, which encourages potentially shy academics to offer their expertise, Soliman says.
The researchers tested LiTweeture during a field study with 13 junior academics who were tasked with writing and responding to queries. Participants said meronymous interactions gave them confidence when asking for help and provided high-quality recommendations.
Participants also used meronyms to seek a certain kind of answer. For instance, a user might disclose their publication history to signal that they are not seeking the most basic recommendations. When responding, individuals used identity signals to reflect their level of confidence in a recommendation, for example by disclosing their expertise.
“That implicit signaling was really interesting to see. I was also very excited to see that people wanted to connect with others based on their identity signals. This sense of relation also motivated some responders to make more effort when answering questions,” Soliman says.
Now that they have built a framework around academia, the researchers want to apply meronymity to other online communities and general social media conversations, especially those around issues where there is a lot of conflict, like politics. But to do that, they will need to find an effective, scalable way for people to present verified aspects of their identities.
“I think this is a tool that could be very helpful in many communities. But we have to figure out how to thread the needle on social inhibition. How can we create an environment where everyone feels safe speaking up, but also preserve enough accountability to discourage bad behavior? says Karger.
“Meronymity is not just a concept; it's a novel technique that subtly blends aspects of identity and anonymity, creating a platform where credibility and privacy coexist. It changes digital communications by allowing safe engagement without full exposure, addressing the traditional anonymity-accountability trade-off. Its impact reaches beyond academia, fostering inclusivity and trust in digital interactions,” says Saiph Savage, assistant professor and director of the Civic A.I. Lab in the Khoury College of Computer Science at Northeastern University, and who was not involved with this work.
This research was funded, in part, by Semantic Scholar.
Researchers from MIT and elsewhere designed a communication framework that enables academics to ask for research help on social media using meronymous communication, in which the asker only reveals certain verified aspects of their identity. They found that meronymous communication encouraged people to ask questions they otherwise might not have for fear of judgment from more senior scientists.
Class of 1958 Career Development Assistant Professor Erin Kara of the Department of Physics has been named as the recipient of the 2023-24 Harold E. Edgerton Faculty Achievement Award.
Established in 1982, the award is a tribute to the late Institute Professor Emeritus Harold E. Edgerton for his support for younger faculty members. This award recognizes exceptional distinction in teaching, research, and service.
Professor Kara is an observational astrophysicist who is a faculty member in the Department of Physics and a member of the MIT Kavli Institute for Astrophysics and Space Research (MKI). She uses high-energy transients and time-variable phenomena to understand the physics behind how black holes grow and how they affect their environments.
Kara has advanced a new technique called X-ray reverberation mapping, which allows astronomers to map the gas falling onto black holes and measure the effects of strongly curved spacetime close to the event horizon. She also works on a variety of transient phenomena, such as tidal disruption events and galactic black hole outbursts.
She is a NASA Participating Scientist for the XRISM Observatory, a joint JAXA/NASA X-ray spectroscopy mission that just launched this past September, and is a NASA Participating Scientist for the ULTRASAT Mission, an ultraviolet all-sky time domain mission, set to launch in 2027. She is also working to develop and launch the next generation of NASA missions, as deputy principal investigator of the AXIS Probe Mission.
“I am delighted for Erin,” says Claude Canizares, the Bruno Rossi Professor of Physics. “She is an exemplary Edgerton awardee. As one of the leading observational astrophysicists of her generation, she has made major advances in our understanding of black holes and their environments. She also plays a leadership role in the design of new space missions, is a passionate and effective teacher, and a thoughtful mentor of graduate students and postdocs.”
Adds Kavli Director Rob Simcoe, “Erin is one of a very rare breed of experimental astrophysicists who have the interest and stamina not only to use observatories built by colleagues before her, but also to dive into a leadership role planning and executing new spaceflight missions that will shape the future of her field.”
The committee also recognized Kara’s work to create “a stimulating and productive multigenerational research group. Her mentorship is thoughtful and intentional, guiding and supporting each student or postdoc while giving them the freedom to grow and become self-reliant.”
During the nomination process, students praised Kara’s teaching skills, enthusiasm, organization, friendly demeanor, and knowledge of the material.
“Erin is the best faculty mentor I have ever had,” says one of her students. “She is supportive, engaged, and able to provide detailed input on projects when needed, but also gives the right amount of freedom to her students/postdocs to aid in their development. Working with Erin has been one of the best parts of my time at MIT.”
Kara received a BA in physics from Barnard College, and an MPhil in physics and a PhD in astronomy from the Institute of Astronomy at Cambridge University. She subsequently served as Hubble Postdoctoral Fellow and then Neil Gehrels Prize Postdoctoral Fellow at the University of Maryland and NASA’s Goddard Space Flight Center. She joined the MIT faculty in 2019.
Her recognitions include the American Astronomical Society‘s Newton Lacy Pierce Prize, for “outstanding achievement, over the past five years, in observational astronomical research,” and the Rossi Prize from the High-Energy Astrophysics Division of the AAS (shared).
The award committee lauded Kara’s service in the field and at MIT, including her participation with the Physics Graduate Admissions Committee, the Pappalardo Postdoctoral Fellowship Committee, and the MKI Anti-Racism Task Force. Professor Kara also participates in dinners and meet-and-greets invited by student groups, such as Undergraduate Women in Physics, Graduate Women in Physics, and the Society of Physics Students.
Her participation in public outreach programs includes her talks “Black Hole Echoes and the Music of the Cosmos” at both the Concord Conservatory of Music and an event with MIT School of Science alumni, and “What’s for dinner? How black holes eat nearby stars” for the MIT Summer Research Program.
“There is nothing more gratifying than being recognized by your peers, and I am so appreciative and touched that my colleagues in physics even thought to nominate me for this award,” says Kara. “I also want to express my gratitude to my awesome research group. They are what makes this job so fun and so rewarding, and I know I wouldn’t be in this position without their hard work, great attitudes, and unwavering curiosity.”
Using a pair of sensors made from carbon nanotubes, researchers from MIT and the Singapore-MIT Alliance for Research and Technology (SMART) have discovered signals that reveal when plans are experiencing stresses such as heat, light, or attack from insects or bacteria.
The sensors detect two signaling molecules that plants use to coordinate their response to stress: hydrogen peroxide and salicylic acid (a molecule similar to aspirin). The researchers found that plants produce these molecules at different timepoints for each type of stress, creating distinctive patterns that could serve as an early warning system.
Farmers could use these sensors to monitor potential threats to their crops, allowing them to intervene before the crops are lost, the researchers say.
“What we found is that these two sensors together can tell the user exactly what kind of stress the plant is undergoing. Inside the plant, in real time, you get chemical changes that rise and fall, and each one serves as a fingerprint of a different stress,” says Michael Strano, the Carbon P. Dubbs Professor of Chemical Engineering at MIT and one of the senior authors of the study. Strano is also the co-lead principal investigator at the Disruptive and Sustainable Technologies for Agricultural Precision research group at SMART.
Sarojam Rajani, a senior principal investigator at the Temasek Life Sciences Laboratory in Singapore, is also a senior author of the paper, which appears in Nature Communications. The paper’s lead authors are Mervin Chun-Yi Ang, associate scientific director at SMART and Jolly Madathiparambil Saju, a research officer at Temasek Life Sciences Laboratory.
Sensing stress
Plants respond to different kinds of stress in different ways. In 2020, Strano’s lab developed a sensor that can detect hydrogen peroxide, which plant cells use as a distress signal when they are under attack from insects or encounter other stresses such as bacterial infection or too much light.
These sensors consist of tiny carbon nanotubes wrapped in polymers. By changing the three-dimensional structure of the polymers, the sensors can be tailored to detect different molecules, giving off a fluorescent signal when the target is present. For the new study, the researchers used this approach to develop a sensor that can detect salicylic acid, a molecule that is involved in regulating many aspects of plant growth, development, and response to stress.
To embed the nanosensors into plants, the researchers dissolve them in a solution, which is then applied to the underside of a plant leaf. The sensors can enter leaves through pores called stomata and take up residence in the mesophyll — the layer where most photosynthesis takes place. When a sensor is activated, the signal can be easily detecting using an infrared camera.
In this study, the researchers applied the sensors for hydrogen peroxide and salicylic acid to pak choi, a leafy green vegetable also known as bok choy or Chinese cabbage. Then, they exposed the plants to four different types of stress — heat, intense light, insect bites, and bacterial infection — and found that the plants generated distinctive responses to each type of stress.
Each type of stress led the plants to produce hydrogen peroxide within minutes, reaching maximum levels within an hour and then returning to normal. Heat, light, and bacterial infection all provoked salicylic acid production within two hours of the stimulus, but at distinct time points. Insect bites did not stimulate salicylic acid production at all.
The findings represent a “language” that plants use to coordinate their response to stress, Strano says. The hydrogen peroxide and salicylic acid waves trigger additional responses that help a plant survive whatever type of stress it’s facing.
For a stress such as an insect bite, this response includes the production of chemical compounds that insects don’t like, driving them away from the plant. Salicylic acid and hydrogen peroxide can also activate signaling pathways that turn on the production of proteins that help plants respond to heat and other stresses.
“Plants don't have a brain, they don't have a central nervous system, but they evolved to send different mixtures of chemicals, and that's how they communicate to the rest of the plant that it's getting too hot, or an insect predator is attacking,” Strano says.
Early warning
This technique is the first that can obtain real-time information from a plant, and the only one that can be applied to nearly any plant. Most existing sensors consist of fluorescent proteins that must be genetically engineered into a specific type of plant, such as tobacco or the common experimental plant Arabidopsis thaliana, and can’t be universally applied.
The researchers are now adapting these sensors to create sentinel plants that could be monitored to give farmers a much earlier warning when their crops are under stress. When plants don’t have enough water, for example, they eventually begin to turn brown, but by the time that happens, it’s usually too late to intervene.
“With climate change and the increasing population, there is a great need to understand better how plants respond and acclimate to stress, and also to engineer plants that are more tolerant to stress. The work reveals the interplay between H2O2, one of the most important reactive oxygen species in plants, and the hormone salicylic acid, which is widely involved in plants’ stress responses, therefore contributing to the mechanistic understanding of plants stress signaling,” says Eleni Stavrinidou, a senior associate professor of bioengineering at Linköping University in Sweden, who was not involved in the research.
This technology could also be used to develop systems that not only sense when plants are in distress but would also trigger a response such as altering the temperature or the amount of light in a greenhouse.
“We're incorporating this technology into diagnostics that can give farmers real-time information much faster than any other sensor can, and fast enough for them to intervene,” Strano says.
The researchers are also developing sensors that could be used to detect other plant signaling molecules, in hopes of learning more about their responses to stress and other stimuli.
The research was supported by the National Research Foundation of Singapore under its Campus for Research Excellence And Technological Enterprise (CREATE) program through SMART, and by the USDA National Institute of Food and Agriculture.
Using a pair of sensors made from carbon nanotubes, researchers discovered signals that help plants respond to stresses such as heat, light, or attack from insects or bacteria. Farmers could use these sensors to monitor threats to their crops, allowing them to intervene before the crops are lost.
Across the country, hundreds of thousands of drivers deliver packages and parcels to customers and companies each day, with many click-to-door times averaging only a few days. Coordinating a supply chain feat of this magnitude in a predictable and timely way is a longstanding problem of operations research, where researchers have been working to optimize the last leg of delivery routes. This is because the last phase of the process is often the costliest due to inefficiencies like long distances between stops due to increased ecommerce demand, weather delays, traffic, lack of parking availability, customer delivery preferences, or partially full trucks — inefficiencies that became more exaggerated and evident during the pandemic.
With newer technology and more individualized and nuanced data, researchers are able to develop models with better routing options but at the same time need to balance the computational cost of running them. Matthias Winkenbach, MIT principal research scientist, director of research for the MIT Center for Transportation and Logistics (CTL) and a researcher with the MIT-IBM Watson AI Lab, discusses how artificial intelligence could provide better and more computationally efficient solutions to a combinatorial optimization problem like this one.
Q: What is the vehicle routing problem, and how do traditional operations research (OR) methods address it?
A: The vehicle routing problem is faced by pretty much every logistics and delivery company like USPS, Amazon, UPS, FedEx, DHL every single day. Simply speaking, it's finding an efficient route that connects a set of customers that need to be either delivered to, or something needs to be picked up from them. It’s deciding which customers each of those vehicles — that you see out there on the road — should visit on a given day and in which sequence. Usually, the objective there is to find routes that lead to the shortest, or the fastest, or the cheapest route. But very often they are also driven by constraints that are specific to a customer. For instance, if you have a customer who has a delivery time window specified, or a customer on the 15th floor in the high-rise building versus the ground floor. This makes these customers more difficult to integrate into an efficient delivery route.
To solve the vehicle routing problem, we obviously we can't do our modeling without proper demand information and, ideally, customer-related characteristics. For instance, we need to know the size or weight of the packages ordered by a given customer, or how many units of a certain product need to be shipped to a certain location. All of this determines the time that you would need to service that particular stop. For realistic problems, you also want to know where the driver can park the vehicle safely. Traditionally, a route planner had to come up with good estimates for these parameters, so very often you find models and planning tools that are making blanket assumptions because there weren’t stop-specific data available.
Machine learning can be very interesting for this because nowadays most of the drivers have smartphones or GPS trackers, so there is a ton of information as to how long it takes to deliver a package. You can now, at scale, in a somewhat automated way, extract that information and calibrate every single stop to be modeled in a realistic way.
Using a traditional OR approach means you write up an optimization model, where you start by defining the objective function. In most cases that's some sort of cost function. Then there are a bunch of other equations that define the inner workings of a routing problem. For instance, you must tell the model that, if the vehicle visits a customer, it also needs to leave the customer again. In academic terms, that's usually called flow conservation. Similarly, you need to make sure that every customer is visited exactly once on a given route. These and many other real-world constraints together define what constitutes a viable route. It may seem obvious to us, but this needs to be encoded explicitly.
Once an optimization problem is formulated, there are algorithms out there that help us find the best possible solution; we refer to them as solvers. Over time they find solutions that comply with all the constraints. Then, it tries to find routes that are better and better, so cheaper and cheaper ones until you either say, "OK, this is good enough for me," or until it can mathematically prove that it found the optimal solution. The average delivery vehicle in a U.S. city makes about 120 stops. It can take a while to solve that explicitly, so that's usually not what companies do, because it's just too computationally expensive. Therefore, they use so-called heuristics, which are algorithms that are very efficient in finding reasonably good solutions but typically cannot quantify how far away these solutions are from the theoretical optimum.
Q: You’re currently applying machine learning to the vehicle routing problem. How are you employing it to leverage and possibly outperform traditional OR methods?
A: That's what we're currently working on with folks from the MIT-IBM Watson AI Lab. Here, the general idea is that you train a model on a large set of existing routing solutions that you either observed in a company’s real-world operations or that you generated using one of these efficient heuristics. In most machine-learning models, you no longer have an explicit objective function. Instead, you need to make the model understand what kind of problem it's actually looking at and what a good solution to the problem looks like. For instance, similar to training a large language model on words in a given language, you need to train a route learning model on the concept of the various delivery stops and their demand characteristics. Like understanding the inherent grammar of natural language, your model needs to understand how to connect these delivery stops in a way that results in a good solution — in our case, a cheap or fast solution. If you then throw a completely new set of customer demands at it, it will still be able to connect the dots quite literally in a way that you would also do if you were trying to find a good route to connect these customers.
For this, we're using model architectures that most people know from the language processing space. It seems a little bit counterintuitive because what does language processing have to do with routing? But actually, the properties of these models, especially transformer models, are good at finding structure in language — connecting words in a way that they form sentences. For instance, in a language, you have a certain vocabulary, and that's fixed. It's a discrete set of possible words that you can use, and the challenge is to combine them in a meaningful way. In routing, it's similar. In Cambridge there are like 40,000 addresses that you can visit. Usually, it's a subset of these addresses that need to be visited, and the challenge is: How do we combine this subset — these "words" — in a sequence that makes sense?
That's kind of the novelty of our approach — leveraging that structure that has proven to be extremely effective in the language space and bringing it into combinatorial optimization. Routing is just a great test bed for us because it's the most fundamental problem in the logistics industry.
Of course, there are already very good routing algorithms out there that emerged from decades of operations research. What we are trying to do in this project is show that with a completely different, purely machine learning-based methodological approach, we are able to predict routes that are pretty much as good as, or better than, the routes that you would get from running a state-of-the-art route optimization heuristic.
Q: What advantages does a method like yours have over other state-of-the-art OR techniques?
A: Right now, the best methods are still very hungry in terms of computational resources that are required to train these models, but you can front-load some of this effort. Then, the trained model is relatively efficient in producing a new solution as it becomes required.
Another aspect to consider is that the operational environment of a route, especially in cities, is constantly changing. The available road infrastructure, or traffic rules and speed limits might be altered, the ideal parking lot may be occupied by something else, or a construction site might block a road. With a pure OR-based approach, you might actually be in trouble because you would have to basically resolve the entire problem instantly once new information about the problem becomes available. Since the operational environment is dynamically changing, you would have to do this over and over again. While if you have a well-trained model that has seen similar issues before, it could potentially suggest the next-best route to take, almost instantaneously. It's more of a tool that would help companies to adjust to increasingly unpredictable changes in the environment.
Moreover, optimization algorithms are often manually crafted to solve the specific problem of a given company. The quality of the solutions obtained from such explicit algorithms is bounded by the level of detail and sophistication that went into the design of the algorithm. A learning-based model, on the other hand, continuously learns a routing policy from data. Once you have defined the model structure, a well-designed route learning model will distill potential improvements to your routing policy from the vast amount of routes it is being trained on. Simply put, a learning-based routing tool will continue to find improvements to your routes without you having to invest into explicitly designing these improvements into the algorithm.
Lastly, optimization-based methods are typically limited to optimizing for a very clearly defined objective function, which often seeks to minimize cost or maximize profits. In reality, the objectives that companies and drivers face are much more complex than that, and often they are also somewhat contradictory. For instance, a company wants to find efficient routes, but it also wants to have a low emissions footprint. The driver also wants to be safe and have a convenient way of serving these customers. On top of all of that, companies also care about consistency. A well-designed route learning model can eventually capture these high-dimensional objectives by itself, and that is something that you would never be able to achieve in the same way with a traditional optimization approach.
So, this is the kind of machine learning application that can actually have a tangible real-world impact in industry, on society, and on the environment. The logistics industry has problems that are much more complex than this. For instance, if you want to optimize an entire supply chain — let's say, the flow of a product from the manufacturer in China through the network of different ports around the world, through the distribution network of a big retailer in North America to your store where you actually buy it — there are so many decisions involved in that, which obviously makes it a much harder task than optimizing a single vehicle route. Our hope is that with this initial work, we can lay the foundation for research and also private sector development efforts to build tools that will eventually enable better end-to-end supply chain optimization.
With newer technology and more individualized and nuanced data, researchers can develop models with better routing options, but they also need to balance the computational cost of running them.
When MIT professor and now Computer Science and Artificial Intelligence Laboratory (CSAIL) member Peter Shor first demonstrated the potential of quantum computers to solve problems faster than classical ones, he inspired scientists to imagine countless possibilities for the emerging technology. Thirty years later, though, the quantum edge remains a peak not yet reached.
Unfortunately, the technology of quantum computing isn’t fully operational yet. One major challenge lies in translating quantum algorithms from abstract mathematical concepts into concrete code that can run on a quantum computer. Whereas programmers for regular computers have access to myriad languages such as Python and C++ with constructs that align with standard classical computing abstractions, quantum programmers have no such luxury; few quantum programming languages exist today, and they are comparatively difficult to use because quantum computing abstractions are still in flux. In their recent work, MIT researchers highlight that this disparity exists because quantum computers don’t follow the same rules for how to complete each step of a program in order — an essential process for all computers called control flow — and present a new abstract model for a quantum computer that could be easier to program.
In a paper soon to be presented at the ACM Conference on Object-oriented Programming, Systems, Languages, and Applications, the group outlines a new conceptual model for a quantum computer, called a quantum control machine, that could bring us closer to making programs as easy to write as those for regular classical computers. Such an achievement would help turbocharge tasks that are impossible for regular computers to efficiently complete, like factoring large numbers, retrieving information in databases, and simulating how molecules interact for drug discoveries.
“Our work presents the principles that govern how you can and cannot correctly program a quantum computer,” says lead author and CSAIL PhD student Charles Yuan SM ’22. “One of these laws implies that if you try to program a quantum computer using the same basic instructions as a regular classical computer, you’ll end up turning that quantum computer into a classical computer and lose its performance advantage. These laws explain why quantum programming languages are tricky to design and point us to a way to make them better.”
Old school vs. new school computing
One reason why classical computers are relatively easier to program today is that their control flow is fairly straightforward. The basic ingredients of a classical computer are simple: binary digits or bits, a simple collection of zeros and ones. These ingredients assemble into the instructions and components of the computer’s architecture. One important component is the program counter, which locates the next instruction in a program much like a chef following a recipe, by recalling the next direction from memory. As the algorithm sequentially navigates through the program, a control flow instruction called a conditional jump updates the program counter to make the computer either advance forward to the next instruction or deviate from its current steps.
By contrast, the basic ingredient of a quantum computer is a qubit, which is a quantum version of a bit. This quantum data exists in a state of zero and one at the same time, known as a superposition. Building on this idea, a quantum algorithm can choose to execute a superposition of two instructions at the same time — a concept called quantum control flow.
The problem is that existing designs of quantum computers don’t include an equivalent of the program counter or a conditional jump. In practice, that means programmers typically implement control flow by manually arranging logical gates that describe the computer’s hardware, which is a tedious and error-prone procedure. To provide these features and close the gap with classical computers, Yuan and his coauthors created the quantum control machine — an instruction set for a quantum computer that works like the classical idea of a virtual machine. In their paper, the researchers envision how programmers could use this instruction set to implement quantum algorithms for problems such as factoring numbers and simulating chemical interactions.
As the technical crux of this work, the researchers prove that a quantum computer cannot support the same conditional jump instruction as a classical computer, and show how to modify it to work correctly on a quantum computer. Specifically, the quantum control machine features instructions that are all reversible — they can run both forward and backward in time. A quantum algorithm needs all instructions, including those for control flow, to be reversible so that it can process quantum information without accidentally destroying its superposition and producing a wrong answer.
The hidden simplicity of quantum computers
According to Yuan, you don’t need to be a physicist or mathematician to understand how this futuristic technology works. Quantum computers don’t necessarily have to be arcane machines, he says, that require scary equations to understand. With the quantum control machine, the CSAIL team aims to lower the barrier to entry for people to interact with a quantum computer by raising the unfamiliar concept of quantum control flow to a level that mirrors the familiar concept of control flow in classical computers. By highlighting the dos and don’ts of building and programming quantum computers, they hope to educate people outside of the field about the power of quantum technology and its ultimate limits.
Still, the researchers caution that as is the case for many other designs, it’s not yet possible to directly turn their work into a practical hardware quantum computer due to the limitations of today’s qubit technology. Their goal is to develop ways of implementing more kinds of quantum algorithms as programs that make efficient use of a limited number of qubits and logic gates. Doing so would bring us closer to running these algorithms on the quantum computers that could come online in the near future.
“The fundamental capabilities of models of quantum computation has been a central discussion in quantum computation theory since its inception,” says MIT-IBM Watson AI Lab researcher Patrick Rall, who was not involved in the paper. “Among the earliest of these models are quantum Turing machines which are capable of quantum control flow. However, the field has largely moved on to the simpler and more convenient circuit model, for which quantum lacks control flow. Yuan, Villanyi, and Carbin successfully capture the underlying reason for this transition using the perspective of programming languages. While control flow is central to our understanding of classical computation, quantum is completely different! I expect this observation to be critical for the design of modern quantum software frameworks as hardware platforms become more mature.”
The paper lists two additional CSAIL members as authors: PhD student Ági Villányi ’21 and Associate Professor Michael Carbin. Their work was supported, in part, by the National Science Foundation and the Sloan Foundation.
To close the gap with classical computers, researchers created the quantum control machine — an instruction set for a quantum computer that works like the classical idea of a virtual machine.
To save on fuel and reduce aircraft emissions, engineers are looking to build lighter, stronger airplanes out of advanced composites. These engineered materials are made from high-performance fibers that are embedded in polymer sheets. The sheets can be stacked and pressed into one multilayered material and made into extremely lightweight and durable structures.
But composite materials have one main vulnerability: the space between layers, which is typically filled with polymer “glue” to bond the layers together. In the event of an impact or strike, cracks can easily spread between layers and weaken the material, even though there may be no visible damage to the layers themselves. Over time, as these hidden cracks spread between layers, the composite could suddenly crumble without warning.
Now, MIT engineers have shown they can prevent cracks from spreading between composite’s layers, using an approach they developed called “nanostitching,” in which they deposit chemically grown microscopic forests of carbon nanotubes between composite layers. The tiny, densely packed fibers grip and hold the layers together, like ultrastrong Velcro, preventing the layers from peeling or shearing apart.
In experiments with an advanced composite known as thin-ply carbon fiber laminate, the team demonstrated that layers bonded with nanostitching improved the material’s resistance to cracks by up to 60 percent, compared with composites with conventional polymers. The researchers say the results help to address the main vulnerability in advanced composites.
“Just like phyllo dough flakes apart, composite layers can peel apart because this interlaminar region is the Achilles’ heel of composites,” says Brian Wardle, professor of aeronautics and astronautics at MIT. “We’re showing that nanostitching makes this normally weak region so strong and tough that a crack will not grow there. So, we could expect the next generation of aircraft to have composites held together with this nano-Velcro, to make aircraft safer and have greater longevity.”
Wardle and his colleagues have published their results today in the journal ACS Applied Materials and Interfaces. The study’s first author is former MIT visiting graduate student and postdoc Carolina Furtado, along with Reed Kopp, Xinchen Ni, Carlos Sarrado, Estelle Kalfon-Cohen, and Pedro Camanho.
Forest growth
At MIT, Wardle is director of the necstlab (pronounced “next lab”), where he and his group first developed the concept for nanostitching. The approach involves “growing” a forest of vertically aligned carbon nanotubes — hollow fibers of carbon, each so small that tens of billions of the the nanotubes can stand in an area smaller than a fingernail. To grow the nanotubes, the team used a process of chemical vapor deposition to react various catalysts in an oven, causing carbon to settle onto a surface as tiny, hair-like supports. The supports are eventually removed, leaving behind a densely packed forest of microscopic, vertical rolls of carbon.
The lab has previously shown that the nanotube forests can be grown and adhered to layers of composite material, and that this fiber-reinforced compound improves the material’s overall strength. The researchers had also seen some signs that the fibers can improve a composite’s resistance to cracks between layers.
In their new study, the engineers took a more in-depth look at the between-layer region in composites to test and quantify how nanostitching would improve the region’s resistance to cracks. In particular, the study focused on an advanced composite material known as thin-ply carbon fiber laminates.
“This is an emerging composite technology, where each layer, or ply, is about 50 microns thin, compared to standard composite plies that are 150 microns, which is about the diameter of a human hair. There’s evidence to suggest they are better than standard-thickness composites. And we wanted to see whether there might be synergy between our nanostitching and this thin-ply technology, since it could lead to more resilient aircraft, high-value aerospace structures, and space and military vehicles,” Wardle says.
Velcro grip
The study’s experiments were led by Carolina Furtado, who joined the effort as part of the MIT-Portugal program in 2016, continued the project as a postdoc, and is now a professor at the University of Porto in Portugal, where her research focuses on modeling cracks and damage in advanced composites.
In her tests, Furtado used the group’s techniques of chemical vapor deposition to grow densely packed forests of vertically aligned carbon nanotubes. She also fabricated samples of thin-ply carbon fiber laminates. The resulting advanced composite was about 3 millimeters thick and comprised 60 layers, each made from stiff, horizontal fibers embedded in a polymer sheet.
She transferred and adhered the nanotube forest in between the two middle layers of the composite, then cooked the material in an autoclave to cure. To test crack resistance, the researchers placed a crack on the edge of the composite, right at the start of the region between the two middle layers.
“In fracture testing, we always start with a crack because we want to test whether and how far the crack will spread,” Furtado explains.
The researchers then placed samples of the nanotube-reinforced composite in an experimental setup to test their resilience to “delamination,” or the potential for layers to separate.
“There’s lots of ways you can get precursors to delamination, such as from impacts, like tool drop, bird strike, runway kickup in aircraft, and there could be almost no visible damage, but internally it has a delamination,” Wardle says. “Just like a human, if you’ve got a hairline fracture in a bone, it’s not good. Just because you can’t see it doesn’t mean it’s not impacting you. And damage in composites is hard to inspect.”
To examine nanostitching’s potential to prevent delamination, the team placed their samples in a setup to test three delamination modes, in which a crack could spread through the between-layer region and peel the layers apart or cause them to slide against each other, or do a combination of both. All three of these modes are the most common ways in which conventional composites can internally flake and crumble.
The tests, in which the researchers precisely measured the force required to peel or shear the composite’s layers, revealed that the nanostitched held fast, and the initial crack that the researchers made was unable to spread further between the layers. The nanostitched samples were up to 62 percent tougher and more resistant to cracks, compared with the same advanced composite material that was held together with conventional polymers.
“This is a new composite technology, turbocharged by our nanotubes,” Wardle says.
“The authors have demonsrated that thin plies and nanostitching together have made significant increase in toughness,” says Stephen Tsai, emeritus professor of aeronautics and astronautics at Stanford University. “Composites are degraded by their weak interlaminar strength. Any improvement shown in this work will increase the design allowable, and reduce the weight and cost of composites technology.”
The researchers envision that any vehicle or structure that incorporates conventional composites could be made lighter, tougher, and more resilient with nanostitching.
“You could have selective reinforcement of problematic areas, to reinforce holes or bolted joints, or places where delamination might happen,” Furtado says. “This opens a big window of opportunity.”
This schematic shows an engineered material with composite layers. Layers of carbon fibers (the long silver tubes) have microscopic forests of carbon nanotubes between them (the array of tiny brown objects). These tiny, densely packed fibers grip and hold the layers together, like ultrastrong Velcro, preventing the layers from peeling or shearing apart.
Watching her uncle play a video game when she was a small child started Shaniel Bowen on her path to becoming a biomedical engineer. The game, “Metal Gear Solid 2,” introduced her to exoskeletons, wearable devices that enhance physical abilities.
“The game piqued my interest when it started showing and discussing exoskeletons,” Bowen says. “I went to the library soon after to learn more about it. That was when I first learned about biomedical engineering and became interested in pursuing it as a profession.”
Fast-forward to her senior year at the University of Connecticut. Bowen and an interdisciplinary team of biomedical, electrical, and computer engineers developed a device using musculoskeletal modeling and computer-aided design that could help people with leg weakness to stand. The system provided just enough assistance that the person would still use their own muscles, strengthening them with repeated use. Bowen was on her way to creating her own exoskeleton.
That changed, however, when she was starting graduate school and was diagnosed with ovarian torsion caused by a large ovarian teratoma.
Not only was she dealing with a serious medical condition, but as a Black woman raised by Jamaican immigrants, she was personally confronted with inequities in health care that result in discrepancies in treatment.
“Like many Black, Indigenous, and people of color (BIPOC) women, I was initially apprehensive and discouraged from seeking medical care for a long time, which led me to trivialize my symptoms,” Bowen says. “A serious gynecological condition that required surgery was almost left untreated.”
After her surgery, Bowen pivoted from her work in human movement and biodynamics to biomedical engineering focused on women’s health.
“I became interested in applying my engineering expertise to women’s health issues in order to gain a better understanding of various pathologies from a biomechanics perspective and to bring awareness not only to individuals in my field but also to women who suffer from or may be at risk for these conditions,” she says.
During her doctoral program, Bowen studied the effects of age and pelvic reconstructive surgery on female pelvic anatomy and function using computational modeling. She received a Ford Foundation Fellowship from the National Academies of Sciences, Engineering, and Medicine to study the biomechanical processes involved in pelvic organ prolapse (POP), a common condition that can cause extreme discomfort, sexual dysfunction, and incontinence. POP can be surgically corrected, but the repair often fails within five years, and it is unclear exactly why. Bowen’s research set out to develop a tool to better assess the biomechanics of such failures and to prevent them.
“It is hoped that our findings, based on postoperative imaging and clinical data, will encourage longitudinal trials and studies that incorporate both clinical and engineering approaches to better understand POP surgeries and pelvic floor function and dysfunction following pelvic reconstructive procedures,” she says.
After earning her PhD at the University of Pittsburgh, Bowen received multiple offers to do postdoctoral research. She chose the MIT School of Engineering’s Postdoctoral Fellowship Program for Engineering Excellence and started work in the Edelman Lab in September 2023.
“The program and my principal investigators were the most supportive of me exploring my research interests in women’s sexual anatomy and health,” she says, “and learning experimental methods from the ground up, given that my primary experience is computational.”
Elazer Edelman, the Edward J. Poitras Professor in Medical Engineering and Science, director of MIT’s Institute for Medical Engineering and Science, professor of medicine at Harvard Medical School, and senior attending physician in the coronary care unit at Brigham and Women’s Hospital in Boston, speaks admiringly of Bowen and her research.
“I love working with and learning from Shaniel — she is an inspiration and creative spirit who is treading in new spaces and has the potential to add to what we know of health and physiology and change our practice of medicine,” says Edelman.
The Edelman Lab was “one of the few,” Bowen says she found “with a longstanding commitment to public outreach,” which has been a consistent endeavor throughout her academic career.
For nearly 10 years, Bowen has volunteered in mentoring and STEM outreach programs for students of all ages — including at her old high school, at the universities she has attended, and in underserved communities. Currently, Bowen devotes a portion of her time to outreach, health promotion, and education, primarily focusing on women’s health issues.
“My research collaborators and I have worked toward removing the stigma and misconceptions around women’s anatomy and health,” she says, explaining that helping young women from underserved communities to be more comfortable with and better informed about women’s anatomy and health is “integral to health equity and inclusion.” Such work also encourages young women to consider careers in STEM and women’s health, she says.
“It is imperative that women of diverse experiences and perspectives get involved in STEM to develop the next generation of scientists and advocates to improve the treatment of health conditions for all women.”
Part of Bowen’s postdoctoral research involves complementing her computational abilities by acquiring and improving her skills in biochemistry and cell biology, and tissue mechanics and engineering. Her current work on how clitoral anatomy relates to sexual function, especially after gynecological surgery, explores a topic that has seen little research, Bowen says, adding that her work could improve postoperative sexual function outcomes.
The MIT Postdoctoral Fellowship Program for Engineering Excellence — which, while emphasizing research, also provides resources and helps fellows to build a professional network — has provided an excellent system of support, Bowen says.
“It has really helped me learn and explore different career paths while having a great support system of fellows and staff that have provided continued motivation and life advice throughout the ups and downs of navigating through my postdoctoral training and job search,” she says.
Speaking about the MIT Postdoctoral Fellowship Program for Engineering Excellence, Shaniel Bowen says “It has really helped me learn and explore different career paths while having a great support system of fellows and staff that have provided continued motivation and life advice throughout the ups and downs of navigating through my postdoctoral training and job search.”
The radiation detectors used today for applications like inspecting cargo ships for smuggled nuclear materials are expensive and cannot operate in harsh environments, among other disadvantages. Now, in work funded largely by the U.S. Department of Homeland Security with early support from the U.S. Department of Energy, MIT engineers have demonstrated a fundamentally new way to detect radiation that could allow much cheaper detectors and a plethora of new applications.
They are working with Radiation Monitoring Devices, a company in Watertown, Massachusetts, to transfer the research as quickly as possible into detector products.
In a 2022 paper in Nature Materials, many of the same engineers reported for the first time how ultraviolet light can significantly improve the performance of fuel cells and other devices based on the movement of charged atoms, rather than those atoms’ constituent electrons.
In the current work, published recently in Advanced Materials, the team shows that the same concept can be extended to a new application: the detection of gamma rays emitted by the radioactive decay of nuclear materials.
“Our approach involves materials and mechanisms very different than those in presently used detectors, with potentially enormous benefits in terms of reduced cost, ability to operate under harsh conditions, and simplified processing,” says Harry L. Tuller, the R.P. Simmons Professor of Ceramics and Electronic Materials in MIT’s Department of Materials Science and Engineering (DMSE).
Tuller leads the work with key collaborators Jennifer L. M. Rupp, a former associate professor of materials science and engineering at MIT who is now a professor of electrochemical materials at Technical University Munich in Germany, and Ju Li, the Battelle Energy Alliance Professor in Nuclear Engineering and a professor of materials science and engineering. All are also affiliated with MIT’s Materials Research Laboratory
“After learning the Nature Materials work, I realized the same underlying principle should work for gamma-ray detection — in fact, may work even better than [UV] light because gamma rays are more penetrating — and proposed some experiments to Harry and Jennifer,” says Li.
Says Rupp, “Employing shorter-range gamma rays enable [us] to extend the opto-ionic to a radio-ionic effect by modulating ionic carriers and defects at material interfaces by photogenerated electronic ones.”
Other authors of the Advanced Materials paper are first author Thomas Defferriere, a DMSE postdoc, and Ahmed Sami Helal, a postdoc in MIT’s Department of Nuclear Science and Engineering.
Modifying barriers
Charge can be carried through a material in different ways. We are most familiar with the charge that is carried by the electrons that help make up an atom. Common applications include solar cells. But there are many devices — like fuel cells and lithium batteries — that depend on the motion of the charged atoms, or ions, themselves rather than just their electrons.
The materials behind applications based on the movement of ions, known as solid electrolytes, are ceramics. Ceramics, in turn, are composed of tiny crystallite grains that are compacted and fired at high temperatures to form a dense structure. The problem is that ions traveling through the material are often stymied at the boundaries between the grains.
In their 2022 paper, the MIT team showed that ultraviolet (UV) light shone on a solid electrolyte essentially causes electronic perturbations at the grain boundaries that ultimately lower the barrier that ions encounter at those boundaries. The result: “We were able to enhance the flow of the ions by a factor of three,” says Tuller, making for a much more efficient system.
Vast potential
At the time, the team was excited about the potential of applying what they’d found to different systems. In the 2022 work, the team used UV light, which is quickly absorbed very near the surface of a material. As a result, that specific technique is only effective in thin films of materials. (Fortunately, many applications of solid electrolytes involve thin films.)
Light can be thought of as particles — photons — with different wavelengths and energies. These range from very low-energy radio waves to the very high-energy gamma rays emitted by the radioactive decay of nuclear materials. Visible light — and UV light — are of intermediate energies, and fit between the two extremes.
The MIT technique reported in 2022 worked with UV light. Would it work with other wavelengths of light, potentially opening up new applications? Yes, the team found. In the current paper they show that gamma rays also modify the grain boundaries resulting in a faster flow of ions that, in turn, can be easily detected. And because the high-energy gamma rays penetrate much more deeply than UV light, “this extends the work to inexpensive bulk ceramics in addition to thin films,” says Tuller. It also allows a new application: an alternative approach to detecting nuclear materials.
Today’s state-of-the-art radiation detectors depend on a completely different mechanism than the one identified in the MIT work. They rely on signals derived from electrons and their counterparts, holes, rather than ions. But these electronic charge carriers must move comparatively great distances to the electrodes that “capture” them to create a signal. And along the way, they can be easily lost as they, for example, hit imperfections in a material. That’s why today’s detectors are made with extremely pure single crystals of material that allow an unimpeded path. They can be made with only certain materials and are difficult to process, making them expensive and hard to scale into large devices.
Using imperfections
In contrast, the new technique works because of the imperfections — grains — in the material. “The difference is that we rely on ionic currents being modulated at grain boundaries versus the state-of-the-art that relies on collecting electronic carriers from long distances,” Defferriere says.
Says Rupp, “It is remarkable that the bulk ‘grains’ of the ceramic materials tested revealed high stabilities of the chemistry and structure towards gamma rays, and solely the grain boundary regions reacted in charge redistribution of majority and minority carriers and defects.”
Comments Li, “This radiation-ionic effect is distinct from the conventional mechanisms for radiation detection where electrons or photons are collected. Here, the ionic current is being collected.”
Igor Lubomirsky, a professor in the Department of Materials and Interfaces at the Weizmann Institute of Science, Israel, who was not involved in the current work, says, “I found the approach followed by the MIT group in utilizing polycrystalline oxygen ion conductors very fruitful given the [materials’] promise for providing reliable operation under irradiation under the harsh conditions expected in nuclear reactors where such detectors often suffer from fatigue and aging. [They also] benefit from much-reduced fabrication costs.”
As a result, the MIT engineers are hopeful that their work could result in new, less expensive detectors. For example, they envision trucks loaded with cargo from container ships driving through a structure that has detectors on both sides as they leave a port. “Ideally, you’d have either an array of detectors or a very large detector, and that’s where [today’s detectors] really don’t scale very well,” Tuller says.
Another potential application involves accessing geothermal energy, or the extreme heat below our feet that is being explored as a carbon-free alternative to fossil fuels. Ceramic sensors at the ends of drill bits could detect pockets of heat — radiation — to drill toward. Ceramics can easily withstand extreme temperatures of more than 800 degrees Fahrenheit and the extreme pressures found deep below the Earth’s surface.
The team is excited about additional applications for their work. “This was a demonstration of principle with just one material,” says Tuller, “but there are thousands of other materials good at conducting ions.”
Concludes Defferriere: “It’s the start of a journey on the development of the technology, so there’s a lot to do and a lot to discover.”
This work is currently supported by the U.S. Department of Homeland Security, Countering Weapons of Mass Destruction Office. This support does not constitute an express or implied endorsement on the part of the government. It was also funded by the U.S. Defense Threat Reduction Agency.
An MIT team demonstrated a new way to detect radiation that could allow much cheaper detectors and a plethora of new applications. Left to right: Jennifer Rupp, Thomas Defferriere, Harry Tuller, and Ju Li.
In biomedicine, segmentation involves annotating pixels from an important structure in a medical image, like an organ or cell. Artificial intelligence models can help clinicians by highlighting pixels that may show signs of a certain disease or anomaly.
However, these models typically only provide one answer, while the problem of medical image segmentation is often far from black and white. Five expert human annotators might provide five different segmentations, perhaps disagreeing on the existence or extent of the borders of a nodule in a lung CT image.
“Having options can help in decision-making. Even just seeing that there is uncertainty in a medical image can influence someone’s decisions, so it is important to take this uncertainty into account,” says Marianne Rakic, an MIT computer science PhD candidate.
Rakic is lead author of a paper with others at MIT, the Broad Institute of MIT and Harvard, and Massachusetts General Hospital that introduces a new AI tool that can capture the uncertainty in a medical image.
Known as Tyche (named for the Greek divinity of chance), the system provides multiple plausible segmentations that each highlight slightly different areas of a medical image. A user can specify how many options Tyche outputs and select the most appropriate one for their purpose.
Importantly, Tyche can tackle new segmentation tasks without needing to be retrained. Training is a data-intensive process that involves showing a model many examples and requires extensive machine-learning experience.
Because it doesn’t need retraining, Tyche could be easier for clinicians and biomedical researchers to use than some other methods. It could be applied “out of the box” for a variety of tasks, from identifying lesions in a lung X-ray to pinpointing anomalies in a brain MRI.
Ultimately, this system could improve diagnoses or aid in biomedical research by calling attention to potentially crucial information that other AI tools might miss.
“Ambiguity has been understudied. If your model completely misses a nodule that three experts say is there and two experts say is not, that is probably something you should pay attention to,” adds senior author Adrian Dalca, an assistant professor at Harvard Medical School and MGH, and a research scientist in the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL).
Their co-authors include Hallee Wong, a graduate student in electrical engineering and computer science; Jose Javier Gonzalez Ortiz PhD ’23; Beth Cimini, associate director for bioimage analysis at the Broad Institute; and John Guttag, the Dugald C. Jackson Professor of Computer Science and Electrical Engineering. Rakic will present Tyche at the IEEE Conference on Computer Vision and Pattern Recognition, where Tyche has been selected as a highlight.
Addressing ambiguity
AI systems for medical image segmentation typically use neural networks. Loosely based on the human brain, neural networks are machine-learning models comprising many interconnected layers of nodes, or neurons, that process data.
After speaking with collaborators at the Broad Institute and MGH who use these systems, the researchers realized two major issues limit their effectiveness. The models cannot capture uncertainty and they must be retrained for even a slightly different segmentation task.
Some methods try to overcome one pitfall, but tackling both problems with a single solution has proven especially tricky, Rakic says.
“If you want to take ambiguity into account, you often have to use an extremely complicated model. With the method we propose, our goal is to make it easy to use with a relatively small model so that it can make predictions quickly,” she says.
The researchers built Tyche by modifying a straightforward neural network architecture.
A user first feeds Tyche a few examples that show the segmentation task. For instance, examples could include several images of lesions in a heart MRI that have been segmented by different human experts so the model can learn the task and see that there is ambiguity.
The researchers found that just 16 example images, called a “context set,” is enough for the model to make good predictions, but there is no limit to the number of examples one can use. The context set enables Tyche to solve new tasks without retraining.
For Tyche to capture uncertainty, the researchers modified the neural network so it outputs multiple predictions based on one medical image input and the context set. They adjusted the network’s layers so that, as data move from layer to layer, the candidate segmentations produced at each step can “talk” to each other and the examples in the context set.
In this way, the model can ensure that candidate segmentations are all a bit different, but still solve the task.
“It is like rolling dice. If your model can roll a two, three, or four, but doesn’t know you have a two and a four already, then either one might appear again,” she says.
They also modified the training process so it is rewarded by maximizing the quality of its best prediction.
If the user asked for five predictions, at the end they can see all five medical image segmentations Tyche produced, even though one might be better than the others.
The researchers also developed a version of Tyche that can be used with an existing, pretrained model for medical image segmentation. In this case, Tyche enables the model to output multiple candidates by making slight transformations to images.
Better, faster predictions
When the researchers tested Tyche with datasets of annotated medical images, they found that its predictions captured the diversity of human annotators, and that its best predictions were better than any from the baseline models. Tyche also performed faster than most models.
“Outputting multiple candidates and ensuring they are different from one another really gives you an edge,” Rakic says.
The researchers also saw that Tyche could outperform more complex models that have been trained using a large, specialized dataset.
For future work, they plan to try using a more flexible context set, perhaps including text or multiple types of images. In addition, they want to explore methods that could improve Tyche’s worst predictions and enhance the system so it can recommend the best segmentation candidates.
This research is funded, in part, by the National Institutes of Health, the Eric and Wendy Schmidt Center at the Broad Institute of MIT and Harvard, and Quanta Computer.
Researchers from MIT and elsewhere developed a machine-learning framework that can generate multiple plausible answers when asked to identify potential disease in medical images. By capturing the inherent ambiguity in these images, this technique could prevent clinicians from missing crucial information that could inform diagnoses.
The spread of radioactive isotopes from the Fukushima Daiichi Nuclear Power Plant in Japan in 2011 and the ongoing threat of a possible release of radiation from the Zaporizhzhia nuclear complex in the Ukrainian war zone have underscored the need for effective and reliable ways of detecting and monitoring radioactive isotopes. Less dramatically, everyday operations of nuclear reactors, mining and processing of uranium into fuel rods, and the disposal of spent nuclear fuel also require monitoring of radioisotope release.
Now, researchers at MIT and the Lawrence Berkeley National Laboratory (LBNL) have come up with a computational basis for designing very simple, streamlined versions of sensor setups that can pinpoint the direction of a distributed source of radiation. They also demonstrated that by moving that sensor around to get multiple readings, they can pinpoint the physical location of the source. The inspiration for their clever innovation came from a surprising source: the popular computer game “Tetris.”
The team’s findings, which could likely be generalized to detectors for other kinds of radiation, are described in a paper published in Nature Communications, by MIT professors Mingda Li, and Benoit Forget, senior research scientist Lin-Wen Hu, and principal research scientist Gordon Kohse; graduate students Ryotaro Okabe and Shangjie Xue; research scientist Jayson Vavrek SM ’16, PhD ’19 at LBNL; and a number of others at MIT and Lawrence Berkeley.
Radiation is usually detected using semiconductor materials, such as cadmium zinc telluride, that produce an electrical response when struck by high-energy radiation such as gamma rays. But because radiation penetrates so readily through matter, it’s difficult to determine the direction that signal came from with simple counting. Geiger counters, for example, simply provide a click sound when receiving radiation, without resolving the energy or type, so finding a source requires moving around to try to find the maximum sound, similarly to how handheld metal detectors work. The process requires the user to move closer to the source of radiation, which can add risk.
To provide directional information from a stationary device without getting too close, researchers use an array of detector grids along with another grid called a mask, which imprints a pattern on the array that differs depending on the direction of the source. An algorithm interprets the different timings and intensities of signals received by each separate detector or pixel. This often leads to a complex design of detectors.
Typical detector arrays for sensing the direction of radiation sources are large and expensive and include at least 100 pixels in a 10 by 10 array. However, the group found that using as few as four pixels arranged in the tetromino shapes of the figures in the “Tetris” game can come close to matching the accuracy of the large, expensive systems. The key is proper computerized reconstruction of the angles of arrival of the rays, based on the times each sensor detects the signal and the relative intensity each one detects, as reconstructed through an AI-guided study of simulated systems.
Of the different configurations of four pixels the researchers tried — square, or S-, J- or T-shaped — they found through repeated experiments that the most precise results were provided by the S-shaped array. This array gave directional readings that were accurate to within about 1 degree, but all three of the irregular shapes performed better than the square. This approach, Li says, “was literally inspired by ‘Tetris.’”
Key to making the system work is placing an insulating material such as a lead sheet between the pixels to increase the contrast between radiation readings coming into the detector from different directions. The lead between the pixels in these simplified arrays serves the same function as the more elaborate shadow masks used in the larger-array systems. Less symmetrical arrangements, the team found, provide more useful information from a small array, explains Okabe, who is the lead author of the work.
“The merit of using a small detector is in terms of engineering costs,” he says. Not only are the individual detector elements expensive, typically made of cadmium-zinc-telluride, or CZT, but all of the interconnections carrying information from those pixels also become much more complex. “The smaller and simpler the detector is, the better it is in terms of applications,” adds Li.
While there have been other versions of simplified arrays for radiation detection, many are only effective if the radiation is coming from a single localized source. They can be confused by multiple sources or those that are spread out in space, while the “Tetris”-based version can handle these situations well, adds Xue, co-lead author of the work.
In a single-blind field test at the Berkeley Lab with a real cesium radiation source, led by Vavrek, where the researchers at MIT did not know the ground-truth source location, a test device was performed with high accuracy in finding the direction and distance to the source.
“Radiation mapping is of utmost importance to the nuclear industry, as it can help rapidly locate sources of radiation and keep everyone safe,” says co-author Forget, an MIT professor of nuclear engineering and head of the Department of Nuclear Science and Engineering.
Vavrek, another co-lead-author, says that while in their study they focused on gamma-ray sources, he believes the computational tools they developed to extract directional information from the limited number of pixels are “much, much more general.” It isn’t restricted to certain wavelengths, it can also be used for neutrons, or even other forms of light, such as ultraviolet light. Using this machine learning-based algorithm and aerial radiation detection “will allow real-time monitoring and integrated emergency planning of radiological accidents,” adds Hu, a senior scientist at the MIT Nuclear Reactor Lab.
Nick Mann, a scientist with the Defense Systems branch at the Idaho National Laboratory, says, "This work is critical to the U.S. response community and the ever-increasing threat of a radiological incident or accident.”
Additional research team members include Ryan Pavlovsky, Victor Negut, Brian Quiter, and Joshua Cates at Lawrence Berkely National Laboratory, and Jiankai Yu, Tongtong Liu, Stephanie Jegelka at MIT. The work was supported by the U.S. Department of Energy.
A user could ask ChatGPT to write a computer program or summarize an article, and the AI chatbot would likely be able to generate useful code or write a cogent synopsis. However, someone could also ask for instructions to build a bomb, and the chatbot might be able to provide those, too.
To prevent this and other safety issues, companies that build large language models typically safeguard them using a process called red-teaming. Teams of human testers write prompts aimed at triggering unsafe or toxic text from the model being tested. These prompts are used to teach the chatbot to avoid such responses.
But this only works effectively if engineers know which toxic prompts to use. If human testers miss some prompts, which is likely given the number of possibilities, a chatbot regarded as safe might still be capable of generating unsafe answers.
Researchers from Improbable AI Lab at MIT and the MIT-IBM Watson AI Lab used machine learning to improve red-teaming. They developed a technique to train a red-team large language model to automatically generate diverse prompts that trigger a wider range of undesirable responses from the chatbot being tested.
They do this by teaching the red-team model to be curious when it writes prompts, and to focus on novel prompts that evoke toxic responses from the target model.
The technique outperformed human testers and other machine-learning approaches by generating more distinct prompts that elicited increasingly toxic responses. Not only does their method significantly improve the coverage of inputs being tested compared to other automated methods, but it can also draw out toxic responses from a chatbot that had safeguards built into it by human experts.
“Right now, every large language model has to undergo a very lengthy period of red-teaming to ensure its safety. That is not going to be sustainable if we want to update these models in rapidly changing environments. Our method provides a faster and more effective way to do this quality assurance,” says Zhang-Wei Hong, an electrical engineering and computer science (EECS) graduate student in the Improbable AI lab and lead author of a paper on this red-teaming approach.
Hong’s co-authors include EECS graduate students Idan Shenfield, Tsun-Hsuan Wang, and Yung-Sung Chuang; Aldo Pareja and Akash Srivastava, research scientists at the MIT-IBM Watson AI Lab; James Glass, senior research scientist and head of the Spoken Language Systems Group in the Computer Science and Artificial Intelligence Laboratory (CSAIL); and senior author Pulkit Agrawal, director of Improbable AI Lab and an assistant professor in CSAIL. The research will be presented at the International Conference on Learning Representations.
Automated red-teaming
Large language models, like those that power AI chatbots, are often trained by showing them enormous amounts of text from billions of public websites. So, not only can they learn to generate toxic words or describe illegal activities, the models could also leak personal information they may have picked up.
The tedious and costly nature of human red-teaming, which is often ineffective at generating a wide enough variety of prompts to fully safeguard a model, has encouraged researchers to automate the process using machine learning.
Such techniques often train a red-team model using reinforcement learning. This trial-and-error process rewards the red-team model for generating prompts that trigger toxic responses from the chatbot being tested.
But due to the way reinforcement learning works, the red-team model will often keep generating a few similar prompts that are highly toxic to maximize its reward.
For their reinforcement learning approach, the MIT researchers utilized a technique called curiosity-driven exploration. The red-team model is incentivized to be curious about the consequences of each prompt it generates, so it will try prompts with different words, sentence patterns, or meanings.
“If the red-team model has already seen a specific prompt, then reproducing it will not generate any curiosity in the red-team model, so it will be pushed to create new prompts,” Hong says.
During its training process, the red-team model generates a prompt and interacts with the chatbot. The chatbot responds, and a safety classifier rates the toxicity of its response, rewarding the red-team model based on that rating.
Rewarding curiosity
The red-team model’s objective is to maximize its reward by eliciting an even more toxic response with a novel prompt. The researchers enable curiosity in the red-team model by modifying the reward signal in the reinforcement learning set up.
First, in addition to maximizing toxicity, they include an entropy bonus that encourages the red-team model to be more random as it explores different prompts. Second, to make the agent curious they include two novelty rewards. One rewards the model based on the similarity of words in its prompts, and the other rewards the model based on semantic similarity. (Less similarity yields a higher reward.)
To prevent the red-team model from generating random, nonsensical text, which can trick the classifier into awarding a high toxicity score, the researchers also added a naturalistic language bonus to the training objective.
With these additions in place, the researchers compared the toxicity and diversity of responses their red-team model generated with other automated techniques. Their model outperformed the baselines on both metrics.
They also used their red-team model to test a chatbot that had been fine-tuned with human feedback so it would not give toxic replies. Their curiosity-driven approach was able to quickly produce 196 prompts that elicited toxic responses from this “safe” chatbot.
“We are seeing a surge of models, which is only expected to rise. Imagine thousands of models or even more and companies/labs pushing model updates frequently. These models are going to be an integral part of our lives and it’s important that they are verified before released for public consumption. Manual verification of models is simply not scalable, and our work is an attempt to reduce the human effort to ensure a safer and trustworthy AI future,” says Agrawal.
In the future, the researchers want to enable the red-team model to generate prompts about a wider variety of topics. They also want to explore the use of a large language model as the toxicity classifier. In this way, a user could train the toxicity classifier using a company policy document, for instance, so a red-team model could test a chatbot for company policy violations.
“If you are releasing a new AI model and are concerned about whether it will behave as expected, consider using curiosity-driven red-teaming,” says Agrawal.
This research is funded, in part, by Hyundai Motor Company, Quanta Computer Inc., the MIT-IBM Watson AI Lab, an Amazon Web Services MLRA research grant, the U.S. Army Research Office, the U.S. Defense Advanced Research Projects Agency Machine Common Sense Program, the U.S. Office of Naval Research, the U.S. Air Force Research Laboratory, and the U.S. Air Force Artificial Intelligence Accelerator.
Since the 1970s, modern antibiotic discovery has been experiencing a lull. Now the World Health Organization has declared the antimicrobial resistance crisis as one of the top 10 global public health threats.
When an infection is treated repeatedly, clinicians run the risk of bacteria becoming resistant to the antibiotics. But why would an infection return after proper antibiotic treatment? One well-documented possibility is that the bacteria are becoming metabolically inert, escaping detection of traditional antibiotics that only respond to metabolic activity. When the danger has passed, the bacteria return to life and the infection reappears.
“Resistance is happening more over time, and recurring infections are due to this dormancy,” says Jackie Valeri, a former MIT-Takeda Fellow (centered within the MIT Abdul Latif Jameel Clinic for Machine Learning in Health) who recently earned her PhD in biological engineering from the Collins Lab. Valeri is the first author of a new paper published in this month’s print issue of Cell Chemical Biology that demonstrates how machine learning could help screen compounds that are lethal to dormant bacteria.
Tales of bacterial “sleeper-like” resilience are hardly news to the scientific community — ancient bacterial strains dating back to 100 million years ago have been discovered in recent years alive in an energy-saving state on the seafloor of the Pacific Ocean.
MIT Jameel Clinic's Life Sciences faculty lead James J. Collins, a Termeer Professor of Medical Engineering and Science in MIT’s Institute for Medical Engineering and Science and Department of Biological Engineering, recently made headlines for using AI to discover a new class of antibiotics, which is part of the group’s larger mission to use AI to dramatically expand the existing antibiotics available.
According to a paper published by The Lancet, in 2019, 1.27 million deaths could have been prevented had the infections been susceptible to drugs, and one of many challenges researchers are up against is finding antibiotics that are able to target metabolically dormant bacteria.
In this case, researchers in the Collins Lab employed AI to speed up the process of finding antibiotic properties in known drug compounds. With millions of molecules, the process can take years, but researchers were able to identify a compound called semapimod over a weekend, thanks to AI's ability to perform high-throughput screening.
An anti-inflammatory drug typically used for Crohn’s disease, researchers discovered that semapimod was also effective against stationary-phase Escherichia coli and Acinetobacter baumannii.
Another revelation was semapimod's ability to disrupt the membranes of so-called “Gram-negative” bacteria, which are known for their high intrinsic resistance to antibiotics due to their thicker, less-penetrable outer membrane.
Examples of Gram-negative bacteria include E. coli, A. baumannii, Salmonella, and Pseudomonis, all of which are challenging to find new antibiotics for.
“One of the ways we figured out the mechanism of sema [sic] was that its structure was really big, and it reminded us of other things that target the outer membrane,” Valeri explains. “When you start working with a lot of small molecules ... to our eyes, it’s a pretty unique structure.”
By disrupting a component of the outer membrane, semapimod sensitizes Gram-negative bacteria to drugs that are typically only active against Gram-positive bacteria.
Valeri recalls a quote from a 2013 paper published in Trends Biotechnology: “For Gram-positive infections, we need better drugs, but for Gram-negative infections we need any drugs.”
Our muscles are nature’s perfect actuators — devices that turn energy into motion. For their size, muscle fibers are more powerful and precise than most synthetic actuators. They can even heal from damage and grow stronger with exercise.
For these reasons, engineers are exploring ways to power robots with natural muscles. They’ve demonstrated a handful of “biohybrid” robots that use muscle-based actuators to power artificial skeletons that walk, swim, pump, and grip. But for every bot, there’s a very different build, and no general blueprint for how to get the most out of muscles for any given robot design.
Now, MIT engineers have developed a spring-like device that could be used as a basic skeleton-like module for almost any muscle-bound bot. The new spring, or “flexure,” is designed to get the most work out of any attached muscle tissues. Like a leg press that’s fit with just the right amount of weight, the device maximizes the amount of movement that a muscle can naturally produce.
The researchers found that when they fit a ring of muscle tissue onto the device, much like a rubber band stretched around two posts, the muscle pulled on the spring, reliably and repeatedly, and stretched it five times more, compared with other previous device designs.
The team sees the flexure design as a new building block that can be combined with other flexures to build any configuration of artificial skeletons. Engineers can then fit the skeletons with muscle tissues to power their movements.
“These flexures are like a skeleton that people can now use to turn muscle actuation into multiple degrees of freedom of motion in a very predictable way,” says Ritu Raman, the Brit and Alex d'Arbeloff Career Development Professor in Engineering Design at MIT. “We are giving roboticists a new set of rules to make powerful and precise muscle-powered robots that do interesting things.”
Raman and her colleagues report the details of the new flexure design in a paper appearing today in the journal Advanced Intelligent Systems. The study’s MIT co-authors include Naomi Lynch ’12, SM ’23; undergraduate Tara Sheehan; graduate students Nicolas Castro, Laura Rosado, and Brandon Rios; and professor of mechanical engineering Martin Culpepper.
Muscle pull
When left alone in a petri dish in favorable conditions, muscle tissue will contract on its own but in directions that are not entirely predictable or of much use.
“If muscle is not attached to anything, it will move a lot, but with huge variability, where it’s just flailing around in liquid,” Raman says.
To get a muscle to work like a mechanical actuator, engineers typically attach a band of muscle tissue between two small, flexible posts. As the muscle band naturally contracts, it can bend the posts and pull them together, producing some movement that would ideally power part of a robotic skeleton. But in these designs, muscles have produced limited movement, mainly because the tissues are so variable in how they contact the posts. Depending on where the muscles are placed on the posts, and how much of the muscle surface is touching the post, the muscles may succeed in pulling the posts together but at other times may wobble around in uncontrollable ways.
Raman’s group looked to design a skeleton that focuses and maximizes a muscle’s contractions regardless of exactly where and how it is placed on a skeleton, to generate the most movement in a predictable, reliable way.
“The question is: How do we design a skeleton that most efficiently uses the force the muscle is generating?” Raman says.
The researchers first considered the multiple directions that a muscle can naturally move. They reasoned that if a muscle is to pull two posts together along a specific direction, the posts should be connected to a spring that only allows them to move in that direction when pulled.
“We need a device that is very soft and flexible in one direction, and very stiff in all other directions, so that when a muscle contracts, all that force gets efficiently converted into motion in one direction,” Raman says.
Soft flex
As it turns out, Raman found many such devices in Professor Martin Culpepper’s lab. Culpepper’s group at MIT specializes in the design and fabrication of machine elements such as miniature actuators, bearings, and other mechanisms, that can be built into machines and systems to enable ultraprecise movement, measurement, and control, for a wide variety of applications. Among the group’s precision machined elements are flexures — spring-like devices, often made from parallel beams, that can flex and stretch with nanometer precision.
“Depending on how thin and far apart the beams are, you can change how stiff the spring appears to be,” Raman says.
She and Culpepper teamed up to design a flexure specifically tailored with a configuration and stiffness to enable muscle tissue to naturally contract and maximally stretch the spring. The team designed the device’s configuration and dimensions based on numerous calculations they carried out to relate a muscle’s natural forces with a flexure’s stiffness and degree of movement.
The flexure they ultimately designed is 1/100 the stiffness of muscle tissue itself. The device resembles a miniature, accordion-like structure, the corners of which are pinned to an underlying base by a small post, which sits near a neighboring post that is fit directly onto the base. Raman then wrapped a band of muscle around the two corner posts (the team molded the bands from live muscle fibers that they grew from mouse cells), and measured how close the posts were pulled together as the muscle band contracted.
The team found that the flexure’s configuration enabled the muscle band to contract mostly along the direction between the two posts. This focused contraction allowed the muscle to pull the posts much closer together — five times closer — compared with previous muscle actuator designs.
“The flexure is a skeleton that we designed to be very soft and flexible in one direction, and very stiff in all other directions,” Raman says. “When the muscle contracts, all the force is converted into movement in that direction. It’s a huge magnification.”
The team found they could use the device to precisely measure muscle performance and endurance. When they varied the frequency of muscle contractions (for instance, stimulating the bands to contract once versus four times per second), they observed that the muscles “grew tired” at higher frequencies, and didn’t generate as much pull.
“Looking at how quickly our muscles get tired, and how we can exercise them to have high-endurance responses — this is what we can uncover with this platform,” Raman says.
The researchers are now adapting and combining flexures to build precise, articulated, and reliable robots, powered by natural muscles.
“An example of a robot we are trying to build in the future is a surgical robot that can perform minimally invasive procedures inside the body,” Raman says. “Technically, muscles can power robots of any size, but we are particularly excited in making small robots, as this is where biological actuators excel in terms of strength, efficiency, and adaptability.”
MIT engineers have developed a new spring (shown in Petri dish) that maximizes the work of natural muscles. When living muscle tissue is attached to posts at the corners of the device, the muscle’s contractions pull on the spring, forming an effective, natural actuator. The spring can serve as a “skeleton” for future muscle-powered robots.
While 3D printing has exploded in popularity, many of the plastic materials these printers use to create objects cannot be easily recycled. While new sustainable materials are emerging for use in 3D printing, they remain difficult to adopt because 3D printer settings need to be adjusted for each material, a process generally done by hand.
To print a new material from scratch, one must typically set up to 100 parameters in software that controls how the printer will extrude the material as it fabricates an object. Commonly used materials, like mass-manufactured polymers, have established sets of parameters that were perfected through tedious, trial-and-error processes.
But the properties of renewable and recyclable materials can fluctuate widely based on their composition, so fixed parameter sets are nearly impossible to create. In this case, users must come up with all these parameters by hand.
Researchers tackled this problem by developing a 3D printer that can automatically identify the parameters of an unknown material on its own.
A collaborative team from MIT’s Center for Bits and Atoms (CBA), the U.S. National Institute of Standards and Technology (NIST), and the National Center for Scientific Research in Greece (Demokritos) modified the extruder, the “heart” of a 3D printer, so it can measure the forces and flow of a material.
These data, gathered through a 20-minute test, are fed into a mathematical function that is used to automatically generate printing parameters. These parameters can be entered into off-the-shelf 3D printing software and used to print with a never-before-seen material.
The automatically generated parameters can replace about half of the parameters that typically must be tuned by hand. In a series of test prints with unique materials, including several renewable materials, the researchers showed that their method can consistently produce viable parameters.
This research could help to reduce the environmental impact of additive manufacturing, which typically relies on nonrecyclable polymers and resins derived from fossil fuels.
“In this paper, we demonstrate a method that can take all these interesting materials that are bio-based and made from various sustainable sources and show that the printer can figure out by itself how to print those materials. The goal is to make 3D printing more sustainable,” says senior author Neil Gershenfeld, who leads CBA.
His co-authors include first author Jake Read a graduate student in the CBA who led the printer development; Jonathan Seppala, a chemical engineer in the Materials Science and Engineering Division of NIST; Filippos Tourlomousis, a former CBA postdoc who now heads the Autonomous Science Lab at Demokritos; James Warren, who leads the Materials Genome Program at NIST; and Nicole Bakker, a research assistant at CBA. The research is published in the journal Integrating Materials and Manufacturing Innovation.
Shifting material properties
In fused filament fabrication (FFF), which is often used in rapid prototyping, molten polymers are extruded through a heated nozzle layer-by-layer to build a part. Software, called a slicer, provides instructions to the machine, but the slicer must be configured to work with a particular material.
Using renewable or recycled materials in an FFF 3D printer is especially challenging because there are so many variables that affect the material properties.
For instance, a bio-based polymer or resin might be composed of different mixes of plants based on the season. The properties of recycled materials also vary widely based on what is available to recycle.
“In ‘Back to the Future,’ there is a ‘Mr. Fusion’ blender where Doc just throws whatever he has into the blender and it works [as a power source for the DeLorean time machine]. That is the same idea here. Ideally, with plastics recycling, you could just shred what you have and print with it. But, with current feed-forward systems, that won’t work because if your filament changes significantly during the print, everything would break,” Read says.
To overcome these challenges, the researchers developed a 3D printer and workflow to automatically identify viable process parameters for any unknown material.
They started with a 3D printer their lab had previously developed that can capture data and provide feedback as it operates. The researchers added three instruments to the machine’s extruder that take measurements which are used to calculate parameters.
A load cell measures the pressure being exerted on the printing filament, while a feed rate sensor measures the thickness of the filament and the actual rate at which it is being fed through the printer.
“This fusion of measurement, modeling, and manufacturing is at the heart of the collaboration between NIST and CBA, as we work develop what we’ve termed ‘computational metrology,’” says Warren.
These measurements can be used to calculate the two most important, yet difficult to determine, printing parameters: flow rate and temperature. Nearly half of all print settings in standard software are related to these two parameters.
Deriving a dataset
Once they had the new instruments in place, the researchers developed a 20-minute test that generates a series of temperature and pressure readings at different flow rates. Essentially, the test involves setting the print nozzle at its hottest temperature, flowing the material through at a fixed rate, and then turning the heater off.
“It was really difficult to figure out how to make that test work. Trying to find the limits of the extruder means that you are going to break the extruder pretty often while you are testing it. The notion of turning the heater off and just passively taking measurements was the ‘aha’ moment,” says Read.
These data are entered into a function that automatically generates real parameters for the material and machine configuration, based on relative temperature and pressure inputs. The user can then enter those parameters into 3D printing software and generate instructions for the printer.
In experiments with six different materials, several of which were bio-based, the method automatically generated viable parameters that consistently led to successful prints of a complex object.
Moving forward, the researchers plan to integrate this process with 3D printing software so parameters don’t need to be entered manually. In addition, they want to enhance their workflow by incorporating a thermodynamic model of the hot end, which is the part of the printer that melts the filament.
This collaboration is now more broadly developing computational metrology, in which the output of a measurement is a predictive model rather than just a parameter. The researchers will be applying this in other areas of advanced manufacturing, as well as in expanding access to metrology.
“By developing a new method for the automatic generation of process parameters for fused filament fabrication, this study opens the door to the use of recycled and bio-based filaments that have variable and unknown behaviors. Importantly, this enhances the potential for digital manufacturing technology to utilize locally sourced sustainable materials,” says Alysia Garmulewicz, an associate professor in the Faculty of Administration and Economics at the University of Santiago in Chile who was not involved with this work.
This research is supported, in part, by the National Institute of Standards and Technology and the Center for Bits and Atoms Consortia.
A new way of imaging the brain with magnetic resonance imaging (MRI) does not directly detect neural activity as originally reported, according to scientists at MIT’s McGovern Institute for Brain Research.
The method, first described in 2022, generated excitement within the neuroscience community as a potentially transformative approach. But a study from the lab of MIT Professor Alan Jasanoff, reported March 27 in the journal Science Advances, demonstrates that MRI signals produced by the new method are generated in large part by the imaging process itself, not neuronal activity.
Jasanoff, a professor of biological engineering, brain and cognitive sciences, and nuclear science and engineering, as well as an associate investigator of the McGovern Institute, explains that having a noninvasive means of seeing neuronal activity in the brain is a long-sought goal for neuroscientists. The functional MRI methods that researchers currently use to monitor brain activity don’t actually detect neural signaling. Instead, they use blood flow changes triggered by brain activity as a proxy. This reveals which parts of the brain are engaged during imaging, but it cannot pinpoint neural activity to precise locations, and it is too slow to truly track neurons’ rapid-fire communications.
So when a team of scientists reported in 2022 a new MRI method called DIANA, for “direct imaging of neuronal activity,” neuroscientists paid attention. The authors claimed that DIANA detected MRI signals in the brain that corresponded to the electrical signals of neurons, and that it acquired signals far faster than the methods now used for functional MRI.
“Everyone wants this,” Jasanoff says. “If we could look at the whole brain and follow its activity with millisecond precision and know that all the signals that we’re seeing have to do with cellular activity, this would be just wonderful. It could tell us all kinds of things about how the brain works and what goes wrong in disease.”
Jasanoff adds that from the initial report, it was not clear what brain changes DIANA was detecting to produce such a rapid readout of neural activity. Curious, he and his team began to experiment with the method. “We wanted to reproduce it, and we wanted to understand how it worked,” he says.
Recreating the MRI procedure reported by DIANA’s developers, postdoc Valerie Doan Phi Van imaged the brain of a rat as an electric stimulus was delivered to one paw. Phi Van says she was excited to see an MRI signal appear in the brain’s sensory cortex, exactly when and where neurons were expected to respond to the sensation on the paw. “I was able to reproduce it,” she says. “I could see the signal.”
With further tests of the system, however, her enthusiasm waned. To investigate the source of the signal, she disconnected the device used to stimulate the animal’s paw, then repeated the imaging. Again, signals showed up in the sensory processing part of the brain. But this time, there was no reason for neurons in that area to be activated. In fact, Phi Van found, the MRI produced the same kinds of signals when the animal inside the scanner was replaced with a tube of water. It was clear DIANA’s functional signals were not arising from neural activity.
Phi Van traced the source of the specious signals to the pulse program that directs DIANA’s imaging process, detailing the sequence of steps the MRI scanner uses to collect data. Embedded within DIANA’s pulse program was a trigger for the device that delivers sensory input to the animal inside the scanner. That synchronizes the two processes, so the stimulation occurs at a precise moment during data acquisition. That trigger appeared to be causing signals that DIANA’s developers had concluded indicated neural activity.
Phi Van altered the pulse program, changing the way the stimulator was triggered. Using the updated program, the MRI scanner detected no functional signal in the brain in response to the same paw stimulation that had produced a signal before. “If you take this part of the code out, then the signal will also be gone. So that means the signal we see is an artifact of the trigger,” she says.
Jasanoff and Phi Van went on to find reasons why other researchers have struggled to reproduce the results of the original DIANA report, noting that the trigger-generated signals can disappear with slight variations in the imaging process. With their postdoctoral colleague Sajal Sen, they also found evidence that cellular changes that DIANA’s developers had proposed might give rise to a functional MRI signal were not related to neuronal activity.
Jasanoff and Phi Van say it was important to share their findings with the research community, particularly as efforts continue to develop new neuroimaging methods. “If people want to try to repeat any part of the study or implement any kind of approach like this, they have to avoid falling into these pits,” Jasanoff says. He adds that they admire the authors of the original study for their ambition: “The community needs scientists who are willing to take risks to move the field ahead.”
Two rows of MRI brain scans: The top row is a time series showing an MRI artifact generated by the DIANA method; the bottom row is a time series showing the true (negative) result. The pink trace in the center matches the activity shown in the top row, and reflects the artifact generated by the imaging process itself, rather than underlying neural activity.
Globally, computation is booming at an unprecedented rate, fueled by the boons of artificial intelligence. With this, the staggering energy demand of the world’s computing infrastructure has become a major concern, and the development of computing devices that are far more energy-efficient is a leading challenge for the scientific community.
Use of magnetic materials to build computing devices like memories and processors has emerged as a promising avenue for creating “beyond-CMOS” computers, which would use far less energy compared to traditional computers. Magnetization switching in magnets can be used in computation the same way that a transistor switches from open or closed to represent the 0s and 1s of binary code.
While much of the research along this direction has focused on using bulk magnetic materials, a new class of magnetic materials — called two-dimensional van der Waals magnets — provides superior properties that can improve the scalability and energy efficiency of magnetic devices to make them commercially viable.
Although the benefits of shifting to 2D magnetic materials are evident, their practical induction into computers has been hindered by some fundamental challenges. Until recently, 2D magnetic materials could operate only at very low temperatures, much like superconductors. So bringing their operating temperatures above room temperature has remained a primary goal. Additionally, for use in computers, it is important that they can be controlled electrically, without the need for magnetic fields. Bridging this fundamental gap, where 2D magnetic materials can be electrically switched above room temperature without any magnetic fields, could potentially catapult the translation of 2D magnets into the next generation of “green” computers.
A team of MIT researchers has now achieved this critical milestone by designing a “van der Waals atomically layered heterostructure” device where a 2D van der Waals magnet, iron gallium telluride, is interfaced with another 2D material, tungsten ditelluride. In an open-access paper published March 15 in Science Advances,the team shows that the magnet can be toggled between the 0 and 1 states simply by applying pulses of electrical current across their two-layer device.
“Our device enables robust magnetization switching without the need for an external magnetic field, opening up unprecedented opportunities for ultra-low power and environmentally sustainable computing technology for big data and AI,” says lead author Deblina Sarkar, the AT&T Career Development Assistant Professor at the MIT Media Lab and Center for Neurobiological Engineering, and head of the Nano-Cybernetic Biotrek research group. “Moreover, the atomically layered structure of our device provides unique capabilities including improved interface and possibilities of gate voltage tunability, as well as flexible and transparent spintronic technologies.”
Sarkar is joined on the paper by first author Shivam Kajale, a graduate student in Sarkar’s research group at the Media Lab; Thanh Nguyen, a graduate student in the Department of Nuclear Science and Engineering (NSE); Nguyen Tuan Hung, an MIT visiting scholar in NSE and an assistant professor at Tohoku University in Japan; and Mingda Li, associate professor of NSE.
Breaking the mirror symmetries
When electric current flows through heavy metals like platinum or tantalum, the electrons get segregated in the materials based on their spin component, a phenomenon called the spin Hall effect, says Kajale. The way this segregation happens depends on the material, and particularly its symmetries.
“The conversion of electric current to spin currents in heavy metals lies at the heart of controlling magnets electrically,” Kajale notes. “The microscopic structure of conventionally used materials, like platinum, have a kind of mirror symmetry, which restricts the spin currents only to in-plane spin polarization.”
Kajale explains that two mirror symmetries must be broken to produce an “out-of-plane” spin component that can be transferred to a magnetic layer to induce field-free switching. “Electrical current can 'break' the mirror symmetry along one plane in platinum, but its crystal structure prevents the mirror symmetry from being broken in a second plane.”
In their earlier experiments, the researchers used a small magnetic field to break the second mirror plane. To get rid of the need for a magnetic nudge, Kajale and Sarkar and colleagues looked instead for a material with a structure that could break the second mirror plane without outside help. This led them to another 2D material, tungsten ditelluride. The tungsten ditelluride that the researchers used has an orthorhombic crystal structure. The material itself has one broken mirror plane. Thus, by applying current along its low-symmetry axis (parallel to the broken mirror plane), the resulting spin current has an out-of-plane spin component that can directly induce switching in the ultra-thin magnet interfaced with the tungsten ditelluride.
“Because it's also a 2D van der Waals material, it can also ensure that when we stack the two materials together, we get pristine interfaces and a good flow of electron spins between the materials,” says Kajale.
Becoming more energy-efficient
Computer memory and processors built from magnetic materials use less energy than traditional silicon-based devices. And the van der Waals magnets can offer higher energy efficiency and better scalability compared to bulk magnetic material, the researchers note.
The electrical current density used for switching the magnet translates to how much energy is dissipated during switching. A lower density means a much more energy-efficient material. “The new design has one of the lowest current densities in van der Waals magnetic materials,” Kajale says. “This new design has an order of magnitude lower in terms of the switching current required in bulk materials. This translates to something like two orders of magnitude improvement in energy efficiency.”
The research team is now looking at similar low-symmetry van der Waals materials to see if they can reduce current density even further. They are also hoping to collaborate with other researchers to find ways to manufacture the 2D magnetic switch devices at commercial scale.
This work was carried out, in part, using the facilities at MIT.nano. It was funded by the Media Lab, the U.S. National Science Foundation, and the U.S. Department of Energy.
The flow of electrical current in the bottom crystalline slab (representing WTe2) breaks a mirror symmetry (shattered glass), while the material itself breaks the other mirror symmetry (cracked glass). The resulting spin current has vertical polarization that switches the magnetic state of the top 2D ferromagnet.
Mass spectrometry, a technique that can precisely identify the chemical components of a sample, could be used to monitor the health of people who suffer from chronic illnesses. For instance, a mass spectrometer can measure hormone levels in the blood of someone with hypothyroidism.
But mass spectrometers can cost several hundred thousand dollars, so these expensive machines are typically confined to laboratories where blood samples must be sent for testing. This inefficient process can make managing a chronic disease especially challenging.
“Our big vision is to make mass spectrometry local. For someone who has a chronic disease that requires constant monitoring, they could have something the size of a shoebox that they could use to do this test at home. For that to happen, the hardware has to be inexpensive,” says Luis Fernando Velásquez-García, a principal research scientist in MIT’s Microsystems Technology Laboratories (MTL).
He and his collaborators have taken a big step in that direction by 3D printing a low-cost ionizer — a critical component of all mass spectrometers — that performs twice as well as its state-of-the-art counterparts.
Their device, which is only a few centimeters in size, can be manufactured at scale in batches and then incorporated into a mass spectrometer using efficient, pick-and-place robotic assembly methods. Such mass production would make it cheaper than typical ionizers that often require manual labor, need expensive hardware to interface with the mass spectrometer, or must be built in a semiconductor clean room.
By 3D printing the device instead, the researchers were able to precisely control its shape and utilize special materials that helped boost its performance.
“This is a do-it-yourself approach to making an ionizer, but it is not a contraption held together with duct tape or a poor man’s version of the device. At the end of the day, it works better than devices made using expensive processes and specialized instruments, and anyone can be empowered to make it,” says Velásquez-García, senior author of a paper on the ionizer.
He wrote the paper with lead author Alex Kachkine, a mechanical engineering graduate student. The research is published in the Journal of the American Association for Mass Spectrometry.
Low-cost hardware
Mass spectrometers identify the contents of a sample by sorting charged particles, called ions, based on their mass-to-charge ratio. Since molecules in blood don’t have an electric charge, an ionizer is used to give them a charge before they are analyzed.
Most liquid ionizers do this using electrospray, which involves applying a high voltage to a liquid sample and then firing a thin jet of charged particles into the mass spectrometer. The more ionized particles in the spray, the more accurate the measurements will be.
The MIT researchers used 3D printing, along with some clever optimizations, to produce a low-cost electrospray emitter that outperformed state-of-the-art mass spectrometry ionizer versions.
They fabricated the emitter from metal using binder jetting, a 3D printing process in which a blanket of powdered material is showered with a polymer-based glue squirted through tiny nozzles to build an object layer by layer. The finished object is heated in an oven to evaporate the glue and then consolidate the object from a bed of powder that surrounds it.
“The process sounds complicated, but it is one of the original 3D printing methods, and it is highly precise and very effective,” Velásquez-García says.
Then, the printed emitters undergo an electropolishing step that sharpens it. Finally, each device is coated in zinc oxide nanowires which give the emitter a level of porosity that enables it to effectively filter and transport liquids.
Thinking outside the box
One possible problem that impacts electrospray emitters is the evaporation that can occur to the liquid sample during operation. The solvent might vaporize and clog the emitter, so engineers typically design emitters to limit evaporation.
Through modeling confirmed by experiments, the MIT team realized they could use evaporation to their advantage. They designed the emitters as externally-fed solid cones with a specific angle that leverages evaporation to strategically restrict the flow of liquid. In this way, the sample spray contains a higher ratio of charge-carrying molecules.
“We saw that evaporation can actually be a design knob that can help you optimize the performance,” he says.
They also rethought the counter-electrode that applies voltage to the sample. The team optimized its size and shape, using the same binder jetting method, so the electrode prevents arcing. Arcing, which occurs when electrical current jumps a gap between two electrodes, can damage electrodes or cause overheating.
Because their electrode is not prone to arcing, they can safely increase the applied voltage, which results in more ionized molecules and better performance.
They also created a low-cost, printed circuit board with built-in digital microfluidics, which the emitter is soldered to. The addition of digital microfluidics enables the ionizer to efficiently transport droplets of liquid.
Taken together, these optimizations enabled an electrospray emitter that could operate at a voltage 24 percent higher than state-of-the-art versions. This higher voltage enabled their device to more than double the signal-to-noise ratio.
In addition, their batch processing technique could be implemented at scale, which would significantly lower the cost of each emitter and go a long way toward making a point-of-care mass spectrometer an affordable reality.
“Going back to Guttenberg, once people had the ability to print their own things, the world changed completely. In a sense, this could be more of the same. We can give people the power to create the hardware they need in their daily lives,” he says.
Moving forward, the team wants to create a prototype that combines their ionizer with a 3D-printed mass filter they previously developed. The ionizer and mass filter are the key components of the device. They are also working to perfect 3D-printed vacuum pumps, which remain a major hurdle to printing an entire compact mass spectrometer.
“Miniaturization through advanced technology is slowly but surely transforming mass spectrometry, reducing manufacturing cost and increasing the range of applications. This work on fabricating electrospray sources by 3D printing also enhances signal strength, increasing sensitivity and signal-to-noise ratio and potentially opening the way to more widespread use in clinical diagnosis,” says Richard Syms, professor of microsystems technology in the Department of Electrical and Electronic Engineering at Imperial College London, who was not involved with this research.
MIT researchers have 3D printed a miniature ionizer, which is a key component of a mass spectrometer. The new miniature ionizer could someday enable an affordable, in-home mass spectrometer for health monitoring. Pictured are parts of the new device, including a green printed circuit board (PCB) with orange casing on top. Under the casing is a black rectangle where the electrospray emitter is located.
Mo Mirvakili PhD ’17 was in the middle of an experiment as a postdoc at MIT when the Covid-19 pandemic hit. Grappling with restricted access to laboratory facilities, he decided to transform his bathroom into a makeshift lab. Arranging a piece of plywood over the bathtub to support power sources and measurement devices, he conducted a study that was later published in Science Robotics, one of the top journals in the field.
The adversity made for a good story, but the truth is that it didn’t take a global pandemic to force Mirvakili to build the equipment he needed to run his experiments. Even when working in some of the most well-funded labs in the world, he needed to piece together tools to bring his experiments to life.
“My journey reflects a broader truth: With determination and resourcefulness, many of us can achieve remarkable things,” he says. “There are so many people who don't have access to labs yet have great ideas. We need to make it easier for them to bring their experiments to life.”
That’s the idea behind Seron Electronics, a company Mirvakili founded to democratize scientific experimentation. Seron develops scientific equipment that precisely sources and measures power, characterizes materials, and integrates data into a customizable software platform.
By making sophisticated experiments more accessible, Seron aims to spur a new wave of innovation across fields as diverse as microelectronics, clean energy, optics, and biomedicine.
“Our goal is to become one of the leaders in providing accurate and affordable solutions for researchers,” Mirvakili says. “This vision extends beyond academia to include companies, governments, nonprofits, and even high school students. With Seron’s devices, anyone can conduct high-quality experiments, regardless of their background or resources.”
Feeling the need for constant power
Mirvakili earned his bachelor's and master's degrees in electrical engineering, followed by a PhD in mechanical engineering under MIT Professor Ian Hunter, which involved developing a class of high-performance thermal artificial muscles, including nylon artificial muscles. During that time, Mirvakili needed to precisely control the amount of energy that flowed through his experimental setups, but he couldn't find anything online that would solve his problem.
“I had access to all sorts of high-end equipment in our lab and the department,” Mirvakili recalls. “It’s all the latest, state-of-the-art stuff. But I had to bundle all these outside tools together for my work.”
After completing his PhD, Mirvakili joined Institute Professor Bob Langer’s lab as a postdoc, where he worked directly with Langer on a totally different problem in biomedical engineering. In Langer's famously prolific lab, he saw researchers struggling to control temperatures at the microscale for a device that was encapsulating drugs.
Mirvakili realized the researchers were ultimately struggling with the same set of problems: the need to precisely control electric current, voltage, and power. Those are also problems Mirvakili has seen in his more recent research into energy storage and solar cells. After speaking with researchers at conferences from around the world to confirm the need was widespread, he started Seron Electronics.
Seron calls the first version of its products the SE Programmable Power Platforms. The platforms allow users to source and measure precisely defined quantities of electrical voltage, current, power, and charge through a desktop application with minimal signal interference, or noise.
The equipment can be used to study things like semiconductor devices, actuators, and energy storage devices, or to precisely charge batteries without damaging their performance.
The equipment can also be used to study material performance because it can measure how materials react to precise electrical stimulation at a high resolution, and for quality control because it can test chips and flag problems.
The use cases are varied, but Seron’s overarching goal is to enable more innovation faster.
“Because our system is so intuitive, you reduce the time to get results,” Mirvakili says. “You can set it up in less than five minutes. It’s plug-and-play. Researchers tell us it speeds things up a lot.”
New frontiers
In a recent paperMirvakili coauthored with MIT research affiliate Ehsan Haghighat, Seron’s equipment provided constant power to a thermal artificial muscle that integrated machine learning to give it a sort of muscle memory. In another study Mirvakili was not involved in, a nonprofit research organization used Seron’s equipment to identify a new, sustainable sensor material they are in the process of commercializing.
Many uses of the machines have come as a surprise to Seron’s team, and they expect to see a new wave of applications when they release a cheaper, portable version of Seron’s machines this summer. That could include the development of new bedside monitors for patients that can detect diseases, or remote sensors for field work.
Mirvakili thinks part of the beauty of Seron’s devices is that people in the company don’t have to dream up the experiments themselves. Instead, they can focus on providing powerful scientific tools and let the research community decide on the best ways to use them.
“Because of the size and the cost of this new device, it will really open up the possibilities for researchers," Mirvakili says. “Anyone who has a good idea should be able to turn that idea into reality with our equipment and solutions. In my mind, the applications are really unimaginable and endless.”
Seron Electronics makes scientific equipment that can precisely source and measure power, characterize materials, and chart all of that data in a customizable software platform for multiple industries including clean energy, robotics, biomedicine, and more.
Neutrons are subatomic particles that have no electric charge, unlike protons and electrons. That means that while the electromagnetic force is responsible for most of the interactions between radiation and materials, neutrons are essentially immune to that force.
Instead, neutrons are held together inside an atom’s nucleus solely by something called the strong force, one of the four fundamental forces of nature. As its name implies, the force is indeed very strong, but only at very close range — it drops off so rapidly as to be negligible beyond 1/10,000 the size of an atom. But now, researchers at MIT have found that neutrons can actually be made to cling to particles called quantum dots, which are made up of tens of thousands of atomic nuclei, held there just by the strong force.
The new finding may lead to useful new tools for probing the basic properties of materials at the quantum level, including those arising from the strong force, as well as exploring new kinds of quantum information processing devices. The work is reported this week in the journal ACS Nano, in a paper by MIT graduate students Hao Tang and Guoqing Wang and MIT professors Ju Li and Paola Cappellaro of the Department of Nuclear Science and Engineering.
Neutrons are widely used to probe material properties using a method called neutron scattering, in which a beam of neutrons is focused on a sample, and the neutrons that bounce off the material’s atoms can be detected to reveal the material’s internal structure and dynamics.
But until this new work, nobody thought that these neutrons might actually stick to the materials they were probing. “The fact that [the neutrons] can be trapped by the materials, nobody seems to know about that,” says Li, who is also a professor of materials science and engineering. “We were surprised that this exists, and that nobody had talked about it before, among the experts we had checked with,” he says.
The reason this new finding is so surprising, Li explains, is because neutrons don’t interact with electromagnetic forces. Of the four fundamental forces, gravity and the weak force “are generally not important for materials,” he says. “Pretty much everything is electromagnetic interaction, but in this case, since the neutron doesn’t have a charge, the interaction here is through the strong interaction, and we know that is very short-range. It is effective at a range of 10 to the minus 15 power,” or one quadrillionth, of a meter.
“It’s very small, but it’s very intense,” he says of this force that holds the nuclei of atoms together. “But what’s interesting is we’ve got these many thousands of nuclei in this neutronic quantum dot, and that’s able to stabilize these bound states, which have much more diffuse wavefunctions at tens of nanometers [billionths of a meter]. These neutronic bound states in a quantum dot are actually quite akin to Thomson’s plum pudding model of an atom, after his discovery of the electron.”
It was so unexpected, Li calls it “a pretty crazy solution to a quantum mechanical problem.” The team calls the newly discovered state an artificial “neutronic molecule.”
These neutronic molecules are made from quantum dots, which are tiny crystalline particles, collections of atoms so small that their properties are governed more by the exact size and shape of the particles than by their composition. The discovery and controlled production of quantum dots were the subject of the 2023 Nobel Prize in Chemistry, awarded to MIT Professor Moungi Bawendi and two others.
“In conventional quantum dots, an electron is trapped by the electromagnetic potential created by a macroscopic number of atoms, thus its wavefunction extends to about 10 nanometers, much larger than a typical atomic radius,” says Cappellaro. “Similarly, in these nucleonic quantum dots, a single neutron can be trapped by a nanocrystal, with a size well beyond the range of the nuclear force, and display similar quantized energies.” While these energy jumps give quantum dots their colors, the neutronic quantum dots could be used for storing quantum information.
This work is based on theoretical calculations and computational simulations. “We did it analytically in two different ways, and eventually also verified it numerically,” Li says. Although the effect had never been described before, he says, in principle there’s no reason it couldn’t have been found much sooner: “Conceptually, people should have already thought about it,” he says, but as far as the team has been able to determine, nobody did.
Part of the difficulty in doing the computations is the very different scales involved: The binding energy of a neutron to the quantum dots they were attaching to is about one-trillionth that of previously known conditions where the neutron is bound to a small group of nucleons. For this work, the team used an analytical tool called Green’s function to demonstrate that the strong force was sufficient to capture neutrons with a quantum dot with a minimum radius of 13 nanometers.
Then, the researchers did detailed simulations of specific cases, such as the use of a lithium hydride nanocrystal, a material being studied as a possible storage medium for hydrogen. They showed that the binding energy of the neutrons to the nanocrystal is dependent on the exact dimensions and shape of the crystal, as well as the nuclear spin polarizations of the nuclei compared to that of the neutron. They also calculated similar effects for thin films and wires of the material as opposed to particles.
But Li says that actually creating such neutronic molecules in the lab, which among other things requires specialized equipment to maintain temperatures in the range of a few thousandths of a Kelvin above absolute zero, is something that other researchers with the appropriate expertise will have to undertake.
Li notes that “artificial atoms” made up of assemblages of atoms that share properties and can behave in many ways like a single atom have been used to probe many properties of real atoms. Similarly, he says, these artificial molecules provide “an interesting model system” that might be used to study “interesting quantum mechanical problems that one can think about,” such as whether these neutronic molecules will have a shell structure that mimics the electron shell structure of atoms.
“One possible application,” he says, “is maybe we can precisely control the neutron state. By changing the way the quantum dot oscillates, maybe we can shoot the neutron off in a particular direction.” Neutrons are powerful tools for such things as triggering both fission and fusion reactions, but so far it has been difficult to control individual neutrons. These new bound states could provide much greater degrees of control over individual neutrons, which could play a role in the development of new quantum information systems, he says.
“One idea is to use it to manipulate the neutron, and then the neutron will be able to affect other nuclear spins,” Li says. In that sense, he says, the neutronic molecule could serve as a mediator between the nuclear spins of separate nuclei — and this nuclear spin is a property that is already being used as a basic storage unit, or qubit, in developing quantum computer systems.
“The nuclear spin is like a stationary qubit, and the neutron is like a flying qubit,” he says. “That’s one potential application.” He adds that this is “quite different from electromagnetics-based quantum information processing, which is so far the dominant paradigm. So, regardless of whether it’s superconducting qubits or it’s trapped ions or nitrogen vacancy centers, most of these are based on electromagnetic interactions.” In this new system, instead, “we have neutrons and nuclear spin. We’re just starting to explore what we can do with it now.”
Another possible application, he says, is for a kind of imaging, using neutral activation analysis. “Neutron imaging complements X-ray imaging because neutrons are much more strongly interacting with light elements,” Li says. It can also be used for materials analysis, which can provide information not only about elemental composition but even about the different isotopes of those elements. “A lot of the chemical imaging and spectroscopy doesn’t tell us about the isotopes,” whereas the neutron-based method could do so, he says.
The research was supported by the U.S. Office of Naval Research.
MIT researchers discovered “neutronic” molecules, in which neutrons can be made to cling to quantum dots, held just by the strong force. The finding may lead to new tools for probing material properties at the quantum level and exploring new kinds of quantum information processing devices. Here, the red item represents a bound neutron, the sphere is a hydride nanoparticle, and the yellow field represents a neutron wavefunction.
To engineer proteins with useful functions, researchers usually begin with a natural protein that has a desirable function, such as emitting fluorescent light, and put it through many rounds of random mutation that eventually generate an optimized version of the protein.
This process has yielded optimized versions of many important proteins, including green fluorescent protein (GFP). However, for other proteins, it has proven difficult to generate an optimized version. MIT researchers have now developed a computational approach that makes it easier to predict mutations that will lead to better proteins, based on a relatively small amount of data.
Using this model, the researchers generated proteins with mutations that were predicted to lead to improved versions of GFP and a protein from adeno-associated virus (AAV), which is used to deliver DNA for gene therapy. They hope it could also be used to develop additional tools for neuroscience research and medical applications.
“Protein design is a hard problem because the mapping from DNA sequence to protein structure and function is really complex. There might be a great protein 10 changes away in the sequence, but each intermediate change might correspond to a totally nonfunctional protein. It’s like trying to find your way to the river basin in a mountain range, when there are craggy peaks along the way that block your view. The current work tries to make the riverbed easier to find,” says Ila Fiete, a professor of brain and cognitive sciences at MIT, a member of MIT’s McGovern Institute for Brain Research, director of the K. Lisa Yang Integrative Computational Neuroscience Center, and one of the senior authors of the study.
Regina Barzilay, the School of Engineering Distinguished Professor for AI and Health at MIT, and Tommi Jaakkola, the Thomas Siebel Professor of Electrical Engineering and Computer Science at MIT, are also senior authors of an open-access paper on the work, which will be presented at the International Conference on Learning Representations in May. MIT graduate students Andrew Kirjner and Jason Yim are the lead authors of the study. Other authors include Shahar Bracha, an MIT postdoc, and Raman Samusevich, a graduate student at Czech Technical University.
Optimizing proteins
Many naturally occurring proteins have functions that could make them useful for research or medical applications, but they need a little extra engineering to optimize them. In this study, the researchers were originally interested in developing proteins that could be used in living cells as voltage indicators. These proteins, produced by some bacteria and algae, emit fluorescent light when an electric potential is detected. If engineered for use in mammalian cells, such proteins could allow researchers to measure neuron activity without using electrodes.
While decades of research have gone into engineering these proteins to produce a stronger fluorescent signal, on a faster timescale, they haven’t become effective enough for widespread use. Bracha, who works in Edward Boyden’s lab at the McGovern Institute, reached out to Fiete’s lab to see if they could work together on a computational approach that might help speed up the process of optimizing the proteins.
“This work exemplifies the human serendipity that characterizes so much science discovery,” Fiete says. “It grew out of the Yang Tan Collective retreat, a scientific meeting of researchers from multiple centers at MIT with distinct missions unified by the shared support of K. Lisa Yang. We learned that some of our interests and tools in modeling how brains learn and optimize could be applied in the totally different domain of protein design, as being practiced in the Boyden lab.”
For any given protein that researchers might want to optimize, there is a nearly infinite number of possible sequences that could generated by swapping in different amino acids at each point within the sequence. With so many possible variants, it is impossible to test all of them experimentally, so researchers have turned to computational modeling to try to predict which ones will work best.
In this study, the researchers set out to overcome those challenges, using data from GFP to develop and test a computational model that could predict better versions of the protein.
They began by training a type of model known as a convolutional neural network (CNN) on experimental data consisting of GFP sequences and their brightness — the feature that they wanted to optimize.
The model was able to create a “fitness landscape” — a three-dimensional map that depicts the fitness of a given protein and how much it differs from the original sequence — based on a relatively small amount of experimental data (from about 1,000 variants of GFP).
These landscapes contain peaks that represent fitter proteins and valleys that represent less fit proteins. Predicting the path that a protein needs to follow to reach the peaks of fitness can be difficult, because often a protein will need to undergo a mutation that makes it less fit before it reaches a nearby peak of higher fitness. To overcome this problem, the researchers used an existing computational technique to “smooth” the fitness landscape.
Once these small bumps in the landscape were smoothed, the researchers retrained the CNN model and found that it was able to reach greater fitness peaks more easily. The model was able to predict optimized GFP sequences that had as many as seven different amino acids from the protein sequence they started with, and the best of these proteins were estimated to be about 2.5 times fitter than the original.
“Once we have this landscape that represents what the model thinks is nearby, we smooth it out and then we retrain the model on the smoother version of the landscape,” Kirjner says. “Now there is a smooth path from your starting point to the top, which the model is now able to reach by iteratively making small improvements. The same is often impossible for unsmoothed landscapes.”
Proof-of-concept
The researchers also showed that this approach worked well in identifying new sequences for the viral capsid of adeno-associated virus (AAV), a viral vector that is commonly used to deliver DNA. In that case, they optimized the capsid for its ability to package a DNA payload.
“We used GFP and AAV as a proof-of-concept to show that this is a method that works on data sets that are very well-characterized, and because of that, it should be applicable to other protein engineering problems,” Bracha says.
The researchers now plan to use this computational technique on data that Bracha has been generating on voltage indicator proteins.
“Dozens of labs having been working on that for two decades, and still there isn’t anything better,” she says. “The hope is that now with generation of a smaller data set, we could train a model in silico and make predictions that could be better than the past two decades of manual testing.”
The research was funded, in part, by the U.S. National Science Foundation, the Machine Learning for Pharmaceutical Discovery and Synthesis consortium, the Abdul Latif Jameel Clinic for Machine Learning in Health, the DTRA Discovery of Medical Countermeasures Against New and Emerging threats program, the DARPA Accelerated Molecular Discovery program, the Sanofi Computational Antibody Design grant, the U.S. Office of Naval Research, the Howard Hughes Medical Institute, the National Institutes of Health, the K. Lisa Yang ICoN Center, and the K. Lisa Yang and Hock E. Tan Center for Molecular Therapeutics at MIT.
MIT researchers have developed a computational approach that makes it easier to predict mutations that will lead to optimized proteins, based on a relatively small amount of data.
People tend to connect with others who are like them. Alumni from the same alma mater are more likely to collaborate over a research project together, or individuals with the same political beliefs are more likely to join the same political parties, attend rallies, and engage in online discussions. This sociology concept, called homophily, has been observed in many network science studies. But if like-minded individuals cluster in online and offline spaces to reinforce each other’s ideas and form synergies, what does that mean for society?
Researchers at MIT wanted to investigate homophily further to understand how groups of three or more interact in complex societal settings. Prior research on understanding homophily has studied relationships between pairs of people. For example, when two members of Congress co-sponsor a bill, they are likely to be from the same political party.
However, less is known about whether groupinteractionsbetween three or more people are likely to occur between similar individuals. If three members of Congress co-sponsor a bill together, are all three likely to be members of the same party, or would we expect more bipartisanship? When the researchers tried to extend traditional methods to measure homophily in these larger group interactions, they found the results can be misleading.
“We found that homophily observed in pairs, or one-to-one interactions, can make it seem like there’s more homophily in larger groups than there really is,” says Arnab Sarker, graduate student in the Institute for Data, Systems and Society (IDSS) and lead author of the study published in Proceedings of the National Academy of Sciences. “The previous measure didn’t account for the way in which two people already know each other in friendship settings," he adds.
To address this issue, Sarker, along with co-authors Natalie Northrup ’22 and Ali Jadbabaie, the JR East Professor of Engineering, head of the Department of Civil and Environmental Engineering, and core faculty member of IDSS, developed a new way of measuring homophily. Borrowing tools from algebraic topology, a subfield in mathematics typically applied in physics, they developed a new measure to understand whether homophily occurred in group interactions.
The new measure, called simplicial homophily, separates the homophily seen in one-on-one interactions from those in larger group interactions and is based on the mathematical concept of a simplicial complex. The researchers tested this new measure with real-world data from 16 different datasets and found that simplicial homophily provides more accurate insights into how similar things interact in larger groups. Interestingly, the new measure can better identify instances where there is a lack of similarity in larger group interactions, thus rectifying a weakness observed in the previous measure.
One such example of this instance was demonstrated in the dataset from the global hotel booking website, Trivago. They found that when travelers are looking at two hotels in one session, they often pick hotels that are close to one another geographically. But when they look at more than two hotels in one session, they are more likely to be searching for hotels that are farther apart from one another (for example, if they are taking a vacation with multiple stops). The new method showed “anti-homophily” — instead of similar hotels being chosen together, different hotels were chosen together.
“Our measure controls for pairwise connections and is suggesting that there’s more diversity in the hotels that people are looking for as group size increases, which is an interesting economic result,” says Sarker.
Additionally, they discovered that simplicial homophily can help identify when certain characteristics are important for predicting if groups will interact in the future. They found that when there’s a lot of similarity or a lot of difference between individuals who already interact in groups, then knowing individual characteristics can help predict their connection to each other in the future.
Northrup was an undergraduate researcher on the project and worked with Sarker and Jadbabaie over three semesters before she graduated. The project gave her an opportunity to take some of the concepts she learned in the classroom and apply them.
“Working on this project, I really dove into building out the higher-order network model, and understanding the network, the math, and being able to implement it at a large scale,” says Northrup, who was in the civil and environmental engineering systems track with a double major in economics.
The new measure opens up opportunities to study complex group interactions in a broad range of network applications, from ecology to traffic and socioeconomics. One of the areas Sarker has interest in exploring is the group dynamics of people finding jobs through social networks. “Does higher-order homophily affect how people get information about jobs?” he asks.
Northrup adds that it could also be used to evaluate interventions or specific policies to connect people with job opportunities outside of their network. “You can even use it as a measurement to evaluate how effective that might be.”
The research was supported through funding from a Vannevar Bush Fellowship from the Office of the U.S. Secretary of Defense and from the U.S. Army Research Office Multidisciplinary University Research Initiative.
MIT researchers developed a new measure to understand whether homophily occurred in group interactions. Their work can help identify when certain characteristics are important for predicting if groups will interact in the future.
This is part 2 of a two-part MIT News feature examining new job creation in the U.S. since 1940, based on new research from Ford Professor of Economics David Autor. Part 1 is available here.
Ever since the Luddites were destroying machine looms, it has been obvious that new technologies can wipe out jobs. But technical innovations also create new jobs: Consider a computer programmer, or someone installing solar panels on a roof.
Overall, does technology replace more jobs than it creates? What is the net balance between these two things? Until now, that has not been measured. But a new research project led by MIT economist David Autor has developed an answer, at least for U.S. history since 1940.
The study uses new methods to examine how many jobs have been lost to machine automation, and how many have been generated through “augmentation,” in which technology creates new tasks. On net, the study finds, and particularly since 1980, technology has replaced more U.S. jobs than it has generated.
“There does appear to be a faster rate of automation, and a slower rate of augmentation, in the last four decades, from 1980 to the present, than in the four decades prior,” says Autor, co-author of a newly published paper detailing the results.
However, that finding is only one of the study’s advances. The researchers have also developed an entirely new method for studying the issue, based on an analysis of tens of thousands of U.S. census job categories in relation to a comprehensive look at the text of U.S. patents over the last century. That has allowed them, for the first time, to quantify the effects of technology over both job loss and job creation.
Previously, scholars had largely just been able to quantify job losses produced by new technologies, not job gains.
“I feel like a paleontologist who was looking for dinosaur bones that we thought must have existed, but had not been able to find until now,” Autor says. “I think this research breaks ground on things that we suspected were true, but we did not have direct proof of them before this study.”
The paper, “New Frontiers: The Origins and Content of New Work, 1940-2018,” appears in the Quarterly Journal of Economics. The co-authors are Autor, the Ford Professor of Economics; Caroline Chin, a PhD student in economics at MIT; Anna Salomons, a professor in the School of Economics at Utrecht University; and Bryan Seegmiller SM ’20, PhD ’22, an assistant professor at the Kellogg School of Northwestern University.
Automation versus augmentation
The study finds that overall, about 60 percent of jobs in the U.S. represent new types of work, which have been created since 1940. A century ago, that computer programmer may have been working on a farm.
To determine this, Autor and his colleagues combed through about 35,000 job categories listed in the U.S. Census Bureau reports, tracking how they emerge over time. They also used natural language processing tools to analyze the text of every U.S. patent filed since 1920. The research examined how words were “embedded” in the census and patent documents to unearth related passages of text. That allowed them to determine links between new technologies and their effects on employment.
“You can think of automation as a machine that takes a job’s inputs and does it for the worker,” Autor explains. “We think of augmentation as a technology that increases the variety of things that people can do, the quality of things people can do, or their productivity.”
From about 1940 through 1980, for instance, jobs like elevator operator and typesetter tended to get automated. But at the same time, more workers filled roles such as shipping and receiving clerks, buyers and department heads, and civil and aeronautical engineers, where technology created a need for more employees.
From 1980 through 2018, the ranks of cabinetmakers and machinists, among others, have been thinned by automation, while, for instance, industrial engineers, and operations and systems researchers and analysts, have enjoyed growth.
Ultimately, the research suggests that the negative effects of automation on employment were more than twice as great in the 1980-2018 period as in the 1940-1980 period. There was a more modest, and positive, change in the effect of augmentation on employment in 1980-2018, as compared to 1940-1980.
“There’s no law these things have to be one-for-one balanced, although there’s been no period where we haven’t also created new work,” Autor observes.
What will AI do?
The research also uncovers many nuances in this process, though, since automation and augmentation often occur within the same industries. It is not just that technology decimates the ranks of farmers while creating air traffic controllers. Within the same large manufacturing firm, for example, there may be fewer machinists but more systems analysts.
Relatedly, over the last 40 years, technological trends have exacerbated a gap in wages in the U.S., with highly educated professionals being more likely to work in new fields, which themselves are split between high-paying and lower-income jobs.
“The new work is bifurcated,” Autor says. “As old work has been erased in the middle, new work has grown on either side.”
As the research also shows, technology is not the only thing driving new work. Demographic shifts also lie behind growth in numerous sectors of the service industries. Intriguingly, the new research also suggests that large-scale consumer demand also drives technological innovation. Inventions are not just supplied by bright people thinking outside the box, but in response to clear societal needs.
The 80 years of data also suggest that future pathways for innovation, and the employment implications, are hard to forecast. Consider the possible uses of AI in workplaces.
“AI is really different,” Autor says. “It may substitute some high-skill expertise but may complement decision-making tasks. I think we’re in an era where we have this new tool and we don’t know what’s good for. New technologies have strengths and weaknesses and it takes a while to figure them out. GPS was invented for military purposes, and it took decades for it to be in smartphones.”
He adds: “We’re hoping our research approach gives us the ability to say more about that going forward.”
As Autor recognizes, there is room for the research team’s methods to be further refined. For now, he believes the research open up new ground for study.
“The missing link was documenting and quantifying how much technology augments people’s jobs,” Autor says. “All the prior measures just showed automation and its effects on displacing workers. We were amazed we could identify, classify, and quantify augmentation. So that itself, to me, is pretty foundational.”
Support for the research was provided, in part, by The Carnegie Corporation; Google; Instituut Gak; the MIT Work of the Future Task Force; Schmidt Futures; the Smith Richardson Foundation; and the Washington Center for Equitable Growth.
Economists used new methods to examine how many U.S. jobs have been lost to machine automation, and how many have been created as technology leads to new tasks. On net, and particularly since 1980, technology has replaced more U.S. jobs than it has generated.
This is part 1 of a two-part MIT News feature examining new job creation in the U.S. since 1940, based on new research from Ford Professor of Economics David Autor. Part 2 is available here.
In 1900, Orville and Wilbur Wright listed their occupations as “Merchant, bicycle” on the U.S. census form. Three years later, they made their famous first airplane flight in Kitty Hawk, North Carolina. So, on the next U.S. census, in 1910, the brothers each called themselves “Inventor, aeroplane.” There weren’t too many of those around at the time, however, and it wasn’t until 1950 that “Airplane designer” became a recognized census category.
Distinctive as their case may be, the story of the Wright brothers tells us something important about employment in the U.S. today. Most work in the U.S. is new work, as U.S. census forms reveal. That is, a majority of jobs are in occupations that have only emerged widely since 1940, according to a major new study of U.S. jobs led by MIT economist David Autor.
“We estimate that about six out of 10 jobs people are doing at present didn’t exist in 1940,” says Autor, co-author of a newly published paper detailing the results. “A lot of the things that we do today, no one was doing at that point. Most contemporary jobs require expertise that didn’t exist back then, and was not relevant at that time.”
This finding, covering the period 1940 to 2018, yields some larger implications. For one thing, many new jobs are created by technology. But not all: Some come from consumer demand, such as health care services jobs for an aging population.
On another front, the research shows a notable divide in recent new-job creation: During the first 40 years of the 1940-2018 period, many new jobs were middle-class manufacturing and clerical jobs, but in the last 40 years, new job creation often involves either highly paid professional work or lower-wage service work.
Finally, the study brings novel data to a tricky question: To what extent does technology create new jobs, and to what extent does it replace jobs?
The paper, “New Frontiers: The Origins and Content of New Work, 1940-2018,” appears in the Quarterly Journal of Economics. The co-authors are Autor, the Ford Professor of Economics at MIT; Caroline Chin, a PhD student in economics at MIT; Anna Salomons, a professor in the School of Economics at Utrecht University; and Bryan Seegmiller SM ’20, PhD ’22, an assistant professor at the Kellogg School of Northwestern University.
“This is the hardest, most in-depth project I’ve ever done in my research career,” Autor adds. “I feel we’ve made progress on things we didn’t know we could make progress on.”
“Technician, fingernail”
To conduct the study, the scholars dug deeply into government data about jobs and patents, using natural language processing techniques that identified related descriptions in patent and census data to link innovations and subsequent job creation. The U.S. Census Bureau tracks the emerging job descriptions that respondents provide — like the ones the Wright brothers wrote down. Each decade’s jobs index lists about 35,000 occupations and 15,000 specialized variants of them.
Many new occupations are straightforwardly the result of new technologies creating new forms of work. For instance, “Engineers of computer applications” was first codified in 1970, “Circuit layout designers” in 1990, and “Solar photovoltaic electrician” made its debut in 2018.
“Many, many forms of expertise are really specific to a technology or a service,” Autor says. “This is quantitatively a big deal.”
He adds: “When we rebuild the electrical grid, we’re going to create new occupations — not just electricians, but the solar equivalent, i.e., solar electricians. Eventually that becomes a specialty. The first objective of our study is to measure [this kind of process]; the second is to show what it responds to and how it occurs; and the third is to show what effect automation has on employment.”
On the second point, however, innovations are not the only way new jobs emerge. The wants and needs of consumers also generate new vocations. As the paper notes, “Tattooers” became a U.S. census job category in 1950, “Hypnotherapists” was codified in 1980, and “Conference planners” in 1990. Also, the date of U.S. Census Bureau codification is not the first time anyone worked in those roles; it is the point at which enough people had those jobs that the bureau recognized the work as a substantial employment category. For instance, “Technician, fingernail” became a category in 2000.
“It’s not just technology that creates new work, it’s new demand,” Autor says. An aging population of baby boomers may be creating new roles for personal health care aides that are only now emerging as plausible job categories.
All told, among “professionals,” essentially specialized white-collar workers, about 74 percent of jobs in the area have been created since 1940. In the category of “health services” — the personal service side of health care, including general health aides, occupational therapy aides, and more — about 85 percent of jobs have emerged in the same time. By contrast, in the realm of manufacturing, that figure is just 46 percent.
Differences by degree
The fact that some areas of employment feature relatively more new jobs than others is one of the major features of the U.S. jobs landscape over the last 80 years. And one of the most striking things about that time period, in terms of jobs, is that it consists of two fairly distinct 40-year periods.
In the first 40 years, from 1940 to about 1980, the U.S. became a singular postwar manufacturing powerhouse, production jobs grew, and middle-income clerical and other office jobs grew up around those industries.
But in the last four decades, manufacturing started receding in the U.S., and automation started eliminating clerical work. From 1980 to the present, there have been two major tracks for new jobs: high-end and specialized professional work, and lower-paying service-sector jobs, of many types. As the authors write in the paper, the U.S. has seen an “overall polarization of occupational structure.”
That corresponds with levels of education. The study finds that employees with at least some college experience are about 25 percent more likely to be working in new occupations than those who possess less than a high school diploma.
“The real concern is for whom the new work has been created,” Autor says. “In the first period, from 1940 to 1980, there’s a lot of work being created for people without college degrees, a lot of clerical work and production work, middle-skill work. In the latter period, it’s bifurcated, with new work for college graduates being more and more in the professions, and new work for noncollege graduates being more and more in services.”
Still, Autor adds, “This could change a lot. We’re in a period of potentially consequential technology transition.”
At the moment, it remains unclear how, and to what extent, evolving technologies such as artificial intelligence will affect the workplace. However, this is also a major issue addressed in the current research study: How much does new technology augment employment, by creating new work and viable jobs, and how much does new technology replace existing jobs, through automation? In their paper, Autor and his colleagues have produced new findings on that topic, which are outlined in part 2 of this MIT News series.
Support for the research was provided, in part, by the Carnegie Corporation; Google; Instituut Gak; the MIT Work of the Future Task Force; Schmidt Futures; the Smith Richardson Foundation; and the Washington Center for Equitable Growth.
Most U.S. workers are in occupations that have only emerged widely since 1940, according to a large-scale study of 80 years of U.S. census data, led by MIT economist David Autor.
Imagine you and a friend are playing a game where your goal is to communicate secret messages to each other using only cryptic sentences. Your friend's job is to guess the secret message behind your sentences. Sometimes, you give clues directly, and other times, your friend has to guess the message by asking yes-or-no questions about the clues you've given. The challenge is, both of you want to make sure you're understanding each other correctly and agreeing on the secret message.
MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers have created a similar “game” to help improve how AI understands and generates text. The “Consensus Game” involves two parts of an AI system — one part tries to generate sentences (like giving clues), and the other part tries to understand and evaluate those sentences (like guessing the secret message).
The researchers discovered that by treating this interaction as a game, where both parts of the AI work together under specific rules to agree on the right message, they could significantly improve the AI's ability to give correct and coherent answers to questions. They tested this new game-like approach on a variety of tasks, such as reading comprehension, solving math problems, and carrying on conversations, and found that it helped the AI perform better across the board.
Traditionally, language models (LMs) answer one of two ways: generating answers directly from the model (generative querying) or using the model to score a set of predefined answers (discriminative querying), which can lead to differing and sometimes incompatible results. With the generative approach, “Who is the President of the United States?” might yield a straightforward answer like “Joe Biden.” However, a discriminative query could incorrectly dispute this fact when evaluating the same answer, such as “Barack Obama.”
So, how do we reconcile mutually incompatible scoring procedures to achieve coherent, efficient predictions?
“Imagine a new way to help language models understand and generate text, like a game. We've developed a training-free, game-theoretic method that treats the whole process as a complex game of clues and signals, where a generator tries to send the right message to a discriminator using natural language. Instead of chess pieces, they're using words and sentences,” says MIT CSAIL PhD student Athul Jacob. “Our way to navigate this game is finding the 'approximate equilibria,' leading to a new decoding algorithm called 'Equilibrium Ranking.' It's a pretty exciting demonstration of how bringing game-theoretic strategies into the mix can tackle some big challenges in making language models more reliable and consistent.”
When tested across many tasks, like reading comprehension, commonsense reasoning, math problem-solving, and dialogue, the team's algorithm consistently improved how well these models performed. Using the ER algorithm with the LLaMA-7B model even outshone the results from much larger models. “Given that they are already competitive, that people have been working on it for a while, but the level of improvements we saw being able to outperform a model that's 10 times the size was a pleasant surprise,” says Jacob.
Game on
Diplomacy, a strategic board game set in pre-World War I Europe, where players negotiate alliances, betray friends, and conquer territories without the use of dice — relying purely on skill, strategy, and interpersonal manipulation — recently had a second coming. In November 2022, computer scientists, including Jacob, developed “Cicero,” an AI agent that achieves human-level capabilities in the mixed-motive seven-player game, which requires the same aforementioned skills, but with natural language. The math behind this partially inspired The Consensus Game.
While the history of AI agents long predates when OpenAI's software entered the chat (and never looked back) in November 2022, it's well documented that they can still cosplay as your well-meaning, yet pathological friend.
The Consensus Game system reaches equilibrium as an agreement, ensuring accuracy and fidelity to the model's original insights. To achieve this, the method iteratively adjusts the interactions between the generative and discriminative components until they reach a consensus on an answer that accurately reflects reality and aligns with their initial beliefs. This approach effectively bridges the gap between the two querying methods.
In practice, implementing the Consensus Game approach to language model querying, especially for question-answering tasks, does involve significant computational challenges. For example, when using datasets like MMLU, which have thousands of questions and multiple-choice answers, the model must apply the mechanism to each query. Then, it must reach a consensus between the generative and discriminative components for every question and its possible answers.
The system did struggle with a grade school right of passage: math word problems. It couldn't generate wrong answers, which is a critical component of understanding the process of coming up with the right one.
“The last few years have seen really impressive progress in both strategic decision-making and language generation from AI systems, but we’re just starting to figure out how to put the two together. Equilibrium ranking is a first step in this direction, but I think there’s a lot we’ll be able to do to scale this up to more complex problems.”
An avenue of future work involves enhancing the base model by integrating the outputs of the current method. This is particularly promising since it can yield more factual and consistent answers across various tasks, including factuality and open-ended generation. The potential for such a method to significantly improve the base model's performance is high, which could result in more reliable and factual outputs from ChatGPT and similar language models that people use daily.
“Even though modern language models, such as ChatGPT and Gemini, have led to solving various tasks through chat interfaces, the statistical decoding process that generates a response from such models has remained unchanged for decades,” says Google research scientist Ahmad Beirami. “The proposal by the MIT researchers is an innovative game-theoretic framework for decoding from language models through solving the equilibrium of a consensus game. The significant performance gains reported in the research paper are promising, opening the door to a potential paradigm shift in language model decoding that may fuel a flurry of new applications.”
Jacob wrote the paper with MIT-IBM Watson Lab researcher Yikang Shen and MIT Department of Electrical Engineering and Computer Science assistant professors Gabriele Farina and Jacob Andreas, who is also a CSAIL member. They will present their work at the International Conference on Learning Representations (ICLR) this May. The research received a “best paper award” at the NeurIPS R0-FoMo Workshop in December and it will also be highlighted as a "spotlight paper" at ICLR.
Researchers introduce "The Consensus Game," a game-theoretic approach for language model decoding. Their equilibrium-ranking algorithm harmonizes generative and discriminative querying to enhance prediction accuracy across various tasks, outperforming larger models and demonstrating the potential of game theory in improving language model consistency and truthfulness.
Without a map, it can be just about impossible to know not just where you are, but where you’re going, and that’s especially true when it comes to materials properties.
For decades, scientists have understood that while bulk materials behave in certain ways, those rules can break down for materials at the micro- and nano-scales, and often in surprising ways. One of those surprises was the finding that, for some materials, applying even modest strains — a concept known as elastic strain engineering — on materials can dramatically improve certain properties, provided those strains stay elastic and do not relax away by plasticity, fracture, or phase transformations. Micro- and nano-scale materials are especially good at holding applied strains in the elastic form.
Precisely how to apply those elastic strains (or equivalently, residual stress) to achieve certain material properties, however, had been less clear — until recently.
Using a combination of first principles calculations and machine learning, a team of MIT researchers has developed the first-ever map of how to tune crystalline materials to produce specific thermal and electronic properties.
Led by Ju Li, the Battelle Energy Alliance Professor in Nuclear Engineering and professor of materials science and engineering, the team described a framework for understanding precisely how changing the elastic strains on a material can fine-tune properties like thermal and electrical conductivity. The work is described in an open-access paper published in PNAS.
“For the first time, by using machine learning, we’ve been able to delineate the complete six-dimensional boundary of ideal strength, which is the upper limit to elastic strain engineering, and create a map for these electronic and phononic properties,” Li says. “We can now use this approach to explore many other materials. Traditionally, people create new materials by changing the chemistry.”
“For example, with a ternary alloy, you can change the percentage of two elements, so you have two degrees of freedom,” he continues. “What we’ve shown is that diamond, with just one element, is equivalent to a six-component alloy, because you have six degrees of elastic strain freedom you can tune independently.”
Small strains, big material benefits
The paper builds on a foundation laid as far back as the 1980s, when researchers first discovered that the performance of semiconductor materials doubled when a small — just 1 percent — elastic strain was applied to the material.
While that discovery was quickly commercialized by the semiconductor industry and today is used to increase the performance of microchips in everything from laptops to cellphones, that level of strain is very small compared to what we can achieve now, says Subra Suresh, the Vannevar Bush Professor of Engineering Emeritus.
In a 2018 Science paper, Suresh, Dao, and colleagues demonstrated that 1 percent strain was just the tip of the iceberg.
As part of a 2018 study, Suresh and colleagues demonstrated for the first time that diamond nanoneedles could withstand elastic strains of as much as 9 percent and still return to their original state. Later on, several groups independently confirmed that microscale diamond can indeed elastically deform by approximately 7 percent in tension reversibly.
“Once we showed we could bend nanoscale diamonds and create strains on the order of 9 or 10 percent, the question was, what do you do with it,” Suresh says. “It turns out diamond is a very good semiconductor material … and one of our questions was, if we can mechanically strain diamond, can we reduce the band gap from 5.6 electron-volts to two or three? Or can we get it all the way down to zero, where it begins to conduct like a metal?”
To answer those questions, the team first turned to machine learning in an effort to get a more precise picture of exactly how strain altered material properties.
“Strain is a big space,” Li explains. “You can have tensile strain, you can have shear strain in multiple directions, so it’s a six-dimensional space, and the phonon band is three-dimensional, so in total there are nine tunable parameters. So, we’re using machine learning, for the first time, to create a complete map for navigating the electronic and phononic properties and identify the boundaries.”
Armed with that map, the team subsequently demonstrated how strain could be used to dramatically alter diamond’s semiconductor properties.
“Diamond is like the Mt. Everest of electronic materials,” Li says, “because it has very high thermal conductivity, very high dielectric breakdown strengths, a very big carrier mobility. What we have shown is we can controllably squish Mt. Everest down … so we show that by strain engineering you can either improve diamond’s thermal conductivity by a factor of two, or make it much worse by a factor of 20.”
New map, new applications
Going forward, the findings could be used to explore a host of exotic material properties, Li says, from dramatically reduced thermal conductivity to superconductivity.
“Experimentally, these properties are already accessible with nanoneedles and even microbridges,” he says. “And we have seen exotic properties, like reducing diamond’s (thermal conductivity) to only a few hundred watts per meter-Kelvin. Recently, people have shown that you can produce room-temperature superconductors with hydrides if you squeeze them to a few hundred gigapascals, so we have found all kinds of exotic behavior once we have the map.”
The results could also influence the design of next-generation computer chips capable of running much faster and cooler than today’s processors, as well as quantum sensors and communication devices. As the semiconductor manufacturing industry moves to denser and denser architectures, Suresh says the ability to tune a material’s thermal conductivity will be particularly important for heat dissipation.
While the paper could inform the design of future generations of microchips, Zhe Shi, a postdoc in Li’s lab and first author of the paper, says more work will be needed before those chips find their way into the average laptop or cellphone.
“We know that 1 percent strain can give you an order of magnitude increase in the clock speed of your CPU,” Shi says. “There are a lot of manufacturing and device problems that need to be solved in order for this to become realistic, but I think it’s definitely a great start. It’s an exciting beginning to what could lead to significant strides in technology.”
This work was supported with funding from the Defense Threat Reduction Agency, an NSF Graduate Research Fellowship, the Nanyang Technological University School of Biological Sciences, the National Science Foundation (NSF), the MIT Vannevar Bush Professorship, and a Nanyang Technological University Distinguished University Professorship.
The “map,” or the phonon stability boundary, is a graphical representation that plots the stability regions of a crystal as a function of strain. This map helps scientists and engineers determine the conditions under which a material can exist in a particular phase and when it might fail or transition to another phase. By analyzing the phonon stability boundary, researchers can understand material properties at extreme conditions and design new materials with desired characteristics.
From students crafting essays and engineers writing code to call center operators responding to customers, generative artificial intelligence tools have prompted a wave of experimentation over the past year. At MIT, these experiments have raised questions — some new, some ages old — about how these tools can change the way we live and work.
Can these tools make us better at our jobs, or might they make certain skills obsolete? How can we use these tools for good and minimize potential harm?
The generative AI wave has elicited excitement, anxiety, and plenty of speculation about what's to come, but no clear answers to these core questions. To discover how generative AI can lead to better jobs, MIT is convening a working group on Generative AI and the Work of the Future. The working group is kicking off with 25 companies and nonprofits alongside MIT faculty and students. The group is gathering original data on how teams are using generative AI tools — and the impact these tools are having on workers.
“The world counts on MIT to turn sophisticated ideas into positive impact for the good of society,” says MIT President Sally Kornbluth. “This working group is focused on doing exactly that: In the face of broad public concern about AI’s potential to eliminate jobs, they are developing practical strategies for how to use generative AI to make existing jobs better and improve people’s lives.”
Organized at MIT’s Industrial Performance Center (IPC) and led by IPC Executive Director Ben Armstrong and MIT professors Julie Shah and Kate Kellogg, the working group recently released the first edition of its monthly newsletter, Generation AI, to share its early findings — and convened its first meeting of AI leads from a diverse cross-section of global companies. The working group also hosted a workshop on Feb. 29 highlighting responsible AI practices, in partnership with MIT’s Industrial Liaison Program.
The MIT team driving this initiative is a multidisciplinary and multi-talented group including Senior Fellow Carey Goldberg and Work of the Future graduate fellows Sabiyyah Ali, Shakked Noy, Prerna Ravi, Azfar Sulaiman, Leandra Tejedor, Felix Wang, and Whitney Zhang.
Google.org is funding the working group’s research through its Community Grants Fund, in connection with its Digital Futures Project, an initiative that aims to bring together a range of voices to promote efforts to understand and address the opportunities and challenges of AI.
“AI has the potential to expand prosperity and transform economies, and it is essential that we work across sectors to fully realize AI’s opportunities and address its challenges,” says Brigitte Hoyer Gosselink, director of Google.org. “Independent research like this is an important part of better understanding how AI is changing the way people and teams do their work, and it will serve as a resource for all us — governments, civil society, and companies — as we adapt to new ways of working.”
Over the next two years, the working group will engage in three activities. First, it will conduct research on early use cases of generative AI at leading companies around the world. The group’s goal is to understand how these new technologies are being used in practice, how organizations are ensuring that the tools are being used responsibly, and how the workforce is adapting. The group is particularly interested in how these technologies are changing the skills and training required to thrive at work. MIT graduate student Work of the Future Fellows are collaborating with companies in the working group to conduct this research, which will be published as a series of case studies beginning in 2024.
Liberty Mutual Insurance joined the working group as part of its long-standing collaborative relationship with MIT researchers. “In a year of extraordinary advancements in AI, there is no doubt that it will continue shaping the future — and the future of work — at a rapid pace,” says Liberty Mutual CIO Adam L’Italien. “We are excited to collaborate with MIT and the working group to harness it to empower our employees, build new capabilities, and do more for our customers.”
Second, the working group will serve as a convener, hosting virtual quarterly meetings for working group members to share progress and challenges with their uses of generative AI tools, as well as to learn from their peers. MIT will also host a series of in-person summits for working group members and the public to share research results and highlight best practices from member companies.
Third, based on the group’s research and feedback from participating organizations, the working group will develop training resources for organizations working to prepare or retrain workers as they integrate generative AI tools into their teams.
IBM has joined the working group as part of its broader investments in retraining and job transformation related to generative AI. “Skills are the currency of today and tomorrow. It is crucial that employees and employers are equally invested in continuous learning and maintaining a growth mindset,” says Nickle Lamoreaux, senior vice president and chief human resources officer at IBM.
The working group has already interviewed or engaged with more than 40 companies. Working group members include Amsted Automotive, Cushman and Wakefield, Cytiva, Emeritus, Fujitsu, GlobalFoundries, Google Inc., IBM, Liberty Mutual, Mass General Brigham, MFS, Michelin, PwC, Randstad, Raytheon, and Xerox Corp.
To learn more about this project or get involved, visit ipc.mit.edu/gen-ai.
Speaking at the 2024 MIT AI Conference in Cambridge on Feb. 28 and 29 were (left to right) Julie Shah, the H.N. Slater Professor of Aeronautics and Astronautics; Ben Armstrong, executive director of MIT’s Industrial Performance Center; and Kate Kellogg, the David J. McGrath Jr Professor of Management and Innovation.
To achieve the aspirational goal of the Paris Agreement on climate change — limiting the increase in global average surface temperature to 1.5 degrees Celsius above preindustrial levels — will require its 196 signatories to dramatically reduce their greenhouse gas (GHG) emissions. Those greenhouse gases differ widely in their global warming potential (GWP), or ability to absorb radiative energy and thereby warm the Earth’s surface. For example, measured over a 100-year period, the GWP of methane is about 28 times that of carbon dioxide (CO2), and the GWP of sulfur hexafluoride (SF6) is 24,300 times that of CO2, according to the Intergovernmental Panel on Climate Change (IPCC) Sixth Assessment Report.
Used primarily in high-voltage electrical switchgear in electric power grids, SF6 is one of the most potent greenhouse gases on Earth. In the 21st century, atmospheric concentrations of SF6 have risen sharply along with global electric power demand, threatening the world’s efforts to stabilize the climate. This heightened demand for electric power is particularly pronounced in China, which has dominated the expansion of the global power industry in the past decade. Quantifying China’s contribution to global SF6 emissions — and pinpointing its sources in the country — could lead that nation to implement new measures to reduce them, and thereby reduce, if not eliminate, an impediment to the Paris Agreement’s aspirational goal.
To that end, a new study by researchers at the MIT Joint Program on the Science and Policy of Global Change, Fudan University, Peking University, University of Bristol, and Meteorological Observation Center of China Meteorological Administration determined total SF6 emissions in China over 2011-21 from atmospheric observations collected from nine stations within a Chinese network, including one station from the Advanced Global Atmospheric Gases Experiment (AGAGE) network. For comparison, global total emissions were determined from five globally distributed, relatively unpolluted “background” AGAGE stations, involving additional researchers from the Scripps Institution of Oceanography and CSIRO, Australia's National Science Agency.
The researchers found that SF6 emissions in China almost doubled from 2.6 gigagrams (Gg) per year in 2011, when they accounted for 34 percent of global SF6 emissions, to 5.1 Gg per year in 2021, when they accounted for 57 percent of global total SF6 emissions. This increase from China over the 10-year period — some of it emerging from the country’s less-populated western regions — was larger than the global total SF6 emissions rise, highlighting the importance of lowering SF6 emissions from China in the future.
“Adopting maintenance practices that minimize SF6 leakage rates or using SF6-free equipment or SF6 substitutes in the electric power grid will benefit greenhouse-gas mitigation in China,” says Minde An, a postdoc at the MIT Center for Global Change Science (CGCS) and the study’s lead author. “We see our findings as a first step in quantifying the problem and identifying how it can be addressed.”
Emissions of SF6 are expected to last more than 1,000 years in the atmosphere, raising the stakes for policymakers in China and around the world.
“Any increase in SF6 emissions this century will effectively alter our planet’s radiative budget — the balance between incoming energy from the sun and outgoing energy from the Earth — far beyond the multi-decadal time frame of current climate policies,” says MIT Joint Program and CGCS Director Ronald Prinn, a coauthor of the study. “So it’s imperative that China and all other nations take immediate action to reduce, and ultimately eliminate, their SF6 emissions.”
The study was supported by the National Key Research and Development Program of China and Shanghai B&R Joint Laboratory Project, the U.S. National Aeronautics and Space Administration, and other funding agencies.
The contribution of sulfur hexafluoride to the greenhouse effect is more than 24,000 times that of carbon dioxide; the gas is commonly used in electric power grids. A new study quantifies China’s contribution to global SF6 emissions and locates their sources.
Last summer, MIT President Sally Kornbluth and Provost Cynthia Barnhart issued a call for papers to “articulate effective roadmaps, policy recommendations, and calls for action across the broad domain of generative AI.” The response to the call far exceeded expectations with 75 proposals submitted. Of those, 27 proposals were selected for seed funding.
In light of this enthusiastic response, Kornbluth and Barnhart announced a second call for proposals this fall.
“The groundswell of interest and the caliber of the ideas overall made clear that a second round was in order,” they said in their email to MIT’s research community this fall. This second call for proposals resulted in 53 submissions.
Following the second call, the faculty committee from the first round considered the proposals and selected 16 proposals to receive exploratory funding. Co-authored by interdisciplinary teams of faculty and researchers affiliated with all five of the Institute’s schools and the MIT Schwarzman College of Computing, the proposals offer insights and perspectives on the potential impact and applications of generative AI across a broad range of topics and disciplines.
Each selected research group will receive between $50,000 and $70,000 to create 10-page impact papers. Those papers will be shared widely via a publication venue managed and hosted by the MIT Press under the auspices of the MIT Open Publishing Services program.
As with the first round of papers, Thomas Tull, a member of the MIT School of Engineering Dean’s Advisory Council and a former innovation scholar at the School of Engineering, contributed funding to support the effort.
The selected papers are:
“A Road-map for End-to-end Privacy and Verifiability in Generative AI,” led by Alex Pentland, Srini Devadas, Lalana Kagal, and Vinod Vaikuntanathan;
“A Virtuous Cycle: Generative AI and Discovery in the Physical Sciences,” led by Philip Harris and Phiala Shanahan;
“Artificial Cambrian Intelligence: Generating New Forms of Visual Intelligence,” led by Ramesh Raskar and Tomaso A. Poggio;
“Artificial Fictions and the Value of AI-Generated Art,” led by Justin Khoo;
“GenAI for Improving Human-to-human Interactions with a Focus on Negotiations,” led by Lawrence Susskind and Samuel Dinnar;
“Generative AI as a New Applications Platform and Ecosystem,” led by Michael Cusumano;
“Generative AI for Cities: A Civic Engagement Playbook,” led by Sarah Williams, Sara Beery, and Eden Medina;
“Generative AI for Textile Engineering: Advanced Materials from Heritage Lace Craft,” led by Svetlana V. Boriskina;
“Generative AI Impact for Biomedical Innovation and Drug Discovery,” led by Manolis Kellis, Brad Pentelute, and Marinka Zitnik;
“Impact of Generative AI on the Creative Economy,” led by Ashia Wilson and Dylan Hadfield-Menell;
“Redefining Virtuosity: The Role of Generative AI in Live Music Performances,” led by Joseph A. Paradiso and Eran Egozy;
“Reflection-based Learning with Generative AI,” led by Stefanie Mueller;
“Robust and Reliable Systems for Generative AI,” led by Shafi Goldwasser, Yael Kalai, and Vinod Vaikuntanathan;
“Supporting the Aging Population with Generative AI,” led by Pattie Maes;
“The Science of Language in the Era of Generative AI,” led by Danny Fox, Yoon Kim, and Roger Levy; and
“Visual Artists, Technological Shock, and Generative AI,” led by Caroline Jones and Huma Gupta.
Co-authored by interdisciplinary teams of faculty and researchers affiliated with all five of the Institute’s schools and the MIT Schwarzman College of Computing, the proposals offer insights and perspectives on the potential impact and applications of generative AI across a broad range of topics and disciplines.
Are schools that feature strong test scores highly effective, or do they mostly enroll students who are already well-prepared for success? A study co-authored by MIT scholars concludes that widely disseminated school quality ratings reflect the preparation and family background of their students as much or more than a school’s contribution to learning gains.
Indeed, the study finds that many schools that receive relatively low ratings perform better than these ratings would imply. Conventional ratings, the research makes clear, are highly correlated with race. Specifically, many published school ratings are highly positively correlated with the share of the student body that is white.
“A school’s average outcomes reflect, to some extent, the demographic mix of the population it serves,” says MIT economist Josh Angrist, a Nobel Prize winner who has long analyzed education outcomes. Angrist is co-author of a newly published paper detailing the study’s results.
The study, which examines the Denver and New York City school districts, has the potential to significantly improve the way school quality is measured. Instead of raw aggregate measures like test scores, the study uses changes in test scores and a statistical adjustment for racial composition to compute more accurate measures of the causal effects that attending a particular school has on students’ learning gains. This methodologically sophisticated research builds on the fact that Denver and New York City both assign students to schools in ways that allow the researchers to mimic the conditions of a randomized trial.
In documenting a strong correlation between currently used rating systems and race, the study finds that white and Asian students tend to attend higher-rated schools, while Black and Hispanic students tend to be clustered at lower-rated schools.
“Simple measures of school quality, which are based on the average statistics for the school, are invariably highly correlated with race, and those measures tend to be a misleading guide of what you can expect by sending your child to that school,” Angrist says.
The paper, “Race and the Mismeasure of School Quality,” appears in the latest issue of the American Economic Review: Insights. The authors are Angrist, the Ford Professor of Economics at MIT; Peter Hull PhD ’17, a professor of economics at Brown University; Parag Pathak, the Class of 1922 Professor of Economics at MIT; and Christopher Walters PhD ’13, an associate professor of economics at the University of California at Berkeley. Angrist and Pathak are both professors in the MIT Department of Economics and co-founders of MIT’s Blueprint Labs, a research group that often examines school performance.
The study uses data provided by the Denver and New York City public school districts, where 6th-graders apply for seats at certain middle schools, and the districts use a school-assignment system. In these districts, students can opt for any school in the district, but some schools are oversubscribed. In these circumstances, the district uses a random lottery number to determine who gets a seat where.
By virtue of the lottery inside the seat-assignment algorithm, otherwise-similar sets of students randomly attend an array of different schools. This facilitates comparisons that reveal causal effects of school attendance on learning gains, as in a randomized clinical trial of the sort used in medical research. Using math and English test scores, the researchers evaluated student progress in Denver from the 2012-2013 through the 2018-2019 school years, and in New York City from the 2016-2017 through 2018-2019 school years.
Those school-assignment systems, it happens, are mechanisms some of the researchers have helped construct, allowing them to better grasp and measure the effects of school assignment.
“An unexpected dividend of our work designing Denver and New York City’s centralized choice systems is that we see how students are rationed from [distributed among] schools,” says Pathak. “This leads to a research design that can isolate cause and effect.”
Ultimately, the study shows that much of the school-to-school variation in raw aggregate test scores stems from the types of students at any given school. This is a case of what researchers call “selection bias.” In this case, selection bias arises from the fact that more-advantaged families tend to prefer the same sets of schools.
“The fundamental problem here is selection bias,” Angrist says. “In the case of schools, selection bias is very consequential and a big part of American life. A lot of decision-makers, whether they’re families or policymakers, are being misled by a kind of naïve interpretation of the data.”
Indeed, Pathak notes, the preponderance of more simplistic school ratings today (found on many popular websites) not only creates a deceptive picture of how much value schools add for students, but has a self-reinforcing effect — since well-prepared and better-off families bid up housing costs near highly-rated schools. As the scholars write in the paper, “Biased rating schemes direct households to low-minority rather than high-quality schools, while penalizing schools that improve achievement for disadvantaged groups.”
The research team hopes their study will lead districts to examine and improve the way they measure and report on school quality. To that end, Blueprint Labs is working with the New York City Department of Education to pilot a new ratings system later this year. They also plan additional work examining the way families respond to different sorts of information about school quality.
Given that the researchers are proposing to improve ratings in what they believe is a straightforward way, by accounting for student preparation and improvement, they think more officials and districts may be interested in updating their measurement practices.
“We’re hopeful that the simple regression adjustment we propose makes it relatively easy for school districts to use our measure in practice,” Pathak says.
The research received support from the Walton Foundation and the National Science Foundation.
New research by MIT economists shows school quality ratings significantly reflect the preparation of a school’s students, not just the school’s contribution to learning gains.
At the heart of a far-off galaxy, a supermassive black hole appears to have had a case of the hiccups.
Astronomers from MIT, Italy, the Czech Republic, and elsewhere have found that a previously quiet black hole, which sits at the center of a galaxy about 800 million light-years away, has suddenly erupted, giving off plumes of gas every 8.5 days before settling back to its normal, quiet state.
The periodic hiccups are a new behavior that has not been observed in black holes until now. The scientists believe the most likely explanation for the outbursts stems from a second, smaller black hole that is zinging around the central, supermassive black hole and slinging material out from the larger black hole’s disk of gas every 8.5 days.
The team’s findings, which are published today in the journal Science Advances, challenge the conventional picture of black hole accretion disks, which scientists had assumed are relatively uniform disks of gas that rotate around a central black hole. The new results suggest that accretion disks may be more varied in their contents, possibly containing other black holes and even entire stars.
“We thought we knew a lot about black holes, but this is telling us there are a lot more things they can do,” says study author Dheeraj “DJ” Pasham, a research scientist in MIT’s Kavli Institute for Astrophysics and Space Research. “We think there will be many more systems like this, and we just need to take more data to find them.”
The study’s MIT co-authors include postdoc Peter Kosec, graduate student Megan Masterson, Associate Professor Erin Kara, Principal Research Scientist Ronald Remillard, and former research scientist Michael Fausnaugh, along with collaborators from multiple institutions, including the Tor Vergata University of Rome, the Astronomical Institute of the Czech Academy of Sciences, and Masaryk University in the Czech Republic.
“Use it or lose it”
The team’s findings grew out of an automated detection by ASAS-SN (the All Sky Automated Survey for SuperNovae), a network of 20 robotic telescopes situated in various locations across the Northern and Southern Hemispheres. The telescopes automatically survey the entire sky once a day for signs of supernovae and other transient phenomena.
In December of 2020, the survey spotted a burst of light in a galaxy about 800 million light years away. That particular part of the sky had been relatively quiet and dark until the telescopes’ detection, when the galaxy suddenly brightened by a factor of 1,000. Pasham, who happened to see the detection reported in a community alert, chose to focus in on the flare with NASA’s NICER (the Neutron star Interior Composition Explorer), an X-ray telescope aboard the International Space Station that continuously monitors the sky for X-ray bursts that could signal activity from neutron stars, black holes, and other extreme gravitational phenomena. The timing was fortuitous, as it was getting toward the end of the yearlong period during which Pasham had permission to point, or “trigger,” the telescope.
“It was either use it or lose it, and it turned out to be my luckiest break,” he says.
He trained NICER to observe the far-off galaxy as it continued to flare. The outburst lasted about four months before petering out. During that time, NICER took measurements of the galaxy’s X-ray emissions on a daily, high-cadence basis. When Pasham looked closely at the data, he noticed a curious pattern within the four-month flare: subtle dips, in a very narrow band of X-rays, that seemed to reappear every 8.5 days.
It seemed that the galaxy’s burst of energy periodically dipped every 8.5 days. The signal is similar to what astronomers see when an orbiting planet crosses in front of its host star, briefly blocking the star’s light. But no star would be able to block a flare from an entire galaxy.
“I was scratching my head as to what this means because this pattern doesn’t fit anything that we know about these systems,” Pasham recalls.
Punch it
As he was looking for an explanation to the periodic dips, Pasham came across a recent paper by theoretical physicists in the Czech Republic. The theorists had separately worked out that it would be possible, in theory, for a galaxy’s central supermassive black hole to host a second, much smaller black hole. That smaller black hole could orbit at an angle from its larger companion’s accretion disk.
As the theorists proposed, the secondary would periodically punch through the primary black hole’s disk as it orbits. In the process, it would release a plume of gas, like a bee flying through a cloud of pollen. Powerful magnetic fields, to the north and south of the black hole, could then slingshot the plume up and out of the disk. Each time the smaller black hole punches through the disk, it would eject another plume, in a regular, periodic pattern. If that plume happened to point in the direction of an observing telescope, it might observe the plume as a dip in the galaxy’s overall energy, briefly blocking the disk’s light every so often.
“I was super excited by this theory, and I immediately emailed them to say, ‘I think we’re observing exactly what your theory predicted,’” Pasham says.
He and the Czech scientists teamed up to test the idea, with simulations that incorporated NICER’s observations of the original outburst, and the regular, 8.5-day dips. What they found supports the theory: The observed outburst was likely a signal of a second, smaller black hole, orbiting a central supermassive black hole, and periodically puncturing its disk.
Specifically, the team found that the galaxy was relatively quiet prior to the December 2020 detection. The team estimates the galaxy’s central supermassive black hole is as massive as 50 million suns. Prior to the outburst, the black hole may have had a faint, diffuse accretion disk rotating around it, as a second, smaller black hole, measuring 100 to 10,000 solar masses, was orbiting in relative obscurity.
The researchers suspect that, in December 2020, a third object — likely a nearby star — swung too close to the system and was shredded to pieces by the supermassive black hole’s immense gravity — an event that astronomers know as a “tidal disruption event.” The sudden influx of stellar material momentarily brightened the black hole’s accretion disk as the star’s debris swirled into the black hole. Over four months, the black hole feasted on the stellar debris as the second black hole continued orbiting. As it punched through the disk, it ejected a much larger plume than it normally would, which happened to eject straight out toward NICER’s scope.
The team carried out numerous simulations to test the periodic dips. The most likely explanation, they conclude, is a new kind of David-and-Goliath system — a tiny, intermediate-mass black hole, zipping around a supermassive black hole.
“This is a different beast,” Pasham says. “It doesn’t fit anything that we know about these systems. We’re seeing evidence of objects going in and through the disk, at different angles, which challenges the traditional picture of a simple gaseous disk around black holes. We think there is a huge population of these systems out there.”
“This is a brilliant example of how to use the debris from a disrupted star to illuminate the interior of a galactic nucleus which would otherwise remain dark. It is akin to using fluorescent dye to find a leak in a pipe,” says Richard Saxton, an X-ray astronomer from the European Space Astronomy Centre (ESAC) in Madrid, who was not involved in the study. “This result shows that very close super-massive black hole binaries could be common in galactic nuclei, which is a very exciting development for future gravitational wave detectors.”
Scientists have found a large black hole that “hiccups,” giving off plumes of gas. Analysis revealed a tiny black hole was repeatedly punching through the larger black hole’s disk of gas, causing the plumes to release. Powerful magnetic fields, to the north and south of the black hole and represented by the orange cone, slingshot the plume up and out of the disk. Each time the smaller black hole punches through the disk, it would eject another plume, in a regular, periodic pattern.
MIT chemical engineers have devised an efficient way to convert carbon dioxide to carbon monoxide, a chemical precursor that can be used to generate useful compounds such as ethanol and other fuels.
If scaled up for industrial use, this process could help to remove carbon dioxide from power plants and other sources, reducing the amount of greenhouse gases that are released into the atmosphere.
“This would allow you to take carbon dioxide from emissions or dissolved in the ocean, and convert it into profitable chemicals. It’s really a path forward for decarbonization because we can take CO2, which is a greenhouse gas, and turn it into things that are useful for chemical manufacture,” says Ariel Furst, the Paul M. Cook Career Development Assistant Professor of Chemical Engineering and the senior author of the study.
The new approach uses electricity to perform the chemical conversion, with help from a catalyst that is tethered to the electrode surface by strands of DNA. This DNA acts like Velcro to keep all the reaction components in close proximity, making the reaction much more efficient than if all the components were floating in solution.
Furst has started a company called Helix Carbon to further develop the technology. Former MIT postdoc Gang Fan is the lead author of the paper, which appears in the Journal of the American Chemical Society Au. Other authors include Nathan Corbin PhD ’21, Minju Chung PhD ’23, former MIT postdocs Thomas Gill and Amruta Karbelkar, and Evan Moore ’23.
Breaking down CO2
Converting carbon dioxide into useful products requires first turning it into carbon monoxide. One way to do this is with electricity, but the amount of energy required for that type of electrocatalysis is prohibitively expensive.
To try to bring down those costs, researchers have tried using electrocatalysts, which can speed up the reaction and reduce the amount of energy that needs to be added to the system. One type of catalyst used for this reaction is a class of molecules known as porphyrins, which contain metals such as iron or cobalt and are similar in structure to the heme molecules that carry oxygen in blood.
During this type of electrochemical reaction, carbon dioxide is dissolved in water within an electrochemical device, which contains an electrode that drives the reaction. The catalysts are also suspended in the solution. However, this setup isn’t very efficient because the carbon dioxide and the catalysts need to encounter each other at the electrode surface, which doesn’t happen very often.
To make the reaction occur more frequently, which would boost the efficiency of the electrochemical conversion, Furst began working on ways to attach the catalysts to the surface of the electrode. DNA seemed to be the ideal choice for this application.
“DNA is relatively inexpensive, you can modify it chemically, and you can control the interaction between two strands by changing the sequences,” she says. “It’s like a sequence-specific Velcro that has very strong but reversible interactions that you can control.”
To attach single strands of DNA to a carbon electrode, the researchers used two “chemical handles,” one on the DNA and one on the electrode. These handles can be snapped together, forming a permanent bond. A complementary DNA sequence is then attached to the porphyrin catalyst, so that when the catalyst is added to the solution, it will bind reversibly to the DNA that’s already attached to the electrode — just like Velcro.
Once this system is set up, the researchers apply a potential (or bias) to the electrode, and the catalyst uses this energy to convert carbon dioxide in the solution into carbon monoxide. The reaction also generates a small amount of hydrogen gas, from the water. After the catalysts wear out, they can be released from the surface by heating the system to break the reversible bonds between the two DNA strands, and replaced with new ones.
An efficient reaction
Using this approach, the researchers were able to boost the Faradaic efficiency of the reaction to 100 percent, meaning that all of the electrical energy that goes into the system goes directly into the chemical reactions, with no energy wasted. When the catalysts are not tethered by DNA, the Faradaic efficiency is only about 40 percent.
This technology could be scaled up for industrial use fairly easily, Furst says, because the carbon electrodes the researchers used are much less expensive than conventional metal electrodes. The catalysts are also inexpensive, as they don’t contain any precious metals, and only a small concentration of the catalyst is needed on the electrode surface.
By swapping in different catalysts, the researchers plan to try making other products such as methanol and ethanol using this approach. Helix Carbon, the company started by Furst, is also working on further developing the technology for potential commercial use.
The research was funded by the U.S. Army Research Office, the CIFAR Azrieli Global Scholars Program, the MIT Energy Initiative, and the MIT Deshpande Center.
MIT chemical engineers have shown that by using DNA to tether a catalyst (blue circles) to an electrode, they can make the conversion of carbon dioxide to carbon monoxide much more efficient.
A growing number of tools enable users to make online data representations, like charts, that are accessible for people who are blind or have low vision. However, most tools require an existing visual chart that can then be converted into an accessible format.
This creates barriers that prevent blind and low-vision users from building their own custom data representations, and it can limit their ability to explore and analyze important information.
A team of researchers from MIT and University College London (UCL) wants to change the way people think about accessible data representations.
They created a software system called Umwelt (which means “environment” in German) that can enable blind and low-vision users to build customized, multimodal data representations without needing an initial visual chart.
Umwelt, an authoring environment designed for screen-reader users, incorporates an editor that allows someone to upload a dataset and create a customized representation, such as a scatterplot, that can include three modalities: visualization, textual description, and sonification. Sonification involves converting data into nonspeech audio.
The system, which can represent a variety of data types, includes a viewer that enables a blind or low-vision user to interactively explore a data representation, seamlessly switching between each modality to interact with data in a different way.
The researchers conducted a study with five expert screen-reader users who found Umwelt to be useful and easy to learn. In addition to offering an interface that empowered them to create data representations — something they said was sorely lacking — the users said Umwelt could facilitate communication between people who rely on different senses.
“We have to remember that blind and low-vision people aren’t isolated. They exist in these contexts where they want to talk to other people about data,” says Jonathan Zong, an electrical engineering and computer science (EECS) graduate student and lead author of a paper introducing Umwelt. “I am hopeful that Umwelt helps shift the way that researchers think about accessible data analysis. Enabling the full participation of blind and low-vision people in data analysis involves seeing visualization as just one piece of this bigger, multisensory puzzle.”
Joining Zong on the paper are fellow EECS graduate students Isabella Pedraza Pineros and Mengzhu “Katie” Chen; Daniel Hajas, a UCL researcher who works with the Global Disability Innovation Hub; and senior author Arvind Satyanarayan, associate professor of computer science at MIT who leads the Visualization Group in the Computer Science and Artificial Intelligence Laboratory. The paper will be presented at the ACM Conference on Human Factors in Computing.
De-centering visualization
The researchers previously developed interactive interfaces that provide a richer experience for screen reader users as they explore accessible data representations. Through that work, they realized most tools for creating such representations involve converting existing visual charts.
Aiming to decenter visual representations in data analysis, Zong and Hajas, who lost his sight at age 16, began co-designing Umwelt more than a year ago.
At the outset, they realized they would need to rethink how to represent the same data using visual, auditory, and textual forms.
“We had to put a common denominator behind the three modalities. By creating this new language for representations, and making the output and input accessible, the whole is greater than the sum of its parts,” says Hajas.
To build Umwelt, they first considered what is unique about the way people use each sense.
For instance, a sighted user can see the overall pattern of a scatterplot and, at the same time, move their eyes to focus on different data points. But for someone listening to a sonification, the experience is linear since data are converted into tones that must be played back one at a time.
“If you are only thinking about directly translating visual features into nonvisual features, then you miss out on the unique strengths and weaknesses of each modality,” Zong adds.
They designed Umwelt to offer flexibility, enabling a user to switch between modalities easily when one would better suit their task at a given time.
To use the editor, one uploads a dataset to Umwelt, which employs heuristics to automatically creates default representations in each modality.
If the dataset contains stock prices for companies, Umwelt might generate a multiseries line chart, a textual structure that groups data by ticker symbol and date, and a sonification that uses tone length to represent the price for each date, arranged by ticker symbol.
The default heuristics are intended to help the user get started.
“In any kind of creative tool, you have a blank-slate effect where it is hard to know how to begin. That is compounded in a multimodal tool because you have to specify things in three different representations,” Zong says.
The editor links interactions across modalities, so if a user changes the textual description, that information is adjusted in the corresponding sonification. Someone could utilize the editor to build a multimodal representation, switch to the viewer for an initial exploration, then return to the editor to make adjustments.
Helping users communicate about data
To test Umwelt, they created a diverse set of multimodal representations, from scatterplots to multiview charts, to ensure the system could effectively represent different data types. Then they put the tool in the hands of five expert screen reader users.
Study participants mostly found Umwelt to be useful for creating, exploring, and discussing data representations. One user said Umwelt was like an “enabler” that decreased the time it took them to analyze data. The users agreed that Umwelt could help them communicate about data more easily with sighted colleagues.
“What stands out about Umwelt is its core philosophy of de-emphasizing the visual in favor of a balanced, multisensory data experience. Often, nonvisual data representations are relegated to the status of secondary considerations, mere add-ons to their visual counterparts. However, visualization is merely one aspect of data representation. I appreciate their efforts in shifting this perception and embracing a more inclusive approach to data science,” says JooYoung Seo, an assistant professor in the School of Information Sciences at the University of Illinois at Urbana-Champagne, who was not involved with this work.
Moving forward, the researchers plan to create an open-source version of Umwelt that others can build upon. They also want to integrate tactile sensing into the software system as an additional modality, enabling the use of tools like refreshable tactile graphics displays.
“In addition to its impact on end users, I am hoping that Umwelt can be a platform for asking scientific questions around how people use and perceive multimodal representations, and how we can improve the design beyond this initial step,” says Zong.
This work was supported, in part, by the National Science Foundation and the MIT Morningside Academy for Design Fellowship.
Umwelt is a new system that enables blind and low-vision users to author accessible, interactive charts representing data in three modalities: visualization, textual description, and sonification.
To assess a community’s risk of extreme weather, policymakers rely first on global climate models that can be run decades, and even centuries, forward in time, but only at a coarse resolution. These models might be used to gauge, for instance, future climate conditions for the northeastern U.S., but not specifically for Boston.
To estimate Boston’s future risk of extreme weather such as flooding, policymakers can combine a coarse model’s large-scale predictions with a finer-resolution model, tuned to estimate how often Boston is likely to experience damaging floods as the climate warms. But this risk analysis is only as accurate as the predictions from that first, coarser climate model.
“If you get those wrong for large-scale environments, then you miss everything in terms of what extreme events will look like at smaller scales, such as over individual cities,” says Themistoklis Sapsis, the William I. Koch Professor and director of the Center for Ocean Engineering in MIT’s Department of Mechanical Engineering.
Sapsis and his colleagues have now developed a method to “correct” the predictions from coarse climate models. By combining machine learning with dynamical systems theory, the team’s approach “nudges” a climate model’s simulations into more realistic patterns over large scales. When paired with smaller-scale models to predict specific weather events such as tropical cyclones or floods, the team’s approach produced more accurate predictions for how often specific locations will experience those events over the next few decades, compared to predictions made without the correction scheme.
Sapsis says the new correction scheme is general in form and can be applied to any global climate model. Once corrected, the models can help to determine where and how often extreme weather will strike as global temperatures rise over the coming years.
“Climate change will have an effect on every aspect of human life, and every type of life on the planet, from biodiversity to food security to the economy,” Sapsis says. “If we have capabilities to know accurately how extreme weather will change, especially over specific locations, it can make a lot of difference in terms of preparation and doing the right engineering to come up with solutions. This is the method that can open the way to do that.”
The team’s results appear today in the Journal of Advances in Modeling Earth Systems. The study’s MIT co-authors include postdoc Benedikt Barthel Sorensen and Alexis-TzianniCharalampopoulos SM ’19, PhD ’23, with Shixuan Zhang, Bryce Harrop, and Ruby Leung of the Pacific Northwest National Laboratory in Washington state.
Over the hood
Today’s large-scale climate models simulate weather features such as the average temperature, humidity, and precipitation around the world, on a grid-by-grid basis. Running simulations of these models takes enormous computing power, and in order to simulate how weather features will interact and evolve over periods of decades or longer, models average out features every 100 kilometers or so.
“It’s a very heavy computation requiring supercomputers,” Sapsis notes. “But these models still do not resolve very important processes like clouds or storms, which occur over smaller scales of a kilometer or less.”
To improve the resolution of these coarse climate models, scientists typically have gone under the hood to try and fix a model’s underlying dynamical equations, which describe how phenomena in the atmosphere and oceans should physically interact.
“People have tried to dissect into climate model codes that have been developed over the last 20 to 30 years, which is a nightmare, because you can lose a lot of stability in your simulation,” Sapsis explains. “What we’re doing is a completely different approach, in that we’re not trying to correct the equations but instead correct the model’s output.”
The team’s new approach takes a model’s output, or simulation, and overlays an algorithm that nudges the simulation toward something that more closely represents real-world conditions. The algorithm is based on a machine-learning scheme that takes in data, such as past information for temperature and humidity around the world, and learns associations within the data that represent fundamental dynamics among weather features. The algorithm then uses these learned associations to correct a model’s predictions.
“What we’re doing is trying to correct dynamics, as in how an extreme weather feature, such as the windspeeds during a Hurricane Sandy event, will look like in the coarse model, versus in reality,” Sapsis says. “The method learns dynamics, and dynamics are universal. Having the correct dynamics eventually leads to correct statistics, for example, frequency of rare extreme events.”
Climate correction
As a first test of their new approach, the team used the machine-learning scheme to correct simulations produced by the Energy Exascale Earth System Model (E3SM), a climate model run by the U.S. Department of Energy, that simulates climate patterns around the world at a resolution of 110 kilometers. The researchers used eight years of past data for temperature, humidity, and wind speed to train their new algorithm, which learned dynamical associations between the measured weather features and the E3SM model. They then ran the climate model forward in time for about 36 years and applied the trained algorithm to the model’s simulations. They found that the corrected version produced climate patterns that more closely matched real-world observations from the last 36 years, not used for training.
“We’re not talking about huge differences in absolute terms,” Sapsis says. “An extreme event in the uncorrected simulation might be 105 degrees Fahrenheit, versus 115 degrees with our corrections. But for humans experiencing this, that is a big difference.”
When the team then paired the corrected coarse model with a specific, finer-resolution model of tropical cyclones, they found the approach accurately reproduced the frequency of extreme storms in specific locations around the world.
“We now have a coarse model that can get you the right frequency of events, for the present climate. It’s much more improved,” Sapsis says. “Once we correct the dynamics, this is a relevant correction, even when you have a different average global temperature, and it can be used for understanding how forest fires, flooding events, and heat waves will look in a future climate. Our ongoing work is focusing on analyzing future climate scenarios.”
“The results are particularly impressive as the method shows promising results on E3SM, a state-of-the-art climate model,” says Pedram Hassanzadeh, an associate professor who leads the Climate Extremes Theory and Data group at the University of Chicago and was not involved with the study. “It would be interesting to see what climate change projections this framework yields once future greenhouse-gas emission scenarios are incorporated.”
This work was supported, in part, by the U.S. Defense Advanced Research Projects Agency.
The beautiful, gnarled, nooked-and-crannied reefs that surround tropical islands serve as a marine refuge and natural buffer against stormy seas. But as the effects of climate change bleach and break down coral reefs around the world, and extreme weather events become more common, coastal communities are left increasingly vulnerable to frequent flooding and erosion.
An MIT team is now hoping to fortify coastlines with “architected” reefs — sustainable, offshore structures engineered to mimic the wave-buffering effects of natural reefs while also providing pockets for fish and other marine life.
The team’s reef design centers on a cylindrical structure surrounded by four rudder-like slats. The engineers found that when this structure stands up against a wave, it efficiently breaks the wave into turbulent jets that ultimately dissipate most of the wave’s total energy. The team has calculated that the new design could reduce as much wave energy as existing artificial reefs, using 10 times less material.
The researchers plan to fabricate each cylindrical structure from sustainable cement, which they would mold in a pattern of “voxels” that could be automatically assembled, and would provide pockets for fish to explore and other marine life to settle in. The cylinders could be connected to form a long, semipermeable wall, which the engineers could erect along a coastline, about half a mile from shore. Based on the team’s initial experiments with lab-scale prototypes, the architected reef could reduce the energy of incoming waves by more than 95 percent.
“This would be like a long wave-breaker,” says Michael Triantafyllou, the Henry L. and Grace Doherty Professor in Ocean Science and Engineering in the Department of Mechanical Engineering. “If waves are 6 meters high coming toward this reef structure, they would be ultimately less than a meter high on the other side. So, this kills the impact of the waves, which could prevent erosion and flooding.”
Details of the architected reef design are reported today in a study appearing in the open-access journal PNAS Nexus. Triantafyllou’s MIT co-authors are Edvard Ronglan SM ’23; graduate students Alfonso Parra Rubio, Jose del Aguila Ferrandis, and Erik Strand; research scientists Patricia Maria Stathatou and Carolina Bastidas; and Professor Neil Gershenfeld, director of the Center for Bits and Atoms; along with Alexis Oliveira Da Silva at the Polytechnic Institute of Paris, Dixia Fan of Westlake University, and Jeffrey Gair Jr. of Scinetics, Inc.
Leveraging turbulence
Some regions have already erected artificial reefs to protect their coastlines from encroaching storms. These structures are typically sunken ships, retired oil and gas platforms, and even assembled configurations of concrete, metal, tires, and stones. However, there’s variability in the types of artificial reefs that are currently in place, and no standard for engineering such structures. What’s more, the designs that are deployed tend to have a low wave dissipation per unit volume of material used. That is, it takes a huge amount of material to break enough wave energy to adequately protect coastal communities.
The MIT team instead looked for ways to engineer an artificial reef that would efficiently dissipate wave energy with less material, while also providing a refuge for fish living along any vulnerable coast.
“Remember, natural coral reefs are only found in tropical waters,” says Triantafyllou, who is director of the MIT Sea Grant. “We cannot have these reefs, for instance, in Massachusetts. But architected reefs don’t depend on temperature, so they can be placed in any water, to protect more coastal areas.”
The new effort is the result of a collaboration between researchers in MIT Sea Grant, who developed the reef structure’s hydrodynamic design, and researchers at the Center for Bits and Atoms (CBA), who worked to make the structure modular and easy to fabricate on location. The team’s architected reef design grew out of two seemingly unrelated problems. CBA researchers were developing ultralight cellular structures for the aerospace industry, while Sea Grant researchers were assessing the performance of blowout preventers in offshore oil structures — cylindrical valves that are used to seal off oil and gas wells and prevent them from leaking.
The team’s tests showed that the structure’s cylindrical arrangement generated a high amount of drag. In other words, the structure appeared to be especially efficient in dissipating high-force flows of oil and gas. They wondered: Could the same arrangement dissipate another type of flow, in ocean waves?
The researchers began to play with the general structure in simulations of water flow, tweaking its dimensions and adding certain elements to see whether and how waves changed as they crashed against each simulated design. This iterative process ultimately landed on an optimized geometry: a vertical cylinder flanked by four long slats, each attached to the cylinder in a way that leaves space for water to flow through the resulting structure. They found this setup essentially breaks up any incoming wave energy, causing parts of the wave-induced flow to spiral to the sides rather than crashing ahead.
“We’re leveraging this turbulence and these powerful jets to ultimately dissipate wave energy,” Ferrandis says.
Standing up to storms
Once the researchers identified an optimal wave-dissipating structure, they fabricated a laboratory-scale version of an architected reef made from a series of the cylindrical structures, which they 3D-printed from plastic. Each test cylinder measured about 1 foot wide and 4 feet tall. They assembled a number of cylinders, each spaced about a foot apart, to form a fence-like structure, which they then lowered into a wave tank at MIT. They then generated waves of various heights and measured them before and after passing through the architected reef.
“We saw the waves reduce substantially, as the reef destroyed their energy,” Triantafyllou says.
The team has also looked into making the structures more porous, and friendly to fish. They found that, rather than making each structure from a solid slab of plastic, they could use a more affordable and sustainable type of cement.
“We’ve worked with biologists to test the cement we intend to use, and it’s benign to fish, and ready to go,” he adds.
They identified an ideal pattern of “voxels,” or microstructures, that cement could be molded into, in order to fabricate the reefs while creating pockets in which fish could live. This voxel geometry resembles individual egg cartons, stacked end to end, and appears to not affect the structure’s overall wave-dissipating power.
“These voxels still maintain a big drag while allowing fish to move inside,” Ferrandis says.
The team is currently fabricating cement voxel structures and assembling them into a lab-scale architected reef, which they will test under various wave conditions. They envision that the voxel design could be modular, and scalable to any desired size, and easy to transport and install in various offshore locations. “Now we’re simulating actual sea patterns, and testing how these models will perform when we eventually have to deploy them,” says Anjali Sinha, a graduate student at MIT who recently joined the group.
Going forward, the team hopes to work with beach towns in Massachusetts to test the structures on a pilot scale.
“These test structures would not be small,” Triantafyllou emphasizes. “They would be about a mile long, and about 5 meters tall, and would cost something like 6 million dollars per mile. So it’s not cheap. But it could prevent billions of dollars in storm damage. And with climate change, protecting the coasts will become a big issue.”
This work was funded, in part, by the U.S. Defense Advanced Research Projects Agency.
An MIT team is hoping to fortify coastlines with “architected” reefs — sustainable, offshore structures that are engineered to mimic the wave-buffering effects of natural reefs while also providing pockets for fish and other marine life to live.
Granular materials, those made up of individual pieces, whether grains of sand or coffee beans or pebbles, are the most abundant form of solid matter on Earth. The way these materials move and react to external forces can determine when landslides or earthquakes happen, as well as more mundane events such as how cereal gets clogged coming out of the box. Yet, analyzing the way these flow events take place and what determines their outcomes has been a real challenge, and most research has been confined to two-dimensional experiments that don’t reveal the full picture of how these materials behave.
Now, researchers at MIT have developed a method that allows for detailed 3D experiments that can reveal exactly how forces are transmitted through granular materials, and how the shapes of the grains can dramatically change the outcomes. The new work may lead to better ways of understanding how landslides are triggered, as well as how to control the flow of granular materials in industrial processes. The findings are described in the journal PNAS in a paper by MIT professor of civil and environmental engineering Ruben Juanes and Wei Li SM ’14, PhD ’19, who is now on the faculty at Stony Brook University.
From soil and sand to flour and sugar, granular materials are ubiquitous. “It’s an everyday item, it’s part of our infrastructure,” says Li. “When we do space exploration, our space vehicles land on granular material. And the failure of granular media can be catastrophic, such as landslides.”
“One major finding of this study is that we provide a microscopic explanation of why a pack of angular particles is stronger than a pack of spheres,” Li says.
Juanes adds, “It is always important, at a fundamental level to understand the overall response of the material. And I can see that moving forward, this can provide a new way to make predictions of when a material will fail.”
Scientific understanding of these materials really began a few decades ago, Juanes explains, with the invention of a way to model their behavior using two-dimensional discs representing how forces are transmitted through a collection of particles. While this provided important new insights, it also faced severe limitations.
In previous work, Li developed a way of making three-dimensional particles through a squeeze-molding technique that produces plastic particles that are free of residual stresses and can be made in virtually any irregular shape. Now, in this latest research, he and Juanes have applied this method to reveal the internal stresses in a granular material as loads are applied, in a fully three-dimensional system that much more accurately represents real-world granular materials.
These particles are photoelastic, Juanes explains, which means that when under stress, they modify any light passing through them according to the amount of stress. “So, if you shine polarized light through it and you stress the material, you can see where that stress change is taking place visually, in the form of a different color and different brightness in the material.”
Such materials have been used for a long time, Juanes says, but “one of the key things that had never been accomplished was the ability to image the stresses of these materials when they are immersed in a fluid, where the fluid can flow through the material itself.”
Being able to do so is important, he stresses, because “porous media of interest — biological porous media, industrial porous media, and geological porous media — they often contain fluid in their pore spaces, and that fluid will be hydraulically transported through those pore openings. And the two phenomena are coupled: how the stress is transmitted and what the pore fluid pressure is.”
The problem was, when using a collection of two-dimensional discs for an experiment, the discs would pack in such a way as to block the fluid completely. Only with a three-dimensional mass of grains would there always be pathways for the fluid to flow through, so that the stresses could be monitored while fluid was moving.
Using this method, they were able to show that “when you compress a granular material, that force is transmitted in the form of what we would call chains, or filaments, that this new technique is able to visualize and depict in three dimensions,” Juanes says.
To get that 3D view, they use a combination of the photoelasticity to illuminate the force chains, along with a method called computed tomography, similar to that used in medical CT scans, to reconstruct a full 3D image from a series of 2,400 flat images taken as the object rotates through 360 degrees.
Because the grains are immersed in a fluid that has exactly the same refractive index as the polyurethane grains themselves, the beads are invisible when light shines through their container if they are not under stress. Then, stress is applied, and when polarized light is shone through, that reveals the stresses as light and color, Juanes says. “What’s really remarkable and exciting is that we’re not imaging the porous medium. We’re imaging the forces that are transmitted through the porous medium. This opens up, I think, a new way to interrogate stress changes in granular materials.” He adds that “this has really been a dream of mine for many years,” and he says it was realized thanks to Li’s work on the project.
Using the method, they were able to demonstrate exactly how it is that irregular, angular grains produce a stronger, more stable material than spherical ones. While this was known empirically, the new technique makes it possible to demonstrate exactly why that is, based on the way the forces are distributed, and will make it possible in future work to study a wide variety of grain types to determine exactly what characteristics are most important in producing stable structures, such as the ballast of railroad beds or the riprap on breakwaters.
Because there has been no way to observe the 3D force chains in such materials, Juanes says, “right now it is very difficult to make predictions as to when a landslide will occur precisely, because we don’t know about the architecture of the force chains for different materials.”
It will take time to develop the method to be able to make such predictions, Li says, but that ultimately could be a significant contribution of this new technique. And many other applications of the method are also possible, even in areas as seemingly unrelated as how fish eggs respond as the fish carrying them moves through the water, or in helping to design new kinds of robotic grippers that can easily adapt to picking up objects of any shape.
The work was supported by the U.S. National Science Foundation.
MIT researchers developed a method that allows for 3D experiments that can reveal how forces are transmitted through granular materials, and how the shapes of the grains can dramatically change the outcomes. In this photo, 3D photoelastic particles light up and change color under external loads.
From wiping up spills to serving up food, robots are being taught to carry out increasingly complicated household tasks. Many such home-bot trainees are learning through imitation; they are programmed to copy the motions that a human physically guides them through.
It turns out that robots are excellent mimics. But unless engineers also program them to adjust to every possible bump and nudge, robots don’t necessarily know how to handle these situations, short of starting their task from the top.
Now MIT engineers are aiming to give robots a bit of common sense when faced with situations that push them off their trained path. They’ve developed a method that connects robot motion data with the “common sense knowledge” of large language models, or LLMs.
Their approach enables a robot to logically parse many given household task into subtasks, and to physically adjust to disruptions within a subtask so that the robot can move on without having to go back and start a task from scratch — and without engineers having to explicitly program fixes for every possible failure along the way.
“Imitation learning is a mainstream approach enabling household robots. But if a robot is blindly mimicking a human’s motion trajectories, tiny errors can accumulate and eventually derail the rest of the execution,” says Yanwei Wang, a graduate student in MIT’s Department of Electrical Engineering and Computer Science (EECS). “With our method, a robot can self-correct execution errors and improve overall task success.”
Wang and his colleagues detail their new approach in a study they will present at the International Conference on Learning Representations (ICLR) in May. The study’s co-authors include EECS graduate students Tsun-Hsuan Wang and Jiayuan Mao, Michael Hagenow, a postdoc in MIT’s Department of Aeronautics and Astronautics (AeroAstro), and Julie Shah, the H.N. Slater Professor in Aeronautics and Astronautics at MIT.
Language task
The researchers illustrate their new approach with a simple chore: scooping marbles from one bowl and pouring them into another. To accomplish this task, engineers would typically move a robot through the motions of scooping and pouring — all in one fluid trajectory. They might do this multiple times, to give the robot a number of human demonstrations to mimic.
“But the human demonstration is one long, continuous trajectory,” Wang says.
The team realized that, while a human might demonstrate a single task in one go, that task depends on a sequence of subtasks, or trajectories. For instance, the robot has to first reach into a bowl before it can scoop, and it must scoop up marbles before moving to the empty bowl, and so forth. If a robot is pushed or nudged to make a mistake during any of these subtasks, its only recourse is to stop and start from the beginning, unless engineers were to explicitly label each subtask and program or collect new demonstrations for the robot to recover from the said failure, to enable a robot to self-correct in the moment.
“That level of planning is very tedious,” Wang says.
Instead, he and his colleagues found some of this work could be done automatically by LLMs. These deep learning models process immense libraries of text, which they use to establish connections between words, sentences, and paragraphs. Through these connections, an LLM can then generate new sentences based on what it has learned about the kind of word that is likely to follow the last.
For their part, the researchers found that in addition to sentences and paragraphs, an LLM can be prompted to produce a logical list of subtasks that would be involved in a given task. For instance, if queried to list the actions involved in scooping marbles from one bowl into another, an LLM might produce a sequence of verbs such as “reach,” “scoop,” “transport,” and “pour.”
“LLMs have a way to tell you how to do each step of a task, in natural language. A human’s continuous demonstration is the embodiment of those steps, in physical space,” Wang says. “And we wanted to connect the two, so that a robot would automatically know what stage it is in a task, and be able to replan and recover on its own.”
Mapping marbles
For their new approach, the team developed an algorithm to automatically connect an LLM’s natural language label for a particular subtask with a robot’s position in physical space or an image that encodes the robot state. Mapping a robot’s physical coordinates, or an image of the robot state, to a natural language label is known as “grounding.” The team’s new algorithm is designed to learn a grounding “classifier,” meaning that it learns to automatically identify what semantic subtask a robot is in — for example, “reach” versus “scoop” — given its physical coordinates or an image view.
“The grounding classifier facilitates this dialogue between what the robot is doing in the physical space and what the LLM knows about the subtasks, and the constraints you have to pay attention to within each subtask,” Wang explains.
The team demonstrated the approach in experiments with a robotic arm that they trained on a marble-scooping task. Experimenters trained the robot by physically guiding it through the task of first reaching into a bowl, scooping up marbles, transporting them over an empty bowl, and pouring them in. After a few demonstrations, the team then used a pretrained LLM and asked the model to list the steps involved in scooping marbles from one bowl to another. The researchers then used their new algorithm to connect the LLM’s defined subtasks with the robot’s motion trajectory data. The algorithm automatically learned to map the robot’s physical coordinates in the trajectories and the corresponding image view to a given subtask.
The team then let the robot carry out the scooping task on its own, using the newly learned grounding classifiers. As the robot moved through the steps of the task, the experimenters pushed and nudged the bot off its path, and knocked marbles off its spoon at various points. Rather than stop and start from the beginning again, or continue blindly with no marbles on its spoon, the bot was able to self-correct, and completed each subtask before moving on to the next. (For instance, it would make sure that it successfully scooped marbles before transporting them to the empty bowl.)
“With our method, when the robot is making mistakes, we don’t need to ask humans to program or give extra demonstrations of how to recover from failures,” Wang says. “That’s super exciting because there’s a huge effort now toward training household robots with data collected on teleoperation systems. Our algorithm can now convert that training data into robust robot behavior that can do complex tasks, despite external perturbations.”
In this collaged image, a robotic hand tries to scoop up red marbles and put them into another bowl while a researcher’s hand frequently disrupts it. The robot eventually succeeds.
Large language models, such as those that power popular artificial intelligence chatbots like ChatGPT, are incredibly complex. Even though these models are being used as tools in many areas, such as customer support, code generation, and language translation, scientists still don’t fully grasp how they work.
In an effort to better understand what is going on under the hood, researchers at MIT and elsewhere studied the mechanisms at work when these enormous machine-learning models retrieve stored knowledge.
They found a surprising result: Large language models (LLMs) often use a very simple linear function to recover and decode stored facts. Moreover, the model uses the same decoding function for similar types of facts. Linear functions, equations with only two variables and no exponents, capture the straightforward, straight-line relationship between two variables.
The researchers showed that, by identifying linear functions for different facts, they can probe the model to see what it knows about new subjects, and where within the model that knowledge is stored.
Using a technique they developed to estimate these simple functions, the researchers found that even when a model answers a prompt incorrectly, it has often stored the correct information. In the future, scientists could use such an approach to find and correct falsehoods inside the model, which could reduce a model’s tendency to sometimes give incorrect or nonsensical answers.
“Even though these models are really complicated, nonlinear functions that are trained on lots of data and are very hard to understand, there are sometimes really simple mechanisms working inside them. This is one instance of that,” says Evan Hernandez, an electrical engineering and computer science (EECS) graduate student and co-lead author of a paper detailing these findings.
Hernandez wrote the paper with co-lead author Arnab Sharma, a computer science graduate student at Northeastern University; his advisor, Jacob Andreas, an associate professor in EECS and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL); senior author David Bau, an assistant professor of computer science at Northeastern; and others at MIT, Harvard University, and the Israeli Institute of Technology. The research will be presented at the International Conference on Learning Representations.
Finding facts
Most large language models, also called transformer models, are neural networks. Loosely based on the human brain, neural networks contain billions of interconnected nodes, or neurons, that are grouped into many layers, and which encode and process data.
Much of the knowledge stored in a transformer can be represented as relations that connect subjects and objects. For instance, “Miles Davis plays the trumpet” is a relation that connects the subject, Miles Davis, to the object, trumpet.
As a transformer gains more knowledge, it stores additional facts about a certain subject across multiple layers. If a user asks about that subject, the model must decode the most relevant fact to respond to the query.
If someone prompts a transformer by saying “Miles Davis plays the. . .” the model should respond with “trumpet” and not “Illinois” (the state where Miles Davis was born).
“Somewhere in the network’s computation, there has to be a mechanism that goes and looks for the fact that Miles Davis plays the trumpet, and then pulls that information out and helps generate the next word. We wanted to understand what that mechanism was,” Hernandez says.
The researchers set up a series of experiments to probe LLMs, and found that, even though they are extremely complex, the models decode relational information using a simple linear function. Each function is specific to the type of fact being retrieved.
For example, the transformer would use one decoding function any time it wants to output the instrument a person plays and a different function each time it wants to output the state where a person was born.
The researchers developed a method to estimate these simple functions, and then computed functions for 47 different relations, such as “capital city of a country” and “lead singer of a band.”
While there could be an infinite number of possible relations, the researchers chose to study this specific subset because they are representative of the kinds of facts that can be written in this way.
They tested each function by changing the subject to see if it could recover the correct object information. For instance, the function for “capital city of a country” should retrieve Oslo if the subject is Norway and London if the subject is England.
Functions retrieved the correct information more than 60 percent of the time, showing that some information in a transformer is encoded and retrieved in this way.
“But not everything is linearly encoded. For some facts, even though the model knows them and will predict text that is consistent with these facts, we can’t find linear functions for them. This suggests that the model is doing something more intricate to store that information,” he says.
Visualizing a model’s knowledge
They also used the functions to determine what a model believes is true about different subjects.
In one experiment, they started with the prompt “Bill Bradley was a” and used the decoding functions for “plays sports” and “attended university” to see if the model knows that Sen. Bradley was a basketball player who attended Princeton.
“We can show that, even though the model may choose to focus on different information when it produces text, it does encode all that information,” Hernandez says.
They used this probing technique to produce what they call an “attribute lens,” a grid that visualizes where specific information about a particular relation is stored within the transformer’s many layers.
Attribute lenses can be generated automatically, providing a streamlined method to help researchers understand more about a model. This visualization tool could enable scientists and engineers to correct stored knowledge and help prevent an AI chatbot from giving false information.
In the future, Hernandez and his collaborators want to better understand what happens in cases where facts are not stored linearly. They would also like to run experiments with larger models, as well as study the precision of linear decoding functions.
“This is an exciting work that reveals a missing piece in our understanding of how large language models recall factual knowledge during inference. Previous work showed that LLMs build information-rich representations of given subjects, from which specific attributes are being extracted during inference. This work shows that the complex nonlinear computation of LLMs for attribute extraction can be well-approximated with a simple linear function,” says Mor Geva Pipek, an assistant professor in the School of Computer Science at Tel Aviv University, who was not involved with this work.
This research was supported, in part, by Open Philanthropy, the Israeli Science Foundation, and an Azrieli Foundation Early Career Faculty Fellowship.
Researchers from MIT and elsewhere found that complex large language machine-learning models use a simple mechanism to retrieve stored knowledge when they respond to a user prompt. The researchers can leverage these simple mechanisms to see what the model knows about different subjects, and also possibly correct false information that it has stored.
On the surface, the movement disorder amyotrophic lateral sclerosis (ALS), also known as Lou Gehrig’s disease, and the cognitive disorder frontotemporal lobar degeneration (FTLD), which underlies frontotemporal dementia, manifest in very different ways. In addition, they are known to primarily affect very different regions of the brain.
However, doctors and scientists have noted several similarities over the years, and a new study appearing in the journal Cell reveals that the diseases have remarkable overlaps at the cellular and molecular levels, revealing potential targets that could yield therapies applicable to both disorders.
The paper, led by scientists at MIT and the Mayo Clinic, tracked RNA expression patterns in 620,000 cells spanning 44 different cell types across motor cortex and prefrontal cortex from postmortem brain samples of 73 donors diagnosed with ALS, FTLD, or who were neurologically unaffected.
“We focused on two brain regions that we expected would be differentially affected between the two disorders,” says Manolis Kellis, co-senior author of the paper, professor of computer science, and a principal investigator in the MIT Computer Science and Artificial Intelligence Laboratory. “It turns out that at the molecular and cellular level, the changes we found were nearly identical in the two disorders, and affected nearly identical subsets of cell types between the two regions.”
Indeed, one of the most prominent findings of the study revealed that in both diseases the most vulnerable neurons were almost identical both in the genes that they express, and in how these genes changed in expression in each disease.
“These similarities were quite striking, suggesting that therapeutics for ALS may also apply to FTLD and vice versa,” says lead corresponding author Myriam Heiman, who is an associate professor of brain and cognitive sciences and an investigator in The Picower Institute for Learning and Memory at MIT. “Our study can help guide therapeutic programs that would likely be effective for both diseases.”
Heiman and Kellis collaborated with co-senior author Veronique Belzil, then associate professor of neuroscience at the Mayo Clinic Florida, now director of the ALS Research Center at Vanderbilt University.
Another key realization from the study is that brain donors with inherited versus sporadic forms of the disease showed similarly altered gene expression changes, even though these were previously thought to have different causes. That suggests that similar molecular processes could be going awry downstream of the diseases’ origins.
“The molecular similarity between the familial (monogenic) form and the sporadic (polygenic) forms of these disorders suggests that convergence of diverse etiologies into common pathways,” Kellis says. “This has important implications for both understanding patient heterogeneity and understanding complex and rare disorders more broadly.”
“Practically indistinguishable” profiles
The overlap was especially evident, the study found, when looking at the most-affected cells. In ALS, known to cause progressive paralysis and ultimately death, the most endangered cells in the brain are upper motor neurons (UMN) in layer 5 of the motor cortex. Meanwhile in behavioral variant frontotemporal dementia (bvFTD), the most common type of FTLD that is characterized instead by changes to personality and behavior, the most vulnerable neurons are spindle neurons, or von Economo cells, found in layer 5 of more frontal brain regions.
The new study shows that while the cells look different under the microscope, and make distinct connections in brain circuits, their gene expression in health and disease is nevertheless strikingly similar.
“UMNs and spindle neurons look nothing alike and live in very different areas of the brain” says Sebastian Pineda, lead author of the study, and a graduate student jointly supervised by Heiman and Kellis. “It was remarkable to see that they appear practically indistinguishable at the molecular level and respond very similarly to disease.”
The researchers found many of the genes involved in the two diseases implicated primary cilia, tiny antenna-like structures on the cell’s surface that sense chemical changes in the cell’s surrounding environment. Cilia are necessary for guiding the growth of axons, or long nerve fibers that neurons extend to connect with other neurons. Cells that are more dependent on this process, typically those with the longest projections, were found to be more vulnerable in each disease.
The analysis also found another type of neuron, which highly expresses the gene SCN4B and which was not previously associated with either disease, also shared many of these same characteristics and showed similar disruptions.
“It may be that changes to this poorly characterized cell population underlie various clinically relevant disease phenomena,” Heiman says.
The study also found that the most vulnerable cells expressed genes known to be genetically-associated with each disease, providing a potential mechanistic basis for some of these genetic associations. This pattern is not always the case in neurodegenerative conditions, Heiman says. For example, Huntington’s disease is caused by a well-known mutation in the huntingtin gene, but the most highly affected neurons don’t express huntingtin more than other cells, and the same is true for some genes associated with Alzheimer’s disease.
Not just neurons
Looking beyond neurons, the study characterized gene expression differences in many other brain cell types. Notably, researchers saw several signs of trouble in the brain’s circulatory system. The blood-brain barrier (BBB), a filtering system that tightly regulates which molecules can go into or come out of the brain through blood vessels, is believed to be compromised in both disorders.
Building on their previous characterization of human brain vasculature and its changes in Huntington’s and Alzheimer’s disease by Heiman, Kellis, and collaborators including Picower Institute Director Li-Huei Tsai, the researchers found that proteins needed to maintain blood vessel integrity are reduced or misplaced in neurodegeneration. They also found a reduction of HLA-E, a molecule thought to inhibit BBB degradation by the immune system.
Given the many molecular and mechanistic similarities in ALS and FTLD, Heiman and Kellis said they are curious why some patients present with ALS and others with FTLD, and others with both but in different orders.
While the present study examined “upper” motor neurons in the brain, Heiman and Kellis are now seeking to also characterize connected “lower” motor neurons in the spinal cord, also in collaboration with Belzil.
“Our single-cell analyses have revealed many shared biological pathways across ALS, FTLD, Huntington’s, Alzheimer’s, vascular dementia, Lewy body dementia, and several other rare neurodegenerative disorders,” says Kellis. “These common hallmarks can pave the path for a new modular approach for precision and personalized therapeutic development, which can bring much-needed new insights and hope.”
In addition to Pineda, Belzil, Kellis, and Heiman, the study’s other authors are Hyeseung Lee, Maria Ulloa-Navas, Raleigh Linville, Francisco Garcia, Kyriaktisa Galani, Erica Engelberg-Cook, Monica Castanedes, Brent Fitzwalter, Luc Pregent, Mahammad Gardashli, Michael DeTure, Diana Vera-Garcia, Andre Hucke, Bjorn Oskarsson, Melissa Murray, and Dennis Dickson.
Support for the study came from the National Institutes of Health, Mitsubishi Tanabe Pharma Holdings, The JPB Foundation, The Picower Institute for Learning and Memory, the Robert Packard Center for ALS Research at Johns Hopkins, The LiveLikeLou Foundation, the Gerstner Family Foundation, The Mayo Clinic Center for Individualized Medicine, and the Cure Alzheimer’s Fund.
Researchers studying ALS and FTLD in human brain samples saw many similarities at the cellular and molecular level. Here, stained motor cortex tissue from a donor with ALS (right) shows reduced amounts of the protein HLA-E (green) in blood vessels. HLA-E is thought to inhibit degradation of the blood brain barrier by the immune system. Researchers found reduced expression of HLA-E in both ALS and FTLD.
Building construction accounts for a huge chunk of greenhouse gas emissions: About 36 percent of carbon dioxide emissions and 40 percent of energy consumption in Europe, for instance. That’s why the European Union has developed regulations about the reuse of building materials.
Some cities are adding more material reuse into construction already. Amsterdam, for example, is attempting to slash its raw material use by half by 2030. The Netherlands as a whole aims for a “circular economy” of completely reused materials by 2050.
But the best way to organize the reuse of construction waste is still being determined. For one thing: Where should reusable building materials be stored before they are reused? A newly published study focusing on Amsterdam finds the optimal material reuse system for construction has many local storage “hubs” that keep materials within a few miles of where they will be needed.
“Our findings provide a starting point for policymakers in Amsterdam to strategize land use effectively,” says Tanya Tsui, a postdoc at MIT and a co-author of the new paper. “By identifying key locations repeatedly favored across various hub scenarios, we underscore the importance of prioritizing these areas for future circular economy endeavors in Amsterdam.”
The study adds to an emerging research area that connects climate change and urban planning.
“The issue is where you put material in between demolition and new construction,” says Fábio Duarte, a principal researcher at MIT’s Senseable City Lab and a co-author of the new paper. “It will have huge impacts in terms of transportation. So you have to define the best sites. Should there be only one? Should we hold materials across a wide number of sites? Or is there an optimal number, even if it changes over time? This is what we examined in the paper.”
The paper, “Spatial optimization of circular timber hubs,” is published in NPJ Nature Urban Sustainability. The authors are Tsui, who is a postdoc at the MIT Senseable Amsterdam Lab in the Amsterdam Institute for Advanced Metropolitan Solutions (AMS); Titus Venverloo, a research fellow at MIT Senseable Amsterdam Lab and AMS; Tom Benson, a researcher at the Senseable City Lab; and Duarte, who is also a lecturer in MIT’s Department of Urban Studies and Planning and the MIT Center for Real Estate.
Numerous experts have previously studied at what scale the “circular economy” of reused materials might best operate. Some have suggested that very local circuits of materials recycling make the most sense; others have proposed that building-materials recycling will work best at a regional scale, with a radius of distribution covering 30 or more miles. Some analyses contend that global-scale reuse will be necessary to an extent.
The current study adds to this examination of the best geographic scale for using construction materials again. Currently the storage hubs that do exist for such reused materials are chosen by individual companies, but those locations might not be optimal either economically or environmentally.
To conduct the study, the researchers essentially conducted a series of simulations of the Amsterdam metropolitan area, focused exclusively on timber reuse. The simulations examined how the system would work if anywhere from one to 135 timber storage hubs existed in greater Amsterdam. The modeling accounted for numerous variables, such as emissions reductions, logistical factors, and even how changing supply-and-demand scenarios would affect the viability of the reusehubs.
Ultimately, the research found that Amsterdam’s optimal system would have 29 timber hubs, each serving a radius of about 2 miles. That setup generated 95 percent of the maximum reduction in CO2 emissions, while retaining logistical and economic benefits.
That results also lands firmly on the side of having more localized networks for keeping construction materials in use.
“If we have demolition happening in certain sites, then we can project where the best spots around the city are to have these circular economy hubs, as we call them,” Duarte says. “It’s not only one big hub — or one hub per construction site.”
The study seeks to identify not only the optimal number of storage sites, but to identify where those sites might be.
“[We hope] our research sparks discussions regarding the location and scale of circular hubs,” Tsui says. “While much attention has been given to governance aspects of the circular economy in cities, our study demonstrates the potential of utilizing location data on materials to inform decisions in urban planning.”
The simulations also illuminated the dynamics of materials reuse. In scenarios where Amsterdam had from two to 20 timber recycling hubs, the costs involved lowered as the number of hubs increased — because having more hubs reduces transportation costs. But when the number of hubs went about 40, the system as a whole became more expensive — because each timber depot was not storing enough material to justify the land use.
As such, the results may be of interest to climate policymakers, urban planners, and business interests getting involved in implementing the circular economy in the construction industry.
“Ultimately,” Tsui says, “we envision our research catalyzing meaningful discussions and guiding policymakers toward more informed decisions in advancing the circular economy agenda in urban contexts."
The research was supported, in part, by the European Union’s Horizon 2020 research and innovation program.
Studying Amsterdam, MIT researchers found the optimal system for reusing construction materials has many local storage “hubs” that keep materials within a few miles of where they will be needed. The findings could help policymakers and urban planners develop circular economies of reused materials.
For most people, reading about the difference between a global average temperature rise of 1.5 C versus 2 C doesn’t conjure up a clear image of how their daily lives will actually be affected. So, researchers at MIT have come up with a different way of measuring and describing what global climate change patterns, in specific regions around the world, will mean for people’s daily activities and their quality of life.
The new measure, called “outdoor days,” describes the number of days per year that outdoor temperatures are neither too hot nor too cold for people to go about normal outdoor activities, whether work or leisure, in reasonable comfort. Describing the impact of rising temperatures in those terms reveals some significant global disparities, the researchers say.
The findings are described in a research paper written by MIT professor of civil and environmental engineering Elfatih Eltahir and postdocs Yeon-Woo Choi and Muhammad Khalifa, and published in the Journal of Climate.
Eltahir says he got the idea for this new system during his hourlong daily walks in the Boston area. “That’s how I interface with the temperature every day,” he says. He found that there have been more winter days recently when he could walk comfortably than in past years. Originally from Sudan, he says that when he returned there for visits, the opposite was the case: In winter, the weather tends to be relatively comfortable, but the number of these clement winter days has been declining. “There are fewer days that are really suitable for outdoor activity,” Eltahir says.
Rather than predefine what constitutes an acceptable outdoor day, Eltahir and his co-authors created a website where users can set their own definition of the highest and lowest temperatures they consider comfortable for their outside activities, then click on a country within a world map, or a state within the U.S., and get a forecast of how the number of days meeting those criteria will change between now and the end of this century. The website is freely available for anyone to use.
“This is actually a new feature that’s quite innovative,” he says. “We don’t tell people what an outdoor day should be; we let the user define an outdoor day. Hence, we invite them to participate in defining how future climate change will impact their quality of life, and hopefully, this will facilitate deeper understanding of how climate change will impact individuals directly.”
After deciding that this was a way of looking at the issue of climate change that might be useful, Eltahir says, “we started looking at the data on this, and we made several discoveries that I think are pretty significant.”
First of all, there will be winners and losers, and the losers tend to be concentrated in the global south. “In the North, in a place like Russia or Canada, you gain a significant number of outdoor days. And when you go south to places like Bangladesh or Sudan, it’s bad news. You get significantly fewer outdoor days. It is very striking.”
To derive the data, the software developed by the team uses all of the available climate models, about 50 of them, and provides output showing all of those projections on a single graph to make clear the range of possibilities, as well as the average forecast.
When we think of climate change, Eltahir says, we tend to look at maps that show that virtually everywhere, temperatures will rise. “But if you think in terms of outdoor days, you see that the world is not flat. The North is gaining; the South is losing.”
While North-South disparity in exposure and vulnerability has been broadly recognized in the past, he says, this way of quantifying the effects on the hazard (change in weather patterns) helps to bring home how strong the uneven risks from climate change on quality of life will be. “When you look at places like Bangladesh, Colombia, Ivory Coast, Sudan, Indonesia — they are all losing outdoor days.”
The same kind of disparity shows up in Europe, he says. The effects are already being felt, and are showing up in travel patterns: “There is a shift to people spending time in northern European states. They go to Sweden and places like that instead of the Mediterranean, which is showing a significant drop,” he says.
Placing this kind of detailed and localized information at people’s fingertips, he says, “I think brings the issue of communication of climate change to a different level.” With this tool, instead of looking at global averages, “we are saying according to your own definition of what a pleasant day is, [this is] how climate change is going to impact you, your activities.”
And, he adds, “hopefully that will help society make decisions about what to do with this global challenge.”
The project received support from the MIT Climate Grand Challenges project “Jameel Observatory - Climate Resilience Early Warning System Network,” as well as from the Abdul Latif Jameel Water and Food Systems Lab.
A new measure of rising temperatures, called “outdoor days,” describes the number of days per year that outdoor temperatures are neither too hot nor too cold for people to go about normal outdoor activities, whether work or leisure, in reasonable comfort.
Hydrosocial displacement refers to the idea that resolving water conflict in one area can shift the conflict to a different area. The concept was coined by Scott Odell, a visiting researcher in MIT’s Environmental Solutions Initiative (ESI). As part of ESI’s Program on Mining and the Circular Economy, Odell researches the impacts of extractive industries on local environments and communities, especially in Latin America. He discovered that hydrosocial displacements are often in regions where the mining industry is vying for use of precious water sources that are already stressed due to climate change.
Odell is working with John Fernández, ESI director and professor in the Department of Architecture, on a project that is examining the converging impacts of climate change, mining, and agriculture in Chile. The work is funded by a seed grant from MIT’s Abdul Latif Jameel Water and Food Systems Lab (J-WAFS). Specifically, the project seeks to answer how the expansion of seawater desalination by the mining industry is affecting local populations, and how climate change and mining affect Andean glaciers and the agricultural communities dependent upon them.
By working with communities in mining areas, Odell and Fernández are gaining a sense of the burden that mining minerals needed for the clean energy transition is placing on local populations, and the types of conflicts that arise when water sources become polluted or scarce. This work is of particular importance considering over 100 countries pledged a commitment to the clean energy transition at the recent United Nations climate change conference, known as COP28.
Water, humanity’s lifeblood
At the March 2023 United Nations (U.N.) Water Conference in New York, U.N. Secretary-General António Guterres warned “water is in deep trouble. We are draining humanity’s lifeblood through vampiric overconsumption and unsustainable use and evaporating it through global heating.” A quarter of the world’s population already faces “extremely high water stress,” according to the World Resources Institute. In an effort to raise awareness of major water-related issues and inspire action for innovative solutions, the U.N. created World Water Day, observed every year on March 22. This year’s theme is “Water for Peace,” underscoring the fact that even though water is a basic human right and intrinsic to every aspect of life, it is increasingly fought over as supplies dwindle due to problems including drought, overuse, and mismanagement.
The “Water for Peace” theme is exemplified in Fernández and Odell’s J-WAFS project, where findings are intended to inform policies to reduce social and environmental harms inflicted on mining communities and their limited water sources.
“Despite broad academic engagement with mining and climate change separately, there has been a lack of analysis of the societal implications of the interactions between mining and climate change,” says Odell. “This project is helping to fill the knowledge gap. Results will be summarized in Spanish and English and distributed to interested and relevant parties in Chile, ensuring that the results can be of benefit to those most impacted by these challenges,” he adds.
The effects of mining for the clean energy transition
Global climate change is understood to be the most pressing environmental issue facing humanity today. Mitigating climate change requires reducing carbon emissions by transitioning away from conventional energy derived from burning fossil fuels, to more sustainable energy sources like solar and wind power. Because copper is an excellent conductor of electricity, it will be a crucial element in the clean energy transition, in which more solar panels, wind turbines, and electric vehicles will be manufactured. “We are going to see a major increase in demand for copper due to the clean energy transition,” says Odell.
In 2021, Chile produced 26 percent of the world's copper, more than twice as much as any other country, Odell explains. Much of Chile’s mining is concentrated in and around the Atacama Desert — the world’s driest desert. Unfortunately, mining requires large amounts of water for a variety of processes, including controlling dust at the extraction site, cooling machinery, and processing and transporting ore.
Chile is also one of the world’s largest exporters of agricultural products. Farmland is typically situated in the valleys downstream of several mines in the high Andes region, meaning mines get first access to water. This can lead to water conflict between mining operations and agricultural communities. Compounding the problem of mining for greener energy materials to combat climate change, are the very effects of climate change. According to the Chilean government, the country has suffered 13 years of the worst drought in history. While this is detrimental to the mining industry, it is also concerning for those working in agriculture, including the Indigenous Atacameño communities that live closest to the Escondida mine, the largest copper mine in the world. “There was never a lot of water to go around, even before the mine,” Odell says. The addition of Escondida stresses an already strained water system, leaving Atacameño farmers and individuals vulnerable to severe water insecurity.
What’s more, waste from mining, known as tailings, includes minerals and chemicals that can contaminate water in nearby communities if not properly handled and stored. Odell says the secure storage of tailings is a high priority in earthquake-prone Chile. “If an earthquake were to hit and damage a tailings dam, it could mean toxic materials flowing downstream and destroying farms and communities,” he says.
Chile’s treasured glaciers are another piece of the mining, climate change, and agricultural puzzle. Caroline White-Nockleby, a PhD candidate in MIT’s Program in Science, Technology, and Society, is working with Odell and Fernández on the J-WAFS project and leading the research specifically on glaciers. “These may not be the picturesque bright blue glaciers that you might think of, but they are, nonetheless, an important source of water downstream,” says White-Nockleby. She goes on to explain that there are a few different ways that mines can impact glaciers.
In some cases, mining companies have proposed to move or even destroy glaciers to get at the ore beneath. Other impacts include dust from mining that falls on glaciers. White-Nockleby says, “this makes the glaciers a darker color, so, instead of reflecting the sun's rays away, [the glacier] may absorb the heat and melt faster.” This shows that even when not directly intervening with glaciers, mining activities can cause glacial decline, adding to the threat glaciers already face due to climate change. She also notes that “glaciers are an important water storage facility,” describing how, on an annual cycle, glaciers freeze and melt, allowing runoff that downstream agricultural communities can utilize. If glaciers suddenly melt too quickly, flooding of downstream communities can occur.
Desalination offers a possible, but imperfect, solution
Chile’s extensive coastline makes it uniquely positioned to utilize desalination — the removal of salts from seawater — to address water insecurity. Odell says that “over the last decade or so, there's been billions of dollars of investments in desalination in Chile.”
As part of his dissertation work at Clark University, Odell found broad optimism in Chile for solving water issues in the mining industry through desalination. Not only was the mining industry committed to building desalination plants, there was also political support, and support from some community members in highland communities near the mines. Yet, despite the optimism and investment, desalinated water was not replacing the use of continental water. He concluded that “desalination can’t solve water conflict if it doesn't reduce demand for continental water supplies.”
However, after publishing those results, Odell learned that new estimates at the national level showed that desalination operations had begun to replace the use of continental water after 2018. In two case studies that he currently focuses on — the Escondida and Los Pelambres copper mines — the mining companies have expanded their desalination objectives in order to reduce extraction from key continental sources. This seems to be due to a variety of factors. For one thing, in 2022, Chile’s water code was reformed to prioritize human water consumption and environmental protection of water during scarcity and in the allocation of future rights. It also shortened the granting of water rights from “in perpetuity” to 30 years. Under this new code, it is possible that the mining industry may have expanded its desalination efforts because it viewed continental water resources as less secure, Odell surmises.
As part of the J-WAFS project, Odell has found that recent reactions have been mixed when it comes to the rapid increase in the use of desalination. He spent over two months doing fieldwork in Chile by conducting interviews with members of government, industry, and civil society at the Escondida, Los Pelambres, and Andina mining sites, as well as in Chile’s capital city, Santiago. He has spoken to local and national government officials, leaders of fishing unions, representatives of mining and desalination companies, and farmers. He observed that in the communities where the new desalination plants are being built, there have been concerns from community members as to whether they will get access to the desalinated water, or if it will belong solely to the mines.
Interviews at the Escondida and Los Pelambres sites, in which desalination operations are already in place or under construction, indicate acceptance of the presence of desalination plants combined with apprehension about unknown long-term environmental impacts. At a third mining site, Andina, there have been active protests against a desalination project that would supply water to a neighboring mine, Los Bronces. In that community, there has been a blockade of the desalination operation by the fishing federation. “They were blockading that operation for three months because of concerns over what the desalination plant would do to their fishing grounds,” Odell says. And this is where the idea of hydrosocial displacement comes into the picture, he explains. Even though desalination operations are easing tensions with highland agricultural communities, new issues are arising for the communities on the coast. “We can't just look to desalination to solve our problems if it's going to create problems somewhere else” Odell advises.
Within the process of hydrosocial displacement, interacting geographical, technical, economic, and political factors constrain the range of responses to address the water conflict. For example, communities that have more political and financial power tend to be better equipped to solve water conflict than less powerful communities. In addition, hydrosocial concerns usually follow the flow of water downstream, from the highlands to coastal regions. Odell says that this raises the need to look at water from a broader perspective.
“We tend to address water concerns one by one and that can, in practice, end up being kind of like whack-a-mole,” says Odell. “When we think of the broader hydrological system, water is very much linked, and we need to look across the watershed. We can't just be looking at the specific community affected now, but who else is affected downstream, and will be affected in the long term. If we do solve a water issue by moving it somewhere else, like moving a tailings dam somewhere else, or building a desalination plant, resources are needed in the receiving community to respond to that,” suggests Odell.
The company building the desalination plant and the fishing federation ultimately reached an agreement and the desalination operation will be moving forward. But Odell notes, “the protest highlights concern about the impacts of the operation on local livelihoods and environments within the much larger context of industrial pollution in the area.”
The power of communities
The protest by the fishing federation is one example of communities coming together to have their voices heard. Recent proposals by mining companies that would affect glaciers and other water sources used by agriculture communities have led to other protests that resulted in new agreements to protect local water supplies and the withdrawal of some of the mining proposals.
Odell observes that communities have also gone to the courts to raise their concerns. The Atacameño communities, for example, have drawn attention to over-extraction of water resources by the Escondida mine. “Community members are also pursuing education in these topics so that there's not such a power imbalance between mining companies and local communities,” Odell remarks. This demonstrates the power local communities can have to protect continental water resources.
The political and social landscape of Chile may also be changing in favor of local communities. Beginning with what is now referred to as the Estallido Social (social outburst) over inequality in 2019, Chile has undergone social upheaval that resulted in voters calling for a new constitution. Gabriel Boric, a progressive candidate, whose top priorities include social and environmental issues, was elected president during this period. These trends have brought major attention to issues of economic inequality, environmental harms of mining, and environmental justice, which is putting pressure on the mining industry to make a case for its operations in the country, and to justify the environmental costs of mining.
What happens after the mine dries up?
From his fieldwork interviews, Odell has learned that the development of mines within communities can offer benefits. Mining companies typically invest directly in communities through employment, road construction, and sometimes even by building or investing in schools, stadiums, or health clinics. Indirectly, mines can have spillover effects in the economy since miners might support local restaurants, hotels, or stores. But what happens when the mine closes? As one community member Odell interviewed stated: “When the mine is gone, what are we going to have left besides a big hole in the ground?”
Odell suggests that a multi-pronged approach should be taken to address the future state of water and mining. First, he says we need to have broader conversations about the nature of our consumption and production at domestic and global scales. “Mining is driven indirectly by our consumption of energy and directly by our consumption of everything from our buildings to devices to cars,” Odell states. “We should be looking for ways to moderate our consumption and consume smarter through both policy and practice so that we don’t solve climate change while creating new environmental harms through mining.”
One of the main ways we can do this is by advancing the circular economy by recycling metals already in the system, or even in landfills, to help build our new clean energy infrastructure. Even so, the clean energy transition will still require mining, but according to Odell, that mining can be done better. “Mining companies and government need to do a better job of consulting with communities. We need solid plans and financing for mine closures in place from the beginning of mining operations, so that when the mine dries up, there's the money needed to secure tailings dams and protect the communities who will be there forever,” Odell concludes.
Overall, it will take an engaged society — from the mining industry to government officials to individuals — to think critically about the role we each play in our quest for a more sustainable planet, and what that might mean for the most vulnerable populations among us.
When a devastating earthquake and tsunami overwhelmed the protective systems at the Fukushima Dai’ichi nuclear power plant complex in Japan in March 2011, it triggered a sequence of events leading to one of the worst releases of radioactive materials in the world to date. Although nuclear energy is having a revival as a low-emissions energy source to mitigate climate change, the Fukushima accident is still cited as a reason for hesitancy in adopting it.
A new study synthesizes information from multidisciplinary sources to understand how the Fukushima Dai’ichi disaster unfolded, and points to the importance of mitigation measures and last lines of defense — even against accidents considered highly unlikely. These procedures have received relatively little attention, but they are critical in determining how severe the consequences of a reactor failure will be, the researchers say.
The researchers note that their synthesis is one of the few attempts to look at data across disciplinary boundaries, including: the physics and engineering of what took place within the plant’s systems, the plant operators’ actions throughout the emergency, actions by emergency responders, the meteorology of radionuclide releases and transport, and the environmental and health consequences documented since the event.
The study appears in the journal iScience, in an open-access paper by postdoc Ali Ayoub and Professor Haruko Wainwright at MIT, along with others in Switzerland, Japan, and New Mexico.
Since 2013, Wainwright has been leading the research to integrate all the radiation monitoring data in the Fukushima region into integrated maps. “I was staring at the contamination map for nearly 10 years, wondering what created the main plume extending in the northwest direction, but I could not find exact information,” Wainwright says. “Our study is unique because we started from the consequence, the contamination map, and tried to identify the key factors for the consequence. Other people study the Fukushima accident from the root cause, the tsunami.”
One thing they found was that while all the operating reactors, units 1, 2, and 3, suffered core meltdowns as a result of the failure of emergency cooling systems, units 1 and 3 — although they did experience hydrogen explosions — did not release as much radiation to the environment because their venting systems essentially worked to relieve pressure inside the containment vessels as intended. But the same system in unit 2 failed badly.
“People think that the hydrogen explosion or the core meltdown were the worst things, or the major driver of the radiological consequences of the accident,” Wainright says, “but our analysis found that’s not the case.” Much more significant in terms of the radiological release was the failure of the one venting mechanism.
“There is a pressure-release mechanism that goes through water where a lot of the radionuclides get filtered out,” she explains. That system was effective in units 1 and 3, filtering out more than 90 percent of the radioactive elements before the gas was vented. However, “in unit 2, that pressure release mechanism got stuck, and the operators could not manually open it.” A hydrogen explosion in unit 1 had damaged the pressure relief mechanism of unit 2. This led to a breach of the containment structure and direct, unfiltered venting to the atmosphere, which, according to the new study, was what produced the greatest amount of contamination from the whole weeks-long event.
Another factor was the timing of the attempt to vent the pressure buildup in the reactor. Guidelines at the time, and to this day in many reactors, specified that no venting should take place until the pressure inside the reactor containment vessel reached a specified threshold, with no regard to the wind directions at the time. In the case of Fukushima, an earlier venting could have dramatically reduced the impact: Much of the release happened when winds were blowing directly inland, but earlier the wind had been blowing offshore.
“That pressure-release mechanism has not been a major focus of the engineering community,” she says. While there is appropriate attention to measures that prevent a core meltdown in the first place, “this sort of last line of defense has not been the main focus and should get more attention.”
Wainwright says the study also underlines several successes in the management of the Fukushima accident. Many of the safety systems did work as they were designed. For example, even though the oldest reactor, unit 1, suffered the greatest internal damage, it released little radioactive material. Most people were able to evacuate from the 20-kilometer (12-mile) zone before the largest release happened. The mitigation measures were “somewhat successful,” Wainwright says. But there was tremendous confusion and anger during and after the accident because there were no preparations in place for such an event.
Much work has focused on ways to prevent the kind of accidents that happened at Fukushima — for example, in the U.S. reactor operators can deploy portable backup power supplies to maintain proper reactor cooling at any reactor site. But the ongoing situation at the Zaporizhzhia nuclear complex in Ukraine, where nuclear safety is challenged by acts of war, demonstrates that despite engineers’ and operators’ best efforts to prevent it, “the totally unexpected could still happen,” Wainwright says.
“The big-picture message is that we should have equal attention to both prevention and mitigation of accidents,” she says. “This is the essence of resilience, and it applies beyond nuclear power plants to all essential infrastructure of a functioning society, for example, the electric grid, the food and water supply, the transportation sector, etc.”
One thing the researchers recommend is that in designing evacuation protocols, planners should make more effort to learn from much more frequent disasters such as wildfires and hurricanes. “We think getting more interdisciplinary, transdisciplinary knowledge from other kinds of disasters would be essential,” she says. Most of the emergency response strategies presently in place, she says, were designed in the 1980s and ’90s, and need to be modernized. “Consequences can be mitigated. A nuclear accident does not have to be a catastrophe, as is often portrayed in popular culture,” Wainright says.
The research team included Giovanni Sansavini at ETH Zurich in Switzerland; Randall Gauntt at Sandia National Laboratories in New Mexico; and Kimiaki Saito at the Japan Atomic Energy Agency.
A new study maps how the Fukushima Dai’ichi nuclear accident unfolded, and points to the importance of mitigation measures and last lines of defense. Here, International Atomic Energy Agency experts visit Fukushima Dai’ichi Nuclear Power Plant Unit 4 in 2013.
Most discussions of how to avertclimate change focus on solar and wind generation as key to the transition to a future carbon-free power system. But Michael Short, the Class of ’42 Associate Professor of Nuclear Science and Engineering at MIT and associate director of the MIT Plasma Science and Fusion Center (PSFC), is impatient with such talk. “We can say we should have only wind and solar someday. But we don’t have the luxury of ‘someday’ anymore, so we can’t ignore other helpful ways to combat climate change,” he says. “To me, it’s an ‘all-hands-on-deck’ thing. Solar and wind are clearly a big part of the solution. But I think that nuclear power also has a critical role to play.”
For decades, researchers have been working on designs for both fission and fusion nuclear reactors using molten salts as fuels or coolants. While those designs promise significant safety and performance advantages, there’s a catch: Molten salt and the impurities within it often corrode metals, ultimately causing them to crack, weaken, and fail. Inside a reactor, key metal components will be exposed not only to molten salt but also simultaneously to radiation, which generally has a detrimental effect on materials, making them more brittle and prone to failure. Will irradiation make metal components inside a molten salt-cooled nuclear reactor corrode even more quickly?
Short and Weiyue Zhou PhD ’21, a postdoc in the PSFC, have been investigating that question for eight years. Their recent experimental findings show that certain alloys will corrode more slowly when they’re irradiated — and identifying them among all the available commercial alloys can be straightforward.
The first challenge — building a test facility
When Short and Zhou began investigating the effect of radiation on corrosion, practically no reliable facilities existed to look at the two effects at once. The standard approach was to examine such mechanisms in sequence: first corrode, then irradiate, then examine the impact on the material. That approach greatly simplifies the task for the researchers, but with a major trade-off. “In a reactor, everything is going to be happening at the same time,” says Short. “If you separate the two processes, you’re not simulating a reactor; you’re doing some other experiment that’s not as relevant.”
So, Short and Zhou took on the challenge of designing and building an experimental setup that could do both at once. Short credits a team at the University of Michigan for paving the way by designing a device that could accomplish that feat in water, rather than molten salts. Even so, Zhou notes, it took them three years to come up with a device that would work with molten salts. Both researchers recall failure after failure, but the persistent Zhou ultimately tried a totally new design, and it worked. Short adds that it also took them three years to precisely replicate the salt mixture used by industry — another factor critical to getting a meaningful result. The hardest part was achieving and ensuring that the purity was correct by removing critical impurities such as moisture, oxygen, and certain other metals.
As they were developing and testing their setup, Short and Zhou obtained initial results showing that proton irradiation did not always accelerate corrosion but sometimes actually decelerated it. They and others had hypothesized that possibility, but even so, they were surprised. “We thought we must be doing something wrong,” recalls Short. “Maybe we mixed up the samples or something.” But they subsequently made similar observations for a variety of conditions, increasing their confidence that their initial observations were not outliers.
The successful setup
Central to their approach is the use of accelerated protons to mimic the impact of the neutrons inside a nuclear reactor. Generating neutrons would be both impractical and prohibitively expensive, and the neutrons would make everything highly radioactive, posing health risks and requiring very long times for an irradiated sample to cool down enough to be examined. Using protons would enable Short and Zhou to examine radiation-altered corrosion both rapidly and safely.
Key to their experimental setup is a test chamber that they attach to a proton accelerator. To prepare the test chamber for an experiment, they place inside it a thin disc of the metal alloy being tested on top of a a pellet of salt. During the test, the entire foil disc is exposed to a bath of molten salt. At the same time, a beam of protons bombards the sample from the side opposite the salt pellet, but the proton beam is restricted to a circle in the middle of the foil sample. “No one can argue with our results then,” says Short. “In a single experiment, the whole sample is subjected to corrosion, and only a circle in the center of the sample is simultaneously irradiated by protons. We can see the curvature of the proton beam outline in our results, so we know which region is which.”
The results with that arrangement were unchanged from the initial results. They confirmed the researchers’ preliminary findings, supporting their controversial hypothesis that rather than accelerating corrosion, radiation would actually decelerate corrosion in some materials under some conditions. Fortunately, they just happen to be the same conditions that will be experienced by metals in molten salt-cooled reactors.
Why is that outcome controversial? A closeup look at the corrosion process will explain. When salt corrodes metal, the salt finds atomic-level openings in the solid, seeps in, and dissolves salt-soluble atoms, pulling them out and leaving a gap in the material — a spot where the material is now weak. “Radiation adds energy to atoms, causing them to be ballistically knocked out of their positions and move very fast,” explains Short. So, it makes sense that irradiating a material would cause atoms to move into the salt more quickly, increasing the rate of corrosion. Yet in some of their tests, the researchers found the opposite to be true.
Experiments with “model” alloys
The researchers’ first experiments in their novel setup involved “model” alloys consisting of nickel and chromium, a simple combination that would give them a first look at the corrosion process in action. In addition, they added europium fluoride to the salt, a compound known to speed up corrosion. In our everyday world, we often think of corrosion as taking years or decades, but in the more extreme conditions of a molten salt reactor it can noticeably occur in just hours. The researchers used the europium fluoride to speed up corrosion even more without changing the corrosion process. This allowed for more rapid determination of which materials, under which conditions, experienced more or less corrosion with simultaneous proton irradiation.
The use of protons to emulate neutron damage to materials meant that the experimental setup had to be carefully designed and the operating conditions carefully selected and controlled. Protons are hydrogen atoms with an electrical charge, and under some conditions the hydrogen could chemically react with atoms in the sample foil, altering the corrosion response, or with ions in the salt, making the salt more corrosive. Therefore, the proton beam had to penetrate the foil sample but then stop in the salt as soon as possible. Under these conditions, the researchers found they could deliver a relatively uniform dose of radiation inside the foil layer while also minimizing chemical reactions in both the foil and the salt.
Tests showed that a proton beam accelerated to 3 million electron-volts combined with a foil sample between 25 and 30 microns thick would work well for their nickel-chromium alloys. The temperature and duration of the exposure could be adjusted based on the corrosion susceptibility of the specific materials being tested.
Optical images of samples examined after tests with the model alloys showed a clear boundary between the area that was exposed only to the molten salt and the area that was also exposed to the proton beam. Electron microscope images focusing on that boundary showed that the area that had been exposed only to the molten salt included dark patches where the molten salt had penetrated all the way through the foil, while the area that had also been exposed to the proton beam showed almost no such dark patches.
To confirm that the dark patches were due to corrosion, the researchers cut through the foil sample to create cross sections. In them, they could see tunnels that the salt had dug into the sample. “For regions not under radiation, we see that the salt tunnels link the one side of the sample to the other side,” says Zhou. “For regions under radiation, we see that the salt tunnels stop more or less halfway and rarely reach the other side. So we verified that they didn’t penetrate the whole way.”
The results “exceeded our wildest expectations,” says Short. “In every test we ran, the application of radiation slowed corrosion by a factor of two to three times.”
More experiments, more insights
In subsequent tests, the researchers more closely replicated commercially available molten salt by omitting the additive (europium fluoride) that they had used to speed up corrosion, and they tweaked the temperature for even more realistic conditions. “In carefully monitored tests, we found that by raising the temperature by 100 degrees Celsius, we could get corrosion to happen about 1,000 times faster than it would in a reactor,” says Short.
Images from experiments with the nickel-chromium alloy plus the molten salt without the corrosive additive yielded further insights. Electron microscope images of the side of the foil sample facing the molten salt showed that in sections only exposed to the molten salt, the corrosion is clearly focused on the weakest part of the structure — the boundaries between the grains in the metal. In sections that were exposed to both the molten salt and the proton beam, the corrosion isn’t limited to the grain boundaries but is more spread out over the surface. Experimental results showed that these cracks are shallower and less likely to cause a key component to break.
Short explains the observations. Metals are made up of individual grains inside which atoms are lined up in an orderly fashion. Where the grains come together there are areas — called grain boundaries — where the atoms don’t line up as well. In the corrosion-only images, dark lines track the grain boundaries. Molten salt has seeped into the grain boundaries and pulled out salt-soluble atoms. In the corrosion-plus-irradiation images, the damage is more general. It’s not only the grain boundaries that get attacked but also regions within the grains.
So, when the material is irradiated, the molten salt also removes material from within the grains. Over time, more material comes out of the grains themselves than from the spaces between them. The removal isn’t focused on the grain boundaries; it’s spread out over the whole surface. As a result, any cracks that form are shallower and more spread out, and the material is less likely to fail.
Testing commercial alloys
The experiments described thus far involved model alloys — simple combinations of elements that are good for studying science but would never be used in a reactor. In the next series of experiments, the researchers focused on three commercially available alloys that are composed of nickel, chromium, iron, molybdenum, and other elements in various combinations.
Results from the experiments with the commercial alloys showed a consistent pattern — one that confirmed an idea that the researchers had going in: the higher the concentration of salt-soluble elements in the alloy, the worse the radiation-induced corrosion damage. Radiation will increase the rate at which salt-soluble atoms such as chromium leave the grain boundaries, hastening the corrosion process. However, if there are more not-soluble elements such as nickel present, those atoms will go into the salt more slowly. Over time, they’ll accumulate at the grain boundary and form a protective coating that blocks the grain boundary — a “self-healing mechanism that decelerates the rate of corrosion,” say the researchers.
Thus, if an alloy consists mostly of atoms that don’t dissolve in molten salt, irradiation will cause them to form a protective coating that slows the corrosion process. But if an alloy consists mostly of atoms that dissolve in molten salt, irradiation will make them dissolve faster, speeding up corrosion. As Short summarizes, “In terms of corrosion, irradiation makes a good alloy better and a bad alloy worse.”
Real-world relevance plus practical guidelines
Short and Zhou find their results encouraging. In a nuclear reactor made of “good” alloys, the slowdown in corrosion will probably be even more pronounced than what they observed in their proton-based experiments because the neutrons that inflict the damage won’t chemically react with the salt to make it more corrosive. As a result, reactor designers could push the envelope more in their operating conditions, allowing them to get more power out of the same nuclear plant without compromising on safety.
However, the researchers stress that there’s much work to be done. Many more projects are needed to explore and understand the exact corrosion mechanism in specific alloys under different irradiation conditions. In addition, their findings need to be replicated by groups at other institutions using their own facilities. “What needs to happen now is for other labs to build their own facilities and start verifying whether they get the same results as we did,” says Short. To that end, Short and Zhou have made the details of their experimental setup and all of their data freely available online. “We’ve also been actively communicating with researchers at other institutions who have contacted us,” adds Zhou. “When they’re planning to visit, we offer to show them demonstration experiments while they’re here.”
But already their findings provide practical guidance for other researchers and equipment designers. For example, the standard way to quantify corrosion damage is by “mass loss,” a measure of how much weight the material has lost. But Short and Zhou consider mass loss a flawed measure of corrosion in molten salts. “If you’re a nuclear plant operator, you usually care whether your structural components are going to break,” says Short. “Our experiments show that radiation can change how deep the cracks are, when all other things are held constant. The deeper the cracks, the more likely a structural component is to break, leading to a reactor failure.”
In addition, the researchers offer a simple rule for identifying good metal alloys for structural components in molten salt reactors. Manufacturers provide extensive lists of available alloys with different compositions, microstructures, and additives. Faced with a list of options for critical structures, the designer of a new nuclear fission or fusion reactor can simply examine the composition of each alloy being offered. The one with the highest content of corrosion-resistant elements such as nickel will be the best choice. Inside a nuclear reactor, that alloy should respond to a bombardment of radiation not by corroding more rapidly but by forming a protective layer that helps block the corrosion process. “That may seem like a trivial result, but the exact threshold where radiation decelerates corrosion depends on the salt chemistry, the density of neutrons in the reactor, their energies, and a few other factors,” says Short. “Therefore, the complete guidelines are a bit more complicated. But they’re presented in a straightforward way that users can understand and utilize to make a good choice for the molten salt–based reactor they’re designing.”
This research was funded, in part, by Eni S.p.A. through the MIT Plasma Science and Fusion Center’s Laboratory for Innovative Fusion Technologies. Earlier work was funded, in part, by the Transatomic Power Corporation and by the U.S. Department of Energy Nuclear Energy University Program. Equipment development and testing was supported by the Transatomic Power Corporation.
This article appears in the Winter 2024 issue of Energy Futures, the magazine of the MIT Energy Initiative.
Postdoc Weiyue Zhou (left) and Associate Professor Michael Short attach a novel test chamber containing a metal sample and salt to the end of a proton accelerator. Experiments to date show that proton irradiation decreases the rate of corrosion in certain metal alloys — potentially good news for designers of promising nuclear power reactors that rely on molten salts, which tend to be highly corrosive.
In our current age of artificial intelligence, computers can generate their own “art” by way of diffusion models, iteratively adding structure to a noisy initial state until a clear image or video emerges. Diffusion models have suddenly grabbed a seat at everyone’s table: Enter a few words and experience instantaneous, dopamine-spiking dreamscapes at the intersection of reality and fantasy. Behind the scenes, it involves a complex, time-intensive process requiring numerous iterations for the algorithm to perfect the image.
MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers have introduced a new framework that simplifies the multi-step process of traditional diffusion models into a single step, addressing previous limitations. This is done through a type of teacher-student model: teaching a new computer model to mimic the behavior of more complicated, original models that generate images. The approach, known as distribution matching distillation (DMD), retains the quality of the generated images and allows for much faster generation.
“Our work is a novel method that accelerates current diffusion models such as Stable Diffusion and DALLE-3 by 30 times,” says Tianwei Yin, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and the lead researcher on the DMD framework. “This advancement not only significantly reduces computational time but also retains, if not surpasses, the quality of the generated visual content. Theoretically, the approach marries the principles of generative adversarial networks (GANs) with those of diffusion models, achieving visual content generation in a single step — a stark contrast to the hundred steps of iterative refinement required by current diffusion models. It could potentially be a new generative modeling method that excels in speed and quality.”
This single-step diffusion model could enhance design tools, enabling quicker content creation and potentially supporting advancements in drug discovery and 3D modeling, where promptness and efficacy are key.
Distribution dreams
DMD cleverly has two components. First, it uses a regression loss, which anchors the mapping to ensure a coarse organization of the space of images to make training more stable. Next, it uses a distribution matching loss, which ensures that the probability to generate a given image with the student model corresponds to its real-world occurrence frequency. To do this, it leverages two diffusion models that act as guides, helping the system understand the difference between real and generated images and making training the speedy one-step generator possible.
The system achieves faster generation by training a new network to minimize the distribution divergence between its generated images and those from the training dataset used by traditional diffusion models. “Our key insight is to approximate gradients that guide the improvement of the new model using two diffusion models,” says Yin. “In this way, we distill the knowledge of the original, more complex model into the simpler, faster one, while bypassing the notorious instability and mode collapse issues in GANs.”
Yin and colleagues used pre-trained networks for the new student model, simplifying the process. By copying and fine-tuning parameters from the original models, the team achieved fast training convergence of the new model, which is capable of producing high-quality images with the same architectural foundation. “This enables combining with other system optimizations based on the original architecture to further accelerate the creation process,” adds Yin.
When put to the test against the usual methods, using a wide range of benchmarks, DMD showed consistent performance. On the popular benchmark of generating images based on specific classes on ImageNet, DMD is the first one-step diffusion technique that churns out pictures pretty much on par with those from the original, more complex models, rocking a super-close Fréchet inception distance (FID) score of just 0.3, which is impressive, since FID is all about judging the quality and diversity of generated images. Furthermore, DMD excels in industrial-scale text-to-image generation and achieves state-of-the-art one-step generation performance. There's still a slight quality gap when tackling trickier text-to-image applications, suggesting there's a bit of room for improvement down the line.
Additionally, the performance of the DMD-generated images is intrinsically linked to the capabilities of the teacher model used during the distillation process. In the current form, which uses Stable Diffusion v1.5 as the teacher model, the student inherits limitations such as rendering detailed depictions of text and small faces, suggesting that DMD-generated images could be further enhanced by more advanced teacher models.
“Decreasing the number of iterations has been the Holy Grail in diffusion models since their inception,” says Fredo Durand, MIT professor of electrical engineering and computer science, CSAIL principal investigator, and a lead author on the paper. “We are very excited to finally enable single-step image generation, which will dramatically reduce compute costs and accelerate the process.”
“Finally, a paper that successfully combines the versatility and high visual quality of diffusion models with the real-time performance of GANs,” says Alexei Efros, a professor of electrical engineering and computer science at the University of California at Berkeley who was not involved in this study. “I expect this work to open up fantastic possibilities for high-quality real-time visual editing.”
Yin and Durand’s fellow authors are MIT electrical engineering and computer science professor and CSAIL principal investigator William T. Freeman, as well as Adobe research scientists Michaël Gharbi SM '15, PhD '18; Richard Zhang; Eli Shechtman; and Taesung Park. Their work was supported, in part, by U.S. National Science Foundation grants (including one for the Institute for Artificial Intelligence and Fundamental Interactions), the Singapore Defense Science and Technology Agency, and by funding from Gwangju Institute of Science and Technology and Amazon. Their work will be presented at the Conference on Computer Vision and Pattern Recognition in June.
With their DMD method, MIT researchers created a one-step AI image generator that achieves image quality comparable to StableDiffusion v1.5 while being 30 times faster.
If there is life in the solar system beyond Earth, it might be found in the clouds of Venus. In contrast to the planet’s blisteringly inhospitable surface, Venus’ cloud layer, which extends from 30 to 40 miles above the surface, hosts milder temperatures that could support some extreme forms of life.
If it’s out there, scientists have assumed that any Venusian cloud inhabitant would look very different from life forms on Earth. That’s because the clouds themselves are made from highly toxic droplets of sulfuric acid — an intensely corrosive chemical that is known to dissolve metals and destroy most biological molecules on Earth.
But a new study by MIT researchers may challenge that assumption. Appearing today in the journal Astrobiology, the study reports that, in fact, some key building blocks of life can persist in solutions of concentrated sulfuric acid.
The study’s authors have found that 19 amino acids that are essential to life on Earth are stable for up to four weeks when placed in vials of sulfuric acid at concentrations similar to those in Venus’ clouds. In particular, they found that the molecular “backbone” of all 19 amino acids remained intact in sulfuric acid solutions ranging in concentration from 81 to 98 percent.
“What is absolutely surprising is that concentrated sulfuric acid is not a solvent that is universally hostile to organic chemistry,” says study co-author Janusz Petkowski, a research affiliate in MIT’s Department of Earth, Atmospheric and Planetary Sciences (EAPS).
“We are finding that building blocks of life on Earth are stable in sulfuric acid, and this is very intriguing for the idea of the possibility of life on Venus,” adds study author Sara Seager, MIT’s Class of 1941 Professor of Planetary Sciences in EAPS and a professor in the departments of Physics and of Aeronautics and Astronautics. “It doesn’t mean that life there will be the same as here. In fact, we know it can’t be. But this work advances the notion that Venus’ clouds could support complex chemicals needed for life.”
The study’s co-authors include first author Maxwell Seager, an undergraduate in the Department of Chemistry at Worcester Polytechnic Institute and Seager’s son, and William Bains, a research affiliate at MIT and a scientist at Cardiff University.
Building blocks in acid
The search for life in Venus’ clouds has gained momentum in recent years, spurred in part by a controversial detection of phosphine — a molecule that is considered to be one signature of life — in the planet’s atmosphere. While that detection remains under debate, the news has reinvigorated an old question: Could Earth’s sister planet actually host life?
In search of an answer, scientists are planning several missions to Venus, including the first largely privately funded mission to the planet, backed by California-based launch company Rocket Lab. That mission, on which Seager is the science principal investigator, aims to send a spacecraft through the planet’s clouds to analyze their chemistry for signs of organic molecules.
Ahead of the mission’s January 2025 launch, Seager and her colleagues have been testing various molecules in concentrated sulfuric acid to see what fragments of life on Earth might also be stable in Venus’ clouds, which are estimated to be orders of magnitude more acidic than the most acidic places on Earth.
“People have this perception that concentrated sulfuric acid is an extremely aggressive solvent that will chop everything to pieces,” Petkowski says. “But we are finding this is not necessarily true.”
In fact, the team has previously shown that complex organic molecules such as some fatty acids and nucleic acids remain surprisingly stable in sulfuric acid. The scientists are careful to emphasize, as they do in their current paper, that “complex organic chemistry is of course not life, but there is no life without it.”
In other words, if certain molecules can persist in sulfuric acid, then perhaps the highly acidic clouds of Venus are habitable, if not necessarily inhabited.
In their new study, the team turned their focus on amino acids — molecules that combine to make essential proteins, each with their own specific function. Every living thing on Earth requires amino acids to make proteins that in turn carry out life-sustaining functions, from breaking down food to generating energy, building muscle, and repairing tissue.
“If you consider the four major building blocks of life as nucleic acid bases, amino acids, fatty acids, and carbohydrates, we have demonstrated that some fatty acids can form micelles and vesicles in sulfuric acid, and the nucleic acid bases are stable in sulfuric acid. Carbohydrates have been shown to be highly reactive in sulfuric acid,” Maxwell
Seager explains. “That only left us with amino acids as the last major building block to
study.”
A stable backbone
The scientists began their studies of sulfuric acid during the pandemic, carrying out their experiments in a home laboratory. Since that time, Seager and her son continued work on chemistry in concentrated sulfuric acid. In early 2023, they ordered powder samples of 20 “biogenic” amino acids — those amino acids that are essential to all life on Earth. They dissolved each type of amino acid in vials of sulfuric acid mixed with water, at concentrations of 81 and 98 percent, which represent the range that exists in Venus’ clouds.
The team then let the vials incubate for a day before transporting them to MIT’s Department of Chemistry Instrumentation Facility (DCIF), a shared, 24/7 laboratory that offers a number of automated and manual instruments for MIT scientists to use. For their part, Seager and her team used the lab’s nuclear magnetic resonance (NMR) spectrometer to analyze the structure of amino acids in sulfuric acid.
After analyzing each vial several times over four weeks, the scientists found, to their surprise, that the basic molecular structure, or “backbone” in 19 of the 20 amino acids remained stable and unchanged, even in highly acidic conditions.
“Just showing that this backbone is stable in sulfuric acid doesn’t mean there is life on Venus,” notes Maxwell Seager. “But if we had shown that this backbone was compromised, then there would be no chance of life as we know it.”
“Now, with the discovery that many amino acids and nucleic acids are stable in 98 percent sulfuric acid, the possibility of life surviving in sulfuric acid may not be so far-fetched or fantastic,” says Sanjay Limaye, a planetary scientist at the University of Wisconsin who has studied Venus for over 45 years, and who was not involved with this study. “Of course, many obstacles lie ahead, but life that evolved in water and adapted to sulfuric acid may not be easily dismissed.”
The team acknowledges that Venus’ cloud chemistry is likely messier than the study’s “test tube” conditions. For instance, scientists have measured various trace gases, in addition to sulfuric acid, in the planet’s clouds. As such, the team plans to incorporate certain trace gases in future experiments.
“There are only a few groups in the world now that are working on chemistry in sulfuric acid, and they will all agree that no one has intuition,” adds Sara Seager. “I think we are just more happy than anything that this latest result adds one more ‘yes’ for the possibility of life on Venus.”
MIT researchers have found that amino acids — major building blocks for life on Earth — are stable in highly concentrated sulfuric acid. Their results support the idea that these same molecules may be stable in Venus’ highly sulfuric clouds.
Lyme disease, a bacterial infection transmitted by ticks, affects nearly half a million people in the United States every year. In most cases, antibiotics effectively clear the infection, but for some patients, symptoms linger for months or years.
Researchers at MIT and the University of Helsinki have now discovered that human sweat contains a protein that can protect against Lyme disease. They also found that about one-third of the population carries a genetic variant of this protein that is associated with Lyme disease in genome-wide association studies.
It’s unknown exactly how the protein inhibits the growth of the bacteria that cause Lyme disease, but the researchers hope to harness the protein’s protective abilities to create skin creams that could help prevent the disease, or to treat infections that don’t respond to antibiotics.
“This protein may provide some protection from Lyme disease, and we think there are real implications here for a preventative and possibly a therapeutic based on this protein,” says Michal Caspi Tal, a principal research scientist in MIT’s Department of Biological Engineering and one of the senior authors of the new study.
Hanna Ollila, a senior researcher at the Institute for Molecular Medicine at the University of Helsinki and a researcher at the Broad Institute of MIT and Harvard, is also a senior author of the paper, which appears today in Nature Communications. The paper’s lead author is Satu Strausz, a postdoc at the Institute for Molecular Medicine at the University of Helsinki.
A surprising link
Lyme disease is most often caused by a bacterium called Borrelia burgdorferi. In the United States, this bacterium is spread by ticks that are carried by mice, deer, and other animals. Symptoms include fever, headache, fatigue, and a distinctive bulls-eye rash.
Most patients receive doxycycline, an antibiotic that usually clears up the infection. In some patients, however, symptoms such as fatigue, memory problems, sleep disruption, and body aches can persist for months or years.
Tal and Ollila, who were postdocs together at Stanford University, began this study a few years ago in hopes of finding genetic markers of susceptibility to Lyme disease. To that end, they decided to run a genome-wide association study (GWAS) on a Finnish dataset that contains genome sequences for 410,000 people, along with detailed information on their medical histories.
This dataset includes about 7,000 people who had been diagnosed with Lyme disease, allowing the researchers to look for genetic variants that were more frequently found in people who had had Lyme disease, compared with those who hadn’t.
This analysis revealed three hits, including two found in immune molecules that had been previously linked with Lyme disease. However, their third hit was a complete surprise — a secretoglobin called SCGB1D2.
Secretoglobins are a family of proteins found in tissues that line the lungs and other organs, where they play a role in immune responses to infection. The researchers discovered that this particular secretoglobin is produced primarily by cells in the sweat glands.
To find out how this protein might influence Lyme disease, the researchers created normal and mutated versions of SCGB1D2 and exposed them to Borrelia burgdorferi grown in the lab. They found that the normal version of the protein significantly inhibited the growth of Borrelia burgdorferi. However, when they exposed bacteria to the mutated version, twice as much protein was required to suppress bacterial growth.
The researchers then exposed bacteria to either the normal or mutated variant of SCGB1D2 and injected them into mice. Mice injected with the bacteria exposed to the mutant protein became infected with Lyme disease, but mice injected with bacteria exposed to the normal version of SCGB1D2 did not.
“In the paper we show they stayed healthy until day 10, but we followed the mice for over a month, and they never got infected. This wasn’t a delay, this was a full stop. That was really exciting,” Tal says.
Preventing infection
After the MIT and University of Helsinki researchers posted their initial findings on a preprint server, researchers in Estonia replicated the results of the genome-wide association study, using data from the Estonian Biobank. These data, from about 210,000 people, including 18,000 with Lyme disease, were later added to the final Nature Communications study.
The researchers aren’t sure yet how SCGB1D2 inhibits bacterial growth, or why the variant is less effective. However, they did find that the variant causes a shift from the amino acid proline to leucine, which may interfere with the formation of a helix found in the normal version.
They now plan to investigate whether applying the protein to the skin of mice, which do not naturally produce SCGB1D2, could prevent them from being infected by Borrelia burgdorferi. They also plan to explore the protein’s potential as a treatment for infections that don’t respond to antibiotics.
“We have fantastic antibiotics that work for 90 percent of people, but in the 40 years we’ve known about Lyme disease, we have not budged that,” Tal says. “Ten percent of people don’t recover after having antibiotics, and there’s no treatment for them.”
“This finding opens the door to a completely new approach to preventing Lyme disease in the first place, and it will be interesting to see if it could be useful for preventing other types of skin infections too,” says Kara Spiller, a professor of biomedical innovation in the School of Biomedical Engineering at Drexel University, who was not involved in the study.
The researchers note that people who have the protective version of SCGB1D2 can still develop Lyme disease, and they should not assume that they won’t. One factor that may play a role is whether the person happens to be sweating when they’re bitten by a tick carrying Borrelia burgdorferi.
SCGB1D2 is just one of 11 secretoglobin proteins produced by the human body, and Tal also plans to study what some of those other secretoglobins may be doing in the body, especially in the lungs, where many of them are found.
“The thing I’m most excited about is this idea that secretoglobins might be a class of antimicrobial proteins that we haven’t thought about. As immunologists, we talk nonstop about immunoglobulins, but I had never heard of a secretoglobin before this popped up in our GWAS study. This is why it’s so fun for me now. I want to know what they all do,” she says.
The research was funded, in part, by Emily and Malcolm Fairbairn, the Instrumentarium Science Foundation, the Academy of Finland, the Finnish Medical Foundation, the Younger Family, and the Bay Area Lyme Foundation.
Human sweat contains a protein that may protect against Lyme disease, according to a study from MIT and the University of Helsinki. About one-third of the population carries a genetic variant of this protein that is associated with Lyme disease in genome-wide association studies.
Imagine yourself glancing at a busy street for a few moments, then trying to sketch the scene you saw from memory. Most people could draw the rough positions of the major objects like cars, people, and crosswalks, but almost no one can draw every detail with pixel-perfect accuracy. The same is true for most modern computer vision algorithms: They are fantastic at capturing high-level details of a scene, but they lose fine-grained details as they process information.
Now, MIT researchers have created a system called “FeatUp” that lets algorithms capture all of the high- and low-level details of a scene at the same time — almost like Lasik eye surgery for computer vision.
When computers learn to “see” from looking at images and videos, they build up “ideas” of what's in a scene through something called “features.” To create these features, deep networks and visual foundation models break down images into a grid of tiny squares and process these squares as a group to determine what's going on in a photo. Each tiny square is usually made up of anywhere from 16 to 32 pixels, so the resolution of these algorithms is dramatically smaller than the images they work with. In trying to summarize and understand photos, algorithms lose a ton of pixel clarity.
The FeatUp algorithm can stop this loss of information and boost the resolution of any deep network without compromising on speed or quality. This allows researchers to quickly and easily improve the resolution of any new or existing algorithm. For example, imagine trying to interpret the predictions of a lung cancer detection algorithm with the goal of localizing the tumor. Applying FeatUp before interpreting the algorithm using a method like class activation maps (CAM) can yield a dramatically more detailed (16-32x) view of where the tumor might be located according to the model.
FeatUp not only helps practitioners understand their models, but also can improve a panoply of different tasks like object detection, semantic segmentation (assigning labels to pixels in an image with object labels), and depth estimation. It achieves this by providing more accurate, high-resolution features, which are crucial for building vision applications ranging from autonomous driving to medical imaging.
“The essence of all computer vision lies in these deep, intelligent features that emerge from the depths of deep learning architectures. The big challenge of modern algorithms is that they reduce large images to very small grids of 'smart' features, gaining intelligent insights but losing the finer details,” says Mark Hamilton, an MIT PhD student in electrical engineering and computer science, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) affiliate, and a co-lead author on a paper about the project. “FeatUp helps enable the best of both worlds: highly intelligent representations with the original image’s resolution. These high-resolution features significantly boost performance across a spectrum of computer vision tasks, from enhancing object detection and improving depth prediction to providing a deeper understanding of your network's decision-making process through high-resolution analysis.”
Resolution renaissance
As these large AI models become more and more prevalent, there’s an increasing need to explain what they’re doing, what they’re looking at, and what they’re thinking.
But how exactly can FeatUp discover these fine-grained details? Curiously, the secret lies in wiggling and jiggling images.
In particular, FeatUp applies minor adjustments (like moving the image a few pixels to the left or right) and watches how an algorithm responds to these slight movements of the image. This results in hundreds of deep-feature maps that are all slightly different, which can be combined into a single crisp, high-resolution, set of deep features. “We imagine that some high-resolution features exist, and that when we wiggle them and blur them, they will match all of the original, lower-resolution features from the wiggled images. Our goal is to learn how to refine the low-resolution features into high-resolution features using this 'game' that lets us know how well we are doing,” says Hamilton. This methodology is analogous to how algorithms can create a 3D model from multiple 2D images by ensuring that the predicted 3D object matches all of the 2D photos used to create it. In FeatUp’s case, they predict a high-resolution feature map that’s consistent with all of the low-resolution feature maps formed by jittering the original image.
The team notes that standard tools available in PyTorch were insufficient for their needs, and introduced a new type of deep network layer in their quest for a speedy and efficient solution. Their custom layer, a special joint bilateral upsampling operation, was over 100 times more efficient than a naive implementation in PyTorch. The team also showed this new layer could improve a wide variety of different algorithms including semantic segmentation and depth prediction. This layer improved the network’s ability to process and understand high-resolution details, giving any algorithm that used it a substantial performance boost.
“Another application is something called small object retrieval, where our algorithm allows for precise localization of objects. For example, even in cluttered road scenes algorithms enriched with FeatUp can see tiny objects like traffic cones, reflectors, lights, and potholes where their low-resolution cousins fail. This demonstrates its capability to enhance coarse features into finely detailed signals,” says Stephanie Fu ’22, MNG ’23, a PhD student at the University of California at Berkeley and another co-lead author on the new FeatUp paper. “This is especially critical for time-sensitive tasks, like pinpointing a traffic sign on a cluttered expressway in a driverless car. This can not only improve the accuracy of such tasks by turning broad guesses into exact localizations, but might also make these systems more reliable, interpretable, and trustworthy.”
What next?
Regarding future aspirations, the team emphasizes FeatUp’s potential widespread adoption within the research community and beyond, akin to data augmentation practices. “The goal is to make this method a fundamental tool in deep learning, enriching models to perceive the world in greater detail without the computational inefficiency of traditional high-resolution processing,” says Fu.
“FeatUp represents a wonderful advance towards making visual representations really useful, by producing them at full image resolutions,” says Cornell University computer science professor Noah Snavely, who was not involved in the research. “Learned visual representations have become really good in the last few years, but they are almost always produced at very low resolution — you might put in a nice full-resolution photo, and get back a tiny, postage stamp-sized grid of features. That’s a problem if you want to use those features in applications that produce full-resolution outputs. FeatUp solves this problem in a creative way by combining classic ideas in super-resolution with modern learning approaches, leading to beautiful, high-resolution feature maps.”
“We hope this simple idea can have broad application. It provides high-resolution versions of image analytics that we’d thought before could only be low-resolution,” says senior author William T. Freeman, an MIT professor of electrical engineering and computer science professor and CSAIL member.
Lead authors Fu and Hamilton are accompanied by MIT PhD students Laura Brandt SM ’21 and Axel Feldmann SM ’21, as well as Zhoutong Zhang SM ’21, PhD ’22, all current or former affiliates of MIT CSAIL. Their research is supported, in part, by a National Science Foundation Graduate Research Fellowship, by the National Science Foundation and Office of the Director of National Intelligence, by the U.S. Air Force Research Laboratory, and by the U.S. Air Force Artificial Intelligence Accelerator. The group will present their work in May at the International Conference on Learning Representations.
FeatUp is an algorithm that upgrades the resolution of deep networks for improved performance in computer vision tasks such as object recognition, scene parsing, and depth measurement.
Cancer Grand Challenges recently announced five winning teams for 2024, which included five researchers from MIT: Michael Birnbaum, Regina Barzilay, Brandon DeKosky, Seychelle Vos, and Ömer Yilmaz. Each team is made up of interdisciplinary cancer researchers from across the globe and will be awarded $25 million over five years.
Birnbaum, an associate professor in the Department of Biological Engineering, leads Team MATCHMAKERS and is joined by co-investigators Barzilay, the School of Engineering Distinguished Professor for AI and Health in the Department of Electrical Engineering and Computer Science and the AI faculty lead at the MIT Abdul Latif Jameel Clinic for Machine Learning in Health; and DeKosky, Phillip and Susan Ragon Career Development Professor of Chemical Engineering. All three are also affiliates of the Koch Institute for Integrative Cancer Research At MIT.
Team MATCHMAKERS will take advantage of recent advances in artificial intelligence to develop tools for personalized immunotherapies for cancer patients. Cancer immunotherapies, which recruit the patient’s own immune system against the disease, have transformed treatment for some cancers, but not for all types and not for all patients.
T cells are one target for immunotherapies because of their central role in the immune response. These immune cells use receptors on their surface to recognize protein fragments called antigens on cancer cells. Once T cells attach to cancer antigens, they mark them for destruction by the immune system. However, T cell receptors are exceptionally diverse within one person’s immune system and from person to person, making it difficult to predict how any one cancer patient will respond to an immunotherapy.
Team MATCHMAKERS will collect data on T cell receptors and the different antigens they target and build computer models to predict antigen recognition by different T cell receptors. The team’s overarching goal is to develop tools for predicting T cell recognition with simple clinical lab tests and designing antigen-specific immunotherapies. “If successful, what we learn on our team could help transform prediction of T cell receptor recognition from something that is only possible in a few sophisticated laboratories in the world, for a few people at a time, into a routine process,” says Birnbaum.
“The MATCHMAKERS project draws on MIT’s long tradition of developing cutting-edge artificial intelligence tools for the benefit of society,” comments Ryan Schoenfeld, CEO of The Mark Foundation for Cancer Research. “Their approach to optimizing immunotherapy for cancer and many other diseases is exemplary of the type of interdisciplinary research The Mark Foundation prioritizes supporting.” In addition to The Mark Foundation, the MATCHMAKERS team is funded by Cancer Research UK and the U.S. National Cancer Institute.
Vos, the Robert A. Swanson (1969) Career Development Professor of Life Sciences and HHMI Freeman Hrabowksi Scholar in the Department of Biology, will be a co-investigator on Team KOODAC. The KOODAC team will develop new treatments for solid tumors in children, using protein degradation strategies to target previously “undruggable” drivers of cancers. KOODAC is funded by Cancer Research UK, France's Institut National Du Cancer, and KiKa (Children Cancer Free Foundation) through Cancer Grand Challenges.
As a co-investigator on team PROSPECT, Yilmaz, who is also a Koch Institute affiliate, will help address early-onset colorectal cancers, an emerging global problem among individuals younger than 50 years. The team seeks to elucidate pathways, risk factors, and molecules involved in the disease’s development. Team PROSPECT is supported by Cancer Research UK, the U.S. National Cancer Institute, the Bowelbabe Fund for Cancer Research UK, and France's Institut National Du Cancer through Cancer Grand Challenges.
Clockwise from top left: Michael Birnbaum, Regina Barzilay, Brandon DeKosky, Seychelle Vos, and Ömer Yilmaz
When it comes to global climate change, livestock grazing can be either a blessing or a curse, according to a new study, which offers clues on how to tell the difference.
If managed properly, the study shows, grazing can actually increase the amount of carbon from the air that gets stored in the ground and sequestered for the long run. But if there is too much grazing, soil erosion can result, and the net effect is to cause more carbon losses, so that the land becomes a net carbon source, instead of a carbon sink. And the study found that the latter is far more common around the world today.
The new work, published today in the journal Nature Climate Change, provides ways to determine the tipping point between the two, for grazing lands in a given climate zone and soil type. It also provides an estimate of the total amount of carbon that has been lost over past decades due to livestock grazing, and how much could be removed from the atmosphere if grazing optimization management implemented. The study was carried out by Cesar Terrer, an assistant professor of civil and environmental engineering at MIT; Shuai Ren, a PhD student at the Chinese Academy of Sciences whose thesis is co-supervised by Terrer; and four others.
“This has been a matter of debate in the scientific literature for a long time,” Terrer says. “In general experiments, grazing decreases soil carbon stocks, but surprisingly, sometimes grazing increases soil carbon stocks, which is why it’s been puzzling.”
What happens, he explains, is that “grazing could stimulate vegetation growth through easing resource constraints such as light and nutrients, thereby increasing root carbon inputs to soils, where carbon can stay there for centuries or millennia.”
But that only works up to a certain point, the team found after a careful analysis of 1,473 soil carbon observations from different grazing studies from many locations around the world. “When you cross a threshold in grazing intensity, or the amount of animals grazing there, that is when you start to see sort of a tipping point — a strong decrease in the amount of carbon in the soil,” Terrer explains.
That loss is thought to be primarily from increased soil erosion on the denuded land. And with that erosion, Terrer says, “basically you lose a lot of the carbon that you have been locking in for centuries.”
The various studies the team compiled, although they differed somewhat, essentially used similar methodology, which is to fence off a portion of land so that livestock can’t access it, and then after some time take soil samples from within the enclosure area, and from comparable nearby areas that have been grazed, and compare the content of carbon compounds.
“Along with the data on soil carbon for the control and grazed plots,” he says, “we also collected a bunch of other information, such as the mean annual temperature of the site, mean annual precipitation, plant biomass, and properties of the soil, like pH and nitrogen content. And then, of course, we estimate the grazing intensity — aboveground biomass consumed, because that turns out to be the key parameter.”
With artificial intelligence models, the authors quantified the importance of each of these parameters, those drivers of intensity — temperature, precipitation, soil properties — in modulating the sign (positive or negative) and magnitude of the impact of grazing on soil carbon stocks. “Interestingly, we found soil carbon stocks increase and then decrease with grazing intensity, rather than the expected linear response,” says Ren.
Having developed the model through AI methods and validated it, including by comparing its predictions with those based on underlying physical principles, they can then apply the model to estimating both past and future effects. “In this case,” Terrer says, “we use the model to quantify the historical loses in soil carbon stocks from grazing. And we found that 46 petagrams [billion metric tons] of soil carbon, down to a depth of one meter, have been lost in the last few decades due to grazing.”
By way of comparison, the total amount of greenhouse gas emissions per year from all fossil fuels is about 10 petagrams, so the loss from grazing equals more than four years’ worth of all the world’s fossil emissions combined.
What they found was “an overall decline in soil carbon stocks, but with a lot of variability.” Terrer says. The analysis showed that the interplay between grazing intensity and environmental conditions such as temperature could explain the variability, with higher grazing intensity and hotter climates resulting in greater carbon loss. “This means that policy-makers should take into account local abiotic and biotic factors to manage rangelands efficiently,” Ren notes. “By ignoring such complex interactions, we found that using IPCC [Intergovernmental Panel on Climate Change] guidelines would underestimate grazing-induced soil carbon loss by a factor of three globally.”
Using an approach that incorporates local environmental conditions, the team produced global, high-resolution maps of optimal grazing intensity and the threshold of intensity at which carbon starts to decrease very rapidly. These maps are expected to serve as important benchmarks for evaluating existing grazing practices and provide guidance to local farmers on how to effectively manage their grazing lands.
Then, using that map, the team estimated how much carbon could be captured if all grazing lands were limited to their optimum grazing intensity. Currently, the authors found, about 20 percent of all pasturelands have crossed the thresholds, leading to severe carbon losses. However, they found that under the optimal levels, global grazing lands would sequester 63 petagrams of carbon. “It is amazing,” Ren says. “This value is roughly equivalent to a 30-year carbon accumulation from global natural forest regrowth.”
That would be no simple task, of course. To achieve optimal levels, the team found that approximately 75 percent of all grazing areas need to reduce grazing intensity. Overall, if the world seriously reduces the amount of grazing, “you have to reduce the amount of meat that’s available for people,” Terrer says.
“Another option is to move cattle around,” he says, “from areas that are more severely affected by grazing intensity, to areas that are less affected. Those rotations have been suggested as an opportunity to avoid the more drastic declines in carbon stocks without necessarily reducing the availability of meat.”
This study didn’t delve into these social and economic implications, Terrer says. “Our role is to just point out what would be the opportunity here. It shows that shifts in diets can be a powerful way to mitigate climate change.”
“This is a rigorous and careful analysis that provides our best look to date at soil carbon changes due to livestock grazing practiced worldwide,” say Ben Bond-Lamberty, a terrestrial ecosystem research scientist at Pacific Northwest National Laboratory, who was not associated with this work. “The authors’ analysis gives us a unique estimate of soil carbon losses due to grazing and, intriguingly, where and how the process might be reversed.”
He adds: “One intriguing aspect to this work is the discrepancies between its results and the guidelines currently used by the IPCC — guidelines that affect countries’ commitments, carbon-market pricing, and policies.” However, he says, “As the authors note, the amount of carbon historically grazed soils might be able to take up is small relative to ongoing human emissions. But every little bit helps!”
“Improved management of working lands can be a powerful tool to combat climate change,” says Jonathan Sanderman, carbon program director of the Woodwell Climate Research Center in Falmouth, Massachusetts, who was not associated with this work. He adds, “This work demonstrates that while, historically, grazing has been a large contributor to climate change, there is significant potential to decrease the climate impact of livestock by optimizing grazing intensity to rebuild lost soil carbon.”
Terrer states that for now, “we have started a new study, to evaluate the consequences of shifts in diets for carbon stocks. I think that’s the million-dollar question: How much carbon could you sequester, compared to business as usual, if diets shift to more vegan or vegetarian?” The answers will not be simple, because a shift to more vegetable-based diets would require more cropland, which can also have different environmental impacts. Pastures take more land than crops, but produce different kinds of emissions. “What’s the overall impact for climate change? That is the question we’re interested in,” he says.
The research team included Juan Li, Yingfao Cao, Sheshan Yang, and Dan Liu, all with the Chinese Academy of Sciences. The work was supported by the MIT Climate and Sustainability Consortium, the Second Tibetan Plateau Scientific Expedition and Research Program, and the Science and Technology Major Project of Tibetan Autonomous Region of China.
Cattle grazing can either be a source of greenhouse gas emissions or a sink for these emissions, depending on the intensity of grazing, according to a new study by scientists at MIT and in China.
If a robot traveling to a destination has just two possible paths, it needs only to compare the routes’ travel time and probability of success. But if the robot is traversing a complex environment with many possible paths, choosing the best route amid so much uncertainty can quickly become an intractable problem.
MIT researchers developed a method that could help this robot efficiently reason about the best routes to its destination. They created an algorithm for constructing roadmaps of an uncertain environment that balances the tradeoff between roadmap quality and computational efficiency, enabling the robot to quickly find a traversable route that minimizes travel time.
The algorithm starts with paths that are certain to be safe and automatically finds shortcuts the robot could take to reduce the overall travel time. In simulated experiments, the researchers found that their algorithm can achieve a better balance between planning performance and efficiency in comparison to other baselines, which prioritize one or the other.
This algorithm could have applications in areas like exploration, perhaps by helping a robot plan the best way to travel to the edge of a distant crater across the uneven surface of Mars. It could also aid a search-and-rescue drone in finding the quickest route to someone stranded on a remote mountainside.
“It is unrealistic, especially in very large outdoor environments, that you would know exactly where you can and can’t traverse. But if we have just a little bit of information about our environment, we can use that to build a high-quality roadmap,” says Yasmin Veys, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this technique.
Veys wrote the paper with Martina Stadler Kurtz, a graduate student in the MIT Department of Aeronautics and Astronautics, and senior author Nicholas Roy, an MIT professor of aeronautics and astronautics and a member of the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). The research will be presented at the International Conference on Robotics and Automation.
Generating graphs
To study motion planning, researchers often think about a robot’s environment like a graph, where a series of “edges,” or line segments, represent possible paths between a starting point and a goal.
Veys and her collaborators used a graph representation called the Canadian Traveler’s Problem (CTP), which draws its name from frustrated Canadian motorists who must turn back and find a new route when the road ahead is blocked by snow.
In a CTP, each edge of the graph has a weight associated with it, which represents how long that path will take to traverse, and a probability of how likely it is to be traversable. The goal in a CTP is to minimize travel time to the destination.
The researchers focused on how to automatically generate a CTP graph that effectively represents an uncertain environment.
“If we are navigating in an environment, it is possible that we have some information, so we are not just going in blind. While it isn’t a detailed navigation plan, it gives us a sense of what we are working with. The crux of this work is trying to capture that within the CTP graph,” adds Kurtz.
Their algorithm assumes this partial information — perhaps a satellite image — can be divided into specific areas (a lake might be one area, an open field another, etc.)
Each area has a probability that the robot can travel across it. For instance, it is more likely a nonaquatic robot can drive across a field than through a lake, so the probability for a field would be higher.
The algorithm uses this information to build an initial graph through open space, mapping out a conservative path that is slow but definitely traversable. Then it uses a metric the team developed to determine which edges, or shortcut paths through uncertain regions, should be added to the graph to cut down on the overall travel time.
Selecting shortcuts
By only selecting shortcuts that are likely to be traversable, the algorithm keeps the planning process from becoming needlessly complicated.
“The quality of the motion plan is dependent on the quality of graph. If that graph doesn’t have good paths in it, then the algorithm can’t give you a good plan,” Veys explains.
After testing the algorithm in more than 100 simulated experiments with increasingly complex environments, the researchers found that it could consistently outperform baseline methods that don’t consider probabilities. They also tested it using an aerial campus map of MIT to show that it could be effective in real-world, urban environments.
In the future, they want to enhance the algorithm so it can work in more than two dimensions, which could enable its use for complicated robotic manipulation problems. They are also interested in studying the mismatch between CTP graphs and the real-world environments those graphs represent.
“Robots that operate in the real world are plagued by uncertainty, whether in the available sensor data, prior knowledge about the environment, or about how other agents will behave. Unfortunately, dealing with these uncertainties incurs a high computational cost,” says Seth Hutchinson, professor and KUKA Chair for Robotics in the School of Interactive Computing at Georgia Tech, who was not involved with this research. “This work addresses these issues by proposing a clever approximation scheme that can be used to efficiently compute uncertainty-tolerant plans.”
This research was funded, in part, by the U.S. Army Research Labs under the Distributed Collaborative Intelligent Systems and Technologies Collaborative Research Alliance and by the Joseph T. Corso and Lily Corso Graduate Fellowship.
MIT researchers developed an algorithm that can automatically select the best shortcuts for a robot to take on its way to a destination that will reduce the overall travel time while limiting the likelihood that the robot will meet an impassable obstacle.
Many employees believe their counterparts at other firms make less in salary than is actually the case — an assumption that costs them money, according to a study co-authored by MIT scholars.
“Workers wrongly anchor their beliefs about outside options on their current wage,” says MIT economist Simon Jäger, co-author of a newly published paper detailing the study’s results.
As a top-line figure, the study indicates that workers who would experience a 10 percent wage increase by switching firms only expect a 1 percent wage increase instead, leading them to earn less than they otherwise might.
That is one of multiple related findings in the study, which also shows that workers in lower-paying firms are highly susceptible to underestimating wages at other companies; and that giving workers correct information about the salary structure in their industry makes them more likely to declare that they intend to leave their current jobs.
The study also has implications for further economics research, since economists’ job-search models generally assume workers have accurate salary information about their industries. The study was performed using data from Germany, although it quite likely applies to other countries as well.
“Misperceptions about outside options have substantial consequences on wages,” says Nina Roussille, an economist at MIT and also a co-author of the paper. “The intuition is simple: If low-wage workers do not know that they could make more elsewhere, then these workers stay put in low-wage firms. In turn, these low-wage firms do not feel the competitive pressure from the external labor market to raise their wages.”
The paper, “Worker Beliefs about Outside Options,” appears in advance online form in the Quarterly Journal of Economics. The authors are Jäger, the Silverman Family Career Development Associate Professor in MIT’s Department of Economics; Christopher Roth, a professor of economics at the University of Cologne; Roussille, an assistant professor in MIT’s Department of Economics; and Benjamin Schoefer, an associate professor of economics at the University of California at Berkeley.
Updating beliefs
To conduct the study, the researchers incorporated a survey module into the Innovation Sample of the German Socio-Economic Panel, an annual survey of a representative sample of the German population. They used their survey questions to find out the nature of worker beliefs about outside employment opportunities. The scholars then linked these findings to actual job and salary data collected from the German government’s Institute for Employment Research (IAB), with the prior consent of 558 survey respondents.
Linking those two data sources allowed the scholars to quantify the mismatch between what workers believe about industry-wide salaries, and what wages are in reality. One good piece of evidence on the compression of those beliefs is that about 56 percent of respondents believe they have a salary in between the 40th and 60th percentiles among comparable workers.
The scholars then added another element to the research project. They conducted an online experiment with 2,448 participants, giving these workers correct information about salaries at other companies, and then measuring the employees’ intention to find other job opportunities, among other things.
By adding this layer to the study, the scholars found that a 10 percentage point increase in the belief about salaries at other firms leads to a 2.6 percentage point increase in a worker intending to leave their present firm.
“This updating of beliefs causes workers to adjust their job search and wage negotiation intentions,” Roussille observes.
While the exact circumstances in every job market may vary somewhat, the researchers think the basic research findings from Germany could well apply in many other places.
“We are confident the results are representative of the German labor market,” Jäger says. “Of course, the German labor market may differ from, say, the U.S. labor market. Our intuition, though, is that, if anything, misperceptions would be even more consequential in a country like the U.S. where wages are more unequal than in Europe.”
Moreover, he adds, the recent dynamics of the U.S. job market during the Covid-19 pandemic, when many workers searched for new work and ended up in higher-paying jobs, is “consistent with the idea that workers had been stuck in low-paying jobs for a long time without realizing that there may have been better opportunities elsewhere.”
Data informing theory
The findings of Jäger, Roth, Roussille, Schoefer stand in contrast to established economic theory in this area, which has often worked from the expectation that employees have an accurate perception of industry wages and make decisions on that basis.
Roussille says the feedback the scholars have received from economics colleagues has been favorable, since other economists perceive “an opportunity to better tailor our models to reality,” as she puts it. “This follows a broader trend in economics in the past 20 to 30 years: The combination of better data collection and access with greater computing power has allowed the field to challenge longstanding but untested assumptions, learn from new empirical evidence, and build more realistic models.”
The findings have also encouraged the scholars to explore the topic further, especially by examining what the state of industry-wide wage knowledge is among employers.
“One natural follow-up to this project would be to better understand the firm side,” Jäger says. “Are firms aware of these misperceptions? Do they also hold inaccurate beliefs about the wages at their competitors?”
To this end, the researchers have already conducted a survey of managers on this topic, and intend to pursue further related work.
Support for the research was provided, in part, by the Sloan Foundation’s Working Longer Program; the Stiftung Grundeinkommen (Basic Income Foundation); and the Deutsche Forschungsgemeinschaft (German Research Foundation) under Germany’s Excellence Strategy.
The study indicates that workers who would experience a 10 percent wage increase by switching firms only expect a 1 percent wage increase instead, leading them to earn less than they otherwise might.
More than 20 million Americans undergo colonoscopy screenings every year, and in many of those cases, doctors end up removing polyps that are 2 cm or larger and require additional care. This procedure has greatly reduced the overall incidence of colon cancer, but not without complications, as patients may experience gastrointestinal bleeding both during and after the procedure.
In hopes of preventing those complications from occurring, researchers at MIT have developed a new gel, GastroShield, that can be sprayed onto the surgical sites through an endoscope. This gel forms a tough but flexible protective layer that serves as a shield for the damaged area. The material prevents delayed bleeding and reinforces the mechanical integrity of the tissue.
“Our tissue-responsive adhesive technology is engineered to interact with the tissue via complimentary covalent and ionic interactions as well as physical interactions to provide prolonged lesion protection over days to prevent complications following polyp removal, and other wounds at risk of bleeding across the gastrointestinal tract,” says Natalie Artzi, a principal research scientist in MIT’s Institute for Medical Engineering and Science, an associate professor of medicine at Harvard Medical School, and the senior author of the paper.
In an animal study, the researchers showed that the GastroShield application integrates seamlessly with current endoscopic procedures, and provides wound protection for three to seven days where it helps tissue to heal following surgery. Artzi and other members of the research team have started a company called BioDevek that now plans to further develop the material for use in humans.
Gonzalo Muñoz Taboada, CEO of BioDevek, and Daniel Dahis, lead scientist at BioDevek, are the lead authors of the study, which appears in the journal Advanced Materials. Elazer Edelman, the Edward J. Poitras Professor in Medical Engineering and Science at MIT and the director of IMES, and Pere Dosta, a former postdoc in Artzi’s lab, are also authors of the paper.
Adhesive gels
Routine colon cancer screenings often reveal small precancerous polyps, which can be removed before they become cancerous. This is usually done using an endoscope. If any bleeding occurs during the polyp removal, doctors can cauterize the wound to seal it, but this method creates a scar that may delay the healing, and result in additional complications.
Additionally, in some patients, bleeding doesn’t occur until a few days after the procedure. This can be dangerous and may require patients to return to the hospital for additional treatment. Other patients may develop small tears that lead the intestinal contents to leak into the abdomen, which can lead to severe infection and requires emergency care.
When tissue reinforcement is required, doctors often insert metal clips to hold tissue together, but these can’t be used with larger polyps and aren’t always effective. Efforts to develop a gel that could seal the surgical wounds have not been successful, mainly because the materials could not adhere to the surgical site for more than 24 hours.
The MIT team tested dozens of combinations of materials that they thought could have the right properties for this use. They wanted to find formulations that would display a low enough viscosity to be easily delivered and sprayed through a nozzle at the end of a catheter that fits inside commercial endoscopes. Simultaneously, upon tissue contact, this formulation should instantly form a tough gel that adheres strongly to the tissue. They also wanted the gel to be flexible enough that it could withstand the forces generated by the peristaltic movements of the digestive tract and the food flowing by.
The researchers came up with a winning combination that includes a polymer called pluronic, which is a type of block copolymer that can self-assemble into spheres called micelles. The ends of these polymers contain multiple amine groups, which end up on the surface of the micelles. The second component of the gel is oxidized dextran, a polysaccharide that can form strong but reversible bonds with the amine groups of the pluronic micelles.
When sprayed, these materials instantly react with each other and with the lining of the gastrointestinal tract, forming a solid gel in less than five seconds. The micelles that make up the gel are “self-healing” and can absorb forces that they encounter from peristaltic movements and food moving along the digestive tract, by temporarily breaking apart and then re-assembling.
“To obtain a material that adheres to the design criteria and can be delivered through existing colonoscopes, we screened through libraries of materials to understand how different parameters affect gelation, adhesion, retention, and compatibility,” Artzi says.
A protective layer
The gel can also withstand the low pH and enzymatic activity in the digestive tract, and protect tissue from that harsh environment while it heals itself, underscoring its potential for use in other gastrointestinal wounds at high risk of bleeding, such as stomach ulcers, which affect more than 4 million Americans every year.
In tests in animals, the researchers found that every animal treated with the new gel showed rapid sealing, and there were no perforations, leakages, or bleeding in the week following the treatment. The material lasted for about five days, after which it was sloughed off along with the top layer of tissue as the surgical wounds healed.
The researchers also performed several biocompatibility studies and found that the gel did not cause any adverse effects.
“A key feature of this new technology is our aim to make it translational. GastroShield was designed to be stored in liquid form in a ready-to-use kit. Additionally, it doesn’t require any activation, light, or trigger solution to form the gel, aiming to make endoscopic use easy and fast,” says Muñoz, who is currently leading the translational effort for GastroShield.
BioDevek is now working on further developing the material for possible use in patients. In addition to its potential use in colonoscopies, this gel could also be useful for treating stomach ulcers and inflammatory conditions such as Crohn’s disease, or for delivering cancer drugs, Artzi says.
The research was funded, in part, by the National Science Foundation.
Researchers at MIT have developed a new gel, GastroShield, that can be sprayed onto the surgical sites via catheter, through an endoscope, pictured. This gel forms a tough but flexible protective layer that controls and prevents delayed bleeding and mechanically reinforces the tissue, sealing up perforations that might appear after the polyp is removed and enabling wound healing to occur.
Tumors can carry mutations in hundreds of different genes, and each of those genes may be mutated in different ways — some mutations simply replace one DNA nucleotide with another, while others insert or delete larger sections of DNA.
Until now, there has been no way to quickly and easily screen each of those mutations in their natural setting to see what role they may play in the development, progression, and treatment response of a tumor. Using a variant of CRISPR genome-editing known as prime editing, MIT researchers have now come up with a way to screen those mutations much more easily.
The researchers demonstrated their technique by screening cells with more than 1,000 different mutations of the tumor suppressor gene p53, all of which have been seen in cancer patients. This method, which is easier and faster than any existing approach, and edits the genome rather than introducing an artificial version of the mutant gene, revealed that some p53 mutations are more harmful than previously thought.
This technique could also be applied to many other cancer genes, the researchers say, and could eventually be used for precision medicine, to determine how an individual patient’s tumor will respond to a particular treatment.
“In one experiment, you can generate thousands of genotypes that are seen in cancer patients, and immediately test whether one or more of those genotypes are sensitive or resistant to any type of therapy that you’re interested in using,” says Francisco Sanchez-Rivera, an MIT assistant professor of biology, a member of the Koch Institute for Integrative Cancer Research, and the senior author of the study.
MIT graduate student Samuel Gould is the lead author of the paper, which appears today in Nature Biotechnology.
Editing cells
The new technique builds on research that Sanchez-Rivera began 10 years ago as an MIT graduate student. At that time, working with Tyler Jacks, the David H. Koch Professor of Biology, and then-postdoc Thales Papagiannakopoulos, Sanchez-Rivera developed a way to use CRISPR genome-editing to introduce into mice genetic mutations linked to lung cancer.
In that study, the researchers showed that they could delete genes that are often lost in lung tumor cells, and the resulting tumors were similar to naturally arising tumors with those mutations. However, this technique did not allow for the creation of point mutations (substitutions of one nucleotide for another) or insertions.
“While some cancer patients have deletions in certain genes, the vast majority of mutations that cancer patients have in their tumors also include point mutations or small insertions,” Sanchez-Rivera says.
Since then, David Liu, a professor in the Harvard University Department of Chemistry and Chemical Biology and a core institute member of the Broad Institute, has developed new CRISPR-based genome editing technologies that can generate additional types of mutations more easily. With base editing, developed in 2016, researchers can engineer point mutations, but not all possible point mutations. In 2019, Liu, who is also an author of the Nature Biotechnology study, developed a technique called prime editing, which enables any kind of point mutation to be introduced, as well as insertions and deletions.
“Prime editing in theory solves one of the major challenges with earlier forms of CRISPR-based editing, which is that it allows you to engineer virtually any type of mutation,” Sanchez-Rivera says.
When they began working on this project, Sanchez-Rivera and Gould calculated that if performed successfully, prime editing could be used to generate more than 99 percent of all small mutations seen in cancer patients.
However, to achieve that, they needed to find a way to optimize the editing efficiency of the CRISPR-based system. The prime editing guide RNAs (pegRNAs) used to direct CRISPR enzymes to cut the genome in certain spots have varying levels of efficiency, which leads to “noise” in the data from pegRNAs that simply aren’t generating the correct target mutation. The MIT team devised a way to reduce that noise by using synthetic target sites to help them calculate how efficiently each guide RNA that they tested was working.
“We can design multiple prime-editing guide RNAs with different design properties, and then we get an empirical measurement of how efficient each of those pegRNAs is. It tells us what percentage of the time each pegRNA is actually introducing the correct edit,” Gould says.
Analyzing mutations
The researchers demonstrated their technique using p53, a gene that is mutated in more than half of all cancer patients. From a dataset that includes sequencing information from more than 40,000 patients, the researchers identified more than 1,000 different mutations that can occur in p53.
“We wanted to focus on p53 because it’s the most commonly mutated gene in human cancers, but only the most frequent variants in p53 have really been deeply studied. There are many variants in p53 that remain understudied,” Gould says.
Using their new method, the researchers introduced p53 mutations in human lung adenocarcinoma cells, then measured the survival rates of these cells, allowing them to determine each mutation’s effect on cell fitness.
Among their findings, they showed that some p53 mutations promoted cell growth more than had been previously thought. These mutations, which prevent the p53 protein from forming a tetramer — an assembly of four p53 proteins — had been studied before, using a technique that involves inserting artificial copies of a mutated p53 gene into a cell.
Those studies found that these mutations did not confer any survival advantage to cancer cells. However, when the MIT team introduced those same mutations using the new prime editing technique, they found that the mutation prevented the tetramer from forming, allowing the cells to survive. Based on the studies done using overexpression of artificial p53 DNA, those mutations would have been classified as benign, while the new work shows that under more natural circumstances, they are not.
“This is a case where you could only observe these variant-induced phenotypes if you're engineering the variants in their natural context and not with these more artificial systems,” Gould says. “This is just one example, but it speaks to a broader principle that we’re going to be able to access novel biology using these new genome-editing technologies.”
Because it is difficult to reactivate tumor suppressor genes, there are few drugs that target p53, but the researchers now plan to investigate mutations found in other cancer-linked genes, in hopes of discovering potential cancer therapies that could target those mutations. They also hope that the technique could one day enable personalized approaches to treating tumors.
“With the advent of sequencing technologies in the clinic, we'll be able to use this genetic information to tailor therapies for patients suffering from tumors that have a defined genetic makeup,” Sanchez-Rivera says. “This approach based on prime editing has the potential to change everything.”
The research was funded, in part, by the National Institute of General Medical Sciences, an MIT School of Science Fellowship in Cancer Research, a Howard Hughes Medical Institute Hanna Gray Fellowship, the V Foundation for Cancer Research, a National Cancer Institute Cancer Center Support Grant, the Ludwig Center at MIT, the Koch Institute Frontier Research Program via the Casey and Family Foundation Cancer Research Fund, Upstage Lung Cancer, and the Michael (1957) and Inara Erdei Cancer Research Fund, and the MIT Research Support Committee.
Using a variant of CRISPR genome-editing known as prime editing, MIT researchers have developed a method to screen cancer-associated genetic mutations much more easily and quickly than any existing approach. This illustration, by Samuel Gould’s brother Owen Gould, is an artistic interpretation of the research and the idea of “rewriting the genome,” explains Samuel.
Farming can be a low-margin, high-risk business, subject to weather and climate patterns, insect population cycles, and other unpredictable factors. Farmers need to be savvy managers of the many resources they deal, and chemical fertilizers and pesticides are among their major recurring expenses.
Despite the importance of these chemicals, a lack of technology that monitors and optimizes sprays has forced farmers to rely on personal experience and rules of thumb to decide how to apply these chemicals. As a result, these chemicals tend to be over-sprayed, leading to their runoff into waterways and buildup up in the soil.
That could change, thanks to a new approach of feedback-optimized spraying, invented by AgZen, an MIT spinout founded in 2020 by Professor Kripa Varanasi and Vishnu Jayaprakash SM ’19, PhD ’22.
Over the past decade, AgZen’s founders have developed products and technologies to control the interactions of droplets and sprays with plant surfaces. The Boston-based venture-backed company launched a new commercial product in 2024 and is currently piloting another related product. Field tests of both have shown the products can help farmers spray more efficiently and effectively, using fewer chemicals overall.
“Worldwide, farms spend approximately $60 billion a year on pesticides. Our objective is to reduce the number of pesticides sprayed and lighten the financial burden on farms without sacrificing effective pest management,” Varanasi says.
Getting droplets to stick
While the world pesticide market is growing rapidly, a lot of the pesticides sprayed don’t reach their target. A significant portion bounces off the plant surfaces, lands on the ground, and becomes part of the runoff that flows to streams and rivers, often causing serious pollution. Some of these pesticides can be carried away by wind over very long distances.
“Drift, runoff, and poor application efficiency are well-known, longstanding problems in agriculture, but we can fix this by controlling and monitoring how sprayed droplets interact with leaves,” Varanasi says.
With support from MIT Tata Center and the Abdul Latif Jameel Water and Food Systems Lab, Varanasi and his team analyzed how droplets strike plant surfaces, and explored ways to increase application efficiency. This research led them to develop a novel system of nozzles that cloak droplets with compounds that enhance the retention of droplets on the leaves, a product they call EnhanceCoverage.
Field studies across regions — from Massachusetts to California to Italy and France —showed that this droplet-optimization system could allow farmers to cut the amount of chemicals needed by more than half because more of the sprayed substances would stick to the leaves.
Measuring coverage
However, in trying to bring this technology to market, the researchers faced a sticky problem: Nobody knew how well pesticide sprays were adhering to the plants in the first place, so how could AgZen say that the coverage was better with its new EnhanceCoverage system?
“I had grown up spraying with a backpack on a small farm in India, so I knew this was an issue,” Jayaprakash says. “When we spoke to growers, they told me how complicated spraying is when you’re on a large machine. Whenever you spray, there are so many things that can influence how effective your spray is. How fast do you drive the sprayer? What flow rate are you using for the chemicals? What chemical are you using? What’s the age of the plants, what’s the nozzle you’re using, what is the weather at the time? All these things influence agrochemical efficiency.”
Agricultural spraying essentially comes down to dissolving a chemical in water and then spraying droplets onto the plants. “But the interaction between a droplet and the leaf is complex,” Varanasi says. “We were coming in with ways to optimize that, but what the growers told us is, hey, we’ve never even really looked at that in the first place.”
Although farmers have been spraying agricultural chemicals on a large scale for about 80 years, they’ve “been forced to rely on general rules of thumb and pick all these interlinked parameters, based on what’s worked for them in the past. You pick a set of these parameters, you go spray, and you’re basically praying for outcomes in terms of how effective your pest control is,” Varanasi says.
Before AgZen could sell farmers on the new system to improve droplet coverage, the company had to invent a way to measure precisely how much spray was adhering to plants in real-time.
Comparing before and after
The system they came up with, which they tested extensively on farms across the country last year, involves a unit that can be bolted onto the spraying arm of virtually any sprayer. It carries two sensor stacks, one just ahead of the sprayer nozzles and one behind. Then, built-in software running on a tablet shows the operator exactly how much of each leaf has been covered by the spray. It also computes how much those droplets will spread out or evaporate, leading to a precise estimate of the final coverage.
“There’s a lot of physics that governs how droplets spread and evaporate, and this has been incorporated into software that a farmer can use,” Varanasi says. “We bring a lot of our expertise into understanding droplets on leaves. All these factors, like how temperature and humidity influence coverage, have always been nebulous in the spraying world. But now you have something that can be exact in determining how well your sprays are doing.”
“We’re not only measuring coverage, but then we recommend how to act,” says Jayaprakash, who is AgZen’s CEO. “With the information we collect in real-time and by using AI, RealCoverage tells operators how to optimize everything on their sprayer, from which nozzle to use, to how fast to drive, to how many gallons of spray is best for a particular chemical mix on a particular acre of a crop.”
The tool was developed to prove how much AgZen’s EnhanceCoverage nozzle system (which will be launched in 2025) improves coverage. But it turns out that monitoring and optimizing droplet coverage on leaves in real-time with this system can itself yield major improvements.
“We worked with large commercial farms last year in specialty and row crops,” Jayaprakash says. “When we saved our pilot customers up to 50 percent of their chemical cost at a large scale, they were very surprised.” He says the tool has reduced chemical costs and volume in fallow field burndowns, weed control in soybeans, defoliation in cotton, and fungicide and insecticide sprays in vegetables and fruits. Along with data from commercial farms, field trials conducted by three leading agricultural universities have also validated these results.
“Across the board, we were able to save between 30 and 50 percent on chemical costs and increase crop yields by enabling better pest control,” Jayaprakash says. “By focusing on the droplet-leaf interface, our product can help any foliage spray throughout the year, whereas most technological advancements in this space recently have been focused on reducing herbicide use alone.” The company now intends to lease the system across thousands of acres this year.
And these efficiency gains can lead to significant returns at scale, he emphasizes: In the U.S., farmers currently spend $16 billion a year on chemicals, to protect about $200 billion of crop yields.
The company launched its first product, the coverage optimization system called RealCoverage, this year, reaching a wide variety of farms with different crops and in different climates. “We’re going from proof-of-concept with pilots in large farms to a truly massive scale on a commercial basis with our lease-to-own program,” Jayaprakash says.
“We’ve also been tapped by the USDA to help them evaluate practices to minimize pesticides in watersheds,” Varanasi says, noting that RealCoverage can also be useful for regulators, chemical companies, and agricultural equipment manufacturers.
Once AgZen has proven the effectiveness of using coverage as a decision metric, and after the RealCoverage optimization system is widely in practice, the company will next roll out its second product, EnhanceCoverage, designed to maximize droplet adhesion. Because that system will require replacing all the nozzles on a sprayer, the researchers are doing pilots this year but will wait for a full rollout in 2025, after farmers have gained experience and confidence with their initial product.
“There is so much wastage,” Varanasi says. “Yet farmers must spray to protect crops, and there is a lot of environmental impact from this. So, after all this work over the years, learning about how droplets stick to surfaces and so on, now the culmination of it in all these products for me is amazing, to see all this come alive, to see that we’ll finally be able to solve the problem we set out to solve and help farmers.”
AgZen has developed a system for farming that can monitor exactly how much of the sprayed chemicals adheres to plants, in real time, as the sprayer drives through a field.
Cells rely on complex molecular machines composed of protein assemblies to perform essential functions such as energy production, gene expression, and protein synthesis. To better understand how these machines work, scientists capture snapshots of them by isolating proteins from cells and using various methods to determine their structures. However, isolating proteins from cells also removes them from the context of their native environment, including protein interaction partners and cellular location.
Recently, cryogenic electron tomography (cryo-ET) has emerged as a way to observe proteins in their native environment by imaging frozen cells at different angles to obtain three-dimensional structural information. This approach is exciting because it allows researchers to directly observe how and where proteins associate with each other, revealing the cellular neighborhood of those interactions within the cell.
With the technology available to image proteins in their native environment, MIT graduate student Barrett Powell wondered if he could take it one step further: What if molecular machines could be observed in action? In a paper published March 8 in Nature Methods, Powell describes the method he developed, called tomoDRGN, for modeling structural differences of proteins in cryo-ET data that arise from protein motions or proteins binding to different interaction partners. These variations are known as structural heterogeneity.
Although Powell had joined the lab of MIT associate professor of biology Joey Davis as an experimental scientist, he recognized the potential impact of computational approaches in understanding structural heterogeneity within a cell. Previously, the Davis Lab developed a related methodology named cryoDRGN to understand structural heterogeneity in purified samples. As Powell and Davis saw cryo-ET rising in prominence in the field, Powell took on the challenge of re-imagining this framework to work in cells.
When solving structures with purified samples, each particle is imaged only once. By contrast, cryo-ET data is collected by imaging each particle more than 40 times from different angles. That meant tomoDRGN needed to be able to merge the information from more than 40 images, which was where the project hit a roadblock: the amount of data led to an information overload.
To address this, Powell successfully rebuilt the cryoDRGN model to prioritize only the highest-quality data. When imaging the same particle multiple times, radiation damage occurs. The images acquired earlier, therefore, tend to be of higher quality because the particles are less damaged.
“By excluding some of the lower-quality data, the results were actually better than using all of the data — and the computational performance was substantially faster,” Powell says.
Just as Powell was beginning work on testing his model, he had a stroke of luck: The authors of a groundbreaking new study that visualized, for the first time, ribosomes inside cells at near-atomic resolution, shared their raw data on the Electric Microscopy Public Image Archive (EMPIAR). This dataset was an exemplary test case for Powell, through which he demonstrated that tomoDRGN could uncover structural heterogeneity within cryo-ET data.
According to Powell, one exciting result is what tomoDRGN found surrounding a subset of ribosomes in the EMPIAR dataset. Some of the ribosomal particles were associated with a bacterial cell membrane and engaged in a process called cotranslational translocation. This occurs when a protein is being simultaneously synthesized and transported across a membrane. Researchers can use this result to make new hypotheses about how the ribosome functions with other protein machinery integral to transporting proteins outside of the cell, now guided by a structure of the complex in its native environment.
After seeing that tomoDRGN could resolve structural heterogeneity from a structurally diverse dataset, Powell was curious: How small of a population could tomoDRGN identify? For that test, he chose a protein named apoferritin, which is a commonly used benchmark for cryo-ET and is often treated as structurally homogeneous. Ferritin is a protein used for iron storage and is referred to as apoferritin when it lacks iron.
Surprisingly, in addition to the expected particles, tomoDRGN revealed a minor population of ferritin particles — with iron bound — making up just 2 percent of the dataset, that was not previously reported. This result further demonstrated tomoDRGN's ability to identify structural states that occur so infrequently that they would be averaged out of a 3D reconstruction.
Powell and other members of the Davis Lab are excited to see how tomoDRGN can be applied to further ribosomal studies and to other systems. Davis works on understanding how cells assemble, regulate, and degrade molecular machines, so the next steps include exploring ribosome biogenesis within cells in greater detail using this new tool.
“What are the possible states that we may be losing during purification?” Davis asks. “Perhaps more excitingly, we can look at how they localize within the cell and what partners and protein complexes they may be interacting with.”
Cryogenic electron tomography (cryo-ET) is a way to observe proteins in their native environment by imaging frozen cells at different angles to obtain 3D structural information. This illustration shows how an additional tool, developed at MIT, generates images of ribosome structures, revealing ribosome-ribosome and ribosome-membrane interactions from cryo-ET data.
To help curb climate change, theUnited States is working to reduce carbon emissions from all sectors of the energy economy. Much of the current effort involves electrification — switching to electric cars for transportation, electric heat pumps for home heating, and so on. But in the United States, the electric power sector already generates about a quarter of all carbon emissions. “Unless we decarbonize our electric power grids, we’ll just be shifting carbon emissions from one source to another,” says Amanda Farnsworth, a PhD candidate in chemical engineering and research assistant at the MIT Energy Initiative (MITEI).
But decarbonizing the nation’s electric power grids will be challenging. The availability of renewable energy resources such as solar and wind varies in different regions of the country. Likewise, patterns of energy demand differ from region to region. As a result, the least-cost pathway to a decarbonized grid will differ from one region to another.
Over the past two years, Farnsworth and Emre Gençer, a principal research scientist at MITEI, developed a power system model that would allow them to investigate the importance of regional differences — and would enable experts and laypeople alike to explore their own regions and make informed decisions about the best way to decarbonize. “With this modeling capability you can really understand regional resources and patterns of demand, and use them to do a ‘bespoke’ analysis of the least-cost approach to decarbonizing the grid in your particular region,” says Gençer.
To demonstrate the model’s capabilities, Gençer and Farnsworth performed a series of case studies. Their analyses confirmed that strategies must be designed for specific regions and that all the costs and carbon emissions associated with manufacturing and installing solar and wind generators must be included for accurate accounting. But the analyses also yielded some unexpected insights, including a correlation between a region’s wind energy and the ease of decarbonizing, and the important role of nuclear power in decarbonizing the California grid.
A novel model
For many decades, researchers have been developing “capacity expansion models” to help electric utility planners tackle the problem of designing power grids that are efficient, reliable, and low-cost. More recently, many of those models also factor in the goal of reducing or eliminating carbon emissions. While those models can provide interesting insights relating to decarbonization, Gençer and Farnsworth believe they leave some gaps that need to be addressed.
For example, most focus on conditions and needs in a single U.S. region without highlighting the unique peculiarities of their chosen area of focus. Hardly any consider the carbon emitted in fabricating and installing such “zero-carbon” technologies as wind turbines and solar panels. And finally, most of the models are challenging to use. Even experts in the field must search out and assemble various complex datasets in order to perform a study of interest.
Gençer and Farnsworth’s capacity expansion model — called Ideal Grid, or IG — addresses those and other shortcomings. IG is built within the framework of MITEI’s Sustainable Energy System Analysis Modeling Environment (SESAME), an energy system modeling platform that Gençer and his colleagues at MITEI have been developing since 2017. SESAME models the levels of greenhouse gas emissions from multiple, interacting energy sectors in future scenarios.
Importantly, SESAME includes both techno-economic analyses and life-cycle assessments of various electricity generation and storage technologies. It thus considers costs and emissions incurred at each stage of the life cycle (manufacture, installation, operation, and retirement) for all generators. Most capacity expansion models only account for emissions from operation of fossil fuel-powered generators. As Farnsworth notes, “While this is a good approximation for our current grid, emissions from the full life cycle of all generating technologies become non-negligible as we transition to a highly renewable grid.”
Through its connection with SESAME, the IG model has access to data on costs and emissions associated with many technologies critical to power grid operation. To explore regional differences in the cost-optimized decarbonization strategies, the IG model also includes conditions within each region, notably details on demand profiles and resource availability.
In one recent study, Gençer and Farnsworth selected nine of the standard North American Electric Reliability Corporation (NERC) regions. For each region, they incorporated hourly electricity demand into the IG model. Farnsworth also gathered meteorological data for the nine U.S. regions for seven years — 2007 to 2013 — and calculated hourly power output profiles for the renewable energy sources, including solar and wind, taking into account the geography-limited maximum capacity of each technology.
The availability of wind and solar resources differs widely from region to region. To permit a quick comparison, the researchers use a measure called “annual capacity factor,” which is the ratio between the electricity produced by a generating unit in a year and the electricity that could have been produced if that unit operated continuously at full power for that year. Values for the capacity factors in the nine U.S. regions vary between 20 percent and 30 percent for solar power and between 25 percent and 45 percent for wind.
Calculating optimized grids for different regions
For their first case study, Gençer and Farnsworth used the IG model to calculate cost-optimized regional grids to meet defined caps on carbon dioxide (CO2) emissions. The analyses were based on cost and emissions data for 10 technologies: nuclear, wind, solar, three types of natural gas, three types of coal, and energy storage using lithium-ion batteries. Hydroelectric was not considered in this study because there was no comprehensive study outlining potential expansion sites with their respective costs and expected power output levels.
To make region-to-region comparisons easy, the researchers used several simplifying assumptions. Their focus was on electricity generation, so the model calculations assume the same transmission and distribution costs and efficiencies for all regions. Also, the calculations did not consider the generator fleet currently in place. The goal was to investigate what happens if each region were to start from scratch and generate an “ideal” grid.
To begin, Gençer and Farnsworth calculated the most economic combination of technologies for each region if it limits its total carbon emissions to 100, 50, and 25 grams of CO2 per kilowatt-hour (kWh) generated. For context, the current U.S. average emissions intensity is 386 grams of CO2 emissions per kWh.
Given the wide variation in regional demand, the researchers needed to use a new metric to normalize their results and permit a one-to-one comparison between regions. Accordingly, the model calculates the required generating capacity divided by the average demand for each region. The required capacity accounts for both the variation in demand and the inability of generating systems — particularly solar and wind — to operate at full capacity all of the time.
The analysis was based on regional demand data for 2021 — the most recent data available. And for each region, the model calculated the cost-optimized power grid seven times, using weather data from seven years. This discussion focuses on mean valuesfor cost and total capacity installed and also total values for coal and for natural gas, although the analysis considered three separate technologies for each fuel.
The results of the analyses confirm that there’s a wide variation in the cost-optimized system from one region to another. Most notable is that some regions require a lot of energy storage while others don’t require any at all. The availability of wind resources turns out to play an important role, while the use of nuclear is limited: the carbon intensity of nuclear (including uranium mining and transportation) is lower than that of either solar or wind, but nuclear is the most expensive technology option, so it’s added only when necessary. Finally, the change in the CO2 emissions cap brings some interesting responses.
Under the most lenient limit on emissions — 100 grams of CO2 per kWh — there’s no coal in the mix anywhere. It’s the first to go, in general being replaced by the lower-carbon-emitting natural gas. Texas, Central, and North Central — the regions with the most wind — don’t need energy storage, while the other six regions do. The regions with the least wind — California and the Southwest — have the highest energy storage requirements. Unlike the other regions modeled, California begins installing nuclear, even at the most lenient limit.
As the model plays out, under the moderate cap — 50 grams of CO2 per kWh — most regions bring in nuclear power. California and the Southeast — regions with low wind capacity factors — rely on nuclear the most. In contrast, wind-rich Texas, Central, and North Central don’t incorporate nuclear yet but instead add energy storage — a less-expensive option — to their mix. There’s still a bit of natural gas everywhere, in spite of its CO2 emissions.
Under the most restrictive cap — 25 grams of CO2 per kWh — nuclear is in the mix everywhere. The highest use of nuclear is again correlated with low wind capacity factor. Central and North Central depend on nuclear the least. All regions continue to rely on a little natural gas to keep prices from skyrocketing due to the necessary but costly nuclear component. With nuclear in the mix, the need for storage declines in most regions.
Results of the cost analysis are also interesting. Texas, Central, and North Central all have abundant wind resources, and they can delay incorporating the costly nuclear option, so the cost of their optimized system tends to be lower than costs for the other regions. In addition, their total capacity deployment — including all sources — tends to be lower than for the other regions. California and the Southwest both rely heavily on solar, and in both regions, costs and total deployment are relatively high.
Lessons learned
One unexpected result is the benefit of combining solar and wind resources. The problem with relying on solar alone is obvious: “Solar energy is available only five or six hours a day, so you need to build a lot of other generating sources and abundant storage capacity,” says Gençer. But an analysis of unit-by-unit operations at an hourly resolution yielded a less-intuitive trend: While solar installations only produce power in the midday hours, wind turbines generate the most power in the nighttime hours. As a result, solar and wind power are complementary. Having both resources available is far more valuable than having either one or the other. And having both impacts the need for storage, says Gençer: “Storage really plays a role either when you’re targeting a very low carbon intensity or where your resources are mostly solar and they’re not complemented by wind.”
Gençer notes that the target for the U.S. electricity grid is to reach net zero by 2035. But the analysis showed that reaching just 100 grams of CO2 per kWh would require at least 50 percent of system capacity to be wind and solar. “And we’re nowhere near that yet,” he says.
Indeed, Gençer and Farnsworth’s analysis doesn’t even include a zero emissions case. Why not? As Gençer says, “We cannot reach zero.” Wind and solar are usually considered to be net zero, but that’s not true. Wind, solar, and even storage have embedded carbon emissions due to materials, manufacturing, and so on. “To go to true net zero, you’d need negative emission technologies,” explains Gençer, referring to techniques that remove carbon from the air or ocean. That observation confirms the importance of performing life-cycle assessments.
Farnsworth voices another concern: Coal quickly disappears in all regions because natural gas is an easy substitute for coal and has lower carbon emissions. “People say they’ve decreased their carbon emissions by a lot, but most have done it by transitioning from coal to natural gas power plants,” says Farnsworth. “But with that pathway for decarbonization, you hit a wall. Once you’ve transitioned from coal to natural gas, you’ve got to do something else. You need a new strategy — a new trajectory to actually reach your decarbonization target, which most likely will involve replacing the newly installed natural gas plants.”
Gençer makes one final point: The availability of cheap nuclear — whether fission or fusion — would completely change the picture. When the tighter caps require the use of nuclear, the cost of electricity goes up. “The impact is quite significant,” says Gençer. “When we go from 100 grams down to 25 grams of CO2 per kWh, we see a 20 percent to 30 percent increase in the cost of electricity.” If it were available, a less-expensive nuclear option would likely be included in the technology mix under more lenient caps, significantly reducing the cost of decarbonizing power grids in all regions.
The special case of California
In another analysis, Gençer and Farnsworth took a closer look at California. In California, about 10 percent of total demand is now met with nuclear power. Yet current power plants are scheduled for retirement very soon, and a 1976 law forbids the construction of new nuclear plants. (The state recently extended the lifetime of one nuclear plant to prevent the grid from becoming unstable.) “California is very motivated to decarbonize their grid,” says Farnsworth. “So how difficult will that be without nuclear power?”
To find out, the researchers performed a series of analyses to investigate the challenge of decarbonizing in California with nuclear power versus without it. At 200 grams of CO2 per kWh — about a 50 percent reduction — the optimized mix and cost look the same with and without nuclear. Nuclear doesn’t appear due to its high cost. At 100 grams of CO2 per kWh — about a 75 percent reduction — nuclear does appear in the cost-optimized system, reducing the total system capacity while having little impact on the cost.
But at 50 grams of CO2 per kWh, the ban on nuclear makes a significant difference. “Without nuclear, there’s about a 45 percent increase in total system size, which is really quite substantial,” says Farnsworth. “It’s a vastly different system, and it’s more expensive.” Indeed, the cost of electricity would increase by 7 percent.
Going one step further, the researchers performed an analysis to determine the most decarbonized system possible in California. Without nuclear, the state could reach 40 grams of CO2 per kWh. “But when you allow for nuclear, you can get all the way down to 16 grams of CO2 per kWh,” says Farnsworth. “We found that California needs nuclear more than any other region due to its poor wind resources.”
Impacts of a carbon tax
One more case study examined a policy approach to incentivizing decarbonization. Instead of imposing a ceiling on carbon emissions, this strategy would tax every ton of carbon that’s emitted. Proposed taxes range from zero to $100 per ton.
To investigate the effectiveness of different levels of carbon tax, Farnsworth and Gençer used the IG model to calculate the minimum-cost system for each region, assuming a certain cost for emitting each ton of carbon. The analyses show that a low carbon tax — just $10 per ton — significantly reduces emissions in all regions by phasing out all coal generation. In the Northwest region, for example, a carbon tax of $10 per ton decreases system emissions by 65 percent while increasing system cost by just 2.8 percent (relative to an untaxed system).
After coal has been phased out of all regions, every increase in the carbon tax brings a slow but steady linear decrease in emissions and a linear increase in cost. But the rates of those changes vary from region to region. For example, the rate of decrease in emissions for each added tax dollar is far lower in the Central region than in the Northwest, largely due to the Central region’s already low emissions intensity without a carbon tax. Indeed, the Central region without a carbon tax has a lower emissions intensity than the Northwest region with a tax of $100 per ton.
As Farnsworth summarizes, “A low carbon tax — just $10 per ton — is very effective in quickly incentivizing the replacement of coal with natural gas. After that, it really just incentivizes the replacement of natural gas technologies with more renewables and more energy storage.” She concludes, “If you’re looking to get rid of coal, I would recommend a carbon tax.”
Future extensions of IG
The researchers have already added hydroelectric to the generating options in the IG model, and they are now planning further extensions. For example, they will include additional regions for analysis, add other long-term energy storage options, and make changes that allow analyses to take into account the generating infrastructure that already exists. Also, they will use the model to examine the cost and value of interregional transmission to take advantage of the diversity of available renewable resources.
Farnsworth emphasizes that the analyses reported here are just samples of what’s possible using the IG model. The model is a web-based tool that includes embedded data covering the whole United States, and the output from an analysis includes an easy-to-understand display of the required installations, hourly operation, and overall techno-economic analysis and life-cycle assessment results. “The user is able to go in and explore a vast number of scenarios with no data collection or pre-processing,” she says. “There’s no barrier to begin using the tool. You can just hop on and start exploring your options so you can make an informed decision about the best path forward.”
This work was supported by the International Energy Agency Gas and Oil Technology Collaboration Program and the MIT Energy Initiative Low-Carbon Energy Centers.
This article appears in the Winter 2024 issue of Energy Futures, the magazine of the MIT Energy Initiative.
An online model developed by an MIT Energy Initiative team enables other researchers and operators of U.S. regional grids to explore possible pathways to decarbonization. Case studies of the nine regional power grids shown here confirm the importance of designing a strategy based on the resources and electricity demand profiles of specific regions.
MIT chemists have designed a sensor that detects tiny quantities of perfluoroalkyl and polyfluoroalkyl substances (PFAS) — chemicals found in food packaging, nonstick cookware, and many other consumer products.
These compounds, also known as “forever chemicals” because they do not break down naturally, have been linked to a variety of harmful health effects, including cancer, reproductive problems, and disruption of the immune and endocrine systems.
Using the new sensor technology, the researchers showed that they could detect PFAS levels as low as 200 parts per trillion in a water sample. The device they designed could offer a way for consumers to test their drinking water, and it could also be useful in industries that rely heavily on PFAS chemicals, including the manufacture of semiconductors and firefighting equipment.
“There’s a real need for these sensing technologies. We’re stuck with these chemicals for a long time, so we need to be able to detect them and get rid of them,” says Timothy Swager, the John D. MacArthur Professor of Chemistry at MIT and the senior author of the study, which appears this week in the Proceedings of the National Academy of Sciences.
Other authors of the paper are former MIT postdoc and lead author Sohyun Park and MIT graduate student Collette Gordon.
Detecting PFAS
Coatings containing PFAS chemicals are used in thousands of consumer products. In addition to nonstick coatings for cookware, they are also commonly used in water-repellent clothing, stain-resistant fabrics, grease-resistant pizza boxes, cosmetics, and firefighting foams.
These fluorinated chemicals, which have been in widespread use since the 1950s, can be released into water, air, and soil, from factories, sewage treatment plants, and landfills. They have been found in drinking water sources in all 50 states.
In 2023, the Environmental Protection Agency determined “health advisory levels” for two of the most hazardous PFAS chemicals, known as perfluorooctanoic acid (PFOA) and perfluorooctyl sulfonate (PFOS), in drinking water, setting them at 0.004 parts per trillion and 0.02 parts per trillion, respectively.
Currently, the only way that a consumer could determine if their drinking water contains PFAS is to send a water sample to a laboratory that performs mass spectrometry testing. However, this process takes several weeks and costs hundreds of dollars.
To create a cheaper and faster way to test for PFAS, the MIT team designed a sensor based on lateral flow technology — the same approach used for rapid Covid-19 tests and pregnancy tests. Instead of a test strip coated with antibodies, the new sensor is embedded with a special polymer known as polyaniline, which can switch between semiconducting and conducting states when protons are added to the material.
The researchers deposited these polymers onto a strip of nitrocellulose paper and coated them with a surfactant that can pull fluorocarbons such as PFAS out of a drop of water placed on the strip. When this happens, protons from the PFAS are drawn into the polyaniline and turn it into a conductor, reducing the electrical resistance of the material. This change in resistance, which can be measured precisely using electrodes and sent to an external device such as a smartphone, gives a quantitative measurement of how much PFAS is present.
This approach works only with PFAS that are acidic, which includes two of the most harmful PFAS — PFOA and perfluorobutanoic acid (PFBA).
A user-friendly system
The current version of the sensor can detect concentrations as low as 200 parts per trillion for PFBA, and 400 parts per trillion for PFOA. This is not quite low enough to meet the current EPA guidelines, but the sensor uses only a fraction of a milliliter of water. The researchers are now working on a larger-scale device that would be able to filter about a liter of water through a membrane made of polyaniline, and they believe this approach should increase the sensitivity by more than a hundredfold, with the goal of meeting the very low EPA advisory levels.
“We do envision a user-friendly, household system,” Swager says. “You can imagine putting in a liter of water, letting it go through the membrane, and you have a device that measures the change in resistance of the membrane.”
Such a device could offer a less expensive, rapid alternative to current PFAS detection methods. If PFAS are detected in drinking water, there are commercially available filters that can be used on household drinking water to reduce those levels. The new testing approach could also be useful for factories that manufacture products with PFAS chemicals, so they could test whether the water used in their manufacturing process is safe to release into the environment.
The research was funded by an MIT School of Science Fellowship to Gordon, a Bose Research Grant, and a Fulbright Fellowship to Park.
An MIT sensor can detect “forever chemicals” known as PFAS (perfluoroalkyl and polyfluoroalkyl substances) in drinking water. PFAS are found in many consumer products and are linked to cancer and other health problems.
A new study of people who speak many languages has found that there is something special about how the brain processes their native language.
In the brains of these polyglots — people who speak five or more languages — the same language regions light up when they listen to any of the languages that they speak. In general, this network responds more strongly to languages in which the speaker is more proficient, with one notable exception: the speaker’s native language. When listening to one’s native language, language network activity drops off significantly.
The findings suggest there is something unique about the first language one acquires, which allows the brain to process it with minimal effort, the researchers say.
“Something makes it a little bit easier to process — maybe it’s that you’ve spent more time using that language — and you get a dip in activity for the native language compared to other languages that you speak proficiently,” says Evelina Fedorenko, an associate professor of neuroscience at MIT, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study.
Saima Malik-Moraleda, a graduate student in the Speech and Hearing Bioscience and Technology Program at Harvard University, and Olessia Jouravlev, a former MIT postdoc who is now an associate professor at Carleton University, are the lead authors of the paper, which appears today in the journal Cerebral Cortex.
Many languages, one network
The brain’s language processing network, located primarily in the left hemisphere, includes regions in the frontal and temporal lobes. In a 2021 study, Fedorenko’s lab found that in the brains of polyglots, the language network was less active when listening to their native language than the language networks of people who speak only one language.
In the new study, the researchers wanted to expand on that finding and explore what happens in the brains of polyglots as they listen to languages in which they have varying levels of proficiency. Studying polyglots can help researchers learn more about the functions of the language network, and how languages learned later in life might be represented differently than a native language or languages.
“With polyglots, you can do all of the comparisons within one person. You have languages that vary along a continuum, and you can try to see how the brain modulates responses as a function of proficiency,” Fedorenko says.
For the study, the researchers recruited 34 polyglots, each of whom had at least some degree of proficiency in five or more languages but were not bilingual or multilingual from infancy. Sixteen of the participants spoke 10 or more languages, including one who spoke 54 languages with at least some proficiency.
Each participant was scanned with functional magnetic resonance imaging (fMRI) as they listened to passages read in eight different languages. These included their native language, a language they were highly proficient in, a language they were moderately proficient in, and a language in which they described themselves as having low proficiency.
They were also scanned while listening to four languages they didn’t speak at all. Two of these were languages from the same family (such as Romance languages) as a language they could speak, and two were languages completely unrelated to any languages they spoke.
The passages used for the study came from two different sources, which the researchers had previously developed for other language studies. One was a set of Bible stories recorded in many different languages, and the other consisted of passages from “Alice in Wonderland” translated into many languages.
Brain scans revealed that the language network lit up the most when participants listened to languages in which they were the most proficient. However, that did not hold true for the participants’ native languages, which activated the language network much less than non-native languages in which they had similar proficiency. This suggests that people are so proficient in their native language that the language network doesn’t need to work very hard to interpret it.
“As you increase proficiency, you can engage linguistic computations to a greater extent, so you get these progressively stronger responses. But then if you compare a really high-proficiency language and a native language, it may be that the native language is just a little bit easier, possibly because you've had more experience with it,” Fedorenko says.
Brain engagement
The researchers saw a similar phenomenon when polyglots listened to languages that they don’t speak: Their language network was more engaged when listening to languages related to a language that they could understand, than compared to listening to completely unfamiliar languages.
“Here we’re getting a hint that the response in the language network scales up with how much you understand from the input,” Malik-Moraleda says. “We didn’t quantify the level of understanding here, but in the future we’re planning to evaluate how much people are truly understanding the passages that they're listening to, and then see how that relates to the activation.”
The researchers also found that a brain network known as the multiple demand network, which turns on whenever the brain is performing a cognitively demanding task, also becomes activated when listening to languages other than one’s native language.
“What we’re seeing here is that the language regions are engaged when we process all these languages, and then there’s this other network that comes in for non-native languages to help you out because it’s a harder task,” Malik-Moraleda says.
In this study, most of the polyglots began studying their non-native languages as teenagers or adults, but in future work, the researchers hope to study people who learned multiple languages from a very young age. They also plan to study people who learned one language from infancy but moved to the United States at a very young age and began speaking English as their dominant language, while becoming less proficient in their native language, to help disentangle the effects of proficiency versus age of acquisition on brain responses.
The research was funded by the McGovern Institute for Brain Research, MIT’s Department of Brain and Cognitive Sciences, and the Simons Center for the Social Brain.
An MIT study of polyglots found the brain’s language network responds more strongly when hearing languages a speaker is more proficient in — and much more weakly to the speaker’s native language.
Peripheral vision enables humans to see shapes that aren’t directly in our line of sight, albeit with less detail. This ability expands our field of vision and can be helpful in many situations, such as detecting a vehicle approaching our car from the side.
Unlike humans, AI does not have peripheral vision. Equipping computer vision models with this ability could help them detect approaching hazards more effectively or predict whether a human driver would notice an oncoming object.
Taking a step in this direction, MIT researchers developed an image dataset that allows them to simulate peripheral vision in machine learning models. They found that training models with this dataset improved the models’ ability to detect objects in the visual periphery, although the models still performed worse than humans.
Their results also revealed that, unlike with humans, neither the size of objects nor the amount of visual clutter in a scene had a strong impact on the AI’s performance.
“There is something fundamental going on here. We tested so many different models, and even when we train them, they get a little bit better but they are not quite like humans. So, the question is: What is missing in these models?” says Vasha DuTell, a postdoc and co-author of a paper detailing this study.
Answering that question may help researchers build machine learning models that can see the world more like humans do. In addition to improving driver safety, such models could be used to develop displays that are easier for people to view.
Plus, a deeper understanding of peripheral vision in AI models could help researchers better predict human behavior, adds lead author Anne Harrington MEng ’23.
“Modeling peripheral vision, if we can really capture the essence of what is represented in the periphery, can help us understand the features in a visual scene that make our eyes move to collect more information,” she explains.
Their co-authors include Mark Hamilton, an electrical engineering and computer science graduate student; Ayush Tewari, a postdoc; Simon Stent, research manager at the Toyota Research Institute; and senior authors William T. Freeman, the Thomas and Gerd Perkins Professor of Electrical Engineering and Computer Science and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL); and Ruth Rosenholtz, principal research scientist in the Department of Brain and Cognitive Sciences and a member of CSAIL. The research will be presented at the International Conference on Learning Representations.
“Any time you have a human interacting with a machine — a car, a robot, a user interface — it is hugely important to understand what the person can see. Peripheral vision plays a critical role in that understanding,” Rosenholtz says.
Simulating peripheral vision
Extend your arm in front of you and put your thumb up — the small area around your thumbnail is seen by your fovea, the small depression in the middle of your retina that provides the sharpest vision. Everything else you can see is in your visual periphery. Your visual cortex represents a scene with less detail and reliability as it moves farther from that sharp point of focus.
Many existing approaches to model peripheral vision in AI represent this deteriorating detail by blurring the edges of images, but the information loss that occurs in the optic nerve and visual cortex is far more complex.
For a more accurate approach, the MIT researchers started with a technique used to model peripheral vision in humans. Known as the texture tiling model, this method transforms images to represent a human’s visual information loss.
They modified this model so it could transform images similarly, but in a more flexible way that doesn’t require knowing in advance where the person or AI will point their eyes.
“That let us faithfully model peripheral vision the same way it is being done in human vision research,” says Harrington.
The researchers used this modified technique to generate a huge dataset of transformed images that appear more textural in certain areas, to represent the loss of detail that occurs when a human looks further into the periphery.
Then they used the dataset to train several computer vision models and compared their performance with that of humans on an object detection task.
“We had to be very clever in how we set up the experiment so we could also test it in the machine learning models. We didn’t want to have to retrain the models on a toy task that they weren’t meant to be doing,” she says.
Peculiar performance
Humans and models were shown pairs of transformed images which were identical, except that one image had a target object located in the periphery. Then, each participant was asked to pick the image with the target object.
“One thing that really surprised us was how good people were at detecting objects in their periphery. We went through at least 10 different sets of images that were just too easy. We kept needing to use smaller and smaller objects,” Harrington adds.
The researchers found that training models from scratch with their dataset led to the greatest performance boosts, improving their ability to detect and recognize objects. Fine-tuning a model with their dataset, a process that involves tweaking a pretrained model so it can perform a new task, resulted in smaller performance gains.
But in every case, the machines weren’t as good as humans, and they were especially bad at detecting objects in the far periphery. Their performance also didn’t follow the same patterns as humans.
“That might suggest that the models aren’t using context in the same way as humans are to do these detection tasks. The strategy of the models might be different,” Harrington says.
The researchers plan to continue exploring these differences, with a goal of finding a model that can predict human performance in the visual periphery. This could enable AI systems that alert drivers to hazards they might not see, for instance. They also hope to inspire other researchers to conduct additional computer vision studies with their publicly available dataset.
“This work is important because it contributes to our understanding that human vision in the periphery should not be considered just impoverished vision due to limits in the number of photoreceptors we have, but rather, a representation that is optimized for us to perform tasks of real-world consequence,” says Justin Gardner, an associate professor in the Department of Psychology at Stanford University who was not involved with this work. “Moreover, the work shows that neural network models, despite their advancement in recent years, are unable to match human performance in this regard, which should lead to more AI research to learn from the neuroscience of human vision. This future research will be aided significantly by the database of images provided by the authors to mimic peripheral human vision.”
This work is supported, in part, by the Toyota Research Institute and the MIT CSAIL METEOR Fellowship.
A dataset of transformed images can be used to effectively simulate peripheral vision in a machine-learning model, improving the performance of these models on detecting and recognizing objects that are off to the side or in the corner of a scene.
Studies at MIT and elsewhere are producing mounting evidence that light flickering and sound clicking at the gamma brain rhythm frequency of 40 hertz (Hz) can reduce Alzheimer’s disease (AD) progression and treat symptoms in human volunteers as well as lab mice. In a new open-access study in Natureusing a mouse model of the disease, MIT researchers reveal a key mechanism that may contribute to these beneficial effects: clearance of amyloid proteins, a hallmark of AD pathology, via the brain’s glymphatic system, a recently discovered “plumbing” network parallel to the brain’s blood vessels.
“Ever since we published our first results in 2016, people have asked me how does it work? Why 40Hz? Why not some other frequency?” says study senior author Li-Huei Tsai, Picower Professor of Neuroscience and director of The Picower Institute for Learning and Memory of MIT and MIT’s Aging Brain Initiative. “These are indeed very important questions we have worked very hard in the lab to address.”
The new paper describes a series of experiments, led by Mitch Murdock PhD '23 when he was a brain and cognitive sciences doctoral student at MIT, showing that when sensory gamma stimulation increases 40Hz power and synchrony in the brains of mice, that prompts a particular type of neuron to release peptides. The study results further suggest that those short protein signals then drive specific processes that promote increased amyloid clearance via the glymphatic system.
“We do not yet have a linear map of the exact sequence of events that occurs,” says Murdock, who was jointly supervised by Tsai and co-author and collaborator Ed Boyden, Y. Eva Tan Professor of Neurotechnology at MIT, a member of the McGovern Institute for Brain Research and an affiliate member of the Picower Institute. “But the findings in our experiments support this clearance pathway through the major glymphatic routes.”
From gamma to glymphatics
Because prior research has shown that the glymphatic system is a key conduit for brain waste clearance and may be regulated by brain rhythms, Tsai and Murdock’s team hypothesized that it might help explain the lab’s prior observations that gamma sensory stimulation reduces amyloid levels in Alzheimer’s model mice.
Working with “5XFAD” mice, which genentically model Alzheimer’s, Murdock and co-authors first replicated the lab’s prior results that 40Hz sensory stimulation increases 40Hz neuronal activity in the brain and reduces amyloid levels. Then they set out to measure whether there was any correlated change in the fluids that flow through the glymphatic system to carry away wastes. Indeed, they measured increases in cerebrospinal fluid in the brain tissue of mice treated with sensory gamma stimulation compared to untreated controls. They also measured an increase in the rate of interstitial fluid leaving the brain. Moreover, in the gamma-treated mice he measured increased diameter of the lymphatic vessels that drain away the fluids and measured increased accumulation of amyloid in cervical lymph nodes, which is the drainage site for that flow.
To investigate how this increased fluid flow might be happening, the team focused on the aquaporin 4 (AQP4) water channel of astrocyte cells, which enables the cells to facilitate glymphatic fluid exchange. When they blocked APQ4 function with a chemical, that prevented sensory gamma stimulation from reducing amyloid levels and prevented it from improving mouse learning and memory. And when, as an added test, they used a genetic technique for disrupting AQP4, that also interfered with gamma-driven amyloid clearance.
In addition to the fluid exchange promoted by APQ4 activity in astrocytes, another mechanism by which gamma waves promote glymphatic flow is by increasing the pulsation of neighboring blood vessels. Several measurements showed stronger arterial pulsatility in mice subjected to sensory gamma stimulation compared to untreated controls.
One of the best new techniques for tracking how a condition, such as sensory gamma stimulation, affects different cell types is to sequence their RNA to track changes in how they express their genes. Using this method, Tsai and Murdock’s team saw that gamma sensory stimulation indeed promoted changes consistent with increased astrocyte AQP4 activity.
Prompted by peptides
The RNA sequencing data also revealed that upon gamma sensory stimulation a subset of neurons, called “interneurons,” experienced a notable uptick in the production of several peptides. This was not surprising in the sense that peptide release is known to be dependent on brain rhythm frequencies, but it was still notable because one peptide in particular, VIP, is associated with Alzheimer’s-fighting benefits and helps to regulate vascular cells, blood flow, and glymphatic clearance.
Seizing on this intriguing result, the team ran tests that revealed increased VIP in the brains of gamma-treated mice. The researchers also used a sensor of peptide release and observed that sensory gamma stimulation resulted in an increase in peptide release from VIP-expressing interneurons.
But did this gamma-stimulated peptide release mediate the glymphatic clearance of amyloid? To find out, the team ran another experiment: They chemically shut down the VIP neurons. When they did so, and then exposed mice to sensory gamma stimulation, they found that there was no longer an increase in arterial pulsatility and there was no more gamma-stimulated amyloid clearance.
“We think that many neuropeptides are involved,” Murdock says. Tsai added that a major new direction for the lab’s research will be determining what other peptides or other molecular factors may be driven by sensory gamma stimulation.
Tsai and Murdock add that while this paper focuses on what is likely an important mechanism — glymphatic clearance of amyloid — by which sensory gamma stimulation helps the brain, it’s probably not the only underlying mechanism that matters. The clearance effects shown in this study occurred rather rapidly, but in lab experiments and clinical studies weeks or months of chronic sensory gamma stimulation have been needed to have sustained effects on cognition.
With each new study, however, scientists learn more about how sensory stimulation of brain rhythms may help treat neurological disorders.
In addition to Tsai, Murdock, and Boyden, the paper’s other authors are Cheng-Yi Yang, Na Sun, Ping-Chieh Pao, Cristina Blanco-Duque, Martin C. Kahn, Nicolas S. Lavoie, Matheus B. Victor, Md Rezaul Islam, Fabiola Galiana, Noelle Leary, Sidney Wang, Adele Bubnys, Emily Ma, Leyla A. Akay, TaeHyun Kim, Madison Sneve, Yong Qian, Cuixin Lai, Michelle M. McCarthy, Nancy Kopell, Manolis Kellis, and Kiryl D. Piatkevich.
Support for the study came from Robert A. and Renee E. Belfer, the Halis Family Foundation, Eduardo Eurnekian, the Dolby family, Barbara J. Weedon, Henry E. Singleton, the Hubolow family, the Ko Hahn family, Carol and Gene Ludwig Family Foundation, Lester A. Gimpelson, Lawrence and Debra Hilibrand, Glenda and Donald Mattes, Kathleen and Miguel Octavio, David B. Emmes, the Marc Haas Foundation, Thomas Stocky and Avni Shah, the JPB Foundation, the Picower Institute, and the National Institutes of Health.
Bright staining highlights VIP-expressing interneurons in this cross-section of a mouse brain. The neurons may help drive glymphatic clearance of amyloid via the release of peptides.
MIT researchers have discovered a brain circuit that drives vocalization and ensures that you talk only when you breathe out, and stop talking when you breathe in.
The newly discovered circuit controls two actions that are required for vocalization: narrowing of the larynx and exhaling air from the lungs. The researchers also found that this vocalization circuit is under the command of a brainstem region that regulates the breathing rhythm, which ensures that breathing remains dominant over speech.
“When you need to breathe in, you have to stop vocalization. We found that the neurons that control vocalization receive direct inhibitory input from the breathing rhythm generator,” says Fan Wang, an MIT professor of brain and cognitive sciences, a member of MIT’s McGovern Institute for Brain Research, and the senior author of the study.
Jaehong Park, a Duke University graduate student who is currently a visiting student at MIT, is the lead author of the study, which appears today in Science. Other authors of the paper include MIT technical associates Seonmi Choi and Andrew Harrahill, former MIT research scientist Jun Takatoh, and Duke University researchers Shengli Zhao and Bao-Xia Han.
Vocalization control
Located in the larynx, the vocal cords are two muscular bands that can open and close. When they are mostly closed, or adducted, air exhaled from the lungs generates sound as it passes through the cords.
The MIT team set out to study how the brain controls this vocalization process, using a mouse model. Mice communicate with each other using sounds known as ultrasonic vocalizations (USVs), which they produce using the unique whistling mechanism of exhaling air through a small hole between nearly closed vocal cords.
“We wanted to understand what are the neurons that control the vocal cord adduction, and then how do those neurons interact with the breathing circuit?” Wang says.
To figure that out, the researchers used a technique that allows them to map the synaptic connections between neurons. They knew that vocal cord adduction is controlled by laryngeal motor neurons, so they began by tracing backward to find the neurons that innervate those motor neurons.
This revealed that one major source of input is a group of premotor neurons found in the hindbrain region called the retroambiguus nucleus (RAm). Previous studies have shown that this area is involved in vocalization, but it wasn’t known exactly which part of the RAm was required or how it enabled sound production.
The researchers found that these synaptic tracing-labeled RAm neurons were strongly activated during USVs. This observation prompted the team to use an activity-dependent method to target these vocalization-specific RAm neurons, termed as RAmVOC. They used chemogenetics and optogenetics to explore what would happen if they silenced or stimulated their activity. When the researchers blocked the RAmVOC neurons, the mice were no longer able to produce USVs or any other kind of vocalization. Their vocal cords did not close, and their abdominal muscles did not contract, as they normally do during exhalation for vocalization.
Conversely, when the RAmVOC neurons were activated, the vocal cords closed, the mice exhaled, and USVs were produced. However, if the stimulation lasted two seconds or longer, these USVs would be interrupted by inhalations, suggesting that the process is under control of the same part of the brain that regulates breathing.
“Breathing is a survival need,” Wang says. “Even though these neurons are sufficient to elicit vocalization, they are under the control of breathing, which can override our optogenetic stimulation.”
Rhythm generation
Additional synaptic mapping revealed that neurons in a part of the brainstem called the pre-Bötzinger complex, which acts as a rhythm generator for inhalation, provide direct inhibitory input to the RAmVOC neurons.
“The pre-Bötzinger complex generates inhalation rhythms automatically and continuously, and the inhibitory neurons in that region project to these vocalization premotor neurons and essentially can shut them down,” Wang says.
This ensures that breathing remains dominant over speech production, and that we have to pause to breathe while speaking.
The researchers believe that although human speech production is more complex than mouse vocalization, the circuit they identified in mice plays the conserved role in speech production and breathing in humans.
“Even though the exact mechanism and complexity of vocalization in mice and humans is really different, the fundamental vocalization process, called phonation, which requires vocal cord closure and the exhalation of air, is shared in both the human and the mouse,” Park says.
The researchers now hope to study how other functions such as coughing and swallowing food may be affected by the brain circuits that control breathing and vocalization.
The research was funded by the National Institutes of Health.
MIT researchers discovered a brain circuit that drives vocalization and ensures that you talk only when you breathe out, and stop talking when you breathe in.
Before a robot can grab dishes off a shelf to set the table, it must ensure its gripper and arm won’t crash into anything and potentially shatter the fine china. As part of its motion planning process, a robot typically runs “safety check” algorithms that verify its trajectory is collision-free.
However, sometimes these algorithms generate false positives, claiming a trajectory is safe when the robot would actually collide with something. Other methods that can avoid false positives are typically too slow for robots in the real world.
Now, MIT researchers have developed a safety check technique which can prove with 100 percent accuracy that a robot’s trajectory will remain collision-free (assuming the model of the robot and environment is itself accurate). Their method, which is so precise it can discriminate between trajectories that differ by only millimeters, provides proof in only a few seconds.
But a user doesn’t need to take the researchers’ word for it — the mathematical proof generated by this technique can be checked quickly with relatively simple math.
The researchers accomplished this using a special algorithmic technique, called sum-of-squares programming, and adapted it to effectively solve the safety check problem. Using sum-of-squares programming enables their method to generalize to a wide range of complex motions.
This technique could be especially useful for robots that must move rapidly avoid collisions in spaces crowded with objects, such as food preparation robots in a commercial kitchen. It is also well-suited for situations where robot collisions could cause injuries, like home health robots that care for frail patients.
“With this work, we have shown that you can solve some challenging problems with conceptually simple tools. Sum-of-squares programming is a powerful algorithmic idea, and while it doesn’t solve every problem, if you are careful in how you apply it, you can solve some pretty nontrivial problems,” says Alexandre Amice, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this technique.
Amice is joined on the paper fellow EECS graduate student Peter Werner and senior author Russ Tedrake, the Toyota Professor of EECS, Aeronautics and Astronautics, and Mechanical Engineering, and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL). The work will be presented at the International Conference on Robots and Automation.
Certifying safety
Many existing methods that check whether a robot’s planned motion is collision-free do so by simulating the trajectory and checking every few seconds to see whether the robot hits anything. But these static safety checks can’t tell if the robot will collide with something in the intermediate seconds.
This might not be a problem for a robot wandering around an open space with few obstacles, but for robots performing intricate tasks in small spaces, a few seconds of motion can make an enormous difference.
Conceptually, one way to prove that a robot is not headed for a collision would be to hold up a piece of paper that separates the robot from any obstacles in the environment. Mathematically, this piece of paper is called a hyperplane. Many safety check algorithms work by generating this hyperplane at a single point in time. However, each time the robot moves, a new hyperplane needs to be recomputed to perform the safety check.
Instead, this new technique generates a hyperplane function that moves with the robot, so it can prove that an entire trajectory is collision-free rather than working one hyperplane at a time.
The researchers used sum-of-squares programming, an algorithmic toolbox that can effectively turn a static problem into a function. This function is an equation that describes where the hyperplane needs to be at each point in the planned trajectory so it remains collision-free.
Sum-of-squares can generalize the optimization program to find a family of collision-free hyperplanes. Often, sum-of-squares is considered a heavy optimization that is only suitable for offline use, but the researchers have shown that for this problem it is extremely efficient and accurate.
“The key here was figuring out how to apply sum-of-squares to our particular problem. The biggest challenge was coming up with the initial formulation. If I don’t want my robot to run into anything, what does that mean mathematically, and can the computer give me an answer?” Amice says.
In the end, like the name suggests, sum-of-squares produces a function that is the sum of several squared values. The function is always positive, since the square of any number is always a positive value.
Trust but verify
By double-checking that the hyperplane function contains squared values, a human can easily verify that the function is positive, which means the trajectory is collision-free, Amice explains.
While the method certifies with perfect accuracy, this assumes the user has an accurate model of the robot and environment; the mathematical certifier is only as good as the model.
“One really nice thing about this approach is that the proofs are really easy to interpret, so you don’t have to trust me that I coded it right because you can check it yourself,” he adds.
They tested their technique in simulation by certifying that complex motion plans for robots with one and two arms were collision-free. At its slowest, their method took just a few hundred milliseconds to generate a proof, making it much faster than some alternate techniques.
“This new result suggests a novel approach to certifying that a complex trajectory of a robot manipulator is collision free, elegantly harnessing tools from mathematical optimization, turned into surprisingly fast (and publicly available) software. While not yet providing a complete solution to fast trajectory planning in cluttered environments, this result opens the door to several intriguing directions of further research,” says Dan Halperin, a professor of computer science at Tel Aviv University, who was not involved with this research.
While their approach is fast enough to be used as a final safety check in some real-world situations, it is still too slow to be implemented directly in a robot motion planning loop, where decisions need to be made in microseconds, Amice says.
The researchers plan to accelerate their process by ignoring situations that don’t require safety checks, like when the robot is far away from any objects it might collide with. They also want to experiment with specialized optimization solvers that could run faster.
“Robots often get into trouble by scraping obstacles due to poor approximations that are made when generating their routes. Amice, Werner, and Tedrake have come to the rescue with a powerful new algorithm to quickly ensure that robots never overstep their bounds, by carefully leveraging advanced methods from computational algebraic geometry,” adds Steven LaValle, professor in the Faculty of Information Technology and Electrical Engineering at the University of Oulu in Finland, and who was not involved with this work.
This work was supported, in part, by Amazon and the U.S. Air Force Research Laboratory.
At a time in which scientific research is increasingly cross-disciplinary, Ernest Fraenkel, the Grover M. Hermann Professor in Health Sciences and Technology in MIT’s Department of Biological Engineering, stands out as both a very early adopter of drawing from different scientific fields and a great advocate of the practice today.
When Fraenkel’s students find themselves at an impasse in their work, he suggests they approach their problem from a different angle or look for inspiration in a completely unrelated field.
“I think the thing that I always come back to is try going around it from the side,” Fraenkel says. “Everyone in the field is working in exactly the same way. Maybe you’ll come up with a solution by doing something different.”
Fraenkel’s work untangling the often-complicated mechanisms of disease to develop targeted therapies employs methods from the world of computer science, including algorithms that bring focus to processes most likely to be relevant. Using such methods, he has decoded fundamental aspects of Huntington’s disease and glioblastoma, and he and his collaborators are working to understand the mechanisms behind amyotrophic lateral sclerosis (ALS), also known as Lou Gehrig’s disease.
Very early on, Fraenkel was exposed to a merging of scientific disciplines. One of his teachers in high school, who was a student at Columbia University, started a program in which chemistry, physics, and biology were taught together. The teacher encouraged Fraenkel to visit a lab at Columbia run by Cyrus Levinthal, a physicist who taught one of the first biophysics classes at MIT. Fraenkel not only worked at the lab for a summer, he left high school (later earning an equivalency diploma) and started working at the lab full time and taking classes at Columbia.
“Here was a lab that was studying really important questions in biology, but the head of it had trained in physics,” Fraenkel says. “The idea that you could get really important insights by cross-fertilization, that’s something that I’ve always really appreciated. And now, we can see how this approach can impact how people are being treated for diseases or reveal really important fundamentals of science.”
Breaking barriers
At MIT, Fraenkel works in the Department of Biological Engineering and co-directs the Computational Systems Biology graduate program. For the study of ALS, he and his collaborators at Massachusetts General Hospital (MGH), including neurologist and neuroscientist Merit Cudkowicz, were recently awarded $1.25 million each from the nonprofit EverythingALS organization. The strategy behind the gift, Fraenkel says, is to encourage MIT and MGH to increase their collaboration, eventually enlisting other organizations as well, to form a hub for ALS research “to break down barriers in the field and really focus on the core problems.”
Fraenkel has been working with EverythingALS and their data scientists in collaboration with doctors James Berry of MGH and Lyle Ostrow of Temple University. He also works extensively with the nonprofit Answer ALS, a consortium of scientists studying the disease.
Fraenkel first got interested in ALS and other neurodegenerative diseases because traditional molecular biology research had not yielded effective therapies or, in the case of ALS, much insight into the disease’s causes.
“I was interested in places where the traditional approaches of molecular biology” — in which researchers hypothesize that a certain protein or gene or pathway is key to understanding a disease — “were not having a lot of luck or impact,” Fraenkel says. “Those are the places where if you come at it from another direction, the field could really advance.”
Fraenkel says that while traditional molecular biology has produced many valuable discoveries, it’s not very systematic. “If you start with the wrong hypothesis, you’re not going to get very far,” he says.
Systems biology, on the other hand, measures many cellular changes — including transcription of genes, protein-DNA interactions, of thousands of chemical compounds and of protein modifications — and can apply artificial intelligence and machine learning to those measurements to collectively identify the most important interactions.
“The goal of systems biology is to systematically measure as many cellular changes as possible, integrate this data, and let the data guide you to the most promising hypotheses,” Fraenkel says.
The Answer ALS project, with which Frankel works, involves approximately a thousand people with ALS who provided clinical information about their disease and blood cells. Their blood cells were reprogrammed to be pluripotent stem cells, meaning that the cells could be used to grow neurons that are studied and compared to neurons from a control group.
Emotional connection
While Fraenkel was intellectually inspired to apply systems biology to the challenging problem of understanding ALS — there is no known cause or cure for 80 to 90 percent of people with ALS — he also felt a strong emotional connection to the community of people with ALS and their advocates.
He tells a story of going to meet the director of an ALS organization in Israel who was trying to encourage scientists to work on the disease. Fraenkel knew the man had ALS. What he didn’t know before arriving at the meeting was that he was immobilized, lying in a hospital bed in his living room and only able to communicate with eye-blinking software.
“I sat down so we could both see the screen he was using to type characters out,” Fraenkel says, “and we had this fascinating conversation.”
“Here was a young guy in the prime of life, suffering in a way that’s unimaginable. At the same time, he was doing something amazing, running this organization to try to make a change. And he wasn’t the only one,” he says. “You meet one, and then another and then another — people who are sometimes on their last breaths and are still pushing to make a difference and cure the disease.”
The gift from EverythingALS — which was founded by Indu Navar after losing her husband, Peter Cohen, to ALS and later merged with CureALS, founded by Bill Nuti, who is living with ALS — aims to research the root causes of the disease, in the hope of finding therapies to stop its progression, and natural healing processes that could possibly restore function of damaged nerves.
To achieve those goals, Fraenkel says it is crucial to measure molecular changes in the cells of people with ALS and also to quantify the symptoms of ALS, which presents very differently from person to person. Fraenkel refers to how understanding the differences in various types of cancer has led to much better treatments, pointing out that ALS is nowhere near as well categorized or understood.
“The subtyping is really going to be what the field needs,” he says. “The prognosis for more than 80 percent of people with ALS is not appreciably different than it would have been 20, or maybe even 100, years ago.”
In the same way that Fraenkel was fascinated as a high school student by doing biology in a physicist’s lab, he says he loves that at MIT, different disciplines work together easily.
“You reach out to MIT colleagues in other departments, and they’re not surprised to hear from someone who’s not in their field,” Fraenkel says. “We’re a goal-oriented institution that focuses on solving hard problems.”
Ernest Fraenkel, the Grover M. Hermann Professor in Health Sciences and Technology in MIT’s Department of Biological Engineering, is working to understand the mechanisms behind amyotrophic lateral sclerosis (ALS), also known as Lou Gehrig’s disease.
Patients undergoing chemotherapy often experience cognitive effects such as memory impairment and difficulty concentrating — a condition commonly known as “chemo brain.”
MIT researchers have now shown that a noninvasive treatment that stimulates gamma frequency brain waves may hold promise for treating chemo brain. In a study of mice, they found that daily exposure to light and sound with a frequency of 40 hertz protected brain cells from chemotherapy-induced damage. The treatment also helped to prevent memory loss and impairment of other cognitive functions.
This treatment, which was originally developed as a way to treat Alzheimer’s disease, appears to have widespread effects that could help with a variety of neurological disorders, the researchers say.
“The treatment can reduce DNA damage, reduce inflammation, and increase the number of oligodendrocytes, which are the cells that produce myelin surrounding the axons,” says Li-Huei Tsai, director of MIT’s Picower Institute for Learning and Memory and the Picower Professor in the MIT Department of Brain and Cognitive Sciences. “We also found that this treatment improved learning and memory, and enhanced executive function in the animals.”
Tsai is the senior author of the new study, which appears today in Science Translational Medicine. The paper’s lead author is TaeHyun Kim, an MIT postdoc.
Protective brain waves
Several years ago, Tsai and her colleagues began exploring the use of light flickering at 40 hertz (cycles per second) as a way to improve the cognitive symptoms of Alzheimer’s disease. Previous work had suggested that Alzheimer’s patients have impaired gamma oscillations — brain waves that range from 25 to 80 hertz (cycles per second) and are believed to contribute to brain functions such as attention, perception, and memory.
Tsai’s studies in mice have found that exposure to light flickering at 40 hertz or sounds with a pitch of 40 hertz can stimulate gamma waves in the brain, which has many protective effects, including preventing the formation of amyloid beta plaques. Using light and sound together provides even more significant protection. The treatment also appears promising in humans: Phase 1 clinical trials in people with early-stage Alzheimer’s disease have found the treatment is safe and does offer some neurological and behavioral benefits.
In the new study, the researchers set out to see whether this treatment could also counteract the cognitive effects of chemotherapy treatment. Research has shown that these drugs can induce inflammation in the brain, as well as other detrimental effects such as loss of white matter — the networks of nerve fibers that help different parts of the brain communicate with each other. Chemotherapy drugs also promote loss of myelin, the protective fatty coating that allows neurons to propagate electrical signals. Many of these effects are also seen in the brains of people with Alzheimer’s.
“Chemo brain caught our attention because it is extremely common, and there is quite a lot of research on what the brain is like following chemotherapy treatment,” Tsai says. “From our previous work, we know that this gamma sensory stimulation has anti-inflammatory effects, so we decided to use the chemo brain model to test whether sensory gamma stimulation can be beneficial.”
As an experimental model, the researchers used mice that were given cisplatin, a chemotherapy drug often used to treat testicular, ovarian, and other cancers. The mice were given cisplatin for five days, then taken off of it for five days, then on again for five days. One group received chemotherapy only, while another group was also given 40-hertz light and sound therapy every day.
After three weeks, mice that received cisplatin but not gamma therapy showed many of the expected effects of chemotherapy: brain volume shrinkage, DNA damage, demyelination, and inflammation. These mice also had reduced populations of oligodendrocytes, the brain cells responsible for producing myelin.
However, mice that received gamma therapy along with cisplatin treatment showed significant reductions in all of those symptoms. The gamma therapy also had beneficial effects on behavior: Mice that received the therapy performed much better on tests designed to measure memory and executive function.
“A fundamental mechanism”
Using single-cell RNA sequencing, the researchers analyzed the gene expression changes that occurred in mice that received the gamma treatment. They found that in those mice, inflammation-linked genes and genes that trigger cell death were suppressed, especially in oligodendrocytes, the cells responsible for producing myelin.
In mice that received gamma treatment along with cisplatin, some of the beneficial effects could still be seen up to four months later. However, the gamma treatment was much less effective if it was started three months after the chemotherapy ended.
The researchers also showed that the gamma treatment improved the signs of chemo brain in mice that received a different chemotherapy drug, methotrexate, which is used to treat breast, lung, and other types of cancer.
“I think this is a very fundamental mechanism to improve myelination and to promote the integrity of oligodendrocytes. It seems that it’s not specific to the agent that induces demyelination, be it chemotherapy or another source of demyelination,” Tsai says.
Because of its widespread effects, Tsai’s lab is also testing gamma treatment in mouse models of other neurological diseases, including Parkinson’s disease and multiple sclerosis. Cognito Therapeutics, a company founded by Tsai and MIT Professor Edward Boyden, has finished a phase 2 trial of gamma therapy in Alzheimer’s patients, and plans to begin a phase 3 trial this year.
“My lab’s major focus now, in terms of clinical application, is Alzheimer’s; but hopefully we can test this approach for a few other indications, too,” Tsai says.
The research was funded by the JPB Foundation, the Ko Hahn Seed Fund, and the National Institutes of Health.
A noninvasive treatment may help to counter “chemo brain” impairment often seen in chemotherapy patients: Exposure to light and sound with a frequency of 40 hertz protected brain cells from chemotherapy-induced damage in mice, MIT researchers found.
Many vaccines, including vaccines for hepatitis B and whooping cough, consist of fragments of viral or bacterial proteins. These vaccines often include other molecules called adjuvants, which help to boost the immune system’s response to the protein.
Most of these adjuvants consist of aluminum salts or other molecules that provoke a nonspecific immune response. A team of MIT researchers has now shown that a type of nanoparticle called a metal organic framework (MOF) can also provoke a strong immune response, by activating the innate immune system — the body’s first line of defense against any pathogen — through cell proteins called toll-like receptors.
In a study of mice, the researchers showed that this MOF could successfully encapsulate and deliver part of the SARS-CoV-2 spike protein, while also acting as an adjuvant once the MOF is broken down inside cells.
While more work would be needed to adapt these particles for use as vaccines, the study demonstrates that this type of structure can be useful for generating a strong immune response, the researchers say.
“Understanding how the drug delivery vehicle can enhance an adjuvant immune response is something that could be very helpful in designing new vaccines,” says Ana Jaklenec, a principal investigator at MIT’s Koch Institute for Integrative Cancer Research and one of the senior authors of the new study.
Robert Langer, an MIT Institute Professor and member of the Koch Institute, and Dan Barouch, director of the Center for Virology and Vaccine Research at Beth Israel Deaconess Medical Center and a professor at Harvard Medical School, are also senior authors of the paper, which appears today in Science Advances. The paper’s lead author is former MIT postdoc and Ibn Khaldun Fellow Shahad Alsaiari.
Immune activation
In this study, the researchers focused on a MOF called ZIF-8, which consists of a lattice of tetrahedral units made up of a zinc ion attached to four molecules of imidazole, an organic compound. Previous work has shown that ZIF-8 can significantly boost immune responses, but it wasn’t known exactly how this particle activates the immune system.
To try to figure that out, the MIT team created an experimental vaccine consisting of the SARS-CoV-2 receptor-binding protein (RBD) embedded within ZIF-8 particles. These particles are between 100 and 200 nanometers in diameter, a size that allows them to get into the body’s lymph nodes directly or through immune cells such as macrophages.
Once the particles enter the cells, the MOFs are broken down, releasing the viral proteins. The researchers found that the imidazole components then activate toll-like receptors (TLRs), which help to stimulate the innate immune response.
“This process is analogous to establishing a covert operative team at the molecular level to transport essential elements of the Covid-19 virus to the body’s immune system, where they can activate specific immune responses to boost vaccine efficacy,” Alsaiari says.
RNA sequencing of cells from the lymph nodes showed that mice vaccinated with ZIF-8 particles carrying the viral protein strongly activated a TLR pathway known as TLR-7, which led to greater production of cytokines and other molecules involved in inflammation.
Mice vaccinated with these particles generated a much stronger response to the viral protein than mice that received the protein on its own.
“Not only are we delivering the protein in a more controlled way through a nanoparticle, but the compositional structure of this particle is also acting as an adjuvant,” Jaklenec says. “We were able to achieve very specific responses to the Covid protein, and with a dose-sparing effect compared to using the protein by itself to vaccinate.”
Vaccine access
While this study and others have demonstrated ZIF-8’s immunogenic ability, more work needs to be done to evaluate the particles’ safety and potential to be scaled up for large-scale manufacturing. If ZIF-8 is not developed as a vaccine carrier, the findings from the study should help to guide researchers in developing similar nanoparticles that could be used to deliver subunit vaccines, Jaklenec says.
“Most subunit vaccines usually have two separate components: an antigen and an adjuvant,” Jaklenec says. “Designing new vaccines that utilize nanoparticles with specific chemical moieties which not only aid in antigen delivery but can also activate particular immune pathways have the potential to enhance vaccine potency.”
One advantage to developing a subunit vaccine for Covid-19 is that such vaccines are usually easier and cheaper to manufacture than mRNA vaccines, which could make it easier to distribute them around the world, the researchers say.
“Subunit vaccines have been around for a long time, and they tend to be cheaper to produce, so that opens up more access to vaccines, especially in times of pandemic,” Jaklenec says.
The research was funded by Ibn Khaldun Fellowships for Saudi Arabian Women and in part by the Koch Institute Support (core) Grant from the U.S. National Cancer Institute.
MIT engineers designed a nanoparticle vaccine made from a metal organic framework called ZIF-8, which is coated with the SARS-CoV-2 receptor binding protein (blue) and an adjuvant called Gdq (green).
Generative AI is getting plenty of attention for its ability to create text and images. But those media represent only a fraction of the data that proliferate in our society today. Data are generated every time a patient goes through a medical system, a storm impacts a flight, or a person interacts with a software application.
Using generative AI to create realistic synthetic data around those scenarios can help organizations more effectively treat patients, reroute planes, or improve software platforms — especially in scenarios where real-world data are limited or sensitive.
For the last three years, the MIT spinout DataCebo has offered a generative software system called the Synthetic Data Vault to help organizations create synthetic data to do things like test software applications and train machine learning models.
The Synthetic Data Vault, or SDV, has been downloaded more than 1 million times, with more than 10,000 data scientists using the open-source library for generating synthetic tabular data. The founders — Principal Research Scientist Kalyan Veeramachaneni and alumna Neha Patki ’15, SM ’16 — believe the company’s success is due to SDV’s ability to revolutionize software testing.
SDV goes viral
In 2016, Veeramachaneni’s group in the Data to AI Lab unveiled a suite of open-source generative AI tools to help organizations create synthetic data that matched the statistical properties of real data.
Companies can use synthetic data instead of sensitive information in programs while still preserving the statistical relationships between datapoints. Companies can also use synthetic data to run new software through simulations to see how it performs before releasing it to the public.
Veeramachaneni’s group came across the problem because it was working with companies that wanted to share their data for research.
“MIT helps you see all these different use cases,” Patki explains. “You work with finance companies and health care companies, and all those projects are useful to formulate solutions across industries.”
In 2020, the researchers founded DataCebo to build more SDV features for larger organizations. Since then, the use cases have been as impressive as they’ve been varied.
With DataCebo's new flight simulator, for instance, airlines can plan for rare weather events in a way that would be impossible using only historic data. In another application, SDV users synthesized medical records to predict health outcomes for patients with cystic fibrosis. A team from Norway recently used SDV to create synthetic student data to evaluate whether various admissions policies were meritocratic and free from bias.
In 2021, the data science platform Kaggle hosted a competition for data scientists that used SDV to create synthetic data sets to avoid using proprietary data. Roughly 30,000 data scientists participated, building solutions and predicting outcomes based on the company’s realistic data.
And as DataCebo has grown, it’s stayed true to its MIT roots: All of the company’s current employees are MIT alumni.
Supercharging software testing
Although their open-source tools are being used for a variety of use cases, the company is focused on growing its traction in software testing.
“You need data to test these software applications,” Veeramachaneni says. “Traditionally, developers manually write scripts to create synthetic data. With generative models, created using SDV, you can learn from a sample of data collected and then sample a large volume of synthetic data (which has the same properties as real data), or create specific scenarios and edge cases, and use the data to test your application.”
For example, if a bank wanted to test a program designed to reject transfers from accounts with no money in them, it would have to simulate many accounts simultaneously transacting. Doing that with data created manually would take a lot of time. With DataCebo’s generative models, customers can create any edge case they want to test.
“It’s common for industries to have data that is sensitive in some capacity,” Patki says. “Often when you’re in a domain with sensitive data you’re dealing with regulations, andeven if there aren’t legal regulations, it’s in companies’ best interest to be diligent about who gets access to what at which time. So, synthetic data is always better from a privacy perspective.”
Scaling synthetic data
Veeramachaneni believes DataCebo is advancing the field of what it calls synthetic enterprise data, or data generated from user behavior on large companies’ software applications.
“Enterprise data of this kind is complex, and there is no universal availability of it, unlike language data,” Veeramachaneni says. “When folks use our publicly available software and report back if works on a certain pattern, we learn a lot of these unique patterns, and it allows us to improve our algorithms. From one perspective, we are building a corpus of these complex patterns, which for language and images is readily available. “
DataCebo also recently released features to improve SDV’s usefulness, including tools to assess the “realism” of the generated data, called the SDMetrics library as well as a way to compare models’ performances called SDGym.
“It’s about ensuring organizations trust this new data,” Veeramachaneni says. “[Our tools offer] programmable synthetic data, which means we allow enterprises to insert their specific insight and intuition to build more transparent models.”
As companies in every industry rush to adopt AI and other data science tools, DataCebo is ultimately helping them do so in a way that is more transparent and responsible.
“In the next few years, synthetic data from generative models will transform all data work,” Veeramachaneni says. “We believe 90 percent of enterprise operations can be done with synthetic data.”
DataCebo offers a generative software system called the Synthetic Data Vault to help organizations create synthetic data to do things like test software applications and train machine learning models.
When listening to music, the human brain appears to be biased toward hearing and producing rhythms composed of simple integer ratios — for example, a series of four beats separated by equal time intervals (forming a 1:1:1 ratio).
However, the favored ratios can vary greatly between different societies, according to a large-scale study led by researchers at MIT and the Max Planck Institute for Empirical Aesthetics and carried out in 15 countries. The study included 39 groups of participants, many of whom came from societies whose traditional music contains distinctive patterns of rhythm not found in Western music.
“Our study provides the clearest evidence yet for some degree of universality in music perception and cognition, in the sense that every single group of participants that was tested exhibits biases for integer ratios. It also provides a glimpse of the variation that can occur across cultures, which can be quite substantial,” says Nori Jacoby, the study’s lead author and a former MIT postdoc, who is now a research group leader at the Max Planck Institute for Empirical Aesthetics in Frankfurt, Germany.
The brain’s bias toward simple integer ratios may have evolved as a natural error-correction system that makes it easier to maintain a consistent body of music, which human societies often use to transmit information.
“When people produce music, they often make small mistakes. Our results are consistent with the idea that our mental representation is somewhat robust to those mistakes, but it is robust in a way that pushes us toward our preexisting ideas of the structures that should be found in music,” says Josh McDermott, an associate professor of brain and cognitive sciences at MIT and a member of MIT’s McGovern Institute for Brain Research and Center for Brains, Minds, and Machines.
McDermott is the senior author of the study, which appears today in Nature Human Behaviour. The research team also included scientists from more than two dozen institutions around the world.
A global approach
The new study grew out of a smaller analysis that Jacoby and McDermott published in 2017. In that paper, the researchers compared rhythm perception in groups of listeners from the United States and the Tsimane’, an Indigenous society located in the Bolivian Amazon rainforest.
To measure how people perceive rhythm, the researchers devised a task in which they play a randomly generated series of four beats and then ask the listener to tap back what they heard. The rhythm produced by the listener is then played back to the listener, and they tap it back again. Over several iterations, the tapped sequences became dominated by the listener’s internal biases, also known as priors.
“The initial stimulus pattern is random, but at each iteration the pattern is pushed by the listener’s biases, such that it tends to converge to a particular point in the space of possible rhythms,” McDermott says. “That can give you a picture of what we call the prior, which is the set of internal implicit expectations for rhythms that people have in their heads.”
When the researchers first did this experiment, with American college students as the test subjects, they found that people tended to produce time intervals that are related by simple integer ratios. Furthermore, most of the rhythms they produced, such as those with ratios of 1:1:2 and 2:3:3, are commonly found in Western music.
The researchers then went to Bolivia and asked members of the Tsimane’ society to perform the same task. They found that Tsimane’ also produced rhythms with simple integer ratios, but their preferred ratios were different and appeared to be consistent with those that have been documented in the few existing records of Tsimane’ music.
“At that point, it provided some evidence that there might be very widespread tendencies to favor these small integer ratios, and that there might be some degree of cross-cultural variation. But because we had just looked at this one other culture, it really wasn’t clear how this was going to look at a broader scale,” Jacoby says.
To try to get that broader picture, the MIT team began seeking collaborators around the world who could help them gather data on a more diverse set of populations. They ended up studying listeners from 39 groups, representing 15 countries on five continents — North America, South America, Europe, Africa, and Asia.
“This is really the first study of its kind in the sense that we did the same experiment in all these different places, with people who are on the ground in those locations,” McDermott says. “That hasn’t really been done before at anything close to this scale, and it gave us an opportunity to see the degree of variation that might exist around the world.”
Cultural comparisons
Just as they had in their original 2017 study, the researchers found that in every group they tested, people tended to be biased toward simple integer ratios of rhythm. However, not every group showed the same biases. People from North America and Western Europe, who have likely been exposed to the same kinds of music, were more likely to generate rhythms with the same ratios. However, many groups, for example those in Turkey, Mali, Bulgaria, and Botswana showed a bias for other rhythms.
“There are certain cultures where there are particular rhythms that are prominent in their music, and those end up showing up in the mental representation of rhythm,” Jacoby says.
The researchers believe their findings reveal a mechanism that the brain uses to aid in the perception and production of music.
“When you hear somebody playing something and they have errors in their performance, you’re going to mentally correct for those by mapping them onto where you implicitly think they ought to be,” McDermott says. “If you didn’t have something like this, and you just faithfully represented what you heard, these errors might propagate and make it much harder to maintain a musical system.”
Among the groups that they studied, the researchers took care to include not only college students, who are easy to study in large numbers, but also people living in traditional societies, who are more difficult to reach. Participants from those more traditional groups showed significant differences from college students living in the same countries, and from people who live in those countries but performed the test online.
“What’s very clear from the paper is that if you just look at the results from undergraduate students around the world, you vastly underestimate the diversity that you see otherwise,” Jacoby says. “And the same was true of experiments where we tested groups of people online in Brazil and India, because you’re dealing with people who have internet access and presumably have more exposure to Western music.”
The researchers now hope to run additional studies of different aspects of music perception, taking this global approach.
“If you’re just testing college students around the world or people online, things look a lot more homogenous. I think it’s very important for the field to realize that you actually need to go out into communities and run experiments there, as opposed to taking the low-hanging fruit of running studies with people in a university or on the internet,” McDermott says.
The research was funded by the James S. McDonnell Foundation, the Canadian National Science and Engineering Research Council, the South African National Research Foundation, the United States National Science Foundation, the Chilean National Research and Development Agency, the Austrian Academy of Sciences, the Japan Society for the Promotion of Science, the Keio Global Research Institute, the United Kingdom Arts and Humanities Research Council, the Swedish Research Council, and the John Fell Fund.
The study included 39 groups of participants, many of whom came from societies whose traditional music contains distinctive patterns of rhythm not found in Western music.
In the predawn hours of Sept. 5, 2021, engineers achieved a major milestone in the labs of MIT’s Plasma Science and Fusion Center (PSFC), when a new type of magnet, made from high-temperature superconducting material, achieved a world-record magnetic field strength of 20 tesla for a large-scale magnet. That’s the intensity needed to build a fusion power plant that is expected to produce a net output of power and potentially usher in an era of virtually limitless power production.
The test was immediately declared a success, having met all the criteria established for the design of the new fusion device, dubbed SPARC, for which the magnets are the key enabling technology. Champagne corks popped as the weary team of experimenters, who had labored long and hard to make the achievement possible, celebrated their accomplishment.
But that was far from the end of the process. Over the ensuing months, the team tore apart and inspected the components of the magnet, pored over and analyzed the data from hundreds of instruments that recorded details of the tests, and performed two additional test runs on the same magnet, ultimately pushing it to its breaking point in order to learn the details of any possible failure modes.
All of this work has now culminated in a detailed report by researchers at PSFC and MIT spinout company Commonwealth Fusion Systems (CFS), published in a collection of six peer-reviewed papers in a special edition of the March issue of IEEE Transactions on Applied Superconductivity. Together, the papers describe the design and fabrication of the magnet and the diagnostic equipment needed to evaluate its performance, as well as the lessons learned from the process. Overall, the team found, the predictions and computer modeling were spot-on, verifying that the magnet’s unique design elements could serve as the foundation for a fusion power plant.
Enabling practical fusion power
The successful test of the magnet, says Hitachi America Professor of Engineering Dennis Whyte, who recently stepped down as director of the PSFC, was “the most important thing, in my opinion, in the last 30 years of fusion research.”
Before the Sept. 5 demonstration, the best-available superconducting magnets were powerful enough to potentially achieve fusion energy — but only at sizes and costs that could never be practical or economically viable. Then, when the tests showed the practicality of such a strong magnet at a greatly reduced size, “overnight, it basically changed the cost per watt of a fusion reactor by a factor of almost 40 in one day,” Whyte says.
“Now fusion has a chance,” Whyte adds. Tokamaks, the most widely used design for experimental fusion devices, “have a chance, in my opinion, of being economical because you’ve got a quantum change in your ability, with the known confinement physics rules, about being able to greatly reduce the size and the cost of objects that would make fusion possible.”
The comprehensive data and analysis from the PSFC’s magnet test, as detailed in the six new papers, has demonstrated that plans for a new generation of fusion devices — the one designed by MIT and CFS, as well as similar designs by other commercial fusion companies — are built on a solid foundation in science.
The superconducting breakthrough
Fusion, the process of combining light atoms to form heavier ones, powers the sun and stars, but harnessing that process on Earth has proved to be a daunting challenge, with decades of hard work and many billions of dollars spent on experimental devices. The long-sought, but never yet achieved, goal is to build a fusion power plant that produces more energy than it consumes. Such a power plant could produce electricity without emitting greenhouse gases during operation, and generating very little radioactive waste. Fusion’s fuel, a form of hydrogen that can be derived from seawater, is virtually limitless.
But to make it work requires compressing the fuel at extraordinarily high temperatures and pressures, and since no known material could withstand such temperatures, the fuel must be held in place by extremely powerful magnetic fields. Producing such strong fields requires superconducting magnets, but all previous fusion magnets have been made with a superconducting material that requires frigid temperatures of about 4 degrees above absolute zero (4 kelvins, or -270 degrees Celsius). In the last few years, a newer material nicknamed REBCO, for rare-earth barium copper oxide, was added to fusion magnets, and allows them to operate at 20 kelvins, a temperature that despite being only 16 kelvins warmer, brings significant advantages in terms of material properties and practical engineering.
Taking advantage of this new higher-temperature superconducting material was not just a matter of substituting it in existing magnet designs. Instead, “it was a rework from the ground up of almost all the principles that you use to build superconducting magnets,” Whyte says. The new REBCO material is “extraordinarily different than the previous generation of superconductors. You’re not just going to adapt and replace, you’re actually going to innovate from the ground up.” The new papers in Transactions on Applied Superconductivity describe the details of that redesign process, now that patent protection is in place.
A key innovation: no insulation
One of the dramatic innovations, which had many others in the field skeptical of its chances of success, was the elimination of insulation around the thin, flat ribbons of superconducting tape that formed the magnet. Like virtually all electrical wires, conventional superconducting magnets are fully protected by insulating material to prevent short-circuits between the wires. But in the new magnet, the tape was left completely bare; the engineers relied on REBCO’s much greater conductivity to keep the current flowing through the material.
“When we started this project, in let’s say 2018, the technology of using high-temperature superconductors to build large-scale high-field magnets was in its infancy,” says Zach Hartwig, the Robert N. Noyce Career Development Professor in the Department of Nuclear Science and Engineering. Hartwig has a co-appointment at the PSFC and is the head of its engineering group, which led the magnet development project. “The state of the art was small benchtop experiments, not really representative of what it takes to build a full-size thing. Our magnet development project started at benchtop scale and ended up at full scale in a short amount of time,” he adds, noting that the team built a 20,000-pound magnet that produced a steady, even magnetic field of just over 20 tesla — far beyond any such field ever produced at large scale.
“The standard way to build these magnets is you would wind the conductor and you have insulation between the windings, and you need insulation to deal with the high voltages that are generated during off-normal events such as a shutdown.” Eliminating the layers of insulation, he says, “has the advantage of being a low-voltage system. It greatly simplifies the fabrication processes and schedule.” It also leaves more room for other elements, such as more cooling or more structure for strength.
The magnet assembly is a slightly smaller-scale version of the ones that will form the donut-shaped chamber of the SPARC fusion device now being built by CFS in Devens, Massachusetts. It consists of 16 plates, called pancakes, each bearing a spiral winding of the superconducting tape on one side and cooling channels for helium gas on the other.
But the no-insulation design was considered risky, and a lot was riding on the test program. “This was the first magnet at any sufficient scale that really probed what is involved in designing and building and testing a magnet with this so-called no-insulation no-twist technology,” Hartwig says. “It was very much a surprise to the community when we announced that it was a no-insulation coil.”
Pushing to the limit … and beyond
The initial test, described in previous papers, proved that the design and manufacturing process not only worked but was highly stable — something that some researchers had doubted. The next two test runs, also performed in late 2021, then pushed the device to the limit by deliberately creating unstable conditions, including a complete shutoff of incoming power that can lead to a catastrophic overheating. Known as quenching, this is considered a worst-case scenario for the operation of such magnets, with the potential to destroy the equipment.
Part of the mission of the test program, Hartwig says, was “to actually go off and intentionally quench a full-scale magnet, so that we can get the critical data at the right scale and the right conditions to advance the science, to validate the design codes, and then to take the magnet apart and see what went wrong, why did it go wrong, and how do we take the next iteration toward fixing that. … It was a very successful test.”
That final test, which ended with the melting of one corner of one of the 16 pancakes, produced a wealth of new information, Hartwig says. For one thing, they had been using several different computational models to design and predict the performance of various aspects of the magnet’s performance, and for the most part, the models agreed in their overall predictions and were well-validated by the series of tests and real-world measurements. But in predicting the effect of the quench, the model predictions diverged, so it was necessary to get the experimental data to evaluate the models’ validity.
“The highest-fidelity models that we had predicted almost exactly how the magnet would warm up, to what degree it would warm up as it started to quench, and where would the resulting damage to the magnet would be,” he says. As described in detail in one of the new reports, “That test actually told us exactly the physics that was going on, and it told us which models were useful going forward and which to leave by the wayside because they’re not right.”
Whyte says, “Basically we did the worst thing possible to a coil, on purpose, after we had tested all other aspects of the coil performance. And we found that most of the coil survived with no damage,” while one isolated area sustained some melting. “It’s like a few percent of the volume of the coil that got damaged.” And that led to revisions in the design that are expected to prevent such damage in the actual fusion device magnets, even under the most extreme conditions.
Hartwig emphasizes that a major reason the team was able to accomplish such a radical new record-setting magnet design, and get it right the very first time and on a breakneck schedule, was thanks to the deep level of knowledge, expertise, and equipment accumulated over decades of operation of the Alcator C-Mod tokamak, the Francis Bitter Magnet Laboratory, and other work carried out at PSFC. “This goes to the heart of the institutional capabilities of a place like this,” he says. “We had the capability, the infrastructure, and the space and the people to do these things under one roof.”
The collaboration with CFS was also key, he says, with MIT and CFS combining the most powerful aspects of an academic institution and private company to do things together that neither could have done on their own. “For example, one of the major contributions from CFS was leveraging the power of a private company to establish and scale up a supply chain at an unprecedented level and timeline for the most critical material in the project: 300 kilometers (186 miles) of high-temperature superconductor, which was procured with rigorous quality control in under a year, and integrated on schedule into the magnet.”
The integration of the two teams, those from MIT and those from CFS, also was crucial to the success, he says. “We thought of ourselves as one team, and that made it possible to do what we did.”
As it trundles around an ancient lakebed on Mars, NASA’s Perseverance rover is assembling a one-of-a-kind rock collection. The car-sized explorer is methodically drilling into the Red Planet’s surface and pulling out cores of bedrock that it’s storing in sturdy titanium tubes. Scientists hope to one day return the tubes to Earth and analyze their contents for traces of embedded microbial life.
Since it touched down on the surface of Mars in 2021, the rover has filled 20 of its 43 tubes with cores of bedrock. Now, MIT geologists have remotely determined a crucial property of the rocks collected to date, which will help scientists answer key questions about the planet’s past.
In a study appearing today in the journal Earth and Space Science, an MIT team reports that they have determined the original orientation of most bedrock samples collected by the rover to date. By using the rover’s own engineering data, such as the positioning of the vehicle and its drill, the scientists could estimate the orientation of each sample of bedrock before it was drilled out from the Martian ground.
The results represent the first time scientists have oriented samples of bedrock on another planet. The team’s method can be applied to future samples that the rover collects as it expands its exploration outside the ancient basin. Piecing together the orientations of multiple rocks at various locations can then give scientists clues to the conditions on Mars in which the rocks originally formed.
“There are so many science questions that rely on being able to know the orientation of the samples we’re bringing back from Mars,” says study author Elias Mansbach, a graduate student in MIT’s Department of Earth, Atmospheric and Planetary Sciences.
“The orientation of rocks can tell you something about any magnetic field that may have existed on the planet,” adds Benjamin Weiss, professor of planetary sciences at MIT. “You can also study how water and lava flowed on the planet, the direction of the ancient wind, and tectonic processes, like what was uplifted and what sunk. So it’s a dream to be able to orient bedrock on another planet, because it’s going to open up so many scientific investigations.”
Weiss and Mansbach’s co-authors are Tanja Bosak and Jennifer Fentress at MIT, along with collaborators at multiple institutions including the Jet Propulsion Laboratory at Caltech.
Profound shift
The Perseverance rover, nicknamed “Percy,” is exploring the floor of Jezero Crater, a large impact crater layered with igneous rocks, which may have been deposited from past volcanic eruptions, as well as sedimentary rocks that likely formed from long-dried-out rivers that fed into the basin.
“Mars was once warm and wet, and there’s a possibility there was life there at one time,” Weiss says. “It’s now cold and dry, and something profound must have happened on the planet.”
Many scientists, including Weiss, suspect that Mars, like Earth, once harbored a magnetic field that shielded the planet from the sun’s solar wind. Conditions then may have been favorable for water and life, at least for a time.
“Once that magnetic field went away, the sun’s solar wind — this plasma that boils off the sun and moves faster than the speed of sound — just slammed into Mars’ atmosphere and may have removed it over billions of years,” Weiss says. “We want to know what happened, and why.”
The rocks beneath the Martian surface likely hold a record of the planet’s ancient magnetic field. When rocks first form on a planet’s surface, the direction of their magnetic minerals is set by the surrounding magnetic field. The orientation of rocks can thus help to retrace the direction and intensity of the planet’s magnetic field and how it changed over time.
Since the Perseverance rover was collecting samples of bedrock, along with surface soil and air, as part of its exploratory mission, Weiss, who is a member of the rover’s science team, and Mansbach looked for ways to determine the original orientation of the rover’s bedrock samples as a first step toward reconstructing Mars’ magnetic history.
“It was an amazing opportunity, but initially there was no mission requirement to orient bedrock,” Mansbach notes.
Roll with it
Over several months, Mansbach and Weiss met with NASA engineers to hash out a plan for how to estimate the original orientation of each sample of bedrock before it was drilled out of the ground. The problem was a bit like predicting what direction a small circle of sheetcake is pointing, before twisting a round cookie cutter in to pull out a piece. Similarly, to sample bedrock, Perseverance corkscrews a tube-shaped drill into the ground at a perpendicular angle, then pulls the drill directly back out, along with any rock that it penetrates.
To estimate the orientation of the rock before it was drilled out of the ground, the team realized they need to measure three angles, the hade, azimuth, and roll, which are similar to the pitch, yaw, and roll of a boat. The hade is essentially the tilt of the sample, while the azimuth is the absolute direction the sample is pointing relative to true north. The roll refers to how much a sample must turn before returning to its original position.
In talking with engineers at NASA, the MIT geologists found that the three angles they required were related to measurements that the rover takes on its own in the course of its normal operations. They realized that to estimate a sample’s hade and azimuth they could use the rover’s measurements of the drill’s orientation, as they could assume the tilt of the drill is parallel to any sample that it extracts.
To estimate a sample’s roll, the team took advantage of one of the rover’s onboard cameras, which snaps an image of the surface where the drill is about to sample. They reasoned that they could use any distinguishing features on the surface image to determine how much the sample would have to turn in order to return to its original orientation.
In cases where the surface bore no distinguishing features, the team used the rover’s onboard laser to make a mark in the rock, in the shape of the letter “L,” before drilling out a sample — a move that was jokingly referred to at the time as the first graffiti on another planet.
By combining all the rover’s positioning, orienting, and imaging data, the team estimated the original orientations of all 20 of the Martian bedrock samples collected so far, with a precision that is comparable to orienting rocks on Earth.
“We know the orientations to within 2.7 degrees uncertainty, which is better than what we can do with rocks in the Earth,” Mansbach says. “We’re working with engineers now to automate this orienting process so that it can be done with other samples in the future.”
“The next phase will be the most exciting,” Weiss says. “The rover will drive outside the crater to get the oldest known rocks on Mars, and it’s an incredible opportunity to be able to orient these rocks, and hopefully uncover a lot of these ancient processes.”
This research was supported, in part, by NASA and the Mars 2020 Participating Scientist program.
MIT geologists determined the original orientation of many of the bedrock samples collected on Mars by the Perseverance rover, depicted in this image rendering. The findings can give scientists clues to the conditions in which the rocks originally formed.
The term “fog of war” expresses the chaos and uncertainty of the battlefield. Often, it is only in hindsight that people can grasp what was unfolding around them.
Now, additional clarity about the Iraq War has arrived in the form of a new book by MIT political scientist Roger Petersen, which dives into the war’s battlefield operations, political dynamics, and long-term impact. The U.S. launched the Iraq War in 2003 and formally wrapped it up in 2011, but Petersen analyzes the situation in Iraq through the current day and considers what the future holds for the country.
After a decade of research, Petersen identifies four key factors for understanding Iraq’s situation. First, the U.S. invasion created chaos and a lack of clarity in terms of the hierarchy among Shia, Sunni, and Kurdish groups. Second, given these conditions, organizations that comprised a mix of militias, political groups, and religious groups came to the fore and captured elements of the new state the U.S. was attempting to set up. Third, by about 2018, the Shia groups became dominant, establishing a hierarchy, and along with that dominance, sectarian violence has fallen. Finally, the hybrid organizations established many years ago are now highly integrated into the Iraqi state.
Petersen has also come to believe two things about the Iraq War are not fully appreciated. One is how widely U.S. strategy varied over time in response to shifting circumstances.
“This was not one war,” says Petersen. “This was many different wars going on. We had at least five strategies on the U.S. side.”
And while the expressed goal of many U.S. officials was to build a functioning democracy in Iraq, the intense factionalism of Iraqi society led to further military struggles, between and among religious and ethnic groups. Thus, U.S. military strategy shifted as this multisided conflict evolved.
“What really happened in Iraq, and the thing the United States and Westerners did not understand at first, is how much this would become a struggle for dominance among Shias, Sunnis, and Kurds,” says Petersen. “The United States thought they would build a state, and the state would push down and penetrate society. But it was society that created militias and captured the state.”
Attempts to construct a well-functioning state, in Iraq or elsewhere must confront this factor, Petersen adds. “Most people think in terms of groups. They think in terms of group hierarchies, and they’re motivated when they believe their own group is not in a proper space in the hierarchy. This is this emotion of resentment. I think this is just human nature.”
Petersen spent years interviewing people who were on the ground in Iraq during the war, from U.S. military personnel to former insurgents to regular Iraqi citizens, while extensively analyzing data about the conflict.
“I didn’t really come to conclusions about Iraq until six or seven years of applying this method,” he says.
Ultimately, one core fact about the country heavily influenced the trajectory of the war. Iraq’s Sunni Muslims made up about 20 percent or less of the country’s population but had been politically dominant before the U.S. took military action. After the U.S. toppled former dictator Saddam Hussein, it created an opening for the Shia majority to grasp more power.
“The United States said, ‘We’re going to have democracy and think in individual terms,’ but this is not the way it played out,” Petersen says. “The way it played out was, over the years, the Shia organizations became the dominant force. The Sunnis and Kurds are now basically subordinate within this Shia-dominated state. The Shias also had advantages in organizing violence over the Sunnis, and they’re the majority. They were going to win.”
As Petersen details in the book, a central unit of power became the political militia, based on ethnic and religious identification. One Shia militia, the Badr Organization, had trained professionally for years in Iran. The local Iraqi leader Moqtada al-Sadr could recruit Shia fighters from among the 2 million people living in the Sadr City slum. And no political militia wanted to back a strong multiethnic government.
“They liked this weaker state,” Petersen says. “The United States wanted to build a new Iraqi state, but what we did was create a situation where multiple and large Shia militia make deals with each other.”
A captain’s war
In turn, these dynamics meant the U.S. had to shift military strategies numerous times, occasionally in high-profile ways. The five strategies Petersen identifies are clear, hold, build (CHB); decapitation; community mobilization; homogenization; and war-fighting.
“The war from the U.S. side was highly decentralized,” Petersen says. Military captains, who typically command about 140 to 150 soldiers, had fairly wide berth in terms of how they were choosing to fight.
“It was a captain’s war in a lot of ways,” Petersen adds.
The point is emphatically driven home in one chapter, “Captain Wright goes to Baghdad,” co-authored with Col. Timothy Wright PhD ’18, who wrote his MIT political science dissertation based on his experience and company command during the surge period.
As Petersen also notes, drawing on government data, the U.S. also managed to suppress violence fairly effectively at times, particularly before 2006 and after 2008. “The professional soldiers tried to do a good job, but some of the problems they weren’t going to solve,” Petersen says.
Still, all of this raises a conundrum. If trying to start a new state in Iraq was always likely to lead to an increase in Shia power, is there really much the U.S. could have done differently?
“That’s a million-dollar question,” Petersen says.
Perhaps the best way to engage with it, Petersen notes, is to recognize the importance of studying how factional groups grasp power through use of violence, and how that emerges in society. It is a key issue running throughout Petersen’s work, and one, he notes, that has often been studied by his graduate students in MIT’s Security Studies Program.
“Death, Dominance, and State-Building” has received praise from foreign-policy scholars. Paul Staniland, a political scientist at the University of Chicago, has said the work combines “intellectual creativity with careful attention to on-the ground dynamics,” and is “a fascinating macro-level account of the politics of group competition in Iraq. This book is required reading for anyone interested in civil war, U.S. foreign policy, or the politics of violent state-building."
Petersen, for his part, allows that he was pleased when one marine who served in Iraq read the manuscript in advance and found it interesting.
“He said, ‘This is good, and it’s not the way we think about it,’” Petersen says. “That’s my biggest compliment, to have a practitioner say it make them think. If I can get that kind of reaction, I’ll be pleased.”
“Death, Dominance, and State-Building,” a new book by MIT Professor Roger Petersen, takes a close look at military operations and political dynamics of the Iraq War.
Individuals with mild cognitive impairment, especially of the “amnestic subtype” (aMCI), are at increased risk for dementia due to Alzheimer’s disease relative to cognitively healthy older adults. Now, a study co-authored by researchers from MIT, Cornell University, and Massachusetts General Hospital has identified a key deficit in people with aMCI, which relates to producing complex language.
This deficit is independent of the memory deficit that characterizes this group and may provide an additional “cognitive biomarker” to aid in early detection — the time when treatments, as they continue to be developed, are likely to be most effective.
The researchers found that while individuals with aMCI could appreciate the basic structure of sentences (syntax) and their meaning (semantics), they struggled with processing certain ambiguous sentences in which pronouns alluded to people not referenced in the sentences themselves.
“These results are among the first to deal with complex syntax and really get at the abstract computation that’s involved in processing these linguistic structures,” says MIT linguistics scholar Suzanne Flynn, co-author of a paper detailing the results.
The focus on subtleties in language processing, in relation to aMCI and its potential transition to dementia such as Alzheimer’s disease is novel, the researchers say.
“Previous research has looked most often at single words and vocabulary,” says co-author Barbara Lust, a professor emerita at Cornell University. “We looked at a more complex level of language knowledge. When we process a sentence, we have to both grasp its syntax and construct a meaning. We found a breakdown at that higher level where you’re integrating form and meaning.”
The paper’s authors are Flynn, a professor in MIT’s Department of Linguistics and Philosophy; Lust, a professor emerita in the Department of Psychology at Cornell and a visiting scholar and research affiliate in the MIT Department of Linguistics and Philosophy; Janet Cohen Sherman, an associate professor of psychology in the Department of Psychiatry at Massachusetts General Hospital and director of the MGH Psychology Assessment Center; and, posthumously, the scholars James Gair and Charles Henderson of Cornell University.
Anaphora and ambiguity
To conduct the study, the scholars ran experiments comparing the cognitive performance of aMCI patients to cognitively healthy individuals in separate younger and older control groups. The research involved 61 aMCI patients of Massachusetts General Hospital, with control group research conducted at Cornell and MIT.
The study pinpointed how well people process and reproduce sentences involving “anaphora.” In linguistics terms, this generally refers to the relation between a word and another form in the sentence, such the use of “his” in the sentence, “The electrician repaired his equipment.” (The term “anaphora” has another related use in the field of rhetoric, involving the repetition of terms.)
In the study, the researchers ran a variety of sentence constructions past aMCI patients and the control groups. For instance, in the sentence, “The electrician fixed the light switch when he visited the tenant,” it is not actually clear if “he” refers to the electrician, or somebody else entirely. The “he” could be a family member, friend, or landlord, among other possibilities.
On the other hand, in the sentence, “He visited the tenant when the electrician repaired the light switch,” “he” and the electrician cannot be the same person. Alternately, in the sentence, “The babysitter emptied the bottle and prepared the formula,” there is no reference at all to a person beyond the sentence.
Ultimately, aMCI patients performed significantly worse than the control groups when producing sentences with “anaphoric coreference,” the ones with ambiguity about the identity of the person referred to via a pronoun.
“It’s not that aMCI patients have lost the ability to process syntax or put complex sentences together, or lost words; it’s that they’re showing a deficit when the mind has to figure out whether to stay in the sentence or go outside it, to figure out who we’re talking about,” Lust explains. “When they didn’t have to go outside the sentence for context, sentence production was preserved in the individuals with aMCI whom we studied.”
Flynn notes: “This adds to our understanding of the deterioration that occurs in early stages of the dementia process. Deficits extend beyond memory loss. While the participants we studied have memory deficits, their memory difficulties do not explain our language findings, as evidenced by a lack of correlation in their performance on the language task and their performances on measures of memory. This suggests that in addition to the memory difficulties that individuals with aMCI experience, they are also struggling with this central aspect of language.”
Looking for a path to treatment
The current paper is part of an ongoing series of studies that Flynn, Lust, Sherman, and their colleagues have performed. The findings have implications for potentially steering neuroscience studies toward regions of the brain that process language, when investigating MCI and other forms of dementia, such as primary progressive aphasia. The study may also help inform linguistics theory concerning various forms of anaphora.
Looking ahead, the scholars say they would like to increase the size of the studies as part of an effort to continue to define how it is that diseases progress and how language may be a predictor of that.
“Our data is a small population but very richly theoretically guided,” Lust says. “You need hypotheses that are linguistically informed to make advances in neurolinguistics. There’s so much interest in the years before Alzheimer’s disease is diagnosed, to see if it can be caught and its progression stopped.”
As Flynn adds, “The more precise we can become about the neuronal locus of deterioration, that’s going to make a big difference in terms of developing treatment.”
Support for the research was provided by the Cornell University Podell Award, Shamitha Somashekar and Apple Corporation, Federal Formula Funds, Brad Hyman at Massachusetts General Hospital, the Cornell Bronfenbrenner Center for Life Course Development, the Cornell Institute for Translational Research on Aging, the Cornell Institute for Social Science Research, and the Cornell Cognitive Science Program.
Language-processing difficulties are more of an indicator than memory loss of amnestic mild cognitive impairment (aMCI), a risk factor for dementia due to Alzheimer’s disease, according to a new study.
One of the immune system’s primary roles is to detect and kill cells that have acquired cancerous mutations. However, some early-stage cancer cells manage to evade this surveillance and develop into more advanced tumors.
A new study from MIT and Dana-Farber Cancer Institute has identified one strategy that helps these precancerous cells avoid immune detection. The researchers found that early in colon cancer development, cells that turn on a gene called SOX17 can become essentially invisible to the immune system.
If scientists could find a way to block SOX17 function or the pathway that it activates, this may offer a new way to treat early-stage cancers before they grow into larger tumors, the researchers say.
“Activation of the SOX17 program in the earliest innings of colorectal cancer formation is a critical step that shields precancerous cells from the immune system. If we can inhibit the SOX17 program, we might be better able to prevent colon cancer, particularly in patients that are prone to developing colon polyps,” says Omer Yilmaz, an MIT associate professor of biology, a member of MIT’s Koch Institute for Integrative Cancer Research, and one of the senior authors of the study.
Judith Agudo, a principal investigator at Dana-Farber Cancer Institute and an assistant professor at Harvard Medical School, is also a senior author of the study, which appears today in Nature. The paper’s lead author is MIT Research Scientist Norihiro Goto. Other collaborators include Tyler Jacks, a professor of biology and a member of MIT’s Koch Institute; Peter Westcott, a former Jacks lab postdoc who is now an assistant professor at Cold Spring Harbor Laboratory; and Saori Goto, an MIT postdoc in the Yilmaz lab.
Immune evasion
Colon cancer usually arises in long-lived cells called intestinal stem cells, whose job is to continually regenerate the lining of the intestines. Over their long lifetime, these cells can accumulate cancerous mutations that lead to the formation of polyps, a type of premalignant growth that can eventually become metastatic colon cancer.
To learn more about how these precancerous growths evade the immune system, the researchers used a technique they had previously developed for growing mini colon tumors in a lab dish and then implanting them into mice. In this case, the researchers engineered the tumors to express mutated versions of cancer-linked genes Kras, p53, and APC, which are often found in human colon cancers.
Once these tumors were implanted in mice, the researchers observed a dramatic increase in the tumors’ expression of SOX17. This gene encodes a transcription factor that is normally active only during embryonic development, when it helps to control development of the intestines and the formation of blood vessels.
The researchers’ experiments revealed that when SOX17 is turned on in cancer cells, it helps the cells to create an immunosuppressive environment. Among its effects, SOX17 prevents cells from synthesizing the receptor that normally detects interferon gamma, a molecule that is one of the immune system’s primary weapons against cancer cells.
Without those interferon gamma receptors, cancerous and precancerous cells can simply ignore messages from the immune system, which would normally direct them to undergo programmed cell death.
“One of SOX17’s main roles is to turn off the interferon gamma signaling pathway in colorectal cancer cells and in precancerous adenoma cells. By turning off interferon gamma receptor signaling in the tumor cells, the tumor cells become hidden from T cells and can grow in the presence of an immune system,” Yilmaz says.
Without interferon gamma signaling, cancer cells also minimize their production of molecules called MHC proteins, which are responsible for displaying cancerous antigens to the immune system. The cells’ insensitivity to interferon gamma also prevents them from producing immune molecules called chemokines, which normally recruit T cells that would help destroy the cancerous cells.
Targeting SOX17
When the researchers generated colon tumor organoids with SOX17 knocked out, and implanted those into mice, the immune system was able to attack those tumors much more effectively. This suggests that preventing cancer cells from turning off SOX17 could offer a way to treat colon cancer in its earliest stages.
“Just by turning off SOX17 in fairly complex tumors, we were able to essentially obliterate the ability of these tumor cells to persist,” Goto says.
As part of their study, the researchers also analyzed gene expression data from patients with colon cancer and found that SOX17 tended to be highly expressed in early-stage colon cancers but dropped off as the tumors became more invasive and metastatic.
“We think this makes a lot of sense because as colorectal cancers become more invasive and metastatic, there are other mechanisms that create an immunosuppressive environment,” Yilmaz says. “As the colon cancer becomes more aggressive and activates these other mechanisms, then there’s less importance for SOX17.”
Transcription factors such as SOX17 are considered difficult to target using drugs, in part because of their disorganized structure, so the researchers now plan to identify other proteins that SOX17 interacts with, in hopes that it might be easier to block some of those interactions.
The researchers also plan to investigate what triggers SOX17 to turn on in precancerous cells.
The research was funded by the MIT Stem Cell Initiative via Fondation MIT, the National Institutes of Health/National Cancer Institute, and a Koch Institute-Dana Farber Harvard Cancer Center Bridge Project grant.
In these intestinal tumor cells, the Sox17 protein is labeled red. MIT researchers have found that when tumor cells turn on the Sox17 gene, it helps them evade immune detection, in part by turning off the expression of a protein called Lgr-5, labeled in green.
Perovskites, a broad class of compounds with a particular kind of crystal structure, have long been seen as a promising alternative or supplement to today’s silicon or cadmium telluride solar panels. They could be far more lightweight and inexpensive, and could be coated onto virtually any substrate, including paper or flexible plastic that could be rolled up for easy transport.
In their efficiency at converting sunlight to electricity, perovskites are becoming comparable to silicon, whose manufacture still requires long, complex, and energy-intensive processes. One big remaining drawback is longevity: They tend to break down in a matter of months to years, while silicon solar panels can last more than two decades. And their efficiency over large module areas still lags behind silicon. Now, a team of researchers at MIT and several other institutions has revealed ways to optimize efficiency and better control degradation, by engineering the nanoscale structure of perovskite devices.
The study reveals new insights on how to make high-efficiency perovskite solar cells, and also provides new directions for engineers working to bring these solar cells to the commercial marketplace. The work is described today in the journal Nature Energy, in a paper by Dane deQuilettes, a recent MIT postdoc who is now co-founder and chief science officer of the MIT spinout Optigon, along with MIT professors Vladimir Bulovic and Moungi Bawendi, and 10 others at MIT and in Washington state, the U.K., and Korea.
“Ten years ago, if you had asked us what would be the ultimate solution to the rapid development of solar technologies, the answer would have been something that works as well as silicon but whose manufacturing is much simpler,” Bulovic says. “And before we knew it, the field of perovskite photovoltaics appeared. They were as efficient as silicon, and they were as easy to paint on as it is to paint on a piece of paper. The result was tremendous excitement in the field.”
Nonetheless, “there are some significant technical challenges of handling and managing this material in ways we’ve never done before,” he says. But the promise is so great that many hundreds of researchers around the world have been working on this technology. The new study looks at a very small but key detail: how to “passivate” the material’s surface, changing its properties in such a way that the perovskite no longer degrades so rapidly or loses efficiency.
“The key is identifying the chemistry of the interfaces, the place where the perovskite meets other materials,” Bulovic says, referring to the places where different materials are stacked next to perovskite in order to facilitate the flow of current through the device.
Engineers have developed methods for passivation, for example by using a solution that creates a thin passivating coating. But they’ve lacked a detailed understanding of how this process works — which is essential to make further progress in finding better coatings. The new study “addressed the ability to passivate those interfaces and elucidate the physics and science behind why this passivation works as well as it does,” Bulovic says.
The team used some of the most powerful instruments available at laboratories around the world to observe the interfaces between the perovskite layer and other materials, and how they develop, in unprecedented detail. This close examination of the passivation coating process and its effects resulted in “the clearest roadmap as of yet of what we can do to fine-tune the energy alignment at the interfaces of perovskites and neighboring materials,” and thus improve their overall performance, Bulovic says.
While the bulk of a perovskite material is in the form of a perfectly ordered crystalline lattice of atoms, this order breaks down at the surface. There may be extra atoms sticking out or vacancies where atoms are missing, and these defects cause losses in the material’s efficiency. That’s where the need for passivation comes in.
“This paper is essentially revealing a guidebook for how to tune surfaces, where a lot of these defects are, to make sure that energy is not lost at surfaces,” deQuilettes says. “It’s a really big discovery for the field,” he says. “This is the first paper that demonstrates how to systematically control and engineer surface fields in perovskites.”
The common passivation method is to bathe the surface in a solution of a salt called hexylammonium bromide, a technique developed at MIT several years ago by Jason Jungwan Yoo PhD ’20, who is a co-author of this paper, that led to multiple new world-record efficiencies. By doing that “you form a very thin layer on top of your defective surface, and that thin layer actually passivates a lot of the defects really well,” deQuilettes says. “And then the bromine, which is part of the salt, actually penetrates into the three-dimensional layer in a controllable way.” That penetration helps to prevent electrons from losing energy to defects at the surface.
These two effects, produced by a single processing step, produces the two beneficial changes simultaneously. “It’s really beautiful because usually you need to do that in two steps,” deQuilettes says.
The passivation reduces the energy loss of electrons at the surface after they have been knocked loose by sunlight. These losses reduce the overall efficiency of the conversion of sunlight to electricity, so reducing the losses boosts the net efficiency of the cells.
That could rapidly lead to improvements in the materials’ efficiency in converting sunlight to electricity, he says. The recent efficiency records for a single perovskite layer, several of them set at MIT, have ranged from about 24 to 26 percent, while the maximum theoretical efficiency that could be reached is about 30 percent, according to deQuilettes.
An increase of a few percent may not sound like much, but in the solar photovoltaic industry such improvements are highly sought after. “In the silicon photovoltaic industry, if you’re gaining half of a percent in efficiency, that’s worth hundreds of millions of dollars on the global market,” he says. A recent shift in silicon cell design, essentially adding a thin passivating layer and changing the doping profile, provides an efficiency gain of about half of a percent. As a result, “the whole industry is shifting and rapidly trying to push to get there.” The overall efficiency of silicon solar cells has only seen very small incremental improvements for the last 30 years, he says.
The record efficiencies for perovskites have mostly been set in controlled laboratory settings with small postage-stamp-size samples of the material. “Translating a record efficiency to commercial scale takes a long time,” deQuilettes says. “Another big hope is that with this understanding, people will be able to better engineer large areas to have these passivating effects.”
There are hundreds of different kinds of passivating salts and many different kinds of perovskites, so the basic understanding of the passivation process provided by this new work could help guide researchers to find even better combinations of materials, the researchers suggest. “There are so many different ways you could engineer the materials,” he says.
“I think we are on the doorstep of the first practical demonstrations of perovskites in the commercial applications,” Bulovic says. “And those first applications will be a far cry from what we’ll be able to do a few years from now.” He adds that perovskites “should not be seen as a displacement of silicon photovoltaics. It should be seen as an augmentation — yet another way to bring about more rapid deployment of solar electricity.”
“A lot of progress has been made in the last two years on finding surface treatments that improve perovskite solar cells,” says Michael McGehee, a professor of chemical engineering at the University of Colorado who was not associated with this research. “A lot of the research has been empirical with the mechanisms behind the improvements not being fully understood. This detailed study shows that treatments can not only passivate defects, but can also create a surface field that repels carriers that should be collected at the other side of the device. This understanding might help further improve the interfaces.”
The team included researchers at the Korea Research Institute of Chemical Technology, Cambridge University, the University of Washington in Seattle, and Sungkyunkwan University in Korea. The work was supported by the Tata Trust, the MIT Institute for Soldier Nanotechnologies, the U.S. Department of Energy, and the U.S. National Science Foundation.
A team of MIT researchers and several other institutions has revealed ways to optimize efficiency and better control degradation, by engineering the nanoscale structure of perovskite devices. Team members include Madeleine Laitz, left, and lead author Dane deQuilettes.
Hundreds of robots zip back and forth across the floor of a colossal robotic warehouse, grabbing items and delivering them to human workers for packing and shipping. Such warehouses are increasingly becoming part of the supply chain in many industries, from e-commerce to automotive production.
However, getting 800 robots to and from their destinations efficiently while keeping them from crashing into each other is no easy task. It is such a complex problem that even the best path-finding algorithms struggle to keep up with the breakneck pace of e-commerce or manufacturing.
In a sense, these robots are like cars trying to navigate a crowded city center. So, a group of MIT researchers who use AI to mitigate traffic congestion applied ideas from that domain to tackle this problem.
They built a deep-learning model that encodes important information about the warehouse, including the robots, planned paths, tasks, and obstacles, and uses it to predict the best areas of the warehouse to decongest to improve overall efficiency.
Their technique divides the warehouse robots into groups, so these smaller groups of robots can be decongested faster with traditional algorithms used to coordinate robots. In the end, their method decongests the robots nearly four times faster than a strong random search method.
In addition to streamlining warehouse operations, this deep learning approach could be used in other complex planning tasks, like computer chip design or pipe routing in large buildings.
“We devised a new neural network architecture that is actually suitable for real-time operations at the scale and complexity of these warehouses. It can encode hundreds of robots in terms of their trajectories, origins, destinations, and relationships with other robots, and it can do this in an efficient manner that reuses computation across groups of robots,” says Cathy Wu, the Gilbert W. Winslow Career Development Assistant Professor in Civil and Environmental Engineering (CEE), and a member of a member of the Laboratory for Information and Decision Systems (LIDS) and the Institute for Data, Systems, and Society (IDSS).
Wu, senior author of a paper on this technique, is joined by lead author Zhongxia Yan, a graduate student in electrical engineering and computer science. The work will be presented at the International Conference on Learning Representations.
Robotic Tetris
From a bird’s eye view, the floor of a robotic e-commerce warehouse looks a bit like a fast-paced game of “Tetris.”
When a customer order comes in, a robot travels to an area of the warehouse, grabs the shelf that holds the requested item, and delivers it to a human operator who picks and packs the item. Hundreds of robots do this simultaneously, and if two robots’ paths conflict as they cross the massive warehouse, they might crash.
Traditional search-based algorithms avoid potential crashes by keeping one robot on its course and replanning a trajectory for the other. But with so many robots and potential collisions, the problem quickly grows exponentially.
“Because the warehouse is operating online, the robots are replanned about every 100 milliseconds. That means that every second, a robot is replanned 10 times. So, these operations need to be very fast,” Wu says.
Because time is so critical during replanning, the MIT researchers use machine learning to focus the replanning on the most actionable areas of congestion — where there exists the most potential to reduce the total travel time of robots.
Wu and Yan built a neural network architecture that considers smaller groups of robots at the same time. For instance, in a warehouse with 800 robots, the network might cut the warehouse floor into smaller groups that contain 40 robots each.
Then, it predicts which group has the most potential to improve the overall solution if a search-based solver were used to coordinate trajectories of robots in that group.
An iterative process, the overall algorithm picks the most promising robot group with the neural network, decongests the group with the search-based solver, then picks the next most promising group with the neural network, and so on.
Considering relationships
The neural network can reason about groups of robots efficiently because it captures complicated relationships that exist between individual robots. For example, even though one robot may be far away from another initially, their paths could still cross during their trips.
The technique also streamlines computation by encoding constraints only once, rather than repeating the process for each subproblem. For instance, in a warehouse with 800 robots, decongesting a group of 40 robots requires holding the other 760 robots as constraints. Other approaches require reasoning about all 800 robots once per group in each iteration.
Instead, the researchers’ approach only requires reasoning about the 800 robots once across all groups in each iteration.
“The warehouse is one big setting, so a lot of these robot groups will have some shared aspects of the larger problem. We designed our architecture to make use of this common information,” she adds.
They tested their technique in several simulated environments, including some set up like warehouses, some with random obstacles, and even maze-like settings that emulate building interiors.
By identifying more effective groups to decongest, their learning-based approach decongests the warehouse up to four times faster than strong, non-learning-based approaches. Even when they factored in the additional computational overhead of running the neural network, their approach still solved the problem 3.5 times faster.
In the future, the researchers want to derive simple, rule-based insights from their neural model, since the decisions of the neural network can be opaque and difficult to interpret. Simpler, rule-based methods could also be easier to implement and maintain in actual robotic warehouse settings.
“This approach is based on a novel architecture where convolution and attention mechanisms interact effectively and efficiently. Impressively, this leads to being able to take into account the spatiotemporal component of the constructed paths without the need of problem-specific feature engineering. The results are outstanding: Not only is it possible to improve on state-of-the-art large neighborhood search methods in terms of quality of the solution and speed, but the model generalizes to unseen cases wonderfully,” says Andrea Lodi, the Andrew H. and Ann R. Tisch Professor at Cornell Tech, and who was not involved with this research.
This work was supported by Amazon and the MIT Amazon Science Hub.
A group of MIT researchers who use AI to mitigate traffic congestion applied ideas from that domain to tackle the problem of multiple robots in a warehouse setting.
Imagine being able to build an entire dialysis machine using nothing more than a 3D printer.
This could not only reduce costs and eliminate manufacturing waste, but since this machine could be produced outside a factory, people with limited resources or those who live in remote areas may be able to access this medical device more easily.
While multiple hurdles must be overcome to develop electronic devices that are entirely 3D printed, a team at MIT has taken an important step in this direction by demonstrating fully 3D-printed, three-dimensional solenoids.
Solenoids, electromagnets formed by a coil of wire wrapped around a magnetic core, are a fundamental building block of many electronics, from dialysis machines and respirators to washing machines and dishwashers.
The researchers modified a multimaterial 3D printer so it could print compact, magnetic-cored solenoids in one step. This eliminates defects that might be introduced during post-assembly processes.
This customized printer, which could utilize higher-performing materials than typical commercial printers, enabled the researchers to produce solenoids that could withstand twice as much electric current and generate a magnetic field that was three times larger than other 3D-printed devices.
In addition to making electronics cheaper on Earth, this printing hardware could be particularly useful in space exploration. For example, instead of shipping replacement electronic parts to a base on Mars, which could take years and cost millions of dollars, one could send a signal containing files for the 3D printer, says Luis Fernando Velásquez-García, a principal research scientist in MIT’s Microsystems Technology Laboratories (MTL).
“There is no reason to make capable hardware in only a few centers of manufacturing when the need is global. Instead of trying to ship hardware all over the world, can we empower people in distant places to make it themselves? Additive manufacturing can play a tremendous role in terms of democratizing these technologies,” adds Velásquez-García, the senior author of a new paper on the 3D printed solenoids that appears in the journal Virtual and Physical Prototyping.
He is joined on the paper by lead author Jorge Cañada, an electrical engineering and computer science graduate student; and Hyeonseok Kim, a mechanical engineering graduate student.
Additive advantages
A solenoid generates a magnetic field when an electrical current is passed through it. When someone rings a doorbell, for instance, electric current flows through a solenoid, which generates a magnetic field that moves an iron rod so it strikes a chime.
Integrating solenoids onto electrical circuits manufactured in a clean room poses significant challenges, as they have very different form factors and are made using incompatible processes that require post assembly. Consequently, researchers have investigated making solenoids utilizing many of the same processes that make semiconductor chips. But these techniques limit the size and shape of solenoids, which hampers performance.
With additive manufacturing, one can produce devices that are practically any size and shape. However, this presents its own challenges, since making a solenoid involves coiling thin layers made from multiple materials that may not all be compatible with one machine.
To overcome these challenges, the researchers needed to modify a commercial extrusion 3D printer.
Extrusion printing fabricates objects one layer at a time by squirting material through a nozzle. Typically, a printer uses one type of material feedstock, often spools of filament.
“Some people in the field look down on them because they are simple and don’t have a lot of bells and whistles, but extrusion is one of very few methods that allows you to do multimaterial, monolithic printing,” says Velásquez-García.
This is key, since the solenoids are produced by precisely layering three different materials — a dielectric material that serves as an insulator, a conductive material that forms the electric coil, and a soft magnetic material that makes up the core.
The team selected a printer with four nozzles — one dedicated to each material to prevent cross-contamination. They needed four extruders because they tried two soft magnetic materials, one based on a biodegradable thermoplastic and the other based on nylon.
Printing with pellets
They retrofitted the printer so one nozzle could extrude pellets, rather than filament. The soft magnetic nylon, which is made from a pliable polymer studded with metallic microparticles, is virtually impossible to produce as a filament. Yet this nylon material offers far better performance than filament-based alternatives.
Using the conductive material also posed challenges, since it would start melting and jam the nozzle. The researchers found that adding ventilation to cool the material prevented this. They also built a new spool holder for the conductive filament that was closer to the nozzle, reducing friction that could damage the thin strands.
Even with the team’s modifications, the customized hardware cost about $4,000, so this technique could be employed by others at a lower cost than other approaches, adds Velásquez-García.
The modified hardware prints a U.S. quarter-sized solenoid as a spiral by layering material around the soft magnetic core, with thicker conductive layers separated by thin insulating layers.
Precisely controlling the process is of paramount importance because each material prints at a different temperature. Depositing one on top of another at the wrong time might cause the materials to smear.
Because their machine could print with a more effective soft magnetic material, the solenoids achieved higher performance than other 3D-printed devices.
The printing method enabled them to build a three-dimensional device comprising eight layers, with coils of conductive and insulating material stacked around the core like a spiral staircase. Multiple layers increase the number of coils in the solenoid, which improves the amplification of the magnetic field.
Due to the added precision of the modified printer, they could make solenoids that were about 33 percent smaller than other 3D-printed versions. More coils in a smaller area also boosts amplification.
In the end, their solenoids could produce a magnetic field that was about three times larger than what other 3D-printed devices can achieve.
“We were not the first people to be able to make inductors that are 3D-printed, but we were the first ones to make them three-dimensional, and that greatly amplifies the kinds of values you can generate. And that translates into being able to satisfy a wider range of applications,” he says.
For instance, while these solenoids can’t generate as much magnetic field as those made with traditional fabrication techniques, they could be used as power convertors in small sensors or actuators in soft robots.
Moving forward, the researchers are looking to continue enhancing their performance.
For one, they could try using alternate materials that might have better properties. They are also exploring additional modifications that could more precisely control the temperature at which each material is deposited, reducing defects.
This work is funded by Empiriko Corporation and a fellowship from La Caixa Foundation.
MIT researchers modified a multi-material 3D printer so it could produce three-dimensional solenoids in one step by layering ultrathin coils of three different materials. It rints a U.S. quarter-sized solenoid as a spiral by layering material around the soft magnetic core, with thicker conductive layers separated by thin insulating layers.
Experimental computer memories and processors built from magnetic materials use far less energy than traditional silicon-based devices. Two-dimensional magnetic materials, composed of layers that are only a few atoms thick, have incredible properties that could allow magnetic-based devices to achieve unprecedented speed, efficiency, and scalability.
While many hurdles must be overcome until these so-called van der Waals magnetic materials can be integrated into functioning computers, MIT researchers took an important step in this direction by demonstrating precise control of a van der Waals magnet at room temperature.
This is key, since magnets composed of atomically thin van der Waals materials can typically only be controlled at extremely cold temperatures, making them difficult to deploy outside a laboratory.
The researchers used pulses of electrical current to switch the direction of the device’s magnetization at room temperature. Magnetic switching can be used in computation, the same way a transistor switches between open and closed to represent 0s and 1s in binary code, or in computer memory, where switching enables data storage.
The team fired bursts of electrons at a magnet made of a new material that can sustain its magnetism at higher temperatures. The experiment leveraged a fundamental property of electrons known as spin, which makes the electrons behave like tiny magnets. By manipulating the spin of electrons that strike the device, the researchers can switch its magnetization.
“The heterostructure device we have developed requires an order of magnitude lower electrical current to switch the van der Waals magnet, compared to that required for bulk magnetic devices,” says Deblina Sarkar, the AT&T Career Development Assistant Professor in the MIT Media Lab and Center for Neurobiological Engineering, head of the Nano-Cybernetic Biotrek Lab, and the senior author of a paper on this technique. “Our device is also more energy efficient than other van der Waals magnets that are unable to switch at room temperature.”
In the future, such a magnet could be used to build faster computers that consume less electricity. It could also enable magnetic computer memories that are nonvolatile, which means they don’t leak information when powered off, or processors that make complex AI algorithms more energy-efficient.
“There is a lot of inertia around trying to improve materials that worked well in the past. But we have shown that if you make radical changes, starting by rethinking the materials you are using, you can potentially get much better solutions,” says Shivam Kajale, a graduate student in Sarkar’s lab and co-lead author of the paper.
Kajale and Sarkar are joined on the paper by co-lead author Thanh Nguyen, a graduate student in the Department of Nuclear Science and Engineering (NSE); Corson Chao, a graduate student in the Department of Materials Science and Engineering (DSME); David Bono, a DSME research scientist; Artittaya Boonkird, an NSE graduate student; and Mingda Li, associate professor of nuclear science and engineering. The research appears this week in Nature Communications.
An atomically thin advantage
Methods to fabricate tiny computer chips in a clean room from bulk materials like silicon can hamper devices. For instance, the layers of material may be barely 1 nanometer thick, so minuscule rough spots on the surface can be severe enough to degrade performance.
By contrast, van der Waals magnetic materials are intrinsically layered and structured in such a way that the surface remains perfectly smooth, even as researchers peel off layers to make thinner devices. In addition, atoms in one layer won’t leak into other layers, enabling the materials to retain their unique properties when stacked in devices.
“In terms of scaling and making these magnetic devices competitive for commercial applications, van der Waals materials are the way to go,” Kajale says.
But there’s a catch. This new class of magnetic materials have typically only been operated at temperatures below 60 kelvins (-351 degrees Fahrenheit). To build a magnetic computer processor or memory, researchers need to use electrical current to operate the magnet at room temperature.
To achieve this, the team focused on an emerging material called iron gallium telluride. This atomically thin material has all the properties needed for effective room temperature magnetism and doesn’t contain rare earth elements, which are undesirable because extracting them is especially destructive to the environment.
Nguyen carefully grew bulk crystals of this 2D material using a special technique. Then, Kajale fabricated a two-layer magnetic device using nanoscale flakes of iron gallium telluride underneath a six-nanometer layer of platinum.
Tiny device in hand, they used an intrinsic property of electrons known as spin to switch its magnetization at room temperature.
Electron ping-pong
While electrons don’t technically “spin” like a top, they do possess the same kind of angular momentum. That spin has a direction, either up or down. The researchers can leverage a property known as spin-orbit coupling to control the spins of electrons they fire at the magnet.
The same way momentum is transferred when one ball hits another, electrons will transfer their “spin momentum” to the 2D magnetic material when they strike it. Depending on the direction of their spins, that momentum transfer can reverse the magnetization.
In a sense, this transfer rotates the magnetization from up to down (or vice-versa), so it is called a “torque,” as in spin-orbit torque switching. Applying a negative electric pulse causes the magnetization to go downward, while a positive pulse causes it to go upward.
The researchers can do this switching at room temperature for two reasons: the special properties of iron gallium telluride and the fact that their technique uses small amounts of electrical current. Pumping too much current into the device would cause it to overheat and demagnetize.
The team faced many challenges over the two years it took to achieve this milestone, Kajale says. Finding the right magnetic material was only half the battle. Since iron gallium telluride oxidizes quickly, fabrication must be done inside a glovebox filled with nitrogen.
“The device is only exposed to air for 10 or 15 seconds, but even after that I have to do a step where I polish it to remove any oxide,” he says.
Now that they have demonstrated room-temperature switching and greater energy efficiency, the researchers plan to keep pushing the performance of magnetic van der Waals materials.
“Our next milestone is to achieve switching without the need for any external magnetic fields. Our aim is to enhance our technology and scale up to bring the versatility of van der Waals magnet to commercial applications,” Sarkar says.
This work was carried out, in part, using the facilities at MIT.Nano and the Harvard University Center for Nanoscale Systems.
This illustration shows electric current being pumped into platinum (the bottom slab), which results in the creation of an electron spin current that switches the magnetic state of the 2D ferromagnet on top. The colored spheres represent the atoms in the 2D material.
The electron is the basic unit of electricity, as it carries a single negative charge. This is what we’re taught in high school physics, and it is overwhelmingly the case in most materials in nature.
But in very special states of matter, electrons can splinter into fractions of their whole. This phenomenon, known as “fractional charge,” is exceedingly rare, and if it can be corralled and controlled, the exotic electronic state could help to build resilient, fault-tolerant quantum computers.
To date, this effect, known to physicists as the “fractional quantum Hall effect,” has been observed a handful of times, and mostly under very high, carefully maintained magnetic fields. Only recently have scientists seen the effect in a material that did not require such powerful magnetic manipulation.
Now, MIT physicists have observed the elusive fractional charge effect, this time in a simpler material: five layers of graphene — an atom-thin layer of carbon that stems from graphite and common pencil lead. They report their results today in Nature.
They found that when five sheets of graphene are stacked like steps on a staircase, the resulting structure inherently provides just the right conditions for electrons to pass through as fractions of their total charge, with no need for any external magnetic field.
The results are the first evidence of the “fractional quantum anomalous Hall effect” (the term “anomalous” refers to the absence of a magnetic field) in crystalline graphene, a material that physicists did not expect to exhibit this effect.
“This five-layer graphene is a material system where many good surprises happen,” says study author Long Ju, assistant professor of physics at MIT. “Fractional charge is just so exotic, and now we can realize this effect with a much simpler system and without a magnetic field. That in itself is important for fundamental physics. And it could enable the possibility for a type of quantum computing that is more robust against perturbation.”
Ju’s MIT co-authors are lead author Zhengguang Lu, Tonghang Han, Yuxuan Yao, Aidan Reddy, Jixiang Yang, Junseok Seo, and Liang Fu, along with Kenji Watanabe and Takashi Taniguchi at the National Institute for Materials Science in Japan.
A bizarre state
The fractional quantum Hall effect is an example of the weird phenomena that can arise when particles shift from behaving as individual units to acting together as a whole. This collective “correlated” behavior emerges in special states, for instance when electrons are slowed from their normally frenetic pace to a crawl that enables the particles to sense each other and interact. These interactions can produce rare electronic states, such as the seemingly unorthodox splitting of an electron’s charge.
In 1982, scientists discovered the fractional quantum Hall effect in heterostructures of gallium arsenide, where a gas of electrons confined in a two-dimensional plane is placed under high magnetic fields. The discovery later won the group a Nobel Prize in Physics.
“[The discovery] was a very big deal, because these unit charges interacting in a way to give something like fractional charge was very, very bizarre,” Ju says. “At the time, there were no theory predictions, and the experiments surprised everyone.”
Those researchers achieved their groundbreaking results using magnetic fields to slow down the material’s electrons enough for them to interact. The fields they worked with were about 10 times stronger than what typically powers an MRI machine.
In August 2023, scientists at the University of Washington reported the first evidence of fractional charge without a magnetic field. They observed this “anomalous” version of the effect, in a twisted semiconductor called molybdenum ditelluride. The group prepared the material in a specific configuration, which theorists predicted would give the material an inherent magnetic field, enough to encourage electrons to fractionalize without any external magnetic control.
The “no magnets” result opened a promising route to topological quantum computing — a more secure form of quantum computing, in which the added ingredient of topology (a property that remains unchanged in the face of weak deformation or disturbance) gives a qubit added protection when carrying out a computation. This computation scheme is based on a combination of fractional quantum Hall effect and a superconductor. It used to be almost impossible to realize: One needs a strong magnetic field to get fractional charge, while the same magnetic field will usually kill the superconductor. In this case the fractional charges would serve as a qubit (the basic unit of a quantum computer).
Making steps
That same month, Ju and his team happened to also observe signs of anomalous fractional charge in graphene — a material for which there had been no predictions for exhibiting such an effect.
Ju’s group has been exploring electronic behavior in graphene, which by itself has exhibited exceptional properties. Most recently, Ju’s group has looked into pentalayer graphene — a structure of five graphene sheets, each stacked slightly off from the other, like steps on a staircase. Such pentalayer graphene structure is embedded in graphite and can be obtained by exfoliation using Scotch tape. When placed in a refrigerator at ultracold temperatures, the structure’s electrons slow to a crawl and interact in ways they normally wouldn’t when whizzing around at higher temperatures.
In their new work, the researchers did some calculations and found that electrons might interact with each other even more strongly if the pentalayer structure were aligned with hexagonal boron nitride (hBN) — a material that has a similar atomic structure to that of graphene, but with slightly different dimensions. In combination, the two materials should produce a moiré superlattice — an intricate, scaffold-like atomic structure that could slow electrons down in ways that mimic a magnetic field.
“We did these calculations, then thought, let’s go for it,” says Ju, who happened to install a new dilution refrigerator in his MIT lab last summer, which the team planned to use to cool materials down to ultralow temperatures, to study exotic electronic behavior.
The researchers fabricated two samples of the hybrid graphene structure by first exfoliating graphene layers from a block of graphite, then using optical tools to identify five-layered flakes in the steplike configuration. They then stamped the graphene flake onto an hBN flake and placed a second hBN flake over the graphene structure. Finally, they attached electrodes to the structure and placed it in the refrigerator, set to near absolute zero.
As they applied a current to the material and measured the voltage output, they started to see signatures of fractional charge, where the voltage equals the current multiplied by a fractional number and some fundamental physics constants.
“The day we saw it, we didn’t recognize it at first,” says first author Lu. “Then we started to shout as we realized, this was really big. It was a completely surprising moment.”
“This was probably the first serious samples we put in the new fridge,” adds co-first author Han. “Once we calmed down, we looked in detail to make sure that what we were seeing was real.”
With further analysis, the team confirmed that the graphene structure indeed exhibited the fractional quantum anomalous Hall effect. It is the first time the effect has been seen in graphene.
“Graphene can also be a superconductor,” Ju says. “So, you could have two totally different effects in the same material, right next to each other. If you use graphene to talk to graphene, it avoids a lot of unwanted effects when bridging graphene with other materials.”
For now, the group is continuing to explore multilayer graphene for other rare electronic states.
“We are diving in to explore many fundamental physics ideas and applications,” he says. “We know there will be more to come.”
This research is supported in part by the Sloan Foundation, and the National Science Foundation.
The fractional quantum Hall effect has generally been seen under very high magnetic fields, but MIT physicists have now observed it in simple graphene. In a five-layer graphene/ hexagonal boron nitride (hBN) moire superlattice, electrons (blue ball) interact with each other strongly and behave as if they are broken into fractional charges.
Pollsters trying to predict presidential election results and physicists searching for distant exoplanets have at least one thing in common: They often use a tried-and-true scientific technique called Bayesian inference.
Bayesian inference allows these scientists to effectively estimate some unknown parameter — like the winner of an election — from data such as poll results. But Bayesian inference can be slow, sometimes consuming weeks or even months of computation time or requiring a researcher to spend hours deriving tedious equations by hand.
Researchers from MIT and elsewhere have introduced an optimization technique that speeds things up without requiring a scientist to do a lot of additional work. Their method can achieve more accurate results faster than another popular approach for accelerating Bayesian inference.
Using this new automated technique, a scientist could simply input their model and then the optimization method does all the calculations under the hood to provide an approximation of some unknown parameter. The method also offers reliable uncertainty estimates that can help a researcher understand when to trust its predictions.
This versatile technique could be applied to a wide array of scientific quandaries that incorporate Bayesian inference. For instance, it could be used by economists studying the impact of microcredit loans in developing nations or sports analysts using a model to rank top tennis players.
“When you actually dig into what people are doing in the social sciences, physics, chemistry, or biology, they are often using a lot of the same tools under the hood. There are so many Bayesian analyses out there. If we can build a really great tool that makes these researchers lives easier, then we can really make a difference to a lot of people in many different research areas,” says senior author Tamara Broderick, an associate professor in MIT’s Department of Electrical Engineering and Computer Science (EECS) and a member of the Laboratory for Information and Decision Systems and the Institute for Data, Systems, and Society.
Broderick is joined on the paper by co-lead authors Ryan Giordano, an assistant professor of statistics at the University of California at Berkeley; and Martin Ingram, a data scientist at the AI company KONUX. The paper was recently published in the Journal of Machine Learning Research.
Faster results
When researchers seek a faster form of Bayesian inference, they often turn to a technique called automatic differentiation variational inference (ADVI), which is often both fast to run and easy to use.
But Broderick and her collaborators have found a number of practical issues with ADVI. It has to solve an optimization problem and can do so only approximately. So, ADVI can still require a lot of computation time and user effort to determine whether the approximate solution is good enough. And once it arrives at a solution, it tends to provide poor uncertainty estimates.
Rather than reinventing the wheel, the team took many ideas from ADVI but turned them around to create a technique called deterministic ADVI (DADVI) that doesn’t have these downsides.
With DADVI, it is very clear when the optimization is finished, so a user won’t need to spend extra computation time to ensure that the best solution has been found. DADVI also permits the incorporation of more powerful optimization methods that give it an additional speed and performance boost.
Once it reaches a result, DADVI is set up to allow the use of uncertainty corrections. These corrections make its uncertainty estimates much more accurate than those of ADVI.
DADVI also enables the user to clearly see how much error they have incurred in the approximation to the optimization problem. This prevents a user from needlessly running the optimization again and again with more and more resources to try and reduce the error.
“We wanted to see if we could live up to the promise of black-box inference in the sense of, once the user makes their model, they can just run Bayesian inference and don’t have to derive everything by hand, they don’t need to figure out when to stop their algorithm, and they have a sense of how accurate their approximate solution is,” Broderick says.
Defying conventional wisdom
DADVI can be more effective than ADVI because it uses an efficient approximation method, called sample average approximation, which estimates an unknown quantity by taking a series of exact steps.
Because the steps along the way are exact, it is clear when the objective has been reached. Plus, getting to that objective typically requires fewer steps.
Often, researchers expect sample average approximation to be more computationally intensive than a more popular method, known as stochastic gradient, which is used by ADVI. But Broderick and her collaborators showed that, in many applications, this is not the case.
“A lot of problems really do have special structure, and you can be so much more efficient and get better performance by taking advantage of that special structure. That is something we have really seen in this paper,” she adds.
They tested DADVI on a number of real-world models and datasets, including a model used by economists to evaluate the effectiveness of microcredit loans and one used in ecology to determine whether a species is present at a particular site.
Across the board, they found that DADVI can estimate unknown parameters faster and more reliably than other methods, and achieves as good or better accuracy than ADVI. Because it is easier to use than other techniques, DADVI could offer a boost to scientists in a wide variety of fields.
In the future, the researchers want to dig deeper into correction methods for uncertainty estimates so they can better understand why these corrections can produce such accurate uncertainties, and when they could fall short.
“In applied statistics, we often have to use approximate algorithms for problems that are too complex or high-dimensional to allow exact solutions to be computed in reasonable time. This new paper offers an interesting set of theory and empirical results that point to an improvement in a popular existing approximate algorithm for Bayesian inference,” says Andrew Gelman ’85, ’86, a professor of statistics and political science at Columbia University, who was not involved with the study. “As one of the team involved in the creation of that earlier work, I'm happy to see our algorithm superseded by something more stable.”
This research was supported by a National Science Foundation CAREER Award and the U.S. Office of Naval Research.
You’ve likely met someone who identifies as a visual or auditory learner, but others absorb knowledge through a different modality: touch. Being able to understand tactile interactions is especially important for tasks such as learning delicate surgeries and playing musical instruments, but unlike video and audio, touch is difficult to record and transfer.
To tap into this challenge, researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and elsewhere developed an embroidered smart glove that can capture, reproduce, and relay touch-based instructions. To complement the wearable device, the team also developed a simple machine-learning agent that adapts to how different users react to tactile feedback, optimizing their experience. The new system could potentially help teach people physical skills, improve responsive robot teleoperation, and assist with training in virtual reality.
To create their smart glove, the researchers used a digital embroidery machine to seamlessly embed tactile sensors and haptic actuators (a device that provides touch-based feedback) into textiles. This technology is present in smartphones, where haptic responses are triggered by tapping on the touch screen. For example, if you press down on an iPhone app, you’ll feel a slight vibration coming from that specific part of your screen. In the same way, the new adaptive wearable sends feedback to different parts of your hand to indicate optimal motions to execute different skills.
The smart glove could teach users how to play the piano, for instance. In a demonstration, an expert was tasked with recording a simple tune over a section of keys, using the smart glove to capture the sequence by which they pressed their fingers to the keyboard. Then, a machine-learning agent converted that sequence into haptic feedback, which was then fed into the students’ gloves to follow as instructions. With their hands hovering over that same section, actuators vibrated on the fingers corresponding to the keys below. The pipeline optimizes these directions for each user, accounting for the subjective nature of touch interactions.
“Humans engage in a wide variety of tasks by constantly interacting with the world around them,” says Yiyue Luo MS ’20, lead author of the paper, PhD student in MIT’s Department of Electrical Engineering and Computer Science (EECS), and CSAIL affiliate. “We don’t usually share these physical interactions with others. Instead, we often learn by observing their movements, like with piano-playing and dance routines.
“The main challenge in relaying tactile interactions is that everyone perceives haptic feedback differently,” adds Luo. “This roadblock inspired us to develop a machine-learning agent that learns to generate adaptive haptics for individuals’ gloves, introducing them to a more hands-on approach to learning optimal motion.”
The wearable system is customized to fit the specifications of a user’s hand via a digital fabrication method. A computer produces a cutout based on individuals’ hand measurements, then an embroidery machine stitches the sensors and haptics in. Within 10 minutes, the soft, fabric-based wearable is ready to wear. Initially trained on 12 users’ haptic responses, its adaptive machine-learning model only needs 15 seconds of new user data to personalize feedback.
In two other experiments, tactile directions with time-sensitive feedback were transferred to users sporting the gloves while playing laptop games. In a rhythm game, the players learned to follow a narrow, winding path to bump into a goal area, and in a racing game, drivers collected coins and maintained the balance of their vehicle on their way to the finish line. Luo’s team found that participants earned the highest game scores through optimized haptics, as opposed to without haptics and with unoptimized haptics.
“This work is the first step to building personalized AI agents that continuously capture data about the user and the environment,” says senior author Wojciech Matusik, MIT professor of electrical engineering and computer science and head of the Computational Design and Fabrication Group within CSAIL. “These agents then assist them in performing complex tasks, learning new skills, and promoting better behaviors.”
Bringing a lifelike experience to electronic settings
In robotic teleoperation, the researchers found that their gloves could transfer force sensations to robotic arms, helping them complete more delicate grasping tasks. “It’s kind of like trying to teach a robot to behave like a human,” says Luo. In one instance, the MIT team used human teleoperators to teach a robot how to secure different types of bread without deforming them. By teaching optimal grasping, humans could precisely control the robotic systems in environments like manufacturing, where these machines could collaborate more safely and effectively with their operators.
“The technology powering the embroidered smart glove is an important innovation for robots,” says Daniela Rus, the Andrew (1956) and Erna Viterbi Professor of Electrical Engineering and Computer Science at MIT, CSAIL director, and author on the paper. “With its ability to capture tactile interactions at high resolution, akin to human skin, this sensor enables robots to perceive the world through touch. The seamless integration of tactile sensors into textiles bridges the divide between physical actions and digital feedback, offering vast potential in responsive robot teleoperation and immersive virtual reality training.”
Likewise, the interface could create more immersive experiences in virtual reality. Wearing smart gloves would add tactile sensations to digital environments in video games, where gamers could feel around their surroundings to avoid obstacles. Additionally, the interface would provide a more personalized and touch-based experience in virtual training courses used by surgeons, firefighters, and pilots, where precision is paramount.
While these wearables could provide a more hands-on experience for users, Luo and her group believe they could extend their wearable technology beyond fingers. With stronger haptic feedback, the interfaces could guide feet, hips, and other body parts less sensitive than hands.
Luo also noted that with a more complex artificial intelligence agent, her team's technology could assist with more involved tasks, like manipulating clay or driving an airplane. Currently, the interface can only assist with simple motions like pressing a key or gripping an object. In the future, the MIT system could incorporate more user data and fabricate more conformal and tight wearables to better account for how hand movements impact haptic perceptions.
Luo, Matusik, and Rus authored the paper with EECS Microsystems Technology Laboratories Director and Professor Tomás Palacios; CSAIL members Chao Liu, Young Joong Lee, Joseph DelPreto, Michael Foshey, and professor and principal investigator Antonio Torralba; Kiu Wu of LightSpeed Studios; and Yunzhu Li of the University of Illinois at Urbana-Champaign.
The work was supported, in part, by an MIT Schwarzman College of Computing Fellowship via Google and a GIST-MIT Research Collaboration grant, with additional help from Wistron, Toyota Research Institute, and Ericsson.
A digitally embroidered smart glove developed at MIT can assist with piano lessons and human-robot teleoperation with the help of a machine-learning agent that adapts to how different users react to touch.
Any drug that is taken orally must pass through the lining of the digestive tract. Transporter proteins found on cells that line the GI tract help with this process, but for many drugs, it’s unknown which of those transporters they use to exit the digestive tract.
Identifying the transporters used by specific drugs could help to improve patient treatment because if two drugs rely on the same transporter, they can interfere with each other and should not be prescribed together.
Researchers at MIT, Brigham and Women’s Hospital, and Duke University have now developed a multipronged strategy to identify the transporters used by different drugs. Their approach, which makes use of both tissue models and machine-learning algorithms, has already revealed that a commonly prescribed antibiotic and a blood thinner can interfere with each other.
“One of the challenges in modeling absorption is that drugs are subject to different transporters. This study is all about how we can model those interactions, which could help us make drugs safer and more efficacious, and predict potential toxicities that may have been difficult to predict until now,” says Giovanni Traverso, an associate professor of mechanical engineering at MIT, a gastroenterologist at Brigham and Women’s Hospital, and the senior author of the study.
Learning more about which transporters help drugs pass through the digestive tract could also help drug developers improve the absorbability of new drugs by adding excipients that enhance their interactions with transporters.
Former MIT postdocs Yunhua Shi and Daniel Reker are the lead authors of the study, which appears today in Nature Biomedical Engineering.
Drug transport
Previous studies have identified several transporters in the GI tract that help drugs pass through the intestinal lining. Three of the most commonly used, which were the focus of the new study, are BCRP, MRP2, and PgP.
For this study, Traverso and his colleagues adapted a tissue model they had developed in 2020 to measure a given drug’s absorbability. This experimental setup, based on pig intestinal tissue grown in the laboratory, can be used to systematically expose tissue to different drug formulations and measure how well they are absorbed.
To study the role of individual transporters within the tissue, the researchers used short strands of RNA called siRNA to knock down the expression of each transporter. In each section of tissue, they knocked down different combinations of transporters, which enabled them to study how each transporter interacts with many different drugs.
“There are a few roads that drugs can take through tissue, but you don't know which road. We can close the roads separately to figure out, if we close this road, does the drug still go through? If the answer is yes, then it’s not using that road,” Traverso says.
The researchers tested 23 commonly used drugs using this system, allowing them to identify transporters used by each of those drugs. Then, they trained a machine-learning model on that data, as well as data from several drug databases. The model learned to make predictions of which drugs would interact with which transporters, based on similarities between the chemical structures of the drugs.
Using this model, the researchers analyzed a new set of 28 currently used drugs, as well as 1,595 experimental drugs. This screen yielded nearly 2 million predictions of potential drug interactions. Among them was the prediction that doxycycline, an antibiotic, could interact with warfarin, a commonly prescribed blood-thinner. Doxycycline was also predicted to interact with digoxin, which is used to treat heart failure, levetiracetam, an antiseizure medication, and tacrolimus, an immunosuppressant.
Identifying interactions
To test those predictions, the researchers looked at data from about 50 patients who had been taking one of those three drugs when they were prescribed doxycycline. This data, which came from a patient database at Massachusetts General Hospital and Brigham and Women’s Hospital, showed that when doxycycline was given to patients already taking warfarin, the level of warfarin in the patients’ bloodstream went up, then went back down again after they stopped taking doxycycline.
That data also confirmed the model’s predictions that the absorption of doxycycline is affected by digoxin, levetiracetam, and tacrolimus. Only one of those drugs, tacrolimus, had been previously suspected to interact with doxycycline.
“These are drugs that are commonly used, and we are the first to predict this interaction using this accelerated in silico and in vitro model,” Traverso says. “This kind of approach gives you the ability to understand the potential safety implications of giving these drugs together.”
In addition to identifying potential interactions between drugs that are already in use, this approach could also be applied to drugs now in development. Using this technology, drug developers could tune the formulation of new drug molecules to prevent interactions with other drugs or improve their absorbability. Vivtex, a biotech company co-founded in 2018 by former MIT postdoc Thomas von Erlach, MIT Institute Professor Robert Langer, and Traverso to develop new oral drug delivery systems, is now pursuing that kind of drug-tuning.
The research was funded, in part, by the U.S. National Institutes of Health, the Department of Mechanical Engineering at MIT, and the Division of Gastroenterology at Brigham and Women’s Hospital.
Other authors of the paper include Langer, von Erlach, James Byrne, Ameya Kirtane, Kaitlyn Hess Jimenez, Zhuyi Wang, Natsuda Navamajiti, Cameron Young, Zachary Fralish, Zilu Zhang, Aaron Lopes, Vance Soares, Jacob Wainer, and Lei Miao.
MIT and other researchers developed a multipronged strategy to identify the transporters used by different drugs. Their approach, which makes use of both tissue models and machine-learning algorithms, has already revealed that a commonly prescribed antibiotic and a blood-thinner can interfere with each other.
A few years ago, MIT researchers invented a cryptographic ID tag that is several times smaller and significantly cheaper than the traditional radio frequency tags (RFIDs) that are often affixed to products to verify their authenticity.
This tiny tag, which offers improved security over RFIDs, utilizes terahertz waves, which are smaller and have much higher frequencies than radio waves. But this terahertz tag shared a major security vulnerability with traditional RFIDs: A counterfeiter could peel the tag off a genuine item and reattach it to a fake, and the authentication system would be none the wiser.
The researchers have now surmounted this security vulnerability by leveraging terahertz waves to develop an antitampering ID tag that still offers the benefits of being tiny, cheap, and secure.
They mix microscopic metal particles into the glue that sticks the tag to an object, and then use terahertz waves to detect the unique pattern those particles form on the item’s surface. Akin to a fingerprint, this random glue pattern is used to authenticate the item, explains Eunseok Lee, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on the antitampering tag.
“These metal particles are essentially like mirrors for terahertz waves. If I spread a bunch of mirror pieces onto a surface and then shine light on that, depending on the orientation, size, and location of those mirrors, I would get a different reflected pattern. But if you peel the chip off and reattach it, you destroy that pattern,” adds Ruonan Han, an associate professor in EECS, who leads the Terahertz Integrated Electronics Group in the Research Laboratory of Electronics.
The researchers produced a light-powered antitampering tag that is about 4 square millimeters in size. They also demonstrated a machine-learning model that helps detect tampering by identifying similar glue pattern fingerprints with more than 99 percent accuracy.
Because the terahertz tag is so cheap to produce, it could be implemented throughout a massive supply chain. And its tiny size enables the tag to attach to items too small for traditional RFIDs, such as certain medical devices.
The paper, which will be presented at the IEEE Solid State Circuits Conference, is a collaboration between Han’s group and the Energy-Efficient Circuits and Systems Group of Anantha P. Chandrakasan, MIT’s chief innovation and strategy officer, dean of the MIT School of Engineering, and the Vannevar Bush Professor of EECS. Co-authors include EECS graduate students Xibi Chen, Maitryi Ashok, and Jaeyeon Won.
Preventing tampering
This research project was partly inspired by Han’s favorite car wash. The business stuck an RFID tag onto his windshield to authenticate his car wash membership. For added security, the tag was made from fragile paper so it would be destroyed if a less-than-honest customer tried to peel it off and stick it on a different windshield.
But that is not a terribly reliable way to prevent tampering. For instance, someone could use a solution to dissolve the glue and safely remove the fragile tag.
Rather than authenticating the tag, a better security solution is to authenticate the item itself, Han says. To achieve this, the researchers targeted the glue at the interface between the tag and the item’s surface.
Their antitampering tag contains a series of minuscule slots that enable terahertz waves to pass through the tag and strike microscopic metal particles that have been mixed into the glue.
Terahertz waves are small enough to detect the particles, whereas larger radio waves would not have enough sensitivity to see them. Also, using terahertz waves with a 1-millimeter wavelength allowed the researchers to make a chip that does not need a larger, off-chip antenna.
After passing through the tag and striking the object’s surface, terahertz waves are reflected, or backscattered, to a receiver for authentication. How those waves are backscattered depends on the distribution of metal particles that reflect them.
The researchers put multiple slots onto the chip so waves can strike different points on the object’s surface, capturing more information on the random distribution of particles.
“These responses are impossible to duplicate, as long as the glue interface is destroyed by a counterfeiter,” Han says.
A vendor would take an initial reading of the antitampering tag once it was stuck onto an item, and then store those data in the cloud, using them later for verification.
AI for authentication
But when it came time to test the antitampering tag, Lee ran into a problem: It was very difficult and time-consuming to take precise enough measurements to determine whether two glue patterns are a match.
He reached out to a friend in the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) and together they tackled the problem using AI. They trained a machine-learning model that could compare glue patterns and calculate their similarity with more than 99 percent accuracy.
“One drawback is that we had a limited data sample for this demonstration, but we could improve the neural network in the future if a large number of these tags were deployed in a supply chain, giving us a lot more data samples,” Lee says.
The authentication system is also limited by the fact that terahertz waves suffer from high levels of loss during transmission, so the sensor can only be about 4 centimeters from the tag to get an accurate reading. This distance wouldn’t be an issue for an application like barcode scanning, but it would be too short for some potential uses, such as in an automated highway toll booth. Also, the angle between the sensor and tag needs to be less than 10 degrees or the terahertz signal will degrade too much.
They plan to address these limitations in future work, and hope to inspire other researchers to be more optimistic about what can be accomplished with terahertz waves, despite the many technical challenges, says Han.
“One thing we really want to show here is that the application of the terahertz spectrum can go well beyond broadband wireless. In this case, you can use terahertz for ID, security, and authentication. There are a lot of possibilities out there,” he adds.
This work is supported, in part, by the U.S. National Science Foundation and the Korea Foundation for Advanced Studies.
A cryptographic tag developed at MIT uses terahertz waves to authenticate items by recognizing the unique pattern of microscopic metal particles that are mixed into the glue that sticks the tag to the item’s surface.
Therapeutic cancer vaccines are an appealing strategy for treating malignancies. In theory, when a patient is injected with peptide antigens — protein fragments from mutant proteins only expressed by tumor cells — T cells learn to recognize and attack cancer cells expressing the corresponding protein. By teaching the patient’s own immune system to attack cancer cells, these vaccines ideally would not only eliminate tumors but prevent them from recurring.
In practice, however, effective cancer vaccines have not materialized, despite decades of research.
“There has been a lot of work to make cancer vaccines more effective,” says Darrell Irvine, a professor in the MIT departments of Biological Engineering and Materials Science and Engineering and a member of the Koch Institute for Integrative Cancer Research at MIT. “But even in mouse and other models, they typically only provoke a weak immune response. And once those vaccines are tested in a clinical setting, their efficacy evaporates.”
New hope may now be on the horizon. A vaccine based on a novel approach developed by Irvine and colleagues at MIT, and refined by researchers at Elicio Therapeutics, an MIT spinout that Irvine founded to translate experiments into treatment, is showing promising results in clinical trials — including Phase 1 data suggesting the vaccine could serve as a viable option for the treatment of pancreatic and other cancers.
Formulating a question
When Haipeng Liu joined Irvine’s laboratory as a postdoc almost 15 years ago, he wanted to dive into the problem of why cancer vaccines have failed to deliver on their promise. He discovered that one important reason peptide vaccines for cancer and other diseases tend not to elicit a strong immune response is because they do not travel in sufficient quantities to lymph nodes, where populations of teachable T cells are concentrated. He knew that attempts to target peptides to the lymph nodes had been imprecise: Even when delivered with nanoparticles or attached to antibodies for lymphatic immune cells, too many vaccine peptides were taken up by the wrong cells in the tissues or never even made it to the lymph nodes.
But Liu, now an associate professor of chemical engineering and materials science at Wayne State University, also had a simple, unanswered question: If vaccine peptides did not make it to the lymph nodes, where did they go?
In the pursuit of an answer, Liu and his Irvine Lab colleagues would make discoveries crucial to trafficking peptides to the lymph nodes and developing a vaccine that provoked surprisingly strong immune responses in mice. That vaccine, now in the hands of Irvine Lab spinout Elicio Therapeutics, Inc., has produced early clinical results showing a similarly strong immune response in human patients.
Liu began with testing peptide vaccines in mouse models, finding that peptides injected in the skin or muscle generally rapidly leak into the bloodstream, where they are diluted and degraded rather than traveling to the lymph nodes. He tried bulking up and protecting the peptide vaccine by enclosing it within a micellar nanoparticle. This type of nanoparticle is composed of “amphiphilic” molecules, with hydrophilic heads that, in a water-based solution, encase a payload attached to its hydrophobic lipid tails. Liu tested two versions, one that locked the micellar molecules together to securely enclose the peptide vaccine and another, the control, that did not. Despite all the sophisticated chemistry that went into the locked micellar nanoparticles, they induced a weak immune response. Liu was crushed.
Irvine, however, was elated. The loosely bound control micelles produced the strongest immune response he had ever seen. Liu had hit on a potential solution — just not the one he expected.
Formulating a vaccine
While Liu was working on micellar nanoparticles, he had also been delving into the biology of the lymph node. He learned that after removing a tumor, surgeons use a small blue dye to image lymph nodes to determine the extent of metastasis. Contrary to expectation raised by the dye molecule’s small molecular weight, it does not vanish into the bloodstream after administration. Instead, the dye binds to albumin, the most common protein in blood and tissue fluids, and tracks reliably to the lymph nodes.
The amphiphiles in Liu’s control group behaved similarly to the imaging dye. Once injected into the tissue, the “loose” micelles were broken up by albumin, which then carried the peptide payload just where it needed to go.
Taking the imaging dye as a model, the lab began to develop a vaccine that used lipid tails to bind their peptide chains to lymph node-targeting albumin molecules.
Once their albumin-hitchhiking vaccine was assembled, they tested it in mouse models of HIV, melanoma, and cervical cancer. In the resulting 2014 study, they observed that peptides modified to bind albumin produced a T cell response that was five to 10 times greater than the response to peptides alone.
In later work, Irvine lab researchers were able to generate even larger immune responses. In one study, the Irvine Lab paired a cancer-targeted vaccine with CAR T cell therapy. CAR T has been used to treat blood cancers such as leukemia successfully but has not worked well for solid tumors, which suppress T cells in their immediate vicinity. The vaccine and CAR T cell therapy together dramatically increased antitumor T cell populations and the number of T cells that successfully invaded the tumor. The combination resulted in the elimination of 60% of solid tumors in mice, while CAR T cell therapy alone had almost no effect.
A model for patient impact
By 2016, Irvine was ready to begin translating the vaccine from lab bench experiments to a patient-ready treatment, spinning out a new company, Elicio.
“We made sure we were setting a high bar in the lab,” said Irvine. “In addition to leveraging albumin biology that is the same in mouse and humans, we aimed for and achieved 10-, 30-, 40-fold greater responses in the animal model relative to other gold standard vaccine approaches, and this gave us hope that these results would translate to greater immune responses in patients.”
At Elicio, Irvine’s vaccine has evolved into a platform combining lipid-linked peptides with an immune adjuvant—no CAR T cells required. In 2021, the company began a clinical trial, AMPLIFY-201, of a vaccine named ELI-002, targeting cancers with mutations in the KRAS gene, with a focus on pancreatic ductal adenocarcinoma (PDAC). The vaccine has the potential to fill an urgent need in cancer treatment: PDAC accounts for 90% of pancreatic cancers, is highly aggressive, and has limited options for effective treatment. KRAS mutations drive 90-95% of all PDAC cases, but there are several variations that must be individually targeted for effective treatment. Elicio’s cancer vaccine has the potential to target up to seven KRAS variants at once covering 88% of PDAC cases. The company has initially tested a version that targets two, and Phase 1 and 2 studies of the version targeting all seven KRAS mutants are ongoing.
Data published last month in Nature Medicine from the Phase 1 clinical trial suggests that an effective therapeutic cancer vaccine could be on the horizon. The robust responses seen in the Irvine Lab’s mouse models have so far translated to the 25 patients (20 pancreatic, 5 colorectal) in the trial: 84% of patients showed an average 56-fold increase in the number of antitumor T cells, with complete elimination of blood biomarkers of residual tumor in 24%. Patients who had a strong immune response saw an 86% reduction in the risk of cancer progression or death. The vaccine was tolerated well by patients, with no serious side effects.
“The reason I joined Elicio was, in part, because my father had KRAS-mutated colorectal cancer,” said Christopher Haqq, executive vice president, head of research and development, and chief medical officer at Elicio. “His journey made me realize the enormous need for new therapy for KRAS-mutated tumors. It gives me hope that we are on the right path to be able to help people just like my dad and many others.”
In the next phase of the PDAC clinical trial, Elicio is currently testing the formulation of the vaccine that targets seven KRAS mutations. The company has plans to address other KRAS-driven cancers, such as colorectal and non-small cell lung cancers. Peter DeMuth PhD '13, a former graduate student in the Irvine Lab and now chief scientific officer at Elicio, credits the Koch Institute’s research culture with shaping the evolution of the vaccine and the company.
“The model adopted by the KI to bring together basic science and engineering while encouraging collaboration at the intersection of complementary disciplines was critical to shaping my view of innovation and passion for technology that can deliver real-world impact,” he recalls. “This proved to be a very special ecosystem for me and many others to cultivate an engineering mindset while building a comprehensive interdisciplinary knowledge of immunology, applied chemistry, and materials science. These themes have become central to our work at Elicio.”
Funding for research on which Elicio’s vaccine platform is based was provided, in part, by a Koch Institute Quinquennial Cancer Research Fellowship, the Marble Center for Cancer Nanomedicine, and the Bridge Project, a partnership between the Koch Institute for Integrative Cancer Research at MIT and the Dana-Farber/Harvard Cancer Center.
This story was updated on Feb. 16 to clarify the goal of a vaccine currently in clinical trials.
Originally developed in the laboratory of Darrell Irvine, "amphiphile" vaccines hitchhike on albumin molecules to the lymph nodes, where they teach the immune system to fight cancer. MIT spinout Elicio Therapeutics is testing vaccines based on the technology in clinical trials, with promising early results in treating pancreatic cancer.
A simple technique that uses small amounts of energy could boost the efficiency of some key chemical processing reactions, by up to a factor of 100,000, MIT researchers report. These reactions are at the heart of petrochemical processing, pharmaceutical manufacturing, and many other industrial chemical processes.
The surprising findings are reported today in the journal Science, in a paper by MIT graduate student Karl Westendorff, professors Yogesh Surendranath and Yuriy Roman-Leshkov, and two others.
“The results are really striking,” says Surendranath, a professor of chemistry and chemical engineering. Rate increases of that magnitude have been seen before but in a different class of catalytic reactions known as redox half-reactions, which involve the gain or loss of an electron. The dramatically increased rates reported in the new study “have never been observed for reactions that don’t involve oxidation or reduction,” he says.
The non-redox chemical reactions studied by the MIT team are catalyzed by acids. “If you’re a first-year chemistry student, probably the first type of catalyst you learn about is an acid catalyst,” Surendranath says. There are many hundreds of such acid-catalyzed reactions, “and they’re super important in everything from processing petrochemical feedstocks to making commodity chemicals to doing transformations in pharmaceutical products. The list goes on and on.”
“These reactions are key to making many products we use daily,” adds Roman-Leshkov, a professor of chemical engineering and chemistry.
But the people who study redox half-reactions, also known as electrochemical reactions, are part of an entirely different research community than those studying non-redox chemical reactions, known as thermochemical reactions. As a result, even though the technique used in the new study, which involves applying a small external voltage, was well-known in the electrochemical research community, it had not been systematically applied to acid-catalyzed thermochemical reactions.
People working on thermochemical catalysis, Surendranath says, “usually don’t consider” the role of the electrochemical potential at the catalyst surface, “and they often don’t have good ways of measuring it. And what this study tells us is that relatively small changes, on the order of a few hundred millivolts, can have huge impacts — orders of magnitude changes in the rates of catalyzed reactions at those surfaces.”
“This overlooked parameter of surface potential is something we should pay a lot of attention to because it can have a really, really outsized effect,” he says. “It changes the paradigm of how we think about catalysis.”
Chemists traditionally think about surface catalysis based on the chemical binding energy of molecules to active sites on the surface, which influences the amount of energy needed for the reaction, he says. But the new findings show that the electrostatic environment is “equally important in defining the rate of the reaction.”
The team has already filed a provisional patent application on parts of the process and is working on ways to apply the findings to specific chemical processes. Westendorff says their findings suggest that “we should design and develop different types of reactors to take advantage of this sort of strategy. And we’re working right now on scaling up these systems.”
While their experiments so far were done with a two-dimensional planar electrode, most industrial reactions are run in three-dimensional vessels filled with powders. Catalysts are distributed through those powders, providing a lot more surface area for the reactions to take place. “We’re looking at how catalysis is currently done in industry and how we can design systems that take advantage of the already existing infrastructure,” Westendorff says.
Surendranath adds that these new findings “raise tantalizing possibilities: Is this a more general phenomenon? Does electrochemical potential play a key role in other reaction classes as well? In our mind, this reshapes how we think about designing catalysts and promoting their reactivity.”
Roman-Leshkov adds that “traditionally people who work in thermochemical catalysis would not associate these reactions with electrochemical processes at all. However, introducing this perspective to the community will redefine how we can integrate electrochemical characteristics into thermochemical catalysis. It will have a big impact on the community in general.”
While there has typically been little interaction between electrochemical and thermochemical catalysis researchers, Surendranath says, “this study shows the community that there’s really a blurring of the line between the two, and that there is a huge opportunity in cross-fertilization between these two communities.”
Westerndorff adds that to make it work, “you have to design a system that’s pretty unconventional to either community to isolate this effect.” And that helps explain why such a dramatic effect had never been seen before. He notes that even their paper’s editor asked them why this effect hadn’t been reported before. The answer has to do with “how disparate those two ideologies were before this,” he says. “It’s not just that people don’t really talk to each other. There are deep methodological differences between how the two communities conduct experiments. And this work is really, we think, a great step toward bridging the two.”
In practice, the findings could lead to far more efficient production of a wide variety of chemical materials, the team says. “You get orders of magnitude changes in rate with very little energy input,” Surendranath says. “That’s what’s amazing about it.”
The findings, he says, “build a more holistic picture of how catalytic reactions at interfaces work, irrespective of whether you’re going to bin them into the category of electrochemical reactions or thermochemical reactions.” He adds that “it’s rare that you find something that could really revise our foundational understanding of surface catalytic reactions in general. We’re very excited.”
“This research is of the highest quality,” says Costas Vayenas, a professor of engineering at the university of Patras, in Greece, who was not associated with the study. The work “is very promising for practical applications, particularly since it extends previous related work in redox catalytic systems,” he says.
The team included MIT postdoc Max Hulsey PhD ’22 and graduate student Thejas Wesley PhD ’23, and was supported by the Air Force Office of Scientific Research and the U.S. Department of Energy Basic Energy Sciences.
A simple technique that uses negligible amounts of energy could boost the efficiency of some key reactions used in chemical processing by a factor of 100,000, MIT researchers report.
Crop maps help scientists and policymakers track global food supplies and estimate how they might shift with climate change and growing populations. But getting accurate maps of the types of crops that are grown from farm to farm often requires on-the-ground surveys that only a handful of countries have the resources to maintain.
Now, MIT engineers have developed a method to quickly and accurately label and map crop types without requiring in-person assessments of every single farm. The team’s method uses a combination of Google Street View images, machine learning, and satellite data to automatically determine the crops grown throughout a region, from one fraction of an acre to the next.
The researchers used the technique to automatically generate the first nationwide crop map of Thailand — a smallholder country where small, independent farms make up the predominant form of agriculture. The team created a border-to-border map of Thailand’s four major crops — rice, cassava, sugarcane, and maize — and determined which of the four types was grown, at every 10 meters, and without gaps, across the entire country. The resulting map achieved an accuracy of 93 percent, which the researchers say is comparable to on-the-ground mapping efforts in high-income, big-farm countries.
The team is applying their mapping technique to other countries such as India, where small farms sustain most of the population but the type of crops grown from farm to farm has historically been poorly recorded.
“It’s a longstanding gap in knowledge about what is grown around the world,” says Sherrie Wang, the d’Arbeloff Career Development Assistant Professor in MIT’s Department of Mechanical Engineering, and the Institute for Data, Systems, and Society (IDSS). Wang, who is one of the new shared faculty hires between the MIT Schwarzman College of Computing and departments across MIT says, “The final goal is to understand agricultural outcomes like yield, and how to farm more sustainably. One of the key preliminary steps is to map what is even being grown — the more granularly you can map, the more questions you can answer.”
Wang, along with MIT graduate student Jordi Laguarta Soler and Thomas Friedel of the agtech company PEAT GmbH, will present a paper detailing their mapping method later this month at the AAAI Conference on Artificial Intelligence.
Ground truth
Smallholder farms are often run by a single family or farmer, who subsist on the crops and livestock that they raise. It’s estimated that smallholder farms support two-thirds of the world’s rural population and produce 80 percent of the world’s food. Keeping tabs on what is grown and where is essential to tracking and forecasting food supplies around the world. But the majority of these small farms are in low to middle-income countries, where few resources are devoted to keeping track of individual farms’ crop types and yields.
Crop mapping efforts are mainly carried out in high-income regions such as the United States and Europe, where government agricultural agencies oversee crop surveys and send assessors to farms to label crops from field to field. These “ground truth” labels are then fed into machine-learning models that make connections between the ground labels of actual crops and satellite signals of the same fields. They then label and map wider swaths of farmland that assessors don’t cover but that satellites automatically do.
“What’s lacking in low- and middle-income countries is this ground label that we can associate with satellite signals,” Laguarta Soler says. “Getting these ground truths to train a model in the first place has been limited in most of the world.”
The team realized that, while many developing countries do not have the resources to maintain crop surveys, they could potentially use another source of ground data: roadside imagery, captured by services such as Google Street View and Mapillary, which send cars throughout a region to take continuous 360-degree images with dashcams and rooftop cameras.
In recent years, such services have been able to access low- and middle-income countries. While the goal of these services is not specifically to capture images of crops, the MIT team saw that they could search the roadside images to identify crops.
Cropped image
In their new study, the researchers worked with Google Street View (GSV) images taken throughout Thailand — a country that the service has recently imaged fairly thoroughly, and which consists predominantly of smallholder farms.
Starting with over 200,000 GSV images randomly sampled across Thailand, the team filtered out images that depicted buildings, trees, and general vegetation. About 81,000 images were crop-related. They set aside 2,000 of these, which they sent to an agronomist, who determined and labeled each crop type by eye. They then trained a convolutional neural network to automatically generate crop labels for the other 79,000 images, using various training methods, including iNaturalist — a web-based crowdsourced biodiversity database, and GPT-4V, a “multimodal large language model” that enables a user to input an image and ask the model to identify what the image is depicting. For each of the 81,000 images, the model generated a label of one of four crops that the image was likely depicting — rice, maize, sugarcane, or cassava.
The researchers then paired each labeled image with the corresponding satellite data taken of the same location throughout a single growing season. These satellite data include measurements across multiple wavelengths, such as a location’s greenness and its reflectivity (which can be a sign of water).
“Each type of crop has a certain signature across these different bands, which changes throughout a growing season,” Laguarta Soler notes.
The team trained a second model to make associations between a location’s satellite data and its corresponding crop label. They then used this model to process satellite data taken of the rest of the country, where crop labels were not generated or available. From the associations that the model learned, it then assigned crop labels across Thailand, generating a country-wide map of crop types, at a resolution of 10 square meters.
This first-of-its-kind crop map included locations corresponding to the 2,000 GSV images that the researchers originally set aside, that were labeled by arborists. These human-labeled images were used to validate the map’s labels, and when the team looked to see whether the map’s labels matched the expert, “gold standard” labels, it did so 93 percent of the time.
“In the U.S., we’re also looking at over 90 percent accuracy, whereas with previous work in India, we’ve only seen 75 percent because ground labels are limited,” Wang says. “Now we can create these labels in a cheap and automated way.”
The researchers are moving to map crops across India, where roadside images via Google Street View and other services have recently become available.
“There are over 150 million smallholder farmers in India,” Wang says. “India is covered in agriculture, almost wall-to-wall farms, but very small farms, and historically it’s been very difficult to create maps of India because there are very sparse ground labels.”
The team is working to generate crop maps in India, which could be used to inform policies having to do with assessing and bolstering yields, as global temperatures and populations rise.
“What would be interesting would be to create these maps over time,” Wang says. “Then you could start to see trends, and we can try to relate those things to anything like changes in climate and policies.”
MIT engineers have developed a method to quickly and accurately label and map crop types using a combination of Google Street View images, machine learning, and satellite data to automatically determine the crops grown throughout a region, from one fraction of an acre to the next.
Every year, around 50,000 people in the United States experience cardiogenic shock — a life-threatening condition, usually caused by a severe heart attack, in which the heart can’t pump enough blood for the body’s needs.
Many of these patients end up receiving help from a mechanical pump that can temporarily help the heart pump blood until it recovers enough to function on its own. However, in nearly half of these patients, the extra help leads to an imbalance between the left and right ventricles, which can pose danger to the patient.
In a new study, MIT researchers have discovered why that imbalance occurs, and identified factors that make it more likely. They also developed a test that doctors could use to determine whether this dysfunction will occur in a particular patient, which could give doctors more confidence when deciding whether to use these pumps, known as ventricular assist devices (VADs).
“As we improve the mechanistic understanding of how these technologies interact with the native physiology, we can improve device utility. And if we have more algorithms and metrics-based guidance, that will ease use for clinicians. This will both improve outcomes across these patients and increase use of these devices more broadly,” says Kimberly Lamberti, an MIT graduate student and the lead author of the study.
Elazer Edelman, the Edward J. Poitras Professor in Medical Engineering and Science and the director of MIT’s Institute for Medical Engineering and Science (IMES), is the senior author of the paper, which appears today in Science Translational Medicine. Steven Keller, an assistant professor of medicine at Johns Hopkins School of Medicine, is also an author of the paper.
Edelman notes that “the beauty of this study is that it uses pathophysiologic insight and advanced computational analyses to provide clinicians with straightforward guidelines as to how to deal with the exploding use of these valuable mechanical devices. We use these devices increasingly in our sickest patients and now have greater strategies as to how to optimize their utility.”
Imbalance in the heart
To treat patients who are experiencing cardiogenic shock, a percutaneous VAD can be inserted through the arteries until it is positioned across the aortic valve, where it helps to pump blood out of the left ventricle. The left ventricle is responsible for pumping blood to most of the organs of the body, while the right ventricle pumps blood to the lungs.
In most cases, the device may be removed after a week or so, once the heart is able to pump on its own. While effective for many patients, in some people the devices can disrupt the coordination and balance between the right and left ventricles, which contract and relax synchronously. Studies have found that this disruption occurs in up to 43 percent of patients who receive VADs.
“The left and right ventricles are highly coupled, so as the device disrupts flow through the system, that can unmask or induce right heart failure in many patients,” Lamberti says. “Across the field it’s well-known that this is a concern, but the mechanism that’s creating that is unclear, and there are limited metrics to predict which patients will experience it.”
In this study, the researchers wanted to figure out why this failure occurs, and come up with a way to help doctors predict whether it will happen for a given patient. If doctors knew that the right heart would also need support, they could implant another VAD that helps the right ventricle.
“What we were trying to do with this study was predict any issues earlier in the patient’s course, so that action can be taken before that extreme state of failure has been reached,” Lamberti says.
To do that, the researchers studied the devices in an animal model of heart failure. A VAD was implanted in the left ventricle of each animal, and the researchers analyzed several different metrics of heart function as the pumping speed of the device was increased and decreased.
The researchers found that the most important factor in how the right ventricle responded to VAD implantation was how well the pulmonary vascular system — the network of vessels that carries blood between the heart and lungs — adapted to changes in blood volume and flow induced by the VAD.
This system was best able to handle that extra flow if it could adjust its resistance (the slowing of steady blood flow through the vessels) and compliance (the slowing of large pulses of blood volume into the vessels).
“We found that in the healthy state, compliance and resistance could change pretty rapidly to accommodate the changes in volume due to the device. But with progressive disease, that ability to adapt becomes diminished,” Lamberti says.
A dynamic test
The researchers also showed that measuring this pulmonary vascular compliance and its adaptability could offer a way to predict how a patient will respond to left ventricle assistance. Using a dataset of eight patients who had received a left VAD, the researchers found that those measurements correlated with the right heart state, therefore predicting how well the patients adapted to the device, validating the findings from the animal study.
To do this test, doctors would need to implant the device as usual and then ramp up the speed while measuring the compliance of the pulmonary vascular system. The researchers determined a metric that can assess this compliance by using just the VAD itself and a pulmonary artery catheter that is commonly implanted in these patients.
“We created this way to dynamically test the system while simultaneously maintaining support of the heart,” Lamberti says. “Once the device is initiated, this quick test could be run, which would inform clinicians of whether the patient might need right heart support.”
The researchers now hope to expand these findings with additional animal studies and continue collaboration with manufacturers of these devices in the future, in hopes of running clinical studies to evaluate whether this test would provide information that would be valuable for doctors.
“Right now, there are few metrics being used to predict device tolerance. Device selection and decision-making is most often based on experiential evidence from the physicians at each institution. Having this understanding will hopefully allow physicians to determine which patients will be intolerant to device support and provide guidance for how to best treat each patient based on right heart state,” Lamberti says.
The research was funded by the National Heart, Lung and Blood Institute; the National Institute of General Medical Sciences; and Abiomed.
A new MIT study sheds light on how the heart responds to ventricle assist devices (VADs), which are often used to treat patients with a failing left ventricle. The VAD includes a pump that helps to pump blood out of the left ventricle (at right in the image) into the aorta (the large pink vessel).
Every time you smoothly drive from point A to point B, you're not just enjoying the convenience of your car, but also the sophisticated engineering that makes it safe and reliable. Beyond its comfort and protective features lies a lesser-known yet crucial aspect: the expertly optimized mechanical performance of microstructured materials. These materials, integral yet often unacknowledged, are what fortify your vehicle, ensuring durability and strength on every journey.
Luckily, MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) scientists have thought about this for you. A team of researchers moved beyond traditional trial-and-error methods to create materials with extraordinary performance through computational design. Their new system integrates physical experiments, physics-based simulations, and neural networks to navigate the discrepancies often found between theoretical models and practical results. One of the most striking outcomes: the discovery of microstructured composites — used in everything from cars to airplanes — that are much tougher and durable, with an optimal balance of stiffness and toughness.
“Composite design and fabrication is fundamental to engineering. The implications of our work will hopefully extend far beyond the realm of solid mechanics. Our methodology provides a blueprint for a computational design that can be adapted to diverse fields such as polymer chemistry, fluid dynamics, meteorology, and even robotics,” says Beichen Li, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and lead researcher on the project.
In the vibrant world of materials science, atoms and molecules are like tiny architects, constantly collaborating to build the future of everything. Still, each element must find its perfect partner, and in this case, the focus was on finding a balance between two critical properties of materials: stiffness and toughness. Their method involved a large design space of two types of base materials — one hard and brittle, the other soft and ductile — to explore various spatial arrangements to discover optimal microstructures.
A key innovation in their approach was the use of neural networks as surrogate models for the simulations, reducing the time and resources needed for material design. “This evolutionary algorithm, accelerated by neural networks, guides our exploration, allowing us to find the best-performing samples efficiently,” says Li.
Magical microstructures
The research team started their process by crafting 3D printed photopolymers, roughly the size of a smartphone but slimmer, and adding a small notch and a triangular cut to each. After a specialized ultraviolet light treatment, the samples were evaluated using a standard testing machine — the Instron 5984 — for tensile testing to gauge strength and flexibility.
Simultaneously, the study melded physical trials with sophisticated simulations. Using a high-performance computing framework, the team could predict and refine the material characteristics before even creating them. The biggest feat, they said, was in the nuanced technique of binding different materials at a microscopic scale — a method involving an intricate pattern of minuscule droplets that fused rigid and pliant substances, striking the right balance between strength and flexibility. The simulations closely matched physical testing results, validating the overall effectiveness.
Rounding the system out was their “Neural-Network Accelerated Multi-Objective Optimization” (NMO) algorithm, for navigating the complex design landscape of microstructures, unveiling configurations that exhibited near-optimal mechanical attributes. The workflow operates like a self-correcting mechanism, continually refining predictions to align closer with reality.
However, the journey hasn't been without challenges. Li highlights the difficulties in maintaining consistency in 3D printing and integrating neural network predictions, simulations, and real-world experiments into an efficient pipeline.
As for the next steps, the team is focused on making the process more usable and scalable. Li foresees a future where labs are fully automated, minimizing human supervision and maximizing efficiency. "Our goal is to see everything, from fabrication to testing and computation, automated in an integrated lab setup," Li concludes.
Joining Li on the paper are senior author and MIT Professor Wojciech Matusik, as well as Pohang University of Science and Technology Associate Professor Tae-Hyun Oh and MIT CSAIL affiliates Bolei Deng, a former postdoc and now assistant professor at Georgia Tech; Wan Shou, a former postdoc and now assistant professor at University of Arkansas; Yuanming Hu MS ’18 PhD ’21; Yiyue Luo MS ’20; and Liang Shi, an MIT graduate student in electrical engineering and computer science. The group’s research was supported, in part, by Baden Aniline and Soda Factory (BASF).
A new computational pipeline developed over three years efficiently identifies stiff and tough microstructures suitable for 3D printing in a wide range of engineering applications. The approach greatly reduces the development time for high-performance microstructure composites and requires minimal materials science expertise.
Wildfires in Southeast Asia significantly affect peoples’ moods, especially if the fires originate outside a person’s own country, according to a new study.
The study, which measures sentiment by analyzing large amounts of social media data, helps show the psychological toll of wildfires that result in substantial air pollution, at a time when such fires are becoming a high-profile marker of climate change.
“It has a substantial negative impact on people’s subjective well-being,” says Siqi Zheng, an MIT professor and co-author of a new paper detailing the results. “This is a big effect.”
The magnitude of the effect is about the same as another shift uncovered through large-scale studies of sentiment expressed online: When the weekend ends and the work week starts, people’s online postings reflect a sharp drop in mood. The new study finds that daily exposure to typical wildfire smoke levels in the region produces an equivalently large change in sentiment.
“People feel anxious or sad when they have to go to work on Monday, and what we find with the fires is that this is, in fact, comparable to a Sunday-to-Monday sentiment drop,” says co-author Rui Du, a former MIT postdoct who is now an economist at Oklahoma State University.
The authors are Zheng, who is the STL Champion Professor of Urban and Real Estate Sustainability in the Center for Real Estate and the Department of Urban Studies and Planning at MIT; Du, an assistant professor of economics at Oklahoma State University’s Spears School of Business; Ajkel Mino, of the Department of Data Science and Knowledge Engineering at Maastricht University; and Jianghao Wang, of the Institute of Geographic Sciences and Natural Resources Research at the Chinese Academy of Sciences.
The research is based on an examination of the events of 2019 in Southeast Asia, in which a huge series of Indonesian wildfires, seemingly related to climate change and deforestation for the palm oil industry, produced a massive amount of haze in the region. The air-quality problems affected seven countries: Brunei, Indonesia, Malaysia, Philippines, Singapore, Thailand, and Vietnam.
To conduct the study, the scholars produced a large-scale analysis of postings from 2019 on X (formerly known as Twitter) to sample public sentiment. The study involved 1,270,927 tweets from 378,300 users who agreed to have their locations made available. The researchers compiled the data with a web crawler program and multilingual natural language processing applications that review the content of tweets and rate them in affective terms based on the vocabulary used. They also used satellite data from NASA and NOAA to create a map of wildfires and haze over time, linking that to the social media data.
Using this method creates an advantage that regular public-opinion polling does not have: It creates a measurement of mood that is effectively a real-time metric rather than an after-the-fact assessment. Moreover, substantial wind shifts in the region at the time in 2019 essentially randomize which countries were exposed to more haze at various points, making the results less likely to be influenced by other factors.
The researchers also made a point to disentangle the sentiment change due to wildfire smoke and that due to other factors. After all, people experience mood changes all the time from various natural and socioeconomic events. Wildfires may be correlated with some of them, which makes it hard to tease out the singular effect of the smoke. By comparing only the difference in exposure to wildfire smoke, blown in by wind, within the same locations over time, this study is able to isolate the impact of local wildfire haze on mood, filtering out nonpollution influences.
“What we are seeing from our estimates is really just the pure causal effect of the transboundary wildfire smoke,” Du says.
The study also revealed that people living near international borders are much more likely to be upset when affected by wildfire smoke that comes from a neighboring country. When similar conditions originate in their own country, there is a considerably more muted reaction.
“Notably, individuals do not seem to respond to domestically produced fire plumes,” the authors write in the paper. The small size of many countries in the region, coupled with a fire-prone climate, make this an ongoing source of concern, however.
“In Southeast Asia this is really a big problem, with small countries clustered together,” Zheng observes.
Zheng also co-authored a 2022 study using a related methodology to study the impact of the Covid-19 pandemic on the moods of residents in about 100 countries. In that case, the research showed that the global pandemic depressed sentiment about 4.7 times as much as the normal Sunday-to-Monday shift.
“There was a huge toll of Covid on people’s sentiment, and while the impact of the wildfires was about one-fifth of Covid, that’s still quite large,” Du says.
In policy terms, Zheng suggests that the global implications of cross-border smoke pollution could give countries a shared incentive to cooperate further. If one country’s fires become another country’s problem, they may all have reason to limit them. Scientists warn of a rising number of wildfires globally, fueled by climate change conditions in which more fires can proliferate, posing a persistent threat across societies.
“If they don’t work on this collaboratively, it could be damaging to everyone,” Zheng says.
The research at MIT was supported, in part, by the MIT Sustainable Urbanization Lab. Jianghao Wang was supported by the National Natural Science Foundation of China.
Wildfires in Southeast Asia significantly affect the moods of people in many neighboring countries, with people becoming more upset if fires originate outside their own country, according to a new study analyzing social media activity. Pictured is a 2019 forest fire in Central Kalimantan.
When a human-AI conversation involves many rounds of continuous dialogue, the powerful large language machine-learning models that drive chatbots like ChatGPT sometimes start to collapse, causing the bots’ performance to rapidly deteriorate.
A team of researchers from MIT and elsewhere has pinpointed a surprising cause of this problem and developed a simple solution that enables a chatbot to maintain a nonstop conversation without crashing or slowing down.
Their method involves a tweak to the key-value cache (which is like a conversation memory) at the core of many large language models. In some methods, when this cache needs to hold more information than it has capacity for, the first pieces of data are bumped out. This can cause the model to fail.
By ensuring that these first few data points remain in memory, the researchers’ method allows a chatbot to keep chatting no matter how long the conversation goes.
The method, called StreamingLLM, enables a model to remain efficient even when a conversation stretches on for more than 4 million words. When compared to another method that avoids crashing by constantly recomputing part of the past conversations, StreamingLLM performed more than 22 times faster.
This could allow a chatbot to conduct long conversations throughout the workday without needing to be continually rebooted, enabling efficient AI assistants for tasks like copywriting, editing, or generating code.
“Now, with this method, we can persistently deploy these large language models. By making a chatbot that we can always chat with, and that can always respond to us based on our recent conversations, we could use these chatbots in some new applications,” says Guangxuan Xiao, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on StreamingLLM.
Xiao’s co-authors include his advisor, Song Han, an associate professor in EECS, a member of the MIT-IBM Watson AI Lab, and a distinguished scientist of NVIDIA; as well as Yuandong Tian, a research scientist at Meta AI; Beidi Chen, an assistant professor at Carnegie Mellon University; and senior author Mike Lewis, a research scientist at Meta AI. The work will be presented at the International Conference on Learning Representations.
A puzzling phenomenon
Large language models encode data, like words in a user query, into representations called tokens. Many models employ what is known as an attention mechanism that uses these tokens to generate new text.
Typically, an AI chatbot writes new text based on text it has just seen, so it stores recent tokens in memory, called a KV Cache, to use later. The attention mechanism builds a grid that includes all tokens in the cache, an “attention map” that maps out how strongly each token, or word, relates to each other token.
Understanding these relationships is one feature that enables large language models to generate human-like text.
But when the cache gets very large, the attention map can become even more massive, which slows down computation.
Also, if encoding content requires more tokens than the cache can hold, the model’s performance drops. For instance, one popular model can store 4,096 tokens, yet there are about 10,000 tokens in an academic paper.
To get around these problems, researchers employ a “sliding cache” that bumps out the oldest tokens to add new tokens. However, the model’s performance often plummets as soon as that first token is evicted, rapidly reducing the quality of newly generated words.
In this new paper, researchers realized that if they keep the first token in the sliding cache, the model will maintain its performance even when the cache size is exceeded.
But this didn’t make any sense. The first word in a novel likely has nothing to do with the last word, so why would the first word be so important for the model to generate the newest word?
In their new paper, the researchers also uncovered the cause of this phenomenon.
Attention sinks
Some models use a Softmax operation in their attention mechanism, which assigns a score to each token that represents how much it relates to each other token. The Softmax operation requires all attention scores to sum up to 1. Since most tokens aren’t strongly related, their attention scores are very low. The model dumps any remaining attention score in the first token.
The researchers call this first token an “attention sink.”
“We need an attention sink, and the model decides to use the first token as the attention sink because it is globally visible — every other token can see it. We found that we must always keep the attention sink in the cache to maintain the model dynamics,” Han says.
In building StreamingLLM, the researchers discovered that having four attention sink tokens at the beginning of the sliding cache leads to optimal performance.
They also found that the positional encoding of each token must stay the same, even as new tokens are added and others are bumped out. If token 5 is bumped out, token 6 must stay encoded as 6, even though it is now the fifth token in the cache.
By combining these two ideas, they enabled StreamingLLM to maintain a continuous conversation while outperforming a popular method that uses recomputation.
For instance, when the cache has 256 tokens, the recomputation method takes 63 milliseconds to decode a new token, while StreamingLLM takes 31 milliseconds. However, if the cache size grows to 4,096 tokens, recomputation requires 1,411 milliseconds for a new token, while StreamingLLM needs just 65 milliseconds.
“The innovative approach of StreamingLLM, centered around the attention sink mechanism, ensures stable memory usage and performance, even when processing texts up to 4 million tokens in length,” says Yang You, a presidential young professor of computer science at the National University of Singapore, who was not involved with this work. “This capability is not just impressive; it's transformative, enabling StreamingLLM to be applied across a wide array of AI applications. The performance and versatility of StreamingLLM mark it as a highly promising technology, poised to revolutionize how we approach AI-driven generation applications.”
Tianqi Chen, an assistant professor in the machine learning and computer science departments at Carnegie Mellon University who also was not involved with this research, agreed, saying “Streaming LLM enables the smooth extension of the conversation length of large language models. We have been using it to enable the deployment of Mistral models on iPhones with great success.”
The researchers also explored the use of attention sinks during model training by prepending several placeholder tokens in all training samples.
They found that training with attention sinks allowed a model to maintain performance with only one attention sink in its cache, rather than the four that are usually required to stabilize a pretrained model’s performance.
But while StreamingLLM enables a model to conduct a continuous conversation, the model cannot remember words that aren’t stored in the cache. In the future, the researchers plan to target this limitation by investigating methods to retrieve tokens that have been evicted or enable the model to memorize previous conversations.
StreamingLLM has been incorporated into NVIDIA's large language model optimization library, TensorRT-LLM.
This work is funded, in part, by the MIT-IBM Watson AI Lab, the MIT Science Hub, and the U.S. National Science Foundation.
About 10 percent of human-made mercury emissions into the atmosphere each year are the result of global deforestation, according to a new MIT study.
The world’s vegetation, from the Amazon rainforest to the savannahs of sub-Saharan Africa, acts as a sink that removes the toxic pollutant from the air. However, if the current rate of deforestation remains unchanged or accelerates, the researchers estimate that net mercury emissions will keep increasing.
“We’ve been overlooking a significant source of mercury, especially in tropical regions,” says Ari Feinberg, a former postdoc in the Institute for Data, Systems, and Society (IDSS) and lead author of the study.
The researchers’ model shows that the Amazon rainforest plays a particularly important role as a mercury sink, contributing about 30 percent of the global land sink. Curbing Amazon deforestation could thus have a substantial impact on reducing mercury pollution.
The team also estimates that global reforestation efforts could increase annual mercury uptake by about 5 percent. While this is significant, the researchers emphasize that reforestation alone should not be a substitute for worldwide pollution control efforts.
“Countries have put a lot of effort into reducing mercury emissions, especially northern industrialized countries, and for very good reason. But 10 percent of the global anthropogenic source is substantial, and there is a potential for that to be even greater in the future. [Addressing these deforestation-related emissions] needs to be part of the solution,” says senior author Noelle Selin, a professor in IDSS and MIT’s Department of Earth, Atmospheric and Planetary Sciences.
Feinberg and Selin are joined on the paper by co-authors Martin Jiskra, a former Swiss National Science Foundation Ambizione Fellow at the University of Basel; Pasquale Borrelli, a professor at Roma Tre University in Italy; and Jagannath Biswakarma, a postdoc at the Swiss Federal Institute of Aquatic Science and Technology. The paper appears today in Environmental Science and Technology.
Modeling mercury
Over the past few decades, scientists have generally focused on studying deforestation as a source of global carbon dioxide emissions. Mercury, a trace element, hasn’t received the same attention, partly because the terrestrial biosphere’s role in the global mercury cycle has only recently been better quantified.
Plant leaves take up mercury from the atmosphere, in a similar way as they take up carbon dioxide. But unlike carbon dioxide, mercury doesn’t play an essential biological function for plants. Mercury largely stays within a leaf until it falls to the forest floor, where the mercury is absorbed by the soil.
Mercury becomes a serious concern for humans if it ends up in water bodies, where it can become methylated by microorganisms. Methylmercury, a potent neurotoxin, can be taken up by fish and bioaccumulated through the food chain. This can lead to risky levels of methylmercury in the fish humans eat.
“In soils, mercury is much more tightly bound than it would be if it were deposited in the ocean. The forests are doing a sort of ecosystem service, in that they are sequestering mercury for longer timescales,” says Feinberg, who is now a postdoc in the Blas Cabrera Institute of Physical Chemistry in Spain.
In this way, forests reduce the amount of toxic methylmercury in oceans.
Many studies of mercury focus on industrial sources, like burning fossil fuels, small-scale gold mining, and metal smelting. A global treaty, the 2013 Minamata Convention, calls on nations to reduce human-made emissions. However, it doesn’t directly consider impacts of deforestation.
The researchers launched their study to fill in that missing piece.
In past work, they had built a model to probe the role vegetation plays in mercury uptake. Using a series of land use change scenarios, they adjusted the model to quantify the role of deforestation.
Evaluating emissions
This chemical transport model tracks mercury from its emissions sources to where it is chemically transformed in the atmosphere and then ultimately to where it is deposited, mainly through rainfall or uptake into forest ecosystems.
They divided the Earth into eight regions and performed simulations to calculate deforestation emissions factors for each, considering elements like type and density of vegetation, mercury content in soils, and historical land use.
However, good data for some regions were hard to come by.
They lacked measurements from tropical Africa or Southeast Asia — two areas that experience heavy deforestation. To get around this gap, they used simpler, offline models to simulate hundreds of scenarios, which helped them improve their estimations of potential uncertainties.
They also developed a new formulation for mercury emissions from soil. This formulation captures the fact that deforestation reduces leaf area, which increases the amount of sunlight that hits the ground and accelerates the outgassing of mercury from soils.
The model divides the world into grid squares, each of which is a few hundred square kilometers. By changing land surface and vegetation parameters in certain squares to represent deforestation and reforestation scenarios, the researchers can capture impacts on the mercury cycle.
Overall, they found that about 200 tons of mercury are emitted to the atmosphere as the result of deforestation, or about 10 percent of total human-made emissions. But in tropical and sub-tropical countries, deforestation emissions represent a higher percentage of total emissions. For example, in Brazil deforestation emissions are 40 percent of total human-made emissions.
In addition, people often light fires to prepare tropical forested areas for agricultural activities, which causes more emissions by releasing mercury stored by vegetation.
“If deforestation was a country, it would be the second highest emitting country, after China, which emits around 500 tons of mercury a year,” Feinberg adds.
And since the Minamata Convention is now addressing primary mercury emissions, scientists can expect deforestation to become a larger fraction of human-made emissions in the future.
“Policies to protect forests or cut them down have unintended effects beyond their target. It is important to consider the fact that these are systems, and they involve human activities, and we need to understand them better in order to actually solve the problems that we know are out there,” Selin says.
By providing this first estimate, the team hopes to inspire more research in this area.
In the future, they want to incorporate more dynamic Earth system models into their analysis, which would enable them to interactively track mercury uptake and better model the timescale of vegetation regrowth.
“This paper represents an important advance in our understanding of global mercury cycling by quantifying a pathway that has long been suggested but not yet quantified. Much of our research to date has focused on primary anthropogenic emissions — those directly resulting from human activity via coal combustion or mercury-gold amalgam burning in artisanal and small-scale gold mining,” says Jackie Gerson, an assistant professor in the Department of Earth and Environmental Sciences at Michigan State University, who was not involved with this research. “This research shows that deforestation can also result in substantial mercury emissions and needs to be considered both in terms of global mercury models and land management policies. It therefore has the potential to advance our field scientifically as well as to promote policies that reduce mercury emissions via deforestation.
This work was funded, in part, by the U.S. National Science Foundation, the Swiss National Science Foundation, and Swiss Federal Institute of Aquatic Science and Technology.
Researchers studied the impact of deforestation on the global mercury cycle and found that deforestation accounts for about 10 percent of global human-made mercury emissions.
MIT engineers have developed a small ultrasound sticker that can monitor the stiffness of organs deep inside the body. The sticker, about the size of a postage stamp, can be worn on the skin and is designed to pick up on signs of disease, such as liver and kidney failure and the progression of solid tumors.
In an open-access study appearing today in Science Advances, the team reports that the sensor can send sound waves through the skin and into the body, where the waves reflect off internal organs and back out to the sticker. The pattern of the reflected waves can be read as a signature of organ rigidity, which the sticker can measure and track.
“When some organs undergo disease, they can stiffen over time,” says the senior author of the paper, Xuanhe Zhao, professor of mechanical engineering at MIT. “With this wearable sticker, we can continuously monitor changes in rigidity over long periods of time, which is crucially important for early diagnosis of internal organ failure.”
The team has demonstrated that the sticker can continuously monitor the stiffness of organs over 48 hours and detect subtle changes that could signal the progression of disease. In preliminary experiments, the researchers found that the sticky sensor can detect early signs of acute liver failure in rats.
The engineers are working to adapt the design for use in humans. They envision that the sticker could be used in intensive care units (ICUs), where the low-profile sensors could continuously monitor patients who are recovering from organ transplants.
“We imagine that, just after a liver or kidney transplant, we could adhere this sticker to a patient and observe how the rigidity of the organ changes over days,” lead author Hsiao-Chuan Liu says. “If there is any early diagnosis of acute liver failure, doctors can immediately take action instead of waiting until the condition becomes severe.” Liu was a visiting scientist at MIT at the time of the study and is currently an assistant professor at the University of Southern California.
The study’s MIT co-authors include Xiaoyu Chen and Chonghe Wang, along with collaborators at USC.
Sensing wobbles
Like our muscles, the tissues and organs in our body stiffen as we age. With certain diseases, stiffening organs can become more pronounced, signaling a potentially precipitous health decline. Clinicians currently have ways to measure the stiffness of organs such as the kidneys and liver using ultrasound elastography — a technique similar to ultrasound imaging, in which a technician manipulates a handheld probe or wand over the skin. The probe sends sound waves through the body, which cause internal organs to vibrate slightly and send waves out in return. The probe senses an organ’s induced vibrations, and the pattern of the vibrations can be translated into how wobbly or stiff the organ must be.
Ultrasound elastography is typically used in the ICU to monitor patients who have recently undergone an organ transplant. Technicians periodically check in on a patient shortly after surgery to quickly probe the new organ and look for signs of stiffening and potential acute failure or rejection.
“After organ transplantation, the first 72 hours is most crucial in the ICU,” says another senior author, Qifa Zhou, a professor at USC. “With traditional ultrasound, you need to hold a probe to the body. But you can’t do this continuously over the long term. Doctors might miss a crucial moment and realize too late that the organ is failing.”
The team realized that they might be able to provide a more continuous, wearable alternative. Their solution expands on an ultrasound sticker they previously developed to image deep tissues and organs.
“Our imaging sticker picked up on longitudinal waves, whereas this time we wanted to pick up shear waves, which will tell you the rigidity of the organ,” Zhao explains.
Existing ultrasound elastrography probes measure shear waves, or an organ’s vibration in response to sonic impulses. The faster a shear wave travels in the organ, the stiffer the organ is interpreted to be. (Think of the bounce-back of a water balloon compared to a soccer ball.)
The team looked to miniaturize ultrasound elastography to fit on a stamp-sized sticker. They also aimed to retain the same sensitivity of commercial hand-held probes, which typically incorporate about 128 piezoelectric transducers, each of which transforms an incoming electric field into outgoing sound waves.
“We used advanced fabrication techniques to cut small transducers from high-quality piezoelectric materials that allowed us to design miniaturized ultrasound stickers,” Zhou says.
The researchers precisely fabricated 128 miniature transducers that they incorporated onto a 25-millimeter-square chip. They lined the chip’s underside with an adhesive made from hydrogel — a sticky and stretchy material that is a mixture of water and polymer, which allows sound waves to travel into and out of the device almost without loss.
In preliminary experiments, the team tested the stiffness-sensing sticker in rats. They found that the stickers were able to take continuous measurements of liver stiffness over 48 hours. From the sticker’s collected data, the researchers observed clear and early signs of acute liver failure, which they later confirmed with tissue samples.
“Once liver goes into failure, the organ will increase in rigidity by multiple times,” Liu notes.
“You can go from a healthy liver as wobbly as a soft-boiled egg, to a diseased liver that is more like a hard-boiled egg,” Zhao adds. “And this sticker can pick up on those differences deep inside the body and provide an alert when organ failure occurs.”
The team is working with clinicians to adapt the sticker for use in patients recovering from organ transplants in the ICU. In that scenario, they don’t anticipate much change to the sticker’s current design, as it can be stuck to a patient’s skin, and any sound waves that it sends and receives can be delivered and collected by electronics that connect to the sticker, similar to electrodes and EKG machines in a doctor’s office.
“The real beauty of this system is that since it is now wearable, it would allow low-weight, conformable, and sustained monitoring over time,” says Shrike Zhang, an associate professor of medicine at Harvard Medical School and associate bioengineer at Brigham and Women’s Hospital, who was not involved with the study. “This would likely not only allow patients to suffer less while achieving prolonged, almost real-time monitoring of their disease progression, but also free trained hospital personnel to other important tasks.”
The researchers are also hoping to work the sticker into a more portable, self-enclosed version, where all its accompanying electronics and processing is miniaturized to fit into a slightly larger patch. Then, they envision that the sticker could be worn by patients at home, to continuously monitor conditions over longer periods, such as the progression of solid tumors, which are known to harden with severity.
“We believe this is a life-saving technology platform,” Zhao says. “In the future, we think that people can adhere a few stickers to their body to measure many vital signals, and image and track the health of major organs in the body.”
This work was supported, in part, by the National Institutes of Health.
A small ultrasound sticker, worn on the skin, can monitor the stiffness of organs deep inside the body. The MIT-developed sensor could detect signs of disease such as liver and kidney failure, and the progression of solid tumors.
In most materials, heat prefers to scatter. If left alone, a hotspot will gradually fade as it warms its surroundings. But in rare states of matter, heat can behave as a wave, moving back and forth somewhat like a sound wave that bounces from one end of a room to the other. In fact, this wave-like heat is what physicists call “second sound.”
Signs of second sound have been observed in only a handful of materials. Now MIT physicists have captured direct images of second sound for the first time.
The new images reveal how heat can move like a wave, and “slosh” back and forth, even as a material’s physical matter may move in an entirely different way. The images capture the pure movement of heat, independent of a material’s particles.
“It’s as if you had a tank of water and made one half nearly boiling,” Assistant Professor Richard Fletcher offers as analogy. “If you then watched, the water itself might look totally calm, but suddenly the other side is hot, and then the other side is hot, and the heat goes back and forth, while the water looks totally still.”
Led by Martin Zwierlein, the Thomas A Frank Professor of Physics, the team visualized second sound in a superfluid — a special state of matter that is created when a cloud of atoms is cooled to extremely low temperatures, at which point the atoms begin to flow like a completely friction-free fluid. In this superfluid state, theorists have predicted that heat should also flow like a wave, though scientists had not been able to directly observe the phenomenon until now.
The new results, reported today in the journal Science, will help physicists get a more complete picture of how heat moves through superfluids and other related materials, including superconductors and neutron stars.
“There are strong connections between our puff of gas, which is a million times thinner than air, and the behavior of electrons in high-temperature superconductors, and even neutrons in ultradense neutron stars,” Zwierlein says. “Now we can probe pristinely the temperature response of our system, which teaches us about things that are very difficult to understand or even reach.”
Zwierlein and Fletcher’s co-authors on the study are first author and former physics graduate student Zhenjie Yan and former physics graduate students Parth Patel and Biswaroop Mukherjee, along with Chris Vale at Swinburne University of Technology in Melbourne, Australia. The MIT researchers are part of the MIT-Harvard Center for Ultracold Atoms (CUA).
Super sound
When clouds of atoms are brought down to temperatures close to absolute zero, they can transition into rare states of matter. Zwierlein’s group at MIT is exploring the exotic phenomena that emerge among ultracold atoms, and specifically fermions — particles, such as electrons, that normally avoid each other.
Under certain conditions, however, fermions can be made to strongly interact and pair up. In this coupled state, fermions can flow in unconventional ways. For their latest experiments, the team employs fermionic lithium-6 atoms, which are trapped and cooled to nanokelvin temperatures.
In 1938, the physicist László Tisza proposed a two-fluid model for superfluidity — that a superfluid is actually a mixture of some normal, viscous fluid and a friction-free superfluid. This mixture of two fluids should allow for two types of sound, ordinary density waves and peculiar temperature waves, which physicist Lev Landau later named “second sound.”
Since a fluid transitions into a superfluid at a certain critical, ultracold temperature, the MIT team reasoned that the two types of fluid should also transport heat differently: In normal fluids, heat should dissipate as usual, whereas in a superfluid, it could move as a wave, similarly to sound.
“Second sound is the hallmark of superfluidity, but in ultracold gases so far you could only see it in this faint reflection of the density ripples that go along with it,” Zwierlein says. “The character of the heat wave could not be proven before.”
Tuning in
Zwierlein and his team sought to isolate and observe second sound, the wave-like movement of heat, independent of the physical motion of fermions in their superfluid. They did so by developing a new method of thermography — a heat-mapping technique. In conventional materials one would use infrared sensors to image heat sources.
But at ultracold temperatures, gases do not give off infrared radiation. Instead, the team developed a method to use radio frequency to “see” how heat moves through the superfluid. They found that the lithium-6 fermions resonate at different radio frequencies depending on their temperature: When the cloud is at warmer temperatures, and carries more normal liquid, it resonates at a higher frequency. Regions in the cloud that are colder resonate at a lower frequency.
The researchers applied the higher resonant radio frequency, which prompted any normal, “hot” fermions in the liquid to ring in response. The researchers then were able to zero in on the resonating fermions and track them over time to create “movies” that revealed heat’s pure motion — a sloshing back and forth, similar to waves of sound.
“For the first time, we can take pictures of this substance as we cool it through the critical temperature of superfluidity, and directly see how it transitions from being a normal fluid, where heat equilibrates boringly, to a superfluid where heat sloshes back and forth,” Zwierlein says.
The experiments mark the first time that scientists have been able to directly image second sound, and the pure motion of heat in a superfluid quantum gas. The researchers plan to extend their work to more precisely map heat’s behavior in other ultracold gases. Then, they say their findings can be scaled up to predict how heat flows in other strongly interacting materials, such as in high-temperature superconductors, and in neutron stars.
“Now we will be able to measure precisely the thermal conductivity in these systems, and hope to understand and design better systems,” Zwierlein concludes.
This work was supported by the National Science Foundation (NSF), the Air Force Office of Scientific Research, and the Vannevar Bush Faculty Fellowship. The MIT team is part of the MIT-Harvard Center for Ultracold Atoms (an NSF Physics Frontier Center) and affiliated with the MIT Department of Physics and the Research Laboratory of Electronics (RLE).
For the first time, MIT physicists have captured direct images of “second sound,” the movement of heat sloshing back and forth within a superfluid. The results will expand scientists’ understanding of heat flow in superconductors and neutron stars.
In quantum sensing, atomic-scale quantum systems are used to measure electromagnetic fields, as well as properties like rotation, acceleration, and distance, far more precisely than classical sensors can. The technology could enable devices that image the brain with unprecedented detail, for example, or air traffic control systems with precise positioning accuracy.
As many real-world quantum sensing devices are emerging, one promising direction is the use of microscopic defects inside diamonds to create “qubits” that can be used for quantum sensing. Qubits are the building blocks of quantum devices.
Researchers at MIT and elsewhere have developed a technique that enables them to identify and control a greater number of these microscopic defects. This could help them build a larger system of qubits that can perform quantum sensing with greater sensitivity.
Their method builds off a central defect inside a diamond, known as a nitrogen-vacancy (NV) center, which scientists can detect and excite using laser light and then control with microwave pulses. This new approach uses a specific protocol of microwave pulses to identify and extend that control to additional defects that can’t be seen with a laser, which are called dark spins.
The researchers seek to control larger numbers of dark spins by locating them through a network of connected spins. Starting from this central NV spin, the researchers build this chain by coupling the NV spin to a nearby dark spin, and then use this dark spin as a probe to find and control a more distant spin which can’t be sensed by the NV directly. The process can be repeated on these more distant spins to control longer chains.
“One lesson I learned from this work is that searching in the dark may be quite discouraging when you don’t see results, but we were able to take this risk. It is possible, with some courage, to search in places that people haven’t looked before and find potentially more advantageous qubits,” says Alex Ungar, a PhD student in electrical engineering and computer science and a member of the Quantum Engineering Group at MIT, who is lead author of a paper on this technique, which is published today in PRX Quantum.
His co-authors include his advisor and corresponding author, Paola Cappellaro, the Ford Professor of Engineering in the Department of Nuclear Science and Engineering and professor of physics; as well as Alexandre Cooper, a senior research scientist at the University of Waterloo’s Institute for Quantum Computing; and Won Kyu Calvin Sun, a former researcher in Cappellaro’s group who is now a postdoc at the University of Illinois at Urbana-Champaign.
Diamond defects
To create NV centers, scientists implant nitrogen into a sample of diamond.
But introducing nitrogen into the diamond creates other types of atomic defects in the surrounding environment. Some of these defects, including the NV center, can host what are known as electronic spins, which originate from the valence electrons around the site of the defect. Valence electrons are those in the outermost shell of an atom. A defect’s interaction with an external magnetic field can be used to form a qubit.
Researchers can harness these electronic spins from neighboring defects to create more qubits around a single NV center. This larger collection of qubits is known as a quantum register. Having a larger quantum register boosts the performance of a quantum sensor.
Some of these electronic spin defects are connected to the NV center through magnetic interaction. In past work, researchers used this interaction to identify and control nearby spins. However, this approach is limited because the NV center is only stable for a short amount of time, a principle called coherence. It can only be used to control the few spins that can be reached within this coherence limit.
In this new paper, the researchers use an electronic spin defect that is near the NV center as a probe to find and control an additional spin, creating a chain of three qubits.
They use a technique known as spin echo double resonance (SEDOR), which involves a series of microwave pulses that decouple an NV center from all electronic spins that are interacting with it. Then, they selectively apply another microwave pulse to pair the NV center with one nearby spin.
Unlike the NV, these neighboring dark spins can’t be excited, or polarized, with laser light. This polarization is a required step to control them with microwaves.
Once the researchers find and characterize a first-layer spin, they can transfer the NV’s polarization to this first-layer spin through the magnetic interaction by applying microwaves to both spins simultaneously. Then once the first-layer spin is polarized, they repeat the SEDOR process on the first-layer spin, using it as a probe to identify a second-layer spin that is interacting with it.
Controlling a chain of dark spins
This repeated SEDOR process allows the researchers to detect and characterize a new, distinct defect located outside the coherence limit of the NV center. To control this more distant spin, they carefully apply a specific series of microwave pulses that enable them to transfer the polarization from the NV center along the chain to this second-layer spin.
“This is setting the stage for building larger quantum registers to higher-layer spins or longer spin chains, and also showing that we can find these new defects that weren’t discovered before by scaling up this technique,” Ungar says.
To control a spin, the microwave pulses must be very close to the resonance frequency of that spin. Tiny drifts in the experimental setup, due to temperature or vibrations, can throw off the microwave pulses.
The researchers were able to optimize their protocol for sending precise microwave pulses, which enabled them to effectively identify and control second-layer spins, Ungar says.
“We are searching for something in the unknown, but at the same time, the environment might not be stable, so you don’t know if what you are finding is just noise. Once you start seeing promising things, you can put all your best effort in that one direction. But before you arrive there, it is a leap of faith,” Cappellaro says.
While they were able to effectively demonstrate a three-spin chain, the researchers estimate they could scale their method to a fifth layer using their current protocol, which could provide access to hundreds of potential qubits. With further optimization, they may be able to scale up to more than 10 layers.
In the future, they plan to continue enhancing their technique to efficiently characterize and probe other electronic spins in the environment and explore different types of defects that could be used to form qubits.
This research is supported, in part, by the U.S. National Science Foundation and the Canada First Research Excellence Fund.
Researchers use microscopic defects inside a diamond to build a chain of three qubits (pictured as small circles with arrows) that they can use for quantum sensing. They start from a central defect, couple it with a nearby defect, and then use this second defect to find and control a third defect.
A tiny device built by scientists at MIT and the Singapore-MIT Alliance for Research and Technology could be used to improve the safety and effectiveness of cell therapy treatments for patients suffering from spinal cord injuries.
In cell therapy, clinicians create what are known as induced pluripotent stem cells by reprogramming some skin or blood cells taken from a patient. To treat a spinal cord injury, they would coax these pluripotent stem cells to become progenitor cells, which are destined to differentiate into spinal cord cells. These progenitors are then transplanted back into the patient.
These new cells can regenerate part of the injured spinal cord. However, pluripotent stem cells that don’t fully change into progenitors can form tumors.
This research team developed a microfluidic cell sorter that can remove about half of the undifferentiated cells — those that can potentially become tumors — in a batch, without causing any damage to the fully-formed progenitor cells.
The high-throughput device, which doesn’t require special chemicals, can sort more than 3 million cells per minute. In addition, the researchers have shown that chaining many devices together can sort more than 500 million cells per minute, making this a more viable method to someday improve the safety of cell therapy treatments.
Plus, the plastic chip that contains the microfluidic cell sorter can be mass-produced in a factory at very low cost, so the device would be easier to implement at scale.
“Even if you have a life-saving cell therapy that is doing wonders for patients, if you cannot manufacture it cost-effectively, reliably, and safely, then its impact might be limited. Our team is passionate about that problem — we want to make these therapies more reliable and easily accessible,” says Jongyoon Han, an MIT professor of electrical engineering and computer science and of biological engineering, a member of the Research Laboratory of Electronics (RLE), and co-lead principal investigator of the CAMP (Critical Analytics for Manufacturing Personalized Medicine) research group at the Singapore-MIT Alliance for Research and Technology (SMART).
Han is joined on the paper by co-senior author Sing Yian Chew, professor of chemistry, chemical engineering, and biotechnology at the Lee Kong Chian School of Medicine and Materials Science and Engineering at Nanyang Technological University in Singapore and a CAMP principal investigator; co-lead authors Tan Dai Nguyen, a CAMP researcher; Wai Hon Chooi, a senior research fellow at the Singapore Agency for Science, Technology, and Research (A*STAR); and Hyungkook Jeon, an MIT postdoc; as well as others at NTU and A*STAR. The research appears today in Stem Cells Translational Medicine.
Reducing risk
The cancer risk posed by undifferentiated induced pluripotent stem cells remains one of the most pressing challenges in this type of cell therapy.
“Even if you have a very small population of cells that are not fully differentiated, they could still turn into cancer-like cells,” Han adds.
Clinicians and researchers often seek to identify and remove these cells by looking for certain markers on their surfaces, but so far researchers have not been able to find a marker that is specific to these undifferentiated cells. Other methods use chemicals to selectively destroy these cells, yet the chemical treatment techniques may be harmful to the differentiated cells.
The high-throughput microfluidic sorter, which can sort cells based on size, had been previously developed by the CAMP team after more than a decade of work. It has been previously used for sorting immune cells and mesenchymal stromal cells (another type of stem cell), and now the team is expanding its use to other stem cell types, such as induced pluripotent stem cells, Han says.
“We are interested in regenerative strategies to enhance tissue repair after spinal cord injuries, as these conditions lead to devasting functional impairment. Unfortunately, there is currently no effective regenerative treatment approach for spinal cord injuries,” Chew says. “Spinal cord progenitor cells derived from pluripotent stem cells hold great promise, since they can generate all cell types found within the spinal cord to restore tissue structure and function. To be able to effectively utilize these cells, the first step would be to ensure their safety, which is the aim of our work.”
The team discovered that pluripotent stem cells tend to be larger than the progenitors derived from them. It is hypothesized that before a pluripotent stem cell differentiates, its nucleus contains a large number of genes that haven’t been turned off, or suppressed. As it differentiates for a specific function, the cell suppresses many genes it will no longer need, significantly shrinking the nucleus.
The microfluidic device leverages this size difference to sort the cells.
Spiral sorting
Microfluidic channels in the quarter-sized plastic chip form an inlet, a spiral, and four outlets that output cells of different sizes. As the cells are forced through the spiral at very high speeds, various forces, including centrifugal forces, act on the cells. These forces counteract to focus the cells in a certain location in the fluid stream. This focusing point will be dependent on the size of the cells, effectively sorting them through separate outlets.
The researchers found they could improve the sorter’s operation by running it twice, first at a lower speed so larger cells stick to the walls and smaller cells are sorted out, then at a higher speed to sort out larger cells.
In a sense, the device operates like a centrifuge, but the microfluidic sorter does not require human intervention to pick out sorted cells, Han adds.
The researchers showed that their device could remove about 50 percent of the larger cells with one pass. They conducted experiments to confirm that the larger cells they removed were, in fact, associated with higher tumor risk.
“While we can’t remove 100 percent of these cells, we still believe this is going to reduce the risk significantly. Hopefully, the original cell type is good enough that we don’t have too many undifferentiated cells. Then this process could make these cells even safer,” he says.
Importantly, the low-cost microfluidic sorter, which can be produced at scale with standard manufacturing techniques, does not use any type of filtration. Filters can become clogged or break down, so a filter-free device can be used for a much longer time.
Now that they have shown success at a small scale, the researchers are embarking on larger studies and animal models to see if the purified cells function better in vivo.
Nondifferentiated cells can become tumors, but they can have other random effects in the body, so removing more of these cells could boost the efficacy of cell therapies, as well as improve safety.
“If we can convincingly demonstrate these benefits in vivo, the future might hold even more exciting applications for this technique,” Han says.
This research is supported, in part, by the National Research Foundation of Singapore and the Singapore-MIT Alliance for Research and Technology.
Scientists developed a tiny microfluidic device that can improve the safety and efficacy of cell therapy techniques for spinal cord injury patients. Their device, which can sort cells by size as shown in the photo, can remove a large percentage of stem cells that have not yet fully become spinal cord cells, which could potentially form tumors after being transplanted into a patient.
Plucking a guitar string is a simple action that generates a harmonic series of overtones. However, skilled guitar players can elevate their performance by applying pressure to the strings while plucking them. This subtle technique causes the pitch of the note to bend — rising or falling with each deft movement — and infuses the music with expressiveness, texture, and character by intentionally harnessing the "nonlinear effects" of guitar strings.
In a study published Jan. 24 in Nature Physics, researchers from MIT and the University of Texas at Austin draw a fascinating scientific parallel to this musical artistry. The paper, authored by MIT graduate student Zhuquan Zhang, University of Texas at Austin postdoc Frank Gao PhD ’22, MIT Haslam and Dewey Professor of Chemistry Keith Nelson, and University of Texas at Austin Assistant Professor Edoardo Baldini, demonstrates the ability to control the dancing patterns of tiny magnetic bits, often referred to as “spin waves” or “magnons,” in a nonlinear manner, akin to how skilled guitar players manipulate guitar strings.
To do this, the researchers used intense terahertz (THz) fields — specially designed laser pulses operating at extreme infrared frequencies — to resonantly launch a spin wave at its characteristic frequency. But instead of simply exciting one spin wave, as one would normally expect — another distinct spin wave with a higher frequency was also excited. “This really surprised us. It meant that we could nonlinearly control the energy flow within these magnetic systems,” says Zhang.
To identify these nonlinear excitation pathways, the researchers developed a sophisticated spectrometer to uncover the mutual coupling between distinct spin waves and reveal their underlying symmetries. “Unlike visible light that can be easily seen by the eye, THz light is challenging to detect,” Gao explains. “These experiments would be otherwise impossible without the technique development which allowed us to measure THz signals with only a single light pulse.”
The team’s work provides new insights into how light can interact with spins in an unconventional way. Since the collective dancing motions of these minuscule magnetic bits and their propagation consume significantly less energy than electrical charges, they have attracted much fanfare from scientists for their potential to revolutionize computing. This discovery provides a tool that brings us ever closer to a future of high-speed spin-based information processing, enabling applications like magnonic transistors and quantum computing devices.
Other authors on the paper include Yu-Che Chien ’23; Zi-Jie Liu and Eric R. Sung, two current MIT chemistry graduate students; Alexander von Hoegen, an MIT postdoc from the Department of Physics; Jonathan B. Curtis and Professor Prineha Narang from the University of California Los Angeles; and Xiaoxuan Ma, Professor Wei Ren, and Professor Shixun Cao from Shanghai University.
This work was primarily supported by the U.S. Department of Energy Office of Basic Energy Sciences, the Robert A. Welch Foundation, and the United States Army Research Office.
This illustration depicts an antiferromagnetic material being driven by a pair of intense THz pulses, with the nonlinear emissions of spin waves being detected using a state-of-the-art polarimetry technique.
A team of MIT researchers will lead a $65.67 million effort, awarded by the U.S. Advanced Research Projects Agency for Health (ARPA-H), to develop ingestible devices that may one day be used to treat diabetes, obesity, and other conditions through oral delivery of mRNA. Such devices could potentially be deployed for needle-free delivery of mRNA vaccines as well.
The five-year project also aims to develop electroceuticals, a new form of ingestible therapies based on electrical stimulation of the body’s own hormones and neural signaling. If successful, this approach could lead to new treatments for a variety of metabolic disorders.
“We know that the oral route is generally the preferred route of administration for both patients and health care providers,” says Giovanni Traverso, an associate professor of mechanical engineering at MIT and a gastroenterologist at Brigham and Women’s Hospital. “Our primary focus is on disorders of metabolism because they affect a lot of people, but the platforms we’re developing could be applied very broadly.”
Traverso is the principal investigator for the project, which also includes Robert Langer, MIT Institute Professor, and Anantha Chandrakasan, dean of the MIT School of Engineering and the Vannevar Bush Professor of Electrical Engineering and Computer Science. As part of the project, the MIT team will collaborate with investigators from Brigham and Women’s Hospital, New York University, and the University of Colorado School of Medicine.
Over the past several years, Traverso’s and Langer’s labs have designed many types of ingestible devices that can deliver drugs to the GI tract. This approach could be especially useful for protein drugs and nucleic acids, which typically can’t be given orally because they break down in the acidic environment of the digestive tract.
Messenger RNA has already proven useful as a vaccine, directing cells to produce fragments of viral proteins that trigger an immune response. Delivering mRNA to cells also holds potential to stimulate production of therapeutic molecules to treat a variety of diseases. In this project, the researchers plan to focus on metabolic diseases such as diabetes.
“What mRNA can do is enable the potential for dosing therapies that are very difficult to dose today, or provide longer-term coverage by essentially creating an internal factory that produces a therapy for a prolonged period,” Traverso says.
In the mRNA portion of the project, the research team intends to identify lipid and polymer nanoparticle formulations that can most effectively deliver mRNA to cells, using machine learning to help identify the best candidates. They will also develop and test ingestible devices to carry the mRNA-nanoparticle payload, with the goal of running a clinical trial in the final year of the five-year project.
The work will build on research that Traverso’s lab has already begun. In 2022, Traverso and his colleagues reported that they could deliver mRNA in capsules that inject mRNA-nanoparticle complexes into the lining of the stomach.
The other branch of the project will focus on ingestible devices that can deliver a small electrical current to the lining of the stomach. In a study published last year, Traverso’s lab demonstrated this approach for the first time, using a capsule coated with electrodes that apply an electrical current to cells of the stomach. In animal studies, they found that this stimulation boosted production of ghrelin, a hormone that stimulates appetite.
Traverso envisions that this type of treatment could potentially replace or complement some of the existing drugs used to prevent nausea and stimulate appetite in people with anorexia or cachexia (loss of body mass that can occur in patients with cancer or other chronic diseases). The researchers also hope to develop ways to stimulate production of GLP-1, a hormone that is used to help manage diabetes and promote weight loss.
“What this approach starts to do is potentially maximize our ability to treat disease without administering a new drug, but instead by simply modulating the body’s own systems through electrical stimulation,” Traverso says.
At MIT, Langer will help to develop nanoparticles for mRNA delivery, and Chandrakasan will work on ways to reduce energy consumption and miniaturize the electronic functions of the capsules, including secure communication, stimulation, and power generation.
The Brigham and Women’s Hospital’s portion of the project will be co-led by Traverso, Ameya Kirtane, Jason Li, and Peter Chai, who will amplify efforts on the formulation and stabilization of the mRNA nanoparticles, engineering of the ingestible devices, and running of clinical trials. At NYU, the effort will be led by assistant professor of bioengineering Khalil Ramadi SM ’16, PhD ’19, focusing on biological characterization of the effects of electrical stimulation. Researchers at the University of Colorado, led by Matthew Wynia and Eric G. Campbell of the CU Center for Bioethics and Humanities, will focus on exploring the ethical dimensions and public perceptions of these types of biomedical interventions.
“We felt like we had an opportunity here not only to do fundamental engineering science and early-stage clinical trials, but also to start to understand the data behind some of the ethical implications and public perceptions of these technologies through this broad collaboration,” Traverso says.
The project described here is supported by ARPA-H under award number D24AC00040-00. The content of this announcement does not necessarily represent the official views of the Advanced Research Projects Agency for Health.
A team of MIT researchers will receive $65.6 million from the Advanced Research Projects Agency for Health (ARPA-H) to develop new ingestible devices that could be used to treat diabetes, obesity, and other conditions through oral delivery of mRNA. Giovanni Traverso, an associate professor of mechanical engineering at MIT and a gastroenterologist at Brigham and Women’s Hospital, is the principal investigator for the project.
A new analysis by MIT researchers shows the places in the U.S. where jobs are most linked to fossil fuels. The research could help policymakers better identify and support areas affected over time by a switch to renewable energy.
While many of the places most potentially affected have intensive drilling and mining operations, the study also measures how areas reliant on other industries, such as heavy manufacturing, could experience changes. The research examines the entire U.S. on a county-by-county level.
“Our result is that you see a higher carbon footprint for jobs in places that drill for oil, mine for coal, and drill for natural gas, which is evident in our maps,” says Christopher Knittel, an economist at the MIT Sloan School of Management and co-author of a new paper detailing the findings. “But you also see high carbon footprints in areas where we do a lot of manufacturing, which is more likely to be missed by policymakers when examining how the transition to a zero-carbon economy will affect jobs.”
So, while certain U.S. areas known for fossil-fuel production would certainly be affected — including west Texas, the Powder River Basin of Montana and Wyoming, parts of Appalachia, and more — a variety of industrial areas in the Great Plains and Midwest could see employment evolve as well.
“Our results are unique in that we cover close to the entire U.S. economy and consider the impacts on places that produce fossil fuels but also on places that consume a lot of coal, oil, or natural gas for energy,” says Graham. “This approach gives us a much more complete picture of where communities might be affected and how support should be targeted.”
Adjusting the targets
The current study stems from prior research Knittel has conducted, measuring carbon footprints at the household level across the U.S. The new project takes a conceptually related approach, but for jobs in a given county. To conduct the study, the researchers used several data sources measuring energy consumption by businesses, as well as detailed employment data from the U.S. Census Bureau.
The study takes advantage of changes in energy supply and demand over time to estimate how strongly a full range of jobs, not just those in energy production, are linked to use of fossil fuels. The sectors accounted for in the study comprise 86 percent of U.S. employment, and 94 percent of U.S. emissions apart from the transportation sector.
The Inflation Reduction Act, passed by Congress and signed into law by President Joe Biden in August 2022, is the first federal legislation seeking to provide an economic buffer for places affected by the transition away from fossil fuels. The act provides expanded tax credits for economic projects located in “energy community” areas — defined largely as places with high fossil-fuel industry employment or tax revenue and with high unemployment. Areas with recently closed or downsized coal mines or power plants also qualify.
Graham and Knittel measured the “employment carbon footprint” (ECF) of each county in the U.S., producing new results. Out of more than 3,000 counties in the U.S., the researchers found that 124 are at the 90th percentile or above in ECF terms, while not qualifying for Inflation Reduction Act assistance. Another 79 counties are eligible for Inflation Reduction Act assistance, while being in the bottom 20 percent nationally in ECF terms.
Those may not seem like colossal differences, but the findings identify real communities potentially being left out of federal policy, and highlight the need for new targeting of such programs. The research by Graham and Knittel offers a precise way to assess the industrial composition of U.S. counties, potentially helping to target economic assistance programs.
“The impact on jobs of the energy transition is not just going to be where oil and natural gas are drilled, it’s going to be all the way up and down the value chain of things we make in the U.S.,” Knittel says. “That’s a more extensive, but still focused, problem.”
Graham adds: “It’s important that policymakers understand these economy-wide employment impacts. Our aim in providing these data is to help policymakers incorporate these considerations into future policies like the Inflation Reduction Act.”
Adapting policy
Graham and Knittel are still evaluating what the best policy measures might be to help places in the U.S. adapt to a move away from fossil fuels.
“What we haven’t necessarily closed the loop on is the right way to build a policy that takes account of these factors,” Knittel says. “The Inflation Reduction Act is the first policy to think about a [fair] energy transition because it has these subsidies for energy-dependent counties.” But given enough political backing, there may be room for additional policy measures in this area.
One thing clearly showing through in the study’s data is that many U.S. counties are in a variety of situations, so there may be no one-size-fits-all approach to encouraging economic growth while making a switch to clean energy. What suits west Texas or Wyoming best may not work for more manufacturing-based local economies. And even among primary energy-production areas, there may be distinctions, among those drilling for oil or natural gas and those producing coal, based on the particular economics of those fuels. The study includes in-depth data about each county, characterizing its industrial portfolio, which may help tailor approaches to a range of economic situations.
“The next step is using this data more specifically to design policies to protect these communities,” Knittel says.
A new map shows which U.S. counties have the highest concentration of jobs that could be affected by the transition to renewable energy, based on new research by Christopher Knittel, the George P. Shultz Professor at the MIT Sloan School of Management, and Kailin Graham, of MIT’s Center for Energy and Environmental Policy Research. Counties in blue are less potentially affected by the energy transition, and counties in red are more potentially affected.
Behrooz Tahmasebi — an MIT PhD student in the Department of Electrical Engineering and Computer Science (EECS) and an affiliate of the Computer Science and Artificial Intelligence Laboratory (CSAIL) — was taking a mathematics course on differential equations in late 2021 when a glimmer of inspiration struck. In that class, he learned for the first time about Weyl’s law, which had been formulated 110 years earlier by the German mathematician Hermann Weyl. Tahmasebi realized it might have some relevance to the computer science problem he was then wrestling with, even though the connection appeared — on the surface — to be thin, at best. Weyl’s law, he says, provides a formula that measures the complexity of the spectral information, or data, contained within the fundamental frequencies of a drum head or guitar string.
Tahmasebi was, at the same time, thinking about measuring the complexity of the input data to a neural network, wondering whether that complexity could be reduced by taking into account some of the symmetries inherent to the dataset. Such a reduction, in turn, could facilitate — as well as speed up — machine learning processes.
Weyl’s law, conceived about a century before the boom in machine learning, had traditionally been applied to very different physical situations — such as those concerning the vibrations of a string or the spectrum of electromagnetic (black-body) radiation given off by a heated object. Nevertheless, Tahmasebi believed that a customized version of that law might help with the machine learning problem he was pursuing. And if the approach panned out, the payoff could be considerable.
He spoke with his advisor, Stefanie Jegelka — an associate professor in EECS and affiliate of CSAIL and the MIT Institute for Data, Systems, and Society — who believed the idea was definitely worth looking into. As Tahmasebi saw it, Weyl’s law had to do with gauging the complexity of data, and so did this project. But Weyl’s law, in its original form, said nothing about symmetry.
He and Jegelka have now succeeded in modifying Weyl’s law so that symmetry can be factored into the assessment of a dataset’s complexity. “To the best of my knowledge,” Tahmasebi says, “this is the first time Weyl’s law has been used to determine how machine learning can be enhanced by symmetry.”
The paper he and Jegelka wrote earned a “Spotlight” designation when it was presented at the December 2023 conference on Neural Information Processing Systems — widely regarded as the world’s top conference on machine learning.
This work, comments Soledad Villar, an applied mathematician at Johns Hopkins University, “shows that models that satisfy the symmetries of the problem are not only correct but also can produce predictions with smaller errors, using a small amount of training points. [This] is especially important in scientific domains, like computational chemistry, where training data can be scarce.”
In their paper, Tahmasebi and Jegelka explored the ways in which symmetries, or so-called “invariances,” could benefit machine learning. Suppose, for example, the goal of a particular computer run is to pick out every image that contains the numeral 3. That task can be a lot easier, and go a lot quicker, if the algorithm can identify the 3 regardless of where it is placed in the box — whether it’s exactly in the center or off to the side — and whether it is pointed right-side up, upside down, or oriented at a random angle. An algorithm equipped with the latter capability can take advantage of the symmetries of translation and rotations, meaning that a 3, or any other object, is not changed in itself by altering its position or by rotating it around an arbitrary axis. It is said to be invariant to those shifts. The same logic can be applied to algorithms charged with identifying dogs or cats. A dog is a dog is a dog, one might say, irrespective of how it is embedded within an image.
The point of the entire exercise, the authors explain, is to exploit a dataset’s intrinsic symmetries in order to reduce the complexity of machine learning tasks. That, in turn, can lead to a reduction in the amount of data needed for learning. Concretely, the new work answers the question: How many fewer data are needed to train a machine learning model if the data contain symmetries?
There are two ways of achieving a gain, or benefit, by capitalizing on the symmetries present. The first has to do with the size of the sample to be looked at. Let’s imagine that you are charged, for instance, with analyzing an image that has mirror symmetry — the right side being an exact replica, or mirror image, of the left. In that case, you don’t have to look at every pixel; you can get all the information you need from half of the image — a factor of two improvement. If, on the other hand, the image can be partitioned into 10 identical parts, you can get a factor of 10 improvement. This kind of boosting effect is linear.
To take another example, imagine you are sifting through a dataset, trying to find sequences of blocks that have seven different colors — black, blue, green, purple, red, white, and yellow. Your job becomes much easier if you don’t care about the order in which the blocks are arranged. If the order mattered, there would be 5,040 different combinations to look for. But if all you care about are sequences of blocks in which all seven colors appear, then you have reduced the number of things — or sequences — you are searching for from 5,040 to just one.
Tahmasebi and Jegelka discovered that it is possible to achieve a different kind of gain — one that is exponential — that can be reaped for symmetries that operate over many dimensions. This advantage is related to the notion that the complexity of a learning task grows exponentially with the dimensionality of the data space. Making use of a multidimensional symmetry can therefore yield a disproportionately large return. “This is a new contribution that is basically telling us that symmetries of higher dimension are more important because they can give us an exponential gain,” Tahmasebi says.
The NeurIPS 2023 paper that he wrote with Jegelka contains two theorems that were proved mathematically. “The first theorem shows that an improvement in sample complexity is achievable with the general algorithm we provide,” Tahmasebi says. The second theorem complements the first, he added, “showing that this is the best possible gain you can get; nothing else is achievable.”
He and Jegelka have provided a formula that predicts the gain one can obtain from a particular symmetry in a given application. A virtue of this formula is its generality, Tahmasebi notes. “It works for any symmetry and any input space.” It works not only for symmetries that are known today, but it could also be applied in the future to symmetries that are yet to be discovered. The latter prospect is not too farfetched to consider, given that the search for new symmetries has long been a major thrust in physics. That suggests that, as more symmetries are found, the methodology introduced by Tahmasebi and Jegelka should only get better over time.
According to Haggai Maron, a computer scientist at Technion (the Israel Institute of Technology) and NVIDIA who was not involved in the work, the approach presented in the paper “diverges substantially from related previous works, adopting a geometric perspective and employing tools from differential geometry. This theoretical contribution lends mathematical support to the emerging subfield of ‘Geometric Deep Learning,’ which has applications in graph learning, 3D data, and more. The paper helps establish a theoretical basis to guide further developments in this rapidly expanding research area.”
New MIT research provides a theoretical proof for a phenomenon observed in practice: that encoding symmetries in the machine learning model helps the model learn with fewer data.
When diagnosing skin diseases based solely on images of a patient’s skin, doctors do not perform as well when the patient has darker skin, according to a new study from MIT researchers.
The study, which included more than 1,000 dermatologists and general practitioners, found that dermatologists accurately characterized about 38 percent of the images they saw, but only 34 percent of those that showed darker skin. General practitioners, who were less accurate overall, showed a similar decrease in accuracy with darker skin.
The research team also found that assistance from an artificial intelligence algorithm could improve doctors’ accuracy, although those improvements were greater when diagnosing patients with lighter skin.
While this is the first study to demonstrate physician diagnostic disparities across skin tone, other studies have found that the images used in dermatology textbooks and training materials predominantly feature lighter skin tones. That may be one factor contributing to the discrepancy, the MIT team says, along with the possibility that some doctors may have less experience in treating patients with darker skin.
“Probably no doctor is intending to do worse on any type of person, but it might be the fact that you don’t have all the knowledge and the experience, and therefore on certain groups of people, you might do worse,” says Matt Groh PhD ’23, an assistant professor at the Northwestern University Kellogg School of Management. “This is one of those situations where you need empirical evidence to help people figure out how you might want to change policies around dermatology education.”
Groh is the lead author of the study, which appears today in Nature Medicine. Rosalind Picard, an MIT professor of media arts and sciences, is the senior author of the paper.
Diagnostic discrepancies
Several years ago, an MIT study led by Joy Buolamwini PhD ’22 found that facial-analysis programs had much higher error rates when predicting the gender of darker skinned people. That finding inspired Groh, who studies human-AI collaboration, to look into whether AI models, and possibly doctors themselves, might have difficulty diagnosing skin diseases on darker shades of skin — and whether those diagnostic abilities could be improved.
“This seemed like a great opportunity to identify whether there’s a social problem going on and how we might want fix that, and also identify how to best build AI assistance into medical decision-making,” Groh says. “I’m very interested in how we can apply machine learning to real-world problems, specifically around how to help experts be better at their jobs. Medicine is a space where people are making really important decisions, and if we could improve their decision-making, we could improve patient outcomes.”
To assess doctors’ diagnostic accuracy, the researchers compiled an array of 364 images from dermatology textbooks and other sources, representing 46 skin diseases across many shades of skin.
Most of these images depicted one of eight inflammatory skin diseases, including atopic dermatitis, Lyme disease, and secondary syphilis, as well as a rare form of cancer called cutaneous T-cell lymphoma (CTCL), which can appear similar to an inflammatory skin condition. Many of these diseases, including Lyme disease, can present differently on dark and light skin.
The research team recruited subjects for the study through Sermo, a social networking site for doctors. The total study group included 389 board-certified dermatologists, 116 dermatology residents, 459 general practitioners, and 154 other types of doctors.
Each of the study participants was shown 10 of the images and asked for their top three predictions for what disease each image might represent. They were also asked if they would refer the patient for a biopsy. In addition, the general practitioners were asked if they would refer the patient to a dermatologist.
“This is not as comprehensive as in-person triage, where the doctor can examine the skin from different angles and control the lighting,” Picard says. “However, skin images are more scalable for online triage, and they are easy to input into a machine-learning algorithm, which can estimate likely diagnoses speedily.”
The researchers found that, not surprisingly, specialists in dermatology had higher accuracy rates: They classified 38 percent of the images correctly, compared to 19 percent for general practitioners.
Both of these groups lost about four percentage points in accuracy when trying to diagnose skin conditions based on images of darker skin — a statistically significant drop. Dermatologists were also less likely to refer darker skin images of CTCL for biopsy, but more likely to refer them for biopsy for noncancerous skin conditions.
“This study demonstrates clearly that there is a disparity in diagnosis of skin conditions in dark skin. This disparity is not surprising; however, I have not seen it demonstrated in the literature such a robust way. Further research should be performed to try and determine more precisely what the causative and mitigating factors of this disparity might be,” says Jenna Lester, an associate professor of dermatology and director of the Skin of Color Program at the University of California at San Francisco, who was not involved in the study.
A boost from AI
After evaluating how doctors performed on their own, the researchers also gave them additional images to analyze with assistance from an AI algorithm the researchers had developed. The researchers trained this algorithm on about 30,000 images, asking it to classify the images as one of the eight diseases that most of the images represented, plus a ninth category of “other.”
This algorithm had an accuracy rate of about 47 percent. The researchers also created another version of the algorithm with an artificially inflated success rate of 84 percent, allowing them to evaluate whether the accuracy of the model would influence doctors’ likelihood to take its recommendations.
“This allows us to evaluate AI assistance with models that are currently the best we can do, and with AI assistance that could be more accurate, maybe five years from now, with better data and models,” Groh says.
Both of these classifiers are equally accurate on light and dark skin. The researchers found that using either of these AI algorithms improved accuracy for both dermatologists (up to 60 percent) and general practitioners (up to 47 percent).
They also found that doctors were more likely to take suggestions from the higher-accuracy algorithm after it provided a few correct answers, but they rarely incorporated AI suggestions that were incorrect. This suggests that the doctors are highly skilled at ruling out diseases and won’t take AI suggestions for a disease they have already ruled out, Groh says.
“They’re pretty good at not taking AI advice when the AI is wrong and the physicians are right. That’s something that is useful to know,” he says.
While dermatologists using AI assistance showed similar increases in accuracy when looking at images of light or dark skin, general practitioners showed greater improvement on images of lighter skin than darker skin.
“This study allows us to see not only how AI assistance influences, but how it influences across levels of expertise,” Groh says. “What might be going on there is that the PCPs don't have as much experience, so they don’t know if they should rule a disease out or not because they aren’t as deep into the details of how different skin diseases might look on different shades of skin.”
The researchers hope that their findings will help stimulate medical schools and textbooks to incorporate more training on patients with darker skin. The findings could also help to guide the deployment of AI assistance programs for dermatology, which many companies are now developing.
The research was funded by the MIT Media Lab Consortium and the Harold Horowitz Student Research Fund.
Doctors do not perform as well diagnosing skin diseases when the patient has darker skin, according to an MIT study. “This is one of those situations where you need empirical evidence to help people figure out how you might want to change policies around dermatology education,” says Matt Groh.
Back in the 1980s, researchers tested a job-training program called JOBSTART in 13 U.S. cities. In 12 locations, the program had a minimal benefit. But in San Jose, California, results were good: After a few years, workers earned about $6,500 more annually than peers not participating in it. So, in the 1990s, U.S. Department of Labor researchers implemented the program in another 12 cities. The results were not replicated, however. The initial San Jose numbers remained an outlier.
This scenario could be a consequence of something scholars call the “winner’s curse.” When programs or policies or ideas get tested, even in rigorous randomized experiments, things that function well one time may perform worse the next time out. (The term “winner’s curse” also refers to high winning bids at an auction, a different, but related, matter.)
This winner’s curse presents a problem for public officials, private-sector firm leaders, and even scientists: In choosing something that has tested well, they may be buying into decline. What goes up will often come down.
“In cases where people have multiple options, they pick the one they think is best, often based on the results of a randomized trial,” says MIT economist Isaiah Andrews. “What you will find is that if you try that program again, it will tend to be disappointing relative to the initial estimate that led people to pick it.”
Andrews is co-author of a newly published study that examines this phenomenon and provides new tools to study it, which could also help people avoid it.
The paper, “Inference on Winners,” appears in the February issue of the Quarterly Journal of Economics. The authors are Andrews, a professor in the MIT Department of Economics and an expert in econometrics, the statistical methods of the field; Toru Kitagawa, a professor of economics at Brown University; and Adam McCloskey, an associate professor of economics at the University of Colorado.
Distinguishing differences
The kind of winner’s curse addressed in this study dates back a few decades as a social science concept, and also comes up in the natural sciences: As the scholars note in the paper, the winner’s curse has been observed in genome-wide association studies, which attempt to link genes to traits.
When seemingly notable findings fail to hold up, there may be varying reasons for it. Sometimes experiments or programs are not all run the same way when people attempt to replicate them. At other times, random variation by itself can create this kind of situation.
“Imagine a world where all these programs are exactly equally effective,” Andrews says. “Well, by chance, one of them is going to look better, and you will tend to pick that one. What that means is you overestimated how effective it is, relative to the other options.” Analyzing the data well can help distinguish whether the outlier result was due to true differences in effectiveness or to random fluctuation.
To distinguish between these two possibilities, Andrews, Kitagawa, and McCloskey have developed new methods for analyzing results. In particular, they have proposed new estimators — a means of projecting results — which are “median unbiased.” That is, they are equally likely to over- and underestimate effectiveness, even in settings with a winner’s curse. The methods also produce confidence intervals that help quantify the uncertainty of these estimates. Additionally, the scholars propose “hybrid” inference approaches, which combine multiple methods of weighing research data, and, as they show, often yield more precise results than alternative methods.
With these new methods, Andrews, Kitagawa, and McCloskey establish firmer boundaries on the use of data from experiments — including confidence intervals, median unbiased estimates, and more. And to test their method’s viability, the scholars applied it to multiple instances of social science research, beginning with the JOBSTART experiment.
Intriguingly, of the different ways experimental results can become outliers, the scholars found that the San Jose result from JOBSTART was probably not just the result of random chance. The results are sufficiently different that there may have been differences in the way the program was administered, or in its setting, compared to the other programs.
The Seattle test
To further test the hybrid inference method, Andrews, Kitagawa, and McCloskey then applied it to another research issue: programs providing housing vouchers to help people move into neighborhoods where residents have greater economic mobility.
Nationwide economics studies have shown that some areas generate greater economic mobility than others, all things being equal. Spurred by these findings, other researchers collaborated with officials in King County, Washington, to develop a program to help voucher recipients move to higher-opportunity areas. However, predictions for the performance of such programs might be susceptible to a winner’s curse, since the level of opportunity in each neighborhood is imperfectly estimated.
Andrews, Kitagawa, and McCloskey thus applied the hybrid inference method to a test of this neighborhood-level data, in 50 “commuting zones” (essentially, metro areas) across the U.S. The hybrid method again helped them understand how certain the previous estimates were.
Simple estimates in this setting suggested that for children growing up in households at the 25th percentile of annual income in the U.S., housing relocation programs would create a 12.25 percentage-point gain in adult income. The hybrid inference method suggests there would instead be a 10.27 percentage-point gain — lower, but still a substantial impact.
Indeed, as the authors write in the paper, “even this smaller estimate is economically large,” and “we conclude that targeting tracts based on estimated opportunity succeeds in selecting higher-opportunity tracts on average.” At the same time, the scholars saw that their method does make a difference.
Overall, Andrews says, “the ways we measure uncertainty can actually become themselves unreliable.” That problem is compounded, he notes, “when the data tells us very little, but we’re wrongly overconfident and think the data is telling us a lot. … Ideally you would like something that is both reliable and telling us as much as possible.”
Support for the research was provided, in part, by the U.S. National Science Foundation, the Economic and Social Research Council of the U.K., and the European Research Council.
MIT economist Isaiah Andrews, with colleagues, has developed tools can help policymakers, business people, and even scientists avoid a "winner's curse" in their work — the pattern in which people select programs that test well at first, but are likely to perform worse upon repetition.
Blood cells make up the majority of cells in the human body. They perform critical functions and their dysfunction is implicated in many important human diseases, from anemias to blood cancers like leukemia. The many types of blood cells include red blood cells that carry oxygen, platelets that promote clotting, as well as the myriad types of immune cells that protect our bodies from threats such as viruses and bacteria.
What these diverse types of blood cells have in common is that they are all produced by hematopoietic stem cells (HSCs). HSCs must keep producing blood cells in large quantities throughout our entire lives in order to continually replenish our bodies’ supply. Researchers want to better understand HSCs and the dynamics of how they produce the many blood cell types, both in order to understand the fundamentals of human blood production and to understand how blood production changes during aging or in cases of disease.
Jonathan Weissman, an MIT professor of biology, member of the Whitehead Institute for Biomedical Research, and a Howard Hughes Medical Investigator; Vijay Sankaran, a Boston Children’s Hospital and Harvard Medical School associate professor who is also a Broad Institute of MIT and Harvard associate member and attending physician at the Dana Farber Cancer Institute; and Chen Weng, a postdoc in both of their labs, have developed a new method that provides a detailed look at the family trees of human blood cells and the characteristics of the individual cells, providing new insights into the differences between lineages of HSCs. The research, published in the journal Nature on Jan. 22, answers some long-standing questions about blood cell production and how it changes as we age. The work also demonstrates how this new technology can give researchers unprecedented access to any human cells’ histories and insight into how those histories have shaped their current states. This will render open to discovery many questions about our own biology that were previously unanswerable.
“We wanted to ask questions that the existing tools could not allow us to,” Weng says. “This is why we brought together Jonathan and Vijay’s different expertise to develop a new technology that allows us to ask those questions and more, so we can solve some of the important unknowns in blood production.”
How to trace the lineages of human cells
Weissman and others have previously developed methods to map the family trees of cells, a process called lineage tracing, but typically this has been done in animals or engineered cell lines. Weissman has used this approach to shed light on how cancers spread and on when and how they develop mutations that make them more aggressive and deadly. However, while these models can illuminate the general principles of processes such as blood production, they do not give researchers a full picture of what happens inside of a living human. They cannot capture the full diversity of human cells or the implications of that diversity on health and disease.
The only way to get a detailed picture of how blood cell lineages change through the generations and what the consequences of those changes are is to perform lineage tracing on cells from human samples. The challenge is that in the research models used in the previous lineage tracing studies, Weissman and colleagues edited the cells to add a trackable barcode, a string of DNA that changes a little with each cell division, so that researchers can map the changes to match cells to their closest relatives and reconstruct the family tree. Researchers cannot add a barcode to the cells in living humans, so they need to find a natural one: some string of DNA that already exists and changes frequently enough to allow this family tree reconstruction.
Looking for mutations across the whole genome is cost-prohibitive and destroys the material that researchers need to collect to learn about the cells’ states. A few years ago, Sankaran and colleagues realized that mitochondrial DNA could be a good candidate for the natural barcode. Mitochondria are in all of our cells, and they have their own genome, which is relatively small and prone to mutation. In that earlier research, Sankaran and colleagues identified mutations in mitochondrial DNA, but they could not find enough mutations to build a complete family tree: in each cell, they only detected an average of zero to one mutations.
Now, in work led by Weng, the researchers have improved their detection of mitochondrial DNA mutations 10-fold, meaning that in each cell they find around 10 mutations — enough to serve as an identifying barcode. They achieved this through improvements in how they detect mitochondrial DNA mutations experimentally and how they verify that those mutations are genuine computationally. Their new and improved lineage tracing method is called ReDeeM, an acronym drawing from single-cell "regulatory multi-omics with deep mitochondrial mutation profiling." Using the method, they can recreate the family tree of thousands of blood cells from a human blood sample, as well as gather information about each individual cell’s state: its gene expression levels and differences in its epigenome, or the availability of regions of DNA to be expressed.
Combining cells’ family trees with each individual cell’s state is key for making sense of how cell lineages change over time and what the effects of those changes are. If a researcher pinpoints the place in the family tree where a blood cell lineage, for example, becomes biased toward producing a certain type of blood cell, they can then look at what changed in the cells’ state preceding that shift in order to figure out what genes and pathways drove that change in behavior. In other words, they can use the combination of data to understand not just that a change occurred, but what mechanisms contributed to that change.
“The goal is to relate the cell’s current state to its past history,” Weissman says. “Being able to do that in an unperturbed human sample lets us watch the dynamics of the blood production process and understand functional differences in hematopoietic stem cells in a way that has just not been possible before.”
Using this approach, the researchers made several interesting discoveries about blood production.
Blood cell lineage diversity shrinks with age
The researchers mapped the family trees of blood cells derived from each HSC. Each one of these lineages is called a clonal group. Researchers have had various hypotheses about how clonal groups work: Perhaps they are interchangeable, with each stem cell producing equivalent numbers and types of blood cells. Perhaps they are specialized, with one stem cell producing red blood cells, and another producing white blood cells. Perhaps they work in shifts, with some HSCs lying dormant while others produce blood cells. The researchers found that in healthy, young individuals, the answer is somewhere in the middle: Essentially every stem cell produced every type of blood cell, but certain lineages had biases toward producing one type of cell over another. The researchers took two samples from each test subject four months apart, and found that these differences between the lineages were stable over time.
Next, the researchers took blood samples from people of older age. They found that as humans age, some clonal groups begin to dominate and produce a significantly above-average percent of the total blood cells. When a clonal group outcompetes others like this, it is called expansion. Researchers knew that in certain diseases, a single clonal group containing a disease-related mutation could expand and become dominant. They didn’t know that clonal expansion was pervasive in aging even in seemingly healthy individuals, or that it was typical for multiple clonal groups to expand. This complicates the understanding of clonal expansion but sheds light on how blood production changes with age: The diversity of clonal groups decreases. The researchers are working on figuring out the mechanisms that enable certain clonal groups to expand over others. They are also interested in testing clonal groups for disease markers to understand which expansions are caused by or could contribute to disease.
ReDeeM enabled the researchers to make a variety of additional observations about blood production, many of which are consistent with previous research. This is what they hoped to see: the fact that the tool efficiently identified known patterns in blood production validates its efficacy. Now that the researchers know how well the method works, they can apply it to many different questions about the relationships between cells and what mechanisms drive changes in cell behavior. They are already using it to learn more about autoimmune disorders, blood cancers, and the origins of certain types of blood cells.
The researchers hope that others will use their method to ask questions about cell dynamics in many scenarios in health and disease. Sankaran, who is a practicing hematologist, also hopes that the method one day revolutionizes the patient data to which clinicians have access.
“In the not-too-distant future, you could look at a patient chart and see that this patient has an abnormally low number of HSCs, or an abnormally high number, and that would inform how you think about their disease risk,” Sankaran says. “ReDeeM provides a new lens through which to understand the clone dynamics of blood production, and how they might be altered in human health and diseases. Ultimately, we will be able to apply those lessons to patient care.”
The only way to get a detailed picture of how blood cell lineages change through the generations and what the consequences of those changes are is to perform lineage tracing on cells from human samples.
Using a novel microscopy technique, MIT and Brigham and Women’s Hospital/Harvard Medical School researchers have imaged human brain tissue in greater detail than ever before, revealing cells and structures that were not previously visible.
Among their findings, the researchers discovered that some “low-grade” brain tumors contain more putative aggressive tumor cells than expected, suggesting that some of these tumors may be more aggressive than previously thought.
The researchers hope that this technique could eventually be deployed to diagnose tumors, generate more accurate prognoses, and help doctors choose treatments.
“We’re starting to see how important the interactions of neurons and synapses with the surrounding brain are to the growth and progression of tumors. A lot of those things we really couldn’t see with conventional tools, but now we have a tool to look at those tissues at the nanoscale and try to understand these interactions,” says Pablo Valdes, a former MIT postdoc who is now an assistant professor of neuroscience at the University of Texas Medical Branch and the lead author of the study.
Edward Boyden, the Y. Eva Tan Professor in Neurotechnology at MIT; a professor of biological engineering, media arts and sciences, and brain and cognitive sciences; a Howard Hughes Medical Institute investigator; and a member of MIT’s McGovern Institute for Brain Research and Koch Institute for Integrative Cancer Research; and E. Antonio Chiocca, a professor of neurosurgery at Harvard Medical School and chair of neurosurgery at Brigham and Women’s Hospital, are the senior authors of the study, which appears today in Science Translational Medicine.
Making molecules visible
The new imaging method is based on expansion microscopy, a technique developed in Boyden’s lab in 2015 based on a simple premise: Instead of using powerful, expensive microscopes to obtain high-resolution images, the researchers devised a way to expand the tissue itself, allowing it to be imaged at very high resolution with a regular light microscope.
The technique works by embedding the tissue into a polymer that swells when water is added, and then softening up and breaking apart the proteins that normally hold tissue together. Then, adding water swells the polymer, pulling all the proteins apart from each other. This tissue enlargement allows researchers to obtain images with a resolution of around 70 nanometers, which was previously possible only with very specialized and expensive microscopes such as scanning electron microscopes.
In 2017, the Boyden lab developed a way to expand preserved human tissue specimens, but the chemical reagents that they used also destroyed the proteins that the researchers were interested in labeling. By labeling the proteins with fluorescent antibodies before expansion, the proteins’ location and identity could be visualized after the expansion process was complete. However, the antibodies typically used for this kind of labeling can’t easily squeeze through densely packed tissue before it’s expanded.
So, for this study, the authors devised a different tissue-softening protocol that breaks up the tissue but preserves proteins in the sample. After the tissue is expanded, proteins can be labelled with commercially available fluorescent antibodies. The researchers then can perform several rounds of imaging, with three or four different proteins labeled in each round. This labelling of proteins enables many more structures to be imaged, because once the tissue is expanded, antibodies can squeeze through and label proteins they couldn’t previously reach.
“We open up the space between the proteins so that we can get antibodies into crowded spaces that we couldn’t otherwise,” Valdes says. “We saw that we could expand the tissue, we could decrowd the proteins, and we could image many, many proteins in the same tissue by doing multiple rounds of staining.”
Working with MIT Assistant Professor Deblina Sarkar, the researchers demonstrated a form of this “decrowding” in 2022 using mouse tissue.
The new study resulted in a decrowding technique for use with human brain tissue samples that are used in clinical settings for pathological diagnosis and to guide treatment decisions. These samples can be more difficult to work with because they are usually embedded in paraffin and treated with other chemicals that need to be broken down before the tissue can be expanded.
In this study, the researchers labeled up to 16 different molecules per tissue sample. The molecules they targeted include markers for a variety of structures, including axons and synapses, as well as markers that identify cell types such as astrocytes and cells that form blood vessels. They also labeled molecules linked to tumor aggressiveness and neurodegeneration.
Using this approach, the researchers analyzed healthy brain tissue, along with samples from patients with two types of glioma — high-grade glioblastoma, which is the most aggressive primary brain tumor, with a poor prognosis, and low-grade gliomas, which are considered less aggressive.
“We wanted to look at brain tumors so that we can understand them better at the nanoscale level, and by doing that, to be able to develop better treatments and diagnoses in the future. At this point, it was more developing a tool to be able to understand them better, because currently in neuro-oncology, people haven't done much in terms of super-resolution imaging,” Valdes says.
A diagnostic tool
To identify aggressive tumor cells in gliomas they studied, the researchers labeled vimentin, a protein that is found in highly aggressive glioblastomas. To their surprise, they found many more vimentin-expressing tumor cells in low-grade gliomas than had been seen using any other method.
“This tells us something about the biology of these tumors, specifically, how some of them probably have a more aggressive nature than you would suspect by doing standard staining techniques,” Valdes says.
When glioma patients undergo surgery, tumor samples are preserved and analyzed using immunohistochemistry staining, which can reveal certain markers of aggressiveness, including some of the markers analyzed in this study.
“These are incurable brain cancers, and this type of discovery will allow us to figure out which cancer molecules to target so we can design better treatments. It also proves the profound impact of having clinicians like us at the Brigham and Women’s interacting with basic scientists such as Ed Boyden at MIT to discover new technologies that can improve patient lives,” Chiocca says.
The researchers hope their expansion microscopy technique could allow doctors to learn much more about patients’ tumors, helping them to determine how aggressive the tumor is and guiding treatment choices. Valdes now plans to do a larger study of tumor types to try to establish diagnostic guidelines based on the tumor traits that can be revealed using this technique.
“Our hope is that this is going to be a diagnostic tool to pick up marker cells, interactions, and so on, that we couldn’t before,” he says. “It’s a practical tool that will help the clinical world of neuro-oncology and neuropathology look at neurological diseases at the nanoscale like never before, because fundamentally it’s a very simple tool to use.”
Boyden’s lab also plans to use this technique to study other aspects of brain function, in healthy and diseased tissue.
“Being able to do nanoimaging is important because biology is about nanoscale things — genes, gene products, biomolecules — and they interact over nanoscale distances,” Boyden says. “We can study all sorts of nanoscale interactions, including synaptic changes, immune interactions, and changes that occur during cancer and aging.”
The research was funded by K. Lisa Yang, the Howard Hughes Medical Institute, John Doerr, Open Philanthropy, the Bill and Melinda Gates Foundation, the Koch Institute Frontier Research Program via the Kathy and Curt Marble Cancer Research Fund, the National Institutes of Health, and the Neurosurgery Research and Education Foundation.
Using a novel microscopy technique, MIT and Harvard Medical School researchers have imaged human brain tissue in greater detail than ever before. In this image of a low-grade glioma, light blue and yellow represent different proteins associated with tumors. Pink indicates a protein used as a marker for astrocytes, and dark blue shows the location of cell nuclei.
The secret to the success of MIT’s Simons Center for the Social Brain is in the name. With a founding philosophy of “collaboration and community” that has supported scores of scientists across more than a dozen Boston-area research institutions, the SCSB advances research by being inherently social.
SCSB’s mission is “to understand the neural mechanisms underlying social cognition and behavior and to translate this knowledge into better diagnosis and treatment of autism spectrum disorders.” When Director Mriganka Sur founded the center in 2012 in partnership with the Simons Foundation Autism Research Initiative (SFARI) of Jim and Marilyn Simons, he envisioned a different way to achieve urgently needed research progress than the traditional approach of funding isolated projects in individual labs. Sur wanted SCSB’s contribution to go beyond papers, though it has generated about 350 and counting. He sought the creation of a sustained, engaged autism research community at MIT and beyond.
“When you have a really big problem that spans so many issues — a clinical presentation, a gene, and everything in between — you have to grapple with multiple scales of inquiry,” says Sur, the Newton Professor of Neuroscience in MIT’s Department of Brain and Cognitive Sciences (BCS) and The Picower Institute for Learning and Memory. “This cannot be solved by one person or one lab. We need to span multiple labs and multiple ways of thinking. That was our vision.”
In parallel with a rich calendar of public colloquia, lunches, and special events, SCSB catalyzes multiperspective, multiscale research collaborations in two programmatic ways. Targeted projects fund multidisciplinary teams of scientists with complementary expertise to collectively tackle a pressing scientific question. Meanwhile, the center supports postdoctoral Simons Fellows with not one, but two mentors, ensuring a further cross-pollination of ideas and methods.
Complementary collaboration
In 11 years, SCSB has funded nine targeted projects. Each one, by design, involves a deep and multifaceted exploration of a major question with both fundamental importance and clinical relevance. The first project, back in 2013, for example, marshaled three labs spanning BCS, the Department of Biology, and The Whitehead Institute for Biomedical Research to advance understanding of how mutation of the Shank3 gene leads to the pathophysiology of Phelan-McDermid Syndrome by working across scales ranging from individual neural connections to whole neurons to circuits and behavior.
Other past projects have applied similarly integrated, multiscale approaches to topics ranging from how 16p11.2 gene deletion alters the development of brain circuits and cognition to the critical role of the thalamic reticular nucleus in information flow during sleep and wakefulness. Two others produced deep examinations of cognitive functions: how we go from hearing a string of words to understanding a sentence’s intended meaning, and the neural and behavioral correlates of deficits in making predictions about social and sensory stimuli. Yet another project laid the groundwork for developing a new animal model for autism research.
SFARI is especially excited by SCSB’s team science approach, says Kelsey Martin, executive vice president of autism and neuroscience at the Simons Foundation. “I’m delighted by the collaborative spirit of the SCSB,” Martin says. “It’s wonderful to see and learn about the multidisciplinary team-centered collaborations sponsored by the center.”
New projects
In the last year, SCSB has launched three new targeted projects. One team is investigating why many people with autism experience sensory overload and is testing potential interventions to help. The scientists hypothesize that patients experience a deficit in filtering out the mundane stimuli that neurotypical people predict are safe to ignore. Studies suggest the predictive filter relies on relatively low-frequency “alpha/beta” brain rhythms from deep layers of the cortex moderating the higher frequency “gamma” rhythms in superficial layers that process sensory information.
Together, the labs of Charles Nelson, professor of pediatrics at Boston Children’s Hospital (BCH), and BCS faculty members Bob Desimone, the Doris and Don Berkey Professor, and Earl K. Miller, the Picower Professor, are testing the hypothesis in two different animal models at MIT and in human volunteers at BCH. In the animals they’ll also try out a new real-time feedback system invented in Miller’s lab that can potentially correct the balance of these rhythms in the brain. And in an animal model engineered with a Shank3 mutation, Desimone’s lab will test a gene therapy, too.
“None of us could do all aspects of this project on our own,” says Miller, an investigator in the Picower Institute. “It could only come about because the three of us are working together, using different approaches.”
Right from the start, Desimone says, close collaboration with Nelson’s group at BCH has been essential. To ensure his and Miller’s measurements in the animals and Nelson’s measurements in the humans are as comparable as possible, they have tightly coordinated their research protocols.
“If we hadn’t had this joint grant we would have chosen a completely different, random set of parameters than Chuck, and the results therefore wouldn’t have been comparable. It would be hard to relate them,” says Desimone, who also directs MIT’s McGovern Institute for Brain Research. “This is a project that could not be accomplished by one lab operating in isolation.”
Another targeted project brings together a coalition of seven labs — six based in BCS (professors Evelina Fedorenko, Edward Gibson, Nancy Kanwisher, Roger Levy, Rebecca Saxe, and Joshua Tenenbaum) and one at Dartmouth College (Caroline Robertson) — for a synergistic study of the cognitive, neural, and computational underpinnings of conversational exchanges. The study will integrate the linguistic and non-linguistic aspects of conversational ability in neurotypical adults and children and those with autism.
Fedorenko said the project builds on advances and collaborations from the earlier language Targeted Project she led with Kanwisher.
“Many directions that we started to pursue continue to be active directions in our labs. But most importantly, it was really fun and allowed the PIs [principal investigators] to interact much more than we normally would and to explore exciting interdisciplinary questions,” Fedorenko says. “When Mriganka approached me a few years after the project’s completion asking about a possible new targeted project, I jumped at the opportunity.”
Gibson and Robertson are studying how people align their dialogue, not only in the content and form of their utterances, but using eye contact. Fedorenko and Kanwisher will employ fMRI to discover key components of a conversation network in the cortex. Saxe will examine the development of conversational ability in toddlers using novel MRI techniques. Levy and Tenenbaum will complement these efforts to improve computational models of language processing and conversation.
The newest Targeted Project posits that the immune system can be harnessed to help treat behavioral symptoms of autism. Four labs — three in BCS and one at Harvard Medical School (HMS) — will study mechanisms by which peripheral immune cells can deliver a potentially therapeutic cytokine to the brain. A study by two of the collaborators, MIT associate professor Gloria Choi and HMS associate professor Jun Huh, showed that when IL-17a reaches excitatory neurons in a region of the mouse cortex, it can calm hyperactivity in circuits associated with social and repetitive behavior symptoms. Huh, an immunologist, will examine how IL-17a can get from the periphery to the brain, while Choi will examine how it has its neurological effects. Sur and MIT associate professor Myriam Heiman will conduct studies of cell types that bridge neural circuits with brain circulatory systems.
“It is quite amazing that we have a core of scientists working on very different things coming together to tackle this one common goal,” Choi says. “I really value that.”
Multiple mentors
While SCSB Targeted Projects unify labs around research, the center’s Simons Fellowships unify labs around young researchers, providing not only funding, but a pair of mentors and free-flowing interactions between their labs. Fellows also gain opportunities to inform and inspire their fundamental research by visiting with patients with autism, Sur says.
“The SCSB postdoctoral program serves a critical role in ensuring that a diversity of outstanding scientists are exposed to autism research during their training, providing a pipeline of new talent and creativity for the field,” adds Martin, of the Simons Foundation.
Simons Fellows praise the extra opportunities afforded by additional mentoring. Postdoc Alex Major was a Simons Fellow in Miller’s lab and that of Nancy Kopell, a mathematics professor at Boston University renowned for her modeling of the brain wave phenomena that the Miller lab studies experimentally.
“The dual mentorship structure is a very useful aspect of the fellowship” Major says. “It is both a chance to network with another PI and provides experience in a different neuroscience sub-field.”
Miller says co-mentoring expands the horizons and capabilities of not only the mentees but also the mentors and their labs. “Collaboration is 21st century neuroscience,” Miller says. “Some our studies of the brain have gotten too big and comprehensive to be encapsulated in just one laboratory. Some of these big questions require multiple approaches and multiple techniques.”
Desimone, who recently co-mentored Seng Bum (Michael Yoo) along with BCS and McGovern colleague Mehrdad Jazayeri in a project studying how animals learn from observing others, agrees.
“We hear from postdocs all the time that they wish they had two mentors, just in general to get another point of view,” Desimone says. “This is a really good thing and it’s a way for faculty members to learn about what other faculty members and their postdocs are doing.”
Indeed, the Simons Center model suggests that research can be very successful when it’s collaborative and social.
The National Academy of Sciences has awarded MIT biologist Nancy Hopkins, the Amgen Professor of Biology Emerita, with the 2024 Public Welfare Medal in recognition of “her courageous leadership over three decades to create and ensure equal opportunity for women in science.”
The award recognizes Hopkins’srole in catalyzing and leading MIT’s “A Study on the Status of Women Faculty in Science,” made public in 1999. The landmark report, the result of the efforts of numerous members of the MIT faculty and administration, revealed inequities in the treatment and resources available to women versus men on the faculty at the Institute, helped drive significant changes to MIT policies and practices, and sparked a national conversation about the unequal treatment of women in science, engineering, and beyond.
Since the medal was established in 1914 to honor extraordinary use of science for the public good, it has been awarded to several MIT-affiliated scientists, including Karl Compton, James R. Killian Jr., and Jerome B. Wiesner, as well as Vannevar Bush, Isidor I. Rabi, and Victor Weiskopf.
“The Public Welfare Medal has been awarded to MIT faculty who have helped define our Institute and scientists who have shaped modern science on the national stage,” says Susan Hockfield, MIT president emerita. “It is more than fitting for Nancy to join their ranks, and — importantly — celebrates her critical role in increasing the participation of women in science and engineering as a significant national achievement.”
When Hopkins joined the faculty of the MIT Center for Cancer Research (CCR) in 1973, she did not set out to become an advocate for equality for women in science. For the first 15 years, she distinguished herself in pioneering studies linking genes of RNA tumor viruses to their roles in causing some forms of cancer. But in 1989, Hopkins changed course: She began developing molecular technologies for the study of zebrafish that would help establish it as an important model for vertebrate development and cancer biology.
To make the pivot, Hopkins needed more space to accommodate fish tanks and new equipment. Although Hopkins strongly suspected that she had been assigned less lab space than her male peers in the building, her hypothesis carried little weight and her request was denied. Ever the scientist, Hopkins believed the path to more lab space was to collect data. One night in 1993, with a measuring tape in hand, she visited each lab to quantify the distribution of space in her building. Her hypothesis appeared correct.
Hopkins shared her initial findings — and her growing sense that there was bias against women scientists — with one female colleague, and then others, many of whom reported similar experiences. The senior women faculty in MIT’s School of Science began meeting to discuss their concerns, ultimately documenting them in a letter to Dean of Science Robert Birgeneau. The letter was signed by professors Susan Carey, Sylvia Ceyer, Sallie “Penny” Chisholm, Suzanne Corkin, Mildred Dresselhaus, Ann Graybiel, Ruth Lehmann, Marcia McNutt, Terry Orr-Weaver, Mary-Lou Pardue, Molly Potter, Paula Malanotte-Rizzoli, Leigh Royden, Lisa Steiner, and Joanne Stubbe. Also important were Hopkins’s discussions with Lorna Gibson, a professor in the Department of Materials Science and Engineering, since Gibson had made similar observations with her female colleagues in the School of Engineering. Despite the biases against these women, they were highly accomplished scientists. Four of them were eventually awarded the U.S. National Medal of Science, and 11 were, or became, members of the National Academy of Sciences.
In response to the women in the School of Science, Birgeneau established the Committee on the Status of Women Faculty in 1995, which included both female faculty and three male faculty who had been department chairs: Jerome Friedman, Dan Kleitman, and Robert Silbey. In addition to interviewing essentially all the female faculty members in the school, they collected data on salaries, space, and other resources. The committee found that of 209 tenuredprofessors in the School of Science only 15 were women, and they often had smaller wages and labs, and were raising more of their salaries from grants than equivalent male faculty.
At the urging of Lotte Bailyn, a professor at the MIT Sloan School of Management and chair of the faculty, Hopkins and the committee summarized their findings to be presented to MIT’s faculty. Struck by the pervasive and well-documented pattern of bias against women across the School of Science, both Birgeneau and MIT President Charles Vest added prefaces to the report before it was published in the faculty newsletter. Vest commented, “I have always believed that contemporary gender discrimination within universities is part reality and part perception. True, but I now understand that reality is by far the greater part of the balance.”
Vest took an “engineers’ approach” to addressing the report’s findings, remarking “anything I can measure, I can fix.” He tasked Provost Robert Brown with establishing committees to produce reports on the status of women faculty for all five of MIT’s schools. The reports were published in 2002 and drew attention to the small number of women faculty in some schools, as well as discrepancies similar to those first documented in the School of Science.
In response, MIT implemented changes in hiring practices, updated pay equity reviews, and worked to improve the working environment for women faculty. On-campus day care facilities were built and leave policies were expanded for the benefit of all faculty members with families. To address underrepresentation of individuals of color, as well as the unique biases against women of color, Brown established the Council on Faculty Diversity with Hopkins and Philip Clay, then MIT’s chancellor and a professor in the Department of Urban Studies and Planning. Meanwhile, Vest spearheaded a collaboration with presidents of other leading universities to increase representation of women faculty.
MIT increased the numbers of women faculty by altering hiring procedures — particularly in the School of Engineering under Dean Thomas Magnanti and in the School of Science under Birgeneau, and later Associate Dean Hazel Sive. MIT did not need to alter its standards for hiring to increase the number of women on its faculty: Women hired with revised policies at the Institute have been equally successful and have gone on to important leadership roles at MIT and other institutions.
In the wake of the 1999 report the press thrust MIT — and Hopkins — into the national spotlight. The careful documentation in the report and first Birgeneau’s and then Vest’s endorsement of and proactive response to its findings were persuasive to many reporters and their readers. The reports and media coverage resonated with women across academia, resulting in a flood of mail to Hopkins’s inbox, as well as many requests for speaking engagements. Hopkins would eventually undertake hundreds of talks across the United States and many other countries about advocating for the equitable treatment of women in science.
Her advocacy work continued after her retirement. In 2019, Hopkins, along with Hockfield and Sangeeta Bhatia, the John J. and Dorothy Wilson Professor of Health Sciences and Technology and of the Department of Electrical Engineering and Computer Science, founded the Boston Biotech Working Group — which later evolved into the Faculty Founder Initiative — to increase women’s representation as founders and board members of biotech companies in Massachusetts.
Hopkins, however, believes she became “this very visible person by chance.”
“An almost uncountable number of people made this happen,” she continues. “Moreover, I know how much work went on before I even set foot on campus, such as by Emily Wick, Shirley Ann Jackson, Sheila Widnall, and Mildred Dresselhaus. I stood on the shoulders of a great institution and the long, hard work of many people that belong to it.”
The National Academy of Sciences will present the 2024 Public Welfare Medal to Hopkins in April at its 161st annual meeting. Hopkins is the recipient of many other awards and honors, both for her scientific achievements and her advocacy for women in science. She is a member of the National Academy of Sciences, the National Academy of Medicine, the American Academy of Arts and Sciences, and the AACR Academy. Other awards include the Centennial Medal from Harvard University, the MIT Gordon Y. Billard Award for “special service” to MIT, the MIT Laya Wiesner Community Award, the Maria Mitchell Women in Science Award, and the STAT Biomedical Innovation Award. In addition, she has received eight honorary doctorates, most recently from Rockefeller University, the Hong Kong University of Science and Technology, and the Weizmann Institute.
MIT Professor Emerita Nancy Hopkins was awarded the National Academy of Sciences Public Welfare Medal for her leadership in advancing women’s representation in science.
The following is a joint announcement from MIT and Applied Materials, Inc.
MIT and Applied Materials, Inc., announced an agreement today that, together with a grant to MIT from the Northeast Microelectronics Coalition (NEMC) Hub, commits more than $40 million of estimated private and public investment to add advanced nano-fabrication equipment and capabilities to MIT.nano, the Institute’s center for nanoscale science and engineering. The collaboration will create a unique open-access site in the United States that supports research and development at industry-compatible scale using the same equipment found in high-volume production fabs to accelerate advances in silicon and compound semiconductors, power electronics, optical computing, analog devices, and other critical technologies.
The equipment and related funding and in-kind support provided by Applied Materials will significantly enhance MIT.nano’s existing capabilities to fabricate up to 200-millimeter (8-inch) wafers, a size essential to industry prototyping and production of semiconductors used in a broad range of markets including consumer electronics, automotive, industrial automation, clean energy, and more. Positioned to fill the gap between academic experimentation and commercialization, the equipment will help establish a bridge connecting early-stage innovation to industry pathways to the marketplace.
“A brilliant new concept for a chip won’t have impact in the world unless companies can make millions of copies of it. MIT.nano’s collaboration with Applied Materials will create a critical open-access capacity to help innovations travel from lab bench to industry foundries for manufacturing,” says Maria Zuber, MIT’s vice president for research and the E. A. Griswold Professor of Geophysics. “I am grateful to Applied Materials for its investment in this vision. The impact of the new toolset will ripple across MIT and throughout Massachusetts, the region, and the nation.”
Applied Materials is the world’s largest supplier of equipment for manufacturing semiconductors, displays, and other advanced electronics. The company will provide at MIT.nano several state-of-the-art process tools capable of supporting 150 and 200mm wafers and will enhance and upgrade an existing tool owned by MIT. In addition to assisting MIT.nano in the day-to-day operation and maintenance of the equipment, Applied engineers will develop new process capabilities that will benefit researchers and students from MIT and beyond.
“Chips are becoming increasingly complex, and there is tremendous need for continued advancements in 200mm devices, particularly compound semiconductors like silicon carbide and gallium nitride,” says Aninda Moitra, corporate vice president and general manager of Applied Materials’ ICAPS Business. “Applied is excited to team with MIT.nano to create a unique, open-access site in the U.S. where the chip ecosystem can collaborate to accelerate innovation. Our engagement with MIT expands Applied’s university innovation network and furthers our efforts to reduce the time and cost of commercializing new technologies while strengthening the pipeline of future semiconductor industry talent.”
The NEMC Hub, managed by the Massachusetts Technology Collaborative (MassTech), will allocate $7.7 million to enable the installation of the tools. The NEMC is the regional “hub” that connects and amplifies the capabilities of diverse organizations from across New England, plus New Jersey and New York. The U.S. Department of Defense (DoD) selected the NEMC Hub as one of eight Microelectronics Commons Hubs and awarded funding from the CHIPS and Science Act to accelerate the transition of critical microelectronics technologies from lab-to-fab, spur new jobs, expand workforce training opportunities, and invest in the region’s advanced manufacturing and technology sectors.
The Microelectronics Commons program is managed at the federal level by the Office of the Under Secretary of Defense for Research and Engineering and the Naval Surface Warfare Center, Crane Division, and facilitated through the National Security Technology Accelerator (NSTXL), which organizes the execution of the eight regional hubs located across the country. The announcement of the public sector support for the project was made at an event attended by leaders from the DoD and NSTXL during a site visit to meet with NEMC Hub members.
“The installation and operation of these tools at MIT.nano will have a direct impact on the members of the NEMC Hub, the Massachusetts and Northeast regional economy, and national security. This is what the CHIPS and Science Act is all about,” says Ben Linville-Engler, deputy director at the MassTech Collaborative and the interim director of the NEMC Hub. “This is an essential investment by the NEMC Hub to meet the mission of the Microelectronics Commons.”
MIT.nano is a 200,000 square-foot facility located in the heart of the MIT campus with pristine, class-100 cleanrooms capable of accepting these advanced tools. Its open-access model means that MIT.nano’s toolsets and laboratories are available not only to the campus, but also to early-stage R&D by researchers from other academic institutions, nonprofit organizations, government, and companies ranging from Fortune 500 multinationals to local startups. Vladimir Bulović, faculty director of MIT.nano, says he expects the new equipment to come online in early 2025.
“With vital funding for installation from NEMC and after a thorough and productive planning process with Applied Materials, MIT.nano is ready to install this toolset and integrate it into our expansive capabilities that serve over 1,100 researchers from academia, startups, and established companies,” says Bulović, who is also the Fariborz Maseeh Professor of Emerging Technologies in MIT’s Department of Electrical Engineering and Computer Science. “We’re eager to add these powerful new capabilities and excited for the new ideas, collaborations, and innovations that will follow.”
As part of its arrangement with MIT.nano, Applied Materials will join the MIT.nano Consortium, an industry program comprising 12 companies from different industries around the world. With the contributions of the company’s technical staff, Applied Materials will also have the opportunity to engage with MIT’s intellectual centers, including continued membership with the Microsystems Technology Laboratories.
MIT.nano (at right), the Institute’s center for nanoscale science and engineering, will receive more than $40M of estimated private and public investment to add advanced nanofabrication equipment to the facility’s toolsets.
Using a virus-like delivery particle made from DNA, researchers from MIT and the Ragon Institute of MGH, MIT, and Harvard have created a vaccine that can induce a strong antibody response against SARS-CoV-2.
The vaccine, which has been tested in mice, consists of a DNA scaffold that carries many copies of a viral antigen. This type of vaccine, known as a particulate vaccine, mimics the structure of a virus. Most previous work on particulate vaccines has relied on protein scaffolds, but the proteins used in those vaccines tend to generate an unnecessary immune response that can distract the immune system from the target.
In the mouse study, the researchers found that the DNA scaffold does not induce an immune response, allowing the immune system to focus its antibody response on the target antigen.
“DNA, we found in this work, does not elicit antibodies that may distract away from the protein of interest,” says Mark Bathe, an MIT professor of biological engineering. “What you can imagine is that your B cells and immune system are being fully trained by that target antigen, and that’s what you want — for your immune system to be laser-focused on the antigen of interest.”
This approach, which strongly stimulates B cells (the cells that produce antibodies), could make it easier to develop vaccines against viruses that have been difficult to target, including HIV and influenza, as well as SARS-CoV-2, the researchers say. Unlike T cells, which are stimulated by other types of vaccines, these B cells can persist for decades, offering long-term protection.
“We’re interested in exploring whether we can teach the immune system to deliver higher levels of immunity against pathogens that resist conventional vaccine approaches, like flu, HIV, and SARS-CoV-2,” says Daniel Lingwood, an associate professor at Harvard Medical School and a principal investigator at the Ragon Institute. “This idea of decoupling the response against the target antigen from the platform itself is a potentially powerful immunological trick that one can now bring to bear to help those immunological targeting decisions move in a direction that is more focused.”
Bathe, Lingwood, and Aaron Schmidt, an associate professor at Harvard Medical School and principal investigator at the Ragon Institute, are the senior authors of the paper, which appears today in Nature Communications. The paper’s lead authors are Eike-Christian Wamhoff, a former MIT postdoc; Larance Ronsard, a Ragon Institute postdoc; Jared Feldman, a former Harvard University graduate student; Grant Knappe, an MIT graduate student; and Blake Hauser, a former Harvard graduate student.
Mimicking viruses
Particulate vaccines usually consist of a protein nanoparticle, similar in structure to a virus, that can carry many copies of a viral antigen. This high density of antigens can lead to a stronger immune response than traditional vaccines because the body sees it as similar to an actual virus. Particulate vaccines have been developed for a handful of pathogens, including hepatitis B and human papillomavirus, and a particulate vaccine for SARS-CoV-2 has been approved for use in South Korea.
These vaccines are especially good at activating B cells, which produce antibodies specific to the vaccine antigen.
“Particulate vaccines are of great interest for many in immunology because they give you robust humoral immunity, which is antibody-based immunity, which is differentiated from the T-cell-based immunity that the mRNA vaccines seem to elicit more strongly,” Bathe says.
A potential drawback to this kind of vaccine, however, is that the proteins used for the scaffold often stimulate the body to produce antibodies targeting the scaffold. This can distract the immune system and prevent it from launching as robust a response as one would like, Bathe says.
“To neutralize the SARS-CoV-2 virus, you want to have a vaccine that generates antibodies toward the receptor binding domain portion of the virus’ spike protein,” he says. “When you display that on a protein-based particle, what happens is your immune system recognizes not only that receptor binding domain protein, but all the other proteins that are irrelevant to the immune response you’re trying to elicit.”
Another potential drawback is that if the same person receives more than one vaccine carried by the same protein scaffold, for example, SARS-CoV-2 and then influenza, their immune system would likely respond right away to the protein scaffold, having already been primed to react to it. This could weaken the immune response to the antigen carried by the second vaccine.
“If you want to apply that protein-based particle to immunize against a different virus like influenza, then your immune system can be addicted to the underlying protein scaffold that it’s already seen and developed an immune response toward,” Bathe says. “That can hypothetically diminish the quality of your antibody response for the actual antigen of interest.”
As an alternative, Bathe’s lab has been developing scaffolds made using DNA origami, a method that offers precise control over the structure of synthetic DNA and allows researchers to attach a variety of molecules, such as viral antigens, at specific locations.
In a 2020 study, Bathe and Darrell Irvine, an MIT professor of biological engineering and of materials science and engineering, showed that a DNA scaffold carrying 30 copies of an HIV antigen could generate a strong antibody response in B cells grown in the lab. This type of structure is optimal for activating B cells because it closely mimics the structure of nano-sized viruses, which display many copies of viral proteins in their surfaces.
“This approach builds off of a fundamental principle in B-cell antigen recognition, which is that if you have an arrayed display of the antigen, that promotes B-cell responses and gives better quantity and quality of antibody output,” Lingwood says.
“Immunologically silent”
In the new study, the researchers swapped in an antigen consisting of the receptor binding protein of the spike protein from the original strain of SARS-CoV-2. When they gave the vaccine to mice, they found that the mice generated high levels of antibodies to the spike protein but did not generate any to the DNA scaffold.
In contrast, a vaccine based on a scaffold protein called ferritin, coated with SARS-CoV-2 antigens, generated many antibodies against ferritin as well as SARS-CoV-2.
“The DNA nanoparticle itself is immunogenically silent,” Lingwood says. “If you use a protein-based platform, you get equally high titer antibody responses to the platform and to the antigen of interest, and that can complicate repeated usage of that platform because you’ll develop high affinity immune memory against it.”
Reducing these off-target effects could also help scientists reach the goal of developing a vaccine that would induce broadly neutralizing antibodies to any variant of SARS-CoV-2, or even to all sarbecoviruses, the subgenus of virus that includes SARS-CoV-2 as well as the viruses that cause SARS and MERS.
To that end, the researchers are now exploring whether a DNA scaffold with many different viral antigens attached could induce broadly neutralizing antibodies against SARS-CoV-2 and related viruses.
The research was primarily funded by the National Institutes of Health, the National Science Foundation, and the Fast Grants program.
The vaccine consists of a DNA scaffold that carries many copies of a viral antigen. This type of vaccine, known as a particulate vaccine, mimics the structure of a virus.
An intricate, honeycomb-like structure of struts and beams could withstand a supersonic impact better than a solid slab of the same material. What’s more, the specific structure matters, with some being more resilient to impacts than others.
That’s what MIT engineers are finding in experiments with microscopic metamaterials — materials that are intentionally printed, assembled, or otherwise engineered with microscopic architectures that give the overall material exceptional properties.
In a study appearing today in the Proceedings of the National Academy of Sciences, the engineers report on a new way to quickly test an array of metamaterial architectures and their resilience to supersonic impacts.
In their experiments, the team suspended tiny printed metamaterial lattices between microscopic support structures, then fired even tinier particles at the materials, at supersonic speeds. With high-speed cameras, the team then captured images of each impact and its aftermath, with nanosecond precision.
Their work has identified a few metamaterial architectures that are more resilient to supersonic impacts compared to their entirely solid, nonarchitected counterparts. The researchers say the results they observed at the microscopic level can be extended to comparable macroscale impacts, to predict how new material structures across length scales will withstand impacts in the real world.
“What we’re learning is, the microstructure of your material matters, even with high-rate deformation,” says study author Carlos Portela, the Brit and Alex d’Arbeloff Career Development Professor in Mechanical Engineering at MIT. “We want to identify impact-resistant structures that can be made into coatings or panels for spacecraft, vehicles, helmets, and anything that needs to be lightweight and protected.”
Other authors on the study include first author and MIT graduate student Thomas Butruille, and Joshua Crone of DEVCOM Army Research Laboratory.
Pure impact
The team’s new high-velocity experiments build off their previous work, in which the engineers tested the resilience of an ultralight, carbon-based material. That material, which was thinner than the width of a human hair, was made from tiny struts and beams of carbon, which the team printed and placed on a glass slide. They then fired microparticles toward the material, at velocities exceeding the speed of sound.
Those supersonic experiments revealed that the microstructured material withstood the high-velocity impacts, sometimes deflecting the microparticles and other times capturing them.
“But there were many questions we couldn’t answer because we were testing the materials on a substrate, which may have affected their behavior,” Portela says.
In their new study, the researchers developed a way to test freestanding metamaterials, to observe how the materials withstand impacts purely on their own, without a backing or supporting substrate.
In their current setup, the researchers suspend a metamaterial of interest between two microscopic pillars made from the same base material. Depending on the dimensions of the metamaterial being tested, the researchers calculate how far apart the pillars must be in order to support the material at either end while allowing the material to respond to any impacts, without any influence from the pillars themselves.
“This way, we ensure that we’re measuring the material property and not the structural property,” Portela says.
Once the team settled on the pillar support design, they moved on to test a variety of metamaterial architectures. For each architecture, the researchers first printed the supporting pillars on a small silicon chip, then continued printing the metamaterial as a suspended layer between the pillars.
“We can print and test hundreds of these structures on a single chip,” Portela says.
Punctures and cracks
The team printed suspended metamaterials that resembled intricate honeycomb-like cross-sections. Each material was printed with a specific three-dimensional microscopic architecture, such as a precise scaffold of repeating octets, or more faceted polygons. Each repeated unit measured as small as a red blood cell. The resulting metamaterials were thinner than the width of a human hair.
The researchers then tested each metamaterial’s impact resilience by firing glass microparticles toward the structures, at speeds of up to 900 meters per second (more than 2,000 miles per hour) — well within the supersonic range. They caught each impact on camera and studied the resulting images, frame by frame, to see how the projectiles penetrated each material. Next, they examined the materials under a microscope and compared each impact’s physical aftermath.
“In the architected materials, we saw this morphology of small cylindrical craters after impact,” Portela says. “But in solid materials, we saw a lot of radial cracks and bigger chunks of material that were gouged out.”
Overall, the team observed that the fired particles created small punctures in the latticed metamaterials, and the materials nevertheless stayed intact. In contrast, when the same particles were fired at the same speeds into solid, nonlatticed materials of equal mass, they created large cracks that quickly spread, causing the material to crumble. The microstructured materials, therefore, were more efficient in resisting supersonic impacts as well as protecting against multiple impact events. And in particular, materials that were printed with the repeating octets appeared to be the most hardy.
“At the same velocity, we see the octet architecture is harder to fracture, meaning that the metamaterial, per unit mass, can withstand impacts up to twice as much as the bulk material,” Portela says. “This tells us that there are some architectures that can make a material tougher which can offer better impact protection.”
Going forward, the team plans to use the new rapid testing and analysis method to identify new metamaterial designs, in hopes of tagging architectures that can be scaled up to stronger and lighter protective gear, garments, coatings, and paneling.
“What I’m most excited about is showing we can do a lot of these extreme experiments on a benchtop,” Portela says. “This will significantly accelerate the rate at which we can validate new, high-performing, resilient materials.”
This work was funded, in part, by DEVCOM ARL Army Research Office through the MIT Institute for Soldier Nanotechnologies (ISN), and carried out, in part, using ISN’s and MIT.nano’s facilities.
By firing microparticles at supersonic speeds, MIT engineers can test the resilience of various metamaterials made from structures as small as a red blood cell. Pictured are four video stills of a microparticle hitting a structure made of metamaterials.
In George Orwell’s novel “1984,” Big Brother watches citizens through two-way, TV-like telescreens to surveil citizens without any cameras. In a similar fashion, our current smart devices contain ambient light sensors, which open the door to a different threat: hackers.
These passive, seemingly innocuous smartphone components receive light from the environment and adjust the screen's brightness accordingly, like when your phone automatically dims in a bright room. Unlike cameras, though, apps are not required to ask for permission to use these sensors. In a surprising discovery, researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) uncovered that ambient light sensors are vulnerable to privacy threats when embedded on a smart device’s screen. The team proposed a computational imaging algorithm to recover an image of the environment from the perspective of the display screen using subtle single-point light intensity changes of these sensors to demonstrate how hackers could use them in tandem with monitors. An open-access paper on this work was published in Science Advances on Jan. 10.
“This work turns your device's ambient light sensor and screen into a camera! Ambient light sensors are tiny devices deployed in almost all portable devices and screens that surround us in our daily lives,” says Princeton University professor Felix Heide, who was not involved with the paper. “As such, the authors highlight a privacy threat that affects a comprehensive class of devices and has been overlooked so far.”
While phone cameras have previously been exposed as security threats for recording user activity, the MIT group found that ambient light sensors can capture images of users’ touch interactions without a camera. According to their new study, these sensors can eavesdrop on regular gestures, like scrolling, swiping, or sliding, and capture how users interact with their phones while watching videos. For example, apps with native access to your screen, including video players and web browsers, could spy on you to gather this permission-free data.
According to the researchers, a commonly held belief is that ambient light sensors don’t reveal meaningful private information to hackers, so programming apps to request access to them is unnecessary. “Many believe that these sensors should always be turned on,” says lead author Yang Liu, a PhD student in MIT's Department of Electrical Engineering and Computer Science and a CSAIL affiliate. “But much like the telescreen, ambient light sensors can passively capture what we’re doing without our permission, while apps are required to request access to our cameras. Our demonstrations show that when combined with a display screen, these sensors could pose some sort of imaging privacy threat by providing that information to hackers monitoring your smart devices.”
Collecting these images requires a dedicated inversion process where the ambient light sensor first collects low-bitrate variations in light intensity, partially blocked by the hand making contact with the screen. Next, the outputs are mapped into a two-dimensional space by forming an inverse problem with the knowledge of the screen content. An algorithm then reconstructs the picture from the screen’s perspective, which is iteratively optimized and denoised via deep learning to reveal a pixelated image of hand activity.
The study introduces a novel combination of passive sensors and active monitors to reveal a previously unexplored imaging threat that could expose the environment in front of the screen to hackers processing the sensor data from another device. “This imaging privacy threat has never been demonstrated before,” says Liu, who worked alongside Frédo Durand on the paper, who is an MIT EECS professor, CSAIL member, and senior author of the paper.
The team suggested two software mitigation measures for operating system providers: tightening up permissions and reducing the precision and speed of the sensors. First, they recommend restricting access to the ambient light sensor by allowing users to approve or deny those requests from apps. To further prevent any privacy threats, the team also proposed limiting the capabilities of the sensors. By reducing the precision and speed of these components, the sensors would reveal less private information. From the hardware side, the ambient light sensor should not be directly facing the user on any smart device, they argued, but instead placed on the side, where it won’t capture any significant touch interactions.
Getting the picture
The inversion process was applied to three demonstrations using an Android tablet. In the first test, the researchers seated a mannequin in front of the device, while different hands made contact with the screen. A human hand pointed to the screen, and later, a cardboard cutout resembling an open-hand gesture touched the monitor, with the pixelated imprints gathered by the MIT team revealing the physical interactions with the screen.
A subsequent demo with human hands revealed that the way users slide, scroll, pinch, swipe, and rotate could be gradually captured by hackers through the same imaging method, although only at a speed of one frame every 3.3 minutes. With a faster ambient light sensor, malicious actors could potentially eavesdrop on user interactions with their devices in real time.
In a third demo, the group found that users are also at risk when watching videos like films and short clips. A human hand hovered in front of the sensor while scenes from Tom and Jerry cartoons played on screen, with a white board behind the user reflecting light to the device. The ambient light sensor captured the subtle intensity changes for each video frame, with the resulting images exposing touch gestures.
While the vulnerabilities in ambient light sensors pose a threat, such a hack is still restricted. The speed of this privacy issue is low, with the current image retrieval rate being 3.3 minutes per frame, which overwhelms the dwell of user interactions. Additionally, these pictures are still a bit blurry if retrieved from a natural video, potentially leading to future research. While telescreens can capture objects away from the screen, this imaging privacy issue is only confirmed for objects that make contact with a mobile device’s screen, much like how selfie cameras cannot capture objects out of frame.
Two other EECS professors are also authors on the paper: CSAIL member William T. Freeman and MIT-IBM Watson AI Lab member Gregory Wornell, who leads the Signals, Information, and Algorithms Laboratory in the Research Laboratory of Electronics. Their work was supported, in part, by the DARPA REVEAL program and an MIT Stata Family Presidential Fellowship.
A computational imaging algorithm from MIT demonstrates how ambient light sensors can expose touch interactions with our phones to hackers, who could process the sensor data from another device.
Star-shredding black holes are everywhere in the sky if you just know how to look for them. That’s one message from a new study by MIT scientists, appearing today in the Astrophysical Journal.
The study’s authors are reporting the discovery of 18 new tidal disruption events (TDEs) — extreme instances when a nearby star is tidally drawn into a black hole and ripped to shreds. As the black hole feasts, it gives off an enormous burst of energy across the electromagnetic spectrum.
Astronomers have detected previous tidal disruption events by looking for characteristic bursts in the optical and X-ray bands. To date, these searches have revealed about a dozen star-shredding events in the nearby universe. The MIT team’s new TDEs more than double the catalog of known TDEs in the universe.
The researchers spotted these previously “hidden” events by looking in an unconventional band: infrared. In addition to giving off optical and X-ray bursts, TDEs can generate infrared radiation, particularly in “dusty” galaxies, where a central black hole is enshrouded with galactic debris. The dust in these galaxies normally absorbs and obscures optical and X-ray light, and any sign of TDEs in these bands. In the process, the dust also heats up, producing infrared radiation that is detectable. The team found that infrared emissions, therefore, can serve as a sign of tidal disruption events.
By looking in the infrared band, the MIT team picked out many more TDEs, in galaxies where such events were previously hidden. The 18 new events occurred in different types of galaxies, scattered across the sky.
“The majority of these sources don’t show up in optical bands,” says lead author Megan Masterson, a graduate student in MIT’s Kavli Institute for Astrophysics and Space Research. “If you want to understand TDEs as a whole and use them to probe supermassive black hole demographics, you need to look in the infrared band.”
Other MIT authors include Kishalay De, Christos Panagiotou, Anna-Christina Eilers, Danielle Frostig, and Robert Simcoe, and MIT assistant professor of physics Erin Kara, along with collaborators from multiple institutions including the Max Planck Institute for Extraterrestrial Physics in Germany.
Heat spike
The team recently detected the closest TDE yet, by searching through infrared observations. The discovery opened a new, infrared-based route by which astronomers can search for actively feeding black holes.
That first detection spurred the group to comb for more TDEs. For their new study, the researchers searched through archival observations taken by NEOWISE — the renewed version of NASA’s Wide-field Infrared Survey Explorer. This satellite telescope launched in 2009 and after a brief hiatus has continued to scan the entire sky for infrared “transients,” or brief bursts.
The team looked through the mission’s archived observations using an algorithm developed by co-author Kishalay De. This algorithm picks out patterns in infrared emissions that are likely signs of a transient burst of infrared radiation. The team then cross-referenced the flagged transients with a catalog of all known nearby galaxies within 200 megaparsecs, or 600 million light years. They found that infrared transients could be traced to about 1,000 galaxies.
They then zoomed in on the signal of each galaxy’s infrared burst to determine whether the signal arose from a source other than a TDE, such as an active galactic nucleus or a supernova. After ruling out these possibilities, the team then analyzed the remaining signals, looking for an infrared pattern that is characteristic of a TDE — namely, a sharp spike followed by a gradual dip, reflecting a process by which a black hole, in ripping apart a star, suddenly heats up the surrounding dust to about 1,000 kelvins before gradually cooling down.
This analysis revealed 18 “clean” signals of tidal disruption events. The researchers took a survey of the galaxies in which each TDE was found, and saw that they occurred in a range of systems, including dusty galaxies, across the entire sky.
“If you looked up in the sky and saw a bunch of galaxies, the TDEs would occur representatively in all of them,” Masteron says. “It’s not that they’re only occurring in one type of galaxy, as people thought based only on optical and X-ray searches.”
“It is now possible to peer through the dust and complete the census of nearby TDEs,” says Edo Berger, professor of astronomy at Harvard University, who was not involved with the study. “A particularly exciting aspect of this work is the potential of follow-up studies with large infrared surveys, and I’m excited to see what discoveries they will yield.”
A dusty solution
The team’s discoveries help to resolve some major questions in the study of tidal disruption events. For instance, prior to this work, astronomers had mostly seen TDEs in one type of galaxy — a “post-starburst” system that had previously been a star-forming factory, but has since settled. This galaxy type is rare, and astronomers were puzzled as to why TDEs seemed to be popping up only in these rarer systems. It so happens that these systems are also relatively devoid of dust, making a TDE’s optical or X-ray emissions naturally easier to detect.
Now, by looking in the infrared band, astronomers are able to see TDEs in many more galaxies. The team’s new results show that black holes can devour stars in a range of galaxies, not only post-starburst systems.
The findings also resolve a “missing energy” problem. Physicists have theoreticially predicted that TDEs should radiate more energy than what has been actually observed. But the MIT team now say that dust may explain the discrepancy. They found that if a TDE occurs in a dusty galaxy, the dust itself could absorb not only optical and X-ray emissions but also extreme ultraviolet radiation, in an amount equivalent to the presumed “missing energy.”
The 18 new detections also are helping astronomers estimate the rate at which TDEs occur in a given galaxy. When they figure the new TDEs in with previous detections, they estimate a galaxy experiences a tidal disruption event once every 50,000 years. This rate comes closer to physicists’ theoretical predictions. With more infrared observations, the team hopes to resolve the rate of TDEs, and the properties of the black holes that power them.
“People were coming up with very exotic solutions to these puzzles, and now we’ve come to the point where we can resolve all of them,” Kara says. “This gives us confidence that we don’t need all this exotic physics to explain what we’re seeing. And we have a better handle on the mechanics behind how a star gets ripped apart and gobbled up by a black hole. We’re understanding these systems better.”
MIT scientists have identified 18 new tidal disruption events (TDEs) — extreme instances when a nearby star is tidally drawn into a black hole and ripped to shreds. The detections more than double the number of known TDEs in the nearby universe.
By clocking the speed of stars throughout the Milky Way galaxy, MIT physicists have found that stars further out in the galactic disk are traveling more slowly than expected compared to stars that are closer to the galaxy’s center. The findings raise a surprising possibility: The Milky Way’s gravitational core may be lighter in mass, and contain less dark matter, than previously thought.
The new results are based on the team’s analysis of data taken by the Gaia and APOGEE instruments. Gaia is an orbiting space telescope that tracks the precise location, distance, and motion of more than 1 billion stars throughout the Milky Way galaxy, while APOGEE is a ground-based survey. The physicists analyzed Gaia’s measurements of more than 33,000 stars, including some of the farthest stars in the galaxy, and determined each star’s “circular velocity,” or how fast a star is circling in the galactic disk, given the star’s distance from the galaxy’s center.
The scientists plotted each star’s velocity against its distance to generate a rotation curve — a standard graph in astronomy that represents how fast matter rotates at a given distance from the center of a galaxy. The shape of this curve can give scientists an idea of how much visible and dark matter is distributed throughout a galaxy.
“What we were really surprised to see was that this curve remained flat, flat, flat out to a certain distance, and then it started tanking,” says Lina Necib, assistant professor of physics at MIT. “This means the outer stars are rotating a little slower than expected, which is a very surprising result.”
The team translated the new rotation curve into a distribution of dark matter that could explain the outer stars’ slow-down, and found the resulting map produced a lighter galactic core than expected. That is, the center of the Milky Way may be less dense, with less dark matter, than scientists have thought.
“This puts this result in tension with other measurements,” Necib says. “There is something fishy going on somewhere, and it’s really exciting to figure out where that is, to really have a coherent picture of the Milky Way.”
The team reports its results this month in the Monthly Notices of the Royal Society Journal. The study’s MIT co-authors, including Necib, are first author Xiaowei Ou, Anna-Christina Eilers, and Anna Frebel.
“In the nothingness”
Like most galaxies in the universe, the Milky Way spins like water in a whirlpool, and its rotation is driven, in part, by all the matter that swirls within its disk. In the 1970s, astronomer Vera Rubin was the first to observe that galaxies rotate in ways that cannot be driven purely by visible matter. She and her colleagues measured the circular velocity of stars and found that the resulting rotation curves were surprisingly flat. That is, the velocity of stars remained the same throughout a galaxy, rather than dropping off with distance. They concluded that some other type of invisible matter must be acting on distant stars to give them an added push.
Rubin’s work in rotation curves was one of the first strong pieces of evidence for the existence of dark matter — an invisible, unknown entity that is estimated to outweigh all the stars and other visible matter in the universe.
Since then, astronomers have observed similar flat curves in far-off galaxies, further supporting dark matter’s presence. Only recently have astronomers attempted to chart the rotation curve in our own galaxy with stars.
“It turns out it’s harder to measure a rotation curve when you’re sitting inside a galaxy,” Ou notes.
In 2019, Anna-Christina Eilers, assistant professor of physics at MIT, worked to chart the Milky Way’s rotation curve, using an earlier batch of data released by the Gaia satellite. That data release included stars as far out as 25 kiloparsecs, or about 81,000 light years, from the galaxy’s center.
Based on these data, Eilers observed that the Milky Way’s rotation curve appeared to be flat, albeit with mild decline, similar to other far-off galaxies, and by inference, the galaxy likely bore a high density of dark matter at its core. But this view now shifted, as the telescope released a new batch of data, this time including stars as far out as 30 kiloparsecs — almost 100,000 light years from the galaxy’s core.
“At these distances, we’re right at the edge of the galaxy where stars start to peter out,” Frebel says. “No one had explored how matter moves around in this outer galaxy, where we’re really in the nothingness.”
Weird tension
Frebel, Necib, Ou, and Eilers jumped on Gaia’s new data, looking to expand on Eilers’ initial rotation curve. To refine their analysis, the team complemented Gaia’s data with measurements by APOGEE — the Apache Point Observatory Galactic Evolution Experiment, which measures extremely detailed properties of more than 700,000 stars in the Milky Way, such as their brightness, temperature, and elemental composition.
“We feed all this information into an algorithm to try to learn connections that can then give us better estimates of a star’s distance,” Ou explains. “That’s how we can push out to farther distances.”
The team established the precise distances for more than 33,000 stars and used these measurements to generate a three-dimensional map of the stars scattered across the Milky Way out to about 30 kiloparsecs. They then incorporated this map into a model of circular velocity, to simulate how fast any one star must be traveling, given the distribution of all the other stars in the galaxy. They then plotted each star’s velocity and distance on a chart to produce an updated rotation curve of the Milky Way.
“That’s where the weirdness came in,” Necib says.
Instead of seeing a mild decline like previous rotation curves, the team observed that the new curve dipped more strongly than expected at the outer end. This unexpected downturn suggests that while stars may travel just as fast out to a certain distance, they suddenly slow down at the farthest distances. Stars at the outskirts appear to travel more slowly than expected.
When the team translated this rotation curve to the amount of dark matter that must exist throughout the galaxy, they found that the Milky Way’s core may contain less dark matter than previously estimated.
“This result is in tension with other measurements,” Necib says. “Really understanding this result will have deep repercussions. This might lead to more hidden masses just beyond the edge of the galactic disk, or a reconsideration of the state of equilibrium of our galaxy. We seek to find these answers in upcoming work, using high resolution simulations of Milky Way-like galaxies."
This research was funded, in part, by the National Science Foundation.
MIT researchers have developed an additive manufacturing technique that can print rapidly with liquid metal, producing large-scale parts like table legs and chair frames in a matter of minutes.
Their technique, called liquid metal printing (LMP), involves depositing molten aluminum along a predefined path into a bed of tiny glass beads. The aluminum quickly hardens into a 3D structure.
The researchers say LMP is at least 10 times faster than a comparable metal additive manufacturing process, and the procedure to heat and melt the metal is more efficient than some other methods.
The technique does sacrifice resolution for speed and scale. While it can print components that are larger than those typically made with slower additive techniques, and at a lower cost, it cannot achieve high resolutions.
For instance, parts produced with LMP would be suitable for some applications in architecture, construction, and industrial design, where components of larger structures often don’t require extremely fine details. It could also be utilized effectively for rapid prototyping with recycled or scrap metal.
In a recent study, the researchers demonstrated the procedure by printing aluminum frames and parts for tables and chairs which were strong enough to withstand postprint machining. They showed how components made with LMP could be combined with high-resolution processes and additional materials to create functional furniture.
“This is a completely different direction in how we think about metal manufacturing that has some huge advantages. It has downsides, too. But most of our built world — the things around us like tables, chairs, and buildings — doesn’t need extremely high resolution. Speed and scale, and also repeatability and energy consumption, are all important metrics,” says Skylar Tibbits, associate professor in the Department of Architecture and co-director of the Self-Assembly Lab, who is senior author of a paper introducing LMP.
Tibbits is joined on the paper by lead author Zain Karsan SM ’23, who is now a PhD student at ETH Zurich; as well as Kimball Kaiser SM ’22 and Jared Laucks, a research scientist and lab co-director. The research was presented at the Association for Computer Aided Design in Architecture Conference and recently published in the association’s proceedings.
Significant speedup
One method for printing with metals that is common in construction and architecture, called wire arc additive manufacturing (WAAM), is able to produce large, low-resolution structures, but these can be susceptible to cracking and warping because some portions must be remelted during the printing process.
LMP, on the other hand, keeps the material molten throughout the process, avoiding some of the structural issues caused by remelting.
Drawing on the group’s previous work on rapid liquid printing with rubber, the researchers built a machine that melts aluminum, holds the molten metal, and deposits it through a nozzle at high speeds. Large-scale parts can be printed in just a few seconds, and then the molten aluminum cools in several minutes.
“Our process rate is really high, but it is also very difficult to control. It is more or less like opening a faucet. You have a big volume of material to melt, which takes some time, but once you get that to melt, it is just like opening a tap. That enables us to print these geometries very quickly,” Karsan explains.
The team chose aluminum because it is commonly used in construction and can be recycled cheaply and efficiently.
Bread loaf-sized pieces of aluminum are deposited into an electric furnace, “which is basically like a scaled-up toaster,” Karsan adds. Metal coils inside the furnace heat the metal to 700 degrees Celsius, slightly above aluminum’s 660-degree melting point.
The aluminum is held at a high temperature in a graphite crucible, and then molten material is gravity-fed through a ceramic nozzle into a print bed along a preset path. They found that the larger the amount of aluminum they could melt, the faster the printer can go.
“Molten aluminum will destroy just about everything in its path. We started with stainless steel nozzles and then moved to titanium before we ended up with ceramic. But even ceramic nozzles can clog because the heating is not always entirely uniform in the nozzle tip,” Karsan says.
By injecting the molten material directly into a granular substance, the researchers don’t need to print supports to hold the aluminum structure as it takes shape.
Perfecting the process
They experimented with a number of materials to fill the print bed, including graphite powders and salt, before selecting 100-micron glass beads. The tiny glass beads, which can withstand the extremely high temperature of molten aluminum, act as a neutral suspension so the metal can cool quickly.
“The glass beads are so fine that they feel like silk in your hand. The powder is so small that it doesn’t really change the surface characteristics of the printed object,” Tibbits says.
The amount of molten material held in the crucible, the depth of the print bed, and the size and shape of the nozzle have the biggest impacts on the geometry of the final object.
For instance, parts of the object with larger diameters are printed first, since the amount of aluminum the nozzle dispenses tapers off as the crucible empties. Changing the depth of the nozzle alters the thickness of the metal structure.
To aid in the LMP process, the researchers developed a numerical model to estimate the amount of material that will be deposited into the print bed at a given time.
Because the nozzle pushes into the glass bead powder, the researchers can’t watch the molten aluminum as it is deposited, so they needed a way to simulate what should be going on at certain points in the printing process, Tibbits explains.
They used LMP to rapidly produce aluminum frames with variable thicknesses, which were durable enough to withstand machining processes like milling and boring. They demonstrated a combination of LMP and these post-processing techniques to make chairs and a table composed of lower-resolution, rapidly printed aluminum parts and other components, like wood pieces.
Moving forward, the researchers want to keep iterating on the machine so they can enable consistent heating in the nozzle to prevent material from sticking, and also achieve better control over the flow of molten material. But larger nozzle diameters can lead to irregular prints, so there are still technical challenges to overcome.
“If we could make this machine something that people could actually use to melt down recycled aluminum and print parts, that would be a game-changer in metal manufacturing. Right now, it is not reliable enough to do that, but that’s the goal,” Tibbits says.
“At Emeco, we come from the world of very analog manufacturing, so seeing the liquid metal printing creating nuanced geometries with the potential for fully structural parts was really compelling,” says Jaye Buchbinder, who leads business development for the furniture company Emeco and was not involved with this work. “The liquid metal printing really walks the line in terms of ability to produce metal parts in custom geometries while maintaining quick turnaround that you don’t normally get in other printing or forming technologies. There is definitely potential for the technology to revolutionize the way metal printing and metal forming are currently handled.”
Additional researchers who worked on this project include Kimball Kaiser, Jeremy Bilotti, Bjorn Sparrman, Schendy Kernizan, and Maria Esteban Casanas.
This research was funded, in part, by Aisin Group, Amada Global, and Emeco.
MIT researchers have developed an additive manufacturing technique that can print rapidly with liquid metal, producing large-scale parts like table legs and chair frames in a matter of minutes.
Coastal cities and communities will face more frequent major hurricanes with climate change in the coming years. To help prepare coastal cities against future storms, MIT scientists have developed a method to predict how much flooding a coastal community is likely to experience as hurricanes evolve over the next decades.
When hurricanes make landfall, strong winds whip up salty ocean waters that generate storm surge in coastal regions. As the storms move over land, torrential rainfall can induce further flooding inland. When multiple flood sources such as storm surge and rainfall interact, they can compound a hurricane’s hazards, leading to significantly more flooding than would result from any one source alone. The new study introduces a physics-based method for predicting how the risk of such complex, compound flooding may evolve under a warming climate in coastal cities.
One example of compound flooding’s impact is the aftermath from Hurricane Sandy in 2012. The storm made landfall on the East Coast of the United States as heavy winds whipped up a towering storm surge that combined with rainfall-driven flooding in some areas to cause historic and devastating floods across New York and New Jersey.
In their study, the MIT team applied the new compound flood-modeling method to New York City to predict how climate change may influence the risk of compound flooding from Sandy-like hurricanes over the next decades.
They found that, in today’s climate, a Sandy-level compound flooding event will likely hit New York City every 150 years. By midcentury, a warmer climate will drive up the frequency of such flooding, to every 60 years. At the end of the century, destructive Sandy-like floods will deluge the city every 30 years — a fivefold increase compared to the present climate.
“Long-term average damages from weather hazards are usually dominated by the rare, intense events like Hurricane Sandy,” says study co-author Kerry Emanuel, professor emeritus of atmospheric science at MIT. “It is important to get these right.”
While these are sobering projections, the researchers hope the flood forecasts can help city planners prepare and protect against future disasters. “Our methodology equips coastal city authorities and policymakers with essential tools to conduct compound flooding risk assessments from hurricanes in coastal cities at a detailed, granular level, extending to each street or building, in both current and future decades,” says study author Ali Sarhadi, a postdoc in MIT’s Department of Earth, Atmospheric and Planetary Sciences.
The team’s open-access study appears online today in the Bulletin of the American Meteorological Society. Co-authors include Raphaël Rousseau-Rizzi at MIT’s Lorenz Center, Kyle Mandli at Columbia University, Jeffrey Neal at the University of Bristol, Michael Wiper at the Charles III University of Madrid, and Monika Feldmann at the Swiss Federal Institute of Technology Lausanne.
The seeds of floods
To forecast a region’s flood risk, weather modelers typically look to the past. Historical records contain measurements of previous hurricanes’ wind speeds, rainfall, and spatial extent, which scientists use to predict where and how much flooding may occur with coming storms. But Sarhadi believes that the limitations and brevity of these historical records are insufficient for predicting future hurricanes’ risks.
“Even if we had lengthy historical records, they wouldn’t be a good guide for future risks because of climate change,” he says. “Climate change is changing the structural characteristics, frequency, intensity, and movement of hurricanes, and we cannot rely on the past.”
Sarhadi and his colleagues instead looked to predict a region’s risk of hurricane flooding in a changing climate using a physics-based risk assessment methodology. They first paired simulations of hurricane activity with coupled ocean and atmospheric models over time. With the hurricane simulations, developed originally by Emanuel, the researchers virtually scatter tens of thousands of “seeds” of hurricanes into a simulated climate. Most seeds dissipate, while a few grow into category-level storms, depending on the conditions of the ocean and atmosphere.
When the team drives these hurricane simulations with climate models of ocean and atmospheric conditions under certain global temperature projections, they can see how hurricanes change, for instance in terms of intensity, frequency, and size, under past, current, and future climate conditions.
The team then sought to precisely predict the level and degree of compound flooding from future hurricanes in coastal cities. The researchers first used rainfall models to simulate rain intensity for a large number of simulated hurricanes, then applied numerical models to hydraulically translate that rainfall intensity into flooding on the ground during landfalling of hurricanes, given information about a region such as its surface and topography characteristics. They also simulated the same hurricanes’ storm surges, using hydrodynamic models to translate hurricanes’ maximum wind speed and sea level pressure into surge height in coastal areas. The simulation further assessed the propagation of ocean waters into coastal areas, causing coastal flooding.
Then, the team developed a numerical hydrodynamic model to predict how two sources of hurricane-induced flooding, such as storm surge and rain-driven flooding, would simultaneously interact through time and space, as simulated hurricanes make landfall in coastal regions such as New York City, in both current and future climates.
“There’s a complex, nonlinear hydrodynamic interaction between saltwater surge-driven flooding and freshwater rainfall-driven flooding, that forms compound flooding that a lot of existing methods ignore,” Sarhadi says. “As a result, they underestimate the risk of compound flooding.”
Amplified risk
With their flood-forecasting method in place, the team applied it to a specific test case: New York City. They used the multipronged method to predict the city’s risk of compound flooding from hurricanes, and more specifically from Sandy-like hurricanes, in present and future climates. Their simulations showed that the city’s odds of experiencing Sandy-like flooding will increase significantly over the next decades as the climate warms, from once every 150 years in the current climate, to every 60 years by 2050, and every 30 years by 2099.
Interestingly, they found that much of this increase in risk has less to do with how hurricanes themselves will change with warming climates, but with how sea levels will increase around the world.
“In future decades, we will experience sea level rise in coastal areas, and we also incorporated that effect into our models to see how much that would increase the risk of compound flooding,” Sarhadi explains. “And in fact, we see sea level rise is playing a major role in amplifying the risk of compound flooding from hurricanes in New York City.”
The team’s methodology can be applied to any coastal city to assess the risk of compound flooding from hurricanes and extratropical storms. With this approach, Sarhadi hopes decision-makers can make informed decisions regarding the implementation of adaptive measures, such as reinforcing coastal defenses to enhance infrastructure and community resilience.
“Another aspect highlighting the urgency of our research is the projected 25 percent increase in coastal populations by midcentury, leading to heightened exposure to damaging storms,” Sarhadi says. “Additionally, we have trillions of dollars in assets situated in coastal flood-prone areas, necessitating proactive strategies to reduce damages from compound flooding from hurricanes under a warming climate.”
This research was supported, in part, by Homesite Insurance.
A good shoe can make a huge difference for runners, from career marathoners to couch-to-5K first-timers. But every runner is unique, and a shoe that works for one might trip up another. Outside of trying on a rack of different designs, there’s no quick and easy way to know which shoe best suits a person’s particular running style.
MIT engineers are hoping to change that with a new model that predicts how certain shoe properties will affect a runner’s performance.
The simple model incorporates a person’s height, weight, and other general dimensions, along with shoe properties such as stiffness and springiness along the midsole. With this input, the model then simulates a person’s running gait, or how they would run, in a particular shoe.
Using the model, the researchers can simulate how a runner’s gait changes with different shoe types. They can then pick out the shoe that produces the best performance, which they define as the degree to which a runner’s expended energy is minimized.
While the model can accurately simulate changes in a runner’s gait when comparing two very different shoe types, it is less discerning when comparing relatively similar designs, including most commercially available running shoes. For this reason, the researchers envision the current model would be best used as a tool for shoe designers looking to push the boundaries of sneaker design.
“Shoe designers are starting to 3D print shoes, meaning they can now make them with a much wider range of properties than with just a regular slab of foam,” says Sarah Fay, a postdoc in MIT’s Sports Lab and the Institute for Data, Systems, and Society (IDSS). “Our model could help them design really novel shoes that are also high-performing.”
The team is planning to improve the model, in hopes that consumers can one day use a similar version to pick shoes that fit their personal running style.
“We’ve allowed for enough flexibility in the model that it can be used to design custom shoes and understand different individual behaviors,” Fay says. “Way down the road, we imagine that if you send us a video of yourself running, we could 3D print the shoe that’s right for you. That would be the moonshot.”
The new model is reported in a study appearing this month in the Journal of Biomechanical Engineering. The study is authored by Fay and Anette “Peko” Hosoi, professor of mechanical engineering at MIT.
Running, revamped
The team’s new model grew out of talks with collaborators in the sneaker industry, where designers have started to 3D print shoes at commercial scale. These designs incorporate 3D-printed midsoles that resemble intricate scaffolds, the geometry of which can be tailored to give a certain bounce or stiffness in specific locations across the sole.
“With 3D printing, designers can tune everything about the material response locally,” Hosoi says. “And they came to us and essentially said, ‘We can do all these things. What should we do?’”
“Part of the design problem is to predict what a runner will do when you put an entirely new shoe on them,” Fay adds. “You have to couple the dynamics of the runner with the properties of the shoe.”
Fay and Hosoi looked first to represent a runner’s dynamics using a simple model. They drew inspiration from Thomas McMahon, a leader in the study of biomechanics at Harvard University, who in the 1970s used a very simple “spring and damper” model to model a runner’s essential gait mechanics. Using this gait model, he predicted how fast a person could run on various track types, from traditional concrete surfaces to more rubbery material. The model showed that runners should run faster on softer, bouncier tracks that supported a runner’s natural gait.
Though this may be unsurprising today, the insight was a revelation at the time, prompting Harvard to revamp its indoor track — a move that quickly accumulated track records, as runners found they could run much faster on the softier, springier surface.
“McMahon’s work showed that, even if we don’t model every single limb and muscle and component of the human body, we’re still able to create meaningful insights in terms of how we design for athletic performance,” Fay says.
Gait cost
Following McMahon’s lead, Fay and Hosoi developed a similar, simplified model of a runner’s dynamics. The model represents a runner as a center of mass, with a hip that can rotate and a leg that can stretch. The leg is connected to a box-like shoe, with springiness and shock absorption that can be tuned, both vertically and horizontally.
They reasoned that they should be able to input into the model a person’s basic dimensions, such as their height, weight, and leg length, along with a shoe’s material properties, such as the stiffness of the front and back midsole, and use the model to simulate what a person’s gait is likely to be when running in that shoe.
But they also realized that a person’s gait can depend on a less definable property, which they call the “biological cost function” — a quality that a runner might not consciously be aware of but nevertheless may try to minimize whenever they run. The team reasoned that if they can identify a biological cost function that is general to most runners, then they might predict not only a person’s gait for a given shoe but also which shoe produces the gait corresponding to the best running performance.
With this in mind, the team looked to a previous treadmill study, which recorded detailed measurements of runners, such as the force of their impacts, the angle and motion of their joints, the spring in their steps, and the work of their muscles as they ran, each in the same type of running shoe.
Fay and Hosoi hypothesized that each runner’s actual gait arose not only from their personal dimensions and shoe properties, but also a subconscious goal to minimize one or more biological measures, yet unknown. To reveal these measures, the team used their model to simulate each runner’s gait multiple times. Each time, they programmed the model to assume the runner minimized a different biological cost, such as the degree to which they swing their leg or the impact that they make with the treadmill. They then compared the modeled gait with the runner’s actual gait to see which modeled gait — and assumed cost — matched the actual gait.
In the end, the team found that most runners tend to minimize two costs: the impact their feet make with the treadmill and the amount of energy their legs expend.
“If we tell our model, ‘Optimize your gait on these two things,’ it gives us really realistic-looking gaits that best match the data we have,” Fay explains. “This gives us confidence that the model can predict how people will actually run, even if we change their shoe.”
As a final step, the researchers simulated a wide range of shoe styles and used the model to predict a runner’s gait and how efficient each gait would be for a given type of shoe.
“In some ways, this gives you a quantitative way to design a shoe for a 10K versus a marathon shoe,” Hosoi says. “Designers have an intuitive sense for that. But now we have a mathematical understanding that we hope designers can use as a tool to kickstart new ideas.”
A model developed by MIT engineers predicts the optimal running shoe design for a given runner. Pictured is a researcher holding a 3-D-printed midsole, designed based on the model’s predictions.
MIT neuroscientists have found that the brain’s sensitivity to rewarding experiences — a critical factor in motivation and attention — can be shaped by socioeconomic conditions.
In a study of 12 to 14-year-olds whose socioeconomic status (SES) varied widely, the researchers found that children from lower SES backgrounds showed less sensitivity to reward than those from more affluent backgrounds.
Using functional magnetic resonance imaging (fMRI), the research team measured brain activity as the children played a guessing game in which they earned extra money for each correct guess. When participants from higher SES backgrounds guessed correctly, a part of the brain called the striatum, which is linked to reward, lit up much more than in children from lower SES backgrounds.
The brain imaging results also coincided with behavioral differences in how participants from lower and higher SES backgrounds responded to correct guesses. The findings suggest that lower SES circumstances may prompt the brain to adapt to the environment by dampening its response to rewards, which are often scarcer in low SES environments.
“If you’re in a highly resourced environment, with many rewards available, your brain gets tuned in a certain way. If you’re in an environment in which rewards are more scarce, then your brain accommodates the environment in which you live. Instead of being overresponsive to rewards, it seems like these brains, on average, are less responsive, because probably their environment has been less consistent in the availability of rewards,” says John Gabrieli, the Grover Hermann Professor of Health Sciences and Technology, a professor of brain and cognitive sciences, and a member of MIT’s McGovern Institute for Brain Research.
Gabrieli and Rachel Romeo, a former MIT postdoc who is now an assistant professor in the Department of Human Development and Quantitative Methodology at the University of Maryland, are the senior authors of the study. MIT postdoc Alexandra Decker is the lead author of the paper, which appears today in the Journal of Neuroscience.
Reward response
Previous research has shown that children from lower SES backgrounds tend to perform worse on tests of attention and memory, and they are more likely to experience depression and anxiety. However, until now, few studies have looked at the possible association between SES and reward sensitivity.
In the new study, the researchers focused on a part of the brain called the striatum, which plays a significant role in reward response and decision-making. Studies in people and animal models have shown that this region becomes highly active during rewarding experiences.
To investigate potential links between reward sensitivity, the striatum, and socioeconomic status, the researchers recruited more than 100 adolescents from a range of SES backgrounds, as measured by household income and how much education their parents received.
Each of the participants underwent fMRI scanning while they played a guessing game. The participants were shown a series of numbers between 1 and 9, and before each trial, they were asked to guess whether the next number would be greater than or less than 5. They were told that for each correct guess, they would earn an extra dollar, and for each incorrect guess, they would lose 50 cents.
Unbeknownst to the participants, the game was set up to control whether the guess would be correct or incorrect. This allowed the researchers to ensure that each participant had a similar experience, which included periods of abundant rewards or few rewards. In the end, everyone ended up winning the same amount of money (in addition to a stipend that each participant received for participating in the study).
Previous work has shown that the brain appears to track the rate of rewards available. When rewards are abundant, people or animals tend to respond more quickly because they don’t want to miss out on the many available rewards. The researchers saw that in this study as well: When participants were in a period when most of their responses were correct, they tended to respond more quickly.
“If your brain is telling you there’s a really high chance that you’re going to receive a reward in this environment, it's going to motivate you to collect rewards, because if you don’t act, you’re missing out on a lot of rewards,” Decker says.
Brain scans showed that the degree of activation in the striatum appeared to track fluctuations in the rate of rewards across time, which the researchers think could act as a motivational signal that there are many rewards to collect. The striatum lit up more during periods in which rewards were abundant and less during periods in which rewards were scarce. However, this effect was less pronounced in the children from lower SES backgrounds, suggesting their brains were less attuned to fluctuations in the rate of reward over time.
The researchers also found that during periods of scarce rewards, participants tended to take longer to respond after a correct guess, another phenomenon that has been shown before. It’s unknown exactly why this happens, but two possible explanations are that people are savoring their reward or that they are pausing to update the reward rate. However, once again, this effect was less pronounced in the children from lower SES backgrounds — that is, they did not pause as long after a correct guess during the scarce-reward periods.
“There was a reduced response to reward, which is really striking. It may be that if you’re from a lower SES environment, you’re not as hopeful that the next response will gain similar benefits, because you may have a less reliable environment for earning rewards,” Gabrieli says. “It just points out the power of the environment. In these adolescents, it’s shaping their psychological and brain response to reward opportunity.”
Environmental effects
The fMRI scans performed during the study also revealed that children from lower SES backgrounds showed less activation in the striatum when they guessed correctly, suggesting that their brains have a dampened response to reward.
The researchers hypothesize that these differences in reward sensitivity may have evolved over time, in response to the children’s environments.
“Socioeconomic status is associated with the degree to which you experience rewards over the course of your lifetime,” Decker says. “So, it’s possible that receiving a lot of rewards perhaps reinforces behaviors that make you receive more rewards, and somehow this tunes the brain to be more responsive to rewards. Whereas if you are in an environment where you receive fewer rewards, your brain might become, over time, less attuned to them.”
The study also points out the value of recruiting study subjects from a range of SES backgrounds, which takes more effort but yields important results, the researchers say.
“Historically, many studies have involved the easiest people to recruit, who tend to be people who come from advantaged environments. If we don’t make efforts to recruit diverse pools of participants, we almost always end up with children and adults who come from high-income, high-education environments,” Gabrieli says. “Until recently, we did not realize that principles of brain development vary in relation to the environment in which one grows up, and there was very little evidence about the influence of SES.”
The research was funded by the William and Flora Hewlett Foundation and a Natural Sciences and Engineering Research Council of Canada Postdoctoral Fellowship.
MIT neuroscientists have found that the brain’s sensitivity to rewarding experiences — a critical factor in motivation and attention — can be shaped by socioeconomic conditions.
Autosomal dominant polycystic kidney disease (ADPKD), the most common form of polycystic kidney disease, can lead to kidney enlargement and eventual loss of function. The disease affects more than 12 million people worldwide, and many patients end up needing dialysis or a kidney transplant by the time they reach their 60s.
Researchers at MIT and Yale University School of Medicine have now found that a compound originally developed as a potential cancer treatment holds promise for treating ADPKD. The drug works by exploiting kidney cyst cells’ vulnerability to oxidative stress — a state of imbalance between damaging free radicals and beneficial antioxidants.
In a study employing two mouse models of the disease, the researchers found that the drug dramatically shrank kidney cysts without harming healthy kidney cells.
“We really believe this has potential to impact the field and provide a different treatment paradigm for this important disease,” says Bogdan Fedeles, a research scientist and program manager in MIT’s Center for Environmental Health Sciences and the lead author of the study, which appears this week in the Proceedings of the National Academy of Sciences.
John Essigmann, the William R. and Betsy P. Leitch Professor of Biological Engineering and Chemistry at MIT; Sorin Fedeles, executive director of the Polycystic Kidney Disease Outcomes Consortium and assistant professor (adjunct) at Yale University School of Medicine; and Stefan Somlo, the C.N.H. Long Professor of Medicine and Genetics and chief of nephrology at Yale University School of Medicine, are the senior authors of the paper.
Cells under stress
ADPKD typically progresses slowly. Often diagnosed when patients are in their 30s, it usually doesn’t cause serious impairment of kidney function until patients reach their 60s. The only drug that is FDA-approved to treat the disease, tolvaptan, slows growth of the cysts but has side effects that include frequent urination and possible liver damage.
Essigmann’s lab did not originally set out to study PKD; the new study grew out of work on potential new drugs for cancer. Nearly 25 years ago, MIT research scientist Robert Croy, also an author of the new PNAS study, designed compounds that contain a DNA-damaging agent known as an aniline mustard, which can induce cell death in cancer cells.
In the mid 2000s, Fedeles, then a grad student in Essigmann’s lab, along with Essigmann and Croy, discovered that in addition to damaging DNA, these compounds also induce oxidative stress by interfering with mitochondria — the organelles that generate energy for cells.
Tumor cells are already under oxidative stress because of their abnormal metabolism. When they are treated with these compounds, known as 11beta compounds, the additional disruption helps to kill the cells. In a study published in 2011, Fedeles reported that treatment with 11beta compounds significantly suppressed the growth of prostate tumors implanted in mice.
A conversation with his brother, Sorin Fedeles, who studies polycystic kidney disease, led the pair to theorize that these compounds might also be good candidates for treating kidney cysts. At the time, research in ADPKD was beginning to suggest that kidney cyst cells also experience oxidative stress, due to an abnormal metabolism that resembles that of cancer cells.
“We were talking about a mechanism of what would be a good drug for polycystic kidney disease, and we had this intuition that the compounds that I was working with might actually have an impact in ADPKD,” Bogdan Fedeles says.
The 11beta compounds work by disrupting the mitochondria’s ability to generate ATP (the molecules that cells use to store energy), as well as a cofactor known as NADPH, which can act as an antioxidant to help cells neutralize damaging free radicals. Tumor cells and kidney cyst cells tend to produce increased levels of free radicals because of the oxidative stress they’re under. When these cells are treated with 11beta compounds, the extra oxidative stress, including the further depletion of NADPH, pushes the cells over the edge.
“A little bit of oxidative stress is OK, but the cystic cells have a low threshold for tolerating it. Whereas normal cells survive treatment, the cystic cells will die because they exceed the threshold,” Essigmann says.
Shrinking cysts
Using two different mouse models of ADPKD, the researchers showed that 11beta-dichloro could significantly reduce the size of kidney cysts and improve kidney function.
The researchers also synthesized a “defanged” version of the compound called 11beta-dipropyl, which does not include any direct DNA-damaging ability and could potentially be safer for use in humans. They tested this compound in the early-onset model of PKD and found that it was as effective as 11beta-dichloro.
In all of the experiments, healthy kidney cells did not appear to be affected by the treatment. That’s because healthy cells are able to withstand a small increase in oxidative stress, unlike the diseased cells, which are highly susceptible to any new disturbances, the researchers say. In addition to restoring kidney function, the treatment also ameliorated other clinical features of ADPKD; biomarkers for tissue inflammation and fibrosis were decreased in the treated mice compared to the control animals.
The results also suggest that in patients, treatment with 11beta compounds once every few months, or even once a year, could significantly delay disease progression, and thus avoid the need for continuous, burdensome antiproliferative therapies such as tolvaptan.
“Based on what we know about the cyst growth paradigm, you could in theory treat patients in a pulsatile manner — once a year, or perhaps even less often — and have a meaningful impact on total kidney volume and kidney function,” Sorin Fedeles says.
The researchers now hope to run further tests on 11beta-dipropyl, as well as develop ways to produce it on a larger scale. They also plan to explore related compounds that could be good drug candidates for PKD.
Other MIT authors who contributed to this work include Research Scientist Nina Gubina, former postdoc Sakunchai Khumsubdee, former postdoc Denise Andrade, and former undergraduates Sally S. Liu ’20 and co-op student Jake Campolo. The research was funded by the PKD Foundation, the U.S. Department of Defense, the National Institutes of Health, and the National Institute of Environmental Health Sciences through the Center for Environmental Health Sciences at MIT.
MIT researchers including Robert Croy (left) and Bogdan Fedeles have discovered that a drug they originally developed as a potential cancer treatment may also hold promise in treating autosomal dominant polycystic kidney disease (ADPKD).
Over the past 30 years, charter schools have emerged as a prominent yet debated public school option. According to the National Center for Education Statistics, 7 percent of U.S. public school students were enrolled in charter schools in 2021, up from 4 percent in 2010. Amid this expansion, families and policymakers want to know more about charter school performance and its systemic impacts. While researchers have evaluated charter schools’ short-term effects on student outcomes, significant knowledge gaps still exist.
MIT Blueprint Labs aims to fill those gaps through its Charter School Research Collaborative, an initiative that brings together practitioners, policymakers, researchers, and funders to make research on charter schools more actionable, rigorous, and efficient. The collaborative will create infrastructure to streamline and fund high-quality, policy-relevant charter research.
Joshua Angrist, MIT Ford Professor of Economics and a Blueprint Labs co-founder and director, says that Blueprint Labs hopes “to increase [its] impact by working with a larger group of academic and practitioner partners.” A nonpartisan research lab, Blueprint's mission is to produce the most rigorous evidence possible to inform policy and practice. Angrist notes, “The debate over charter schools is not always fact-driven. Our goal at the lab is to bring convincing evidence into these discussions.”
Collaborative kickoff
The collaborative launched with a two-day kickoff in November. Blueprint Labs welcomed researchers, practitioners, funders, and policymakers to MIT to lay the groundwork for the collaborative. Over 80 participants joined the event, including leaders of charter school organizations, researchers at top universities and institutes, and policymakers and advocates from a variety of organizations and education agencies.
Through a series of panels, presentations, and conversations, participants including Rhode Island Department of Education Commissioner Angélica Infante-Green, CEO of Noble Schools Constance Jones, former Knowledge is Power Program CEO Richard Barth, president and CEO of National Association of Charter School Authorizers Karega Rausch, and many others discussed critical topics in the charter school space. These conversations influenced the collaborative’s research agenda.
Several sessions also highlighted how to ensure that the research process includes diverse voices to generate actionable evidence. Panelists noted that researchers should be aware of the demands placed on practitioners and should carefully consider community contexts. In addition, collaborators should treat each other as equal partners.
Parag Pathak, the Class of 1922 Professor of Economics at MIT and a Blueprint Labs co-founder and director, explained the kickoff’s aims. “One of our goals today is to begin to forge connections between [attendees]. We hope that [their] conversations are the launching point for future collaborations,” he stated. Pathak also shared the next steps for the collaborative: “Beginning next year, we’ll start investing in new research using the agenda [developed at this event] as our guide. We will also support new partnerships between researchers and practitioners.”
Research agenda
The discussions at the kickoff informed the collaborative’s research agenda. A recent paper summarizing existing lottery-based research on charter school effectiveness by Sarah Cohodes, an associate professor of public policy at the University of Michigan, and Susha Roy, an associate policy researcher at the RAND Corp., also guides the agenda. Their review finds that in randomized evaluations, many charter schools increase students’ academic achievement. However, researchers have not yet studied charter schools’ impacts on long-term, behavioral, or health outcomes in depth, and rigorous, lottery-based research is currently limited to a handful of urban centers.
The current research agenda focuses on seven topics:
the long-term effects of charter schools;
the effect of charters on non-test score outcomes;
which charter school practices have the largest effect on performance;
how charter performance varies across different contexts;
how charter school effects vary with demographic characteristics and student background;
how charter schools impact non-student outcomes, like teacher retention; and
how system-level factors, such as authorizing practices, impact charter school performance.
As diverse stakeholders' priorities continue to shift and the collaborative progresses, the research agenda will continue to evolve.
Information for interested partners
Opportunities exist for charter leaders, policymakers, researchers, and funders to engage with the collaborative. Stakeholders can apply for funding, help shape the research agenda, and develop new research partnerships. A competitive funding process will open this month.
Tumors constantly shed DNA from dying cells, which briefly circulates in the patient’s bloodstream before it is quickly broken down. Many companies have created blood tests that can pick out this tumor DNA, potentially helping doctors diagnose or monitor cancer or choose a treatment.
The amount of tumor DNA circulating at any given time, however, is extremely small, so it has been challenging to develop tests sensitive enough to pick up that tiny signal. A team of researchers from MIT and the Broad Institute of MIT and Harvard has now come up with a way to significantly boost that signal, by temporarily slowing the clearance of tumor DNA circulating in the bloodstream.
The researchers developed two different types of injectable molecules that they call “priming agents,” which can transiently interfere with the body’s ability to remove circulating tumor DNA from the bloodstream. In a study of mice, they showed that these agents could boost DNA levels enough that the percentage of detectable early-stage lung metastases leapt from less than 10 percent to above 75 percent.
This approach could enable not only earlier diagnosis of cancer, but also more sensitive detection of tumor mutations that could be used to guide treatment. It could also help improve detection of cancer recurrence.
“You can give one of these agents an hour before the blood draw, and it makes things visible that previously wouldn’t have been. The implication is that we should be able to give everybody who’s doing liquid biopsies, for any purpose, more molecules to work with,” says Sangeeta Bhatia, the John and Dorothy Wilson Professor of Health Sciences and Technology and of Electrical Engineering and Computer Science at MIT, and a member of MIT’s Koch Institute for Integrative Cancer Research and the Institute for Medical Engineering and Science.
Bhatia is one of the senior authors of the new study, along with J. Christopher Love, the Raymond A. and Helen E. St. Laurent Professor of Chemical Engineering at MIT and a member of the Koch Institute and the Ragon Institute of MGH, MIT, and Harvard and Viktor Adalsteinsson, director of the Gerstner Center for Cancer Diagnostics at the Broad Institute.
Carmen Martin-Alonso PhD ’23, MIT and Broad Institute postdoc Shervin Tabrizi, and Broad Institute scientist Kan Xiong are the lead authors of the paper, which appears today in Science.
Better biopsies
Liquid biopsies, which enable detection of small quantities of DNA in blood samples, are now used in many cancer patients to identify mutations that could help guide treatment. With greater sensitivity, however, these tests could become useful for far more patients. Most efforts to improve the sensitivity of liquid biopsies have focused on developing new sequencing technologies to use after the blood is drawn.
While brainstorming ways to make liquid biopsies more informative, Bhatia, Love, Adalsteinsson, and their trainees came up with the idea of trying to increase the amount of DNA in a patient’s bloodstream before the sample is taken.
“A tumor is always creating new cell-free DNA, and that’s the signal that we’re attempting to detect in the blood draw. Existing liquid biopsy technologies, however, are limited by the amount of material you collect in the tube of blood,” Love says. “Where this work intercedes is thinking about how to inject something beforehand that would help boost or enhance the amount of signal that is available to collect in the same small sample.”
The body uses two primary strategies to remove circulating DNA from the bloodstream. Enzymes called DNases circulate in the blood and break down DNA that they encounter, while immune cells known as macrophages take up cell-free DNA as blood is filtered through the liver.
The researchers decided to target each of these processes separately. To prevent DNases from breaking down DNA, they designed a monoclonal antibody that binds to circulating DNA and protects it from the enzymes.
“Antibodies are well-established biopharmaceutical modalities, and they’re safe in a number of different disease contexts, including cancer and autoimmune treatments,” Love says. “The idea was, could we use this kind of antibody to help shield the DNA temporarily from degradation by the nucleases that are in circulation? And by doing so, we shift the balance to where the tumor is generating DNA slightly faster than is being degraded, increasing the concentration in a blood draw.”
The other priming agent they developed is a nanoparticle designed to block macrophages from taking up cell-free DNA. These cells have a well-known tendency to eat up synthetic nanoparticles.
“DNA is a biological nanoparticle, and it made sense that immune cells in the liver were probably taking this up just like they do synthetic nanoparticles. And if that were the case, which it turned out to be, then we could use a safe dummy nanoparticle to distract those immune cells and leave the circulating DNA alone so that it could be at a higher concentration,” Bhatia says.
Earlier tumor detection
The researchers tested their priming agents in mice that received transplants of cancer cells that tend to form tumors in the lungs. Two weeks after the cells were transplanted, the researchers showed that these priming agents could boost the amount of circulating tumor DNA recovered in a blood sample by up to 60-fold.
Once the blood sample is taken, it can be run through the same kinds of sequencing tests now used on liquid biopsy samples. These tests can pick out tumor DNA, including specific sequences used to determine the type of tumor and potentially what kinds of treatments would work best.
Early detection of cancer is another promising application for these priming agents. The researchers found that when mice were given the nanoparticle priming agent before blood was drawn, it allowed them to detect circulating tumor DNA in blood of 75 percent of the mice with low cancer burden, while none were detectable without this boost.
“One of the greatest hurdles for cancer liquid biopsy testing has been the scarcity of circulating tumor DNA in a blood sample,” Adalsteinsson says. “It’s thus been encouraging to see the magnitude of the effect we’ve been able to achieve so far and to envision what impact this could have for patients.”
After either of the priming agents are injected, it takes an hour or two for the DNA levels to increase in the bloodstream, and then they return to normal within about 24 hours.
“The ability to get peak activity of these agents within a couple of hours, followed by their rapid clearance, means that someone could go into a doctor’s office, receive an agent like this, and then give their blood for the test itself, all within one visit,” Love says. “This feature bodes well for the potential to translate this concept into clinical use.”
The researchers have launched a company called Amplifyer Bio that plans to further develop the technology, in hopes of advancing to clinical trials.
“A tube of blood is a much more accessible diagnostic than colonoscopy screening or even mammography,” Bhatia says. “Ultimately, if these tools really are predictive, then we should be able to get many more patients into the system who could benefit from cancer interception or better therapy.”
The research was funded by the Koch Institute Support (core) Grant from the National Cancer Institute, the Marble Center for Cancer Nanomedicine, the Gerstner Family Foundation, the Ludwig Center at MIT, the Koch Institute Frontier Research Program via the Casey and Family Foundation, and the Bridge Project, a partnership between the Koch Institute and the Dana-Farber/Harvard Cancer Center.
A new way to recover significantly more circulating tumor DNA in a blood sample could improve the sensitivity of liquid biopsies used to detect, monitor, and guide treatment of tumors.
The first documented case of pancreatic cancer dates back to the 18th century. Since then, researchers have undertaken a protracted and challenging odyssey to understand the elusive and deadly disease. To date, there is no better cancer treatment than early intervention. Unfortunately, the pancreas, nestled deep within the abdomen, is particularly elusive for early detection.
MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) scientists, alongside Limor Appelbaum, a staff scientist in the Department of Radiation Oncology at Beth Israel Deaconess Medical Center (BIDMC), were eager to better identify potential high-risk patients. They set out to develop two machine-learning models for early detection of pancreatic ductal adenocarcinoma (PDAC), the most common form of the cancer. To access a broad and diverse database, the team synced up with a federated network company, using electronic health record data from various institutions across the United States. This vast pool of data helped ensure the models' reliability and generalizability, making them applicable across a wide range of populations, geographical locations, and demographic groups.
The two models — the “PRISM” neural network, and the logistic regression model (a statistical technique for probability), outperformed current methods. The team’s comparison showed that while standard screening criteria identify about 10 percent of PDAC cases using a five-times higher relative risk threshold, Prism can detect 35 percent of PDAC cases at this same threshold.
Using AI to detect cancer risk is not a new phenomena — algorithms analyze mammograms, CT scans for lung cancer, and assist in the analysis of Pap smear tests and HPV testing, to name a few applications. “The PRISM models stand out for their development and validation on an extensive database of over 5 million patients, surpassing the scale of most prior research in the field,” says Kai Jia, an MIT PhD student in electrical engineering and computer science (EECS), MIT CSAIL affiliate, and first author on an open-access paper in eBioMedicine outlining the new work. “The model uses routine clinical and lab data to make its predictions, and the diversity of the U.S. population is a significant advancement over other PDAC models, which are usually confined to specific geographic regions, like a few health-care centers in the U.S. Additionally, using a unique regularization technique in the training process enhanced the models' generalizability and interpretability.”
“This report outlines a powerful approach to use big data and artificial intelligence algorithms to refine our approach to identifying risk profiles for cancer,” says David Avigan, a Harvard Medical School professor and the cancer center director and chief of hematology and hematologic malignancies at BIDMC, who was not involved in the study. “This approach may lead to novel strategies to identify patients with high risk for malignancy that may benefit from focused screening with the potential for early intervention.”
Prismatic perspectives
The journey toward the development of PRISM began over six years ago, fueled by firsthand experiences with the limitations of current diagnostic practices. “Approximately 80-85 percent of pancreatic cancer patients are diagnosed at advanced stages, where cure is no longer an option,” says senior author Appelbaum, who is also a Harvard Medical School instructor as well as radiation oncologist. “This clinical frustration sparked the idea to delve into the wealth of data available in electronic health records (EHRs).”
The CSAIL group’s close collaboration with Appelbaum made it possible to understand the combined medical and machine learning aspects of the problem better, eventually leading to a much more accurate and transparent model. “The hypothesis was that these records contained hidden clues — subtle signs and symptoms that could act as early warning signals of pancreatic cancer,” she adds. “This guided our use of federated EHR networks in developing these models, for a scalable approach for deploying risk prediction tools in health care.”
Both PrismNN and PrismLR models analyze EHR data, including patient demographics, diagnoses, medications, and lab results, to assess PDAC risk. PrismNN uses artificial neural networks to detect intricate patterns in data features like age, medical history, and lab results, yielding a risk score for PDAC likelihood. PrismLR uses logistic regression for a simpler analysis, generating a probability score of PDAC based on these features. Together, the models offer a thorough evaluation of different approaches in predicting PDAC risk from the same EHR data.
One paramount point for gaining the trust of physicians, the team notes, is better understanding how the models work, known in the field as interpretability. The scientists pointed out that while logistic regression models are inherently easier to interpret, recent advancements have made deep neural networks somewhat more transparent. This helped the team to refine the thousands of potentially predictive features derived from EHR of a single patient to approximately 85 critical indicators. These indicators, which include patient age, diabetes diagnosis, and an increased frequency of visits to physicians, are automatically discovered by the model but match physicians' understanding of risk factors associated with pancreatic cancer.
The path forward
Despite the promise of the PRISM models, as with all research, some parts are still a work in progress. U.S. data alone are the current diet for the models, necessitating testing and adaptation for global use. The path forward, the team notes, includes expanding the model's applicability to international datasets and integrating additional biomarkers for more refined risk assessment.
“A subsequent aim for us is to facilitate the models' implementation in routine health care settings. The vision is to have these models function seamlessly in the background of health care systems, automatically analyzing patient data and alerting physicians to high-risk cases without adding to their workload,” says Jia. “A machine-learning model integrated with the EHR system could empower physicians with early alerts for high-risk patients, potentially enabling interventions well before symptoms manifest. We are eager to deploy our techniques in the real world to help all individuals enjoy longer, healthier lives.”
Jia wrote the paper alongside Applebaum and MIT EECS Professor and CSAIL Principal Investigator Martin Rinard, who are both senior authors of the paper. Researchers on the paper were supported during their time at MIT CSAIL, in part, by the Defense Advanced Research Projects Agency, Boeing, the National Science Foundation, and Aarno Labs. TriNetX provided resources for the project, and the Prevent Cancer Foundation also supported the team.
To train their machine learning models, MIT researchers synced up with a federated network company, using electronic health record data from various institutions across the United States, to make more equitable models.
In order for natural language to be an effective form of communication, the parties involved need to be able to understand words and their context, assume that the content is largely shared in good faith and is trustworthy, reason about the information being shared, and then apply it to real-world scenarios. MIT PhD students interning with the MIT-IBM Watson AI Lab — Athul Paul Jacob SM ’22, Maohao Shen SM ’23, Victor Butoi, and Andi Peng SM ’23 — are working to attack each step of this process that’s baked into natural language models, so that the AI systems can be more dependable and accurate for users.
To achieve this, Jacob’s research strikes at the heart of existing natural language models to improve the output, using game theory. His interests, he says, are two-fold: “One is understanding how humans behave, using the lens of multi-agent systems and language understanding, and the second thing is, ‘How do you use that as an insight to build better AI systems?’” His work stems from the board game “Diplomacy,” where his research team developed a system that could learn and predict human behaviors and negotiate strategically to achieve a desired, optimal outcome.
“This was a game where you need to build trust; you need to communicate using language. You need to also play against six other players at the same time, which were very different from all the kinds of task domains people were tackling in the past,” says Jacob, referring to other games like poker and GO that researchers put to neural networks. “In doing so, there were a lot of research challenges. One was, ‘How do you model humans? How do you know whether when humans tend to act irrationally?’” Jacob and his research mentors — including Associate Professor Jacob Andreas and Assistant Professor Gabriele Farina of the MIT Department of Electrical Engineering and Computer Science (EECS), and the MIT-IBM Watson AI Lab’s Yikang Shen — recast the problem of language generation as a two-player game.
Using “generator” and “discriminator” models, Jacob’s team developed a natural language system to produce answers to questions and then observe the answers and determine if they are correct. If they are, the AI system receives a point; if not, no point is rewarded. Language models notoriously tend to hallucinate, making them less trustworthy; this no-regret learning algorithm collaboratively takes a natural language model and encourages the system’s answers to be more truthful and reliable, while keeping the solutions close to the pre-trained language model’s priors. Jacob says that using this technique in conjunction with a smaller language model could, likely, make it competitive with the same performance of a model many times bigger.
Once a language model generates a result, researchers ideally want its confidence in its generation to align with its accuracy, but this frequently isn’t the case. Hallucinations can occur with the model reporting high confidence when it should be low. Maohao Shen and his group, with mentors Gregory Wornell, Sumitomo Professor of Engineering in EECS, and lab researchers with IBM Research Subhro Das, Prasanna Sattigeri, and Soumya Ghosh — are looking to fix this through uncertainty quantification (UQ). “Our project aims to calibrate language models when they are poorly calibrated,” says Shen. Specifically, they’re looking at the classification problem. For this, Shen allows a language model to generate free text, which is then converted into a multiple-choice classification task. For instance, they might ask the model to solve a math problem and then ask it if the answer it generated is correct as “yes, no, or maybe.” This helps to determine if the model is over- or under-confident.
Automating this, the team developed a technique that helps tune the confidence output by a pre-trained language model. The researchers trained an auxiliary model using the ground-truth information in order for their system to be able to correct the language model. “If your model is over-confident in its prediction, we are able to detect it and make it less confident, and vice versa,” explains Shen. The team evaluated their technique on multiple popular benchmark datasets to show how well it generalizes to unseen tasks to realign the accuracy and confidence of language model predictions. “After training, you can just plug in and apply this technique to new tasks without any other supervision,” says Shen. “The only thing you need is the data for that new task.”
Victor Butoi also enhances model capability, but instead, his lab team — which includes John Guttag, the Dugald C. Jackson Professor of Computer Science and Electrical Engineering in EECS; lab researchers Leonid Karlinsky and Rogerio Feris of IBM Research; and lab affiliates Hilde Kühne of the University of Bonn and Wei Lin of Graz University of Technology — is creating techniques to allow vision-language models to reason about what they’re seeing, and is designing prompts to unlock new learning abilities and understand key phrases.
Compositional reasoning is just another aspect of the decision-making process that we ask machine-learning models to perform in order for them to be helpful in real-world situations, explains Butoi. “You need to be able to think about problems compositionally and solve subtasks,” says Butoi, “like, if you're saying the chair is to the left of the person, you need to recognize both the chair and the person. You need to understand directions.” And then once the model understands “left,” the research team wants the model to be able to answer other questions involving “left.”
Surprisingly, vision-language models do not reason well about composition, Butoi explains, but they can be helped to, using a model that can “lead the witness”, if you will. The team developed a model that was tweaked using a technique called low-rank adaptation of large language models (LoRA) and trained on an annotated dataset called Visual Genome, which has objects in an image and arrows denoting relationships, like directions. In this case, the trained LoRA model would be guided to say something about “left” relationships, and this caption output would then be used to provide context and prompt the vision-language model, making it a “significantly easier task,” says Butoi.
In the world of robotics, AI systems also engage with their surroundings using computer vision and language. The settings may range from warehouses to the home. Andi Peng and mentors MIT’s H.N. Slater Professor in Aeronautics and Astronautics Julie Shah and Chuang Gan, of the lab and the University of Massachusetts at Amherst, are focusing on assisting people with physical constraints, using virtual worlds. For this, Peng’s group is developing two embodied AI models — a “human” that needs support and a helper agent — in a simulated environment called ThreeDWorld. Focusing on human/robot interactions, the team leverages semantic priors captured by large language models to aid the helper AI to infer what abilities the “human” agent might not be able to do and the motivation behind actions of the “human,” using natural language. The team’s looking to strengthen the helper’s sequential decision-making, bidirectional communication, ability to understand the physical scene, and how best to contribute.
“A lot of people think that AI programs should be autonomous, but I think that an important part of the process is that we build robots and systems for humans, and we want to convey human knowledge,” says Peng. “We don’t want a system to do something in a weird way; we want them to do it in a human way that we can understand.”
A surprising MIT study published in Nature at the end of 2016 helped to spur interest in the possibility that light flickering at the frequency of a particular gamma-band brain rhythm could produce meaningful therapeutic effects for people with Alzheimer’s disease. In a new review paper in the Journal of Internal Medicine, the lab that led those studies takes stock of what a growing number of scientists worldwide have been finding out since then in dozens of clinical and lab benchtop studies.
Brain rhythms (also called brain “waves” or “oscillations”) arise from the synchronized network activity of brain cells and circuits as they coordinate to enable brain functions such as perception or cognition. Lower-range gamma-frequency rhythms, those around 40 cycles a second, or hertz (Hz), are particularly important for memory processes, and MIT’s research has shown that they are also associated with specific changes at the cellular and molecular level. The 2016 study and many others since then have produced evidence, initially in animals and more recently in humans, that various noninvasive means of enhancing the power and synchrony of 40Hz gamma rhythms helps to reduce Alzheimer’s pathology and its consequences.
“What started in 2016 with optogenetic and visual stimulation in mice has expanded to a multitude of stimulation paradigms, a wide range of human clinical studies with promising results, and is narrowing in on the mechanisms underlying this phenomenon,” write the authors including Li-Huei Tsai, Picower Professor in The Picower Institute for Learning and Memory and the Department of Brain and Cognitive Sciences at MIT.
Though the number of studies and methods has increased and the data have typically suggested beneficial clinical effects, the article’s authors also clearly caution that the clinical evidence remains preliminary and that animal studies intended to discern how the approach works have been instructive, but not definitive.
“Research into the clinical potential of these interventions is still in its nascent stages,” the researchers, led by MIT postdoc Cristina Blanco-Duque, write in introducing the review. “The precise mechanisms underpinning the beneficial effects of gamma stimulation in Alzheimer’s disease are not yet fully elucidated, but preclinical studies have provided relevant insights.”
Preliminarily promising
The authors list and summarize results from 16 clinical studies published over the last several years. These employ gamma-frequency sensory stimulation (e.g., exposure to light, sound, tactile vibration, or a combination); transcranial alternating current stimulation (tACS), in which a brain region is stimulated via scalp electrodes; or transcranial magnetic stimulation (TMS), in which electric currents are induced in a brain region using magnetic fields. The studies also vary in their sample size, design, duration, and in what effects they assessed. Some of the sensory studies using light have tested different colors and different exact frequencies. And while some studies show that sensory stimulation appears to affect multiple regions in the brain, tACS and TMS are more regionally focused (though those brain regions still connect and interact with others).
Given the variances, the clinical studies taken together offer a blend of uneven but encouraging evidence, the authors write. Across clinical studies involving patients with Alzheimer’s disease, sensory stimulation has proven safe and well-tolerated. Multiple sensory studies have measured increases in gamma power and brain network connectivity. Sensory studies have also reported improvements in memory and/or cognition, as well as sleep. Some have yielded apparent physiological benefits such as reduction of brain atrophy, in one case, and changes in immune system activity in another. So far, sensory studies have not shown reductions in Alzheimer’s hallmark proteins, amyloid or tau.
Clinical studies stimulating 40Hz rhythms using tACS, ranging in sample size from only one to as many as 60, are the most numerous so far, and many have shown similar benefits. Most report benefits to cognition, executive function, and/or memory (depending sometimes on the brain region stimulated), and some have assessed that benefits endure even after treatment concludes. Some have shown effects on measures of tau and amyloid, blood flow, neuromodulatory chemical activity, or immune activity. Finally, a 40Hz stimulation clinical study using TMS in 37 patients found improvements in cognition, prevention of brain atrophy, and increased brain connectivity.
“The most important test for gamma stimulation is without a doubt whether it is safe and beneficial for patients,” the authors write. “So far, results from several small trials on sensory gamma stimulation suggest that it is safe, evokes rhythmic EEG brain responses, and there are promising signs for AD [Alzheimer's disease] symptoms and pathology. Similarly, studies on transcranial stimulation report the potential to benefit memory and global cognitive function even beyond the end of treatment.”
Studying underlying mechanisms
In parallel, dozens more studies have shown significant benefits in mice including reductions in amyloid and tau, preservation of brain tissue, and improvements in memory. But animal studies also have offered researchers a window into the cellular and molecular mechanisms by which gamma stimulation might have these effects.
Before MIT’s original studies in 2016 and 2019, researchers had not attributed molecular changes in brain cells to changes in brain rhythms, but those and other studies have now shown that they affect not only the molecular state of neurons, but also the brain’s microglia immune cells, astrocyte cells that play key roles in regulating circulation, and indeed the brain’s vasculature system. A hypothesis of Tsai’s lab right now is that sensory gamma stimulation might promote the clearance of amyloid and tau via increased circulatory activity of brain fluids.
A hotly debated aspect of gamma stimulation is how it affects the electrical activity of neurons, and how pervasively. Studies indicate that inhibitory “interneurons” are especially affected, though, offering a clue about how increased gamma activity, and its physiological effects, might propagate.
“The field has generated tantalizing leads on how gamma stimulation may translate into beneficial effects on the cellular and molecular level,” the authors write.
Gamma going forward
As the authors make clear that more definitive clinical studies are needed, they note that at the moment, there are now 15 new clinical studies of gamma stimulation underway. Among these is a phase 3 clinical trial by the company Cognito Therapeutics, which has licensed MIT’s technology. That study plans to enroll hundreds of participants.
Meanwhile, some recent or new clinical and preclinical studies have begun looking at whether gamma stimulation may be applicable to neurological disorders other than Alzheimer’s, including stroke or Down syndrome. In experiments with mouse models, for example, an MIT team has been testing gamma stimulation’s potential to help with cognitive effects of chemotherapy, or “chemobrain.”
“Larger clinical studies are required to ascertain the long-term benefits of gamma stimulation,” the authors conclude. “In animal models the focus should be on delineating the mechanism of gamma stimulation and providing further proof of principle studies on what other applications gamma stimulation may have.”
In addition to Tsai and Blanco-Duque, the paper’s other authors are Diane Chan, Martin Kahn, and Mitch Murdock.
Researchers are finding that stimulating the power of gamma-frequency brain rhythms using sensory, electrical, or magnetic means may have therapeutic benefits for neurological disorders such as Alzheimer's disease.
Many electric vehicles are powered by batteries that contain cobalt — a metal that carries high financial, environmental, and social costs.
MIT researchers have now designed a battery material that could offer a more sustainable way to power electric cars. The new lithium-ion battery includes a cathode based on organic materials, instead of cobalt or nickel (another metal often used in lithium-ion batteries).
In a new study, the researchers showed that this material, which could be produced at much lower cost than cobalt-containing batteries, can conduct electricity at similar rates as cobalt batteries. The new battery also has comparable storage capacity and can be charged up faster than cobalt batteries, the researchers report.
“I think this material could have a big impact because it works really well,” says Mircea Dincă, the W.M. Keck Professor of Energy at MIT. “It is already competitive with incumbent technologies, and it can save a lot of the cost and pain and environmental issues related to mining the metals that currently go into batteries.”
Dincă is the senior author of the study, which appears today in the journal ACS Central Science. Tianyang Chen PhD ’23 and Harish Banda, a former MIT postdoc, are the lead authors of the paper. Other authors include Jiande Wang, an MIT postdoc; Julius Oppenheim, an MIT graduate student; and Alessandro Franceschi, a research fellow at the University of Bologna.
Alternatives to cobalt
Most electric cars are powered by lithium-ion batteries, a type of battery that is recharged when lithium ions flow from a positively charged electrode, called a cathode, to a negatively electrode, called an anode. In most lithium-ion batteries, the cathode contains cobalt, a metal that offers high stability and energy density.
However, cobalt has significant downsides. A scarce metal, its price can fluctuate dramatically, and much of the world’s cobalt deposits are located in politically unstable countries. Cobalt extraction creates hazardous working conditions and generates toxic waste that contaminates land, air, and water surrounding the mines.
“Cobalt batteries can store a lot of energy, and they have all of features that people care about in terms of performance, but they have the issue of not being widely available, and the cost fluctuates broadly with commodity prices. And, as you transition to a much higher proportion of electrified vehicles in the consumer market, it’s certainly going to get more expensive,” Dincă says.
Because of the many drawbacks to cobalt, a great deal of research has gone into trying to develop alternative battery materials. One such material is lithium-iron-phosphate (LFP), which some car manufacturers are beginning to use in electric vehicles. Although still practically useful, LFP has only about half the energy density of cobalt and nickel batteries.
Another appealing option are organic materials, but so far most of these materials have not been able to match the conductivity, storage capacity, and lifetime of cobalt-containing batteries. Because of their low conductivity, such materials typically need to be mixed with binders such as polymers, which help them maintain a conductive network. These binders, which make up at least 50 percent of the overall material, bring down the battery’s storage capacity.
About six years ago, Dincă’s lab began working on a project, funded by Lamborghini, to develop an organic battery that could be used to power electric cars. While working on porous materials that were partly organic and partly inorganic, Dincă and his students realized that a fully organic material they had made appeared that it might be a strong conductor.
This material consists of many layers of TAQ (bis-tetraaminobenzoquinone), an organic small molecule that contains three fused hexagonal rings. These layers can extend outward in every direction, forming a structure similar to graphite. Within the molecules are chemical groups called quinones, which are the electron reservoirs, and amines, which help the material to form strong hydrogen bonds.
Those hydrogen bonds make the material highly stable and also very insoluble. That insolubility is important because it prevents the material from dissolving into the battery electrolyte, as some organic battery materials do, thereby extending its lifetime.
“One of the main methods of degradation for organic materials is that they simply dissolve into the battery electrolyte and cross over to the other side of the battery, essentially creating a short circuit. If you make the material completely insoluble, that process doesn’t happen, so we can go to over 2,000 charge cycles with minimal degradation,” Dincă says.
Strong performance
Tests of this material showed that its conductivity and storage capacity were comparable to that of traditional cobalt-containing batteries. Also, batteries with a TAQ cathode can be charged and discharged faster than existing batteries, which could speed up the charging rate for electric vehicles.
To stabilize the organic material and increase its ability to adhere to the battery’s current collector, which is made of copper or aluminum, the researchers added filler materials such as cellulose and rubber. These fillers make up less than one-tenth of the overall cathode composite, so they don’t significantly reduce the battery’s storage capacity.
These fillers also extend the lifetime of the battery cathode by preventing it from cracking when lithium ions flow into the cathode as the battery charges.
The primary materials needed to manufacture this type of cathode are a quinone precursor and an amine precursor, which are already commercially available and produced in large quantities as commodity chemicals. The researchers estimate that the material cost of assembling these organic batteries could be about one-third to one-half the cost of cobalt batteries.
Lamborghini has licensed the patent on the technology. Dincă’s lab plans to continue developing alternative battery materials and is exploring possible replacement of lithium with sodium or magnesium, which are cheaper and more abundant than lithium.
A new MIT battery material could offer a more sustainable way to power electric cars. Instead of cobalt or nickel, the new lithium-ion battery includes a cathode based on organic materials. In this image, lithium molecules are shown in glowing pink.
Throughout the brain’s cortex, neurons are arranged in six distinctive layers, which can be readily seen with a microscope. A team of MIT and Vanderbilt University neuroscientists has now found that these layers also show distinct patterns of electrical activity, which are consistent over many brain regions and across several animal species, including humans.
The researchers found that in the topmost layers, neuron activity is dominated by rapid oscillations known as gamma waves. In the deeper layers, slower oscillations called alpha and beta waves predominate. The universality of these patterns suggests that these oscillations are likely playing an important role across the brain, the researchers say.
“When you see something that consistent and ubiquitous across cortex, it’s playing a very fundamental role in what the cortex does,” says Earl Miller, the Picower Professor of Neuroscience, a member of MIT’s Picower Institute for Learning and Memory, and one of the senior authors of the new study.
Imbalances in how these oscillations interact with each other may be involved in brain disorders such as attention deficit hyperactivity disorder, the researchers say.
“Overly synchronous neural activity is known to play a role in epilepsy, and now we suspect that different pathologies of synchrony may contribute to many brain disorders, including disorders of perception, attention, memory, and motor control. In an orchestra, one instrument played out of synchrony with the rest can disrupt the coherence of the entire piece of music,” says Robert Desimone, director of MIT’s McGovern Institute for Brain Research and one of the senior authors of the study.
André Bastos, an assistant professor of psychology at Vanderbilt University, is also a senior author of the open-access paper, which appears today in Nature Neuroscience. The lead authors of the paper are MIT research scientist Diego Mendoza-Halliday and MIT postdoc Alex Major.
Layers of activity
The human brain contains billions of neurons, each of which has its own electrical firing patterns. Together, groups of neurons with similar patterns generate oscillations of electrical activity, or brain waves, which can have different frequencies. Miller’s lab has previously shown that high-frequency gamma rhythms are associated with encoding and retrieving sensory information, while low-frequency beta rhythms act as a control mechanism that determines which information is read out from working memory.
His lab has also found that in certain parts of the prefrontal cortex, different brain layers show distinctive patterns of oscillation: faster oscillation at the surface and slower oscillation in the deep layers. One study, led by Bastos when he was a postdoc in Miller’s lab, showed that as animals performed working memory tasks, lower-frequency rhythms generated in deeper layers regulated the higher-frequency gamma rhythms generated in the superficial layers.
In addition to working memory, the brain’s cortex also is the seat of thought, planning, and high-level processing of emotion and sensory information. Throughout the regions involved in these functions, neurons are arranged in six layers, and each layer has its own distinctive combination of cell types and connections with other brain areas.
“The cortex is organized anatomically into six layers, no matter whether you look at mice or humans or any mammalian species, and this pattern is present in all cortical areas within each species,” Mendoza-Halliday says. “Unfortunately, a lot of studies of brain activity have been ignoring those layers because when you record the activity of neurons, it's been difficult to understand where they are in the context of those layers.”
In the new paper, the researchers wanted to explore whether the layered oscillation pattern they had seen in the prefrontal cortex is more widespread, occurring across different parts of the cortex and across species.
Using a combination of data acquired in Miller’s lab, Desimone’s lab, and labs from collaborators at Vanderbilt, the Netherlands Institute for Neuroscience, and the University of Western Ontario, the researchers were able to analyze 14 different areas of the cortex, from four mammalian species. This data included recordings of electrical activity from three human patients who had electrodes inserted in the brain as part of a surgical procedure they were undergoing.
Recording from individual cortical layers has been difficult in the past, because each layer is less than a millimeter thick, so it’s hard to know which layer an electrode is recording from. For this study, electrical activity was recorded using special electrodes that record from all of the layers at once, then feed the data into a new computational algorithm the authors designed, termed FLIP (frequency-based layer identification procedure). This algorithm can determine which layer each signal came from.
“More recent technology allows recording of all layers of cortex simultaneously. This paints a broader perspective of microcircuitry and allowed us to observe this layered pattern,” Major says. “This work is exciting because it is both informative of a fundamental microcircuit pattern and provides a robust new technique for studying the brain. It doesn’t matter if the brain is performing a task or at rest and can be observed in as little as five to 10 seconds.”
Across all species, in each region studied, the researchers found the same layered activity pattern.
“We did a mass analysis of all the data to see if we could find the same pattern in all areas of the cortex, and voilà, it was everywhere. That was a real indication that what had previously been seen in a couple of areas was representing a fundamental mechanism across the cortex,” Mendoza-Halliday says.
Maintaining balance
The findings support a model that Miller’s lab has previously put forth, which proposes that the brain’s spatial organization helps it to incorporate new information, which carried by high-frequency oscillations, into existing memories and brain processes, which are maintained by low-frequency oscillations. As information passes from layer to layer, input can be incorporated as needed to help the brain perform particular tasks such as baking a new cookie recipe or remembering a phone number.
“The consequence of a laminar separation of these frequencies, as we observed, may be to allow superficial layers to represent external sensory information with faster frequencies, and for deep layers to represent internal cognitive states with slower frequencies,” Bastos says. “The high-level implication is that the cortex has multiple mechanisms involving both anatomy and oscillations to separate ‘external’ from ‘internal’ information.”
Under this theory, imbalances between high- and low-frequency oscillations can lead to either attention deficits such as ADHD, when the higher frequencies dominate and too much sensory information gets in, or delusional disorders such as schizophrenia, when the low frequency oscillations are too strong and not enough sensory information gets in.
“The proper balance between the top-down control signals and the bottom-up sensory signals is important for everything the cortex does,” Miller says. “When the balance goes awry, you get a wide variety of neuropsychiatric disorders.”
The researchers are now exploring whether measuring these oscillations could help to diagnose these types of disorders. They are also investigating whether rebalancing the oscillations could alter behavior — an approach that could one day be used to treat attention deficits or other neurological disorders, the researchers say.
The researchers also hope to work with other labs to characterize the layered oscillation patterns in more detail across different brain regions.
“Our hope is that with enough of that standardized reporting, we will start to see common patterns of activity across different areas or functions that might reveal a common mechanism for computation that can be used for motor outputs, for vision, for memory and attention, et cetera,” Mendoza-Halliday says.
The research was funded by the U.S. Office of Naval Research, the U.S. National Institutes of Health, the U.S. National Eye Institute, the U.S. National Institute of Mental Health, the Picower Institute, a Simons Center for the Social Brain Postdoctoral Fellowship, and a Canadian Institutes of Health Postdoctoral Fellowship.
MIT neuroscientists have found that the six anatomical layers of the mammalian brain cortex show distinct patterns of electrical activity which are consistent throughout the entire cortex and across several animal species, including humans.
MIT researchers have developed a battery-free, self-powered sensor that can harvest energy from its environment.
Because it requires no battery that must be recharged or replaced, and because it requires no special wiring, such a sensor could be embedded in a hard-to-reach place, like inside the inner workings of a ship’s engine. There, it could automatically gather data on the machine’s power consumption and operations for long periods of time.
The researchers built a temperature-sensing device that harvests energy from the magnetic field generated in the open air around a wire. One could simply clip the sensor around a wire that carries electricity — perhaps the wire that powers a motor — and it will automatically harvest and store energy which it uses to monitor the motor’s temperature.
“This is ambient power — energy that I don’t have to make a specific, soldered connection to get. And that makes this sensor very easy to install,” says Steve Leeb, the Emanuel E. Landsman Professor of Electrical Engineering and Computer Science (EECS) and professor of mechanical engineering, a member of the Research Laboratory of Electronics, and senior author of a paper on the energy-harvesting sensor.
In the paper, which appeared as the featured article in the January issue of the IEEE Sensors Journal, the researchers offer a design guide for an energy-harvesting sensor that lets an engineer balance the available energy in the environment with their sensing needs.
The paper lays out a roadmap for the key components of a device that can sense and control the flow of energy continually during operation.
The versatile design framework is not limited to sensors that harvest magnetic field energy, and can be applied to those that use other power sources, like vibrations or sunlight. It could be used to build networks of sensors for factories, warehouses, and commercial spaces that cost less to install and maintain.
“We have provided an example of a battery-less sensor that does something useful, and shown that it is a practically realizable solution. Now others will hopefully use our framework to get the ball rolling to design their own sensors,” says lead author Daniel Monagle, an EECS graduate student.
Monagle and Leeb are joined on the paper by EECS graduate student Eric Ponce.
John Donnal, an associate professor of weapons and controls engineering at the U.S. Naval Academy who was not involved with this work, studies techniques to monitor ship systems. Getting access to power on a ship can be difficult, he says, since there are very few outlets and strict restrictions as to what equipment can be plugged in.
“Persistently measuring the vibration of a pump, for example, could give the crew real-time information on the health of the bearings and mounts, but powering a retrofit sensor often requires so much additional infrastructure that the investment is not worthwhile,” Donnal adds. “Energy-harvesting systems like this could make it possible to retrofit a wide variety of diagnostic sensors on ships and significantly reduce the overall cost of maintenance.”
A how-to guide
The researchers had to meet three key challenges to develop an effective, battery-free, energy-harvesting sensor.
First, the system must be able to cold start, meaning it can fire up its electronics with no initial voltage. They accomplished this with a network of integrated circuits and transistors that allow the system to store energy until it reaches a certain threshold. The system will only turn on once it has stored enough power to fully operate.
Second, the system must store and convert the energy it harvests efficiently, and without a battery. While the researchers could have included a battery, that would add extra complexities to the system and could pose a fire risk.
“You might not even have the luxury of sending out a technician to replace a battery. Instead, our system is maintenance-free. It harvests energy and operates itself,” Monagle adds.
To avoid using a battery, they incorporate internal energy storage that can include a series of capacitors. Simpler than a battery, a capacitor stores energy in the electrical field between conductive plates. Capacitors can be made from a variety of materials, and their capabilities can be tuned to a range of operating conditions, safety requirements, and available space.
The team carefully designed the capacitors so they are big enough to store the energy the device needs to turn on and start harvesting power, but small enough that the charge-up phase doesn’t take too long.
In addition, since a sensor might go weeks or even months before turning on to take a measurement, they ensured the capacitors can hold enough energy even if some leaks out over time.
Finally, they developed a series of control algorithms that dynamically measure and budget the energy collected, stored, and used by the device. A microcontroller, the “brain” of the energy management interface, constantly checks how much energy is stored and infers whether to turn the sensor on or off, take a measurement, or kick the harvester into a higher gear so it can gather more energy for more complex sensing needs.
“Just like when you change gears on a bike, the energy management interface looks at how the harvester is doing, essentially seeing whether it is pedaling too hard or too soft, and then it varies the electronic load so it can maximize the amount of power it is harvesting and match the harvest to the needs of the sensor,” Monagle explains.
Self-powered sensor
Using this design framework, they built an energy management circuit for an off-the-shelf temperature sensor. The device harvests magnetic field energy and uses it to continually sample temperature data, which it sends to a smartphone interface using Bluetooth.
The researchers used super-low-power circuits to design the device, but quickly found that these circuits have tight restrictions on how much voltage they can withstand before breaking down. Harvesting too much power could cause the device to explode.
To avoid that, their energy harvester operating system in the microcontroller automatically adjusts or reduces the harvest if the amount of stored energy becomes excessive.
They also found that communication — transmitting data gathered by the temperature sensor — was by far the most power-hungry operation.
“Ensuring the sensor has enough stored energy to transmit data is a constant challenge that involves careful design,” Monagle says.
In the future, the researchers plan to explore less energy-intensive means of transmitting data, such as using optics or acoustics. They also want to more rigorously model and predict how much energy might be coming into a system, or how much energy a sensor might need to take measurements, so a device could effectively gather even more data.
“If you only make the measurements you think you need, you may miss something really valuable. With more information, you might be able to learn something you didn’t expect about a device’s operations. Our framework lets you balance those considerations,” Leeb says.
“This paper is well-documented regarding what a practical self-powered sensor node should internally entail for realistic scenarios. The overall design guidelines, particularly on the cold-start issue, are very helpful,” says Jinyeong Moon, an assistant professor of electrical and computer engineering at Florida A&M University-Florida State University College of Engineering who was not involved with this work. “Engineers planning to design a self-powering module for a wireless sensor node will greatly benefit from these guidelines, easily ticking off traditionally cumbersome cold-start-related checklists.”
The work is supported, in part, by the Office of Naval Research and The Grainger Foundation.
Billions of people worldwide face threats to their livelihood, health, and well-being due to poverty. These problems persist because solutions offered in developed countries often do not meet the requirements — related to factors like price, performance, usability, robustness, and culture — of poor or developing countries. Academic labs frequently try to tackle these challenges, but often to no avail because they lack real-world, on-the-ground knowledge from key stakeholders, and because they do not have an efficient, reliable means of converting breakthroughs to real-world impact.
The new K. Lisa Yang Global Engineering and Research (GEAR) Center at MIT, founded with a $28 million gift from philanthropist and investor Lisa Yang, aims to rethink how products and technologies for resource-constrained communities are conceived, designed, and commercialized. A collaboration between MIT’s School of Engineering and School of Science, the Yang GEAR Center will bring together a multidisciplinary team of MIT researchers to assess today’s most pressing global challenges in three critical areas: global health, climate change mitigation and adaptation, and the water-energy-food nexus.
“As she has shown over and over through her philanthropy, Lisa Yang shares MIT’s passion for connecting fundamental research and real-world data to create positive impact,” says MIT president Sally Kornbluth. “I’m grateful for her powerful vision and incredible generosity in founding the K. Lisa Yang GEAR Center. I can’t imagine a better use of MIT’s talents than working to improve the lives and health of people around the world.”
Yang’s gift expands her exceptional philanthropic support of human health and basic science research at MIT over the past six years. Yang GEAR Center will join MIT’s Yang Tan Collective, an assemblage of six major research centers focused on accelerating collaboration in basic science, research, and engineering to realize translational strategies that improve human health and well-being at a global scale.
“Billions of people face daily life-or-death challenges that could be improved with elegant technologies,” says Yang. “And yet I’ve learned how many products and tools created by top engineers don’t make it out of the lab. They may look like clever ideas during the prototype phase, but they are entirely ill-suited to the communities they were designed for. I am very excited about the potential of a deliberate and thoughtful engineering effort that will prioritize the design of technologies for use in impoverished communities.”
Cost, material availability, cultural suitability, and other market mismatches hinder many major innovations in global health, food, and water from being translated to use in resource-constrained communities. Yang GEAR Center will support a major research and design program with its mission to strategically identify compelling challenges and associated scientific knowledge gaps in resource-constrained communities then address them through academic innovation to create and translate transformative technologies.
The center will be led by Amos Winter, associate professor of mechanical engineering, whose lab focuses on creating technologies that marry innovative, low-cost design with an in-depth understanding of the unique socioeconomic constraints of emerging markets.
“Academia has a key role to play in solving the historically unsolvable challenges in resource-constrained communities,” says Winter. “However, academic research is often disconnected from the real-world requirements that must be satisfied to make meaningful change. Yang GEAR Center will be a catalyst for innovation to impact by helping colleagues identify compelling problems and focus their talents on realizing real-world solutions, and by providing mechanisms for commercial dissemination. I am extremely grateful to find in Lisa a partner who shares a vision for how academic research can play a more efficient and targeted role in addressing the needs of the world’s most disadvantaged populations.”
The backbone of the Yang GEAR Center will be a team of seasoned research scientists and engineers. These individuals will scout real-world problems and distill the relevant research questions then help assemble collaborative teams. As projects develop, center staff will mentor students, build and conduct field pilots, and foster relationships with stakeholders around the world. They will be strategically positioned to translate technology at the end of projects through licensing and startups. Center staff and collaborators will focus on creating products and services for climate-driven migrants, such as solar-powered energy and water networks; technologies for reducing atmospheric carbon and promoting the hydrogen economy; brackish water desalination and irrigation solutions; and high-performance, global health diagnostics and devices.
For instance, a Yang GEAR Center team focused on creating water-saving and solar-powered irrigation solutions for farmers in the Middle East and North Africa will continue its work in the region. They will conduct exploratory research; build a team of stakeholders, including farmers, agricultural outreach organizations, irrigation hardware manufacturers, retailers, water and agriculture scientists, and local government officials; design, rigorously test, and iterate prototypes both in the lab and in the field; and conduct large-scale field trials to garner user feedback and pave the way to product commercialization.
“Grounded in foundational scientific research and blended with excellence in the humanities, MIT provides a framework that integrates people, economics, research, and innovation. By incorporating multiple perspectives — and being attentive to the needs and cultures of the people who will ultimately rely on research outcomes — MIT can have the greatest impact in areas of health, climate science, and resource security,” says Nergis Mavalvala, dean of the School of Science and the Curtis and Kathleen Marble Professor of Astrophysics.
An overarching aim for the center will be to educate graduates who are global engineers, designers, and researchers positioned for a career of addressing compelling, high-impact challenges. The center includes four endowed Hock E. Tan GEAR Center Fellowships that will support graduate students and/or postdoctoral fellows eager to enter the field of global engineering. The fellowships are named for MIT alumnus and Broadcom CEO Hock E. Tan ’75 SM ’75.
“I am thrilled that the Yang GEAR Center is taking a leading role in training problem-solvers who will rethink how products and inventions can help communities facing the most pressing challenges of our time,” adds Anantha Chandrakasan, dean of the School of Engineering and the Vannevar Bush Professor of Electrical Engineering and Computer Science. “These talented young students, postdocs, and staff have the potential to reach across disciplines — and across the globe — to truly transform the impact engineering can have in the future.”
Global Engineering and Research (GEAR) Center founder Lisa Yang (left) sits with GEAR Center director Amos Winter, MIT associate professor of mechanical engineering.
A key chemical reaction — in which the movement of protons between the surface of an electrode and an electrolyte drives an electric current — is a critical step in many energy technologies, including fuel cells and the electrolyzers used to produce hydrogen gas.
For the first time, MIT chemists have mapped out in detail how these proton-coupled electron transfers happen at an electrode surface. Their results could help researchers design more efficient fuel cells, batteries, or other energy technologies.
“Our advance in this paper was studying and understanding the nature of how these electrons and protons couple at a surface site, which is relevant for catalytic reactions that are important in the context of energy conversion devices or catalytic reactions,” says Yogesh Surendranath, a professor of chemistry and chemical engineering at MIT and the senior author of the study.
Among their findings, the researchers were able to trace exactly how changes in the pH of the electrolyte solution surrounding an electrode affect the rate of proton motion and electron flow within the electrode.
MIT graduate student Noah Lewis is the lead author of the paper, which appears today in Nature Chemistry. Ryan Bisbey, a former MIT postdoc; Karl Westendorff, an MIT graduate student; and Alexander Soudackov, a research scientist at Yale University, are also authors of the paper.
Passing protons
Proton-coupled electron transfer occurs when a molecule, often water or an acid, transfers a proton to another molecule or to an electrode surface, which stimulates the proton acceptor to also take up an electron. This kind of reaction has been harnessed for many energy applications.
“These proton-coupled electron transfer reactions are ubiquitous. They are often key steps in catalytic mechanisms, and are particularly important for energy conversion processes such as hydrogen generation or fuel cell catalysis,” Surendranath says.
In a hydrogen-generating electrolyzer, this approach is used to remove protons from water and add electrons to the protons to form hydrogen gas. In a fuel cell, electricity is generated when protons and electrons are removed from hydrogen gas and added to oxygen to form water.
Proton-coupled electron transfer is common in many other types of chemical reactions, for example, carbon dioxide reduction (the conversion of carbon dioxide into chemical fuels by adding electrons and protons). Scientists have learned a great deal about how these reactions occur when the proton acceptors are molecules, because they can precisely control the structure of each molecule and observe how electrons and protons pass between them. However, when proton-coupled electron transfer occurs at the surface of an electrode, the process is much more difficult to study because electrode surfaces are usually very heterogenous, with many different sites that a proton could potentially bind to.
To overcome that obstacle, the MIT team developed a way to design electrode surfaces that gives them much more precise control over the composition of the electrode surface. Their electrodes consist of sheets of graphene with organic, ring-containing compounds attached to the surface. At the end of each of these organic molecules is a negatively charged oxygen ion that can accept protons from the surrounding solution, which causes an electron to flow from the circuit into the graphitic surface.
“We can create an electrode that doesn’t consist of a wide diversity of sites but is a uniform array of a single type of very well-defined sites that can each bind a proton with the same affinity,” Surendranath says. “Since we have these very well-defined sites, what this allowed us to do was really unravel the kinetics of these processes.”
Using this system, the researchers were able to measure the flow of electrical current to the electrodes, which allowed them to calculate the rate of proton transfer to the oxygen ion at the surface at equilibrium — the state when the rates of proton donation to the surface and proton transfer back to solution from the surface are equal. They found that the pH of the surrounding solution has a significant effect on this rate: The highest rates occurred at the extreme ends of the pH scale — pH 0, the most acidic, and pH 14, the most basic.
To explain these results, researchers developed a model based on two possible reactions that can occur at the electrode. In the first, hydronium ions (H3O+), which are in high concentration in strongly acidic solutions, deliver protons to the surface oxygen ions, generating water. In the second, water delivers protons to the surface oxygen ions, generating hydroxide ions (OH-), which are in high concentration in strongly basic solutions.
However, the rate at pH 0 is about four times faster than the rate at pH 14, in part because hydronium gives up protons at a faster rate than water.
A reaction to reconsider
The researchers also discovered, to their surprise, that the two reactions have equal rates not at neutral pH 7, where hydronium and hydroxide concentrations are equal, but at pH 10, where the concentration of hydroxide ions is 1 million times that of hydronium. The model suggests this is because the forward reaction involving proton donation from hydronium or water contributes more to the overall rate than the backward reaction involving proton removal by water or hydroxide.
Existing models of how these reactions occur at electrode surfaces assume that the forward and backward reactions contribute equally to the overall rate, so the new findings suggest that those models may need to be reconsidered, the researchers say.
“That’s the default assumption, that the forward and reverse reactions contribute equally to the reaction rate,” Surendranath says. “Our finding is really eye-opening because it means that the assumption that people are using to analyze everything from fuel cell catalysis to hydrogen evolution may be something we need to revisit.”
The researchers are now using their experimental setup to study how adding different types of ions to the electrolyte solution surrounding the electrode may speed up or slow down the rate of proton-coupled electron flow.
“With our system, we know that our sites are constant and not affecting each other, so we can read out what the change in the solution is doing to the reaction at the surface,” Lewis says.
The research was funded by the U.S. Department of Energy Office of Basic Energy Sciences.
For the first time, MIT chemists have mapped out in detail how proton-coupled electron transfers happen at the surface of an electrode. Their results could help researchers to design more efficient fuel cells, batteries, or other energy technologies.
MIT’s Astrodynamics, Space Robotics, and Controls Laboratory (ARCLab) announced the public beta release of the MIT Orbital Capacity Assessment Tool (MOCAT) during the 2023 Organization for Economic Cooperation and Development (OECD) Space Forum Workshop on Dec. 14. MOCAT enables users to model the long-term future space environment to understand growth in space debris and assess the effectiveness of debris-prevention mechanisms.
With the escalating congestion in low Earth orbit, driven by a surge in satellite deployments, the risk of collisions and space debris proliferation is a pressing concern. Conducting thorough space environment studies is critical for developing effective strategies for fostering responsible and sustainable use of space resources.
MOCAT stands out among orbital modeling tools for its capability to model individual objects, diverse parameters, orbital characteristics, fragmentation scenarios, and collision probabilities. With the ability to differentiate between object categories, generalize parameters, and offer multi-fidelity computations, MOCAT emerges as a versatile and powerful tool for comprehensive space environment analysis and management.
MOCAT is intended to provide an open-source tool to empower stakeholders including satellite operators, regulators, and members of the public to make data-driven decisions. The ARCLab team has been developing these models for the last several years, recognizing that the lack of open-source implementation of evolutionary modeling tools limits stakeholders’ ability to develop consensus on actions to help improve space sustainability. This beta release is intended to allow users to experiment with the tool and provide feedback to help guide further development.
Richard Linares, the principal investigator for MOCAT and an MIT associate professor of aeronautics and astronautics, expresses excitement about the tool’s potential impact: “MOCAT represents a significant leap forward in orbital capacity assessment. By making it open-source and publicly available, we hope to engage the global community in advancing our understanding of satellite orbits and contributing to the sustainable use of space.”
MOCAT consists of two main components. MOCAT-MC evaluates space environment evolution with individual trajectory simulation and Monte Carlo parameter analysis, providing both a high-level overall view for the environment and a fidelity analysis into the individual space objects evolution. MOCAT Source Sink Evolutionary Model (MOCAT-SSEM), meanwhile, uses a lower-fidelity modeling approach that can run on personal computers within seconds to minutes. MOCAT-MC and MOCAT-SSEM can be accessed separately via GitHub.
MOCAT’s initial development has been supported by the Defense Advanced Research Projects Agency (DARPA) and NASA’s Office of Technology and Strategy.
“We are thrilled to support this groundbreaking orbital debris modeling work and the new knowledge it created,” says Charity Weeden, associate administrator for the Office of Technology, Policy, and Strategy at NASA headquarters in Washington. “This open-source modeling tool is a public good that will advance space sustainability, improve evidence-based policy analysis, and help all users of space make better decisions.”
Animation showing the change in orbital population with no future launches, starting in 2023. Red dots represent debris, green shows payload, cyan shows derelict, and white shows rocket bodies. The animation shows a 200-year progression.
Preschool in the United States has grown dramatically in the past several decades. From 1970 to 2018, preschool enrollment increased from 38 percent to 64 percent of eligible students. Fourteen states are currently discussing preschool expansion, with seven likely to pass some form of universal eligibility within the next calendar year. Amid this expansion, families, policymakers, and practitioners want to better understand preschools’ impacts and the factors driving preschool quality.
To address these and other questions, MIT Blueprint Labs recently held a Preschool Research Convening that brought researchers, funders, practitioners, and policymakers to Nashville, Tennessee, to discuss the future of preschool research. Parag Pathak, the Class of 1922 Professor of Economics at MIT and a Blueprint Labs co-founder and director, opened by sharing the goals of the convening: “Our goals for the next two days are to identify pressing, unanswered research questions and connect researchers, practitioners, policymakers, and funders. We also hope to craft a compelling research agenda.”
Pathak added, “Given preschool expansion nationwide, we believe now is the moment to centralize our efforts and create knowledge to inform pressing decisions. We aim to generate rigorous preschool research that will lead to higher-quality and more equitable preschool.”
Over 75 participants hailing from universities, early childhood education organizations, school districts, state education departments, and national policy organizations attended the convening, held Nov. 13-14. Through panels, presentations, and conversations, participants discussed essential subjects in the preschool space, built the foundations for valuable partnerships, and formed an actionable and inclusive research agenda.
Research presented
Among research works presented was a recent paper by Blueprint Labs affiliate Jesse Bruhn, an assistant professor of economics at Brown University and co-author Emily Emick, also of Brown, reviewing the state of lottery-based preschool research. They found that random evaluations from the past 60 years demonstrate that preschool improves children’s short-run academic outcomes, but those effects fade over time. However, positive impacts re-emerge in the long term through improved outcomes like high school graduation and college enrollment. Limited rigorous research studies children’s behavioral outcomes or the factors that lead to high-quality preschool, though trends from preliminary research suggest that full-day programs, language immersion programs, and specific curricula may benefit children.
An earlier Blueprint Labs study that was also presented at the convening is the only recent lottery-based study to provide insight on preschool’s long-term impacts. The work, conducted by Pathak and two others, reveals that enrolling in Boston Public Schools’ universal preschool program boosts children’s likelihood of graduating high school and enrolling in college. Yet, the preschool program had little detectable impact on elementary, middle, and high school state standardized test scores. Students who attended Boston preschool were less likely to be suspended or incarcerated in high school. However, research on preschool’s impacts on behavioral outcomes is limited; it remains an important area for further study. Future work could also fill in other gaps in research, such as access, alternative measures of student success, and variation across geographic contexts and student populations.
More data sought
State policy leaders also spoke at the event, including Lisa Roy, executive director of the Colorado Department of Early Childhood, and Sarah Neville-Morgan, deputy superintendent in the Opportunities for All Branch at the California Department of Education. Local practitioners, such as Elsa Holguín, president and CEO of the Denver Preschool Program, and Kristin Spanos, CEO of First 5 Alameda County, as well as national policy leaders including Lauren Hogan, managing director of policy and professional advancement at the National Association for the Education of Young Children, also shared their perspectives.
In panel discussions held throughout the kickoff, practitioners, policymakers, and researchers shared their perspectives on pressing questions for future research, including: What practices define high-quality preschool? How does preschool affect family systems and the workforce? How can we expand measures of effectiveness to move beyond traditional assessments? What can we learn from preschool’s differential impacts across time, settings, models, and geographies?
Panelists also discussed the need for reliable data, sharing that “the absence of data allows the status quo to persist.” Several sessions focused on involving diverse stakeholders in the research process, highlighting the need for transparency, sensitivity to community contexts, and accessible communication about research findings.
On the second day of the Preschool Research Convening, Pathak shared with attendees, “One of our goals… is to forge connections between all of you in this room and support new partnerships between researchers and practitioners. We hope your conversations are the launching pad for future collaborations.” Jason Sachs, the deputy director of early learning at the Bill and Melinda Gates Foundation and former director of early childhood at Boston Public Schools, provided closing remarks.
The convening laid the groundwork for a research agenda and new research partnerships that can help answer questions about what works, in what context, for which kids, and under which conditions. Answers to these questions will be fundamental to ensure preschool expands in the most evidence-informed and equitable way possible.
With this goal in mind, Blueprint Labs aims to create a new Preschool Research Collaborative to equip practitioners, policymakers, funders, and researchers with rigorous, actionable evidence on preschool performance. Pathak states, “We hope this collaborative will foster evidence-based decision-making that improves children's short- and long-term outcomes.” The connections and research agenda formed at the Preschool Research Convening are the first steps toward achieving that goal.
Sequencing all of the RNA in a cell can reveal a great deal of information about that cell’s function and what it is doing at a given point in time. However, the sequencing process destroys the cell, making it difficult to study ongoing changes in gene expression.
An alternative approach developed at MIT could enable researchers to track such changes over extended periods of time. The new method, which is based on a noninvasive imaging technique known as Raman spectroscopy, doesn’t harm cells and can be performed repeatedly.
Using this technique, the researchers showed that they could monitor embryonic stem cells as they differentiated into several other cell types over several days. This technique could enable studies of long-term cellular processes such as cancer progression or embryonic development, and one day might be used for diagnostics for cancer and other diseases.
“With Raman imaging you can measure many more time points, which may be important for studying cancer biology, developmental biology, and a number of degenerative diseases,” says Peter So, a professor of biological and mechanical engineering at MIT, director of MIT’s Laser Biomedical Research Center, and one of the authors of the paper.
Koseki Kobayashi-Kirschvink, a postdoc at MIT and the Broad Institute of Harvard and MIT, is the lead author of the study, which appears today in Nature Biotechnology. The paper’s senior authors are Tommaso Biancalani, a former Broad Institute scientist; Jian Shu, an assistant professor at Harvard Medical School and an associate member of the Broad Institute; and Aviv Regev, executive vice president at Genentech Research and Early Development, who is on leave from faculty positions at the Broad Institute and MIT’s Department of Biology.
Imaging gene expression
Raman spectroscopy is a noninvasive technique that reveals the chemical composition of tissues or cells by shining near-infrared or visible light on them. MIT’s Laser Biomedical Research Center has been working on biomedical Raman spectroscopy since 1985, and recently, So and others in the center have developed Raman spectroscopy-based techniques that could be used to diagnose breast cancer or measure blood glucose.
However, Raman spectroscopy on its own is not sensitive enough to detect signals as small as changes in the levels of individual RNA molecules. To measure RNA levels, scientists typically use a technique called single-cell RNA sequencing, which can reveal the genes that are active within different types of cells in a tissue sample.
In this project, the MIT team sought to combine the advantages of single-cell RNA sequencing and Raman spectroscopy by training a computational model to translate Raman signals into RNA expression states.
“RNA sequencing gives you extremely detailed information, but it’s destructive. Raman is noninvasive, but it doesn’t tell you anything about RNA. So, the idea of this project was to use machine learning to combine the strength of both modalities, thereby allowing you to understand the dynamics of gene expression profiles at the single cell level over time,” Kobayashi-Kirschvink says.
To generate data to train their model, the researchers treated mouse fibroblast cells, a type of skin cell, with factors that reprogram the cells to become pluripotent stem cells. During this process, cells can also transition into several other cell types, including neural and epithelial cells.
Using Raman spectroscopy, the researchers imaged the cells at 36 time points over 18 days as they differentiated. After each image was taken, the researchers analyzed each cell using single molecule fluorescence in situ hybridization (smFISH), which can be used to visualize specific RNA molecules within a cell. In this case, they looked for RNA molecules encoding nine different genes whose expression patterns vary between cell types.
This smFISH data can then act as a link between Raman imaging data and single-cell RNA sequencing data. To make that link, the researchers first trained a deep-learning model to predict the expression of those nine genes based on the Raman images obtained from those cells.
Then, they used a computational program called Tangram, previously developed at the Broad Institute, to link the smFISH gene expression patterns with entire genome profiles that they had obtained by performing single-cell RNA sequencing on the sample cells.
The researchers then combined those two computational models into one that they call Raman2RNA, which can predict individual cells’ entire genomic profiles based on Raman images of the cells.
Tracking cell differentiation
The researchers tested their Raman2RNA algorithm by tracking mouse embryonic stem cells as they differentiated into different cell types. They took Raman images of the cells four times a day for three days, and used their computational model to predict the corresponding RNA expression profiles of each cell, which they confirmed by comparing it to RNA sequencing measurements.
Using this approach, the researchers were able to observe the transitions that occurred in individual cells as they differentiated from embryonic stem cells into more mature cell types. They also showed that they could track the genomic changes that occur as mouse fibroblasts are reprogrammed into induced pluripotent stem cells, over a two-week period.
“It’s a demonstration that optical imaging gives additional information that allows you to directly track the lineage of the cells and the evolution of their transcription,” So says.
The researchers now plan to use this technique to study other types of cell populations that change over time, such as aging cells and cancerous cells. They are now working with cells grown in a lab dish, but in the future, they hope this approach could be developed as a potential diagnostic for use in patients.
“One of the biggest advantages of Raman is that it’s a label-free method. It’s a long way off, but there is potential for the human translation, which could not be done using the existing invasive techniques for measuring genomic profiles,” says Jeon Woong Kang, an MIT research scientist who is also an author of the study.
The research was funded by the Japan Society for the Promotion of Science Postdoctoral Fellowship for Overseas Researchers, the Naito Foundation Overseas Postdoctoral Fellowship, the MathWorks Fellowship, the Helen Hay Whitney Foundation, the U.S. National Institutes of Health, the U.S. National Institute of Biomedical Imaging and Bioengineering, HubMap, the Howard Hughes Medical Institute, and the Klarman Cell Observatory.
A new method can track changes in live cell gene expression over extended periods of time. Based on Raman spectroscopy, the method doesn’t harm cells and can be performed repeatedly.
MIT’s Electric Vehicle Team, which has a long record of building and racing innovative electric vehicles, including cars and motorcycles, in international professional-level competitions, is trying something very different this year: The team is building a hydrogen-powered electric motorcycle, using a fuel cell system, as a testbed for new hydrogen-based transportation.
The motorcycle successfully underwent its first full test-track demonstration in October. It is designed as an open-source platform that should make it possible to swap out and test a variety of different components, and for others to try their own versions based on plans the team is making freely available online.
Aditya Mehrotra, who is spearheading the project, is a graduate student working with mechanical engineering professor Alex Slocum, the Walter M. May and A. Hazel May Chair in Emerging Technologies. Mehrotra was studying energy systems and happened to also really like motorcycles, he says, “so we came up with the idea of a hydrogen-powered bike. We did an evaluation study, and we thought that this could actually work. We [decided to] try to build it.”
Team members say that while battery-powered cars are a boon for the environment, they still face limitations in range and have issues associated with the mining of lithium and resulting emissions. So, the team was interested in exploring hydrogen-powered vehicles as a clean alternative, allowing for vehicles that could be quickly refilled just like gasoline-powered vehicles.
Unlike past projects by the team, which has been part of MIT since 2005, this vehicle will not be entering races or competitions but will be presented at a variety of conferences. The team, consisting of about a dozen students, has been working on building the prototype since January 2023. In October they presented the bike at the Hydrogen Americas Summit, and in May they will travel to the Netherlands to present it at the World Hydrogen Summit. In addition to the two hydrogen summits, the team plans to show its bike at the Consumer Electronics Show in Las Vegas this month.
“We’re hoping to use this project as a chance to start conversations around ‘small hydrogen’ systems that could increase demand, which could lead to the development of more infrastructure," Mehrotra says. "We hope the project can help find new and creative applications for hydrogen.” In addition to these demonstrations and the online information the team will provide, he adds, they are also working toward publishing papers in academic journals describing their project and lessons learned from it, in hopes of making “an impact on the energy industry.”
The motorcycle took shape over the course of the year piece by piece. “We got a couple of industry sponsors to donate components like the fuel cell and a lot of the major components of the system,” he says. They also received support from the MIT Energy Initiative, the departments of Mechanical Engineering and Electrical Engineering and Computer Science, and the MIT Edgerton Center.
Initial tests were conducted on a dynamometer, a kind of instrumented treadmill Mehrotra describes as “basically a mock road.” The vehicle used battery power during its development, until the fuel cell, provided by South Korean company Doosan, could be delivered and installed. The space the group has used to design and build the prototype, the home of the Electric Vehicle Team, is in MIT’s Building N51 and is well set up to do detailed testing of each of the bike’s components as it is developed and integrated.
Elizabeth Brennan, a senior in mechanical engineering, says she joined the team in January 2023 because she wanted to gain more electrical engineering experience, “and I really fell in love with it.” She says group members “really care and are very excited to be here and work on this bike and believe in the project.”
Brennan, who is the team’s safety lead, has been learning about the safe handling methods required for the bike’s hydrogen fuel, including the special tanks and connectors needed. The team initially used a commercially available electric motor for the prototype but is now working on an improved version, designed from scratch, she says, “which gives us a lot more flexibility.”
As part of the project, team members are developing a kind of textbook describing what they did and how they carried out each step in the process of designing and fabricating this hydrogen electric fuel-cell bike. No such motorcycle yet exists as a commercial product, though a few prototypes have been built.
That kind of guidebook to the process “just doesn’t exist,” Brennan says. She adds that “a lot of the technology development for hydrogen is either done in simulation or is still in the prototype stages, because developing it is expensive, and it’s difficult to test these kinds of systems.” One of the team’s goals for the project is to make everything available as an open-source design, and “we want to provide this bike as a platform for researchers and for education, where researchers can test ideas in both space- and funding-constrained environments.”
Unlike a design built as a commercial product, Mehrotra says, “our vehicle is fully designed for research, so you can swap components in and out, and get real hardware data on how good your designs are.” That can help people work on implementing their new design ideas and help push the industry forward, he says.
The few prototypes developed previously by some companies were inefficient and expensive, he says. “So far as we know, we are the first fully open-source, rigorously documented, tested and released-as-a-platform, [fuel cell] motorcycle in the world. No one else has made a motorcycle and tested it to the level that we have, and documented to the point that someone might actually be able to take this and scale it in the future, or use it in research.”
He adds that “at the moment, this vehicle is affordable for research, but it’s not affordable yet for commercial production because the fuel cell is a very big, expensive component.” Doosan Fuel Cell, which provided the fuel cell for the prototype bike, produces relatively small and lightweight fuel cells mostly for use in drones. The company also produces hydrogen storage and delivery systems.
The project will continue to evolve, says team member Annika Marschner, a sophomore in mechanical engineering. “It’s sort of an ongoing thing, and as we develop it and make changes, make it a stronger, better bike, it will just continue to grow over the years, hopefully,” she says.
While the Electric Vehicle Team has until now focused on battery-powered vehicles, Marschner says, “Right now we’re looking at hydrogen because it seems like something that’s been less explored than other technologies for making sustainable transportation. So, it seemed like an exciting thing for us to offer our time and effort to.”
Making it all work has been a long process. The team is using a frame from a 1999 motorcycle, with many custom-made parts added to support the electric motor, the hydrogen tank, the fuel cell, and the drive train. “Making everything fit in the frame of the bike is definitely something we’ve had to think about a lot because there’s such limited space there. So, it required trying to figure out how to mount things in clever ways so that there are not conflicts,” she says.
Marschner says, “A lot of people don’t really imagine hydrogen energy being something that’s out there being used on the roads, but the technology does exist.” She points out that Toyota and Hyundai have hydrogen-fueled vehicles on the market, and that some hydrogen fuel stations exist, mostly in California, Japan, and some European countries. But getting access to hydrogen, “for your average consumer on the East Coast, is a huge, huge challenge. Infrastructure is definitely the biggest challenge right now to hydrogen vehicles,” she says.
She sees a bright future for hydrogen as a clean fuel to replace fossil fuels over time. “I think it has a huge amount of potential,” she says. “I think one of the biggest challenges with moving hydrogen energy forward is getting these demonstration projects actually developed and showing that these things can work and that they can work well. So, we’re really excited to bring it along further.”
Aditya Mehrotra performs a “shakedown” test — running the hydrogen-powered electric motorcycle at high speeds to ensure that the mechanical and electrical systems hold up.
Your daily to-do list is likely pretty straightforward: wash the dishes, buy groceries, and other minutiae. It’s unlikely you wrote out “pick up the first dirty dish,” or “wash that plate with a sponge,” because each of these miniature steps within the chore feels intuitive. While we can routinely complete each step without much thought, a robot requires a complex plan that involves more detailed outlines.
MIT’s Improbable AI Lab, a group within the Computer Science and Artificial Intelligence Laboratory (CSAIL), has offered these machines a helping hand with a new multimodal framework: Compositional Foundation Models for Hierarchical Planning (HiP), which develops detailed, feasible plans with the expertise of three different foundation models. Like OpenAI’s GPT-4, the foundation model that ChatGPT and Bing Chat were built upon, these foundation models are trained on massive quantities of data for applications like generating images, translating text, and robotics.
Unlike RT2 and other multimodal models that are trained on paired vision, language, and action data, HiP uses three different foundation models each trained on different data modalities. Each foundation model captures a different part of the decision-making process and then works together when it’s time to make decisions. HiP removes the need for access to paired vision, language, and action data, which is difficult to obtain. HiP also makes the reasoning process more transparent.
What’s considered a daily chore for a human can be a robot’s “long-horizon goal” — an overarching objective that involves completing many smaller steps first — requiring sufficient data to plan, understand, and execute objectives. While computer vision researchers have attempted to build monolithic foundation models for this problem, pairing language, visual, and action data is expensive. Instead, HiP represents a different, multimodal recipe: a trio that cheaply incorporates linguistic, physical, and environmental intelligence into a robot.
“Foundation models do not have to be monolithic,” says NVIDIA AI researcher Jim Fan, who was not involved in the paper. “This work decomposes the complex task of embodied agent planning into three constituent models: a language reasoner, a visual world model, and an action planner. It makes a difficult decision-making problem more tractable and transparent.”
The team believes that their system could help these machines accomplish household chores, such as putting away a book or placing a bowl in the dishwasher. Additionally, HiP could assist with multistep construction and manufacturing tasks, like stacking and placing different materials in specific sequences.
Evaluating HiP
The CSAIL team tested HiP’s acuity on three manipulation tasks, outperforming comparable frameworks. The system reasoned by developing intelligent plans that adapt to new information.
First, the researchers requested that it stack different-colored blocks on each other and then place others nearby. The catch: Some of the correct colors weren’t present, so the robot had to place white blocks in a color bowl to paint them. HiP often adjusted to these changes accurately, especially compared to state-of-the-art task planning systems like Transformer BC and Action Diffuser, by adjusting its plans to stack and place each square as needed.
Another test: arranging objects such as candy and a hammer in a brown box while ignoring other items. Some of the objects it needed to move were dirty, so HiP adjusted its plans to place them in a cleaning box, and then into the brown container. In a third demonstration, the bot was able to ignore unnecessary objects to complete kitchen sub-goals such as opening a microwave, clearing a kettle out of the way, and turning on a light. Some of the prompted steps had already been completed, so the robot adapted by skipping those directions.
A three-pronged hierarchy
HiP’s three-pronged planning process operates as a hierarchy, with the ability to pre-train each of its components on different sets of data, including information outside of robotics. At the bottom of that order is a large language model (LLM), which starts to ideate by capturing all the symbolic information needed and developing an abstract task plan. Applying the common sense knowledge it finds on the internet, the model breaks its objective into sub-goals. For example, “making a cup of tea” turns into “filling a pot with water,” “boiling the pot,” and the subsequent actions required.
“All we want to do is take existing pre-trained models and have them successfully interface with each other,” says Anurag Ajay, a PhD student in the MIT Department of Electrical Engineering and Computer Science (EECS) and a CSAIL affiliate. “Instead of pushing for one model to do everything, we combine multiple ones that leverage different modalities of internet data. When used in tandem, they help with robotic decision-making and can potentially aid with tasks in homes, factories, and construction sites.”
These models also need some form of “eyes” to understand the environment they’re operating in and correctly execute each sub-goal. The team used a large video diffusion model to augment the initial planning completed by the LLM, which collects geometric and physical information about the world from footage on the internet. In turn, the video model generates an observation trajectory plan, refining the LLM’s outline to incorporate new physical knowledge.
This process, known as iterative refinement, allows HiP to reason about its ideas, taking in feedback at each stage to generate a more practical outline. The flow of feedback is similar to writing an article, where an author may send their draft to an editor, and with those revisions incorporated in, the publisher reviews for any last changes and finalizes.
In this case, the top of the hierarchy is an egocentric action model, or a sequence of first-person images that infer which actions should take place based on its surroundings. During this stage, the observation plan from the video model is mapped over the space visible to the robot, helping the machine decide how to execute each task within the long-horizon goal. If a robot uses HiP to make tea, this means it will have mapped out exactly where the pot, sink, and other key visual elements are, and begin completing each sub-goal.
Still, the multimodal work is limited by the lack of high-quality video foundation models. Once available, they could interface with HiP’s small-scale video models to further enhance visual sequence prediction and robot action generation. A higher-quality version would also reduce the current data requirements of the video models.
That being said, the CSAIL team’s approach only used a tiny bit of data overall. Moreover, HiP was cheap to train and demonstrated the potential of using readily available foundation models to complete long-horizon tasks. “What Anurag has demonstrated is proof-of-concept of how we can take models trained on separate tasks and data modalities and combine them into models for robotic planning. In the future, HiP could be augmented with pre-trained models that can process touch and sound to make better plans,” says senior author Pulkit Agrawal, MIT assistant professor in EECS and director of the Improbable AI Lab. The group is also considering applying HiP to solving real-world long-horizon tasks in robotics.
Ajay and Agrawal are lead authors on a paper describing the work. They are joined by MIT professors and CSAIL principal investigators Tommi Jaakkola, Joshua Tenenbaum, and Leslie Pack Kaelbling; CSAIL research affiliate and MIT-IBM AI Lab research manager Akash Srivastava; graduate students Seungwook Han and Yilun Du ’19; former postdoc Abhishek Gupta, who is now assistant professor at University of Washington; and former graduate student Shuang Li PhD ’23.
The team’s work was supported, in part, by the National Science Foundation, the U.S. Defense Advanced Research Projects Agency, the U.S. Army Research Office, the U.S. Office of Naval Research Multidisciplinary University Research Initiatives, and the MIT-IBM Watson AI Lab. Their findings were presented at the 2023 Conference on Neural Information Processing Systems (NeurIPS).
The HiP framework developed at MIT CSAIL develops detailed plans for robots using the expertise of three different foundation models, helping it execute tasks in households, factories, and construction that require multiple steps.
In fields such as physics and engineering, partial differential equations (PDEs) are used to model complex physical processes to generate insight into how some of the most complicated physical and natural systems in the world function.
To solve these difficult equations, researchers use high-fidelity numerical solvers, which can be very time-consuming and computationally expensive to run. The current simplified alternative, data-driven surrogate models, compute the goal property of a solution to PDEs rather than the whole solution. Those are trained on a set of data that has been generated by the high-fidelity solver, to predict the output of the PDEs for new inputs. This is data-intensive and expensive because complex physical systems require a large number of simulations to generate enough data.
In a new paper, “Physics-enhanced deep surrogates for partial differential equations,” published in December in Nature Machine Intelligence, a new method is proposedfor developing data-driven surrogate models for complex physical systems in such fields as mechanics, optics, thermal transport, fluid dynamics, physical chemistry, and climate models.
The paper was authored by MIT’s professor of applied mathematics Steven G. Johnson along with Payel Das and Youssef Mroueh of the MIT-IBM Watson AI Lab and IBM Research; Chris Rackauckas of Julia Lab; and Raphaël Pestourie, a former MIT postdoc who is now at Georgia Tech. The authors call their method "physics-enhanced deep surrogate" (PEDS), which combines a low-fidelity, explainable physics simulator with a neural network generator. The neural network generator is trained end-to-end to match the output of the high-fidelity numerical solver.
“My aspiration is to replace the inefficient process of trial and error with systematic, computer-aided simulation and optimization,” says Pestourie. “Recent breakthroughs in AI like the large language model of ChatGPT rely on hundreds of billions of parameters and require vast amounts of resources to train and evaluate. In contrast, PEDS is affordable to all because it is incredibly efficient in computing resources and has a very low barrier in terms of infrastructure needed to use it.”
In the article, they show that PEDS surrogates can be up to three times more accurate than an ensemble of feedforward neural networks with limited data (approximately 1,000 training points), and reduce the training data needed by at least a factor of 100 to achieve a target error of 5 percent. Developed using the MIT-designed Julia programming language, this scientific machine-learning method is thus efficient in both computing and data.
The authors also report that PEDS provides a general, data-driven strategy to bridge the gap between a vast array of simplified physical models with corresponding brute-force numerical solvers modeling complex systems. This technique offers accuracy, speed, data efficiency, and physical insights into the process.
Says Pestourie, “Since the 2000s, as computing capabilities improved, the trend of scientific models has been to increase the number of parameters to fit the data better, sometimes at the cost of a lower predictive accuracy. PEDS does the opposite by choosing its parameters smartly. It leverages the technology of automatic differentiation to train a neural network that makes a model with few parameters accurate.”
“The main challenge that prevents surrogate models from being used more widely in engineering is the curse of dimensionality — the fact that the needed data to train a model increases exponentially with the number of model variables,” says Pestourie. “PEDS reduces this curse by incorporating information from the data and from the field knowledge in the form of a low-fidelity model solver.”
The researchers say that PEDS has the potential to revive a whole body of the pre-2000 literature dedicated to minimal models — intuitive models that PEDS could make more accurate while also being predictive for surrogate model applications.
"The application of the PEDS framework is beyond what we showed in this study,” says Das. “Complex physical systems governed by PDEs are ubiquitous, from climate modeling to seismic modeling and beyond. Our physics-inspired fast and explainable surrogate models will be of great use in those applications, and play a complementary role to other emerging techniques, like foundation models."
The research was supported by the MIT-IBM Watson AI Lab and the U.S. Army Research Office through the Institute for Soldier Nanotechnologies.
To simplify the solving of massive numbers of partial differential equations (PDEs) for computational modeling, new data-driven surrogate models compute the goal property of a solution to PDEs rather than the whole solution.
Hold your hands out in front of you, and no matter how you rotate them, it’s impossible to superimpose one over the other. Our hands are a perfect example of chirality — a geometric configuration by which an object cannot be superimposed onto its mirror image.
Chirality is everywhere in nature, from our hands to the arrangement of our internal organs to the spiral structure of DNA. Chiral molecules and materials have been the key to many drug therapies, optical devices, and functional metamaterials. Scientists have until now assumed that chirality begets chirality — that is, chiral structures emerge from chiral forces and building blocks. But that assumption may need some retuning.
MIT engineers recently discovered that chirality can also emerge in an entirely nonchiral material, and through nonchiral means. In a study appearing today in Nature Communications, the team reports observing chirality in a liquid crystal — a material that flows like a liquid and has non ordered, crystal-like microstructure like a solid. They found that when the fluid flows slowly, its normally nonchiral microstructures spontaneously assemble into large, twisted, chiral structures. The effect is as if a conveyor belt of crayons, all symmetrically aligned, were to suddenly rearrange into large, spiral patterns once the belt reaches a certain speed.
The geometric transformation is unexpected, given that the liquid crystal is naturally nonchiral, or “achiral.” The team’s study thus opens a new path to generating chiral structures. The researchers envision that the structures, once formed, could serve as spiral scaffolds in which to assemble intricate molecular structures. The chiral liquid crystals could also be used as optical sensors, as their structural transformation would change the way they interact with light.
“This is exciting, because this gives us an easy way to structure these kinds of fluids,” says study co-author Irmgard Bischofberger, associate professor of mechanical engineering at MIT. “And from a fundamental level, this is a new way in which chirality can emerge.”
The study’s co-authors include lead author Qing Zhang PhD ’22, Weiqiang Wang and Rui Zhang of Hong Kong University of Science and Technology, and Shuang Zhou of the University of Massachusetts at Amherst.
Striking stripes
A liquid crystal is a phase of matter that embodies properties of both a liquid and a solid. Such in-between materials flow like liquid, and are molecularly structured like solids. Liquid crystals are used as the main element in pixels that make up LCD displays, as the symmetric alignment of their molecules can be uniformly switched with voltage to collectively create high-resolution images.
Bischofberger’s group at MIT studies how fluids and soft materials spontaneously form patterns in nature and in the lab. The team seeks to understand the mechanics underlying fluid transformations, which could be used to create new, reconfigurable materials.
In their new study, the researchers focused on a special type of nematic liquid crystal — a water-based fluid that contains microscopic, rod-like molecular structures. The rods normally align in the same direction throughout the fluid. Zhang was initially curious how the fluid would behave under various flow conditions.
“I tried this experiment for the first time at home, in 2020,” Zhang recalls. “I had samples of the fluid, and a small microscope, and one day I just set it to a low flow. When I came back, I saw this really striking pattern.”
She and her colleagues repeated her initial experiments in the lab. They fabricated a microfluidic channel out of two glass slides, separated by a very thin space, and connected to a main reservoir. The team slowly pumped samples of the liquid crystal through the reservoir and into the space between the plates, then took microscopy images of fluid as it flowed through.
Like Zhang’s initial experiments, the team observed an unexpected transformation: The normally uniform fluid began to form tiger-like stripes as it slowly moved through the channel.
“It was surprising that it formed any structure, but even more surprising once we actually knew what type of structure it formed,” Bischofberger says. “That’s where chirality comes in.”
Twist and flow
The team discovered that the fluid’s stripes were unexpectedly chiral, by using various optical and modeling techniques to effectively retrace the fluid’s flow. They observed that, when unmoving, the fluid’s microscopic rods are normally aligned in near-perfect formation. When the fluid is pumped through the channel quickly, the rods are in complete disarray. But at a slower, in-between flow, the structures start to wiggle, then progressively twist like tiny propellers, each one turning slightly more than the next.
If the fluid continues its slow flow, the twisting crystals assemble into large spiral structures that appear as stripes under the microscope.
“There’s this magic region, where if you just gently make them flow, they form these large spiral structures,” Zhang says.
The researchers modeled the fluid’s dynamics and found that the large spiral patterns emerged when the fluid arrived at a balance between two forces: viscosity and elasticity. Viscosity describes how easily a material flows, while elasticity is essentially how likely a material is to deform (for instance, how easily the fluid’s rods wiggle and twist).
“When these two forces are about the same, that’s when we see these spiral structures,” Bischofberger explains. “It’s kind of amazing that individual structures, on the order of nanometers, can assemble into much larger, millimeter-scale structures that are very ordered, just by pushing them a little bit out of equilibrium.”
The team realized that the twisted assemblages have a chiral geometry: If a mirror image was made of one spiral, it would not be possible to superimpose it over the original, no matter how the spirals were rearranged. The fact that the chiral spirals emerged from a nonchiral material, and through nonchiral means, is a first and points to a relatively simple way to engineer structured fluids.
“The results are indeed surprising and intriguing,” says Giuliano Zanchetta, associate professor at the University of Milan, who was not involved with the study. “It would be interesting to explore the boundaries of this phenomenon. I would see the reported chiral patterns as a promising way to periodically modulate optical properties at the microscale.”
“We now have some knobs to tune this structure,” Bischofberger says. “This might give us a new optical sensor that interacts with light in certain ways. It could also be used as scaffolds to grow and transport molecules for drug delivery. We’re excited to explore this whole new phase space.”
This research was supported, in part, by the U.S. National Science Foundation.
MIT engineers observed that a liquid crystal’s orderly microstructures will spontaneously assemble into large, twisted structures (pictured) when the liquid is made to slowly flow.
Hydrogen is an integral component for the manufacture of steel, fertilizer, and a number of chemicals. Producing hydrogen using renewable electricity offers a way to clean up these and many other hard-to-decarbonize industries.
But supporting the nascent clean hydrogen industry while ensuring it grows into a true force for decarbonization is complicated, in large part because of the challenges of sourcing clean electricity. To assist regulators and to clarify disagreements in the field, MIT researchers published a paper today in Nature Energy that outlines a path to scale the clean hydrogen industry while limiting emissions.
Right now, U.S. electric grids are mainly powered by fossil fuels, so if scaling hydrogen production translates to greater electricity use, it could result in a major emissions increase. There is also the risk that “low-carbon” hydrogen projects could end up siphoning renewable energy that would have been built anyway for the grid. It is therefore critical to ensure that low-carbon hydrogen procures electricity from “additional” renewables, especially when hydrogen production is supported by public subsidies. The challenge is allowing hydrogen producers to procure renewable electricity in a cost-effective way that helps the industry grow, while minimizing the risk of high emissions.
U.S. regulators have been tasked with sorting out this complexity. The Inflation Reduction Act (IRA) is offering generous production tax credits for low-carbon hydrogen. But the law didn’t specify exactly how hydrogen’s carbon footprint should be judged.
To this end, the paper proposes a phased approach to qualify for the tax credits. In the first phase, hydrogen created from grid electricity can receive the credits under looser standards as the industry gets its footing. Once electricity demand for hydrogen production grows, the industry should be required to adhere to stricter standards for ensuring the electricity is coming from renewable sources. Finally, many years from now when the grid is mainly powered by renewable energy, the standards can loosen again.
The researchers say the nuanced approach ensures the law supports the growth of clean hydrogen without coming at the expense of emissions.
“If we can scale low-carbon hydrogen production, we can cut some significant sources of existing emissions and enable decarbonization of other critical industries,” says paper co-author Michael Giovanniello, a graduate student in MIT’s Technology and Policy Program. “At the same time, there’s a real risk of implementing the wrong requirements and wasting lots of money to subsidize carbon-intensive hydrogen production. So, you have to balance scaling the industry with reducing the risk of emissions. I hope there’s clarity and foresight in how this policy is implemented, and I hope our paper makes the argument clear for policymakers.”
Giovanniello’s co-authors on the paper are MIT Energy Initiative (MITEI) Principal Research Scientist Dharik Mallapragada, MITEI Research Assistant Anna Cybulsky, and MIT Sloan School of Management Senior Lecturer Tim Schittekatte.
On definitions and disagreements
When renewable electricity from a wind farm or solar array flows through the grid, it’s mixed with electricity from fossil fuels. The situation raises a question worth billions of dollars in federal tax credits: What are the carbon dioxide emissions of grid users who are also signing agreements to procure electricity from renewables?
One way to answer this question is via energy system models that can simulate various scenarios related to technology configurations and qualifying requirements for receiving the credit.
To date, many studies using such models have come up with very different emissions estimates for electrolytic hydrogen production. One source of disagreement is over “time matching,” which refers to how strictly to align the timing of electric hydrogen production with the generation of clean electricity. One proposed approach, known as hourly time matching, would require that electricity consumption to produce hydrogen is accounted for by procured clean electricity at every hour.
A less stringent approach, called annual time matching, would offer more flexibility in hourly electricity consumption for hydrogen production, so long as the annual consumption matches the annual generation from the procured clean electricity generation. The added flexibility could reduce the cost of hydrogen production, which is critical for scaling its use, but could lead to greater emissions per unit of hydrogen produced.
Another point of disagreement stems from how hydrogen producers purchase renewable electricity. If an electricity user procures energy from an existing solar farm, it’s simply increasing overall electricity demand and taking clean energy away from other users. But if the tax credits only go to electric hydrogen producers that sign power purchase agreements with new renewable suppliers, they’re supporting clean electricity that wouldn’t have otherwise been contributing to the grid. This concept is known as “additionality.”
The researchers analyzed previous studies that reached conflicting conclusions, and identified different interpretations of additionality underlying their methodologies. One interpretation of additionality is that new electrolytic hydrogen projects do not compete with nonhydrogen demand for renewable energy resources. The other assumes that they do compete for all newly deployed renewables — and, because of low-carbon hydrogen subsidies, the electrolyzers take priority.
Using DOLPHYN, an open-source energy systems model, the researchers tested how these two interpretations of additionality (the “compete” and “noncompete” scenarios) impact the cost and emissions of the alternative time-matching requirements (hourly and annual) associated with grid-interconnected hydrogen production. They modeled two regional U.S. grids — in Texas and Florida — which represent the high and low end of renewables deployment. They further tested the interaction of four critical policy factors with the hydrogen tax credits, including renewable portfolio standards, constraints of renewables and energy storage deployment, limits on hydrogen electrolyzer capacity factors, and competition with natural gas-based hydrogen with carbon capture.
They show that the different modeling interpretations of additionality are the primary factor explaining the vastly different estimates of emissions from electrolyzer hydrogen under annual time-matching.
Getting policy right
The paper concludes that the right way to implement the production tax credit qualifying requirements depends on whether you believe we live in a “compete” or “noncompete” world. But reality is not so binary.
“What framework is more appropriate is going to change with time as we deploy more hydrogen and the grid decarbonizes, so therefore the policy has to be adaptive to those changes,” Mallapragada says. “It’s an evolving story that’s tied to what’s happening in the rest of the energy system, and in particular the electric grid, both from the technological as policy perspective.”
Today, renewables deployment is driven, in part, by binding factors, such as state renewable portfolio standards and corporate clean-energy commitments, as well as by purely market forces. Since the electrolyzer is so nascent, and today resembles a “noncompete” world, the researchers argue for starting with the less strict annual requirement. But as hydrogen demand for renewable electricity grows, and market competition drives an increasing quantity of renewables deployment, transitioning to hourly matching will be necessary to avoid high emissions.
This phased approach necessitates deliberate, long-term planning from regulators. “If regulators make a decision and don’t outline when they’ll reassess that decision, they might never reassess that decision, so we might get locked into a bad policy,” Giovanniello explains. In particular, the paper highlights the risk of locking in an annual time-matching requirement that leads to significant emissions in future.
The researchers hope their findings will contribute to upcoming policy decisions around the Inflation Reduction Act’s tax credits. They started looking into this question around a year ago, making it a quick turnaround by academic standards.
“There was definitely a sense to be timely in our analysis so as to be responsive to the needs of policy,” Mallapragada says.
The researchers say the paper can also help policymakers understand the emissions impacts of companies procuring renewable energy credits to meet net-zero targets and electricity suppliers attempting to sell “green” electricity.
“This question is relevant in a lot of different domains,” Schittekatte says. “Other popular examples are the emission impacts of data centers that procure green power, or even the emission impacts of your own electric car sourcing power from your rooftop solar and the grid. There are obviously differences based on the technology in question, but the underlying research question we’ve answered is the same. This is an extremely important topic for the energy transition.”