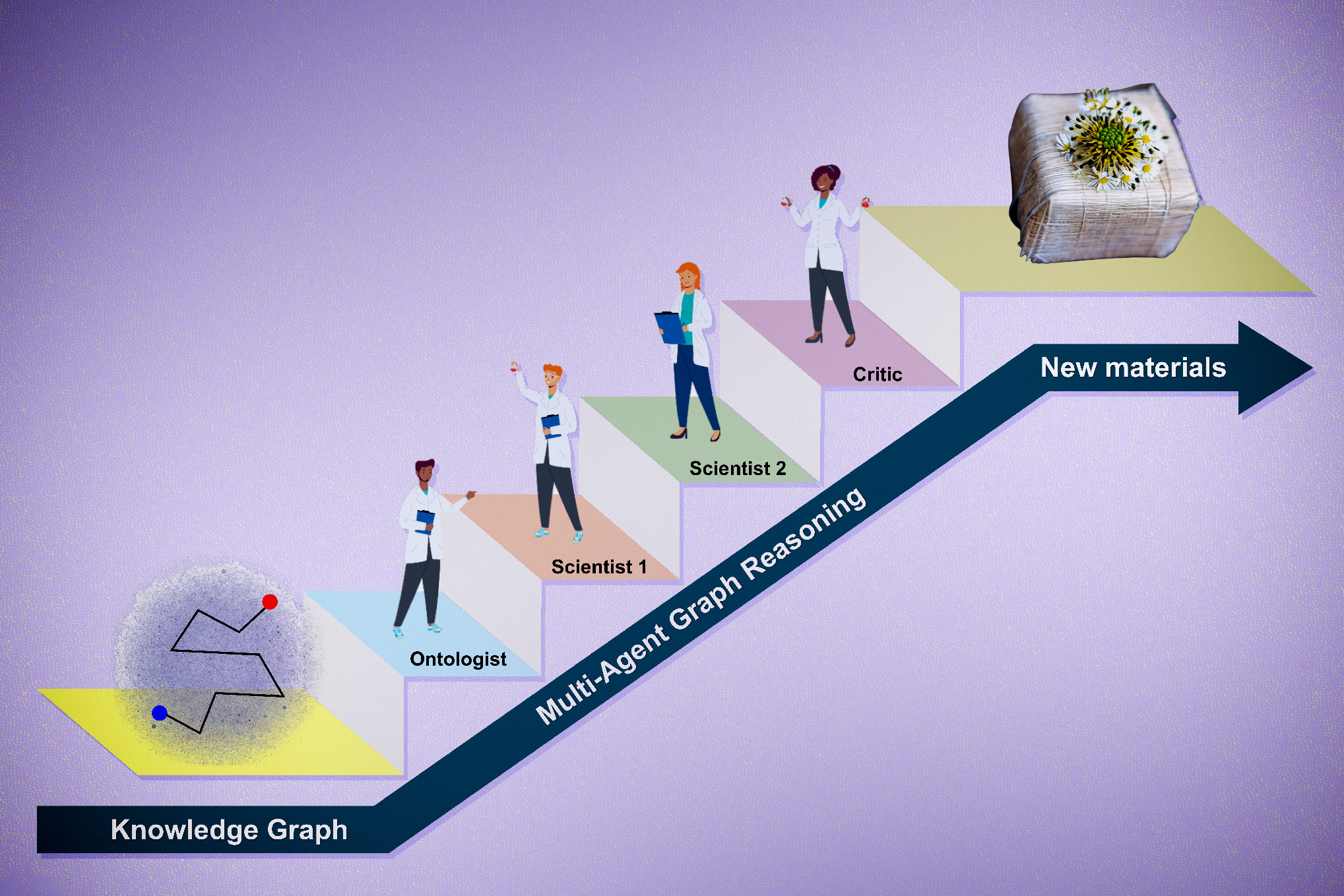
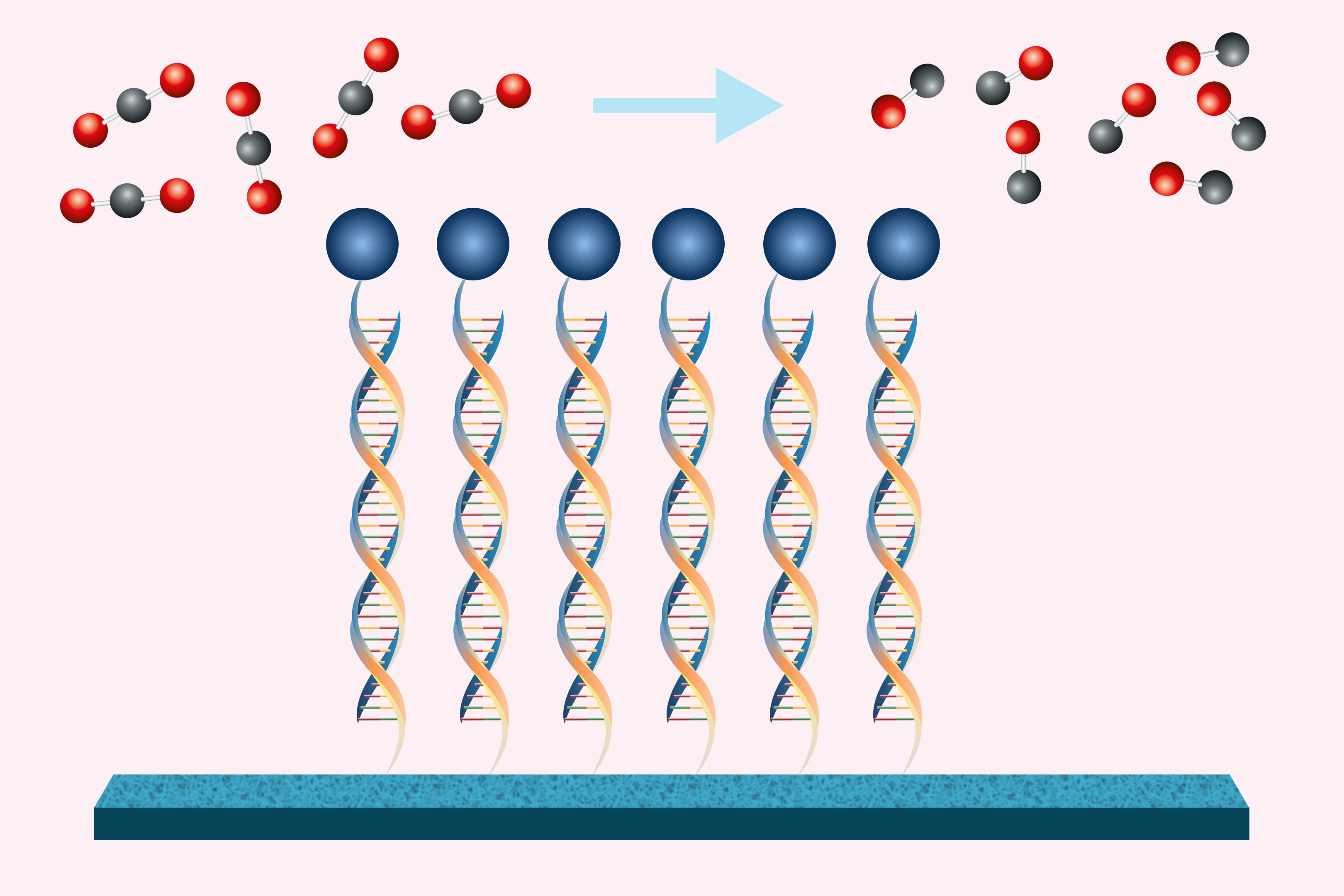
Like human brains, large language models reason about diverse data in a general way
While early language models could only process text, contemporary large language models now perform highly diverse tasks on different types of data. For instance, LLMs can understand many languages, generate computer code, solve math problems, or answer questions about images and audio.
MIT researchers probed the inner workings of LLMs to better understand how they process such assorted data, and found evidence that they share some similarities with the human brain.
Neuroscientists believe the human brain has a “semantic hub” in the anterior temporal lobe that integrates semantic information from various modalities, like visual data and tactile inputs. This semantic hub is connected to modality-specific “spokes” that route information to the hub. The MIT researchers found that LLMs use a similar mechanism by abstractly processing data from diverse modalities in a central, generalized way. For instance, a model that has English as its dominant language would rely on English as a central medium to process inputs in Japanese or reason about arithmetic, computer code, etc. Furthermore, the researchers demonstrate that they can intervene in a model’s semantic hub by using text in the model’s dominant language to change its outputs, even when the model is processing data in other languages.
These findings could help scientists train future LLMs that are better able to handle diverse data.
“LLMs are big black boxes. They have achieved very impressive performance, but we have very little knowledge about their internal working mechanisms. I hope this can be an early step to better understand how they work so we can improve upon them and better control them when needed,” says Zhaofeng Wu, an electrical engineering and computer science (EECS) graduate student and lead author of a paper on this research.
His co-authors include Xinyan Velocity Yu, a graduate student at the University of Southern California (USC); Dani Yogatama, an associate professor at USC; Jiasen Lu, a research scientist at Apple; and senior author Yoon Kim, an assistant professor of EECS at MIT and a member of the Computer Science and Artificial Intelligence Laboratory (CSAIL). The research will be presented at the International Conference on Learning Representations.
Integrating diverse data
The researchers based the new study upon prior work which hinted that English-centric LLMs use English to perform reasoning processes on various languages.
Wu and his collaborators expanded this idea, launching an in-depth study into the mechanisms LLMs use to process diverse data.
An LLM, which is composed of many interconnected layers, splits input text into words or sub-words called tokens. The model assigns a representation to each token, which enables it to explore the relationships between tokens and generate the next word in a sequence. In the case of images or audio, these tokens correspond to particular regions of an image or sections of an audio clip.
The researchers found that the model’s initial layers process data in its specific language or modality, like the modality-specific spokes in the human brain. Then, the LLM converts tokens into modality-agnostic representations as it reasons about them throughout its internal layers, akin to how the brain’s semantic hub integrates diverse information.
The model assigns similar representations to inputs with similar meanings, despite their data type, including images, audio, computer code, and arithmetic problems. Even though an image and its text caption are distinct data types, because they share the same meaning, the LLM would assign them similar representations.
For instance, an English-dominant LLM “thinks” about a Chinese-text input in English before generating an output in Chinese. The model has a similar reasoning tendency for non-text inputs like computer code, math problems, or even multimodal data.
To test this hypothesis, the researchers passed a pair of sentences with the same meaning but written in two different languages through the model. They measured how similar the model’s representations were for each sentence.
Then they conducted a second set of experiments where they fed an English-dominant model text in a different language, like Chinese, and measured how similar its internal representation was to English versus Chinese. The researchers conducted similar experiments for other data types.
They consistently found that the model’s representations were similar for sentences with similar meanings. In addition, across many data types, the tokens the model processed in its internal layers were more like English-centric tokens than the input data type.
“A lot of these input data types seem extremely different from language, so we were very surprised that we can probe out English-tokens when the model processes, for example, mathematic or coding expressions,” Wu says.
Leveraging the semantic hub
The researchers think LLMs may learn this semantic hub strategy during training because it is an economical way to process varied data.
“There are thousands of languages out there, but a lot of the knowledge is shared, like commonsense knowledge or factual knowledge. The model doesn’t need to duplicate that knowledge across languages,” Wu says.
The researchers also tried intervening in the model’s internal layers using English text when it was processing other languages. They found that they could predictably change the model outputs, even though those outputs were in other languages.
Scientists could leverage this phenomenon to encourage the model to share as much information as possible across diverse data types, potentially boosting efficiency.
But on the other hand, there could be concepts or knowledge that are not translatable across languages or data types, like culturally specific knowledge. Scientists might want LLMs to have some language-specific processing mechanisms in those cases.
“How do you maximally share whenever possible but also allow languages to have some language-specific processing mechanisms? That could be explored in future work on model architectures,” Wu says.
In addition, researchers could use these insights to improve multilingual models. Often, an English-dominant model that learns to speak another language will lose some of its accuracy in English. A better understanding of an LLM’s semantic hub could help researchers prevent this language interference, he says.
“Understanding how language models process inputs across languages and modalities is a key question in artificial intelligence. This paper makes an interesting connection to neuroscience and shows that the proposed ‘semantic hub hypothesis’ holds in modern language models, where semantically similar representations of different data types are created in the model’s intermediate layers,” says Mor Geva Pipek, an assistant professor in the School of Computer Science at Tel Aviv University, who was not involved with this work. “The hypothesis and experiments nicely tie and extend findings from previous works and could be influential for future research on creating better multimodal models and studying links between them and brain function and cognition in humans.”
This research is funded, in part, by the MIT-IBM Watson AI Lab.

© Credit: MIT News, iStock