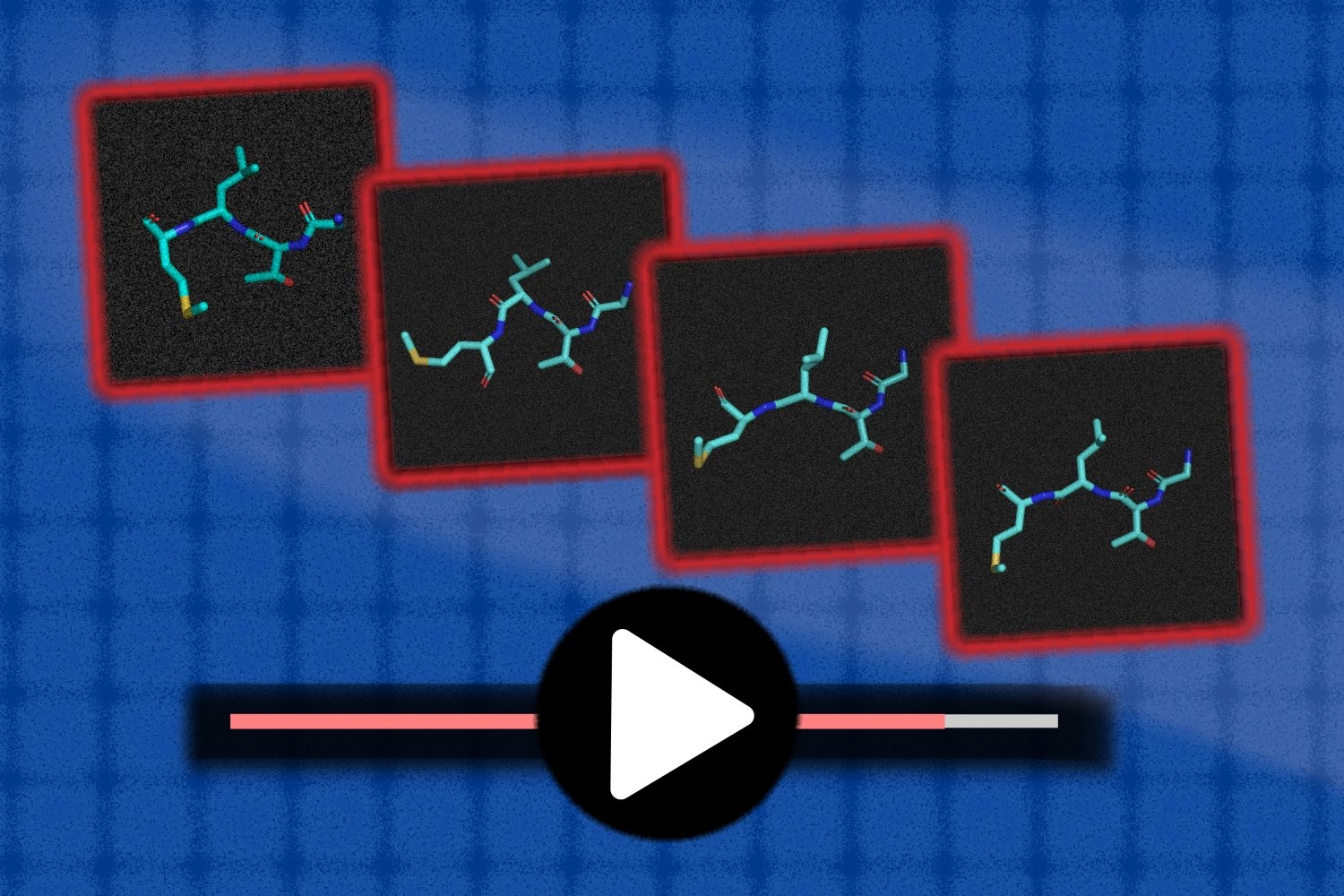
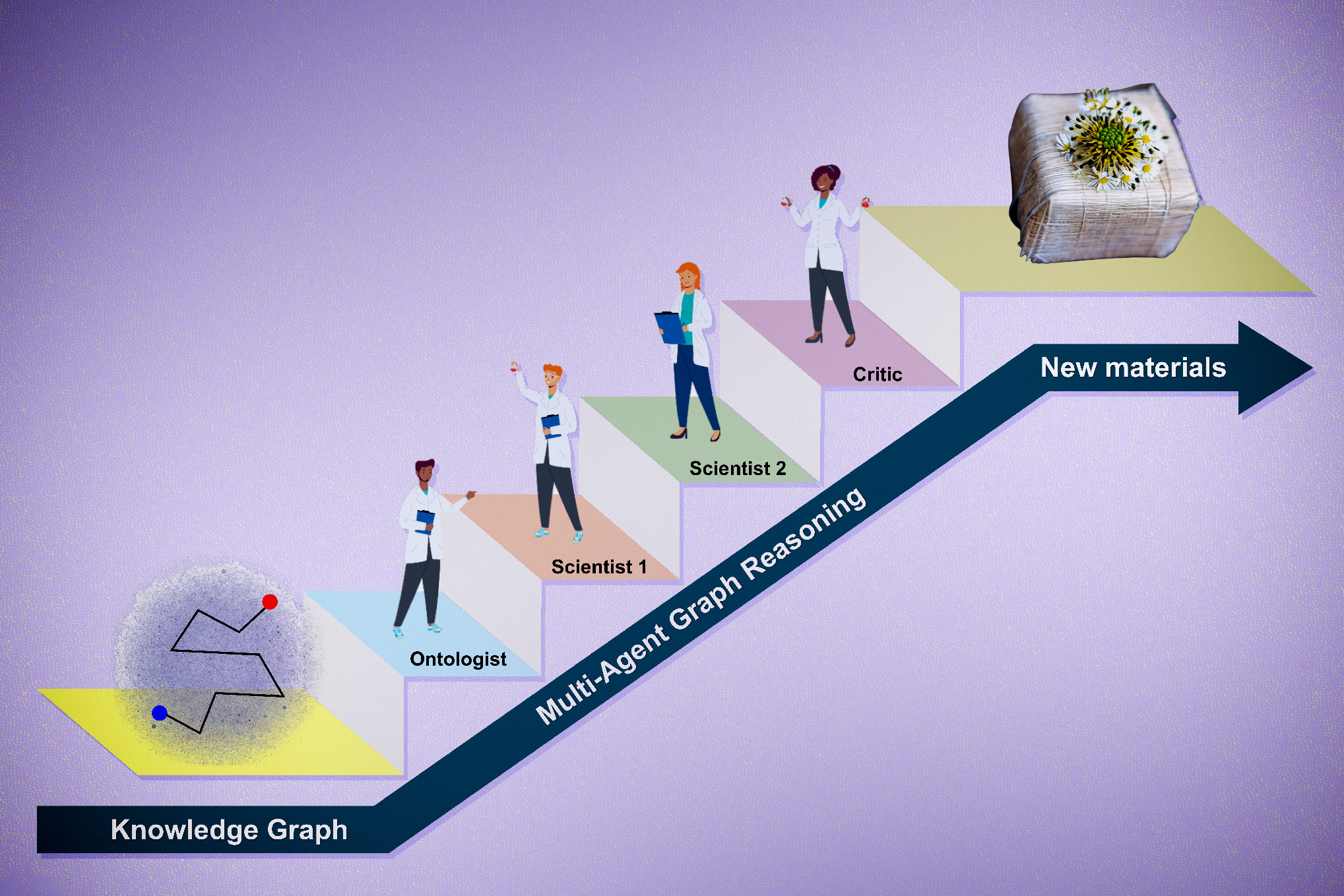
A visual pathway in the brain may do more than recognize objects
When visual information enters the brain, it travels through two pathways that process different aspects of the input. For decades, scientists have hypothesized that one of these pathways, the ventral visual stream, is responsible for recognizing objects, and that it might have been optimized by evolution to do just that.
Consistent with this, in the past decade, MIT scientists have found that when computational models of the anatomy of the ventral stream are optimized to solve the task of object recognition, they are remarkably good predictors of the neural activities in the ventral stream.
However, in a new study, MIT researchers have shown that when they train these types of models on spatial tasks instead, the resulting models are also quite good predictors of the ventral stream’s neural activities. This suggests that the ventral stream may not be exclusively optimized for object recognition.
“This leaves wide open the question about what the ventral stream is being optimized for. I think the dominant perspective a lot of people in our field believe is that the ventral stream is optimized for object recognition, but this study provides a new perspective that the ventral stream could be optimized for spatial tasks as well,” says MIT graduate student Yudi Xie.
Xie is the lead author of the study, which will be presented at the International Conference on Learning Representations. Other authors of the paper include Weichen Huang, a visiting student through MIT’s Research Summer Institute program; Esther Alter, a software engineer at the MIT Quest for Intelligence; Jeremy Schwartz, a sponsored research technical staff member; Joshua Tenenbaum, a professor of brain and cognitive sciences; and James DiCarlo, the Peter de Florez Professor of Brain and Cognitive Sciences, director of the Quest for Intelligence, and a member of the McGovern Institute for Brain Research at MIT.
Beyond object recognition
When we look at an object, our visual system can not only identify the object, but also determine other features such as its location, its distance from us, and its orientation in space. Since the early 1980s, neuroscientists have hypothesized that the primate visual system is divided into two pathways: the ventral stream, which performs object-recognition tasks, and the dorsal stream, which processes features related to spatial location.
Over the past decade, researchers have worked to model the ventral stream using a type of deep-learning model known as a convolutional neural network (CNN). Researchers can train these models to perform object-recognition tasks by feeding them datasets containing thousands of images along with category labels describing the images.
The state-of-the-art versions of these CNNs have high success rates at categorizing images. Additionally, researchers have found that the internal activations of the models are very similar to the activities of neurons that process visual information in the ventral stream. Furthermore, the more similar these models are to the ventral stream, the better they perform at object-recognition tasks. This has led many researchers to hypothesize that the dominant function of the ventral stream is recognizing objects.
However, experimental studies, especially a study from the DiCarlo lab in 2016, have found that the ventral stream appears to encode spatial features as well. These features include the object’s size, its orientation (how much it is rotated), and its location within the field of view. Based on these studies, the MIT team aimed to investigate whether the ventral stream might serve additional functions beyond object recognition.
“Our central question in this project was, is it possible that we can think about the ventral stream as being optimized for doing these spatial tasks instead of just categorization tasks?” Xie says.
To test this hypothesis, the researchers set out to train a CNN to identify one or more spatial features of an object, including rotation, location, and distance. To train the models, they created a new dataset of synthetic images. These images show objects such as tea kettles or calculators superimposed on different backgrounds, in locations and orientations that are labeled to help the model learn them.
The researchers found that CNNs that were trained on just one of these spatial tasks showed a high level of “neuro-alignment” with the ventral stream — very similar to the levels seen in CNN models trained on object recognition.
The researchers measure neuro-alignment using a technique that DiCarlo’s lab has developed, which involves asking the models, once trained, to predict the neural activity that a particular image would generate in the brain. The researchers found that the better the models performed on the spatial task they had been trained on, the more neuro-alignment they showed.
“I think we cannot assume that the ventral stream is just doing object categorization, because many of these other functions, such as spatial tasks, also can lead to this strong correlation between models’ neuro-alignment and their performance,” Xie says. “Our conclusion is that you can optimize either through categorization or doing these spatial tasks, and they both give you a ventral-stream-like model, based on our current metrics to evaluate neuro-alignment.”
Comparing models
The researchers then investigated why these two approaches — training for object recognition and training for spatial features — led to similar degrees of neuro-alignment. To do that, they performed an analysis known as centered kernel alignment (CKA), which allows them to measure the degree of similarity between representations in different CNNs. This analysis showed that in the early to middle layers of the models, the representations that the models learn are nearly indistinguishable.
“In these early layers, essentially you cannot tell these models apart by just looking at their representations,” Xie says. “It seems like they learn some very similar or unified representation in the early to middle layers, and in the later stages they diverge to support different tasks.”
The researchers hypothesize that even when models are trained to analyze just one feature, they also take into account “non-target” features — those that they are not trained on. When objects have greater variability in non-target features, the models tend to learn representations more similar to those learned by models trained on other tasks. This suggests that the models are using all of the information available to them, which may result in different models coming up with similar representations, the researchers say.
“More non-target variability actually helps the model learn a better representation, instead of learning a representation that’s ignorant of them,” Xie says. “It’s possible that the models, although they’re trained on one target, are simultaneously learning other things due to the variability of these non-target features.”
In future work, the researchers hope to develop new ways to compare different models, in hopes of learning more about how each one develops internal representations of objects based on differences in training tasks and training data.
“There could be still slight differences between these models, even though our current way of measuring how similar these models are to the brain tells us they’re on a very similar level. That suggests maybe there’s still some work to be done to improve upon how we can compare the model to the brain, so that we can better understand what exactly the ventral stream is optimized for,” Xie says.
The research was funded by the Semiconductor Research Corporation and the U.S. Defense Advanced Research Projects Agency.

© Image: Courtesy of the researchers